IDENTIFIKASI TIPE FILE DARI FILE FRAGMENT MENGGUNAKAN
LONGEST COMMON SUBSEQUENCES (LCS)
SKRIPSI
FILBERT NICHOLAS
101402066
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
IDENTIFIKASI TIPE FILE DARI FILE FRAGMENT MENGGUNAKAN LONGEST COMMON SUBSEQUENCES (LCS)
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Teknologi Informasi
FILBERT NICHOLAS 101402066
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : IDENTIFIKASI TIPE FILE DARI FILE
FRAGMENT MENGGUNAKAN LONGEST COMMON SUBSEQUENCES (LCS)
Kategori : SKRIPSI
Nama : FILBERT NICHOLAS
Nomor Induk Mahasiswa : 101402066
Program Studi : S1 TEKNOLOGI INFORMASI
Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Romi Fadillah Rahmat, B.Comp.Sc., M.Sc. Prof. Dr. Opim Salim Sitompul, M.Sc NIP 19860303 201012 1 004 NIP 19610817 198701 1 001
Diketahui/Disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
PERNYATAAN
IDENTIFIKASI TIPE FILE DARI FILE FRAGMENT MENGGUNAKAN LONGEST COMMON SUBSEQUENCES (LCS)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 23 Maret 2015
UCAPAN TERIMA KASIH
Puji dan syukur penulis sampaikan kehadirat Tuhan Yang Maha Esa atas berkat dan rahmat yang telah diberikan sehingga penulis dapat menyelesaikan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana Teknologi Informasi Universitas Sumatera Utara.
Penulis mengucapkan banyak terima kasih kepada Bapak Prof. Dr. Opim Salim Sitompul selaku dosen pembimbing pertama dan Bapak Romi Fadillah Rahmat, B.Comp.Sc, M.Sc. selaku dosen pembimbing kedua yang telah membimbing, memberi kritik dan saran kepada penulis selama proses penelitian serta penulisan skripsi. Tanpa inspirasi serta motivasi dari kedua dosen pembimbing, tentunya penulis tidak akan mampu menyelesaikan skripsi ini. Penulis juga mengucapkan terima kasih kepada Ibu Sarah Purnamawati, ST., M.Sc. selaku dosen pembanding pertama dan Bapak Dani Gunawan ST., MT. sebagai dosen pembanding kedua yang telah membantu memberikan kritik dan saran yang membantu penulis dalam pengerjaan skripsi ini. Ucapan terima kasih juga penulis tujukan pada semua dosen, pegawai serta staff pada program studi S1 Teknologi Informasi yang telah membantu dan membimbing penulis selama proses perkuliahan.
Penulis juga berterima kasih terutama kepada kedua orang tua penulis, Bapak Thomas Udjung serta Ibu Jap Mie Giok yang telah membesarkan penulis dengan sabar dan penuh kasih sayang. Penulis juga berterima kasih kepada seluruh anggota keluarga penulis yang namanya tidak dapat disebutkan satu per satu.
ABSTRAK
Analis forensik komputer merupakan pihak yang melakukan investigasi dan pencarian barang bukti digital. Pada kasus tertentu, file yang dibutuhkan sebagai barang bukti digital untuk proses pengadilan telah dihapus. Pada saat proses restore, header file dari file tersebut seringkali hilang atau bahkan file tersebut tidak diketahui tipe file-nya sehingga mempersulit proses rekonstruksi file. Metode identifikasi file fragment melalui ekstensi nama file tidak dapat dilakukan dikarenakan kemungkinan besar file fragment kehilangan header file. Atas dasar ini, metode identifikasi tipe file dari file fragment menjadi hal yang
penting. Metode yang diajukan pada penelitian ini adalah penggunaan metode Longest Common Subsequences, dengan melalui tiga tahap, yaitu tahap training, testing, dan validasi. Pada penelitian ini ditunjukkan bahwa metode yang diajukan mampu melakukan identifikasi tipe file dari file fragment dengan hasil akurasi 92.91% untuk tiga jenis tipe data.
FILE TYPE IDENTIFICATION FROM FILE FRAGMENT USING LONGEST COMMON SUBSEQUENCES (LCS)
ABSTRACT
Computer forensic analyst is a person in charge of investigation and evidence tracking. In certain cases, the file that is needed for digital evidence to be presented to court was deleted. While the file is being restored, it is often lost its header and cannot be identified, therefore it is hard to reconstruct the file. For this reason, a method for file fragment‟s file type identification is needed. The method proposed in this research is using Longest Common Subsequences, consists of three steps: training, testing and validation. In this
research, it can be seen that this method works well and achieves 92.91% accuracy of identifying the file type of file fragment for three data types.
DAFTAR ISI
Hal.
Persetujuan ii
Pernyataan iii
Ucapan Terima Kasih iv
Abstrak v
Abstract vi
Daftar Isi vii
Daftar Tabel ix
Daftar Gambar x
BAB 1 Pendahuluan 1
1.1 Latar Belakang 1
1.2 Rumusan Masalah 2
1.3 Tujuan Penelitian 2
1.4 Batasan Masalah 3
1.5 Manfaat Penelitian 3
1.6 Metodologi Penelitian 3
1.7 Sistematika Penulisan 4
BAB 2 Landasan Teori 6
2.1 Forensik Digital 6
2.2 File 7
2.2.1. File Types and Format 8
2.2.2.File Type Validation 10
2.2.3.File Fragment 10
2.2.4.File Recovery 12
2.3 Jenis-Jenis File 13
2.3.2.RTF 16
2.2.7.DOC 17
2.4 Binary File 18
2.5 Longest Common Subsequences 20
BAB 3 Analisis dan Perancangan Sistem 26
3.1 Arsitektur Umum 26
3.1.1. Fase Training 27
3.1.2. Fase Testing 29
3.1.3. Fase Validasi 29
3.2 Membaca Hex Number dan Generate String 30
3.3 Aplikasi Algoritma LCS 31
3.4 Perhitungan Rata-Rata Persentase untuk Mendapatkan Tipe File 33
3.5 Validasi 34
3.6 Dataset 35
3.7 Proses Pengecekan Akurasi 37
BAB 4 Implementasi dan Pengujian Sistem 38
4.1 Hasil Training 38
4.2 Hasil Testing 40
4.3 Validasi 48
BAB 5 Kesimpulan dan Saran 49
5.1 Kesimpulan 49
5.2 Saran 50
Daftar Pustaka 51
Lampiran A : List File untuk Fase Training 54
DAFTAR TABEL
Hal.
Tabel 2.1. Contoh Signature File pada Header file 8
Tabel 2.2. Komposisi Struktur dari file PDF (Roussev & Garfinkel, 2009) 15
Tabel 3.1. Tabel Perbandingan LCS 31
Tabel 3.2. Tabel Rumus Apabila String Cocok 32
Tabel 3.3. Tabel Rumus Apabila String tidak Cocok 32
Tabel 3.4. Tabel Hasil Perbandingan LCS 32
Tabel 3.5. Spesifikasi file-file data penelitian untuk fase training 36 Tabel 3.6. Spesifikasi file-file data penelitian untuk fase testing 36 Tabel 4.1. Tabel Perbandingan LCS File Utuh dengan File Fragment 40 Tabel 4.2. Tabel Perbandingan LCS Trailer File Utuh dengan File Fragment 41 Tabel 4.2. Tabel Perbandingan LCS Trailer File Utuh dengan File Fragment
(lanjutan) 42
Tabel 4.3. Tabel Akurasi Hasil Pengujian dengan Data Uji File Utuh 43 Tabel 4.4. Tabel Akurasi Hasil Pengujian dengan Data Uji File Fragment 44
Tabel 4.5. Tabel Spesifikasi File HTML 47
Tabel 4.6. Hasil Identifikasi File HTML 47
Tabel 4.7. Tabel Hasil Identifikasi HTML Setelah Training 47
DAFTAR GAMBAR
Hal.
Gambar 2.1. Ilustrasi hex number file terpotong 11
Gambar 2.2. Ilustrasi hex number file tertimpa file lain 11
Gambar 2.3. Komponen dari file PDF (Adobe, 2008) 14
Gambar 2.4. Contoh rangkaian hex number dari random PDF
(Roussev & Garfinkel, 2011) 15
Gambar 2.5. Contoh rangkaian hex number dari random RTF 17 Gambar 2.6. Contoh rangkaian hex number dari random DOC 18
Gambar 2.7. Binary pada file PDF 19
Gambar 2.8. Hex pada file PDF 20
Gambar 2.9. Kesamaan substring S1 dan S2 22
Gambar 2.10. Tabel X dan Y 23
Gambar 2.11. Gambar ilustrasi perhitungan LCS 24
Gambar 3.1. Arsitektur umum fase training 28
Gambar 3.2. Arsitektur umum fase testing 29
Gambar 3.3. Arsitektur umum fase validasi 30
Gambar 4.1. Hasil training LCS PDF 39
Gambar 4.2. Hasil training LCS RTF 39
ABSTRAK
Analis forensik komputer merupakan pihak yang melakukan investigasi dan pencarian barang bukti digital. Pada kasus tertentu, file yang dibutuhkan sebagai barang bukti digital untuk proses pengadilan telah dihapus. Pada saat proses restore, header file dari file tersebut seringkali hilang atau bahkan file tersebut tidak diketahui tipe file-nya sehingga mempersulit proses rekonstruksi file. Metode identifikasi file fragment melalui ekstensi nama file tidak dapat dilakukan dikarenakan kemungkinan besar file fragment kehilangan header file. Atas dasar ini, metode identifikasi tipe file dari file fragment menjadi hal yang
penting. Metode yang diajukan pada penelitian ini adalah penggunaan metode Longest Common Subsequences, dengan melalui tiga tahap, yaitu tahap training, testing, dan validasi. Pada penelitian ini ditunjukkan bahwa metode yang diajukan mampu melakukan identifikasi tipe file dari file fragment dengan hasil akurasi 92.91% untuk tiga jenis tipe data.
