ALGORITMA GENETIKA UNTUK PENDETEKSIAN
PENCILAN PADA ANALISIS REGRESI LINIER
AMRI LUTHFI NAJIH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Algoritma Genetika untuk Pendeteksian Pencilan pada Analisis Regresi Linier adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Agustus 2014
Amri Luthfi Najih
ABSTRAK
AMRI LUTHFI NAJIH. Algoritma Genetika untuk Pendeteksian Pencilan pada Analisis Regresi Linier. Dibimbing oleh BAGUS SARTONO dan ITASIA DINA SULVIANTI.
Masalah yang sering dihadapi ketika melakukan analisis regresi linier adalah keberadaan data pencilan. Pencilan merupakan suatu keganjilan. Seringkali data pencilan memiliki nilai yang berbeda, lain dari biasanya dan tidak mencerminkan karakteristik data secara umum. Pencilan dapat mempengaruhi dugaan model. Dugaan model yang dihasilkan tidak dapat menggambarkan hubungan antara variabel secara umum. Sehingga, analisis atau interpretasi yang dihasilkan menjadi salah. Oleh karena itu perlu dilakukan pendeteksian pencilan sebelum melakukan analisis regresi. Kriteria Informasi dapat digunakan untuk mendeteksi pencilan. Kriteria Informasi dihitung dengan menyisihkan amatan yang diduga sebagai pencilan. Nilai Kriteria Informasi minimum menunjukkan bahwa amatan yang disisihkan merupakan pencilan. Namun akan banyak kombinasi amatan yang diduga sebagai pencilan yang mungkin ditemukan dalam satu gugus data. Hal tersebut akan menyita waktu ketika dilakukan secara manual. Algoritma genetika dapat digunakan untuk menghitung nilai Kriteria Informasi, sehingga dapat digunakan untuk menentukan nilai minimumnya. Algoritma genetika dapat melakukan pendeteksian seluruh amatan yang berpotensi sebagai pencilan secara serempak. Namun ada beberapa kekurangan dalam program ini, yaitu masalah kecepatan program. Semakin banyak amatan semakin banyak juga waktu yang diperlukan. Banyaknya peubah dalam data tidak mempengaruhi kemampuan program untuk mencapai nilai kriteria informasi minimum.
Kata kunci: Algoritma Genetika , Kriteria Informasi, Pencilan, Regresi linier.
ABSTRACT
program, that is the problem of program speed. The more observations the more time is required. The number of variables in the data does not affect the program's ability to achieve the minimum information criterion.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada
Departemen Statistika
ALGORITMA GENETIKA UNTUK PENDETEKSIAN
PENCILAN PADA ANALISIS REGRESI LINIER
AMRI LUTHFI NAJIH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Algoritma Genetika untuk Pendeteksian Pencilan pada Analisis Regresi Linier
Nama : Amri Luthfi Najih NIM : G14100041
Disetujui oleh
Dr Bagus Sartono, MSi Pembimbing I
Dra Itasia Dina Sulvianti, MSi Pembimbing II
Diketahui oleh
Dr Anang Kurnia, MSi Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Karya ilmiah ini berjudul Algoritma Genetika untuk Pendeteksian Pencilan pada Analisis Regresi Linier.
Terselesainya penyusunan karya ilmiah ini tidak lepas dari dukungan, motivasi, saran, dan kerjasama dari berbagai pihak. Oleh karena itu, penulis mengucapkan terima kasih kepada:
1. Bapak Suhamto dan Ibuk Anis Husainiah selaku orangtua penulis, yang selalu mendoakan penulis untuk menggapai cita – citanya, serta selalu mendukung dan mengarahkan segala sesuatu yang telah dilakukan oleh penulis.
2. Bapak Dr Bagus Sartono, MSi dan Dra Itasia Dina Sulvianti, MSi selaku pembimbing skripsi yang selalu bersemangat untuk mebimbing dan selalu memberi arahan yang positif kepada penulis dalam menyelesaikan karya ilmiah ini.
3. Teman – teman Statistika 2010 IPB yang selama tiga tahun telah menjadi sahabat penulis di Bogor, dan sealu memberi motivasi pada penulis.
4. Staf dan pegawai tata usaha Departemen Statistika yang telah membantu penulis untung mengurusi segala administrasi perkuliahan.
Penulis mengucapkan terimakasih juga pada pihak – pihak yang belum disebutkan diatas, atas bantuannya terhadap penulis untuk menyelesaikan karya ilmiah ini.
Semoga karya ilmiah ini bermanfaat.
