BAB 2
LANDASAN TEORI
Bab ini membahas tentang teori penunjang serta penelitian sebelumnya yang berhubungan dengan permasalahan identifikasi jenis file, serta metode Distributed Autonomous Neuro-Gen Learning Engine.
2.1. Forensik Digital
Forensik adalah pengaplikasian ilmu pengetahuan dalam menentukan kriminal sesuai hukum oleh pihak berwenang pada sistem pengadilan (Saferstein, 1998). Salah satu cabang dari forensik adalah forensik digital, dimana forensik digital memiliki ruang lingkup pengolahan, pemulihan serta investigasi pada materi yang ditemukan pada perangkat digital terutama pada tindak kejahatan yang berkaitan dengan komputer (Reith, et al. 2010). Secara umum proses forensik pada forensik digital terdiri atas pengambil alihan perangkat, akusisi data, analisis data dan penyusunan laporan sebagai bukti kolektif (Adams, 2012). Berdasarkan perangkat digital yang terkait, secara teknis forensik digital dibagi atas beberapa cabang, yakni: forensik komputer, forensik jaringan, forensik analisis data dan forensik perangkat mobile.
2.2. Dokumen
Dokumen adalah representasi pengetahuan yang digambarkan atau dituliskan pada secarik kertas (Buckland, 1998). Dokumen berasal dari kata Documentum pada bahasa Latin yang memiliki arti pelajaran. Dokumen pada masa lalu merujuk pada tulisan yang digunakan sebagai bukti pada pengadilan. Pada jaman sekarang, dokumen merujuk pada file yang berisi text, berikut dengan struktur serta desain dan gambar tambahan.
2.3. File
File komputer atau file adalah kumpulan data atau informasi berupa huruf, angka maupun karakter khusus yang ditandai dengan sebuah nama file. Seluruh data dan informasi yang ada dalam sebuah komputer tersimpan dalam bentuk file. Berdasarkan isi informasi yang disimpan, file dibagi atas beberapa jenis file seperti: text file yang
menyimpan informasi berupa text (tulisan), file citra yang menyimpan informasi
berupa gambar, dan file program yang menyimpan program. File komputer dapat dianggap bagaikan dokumen kertas yang digunakan serta disimpan pada kantor.
Sebuah file secara umum terdiri atas tiga bagian, yakni: file header (head), file body, file trailer (tail). File header adalah sebuah “signature” yang diposisikan pada awal sebuah file sehingga, sistem operasi serta perangkat lunak lainnya mengetahui apa yang menjadi isi atau konten dari file. File body adalah konten dari file yang merupakan informasi atau data yang disimpan oleh file. File trailer adalah bagian penutup dari sebuah file yang menandai akhir dari sebuah file. Tergantung pada jenis datanya, metadata atau informasi mengenai struktur serta penjelasan dari data biasanya terdapat pada file header, tetapi bisa juga ditemukan pada file trailer.
2.3.1 Identifikasi format file
sebuah file diatur dan disusun. File dengan jenis yang berbeda akan mempunyai format file yang berbeda. Identifikasi jenis file adalah proses mengetahui format file dari sebuah file tertentu, sehingga dapat diketahui jenis, tujuan serta kegunaan dari file tersebut. Identifikasi format file dilakukan oleh sistem operasi berdasarkan ekstensi dari file ataupun berdasarkan metadata yang tersimpan pada file.
Beberapa teknik yang digunakan untuk melakukan identifikasi jenis file (Hickok, et al. 2005):
1. Identifikasi jenis file berdasarkan ekstensi nama file
Identifikasi file berdasarkan ekstensi nama file adalah metode identifikasi file yang paling sederhana dan naif. Ekstensi nama file adalah kumpulan karakter setelah tanda „.‟ (titik) terakhir pada nama file. Identifikasi jenis file melalui ekstensi nama file dilakukan hanya dengan melihat ekstensi dari nama file yang ada. Sebagai contoh, sebuah file dengan nama file “x.doc” akan memiliki ekstensi doc dan segera dikenali sebagai sebuah file dokumen dengan melihat ekstensi nama file doc. Karena identifikasi file hanya dilakukan melihat dari ekstensi nama
file, identifikasi jenis file dapat dilakukan tanpa membaca file, sehingga identifikasi dengan metode ini dapat dilakukan dengan sangat cepat. Metode ini merupakan metode yang populer digunakan oleh file browser pada sistem operasi
seperti Windows, Mac OS X, serta Linux dalam melakukan identifikasi dari file. 2. Identifikasi jenis file berdasarkan Magic Bytes
Magic bytes atau dikenal juga dengan sebutan magic number adalah kumpulan
byte-byte pada sebuah file yang dapat digunakan sebagai pembeda antar jenis file yang berbeda. Magic bytes biasa terletak pada bagian file header pada sebuah file,
tetapi bisa juga terletak pada bagian file lain seperti file trailer. Selain sebagai
pembeda antar jenis file, magic bytes juga dapat memberikan infromasi tambahan mengenai versi aplikasi yang digunakan untuk membuat file sehingga magic bytes
juga dapat digunakan untuk membedakan file yang dibuat dengan aplikasi yang sama tetapi dengan versi yang berbeda. Identifikasi jenis file dengan metode ini diimplementasikan oleh perintah file() pada sistem operasi berbasis UNIX untuk
Identifikasi jenis file berdasarkan magic bytes sedikit lebih lambat
dibandingkan melakukan identifikasi berdasarkan ekstensi nama file, karena sebuah file harus dibuka terlebih dahulu dan beberapa byte awal dari file tersebut. Beberapa byte awal yang dibaca kemudian dibandingkan dengan magic bytes dari jenis-jenis file yang diketahui sehingga didapatkan hasil identifikasi jenis file. Tabel 2.1. menunjukkan magic bytes untuk beberapa jenis file dokumen.
