ABSTRACT
MUHAMMAD RIDWAN FANSURI, Musical Genre Classification Using Learning Vector Quantization (LVQ). Under the supervision of SONY HARTONO WIJAYA.
Radio stations and music television have a milion of music tapes. A lot of musical genres create a problem when people wants to determine the right genre of a new kind of music. To classify the musical genre is not an easy task, because the musical genre is really difficult to standardization. Automatic musical genre classification can assist the human role in that process and help people to searching for the song acording to the genre that people want.
This research using Mel Frequency Coefficient Cepstrum (MFCC) to obtain feature extraction.
Learning Vector Quantization (LVQ), one kind of artificial neural network used for classification method. The number of genres that are used were four kind of musical genre, that is rock, classic, keroncong, and jazz with four different duration that is 5 second, 10 second, 20 second and 25 second. This research using k- fold cross validation to distribute dataset for training and testing set with the number of folds as much as 2 until 10 fold.
This research succesfully implemented MFCC feature exraction and classification using LVQ. Based on this research, the accuracy of the classification using Learning Vector Quantization reaches 93,75% for the four type musical genre. The highest accuracy value was obtain from the experiments with a duration of 10 second and the number of fold 4. Training time for each duration is 30 minute for 5 second music duration, 45 minute for 10 second music duration 120 minute for 20 second music duration and 150 minute for 25 second music duration.
PENDAHULUAN
Latar Belakang
Genre musik adalah pengelompokan musik sesuai dengan kemiripan satu dengan yang lain, seperti kemiripan dalam hal frekuensi musik, struktur ritmik, dan konten harmoni. Genre musik merupakan hal yang penting bagi masyarakat yang menyukai musik, karena membuat masyarakat dengan mudah mengelompokan musik yang yang mereka sukai.
Pada umumnya pengelompokan lagu dilakukan secara manual yaitu dengan mendengarakan lagu secara langsung kemudian dikelompokkan bedasarkan genre lagu tersebut. Metode ini mempunyai keunggulan yaitu mempunyai tingkat akurasi yang tinggi, tetapi kekurangan dari metode ini adalah sangat tidak efisien untuk data berjumlah banyak, karena harus didengarkan satu persatu. Pengelompokan genre lagu secara otomatis mulai dikembangkan untuk membantu mengelompokan lagu yang berjumlah banyak. Proses ini mempunyai keunggulan dalam jumlah data yang bisa diporses namun kekurangan dari proses otomatis adalah akurasi yang rendah.
Untuk dapat dikelompokkan data musik harus melalui proses ekstraksi ciri yang bertujuan mendapatkan ciri dari lagu tersebut. Salah satu metode yang dapat digunakan adalah Mel-frequency cepstral coefficient (MFCC). MFCC mengekstraksi ciri suara berdasarkan spektrum yang dihasilkan dari musik. Penelitian yang menggunakan MFCC dalam proses ekstraksi ciri antara lain, Prameswari (2010) yang melakukan penelitian pengembangan sistem pengenalan kata berbasis fonem dalam bahasa Indonesia dengan metode resilent backpropagation, dan Wisnudhisastra (2009) tentang pengenalan chord gitar dengan teknik ekstraksi ciri Mel-frequency cepstral coefficient
(MFCC).
Leaning Vector Quantization (LVQ) merupakan salah satu contoh dari jaringan syaraf tiruan yang digunakan untuk proses klasifikasi. Metode LVQ sudah banyak digunakan untuk penelitian, seperti penelitian oleh Effedy et al (2008) mengenai deteksi pornografi pada citra digital menggunakan pengolahan citra dan jaringan syaraf tiruan,
Qur’ani & Rosmalinda (2010) yang meneliti
jaringan syaraf tiruan LVQ untuk aplikasi pengenalan tanda tangan.
Klasifikasi genre musik telah dilakukan oleh Talupur et al (2002). Pada penelitian ini genre
yang diklasifikasikan antara lain klasik, rock, jazz dan country dengan akurasi tertinggi yang dihasilkan sebesar 80 %. Berdasarkan penelitian yang terkait, metode MFCC dan LVQ dapat digunakan untuk klasifikasi genre musik. Rumusan Masalah
Rumusan masalah dalam penelitian ini adalah bagaimana membuat model klasifikasi data audio menggunakan jaringan syaraf tiruan LVQ.
Ruang Lingkup
Ruang lingkup pada penelitian ini antara lain:
1. Dalam penelitian ini, genre musik yang diklasifikasikan dibatasi hanya genre rock, klasik, jazz dan keroncong.
2. Musik yang diolah mempunyai durasi 5, 10, 20, dan 25 detik dengan format wav. 3. Data musik menggunakan chanel mono. Tujuan
Tujuan dari penelitian ini adalah mengembangkan model Learning Vector Quantization untuk klasifikasi genre musik. Manfaat
Penelitian ini diharapkan dapat melakukan klasifikasi pada data musik menggunakan
Learning Vector Quantization agar dapat membantu peran manusia dalam hal menentukan genre musik, sehingga genre musik tidak lagi bersifat relatif, tetapi dapat dikelompokkan dengan standardisasi yang telah ditentukan.
TINJAUAN PUSTAKA
Genre Musik
Genre musik adalah label yang dibuat dan digunakan manusia untuk mengkategorikan dan menggambarkan musik di dunia (Tzanekatis 2002). http://allmusic.com mengelompokan genre musik ke dalam 11 genre utama, yaitu pop/rock, jazz, r&b, rap, country, blues, elektronik, latin, reggae, internasional, dan klasik.
Digitalisasi Gelombang Audio
Gelombang audio merupakan gelombang
PENDAHULUAN
Latar Belakang
Genre musik adalah pengelompokan musik sesuai dengan kemiripan satu dengan yang lain, seperti kemiripan dalam hal frekuensi musik, struktur ritmik, dan konten harmoni. Genre musik merupakan hal yang penting bagi masyarakat yang menyukai musik, karena membuat masyarakat dengan mudah mengelompokan musik yang yang mereka sukai.
Pada umumnya pengelompokan lagu dilakukan secara manual yaitu dengan mendengarakan lagu secara langsung kemudian dikelompokkan bedasarkan genre lagu tersebut. Metode ini mempunyai keunggulan yaitu mempunyai tingkat akurasi yang tinggi, tetapi kekurangan dari metode ini adalah sangat tidak efisien untuk data berjumlah banyak, karena harus didengarkan satu persatu. Pengelompokan genre lagu secara otomatis mulai dikembangkan untuk membantu mengelompokan lagu yang berjumlah banyak. Proses ini mempunyai keunggulan dalam jumlah data yang bisa diporses namun kekurangan dari proses otomatis adalah akurasi yang rendah.
Untuk dapat dikelompokkan data musik harus melalui proses ekstraksi ciri yang bertujuan mendapatkan ciri dari lagu tersebut. Salah satu metode yang dapat digunakan adalah Mel-frequency cepstral coefficient (MFCC). MFCC mengekstraksi ciri suara berdasarkan spektrum yang dihasilkan dari musik. Penelitian yang menggunakan MFCC dalam proses ekstraksi ciri antara lain, Prameswari (2010) yang melakukan penelitian pengembangan sistem pengenalan kata berbasis fonem dalam bahasa Indonesia dengan metode resilent backpropagation, dan Wisnudhisastra (2009) tentang pengenalan chord gitar dengan teknik ekstraksi ciri Mel-frequency cepstral coefficient
(MFCC).
Leaning Vector Quantization (LVQ) merupakan salah satu contoh dari jaringan syaraf tiruan yang digunakan untuk proses klasifikasi. Metode LVQ sudah banyak digunakan untuk penelitian, seperti penelitian oleh Effedy et al (2008) mengenai deteksi pornografi pada citra digital menggunakan pengolahan citra dan jaringan syaraf tiruan,
Qur’ani & Rosmalinda (2010) yang meneliti
jaringan syaraf tiruan LVQ untuk aplikasi pengenalan tanda tangan.
Klasifikasi genre musik telah dilakukan oleh Talupur et al (2002). Pada penelitian ini genre
yang diklasifikasikan antara lain klasik, rock, jazz dan country dengan akurasi tertinggi yang dihasilkan sebesar 80 %. Berdasarkan penelitian yang terkait, metode MFCC dan LVQ dapat digunakan untuk klasifikasi genre musik. Rumusan Masalah
Rumusan masalah dalam penelitian ini adalah bagaimana membuat model klasifikasi data audio menggunakan jaringan syaraf tiruan LVQ.
Ruang Lingkup
Ruang lingkup pada penelitian ini antara lain:
1. Dalam penelitian ini, genre musik yang diklasifikasikan dibatasi hanya genre rock, klasik, jazz dan keroncong.
2. Musik yang diolah mempunyai durasi 5, 10, 20, dan 25 detik dengan format wav. 3. Data musik menggunakan chanel mono. Tujuan
Tujuan dari penelitian ini adalah mengembangkan model Learning Vector Quantization untuk klasifikasi genre musik. Manfaat
Penelitian ini diharapkan dapat melakukan klasifikasi pada data musik menggunakan
Learning Vector Quantization agar dapat membantu peran manusia dalam hal menentukan genre musik, sehingga genre musik tidak lagi bersifat relatif, tetapi dapat dikelompokkan dengan standardisasi yang telah ditentukan.
