SKRIPSI
ANNISA FADHILLAH PULUNGAN 111402050
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
ANNISA FADHILLAH PULUNGAN 111402050
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : KLASIFIKASI KARET RSS (RIBBED SMOKED
SHEET) MENGGUNAKAN METODE LVQ
(LEARNING VECTOR QUANTIZATION)
Kategori : SKRIPSI
Nama : ANNISA FADHILLAH PULUNGAN
Nomor Induk Mahasiswa : 111402050
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Seniman S.Kom, M.Kom Romi Fadillah Rahmat, B.Comp.Sc, M.Sc NIP. 1987052019091001 NIP. 198301292009121003
Diketahui/disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
PERNYATAAN
KLASIFIKASI KARET RSS (RIBBED SMOKE SHEET) MENGGUNAKAN METODE LVQ (LEARNING VECTOR QUANTIZATION)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Januari 2016
UCAPAN TERIMA KASIH
Puji dan syukur kehadirat Allah SWT, karena rahmat dan izin-Nya penulis dapat menyelesaikan penyusunan skripsi ini, sebagai syarat untuk memperoleh gelar Sarjana Komputer, pada Program Studi S1 Ilmu Teknologi Informasi Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
Ucapan terima kasih penulis sampaikan kepada:
1. Bapak Prof. Dr. dr. Syahril Pasaribu, DTM&H, Msc(CTM), Sp.A(K) selaku Rektor Universitas Sumatera Utara.
2. Bapak Prof. Dr. Muhammad Zarlis selaku Dekan Fasilkom-TI USU.
3. Bapak Muhammad Anggia Muchtar, ST., MM.IT selaku Ketua Program Studi S1 Teknologi Informasi Universitas Sumatera Utara.
4. Bapak Mohammad Fadly Syahputra, B.Sc, M.Sc, IT selaku Sekretaris Program Studi S1 Teknologi Informasi Universitas Sumatera Utara.
5. Bapak Romi Fadillah Rahmat, B.Comp.Sc, M.Sc selaku dosen pembimbing I yang telah memberikan bimbingan dan saran kepada penulis.
6. Bapak Seniman, S.Kom, M.Kom selaku Dosen Pembimbing II yang telah memberikan bimbingan dan saran kepada penulis.
7. Bapak Dr. Sawaluddin, M.IT selaku Dosen Pembanding I yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
8. Bapak Sajadin Sembiring, S.Si, M.Comp.Sc selaku Dosen Pembanding II yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
9. Ayahanda H. Gong Martua Pulungan, S.E dan Ibunda Almh. Hj. Zuchrainis Rangkuti, Faridawati Marpaung, S.Si, M.Si yang selalu memberikan doa, kasih sayang dan dukungan kepada penulis.
10. Adik-adik penulis, Nurul Hidayah Pulungan dan Syarif Hidayatullah Pulungan yang selalu mendukung dan medoakan penulis.
12. Para senior Teknologi Informasi, Nanda Putra, S.TI, Hasnul Arif Fikri, S.TI, Yogi Suryo Santoso, Fani Sari Wulandari, S.TI yang telah memberikan dukungan dan masukan kepada penulis.
13. Teman-teman seangkatan Teknologi Informasi, Ossie Zarina Prayitno, Rauva Chairani, Novita Ratu Sianipar, Chairunnisaq, Masyunita, William, Fahrunnisa, Ade Oktariani, Marsha Ayudia, Vanessa Felicia, Dian Aria Ningsih, Susi Elfrida dan lain-lain yang telah membantu penulis menyelesaikan skripsi.
14. Ibu Zullidar Habsyah, S.Pd, M.Si yang telah memberikan dukungan dan arahan kepada penulis.
15. Teman-teman seperjuangan Pimpinan Wilayah IPM SUMUT, Kakanda Maya Puspita Ningrum, S.H, M.H, Abangda Muhammad Arif, S.E, M.M, Erik Syahputra, S.Pd, Syarifah Aini, Winda Handayani, S.Pd dan seluruh anggota PH PW IPM SUMUT yang selalu member semangat kepada penulis.
16. Seluruh keluarga besar Alm. Ramli Rangkuti yang telah memberikan dukungan dan motivasi kepada penulis
17. Semua pihak yang terlibat langsung ataupun tidak langsung yang tidak dapat penulis ucapkan satu per satu yang telah membantu penyelesaian skripsi ini.
Semoga Allah SWT melimpahkan berkah kepada semua pihak yang telah memberikan bantuan, perhatian, serta dukungan kepada penulis dalam menyelesaikan skripsi ini.
Medan, Januari 2016
ABSTRAK
Indonesia merupakan pengekspor bahan alam karet terbesar kedua di dunia setelah Thailand. Salah satu jenis karet olahan yang dijadikan bahan ekspor adalah karet olahan lembar karet asap atau ribbed smoked sheet (RSS). Mutu dari karet olahan RSS sangat mempengaruhi peningkatan ekspor karet RSS. Kualitas karet RSS telah ditetapkan pada SNI 06-001-1987 dan International Standards of Quality And Packing for Natural Rubber Grades (The Green Book). Proses penetapan kualitas karet RSS disebut juga sebagai proses sortasi. Namun, pada beberapa perkebunan karet, proses sortasi masih dilakukan secara manual dengan melihat kadar gelembung pada permukaan lembaran karet secara kasat mata sehingga menghasilkan kualitas yang kurang tepat dan bersifat subjektif. Maka dari itu penelitian ini ditujukan untuk melakukan proses klasifikasi karet RSS secara otomatis dan tepat. Penelitian ini menggunakan proses pengolahan citra dengan citra karet RSS sebagai masukan dan Hasil klasifikasi sebagai keluaran. Proses klasifikasi RSS menggunakan metode Learning Vector Quantization (LVQ) dengan dua kelas klasifikasi yaitu RSS1 dan RSS3. Penelitian ini menggunakan 120 citra RSS sebagai data latih dan 60 citra RSS sebagai data uji dengan nilai akurasi sebesar 89 % dengan nilai epoh terbaik pada epoh ke-15.
CLASSIFICATION OF RSS (RIBBED SMOKED SHEET) USE LVQ (LEARNING VECTOR QUANTIZATION) METHOD
ABSTRACT
Indonesia is the second ranking exporter of natural rubber in the world after Thailand. One of rubber type is used as rubber material exports is Ribbed Smoked Sheet (RSS). The quantity of RSS exports depends on the quality of RSS. RSS rubber quality has been assigned in SNI 06-001-1987 and the International Standards of Quality And Packing for Natural Rubber Grades (The Green Book). RSS quality determination process is also known as the sorting process. However, in the rubber factories, the sorting process is still done manually by looking and detecting at the levels of air bubbles on the surface of the rubber sheet by eyes so the resulting in a lack of proper quality and subjective. Therefore this research has purpose to perform the classification process RSS rubber automatically and precisely. This research uses image processing with image of RSS as an input and the result of classification as an output. The RSS classification used Learning Vector Quantization (LVQ) method with two grades, which are RSS1 and RSS3 classification. This research used 120 RSS images as training dataset and 60 RSS images as testing dataset with an accuracy value of 89% and the best perform epoch in fifteenth epoch.
