7
ANALISIS KOMPONEN UTAMA (AKU) UNTUK PENGELOMPOKAN AREA PELAYANAN
DAN JARINGAN (APJ) DAERAH JAWA TENGAH DAN D.I. YOGYAKARTA
Safaat Yulianto, Ully Putriana
Akademi Statistika (AIS) Muhammadiyah Semarang Email: safaatyulianto@yahoo.com, ullyputri12@gmail.com
Abstract
Principal component analysis is a statistical analysis of multiple variables that can be used to reduce the number of original variables into new variables that are orthogonal and keep the total variability of the original variables. This study will classify each APJ in Central Java and Yogyakarta based on the factors that influence it. The data used is the Data and Statistics Year 2010 issued by PT. PLN (Persero) Distribution Central Java and D.I. Yogyakarta.
Keywords : komponen utama, klaster, metode hirarki, jarak euclidien 1 PENDAHULUAN
Seiring dengan perkembangan teknologi dalam berbagai bidang yang semakin pesat, terjadi peningkatan dalam penyediaan kelistrikan yang disesuaikan dengan kebutuhan masyarakat. Dalam hal ini Perusahaan Listrik Negara (PLN) selaku penyedia energi tersebut dituntut untuk menyediakan listrik. Selain itu, PLN juga dituntut untuk menjaga mutu dari energi tersebut. PLN merupakan salah satu perusahaan milik negara yang memberikan pelayanan kepada calon pelanggan dan masyarakat dalam penyediaan jasa yang berhubungan dengan penjualan tenaga listrik satu-satunya di Indonesia.
Peningkatan energi listrik melonjak begitu pesat dan cepat, pembangunan pusat-pusat tenaga listrik serta jaringan transmisi dan distribusinya meminta investasi yang besar dan waktu yang lama dibandingkan dengan pembangunan industri lainnya. Di pihak lain perlu diusahakan agar dapat memenuhi kebutuhan tenaga listrik tepat pada waktunya, dengan kata lain pembangunan bidang kelistrikan harus dapat mengimbangi kebutuhan tenaga listrik yang terus menerus naik setiap tahunnya.
Jawa Tengah merupakan salah satu provinsi di Indonesia yang terletak di bagian tengah Pulau Jawa, secara geografis Jawa Tengah mencakup wilayah Daerah Istimewa Yogyakarta (DIY). Saat ini perkembangan di Jawa Tengah tidak bisa lepas dari sistem kelistrikan, dilihat dari peningkatan energi listrik Jawa-Bali, cadangan listrik mencapai 1,150 MW dengan beban siang 19,179 MW dan beban pada malam hari 20,343 MW. Pada saat beban puncak pada malam hari, PLN biasanya juga memaksimalkan pasokan dari PLTA, untuk itu jumlah pembangkit yang ada di Jawa Tengah ditargetkan akan ada penambahan seiring penambahan jumlah pelanggan. PT. PLN (Persero) Distribusi Jawa Tengah dan D.I Yogyakarta adalah satuan administrasi yang tidak memiliki fasilitas pembangkitan dan transmisi. Unit ini membeli energi listrik dari unit PLN Pembangkitan yang diterima di outgoing Gardu Induk (GI), termasuk unit dibawahnya yaitu APJ. Salah satu fungsi APJ adalah menyediakan tenaga listrik meliputi pembangunan, sarana kelistrikan, pembangkitan tranmisi serta distribusi bagi kepentingan umum sekaligus memupuk keuntungan berdasarkan prinsip akuntansi, sehingga APJ berperan dalam pengaturan kebutuhan listrik sampai ke pelanggan sesuai dengan kebutuhan energi listrik termasuk
juga dalam masaah pemadaman bergilir yang disebabkan oleh beban puncak.
Sistem kelistrikan di Jawa Tengah dan D.I. Yogyakarta, merupakan bagian dari sistem interkoneksi Jawa-Bali. Aliran listrik di Jawa Tengah dan D.I. Yogyakarta yang diperoleh dari sistem interkoneksi ini, berasal dari beragam jenis pembangkit baik PLTA, PLTU, PLTGU maupun PLTG yang berlokasi diberbagai wilayah Indonesia. Melalui data sekunder yang diperoleh pada Tahun 2010, PT. PLN (Persero) Distribusi Jawa Tengah dan D.I. Yogayakarta akan dilakukan analisis untuk mengetahui karakteristik distribusi setiap APJ di Jawa Tengah dan D.I. Yogyakarta Tahun 2010, sehingga dapat menjadi pertimbangan yang tepat bagi masing-masing APJ untuk mengambil langkah-langkah yang strategis.
