BAB 2
LANDASAN TEORI
Bab ini merupakan pembahasan tentang teori-teori penunjang serta penelitian sebelumnya yang berhubungan dengan identifikasi tipe file serta metode Longest Common Subsequences.
2.1. Forensik Digital
Forensik memiliki pengertian sebagai pengaplikasian ilmu pengetahuan terhadap pelaku kriminal dan wujud dari penegakan hukum oleh pihak kepolisian (Saferstein, 2011). Kebanyakan orang sering mengaitkan digital forensik dengan investigasi tindakan kriminal, namun, forensik digital dalam beberapa tahun terakhir memiliki peran sebagai alat pendekatan untuk memfasilitasi pelestarian dan penjagaan terhadap bukti digital, khususnya dalam proses investigasi bukti-bukti pada masa lampau (John, 2012). Cabang ilmu pengetahuan forensik tersebut merupakan respon dari desakan komunitas penegakan hukum (Whitcomb, 2002).
Secara teknis, forensik digital dapat dibagi atas beberapa cabang berdasarkan perangkat digitalnya, yakni: forensik computer, forensik jaringan, forensik analisis data dan forensik perangkat mobile (Aaron, 2014).
2.2. File
File merupakan sekumpulan informasi berupa huruf, angka, maupun karakter khusus dan ditandai dengan nama file. Seluruh data maupun informasi yang ada dalam sebuah komputer tersimpan dalam bentuk file. File dapat dibagi berdasarkan isi informasi yang disimpan, yakni: text file, image file, dan program file. Text file merupakan file yang menyimpan informasi berupa text (tulisan), image file merupakan file yang menyimpan informasi berupa image (gambar), sedangkan program file merupakan file yang menyimpan program. Isi dari file juga dapat menentukan format file tersebut, karena file merupakan tempat disimpannya data.
Secara umum, sebuah file terdiri atas tiga bagian, yakni: 1. File header
File header adalah sebuah signature file atau magic bytes yang ditempatkan pada awal file. Sistem operasi maupun perangkat lunak lainnya akan membaca informasi yang terdapat pada header tersebut, dan mengetahui jenis file dari sebuah file.
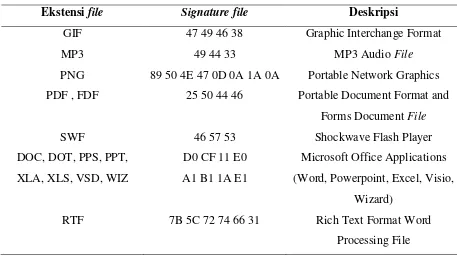
Pada proses investigasi oleh pihak forensik komputer, file header sangat penting karena file header tersebut dapat membantu melacak konten dari file yang terhapus, laporan aktivitas pengguna, dan hal-hal yang bersangkutan lainnya. Sebagai contoh, bila pihak forensik hendak mengembalikan rekaman file activity yang terhapus dari suatu perusahaan, dengan melacak signature daripada hard drive yang berkaitan dengan rekaman file activity, maka sering kali proses recovery dapat berhasil dilakukan. Contoh signature file dapat dilihat pada tabel 2.1.
2. File body
File body adalah isi dari sebuah file yang menjadi data atau informasi utama yang dimiliki oleh file.
3. File trailer
struktur data dan penjelasannya terdapat pada header suatu file, namun informasi tersebut dapat ditemukan juga pada trailer sebuah file (Aaron, 2014).
Tabel 2.1. Contoh Signature File pada Header File
Ekstensi file Signature file Deskripsi
GIF 47 49 46 38 Graphic Interchange Format
MP3 49 44 33 MP3 Audio File
Seiring bertambahnya tingkat penggunaan software, penyimpanan data merupakan hal yang vital bagi user, penyimpanan data ini sendiri menimbulkan suatu polemik di dalam bidang forensik. Terutama untuk hal-hal yang berhubungan dengan munculnya variasi-variasi tipe data. Kenyataannya, hampir mustahil untuk membuat list seluruh tipe file dari komputer, hal ini disebabkan oleh beberapa hal, diantaranya adalah :
1) Beberapa tipe file bersifat umum sedangkan yang lain bersifat sangat spesifik. 2) Beberapa tipe file sangat umum digunakan sedangkan yang lain hanya dipakai
oleh orang atau organisasi tertentu.
3) Detail daripada beberapa file memiliki hak milik sedangkan yang lain bersifat terbuka.