DAFTAR ISI
Halaman
PERSETUJUAN iii
PERNYATAAN iv
UCAPAN TERIMA KASIH v
ABSTRAK vii
ABSTRACT viii
DAFTAR ISI ix
DAFTAR GAMBAR xi
DAFTAR TABEL xii
BAB 1 PENDAHULUAN
1.1 Latar Belakang 1
1.2 Rumusan Masalah 3
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
1.6 Metodologi Penelitian 4
1.7 Sistematika Penulisan 5
BAB 2 LANDASAN TEORI
2.1 Karet Ribbed Smoked Sheet (RSS) 6
2.2 Pengolahan Citra 9
2.3 Ekstraksi Fitur 11
2.4 Metode Zoning 13
2.5 Learning Vector Quantization 14
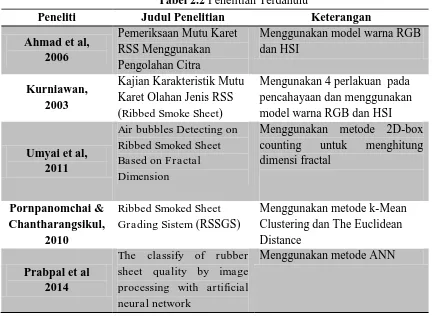
2.6 Penelitian Terdahulu 18
BAB 3 ANALISIS DAN PERANCANGAN
3.1 Data Yang Digunakan 21
3.2 Analisis Aplikasi 22
3.3 Input Citra RSS 23
3.4.1 Resizing 23
3.4.2 Grayscale 24
3.4.3 Thresholding 27
3.5 Ekstraksi Fitur 29
3.4.1 Zoning 29
3.6 Klasifikasi 31
3.6.1 Learning Vector Quantization 31
3.6.2 Proses Pelatihan 32
3.6.3 Proses Pengujian 39
3.7 Rancangan Tampilan Antarmuka 40
3.7.1 Rancangan Halaman Utama 40
3.7.2 Rancangan Halaman Proses Data Latih 41 3.7.3 Rancangan Halaman Proses Data Uji 42 BAB 4 IMPLEMENTASI DAN PENGUJIAN
4.1 Kebutuhan Aplikasi 43
4.1.1 Perangkat Keras 43
4.1.2 Perangkat Lunak 43
4.2 Implementasi Perancangan Antarmuka 44
4.2.1 Halaman Utama 44
4.2.2 Halaman Data Latih 44
4.2.3 Halaman Data Uji 46
4.3 Pengujian Kinerja Aplikasi 47
4.4 Pelatihan Citra 49
4.5 Pengujian Citra 50
BAB 5 KESIMPULAN DAN SARAN
5.1 Kesimpulan 54
5.2 Saran 55
DAFTAR PUSTAKA 56
DAFTAR GAMBAR
Halaman
Gambar 2.1 Karet RSS 6
Gambar 2.2 Arsitektur Jaringan LVQ 15
Gambar 3.1 Karet RSS1 dan RSS3 21
Gambar 3.2 Arsitektur Umum 22
Gambar 3.3 Citra RSS Resize 24
Gambar 3.4 Representasi Piksel Karet RSS 24
Gambar 3.5 Citra 9 (3x3) Piksel 25
Gambar 3.6 Nilai Grayscale pada setiap Piksel 26
Gambar 3.7 Proses Citra Grayscale 26
Gambar 3.8 Nilai Threshold Citra Karet 9 Piksel 28
Gambar 3.9 Proses citra Threshold 29
Gambar 3.10 Hasil Zoning Citra 30
Gambar 3.11 Nilai Ekstraksi Fitur Zoning 31
Gambar 3.12 Arsitektur Learning Vector Quantization 32 Gambar 3.13 Pseudocode Penerapan Algoritma LVQ 33
Gambar 3.14 Flowchart Proses Pengujian 39
Gambar 3.15 Rancangan Halaman Utama Klasifikasi Karet 40
Gambar 3.16 Tampilan Halaman Data Latih 41
Gambar 3.17 Tampilan Halaman Proses Data Uji 42
Gambar 4.1 Tampilan Halaman Utama 44
Gambar 4.2 Tampilan Halaman Data Latih 45
Gambar 4.3 Tampilan Halaman Proses Data Latih 45
Gambar 4.4 Tampilan Halaman Data Uji 46
Gambar 4.5 Tampilan Halaman proses Data Uji 47
DAFTAR TABEL
Halaman
Tabel 2.1 Syarat Kelas Mutu Visual RSS 7
Tabel 2.2 Penelitian Terdahulu 20
Tabel 3.1 Data Vektor Input 34
Tabel 3.2 Tabel Nilai Input Pelatihan 35
Tabel 3.3 Nilai Bobot Pelatihan 35
Tabel 3.4 Nilai Bobot Pertama Baru 36
Tabel 3.5 Nilai Bobot Kedua Baru 37
Tabel 3.6 Hasil Perhitungan Data Latih 38
Tabel 3.7 Nilai Bobot Data Uji 39
Tabel 4.1 Rencana Pengujian Kinerja Aplikasi 47
Tabel 4.2 Hasil Pengujian Kinerja Aplikasi 48
Tabel 4.3 Parameter Pelatihan citra Karet RSS 50
Tabel 4.4 Hasil Uji Citra Karet 50
ABSTRAK
Indonesia merupakan pengekspor bahan alam karet terbesar kedua di dunia setelah Thailand. Salah satu jenis karet olahan yang dijadikan bahan ekspor adalah karet olahan lembar karet asap atau ribbed smoked sheet (RSS). Mutu dari karet olahan RSS sangat mempengaruhi peningkatan ekspor karet RSS. Kualitas karet RSS telah ditetapkan pada SNI 06-001-1987 dan International Standards of Quality And Packing for Natural Rubber Grades (The Green Book). Proses penetapan kualitas karet RSS disebut juga sebagai proses sortasi. Namun, pada beberapa perkebunan karet, proses sortasi masih dilakukan secara manual dengan melihat kadar gelembung pada permukaan lembaran karet secara kasat mata sehingga menghasilkan kualitas yang kurang tepat dan bersifat subjektif. Maka dari itu penelitian ini ditujukan untuk melakukan proses klasifikasi karet RSS secara otomatis dan tepat. Penelitian ini menggunakan proses pengolahan citra dengan citra karet RSS sebagai masukan dan Hasil klasifikasi sebagai keluaran. Proses klasifikasi RSS menggunakan metode Learning Vector Quantization (LVQ) dengan dua kelas klasifikasi yaitu RSS1 dan RSS3. Penelitian ini menggunakan 120 citra RSS sebagai data latih dan 60 citra RSS sebagai data uji dengan nilai akurasi sebesar 89 % dengan nilai epoh terbaik pada epoh ke-15.
CLASSIFICATION OF RSS (RIBBED SMOKED SHEET) USE LVQ (LEARNING VECTOR QUANTIZATION) METHOD
ABSTRACT
Indonesia is the second ranking exporter of natural rubber in the world after Thailand. One of rubber type is used as rubber material exports is Ribbed Smoked Sheet (RSS). The quantity of RSS exports depends on the quality of RSS. RSS rubber quality has been assigned in SNI 06-001-1987 and the International Standards of Quality And Packing for Natural Rubber Grades (The Green Book). RSS quality determination process is also known as the sorting process. However, in the rubber factories, the sorting process is still done manually by looking and detecting at the levels of air bubbles on the surface of the rubber sheet by eyes so the resulting in a lack of proper quality and subjective. Therefore this research has purpose to perform the classification process RSS rubber automatically and precisely. This research uses image processing with image of RSS as an input and the result of classification as an output. The RSS classification used Learning Vector Quantization (LVQ) method with two grades, which are RSS1 and RSS3 classification. This research used 120 RSS images as training dataset and 60 RSS images as testing dataset with an accuracy value of 89% and the best perform epoch in fifteenth epoch.
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Tanaman karet merupakan tanaman yang memiliki peran penting di bidang industri terutama sebagai bahan baku di bidang industri ban dan otomotif (Sinaga, 2011). Indonesia menjadi produsen terbesar kedua di dunia setelah negara Thailand dengan produksi mencapai hampir 3 juta ton pada tahun 2011. Dengan 27,06% dari hasil produksi dikontribusikan kepada produksi karet dunia. Indonesia memiliki 3,4 juta ha lahan karet dengan 85% merupakan perkebunan rakyat (Dhani, 2013). Salah satu karet olahan yang menjadi bahan ekspor adalah lembaran karet asap atau ribbed smoked sheet (RSS).
Karet olahan RSS memiliki kualitas yang telah ditetapkan oleh International Standards of Quality and Packing for Natural Rubber Grades (The Green Book) dan
Beberapa penelitian tentang pengklasifikasian mutu RSS ini telah dilakukan oleh beberapa peneliti sebelumnya diantaranya penelitian yang dilakukan oleh Umyai dkk (2011) dalam mendeteksi gelembung udara pada Ribbed Smoked Sheet dimana gelembung udara merupakan salah satu faktor yang mempengaruhi kualitas RSS. Pendeteksian gelembung RSS diteliti berdasarkan dimensi fraktal pada 500 citra RSS menghasilkan 98% tingkat keberhasilan klasifikasi ada atau tidaknya gelembung pada RSS. Namun tidak membahas tentang pengklasifikasian mutu karet RSS. Pada penelitian yang dilakukan oleh Pornpanomchai & Chantharangsikul (2010) pada sistem pengklasifikasian RSS menggunakan metode k-Means Clustering dan the Euclidean Distance dari identifikasi warna untuk mengklasifikasikan RSS ke dalam lima kualitas yaitu RSS1, RSS2, RSS3, RSS4, dan RSS5 menghasilkan 80.90% tingkat keberhasilan dengan rata rata waktu klasifikasi 10.88 detik per citra RSS.
Berdasarkan kendala dalam pengklasifikasian kualitas karet maka dibutuhkan suatu metode yang dapat digunakan dalam mengklasifikasikan mutu karet RSS dengan baik berdasarkan jumlah gelembung dalam lembaran karet RSS. Salah satu metode yang sering digunakan dalam pengklasifikasian adalah Learning Vector Quantization (LVQ). LVQ merupakan sebuah metode klasifikasi berdasarkan model kohonen yang dikenal sebagai Self-Organizing Map Network (SOM). Namun LVQ berbeda dengan SOM yang bersifat pembelajaran tidak terawasi, LVQ merupakan algoritma pembelajaran terawasi versi model Kohonen dengan arsitektur algoritma yang sederhana sehingga hanya terdiri dari satu lapisan input dan lapisan output (Azara et al, 2012).
1.2Rumusan Masalah
Indonesia telah menjadi pengeksport bahan alam karet kedua di dunia setelah Thailand. Salah satu karet olahan yang menjadi bahan ekspor adalah lembaran karet asap atau ribbed smoked sheet (RSS). Mutu dari karet olahan RSS ini sangat berpengaruh besar dalam peningkatan ekspor RSS. Kualitas RSS disesuaikan dengan SNI 06-001-1987 dan International Standards of Quality And Packing for Natural Rubber Grades (The Green Book). Namun, pada sortasi kualitas yang dilakukan oleh perkebunan masih menggunakan pengamatan manual pada permukaan karet yaitu dengan melihat kadar gelembung pada permukaan karet lembaran sehingga menghasilkan kualifikasi yang kurang tepat dan hanya bersifat subjektif. (Ahmad, et al, 2003). Oleh karena itu, diperlukan suatu pendekatan yang mampu mengklasifikasikan kualitas RSS secara tepat pada produk karet olahan RSS.
1.3Batasan Masalah
Adapun batasan masalah pada penelitian ini adalah :
1. Karet RSS yang akan diteliti telah dilakukan pengasapan terlebih dahulu. 2. Karet RSS yang akan diteliti adalah karet RSS1 dan RSS3.
3. Karet RSS tidak mengalami cacat, sobek, molor, dan basah. 4. Data berupa citra dengan format file .jpeg.
5. Pengklasifikasian hanya berdasarkan gelembung. 6. Sistem bersifat offline.
1.4Tujuan Penelitian
Tujuan dari penelitian ini adalah mengklasifikasikan kualitas karet RSS menggunakan metode Learning Vector Quantization (LVQ).