Bogor, 14 Agustus 2014
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan 2
TINJAUAN PUSTAKA 2
Algoritma Genetika 2
Kriteria Informasi 3
Regresi linier 4
METODE PENELITIAN 6
Data 6
Prosedur Penelitian 7
HASIL DAN PEMBAHASAN 7
Pendeteksian Pencilan Secara Konvensional 7
Algoritma Genetika untuk Mendeteksi Pencilan 8
SIMPULAN 12
DAFTAR PUSTAKA 13
LAMPIRAN 14
DAFTAR TABEL
1 Hasil deteksi pencilan secara konvensional 8
2 Hasil deteksi pencilan dengan algoritma genetika 11
DAFTAR GAMBAR
1 Ilustrasi populasi 8
2 Ilustrasi perhitungan penduga ragam 9
3 Ilustrasi kawin silang 10
4 Waktu yang dibutuhkan algoritma genetika untuk mendeteksi
pencilan. 11
5 Diagram kotak garis banyaknya generasi untuk mencapai nilai
minimum 12
DAFTAR LAMPIRAN
1 Sisaan masing – masing data dari setiap tahap pendeteksian 14
2 Sintaks dalam software R 16
PENDAHULUAN
Latar Belakang
Analisis regresi merupakan alat statistika yang banyak digunakan di berbagai bidang ilmu, tidak hanya matematika dan statistika saja namun juga di bidang–bidang lain seperti biologi, kimia pertanian, teknik, ekonomi, dan lain-lain. Analisis regresi dapat digunakan untuk mengolah data dalam rangka mengetahui hubungan antar dua atau lebih peubah sehingga didapatkan model atau hubungan fungsional antar peubah. Peneliti dapat menggunakan model tersebut untuk berusaha memahami, menerangkan, mengendalikan dan kemudian mendapatkan informasi dari model yang dibangun.
Masalah yang sering dihadapi ketika melakukan analisis regresi linier adalah keberadaan data pencilan. Pencilan merupakan suatu keganjilan. Seringkali data pencilan memiliki nilai yang berbeda dengan lainnya. Pencilan dapat mempengaruhi dugaan model, sehingga analisis atau interpretasi yang dihasilkan menjadi salah. Oleh karena itu perlu dilakukan pendeteksian pencilan sebelum melakukan analisis regresi.
Pendeteksian pencilan bisa terjadi berulang-ulang dalam satu gugus data. Ketika pencilan pertama dihapus dari gugus data kemudian dilakukan pendeteksian kembali, sering muncul pencilan baru dari gugus data tersebut. Pendeteksian pencilan seperti itu selanjutnya dalam tulisan ini disebut dengan pendeteksian pencilan secara konvensional. Pendeteksian pencilan secara konvensional kurang efisien untuk dilakukan. Perlu satu cara untuk melakukan deteksi pencilan secara serempak, agar lebih efisien dilakukan.
Pendeteksian pencilan pada regresi linier telah dilakukan oleh Cook (1977) dengan menggunakan jarak Cook’s. Ukuran jarak Cook’s dirumuskan sebagai kombinasi dari sisaan terbakukan, ragam sisaan, dan ragam nilai dugaan. Seppo (1992) mengusulkan metode pendeteksian pencilan dengan cara membuat suatu besaran yang disebut Kriteria Informasi (KI). Pencilan ditentukan dengan menghitung nilai Kriteria Informasi minimum. Barnet dan Lewis (1994) mendeteksi pencilan dengan cara melihat pengaruh amatan yang tidak konsisten dengan amatan lain pada data dengan banyak peubah. Pena dan Prieto (2001) memperkenalkan metode pendeteksian pencilan yang didasarkan pada proyeksi amatan dari titik- titik data contohnya. Filmoser (2005) melakukan pendeteksian pencilan menggunakan jarak Mahalanobis. Adnan et al. (2003) menguraikan suatu metode untuk mendeteksi pencilan dalam regresi linier yang disebut metode
Least Trimmed of Squares (LTS) dan metode Single Lingkage Clustering (SLC). Xu et al. (2005) mengembangkan pendeteksian pencilan dalam model regresi linier dengan metode Likelihood Displacement (LD) dan metode Likelihood Ratio
(LR). Diaz et al. (2007) mengusulkan pendeteksian pencilan pada model regresi linier dengan modifikasi jarak Cook’s.
2
Pengembangan algoritma genetika dalam pemanfaatannya sebagai alat untuk menghitung solusi optimum dapat diterapkan dalam berbagai kasus pengoptimuman. Pencarian/pendeteksian pencilan dalam suatu analisis regresi dapat dipandang sebagai masalah pengoptimuman, yaitu menyisihkan amatan yang diduga sebagai pencilan sedemikian rupa sehingga nilai KI menjadi minimum. Sehingga, algoritma genetika dapat dimanfaatkan untuk kegiatan pendeteksian pencilan.