Terdapat beberapa cara untuk mengidentifikasi tipe file , yaitu : 1) Berdasarkan ekstensi file
Cara paling mudah untuk mendapatkan indikasi tipe file adalah dengan melihat ekstensi dari nama file tersebut. Ekstensi nama file adalah karakter setelah tanda „.‟ (titik) pada akhir nama file. Sebagai contoh, sebuah file “MyText.txt”, merupakan sebuah file txt(teks), sementara “MyPic.jpg” merupakan sebuah file jpeg (gambar). Permasalahan pada identifikasi file ini terdapat pada mudahnya manipulasi ekstensi sebuah file. File “MyText.txt” tadi dapat dengan mudah diganti ekstensi filenya menjadi “MyText.jpg”. Hal tersebut dapat terjadi secara tidak sengaja maupun secara sengaja. Identifikasi berdasarkan ekstensi file sangat mudah dilakukan dan cepat, tetapi tidak cukup untuk memastikan tipe dari suatu file . 2) Berdasarkan struktur file
Semakin kompleks tipe file, maka file memiliki format spesifikasi yang kaku. Dengan menganalisis struktur sebuah file dan membandingkannya dengan spesifikasi format yang ada, maka tipe file dapat ditentukan.
3) Berdasarkan Magic Bytes
Magic Bytes atau magic number atau dikenal juga dengan sebutan signature file adalah kumpulan byte-byte pada sebuah file yang dapat membedakan antara jenis file yang satu dengan jenis file yang lainnya. Pada umumnya, magic bytes terdapat pada file header, namun pada tipe file yang lain, magic bytes terdapat pada file body atau file trailer. Magic bytes juga dapat digunakan untuk membedakan versi aplikasi yang digunakan untuk membuat file tersebut.
4) Berdasarkan distribusi karakter
Identifikasi berdasarkan distribusi karakter dilakukan dengan membandingkan frekuensi kemunculan byte dari suatu file dengan frekuensi kemunculan byte dari file lainnya. Sebagai contoh, pada file html byte dari karakter /, < dan > memiliki frekuensi kemunculan yang lebih tinggi dibandingkan dengan file lainnya. Sehingga, apabila terdapat sebuah file yang tingkat frekuensi byte karakter /, < dan >, maka kemungkinan besar file tersebut merupakan file html. File yang memiliki tipe data yang berbeda akan cenderung memiliki frekuensi byte yang berbeda pula.
Identifikasi tipe file berdasarkan distribusi karakter memiliki dua kelemahan, yaitu:
a. Adanya beberapa tipe file yang tidak memiliki distribusi karakter yang spesifik.
b. Memiliki akurasi yang cukup rendah (Aaron, 2014).
2.2.2. File Type Validation
Setelah mengidentifikasi tipe file, maka tahap selanjutnya adalah melakukan validasi dari tipe file tersebut. Suatu file dikatakan valid apabila :
a. Dapat digunakan oleh program yang memang bertujuan untuk mengolah file dengan tipe data tersebut.
b. Sesuai dengan spesifikasi tipe file tersebut. Misalnya, file gif bukan hanya menampilkan satu gambar saja, tetapi beberapa gambar yang seperti video. (Lechich, 2007).
2.2.3. File Fragment
Berdasarkan struktur atau konten hex numbernya, tipe-tipe file fragment dapat dibagi menjadi 2, yakni:
1) File yang hex numbernya terpotong. Ilustrasi pada Gambar 2.1.
Gambar 2.1. Ilustrasi hex number file terpotong
2) File yang hex numbernya tertimpa oleh hex number dari file lain. Ilustrasi pada Gambar 2.2.
Fragmentasi sebuah file terjadi dikarenakan penyimpanan suatu file pada media penyimpanan membagi-bagi file menjadi bagian-bagian yang lebih kecil dan tersebar dalam cluster. Sehingga, ketika sebuah file dihapus pada media penyimpanan, cluster tempat dimana file tersebut disimpan menjadi kosong dan dapat ditempati oleh file yang lain. Ketika file mengalami penambahan ukuran, sering kali tidak mungkin untuk melakukan proses penulisan di bagian akhir file sehingga berpotensi menyebabkan proses fragmentasi file. Penempatan penimpaan suatu file terhadap file lain selalu dimulai dari header file, sehingga file menjadi tidak dikenali oleh aplikasi pembaca file tersebut. Fragmentasi pada suatu file juga dapat terjadi pada keseluruhan file sehingga file tidak dapat teridentifikasi.