1.5Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut :
1. Sistem dapat digunakan untuk mengklasifikasikan kualitas karet RSS dengan otomatis dan akurat.
3. Sebagai bahan penelitian selanjutnya. 1.6Metode Penelitian
Adapun tahapan yang akan dilakukan pada penellitian ini adalah sebagai berikut : 1. Studi Literatur
Pada tahap ini, penulis mengumpulkan data dan informasi-informasi yang diperoleh dari beberapa sumber seperti buku, jurnal, prosiding, skripsi dan lain-lain yang diperlukan dalam penelitian.
2. Analisis Permasalahan
Pada tahap ini, dilakukan analisis terhadap berbagai informasi yang didapat dari beberapa sumber yang diperlukan pada penelitian sehingga diperoleh metode yang tepat dalam menyelesaikan masalah penelitian ini.
3. Perancangan Sistem
Pada tahap ini, dilakukan perancangan sistem seperti merancang use case diagram, flowchart, perancangan desain interface untuk selanjutnya diimplementasikan ke dalam sistem.
4. Pengujian Sistem
Pada tahap ini dilakukan pengujian sistem untuk mengetahui apakah sistem berjalan dengan baik dan sesuai dengan kriteria dan kebutuhan yang diinginkan sehingga dapat diketahui kekurangan dari sistem yang dirancang untuk dapat dilakukan perbaikan untuk diperoleh hasil yang lebih baik.
5. Dokumentasi Sistem
1.7Sistematika Penulisan
Sistematika penulisan dari penelitian terdiri dari lima bagian utama sebagai berikut : Bab 1 : Pendahuluan
Bab ini berisi konsep dasar penyusunan penelitian yang terdiri dari latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian dan sistematika penulisan.
Bab 2 : Landasan Teori
Bab ini berisi teori-teori pendukung yang digunakan untuk memahami permasalahan yang akan dibahas pada penelitian ini. Pada bab ini dijelaskan tentang image processing, karet RSS (Ribbed Smoke Sheet), proses preprocessing, ekstraksi fitur dan Learning Vector Quantization dalam proses pengklasifikasian citra.
Bab 3 : Analisis dan Perancangan
Pada bab ini berisi analisis dan perancangan jaringan syaraf tiruan Learning Vector Quantization dalam mengklasifikan kualitas mutu karet serta perancangan tampilan antar muka pada aplikasi.
Bab 4 : Implementasi dan Pengujian
Bab ini berisi pembahasan tentang implementasi dari bab analisis dan perancangan yang telah disusun serta pengujian keakuratan sistem dengan keadaan yang sesuai dengan mutu karet RSS.
Bab 5 : Kesimpulan dan Saran
BAB 2
LANDASAN TEORI
2.1 Karet Ribbed Smoked Sheet (RSS)
Karet Lembaran Asap atau biasa disebut dengan Ribbed Smoke Sheet (RSS) merupakan salah satu jenis produk karet olahan dari getah tanaman karet Hevea brasiliensis yang di peroleh secara perkebunan maupun perorangan (Khomah et all, 2013). Produk olahan tanaman karet ini memiliki banyak kegunaan dalam pasar industri sebagai bahan baku pembuatan industri otomotif dan ban. Di tingkat dunia, Thailand, Indonesia dan Malaysia merupakan pengekspor karet terbesar di dunia. Indonesia memiliki kecenderungan pengeksporan karet ke negara Amerika Serikat (Sinaga, 2011).
Karet Ribbed Smoked Sheet (RSS) diolah secara mekanis dan kimiawi melalui beberapa proses pengolahan yaitu penerimaan lateks kebun, pengenceran, pembekuan, penggilingan, pengasapan dan sortasi. Karet Ribbed Smoked Sheet ini banyak digunakan dalam pembuatan ban kendaraan bermotor. Karet Ribbed Smoked Sheet dapat dilihat pada Gambar 2.1
(a) (b)
Proses pengolahan karet Ribbed Smoked Sheet (RSS) antara lain :
Penerimaan Lateks dari pohon karet yang disadap dan dikumpulkan dalam wadah untuk selanjutnya disaring guna memisahkan kotoran dan bagian lateks yang mengalami prakoagulasi
Lateks dialirkan ke bak koagulasi untuk diencerkan guna memudahkan penyaringan kotoran dan menyeragamkan kadar karet kering agar mutu tetap dapat dijaga
Dilakukan pembekuan lateks di dalam bak koagulasi dengan menambah zat koagulan yang bersifat asam berupa asam semut atau asam asetat dengan konsentrasi 1-2% dengan dosis 4 ml/kg karet kering. Tujuan penambahan zat koagulan adalah untuk menurunkan pH lateks sehingga lateks akan beku. Penambahan koagulan harus disertai pengadukan yang dilakukan sebanyak 6-10 kali maju dan mundur guna mencegah terbentuknya gelembung udara yang akan mempengaruhi lembaran yang dihasilkan.
Setelah proses pembekuan, maka akan dilakukan poses penggilingan untuk mengeluarkan air, mengeluarkan serum, dan membentuk garis pada lembaran dan menipiskan lembaran.
Dilakukan pengasapan di dalam kamar asap untuk mengeringkan lembaran, memberi warna coklat dan menghambat pertumbuhan jamur pada permukaan. Lembaran yang telah matang dari kamar asap akan ditimbang dan dicatat
dalam arsip produksi dan dilakukan proses sortasi. Proses sortasi dilakukan secara manual untuk melihat warna, kotoran, gelembung udara, jamur dan kehalusan gilingan yang telah disesuaikan pada standar SNI 06-0001-1987
Tabel 2.1. Syarat Kelas Mutu Visual RSS
jamur, bercak, karat dan
Sumber : Badan Penelitian Teknologi Karet Bogor (2000)
Namun pada proses sortasi yang dilakukan oleh PT Perkebunan hanya dilandasi pada jumlah gelembung yang terdapat pada permukaan lembaran karet RSS. Setiap proses pengolahan harus selalu diperhatikan dan diawasi dengan benar. Pengolahan yang dilakukan secara salah pada salah satu tahap akan menghasilkan produksi karet RSS yang tidak bagus dan akan menyebabkan kerugian yang besar. Beberapa faktor yang perlu diperhatikan dalam pengolahan karet RSS antara lain :
Getah berasal dari karet yang muda yang menghasilkan karet yang lekat, lembek dan mudah diulur saat digantung di dalam ruang asap.
Kebersihan getah dari mulai masuk ke kebun sampe akan diolah di pabrik harus dijaga sehingga hasil produksi yang dihasilkan sesuai dengan standard mutu
Pemberian koagulan yang berlebihan akan menyebabkan koagulum menjadi keras dan sulit digiling.
Penggilingan RSS dilakukan untuk memisahkan air dari gumpalan. Kecepatan penggilingan berbeda antara rol yang satu dengan yang berikutnya.
2.2 Pengolahan Citra
Pengolahan citra merupakan proses pengolahan dan analisis citra tentang persepsi pada suatu citra. Pengolahan citra digital adalah disiplin ilmu yang mempelajari hal yang berhubungan dengan perbaikan citra, kualitas citra (peningkatan kontras, transformasi warna, restorasi citra), transformasi citra (rotasi, translasi, skala, transformasi geometrik), melakukan pemilihan ciri citra (feature image) yang optimal untuk dianalisis, penarikan informasi pada objek atau pengenalan objek yang terkandung pada citra, melakukan kompresi untuk memperkecil penyimpanan data, transmisi data dan waktu proses data. Input dari pengolahan citra adalah citra dan output-nya berupa citra hasil pengolahan (Sutoyo et al, 2009)
Terminologi yang berkaitan dengan pengolahan citra adalah Computer vision. Computer vision ini mencoba meniru cara kerja sistem visual manusia. Dalam
berbagai aplikasi Computer vision yang banyak dikembangkan adalah proses mengambil informasi dari gambar berupa fitur yang telah diekstraksi secara otomatis dari gambar itu sendiri. Proses ini sering disebut sebagai CBIR (Content-Based Image Retrieval) Proses yang menjadi populer selama beberapa tahun dalam bidang pengolahan citra (Choras, 2007).
CBIR menggabungkan beberapa teknologi seperti multimedia, pengolahan citra dan sinyal, pengenalan pola, interaksi manusia dan komputer serta ilmu informasi persepsi manusia. Proses CBIR dapat dibagi dalam beberapa tahapan yaitu :
1. Preprocessing
2. Ekstraksi Fitur
Proses mengambil nilai inti (fitur) dari citra yang menggambarkan bentuk, tekstur, warna dan lain-lain.
Beberapa algoritma yang digunakan dalam pengembangan CBIR terdiri atas tiga tugas yaitu :
Ekstraksi Fitur Seleksi
Klasifikasi
Dari ketiga tugas ini, ekstraksi fitur memiliki fungsi paling penting karena fitur tertentu didapatkan untuk mendiskriminasikan suatu fitur yang dapat mempengaruhi proses klasifikasi. Pada proses klasifikasi pada CBIR , pengolahan citra dan pengenalan pola merupakan bagian CBIR. Pada CBIR, pengolahan citra merupakan proses awal dan pengenalan pola merupakan proses intepretasi citra.
Pada penelitian ini akan dilakukan beberapa proses pada prapengolahan yang akan digunakan untuk mendapatkan nilai fitur pada proses ekstraksi fitur antara lain :
Resizing
Pada proses ini, citra akan diperkecil ukuran pikselnya guna menambah fokus pada objek yang akan diidentifikasi, membuang citra yang tidak memiliki informasi penting, memperbesar area tertentu pada suatu citra serta mengubah orientasi citra (Fajri, 2014).