Tujuan
Tujuan dari tulisan ini adalah memperkenalkan alternatif metode pendeteksian pencilan dalam analisis regresi linier.
TINJAUAN PUSTAKA
Algoritma Genetika
Algoritma genetika adalah salah satu metode yang dapat digunakan untuk menyelesaikan masalah optimasi. Contoh masalah optimasi dalam kehidupan sehari-hari adalah menyusun barang-barang yang ingin dibawa ketika berlibur. Masalahnya adalah kita dapat membawa barang secara maksimal sesuai dengan kebutuhan namun dibatasi dengan kapasitas koper atau tas yang terbatas. Akan banyak sekali kobinasi barang bawaan kita, namun kita akan memilih barang bawaan yang sesuai dengan kebutuhan. Begitu juga dengan algoritma genetika, algoritma genetika bekerja dengan cara memilih solusi paling optimum dari beberapa solusi yang ada.
Cara kerja algoritma tersebut mengadopsi dari teori evolusi Darwin, sehingga istilah – istilah yang digunakan berkaitan dengan bidang genetika. Individu yang mampu bertahan sampai akhir proses seleksi adalah individu yang akan hidup, dengan prinsip tersebut algoritma genetika akan menghasilkan solusi optimum yang direpresentasikan oleh individu yang bertahan sampai akhir proses seleksi. Komponen - komponen dasar algoritma genetika adalah gen, individu, populasi, nilai fitness, seleksi, kawin silang, mutasi, kriteria konvergensi.
Gen merupakan komponen dasar pembentuk algoritma genetika. Gen dapat menjelaskan solusi dari masalah optimasi. Bentuk dari gen bisa berupa bilangan biner atau bilangan real (Haupt and Haupt 2004). Rangkaian beberapa gen membentuk satu individu. Kumpulan dari individu-individu membentuk populasi. Nilai fitness merupakan nilai dari fungsi objektif, nilai tersebut menggambarkan kebaikan dari satu individu. Tujuan algoritma genetika adalah mencari nilai fitness optimum (bisa maksimum atau minimum).
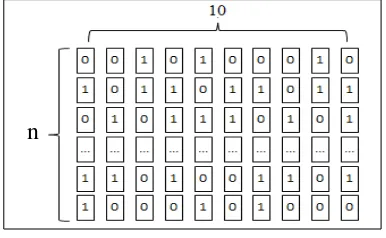
Tulisan ini menggunakan gen dalam bentuk bilangan biner 0 dan 1. Individu merepresentasikan satu gugus data. Banyaknya gen dalam satu individu sama dengan banyaknya amatan dalam satu gugus data. Populasi awal terdiri dari 10 buah individu. Untuk memahami gen, individu dan populasi dapat dilihat pada Gambar 1. Tujuan dari algoritma genetika ini adalah mencari nilai fitness
Individu-3 individu pada populasi dibentuk secara acak dan berevolusi melalui iterasi berurutan yang disebut generasi.
Seleksi dilakukan untuk mengurangi banyaknya individu dalam populasi. Seleksi dilakukan dengan memilih individu dengan nilai fitness minimum. Individu yang terpilih akan dilakukan kawin silang (crossover) untuk mendapatkan individu baru dan menurunkan sifat - sifat baik dari induknya. Dibutuhkan dua individu untuk melakukan kawin silang. Ada beberapa cara yang dapat digunakan untuk memilih dua individu tersebut, antara lain memasangkan individu yang memiliki urutan ganjil dengan individu urutan genap, random pairing, weighted random pairing (berdasarkan ranking atau nilai fitness) atau memasangkan semua individu dengan individu lain kecuali dengan individu itu sendiri. Selanjutnya, ada dua cara yang dapat digunakan untuk melakukan kawin silang, yaitu single point crossover untuk gen berupa bilangan biner dan blending method untuk gen berupa bilangan real.
Adanya pengaruh eksternal, memungkinkan terjadinya mutasi atau perubahan gen setelah kawin silang. Mutasi dalam kehidupan nyata sangat jarang terjadi dan tidak sampai mengubah seluruh populasi. Peluang terjadinya mutasi sangat rendah, biasanya ditetapkan nilainya oleh peneliti. Setelah proses mutasi, terbentuklah generasi baru yang didalamnya merupakan individu dengan karakteristik lebih baik.
Algoritma genetika merupakan proses iterasi atau berulang-ulang. Untuk menghentikan iterasi bisa dengan cara menentukan banyaknya iterasi atau dengan syarat tertentu.