2 TINJAUAN PUSTAKA 2.1 Analisis Komponen Utama
Analisis komponen utama merupakan analisis statistika peubah ganda yang dapat digunakan untuk mereduksi sejumlah peubah asal menjadi beberapa peubah baru yang bersifat ortogonal dan tetap mempertahankan total keragaman dari peubah asalnya (Nugroho, 2008). Peubah-peubah baru itu disebut sebagai komponen utama (principal component). Semua peubah dalam AKU merupakan peubah dengan skala interval/rasio. Analisis ini mengurangi banyaknya dimensi peubah yang saling berkorelasi menjadi komponen utama yang tidak berkorelasi dengan mempertahankan sebanyak mungkin keragaman dalam himpunan data tersebut artinya dengan dimensi yang lebih kecil diharapkan lebih mudah melakukan penafsiran atau interpretasi tanpa kehilangan banyak informasi tentang data. Komponen utama (KU) yang terbentuk diharapkan seminimal mungkin, akan tetapi mampu menerangkan keragaman total yang maksimal. Banyaknya KU yang dipilih dapat ditentukan dengan beberapa prosedur yaitu berdasarkan eigenvalues, scree plot, percentage of variance accounted for, splithalf reliability, dan significance test.
Secara aljabar linier, KU adalah kombinasi-kombinasi linier tertentu dari p peubah acak x1,x2,…,xp, dimana koefisiennya adalah vektor ciri (eigen vector). KU tergantung pada matrik kovarian () dan matrik korelasi () dari x1,x2,…,xp dikarenakan vektor ciri dihasilkan dari akar ciri
8 (eigen value) matrik kovarian atau dapat juga dihasilkan dari matrik korelasi.
Melalui persamaan karakteristik matrik kovarian diperoleh akar ciri-akar cirinya yaitu 12…p0 dan vektor-vektor
cirinya yaitu e1,e2,…,ep. Menyusutkan dimensi peubah asal X
adalah dengan membentuk peubah baru Y= e’X dimana, e adalah matrik tranformasi yang mengubah peubah asal X menjadi KU Y, karena itu sering disebut vektor pembobot.
KU pertama adalah kombinasi linier terbobot dari peubah asal yang mempunyai varian terbesar. KU kedua juga merupakan kombinasi linier terbobot dari peubah asal dengan varian terbesar kedua dan antara kedua KU tersebut tidak berkorelasi demikian seterusnya. Secara umum, KU ke-i dapat dituliskan sebagai
dimana adalah vektor ciri (eigen vector) ke-i yang berpadanan dengan akar cirinya. Melalui persamaan di atas
akan di dapat dan . Hal ini
menunjukkan bahwa komponen utama tidak saling berkorelasi dan komponen utama ke-i memiliki keragaman sama dengan akar ciri ke-i. Oleh karena itu, keragaman total yang mampu diterangkan oleh setiap komponen utama adalah proporsi antara akar ciri komponen utama tersebut dengan jumlah akar ciri matrik kovarian.
Apabila KU yang diambil adalah q buah, dimana q<p, maka proporsi keragaman data yang bisa diterangkan adalah:
Matrik kovarian digunakan jika peubah yang diamati ukurannya pada skala dengan perbedaan tidak besar atau jika satuan ukurannya sama. Bila peubah yang diamati ukurannya pada skala dengan perbedaan yang sangat besar, atau ukurannya tidak sama, maka peubah tersebut perlu dibakukan sehingga KU ditentukan dari peubah baku (Johnson dan Wichern, 1992).
Peubah baku (Z) diperoleh dari transformasi terhadap peubah asal dalam matrik sebagai berikut:
Z = (V1/2)-1(X-)
V1/2 adalah matrik simpangan baku dengan unsur diagonal
utama
(
ii)1/2 dengan unsur lainnya adalah 0. Nilai harapanE(Z)=0 dan keragamannya Cov(Z)=(V1/2)-1(V1/2)-1 = .
Dengan demikian KU dari Z dapat ditentukan dari vektor ciri yang diperoleh melalui matrik korelasi peubah asal .