Grayscale
Proses Grayscale adalah proses merubah nilai - nilai piksel dari warna RGB menjadi graylevel. Proses ini dapat digunakan untuk memisahkan bayangan dengan warna asli pada citra. Pada citra terdiri dari 24 bit yang setiap pikselnya mengandung warna dasar (Red, Green, Blue). Setiap warna dasar ini memiliki 8-bit warna yang berada pada rentang warna 0 (00000000) sampai 255 (11111111). Proses perhitungan nilai grayscale dapat dilakukan dengan persamaan (2.1)
Thresholding
Proses thresholding digunakan untuk mengatur derajat keabuan pada citra. Pada proses thresholding, citra memiliki dua tingkat keabuan yaitu hitam dan putih. Proses penentuan tingkat warna citra pada proses thresholding dilakukan dengan mendapatkan nilai ambang.
Pada proses ini, perhitungan nilai ambang dilakukan pada setiap piksel pada citra. Jika nilai yang dihasilkan kurang dari nilai ambang maka nilai piksel tersebut akan diubah menjadi warna hitam dan jika nilai yang dihasilkan lebih dari nilai rata-rata maka nilai piksel akan diubah menjadi warna putih. Proses perhitungan nilai ambang dapat dilakukan dengan persamaan :
Keterangan :
T = Nilai threshold
fmaks = Nilai piksel maksimum fmin = Nilai piksel minimum
2.3 Ekstraksi Fitur
Ekstraksi fitur merupakan proses pengambilan ciri dari satu pola/bentuk sehingga di dapatkan suatu nilai pada pola citra untuk dilakukan analisis pada proses selanjutnya. Tugas ekstraksi fitur yaitu mengubah konten gambar menjadi berbagai konten fitur. Fitur-fitur yang memungkinkan membantu dalam proses pendiskriminasian citra akan digunakan pada proses selanjutnya. Sedangkan fitur yang tidak terpilih tidak akan digunakan.
Dalam beberapa tahun ini, ekstraksi fitur menjadi trend dalam bidang pengolahan citra. Proses ekstraksi fitur pada konten citra terbukti cukup handal digunakan pada aplikasi professional dalam bidang industri, biomedis, otentifikasi dan pencegahan kejahatan.
Ekstraksi fitur memiliki langkah paling penting karena fitur yang dihasilkan dapat membantu mendiskriminasikan secara langsung dalam proses klasifikasi (Choras, 2007). Hasil akhir dari proses ekstraksi fitur adalah kumpulan fitur dan
sering disebut sebagai vektor fitur. Fitur yang dihasilkan merupakan hasil dari representasi gambar.
Fitur didefinisikan sebagai fungsi dari beberapa pengukuran dimana setiap pengukuran menentukan nilai dari sebuah objek dan dihitung sedemikian rupa sehingga pengukururan karakteristik objek lebih signifikan. Fitur dapat diklasifikasikan sebagai berikut :
1. Fitur umum
Fitur umum merupakan nilai fitur yang bersifat independen seperti warna, tekstur, dan bentuk. Menurut level ekstraksi, fitur umum dibagi menjadi :
Fitur pixel-level yaitu fitur dihitung pada setiap piksel.
Fitur local yaitu fitur dihitung berdasarkan hasil subdivisi dari pola citra pada citra segmentasi ataupun deteksi tepi.
Fitur global yaitu fitur dihitung pada seluruh konten pada citra.
2. Fitur spesifik merupakan nilai fitur yang bersifat dependen seperti wajah manusia, sidik jari, dan lain-lain.
Fitur dapat diklasifikasikan kedalam low-level features dan high-level features. Proses ekstraksi pada low-level features dilakukan pada citra asli, dan proses ekstraksi pada high-level features bergantung pada fitur low-level features. Proses Ekstraksi fitur terbagi menjadi tiga macam yaitu :
a. Ekstraksi fitur bentuk
Ekstraksi fitur bentuk adalah perhitungan kesamaan / kedekatan antara representasi bentuk dengan fiturnya. Bentuk merupakan fitur visual yang penting dan merupakan salah satu fitur sederhana dalam mendeskripsikan konten citra. Fitur bentuk dikategorikan pada teknik yang digunakan. Kategori tersebut terdiri atas :
Berdasarkan batas (boundary-based)
Berdasarkan daerah (region-based)
Teknik ini merepresentasikan bentuk wilayah dengan karakteristik internal.
b. Ekstraksi fitur tekstur
Tekstur adalah salah satu bagian penting dari citra. Tekstur adalah descriptor wilayah yang dapat membantu dalam proses pengambilan informasi. Tekstur tidak memiliki kemampuan untuk menemukan kesamaan citra namun dapat digunakan untuk mengklasifikasikan citra bertekstur dari non-tekstur dan kemudian dapat dikombinasikan dengan fitur lainnya seperti warna untuk mendapatkan pengambilan informasi yang lebih efektif.
Tekstur menjadi karakteristik penting yang dapat digunakan dalam pengklasifikasikan dan mengenal objek dan memiliki kemampuan menemukan persamaan antara citra-citra pada database multimedia. Pada dasarnya, metode representasi tekstur dapat diklasifikasikan menjadi dua kategori yaitu struktural dan statistik. Beberapa metode statistik antara lain Fourier power spectra, co-occurrence matrices, shift-invariant principal component analysis (SPCA), Tamura features, Gabor and wavelet transform.
c. Ekstraksi fitur warna
Pada ciri pembeda pada ekstraksi fitur adalah warna. Ekstraksi fitur warna merupakan fitur visual yang sering digunakan pada proses pengambilan informasi citra. Fitur warna dalam mengklasifikasikan citra memiliki keuntungan yaitu : ketahanan, efektif, implementasi yang sederhana, komputasi yang sederhana dan kemampuan penyimpanan yang kecil. Beberapa model warna yang sering digunakan antara lain : RGB (Red, Green, Blue), HSV (Hue, Saturation, Value) dan Y, Cb, Cr (Luminance and Chrominance).
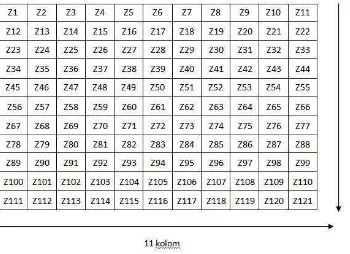
2.4 Metode Zoning
menjadi M x N zona dan dari setiap zona dilakukan perhitungan nilai fitur sehingga didapatkan nilai fitur dan zona M x N. Adapun proses pada metode Zoning antara lain:
Hitung jumlah piksel hitam dari setiap zona dari Z1 sampai Zn.
Tentukan nilai zona yang memiliki nilai piksel hitam paling tinggi. Hitung nilai fitur pada setiap zona dari Z1 sampai Zn dengan
persamaan (2.3).
2.5 Learning Vektor Quantization
Learning Vektor Quantization (LVQ) pertama kali diperkenalkan oleh Tuevo Kohonen yang memperkenalkan Self-Organizing Feature Map juga. LVQ merupakan jaringan hybrid yang menggunakan supervised dan unsupervised learning. Metode LVQ telah digunakan oleh banyak peneliti dalam memecahkan masalah klasifikasi.
LVQ merupakan sebuah metode klasifikasi berdasarkan model kohonen yang dikenal sebagai Self-Organizing Map Network (SOM). Namun LVQ merupakan berbeda dengan SOM yang bersifat pembelajaran tidak terawasi, LVQ merupakan algoritma pembelajaran terawasi versi model Kohonen dengan arsitektur algoritma yang sederhana sehingga hanya terdiri dari satu lapisan input dan lapisan output (Azara et al, 2012).
Learning Vektor Quantization (LVQ) merupakan metode pola klasifikasi pada setiap unit output mewakili sebuah kelas/kategori tertentu. Vektor bobot dari sebuah unit output digunakan sebagai vektor referensi untuk sebuah unit yang diwakili oleh sebuah kelas (Wahyono & Ernastuti, 2009).
Arsitektur LVQ terdiri dari lapisan input (input layer), lapisan kompetitif dan lapisan output (output layer). Sebuah bobot akan menghubungkan lapisan input dengan lapisan kompetitif. Pada lapisan kompetitif, proses pembelajaran dilakukan secara terawasi. Hasil lapisan kompetitif berupa kelas yang dihubungkan dengan lapisan output oleh fungsi aktivasi. Arsitektur Jaringan LVQ dapat dilihat pada Gambar 2.2
Keterangan : nilai yang akan digunakan sebagai nilai input. Dengan nilai W1 sampai Wn sebagai nilai bobot. Nilai input akan dilakukan perhitungan dengan nilai bobot untuk mendapatkan jarak bobot terkecil. H1 dan H2 akan bertindak sebagai lapisan output dimana Lapisan ini akan mewakili satu kelas. Maka pada Gambar 2.2 dapat dilihat bahwa arsitektur memiliki 2 kelas. D1 dan D2 akan bertindak sebagai nilai output pada lapisan output yang akan digunakan sebagai bobot pada proses pengujian.
Adapun kelebihan dari LVQ adalah :
1) Nilai error yang dihasilkan lebih kecil dibandingkan dengan jaringan syaraf tiruan Backpropagation
2) Data set yang besar dapat diringkas menjadi vektor kecil pada tahap klasifikasi 3) Tidak ada pembatasan pada dimensi codebook
4) Model yang dihasilkan dapat dilakukan perbaharuan secara bertahap
Sedangkan Kekurangan dari LVQ antara lain :
1) Diperlukan perhitungan yang akurat terhadap jarak untuk seluruh atribut 2) Akurasi model LVQ bergantung kepada inisialisasi dan parameter yang
digunakan dalam perhitungan
3) Distribusi kelas pada data training mempengaruhi nilai akurasi 4) Sulitnya jumlah vektor yang ditentukan pada masalah yang diberikan.