Langkah – langkah algoritma genetika secara umum adalah sebagai berikut (Sivanandam dan Deepa 2008):
1. Mendefinisikan individu, fungsi objektif, peluang mutasi dan kriteria konvergensi yang sesuai dengan permasalahan.
2. Membangkitkan secara acak sebuah populasi sebagai generasi awal yang berisi beberapa individu.
3. Menghitung nilai fitness untuk masing-masing individu.
4. Memilih � individu dari populasi yang memiliki nilai fitness terbaik. 5. Melakukan kawin silang.
6. Melakukan mutasi dengan peluang yang telah ditentukan. 7. Menempatkan keturunan baru ke populasi baru.
8. Menghitung nilai fitness dari masing – masing individu pada generasi baru.
9. Mengulangi langkah 3 hingga 8 sampai memperoleh generasi yang memenuhi kriteria konvergensi yang telah ditetapkan.
Kriteria Informasi
4
statistik tataan dari sisaan. Dari statistik tataan sisaan tersebut dibentuk fungsi kriteria informasi dengan menggunakan metode kemungkinan maksimum. berikut fungsi kriteria informasi ( ) tersebut:
� �̂ � � �
dengan k adalah banyaknya amatan yang diduga sebagai pencilan, n merupakan banyaknya amatan dan �̂ merupakan penduga kemungkinan maksimum ragam dari data yang telah dibuang amatan yang dianggap sebagai pencilan. Kriteria Informasi ini merupakan fungsi objektif yang digunakan dalam algoritma genetika, yang akan dicari nilai fitness minimumnya.
Regresi Linier
Analisis regresi linier merupakan alat untuk mengevaluasi hubungan antara satu peubah dengan satu peubah lainnya atau antara satu peubah dengan beberapa peubah lainnya (Draper dan Smith 1992). Model yang digunakan untuk analisis regresi linier adalah sebagai berikut:
dengan Y merupakan peubah tidak bebas, p adalah banyaknya peubah bebas, xp merupakan peubah bebas ke–p, βp merupakan koefisien regresi dari peubah bebas ke–p dan ε adalah galat. Model tersebut merupakan model stokastik, karena nilai Y tidak pasti.
Nilai galat yang besar menunjukkan bahwa penyimpangan nilai Y terhadap nilai harapan Y juga besar. Semakin besar nilai galat semakin kecil peluang kejadian dari Y. Amatan dikatakan pencilan ketika peluangnya kurang dari 0.025, sehingga dapat diartikan bahwa nilai pada peubah normal baku lebih dari 1.96. Beberapa literatur melakukan penghampiran nilai 1.96 dengan nilai 2.
Model regresi dapat dinotasikan dalam bentuk matriks sebagai berikut:
merupakan vektor peubah tidak bebas berukuran n×1, dengan n adalah banyaknya amatan. X adalah matriks peubah bebas berukuran n×(p+1). adalah vektor parameter regresi berukuran (p+1)×1 dan adalah vektor galat berukuran
n×1.
Penduga parameter regresi dapat dilakukan dengan metode kuadrat terkecil dengan meminimumkan jumlah kuadrat sisaan sebagai berikut:
∑ �� �
�
� �
5
Kriteria informasi membutuhkan penduga kemungkinan maksimum dari ragam sisaan, maka berikut akan dijabarkan untuk mendapatkan penduga tersebut. Rumus umum model regresi adalah sebagai berikut:
� � � � � � � ; � � � � � �; � adalah ragam galat
� ( � � � � � � � � �
Model regresi tersebut memiliki fungsi kepekatan peluang sebagai berikut:
�
�√ [
� ( � � �)
� ]
�
Berdasarkan fungsi kepekatan peluang tersebut didapatkan fungsi kemungkinan sebagai berikut:
6
sehingga penduga untuk ragam sisaan adalah sebagai berikut:
�̂ � ∑ �� penelitian yang dirangkum oleh Rousseeuw dan Leroy (1987). Penulis menggunakan data – data tersebut karena data tersebut merupakan data real dan sering digunakan untuk mencobakan metode pendeteksian pencilan yang lainnya, kecuali data IV yang merupakan data simulasi.
Berikut merupakan gambaran umum tentang data yang digunakan dalam penelitian ini.