TINJAUAN PUSTAKA
Genre Musik
Genre musik adalah label yang dibuat dan digunakan manusia untuk mengkategorikan dan menggambarkan musik di dunia (Tzanekatis 2002). http://allmusic.com mengelompokan genre musik ke dalam 11 genre utama, yaitu pop/rock, jazz, r&b, rap, country, blues, elektronik, latin, reggae, internasional, dan klasik.
Digitalisasi Gelombang Audio
Gelombang audio merupakan gelombang
Dalam proses digitalisasi audio, gelombang audio melalui dua tahap proses yaitu sampling
dan kuantisasi (Jurafsky & Martin 2000).
Sampling merupakan proses pengambilan nilai dalam jangka waktu tertentu. Nilai yang dimaksud adalah amplitudo, yaitu besarnya volume suara pada suatu waktu. Proses
sampling menghasilkan sebuah vektor yang menyatakan nilai – nilai hasil sampling. Vektor tersebut mempunyai panjang yang bergantung pada lamanya sinyal dan sampling rate yang digunakan. Sampling rate sendiri adalah banyaknya nilai yang diambil setiap detiknya. Untuk mengukur panjang vektor sinyal, digunakan rumus beikut:
= ��×
dengan
S = panjang vektor
��= samplingrate (Hertz)
T = panjang sinyal (detik)
Tahap selanjutnya adalah proses kuantisasi. Kuantisasi bertujuan menyimpan nilai amplitudo ke dalam representasi nilai 8 bit atau 16 bit (Jurafsky & Martin 2000).
Ekstraksi Ciri Sinyal Audio
Ekstraksi ciri berfungsi mengkarakterisasi sinyal audio. Beberapa fitur sinyal audio yang biasa digunakan antara lain Linear Predictive Coding, Perceptual Linear Prediction, dan Mel -Frequency. Proses ini dilakukan karena sinyal audio merupakan sinyal yang bervariasi yang diwaktukan dengan lambat. Jadi pada jangka waktu yang sangat pendek (5–100 ms), karakteristik sinyal tersebut hampir sama, tetapi dalam jangka waktu yang lebih panjang (0,2 detik atau lebih), karakteristik sinyal audio tersebut berubah dan memperlihatkan perbedaan sinyal audio yang diolah (Do 1994). Mel-Frequency Cepstrum Coefficient (MFCC)
Tujuan dari MFCC adalah mengadapatasi kemampuan telinga manusia dalam mendengar dan mengolah suara. Proses MFCC dapat dilihat pada Gambar 1.
Sinyal Kontinu
Frame Blocking
Windowing frame
Fast Fourier Transform
Mel Frequency Wrapping
spectrum
Cepstrum mel spctrum
mel spectrum Windowing
Gambar 1 Diagram blok proses MFCC (Do 1994)
Tahap-tahap dari proses MFCC dapat dijelaskan sebagai berikut (Do 1994):
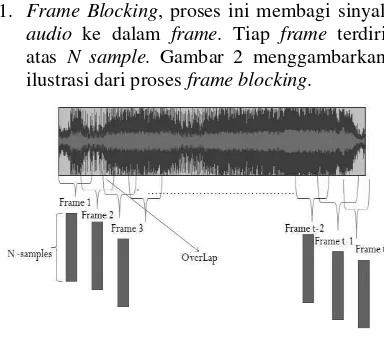
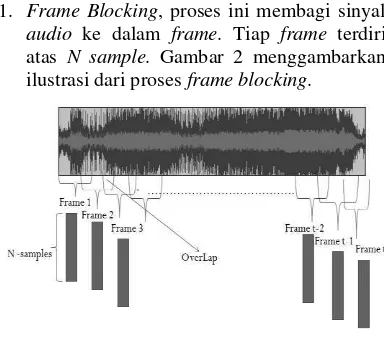
1. Frame Blocking, proses ini membagi sinyal
audio ke dalam frame. Tiap frame terdiri atas N sample. Gambar 2 menggambarkan ilustrasi dari proses frame blocking.
2. Windowing, pada tahap ini sinyal yang telah dibagi ke dalam frame dilakukan proses
windowing untuk meminimalkan diskontinuitas sinyal, dengan cara meminimalkan distorsi spectral dengan menggunakan window untuk memperkecil sinyal hingga mendekati nol pada awal dan akhir tiap frame. Window yang dipakai pada proses ini adalah Hamming window dengan persamaan :
= 0,54−0,46 � � (2� /( −1))
(1) Dengan n = 1, 2, 3... N-1 (N adalah jumlah
frame yang digunakan)
Ilustrasi dari Hamming window dapat dilihat pada Gambar 3.
Gambar 3 Hamming window
3. Fast Fourier Transform (FFT), merupakan
fast algorithm dari Discrete Fourier Transform (DFT) yang berguna untuk konversi setiap frame dari domain waktu menjadi domain frekuensi. Berikut persamaan yang digunakan :
� = �−2� /
−1
=0
(2) dengan n=0, 1, 2 ... N-1, j adalah bilangan imajiner, yaitu j = − 1.
Gambar 4 memperlihatkan sinyal yang sudah berubah ke dalam domain frekuensi.
Gambar 4 Sinyal audio dalam domain frekuensi
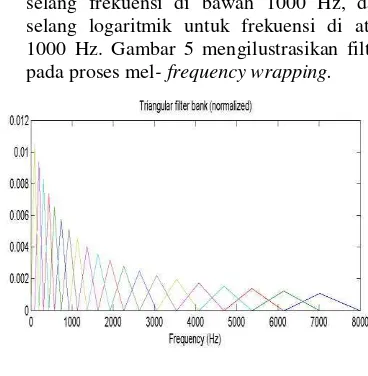
4. Mel-Frequency Wrapping. Berdasarkan studi psikofisik, persepsi manusia terhadap frekuensi sinyal audio tidak berupa skala linier. Jadi untuk setiap nada dengan frekuensi aktual f (dalam Hertz) dapat diukur tinggi subjektifnya menggunakan
skala ‘mel’. Skala mel-frequency adalah
selang frekuensi di bawah 1000 Hz, dan selang logaritmik untuk frekuensi di atas 1000 Hz. Gambar 5 mengilustrasikan filter pada proses mel- frequency wrapping.
Gambar 5 Mel - frequency filter
Proses wrapping terhadap sinyal dalam domain frekuensi menggunakan persamaan berikut :
� = �10 �( )
−1
=0
(3) dengan i= 1,2,3...,M (M adalah jumlah filter segitiga) dan Hi(k) adalah nilai filter segitiga untuk frekuensi akustik sebesar k.
5. Cepstrum, tahap ini menkonversikan log mel spectrum ke dalam domain waktu Hasil proses ini disebut mel frequency cepstrum coefficients. Berikut ini adalah persamaan yang digunakan dalam DCT :
� = � � �( ( −1)/2 �)
=1
Klasifikasi
Klasifikasi merupakan proses menemukan sekumpulan model (atau fungsi) yang menggambarkan dan membedakan konsep atau kelas-kelas data, dengan tujuan agar model tersebut dapat digunakan untuk memprediksi kelas dari suatu objek atau data yang label kelasnya tidak diketahui (Han & Kamber 2001). Klasifikasi terdiri atas dua tahap, yaitu pelatihan dan prediksi (klasifikasi). Pada tahap pelatihan dibentuk sebuah model domain permasalahan dari setiap instance yang ada. Penentuan model tersebut berdasarkan analisis pada sekumpulan data pelatihan, yaitu data yang label kelasnya telah diketahui. Pada tahap klasifikasi, dilakukan prediksi kelas dari
instance (kasus) baru yang telah dibuat pada tahap pelatihan (Güvnir et al 1998).
Jaringan Syaraf Tiruan
Jaringan syaraf tiruan (JST) adalah sistem pemroses informasi yang memiliki karakteristik mirip dengan jaringan syaraf biologi. JST dibentuk sebagai generalisasi model matematika dari jaringan syaraf biologi, dengan asumsi bahwa:
Pemrosesan informasi terjadi pada banyak elemen sederhana (neuron).
Sinyal dikirimkan di antara neuron-neuron melalui penghubung-penghubung (sinapsis).
Untuk menentukan output, setiap neuron menggunakan fungsi aktivasi (Jong 1992). Arsitektur jaringan syaraf tiruan disajikan pada Gambar 6.
Gambar 6 Arsitektur JST sederhana (Jong 1992)
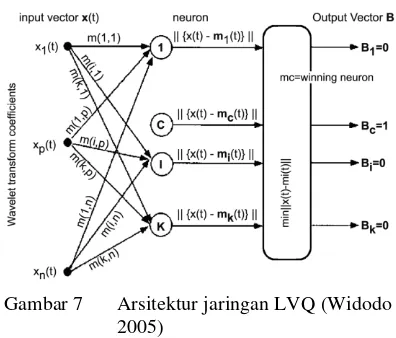
Learning Vector Quantization (LVQ)
Learning Vector Quantization (LVQ) merupakan suatu metode klasifikasi pola yang masing-masing unit output mewakili kategori atau kelas tertentu. Vektor bobot untuk unit
output sering disebut vektor referensi untuk kelas yang dinyatakan oleh unit tersebut. LVQ mengklasifikasikan vektor input dalam kelas yang sama dengan unit output yang memiliki vektor bobot yang paling dekat dengan vektor
input (Widodo 2005). Ilustrasi dari jaringan LVQ dapat dilihat pada Gambar 7.