Sebuah permasalahan di dalam forensik komputer muncul dalam menentukan tipe file dari file fragment. Ketika sebuah file dihapus, entri daripada file di dalam directory bisa tertimpa. Hal tersebut dapat dengan mudah diselesaikan bila header file fragment tersebut masih utuh, tetapi deteksi tipe file akan menjadi sulit dilakukan apabila file fragment dideteksi melalui body file dikarenakan file header yang terhapus atau tidak lengkap. Ada dua metode yang dapat dipakai dalam menentukan tipe file dari file fragment yakni Fisher‟s linear discriminant dan berdasarkan longest common subsequences dari file fragment dengan berbagai macam file yang dipakai sebagai testing dataset ( Calhoun & Coles, 2008).
2.2.4. File Recovery
Penghapusan sebuah file mengakibatkan cluster yang sedang ditempati file tersebut berubah menjadi unallocated space yaitu cluster kosong yang dapat ditempati data lainnya. Secara fisik, file masih terdapat pada cluster tersebut dan masih dapat direcovery selama belum terjadi penimpaan data (overwrite), penghapusan secara keseluruhan (thorough delete) maupun wiping. Recovery file dapat dilakukan dengan proses undelete, file carving, maupun recovery (Aburabie & Alomari, 2006).
Table (MFT) untuk setiap file memiliki pengalokasian daftar cluster untuk penyimpanan file tersebut. Oleh karena itu, recovery file yang telah mengalami fragmentasi masih dapat dilakukan (Casey, 2010).
2.3. Jenis-Jenis File
2.3.1. PDF
PDF atau Portable Document Format adalah tipe file dokumen umum yang mewakili berbagai jenis tipe file dokumen lain yang terdapat di internet sejak tahun 1993
(Taft, et al. 2004). Pada 14 tahun terakhir, dibantu dengan membludaknya penggunaan internet, PDF menjadi tipe file yang paling sering digunakan sebagai media pertukaran dokumen-dokumen.
Berikut adalah detail dari perkembangan PDF : 1) PDF 1.0 / Acrobat 1.0 (1993).
9) PDF 1.7 / Acrobat 9.0 / Adobe Extension Level 3 (2008). 10)PDF 1.7 / Acrobat 9.1 / Adobe Extension Level 5 (2009).
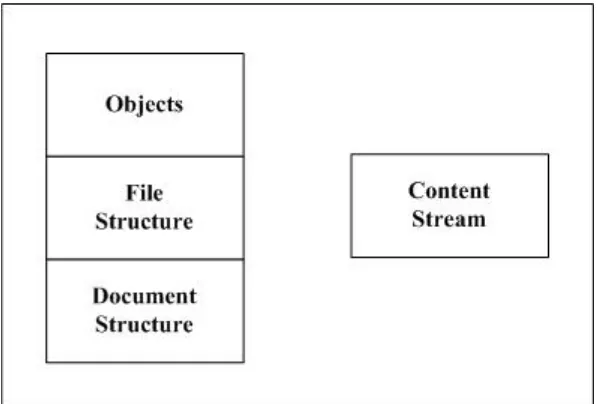
PDF memiliki 4 komponen bagian seperti pada Gambar 2.3, yakni :
1) Objek
2) Struktur file
Struktur sebuah file PDF menentukan bagaimana objek-objek PDF disimpan di dalam file PDF, bagaimana mereka diakses, dan bagaimana mereka diperbarui. Struktur dari PDF ini sendiri bersifat terpisah dari semantik objek-objek tersebut. 3) Struktur dokumen
Struktur sebuah dokumen PDF menjelaskan bagaimana tipe objek sederhana digunakan untuk menunjukkan komponen-komponen dari sebuah dokumen PDF seperti halaman, font, anotasi, dan seterusnya.
4) Content Streams
Content stream dari sebuah PDF berisi sebuah rangkaian instruksi yang mendeskripsikan penampilan dari sebuah halaman. Instruksi ini, walau menggambarkan sebuah objek, secara konseptual berbeda dengan objek-objek yang merepresentasikan struktur dokumen dan diuraikan secara terpisah (Adobe, 2008).