Parameter-parameter yang diperlukan dalam algoritma LVQ antara lain :
1. Learning rate (α) merupakan nilai tingkat pelatihan. Jika α terlalu besar maka algoritma menjadi tidak stabil dan terlalu kecil maka waktu proses yang diperlukan semakin lama. Nilai α berada pada rentang 0 < α < 1.
2. Penurunan Learning rate (Dec α) yaitu penurunan tingkat pelatihan. Penurunan Learning rate dilakukan setelah selesai dilakukan iterasi pada setiap data dan akan dilakukan pada iterasi yang selanjutnya.
3. Minimimum Learning rate (Min α) yaitu tingkat pelatihan yang masih diperbolehkan
4. Maksimum Epoch (MaxEpoch) yaitu jumlah iterasi maksimum yang boleh dilakukan selama proses pelatihan. Selama iterasi yang telah dilakukan telah mencapai iterasi maksimum, maka iterasi akan dihentikan.
Metode LVQ dilakukan dengan proses pengenalan terlebih dahulu terhadap pola input kedalam bentuk vektor untuk memudahkan proses pencarian kelas. Setiap output menyatakan kelas tertentu maka pola input dapat dikenali kelasnya berdasarkan output yang diperoleh. LVQ mengenali pola input dengan kedekatan jarak antara vektor input dan vektor bobot. Pada LVQ terdapat dua proses yaitu :
a. Proses Training
Adapun algoritma metode LVQ (Hermanto et al, 2009) adalah sebagai berikut : 1) Tetapkan nilai bobot (w), maksimum epoch (MaxEpoch), error minimum
(Eps) dan Learning rate (α). 2) Masukkan :
Target : T(1,n) 3) Tetapkan kondisi awal :
Epoch : 0; Err : 1
4) Kerjakan jika (epoch < MaxEpoch) atau (α > Eps) a. Epoch = Epoch + 1
b. Kerjakan untuk i=1 sampai n
i. Tentukan J hingga ||x-wj|| minimum
ii. Perbaiki wj dengan ketentuan :
Jika T = Cj maka :
wj (baru) = wj (lama) + α [x- wj (lama)]
Jika T ≠ Cj maka :
wj (baru) = wj (lama) - α [x- wj (lama)]
c. Kurangi nilai α
Keterangan notasi :
X vektor latih (x1, x2, ..., xn) T kategori benar untuk vektor latih
Wj vektor bobot unit output j (w1j, w2j, wnj )
Cj Kategori yang mewakili output j
||x- wj|| Jarak bobot antara vektor input dan vektor bobot untuk output
Pada tahap Training, Algoritma LVQ akan memproses input dengan menerima vektor input dengan keterangan kelas vektor. Kemudian vektor akan menghitung jarak semua vektor pewakil untuk kelas yang ada dengan menghitung jarak terdekat dengan Euclidean distance. Vektor yang memiliki jarak terdekat akan dianggap sebagai kelas pemenang yang dinamakan sebagai best matching unit (BMU).
Proses pada tahap ini dilakukan secara iterasi dengan learning rate yang mengecil. Satu iterasi dapat disebut sebagai satu epoch. Pada satu epoch, semua data akan dihitung jarak terdekatnya dan akan dilakukan perbaharuan pada vektor pewakil. Untuk melanjutkan ke epoch berikutnya maka learning rate akan dikalikan dengan Dec α. Setelah α telah mencapai minimal α, maka proses training akan dihentikan.
b. Proses Testing
Pada tahap testing, data diklasifikasikan dengan cara yang sama sesuai dengan tahap training. Dimana proses perhitungan dilakukan dengan mencari jarak terdekat dari setiap kelas. Setelah didapatkan jarak pada setiap bobot maka tentukan nilai bobot dengan jarak terdekat. Selanjutya nilai bobot tersebut akan ditetapkan sebagai kelas.
2.6 Penelitian Terdahulu
Beberapa penelitian telah dilakukan untuk menyelesaikan permasalahan pada karet RSS. Pada penelitian yang dilakukan oleh (Ahmad et al, 2006) pada pemeriksaan mutu karet RSS menggunakan pengolahan citra dengan menganalisi karakteristik warna permukaan karet baik menggunakan model warna RGB maupun HSI dan karakteristik tekstur menggunakan analisis tekstur untuk tiap tiap kelas mutu RSS menghasilkan parameter warna dapat digunakan sebagai parameter mutu karet dan fitur tekstur tidak dapat dijadikan parameter mutu karet khususnya dalam menentukan batas RSS-2.
Pada Model RGB, Indeks warna biru dapat digunakan untuk mengklasifikasikan mutu RSS dengan kesesuaian yang cukup tinggi namun hasil yang lebih baik dan konsistern diperoleh dengan menggunakan warna HIS dengan kriteria H ≤ 28 dan I ≥ 220 pada RSS1, H ≥ 68 dan S ≤ 73 untuk RSS3 dan RSS 2 berada pada llingkup selain kriteria RSS1 dan RSS3 dengan tingkat kesesuaian 86% untuk RSS1, 77,5% untuk RSS2, dan 95% untuk RSS3.
tingkat resolusi 192 x 144. Perlakuan II, dengan cahaya lampu dari bawah dengan tingkat resolusi 192 x 144. Perlakuan III, dilakukan pencahayaan dari atas dengan resolusi 341 x 256 dan perlakuan IV, dilakukan pencahayaan dari bawah dengan resolusi 341 x 256.
Dan parameter yang diukur dari citra RSS meliputi indeks warna RGB, komponen warna HIS dan komponen tekstur citra. Hasil pengolahan citra perlakuan I menunjukkan bahwa hanya parameter indeks warna biru saja yang dapat digunakan sebagai parameter sortasi dengan nilai batas atas sebesar 0.2921 dan batas bawah sebesar 0.2843. Hasil pengolahan citra perlakuan II menunjukkan parameter indeks warna merah, hijau, biru dan saturasi dapat digunakan sebagai parameter sortasi dengan batas atas dan batas bawah masing-masing Merah (0.4143 , 0.3914), Hijau (0.3321 , 0.3258), Biru (0.2743, 0.2574) dan Saturasi (95,76).
Hasil perlakukan III ditemukan bahwa hanya parameter indeks warna biru yang dapat digunakan sebagai parameter sortasi dengan nilai batas atas sebesar 0.2929 dan batas bawah sebesar 0.2852. Hasil pengolahan citra perlakuan IV menunjukkan parameter indeks warna merah, hijau, biru dan saturasi dapat digunakan sebagai parameter sortasi dengan batas atas dan batas bawah masing-masing Merah (0.4168, 0.3927), Hijau (0.3305, 0.3241), Biru (0.2740, 0.2570) dan Saturasi (96.77). Dari hasil perbandingan antar setiap perlakukan menghasilkan presentase keberhasilan pemutuan resolusi 341 x 256 lebih tinggi dibandingkan resolusi 192 x 144.
Pada penelitin yang dilakukan oleh (Umyai et al, 2011) dalam mendeteksi gelembung udara pada Ribbed Smoked Sheet berdasarkan dimensi fractal pada 500 citra RSS menghasilkan 98% tingkat keberhasilan klasifikasi ada atau tidaknya gelembung pada RSS.
Pada penelitian yang dilakukan oleh (Prabpal et al, 2014) pada klasifikasi kualitas karet RSS menggunakan pengolahan citra dengan metode ANN menghasilkan tingkat akurasi 90 % pada 100 sampel karet RSS yang dibagi kedalam 4 level yaitu A (Sangat Bagus), B (Bagus), C (Cukup), dan D (Jelek)
BAB 3
ANALISIS DAN PERANCANGAN
Pada bab ini akan membahas analisis metode Learning Vektor Quantization (LVQ) pada sistem dan tahap-tahap yang digunakan dalam proses perancangan sistem yang akan dibangun.
3.1 Data Yang Digunakan
Data yang digunakan dalam penelitian ini berupa citra karet RSS yang akan diklasifikasikan sebagai karet RSS 1 dan karet RSS 3. Data ini diambil melalui proses akuisisi citra pada penelitian di PTPN III Sarang Gitting. Jumlah data citra yang akan digunakan berupa 89 citra RSS1 dan 89 citra RSS2 dengan ukuran 1024 x 1024 piksel pada setiap citra. Gambar 3.1 menunjukkan citra karet RSS1 dan Karet RSS3.