Gambar 7 Arsitektur jaringan LVQ (Widodo 2005)
Algoritme pelatihan LVQ bertujuan memperoleh unit output yang paling dekat dengan vektor input. Bila x dan wcberasal dari kelas yang sama, maka vektor bobot didekatkan ke vektor input, tetapi apabila berasal dari kelas yang berbeda, maka vektor bobot akan dijauhkan dengan vektor input.
Kelebihan dari LVQ adalah:
1. nilai error yang lebih kecil dibandingkan dengan jaringan syaraf tiruan seperti
backpropagation.
2. Dapat meringkas data set yang besar menjadi vektor codebook berukuran kecil untuk klasifikasi.
3. Dimensi dalam codebook tidak dibatasi seperti dalam teknik nearest neighbour. 4. Model yang dihasilkan dapat diperbaharui
secara bertahap.
Kekurangan dari LVQ adalah:
1. Dibutuhkan perhitungan jarak untuk seluruh atribut.
2. Akurasi model dangan bergantung pada inisialisasi model serta parameter yang digunakan (learning rate, iterasi, dan sebagainya).
3. Akurasi juga dipengaruhi distribusi kelas pada data training.
4. Sulit untuk menentukan jumlah codebook
vektor untuk masalah yang diberikan. Algoritme LVQ
Berikut ini adalah algoritme dari LVQ :
Diinisialisasikan nilai bobot, maksimum
epoch, dan learning rate,
Nilai input (m,n), dan kelas target dimasukkan ke dalam vector (1,n)
a. Untuk masing-masing pelatihan vektor input x
b. Dicari j sehingga ||x-wj|| bernilai minimum
c. Perbaiki wj dengan : 1. Jika T = cj maka
wj baru =wj lama +
αx-wj lama
2. Jika T ≠ cj
wj baru =wj lama -
αx-wj lama
d. Learning rate dikurangi e. Kondisi berhenti dilihat K-fold Cross Validation
Metode k-fold cross validation membagi data menjadi k-buah subset, sebanyak k-1 buah
subset digunakan sebagai training set dan 1 buah set sebagai testing set (Guiterez 2000). Sebagai gambaran, pada Gambar 8 terdapat ilustrasi k-fold cross validation menggunakan 4 buah fold.
Gambar 8 Contoh cross validation dengan 4
fold
Confusion Matrix
Confusion matrix mengandung informasi tentang aktual dan prediksi klasifikasi yang dilakukan oleh sistem. Hasil dari sebuah sistem sering dievaluasi menggunakan confusion matrix (Kohavi and Provost 1998).
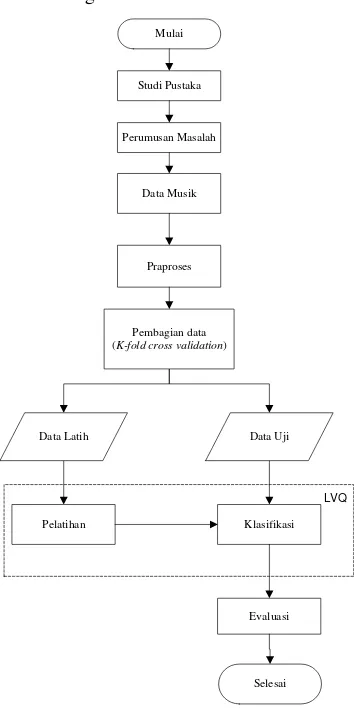
METODE PENELITIAN
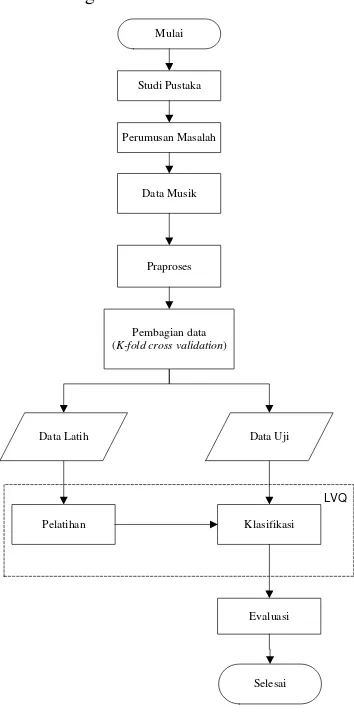
Penelitian ini melalui beberapa tahapan proses. Tahapan proses yang dilakukan dalam penelitian ini disajikan pada Gambar 9. Studi Pustaka
Pada tahap ini, kegiatan yang dilakukan adalah mengumpulkan semua informasi atau literatur yang terkait dalam penelitian.
Informasi tersebut didapatkan dari buku, jurnal, internet dan artikel-artikel yang membahas klasifikasi genre musik.
Mulai
Studi Pustaka
Perumusan Masalah
Data Musik
Pelatihan Klasifikasi
Evaluasi
Selesai Praproses
LVQ
Data Latih Data Uji
Pembagian data (K-fold cross validation)
Gambar 9 Metodologi penelitian Perumusan Masalah
Pada tahap ini dilakukan analisis terhadap permasalahan seperti pemilihan data musik, pemilihan bagian yang akan dijadikan data latih dan data uji.
Data Musik
a. Untuk masing-masing pelatihan vektor input x
b. Dicari j sehingga ||x-wj|| bernilai minimum
c. Perbaiki wj dengan : 1. Jika T = cj maka
wj baru =wj lama +
αx-wj lama
2. Jika T ≠ cj
wj baru =wj lama -
αx-wj lama
d. Learning rate dikurangi e. Kondisi berhenti dilihat K-fold Cross Validation
Metode k-fold cross validation membagi data menjadi k-buah subset, sebanyak k-1 buah
subset digunakan sebagai training set dan 1 buah set sebagai testing set (Guiterez 2000). Sebagai gambaran, pada Gambar 8 terdapat ilustrasi k-fold cross validation menggunakan 4 buah fold.
Gambar 8 Contoh cross validation dengan 4
fold
Confusion Matrix
Confusion matrix mengandung informasi tentang aktual dan prediksi klasifikasi yang dilakukan oleh sistem. Hasil dari sebuah sistem sering dievaluasi menggunakan confusion matrix (Kohavi and Provost 1998).
METODE PENELITIAN
Penelitian ini melalui beberapa tahapan proses. Tahapan proses yang dilakukan dalam penelitian ini disajikan pada Gambar 9. Studi Pustaka
Pada tahap ini, kegiatan yang dilakukan adalah mengumpulkan semua informasi atau literatur yang terkait dalam penelitian.
Informasi tersebut didapatkan dari buku, jurnal, internet dan artikel-artikel yang membahas klasifikasi genre musik.
Mulai
Studi Pustaka
Perumusan Masalah
Data Musik
Pelatihan Klasifikasi
Evaluasi
Selesai Praproses
LVQ
Data Latih Data Uji
Pembagian data (K-fold cross validation)
Gambar 9 Metodologi penelitian Perumusan Masalah
Pada tahap ini dilakukan analisis terhadap permasalahan seperti pemilihan data musik, pemilihan bagian yang akan dijadikan data latih dan data uji.
Data Musik
Data yang pada awalnya berupa chanel stereo diubah ke dalam chanel mono. Kemudian data tersebut disimpan dengan file berekstensi WAV.
Praproses
Pada tahap ini dilakukan ekstraksi ciri menggunakan metode MFCC. Beberapa parameter MFCC yang digunakan pada penelitian ini adalah, sampling rate sebesar 11000 Hz, jumlah data tiap frame sebanyak 512, dan jumlah cepstral coefficient sebesar 13. Pembagian Data Uji dan Data Latih
Untuk pembagian data uji dan data latih digunakan metode k-fold cross validation yang akan membagi data ke dalam subset-subset
sesuai jumlah fold yang digunakan. Fold yang dipakai pada penelitian ini berjumlah 2 hingga 10 fold.
Pelatihan
Input layer merupakan matriks hasil ekstraksi ciri menggunakan MFCC yang dibagi menggunakan k-fold cross validation dengan target kelas pada masing-masing lagu yaitu kelas 1 untuk genre keroncong, kelas 2 untuk genre jazz, kelas 3 untuk genre klasik dan kelas 4 untuk genre rock. Jaringan LVQ yang dibentuk menggunakan 4 neuron sesuai dengan banyaknya genre dalam penelitian. Parameter lain yang digunakan adalah learning rate,
learning rate yang dipilih adalah 0.01. Pengujian
Proses pengujian dilakukan dengan menguji data yang telah dibagi ke dalam matriks data uji menggunakan metode k-fold cross validation. Data uji tersebut kemudian diuji menggunakan fungsi sim dari Matlab. Fungsi ini menghitung jarak data yang diuji menggunakan model JST hasil pelatihan menggunakan jarak eucllidean. Evaluasi
Evaluasi merupakan proses untuk melihat apakah proses klasifikasi sudah tepat atau belum. Pada proses ini akan dilihat apakah tiap-tiap lagu yang diuji apakah sudah masuk ke dalam kelas yang tepat atau belum. Hasil klasifikasi dapat dilihat dalam sebuah confusion matrix yang di dalamnya terdapat jumlah dari data yang masuk ke dalam kelas yang benar dan kelas yang salah.
Lingkungan Pengembangan
Untuk tahap pelatihan, penelitian ini diimplementasikan menggunakan spesifikasi perangkat keras dan lunak sebagai berikut:
i. Perangkat Keras
Prosesor Intel Pentium(R) Dual-Core CPU 2.20 GHz.
Memori 1 GB.
Harddisk 80 GB.
Keyboard dan mouse.
Monitor.
