ABSTRACT
RIFERSON SIJABAT. Sequential Pattern Discovery on Sales Transaction Data using SPADE Algorithm. Supervised by MEUTHIA RACHMANIAH and ANNISA.
The rapid development of information technology that is happening these days requires people to adapt into these developments. This human efforts can be seen from the many activities carried out by computerization that produces large amounts of data. From these available abundant data, the discovery of useful knowledge from large database becomes popular and attractive. This discovery of useful knowledge can be done using the concept of sequential pattern mining. One of the algorithms that applies the concept of sequential pattern mining is Sequential Pattern Discovery using Equivalence classes (SPADE) that is able to determine the sequential pattern of a data transaction. By adopting the functions contained in the SPADE algorithm, the purchasing tendency of items by customer at a specific time period can be seen. This research use the purchase transactions data of Sinar Mart Swalayan in period of 1 March to 31 March 2004. In this research, the minimum support was tested starting from 45% to 89% and minimum confidence from 20% to 96%. Minimum support and minimum confidence which is given is determined based on the condition of the data. Experimental results showed that the maximum value of minimum support that still could generate frequent sequences was 89%.
1 PENDAHULUAN
Latar Belakang
Perkembangan teknologi informasi yang sangat pesat yang terjadi dewasa ini menuntut manusia untuk mampu beradaptasi dengan perkembangan tersebut. Upaya adaptasi yang dilakukan manusia dapat dilihat dari banyaknya kegiatan yang dilakukan secara komputerisasi sehingga menghasilkan data dalam jumlah yang besar. Dengan ketersediaan data yang semakin melimpah tersebut, penemuan pengetahuan yang berguna dari suatu database yang besar semakin populer dan menarik perhatian.
Penemuan pengetahuan yang berguna tersebut dapat dilakukan menggunakan teknik data mining. Data mining merupakan proses ekstraksi informasi atau pola dalam database yang berukuran besar (Han & Kamber 2006). Salah satu teknik data mining adalah sequential pattern mining yang berguna untuk menemukan pola sekuensial yang terdapat pada database yang pertama kali diperkenalkan oleh Agrawal dan Srikant pada tahun 1995.
Pada database, salah satu data yang sering dijumpai adalah data transaksi. Data transaksi merupakan data konsumen atau pelanggan pada sebuah lembaga komersil maupun non-komersil yang berisi id konsumen, waktu transaksi, dan item transaksi. Dari data transaksi seperti halnya transaksi supermarket, dapat ditemukan pola sekuensial untuk mengetahui keterkaitan antarbarang atau item.
Salah satu algoritme yang dapat digunakan untuk mengetahui pola sekuensial dari suatu data transaksi yaitu Sequential PAttern Discovery using Equivalence classes (SPADE). Algoritme SPADE merupakan algoritme berbasis candidate generation and test dan merupakan penyempurnaan dari algoritme penentuan pola sekuensial terdahulu yakni Apriori. Pada perkembangannya, algoritme SPADE masih jarang diimplementasikan sehingga diperlukan kajian yang lebih dalam dengan harapan bahwa apabila implementasi algoritme SPADE berhasil, maka penerapan algoritme berbasis patterrn growth akan semakin menarik untuk dilakukan.
Dengan mengadopsi fungsi-fungsi pada algoritme SPADE, akan dilihat kecenderungan pembelian barang oleh customer dalam kurun waktu tertentu. Sebagai contoh, customer biasa membeli kebutuhan pokok di awal bulan karena sebagian besar mendapatkan gaji pada periode tersebut. Kejadian seperti ini sebenarnya terekam dalam database, hanya saja belum
tergali informasi tentang itu. Dengan mencari pola-pola dari database menggunakan algoritme SPADE, akan terlihat keterkaitan jenis barang yang dibeli oleh pembeli pada waktu tertentu (Zaki 2001). Hal ini dapat dimanfaatkan oleh pemilik supermarket dalam pengambilan keputusan terkait dengan penjualan barang.
Tujuan Penelitian
Penelitian ini bertujuan untuk mengimplementasikan algoritme SPADE untuk melihat keterkaitan antara beberapa item dari suatu data transaksi pembelian.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini dibatasi pada penerapan algoritme SPADE dengan menggunakan data transaksi pembelian Sinar Mart Swalayan selama periode 1 bulan terhitung sejak 1 Maret hingga 31 Maret 2004. Data transaksi pembelian tersebut berisi id pembeli, waktu pembelian berdasarkan tanggal, dan juga jenis barang atau item yang dibeli. Analisis dilakukan terhadap kelompok data tersebut sehingga menghasilkan informasi mengenai pola pembelian barang atau item yang digambarkan dalam bentuk frequent sequences dan juga association rule.