Penggunaan magic bytes dalam identifikasi jenis file memiliki beberapa kelemahan (Hickok, et al. 2005), yakni: identifikasi jenis file berdasarkan magic bytes hanya berlaku untuk file yang memiliki magic bytes, contoh file yang tidak
memiliki magic bytes adalah file dengan ekstensi txt (file text) dan html (file hypertext markup language); tidak adanya standard, bahkan untuk jenis file yang
sama, dalam pembuatan jenis file tertentu, sebagai contoh sebuah file citra dengan ekstensi jpg bisa memiliki magic bytes FF D8 FF FE 00 ataupun FF D8 FF E0 00,
dan keduanya merupakan file citra jpg yang valid; dan adanya kemungkinan kesalahan identifikasi secara kebetulan, sebagai contoh, sebuah file pdf, seperti yang dapat dilihat pada Tabel 2.1. memiliki magic bytes 25 50 44 46 atau
ASCII %PDF, apabila dilakukan identifikasi jenis file berdasarkan magic bytes
terhadap sebuah file txt yang kebetulan dimulai dengan tulisan %PDF, maka file txt tersebut akan dikenali sebagai sebuah file pdf.
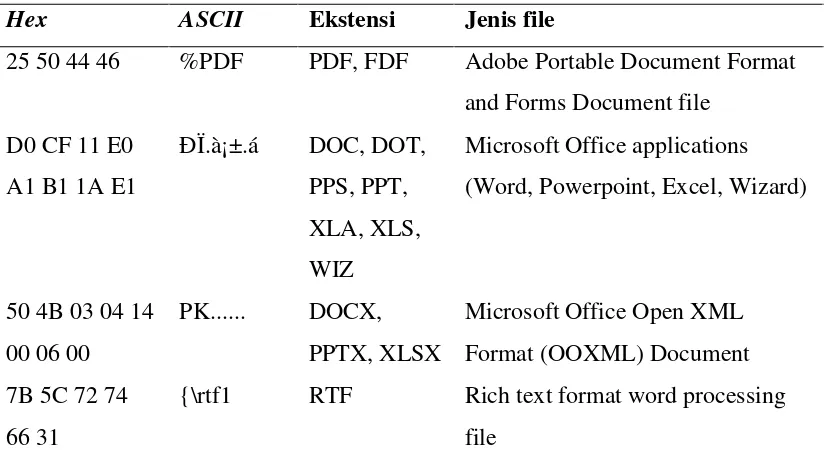
Table 2.1. Daftar magic bytes untuk beberapa jenis file dokumen
Hex ASCII Ekstensi Jenis file
25 50 44 46 %PDF PDF, FDF Adobe Portable Document Format and Forms Document file
D0 CF 11 E0 A1 B1 1A E1
ÐÏ.ࡱ.á DOC, DOT, PPS, PPT, XLA, XLS, WIZ
Microsoft Office applications (Word, Powerpoint, Excel, Wizard)
50 4B 03 04 14 00 06 00
PK... DOCX, PPTX, XLSX
Microsoft Office Open XML Format (OOXML) Document 7B 5C 72 74
66 31
3. Identifikasi jenis file berdasarkan distribusi karakter.
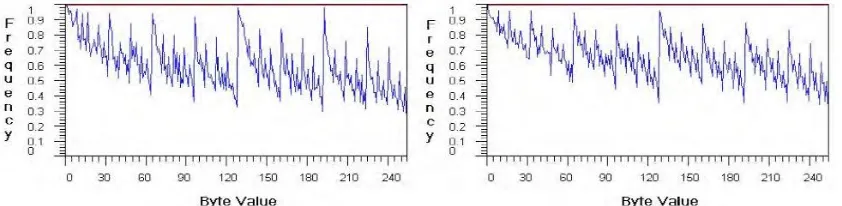
Metode terakhir yang dapat digunakan dalam identifikasi jenis file adalah berdasarkan distribusi karakter yang terdapat pada sebuah file. Konten atau isi dari sebuah file adalah urutan byte-byte, dimana satu byte terdiri atas delapan bit, sehingga satu byte akan memiliki kemungkinan nilai sebanyak 28 atau 256, yakni 0 sampai dengan 255. Pada metode ini dihitung frekuensi kemunculan dari setiap kemungkinan 256 nilai dari sebuah file dan kumpulan frekuensi dari setiap byte disebut dengan byte frequency distribution (BFD) atau distribusi frekuensi byte.
Identifikasi file berdasarkan distribusi karakter dikenal juga dengan nama metode histogram, dimana BFD merupakan histogram byte dari sebuah file. Sebuah BFD merupakan sebuah tabel dengan 256 nilai dimana setiap nilai merupakan frekuensi kemunculan dari nilai yang direpresentasikan oleh sebuah file (Sencar, et al. 2012).
