ANALISIS KOMPONEN UTAMA NONLINIER DAN
ANALISIS KOMPONEN UTAMA DENGAN
SUCCESSIVE
INTERVAL
PADA ANALISIS GEROMBOL
K-MEANS
ARISTA MARLINCE TAMONOB
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Analisis Komponen Utama Nonlinier dan Analisis Komponen Utama dengan Successive Interval pada Analisis Gerombol K-Means adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Desember 2015
Arista M. Tamonob
RINGKASAN
ARISTA MARLINCE TAMONOB. Analisis Komponen Utama Nonlinier dan Analisis Komponen Utama dengan Successive Interval pada Analisis Gerombol
K-Means. Dibimbing oleh ASEP SAEFUDDIN dan AJI HAMIM WIGENA.
Salah satu analisis gerombol non hirarki yang biasa digunakan yaitu analisis gerombol K-Means digunakan untuk data bersifat numerik dan menggunakan konsep jarak euclid sebagai ukuran melihat kemiripan dan ketakmiripan gerombol. Jarak euclid digunakan apabila peubah amatan saling bebas atau tidak berkorelasi satu sama lain.
Salah satu asumsi dalam analisis gerombol yang harus dipenuhi yaitu tidak ada kasus multikoliniearitas antar peubah. Konsep jarak euclid dapat digunakan untuk data numerik dengan cara mentransformasi peubah-peubah asal terlebih dahulu dengan menggunakan analisis komponen utama sedangkan kasus dengan data kategorik dapat diatasi dengan metode yang dikembangkan oleh Gifi pada tahun 1989 yaitu Analisis Komponen Utama Nonlinier (AKUNL) dan dapat diatasi dengan Analisis Komponen Utama (AKU) pada data yang sudah dinumerikkan menggunakan metode successive interval.
Tujuan penelitian ini adalah untuk menerapkan AKUNL dan AKU dengan
successive interval pada data kategorik dan membandingkan kedua metode pada
analisis gerombol K-Means.
Data yang digunakan dalam penelitian ini berasal dari hasil pendataan Survei Sosial Ekonomi Nasional (SUSENAS) Provinsi Nusa Tenggara Timur tahun 2013 dengan 13 peubah kategorik.
Hasil penelitian menunjukkan bahwa AKUNL dan AKU dengan successive
interval sama-sama menghasilkan 8 komponen utama dengan total keragaman
AKUNL sebesar 77% dan AKU dengan successive interval sebesar 78% . Namun dari kedua metode ini, AKU dengan successive interval memiliki rasio keragaman dalam gerombol dan antar gerombol lebih kecil dibandingkan AKUNL yaitu sebesar 0.00033, hal tersebut berarti metode AKU dengan successive interval
merupakan metode yang lebih baik dari AKUNL. Faktor-faktor yang perlu diperhatikan untuk mengurangi kemiskinan di Provinsi NTT berdasarkan metode AKU dengan successive interval yaitu dari segi bangunan tempat tinggal (luas lantai, jenis lantai, atap, dan dinding) yang dihuni oleh masyarakat, dari segi kualitas sumber daya manusia (pendidikan, literasi, dan pekerjaan), dari segi pemenuhan kebutuhan hidup (bahan bakar, air minum, raskin), dari segi fasilitas (aset dan handphone) terkhususnya untuk masyarakat yang jauh dari perkotaan. Kata kunci: analisis gerombol K-Means, analisis komponen utama, analisis
SUMMARY
ARISTA MARLINCE TAMONOB. Nonliniear Principal Componet Analysis and Principal Component Analysis with Successive Interval in K-Means Cluster Analysis. Supervised by ASEP SAEFUDDIN and AJI HAMIM WIGENA.
One of non hierarchical cluster analysis commonly used is the analysis of K-Means cluster used for numerical data and used euclid distance as a measure to see similarity and dissimilarity measured. Euclidean distance is used if the observation variables are independent oruncorrelated with one another.
One of the assumptions in cluster analysis is no multicoliniearity between variables. Euclid distance concept used for numerical data by transforming the variables using principal component analysis, while case with categorical data can be resolved either by the develop method by Gifi in 1989 that is Nonliniear Principal Component Analysis (NLPCA) or by by making categorical data into numerical data by the method called successive interval and then used Principal Component Analysis (PCA).
The aims of this researched were applied NLPCA and PCA with successive interval in categorical data and to compared both of method in K-Means cluster analysis.
The data used is the core data SUSENAS 2013 of East Nusa Tenggara Province. Variables used consisted of 13 categorical variable.
In this study, it was concluded that NLPCA and PCA with successive interval produced 8 principal components with variance total of NLPCA about 77% and from PCA with successive interval about 78%. In K-Means cluster analysis with PCA successive interval had variance ratio within cluster and between cluster smaller than NLPCA about 0.00033. Factors that need to be considered to reduce poverty in NTT based method PCA by successive interval, there are from residential buildings (floor area, type of floor, ceiling, and walls) are inhabited by people, from quality of human resources (education, literacy, and employment), from subsistance (fuel, drinking water, poor rice), from facilities (assest and handphone) especially to communities far from urban areas.
© Hak Cipta Milik IPB, Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Dilarang mengumumkan dan memperbanyak sebagian atau seluruh karya tulis ini
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika Terapan
ANALISIS KOMPONEN UTAMA NONLINIER DAN
ANALISIS KOMPONEN UTAMA DENGAN
SUCCESSIVE
INTERVAL
PADA ANALISIS GEROMBOL
K-MEANS
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2015
Judul Tesis : Analisis Komponen Utama Nonlinier dan Analisis Komponen Utama dengan Successive Interval pada Analisis Gerombol K-Means
Nama : Arista Marlince Tamonob NIM : G152130521
Disetujui oleh Komisi Pembimbing
Prof Dr Ir Asep Saefuddin, MSc Ketua
Dr Ir Aji Hamim Wigena, MSc Anggota
Diketahui oleh
Ketua Program Studi Statistika Terapan
Dr Ir Indahwati, MSi
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
Tanggal Ujian: 09 November 2015
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yesus Kristus atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Mei 2015 ini ialah data kategorik, dengan judul Analisis Komponen Utama Nonlinier dan Analisis Komponen Utama dengan successive interval pada Analisis Gerombol K-Means.
Terima kasih penulis ucapkan kepada Bapak Prof Dr Ir Asep Saefuddin dan Bapak Dr Ir Aji Hamim Wigena selaku pembimbing. Disamping itu, penghargaan penulis sampaikan kepada BPS yang telah membantu dalam pengumpulan data dan DIKTI yang telah membantu dalam hal dana perkuliahan. Ungkapan terima kasih juga disampaikan kepada orangtua tercinta, Bapak Marthen Tamonob dan Mama Paulina Tamonob-Doko, adik-adik tersayang, Yanry Arisandi Tamonob dan Onisimus Tamonob,serta semua teman-teman dan keluarga besar atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Desember 2015
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 3
2 TINJAUAN PUSTAKA 3
Data Kategorik 3
Asosiasi Data Kategorik 3
Analisis Komponen Utama Nonlinier (AKUNL) 4
Analisis Komponen Utama 6
Successive Interval 6
Analisis Gerombol K-Means 8
3 METODE 9
Data 9
Metode Analisis 9
4 HASIL DAN PEMBAHASAN 10
Pengecekan Multikolinieritas 12
Analisis Komponen Utama Nonlinier 12
Analisis Komponen Utama dengan Successive Interval 13
Perbandingan Hasil Gerombol 13
5 SIMPULAN DAN SARAN 16
Simpulan 16
Saran 16
DAFTAR PUSTAKA 16
LAMPIRAN 18
DAFTAR TABEL
1 Uji korelasi atau asosiasi yang dipilih 4
2 Hasil analisis komponen utama nonlinier 12
3 Hasil analisis komponen utama dari data hasil successive interval 13 4 Jumlah objek rumah tangga disetiap gerombol untuk metode AKUNL 14 5 Jumlah objek rumah tangga disetiap gerombol untuk metode AKU
dengan successive interval 14
6 Keragaman antar gerombol dan dalam gerombol dua metode 14 7 Hasil ANOVA analisis gerombol K-Means untuk metode AKU dengan
successive interval 15
8 Koefisien komponen utama metode AKU dengan successive interval 15
DAFTAR GAMBAR
1 Peta Provinsi Nusa Tenggara Timur 10
2 Persentase jenjang pendidikan kepala rumah tangga 11 3 Persentase jenis bahan bakar yang digunakan untuk memasak 11 4 Persentase kepemilikan jamban tiap rumah tangga 11
DAFTAR LAMPIRAN
1 Peubah kategorik awal yang digunakan 18
2 Peubah berskala ordinal 20
3 Deskripsi 15 peubah kategorik 21
4 Asosiasi peubah kategorik 24
1
PENDAHULUAN
Latar Belakang
Dalam penelitian yang berkaitan dengan ilmu sosial dan ilmu perilaku, para peneliti sering dihadapkan dengan peubah-peubah yang banyak dengan skala pengukuran yang berbeda yaitu skala numerik (interval dan rasio) dan skala kategorik (nominal dan ordinal). Analisis gerombol merupakan suatu metode dalam analisis peubah ganda yang dapat digunakan untuk mengelompokkan peubah atau objek. Objek-objek dikelompokkan ke dalam beberapa kelompok berdasarkan tingkat kemiripan antar objek (Johnsons & Wichern 2002). Secara umum, peubah yang digunakan sebagai dasar penggerombolan terdiri dari dua jenis, yaitu peubah kategorik dan peubah numerik.