1. Data I
Gugus data ini merupakan hasil penelitian yang diselenggarakan untuk mengetahui hubungan antara tinggi (x1) dan berat badan pasien penyakit
jantung (x2) dengan panjang kateter yang diperlukan (y). kateter
merupakan sebuah pipa atau selang yang digunakan pada dunia medis, biasanya dipasangkan pada organ dalam. Sebuah kateter dilewatkan ke dalam vena besar atau arteri pada daerah femoral dan menuju ke jantung. Kateter dapat masuk ke daerah - daerah tertentu untuk memberikan informasi mengenai fungsi jantung. Hal seperti ini biasanya diterapkan pada anak - anak dengan cacat jantung bawaan. Panjang yang tepat dari kateter harus diperkirakan oleh dokter. Data diambil dari 12 pasien penyakit jantung.
2. Data II
Gugus data ini merupakan hasil penelitian yang diselenggarakan untuk mengetahui hubungan antara fosfor anorganik (x1) dan fosfor organik
(x1) dalam tanah dengan kandungan fosfor pada jagung yang ditanam
7 3. Data III
Gugus data ini merupakan hasil penelitian yang diselenggarakan untuk mengetahui hubungan antara konsentrasi garam yang tertinggal dalam sungai selama dua minggu (x1), periode mingguan dihitung sejak awal
musim semi (x2) dan volume sungai (x3) dengan kadar garam dalam
sungai (y). Data terdiri dari 28 amatan. 4. Data IV
Gugus data ini merupakan data buatan berdasarkan fungsi
. Semua amatan mengikuti fungsi tersebut, kecuali amatan ke-13 dan lima amatan terakhir.
5. Data V
Gugus data ini merupakan hasil penelitian yang diselenggarakan untuk mengetahui hubungan antara rata – rata pendapatan pegawai di sekolah dasar (x1), persentase ayah berkerah putih (x2), status ekonomi keluarga
siswa (x3), rata – rata nilai akreditasi guru (x4) dan pendidikan ibu siswa
(x5) dengan nilai akreditasi sekolah dasar (y). Data terdiri dari 20 amatan.
Prosedur Penelitian
Berikut adalah langkah – langkah penulis dalam pengembangan algoritma genetika.
1. Menentukan fungsi objektif yang tepat untuk digunakan dalam algoritma genetika.
2. Menyusun algoritma yang tepat untuk mendeteksi pencilan.
3. Mengubah algoritma tersebut dalam bentuk bahasa pemrogaman R dengan menggunakan program R 3.0.3. Hasilnya dapat dilihat pada Lampiran 2. 4. Melakukan pendeteksian pencilan pada data I, II, III, IV dan V
menggunakan cara konvensional.
5. Mengimplementasikan program algoritma genetika untuk mendeteksi pencilan pada data I, II, III, IV dan V.
6. Membandingkan hasil deteksi secara konvensional dengan hasil pendeteksian menggunakan algoritma genetika.
HASIL DAN PEMBAHASAN
Pendeteksian Pencilan Secara Konvensional
8
ada. Pendeteksian pencilan secara konvensional bisa jadi tidak efisien untuk dilakukan, seperti yang terlihat pada Data IV, dimana pendeteksiannya memerlukan hingga empat kali iterasi. Data V hanya memerlukan satu kali iterasi untuk mendeteksi seluruh pencilan.
Pendeteksian pencilan secara konvensional bisa terjadi berkali-kali karena setiap melakukan pendeteksian model regresi yang didapat berbeda. Model berbeda menghasilkan nilai sisaan yang berbeda, sehingga memungkinkan muncul pencilan lagi. Nilai Sisaan terbakukan masing – masing data dari setiap tahap pendeteksian dapat dilihat pada Lampiran 1.
Tabel 1 Hasil deteksi pencilan secara konvensional
Date Pendeteksian Pencilan ke-
1 2 3 4 5
Data I 8 11 - - -
Data II 10 17 - - -
Data III 15, 16, 17 5 - - -
Data IV 23,25 13 24 16,21,22 -
Data V 3, 18 - - - -
Algoritma Genetika untuk Mendeteksi Pencilan
Algoritma diawali dengan membentukan populasi yang beranggotakan 10 individu. Ilustrasi mengenai bentuk populasi dapat dilihat pada Gambar 1. Setiap individu dibentuk dari n buah gen. Individu memberikan informasi banyaknya amatan yang diduga sebagai pencilan. Gen dalam individu berbentuk bilangan biner (0 1), dengan 0 menunjukkan bahwa amatan tersebut diduga bukan pencilan dan 1 menunjukkan bahwa amatan tersebut diduga sebagai pencilan. Banyaknya gen bernilai satu pada individu menggambarakan banyaknya amatan yang diduga sebagai pencilan pada gugus data. Karena peluang kejadian terjadinya pencilan kecil, maka ditentukan banyaknya gen bernilai 1 dalam setiap individu adalah 20% dari banyaknya amatan. Banyaknya gen bernilai 1 akan dibulatkan ke bilangan bulat terdekat, ketika 20% dari banyaknya amatan tidak bilangan bulat. Misalkan banyaknya amatan adalah 23 amatan, maka banyaknya gen bernilai 1 adalah lima buah gen. Gen bernilai 1 dalam setiap individu diletakkan secara acak. Penentuan letak dan banyaknya gen bernilai 1 hanya saat inisialisasi awal saja, saat proses iterasi bisa berubah-ubah letak dan banyaknya gen bernilai 1.