3.2 Analisis Aplikasi
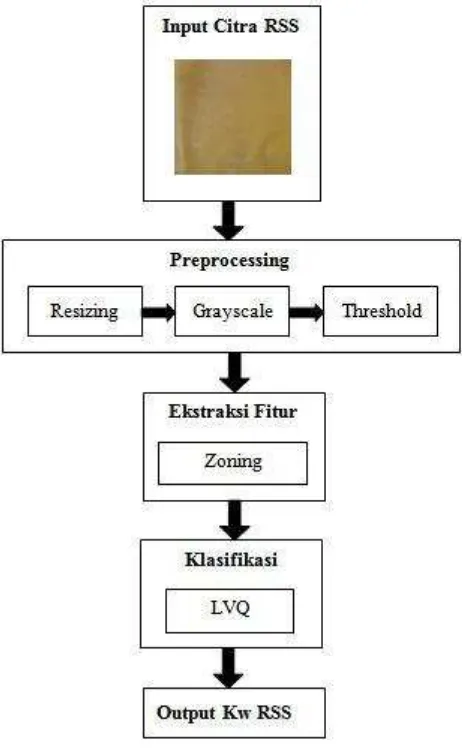
Aplikasi klasifikasi kualitas karet RSS (Ribbed Smoked Sheet) menggunakan metode Learning Vektor Quantization (LVQ) merupakan aplikasi yang dapat mengklasifikasikan kualitas karet RSS (Ribbed Smoked Sheet) secara otomatis berdasarkan tingkat jumlah gelembung yang terdapat pada permukaan karet RSS. Aplikasi ini akan menerima masukan berupa citra karet RSS. Kemudian citra akan diproses melalui tahapan preprocessing, segmentasi, ekstraksi fitur dan klasifikasi menggunakan metode Learning Vektor Quantization (LVQ). Proses perancangan aplikasi pada arsitektur umum terdapat pada Gambar 3.2
3.3 Input citra RSS
Sebelum melakukan proses klasifikasi, perlu dilakukan proses input citra berupa citra karet RSS yang akan diklasifikasikan. Citra yang akan diinput terlebih dahulu akan dilakukan proses akuisisi citra dengan menggunakan pengambilan gambar dengan jarak yang sama pada setiap gambar untuk mendapatkan hasil jarak dan kerenggangan yang sama dari setiap citra sehingga hasil klasifikasi yang akan didapatkan lebih akurat. Adapun langkah-langkah akuisisi citra yang akan dilakukan adalah sebagai berikut :
Sampel yang akan dijadikan citra berupa karet RSS 1 dan Karet RSS 3 yang akan dilakukan proses sortasi
Sampel akan diletakkan pada meja sortasi yang telah tersedia pada ruang sortasi PTPN III Sarang Gitting
Sampel diletakkan pada background putih
Pengambilan citra dilakukan menggunakan kamera digital dengan jarak kamera 50 cm dengan resolusi 2592 x 1944 piksel
Citra akan disimpan dalam bentuk .jpeg
3.4 Preprocessing
Pada tahap preprocessing, dilakukan beberapa tahapan persiapan citra sehingga citra dapat dengan mudah diproses pada tahap selanjutnya. Tahapan preprocessing citra karet RSS terdiri dari resizing, grayscale, thresholding.
3.4.1 Resizing
Gambar 3.3 Citra RSS resize 3.4.2 Grayscale
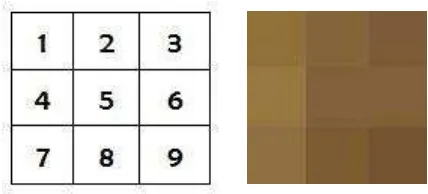
Setelah citra di resizing, akan dilakukan proses grayscale. Proses ini digunakan untuk memisahkan antara bayangan dan warna asli pada citra RSS. Proses ini akan menghasilkan citra hitam putih dengan cara melakukan konversi citra RGB ke citra grayscale. Pada citra terdiri dari 24-bit dimana setiap piksel mengandung nilai warna dasar (R,G,B) yang masing-masing memiliki 8-bit warna dengan nilai warna berada pada 0 (00000000) sampai 255 (11111111). Gambar 3.4 merupakan representasi piksel pada citra karet RSS.
Gambar 3.4 Representasi piksel karet RSS
Gambar 3.5 Citra 9 (3x3) Piksel Adapun nilai Red, Green, Blue pada citra 9 piksel antara lain :
P1 = R, G, B (145, 112, 58 ) P2 = R, G, B (133, 101, 60 ) P3 = R, G, B (151, 118, 56) P4 = R, G, B (145, 112, 65 ) P5 = R, G, B (126, 97, 57 ) P6 = R, G, B (128, 96, 58 ) P7 = R, G, B (142, 111, 64 ) P8 = R, G, B (122, 91, 50 ) P9 = R, G, B (115, 85, 51 )
Citra warna pada RSS diubah menjadi citra grayscale dengan menghitung rata-rata elemen warna dari Red, Green, Blue. Persamaan yang digunakan dalam mengkonversi citra RGB menjadi citra grayscale adalah sebagai berikut
Dengan menggunakan persamaan (3.1) maka nilai grayscale yang akan di dapatkan antara lain sebagai berikut :
P1 = R, G, B (145, 112, 58 ) / 3 = 105 P2 = R, G, B (133, 101, 60 ) / 3 = 98 P3 = R, G, B (151, 118, 56) / 3 = 108.33 P4 = R, G, B (145, 112, 65 ) / 3 = 107.33 P5 = R, G, B (126, 97, 57 ) / 3 = 93.33 P6 = R, G, B (128, 96, 58 ) / 3 = 94 P7 = R, G, B (142, 111, 64 ) / 3 = 105.67 P8 = R, G, B (122, 91, 50 ) / 3 = 87.67
P9 = R, G, B (115, 85, 51 ) / 3 = 83.67
Setelah didapatkan nilai grayscale setiap piksel sesuai persamaan (3.1) maka nilai piksel akan diubah sesuai dengan nilai grayscale sehingga didapatkan nilai grayscale pada setiap piksel dapat dilihat pada Gambar 3.6
105
98
108
107
93
94
105
87
83
Gambar 3.6 Nilai Grayscale pada setiap piksel
Proses perhitungan nilai grayscale pada citra karet RSS 9 piksel (3x3) piksel dapat dilakukan juga pada citra karet RSS 1024 x 1024. Contoh citra karet RSS yang telah dilakukan grayscale pada ukuran 1024 x 1024 piksel ditunjukkan pada Gambar 3.7
a b
3.4.3 Thresholding
Pada tahap selanjutnya citra yang telah digrayscale selanjutnya akan dilakukan proses thresholding dimana citra grayscale akan diubah menjadi citra biner yang bernilai 0 dan 1 (Hitam dan Putih).Pada tahap ini setiap nilai piksel citra grayscale akan diambil nilai ambangnya untuk menentukan nilai biner pada setiap citra.
Jika nilai yang dihasilkan kurang dari ambang yang dihasilkan maka nilai piksel tersebut akan diubah menjadi warna hitam dan jika nilai yang dihasilkan lebih dari nilai rata-rata maka nilai piksel akan diubah menjadi warna putih.
Nilai grayscale pada potongan citra 9 piksel (3x3) piksel akan diubah menjadi nilai threshold sesuai dengan nilai ambang. Nilai ambang yang akan digunakan didapatkan sesuai persamaan (3.2)
Keterangan :
T = Nilai threshold
fmaks = Nilai piksel maksimum fmin = Nilai piksel minimum
Menggunakan persamaan (3.2), maka nilai threshold pada potongan citra 9 piksel (3x3) piksel adalah sebagai berikut
Nilai threshold yang dihasilkan adalah 96. Nilai threshold 96 ini dapat digunakan jika persentase nilai piksel > 96 sebesar lebih dari 50 %, namun jika persentase nilai piksel 96 lebih sedikit dari 50 % maka digunakan persamaan (3.3)
Berdasarkan gambar 3.5, nilai piksel yang berada diatas nilai threshold (96) sebesar 5 piksel dan nilai piksel yang berada dibawah nilai threshold (96) sebesar 4 piksel. Sehingga presentasi yg diperoleh adalah sebagai berikut
(3.2)
Dengan persentasi nilai threshold diatas, diperoleh sebesar 55.56 % nilai piksel yang berada di atas nilai threshold sehingga untuk menentukan nilai threshold dapat digunakan pesamaan (3.2) sehingga diperoleh :
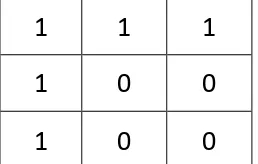
P1 = 105 > 96 = 1 P2 = 98 > 96 = 1 P3 = 108.33 > 96 = 1 P4 = 107.33 > 96 = 1 P5 = 93.33 < 96 = 0 P6 = 94 < 96 = 0 P7 = 105.67 > 96 = 1 P8 = 87.67 < 96 = 0 P9 = 83.67 < 96 = 0
Setelah semua nilai threshold didapatkan pada setiap piksel maka nilai citra grayscale akan diupdate dan diganti dengan nilai threshold sesuai dengan Gambar 3.8
1
1
1
1
0
0
1
0
0
Gambar 3.8 Nilai Threshold Citra karet 9 Piksel
a b
Gambar 3.9 Proses citra thresholding, (a) citra grayscale (b) citra thresholding 3.5 Ekstraksi fitur
Setelah dilakukan proses preprocessing, maka akan dilakukan proses ekstraksi ciri yang membentuk nilai fitur yang bersifat unik untuk mendapatkan ciri dari citra. Nilai fitur yang didapat akan mewakili karakteristik dari citra yang akan diklasifikasikan menggunakan Learning Vektor Quantizatin (LVQ). Pada penelitian ini, ekstraksi fitur yang digunakan menggunakan metode zoning.
3.5.1 Zoning
Gambar 3.10 Hasil Zoning Citra
Adapun proses metode zoning dalam proses ekstraksi fitur pada citra karet RSS antara lain :
1. Hitung jumlah piksel hitam setiap zona dari zona Z1 – Z121 2. Tentukan zona yang memiliki jumlah piksel hitam paling tinggi 3. Hitung nilai fitur setiap zona dari Z1-Z121 dengan persamaan
Dengan 1≤ n ≤ 121
Contoh Perhitungan Zoning antara lain:
1. Jumlah Piksel hitam setiap zona antara lain Z1=20, Z10=80, Z20=40, Z50=50
2. Zona yang memiliki jumlah piksel hitam paling tinggi adalah Z10 = 80 3. Nilai fitur setiap zona antara lain :
Namun dalam penelitian ini, penulis melakukan pembulatan pada nilai fitur setiap zona dengan ketentuan jika :
Pembulatan ini dilakukan agar nilai fitur yang dihasilkan akan berbentuk nilai biner yang akan digunakan sebagai nilai input pada proses klasifikasi pada tahap selanjutnya. Sehingga dari perhitungan zona didapat nilai fitur berupa Z1= 0, Z10=1, Z20 = 1, Z50= 1.