Gambar 2.3. Komponen dari file PDF (Adobe, 2008)
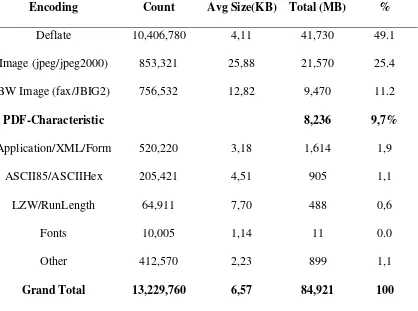
Tabel 2.2. Komposisi Struktur dari File PDF (Roussev & Garfinkel, 2009)
Encoding Count Avg Size(KB) Total (MB) %
Deflate 10,406,780 4,11 41,730 49.1
Image (jpeg/jpeg2000) 853,321 25,88 21,570 25.4
BW Image (fax/JBIG2) 756,532 12,82 9,470 11.2
PDF-Characteristic 8,236 9,7%
Application/XML/Form 520,220 3,18 1,614 1,9
ASCII85/ASCIIHex 205,421 4,51 905 1,1
LZW/RunLength 64,911 7,70 488 0,6
Fonts 10,005 1,14 11 0.0
Other 412,570 2,23 899 1,1
Grand Total 13,229,760 6,57 84,921 100
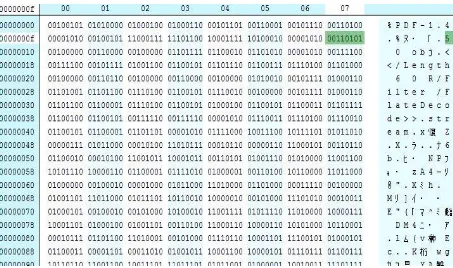
Kolom pertama merupakan metode encoding untuk objek PDF, sedangkan kolom yang lain merupakan jumlah angka dari objek yang ada di dalam PDF, ukuran rata-rata, total ukuran keseluruhan dan persentase dari keseluruhan bagian yang terdapat dalam file PDF (Roussev & Garfinkel, 2009). Contoh isi hex number dari tipe file PDF dapat dilihat pada Gambar 2.4.
Sedangkan struktur dokumen PDF, tersusun atas 4 bagian utama, yakni: 1) PDF Header
Baris pertama pada PDF yang mendefinisikan versi dari format file PDF. Dari header PDF kita juga dapat menemukan informasi dasar dari sebuah file PDF, misalnya header “%PDF-1.5” menunjukkan magic bytes PDF yakni “%PDF” serta “1.5” yang menjelaskan versi PDF tersebut, yakni versi PDF 1.5.
2) PDF Body
Body pada file PDF mengandung objek-objek yang memuat konten dari dokumen tersebut. Objek-objek ini meliputi data berupa gambar, font, anotasi, hyperlinks, bookmark, teks stream dan sebagainya. Pengguna PDF juga dapat mengimplementasikan fitur yang terdapat didalamnya, seperti fitur pengamanan yang membatasi dokumen agar tidak dapat dicetak, dilihat, diedit, maupun dimodifikasi.
3) Cross-Reference Table
Cross-reference table atau dapat disebut juga dengan xref table memuat hubungan antara objek atau elemen yang terdapat di dalam file.
4) Trailer
Trailer pada PDF memuat hubungan pada cross-reference table dan selalu diakhiri dengan “%%EOF” untuk menandakan akhir dari sebuah file PDF. Jika baris tersebut hilang, maka file PDF tidak dapat diproses secara benar.
2.3.2. RTF
RTF atau Rich Text Format adalah format file dokumen yang dipubikasikan oleh Microsoft Corporation pada tahun 1987 untuk mentransfer dokumen teks dengan platform Microsoft.
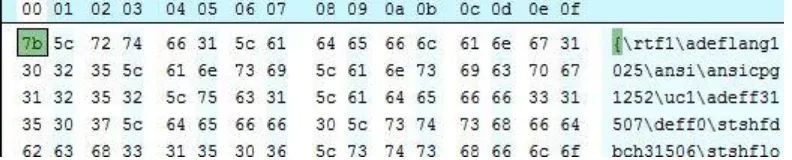
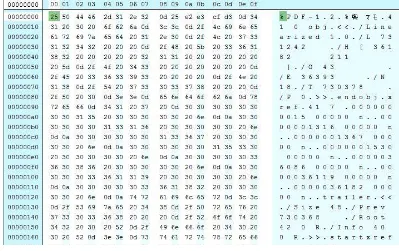
Format file RTF juga mendukung grafik dan tabel dalam dokumen. Contoh rangkaian hex number pada file RTF dapat dilihat pada gambar 2.5. Berikut adalah detail dari perkembangan RTF untuk Microsoft Word:
1) RTF versi 1.0 untuk Microsoft Word 3 (1987). 2) RTF versi 1.1 untuk Microsoft Word 4 (1989). 3) RTF versi 1.2 untuk Microsoft Word 5 (1993). 4) RTF versi 1.3 untuk Microsoft Word 6 (1994).