Speaker.
ii. Perangkat Lunak
Sistem operasi Windows XP Professional.
Matlab 7.R2008b.
Audacity 1.2.6.
Pada tahap pengujian, spesifikasi perangkat keras dan lunak yang digunakan adalah: i. Perangkat Keras
Prosesor Intel Pentium(R) Dual-Core CPU 2.20 GHz
Memori 1 GB.
Harddisk 80 GB.
Keyboard dan mouse.
Monitor.
ii. Perangkat Lunak
Sistem operasi Windows XP Professional.
Matlab 7.R2008b.
HASIL DAN PEMBAHASAN
Data Musik
Data yang pada awalnya berupa chanel stereo diubah ke dalam chanel mono. Kemudian data tersebut disimpan dengan file berekstensi WAV.
Praproses
Pada tahap ini dilakukan ekstraksi ciri menggunakan metode MFCC. Beberapa parameter MFCC yang digunakan pada penelitian ini adalah, sampling rate sebesar 11000 Hz, jumlah data tiap frame sebanyak 512, dan jumlah cepstral coefficient sebesar 13. Pembagian Data Uji dan Data Latih
Untuk pembagian data uji dan data latih digunakan metode k-fold cross validation yang akan membagi data ke dalam subset-subset
sesuai jumlah fold yang digunakan. Fold yang dipakai pada penelitian ini berjumlah 2 hingga 10 fold.
Pelatihan
Input layer merupakan matriks hasil ekstraksi ciri menggunakan MFCC yang dibagi menggunakan k-fold cross validation dengan target kelas pada masing-masing lagu yaitu kelas 1 untuk genre keroncong, kelas 2 untuk genre jazz, kelas 3 untuk genre klasik dan kelas 4 untuk genre rock. Jaringan LVQ yang dibentuk menggunakan 4 neuron sesuai dengan banyaknya genre dalam penelitian. Parameter lain yang digunakan adalah learning rate,
learning rate yang dipilih adalah 0.01. Pengujian
Proses pengujian dilakukan dengan menguji data yang telah dibagi ke dalam matriks data uji menggunakan metode k-fold cross validation. Data uji tersebut kemudian diuji menggunakan fungsi sim dari Matlab. Fungsi ini menghitung jarak data yang diuji menggunakan model JST hasil pelatihan menggunakan jarak eucllidean. Evaluasi
Evaluasi merupakan proses untuk melihat apakah proses klasifikasi sudah tepat atau belum. Pada proses ini akan dilihat apakah tiap-tiap lagu yang diuji apakah sudah masuk ke dalam kelas yang tepat atau belum. Hasil klasifikasi dapat dilihat dalam sebuah confusion matrix yang di dalamnya terdapat jumlah dari data yang masuk ke dalam kelas yang benar dan kelas yang salah.
Lingkungan Pengembangan
Untuk tahap pelatihan, penelitian ini diimplementasikan menggunakan spesifikasi perangkat keras dan lunak sebagai berikut:
i. Perangkat Keras
Prosesor Intel Pentium(R) Dual-Core CPU 2.20 GHz.
Memori 1 GB.
Harddisk 80 GB.
Keyboard dan mouse.
Monitor.
Speaker.
ii. Perangkat Lunak
Sistem operasi Windows XP Professional.
Matlab 7.R2008b.
Audacity 1.2.6.
Pada tahap pengujian, spesifikasi perangkat keras dan lunak yang digunakan adalah: i. Perangkat Keras
Prosesor Intel Pentium(R) Dual-Core CPU 2.20 GHz
Memori 1 GB.
Harddisk 80 GB.
Keyboard dan mouse.
Monitor.
ii. Perangkat Lunak
Sistem operasi Windows XP Professional.
Matlab 7.R2008b.
HASIL DAN PEMBAHASAN
Data Musik
Gambar 10 Grafik durasi 5 detik
Ganbar 11 Grafik durasi 10 detik
Gambar 12 Grafik durasi 20 detik
Gambar 13 Grafik durasi 25 detik Praproses
Data musik yang telah disesuaikan panjang durasinya dilakukan proses ekstraksi ciri menggunakan metode MFCC. Parameter yang digunakan dalam proses MFCC antara lain,
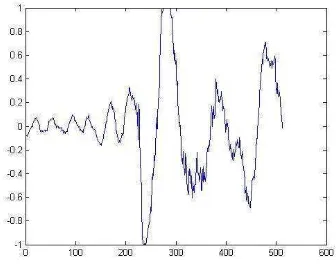
sampling rate sebesar 11000 Hz, banyaknya data dalam satu frame sebanyak 512 data. Parameter ini dipilah berdasarkan parameter yang digunakan pada penelitian Prameswari (2010), apabila nilai sampling rate ditambah maka data yang diambil dalam satu detik semakin banyak dan semakin mendekati sinyal asli, tetapi waktu proses juga akan semakin panjang. Gambar 14 mengilustrasikan sinyal audio yang digunakan dengan sampling rate
sebesar 11000 Hz dengan contoh dari data berdurasi 5 detik.
Gambar 14 Sinyal audio
Sinyal audio tersebut kemudian dilakukan proses frame blocking yang membagi data ke dalam beberapa frame. Overlap antar frame
yang digunakan sebesar 94% dikarenakan
overlap sebesar 94% menghasilkan akurasi yang paling optimal. Pada awal penelitian
overlap antar frame yang digunakan sebesar 50% seperti pada penelitian Prameswari (2010), namun akurasi yang dihasilkan hanya berkisar 65% sehingga digunakan overlap sepanjang 94%. Hasil proses frame blocking dapat dilihat pada Gambar 15.
Gambar 15 Hasil frame blocking
Proses selanjutnya adalah proses windowing
16 mengilustrasikan hasil dari proses
windowing. Hasil praproses untuk genre klasik, rock dan keroncong disajikan pada Lampiran 2.
Gambar 16 Hasil proses windowing
Kemudian dilakukan proses mel-frequency wrapping. Pada proses ini diperlukan beberapa
filter yang saling overlap dalam domain frequensi. Selanjutnya hasil dari proses Mel -frequency wrapping dilakukan proses konversi
log mel spectrum ke dalam domain waktu. Hasil dari proses ini disebut mel frequency cepstrum coefficient. Hasil proses ini disajikan pada Gambar 17, 18, 19 dan 20.
Gambar 17 Hasil ekstraksi ciri untuk genre jazz
Gambar 18 Hasil ekstraksi ciri untuk genre keroncong
Gambar 19 Hasil ekastraksi ciri untuk genre klasik
Gambar 20 Hasil ekstraksi ciri untuk genre rock.
Pelatihan dan Pengujian
Setelah dilakukan proses ekstraksi ciri, selanjutnya dilakukan proses pembagian data menggunakan metode k-fold cross validation.
Data yang akan dilakukan percobaan berupa sebuah matriks berukuran banyaknya sample
dalam satu data dikali banyaknya data yaitu 80 buah lagu. Pada baris terakhir disisipkan kelas dari data tersebut sebagai inputan untuk pelatihan menggunakan LVQ. Untuk pelatihan paramater-parameter yang digunakan antara lain, jumlah folds, epoch, dan learning rate. Dalam penelitian ini jumlah epoch yang digunakan sebanyak 1000 epoch, tetapi proses pelatihan akan dihentikan ketika error rate pada pelatihan sudah stabil meskipun belum mencapai jumlah epoch maksimum. Learning rate yang digunakan adalah 0.01, nilai ini digunakan karena nilai ini yang menghasilkan
error rate yang paling kecil. Ketika nilai
learning rate ditambah proses pelatihan akan semakin cepat, tetapi berimbas pada error rate
learning rate lebih rendah rendah dari 0.01 proses pelatihan akan semakin lambat tetapi
error rate yang dihasilkan tidak lebih baik dari nilai learning rate sebesar 0.01.
Jumlah fold yang digunakan berjumlah 2 hingga 10 fold. Setiap pembagian menghasilkan 2 buah matriks, satu matriks untuk data latih dan matriks lainnya untuk data uji.
Pelatihan menggunakan LVQ menggunakan data dari matriks data latih hasil pembagian metode k-fold cross validation. Hasil dari pelatihan ini adalah sebuah model jaringan syaraf tiruan yang di dalamnya terdapat matriks hasil pelatihan berukuran banyaknya target dari data yang dilatih. Tabel 1 menyajikan hasil klasifikasi tiap fold.
Tabel 1 Akurasi pengujian tiap fold
Durasi Fold Akurasi
2 88,7 %
3 91,02%
4 90%
5 5 90%
6 88,75%
7 88,75%
8 88,75%
9 87,5%
10 88,75%
Durasi Fold Akurasi
2 87,5%
3 92,5%
4 93,75%
5 90%
10 6 90%
7 90%
8 88,75%
9 90%
10 92,5%
Durasi Fold Akurasi
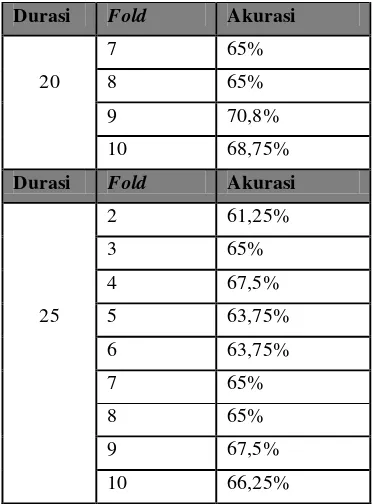
2 66,25%
3 67,5%
20 4 68,75%
5 65%
6 68%
Durasi Fold Akurasi
7 65%
20 8 65%
9 70,8%
10 68,75%
Durasi Fold Akurasi
2 61,25%
3 65%
4 67,5%
25 5 63,75%
6 63,75%
7 65%
8 65%
9 67,5%
10 66,25%
Dari hasil percobaan dapat dilihat bahwa akurasi tertinggi didapatkan dari percobaan dengan durasi 5 dan 10 detik, dengan akurasi masing–masing 90%. Sedangkan percobaan dengan hasil akurasi terendah yaitu sebesar 65% didapatkan dari data dengan durasi sepanjang 25 detik.