FILE TYPE IDENTIFICATION FROM FILE FRAGMENT USING LONGEST COMMON SUBSEQUENCES (LCS)
ABSTRACT
Computer forensic analyst is a person in charge of investigation and evidence tracking. In certain cases, the file that is needed for digital evidence to be presented to court was deleted. While the file is being restored, it is often lost its header and cannot be identified, therefore it is hard to reconstruct the file. For this reason, a method for file fragment‟s file type identification is needed. The method proposed in this research is using Longest Common Subsequences, consists of three steps: training, testing and validation. In this
research, it can be seen that this method works well and achieves 92.91% accuracy of identifying the file type of file fragment for three data types.
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Analis forensik komputer merupakan pihak yang melakukan investigasi dan pencarian barang bukti digital. Pada kasus tertentu, file yang dibutuhkan sebagai barang bukti digital untuk proses pengadilan telah terhapus. Pada saat proses restore, header file dari file tersebut bisa jadi hilang sehingga file tersebut tidak diketahui tipe file-nya dan mempersulit proses rekonstruksi file.
Beberapa penelitian untuk mengidentifikasi file telah dilakukan sebelumnya, diantaranya adalah identifikasi file “fingerprints” (McDaniel & Heydari, 2003) dan identifikasi “fileprints” (Li, et al. 2005), penggunaan linear diskriminan the Fisher (Veenman, 2007) yang diaplikasikan kepada fileprint, entropy, dan pengukuran yang berbasiskan Kolmogorov complexity dan perbandingan dua metode yaitu metode linear discriminant dan longest common substring dan subsequences untuk membedakan 4 tipe file, yakni .pdf, .gif, .bmp, dan .jpg (Calhoun & Coles, 2008). Akan tetapi, penelitian yang dilakukan Calhoun dan Coles tersebut hanya sebatas pembuktian konsep.
mengurangi memory yang diperlukan untuk matrix perbandingan (Calhoun & Coles, 2008). Metode ini dipakai untuk melakukan pencarian sequence terpanjang dari beberapa sequence. Dalam pengujian ini, sequence yang digunakan adalah beberapa sequence dari hex number file utuh, kemudian hasil dari pengujian tersebut akan diuji
kembali dengan sequence dari hex number file fragment, bila cocok, maka akan didapatkan tipe file dari file fragment tersebut.
Setelah mengidentifikasikan file, program yang akan dirancang juga akan melakukan pembuktian akan hasil identifikasi file dengan metode penambahan header file sesuai hasil identifikasi. Misalkan suatu file fragment telah teridentifikasi sebagai
file dengan ekstensi .pdf, maka akan dilakukan verifikasi dengan menambahkan
header file .pdf sehingga dapat dibuka oleh aplikasi pembaca pdf dan isi daripada file tersebut dapat diperiksa dan dibaca.
Berdasarkan latar belakang diatas, penulis mengajukan proposal penelitian dengan judul “Identifikasi tipe file dari file fragment menggunakan longest common subsequences (LCS)”.
1.2 Rumusan Masalah
Penghapusan file untuk menghilangkan barang bukti membuat pihak analis forensik komputer kesulitan dalam merekonstruksi ulang file dari fragment yang tersisa. Untuk merekonstruksi file fragment tersebut, pihak forensik perlu mengetahui tipe file dari file fragment, oleh karena itu, diperlukan suatu metode untuk mengidentifikasi tipe file
dari file fragment.
1.3 Tujuan Penelitian
1.4 Batasan Masalah
Untuk menghindari perluasan permasalahan yang ada, maka penulis membuat batasan masalah, yakni:
1. File yang akan diidentifikasi merupakan file dengan format .pdf, .doc, dan .rtf. 2. Hex number dari file fragment tidak dimanipulasi menggunakan hex editor
atau aplikasi yang serupa.
3. Program yang dibangun hanya sebatas pengaplikasian metode LCS kepada file fragment, tidak sampai kepada tahap program yang dapat membedakan file
utuh dengan file fragment.
1.5 Manfaat Penelitian
Manfaat dari penelitian ini adalah:
1. Membantu mengidentifikasi tipe file dari file fragment. 2. Menjadi referensi untuk penelitian yang akan datang.
1.6 Metodologi Penelitian
Tahapan-tahapan yang akan dilakukan pada pelaksanaan penelitian adalah sebagai berikut:
1. Studi Literatur
Studi literatur dilakukan dalam rangka pengumpulan bahan referensi mengenai forensik digital, file, ekstraksi fitur, identifikasi file dan Longest Common Subsequences.
2. Analisis Permasalahan
3. Pengumpulan Data
Pada tahap ini dilakukan pengumpulan data serta pengujian data dalam training dataset berupa file utuh dan testing dataset berupa file fragment.
4. Implementasi
Pada tahap ini dilakukan implementasi metode Longest Common Subsequences dalam penyelesaian masalah identifikasi tipe file dari file fragment.
5. Evaluasi dan Analisis Hasil
Pada tahap ini dilakukan evaluasi serta analisis terhadap hasil yang didapatkan melalui implementasi metode Longest Common Subsequences dalam penyelesaian
6. Dokumentasi dan Pelaporan
1.7 Sistematika Penulisan
Sistematika penulisan dari skripsi ini terdiri dari lima bagian utama sebagai berikut:
Bab 1: Pendahuluan
Bab ini berisi latar belakang dari penelitian yang dilakukan, rumusan masalah, tujuan penelitian, batasan masalah, manfaat penelitian, metodologi penelitian, dan sistematika penulisan.
Bab 2: Landasan Teori
Bab ini berisi teori-teori yang digunakan untuk memahami permasalahan yang dibahas pada penelitian ini. Pada bab ini akan dijelaskan teori-teori tentang forensic digital, file, file fragment, identifikasi file, serta Longest Common Subsequences (LCS).
Bab 3: Analisis dan Perancangan
Bab 4: Implementasi dan Pengujian
Bab ini berisi pembahasan tentang implementasi dari analisis dan perancangan yang disusun pada bab 3. Selain itu, hasil penelitian akan didapatkan dari pengujian yang telah dilakukan, apakah hasil yang didapat sesuai dengan harapan atau tidak.
Bab 5: Kesimpulan Dan Saran
BAB 2
LANDASAN TEORI
Bab ini merupakan pembahasan tentang teori-teori penunjang serta penelitian sebelumnya yang berhubungan dengan identifikasi tipe file serta metode Longest Common Subsequences.
2.1. Forensik Digital
Forensik memiliki pengertian sebagai pengaplikasian ilmu pengetahuan terhadap pelaku kriminal dan wujud dari penegakan hukum oleh pihak kepolisian (Saferstein, 2011). Kebanyakan orang sering mengaitkan digital forensik dengan investigasi tindakan kriminal, namun, forensik digital dalam beberapa tahun terakhir memiliki peran sebagai alat pendekatan untuk memfasilitasi pelestarian dan penjagaan terhadap bukti digital, khususnya dalam proses investigasi bukti-bukti pada masa lampau (John, 2012). Cabang ilmu pengetahuan forensik tersebut merupakan respon dari desakan komunitas penegakan hukum (Whitcomb, 2002).
Secara teknis, forensik digital dapat dibagi atas beberapa cabang berdasarkan perangkat digitalnya, yakni: forensik computer, forensik jaringan, forensik analisis data dan forensik perangkat mobile (Aaron, 2014).
2.2. File
File merupakan sekumpulan informasi berupa huruf, angka, maupun karakter khusus
dan ditandai dengan nama file. Seluruh data maupun informasi yang ada dalam sebuah komputer tersimpan dalam bentuk file. File dapat dibagi berdasarkan isi informasi yang disimpan, yakni: text file, image file, dan program file. Text file merupakan file yang menyimpan informasi berupa text (tulisan), image file merupakan file yang menyimpan informasi berupa image (gambar), sedangkan program file merupakan file yang menyimpan program. Isi dari file juga dapat menentukan format file tersebut, karena file merupakan tempat disimpannya data.
