BAB 2
LANDASAN TEORI
2.1. Jaringan Syaraf Tiruan
Artificial Neural Network atau Jaringan Syaraf Tiruan (JST) adalah salah satu cabang
dari Artificial Intelligence. JST merupakan suatu sistem pemrosesan informasi yang
memiliki karakteristik menyerupai jaringan syaraf biologi (Fausett, 1994). Demikian
juga Haykin (2008) menyatakan bahwa JST adalah sebuah mesin yang dirancang
untuk memodelkan cara otak manusia mengerjakan fungsi atau tugas-tugas tertentu.
Mesin ini memiliki kemampuan menyimpan pengetahuan berdasarkan pengalaman
dan menjadikan pengetahuan yang dimiliki menjadi bermanfaat.
Menurut Sutojo et al (2010), Jaringan Syaraf Tiruan merupakan sistem
pemrosesan informasi yang memiliki karakteristik yang mirip dengan jaringan syaraf
manusia. Jaringan syaraf tiruan ini juga dapat diterapkan untuk mengenali pola atau
memetakan suatu masukan menjadi keluaran yang dilatih melalui suatu proses
pelatihan dan dikembangkan menjadi pemodelan matematis dari syaraf manusia yang
berdasar pada asumsi bahwa :
a. Proses informasi terjadi pada beberapa elemen sederhana yaitu neuron.
b. Sinyal terhubung diantara neuron menciptakan jaringan koneksi.
c. Setiap jaringan koneksi penghubung memiliki bobot yang terhubung, yang dalam jaringan saraf tertentu mengalikan sinyal yang ditransmisikan.
d. Setiap neuron mempunyai fungsi aktrivasi (biasanya tidak linier) pada jaringan
masukannya (jumlah dari bobot sinyal keluaran) untuk menentukan sinyal
keluarannya.
Karakteristik dari jaringan saraf tiruan adalah :
a. Pola terhubung diantara neuron (yang menjadi arsitekturnya).
b. Metode penentuan bobot dalam koneksi (disebut sebagai proses latihan,
pembelajaran, atau Algoritma).
Kelebihan-kelebihan yang diberikan oleh JST antara lain :
1. Belajar Adaptive, yaitu kemampuan untuk mempelajari bagaimana melakukan
pekerjaan berdasarkan data yang diberikan untuk pelatihan atau pengalaman
awal.
2. Self-Organization, yaitu sebuah JST yang dapat membuat organisasi sendiri
atau representasi dari informasi yang diterimanya selama waktu belajar.
3. Real Time Operation, yaitu perhitungan JST dapat dilakukan secara paralel
sehingga perangkat keras yang dirancang dan diproduksi secara khusus dapat
mengambil keuntungan dari kemampuan ini.
JST juga mempunyai kelemahan-kelemahan antara lain :
1. Tidak efektif jika digunakan untuk melakukan operasi-operasi numerik dengan
presisi tinggi.
2. Tidak efisien jika digunakan untuk melakukan operasi algoritma aritmatik,
operasi logika, dan simbolis.
3. Untuk beroperasi JST butuh pelatihan sehingga bila jumlah datanya besar,
waktu yang digunakan untuk proses pelatihan sangat lama.
2.2. Learning Vector Quantization
LVQ merupakan metode pelatihan pada lapisan kompetitif terawasi yang akan belajar
secara otomatis untuk mengklasifikasikan vektor-vektor input ke dalam kelas-kelas
tertentu. Kelas yang dihasilkan tergantung pada jarak antara vektor-vektor input. Jika
ada 2 vektor input yang nilainya hampir sama maka lapisan kompetitif akan
mengklasifikasikan kedua vektor input tersebut ke dalam kelas yang sama (Sutojo et
al, 2010).
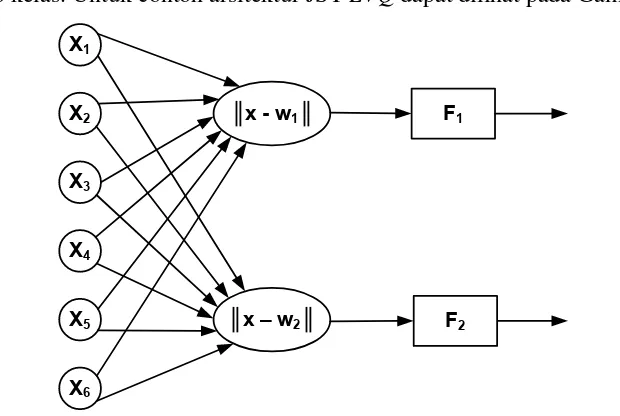
Arsitektur LVQ juga terdiri dari 2 lapisan, input (X) dan output (Y), dimana
antara lapisannya dihubungkan oleh bobot tertentu yang disebut sebagai vektor
pewakil (W), sama halnya dengan metode Self Organizing Map (SOM) yang
sebelumnya juga dikembangkan oleh Teuvo Kohonen. Pada saat pembelajaran,
informasi yang diberikan ke jaringan bukan hanya vektor data saja melainkan
informasi kelas/target dari data juga ikut dimasukkan (Ginting, 2015).