Berdasarkan percobaan dapat dilihat bahwa percobaan menggunakan 4-fold menghasilkan nilai akurasi tertinggi dari tiap panjang durasi.
Hasil klasifikasi genre musik dengan 4-fold
dapat dilihat pada Tabel 2, 3, 4, dan 5.
Tabel 2 Hasil klasifikasi data berdurasi 5 detik
Kelas
Jumlah Data Tiap
Kelas Tingkat
Akurasi
1 2 3 4
1 18 0 1 1 90%
2 0 20 0 0 100%
3 5 0 14 1 70%
4 0 0 0 20 100%
Tabel 3 Hasil klasifikasi data berdurasi 10 detik
Kelas
Jumlah Data Tiap
Kelas Tingkat
Akurasi
1 2 3 4
1 18 0 1 1 90%
2 0 20 0 0 100%
3 2 0 18 0 90%
4 1 0 0 19 95%
Rata-rata 93,75%
Tabel 4 Hasil klasifikasi data berdurasi 20 detik
Kelas
Jumlah Data Tiap
Kelas Tingkat
Akurasi
1 2 3 4
1 16 2 1 1 80%
2 10 7 0 3 35%
3 3 3 14 0 70%
4 1 1 0 18 90%
Rata-rata 65%
Tabel 5 Hasil klasifikasi data berdurasi 25 detik
Kelas
Jumlah Data Tiap
Kelas Tingkat
Akurasi
1 2 3 4
1 16 2 1 1 80%
2 12 6 0 2 30%
3 2 4 14 0 70%
4 1 1 0 18 90%
Rata-rata 67,5%
Kelas 1 pada Tabel 2, 3, 4 ,dan 5 mewakili genre keroncong, kelas 2 mewakili genre jazz, kelas 3 mewakili genre keroncong, dan kelas 4 mewakili genre rock. Hasil klasifikasi untuk data dengan durasi 5 detik disajikan pada Tabel 2. Dari Tabel 2 dapat dilihat untuk genre dengan kelas 2 dan 4 yaitu genre jazz dan rock memiliki tingkat akurasi hingga 100%. Untuk genre keroncong tingkat akurasinya adalah 90% atau sebanyak 18 buah data diklasifikasikan ke kelas
yang benar sedangkan dua buah data yang salah diklasifikasikan ke dalam kelas klasik (3) dan rock (4). Hasil akurasi yang paling rendah adalah genre klasik dengan tingkat akurasi sebesar 70%, sebanyak 5 buah data dari genre klasik diklasifikasikan ke dalam kelas keroncong dan 1 buah diklasifikasikan ke dalam genre rock.
Untuk data dengan durasi 10 detik akurasi tertinggi dimiliki oleh genre jazz dengan akurasi sebesar 100 % seperti disajikan pada Tabel 3. Selanjutnya genre rock meiliki tingkat akurasi sebesar 95% jadi hanya satu data yang salah diklasifikasikan ke dalam kelas keroncong, sementara genre keroncong dan klasik memiliki akurasi yang sama yaitu 90%. Pada genre keroncong 1 data diklasifikasikan ke dalam kelas klasik dan satu lagu ke dalam kelas rock. Sementara untuk genre klasik 2 data yang salah diklasifikasikan ke dalam kelas rock.
Data dengan akurasi sepanjang 20 detik mengalami penurunan tingkat akurasi. Akurasi tertinggi yang pada durasi 10 dan 5 sebesar 100% kini hanya 90% yang dimiliki oleh genre rock seperti yang terlihat pada Tabel 4 dua data yang salah masuk ke dalam kelas keroncong dan jazz. Genre keroncong menghasilkan akurasi sebesar 80% dimana ada 4 buah data yang salah diklasifikasikan, 2 data diklasifikasikan sebagai kelas jazz, 1 data untuk klasik dan satu lagi untuk jazz. Genre klasik menghasilkan tingkat akurasi masing sebesar 70%, 3 buah data salah diklasifikasikan ke dalam genre keroncong dan 3 data lainya ke dalam genre jazz. Hasil akurasi terendah adalah genre jazz sebesar 35%, pada genre jazz sebanyak 10 data atau 50% dari keseluruhan diklasifikasikan ke dalam genre keroncong dan 3 lainya diklasifikasikan ke dalam genre rock . pada durasi 20 detik genre klasik lebih banyak diklasifikasikan ke dalam genre keroncong dikarenakan jarak hasil perhitungan jarak genre keroncong lebih dekat kepada genre keroncong. Penyebab lain adalah semakin panjangnya durasi, semakin banyak juga vektor yang dilakukan perhitungan sehingga membuat genre klasik lebih dekat kepada genre keroncong.
akurasi sebesar 80% dengan 2 data diklasifikasikan sebagai kelas jazz, 1 data diklasifikasikan sebagai kelas klasik dan 1 data sebagai kelas rock. Genre klasik dengan akurasi 70% dengan 2 buah data diklasifikasikan sebagai kelas keroncong dan 4 buah data diklasifikasikan sebagai kelas jaz. Genre jazz menghasilkan akurasi sebesar 30%, sebanyak 12 data diklasifkasikan salah ke dalam kelas keroncong dan 6 buah data diklasifikasikan sebagai kelas jazz. Hal ini disebabkan oleh jarak vector sampel dari genre klasik lebih dekat kepada genre keroncong. Untuk lebih jelasnya Lampiran 3 menampilkan hasil klasifikasi secara lengkap.
Klasifikasi dengan durasi 20 dan 25 sekon mempunyai hasil yang lebih rendah dibandingkan klasifikasi dengan durasi 5 dan 10 sekon. Hal tersebut dikarenakan semakin panjang durasi semakin banyak pula vektor yang dihitung sehingga mempengaruhi hasil dari perhitungan jarak yang menyebabkan proses pelatihan tidak menghasilkan codebook vector yang sesuai.
Untuk waktu pelatihan disajikan pada Gambar 21 , data dengan durasi 5 detik memakan waktu 30 menit, durasi 10 detik memakan waktu 45 menit, durasi 20 memakan waktu 120 menit, dan durasi 25 detik memakan waktu 150 menit.
Gambar 21 Grafik perbandingan waktu proses
KESIMPULAN DAN SARAN
Kesimpulan
Dari hasil percobaan yang dilakukan didapatkan, penelitian ini telah berhasil mengimplementasikan metode MFCC dan LVQ dalam membuat model codebook vector dan melakukan klasifikasi genre musik dengan akurasi sebesar 90% untuk durasi 5 detik, 93,75% untuk durasi 10 detik, 65 untuk durasi 20 detik dan 93,75% untuk durasi 25 detik. Dari hasil percobaan dapat disimpulkan bahwa durasi
10 detik memiliki tingkat akurasi tertinggi. Hasil penelitian ini lebih tinggi dari penelitian Taluput et al (2002) yang menghasilkan akurasi sebesar 80%.
Kecenderungan pengaruh penambahan durasi terhadap penurunan durasi terlihat pada data dengan durasi 10 dan 20 yang detik mengalami penurunan tingkat akurasi dari 93,75% menjadi 65%.
Saran
Saran yang penulis dapat berikan untuk penelitian selanjutnya yang berkaitan antara lain:
1. Penelitian ini hanya menggunakan 4 buah genre musik dari genre musik utama. Pada penelitian selanjutnya diharapkan menggunakan genre musik yang lebih beragam dan berasal dari sub genre.
2. Durasi yang digunakan pada penelitian ini adalah 5, 10, 20 dan 25 dan chanel yang digunakan adalah chanel mono. Diharapkan pada penelitian selanjutnya menggunakan durasi yang lebih beragam dan chanel
stereo.
3. Untuk pengujian diperhatikan aspek distribusi, jadi tidak hanya dilihat dari jarak data uji terhadap codebook vector.
DAFTAR PUSTAKA
Campbell,Jr JP. 1997. Speaker Recognition: A Tutorial. Procedding IEEE, Vol 85 No.9, September 1997.
Do MN. 1994. Digital Signal Processing Mini-Project: An Automatic Speaker Recognition System. Audio Visual Communication Laboratory, Swiss Federal Institute of technology, Laussanne,Switzerland. Fausett L. 1994. Fundamental of Neural
Network Architectures, Algorithm, and Applications. New Jersey: Prentice Hall. Han J, Kamber M. 2001. Data Minning
Concepts & Techniques. USA: Academic Press
Prameswari. 2010. Pengembangan Sistem Pengenalan Kata Berbasiskan Fonem dalam Bahasa Indonesia dengan Metode Resilent Backpropagation. [Skripsi]. Bogor: Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
30 45 120 150 0 50 100 150 200
5 Sekon 10 Sekon
20 Sekon
akurasi sebesar 80% dengan 2 data diklasifikasikan sebagai kelas jazz, 1 data diklasifikasikan sebagai kelas klasik dan 1 data sebagai kelas rock. Genre klasik dengan akurasi 70% dengan 2 buah data diklasifikasikan sebagai kelas keroncong dan 4 buah data diklasifikasikan sebagai kelas jaz. Genre jazz menghasilkan akurasi sebesar 30%, sebanyak 12 data diklasifkasikan salah ke dalam kelas keroncong dan 6 buah data diklasifikasikan sebagai kelas jazz. Hal ini disebabkan oleh jarak vector sampel dari genre klasik lebih dekat kepada genre keroncong. Untuk lebih jelasnya Lampiran 3 menampilkan hasil klasifikasi secara lengkap.