Pada umumnya terdapat dua metode dalam melakukan penggerombolan, yaitu metode penggerombolan hirarki dan non hirarki. Metode penggerombolan hirarki digunakan jika jumlah gerombol yang diinginkan belum diketahui sebelumnya sedangkan metode penggerombolan non hirarki digunakan jika jumlah gerombol yang diinginkan sudah ditetapkan sebelumnya. Salah satu analisis gerombol non hirarki yang biasa digunakan yaitu analisis gerombol
K-Means yang digunakan untuk data bersifat numerik dan menggunakan konsep
jarak euclid sebagai ukuran untuk mengetahui kemiripan dan ketakmiripan gerombol. Jarak euclid digunakan apabila peubah amatan saling bebas atau tidak berkorelasi satu sama lain.
Salah satu asumsi dalam analisis gerombol yang harus dipenuhi yaitu tidak ada kasus multikoliniearitas antar peubah (Hair et al. 2010). Konsep jarak euclid
dapat digunakan untuk data numerik dengan cara mentransformasi peubah-peubah asal terlebih dahulu dengan menggunakan analisis komponen utama (Kaufman & Petter 2005) sedangkan untuk data kategorik dapat diatasi dengan metode yang dikembangkan oleh Gifi pada tahun 1989 yaitu analisis komponen utama nonlinier (AKUNL). Analisis komponen utama nonlinier menghasilkan skor komponen objek dan skor komponen utama yang berjenis data numerik sehingga dapat dianalisis lebih lanjut dengan analisis gerombol menggunakan konsep jarak
euclid (Safitri et al. 2012).
Data kategorik dengan skala pengukuran ordinal dapat dijadikan skala interval dengan menggunakan metode yang dikemukakan oleh Hays pada tahun 1976 (Waryanto & Millafati 2006) yaitu successive interval. Analisis komponen utama (AKU) dapat digunakan pada data hasil successive interval untuk mereduksi data dan mengatasi multikolinieritas sehingga dapat dianalisis lebih lanjut dengan analisis gerombol.
2
karyawan di PT Sinar Sosro, Jawa Timur. Penelitian-penelitan sebelumnya yang berkaitan dengan analisis gerombol menggunakan AKUNL telah dilakukan oleh Ahzan (2010) yang meneliti tentang analisis gerombol hirarki pada data kategorik dengan menggunakan AKUNL pada analisis gerombol hirarki diperoleh hasil bahwa metode pautan lengkap lebih menghasilkan gerombol yang lebih menggambarkan kondisi sesungguhnya dibandingkan dengan hasil metode pautan tunggal dan pautan rataan. Selain itu untuk kasus data campuran, Islamiyati (2010) meneliti tentang aplikasi analisis komponen utama nonlinier (PRINCALS) pada peningkatan mutu pendidikan tinggi dengan menggunakan analisis gerombol
K-Means dan diperoleh faktor-faktor yang berpengaruh terhadap prestasi belajar adalah umur masuk, nilai NEM, status sekolah, jalur masuk, pekerjaan ayah, pendidikan ayah dan ibu, dan status tempat tinggal, Yunianto (2011) meneliti tentang perbandingan penggerombolan dengan analisis komponen utama nonlinier dan gerombol dua langkah pada data campuran dan diperoleh hasil bahwa metode gerombol dua langkah dapat menjelaskan hasil penggerombolan lebih baik dan lebih spesifik dibandingkan dengan metode pautan centroid dengan transformasi AKU.
Berdasarkan penelitian-penelitian tersebut maka penelitian kali ini bertujuan untuk meneliti tentang perbandingan AKUNL dan AKU dengan successive
interval untuk data kategorik pada analisis gerombol K-Means dengan
menggunakan data kriteria kemiskinan Provinsi Nusa Tenggara Timur tahun (NTT) 2013 dan mengetahui peubah-peubah yang signifikan terhadap kemiskinan di NTT.
Perumusan Masalah
Masalah yang dirumuskan dalam penelitian ini adalah bagaimana penerapan analisis gerombol K-Means pada data kategorik menggunakan analisis komponen utama nonlinier dan analisis komponen utama dengan successive interval, manakah metode yang terbaik dari kedua metode tersebut pada analisis gerombol
K-Means, dan peubah-peubah yang berpengaruh terhadap kemiskinan di Provinsi
NTT dari metode terbaik.
Tujuan Penelitian
Tujuan penelitian ini untuk menerapkan analisis komponen utama nonlinier dan analisis komponen utama dengan successive interval pada data kategorik, membandingkan metode analisis komponen utama nonliniear dan analisis komponen utama dengan successive interval pada analisis gerombol K-Means, dan mengetahui peubah-peubah yang signifikan terhadap kemiskinan di Provinsi NTT dari metode yang terbaik.
Manfaat Penelitian
3 Ruang Lingkup Penelitian
Penelitian terbatas pada data kategorik untuk data kemiskinan Provinsi Nusa Tenggara Timur tahun 2013.
2
TINJAUAN PUSTAKA
Data Kategorik
Berdasarkan jenisnya data dibedakan menjadi data numerik (kuantitatif) dan data kategorik (kualitatif). Data numerik yaitu data yang dinyatakan dalam besaran numerik (angka), misalkan data pendapatan per kapita, pengeluaran, harga, dan lain-lain, sedangkan data kategorik diklasifikasikan berdasarkan kategori atau kelas tertentu.
Data kategorik dapat dibedakan menjadi: a. Data nominal
Data dengan urutan atau nilai tidak menunjukkan tingkatan hanya sebagai label saja. Contoh: agama, jenis kelamin, suku atau ras.
b. Data ordinal
Data dengan urutan kategori menunjukkan tingkatan atau ranking. Contoh: jenjang pendidikan dan kebiasaan merokok.
Data kategorik dapat pula diperoleh dengan mengelompokkan data kontinu namun resikonya bisa kehilangan informasi. Dalam penerapannya lebih mudah mencatat data kategorik daripada data kontinu, responden lebih mudah menjawab kategori dalam hal ini untuk pertanyaan sensitif, secara makna lebih praktis. Penyajian data kategorik dapat berupa frekuensi, tabel frekuensi, dan tabel kontingensi (Agresti 2002).