5) RTF versi 1.4 untuk Microsoft Word 95/Word 7 (1995). 6) RTF versi 1.5 untuk Microsoft Word 97/Word 8 (1997). 7) RTF versi 1.6 untuk Microsoft Word 2000/Word 9 (1999). 8) RTF versi 1.7 untuk Microsoft Word 2002/Word 10 (2001). 9) RTF versi 1.8 untuk Microsoft Word 2003/Word 11 (2004).
10)RTF versi 1.9.1 untuk Microsoft Word 2007/Word 12 (2008). (Microsoft Corporation, 2007).
Gambar 2.5. Contoh rangkaian hex number dari random RTF
2.3.4. DOC
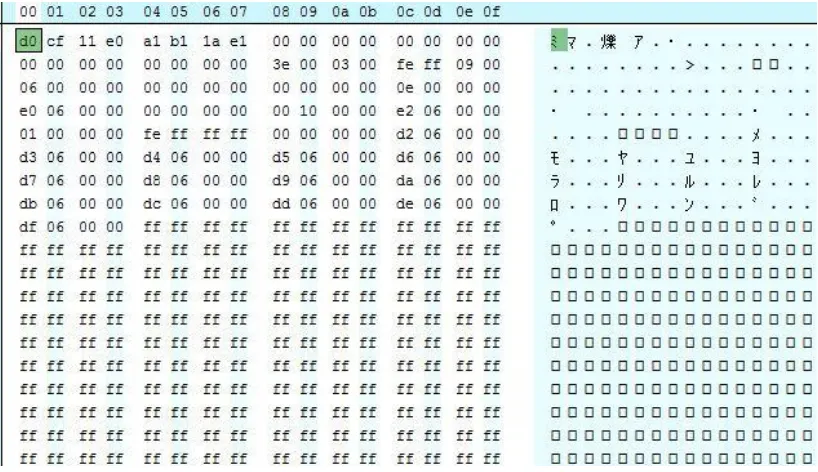
DOC atau document adalah salah satu ekstensi tipe file dokumen pengolah kata. DOC merupakan format file binary yang digunakan oleh aplikasi Microsoft Word 97, Microsoft Word 2000, Microsoft Word 2002, dan Microsoft Office Word 2003 (Microsoft, 2014). DOC memiliki rangkaian hex number berupa „D0 CF 11 E0 A1 B1 1A E1‟.
Sebuah file DOC memuat informasi berupa: 1) Main Stream
3) Table Stream 4) Data Stream
5) Custom XML Storage (Microsoft Word 2007)
6) Bit 0 atau object stream yang memuat data privat untuk objek OLE 2.0 (Object Linking and Embedding 2.0) yang di-embed ke dokumen Word (Microsoft, 2007). Contoh hex number dari tipe file DOC terdapat pada Gambar 2.6.
Gambar 2.6. Contoh rangkaian hex number dari random DOC
2.4. Binary File
Binary file merupakan sebuah file komputer yang bukan merupakan file teks. File tersebut bisa saja memuat tipe data apa saja, kemudian diubah ke dalam bentuk binary untuk tujuan penyimpanan dan pemrosesan komputer. Banyak format file binary yang memuat bagian yang dapat diterjemahkan ke dalam teks, sebagai contoh beberapa file dokumen seperti file Microsoft Word dengan ekstensi doc yang memuat informasi berupa teks yang terdapat pada file tersebut dan juga informasi-informasi lainnya dalam bentuk binary.
header, blok-blok metadata yang digunakan oleh program komputer untuk menerjemahkan data yang ada di dalam file. Pada file header umumnya berisi signature atau magic number yang dapat mengidentifikasi format file. Binary file yang tidak memiliki header disebut juga sebagai flat binary file.