Untuk mencari akar ciri dan menentukan vektor pembobotnya sama seperti pada matrik . Akar ciri yang didapat dari matrik korelasi akan memiliki trace (jumlah seluruh akar ciri) sama dengan jumlah peubah (p) yang dipakai.
2.2 Analisis Klaster (Cluster)
Analisis klaster merupakan suatu metode untuk mengelompokkan individu ke dalam beberapa kelompok dimana setiap unit pengamatan dalam suatu kelompok akan mempunyai ciri yang relatif sama dengankan antar kelompok unit pengamatan memiliki sifat yang berbeda.
Asumsi yang harus dipenuhi dalam penerapan analisis klaster adalah:
1. Sampel yang diambil harus dapat mewakili populasi yang ada.
2. Multikolinieritas. Multikolinieritas adalah kemungkinan adanya korelasi antar peubah bebas. Sebaiknya tidak ada atau seandainya ada, besar multikolinieraitas tersebut tidaklah tinggi. Bila data yang digunakan dalam analisis klaster adalah data skor komponen dari hasil AKU, maka tidak akan ditemukan lagi adanya multikolinieritas. Sebelum melakukan pengelompokkan terlebih dulu ditentukan jarak kedekatan (similarity) antar individu. Penentuan ukuran individu ini meliputi ukuran keragaman dalam kelompok yang terbentuk dan ukuran keragaman antar kelompok. Ukuran keragaman dalam kelompok relatif lebih kecil daripada keragaman antar kelompok. Keragaman antar kelompok dapat ditetapkan oleh taksiran jarak diantara dua nilai pusat kelompok dalam membandingkan dengan jarak dari anggota kelompok terhadap pusat kelompok.
Ukuran kedekatan yang digunakan adalah jarak euclidien. Jarak ini digunakan apabila antar peubah-peubah individu tidak berkorelasi. Ukuran jarak euclidien untuk dua buah unit X dan Y adalah:
2 1
= − = p k jk ik ij x x ddengan, = jarak euclidien, xik = nilai objek ke-i pada variablel k, = nilai objek ke-j pada variabel k,(k = 1,2,3....p) 3 METODOLOGI PENELITIAN
Dalam penelitian ini, digunakan 7 variabel untuk menentukan distribusi PT. PLN (Persero) daerah Jawa Tengah dan D.I. Yogyakarta, yang terdiri dari: Luas Wilayah (Km2),
Jumlah Penduduk (Jiwa), Jumlah Pelanggan (Orang), Daya Tersambung (MVA), Energi Terjual (MWh), Jumlah Pendapatan (Juta), Beban Puncak (MW).
4 HASIL PENELITIAN 4.1 Analisis Komponen Utama
Sebelum dilakukan Analisis Komponen Utama (AKU), seluruh data distandarisasi terlebih dahulu dengan mentransformasikan data ke dalam bentuk Z-score. Hal ini untuk menghilangkan bias yang disebabkan satuan dan rentang data yang bervariasi.
9 Pada hasil tersebut dapat diketahui nilai uji Bartlett sebesar 116.908 pada derajat bebas 21 dengan tingkat signifikansi 0.000 jauh di bawah 0.05 menunjukkan bahwa matrik korelasi bukan matrik identitas sehingga dapat dilakukan analisis komponen utama.
Matriks Anti-Image digunakan untuk melihat peubah mana saja yang harus dikeluarkan karena tidak bisa diprediksi dan tidak bisa dianalisis lebih lanjut. Peubah yang dikeluarkan adalah peubah yang memiliki Measures of Sampling Adequacy (MSA) < 0.5. Sedangkan bila terdapat lebih dari satu peubah yang memiliki MSA (dalam output bertanda a) < 0.5 maka yang dikeluarkan adalah peubah dengan MSA terkecil.
MSA adalah ukuran kecukupan sampel yang digunakan untuk penelitian, jadi sangat penting untuk diperhatikan apabila data yang digunakan berupa sampel untuk mengestimasi nilai populasi penelitian.
Tabel 2. Nilai MSA 7 Peubah.
Peubah Nilai MSA
Zscore : luas wilayah 0.568 Zscore : jumlah penduduk 0.638 Zscore : jumlah pelanggan 0.585 Zscore : daya tersambung 0.675 Zscore : energy terjual 0.753
Zscore : pendapatan 0.612
Zscore : beban puncak 0.793
Berdasarkan tabel tersebut dapat diketahui bahwa nilai MSA > 0.5 maka tidak ada peubah yang harus dikeluarkan sehingga dapat dianalisis lebih lanjut.