Asosiasi Data Kategorik
Dalam kasus dimana peubah yang dihubungkan bersifat numerik, maka analisis menggunakan korelasi merupakan salah satu pilihan. Namun, jika kedua peubah yang dihubungkan bersifat kategorik, maka penggunaan analisis korelasi tidak bisa digunakan karena angka pada suatu kategori hanya berupa kode bukan nilai yang sebenarnya. Alasan yang lain mengapa analisis korelasi tidak bisa digunakan pada data kategorik karena salah satu tipe peubah kategorik adalah nominal yang tidak bisa diurutkan kategorinya. Pemberian urutan yang berbeda jelas akan memberikan nilai korelasi yang berbeda pula sehingga dua orang yang menghitung nilai korelasi besar kemungkinan memberikan hasil yang tidak sama. Untuk itulah maka analisis khi-kuadrat yang akan digunakan untuk mencari hubungan (asosiasi) antar peubah-peubah kategorik tersebut.
Analisis khi-kuadrat didasarkan pada tabel kontingensi (sering juga disebut tabulasi silang). Tabel kontingensi adalah tabel yang sel-selnya berisi frekuensi dari perpotongan baris dan kolom. Bentuk umum dari tabel kontingensi dengan peubah pertama memiliki m kategori dan peubah kedua memiliki k
4
Hipotesis yang akan diuji 0
H
: kedua peubah saling bebas (tidak ada asosisasi) 1H
: kedua peubah tidak bebas (ada asosiasi) Statistik uji yang digunakan:2 2 1 1 k m ij ij hitung
j i ij
O E E
Jika nilai
2hitung bernilai lebih besar daripada nilai 2( ; ) tabel db
dengan derajat bebas (m1)(k1) maka tolakH
0.Kuat atau lemahnya asosiasi dapat dilihat dari nilai asosiasi antara selang -1 sampai dengan 1. Nilai asosiasi sama dengan 1 berarti ada asosiasi kuat antar peubah, jika nilai asosiasi sama dengan nol berarti tidak ada asosiasi antar peubah. Uji korelasi atau uji asosiasi dengan skala ukur yang berbeda dapat dilihat pada Tabel 1. Data berskala ukur ordinal dapat dilihat hubungan keeratan antar peubah dengan menggunakan koefisien korelasi rank Spearman.
2 1 2 1 6 ( ) n i i s d r
n n n
dengan:koefisien korelasi Spearman d selisih peringkat untuk setiap data n = jumlah sampel atau data
s
i
r
Tabel 1 Uji korelasi atau asosiasi yang dipilih
Analisis Komponen Utama Nonlinier (AKUNL)
Analisis Komponen Utama Nonlinier merupakan pengembangan dari analisis Komponen Utama dan biasa disebut juga PRINCALS (Principal
Component Analysis by Alternating Least Square) atau Analisis Komponen
Utama dengan menggunakan pendekatan Alternating Least Square yang diperkenalkan oleh Gifi pada tahun 1989. AKUNL menghasilkan tiga kelompok unsur, yaitu bobot peubah atau skor komponen utama (variable loadings), kategori kuantifikasi (category quantifications) dan skor komponen objek (object
scores). Dalam AKUNL, kategori semua peubah dengan skala bukan numerik
akan diberi kuantifikasi kategori dengan skala numerik yang sesuai. Analisis Peubah 1 Peubah 2 Uji korelasi atau asosiasi yang dipilih
Nominal Nominal Koefisien Kontingensi, Lambda, Phi, dan Cramer
Nominal Ordinal Koefisien Kontingensi, Lambda Ordinal Ordinal Spearman, Gamma, Somers’d Ordinal Numerik Spearman
5 Komponen Utama Nonlinier bertujuan untuk mengoptimalkan atau mencari rata-rata kuadrat korelasi yang optimal antara peubah yang telah diberi kuantifikasi kategori dengan komponen. Dalam pencarian nilai optimal tersebut, baik komponen loading dan kuantifikasi kategori akan memberikan nilai yang bervariasi sampai nilai optimum ditemukan (Konig 2002 diacu dalam Azizah et al
2014).
Apabila terdapat suatu data yang dibentuk ke dalam matriks H yang berukuran n m maka untuk memudahkan perhitungan AKUNL dipakai notasi:
n = banyak pengamatan (objek); i1, 2,..,n m = banyak peubah
kj = banyak kategori pada peubah ke-j; j1, 2,..,m
j
h = vektor kolom ke-j dari matriks H berukuran n1
j
G = matriks indikator dari hj berukuran n k j dengan:
( )
1, jika objek ke-i berada dalam kategori ke -r dari peubah j 0, jika objek ke-i tidak berada dalam ketegori ke-r dari peubah j
j ir
g
1, 2,..., ; 1, 2,..., j
i n r k
j
G merupakan matriks yang berisi frekuensi dari tiap kategori pada tiap kategori pada setiap peubah. Gjdikatakan lengkap apabila dari setiap baris pada
j
G mempunyai satu unsur bernilai satu dan lainnya nol.
Analisis Komponen Utama Nonlinier didasarkan pada teori meet loss yang bertujuan untuk meminimumkan fungsi homogeneity loss
(
M)
.1 1 1 ( , ,..., ) ( ) '( ) m M m j
X Y Y m
X G Y j j X G Y j jdengan normalisiasi AVE
(
X
s) 0
untuk dimensi s=1,..,p dan X’X=I. AVE(
X
s)
adalah vektor yang merupakan rata-rata kolom dari elemen matriks
X
s. NotasiM
digunakan karena
M( , ) 0
X Y
yang berimplikasi pada nilai ranking Gjpaling sedikit p.
Fungsi
M diminimumkan menggunakan metode alternating least squareuntuk mendapatkan pendugaan nilai bobot peubah aj . Algoritma untuk menghitung p dimensi pertama secara simultan dan meminimumkan
M denganmenggunakan alternating least square adalah :
dengan
-1 'j j j j j j
Y
D G X
D = G 'G
1
m
j
j jZ G Y GRAM
X = (Z) X adalah skor komponen objek berukuran np (p = banyak peubah), Yj
6
matriks ortogonal dari ortogonalisasi Gram-Schmidt dari matriks Z, dan aj adalah
bobot peubah untuk peubah j (Gifi 1989).
Analisis Komponen Utama
Analisis Komponen Utama adalah metode analisis peubah ganda yang bertujuan memperkecil dimensi peubah asal sehingga diperoleh peubah baru (komponen utama) yang tidak saling berkorelasi tetapi menyimpan sebagian besar informasi yang terkandung pada peubah asal (Johnson & Wichern 2002). Misalkan X X1, 2,...,Xp adalah peubah acak yang menyebar menurut sebaran tertentu dengan vektor nilai tengah
μ
dan matriks peragam Σ.Komponen utama merupakan kombinasi liniear terboboti dari peubah-peubah asal yang mampu menerangkan data secara maksimum.
Komponen utama ke-j dari p peubah dapat dinyatakan sebagai berikut: 1 1 2 2
Yj a xj a xj ... a xpj pa x' dan keragaman komponen utama ke-j adalah
Var( )Yj
j; j1, 2,...,p1, 2,..., p
adalah akar ciri yang diperoleh dari persaman: 0j
Σ I
dimana
1 2 ...
p 0. Vektor ciri a sebagai pembobot dari transformasi linear peubah asal diperoleh dari persamaan :
ΣjI a
j 0 Total keragaman komponen utama adalah
1 2...
ptr
Σ
dan persentase total keragaman data yang mampu diterangkan oleh komponenutama ke-j adalah :
j x100%tr
Σ
Persentase keragaman dianggap cukup mewakili total keragaman jika data 75% atau lebih. Pembangkitan komponen utama tergantung dari jenis data asal yang digunakan. Apabila data yang digunakan memiliki satuan pengukuran yang sama maka digunakan matriks peragam. Jika syarat di atas tidak terpenuhi, maka digunakan matriks korelasi.
Successive Interval
7 sehingga dapat ditanyakan terhadap responden. Pada umumnya, jawaban responden yang diukur menggunakan skala likert (likert scale) diadakan skoring yakni pemberian nilai numerikal 1, 2, 3, 4, dan 5, setiap skor yang diperoleh akan memiliki tingkat pengkuran ordinal.
Dalam penggunaan alat analisis, umumnya ditentukan skala minimal dari data yang dibutuhkan. Dalam kasus penelitian di bidang sosial yang biasanya ditemui banyak menggunakan skala ordinal sementara persyaratan alat analisis membutuhkan data dengan skala minimal adalah data interval. Dalam kondisi tersebut, kita perlu mentransformasikan data dari skala ordinal ke interval.