Gambar 2.1. Distribusi Frekuensi untuk dua file rtf yang berbeda (McDaniel, 2001)
Gambar 2.2. Distribusi Frekuensi untuk dua file gif yang berbeda (McDaniel, 2001)
Beberapa kelemahan dari identifikasi jenis file berdasarkan distribusi karakter adalah adanya beberapa jenis file yang tidak mempunyai distribusi karakter yang spesifik, kemungkinan terjadinya kesalahan identifikasi disebabkan konten file yang unik ataupun tidak normal, serta kecepatan identifikasi yang lebih lambat dibandingkan identifikasi jenis file berdasarkan ekstensi nama file dan magic bytes. Identifikasi file berdasarkan distribusi karakter memiliki akurasi
yang cukup rendah, yakni 27,5% (McDaniel, 2001). Pada penelitian lain, (Amirani, et al. 2008) menggunakan BFD sebagai fitur dari sebuah file dan melakukan ekstraksi fitur menggunakan Principal Component Analysis (PCA)
dan melakukan klasifikasi jenis file menggunakan Multi-Layer Perceptron. BFD
juga digunakan bersamaan dengan Neural Network atau jaringan saraf tiruan
2.3.2. File Forgery
Dalam menyembunyikan file-file dokumen yang dapat menjadi bukti tindak kejahatan, pelaku tindak kejahatan sering kali menggunakan teknik-teknik anti-forensik, yakni sekumpulan teknik pemalsuan serta penghancuran yang digunakan untuk memanipulasi proses forensik (Harris, 2007). Salah satu teknik anti-forensik yang paling sering digunakan adalah file forgery atau pemalsuan file. Pemalsuan file adalah teknik pemalsuan suatu file sehingga jenis file sebenarnya serta kegunaan dari file tersebut tidak lagi dapat dikenali dengan mudah.
Pemalsuan file dapat dilakukan dengan cara: 1. Pengubahan ekstensi file
Pemalsuan file dapat dilakukan dengan sangat mudah dengan melakukan pengubahan ekstensi nama file yang terdapat pada nama file. Pengubahan ekstensi file dari nama file secara langsung akan mengakibatkan file browser
secara umum menjadi tidak dapat mengenali jenis file sebenarnya dari file yang telah diubah ekstensinya tersebut. Hal ini dikarenakan file browser pada sistem
operasi secara umum mengenali jenis dari sebuah file hanya dari ekstensi file yang terdapat pada nama file. Sebagai contoh: seorang pelaku tindak kejahatan dapat memalsukan sebuah file dokumen Microsoft Word dengan ekstensi doc
dengan cara mengubah ekstensi nama file dari file tersebut menjadi jpg. Hal ini akan mengakibatkan file browser mengenali file tersebut sebagai sebuah file citra
dengan ekstensi jpg, bukan lagi sebagai sebuah file dokumen.
2. Pengubahan Magic Bytes
Seperti yang telah dijelaskan pada bagian sebelumnya, magic bytes adalah
kumpulan beberapa byte pada awal sebuah file, dimana magic bytes untuk setiap jenis file adalah berbeda, sehingga magic bytes dapat digunakan sebagai salah satu indikasi yang menunjukkan jenis file sebenarnya dari sebuah file. Akan tetapi,
magic bytes dapat dengan mudah diedit menggunakan hex editor ataupun tools
lainnya. Mengubah magic bytes dari suatu file akan mengakibatkan algoritma
yang melakukan pengecekan magic bytes untuk menentukan jenis file, tidak dapat
file dokumen RTF (Rich Text Format) mempunyai magic bytes “7B 5C 72 74 66
31“, apabila magic bytes ini diubah menjadi “25 50 44 46” yang merupakan magic bytes dari file dokumen PDF, maka algoritma yang melakukan identifikasi jenis file berdasarkan magic bytes akan mengenali file RTF tersebut sebagai sebuah file PDF.
Pemalsuan file dapat dengan mudah dilakukan dengan mengubah indikator yang menunjukkan jenis file dari sebuah file, seperti ekstensi file dan magic bytes, Sehingga diperlukan suatu metode untuk melakukan identifikasi jenis file sebenarnya berdasarkan konten atau isi dari file.
2.4. Normalisasi
Pada bidang analisis data, penggunaan satuan ukuran dapat mempengaruhi hasil dari analisis yang didapatkan. Sebagai contoh, penggunaan ukuran meter pada pengukuran panjang akan memberikan hasil yang berbeda dengan pengukuran panjang menggunakan ukuran inci. Normalisasi data adalah metode statistika yang digunakan untuk mengatur nilai yang diukur pada suatu skala menjadi nilai pada skala berbeda yang lebih umum sehingga seluruh atribut dari data memiliki jangkauan nilai yang sama (Han, et al. 2011). Pada normalisasi, data ditransformasi sehingga memiliki jangkuan [-1,0, 1,0] ataupun [0,0, 1,0]. Normalisasi merupakan proses yang sangat penting terutama pada implementasi algoritma jaringan saraf tiruan, karena perbedaan bobot dapat mempengaruhi hasil yang didapatkan.
Berikut beberapa rumus yang dapat digunakan dalam normalisasi data (Han, et al. 2011):
1. Min-max Normalization
Normalisasi min-max melakukan transformasi linear terhadap data asli, dengan
menggunakan persamaan berikut:
A A
AA A
A i
i new new new
v
v _max _min _min
min max
min
'
dimana v‟i merupakan nilai hasil normalisasi dengan jangkauan [new_minA,
new_maxA]; vi merupakan nilai sebelum normalisasi; minA adalah nilai minimum
dari data asli; maxA adalah nilai maksimum dari data asli; new_minA adalah nilai
minimum baru untuk data hasil normalisasi; new_maxA adalah nilai maksimum
baru untuk data hasil normalisasi. Normalisasi ini tetap menjaga keterhubungan antara nilai data yang sebenarnya.
2. Z-score Normalization
Normalisasi z-score atau disebut juga normalisasi zero-mean, dimana nilai dari data dinormalisasi berdasarkan nilai mean dan nilai standard deviasi degan rumus:
A i i
A v v
' (2.2)
dimana v‟i merupakan nilai hasil normalisasi; vi merupakan nilai sebelum
normalisasi; Amerupakan nilai rata-rata dari data asli; A merupakan nilai akar
dari varian atau standard deviasi dari data sebenarnya.