Untuk mengirim binary file melalui sebuah sistem khusus seperti e-mail yang tidak mendukung semua jenis data, biasanya binary tersebut diubah menjadi plain teks atau lambang-lambang khusus sebagai representasi, misalnya menggunakan Base64. Proses mengubah atau encoding tersebut biasanya memiliki kelemahan, seperti ukuran file yang bertambah pada saat proses mengirim, serta dibutuhkan proses penerjemahan dari plain teks ke binary setelah file diterima. Permasalahan ukuran file yang bertambah dapat diselesaikan dengan cara melakukan kompresi data, sehingga data yang dikirim memiliki ukuran file yang relatif sama dengan file asli.
Hex editor merupakan aplikasi untuk membaca binary yang terdapat pada suatu file maupun mengubah tipe data binary menjadi tipe data hexadecimal, decimal maupun karakter ASCII. Perbandingan binary dan hex pada satu file .pdf dapat dilihat pada Gambar 2.7 dan Gambar 2.8.
Gambar 2.8. Hex pada file PDF
2.6. Longest Common Subsequences
Dalam permasalahan matematika, sebuah subsequence adalah sebuah sequence yang diturunkan dari sequence lain dengan menghapus beberapa elemen tanpa mengganti urutan dari sisa element tersebut. Sebagai contoh, sequence “A B D” merupakan subsequence dari sequence “A B C D E”. Secara singkat, subsequence merupakan bagian dari sebuah sequence.
Longest Common Subsequences merupakan sebuah metode untuk mencari sequence terpanjang yang sama, sebuah basis dari pemrograman untuk perbandingan data komputer. Pada kasus identifikasi tipe file, Longest Common Subsequences dapat digunakan untuk membandingkan sequence hex number beberapa file. Secara umum, Longest Common Subsequence adalah sebuah metode untuk mendapatkan sequence terpanjang dengan membandingkan beberapa sequence.
1. Sequence dari DNA atau gen yang dapat direpresentasikan sebagai deretan 4 huruf ACGT. Pada saat seorang ahli biologi yang meneliti tentang gen, bila dia menemukan suatu sequence yang baru pada gen tersebut, biasanya mereka akan mencari tahu sequence lainnya yang mirip dengan sequence baru tersebut.
2. Pada program UNIX, „diff‟ digunakan untuk membandingkan dua file yang sama dengan versi yang berbeda, untuk menemukan perubahan yang terdapat pada file tersebut. Hal tersebut dilakukan dengan cara menemukan Longest Common Subsequences dari kedua file tersebut, dan menemukan subsequence yang tidak berubah, sehingga dapat ditemukan baris subsequence yang berbeda atau diganti.
3. Banyak text editor seperti “emacs” menampikan bagian dari sebuah file ke monitor, dan setiap kali file tersebut diganti, maka monitor akan ter-update. Program tersebut ingin mengirimkan teks sesedikit mungkin ke terminal sehingga proses update tersebut dapat ditampilkan secara benar. Diperlukan metode Longest Common Subsequences sehingga karakter-karakter pada file yang tidak berubah tetap tinggal di terminal dan hanya mengirimkan karakter-karakter yang berubah saja (University of California, 1996).
Sebagai contoh, terdapat dua buah string, string S1 mencakup deretan string
berupa “AAACCGTGAGTTATTCGTTCTAGAA”, dan string S2 mencakup deretan
string “CACCCCTAAGGTACCTTTGGTTC”. Kesamaan substring pada string S1
dan S2 dapat dilihat pada Gambar 2.9. Pencarian subsequence terpanjang pada dua
Gambar 2.9. Kesamaan substring S1 dan S2
Bila terdapat dua buah sequences yaitu X dan Y, dengan X = <X1, X2, ..., Xm>
dan Y = <Y1, Y2, ..., Yn>. Kemudian Z merupakan Longest Common Subsequences
daripada sequence X dan Y dengan persamaan Z = <Z1, Z2, ..., Zk>. Maka akan
terdapat persamaan-persamaan sebagai berikut :
1. Jika Xm = Yn, maka dapat dipastikan bahwa Zk = Xm = Yn.
2. Jika Xm <> Yn, maka Xm <> Zk mengindikasikan bahwa Z terdapat pada
LCS(Xm-1, Y).
3. Jika Xm <> Yn, maka Yn <> Zk mengindikasikan bahwa Z terdapat pada
LCS(X, Yn-1) (Klappenecker, 2011).
Ilustrasi pencarian subsequence dari dua buah string dengan metode Longest Common Subsequences adalah sebagai berikut:
Misalkan X memiliki sequence BDCB, dan Y memiliki sequence BACDB. Sequence X dan sequence Y diletakkan pada tabel seperti pada gambar 2.10.