Sebuah metode untuk mentransformasi data dari skala ordinal ke interval diperkenalkan oleh Hays (1976) dalam bukunya Quantification in Psychology. Metode successive interval merupakan proses untuk mengubah data dengan skala pengukuran ordinal menjadi data interval.
Tahapan dalam metode successive interval (Waryanto & Millafati 2006), yaitu:
a. Menghitung frekuensi dari setiap data kategori
Frekuensi merupakan banyaknya tanggapan responden dalam memilih poin disetiap kategori yang ada.
b. Menghitung proporsi berdasarkan frekuensi setiap kategori
Proporsi dihitung dengan membagi setiap frekuensi dengan jumlah responden. c. Menghitung proporsi kumulatif
Proporsi kumulatif dihitung dengan menjumlahkan proporsi secara berurutan untuk setiap nilai.
d. Menghitung nilai z untuk setiap proporsi kumulatif
Nilai z diperoleh dari tabel distribusi normal baku, dengan asumsi bahwa proporsi kumulatif berdistribusi normal baku.
e. Menghitung nilai densitas fungsi z
Nilai densitas dihitung dengan menggunakan rumus sebagai berikut: 2
1 1
( ) exp
2 2
f z z
f. Menghitung scale value (interval rata-rata) untuk setiap kategori Menghitung scale value digunakan rumus
density at lower limit-density at upper limit SV=
area under offer limit-area under lower limit dengan:
nilai = nilai diambil dari densitas z = nilai diambil dari proporsi kumulatif
density
area
g. Menghitung nilai hasil penskalaan
8
Analisis Gerombol K-Means
Analisis gerombol K-Means dikembangkan oleh Mac Queen pada tahun 1967 dan merupakan salah satu metode pengelompokkan data non hirarki yang paling terkenal dan banyak digunakan di berbagai bidang karena sederhana dan mudah diimplementasikan (Johnson & Wichern 2002). K-Means merupakan metode penggerombolan secara partitioning yang memisahkan data ke dalam kelompok yang berbeda. Tujuan dari penggelompokkan data ini adalah untuk meminimalisasi ragam didalam suatu kelompok dan memaksimalkan ragam antar kelompok.
Dasar algoritma K-Means adalah sebagai berikut:
1. Menentukan nilai k sebagai jumlah gerombol yang ingin dibentuk 2. Membangkitkan titik pusat gerombol k awal secara acak
3. Menghitung jarak setiap data ke masing-masing pusat gerombol menggunakan jarak euclid
4. Mengelompokan setiap data berdasarkan jarak antar terdekat antar data dengan pusatnya
5. Menentukan posisi pusat gerombol baru dengan cara menghitung nilai rata-rata dari data-data yang ada pada pusat gerombol yang sama
Hasil penggerombolan yang baik apabila objek dalam gerombol yang sama memiliki keragaman yang rendah sedangkan objek antar gerombol memiliki tingkat keragaman yang tinggi (Serban & Grigoretta 2006).
Keragaman antar gerombol . 2
1 ( ) j n j j j
SSB n x x
dengan:.
rata-rata total seluruh objek banyaknya objek gerombol ke-j
rata-rata objek pada gerombol ke-j
j j x n x
Keragaman dalam gerombol . 2
1 1 ( ) j n k ij j j i
SSW x x
dengan:.
objek ke-i gerombol ke-j
rata-rata objek pada gerombol ke-j banyaknya gerombol ij j x x k
Untuk perbandingan dua metode dilihat rasio keragaman dalam gerombol dan antar gerombol. Rasio keragaman yang lebih kecil menunjukkan bahwa metode tersebut merupakan metode terbaik (Yunianto 2011).
Keragaman dalam gerombol (SSW) Rasio Keragaman=
9
3
METODE
Data
Penelitian ini menggunakan data kor SUSENAS Provinsi Nusa Tenggara Timur tahun 2013. Peubah yang digunakan terdiri dari 13 peubah kategorik (Afandi 2009) dengan 2 peubah berskala ordinal dan 11 peubah berskala nominal yaitu pendidikan (X1) berskala ordinal, luas lantai (X2) berskala ordinal, jenis lantai (X3) berskala nominal, dinding (X4) berskala nominal, atap (X5) berskala nominal, jamban (X6) berskala nominal, air minum (X7) berskala nominal, bahan bakar (X8) berskala nominal, aset (X9) berskala nominal, literasi (X10) berskala nominal, pekerjaan (X11) berskala nominal, raskin (X12) berskala nominal, dan
handphone (X13) berskala nominal.
Dalam metode successive interval memerlukan data berskala ukur ordinal sehingga 11 data berskala nominal tersebut dijadikan data berskala ordinal dengan merubah urutan kategori sehingga terurut dari kategori yang paling rendah sampai dengan kategori paling tinggi. Sebagai contoh, peubah X6 yaitu peubah kepemilikan jamban dengan kategori awal berskala nominal yaitu:
1) milik sendiri
2) bukan milik sendiri 3) tidak ada
diubah urutan kategorinya, diawali dengan kategori paling rendah sampai dengan kategori tertinggi sehingga kategori pada peubah X6 menjadi berskala ordinal yaitu:
1) tidak ada
2) bukan milik sendiri 3) milik sendiri
Peubah beserta kategori awal dapat dilihat pada Lampiran 1 sedangkan peubah beserta kategori berskala ordinal dapat dilihat pada Lampiran 2. Kelompok untuk analisis gerombol terdiri dari 2 kelompok yaitu kelompok rumah tangga miskin dan kelompok rumah tangga tidak miskin.
Metode Analisis
1. Melakukan eksplorasi data
Data dieksplorasi dan dilakukan pemeriksaan adanya multikoliniearitas antar peubah, karena data yang digunakan berskala ordinal maka dilihat asosiasi antar peubah dengan menggunakan korelasi spearman.
2. Melakukan analisis komponen utama nonlinier
Data kemiskinan bertipe kategorik dilakukan analisis komponen utama nonlinier sehingga diperoleh skor komponen utama yang akan digunakan pada analisis gerombol K-Means.
3. Melakukan successive interval terhadap data peubah bebas
Data berskala ordinal dijadikan berskala interval dengan menggunakan metode
successive interval.
10
Data hasil successive interval dilakukan analisis komponen utama untuk mereduksi data dan mengatasi multikoliniearitas sehingga diperoleh skor komponen utama yang akan digunakan pada analisis gerombol K-Means. 5. Menerapkan analisis gerombol K-Means pada skor komponen utama AKUNL
dan AKU dengan successive interval dari poin 2 dan 4. 6. Membandingkan kedua metode
Kedua metode dibandingkan dengan melihat rasio keragaman antar gerombol dan dalam gerombol.
4
HASIL DAN PEMBAHASAN
Provinsi Nusa Tenggara Timur (NTT) merupakan sebuah provinsi di Indonesia yang terletak di bagian Tenggara Indonesia. Provinsi ini terdiri dari 21 kabupaten dan 1 kota yang tersebar di beberapa pulau besar diantaranya pulau Timor, pulau Sumba, pulau Flores, dan pulau Alor seperti yang terlihat pada Gambar 1. Menurut BPS (2014), NTT menempati urutan ketiga dari 33 provinsi di Indonesia yang memiliki persentase penduduk miskin tertinggi yaitu sebesar 19.60% setelah Papua sebesar 27.80% dan Papua Barat 26.26%.
Deskripsi data menggunakan data yang telah berskala ukur ordinal dengan hanya menampilkan 3 peubah yaitu pendidikan, bahan bakar, dan jamban. Deskripsi data untuk 10 peubah kategorik lainnya dapat dilihat pada Lampiran 3.