Secara umum, sebuah file terdiri atas tiga bagian, yakni: 1. File header
File header adalah sebuah signature file atau magic bytes yang ditempatkan pada awal file. Sistem operasi maupun perangkat lunak lainnya akan membaca informasi yang terdapat pada header tersebut, dan mengetahui jenis file dari sebuah file.
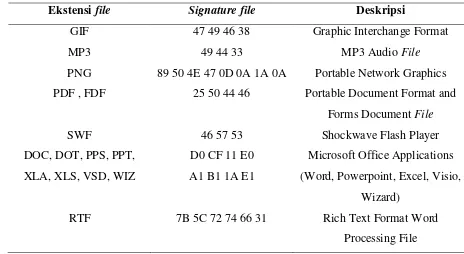
Pada proses investigasi oleh pihak forensik komputer, file header sangat penting karena file header tersebut dapat membantu melacak konten dari file yang terhapus, laporan aktivitas pengguna, dan hal-hal yang bersangkutan lainnya. Sebagai contoh, bila pihak forensik hendak mengembalikan rekaman file activity yang terhapus dari suatu perusahaan, dengan melacak signature daripada hard drive yang berkaitan dengan rekaman file activity, maka sering kali proses recovery dapat berhasil dilakukan. Contoh signature file dapat dilihat pada tabel 2.1.
2. File body
File body adalah isi dari sebuah file yang menjadi data atau informasi utama
yang dimiliki oleh file. 3. File trailer
struktur data dan penjelasannya terdapat pada header suatu file, namun informasi tersebut dapat ditemukan juga pada trailer sebuah file (Aaron, 2014).
Tabel 2.1. Contoh Signature File pada Header File
Ekstensi file Signature file Deskripsi
GIF 47 49 46 38 Graphic Interchange Format
MP3 49 44 33 MP3 Audio File
PNG 89 50 4E 47 0D 0A 1A 0A Portable Network Graphics
PDF , FDF 25 50 44 46 Portable Document Format and
Forms Document File
SWF 46 57 53 Shockwave Flash Player
DOC, DOT, PPS, PPT, XLA, XLS, VSD, WIZ
D0 CF 11 E0 A1 B1 1A E1
Microsoft Office Applications (Word, Powerpoint, Excel, Visio,
Wizard)
RTF 7B 5C 72 74 66 31 Rich Text Format Word
Processing File
2.2.1. File Types and Formats
Seiring bertambahnya tingkat penggunaan software, penyimpanan data merupakan hal yang vital bagi user, penyimpanan data ini sendiri menimbulkan suatu polemik di dalam bidang forensik. Terutama untuk hal-hal yang berhubungan dengan munculnya variasi-variasi tipe data. Kenyataannya, hampir mustahil untuk membuat list seluruh tipe file dari komputer, hal ini disebabkan oleh beberapa hal, diantaranya adalah :
1) Beberapa tipe file bersifat umum sedangkan yang lain bersifat sangat spesifik. 2) Beberapa tipe file sangat umum digunakan sedangkan yang lain hanya dipakai
oleh orang atau organisasi tertentu.
3) Detail daripada beberapa file memiliki hak milik sedangkan yang lain bersifat terbuka.
Terdapat beberapa cara untuk mengidentifikasi tipe file , yaitu : 1) Berdasarkan ekstensi file
Cara paling mudah untuk mendapatkan indikasi tipe file adalah dengan melihat ekstensi dari nama file tersebut. Ekstensi nama file adalah karakter setelah tanda „.‟ (titik) pada akhir nama file. Sebagai contoh, sebuah file “MyText.txt”, merupakan sebuah file txt(teks), sementara “MyPic.jpg” merupakan sebuah file jpeg (gambar). Permasalahan pada identifikasi file ini terdapat pada mudahnya manipulasi ekstensi sebuah file. File “MyText.txt” tadi dapat dengan mudah diganti ekstensi filenya menjadi “MyText.jpg”. Hal tersebut dapat terjadi secara tidak sengaja maupun secara sengaja. Identifikasi berdasarkan ekstensi file sangat mudah dilakukan dan cepat, tetapi tidak cukup untuk memastikan tipe dari suatu file . 2) Berdasarkan struktur file
Semakin kompleks tipe file, maka file memiliki format spesifikasi yang kaku. Dengan menganalisis struktur sebuah file dan membandingkannya dengan spesifikasi format yang ada, maka tipe file dapat ditentukan.
3) Berdasarkan Magic Bytes
Magic Bytes atau magic number atau dikenal juga dengan sebutan signature file adalah kumpulan byte-byte pada sebuah file yang dapat membedakan antara jenis file yang satu dengan jenis file yang lainnya. Pada umumnya, magic bytes terdapat
pada file header, namun pada tipe file yang lain, magic bytes terdapat pada file body atau file trailer. Magic bytes juga dapat digunakan untuk membedakan versi
aplikasi yang digunakan untuk membuat file tersebut. 4) Berdasarkan distribusi karakter
Identifikasi berdasarkan distribusi karakter dilakukan dengan membandingkan frekuensi kemunculan byte dari suatu file dengan frekuensi kemunculan byte dari file lainnya. Sebagai contoh, pada file html byte dari karakter /, < dan > memiliki frekuensi kemunculan yang lebih tinggi dibandingkan dengan file lainnya. Sehingga, apabila terdapat sebuah file yang tingkat frekuensi byte karakter /, < dan >, maka kemungkinan besar file tersebut merupakan file html. File yang memiliki tipe data yang berbeda akan cenderung memiliki frekuensi byte yang berbeda pula.
Identifikasi tipe file berdasarkan distribusi karakter memiliki dua kelemahan, yaitu:
a. Adanya beberapa tipe file yang tidak memiliki distribusi karakter yang spesifik.
b. Memiliki akurasi yang cukup rendah (Aaron, 2014).
2.2.2. File Type Validation
Setelah mengidentifikasi tipe file, maka tahap selanjutnya adalah melakukan validasi dari tipe file tersebut. Suatu file dikatakan valid apabila :
a. Dapat digunakan oleh program yang memang bertujuan untuk mengolah file dengan tipe data tersebut.
b. Sesuai dengan spesifikasi tipe file tersebut. Misalnya, file gif bukan hanya menampilkan satu gambar saja, tetapi beberapa gambar yang seperti video. (Lechich, 2007).
2.2.3. File Fragment
File fragment adalah potongan file yang tidak lengkap, dikarenakan recovery file yang
Berdasarkan struktur atau konten hex numbernya, tipe-tipe file fragment dapat dibagi menjadi 2, yakni:
1) File yang hex numbernya terpotong. Ilustrasi pada Gambar 2.1.
Gambar 2.1. Ilustrasi hex number file terpotong
2) File yang hex numbernya tertimpa oleh hex number dari file lain. Ilustrasi pada Gambar 2.2.
Fragmentasi sebuah file terjadi dikarenakan penyimpanan suatu file pada media penyimpanan membagi-bagi file menjadi bagian-bagian yang lebih kecil dan tersebar dalam cluster. Sehingga, ketika sebuah file dihapus pada media penyimpanan, cluster tempat dimana file tersebut disimpan menjadi kosong dan dapat ditempati oleh
file yang lain. Ketika file mengalami penambahan ukuran, sering kali tidak mungkin
untuk melakukan proses penulisan di bagian akhir file sehingga berpotensi menyebabkan proses fragmentasi file. Penempatan penimpaan suatu file terhadap file lain selalu dimulai dari header file, sehingga file menjadi tidak dikenali oleh aplikasi pembaca file tersebut. Fragmentasi pada suatu file juga dapat terjadi pada keseluruhan file sehingga file tidak dapat teridentifikasi.
Sebuah permasalahan di dalam forensik komputer muncul dalam menentukan tipe file dari file fragment. Ketika sebuah file dihapus, entri daripada file di dalam directory bisa tertimpa. Hal tersebut dapat dengan mudah diselesaikan bila header file
fragment tersebut masih utuh, tetapi deteksi tipe file akan menjadi sulit dilakukan apabila file fragment dideteksi melalui body file dikarenakan file header yang terhapus atau tidak lengkap. Ada dua metode yang dapat dipakai dalam menentukan tipe file dari file fragment yakni Fisher‟s linear discriminant dan berdasarkan longest common subsequences dari file fragment dengan berbagai macam file yang dipakai sebagai testing dataset ( Calhoun & Coles, 2008).
2.2.4. File Recovery
Penghapusan sebuah file mengakibatkan cluster yang sedang ditempati file tersebut berubah menjadi unallocated space yaitu cluster kosong yang dapat ditempati data lainnya. Secara fisik, file masih terdapat pada cluster tersebut dan masih dapat direcovery selama belum terjadi penimpaan data (overwrite), penghapusan secara keseluruhan (thorough delete) maupun wiping. Recovery file dapat dilakukan dengan proses undelete, file carving, maupun recovery (Aburabie & Alomari, 2006).
Table (MFT) untuk setiap file memiliki pengalokasian daftar cluster untuk penyimpanan file tersebut. Oleh karena itu, recovery file yang telah mengalami fragmentasi masih dapat dilakukan (Casey, 2010).