Klasifikasi dengan durasi 20 dan 25 sekon mempunyai hasil yang lebih rendah dibandingkan klasifikasi dengan durasi 5 dan 10 sekon. Hal tersebut dikarenakan semakin panjang durasi semakin banyak pula vektor yang dihitung sehingga mempengaruhi hasil dari perhitungan jarak yang menyebabkan proses pelatihan tidak menghasilkan codebook vector yang sesuai.
Untuk waktu pelatihan disajikan pada Gambar 21 , data dengan durasi 5 detik memakan waktu 30 menit, durasi 10 detik memakan waktu 45 menit, durasi 20 memakan waktu 120 menit, dan durasi 25 detik memakan waktu 150 menit.
Gambar 21 Grafik perbandingan waktu proses
KESIMPULAN DAN SARAN
Kesimpulan
Dari hasil percobaan yang dilakukan didapatkan, penelitian ini telah berhasil mengimplementasikan metode MFCC dan LVQ dalam membuat model codebook vector dan melakukan klasifikasi genre musik dengan akurasi sebesar 90% untuk durasi 5 detik, 93,75% untuk durasi 10 detik, 65 untuk durasi 20 detik dan 93,75% untuk durasi 25 detik. Dari hasil percobaan dapat disimpulkan bahwa durasi
10 detik memiliki tingkat akurasi tertinggi. Hasil penelitian ini lebih tinggi dari penelitian Taluput et al (2002) yang menghasilkan akurasi sebesar 80%.
Kecenderungan pengaruh penambahan durasi terhadap penurunan durasi terlihat pada data dengan durasi 10 dan 20 yang detik mengalami penurunan tingkat akurasi dari 93,75% menjadi 65%.
Saran
Saran yang penulis dapat berikan untuk penelitian selanjutnya yang berkaitan antara lain:
1. Penelitian ini hanya menggunakan 4 buah genre musik dari genre musik utama. Pada penelitian selanjutnya diharapkan menggunakan genre musik yang lebih beragam dan berasal dari sub genre.
2. Durasi yang digunakan pada penelitian ini adalah 5, 10, 20 dan 25 dan chanel yang digunakan adalah chanel mono. Diharapkan pada penelitian selanjutnya menggunakan durasi yang lebih beragam dan chanel
stereo.
3. Untuk pengujian diperhatikan aspek distribusi, jadi tidak hanya dilihat dari jarak data uji terhadap codebook vector.
DAFTAR PUSTAKA
Campbell,Jr JP. 1997. Speaker Recognition: A Tutorial. Procedding IEEE, Vol 85 No.9, September 1997.
Do MN. 1994. Digital Signal Processing Mini-Project: An Automatic Speaker Recognition System. Audio Visual Communication Laboratory, Swiss Federal Institute of technology, Laussanne,Switzerland. Fausett L. 1994. Fundamental of Neural
Network Architectures, Algorithm, and Applications. New Jersey: Prentice Hall. Han J, Kamber M. 2001. Data Minning
Concepts & Techniques. USA: Academic Press
Prameswari. 2010. Pengembangan Sistem Pengenalan Kata Berbasiskan Fonem dalam Bahasa Indonesia dengan Metode Resilent Backpropagation. [Skripsi]. Bogor: Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
30 45 120 150 0 50 100 150 200
5 Sekon 10 Sekon
20 Sekon
KLASIFIKASI GENRE
MUSIK MENGGUNAKAN
LEARNING
VECTOR QUANTIZATION
(LVQ)
MUHAMMAD RIDWAN FANSURI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
akurasi sebesar 80% dengan 2 data diklasifikasikan sebagai kelas jazz, 1 data diklasifikasikan sebagai kelas klasik dan 1 data sebagai kelas rock. Genre klasik dengan akurasi 70% dengan 2 buah data diklasifikasikan sebagai kelas keroncong dan 4 buah data diklasifikasikan sebagai kelas jaz. Genre jazz menghasilkan akurasi sebesar 30%, sebanyak 12 data diklasifkasikan salah ke dalam kelas keroncong dan 6 buah data diklasifikasikan sebagai kelas jazz. Hal ini disebabkan oleh jarak vector sampel dari genre klasik lebih dekat kepada genre keroncong. Untuk lebih jelasnya Lampiran 3 menampilkan hasil klasifikasi secara lengkap.
Klasifikasi dengan durasi 20 dan 25 sekon mempunyai hasil yang lebih rendah dibandingkan klasifikasi dengan durasi 5 dan 10 sekon. Hal tersebut dikarenakan semakin panjang durasi semakin banyak pula vektor yang dihitung sehingga mempengaruhi hasil dari perhitungan jarak yang menyebabkan proses pelatihan tidak menghasilkan codebook vector yang sesuai.
Untuk waktu pelatihan disajikan pada Gambar 21 , data dengan durasi 5 detik memakan waktu 30 menit, durasi 10 detik memakan waktu 45 menit, durasi 20 memakan waktu 120 menit, dan durasi 25 detik memakan waktu 150 menit.
Gambar 21 Grafik perbandingan waktu proses
KESIMPULAN DAN SARAN
Kesimpulan
Dari hasil percobaan yang dilakukan didapatkan, penelitian ini telah berhasil mengimplementasikan metode MFCC dan LVQ dalam membuat model codebook vector dan melakukan klasifikasi genre musik dengan akurasi sebesar 90% untuk durasi 5 detik, 93,75% untuk durasi 10 detik, 65 untuk durasi 20 detik dan 93,75% untuk durasi 25 detik. Dari hasil percobaan dapat disimpulkan bahwa durasi
10 detik memiliki tingkat akurasi tertinggi. Hasil penelitian ini lebih tinggi dari penelitian Taluput et al (2002) yang menghasilkan akurasi sebesar 80%.
Kecenderungan pengaruh penambahan durasi terhadap penurunan durasi terlihat pada data dengan durasi 10 dan 20 yang detik mengalami penurunan tingkat akurasi dari 93,75% menjadi 65%.
Saran
Saran yang penulis dapat berikan untuk penelitian selanjutnya yang berkaitan antara lain:
1. Penelitian ini hanya menggunakan 4 buah genre musik dari genre musik utama. Pada penelitian selanjutnya diharapkan menggunakan genre musik yang lebih beragam dan berasal dari sub genre.
2. Durasi yang digunakan pada penelitian ini adalah 5, 10, 20 dan 25 dan chanel yang digunakan adalah chanel mono. Diharapkan pada penelitian selanjutnya menggunakan durasi yang lebih beragam dan chanel
stereo.
3. Untuk pengujian diperhatikan aspek distribusi, jadi tidak hanya dilihat dari jarak data uji terhadap codebook vector.
DAFTAR PUSTAKA
Campbell,Jr JP. 1997. Speaker Recognition: A Tutorial. Procedding IEEE, Vol 85 No.9, September 1997.
Do MN. 1994. Digital Signal Processing Mini-Project: An Automatic Speaker Recognition System. Audio Visual Communication Laboratory, Swiss Federal Institute of technology, Laussanne,Switzerland. Fausett L. 1994. Fundamental of Neural
Network Architectures, Algorithm, and Applications. New Jersey: Prentice Hall. Han J, Kamber M. 2001. Data Minning
Concepts & Techniques. USA: Academic Press
Prameswari. 2010. Pengembangan Sistem Pengenalan Kata Berbasiskan Fonem dalam Bahasa Indonesia dengan Metode Resilent Backpropagation. [Skripsi]. Bogor: Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
30 45 120 150 0 50 100 150 200
5 Sekon 10 Sekon
20 Sekon
Suhartono MN. 2007. Pengembangan Model Identifikasi Pembicara dengan Probabilistic Neural Network. [Skripsi]. Bogor: Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Talupur M, Suman N, Yan H. 2002.
Classification of Music Genre. Computer Science Department. Carnegie Mellon University.
Widodo TN. 2005. Sistem Neuro Fuzzy. Graha Ilmu, Yogyakarta.
KLASIFIKASI GENRE
MUSIK MENGGUNAKAN
LEARNING
VECTOR QUANTIZATION
(LVQ)
MUHAMMAD RIDWAN FANSURI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
KLASIFIKASI GENRE
MUSIK MENGGUNAKAN
LEARNING
VECTOR QUANTIZATION
(LVQ)
MUHAMMAD RIDWAN FANSURI
G64062253
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
MUHAMMAD RIDWAN FANSURI, Musical Genre Classification Using Learning Vector Quantization (LVQ). Under the supervision of SONY HARTONO WIJAYA.
Radio stations and music television have a milion of music tapes. A lot of musical genres create a problem when people wants to determine the right genre of a new kind of music. To classify the musical genre is not an easy task, because the musical genre is really difficult to standardization. Automatic musical genre classification can assist the human role in that process and help people to searching for the song acording to the genre that people want.