Gambar 1 Peta Provinsi Nusa Tenggara Timur
11
Gambar 2 Persentase jenjang pendidikan kepala rumah tangga
Tingkat pendidikan di Nusa Tenggara Timur masih memprihatinkan. Berdasarkan Gambar 2, sebanyak 54% masyarakat NTT hanya menempuh jenjang pendidikan sampai tingkat SD atau setara. Fasilitas sekolah yang masih minim di daerah pedesaan, tenaga pendidik yang masih relatif sedikit untuk bekerja di daerah terpencil, biaya pendidikan yang masih dianggap mahal oleh masyarakat, serta kesadaran diri dari masyarakat untuk bersekolah menjadi beberapa penyebab hal ini.
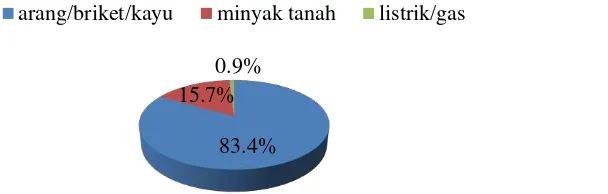
Gambar 3 Persentase jenis bahan bakar yang digunakan untuk memasak Sebagai salah satu provinsi yang belum melakukan program konversi minyak tanah ke gas tentu saja penggunaan bahan bakar berupa minyak tanah masih didominasi oleh minyak tanah yaitu sebesar 83.4%. Berdasarkan Gambar 3, penggunaan gas masih sangat minim yaitu sebesar 0.9%, gas biasanya digunakan oleh masyarakat yang tinggal di perkotaan dengan tingkat ekonomi diatas rata-rata.
Gambar 4 Persentase kepemilikan jamban tiap rumah tangga
Berdasarkan Gambar 4, kepemilikan jamban untuk tiap rumah tangga di NTT masih sebanyak 21.3% rumah tangga yang tidak memiliki jamban dan 14.5% rumah tangga masih menggunakan jamban milik rumah tangga lain. Jenis jamban di daerah pedesaan masih kurang layak digunakan, jamban biasanya terbuat dari potongan-potongan kayu yang diletakkan diatas sebuah lubang. Hal
10,7%
54% 12,6%
15,6%7%
tidak tamat SD tamat SD/sederajat
tamat SMP/sederajat tamat SMA/sederajat
83.4% 15.7%
0.9%
arang/briket/kayu minyak tanah listrik/gas
21.3%
14.5% 64.2%
12
tersebut disebabkan oleh kemampuan ekonomi dan pengetahuan tentang sanitasi yang masih minim dari penduduk di NTT.
Pengecekan Multikolinieritas
Dari 13 peubah bebas berskala ordinal tersebut dilakukan uji asumsi multikolinieritas dengan melihat nilai korelasi spearman antar peubah. Dari nilai korelasi spearman terdapat asosiasi atau hubungan cukup besar antara peubah literasi dan pendidikan sebesar 0.553, antara pendidikan dan bahan bakar sebesar 0.434. Nilai asosiasi dapat dilihat pada Lampiran 4.
Analisis Komponen Utama Nonlinier
Analisis komponen utama nonlinier dilakukan terhadap seluruh peubah kategorik untuk mereduksi jumlah peubah dan mentransformasi peubah tersebut menjadi peubah baru (komponen utama) yang berskala rasio dan tidak saling berkorelasi.
Pemilihan komponen utama yang akan digunakan dalam analisis gerombol
K-Means didasarkan pada persentase keragaman kumulatif yang ditunjukkan oleh
Tabel 2. Persentase keragaman dianggap cukup mewakili total keragaman data sebesar 75% atau lebih (Morisson 1990).
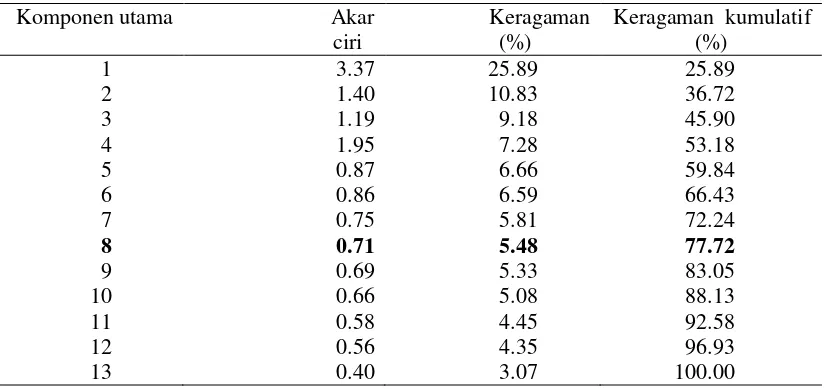
Sebanyak 13 komponen utama yang dihasilkan dari AKUNL tidak digunakan semua melainkan hanya 8 komponen utama saja. Hasil AKUNL menunjukkan bahwa apabila dua komponen utama yang diambil berarti hanya dapat menjelaskan 36% keragaman data awal. Untuk dapat mewakili keragaman data dalam penelitian ini maka diambil 8 komponen utama dengan total keragaman sebesar 77%. Hasil akhir AKUNL adalah skor komponen utama yang digunakan untuk analisis gerombol K-Means yang telah berupa data bertipe numerik. Skor komponen utama sebanyak 8 komponen utama dengan objek sebanyak 10422 rumah tangga.
Tabel 2 Hasil analisis komponen utama nonlinier
Komponen utama Akar
ciri
Keragaman (%)
13 Analisis Komponen Utama dengan Successive Interval
Data dengan 13 peubah berskala ukur ordinal ditransformasi menjadi data berskala interval dengan menggunakan metode successive interval. Data hasil
successive interval dapat dilihat pada Lampiran 5. Data hasil successive interval
sebanyak 10422 objek dengan 13 peubah direduksi menggunakan analisis komponen utama sehingga diperoleh peubah baru (komponen utama) yang tidak saling berkorelasi.
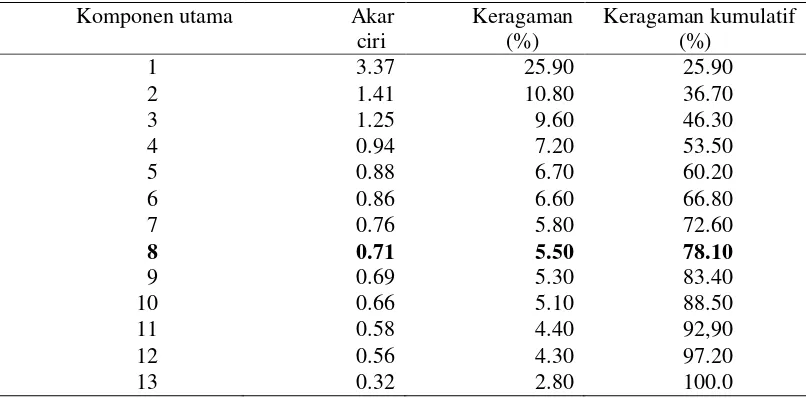
Berdasarkan Tabel 3, hasil AKU menunjukkan bahwa apabila dua komponen utama yang diambil berarti hanya dapat menjelaskan 36% keragaman data awal. Untuk dapat mewakili keragaman data dalam penelitian ini maka diambil 8 komponen utama dengan total keragaman sebesar 78%. Hasil akhir AKU adalah skor komponen utama yang digunakan untuk analisis gerombol
K-Means. Skor komponen utama sebanyak 8 komponen utama dengan objek
sebanyak 10422 rumah tangga.
Perbandingan Hasil Gerombol
Hasil penggerombolan yang baik apabila objek dalam gerombol yang sama memiliki keragaman yang rendah sedangkan objek antar gerombol memiliki tingkat keragaman yang tinggi. Dengan kata lain, objek dalam satu gerombol memiliki tingkat kemiripan yang tinggi dan objek berbeda gerombol memiliki tingkat kemiripan yang rendah (Serban & Grigoreta 2006).
Berdasarkan skor komponen utama yang diperoleh dari kedua metode maka dilakukan analisis gerombol K-Means dengan 10422 objek rumah tangga dan 2 gerombol yang telah ditentukan terlebih dahulu.
Berikut jumlah objek rumah tangga yang terdapat pada gerombol pertama dan kedua dari kedua metode dapat dilihat pada Tabel 4 dan Tabel 5.