2.3. Jenis-Jenis File
2.3.1. PDF
PDF atau Portable Document Format adalah tipe file dokumen umum yang mewakili berbagai jenis tipe file dokumen lain yang terdapat di internet sejak tahun 1993
(Taft, et al. 2004). Pada 14 tahun terakhir, dibantu dengan membludaknya penggunaan internet, PDF menjadi tipe file yang paling sering digunakan sebagai media pertukaran dokumen-dokumen.
Berikut adalah detail dari perkembangan PDF : 1) PDF 1.0 / Acrobat 1.0 (1993).
2) PDF 1.1 / Acrobat 2.0 (1994). 3) PDF 1.2 / Acrobat 3.0 (1996). 4) PDF 1.3 / Acrobat 4.0 (1999). 5) PDF 1.4 / Acrobat 5.0 (2001). 6) PDF 1.5 / Acrobat 6.0 (2003). 7) PDF 1.6 / Acrobat 7.0 (2005). 8) PDF 1.7 / Acrobat 8.0 (2006).
9) PDF 1.7 / Acrobat 9.0 / Adobe Extension Level 3 (2008). 10)PDF 1.7 / Acrobat 9.1 / Adobe Extension Level 5 (2009).
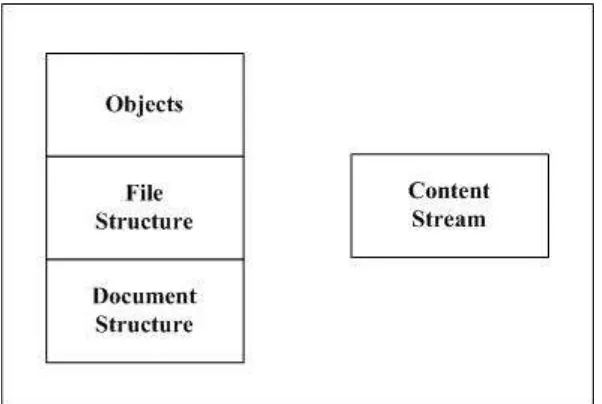
PDF memiliki 4 komponen bagian seperti pada Gambar 2.3, yakni :
1) Objek
2) Struktur file
Struktur sebuah file PDF menentukan bagaimana objek-objek PDF disimpan di dalam file PDF, bagaimana mereka diakses, dan bagaimana mereka diperbarui. Struktur dari PDF ini sendiri bersifat terpisah dari semantik objek-objek tersebut. 3) Struktur dokumen
Struktur sebuah dokumen PDF menjelaskan bagaimana tipe objek sederhana digunakan untuk menunjukkan komponen-komponen dari sebuah dokumen PDF seperti halaman, font, anotasi, dan seterusnya.
4) Content Streams
Content stream dari sebuah PDF berisi sebuah rangkaian instruksi yang mendeskripsikan penampilan dari sebuah halaman. Instruksi ini, walau menggambarkan sebuah objek, secara konseptual berbeda dengan objek-objek yang merepresentasikan struktur dokumen dan diuraikan secara terpisah (Adobe, 2008).
Gambar 2.3. Komponen dari file PDF (Adobe, 2008)
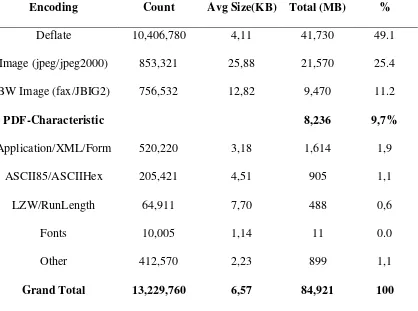
Tabel 2.2. Komposisi Struktur dari File PDF (Roussev & Garfinkel, 2009)
Encoding Count Avg Size(KB) Total (MB) %
Deflate 10,406,780 4,11 41,730 49.1
Image (jpeg/jpeg2000) 853,321 25,88 21,570 25.4
BW Image (fax/JBIG2) 756,532 12,82 9,470 11.2
PDF-Characteristic 8,236 9,7%
Application/XML/Form 520,220 3,18 1,614 1,9
ASCII85/ASCIIHex 205,421 4,51 905 1,1
LZW/RunLength 64,911 7,70 488 0,6
Fonts 10,005 1,14 11 0.0
Other 412,570 2,23 899 1,1
Grand Total 13,229,760 6,57 84,921 100
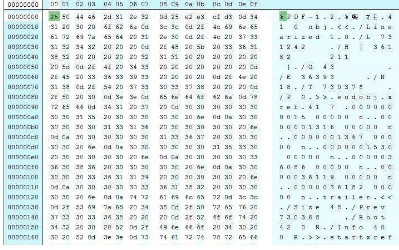
Kolom pertama merupakan metode encoding untuk objek PDF, sedangkan kolom yang lain merupakan jumlah angka dari objek yang ada di dalam PDF, ukuran rata-rata, total ukuran keseluruhan dan persentase dari keseluruhan bagian yang terdapat dalam file PDF (Roussev & Garfinkel, 2009). Contoh isi hex number dari tipe file PDF dapat dilihat pada Gambar 2.4.
Gambar 2.4. Contoh rangkaian hex number dari random PDF (Roussev &
Sedangkan struktur dokumen PDF, tersusun atas 4 bagian utama, yakni: 1) PDF Header
Baris pertama pada PDF yang mendefinisikan versi dari format file PDF. Dari header PDF kita juga dapat menemukan informasi dasar dari sebuah file PDF, misalnya header “%PDF-1.5” menunjukkan magic bytes PDF yakni “%PDF” serta “1.5” yang menjelaskan versi PDF tersebut, yakni versi PDF 1.5.
2) PDF Body
Body pada file PDF mengandung objek-objek yang memuat konten dari dokumen tersebut. Objek-objek ini meliputi data berupa gambar, font, anotasi, hyperlinks, bookmark, teks stream dan sebagainya. Pengguna PDF juga dapat mengimplementasikan fitur yang terdapat didalamnya, seperti fitur pengamanan yang membatasi dokumen agar tidak dapat dicetak, dilihat, diedit, maupun dimodifikasi.
3) Cross-Reference Table
Cross-reference table atau dapat disebut juga dengan xref table memuat hubungan antara objek atau elemen yang terdapat di dalam file.
4) Trailer
Trailer pada PDF memuat hubungan pada cross-reference table dan selalu diakhiri dengan “%%EOF” untuk menandakan akhir dari sebuah file PDF. Jika baris tersebut hilang, maka file PDF tidak dapat diproses secara benar.
2.3.2. RTF
RTF atau Rich Text Format adalah format file dokumen yang dipubikasikan oleh Microsoft Corporation pada tahun 1987 untuk mentransfer dokumen teks dengan
platform Microsoft.
Format file RTF juga mendukung grafik dan tabel dalam dokumen. Contoh rangkaian hex number pada file RTF dapat dilihat pada gambar 2.5. Berikut adalah detail dari perkembangan RTF untuk Microsoft Word:
1) RTF versi 1.0 untuk Microsoft Word 3 (1987). 2) RTF versi 1.1 untuk Microsoft Word 4 (1989). 3) RTF versi 1.2 untuk Microsoft Word 5 (1993). 4) RTF versi 1.3 untuk Microsoft Word 6 (1994).
5) RTF versi 1.4 untuk Microsoft Word 95/Word 7 (1995). 6) RTF versi 1.5 untuk Microsoft Word 97/Word 8 (1997). 7) RTF versi 1.6 untuk Microsoft Word 2000/Word 9 (1999). 8) RTF versi 1.7 untuk Microsoft Word 2002/Word 10 (2001). 9) RTF versi 1.8 untuk Microsoft Word 2003/Word 11 (2004).
10)RTF versi 1.9.1 untuk Microsoft Word 2007/Word 12 (2008). (Microsoft Corporation, 2007).
Gambar 2.5. Contoh rangkaian hex number dari random RTF
2.3.4. DOC
DOC atau document adalah salah satu ekstensi tipe file dokumen pengolah kata. DOC merupakan format file binary yang digunakan oleh aplikasi Microsoft Word 97, Microsoft Word 2000, Microsoft Word 2002, dan Microsoft Office Word 2003 (Microsoft, 2014). DOC memiliki rangkaian hex number berupa „D0 CF 11 E0 A1 B1 1A E1‟.
Sebuah file DOC memuat informasi berupa: 1) Main Stream
3) Table Stream 4) Data Stream
5) Custom XML Storage (Microsoft Word 2007)
6) Bit 0 atau object stream yang memuat data privat untuk objek OLE 2.0 (Object Linking and Embedding 2.0) yang di-embed ke dokumen Word (Microsoft,
2007). Contoh hex number dari tipe file DOC terdapat pada Gambar 2.6.