Tabel 3. Komponen Utama Yang Terbentuk Berdasarkan Akar Ciri, Persentase Keragaman dan Persentase Keragaman
Komulatif. Komponen Utama Akar Ciri Persentase Keragaman Persentase Keragaman Kumulatif 1 5.678 81.115 81.115 2 1.104 15.765 96.880 3 .113 1.619 98.499 Komponen Utama Akar Ciri Persentase Keragaman Persentase Keragaman Kumulatif 4 .066 .939 99.438 5 .025 .353 99.791 6 .012 .170 99.961 7 .003 .039 100.000
Tabel 3. memperlihatkan bahwa banyaknya komponen utama yang terbentuk sama dengan banyaknya peubah asal yaitu tujuh komponen utama. Dengan melihat dari akar ciri, maka didapat dua komponen utama yang mempunyai akar ciri lebih dari satu yaitu komponen utama 1 dan 2. Kedua komponen utama tersebut kemudian disebut faktor dimana faktor-faktor tersebut mampu menerangkan keragaman total peubah asal sebesar 96.80 persen. Pada hasil pengolahan menunjukkan bahwa persentase keragaman kumulatif tidak kurang dari 75 persen sehingga dapat dikatakan bahwa komponen utama yang terbentuk sudah menggambarkan data asalnya.
Tabel 4. Matrik Transformasi Komponen Berdasarkan 7 Peubah.
Komponen 1 2 1 0.784 0.621 2 -0.621 0.784
Pada tabel 4. yang perlu diperhatikan adalah nilai-nilai yang ada pada diagonal antara komponen satu dengan komponen satu, komponen dua dengan komponen dua. Terlihat bahwa kedua angka jauh di atas 0.50, hal ini membuktikan bahwa kedua faktor (component) yang terbentuk sudah tepat, karena mempunyai korelasi yang tinggi.
4.2 Analisis Klaster (Cluster)
Proses analisis dilakukan dengan metode pengelompokan hirarki menggunakan jarak euclidean dan pautan rata-rata (average linkage) diperoleh tabel amalgamation steps, yaitu tahap penggabungan dimana masing-masing tahap, dua objek yang terdekat bergabung menjadi satu kelompok.
Pengelompokan masing-masing objek dilakukan dengan metode agglomeratif sehingga terbentuk kelompok-kelompok sendiri. Proses agglomeratif adalah menentukan jarak terdekat antar objek yang akan di gabung. Proses penggabungan dua objek atau lebih dapat dilihat pada tabel agglomeration schedule, yang tahapnya meliputi:
▪ Pada tahap (stage) 1 terbentuk satu klaster antara APJ Magelang dan APJ Pekalongan dengan nilai koefisien 0.177, angka tersebut menunjukan jarak antara APJ Magelang dan APJ Pekalongan, jarak tersebut merupakan jarak yang paling dekat.
Bartlett’s Test of Sphericity Approx. Chi-Square Df Signifikan
10 ▪ Pada tahap 2, dapat dilihat terbentuknya klaster antar APJ
Purwokerto dengan APJ Magelang, maka sekarang klaster terdiri dari tiga objek yaitu APJ Purwokerto, APJ Magelang dan APJ Peklongan. Nila koefisien sebesar 1.141 yang menunjukan besarnya jarak terdekat antara APJ Purwokerto dengan klaster sebelumnya (APJ Magelang dan APJ Pekalongan).
▪ Demikian proses klaster dilakukan hingga kolom tahap selanjutnya menunjukan nilai tahap 0 (sampai ke tahap yang terakhir), yang berarti proses pengelompokan dengan agglomeratife berhenti.
Tabel 5. Hasil Pengelompokan dengan metode hirarki pautan rata -rata (Average linkage).
Kelompo k
Anggota kelompok Area Pelayanan dan Jaringan ( APJ )
I APJ Semarang, APJ Yogyakarta, APJ Surakarta II APJ Purwokerto, APJ Tegal, APJ Magelang, APJ
Kudus, APJ Cilacap
III APJ Salatiga, APJ Klaten, APJ Pekalongan
Kelompok I mempunyai 3 anggota, kelompok II mempunyai 5 anggota dan kelompok III mempunyai 3 anggota. Setiap anggota dalam satu kelompok mempunyai kemiripan atau partisipasi pendistribusian yang relatif sama. Kelompok I terdiri dari APJ Semarang, APJ Yogyakarta, APJ Surakarta, kelompok II terdiri dari APJ Purwokerto, APJ Tegal, APJ Magelang, APJ Kudus, APJ Cilacap. Sedangkan kelompok III terdiri dari APJ Salatiga, APJ Klaten, APJ Pekalongan.