Tabel 3 Hasil analisis komponen utama dari data hasil successive interval
Komponen utama Akar ciri
Keragaman (%)
Keragaman kumulatif (%)
1 3.37 25.90 25.90
2 1.41 10.80 36.70
3 1.25 9.60 46.30
4 0.94 7.20 53.50
5 0.88 6.70 60.20
6 0.86 6.60 66.80
7 0.76 5.80 72.60
8 0.71 5.50 78.10
9 0.69 5.30 83.40
10 0.66 5.10 88.50
11 0.58 4.40 92,90
12 0.56 4.30 97.20
14
Tabel 4 Jumlah objek rumah tangga disetiap gerombol untuk metode AKUNL
Dapat dilihat pada Tabel 4, jumlah rumah tangga untuk metode AKUNL untuk gerombol 1 yaitu sebanyak 5042 rumah tangga dan untuk gerombol 2 sebanyak 5380 rumah tangga. Pada Tabel 5 terlihat bahwa jumlah rumah tangga dari metode AKU dengan successive interval untuk gerombol 1 sebanyak 4860 rumah tangga dan untuk gerombol 2 sebanyak 5562 rumah tangga.
Tabel 5 Jumlah objek rumah tangga disetiap gerombol untuk metode AKU dengan successive interval
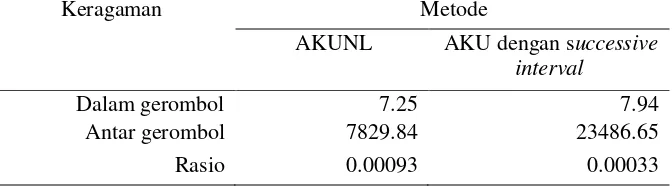
Dari kedua metode masing-masing metode menghasilkan keragaman yang berbeda, baik keragaman antar gerombol maupun keragaman dalam gerombol. Perbandingan keragaman gerombol untuk setiap metode dapat dilihat pada Tabel 6.
Dari Tabel 6 terlihat bahwa keragaman dalam gerombol metode AKUNL sebesar 7.25 dan keragaman antar gerombol sebesar 7829.84 sedangkan keragaman dalam gerombol metode AKU dengan successive interval sebesar 7.94 dan keragaman dalam gerombol sebesar 23486.65. Ditinjau dari rasio keragaman dalam gerombol dan antar gerombol dapat dilihat bahwa metode AKU dengan data hasil successive interval menghasilkan rasio keragaman dalam gerombol dan antar gerombol lebih kecil dibandingkan dengan AKUNL yaitu sebesar 0.00033. Hal ini menjelaskan bahwa metode AKU dengan successive interval lebih baik dibandingkan metode AKUNL untuk kasus menggunakan data kemiskinan provinsi NTT tahun 2013.
Gerombol Jumlah objek rumah tangga
1 5042
2 5380
Total 10422
Gerombol Jumlah objek rumah tangga
1 4857
2 5565
Total 10422
Tabel 6 Keragaman antar gerombol dan dalam gerombol dua metode
Keragaman Metode
AKUNL AKU dengan successive interval
Dalam gerombol 7.25 7.94
Antar gerombol 7829.84 23486.65
15 Tabel 7 Hasil ANOVA analisis gerombol K-Means untuk metode AKU dengan
successive interval
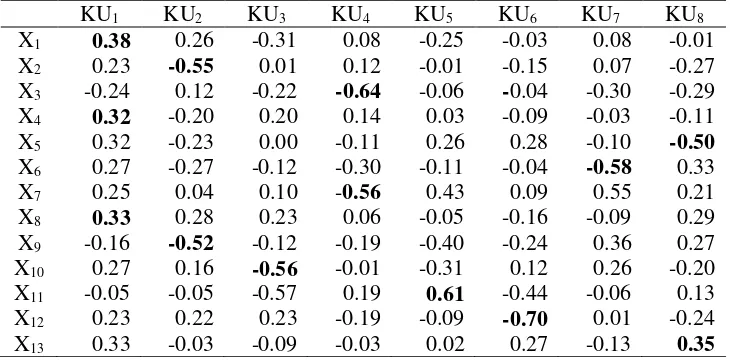
Dari hasil ANOVA penggerombolan 10422 rumah tangga pada Tabel 7 diperoleh bahwa KU1, KU2, KU3, KU4, KU5, KU6, KU8 berpengaruh secara signifikan dengan nilai-p kurang dari 0.05. Dari komponen-komponen utama yang signifikan ini maka dilihat koefisien dari setiap komponen utama untuk melihat peubah-peubah yang mendominasi pada setiap komponen utama tersebut.
Koefisien komponen utama adalah suatu skor yang menunjukkan besar kecilnya nilai atau kontribusi dari setiap komponen utama terhadap masing-masing unit pengamatan. Nilai koefisien komponen utama dapat bernilai positif maupun negatif. Nilai positif berarti suatu komponen utama memberi kontribusi yang besar dan berpengaruh positif terhadap unit pengamatan demikian sebaliknya (Handoyo & Setiawan 2009).
Tabel 8 Koefisien komponen utama metode AKU dengan successive interval
Berdasarkan koefisien komponen utama pada Tabel 8 diperoleh peubah yang mendominasi tiap komponen utama yang berpengaruh signifikan. Untuk KU1 yakni peubah X1 (pendidikan) sebesar 0.38, X4 (dinding) sebesar 0.32, dan X8 (bahan bakar) sebesar 0.33, KU2 yaitu peubah X2 (luas lantai) sebesar -0.55 dan X9 (aset) sebesar -0.52, untuk KU3 terdapat peubah X10 (literasi) sebesar -0,56, untuk KU4 yaitu peubah X3 (jenis lantai) sebesar -0.64 dan peubah X7 (air minum) sebesar -0.56, untuk KU5 yaitu X11 (pekerjaan) sebesar 0.61, untuk KU6 yaitu peubah X12 (raskin) sebesar -0.70, sedangkan untuk KU8 yaitu peubah X5 (atap)
Komponen Utama
Mean Square
antar gerombol
Mean square
dalam gerombol
F-hitung Nilai-p
KU1 23302.39 1.13 20493.46 0.00
KU2 62.13 1.40 44.27 0.00
KU3 70.95 1.24 57.01 0.00
KU4 16.72 0.94 17.78 0.00
KU5 10.52 0.88 12.00 0.01
KU6 11.99 0.87 13.91 0.00
KU7 1.03 0.76 1.36 0.24
KU8 10.922 0.71 15.32 0.00
KU1 KU2 KU3 KU4 KU5 KU6 KU7 KU8
X1 0.38 0.26 -0.31 0.08 -0.25 -0.03 0.08 -0.01
X2 0.23 -0.55 0.01 0.12 -0.01 -0.15 0.07 -0.27 X3 -0.24 0.12 -0.22 -0.64 -0.06 -0.04 -0.30 -0.29
X4 0.32 -0.20 0.20 0.14 0.03 -0.09 -0.03 -0.11
X5 0.32 -0.23 0.00 -0.11 0.26 0.28 -0.10 -0.50 X6 0.27 -0.27 -0.12 -0.30 -0.11 -0.04 -0.58 0.33 X7 0.25 0.04 0.10 -0.56 0.43 0.09 0.55 0.21
X8 0.33 0.28 0.23 0.06 -0.05 -0.16 -0.09 0.29
16
sebesar -0.50 dan X13 (handphone) sebesar 0.35. Peubah-peubah yang mendominasi sebagian besar berpengaruh positif terhadap unit pengamatan dalam hal ini rumah tangga. Oleh karena itu, faktor-faktor yang perlu diperhatikan oleh pemerintah Provinsi NTT untuk mengurangi masalah kemiskinan yaitu dari segi bangunan tempat tinggal (luas lantai, jenis lantai, atap, dan dinding) yang dihuni oleh masyarakat, dari segi kualitas sumber daya manusia (pendidikan, literasi, dan pekerjaan), dari segi pemenuhan kebutuhan hidup (bahan bakar, air minum, raskin), dari segi fasilitas (aset dan handphone) terkhususnya untuk masyarakat yang jauh dari perkotaan.