Pada LVQ standar, umumnya cara menentukan vektor bobot awal tersebut
kedua dengan kelas yang berbeda apabila hanya terdapat dua kelas dalam sekumpulan
data kasus. Namun apabila dua vektor bobot tersebut memiliki nilai yang hampir
sama, maka akan mengalami proses pembelajaran yang lama untuk mengenali data
pada setiap kelas. Untuk contoh arsitektur JST LVQ dapat dilihat pada Gambar 2.1.
Gambar 2.1 Arsitektur JST LVQ (Kusumadewi, 2003)
Secara umum, algoritma LVQ adalah sebagai berikut (Safwandi, 2016) :
1. Langkah pertama adalah menentukan bobot dari data setiap kelas, menetapkan
learning rate(α) dan penurunan learning rate.
2. Bandingkan masing-masing input dengan masing-masing bobot yang telah
ditetapkan dengan melakukan pengukuran jarak antara masing-masing bobot
0 dan input � , persamaannya sebagai berikut :
(2.1)
3. Nilai minimum dari hasil perbandingan itu akan menentukan kelas dari vektor
input dan perubahan bobot dari kelas tersebut. Perubahan untuk bobot baru
(w0’) dapat dihitung dengan persamaan berikut :
Untuk input dan bobot yang memiliki kelas yang sama :
(2.2)
Untuk input dan bobot yang memiliki kelas yang berbeda :
(2.3)
Pada dasarnya perhitungan diatas akan dilakukan terus-menerus sampai nilai
bobot tidak berubah jika ada input baru. Hal ini tentu saja membutuhkan keperluan
X1
X2
X4 X3
X6 X5
║x - w1║
║x – w2║
F1
memori yang sangat besar untuk perhitungan. Untuk itu, dalam melakukan
perhitungan LVQ bisa ditentukan maksimal perulangan (epoch). Setelah dilakukan
pelatihan, akan diperoleh bobot akhir (W). Bobot ini nantinya akan digunakan untuk
melakukan simulasi atau pengujian terhadap data yang lain.
2.3. Metode Entropy
Metode Entropy merupakan metode yang dapat digunakan untuk menentukan suatu
bobot. Entropy mampu menyelidiki keserasian dalam diskriminasi diantara
sekumpulan data. Sekumpulan data nilai alternatif pada kriteria tertentu digambarkan
dalam Decision Matrix (DM). Menggunakan metode Entropy, kriteria dengan variasi
nilai tertinggi akan mendapatkan bobot tertinggi. Dengan demikian, metode Entropy
dapat menghitung kemungkinan maksimum (maximum Entropy) untuk setiap data
tunggal dalam suatu kumpulan (entitas) yang memiliki kemungkinan berbeda-beda.
Secara spesifik, Entropy juga mampu beradaptasi dengan sekumpulan data beratribut
jamak yang meiliki variasi berbeda-beda antar satu kriteria dengan kriteria lainnya.
Adapun langkah-langkah pembobotan dengan menggunakan metode Entropy
adalah sebagai berikut (Tiyaswiyoso, 2012)
1. Normalisasi Data Kriteria
Rumus normalisasi adalah sebagai berikut :
(2.4)
∑
i = 1, 2, ... , n (2.5)Dimana :
= nilai data yang telah dinormalisasi = nilai data yang belum dinormalisasi
= nilai datang yang belum dinormalisasi yang mempunyai nilai
paling tinggi
= jumlah nilai data yang telah dinromalisasi
= jumlah alternatif
Rumusnya adalah :
(2.6)
(2.7)
∑
(2.8)
Dimana :
= Entropy maksimum
K = konstanta Entropy
= Entropy untuk setiap atribut/ kriteria ke-i
Setelah mendapatkan untuk masing-masing kriteria, maka dapat
ditentukan total Entropy untuk masing-masing kriteria, rumusnya adalah :
∑
n adalah jumlah kriteria (2.9)
3. Perhitungan Bobot Entropy
Langkah berikutnya adalah menghitung bobot dengan menggunakan rumus
sebagai berikut :
̅
[
]
̅
(2.10)
∑
̅
(2.11)
Dimana :
̅
= bobot Entropy sementara n = jumlah atribut/kriteria
E = total Entropy untuk masing-masing kriteria
2.4. Penelitian-Penelitian Terkait
2.4.1. Penelitian Terdahulu
Peneletian-penelitian tentang metode LVQ telah banyak diteliti santara lain yang telah
dilakukan oleh Maharani dan Irawan (2012) dengan membandingkan metode JST
Backpropagation dengan LVQ pada pengenalan wajah. Backpropagation dan LVQ
merupakan metode JST yang terawasi karena metode tersebut sama-sama
masukan, lapisan tersembunyi, dan lapisan keluar, sedangkan pada LVQ hanya
memiliki dua lapisan saja yaitu lapisan masukan dan keluar. Pada kedua algoritma
sama menggunakan bobot awal pada setiap awal proses algortimanya, pada
Backpropagation bobot awal diperoleh dari bilangan acak sedangkan LVQ diambil
dari data. Dari hasil penelitian didapat bahwa dari segi akusari dan waktu, LVQ lebih
baik dibandingkan dengan dengan Backpropagation.