Gambar 2.6. Contoh rangkaian hex number dari random DOC
2.4. Binary File
Binary file merupakan sebuah file komputer yang bukan merupakan file teks. File
tersebut bisa saja memuat tipe data apa saja, kemudian diubah ke dalam bentuk binary untuk tujuan penyimpanan dan pemrosesan komputer. Banyak format file binary yang memuat bagian yang dapat diterjemahkan ke dalam teks, sebagai contoh beberapa file dokumen seperti file Microsoft Word dengan ekstensi doc yang memuat informasi berupa teks yang terdapat pada file tersebut dan juga informasi-informasi lainnya dalam bentuk binary.
header, blok-blok metadata yang digunakan oleh program komputer untuk menerjemahkan data yang ada di dalam file. Pada file header umumnya berisi signature atau magic number yang dapat mengidentifikasi format file. Binary file yang
tidak memiliki header disebut juga sebagai flat binary file.
Untuk mengirim binary file melalui sebuah sistem khusus seperti e-mail yang tidak mendukung semua jenis data, biasanya binary tersebut diubah menjadi plain teks atau lambang-lambang khusus sebagai representasi, misalnya menggunakan Base64. Proses mengubah atau encoding tersebut biasanya memiliki kelemahan, seperti ukuran file yang bertambah pada saat proses mengirim, serta dibutuhkan proses penerjemahan
dari plain teks ke binary setelah file diterima. Permasalahan ukuran file yang bertambah dapat diselesaikan dengan cara melakukan kompresi data, sehingga data yang dikirim memiliki ukuran file yang relatif sama dengan file asli.
Hex editor merupakan aplikasi untuk membaca binary yang terdapat pada suatu file maupun mengubah tipe data binary menjadi tipe data hexadecimal, decimal maupun karakter ASCII. Perbandingan binary dan hex pada satu file .pdf dapat dilihat pada Gambar 2.7 dan Gambar 2.8.
Gambar 2.8. Hex pada file PDF
2.6. Longest Common Subsequences
Dalam permasalahan matematika, sebuah subsequence adalah sebuah sequence yang diturunkan dari sequence lain dengan menghapus beberapa elemen tanpa mengganti urutan dari sisa element tersebut. Sebagai contoh, sequence “A B D” merupakan subsequence dari sequence “A B C D E”. Secara singkat, subsequence merupakan bagian dari sebuah sequence.
Longest Common Subsequences merupakan sebuah metode untuk mencari sequence terpanjang yang sama, sebuah basis dari pemrograman untuk perbandingan
data komputer. Pada kasus identifikasi tipe file, Longest Common Subsequences dapat digunakan untuk membandingkan sequence hex number beberapa file. Secara umum, Longest Common Subsequence adalah sebuah metode untuk mendapatkan sequence terpanjang dengan membandingkan beberapa sequence.
1. Sequence dari DNA atau gen yang dapat direpresentasikan sebagai deretan 4 huruf ACGT. Pada saat seorang ahli biologi yang meneliti tentang gen, bila dia menemukan suatu sequence yang baru pada gen tersebut, biasanya mereka akan mencari tahu sequence lainnya yang mirip dengan sequence baru tersebut.
2. Pada program UNIX, „diff‟ digunakan untuk membandingkan dua file yang sama dengan versi yang berbeda, untuk menemukan perubahan yang terdapat pada file tersebut. Hal tersebut dilakukan dengan cara menemukan Longest Common Subsequences dari kedua file tersebut, dan menemukan subsequence
yang tidak berubah, sehingga dapat ditemukan baris subsequence yang berbeda atau diganti.
3. Banyak text editor seperti “emacs” menampikan bagian dari sebuah file ke monitor, dan setiap kali file tersebut diganti, maka monitor akan ter-update. Program tersebut ingin mengirimkan teks sesedikit mungkin ke terminal sehingga proses update tersebut dapat ditampilkan secara benar. Diperlukan metode Longest Common Subsequences sehingga karakter-karakter pada file yang tidak berubah tetap tinggal di terminal dan hanya mengirimkan karakter-karakter yang berubah saja (University of California, 1996).
Sebagai contoh, terdapat dua buah string, string S1 mencakup deretan string
berupa “AAACCGTGAGTTATTCGTTCTAGAA”, dan string S2 mencakup deretan
string “CACCCCTAAGGTACCTTTGGTTC”. Kesamaan substring pada string S1
dan S2 dapat dilihat pada Gambar 2.9. Pencarian subsequence terpanjang pada dua
buah sequence secara manual tersebut akan memakan waktu yang sangat lama bahkan mustahil dilakukan bila mencakup binary file sebagai input, dikarenakan binary file dapat mencapai ratusan bahkan ribuan baris sequence. Oleh karena itu, metode Longest Common Subsequences dipakai untuk menyelesaikan kasus-kasus pencarian
Gambar 2.9. Kesamaan substring S1 dan S2
Bila terdapat dua buah sequences yaitu X dan Y, dengan X = <X1, X2, ..., Xm>
dan Y = <Y1, Y2, ..., Yn>. Kemudian Z merupakan Longest Common Subsequences
daripada sequence X dan Y dengan persamaan Z = <Z1, Z2, ..., Zk>. Maka akan
terdapat persamaan-persamaan sebagai berikut :
1. Jika Xm = Yn, maka dapat dipastikan bahwa Zk = Xm = Yn.
2. Jika Xm <> Yn, maka Xm <> Zk mengindikasikan bahwa Z terdapat pada
LCS(Xm-1, Y).
3. Jika Xm <> Yn, maka Yn <> Zk mengindikasikan bahwa Z terdapat pada
LCS(X, Yn-1) (Klappenecker, 2011).
Ilustrasi pencarian subsequence dari dua buah string dengan metode Longest Common Subsequences adalah sebagai berikut:
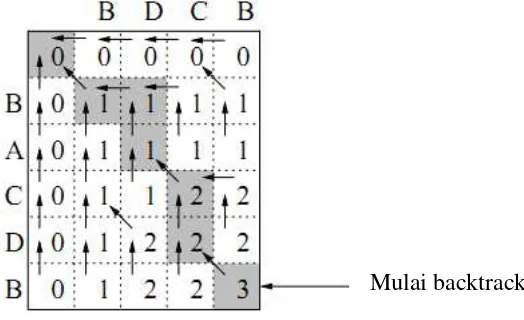
Misalkan X memiliki sequence BDCB, dan Y memiliki sequence BACDB. Sequence X dan sequence Y diletakkan pada tabel seperti pada gambar 2.10.
1. Letak sequence X dan Y tidak berpengaruh terhadap perhitungan. 2. Input kolom paling kiri dan paling atas dengan angka 0.
3. Kemudian pertemukan setiap sequence satu per satu. Bila X sama dengan Y, maka nilai pada kolom tersebut adalah (n,n) = (n-1,n-1) + 1. Sedangkan bila X tidak sama dengan Y, maka nilai yang menjadi input adalah nilai terbesar yang terdapat pada kolom (n-1,n) atau pada kolom (n,n-1). Misalkan nilai X = B dan nilai Y = B, bertemu pada kolom (2,2), maka input kolom tersebut dengan nilai (1,1) + 1, dalam hal ini nilai (1,1) = 0, sehingga 0+1 = 1.
yang bernilai 0. Nilai 1 > 0, maka input pada kolom (3,2) adalah 1. Apabila nilai pada kolom (2,2) sama dengan nilai pada kolom (3,1) maka input kolom (3,2) sama dengan kedua kolom tersebut.
4. Input seluruh kolom yang tersisa.
Gambar 2.10. Tabel X dan Y
Setelah itu, akan ditentukan Longest Common Subsequences (LCS) dari tabel yang sudah terisi tersebut. Langkah-langkah yang akan dilakukan adalah :
1. Meletakkan pointer pada kolom sudut kanan bawah, yakni kolom (5,6).
2. Pointer akan bergerak dengan salah satu pola, yakni ke kiri lalu ke atas atau ke kanan lalu ke atas. Tetapi pointer tidak bisa bergerak menggunakan pola ini bila nilai pada kolom yang dituju tidak sama dengan nilai pada kolom semula. Bila hal ini terjadi, maka pointer akan bergerak menyerong, misalnya dari (5,6) ke (4,5).
3. Sequence tersebut akan diletakkan dengan urutan dari kanan ke kiri.
4. Pointer akan terus bergerak sampai pada kolom dengan nilai 0. Pointer akan berhenti, dan nilai dari LCS telah didapat.
Gambar 2.11. Gambar ilustrasi perhitungan LCS
6. Setelah mendapatkan nilai LCS, maka penelitian akan dilanjutkan pada tahap mencocokkan nilai LCS yang didapat dengan hex number pada file yang hendak diuji.