5
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan dapat disimpulkan bahwa: 1. Analisis komponen utama nonlinier dan analisis komponen utama dengan
successive interval menghasilkan 8 komponen utama dengan total keragaman
untuk AKUNL sebesar 77% dan untuk AKU dengan successive interval
sebesar 78%.
2. Pada analisis gerombol K-Means, AKU dengan successive interval
menghasilkan rasio keragaman dalam gerombol dan antar gerombol lebih kecil dibandingkan dengan AKUNL yaitu sebesar 0.00033.
3. Faktor-faktor yang perlu diperhatikan oleh pemerintah Provinsi NTT untuk mengurangi masalah kemiskinan yaitu dari segi bangunan tempat tinggal (luas lantai, jenis lantai, atap, dan dinding) yang dihuni oleh masyarakat, dari segi kualitas sumber daya manusia (pendidikan, literasi, dan pekerjaan), dari segi pemenuhan kebutuhan hidup (bahan bakar, air minum, raskin), dari segi fasilitas (aset dan handphone) terkhususnya untuk masyarakat yang jauh dari perkotaan.
Saran
Beberapa hal yang dapat dikembangkan lebih lanjut dari penelitian ini yaitu: 1. Dapat membandingkan analisis komponen utama nonlinier dengan metode analisis gerombol lainnya untuk data kategorik seperti analisis gerombol latent. 2. Dapat menggunakan kajian simulasi untuk penelitian lanjut.
DAFTAR PUSTAKA
Afandi W N. 2009. Identifikasi Karakteristik Rumah Tangga Miskin di Kabupaten
Padang Pariaman (Studi Kasus Nagari Malai V Suku) [tesis]. Padang (ID):
17 Ahzan H. 2010. Analisis Gerombol Berhirarki pada Data Kategorik. [skripsi].
Bogor(ID): Institut Pertanian Bogor.
Agresti A. 2002. An Introduction to Categorical Data Analysis. New York (US). John Wiley and Sons.
Ar H. 2015. Peta Provinsi Nusa Tenggara Timur [Internet]. [diunduh 2015 Okt 23]. Tersedia pada http://harunarcom.blogspot.co.id/2011/02/peta-provinsi-nusa-tenggara-timur-ntt.html.
Azizah M, Soehono L, Solimun. 2014. Analisis Cluster Komponen Utama Nonlinier dan Analisis Two Step Cluster untuk Data Berskala Campuran.
Jurnal Mahasiswa Statistik. 2(1):1-4
[BPS] Badan Pusat Statistik. 2014. Nusa Tenggara Timur dalam Angka 2014. Kupang: BPS Nusa Tenggara Timur.
Gifi A. 1989. Nonlinear Multivariate Analysis. Chichester: John Wiley & Sons. Hair JF, Black WC, Babin BJ, Anderson RE. 2010. Multivariate Data Analysis.
Seventh Edition. New Jersey: Prentice Hall International Inc.
Handoyo E, Setiawan A. 2009. Analisis Kebutuhan Perangkat Lunak menggunakan Analisis Faktor pada Program Studi Ilmu Keperawatan UNDIP. Jurnal Teknik. 30(1):30-38.
Hays WL. 1976. Quantification in Psychology. New Delhi: Prentice Hall.
Islamiyati A, Talangko L. 2010. Aplikasi Komponen Utama Non Linear (Princals)
pada Peningkatan Mutu Pendidikan Tinggi [skripsi]. Makassar (ID):
Universitas Hasanudin.
Johnson R, Wichern D. 2002. Applied Multivariate Statistical Analysis. New Jersey: Prentice Hall
Kaufman L, Petter JR. 2005. Finding Groups in Data an Introduction to Cluster
Analysis. New York: John Wiley & Sons Inc.
Kuroda M, Mori Y, Masaya I, Sakakihara M. 2013. Alternating Least Squares in Nonliniear Principal Components. Wires Computational Statistics. 5(6): 456-464.
Kusnadi D. 2012. Perubahan Status Kelembagaan dan Kualitas Pelayanan Rumah Sakit. Jurnal Kesehatan Mayarakat Nasional. 7(2):63-67.
Morrison DF. 1990. Multivariate Statistical Methods Third Edition. New York: McGraw-Hill Inc.
Rahmawati N, Astuti R, Ikasari DM. 2014. Analisis Pengaruh Motivasi dan Lingkungan Kerja terhadap Kepuasan Kerja dan Kinerja Karyawan di PT. Sinar Sosro Kantor Penjualan Wilayah (KPW) Waru, Sidoarjo-Jawa Timur.
Jurnal Lulusan TIP FTP UB. 1:1-12
Safitri D, Widiharih T, Wilandari Y, Saputra AH. 2012. Analisis Cluster pada Kabupaten/Kota di Jawa Tengah berdasarkan Produksi Palawija. Jurnal Media Statistika. 5(1):11-16.
Serban G, Grigoreta SM. 2006. A Comparison of Clustering Techniques in Aspect Mining. Studia Univ. Babes Bolyai Informatica. L1(1):69-78.
Waryanto B, Millafati YA. 2006. Transformasi Data Skala Ordinal ke Interval Menggunakan Makro Minitab. Jurnal Informatika Pertanian. 15:881-895. Yunianto Y. 2011. Perbandingan Metode Penggerombolan dengan Komponen
Utama Nonlinier dan Gerombol Dua Langkah pada Data Campuran
18
LAMPIRAN
Lampiran 1 Peubah kategorik awal yang digunakanNo Peubah Definisi label Kategori Skala
pengukuran 1 Pendidikan (X1) Jenjang pendidikan terakhir
kepala rumah tangga.
1:Tidak tamat SD 2:Tamat SD/sederajat 3:Tamat SMP/sederajat 4:Tamat SMA/sederajat 5:Tamat perguruan
tinggi/sederajat
Ordinal
2 Lantai kap (X2) Luas lantai per kapita (Luas lantai dibagi dengan jumlah anggota rumah tangga)
1:8m2/kap
2:8 30 m2/kap
3:31 50 m2/kap
4:50m2/kap
Ordinal
3 Jenis lantai (X3) Jenis lantai terluas yang dihuni rumah tangga
1:Tanah 2:Bukan tanah
Nominal
4 Dinding (X4) Jenis dinding terluas dari rumah yang dihuni
1:Tembok 2:Bukan tembok
Nominal
5 Atap (X5) Jenis atap rumah 1:Seng/beton/genteng/ asbes
2:Sirap/ijuk/lainnya
Nominal
6 Jamban (X6) Fasilitas pembuangan air besar
1:Milik sendiri 2:Bukan milik sendiri 3:Tidak ada
Nominal
7 Air minum (X7) Sumber air minum yang digunakan sehari-hari dalam rumah tangga
1:Sumber terlindung 2:Sumber tidak Terlindung
Nominal
8 Bahan bakar (X8)
Jenis bahan bakar yang digunakan untuk memasak
1:Listrik/gas 2:Minyak tanah 3:Arang/briket/kayu
Nominal
9 Aset (X9) Status kepemilikan rumah tinggal
1:Milik sendiri 2:Bukan milik sendiri
Nominal
10 Literasi (X10) Kemampuan baca/tulis kepala rumah tangga
1:Tidak bisa bahasa latin 2: Bisa bahasa latin
Nominal
11 Pekerjaan (X11) Lapangan usaha utama kepala rumah tangga
1:Pertanian 2:Perikanan 3:Peternakan 4:Pertambangan/ penggalian 5:Industri pengolahan 6:Listrik/gas 7:Konstruksi 8:Perdagangan/hotel dan rumah makan dan akomodasi
9:Angkutan, pergudangan, komunikasi
19
No Peubah Definisi label Kategori Skala
pengukuran 10:Jasa, keuangan, real
estate, persewaan 11:Jasa kemasyrakatan,
sosial 12:Lainnya 13:Tidak bekerja 12 Raskin (X12) Terdata pernah menerima
manfaat program beras murah / beras miskin dari pemerintah
1: Ya
2: Tidak Nominal
13 Handphone (X13)
Kepemilikan minimal satu buah handphone dalam rumah tangga tersebut
1: Ya 2: Tidak
20
Lampiran 2 Peubah berskala ordinal
No Peubah Definisi label Kategori Skala
pengukuran 1 Pendidikan (X1) Jenjang pendidikan terakhir
kepala rumah tangga.