Pada penelitain lainnya (Mahrina, 2015) yaitu dengan mengkombinasikan
algoritma LVQ dan Self-Organizing Kohonen untuk mempercepat pengenalan pola
tanda tangan. Dasar dari penelitian tersebut dikarenakan proses yang terjadi pada
motede JST memerlukan waktu yang relatif lama, hal ini dipengaruhi banyaknya
sampel data yang digunakan sebagai alat update bobot yang dilatih. Peneliti
menggabungkan beberapa karakterisitik dari Self-Organizing Kohonen ke dalam
proses algoritma LVQ yang disebut algoritma New JST. Untuk mengetahui seberapa
cepat algoritma yang dihasilkan dari New JST, peneliti membandingkan New JST
dengan LVQ standar dan Self-Organizing Kohonen. Kemudian dalam menentukan
bobot awal ditentukan dengan nilai kecil yaitu pembentukan bobot awal dengan nilai
yang kecil dari 1 dan lebih besar dari 0 untuk mengurangi waktu proses. Hasil dari
percobaan tersebut bahwa algoritma New JST memiliki waktu paling sedikikt
dibandingkan dengan LVQ dan Self-Organizing Kohonen dalam segi training dan
recognition.
Pada penelitian oleh Eliasta Ketaren (2016), yang mengembangkan JST LVQ
pada pengenalan wajah dengan cara memasukkan karakteristik Backpropagation yaitu
hidden layer dan bobot acak yang dinamakan Modified LVQ (MLVQ). Hasil dari
penelitian tersebut adalah perbandingan antara algoritma Backpropagation, LVQ, dan
MLVQ pada pengenalan wajah. Dari hasil pengenalan diperoleh algoritma LVQ lebih
cepat dalam melakukan pelatihan dibandingkan dengan Backpropation dan MLVQ,
namun MLVQ memiliki tingkat akurasi lebih baik dibandingkan dengan algoritma
Backpropation dan LVQ.
Penelitian tentang pengembangan LVQ juga telah dilakukan oleh Luh Arida
Ayu (2016), yaitu dengan mengkombinasikan LVQ dengan Self-Organizing Maps
pada klasifikasi genre musik. Kombinasi tersebut terletak pada penentuan vektor
atau sensitif terhadap pemilihan vektor bobot awal yang digunakan sebagai bobot
awal. Pada umumnya penentuan vektor bobot awal dengan cara memilih langsung
sejumlah vektor input sebagai perwakilan dari masing-masing kelas, namun dengan
cara ini sangat sensitif terhadap tingkat akuasi karena ketidakpastian dalam
pemilihannya dapat menghasilkan akurasi yang buruk. Oleh karena itu, peneliti
memilih metode SOM untuk menentukan vektor bobot awal pada jaringan LVQ. Dari
hasil pengujian yang telah dilakukan menunjukkan bahwa klasifikasi genre musik
menggunakan kombinasi LVQ dan SOM memberikan hasil yang lebih baik
dibandingkan dengan LVQ saja.
Ringkasan dari penelitian terdahulu dapat dilihat pada Tabel 2.1.
Tabel 2.1 Penelitian Terdahulu
No. Peneliti
(tahun) Metode yang digunakan Hasil 1 Maharani &
Irawan (2012)
Perbandingan JST Backpropagation dan LVQ pada pengenalan wajah
LVQ lebih baik dari Organizing Kohonen dalam mempercepat pola pengenalan tanda tangan. Kombinasi LVQ dan
Mengembangkan JST dengan cara memasukkan karakteristik Backpropagation yaitu hidden layer dan bobot awal secara acak yang dinamakan Modified LVQ
LVQ memiliki pelatihan
lebih cepat
dibandingkan
Backpropagation dan MLVQ, namun MLVQ memiliki akurasi yang lebih dari yang lainnya. 4 Luh Arida
Ayu (2016)
Kombinasi LVQ dan Self Organizing Maps pada klasifikasi genre musik. Kombinasi terletak pada penentuan vektor bobot acuan/awal.
2.4.2. Perbedaan dengan Penelitian Terdahulu
Perbedaan penelitian dengan yang telah dilakukan terdahulu adalah penentuan vektor
bobot awal (perwakilan) dilakukan dengan menggunakan metode Entropy.
2.4.3. Kontribusi Penelitian
Diharapkan dari penelitian ini, akan didapatkan suatu pendekatan dalam penentuan
vektor bobot awal agar mempercepat proses pembelajaran dalam LVQ dan