3. Decimal Scaling
Normalisasi decimal scaling dilakukan dengan menggeser nilai titik decimal dari
seluruh nilai data. Banyak penggeseran titik desimal bergantung pada nilai maksimum dari data sebenarnya. Berikut rumus yang digunakan pada decimal scaling:
j i i
v v
10
' (2.3)
dimana v‟i merupakan nilai hasil normalisasi; vi merupakan nilai sebelum
2.5. Companding Function
Companding merupakan sebuah metode kuantisasi pada bidang telekomunikasi dalam
pengiriman signal (Bosi, et al. 2003). Companding function atau disebut juga fungsi
kompresi dan ekspansi, dimana kata companding merupakan gabungan dari dua kata compressing dan expanding. Fungsi kompresi dan ekspansi digunakan untuk memetakan sebuah input x pada nilai y dengan persamaan y = c(x), dimana nilai y akan memiliki nilai yang lebih tinggi dibandingkan x dan c adalah companding function (Bosi, et al. 2003). Fungsi kompresi dan ekspansi biasanya bersifat non-simetris diantara garis x=0, sehingga nilai negatif tetap dimetakan pada nilai negatif. Fungsi ini akan memetakan nilai dengan jangkauan [0,0, 1,0] tetap pada jangkauan [0,0, 1,0], tetapi dengan nilai varian lebih tinggi. Terdapat dua aturan companding
yang digunakan secara luas, yakni: A-Law Companding yang digunakan di Eropa dan µ-Law Companding yang digunakan di Amerika Utara (Manassah, 2012).
Kedua fungsi kompresi dan ekspansi A-Law Companding dan µ-Law Companding dapat direpresentasikan dengan persamaan berikut:
1
x
y (2.4)
dimana y adalah nilai setelah kompresi dan ekspansi; x adalah nilai sebelum kompresi dan ekspansi; β merupakan sebuah konstanta dengan nilai 1.5, yang merupakan nilai paling optimum dalam fungsi kompresi dan ekspansi untuk identifikasi file (McDaniel, 2001).
2.6. Ekstraksi Fitur menggunakan Principal Component Analysis
redundan, sehingga diperlukan reduksi dimensionalitas dari input data untuk menghilangkan data yang redundan tersebut. Ekstraksi fitur dilakukan dengan melakukan transformasi data input menjadi kumpulan fitur yang disebut fitur hasil ekstraksi dengan tidak mengurangi informasi yang terkandung pada data input. Alasan lain melakukan ekstraksi fitur adalah untuk mengurangi memori serta kekuatan komputasi yang diperlukan dalam memproses data.
Salah satu teknik yang umum digunakan dalam ekstraksi fitur adalah Principal Components Analysis (PCA). PCA telah diimplementasikan dalam pengenalan wajah (Morizet, 2007) serta dalam peningkatan kemampuan model prediktif (Vivanco, 2008).
PCA adalah sebuah teknik statistika yang melakukan transformasi terhadap himpunan
asli sekumpulan variabel menjadi himpunan variabel yang lebih kecil dan tidak saling berkorelasi tetapi tetap mampu merepresentasikan informasi yang terdapat pada himpunan variabel asli (Dunteman, 1989). Himpunan variabel yang lebih kecil dan tidak saling berkorelasi ini disebut juga dengan principal components. Adapun tujuan
utama dari PCA adalah untuk mengurangi dimensionalitas dari data asli, sehingga data
akan lebih mudah dimengerti dan digunakan dalam analisis lebih jauh.
Metode PCA akan mencoba untuk mencari sebuah dataset yang mampu
mendeskripsikan dataset asli dengan tetap menjaga informasi yang tersimpan sebanyak mungkin (Amirani, et al. 2008). Misalkan X = {xnRd | n = 1, 2, ..., N}
merepresentasikan sebuah dataset dengan dimensi d, PCA akan menghasilkan sebuah
dataset Z, dimana Z = {znRk | n = 1, 2, ..., N} dengan dimensi k, dimana nilai k
adalah lebih kecil dari d. Langkah-langkah yang dilakukan dalam PCA terdiri atas
(Jolliffe, 2002):
1. Lakukan normalisasi Z-score pada setiap dimensi data yang ada menggunakan rumus 2.2. Tahap ini akan menghasilkan sebuah dataset dengan mean atau rata-rata bernilai nol.
2. Komputasikan nilai matriks kovarian menggunakan rumus:
X X m
T
1
dimana adalah matriks kovarian; m merupakan banyak data pada dataset; X adalah dataset asli yang disusun dalam bentuk matriks dengan setiap kolom merupakan fitur, dan setiap baris merupakan kumpulan fitur untuk satu objek; XT merupakan transpos dari matriks X. Apabila data asli memiliki dimensi d maka hasil dari matriks kovarian adalah sebuah matriks dengan ukuran dxd.
3. Kalkulasikan nilai dari eigenvalue serta eigenvector dari matriks kovarian, serta urutkan eigenvector sesuai dengan nilai eigenvalue yang dimiliki secara menurun (eigenvector dengan nilai eigenvalue yang lebih tinggi berada pada sisi kiri matriks). Eigenvalue dan eigenvector merupakan vector-vector yang
mengkarakterisasikan data.