Dari perhitungan zoning pada tahap ekstraksi fitur akan menghasilkan 121 fitur yang akan digunakan sebagai nilai input pada proses klasifikasi menggunakan LVQ yang sesuai dengan gambar 3.11
Gambar 3.11 Nilai ekstraksi fitur menggunakan Zoning 3.6 Klasifikasi
Setelah didapat nilai fitur pada proses ekstraksi fitur menggunakan Zoning, tahapan berikutnya yaitu proses klasifikasi citra menggunakan metode learning vektor quantization (LVQ). Tahapan ini memiliki dua proses yaitu proses pelatihan dan proses pengujian. Proses pelatihan menggunakan nilai fitur yang didapat dari data latih yang telah diekstraksi fitur. Pada proses pengujian dilakukan nilai pendekatan dengan menggunakan nilai fitur yang didapat pada data uji.
3.6.1 Learning Vektor Quantization
Dalam penelitian ini, Learning Vektor Quantization digunakan untuk melakukan klasifikasi pola ke dalam beberapa kelas dengan mencari bobot akhir untuk proses klasifikasi dengan menghitung jarak antar data dan bobot akhir. Arsitektur LVQ terdiri atas dua lapisan yaitu lapisan input dan lapisan output.
Lapisan input pada penelitian ini diperoleh dari proses ekstraksi fitur berupa 121 nilai fitur dan lapisan output merupakan kelas dari proses klasifikasi yaitu kelas
RSS1 dan kelas RSS3. Adapun arsitektur umum Learning Vektor Quantization (LVQ) dapat dilihat pada Gambar 3.12
Gambar 3.12 Arsitektur Learning Vektor Quantization (LVQ)
Keterangan :
X1, X2, X3,…, X121 = Nilai input dari hasil ekstraksi fitur
||X-W1||, ||X-W2|| = Jarak bobot
H1, H2 = Lapisan Output
D1, D2 = Nilai Output yang akan digunakan dalam proses uji W1, W2.. W121 = Nilai data inisialisasi
3.6.2 Proses Pelatihan
Pada tahap pelatihan, algoritma LVQ akan memproses input dengan menerima vektor masukan sebanyak 121 fitur dengan keterangan kelas fitur tersebut. Kemudian vektor akan menghitung jarak semua vektor pewakil untuk kelas yang ada dengan menggunakan Euclidean distance.
Gambar 3.13 Pseudocode Penerapan Algoritma LVQ pada Citra RSS Adapun penjelasan dari Gambar 3.13 adalah sebagai berikut :
Tahap awal pada algoritma LVQ adalah tahap inisialisasi untuk penentuan awal bobot, maksimal iterasi, minimum error dan learning rate untuk mendapatkan hasil akhir yang akurat pada citra.
Tahap selanjutnya yaitu tahap inisialisasi nilai input dan target dari input. Nilai input didapat dari hasil ekstraksi fitur. Pada tahap ini, setiap nilai input citra telah ditentukan target kelas citranya (RSS1 atau RSS3).
Tahap berikutnya yaitu inisialisai kondisi awal yaitu epoch = 0 dan error = 1. Perhitungan bobot dimulai dari kondisi awal epoch sampai epoch maksimum yang telah ditentukan
Tahap selanjutnya yaitu bandingkan target kelas dengan bobot. Jika Target kelas dan bobot sama maka perbaharui nilai bobot dengan persamaan berikut :
w
j(baru)= w
j(lama)+ α [x
-w
j(lama)]
Tetapi jika target kelas dan bobot berbeda maka perbaharui nilai dengan dengan persamaan berikut:
w
j(baru)= w
j(lama)+ α [x
-w
j(lama)]
Lakukan perhitungan yang sama seperti input awal pada setiap input dengan menggunakan bobot yang telah diperbaharui.
Setelah setiap input selesai dilakukan perhitungan, maka kurangi nilai
α
dan lakukan iterasi epoch sampai epoch mencapai maksimal epoch atau α mendekati nilai Eps Pada tahap terakhir yaitu jika iterasi epoch berakhir maka tetapkan bobot baru pada epoch terakhir sebagai bobot akhir yang akan digunakan sebagai nilai bobot pada proses data latih.
Pada tahap pelatihan, penulis akan memaparkan proses perhitungan LVQ dalam mendapatkan nilai bobot yang akan disimpan sebagai bobot akhir yang akan digunakan dalam tahap pengujian. Namun penulis hanya mengilustrasikan input hanya dalam beberapa vektor. Adapun data yang akan digunakan sebagai proses perhitungan LVQ pada proses pelatihan dapat dilihat pada tabel 3.1
Tabel 3.1 Data Vektor Input
No Nama Karet X1 X2 X3 X4 X5 X6 Vektor Kelas
1 Karet1 0 0 0 0 1 1 000011 RSS1
2 Karet2 0 0 1 1 0 1 001101 RSS3
3 Karet3 0 1 1 0 1 1 011011 RSS1
4 Karet4 0 0 1 1 0 0 001100 RSS3
5 Karet5 0 1 0 0 1 1 010011 RSS1
Dari keenam data yang akan dilakukan proses pelatihan, empat data akan diambil sebagai nilai input. Nilai input dapat dilihat pada tabel 3.2.
Tabel 3.2 Tabel Nilai Input Pelatihan
No Nama Karet X1 X2 X3 X4 X5 X6 Vektor Kelas
1 Karet3 0 1 1 0 1 1 011011 RSS1
2 Karet4 0 0 1 1 0 0 001100 RSS3
3 Karet5 0 1 0 0 1 1 010011 RSS1
4 Karet6 1 1 1 0 0 1 111001 RSS3
Dan dua data dengan kelas berbeda yakni RSS1 dan RSS akan diambil sebagai nilai bobot untuk proses pelatihan. Nilai bobot pelatihan dapat dilihat pada tabel 3.3
Tabel 3.3. Nilai Bobot Pelatihan
No Nama Karet X1 X2 X3 X4 X5 X6 Vektor Kelas
1 Karet1 0 0 0 0 1 1 000011 RSS1
2 Karet2 0 1 1 1 0 1 011101 RSS3
Parameter-parameter yang digunakan pada penelitian ini adalah sebagai berikut : 1. Learning rate (α) = 0.05
2. Penurunan Learning rate, Dec α = 0.1 3. Minimum Learning rate, Min α = 0.0001 4. Maksimum Epoch, MaxEpoch = 5 Proses Perhitungan
Epoch ke-1
Data Ke-1 : ( 0, 1, 1, 0, 1, 1 ) Bobot Ke-1 : ( 0, 0, 0, 0, 1, 1 ) Jarak pada bobot ke-1
Bobot Ke-2 : ( 0, 0, 1, 1, 0, 0 ) Jarak pada bobot ke-2
Wj Wj= = 1,732051
Jarak terpendek pada Bobot ke-1
Kelas data ke-1 (RSS1) = Target Bobot ke-1 (RSS1) Bobot ke-1 baru :
W1 = W1+ α * (X1– W1) = 0 + 0.05 * (0-0) = 0
W2 = W2+ α * (X2– W2) = 0 + 0.05 * (1-0) = 0.05
W3 = W3+ α * (X3– W3) = 0 + 0.05 * (1-0) = 0.05
W4 = W4+ α * (X4– W4) = 0 + 0.05 * (0-0) = 0
W5 = W5+ α * (X5– W5) = 1 + 0.05 * (1-1) = 1
W6 = W6+ α * (X6– W6) = 1 + 0.05 * (1-1) = 1
Wi (baru) = ( 0, 0.05, 0.05, 0, 1, 1)
Setelah didapatkan nilai bobot kesatu yang baru, maka lakukan update pada bobot yang lama dan ganti dengan bobot kesatu yang baru. Nilai bobot yang baru akan digunakan pada perhitungan data selanjutnya. Bobot baru pertama dapat dilihat pada tabel 3.4
Tabel 3.4 Nilai Bobot Pertama Baru
No Nama Karet X1 X2 X3 X4 X5 X6 Kelas 1 Karet1 0 0.05 0.05 0 1 1 RSS1
2 Karet2 0 0 1 1 0 1 RSS3
Data Ke-2 : ( 0, 0, 1, 1, 0, 0 ) Bobot Ke-1 : ( 0, 0.05, 0.05, 0, 1, 1 ) Jarak pada bobot ke-1
Bobot Ke-2 : ( 0,0, 1, 1, 0, 1 ) Jarak pada bobot ke-2
Wj = = 1
Jarak terpendek pada Bobot ke-2
Kelas data ke-2 (RSS3) = Target Bobot ke-2 (RSS3) Bobot ke-2 baru :
W1 = W1+ α * (X1– W1) = 0 + 0.05 * (0-0) = 0
W2 = W2+ α * (X2– W2) = 0 + 0.05 * (0-0) = 0
W3 = W3+ α * (X3– W3) = 1 + 0.05 * (1-1) = 1
W4 = W4+ α * (X4– W4) = 1 + 0.05 * (1-1) = 1
W5 = W5+ α * (X5– W5) = 0 + 0.05 * (0-0) = 0
W6 = W6+ α * (X6– W6) = 1 + 0.05 * (0-1) = 0.95
Wj (baru) = ( 0, 0, 1, 1, 0, 0.95)
Setelah didapatkan nilai bobot kedua yang baru, maka lakukan update pada bobot yang lama dan ganti dengan bobot kedua yang baru. Nilai bobot yang baru akan digunakan pada perhitungan data selanjutnya. Bobot baru kedua dapat dilihat pada tabel 3.5
Tabel 3.5 Nilai Bobot Kedua Baru
No Nama Karet X1 X2 X3 X4 X5 X6 Kelas 1 Karet1 0 0.05 0.05 0 1 1 RSS1
2 Karet2 0 0 1 1 0 0.95 RSS3
Proses ini diteruskan sampai data terakhir. Setelah itu proses dilanjutkan ke iterasi (epoch) ke-2 sampai epoch yang ditentukan . Namun sebelum dilakukan epoch selanjutnya, lakukan update learning rate (α) dengan Decα.