2.7. Penelitian Terdahulu
Pada tahun 2003, McDaniel & Heydari mengajukan metode “fingerprints” untuk memprediksi tipe file dengan membandingkan histogram file. Akan tetapi, hasil penelitian menunjukkan bahwa sangat sulit untuk menghasilkan representasi fingerprint untuk seluruh kelas tipe file. Li, et al. pada tahun 2005 mengimplementasikan metode fileprints yang mengidentifikasikan tipe file dengan menganalisa n-gram. Hasil penelitian menunjukkan bahwa metode fileprints dengan menggunakan model centroid untuk representasi distribusi nilai byte per tipe file dapat mengidentifikasi tipe file secara efektif saat melakukan streaming file dari ataupun menuju disk drive. Veenman pada tahun 2007 mengajukan metode linear diskriminan the Fischer untuk yang diaplikasikan kepada fileprint, entropy, dan pengukuran berbasiskan Kolgomorov complexity. Hasil penelitian menunjukkan bahwa metode linear discriminant dapat digunakan untuk mengidentifikasi tipe file. Calhoun dan Coles pada tahun 2008 melakukan perbandingan dua metode yaitu metode linear discriminant dan longest common subsequences untuk membandingkan 4 tipe file yakni pdf, gif, bmp, dan jpg. Hasil penelitian menunjukkan bahwa metode longest common subsequences dapat membedakan file utuh antara pdf, gif, bmp, dan jpg dan
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Bab ini merupakan pembahasan tentang implementasi metode Longest Common Subsequences dalam proses identifikasi tipe file dari file fragment. Bab ini juga akan membahas tentang proses yang terjadi dalam fase training, fase testing, serta fase validasi.
3.1 Arsitektur Umum
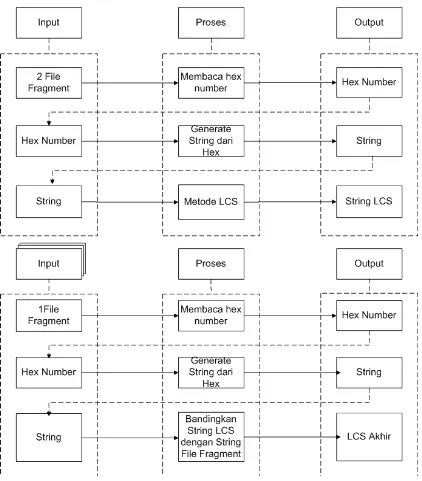
Arsitektur umum yang menunjukkan rangkaian langkah yang dilakukan untuk melakukan identifikasi tipe file dari file fragment terdiri dari 3 bagian, yaitu fase training, fase testing dan fase validasi. Pada awalnya dilakukan pengumpulan data
training berupa file-file dokumen; pengumpulan data testing berupa file-file fragment
yang digenerate dari file-file dokumen lain dengan format file yang bervariasi dengan cara menimpa beberapa hex pada file secara acak dan mengganti nama ekstensi file menjadi .tmp sehingga file menjadi tidak dapat terbaca; pada fase training, kalkulasi Longest Common Subsequences dari setiap tipe file; simpan hasil kalkulasi pada file eksternal; lakukan lagi kalkulasi Longest Common Subsequences dari setiap file dengan hasil dari file eksternal tersebut; hasil akhir yang didapat akan dipakai untuk fase testing; pada fase testing, file fragment tersebut diuji untuk dilihat apakah program dapat mendeteksi tipe file, untuk kemudian dihitung akurasi kebenaran dari hasil identifikasi.
informasi yang cukup untuk membuka file tersebut dan file menjadi corrupt. Persentase keberhasilan proses validasi juga akan dihitung. Tahapan-tahapan yang dilakukan akan dibahas dengan lebih terperinci pada bagian-bagian selanjutnya.
3.1.1. Fase Training
Pada fase ini, input berupa file-file utuh dengan ekstensi sama, misalnya .pdf yang dimasukkan ke dalam satu folder untuk di training. Program akan membaca seluruh isi file dari folder tersebut. Program akan memasukkan input berupa 2 file secara berurutan. Hex number daripada kedua file tersebut akan dibaca dan diubah dalam bentuk string kemudian metode LCS diaplikasikan untuk mendapatkan sequence terpanjang dari kedua file tersebut. LCS yang didapat akan disimpan ke dalam file buffer.
Program kemudian memeriksa apakah ada file yang belum dimasukkan sebagai input dalam proses training, bila ada, maka string hex number dari file tersebut akan dibandingkan dengan hasil LCS yang terdapat pada file buffer dengan metode LCS. Program akan melakukan perbandingan secara terus menerus selama masih terdapat file yang belum ditraining di dalam folder. Jika seluruh file sudah dimasukkan sebagai input, maka program akan berhenti melakukan proses training dan hasil akhir dapat ditemukan dalam file buffer.
Setelah proses training selesai, maka akan dilakukan penghapusan karakter-karakter spasi yang terdapat dalam file buffer dikarenakan karakter spasi merupakan hex number 00 yang merepresentasikan slack space yang bukan merupakan struktur utama pada file melainkan merupakan hex number yang diisi pada cluster file yang tidak terpakai. Selain karakter spasi, karakter tanda tanya juga dihapus, dikarenakan karakter tanda tanya merupakan chinese character yang tidak dapat terbaca, sehingga dikonversi menjadi karakter tanda tanya.
Training kemudian akan dilanjutkan dengan menggunakan file dengan ekstensi
Gambar 3.1. Arsitektur umum fase training
3.1.2. Fase Testing
Gambar 3.2. Arsitektur umum fase testing
3.1.3. Fase Validasi
File fragment yang telah selesai diidentifikasi akan ditambahkan header file sesuai
pembaca yang sesuai dengan tipe file tersebut sehingga kita dapat membaca isi potongan file fragment tersebut. Skema fase validasi dapat dilihat pada Gambar 3.3.
Gambar 3.3. Arsitektur umum fase validasi
3.2 Membaca Hex Number dan Generate String
Pada tahap ini, program akan membaca hex number yang membentuk input file, kemudian mengubahnya ke dalam string. Pseudocode pada proses ini meliputi:
int count char temp
check hex number from file with StringBuffer StringBuffer result = new StringBuffer(“ “) while (true){
if count >= file length break
else
read hex number
store hex number at temp count++
result.append(temp)
return result.toString()
3.3 Aplikasi Algoritma LCS
Pada tahap ini, program akan melakukan perhitungan Longest Common Subsequences untuk mendapatkan sequence terpanjang yang akan digunakan pada fase testing dan persentase kemiripan antara file fragment dengan file utuh pdf, rtf, dan doc. Langkah-langkah aplikasi algoritma LCS dengan input BDCABA dan ABCBDAB, adalah sebagai berikut:
1) Menghitung panjang string kedua input. Panjang karakter BDCABA = 6 karakter. Panjang karakter ABCBDAB = 7 karakter.
2) Menyediakan tabel perbandingan untuk perhitungan LCS sesuai dengan panjang string input dengan tambahan 1 kolom untuk diisi dengan nilai 0. Tabel perbandingan dapat dilihat pada tabel 3.1.
Tabel 3.1. Tabel Perbandingan LCS
B D C A B A
0 0 0 0 0 0 0
A 0
B 0
C 0
B 0
D 0
A 0
B 0
Tabel 3.2. Tabel Rumus Apabila String Cocok
x
a b if x = y
y c a + 1
Apabila string x dan y cocok, maka program akan mengisi tabel tersebut dengan nilai a+1.
Tabel 3.3 Tabel Rumus Apabila String tidak Cocok
x
a c if x != y
y b d d = nilai terbesar antara b dan c
Apabila string x dan y tidak cocok, maka program akan membandingkan nilai b dan c, apabila nilai berbobot sama, maka program akan langsung memasukkan nilai tersebut.
4) Hasil perbandingan dapat dilihat pada tabel 3.4.
Tabel 3.4. Tabel Hasil Perbandingan LCS
B D C A B A
0 0 0 0 0 0 0
A 0 0 0 0 1 1 1
B 0 1 1 1 1 2 2
C 0 1 1 2 2 2 2
B 0 1 1 2 2 3 3
D 0 1 2 2 2 3 3
A 0 1 2 2 3 3 4
5) Nilai terbesar pada tabel hasil perbandingan dapat melambangkan panjang LCS yang didapat, dalam hal ini adalah 4 karakter. Untuk mendapatkan 4 karakter tersebut, program akan melakukan backtrack.