This research using Mel Frequency Coefficient Cepstrum (MFCC) to obtain feature extraction.
Learning Vector Quantization (LVQ), one kind of artificial neural network used for classification method. The number of genres that are used were four kind of musical genre, that is rock, classic, keroncong, and jazz with four different duration that is 5 second, 10 second, 20 second and 25 second. This research using k- fold cross validation to distribute dataset for training and testing set with the number of folds as much as 2 until 10 fold.
This research succesfully implemented MFCC feature exraction and classification using LVQ. Based on this research, the accuracy of the classification using Learning Vector Quantization reaches 93,75% for the four type musical genre. The highest accuracy value was obtain from the experiments with a duration of 10 second and the number of fold 4. Training time for each duration is 30 minute for 5 second music duration, 45 minute for 10 second music duration 120 minute for 20 second music duration and 150 minute for 25 second music duration.
Judul Penelitian : Klasifikasi Genre Musik Menggunakan Learning Vector Quantization (LVQ) Nama : Muhammad Ridwan Fansuri
NRP : G64062253
Menyetujui: Pembimbing,
Sony Hartono Wijaya, M.Kom NIP. 19810809 200812 1 002
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc NIP. 19601126 198601 2 001
PRAKATA
Alhamdulilahi Rabbil ‘alamin, puji dan syukur penulis panjatkan kepada Allah SWT atas segala
limpahan karunia sehingga skripsi penulis dengan judul Klasifikasi Genre Musik Menggunakan
Learning Vector Quantization (LVQ) dapat diselesaikan. Penelitian ini dilakukan mulai Januari 2010 sampai dengan Desember 2010.
Selama pelaksanaan skripsi ini, penulis memperoleh banyak sekali bantuan dari berbagai pihak. Dengan segala kerendahan hati penulis menyampaikan ucapan terima kasih kepada:
1 Kedua orang tua tercinta yang selalu memberikan kasih sayang, doa, dan dukungan moral.
2 Bapak Sony Hartono Wijaya, M.Kom selaku pembimbing atas bimbingan, arahan, dan nasihat yang diberikan selama pengerjaan tugas akhir ini.
3 Bapak Dr. Ir. Agus Buono, M.Si., M.Kom dan Bapak Rindang Karyadin, S.T., M.Kom selaku dosen penguji.
4 Ibu Dra. Psi. Waysima, M.Sc. atas segala bantuan selama penulis kuliah. 5 Rekan-rekan satu bimbingan Gunawan, Yoga, Kanta dan Subhan 6 Rekan-rekan Ilmu Komputer 43
7 Departemen Ilmu Komputer, staf, dan dosen yang telah banyak membantu baik selama penelitian maupun pada masa perkuliahan.
Penulis menyadari masih banyak kekurangan dalam penelitian ini. Oleh karena itu, kritik dan saran sangat penulis harapkan untuk perbaikan di masa mendatang semoga penelitian ini dapat bermanfaat, Amin.
Bogor, Maret 2011
RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 21 Mei 1988 sebagai anak pertama dari tiga bersaudara dari pasangan Bapak Udjang Sugiman dan Ibu N. Badrianingsih.
DAFTAR ISI
Halaman
DAFTAR TABEL ... v DAFTAR GAMBAR ... v DAFTAR LAMPIRAN ... v PENDAHULUAN 1 Latar Belakang ... 1 Rumusan Masalah ... 1 Tujuan ... 1 Ruang Lingkup ... 1 Manfaat ... 1 TINJAUAN PUSTAKA 1 Genre Musik ... 1 Digitalisasi Gelombang Audio ... 1 Ekstraksi Ciri Sinyal Audio ... 2 Mel-Frequency Ceostrum Coefficient (MFCC) ... 2 Klasifikasi ... 4 Jaringan Syaraf Tiruan ... 4
Learning Vector Quantization (LVQ) ... 4
K-fold Cross Validtion ... 5
DAFTAR TABEL
Halaman
1 Akurasi pengujian tiap fold ... 9 2 Hasil klasifikasi data berdurasi 5 detik ... 9 3 Hasil klasifikasi data berdurasi 10 detik ... 10 4 Hasil klasifikasi data berdurasi 20 detik. ... 10 5 Hasil klasifikasi data berdurasi 25 detik. ... 10
DAFTAR GAMBAR
Halaman
1 Diagram blok proses MFCC. ... 2 2 Proses frame blocking. ... 2 3 Hamming window. ... 3 4 Sinyal audio dalam domain frekuensi. ... 3 5 Mel- frequency wrapping. ... 3 6 Arsitektur JST. ... 4 7 Arsitektur jaringan LVQ. ... 4 8 Contoh k - fold cross validation. ... 5 9 Metodologi penelitian. ... 5 10 Grafik durasi 5 detik. ... 7 11 Grafik durasi 10 detik. ... 7 12 Grafik durasi 20 detik. ... 7 13 Grafik durasi 25 detik. ... 7 14 Sinyal audio. ... 7 15 Hasil frame blocking. ... 8 16 Hasil proses windowing. ... 8 17 Hasil ekstraksi ciri untuk genre jazz. ... 8 18 Hasil ekstraksi ciri untuk genre keroncong. ... 8 19 Hasil ekstraksi ciri untuk genre klasik. ... 8 20 Hasil ekstraksi ciri untuk genre rock. ... 8 21 Grafik perbandingan waktu proses. ... 11
DAFTAR LAMPIRAN
Halaman
PENDAHULUAN
Latar Belakang
Genre musik adalah pengelompokan musik sesuai dengan kemiripan satu dengan yang lain, seperti kemiripan dalam hal frekuensi musik, struktur ritmik, dan konten harmoni. Genre musik merupakan hal yang penting bagi masyarakat yang menyukai musik, karena membuat masyarakat dengan mudah mengelompokan musik yang yang mereka sukai.
Pada umumnya pengelompokan lagu dilakukan secara manual yaitu dengan mendengarakan lagu secara langsung kemudian dikelompokkan bedasarkan genre lagu tersebut. Metode ini mempunyai keunggulan yaitu mempunyai tingkat akurasi yang tinggi, tetapi kekurangan dari metode ini adalah sangat tidak efisien untuk data berjumlah banyak, karena harus didengarkan satu persatu. Pengelompokan genre lagu secara otomatis mulai dikembangkan untuk membantu mengelompokan lagu yang berjumlah banyak. Proses ini mempunyai keunggulan dalam jumlah data yang bisa diporses namun kekurangan dari proses otomatis adalah akurasi yang rendah.
Untuk dapat dikelompokkan data musik harus melalui proses ekstraksi ciri yang bertujuan mendapatkan ciri dari lagu tersebut. Salah satu metode yang dapat digunakan adalah Mel-frequency cepstral coefficient (MFCC). MFCC mengekstraksi ciri suara berdasarkan spektrum yang dihasilkan dari musik. Penelitian yang menggunakan MFCC dalam proses ekstraksi ciri antara lain, Prameswari (2010) yang melakukan penelitian pengembangan sistem pengenalan kata berbasis fonem dalam bahasa Indonesia dengan metode resilent backpropagation, dan Wisnudhisastra (2009) tentang pengenalan chord gitar dengan teknik ekstraksi ciri Mel-frequency cepstral coefficient
(MFCC).
Leaning Vector Quantization (LVQ) merupakan salah satu contoh dari jaringan syaraf tiruan yang digunakan untuk proses klasifikasi. Metode LVQ sudah banyak digunakan untuk penelitian, seperti penelitian oleh Effedy et al (2008) mengenai deteksi pornografi pada citra digital menggunakan pengolahan citra dan jaringan syaraf tiruan,
Qur’ani & Rosmalinda (2010) yang meneliti
jaringan syaraf tiruan LVQ untuk aplikasi pengenalan tanda tangan.
Klasifikasi genre musik telah dilakukan oleh Talupur et al (2002). Pada penelitian ini genre
yang diklasifikasikan antara lain klasik, rock, jazz dan country dengan akurasi tertinggi yang dihasilkan sebesar 80 %. Berdasarkan penelitian yang terkait, metode MFCC dan LVQ dapat digunakan untuk klasifikasi genre musik. Rumusan Masalah
Rumusan masalah dalam penelitian ini adalah bagaimana membuat model klasifikasi data audio menggunakan jaringan syaraf tiruan LVQ.
Ruang Lingkup
Ruang lingkup pada penelitian ini antara lain:
1. Dalam penelitian ini, genre musik yang diklasifikasikan dibatasi hanya genre rock, klasik, jazz dan keroncong.
2. Musik yang diolah mempunyai durasi 5, 10, 20, dan 25 detik dengan format wav. 3. Data musik menggunakan chanel mono. Tujuan
Tujuan dari penelitian ini adalah mengembangkan model Learning Vector Quantization untuk klasifikasi genre musik. Manfaat
Penelitian ini diharapkan dapat melakukan klasifikasi pada data musik menggunakan
Learning Vector Quantization agar dapat membantu peran manusia dalam hal menentukan genre musik, sehingga genre musik tidak lagi bersifat relatif, tetapi dapat dikelompokkan dengan standardisasi yang telah ditentukan.
TINJAUAN PUSTAKA
Genre Musik
Genre musik adalah label yang dibuat dan digunakan manusia untuk mengkategorikan dan menggambarkan musik di dunia (Tzanekatis 2002). http://allmusic.com mengelompokan genre musik ke dalam 11 genre utama, yaitu pop/rock, jazz, r&b, rap, country, blues, elektronik, latin, reggae, internasional, dan klasik.