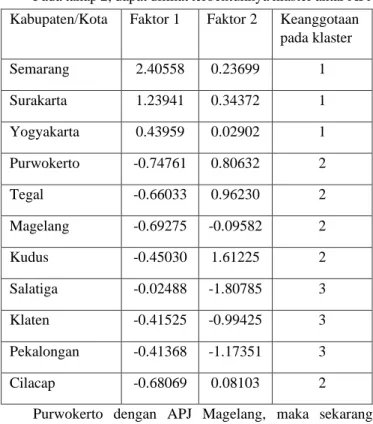
Tabel 6. Nilai Tiap Faktor Utama dan Keanggotaan Klaster Menurut Area Pelayanan dan Jaringan (APJ) di Jawa Tengah
dan D.I. Yogyakarta
Pada Tabel 6 memudahkan kita melihat ringkasan dari keanggotaan tiap APJ pada klaster dan nilai dari faktor 1 dan 2 tiap-tiap APJ. Dari tabel di atas dapat dihitung nilai rata-rata tiap faktor masing-masing klaster sehingga mudah dalam menginterpretasikan keadaan tiap klaster.
Tabel 7. Rata-Rata Skor Faktor Tiap Klaster.
Klaster Faktor1 Faktor 2
I 1.36153 0.20324
II -0.64634 0.35077
III -0.28460 -1.32520
5 Kesimpulan
Berdasarkan hasil analisa data dan pembahasan yang telah dilakukan maka dapat ditarik kesimpulan sebagai berikut: 1. Pendistribusian terbesar terdapat pada APJ Semarang
meskipun ada satu variabel yaitu luas wilayah yang terluas terdapat pada APJ Kudus, sehingga luas wilayah tidak begitu berpengaruh dalam pendistribusian pada setiap APJ. 2. Ada tiga klaster APJ Jawa Tengah dan D.I. Yogyakarta
berdasarkan karakteristik distribusi:
a. APJ dengan Pendistribusian tinggi yang terdiri dari APJ Semarang, APJ Surakarta, dan APJ Yogyakarta. b. APJ dengan Pendistribusiam sedang, yang terdiri dari APJ Purwokerto, APJ Tegal, APJ Magelang, APJ Kudus, APJ Cilacap.
c. APJ yang memiliki pendistribusian rendah, yang terdiri dari APJ Salatiga, APJ Klaten, APJ Pekalongan.
DAFTAR PUSTAKA
Ghozali, I. 2006. Aplikasi Analisis Multivariat Dengan Program SPSS, Cetakan IV. Semarang: Badan Penerbit Universitas Diponegoro.
Johnson R, Wichern D. 1992. Applied Multivariate Statistical Analysis. Third Edition. New Jersey : A Paramount Communications Company.
Nugroho, S. 2008. Statistika Multivariat Terapan, Edisi 1. Bengkulu: UNIB Press.
[PT PLN] PT Perusahaan Listrik Negara (Persero) (2010). Data Dan Statistik Tahun 2010. Semarang. (tidak diterbitkan).
______(2010). Electricity for Business in Jawa Tengah D.I Yogyakarta. Semarang. (tidak diterbitkan).
Kabupaten/Kota Faktor 1 Faktor 2 Keanggotaan pada klaster Semarang 2.40558 0.23699 1 Surakarta 1.23941 0.34372 1 Yogyakarta 0.43959 0.02902 1 Purwokerto -0.74761 0.80632 2 Tegal -0.66033 0.96230 2 Magelang -0.69275 -0.09582 2 Kudus -0.45030 1.61225 2 Salatiga -0.02488 -1.80785 3 Klaten -0.41525 -0.99425 3 Pekalongan -0.41368 -1.17351 3 Cilacap -0.68069 0.08103 2
11 ______(2011). PT PLN (Persero) [terhubung berkala].
http://www.pln.co.id [17/02/2012]
Supranto, J. 2004. Analisis Multivariat (Arti dan Interpretasi). Jakarta: Rineka Cipta.