6) Pada saat melakukan proses backtrack, program akan memulai dengan meletakkan pointer pada kotak sudut kanan bawah. Proses backtrack akan berhenti apabila pointer mencapat nilai 0. Pointer akan melakukan proses backtrack dengan langkah atas lalu ke kiri secara konsisten. Apabila pointer melewati nilai yang berbeda, misalnya dari kotak dengan nilai 4 menuju kotak dengan nilai 3, program akan menyimpan string yang membentuk angka tersebut, lalu menuju ke kotak dengan arah diagonal. Pseudocode pada proses ini meliputi:
Initialize a two-dimension-array i*j Currently i equal to 8 and j equal to 7 While i and j not equal to 0
If Array[i][j] equal to Array[i-1][j-1]+1 lcs equal to char from Array[i][j] + lcs Array[i][j] go diagonal
If Array[i-1][j] more than or equal to Array[i][j-1]{
go up
If Array[i][j] equal to Array[i][j-1]{ go left
Return lcs
3.4 Perhitungan Rata-Rata Persentase untuk Mendapatkan Tipe File
Pada tahap ini, program akan menghitung rata-rata persentase setiap tipe file. Output yang dihasilkan pada aplikasi algoritma LCS adalah persentase kemiripan file fragment dengan LCS file pdf, rtf, dan doc serta persentase kemiripan trailer file fragment dengan trailer pdf, rtf, dan doc. Pseudocode pada tahap ini meliputi :
3.5 Validasi
Pada tahap ini, program akan melakukan validasi terhadap file yang telah diidentifikasi. Program akan membuat sebuah file teks kosong, kemudian menambahkan header file sesuai hasil identifikasi. Setelah itu, program akan membaca hex number dari file fragment kemudian dan menambahkan hex number dari file fragment ke file yang sudah ditambahkan header file. Ekstensi file juga akan diubah sesuai hasil identifikasi. Pseudocode pada proses ini meliputi:
Create new text file
Read identification result If result == pdf
read pdf header hex bytes
add pdf hex bytes to new text file read file fragment hex bytes
add hex bytes to new text file with pdf header change text file extension to .pdf
else if result == rtf
read rtf header hex bytes
add rtf hex bytes to new text file read file fragment hex bytes
add hex bytes to new text file with rtf header change text file extension to .rtf
else if result == doc
read doc header hex bytes
add doc hex bytes to new text file read file fragment hex bytes
add hex bytes to new text file with doc header change text file extension to .doc
else
3.6 Dataset
Data yang digunakan untuk dilakukan fase training dan fase testing merupakan file-file dokumen pemerintahan yang dikumpulkan secara acak dari http://digitalcorpora.org/corpora/files. Data tersebut dibagi menjadi 2 bagian yaitu :
1. Data training
Data training merupakan data yang dipakai untuk mendapatkan Longest Common Subsequences yang akan dipergunakan untuk dijadikan acuan perbandingan dengan data testing.
2. Data testing
Data testing merupakan data yang dipakai untuk mendapatkan hasil akhir berupa tipe file. Data testing ini berupa file fragment yang di-generate dari file utuh.
Adapun jenis-jenis file yang digunakan dalam penelitian ini adalah file aplikasi Adobe Portable Document Format (pdf), Rich Text Format (rtf), serta Microsoft Office Word (doc). Total keseluruhan file yang dikumpulkan berjumlah 615
file. 300 file berupa file untuk fase training, 75 file utuh dan 240 file fragment yang
Tabel 3.5. Spesifikasi File-File Data Penelitian untuk Fase Training
Jenis file Banyak file Ukuran file
minimum (byte)
Ukuran file
maksimum (byte)
Pdf 100 150,735 594,339
Rtf 100 6,876 48,258,055
Doc 100 762,880 1,502,208
Pada tabel 3.5, dapat dilihat bahwa untuk masing-masing jenis file untuk fase training dipakai file sebanyak 100 file. Ukuran file pdf yang dipakai berkisar antara
150,735 byte sampai 594,339 byte. Untuk rtf, ukuran file yang dipakai berkisar antara 6,876 byte sampai 48,258,055 byte. Sedangkan file doc, ukuran file yang dipakai berkisar antara 762,880 sampa 1,502,208. Kemudian, spesifikasi file-file untuk fase testing dapat dilihat pada tabel 3.6.
Tabel 3.6. Spesifikasi File-File Data Penelitian untuk Fase Testing
Jenis file Banyak file Ukuran file
minimum (byte)
Ukuran file
maksimum (byte)
Pdf 25 75,509 178,805
Rtf 25 255,469 437,361
Doc 25 93,696 109,568
Pdf fragment 80 167,770 204,648
Rtf fragment 80 252,133 575,967
Doc fragment 80 107,520 167,936
sebanyak 75 file. Ukuran file utuh pdf yang digunakan antara 75,509 byte sampai 178,805 byte. Ukuran file utuh rtf yang digunakan antara 255,469 byte sampai 437,361 byte. Ukuran file utuh doc yang digunakan antara 93,696 byte sampai 109,568 byte. Selanjutnya, file fragment yang digunakan sebanyak 240 file. Ukuran file fragment pdf yang digunakan antara 167,770 byte sampai 204,648 byte. Ukuran file fragment rtf yang digunakan antara 252,133 byte sampai 575,967 byte. Ukuran file
fragment doc yang digunakan antara 107,520 byte sampai 167,936 byte.
File-file yang sudah dikumpulkan terbagi menjadi dua dataset, yaitu: training
dataset atau data pelatihan, dan testing dataset atau dataset pengujian yang berupa file-file fragment. Sebelum dilakukan pengujian untuk mengidentifikasi file fragment,
program akan terlebih dahulu diuji untuk mengidentifikasi file utuh dari masing-masing tipe data.
3.7. Proses Pengecekan Akurasi
Akurasi identifikasi tipe file dari file fragment akan dilakukan dengan cara sebagai berikut:
1. Pengelompokan file fragment pdf, gif, dan doc ke dalam folder yang terpisah. 2. Program melakukan identifikasi LCS dengan menghitung tingkat persentase
kemiripan LCS pada folder file fragment pdf, serta menghitung tingkat persentase kemiripan LCS pada signature trailer dan menghitung akurasi program mengidentifikasi file-file di dalam folder tersebut sebagai pdf, rtf, dan doc.
BAB 4
IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini membahas hasil penelitian yang dilakukan dari identifikasi tipe file dari file fragment dengan metode Longest Common Subsequences (LCS) sesuai dengan spesifikasi penerapan yang telah dibahas pada Bab 3. Bab ini akan menjabarkan hasil dari akurasi metode LCS dalam mengidentifikasi tipe file serta hasil validasi dari file tersebut.
4.1. Hasil Training
Pada bagian ini akan dijabarkan hasil training yang dilakukan. Training dilakukan dengan menggunakan tiga tipe data, yaitu jpg, rtf, dan doc dengan jumlah 100 file per tipe data. Prosedur training LCS yang dilakukan adalah dengan memasukkan seluruh file training dengan tipe data yang serupa ke dalam folder, kemudian program akan
4.3 secara berturut-turut. Sedangkan rincian hasil training dapat dilihat pada lampiran B.
Gambar 4.1. Hasil training LCS PDF
Hasil training LCS pdf pada gambar 4.1 di atas menghasilkan LCS sepanjang 25 karakter.
Gambar 4.2. Hasil training LCS RTF
Hasil training LCS rtf pada gambar 4.2 menghasilkan LCS sepanjang 116 karakter.
Gambar 4.3. Hasil training LCS DOC
4.2. Hasil Testing
Pada bagian ini, akan dilakukan pengujian untuk menghitung kemiripan antara hasil LCS fase training dengan file fragment. Pengujian dilakukan dengan cara membandingkan file yang diinput dengan LCS yang dihasilkan pada fase training dengan menggunakan metode Longest Common Subsequences. Hasil pengujian dapat dilihat pada tabel 4.1.
Tabel 4.1. Tabel Perbandingan LCS File Utuh dengan File Fragment
Tipe
Data
Fragmented Banyak File Persentase Kemiripan
Persentase
Terendah
Persentase
Tertinggi
Pdf 1-10% 20 23% 65%
11-30% 20 23% 23%
31-50% 20 61.5% 61.5%
>50% 20 65% 65%
Rtf 1-10% 20 11% 98%
11-30% 20 15% 15%
31-50% 20 15% 16%
>50% 20 16% 16%
Doc 1-10% 20 84% 84%
11-30% 20 69% 84%
31-50% 20 15% 15%
Hasil pengujian menunjukkan persentase kemiripan LCS fase training dengan file fragment. Hasil yang ditunjukkan hanya hasil dengan tingkat kemiripan tertinggi
dan terendah dari keseluruhan pengujian yang dibagi berdasarkan tipe file untuk menentukan apakah tipe file dapat dideteksi hanya dengan menguji kemiripan antara LCS fase training dengan file fragment. Persentase kemiripan yang rendah menunjukkan bahwa sequence yang merupakan bagian dari LCS fase training sebagian besar terdapat pada header file. Oleh karena itu, file fragment akan sulit dideteksi apabila hanya dilakukan satu kali pengujian LCS.
Selanjutnya, pengujian LCS dilakukan hanya pada bagian trailer file fragment. Apabila keseluruhan file fragment tidak tertimpa, kemungkinan besar hex number pada bagian trailer file fragment juga tidak ikut tertimpa. Pada pengujian ini, akan dilakukan identifikasi kemiripan trailer file fragment terhadap signature trailer file yang hendak kita tentukan tipe datanya, yakni : .pdf, .rtf, dan .doc. Hasil pengujian dapat dilihat pada tabel 4.2.