Digitalisasi Gelombang Audio
Gelombang audio merupakan gelombang
Dalam proses digitalisasi audio, gelombang audio melalui dua tahap proses yaitu sampling
dan kuantisasi (Jurafsky & Martin 2000).
Sampling merupakan proses pengambilan nilai dalam jangka waktu tertentu. Nilai yang dimaksud adalah amplitudo, yaitu besarnya volume suara pada suatu waktu. Proses
sampling menghasilkan sebuah vektor yang menyatakan nilai – nilai hasil sampling. Vektor tersebut mempunyai panjang yang bergantung pada lamanya sinyal dan sampling rate yang digunakan. Sampling rate sendiri adalah banyaknya nilai yang diambil setiap detiknya. Untuk mengukur panjang vektor sinyal, digunakan rumus beikut:
= ��×
dengan
S = panjang vektor
��= samplingrate (Hertz)
T = panjang sinyal (detik)
Tahap selanjutnya adalah proses kuantisasi. Kuantisasi bertujuan menyimpan nilai amplitudo ke dalam representasi nilai 8 bit atau 16 bit (Jurafsky & Martin 2000).
Ekstraksi Ciri Sinyal Audio
Ekstraksi ciri berfungsi mengkarakterisasi sinyal audio. Beberapa fitur sinyal audio yang biasa digunakan antara lain Linear Predictive Coding, Perceptual Linear Prediction, dan Mel -Frequency. Proses ini dilakukan karena sinyal audio merupakan sinyal yang bervariasi yang diwaktukan dengan lambat. Jadi pada jangka waktu yang sangat pendek (5–100 ms), karakteristik sinyal tersebut hampir sama, tetapi dalam jangka waktu yang lebih panjang (0,2 detik atau lebih), karakteristik sinyal audio tersebut berubah dan memperlihatkan perbedaan sinyal audio yang diolah (Do 1994). Mel-Frequency Cepstrum Coefficient (MFCC)
Tujuan dari MFCC adalah mengadapatasi kemampuan telinga manusia dalam mendengar dan mengolah suara. Proses MFCC dapat dilihat pada Gambar 1.
Sinyal Kontinu
Frame Blocking
Windowing frame
Fast Fourier Transform
Mel Frequency Wrapping
spectrum
Cepstrum mel spctrum
mel spectrum Windowing
Gambar 1 Diagram blok proses MFCC (Do 1994)
Tahap-tahap dari proses MFCC dapat dijelaskan sebagai berikut (Do 1994):
1. Frame Blocking, proses ini membagi sinyal
audio ke dalam frame. Tiap frame terdiri atas N sample. Gambar 2 menggambarkan ilustrasi dari proses frame blocking.
2. Windowing, pada tahap ini sinyal yang telah dibagi ke dalam frame dilakukan proses
windowing untuk meminimalkan diskontinuitas sinyal, dengan cara meminimalkan distorsi spectral dengan menggunakan window untuk memperkecil sinyal hingga mendekati nol pada awal dan akhir tiap frame. Window yang dipakai pada proses ini adalah Hamming window dengan persamaan :
= 0,54−0,46 � � (2� /( −1))
(1) Dengan n = 1, 2, 3... N-1 (N adalah jumlah
frame yang digunakan)
[image:30.595.317.501.170.358.2]Ilustrasi dari Hamming window dapat dilihat pada Gambar 3.
Gambar 3 Hamming window
3. Fast Fourier Transform (FFT), merupakan
fast algorithm dari Discrete Fourier Transform (DFT) yang berguna untuk konversi setiap frame dari domain waktu menjadi domain frekuensi. Berikut persamaan yang digunakan :
� = �−2� /
−1
=0
(2) dengan n=0, 1, 2 ... N-1, j adalah bilangan imajiner, yaitu j = − 1.
Gambar 4 memperlihatkan sinyal yang sudah berubah ke dalam domain frekuensi.
Gambar 4 Sinyal audio dalam domain frekuensi
4. Mel-Frequency Wrapping. Berdasarkan studi psikofisik, persepsi manusia terhadap frekuensi sinyal audio tidak berupa skala linier. Jadi untuk setiap nada dengan frekuensi aktual f (dalam Hertz) dapat diukur tinggi subjektifnya menggunakan
skala ‘mel’. Skala mel-frequency adalah
selang frekuensi di bawah 1000 Hz, dan selang logaritmik untuk frekuensi di atas 1000 Hz. Gambar 5 mengilustrasikan filter pada proses mel- frequency wrapping.
Gambar 5 Mel - frequency filter
Proses wrapping terhadap sinyal dalam domain frekuensi menggunakan persamaan berikut :
� = �10 �( )
−1
=0
(3) dengan i= 1,2,3...,M (M adalah jumlah filter segitiga) dan Hi(k) adalah nilai filter segitiga untuk frekuensi akustik sebesar k.
5. Cepstrum, tahap ini menkonversikan log mel spectrum ke dalam domain waktu Hasil proses ini disebut mel frequency cepstrum coefficients. Berikut ini adalah persamaan yang digunakan dalam DCT :
� = � � �( ( −1)/2 �)
=1
[image:30.595.110.282.311.431.2]Klasifikasi
Klasifikasi merupakan proses menemukan sekumpulan model (atau fungsi) yang menggambarkan dan membedakan konsep atau kelas-kelas data, dengan tujuan agar model tersebut dapat digunakan untuk memprediksi kelas dari suatu objek atau data yang label kelasnya tidak diketahui (Han & Kamber 2001). Klasifikasi terdiri atas dua tahap, yaitu pelatihan dan prediksi (klasifikasi). Pada tahap pelatihan dibentuk sebuah model domain permasalahan dari setiap instance yang ada. Penentuan model tersebut berdasarkan analisis pada sekumpulan data pelatihan, yaitu data yang label kelasnya telah diketahui. Pada tahap klasifikasi, dilakukan prediksi kelas dari
instance (kasus) baru yang telah dibuat pada tahap pelatihan (Güvnir et al 1998).
Jaringan Syaraf Tiruan
Jaringan syaraf tiruan (JST) adalah sistem pemroses informasi yang memiliki karakteristik mirip dengan jaringan syaraf biologi. JST dibentuk sebagai generalisasi model matematika dari jaringan syaraf biologi, dengan asumsi bahwa:
Pemrosesan informasi terjadi pada banyak elemen sederhana (neuron).
Sinyal dikirimkan di antara neuron-neuron melalui penghubung-penghubung (sinapsis).
[image:31.595.314.512.108.277.2] Untuk menentukan output, setiap neuron menggunakan fungsi aktivasi (Jong 1992). Arsitektur jaringan syaraf tiruan disajikan pada Gambar 6.
Gambar 6 Arsitektur JST sederhana (Jong 1992)
Learning Vector Quantization (LVQ)
Learning Vector Quantization (LVQ) merupakan suatu metode klasifikasi pola yang masing-masing unit output mewakili kategori atau kelas tertentu. Vektor bobot untuk unit
output sering disebut vektor referensi untuk kelas yang dinyatakan oleh unit tersebut. LVQ mengklasifikasikan vektor input dalam kelas yang sama dengan unit output yang memiliki vektor bobot yang paling dekat dengan vektor
[image:31.595.101.289.517.621.2]input (Widodo 2005). Ilustrasi dari jaringan LVQ dapat dilihat pada Gambar 7.
Gambar 7 Arsitektur jaringan LVQ (Widodo 2005)
Algoritme pelatihan LVQ bertujuan memperoleh unit output yang paling dekat dengan vektor input. Bila x dan wcberasal dari kelas yang sama, maka vektor bobot didekatkan ke vektor input, tetapi apabila berasal dari kelas yang berbeda, maka vektor bobot akan dijauhkan dengan vektor input.
Kelebihan dari LVQ adalah:
1. nilai error yang lebih kecil dibandingkan dengan jaringan syaraf tiruan seperti
backpropagation.
2. Dapat meringkas data set yang besar menjadi vektor codebook berukuran kecil untuk klasifikasi.
3. Dimensi dalam codebook tidak dibatasi seperti dalam teknik nearest neighbour. 4. Model yang dihasilkan dapat diperbaharui
secara bertahap.
Kekurangan dari LVQ adalah:
1. Dibutuhkan perhitungan jarak untuk seluruh atribut.
2. Akurasi model dangan bergantung pada inisialisasi model serta parameter yang digunakan (learning rate, iterasi, dan sebagainya).
3. Akurasi juga dipengaruhi distribusi kelas pada data training.
4. Sulit untuk menentukan jumlah codebook
vektor untuk masalah yang diberikan. Algoritme LVQ
Berikut ini adalah algoritme dari LVQ :
Diinisialisasikan nilai bobot, maksimum
epoch, dan learning rate,
Nilai input (m,n), dan kelas target dimasukkan ke dalam vector (1,n)
a. Untuk masing-masing pelatihan vektor input x
b. Dicari j sehingga ||x-wj|| bernilai minimum
c. Perbaiki wj dengan : 1. Jika T = cj maka
wj baru =wj lama +
αx-wj lama
2. Jika T ≠ cj
wj baru =wj lama -
αx-wj lama
d. Learning rate dikurangi e. Kondisi berhenti dilihat K-fold Cross Validation
Metode k-fold cross validation membagi data menjadi k-buah subset, sebanyak k-1 buah
[image:32.595.129.294.85.258.2]subset digunakan sebagai training set dan