4. Pilih komponen dari eigenvector dan membentuk sebuah vektor fitur U. Apabila
dimiliki data awal dengan dimensi d, maka akan didapatkan eigenvector sebanyak
d, sehingga apabila dari d eigenvector tersebut dipilih k eigenvector, maka akan
dihasilkan data hasil PCA dengan dimensi k. Pemilihan eigenvector dilakukan
berdasarkan nilai eigenvalue yang dimiliki oleh eigenvector. Apabila dipilih eigenvector dengan nilai eigenvalue rendah, maka informasi yang tersimpan pada
data asli akan berkurang pada data hasil PCA, karena eigenvector dengan eigenvalue rendah menunjukkan data yang direpresentasikan pada vektor tersebut
kurang signifikan, tetapi apabila dipilih eigenvector dengan nilai eigenvalue
tinggi, maka informasi data asli tetap akan terjaga pada data hasil PCA.
Penentuan nilai dimensi k untuk dataset hasil PCA biasanya ditentukan
dengan memperhitungkan nilai retain rate. Retain rate adalah persentase
informasi yang direpresentasikan oleh data asli dan tetap terjaga pada data hasil
PCA. Pemilihan nilai dimensi k pada umumnya dipilih dengan menjaga retain rate pada 0,99, atau dengan kata lain hampir seluruh informasi pada data asli tetap dapat direpresentasikan oleh data hasil PCA. Secara teknis hal ini dapat dilakukan dengan memilih nilai k terkecil yang memenuhi persamaan berikut:
dimana Si adalah eigenvalue pada posisi ke-i dengan eigenvector serta eigenvalue
telah diurutkan secara menurun. Seluruh nilai dari eigenvector yang dipilih
kemudian disusun menjadi sebuah matriks vektor fitur U, dimana setiap
eigenvector yang dipilih akan menjadi kolom dari matriks vektor fitur U. 5. Hitung nilai dari dataset final dengan menggunakan rumus
X U
Z T (2.7)
dimana Z merupakan dataset hasil PCA dalam bentuk matriks; U adalah matriks
vektor yang didapatkan pada tahap sebelumnya; X adalah matriks dataset asli.
2.7. Artificial Neural Network
Artificial Neural Network atau jaringan saraf tiruan dapat didefinisikan sebagai sebuah
model logika yang berdasarkan otak manusia. Sebuah jaringan saraf tiruan memodelkan otak dengan menggunakan sejumlah neuron yang sederhana dan saling terkoneksi dengan sebuah nilai bobot yang meneruskan signal dari satu neuron menuju neuron lainnya (Negnevitsky, 2005). Setiap neuron akan menerima sejumlah input melalui hubungannya, kemudian neuron tersebut akan menghasilkan satu output, sesuai dengan nilai bobot yang pada hubungan tersebut, kemudian diteruskan kembali ke neuron yang lain. Setiap neuron pada jaringan saraf tiruan akan tersusun dalam beberapa layer atau lapisan. Secara umum, sebuah jaringan saraf tiruan terdiri atas tiga
layer, yakni: input layer yang merupakan node-node yang menerima signal input,
middle layer atau sering disebut juga dengan hidden layer yang terdiri atas node yang
Gambar 2.3. Arsitektur umum sebuah jaringan saraf tiruan (Negnetvisky, 2005)
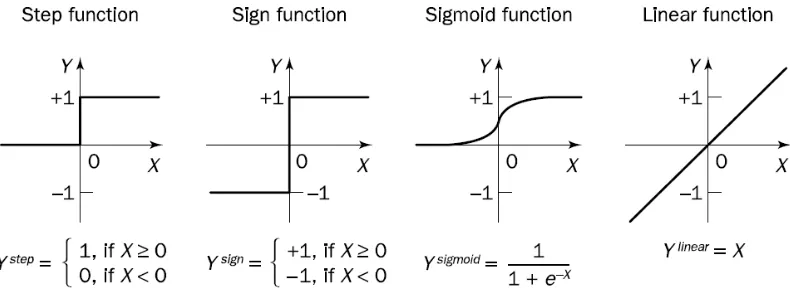
Penentuan output dari sebuah neuron ditentukan menggunakan sebuah fungsi yang disebut dengan fungsi aktivasi. Ada beberapa jenis fungsi aktivasi yang bisa digunakan dalam menentukan output dari sebuah neuron dengan empat fungsi aktivasi yang secara umum digunakan (Negnetvisky, 2005), yakni: step function, sign function, sigmoid function dan linear function. Masing-masing fungsi aktivasi beserta grafik
yang menggambarkan fungsi dapat dilihat pada gambar 2.4.
Gambar 2.4. Fungsi aktivasi dari sebuah neuron (Negnetvisky, 2005)
Step function dan sign function atau disebut juga fungsi pembatasan kasar,
dimana kedua fungsi ini secara umum digunakan pada permasalahan klasifikasi dan pengenalan pola. Sigmoid function mengubah input yang memiliki jangkauan nilai [-∞,
sama dengan input yang diterima oleh neuron dan fungsi ini biasanya digunakan pada pendekatan linear.
2.7.1. Kelemahan Artificial Neural Network
Adapun beberapa kelemahan dari jaringan saraf tiruan pada saat diterapkan pada proses evolusi yang kompleks (Kasabov, 2007):
1. Kesulitan dalam memilih arsitektur dari sistem, dimana jaringan saraf tiruan biasanya memiliki arsitektur yang tetap (jumlah neuron serta koneksi tetap). Hal ini mengakibatkan sistem akan susah beradaptasi terhadap data yang belum diketahui distribusinya, Selain itu, arsitektur yang tetap juga menyebabkan jaringan saraf tiruan untuk melakukan pembelajaran untuk waktu yang panjang. 2. Dalam mempelajari data yang baru, jaringan saraf tiruan akan melupakan
pengetahuan lama yang telah dipelajarinya. Fenomena ini dikenal dengan sebutan
catastrophic forgetting.