Tabel 4.2. Tabel Perbandingan LCS Trailer File Utuh dengan File Fragment
Tipe Data Fragmented Banyak
File
Persentase Kemiripan
Persentase
Terendah
Persentase
Tertinggi
PDF 1-10% 20 57% 100%
11-30% 20 71% 100%
31-50% 20 57% 100%
>50% 20 57% 100%
RTF 1-10% 20 85% 100%
Tabel 4.2. Tabel Perbandingan LCS TrailerFile Utuh dengan File Fragment
(lanjutan)
Tipe Data Fragmented Banyak
File
Persentase Kemiripan
Persentase
Terendah
Persentase
Tertinggi
RTF 31-50% 20 85% 100%
>50% 20 0% 100%
DOC 1-10% 20 85% 90%
11-30% 20 85% 90%
31-50% 20 85% 90%
>50% 20 85% 90%
Hasil pengujian pada tabel 4.2 menunjukkan bahwa persentase kemiripan antara trailer file dengan trailer file fragment mencapai persentase yang tinggi. Maka dari itu, pointer pertama dalam mengidentifikasi tipe file dari file fragment adalah dengan mengidentifikasi kemiripan trailer dari file fragment.
Program pertama kali akan memeriksa kemiripan yang terdapat pada trailer file, apabila persentase kemiripan mencapai 70%, maka program akan melanjutkan
pengecekan keseluruhan hex number dan dihitung persentase kemiripannya, angka 70% diambil dari nilai rata-rata dari persentase terendah pada tabel 4.2, apabila persentase kemiripan trailer file tidak mencapat 70%, maka program akan mengidentifikasi file tersebut bukan sebagai file dengan tipe data pdf, rtf, maupun doc. Selanjutnya, persentase kemiripan LCS trailer file dengan LCS keseluruhan hex number akan dijumlahkan dan dibagi dua, apabila hasil akhir mencapai 50% yang didapat dari hasil rata-rata persentase terendah pada tabel 4.1 dan tabel 4.2, maka program dapat mengidentifikasi tipe data dari file tersebut.
Sebelum pengujian dilakukan terhadap file fragment, pengujian akan terlebih dahulu dilakukan terhadap file utuh untuk melihat kemampuan program dalam mengidentifikasi tipe data. Akurasi hasil pengujian dengan data uji file utuh dapat dilihat pada tabel 4.3.
Tabel 4.3. Tabel Akurasi Hasil Pengujian dengan Data Uji File Utuh
Tipe File Banyak File Akurasi
PDF 25 96%
RTF 25 100%
DOC 25 96%
dengan identifikasi file fragment. Hasil akhir daripada proses pengujian dapat dilihat pada tabel 4.4.
Tabel 4.4. Akurasi Hasil Pengujian dengan Data Uji FileFragment
Tipe data Fragmented Banyak File Akurasi
Pdf 1-10% 20 75%
11-30% 20 70%
31-50% 20 95%
>50% 20 95%
Rtf 1-10% 20 100%
11-30% 20 100%
31-50% 20 100%
>50% 20 100%
Doc 1-10% 20 95%
11-30% 20 100%
31-50% 20 85%
>50% 20 100%
Rata-rata pengujian dengan data uji file fragment 92.91%
yang mirip, misalnya file .doc memiliki struktur file yang serupa dengan file dengan ekstensi .ppt atau .xlc.
Hasil identifikasi menunjukkan pada file pdf dengan fragmentasi sebanyak 0-10%, terdapat 5 file yang tidak dapat teridentifikasi serta 15 file lainnya berhasil diidentifikasi sebagai pdf. Pada fragmentasi sebanyak 11-30%, terdapat 6 file yang tidak teridentifikasi serta 14 file yang berhasil diidentifikasi sebagai pdf. Program juga dapat mengidentifikasi sebanyak 19 file dan 1 file tidak dapat teridentifikasi pada masing-masing persentase fragmentasi sebesar 31-50%. Hasil serupa juga didapati pada fragmentasi di atas 50%, yakni dengan 19 file berhasil diidentifikasi dan 1 file tidak berhasil diidentifikasi. Grafik hasil identifikasi dapat dilihat pada gambar 4.4.
Gambar 4.4. Grafik Hasil Identifikasi dengan Tipe File Fragment PDF Sedangkan pada gambar 4.5, dapat dilihat bahwa program dapat mengidentifikasi seluruh file fragment dengan tipe data rtf. Hasil identifikasi dari tipe file rtf dengan fragmentasi sebesar 0-10%, 11-30%, 31-50%, dan >50% mencapai persentase 100% dari 80 file fragment.
Gambar 4.5. Grafik Hasil Identifikasi dengan Tipe File Fragment RTF
Pada gambar 4.6, grafik identifikasi file fragment doc menunjukkan bahwa pada tingkat fragmentasi dengan persentase 0-10%, program berhasil mengidentifikasi 19 file dan 1 file tidak dapat teridentifikasi, sedangkan pada tingkat fragmentasi dengan persentase 31-50%, terdapat 17 file yang berhasil diidentifikasi dan 3 file tidak dapat teridentifikasi. Akan tetapi, pada persentase 11-30% dan di atas 50%, program berhasil mengidentifikasi seluruh file dengan benar.
Akurasi hasil pengujian menunjukkan bahwa metode LCS mampu mengatasi permasalahan identifikasi tipe data pada file fragment yang bertipe data pdf, rtf, dan doc dengan tingkat akurasi mencapai 92.91% dari 240 file fragment.
Selanjutnya untuk mengetahui apakah program dapat mengidentifikasi tipe file lain sebagai file yang tidak dapat diidentifikasi, akan dilakukan pengujian dengan tipe file lain, dalam hal ini penulis memakai tipe file dengan ekstensi .html. Pengujian akan
dilakukan dengan menggunakan 25 file .html dan akan dibandingkan dengan LCS file .pdf, .rtf, dan .doc. Spesifikasi file .html yang diidentifikasi dapat dilihat pada tabel 4.5.
Tabel 4.5. Tabel Spesifikasi File HTML
Banyak File Ukuran File Minimum
(byte)
Ukuran File Maksimum
(byte)
25 44,214 53,481
Hasil identifikasi hex number file .html terhadap LCS .pdf, .rtf, dan .doc dapat dilihat pada tabel 4.6.
Tabel 4.6. Hasil Identifikasi File HTML
File HTML Teridentifikasi sebagai
PDF RTF DOC Unidentified
25 file 22 file 0 file 0 file 3 file
hasil tersebut diperoleh dikarenakan metode yang dipakai untuk mengidentifikasi file fragment tidak dapat digunakan untuk mengidentifikasi file yang tidak dilatih.
Untuk menentukan apakah metode yang digunakan memang tidak dapat mengidentifikasi file yang tidak dilatih, maka file html akan dilatih dan dilakukan testing. Hasil identifikasi setelah file html dilatih dapat dilihat pada tabel 4.7.
Tabel 4.7. Tabel Hasil Identifikasi HTML Setelah Training
File HTML Akurasi Persentase
Kemiripan Tertinggi
Persentase
Kemiripan Terendah
25 file 100% 97,7% 97,7%
Hasil identifikasi menunjukkan bahwa program dapat mengenali tipe file yang sudah dilatih. Program dapat mengenal tipe file HTML dengan persentase kemiripan semuanya bernilai 97.7% dari 25 file HTML.
4.3. Validasi
Pada tahap ini akan dilakukan penambahan header file pada file fragment dengan fragmentasi terendah, bila berhasil maka akan dilanjutkan ke file fragment dengan fragmentasi yang lebih tinggi. Kemudian file akan dibuka bila file tidak corrupt. Jumlah file yang tidak dapat terbuka dapat dilihat pada tabel 4.8.
Tabel 4.8. Tabel Hasil Validasi
Tipe File Fragmentasi Jumlah File Corrupt Dapat dibuka
PDF 0-10% 20 20 0
RTF 0-10% 20 20 0
DOC 0-10% 20 20 0
BAB 5
KESIMPULAN DAN SARAN
Bab ini membahas tentang kesimpulan dari metode yang diajukan untuk mengidentifikasi file fragment pada bagian 5.1, serta pembahasan saran-saran untuk pengembangan penelitian selanjutnya pada bagian 5.2.
5.1. Kesimpulan
Berdasarkan penerapan metode Longest Common Subsequences untuk mengidentifikasi file fragment, didapat beberapa kesimpulan, yaitu:
1. Penerapan metode yang diajukan menghasilkan tingkat akurasi sebesar 83.75% untuk file fragment dengan tipe data .pdf; 100% untuk file fragment dengan tipe data .rtf; 95% untuk file fragment dengan tipe data .doc; dan rata-rata keseluruhan akurasi hasil pengujian sebesar 92.91%. Sehingga dapat disimpulkan bahwa metode Longest Common Subsequences yang diajukan mampu mengidentifikasi file fragment dengan tipe data .pdf, .rtf., dan .doc.
2. Metode Longest Common Subsequences mampu mengidentifikasi file fragment dengan hex number yang tidak tertimpa seluruhnya, dikarenakan metode LCS membutuhkan setidaknya sebagian kecil hex number yang terletak pada trailer file untuk melakukan identifikasi. Tingkat keberhasilan juga dipengaruhi oleh tipe data yang menimpa file yang hendak diidentifikasi.