Tabel 3.6 Hasil Perhitungan Data Latih
Epoch Nama Input
Vektor
Bobot Ke-1
Bobot Ke-2
Jarak
terdekat Bobot Ke 1 Baru Bobot Ke-2 Baru
1 α=0.05
Karet3 011011 1.41 1.73 Bobot 1 0 0.05 0.05 0 1 1 0 0 1 1 0 1 Karet4 001100 1.97 1 Bobot 2 0 0.05 0.05 0 1 1 0 0 1 1 0 0.95 Karet5 010011 0.905 2 Bobot 1 0 0.097 0.047 0 1 1 0 0 1 1 0 0.95 Karet6 111001 1.929 1.73 Bobot 2 0 0.097 0.047 0 1 1 0.05 0.05 1 0.95 0 0.95
2 α=0.005
Karet3 011011 1.31 1.67 Bobot 1 0 0.1 0.05 0 1 1 0.05 0.05 1 0.95 0 0.95 Karet4 001100 1.97 0.95 Bobot 2 0 0.1 0.05 0 1 1 0.05 0.05 1 0.95 0 0.95 Karet5 010011 0.90 1.95 Bobot 1 0 0.1 0.05 0 1 1 0.05 0.05 1 0.95 0 0.95 Karet6 111001 1.92 1.64 Bobot 2 0 0.1 0.05 0 1 1 0.05 0.055 1 0.95 0.005 0.95
3 α=0.0005
3.6.3 Proses pengujian
Dari Tabel 3.5, hasil perhitungan data latih tidak lagi mengalami perubahan di epoch ke-3 dengan α = 0.0005. Sehingga bobot yang dihasilkan pada epoch terakhir pada data terakhir akan dijadikan nilai bobot pada data uji dalam proses klasifikasi. Adapun hasil bobot akhir yang akan digunakan pada data uji dapat dilihat pada tabel 3.6
Tabel 3.7 Nilai Bobot Data Uji
No Jenis Bobot X1 X2 X3 X4 X5 X6 Kelas
1 Bobot Ke 1 0 0.1 0.05 0 1 1 RSS1
2 Bobot ke -2 0.05 0.055 1 0.95 0.005 0.95 RSS3
Pada tahap pengujian, data input diklasifikasikan dengan cara yang sama dengan tahap pelatihan yaitu dengan menghitung nilai setiap bobot pada input dan memilih jarak terkecil pada kedua bobot. Nilai pada jarak bobot terkecil akan mewakili kelas pada citra masukan. Adapun alur flowchart pada proses pengujian dapat dilihat pada gambar 3.14
3.7 Rancangan Tampilan Antarmuka
Tampilan antarmuka (interface) merupakan tampilan yang menengahi komunikasi antara manusia dan computer. Perancangan antarmuka bertujuan untuk memberikan gambaran umum tampilan dari aplikasi yang akan dibuat dan tujuan serta maksud dalam pembuatan tampilan antarmuka.
3.7.1 Rancangan halaman utama
Gambar 3.15 Rancangan halaman utama klasifikasi karet Keterangan :
1. Logo yang akan digunakan adalah logo universitas sumatera Utara
2. Tombol “Data Latih” akan menghubungkan pengguna untuk masuk ke halaman proses data latih karet RSS dalam melakukan pengenalan klasifikasi karet RSS
3. Tombol “Data Uji” akan menghubungkan pengguna untuk masuk ke halaman pengujian klasifikasi karet
4. Tombol “Tentang Sistem” akan menghubungkan pengguna untuk masuk ke halaman penjelasan singkat tentang sistem
5. Tombol “Keluar” akan memungkinkan pengguna untuk keluar dari sistem Klasifikasi Kualitas Karet RSS (Ribbed Smoke Sheet) Dengan
Metode Learning Vector Quantization (LVQ)
1
LOGO
Data Latih Data Uji Tentang Sistem Keluar 1
3.7.2 Rancangan halaman proses data latih
Gambar 3.16 Tampilan Halaman Data Latih
Keterangan
1. Berisi tampilan data citra karet yaitu form nama citra yang diisi oleh pengguna, form jenis karet yang diisi oleh pengguna serta button “pilih file” untuk memilih file citra yang akan dikenali klasifikasinya dan terdapat button “Proses” untuk melakukan proses klasifikasi citra.
2. Merupakan setiap proses yang akan ditunjukkan setelah pengguna memilih button “Proses”.
3. Button “Simpan” untuk menyimpan nilai bobot yang akan digunakan pada proses klasifikasi
1 2 3
Proses Data Latih
Nama Karet
Jenis Karet :
Pilih File
Proses
Grayscale Threshold Nilai Fitur
Simpan
1 2
3.7.3 Rancangan halaman proses data uji
Gambar 3.17 Tampilan Halaman Proses Data Uji Keterangan :
1. Berisi button “Bobot LVQ” untuk melakukan proses hitung bobot sesuai dengan nilai epoh yang di input dan tampilan nilai bobot yang telah dihitung. 2. Berisi tampilan data citra karet yaitu form nama citra yang diisi oleh
pengguna, serta button “pilih file” untuk memilih file citra yang akan diklasifikasi dan button “Proses” untuk melakukan proses klasifikasi.
3. Merupakan setiap proses yang akan ditunjukkan setelah pengguna memilih button “Proses”.
Proses Data Uji
Nama Karet
Pilih File
Proses
Bobot Ke-1
Grayscale Threshold
Bobot LVQ Bobot Ke-2
Klasifikasi
Nilai Fitur Bobot LVQ
Epoh Bobot 1 (RSS1) Bobot 2 (RSS3)
3 2
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Pada bab ini, akan dibahas proses pengimplementasian dan pengujian aplikasi berdasarkan analisis dan perancangan aplikasi yang telah dibahas pada bab sebelumnya. Pada tahap ini, bertujuan untuk menampilkan hasil perancangan aplikasi yang telah dibangun dan proses pengujian aplikasi dalam mengklasifikasikan citra karet RSS (Ribbed Smoked Sheet).
4.1 Kebutuhan Aplikasi
Dalam perancangan aplikasi klasifikasi karet RSS (Ribbed Smoked Sheet) menggunakan metode LVQ (Learning Vector Quantization) memerlukan perangkat keras dan perangkat lunak pendukung antara lain :
4.1.1 Perangkat keras
Spesifikasi perangkat keras yang digunakan pada aplikasi ini antara lain : Processor : Intel (R) Celeron (R) CPU N2840 2.16 GHz
RAM : 2.00 GB
Harddisk : 500 GB
4.1.2 Perangkat lunak
Spesifikasi perangkat lunak yang digunakan pada aplikasi ini antara lain : Windows 7 Home Premium 32 bit
4.2 Implementasi Perancangan Antar Muka
Adapun tampilan dari perancangan antar muka yang telah diimplementasikan antara lain sebagai berikut :
4.2.1 Halaman utama
Halaman utama pada aplikasi ini merupakan halaman yang akan pertama kali muncul ketika aplikasi dijalankan. Pada halaman ini akan ditampilkan menu-menu yang akan membawa user ke halaman-halaman lain seperti halaman data latih, halaman data uji dan halaman tentang. Contoh halaman utama aplikasi dapat dilihat pada Gambar 4.1 :
Gambar 4.1 Tampilan Halaman Utama
4.2.2 Halaman data latih
Gambar 4.2 Tampilan Halaman Data Latih
Gambar 4.3 Tampilan Halaman Proses Data Latih
4.2.3 Halaman data uji
Tampilan Halaman data uji akan ditampilkan ketika pengguna memilih menu Data Uji pada halaman utama. Tampilan halaman data uji ditujukan untuk melakukan proses uji citra dan pengenalan jenis citra karet. Proses pengujian citra dan pengenalannya dapat dilakukan oleh pengguna dengan melakukan perhitungan bobot terlebih dahulu. Proses perhitungan bobot digunakan untuk mendapatkan nilai bobot dari nilai fitur yang telah didapatkan pada proses latih data untuk menghitung jarak terdekat bobot pada data latih. Tampilan halaman data uji dapat dilihat pada Gambar 4.4.
Gambar 4.4 Tampilan Halaman Data Uji
pengenalan citra berupa citra asli, citra grayscale, citra threshold, nilai fitur ekstraksi, jarak setiap bobot dan jenis klasifikasi karet. Halaman proses data uji dapat dilihat pada Gambar 4.5.
Gambar 4.5 Tampilan Halaman Proses Data Uji
4.3 Pengujian Kinerja aplikasi
Rencana proses pengujian kinerja aplikasi yang akan diuji dapat dilihat pada table 4.1
Tabel 4.1 Rencana Pengujian Kinerja Aplikasi
NO Halaman Aplikasi yang Diuji Butir Uji
1 Halaman Utama Tombol “Data Latih”
Tombol “Uji Data” Tombol “Tentang” Tombol “Keluar” 2 Halaman Data Latih Tombol “Pilih Citra”
Tombol “Proses Tombol “Simpan”