3. Pelatihan sebuah jaringan saraf tiruan akan memerlukan banyak iterasi serta propagasi data melalui struktur jaringan saraf tiruan, sehingga diperlukan waktu pelatihan yang lama dalam melatih sebuah jaringan saraf tiruan.
4. Kurangnya fasilitas representasi pengetahuan pada jaringan saraf tiruan, dimana jaringan saraf tiruan mampu menagkap parameter statistik, tetapi tidak dapat memfasilitasi ekstraksi aturan evolusi secara berarti. Permasalahan ini juga dikenal dengan sebutan black box problem.
2.7.2. Multilayer Perceptron
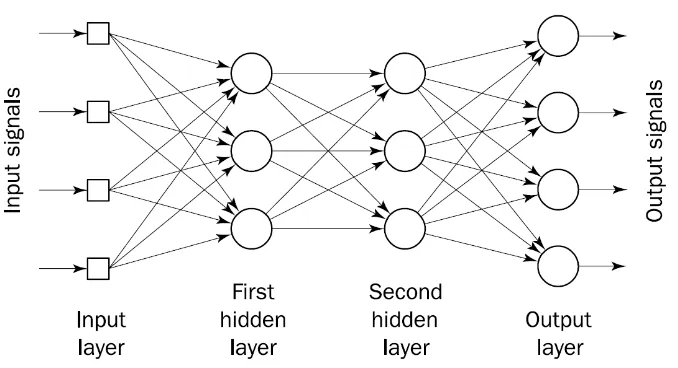
Multilayer perceptron adalah sebuah jaringan saraf tiruan dengan satu atau lebih
hidden layer. Multilayer perceptron terdri atas input layer, satu atau lebih hidden layer dan output layer. Gambar 2.5. menunjukkan arsitektur dari sebuah Multilayer perceptron dengan dua hidden layer. Untuk menentukan output pada sebuah Multilayer perceptron digunakan fungsi aktivasi sigmoid function sesuai dengan
Gambar 2.5. Arsitektur Multilayer perceptron dengan dua hidden layer
(Negnetvisky, 2005)
Salah satu algoritma yang digunakan dalam pelatihan multilayer perceptron
adalah back-propagation training algorithm atau algoritma pelatihan propagasi balik,
dimana tahapan yang dilakukan algorima ini dapat dilihat sebagai berikut (Negnetvisky, 2005):
1. Inisialisasi
Berikan nilai acak pada setiap bobot yang menghubungkan seluruh neuron yang ada dengan distribusi yang merata dan dengan jangkauan yang kecil (Haykin, 1999), sesuai rumus:
i
i F
F
4 , 2 , 4 , 2
(2.8)
dimana Fi adalah banyak input dari neuron i pada jaringan.
2. Aktivasi
Aktivasi dari jaringan saraf tiruan dilakukan dengan mengaplikasikan input x1(p),
x2(p), ..., xn(p) dan output yang diharapkan yd1(p), yd2(p), ..., ydn(p), dengan p
adalah jumlah perulangan yang sudah dilakukan dan p memiliki nilai awal 0. a. Kalkulasikan output sebenarnya dari setiap neuron pada hidden layer, dengan
b. Kalkulasikan output sebenarnya dari setiap neuron pada output layer dengan
rumus:
dimana m adalah banyak input dari neuron k pada output layer dan sigmoid
adalah fungsi aktivasi sigmoid. 3. Pelatihan bobot
Lakukan update atau pembaruan nilai dari setiap bobot pada jaringan saraf tiruan
dengan melakukan propagasi balik terhadap error pada output layer.
a. Hitung error pada setiap neuron pada output layer dengan rumus:
)
kemudian hitung perbaikan bobot menggunakan rumus:
)
dimana α adalah sebuah konstanta yang menentukan kecepatan pembelajaran dari algoritma propagasi balik dan disebut dengan learning rate; µ adalah
sebuah konstanta yang menentukan besar perubahan update dari bobot dan
disebut dengan momentum.
Lakukan update untuk setiap bobot yang terhubung dengan neuron pada output layer menggunakan rumus:
)
1 ( )
kemudian hitung perbaikan bobot menggunakan rumus:
)
dimana α adalah sebuah konstanta yang menentukan kecepatan pembelajaran dari algoritma propagasi balik dan disebut dengan learning rate; µ adalah sebuah konstanta yang menentukan besar perubahan update dari bobot dan disebut dengan momentum.
Lakukan update untuk setiap bobot yang terhubung dengan neuron pada output layer menggunakan rumus:
)
Apabila kriteria error belum terpenuhi, lakukan penambahan nilai perulangan p sebanyak satu, kemudian kembali ke langkah 2. Apabila kriteria error telah dipenuhi, maka algoritma pelatihan propagasi balik selesai.