9
Nilai fitness masing-masing individu dihitung menggunakan fungsi objektif berikut:
� �̂ � � �
dengan k adalah banyaknya amatan yang diduga sebagai pencilan, � merupakan banyaknya amatan dan �̂ merupakan penduga kemungkinan maksimum ragam sisaan dari data dengan membuang amatan yang dianggap sebagai pencilan. Gambar 2 merupakan ilustrasi perhitungan ragam sisaan dalam program. Individu dengan bentuk (0 1 0 1 0 0) menggambarkan bahwa amatan ke-2 dan ke-4 diduga sebagai pencilan, sehingga perhitungan ragam sisaan dilakukan tanpa amatan ke-2 dan ke-4. Nilai ragam sisaan digunakan untuk menghitung Kriteria Informasi, dengan n=6 dan k=2.
Gambar 2 Ilustrasi perhitungan penduga ragam sisaan
Masing-masing individu memiliki nilai KI. Seleksi dilakukan dengan cara mengurutkan individu dengan KI terkecil hingga terbesar, lalu diambil 5 individu dengan KI paling kecil.
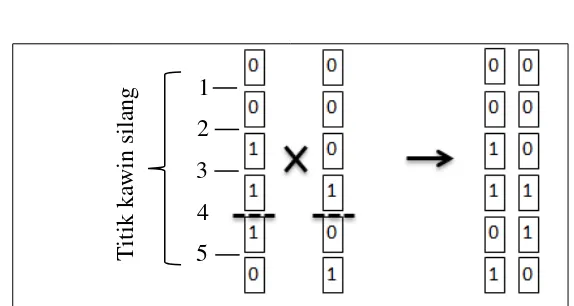
Langkah selanjutnya adalah kawin silang. Kawin silang dilakukan kepada setiap kombinasi 5 individu (hasil proses seleksi). Metode kawin silang yang digunakan adalah Single Point Crossover. Metode Single Point Crossover
10
Gambar 3 Ilustrasi kawin silang dengan metode single point crossover
Proses selanjutnya setelah kawin silang adalah mutasi. Mutasi dilakukan untuk menghindari terjadinya local optimum. Maksud dari local optimum adalah nilai KI yang didapat belum optimal secara global. Peluang terjadinya mutasi sebesar 0.01. Merubah nilai biner pada gen yang terpilih, jika nilainya 0 akan diganti menjadi 1 dan jika nilainya 1 akan diganti menjadi 0.
Individu baru yang terbentuk digunakan kembali dalam proses seleksi, kawin silang dan mutasi. Proses iterasi tersebut berhenti sampai nilai KI individu kesatu dan kesepuluh pada satu populasi memiliki nilai yang sama.
Tabel 2 merupakan hasil pendeteksian pencilan menggunakan algoritma genetika. Pendeteksian pencilan menggunakan algoritma genetika memberikan hasil yang sama dengan cara konvensional, kecuali pada Data IV. Perbedaan antara pendeteksian pencilan menggunakan agoritma genetika dan cara konvensional adalah banyaknya pendeteksian yang dilakukan. algoritma genetika hanya satu kali pendeteksian, sedangkan cara konvensional lebih dari satu kali. Sebagai ilustrasi, kita lihat hasil pendeteksian pada Data I dengan algoritma genetika dan cara konvensional. algoritma genetika mampu mendeteksi pencilan amatan 8 dan 11 dengan satu kali iterasi, sedangkan cara konvensional memerlukan dua kali iterasi untuk mendapatkan pencilan amatan 8 dan 11. Begitu juga pada Data II, Data III dan Data IV. Pada Data V pendeteksian pencilan yang dilakukan algoritma genetika dan cara konvensional sama-sama memerlukan satu kali iterasi.