1. Letak sequence X dan Y tidak berpengaruh terhadap perhitungan. 2. Input kolom paling kiri dan paling atas dengan angka 0.
3. Kemudian pertemukan setiap sequence satu per satu. Bila X sama dengan Y, maka nilai pada kolom tersebut adalah (n,n) = (n-1,n-1) + 1. Sedangkan bila X tidak sama dengan Y, maka nilai yang menjadi input adalah nilai terbesar yang terdapat pada kolom (n-1,n) atau pada kolom (n,n-1). Misalkan nilai X = B dan nilai Y = B, bertemu pada kolom (2,2), maka input kolom tersebut dengan nilai (1,1) + 1, dalam hal ini nilai (1,1) = 0, sehingga 0+1 = 1.
yang bernilai 0. Nilai 1 > 0, maka input pada kolom (3,2) adalah 1. Apabila nilai pada kolom (2,2) sama dengan nilai pada kolom (3,1) maka input kolom (3,2) sama dengan kedua kolom tersebut.
4. Input seluruh kolom yang tersisa.
Gambar 2.10. Tabel X dan Y
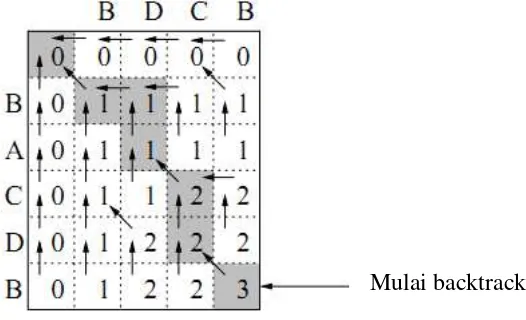
Setelah itu, akan ditentukan Longest Common Subsequences (LCS) dari tabel yang sudah terisi tersebut. Langkah-langkah yang akan dilakukan adalah :
1. Meletakkan pointer pada kolom sudut kanan bawah, yakni kolom (5,6).
2. Pointer akan bergerak dengan salah satu pola, yakni ke kiri lalu ke atas atau ke kanan lalu ke atas. Tetapi pointer tidak bisa bergerak menggunakan pola ini bila nilai pada kolom yang dituju tidak sama dengan nilai pada kolom semula. Bila hal ini terjadi, maka pointer akan bergerak menyerong, misalnya dari (5,6) ke (4,5).
3. Sequence tersebut akan diletakkan dengan urutan dari kanan ke kiri.
4. Pointer akan terus bergerak sampai pada kolom dengan nilai 0. Pointer akan berhenti, dan nilai dari LCS telah didapat.
Gambar 2.11. Gambar ilustrasi perhitungan LCS
6. Setelah mendapatkan nilai LCS, maka penelitian akan dilanjutkan pada tahap mencocokkan nilai LCS yang didapat dengan hex number pada file yang hendak diuji.
2.7. Penelitian Terdahulu
Pada tahun 2003, McDaniel & Heydari mengajukan metode “fingerprints” untuk memprediksi tipe file dengan membandingkan histogram file. Akan tetapi, hasil penelitian menunjukkan bahwa sangat sulit untuk menghasilkan representasi fingerprint untuk seluruh kelas tipe file. Li, et al. pada tahun 2005 mengimplementasikan metode fileprints yang mengidentifikasikan tipe file dengan menganalisa n-gram. Hasil penelitian menunjukkan bahwa metode fileprints dengan menggunakan model centroid untuk representasi distribusi nilai byte per tipe file dapat mengidentifikasi tipe file secara efektif saat melakukan streaming file dari ataupun menuju disk drive. Veenman pada tahun 2007 mengajukan metode linear diskriminan the Fischer untuk yang diaplikasikan kepada fileprint, entropy, dan pengukuran berbasiskan Kolgomorov complexity. Hasil penelitian menunjukkan bahwa metode linear discriminant dapat digunakan untuk mengidentifikasi tipe file. Calhoun dan Coles pada tahun 2008 melakukan perbandingan dua metode yaitu metode linear discriminant dan longest common subsequences untuk membandingkan 4 tipe file yakni pdf, gif, bmp, dan jpg. Hasil penelitian menunjukkan bahwa metode longest common subsequences dapat membedakan file utuh antara pdf, gif, bmp, dan jpg dan