2.8. Distributed Autonomous Neuro-Gen Learning Engine
Untuk mengatasi kelemahan dari jaringan saraf tiruan yang telah dijabarkan pada bagian 2.7.1, (Rahmat, 2008) mengajukan sebuah metode pembelajaran mesin yang baru yang disebut Distributed Autonomous Neuro-Gen Learning Engine (DANGLE). DANGLE adalah sebuah metode pembelajaran mesin yang menyediakan fleksibilitas,
adaptibilitas dan pembelajaran terus menerus serta kemampuan kompitasional yang kuat (Pasha, 2010). DANGLE telah digunakan sebagai gene knowledge discovery engine (Hasibuan, 2009) dan juga Lattice Analysis dalam identifikasi struktur kubik
pada bidang kristalografi (Pasha, 2010).
jaringan neural yang disebut dengan Distributed Adaptive Neural Network (DANN)
(Pasha, 2010). GRE memiliki tugas untuk melakukan regulasi, konstruksi, serta
melatih seluruh jaringan yang terdapat pada DANN. DANN terdiri atas beberapa jaringan saraf tiruan yang terhubung pada GRE secara distributif dan adaptif, dimana setiap jaringan saraf tiruan pada DANN akan memiliki gen masing-masing yang diatur oleh GRE. DANN akan mengkonstruksikan jaringan saraf tiruan sesuai dengan gen yang dimiliki, kemudian hasil output dari DANN akan dikembalikan pada GRE untuk pengembangan gen selanjutnya.
2.8.1. Gene Regulatory Engine
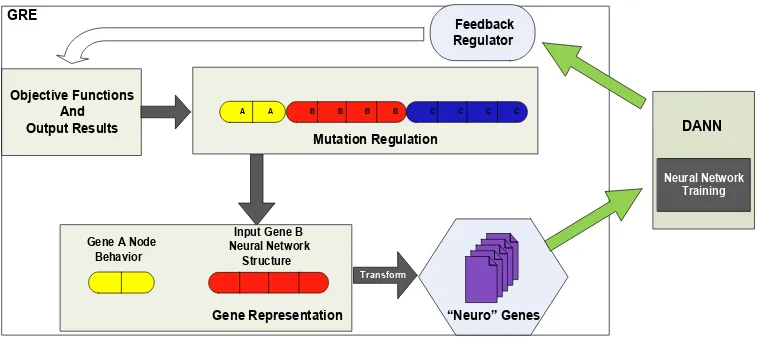
Gene Regulatory Engine (GRE) merupakan sebuah regulator gen sederhana yang
diinspirasi oleh interaksi gen satu ke satu dari Gene Regulatory Network pada bidang
biologi. GRE digunakan untuk mengendalikan, memutasi, serta melatih gen sebelum
gen dikirimkan pada DANN. Secara sederhana, GRE mengimplementasikan sebuah Genetic Algorithm (GA) tanpa proses crossover dan parent selection, serta inisialisasi
populasi secara acak juga tidak terjadi pada GRE. Arsitektur keseluruhan GRE dapat
dilihat pada gambar 2.6. Secara spesifik diagram lengkap dari model GRE dapat
Gambar 2.7. Diagram lengkap model GRE (Rahmat, 2008)
Adapun komponen-komponen dari GRE dapat dijabarkan sebagai berikut
(Rahmat, 2008): 1. Representasi Gen
Secara umum, GRE menggunakan 3 himpunan gene yang berbeda, yakni:
a. Node Behavior’s Gene
saraf tiruan lainnya, bergantung pada implementasi pada bagian DANN.
Variabel kedua menunjukkan identifikasi dari node (ID Node).
Jenis Jaringan Saraf Tiruan { BNN, MLP, SNN, etc. }
ID Node { 1,2,..,n} Gambar 2.8. Node Behavior’s Gene (Pasha, 2010)
b. Neural Network’s Gene
Himpunan gen ini mengandung variabel untuk setiap parameter jaringan saraf tiruan untuk setiap node yang ada pada DANN seperti yang dapat dilihat pada
gambar 2.9. Parameter-parameter jaringan saraf tiruan yang dimaksud terdiri atas: banyak neuron pada input layer, banyak neuron pada output layer,
banyak hidden layer, banyak neuron pada setiap hidden layer, banyak epoch
(jumlah perulangan yang dilakukan pada proses pelatihan), learning rate, dan
momentum rate.
Gambar 2.9. Neural Network’s Gene (Rahmat, 2008) 2. Fitness Function
Untuk melakukan verifikasi dan mengukur objektivitas dari DANN digunakan
root mean squared error (RMSE)atau error akar kuadrat dengan rumus:
NG fungsi kecocokan untuk DANN adalah sama dengan EAVGyang merupakan
rata-rata dari setiap fungsi objektif dari seluruh jaringan saraf tiruan dalam DANN
(Rahmat, 2008). 3. Regulator Mutasi
Komponen regulator mutasi merupakan komponen yang paling penting dalam
DANGLE yang memungkinkan setiap jaringan saraf tiruan dalam DANN menjadi
adaptif. Apabila terjadi mutasi pada sebuah gen, maka jaringan saraf tiruan yang terasosiasi pada gen tersebut harus dilatih ulang sehingga mampu beradaptasi terhadap struktur jaringan yang baru (Pasha, 2010). Lima entitas yang dimutasi oleh regulator mutasi adalah banyak hidden layer, banyak neuron pada setiap hidden layer, epoch, learning rate dan momentum rate. Aturan yang digunakan
dalam melakukan mutasi gen dapat dilihat pada pseudocode berikut:
if (generation = 1) then epoch += 2
else
calculate delta_O = delta_O[generation] – delta_O[generation-1] if (delta_O > 0.005) then
epoch += rand(3)
else if (0.002 < delta_O <= 0.005) then O_smaller_than_0_005++
end if end if
4. Proses Pelatihan
Proses pelatihan adalah proses dalam sebuah jaringan saraf tiruan untuk mendapatkan bobot yang tepat untuk menghasilkan output yang diharapkan. Pada
DANGLE, pelatihan tidak hanya terjadi pada jaringan saraf tiruan, melainkan juga terjadi pada GRE (Rahmat, 2008).