Hasil pendeteksian pencilan menggunakan algoritma genetika pada Data IV berbeda dengan hasil pendeteksian dengan cara konvensional. Metode konvensional mendeteksi amatan 16 sebagai pencilan, sedangkan algoritma genetika tidak mendeteksi amatan 16 sebagai pencilan. Data IV merupakan data bangkitan dan sudah ditetapkan pencilannya. Data IV dibangkitkan mengikuti persamaan . Amatan 13, 21, 22, 23, 24 dan 25 dibuat sebagai pencilan dengan cara menambahka nilai y dengan suatu nilai. Amatan 16 tidak dibuat sebagai pencilan, nilainya sesuai dengan persamaan tersebut, yaitu
x1=2; x2=3; x3=1; x4=0 dan y=11. Data IV tanpa amatan 13, 16, 21, 22, 23, 24, 25
menghasilkan R2=100% dan KI = -583.21, sedangkan Data IV tanpa amatan 13, 21, 22, 23, 24, 25 menghasilkan R2=100% dan KI = -617.19. Meskipun memiliki nilai R2 yang sama, namun tanpa menghapus amatan ke-16 dapat menghasilkan nilai KI yang lebih kecil, sehingga pada algoritma genetika amatan ke-16 tidak dideteksi sebagai pencilan. Dari kasus pada Data IV terlihat bahwa algoritma genetika lebih sensitif terhadap pencilan.
11
Tabel 2 Hasil deteksi pencilan dengan algoritma genetika Data Pendeteksian Pencilan ke-
1
Data I 8,11
Data II 10,17
Data III 5,15, 16, 17 Data IV 13,21,22,23,24,25
Data V 3, 18
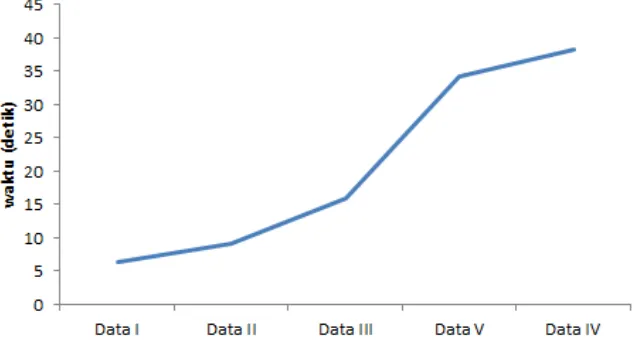
Banyaknya amatan dan peubah dapat mempengaruhi waktu proses pendeteksian menggunakan algoritma genetika. Semakin banyak amatan dan semakin banyak peubah waktu yang diperlukan semakin banyak juga, hal tersebut dapat dilihat pada Gambar 4.
Gambar 4 Waktu yang dibutuhkan algoritma genetika untuk mendeteksi pencilan.
Data II memiliki jumlah amatan sebanyak 18 dan data V memiliki amatan sebanyak 20, tapi pada Gambar 4 terlihat perbedaan waktu yang mencolok antara data II dan data V. Data V memiliki jumlah peubah lebih banyak yaitu sebanyak 5 peubah dibandingkan dengan data II yang hanya memiliki 2 peubah. Ternyata banyaknya peubah juga mempengaruhi waktu.
12
dibanding yang lain. Hal tersebut disebabkan banyaknya amatan pada data III lebih banyak dibandingkan dengan data yang lain. Data V memiliki banyaknya parameter yang lebih banyak dibandingkan dengan data II, namun rata – rata generasi/iterasi pada kedua data tersebut hampir sama. Sehingga dapat dikatakan bahwa banyaknya amatan mempengaruhi kemampuan program dalam mencapai nilai kriteria informasi minimum, sedangkan banyaknya peubah dalam data tidak mempengaruhi kemampuan program untuk mencapai nilai kriteria informasi minimum.
Gambar 5 Diagram kotak garis banyaknya generasi untuk mencapai nilai minimum
SIMPULAN
13
DAFTAR PUSTAKA
Adnan R, Mohamad MN, and Setan H. 2003. Multiple Outliers Detection Procedures in Linear Regression. Matematika1: 29-45.
Barnett V, Lewis T. 1994. Outliers in Statistical Data. New Jersey(US): Jhon Wiley and Sons, Inc.
Cook RD, Sanford W. 1947. Residuals and Influence in Regression. London(UK): Champ and Hall.
Cook RD. 1977 Detection of Influential Observation in Linear Regression,
Technometrics. 42(1): 65-68.
Diaz-Garcia JA, Gonzalez-Farias G, and Alvarado-Castro V. 2007. Exact Distributions for Sensitivity Analysis in Linear Regression. Applied Mathematical Sciences. 22(1):1083-1100.
Draper NR, Smith H. 1992. Analisis Regresi Terapan. Jakarta(ID): PT. Gramedia Pustaka Utama.
Filzmoser P. 2005. Identification of Multivariate Outliers: A Performance Study.