1: Tidak tamat SD 2: Tamat SD/sederajat 3: Tamat SMP/sederajat 4: Tamat SMA/sederajat 5: Tamat perguruan
tinggi/sederajat
Ordinal
2 Lantai kap (X2) Luas lantai per kapita (Luas lantai dibagi dengan jumlah anggota rumah tangga)
1:8m2/kap
2:8 30 m2 /kap
3:31 50 m2/kap
4:50m2/kap
Ordinal
3 Jenis lantai (X3) Jenis lantai terluas yang dihuni rumah tangga
1: Bukan Tanah 2: Tanah
Ordinal
4 Dinding (X4) Jenis dinding terluas dari rumah yang dihuni
1: Bukan Tembok 2: Tembok
Ordinal
5 Atap (X5) Jenis atap rumah 1: Bukan Seng/Genteng 2: Seng/Genteng
Ordinal
6 Jamban (X6) Fasilitas pembuangan air besar
1: Tidak ada
2: Bukan milik sendiri 3: Milik endiri
Ordinal
7 Air minum (X7) Sumber air minum yang digunakan sehari-hari dalam rumah tangga
1: Sumber tidak terlindung 2: Sumber terlindung
Ordinal
8 Bahan bakar (X8) Jenis bahan bakar yang digunakan untuk memasak
1: Arang/briket/kayu 2: Minyak tanah 3: Listrik/gas
Ordinal
9 Aset (X9) Status kepemilikan rumah tinggal
1: Bukan milik sendiri 2: Milik sendiri
Ordinal
10 Literasi (X10) Kemampuan baca/tulis kepala rumah tangga
1:Tidak bisa bahasa latin 2: Bisa bahasa latin
Ordinal
11 Pekerjaan (X11) Lapangan usaha utama kepala rumah tangga
1: Tidak Bekerja 2: Bekerja
Ordinal
12 Raskin (X12) Terdata pernah menerima manfaat program beras murah / beras miskin dari pemerintah
1: Pernah
2: Tidak Pernah Ordinal
13 Handphone (X13) Kepemilikan minimal satu
buah handphone dalam rumah tangga tersebut
1: Tidak Punya 2: Punya
21 Lampiran 3 Deskripsi 15 peubah kategorik
X3 (Jenis Lantai)
Frekuensi Persentase Presentase kumulatif
Bukan Tanah 7526 72.2 72.2
Tanah 2896 27.8 100.0
Total 10422 100.0
X1(Pendidikan)
Frekuensi Persentase Persentase kumulatif
Tidak Tamat SD 1117 10.7 10.7
Tamat SD/Sederajat 5623 54.0 64.7
Tamat SMP/Sederajat 1317 12.6 77.3
Tamat SMA/Sederajat 1631 15.6 93.0
Tamat Perguruan Tinggi/Sederajat
734 7.0 100.0
Total 10422 100.0
X2(Luas Lantai)
Frekuensi Persentase Persentase kumulatif
<8m2/kap 30 0.3 0.3
8-30m2/kap 1598 15.3 15.6
31-50m2/kap 4365 41.9 57.5
>50m2/kap 4429 42.5 100.0
Total 10422 100.0
X4 (Jenis Dinding)
Frekuensi Persentase
Persentase kumulatif
Tembok 7019 67.3 67.3
Bukan Tembok 3403 32.7 100.0
22
X5 (Atap)
Frekuensi Persentase Persentase kumulatif
Bukan Seng/Genteng 2012 19.3 19.3
Seng/Genteng 8410 80.7 100.0
Total 10422 100.0
X6 (Jamban)
Frekuensi Persentase Persentase kumulatif
Tidak Ada 2225 21.3 21.3
Bukan Milik Sendiri 1510 14.5 35.8
Milik Sendiri 6687 64.2 100.0
Total 10422 100.0
X7 (Air Minum)
Frekuensi Persentase Persentase kumulatif
Sumber Tidak Terlindung 3026 29.0 29.0
Sumber Terlindung 7396 71.0 100.0
Total 10422 100.0
X8 (Bahan Bakar)
Frekuensi Persentase Persentase kumulatif
Arang/Briket/Kayu 8687 83.4 83.4
Minyak Tanah 1638 15.7 99.1
Listrik/Gas 97 0.9 100.0
Total 10422 100.0
X9 (Aset)
Frekuensi Persentase Persentase kumulatif
Bukan Milik Sendiri 1178 11.3 11.3
Milik Sendiri 9244 88.7 100.0
23
X12 (Raskin)
Frekuensi Persentase Persentase kumulatif
Pernah 5542 53.2 53.2
Tidak Pernah 4880 46.8 100.0
Total 10422 100.0
X13 (Handphone)
Frekuensi Persentase
Persentase kumulatif
Tidak Punya 3623 34.8 34.8
Punya 6799 65.2 100.0
Total 10422 100.0
X10 (Literasi)
Frekuensi Persentase
Persentase kumulatif
Tidak Bisa Bahasa Latin 1515 14.5 14.5
Bisa Bahasa Latin 8907 85.5 100.0
Total 10422 100.0
X11 (Pekerjaan)
Frekuensi Persentase Persentase kumulatif Tidak Bekerja
Bekerja
914 9508
8.8 91.2
8.8 100.0
24
Lampiran 4 Asosiasi peubah kategorik
Peubah X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12 X13
X1 1
X2 0.150 1
X3 -0.211 -0.240 1
X4 0.288 0.342 -0.274 1
X5 0.247 0.311 -0.213 0.321 1
X6 0.254 0.272 -0.126 0.250 0.282 1
X7 0.207 0.113 -0.103 0.207 0.255 0.169 1
X8 0.434 0.098 -0.241 0.326 0.205 0.177 0.242 1
X9 -0.242 0.121 0.104 -0.086 -0.113 0.033 -0.118 -0.268 1
X10 0.553 0.097 -0.092 0.133 0.214 0.185 0.145 0.154 -0.100 1
X11 0.014 -0.005 0.067 -0.088 -0.047 -0.005 -0.058 -0.136 0.039 0.086 1
X12 -0.271 -0.102 0.124 -0.193 -0.141 -0.130 -0.191 -0.322 0.156 -0.105 0.088 1
25 Lampiran 5 Data hasil successive interval
Objek X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12 X13 1 2.375 4.984 1.000 2.640 2.759 2.945 2.662 1.000 2.912 2.838 2.991 2.597 2.629 2 4.637 4.984 1.000 2.640 2.759 2.945 2.662 2.729 2.912 2.838 2.991 2.597 2.629 3 4.637 4.984 1.000 2.640 2.759 2.945 2.662 2.729 2.912 2.838 2.991 2.597 2.629 4 3.786 4.984 1.000 2.640 2.759 2.945 2.662 2.729 2.912 2.838 2.991 2.597 2.629 5 3.786 4.984 1.000 2.640 2.759 2.945 2.662 2.729 2.912 2.838 2.991 2.597 2.629
26
RIWAYAT HIDUP
Penulis dilahirkan di Kupang, Kelurahan Fatululi, Kecamatan Oebobo, Kota Kupang Nusa Tenggara Timur pada tanggal 9 Agustus 1990 sebagai anak pertama dari pasangan Bapak Marthen Tamonob dan Ibu Paulina Tamonob-Doko. Penulis menyelesaikan studi SD di SD Negeri Oebobo 2 pada tahun 2002. Pada tahun yang sama penulis melanjutkan pendididikan di SMP Negeri 2 Kupang dan tamat pada tahun 2005, lalu dilanjutkan ke SMA Negeri 1 Kupang dan menamatkan pendidikan SMA pada tahun 2008. Pendidikan sarjana dilanjutkan pada tahun yang sama di Universitas Nusa Cendana Kupang pada Jurusan Matematika, Fakultas Sains dan Teknik dan selesai pada tahun 2012.