5. Neuro-Gene
Transformasi Neuro-Gene adalah sebuah proses pengaturan eksekusi ataupun pelatihan jaringan saraf tiruan pada setiap node(Rahmat, 2008).
Algoritma utama pada GRE didesain untuk mengendalikan gen yang ada, dimana algoritma utama GRE mengusung konsep mutasi pada Genetic Algorithm
(GA). Dengan kata lain, GRE adalah sebuah GA sederhana yang hanya memiliki
operator mutasi di dalamnya. Algoritma utama GRE dapat dijabarkan sebagai berikut
(Rahmat, 2008):
1. Inisialisasi seluruh nilai variabel gene untuk setiap jaringan saraf tiruan, yakni seluruh neuron pada input layer dan output layer, jumlah hidden layer dan setiap
neuron pada hidden layer, generasi, epoch¸learning rate serta momentum rate.
2. Kirim seluruh gen jaringan saraf tiruan ke DANN.
3. Terima hasil fungsi objektif dan output yang dihasilkan setiap jaringan saraf tiruan. Hitung nilai dari fitness function dengan rumus 2.18 untuk setiap jaringan
saraf tiruan. Apabila nilai error rata-rata (EAVGyang merupakan hasil dari fitness
function) lebih rendah dari nilai kriteria terminasi DANGLE, lanjutkan ke langkah
6. Apabila nilai error rata-rata lebih tinggi atau masih sama dengan nilai kriteria terminasi DANGLE, lanjutkan ke langkah 4.
kriteria terminasi mutasi, maka mutasi tidak dilakukan untuk setiap gen jaringan saraf tiruan.
5. Bentuk gene baru hasil mutasi sesuai dengan hasil struktur yang didapatkan dari mutasi regulasi yang dilakukan pada langkah 4. Tambah nilai generasi dengan satu (generation = generation + 1). Kembali ke langkah 2.
6. Hentikan proses GRE, dimana pelatihan telah selesai dilakukan.
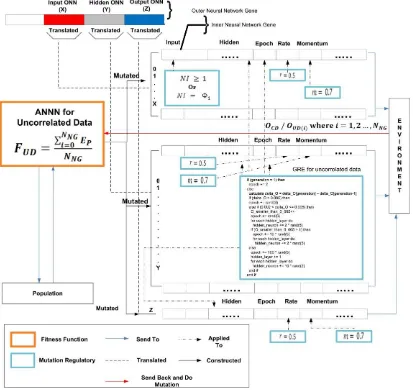
2.8.2. Distributed Adaptive Neural Network
Distributed Adaptive Neural Network (DANN) dapat juga disebut sebagai sebuah Adaptive Nested Neural Network (ANNN) for Uncorrelated Data. DANN didesain
untuk menyelesaikan permasalahan dengan setiap partisi data tidak mempunyai korelasi atau hubungan dengan partisi data yang lain (Rahmat, 2008). Secara konseptual, DANN menggunakan beberapa jaringan saraf tiruan dan membagi beban
kerja pada setiap jaringan saraf tiruan, dibandingkan dengan membiarkan sebuah jaringan saraf tiruan yang besar dan kompleks memproses seluruh data yang ada (Pasha, 2010). DANN diaplikasikan untuk mengurangi kompleksitas dari data serta
permasalahan. Setiap agen pada DANN dimodelkan untuk menerima input yang
berbeda, kemudian setiap output dari setiap agen akan dikembalikan pada GRE untuk
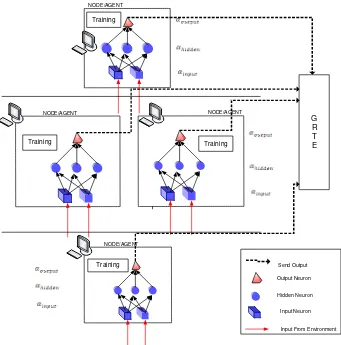
digunakan sebagai parameter pada proses mutasi. Gambar 2.10. menunjukkan arsitektur dari DANN, dimana sebuah node merujuk pada sebuah agen yang memiliki
sebuah jaringan saraf tiruan. Setiap node memiliki gen masing-masing dan berjalan secara paralel pada lingkungan yang berbeda. Adapun jaringan saraf yang digunakan pada setiap agen dapat berupa jaringan saraf tiruan dengan jenis apapun.
Algoritma utama yang diimplementasikan pada setiap jaringan saraf tiruan dalam DANN, dengan jaringan saraf yang digunakan adalah multilayer perceptron,
dijabarkan sebagai berikut (Pasha, 2010):
Output Neuron
Input Neuron Hidden Neuron
Input From Environment NODE/AGENT
NODE/AGENT NODE/AGENT
G R T E
Send Output
Training Training
Training
NODE/AGENT
Training
Gambar 2.10. Arsitektur umum dari Distributed Autonomous Neural Network
(Rahmat, 2008)
2. Lakukan proses pelatihan sesuai dengan algoritma pelatihan jaringan multilayer perceptron yang sudah dijelaskan pada bagian 2.7.2. sebanyak epoch yang terdapat pada gen yang dikirimkan dari GRE
3. Hitung nilai dari fungsi objektifuntuk jaringan saraf tiruandengan rumus 2.14. 4. Hitung nilai selisih nilai output yang diharapkan dengan output yang sebenarnya
didapatkan dengan rumus:
a
d y
y
O (2.19)
dimana O merupakan selisih nilai output; yd merupakan nilai output yang
diharapkan; yaadalah nilai output aktual yang didapatkan.
5. Kirimkan kembali nilai fungsi objektif dan nilai O, yang telah didapatkan pada