Austrian Journal of Statistics. 34(2):127-138.
Haupt RL, Haupt SE. 2004. Practical Genetic Algorithms Second Edition. New Jersey(US): Jhon Wiley and Sons, Inc
Pena D, Prieto FJ. 2001. Multivariate outlier detection and robust covariance matrix estimation.. Technometrics, 43(3):286–310.
Rousseeuw PJ dan Leroy AM. 1987. Robust Regression and Outlier Detection. New York(US): Jhon Wiley and Sons, Inc.
Seppo P. 1992. Detection of Outliers in Regression Analysis by Information Criteria. Proceedings of the University of Vaasa , number 146.
Schwarz G. 1978. Estimating The Dimention of a model. The annals Stat. 6(1): 461-464.
Sivanandam SN, Deepa SN. 2008. Introduction to Genetic Algorithms. New York(US): Springer
14
16
Lampiran 2 Sintaks dalam software R fitness <- function(d)
{
d <- d[-1,]
x <- as.matrix(cbind(1,d[,2:ncol(data)])) y <- as.matrix(d[,1])
b <- solve(t(x)%*%x)%*%t(x)%*%y sse <- (t(y)%*%y)-(t(b)%*%t(x)%*%y) satu <- matrix(1,nrow(d),1)
sst <- (t(y)%*%y)-((t(y)%*%satu%*%t(satu)%*%y)/nrow(d)) r2 <- 1-(sse/sst)
n <- nrow(d)
BIC <- n*log(sse/(n))-2*log(factorial(n-k))+1*log(n) list("BIC"=BIC)
}
data <- read.table("D:/document/bahan- bahan/outlier/data/data4.txt", header=TRUE)
#Populasi
pop <- matrix(0,nrow(data),10) for(i in 1:ncol(pop))
{
a <- as.matrix(sample(nrow(data),0.2*nrow(data))) for(j in 1:nrow(a))
{
pop[a[j,],i] <-1 } }
#Fitness
popF <- rbind(pop,0) for(i in 1:ncol(pop)) {
d <- 0 k <- 0
for(j in 1:(nrow(pop))) {
ifelse(pop[j,i]==0,d <- rbind(d,data[j,]),k <- k+1) }
fit <- fitness(d=d)$BIC
17
maxiter<-1000 for(iter in 1:maxiter) {
#Seleksi
ur <- popF[,order(popF[nrow(popF),],decreasing=F)] x.select <- ur[-nrow(ur),1:5]
#Cross_Over x.cross <- x.select
for(i in 1:(ncol(x.select)-1)) {
for(j in 1:ncol(x.select)) {
if(j>i){
a <- sample(nrow(x.select)-1,1) x.cross
<-cbind(x.cross,c(x.select[1:a,i],x.select[(a+1):nrow(x.select),j]),c(x.select[(a+1):nro w(x.select),i],x.select[1:a,j]))
} } }
#Mutasi
x.mutasi <- x.cross
mut<-rbinom(nrow(x.mutasi)*(ncol(x.mutasi)-5),1,0.01) {
if (sum(mut)!=0) {
mut1<-matrix(mut,nrow(x.mutasi),(ncol(x.mutasi)-5)) in.mutasi<-t(which(mut1==1,arr.ind=TRUE))
in.mutasi<-rbind(in.mutasi[1,],(in.mutasi[2,]+5)) for(i in 1:ncol(in.mutasi))
{
x.mutasi[in.mutasi[1,i],in.mutasi[2,i]]<-
ifelse(x.mutasi[in.mutasi[1,i],in.mutasi[2,i]]==1,0,1) }
pop <- x.mutasi }
else {
18 }
#hitung_fitness_lagi popF <- rbind(pop,0) for(i in 1:ncol(pop)) {
d <- 0 k <- 0
for(j in 1:(nrow(pop))) {
ifelse(pop[j,i]==0,d <- rbind(d,data[j,]),k <- k+1) }
fit <- fitness(d=d)$BIC popF[j+1,i] <- fit }
cek1 <- popF[,order(popF[nrow(popF),],decreasing=F)] cek <- cek1[nrow(cek1),1]-cek1[nrow(cek1),10]
if (cek==0){break} }
{
if(sum(x.select[,1])==0) {
h <- "Tidak Terdapat Pencilan" }
else {
h <- c(1:nrow(x.select)) for (i in nrow(x.select):1) {
if(x.select[i,1]==0) {
h <- h[-i] }
} }
}
c <- ur[nrow(ur),1]
19 Lampiran 3 Kemampuan program konvergen ke suatu nilai
Data I Data II
Data III Data IV
20