Manfaat Penelitian
Hasil penelitian ini diharapkan mampu melihat keterkaitan antarbarang yang dibeli oleh pembeli pada data transaksi pembelian. Keterkaitan antara barang atau item tersebut dapat digunakan sebagai bahan pertimbangan dalam pengambilan keputusan yang berhubungan dengan penjualan barang atau item pada periode berikutnya. Selain itu, penelitian ini juga diharapkan dapat menjadi dasar penelitian selanjutnya yang terkait dengan penentuan pola sekuensial sehingga didapatkan algoritme yang memiliki kinerja yang lebih efektif dan efisien.
TINJAUAN PUSTAKA
Knowledge Discovery from Data (KDD)
1 PENDAHULUAN
Latar Belakang
Perkembangan teknologi informasi yang sangat pesat yang terjadi dewasa ini menuntut manusia untuk mampu beradaptasi dengan perkembangan tersebut. Upaya adaptasi yang dilakukan manusia dapat dilihat dari banyaknya kegiatan yang dilakukan secara komputerisasi sehingga menghasilkan data dalam jumlah yang besar. Dengan ketersediaan data yang semakin melimpah tersebut, penemuan pengetahuan yang berguna dari suatu database yang besar semakin populer dan menarik perhatian.
Penemuan pengetahuan yang berguna tersebut dapat dilakukan menggunakan teknik data mining. Data mining merupakan proses ekstraksi informasi atau pola dalam database yang berukuran besar (Han & Kamber 2006). Salah satu teknik data mining adalah sequential pattern mining yang berguna untuk menemukan pola sekuensial yang terdapat pada database yang pertama kali diperkenalkan oleh Agrawal dan Srikant pada tahun 1995.
Pada database, salah satu data yang sering dijumpai adalah data transaksi. Data transaksi merupakan data konsumen atau pelanggan pada sebuah lembaga komersil maupun non-komersil yang berisi id konsumen, waktu transaksi, dan item transaksi. Dari data transaksi seperti halnya transaksi supermarket, dapat ditemukan pola sekuensial untuk mengetahui keterkaitan antarbarang atau item.
Salah satu algoritme yang dapat digunakan untuk mengetahui pola sekuensial dari suatu data transaksi yaitu Sequential PAttern Discovery using Equivalence classes (SPADE). Algoritme SPADE merupakan algoritme berbasis candidate generation and test dan merupakan penyempurnaan dari algoritme penentuan pola sekuensial terdahulu yakni Apriori. Pada perkembangannya, algoritme SPADE masih jarang diimplementasikan sehingga diperlukan kajian yang lebih dalam dengan harapan bahwa apabila implementasi algoritme SPADE berhasil, maka penerapan algoritme berbasis patterrn growth akan semakin menarik untuk dilakukan.
Dengan mengadopsi fungsi-fungsi pada algoritme SPADE, akan dilihat kecenderungan pembelian barang oleh customer dalam kurun waktu tertentu. Sebagai contoh, customer biasa membeli kebutuhan pokok di awal bulan karena sebagian besar mendapatkan gaji pada periode tersebut. Kejadian seperti ini sebenarnya terekam dalam database, hanya saja belum
tergali informasi tentang itu. Dengan mencari pola-pola dari database menggunakan algoritme SPADE, akan terlihat keterkaitan jenis barang yang dibeli oleh pembeli pada waktu tertentu (Zaki 2001). Hal ini dapat dimanfaatkan oleh pemilik supermarket dalam pengambilan keputusan terkait dengan penjualan barang.
Tujuan Penelitian
Penelitian ini bertujuan untuk mengimplementasikan algoritme SPADE untuk melihat keterkaitan antara beberapa item dari suatu data transaksi pembelian.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini dibatasi pada penerapan algoritme SPADE dengan menggunakan data transaksi pembelian Sinar Mart Swalayan selama periode 1 bulan terhitung sejak 1 Maret hingga 31 Maret 2004. Data transaksi pembelian tersebut berisi id pembeli, waktu pembelian berdasarkan tanggal, dan juga jenis barang atau item yang dibeli. Analisis dilakukan terhadap kelompok data tersebut sehingga menghasilkan informasi mengenai pola pembelian barang atau item yang digambarkan dalam bentuk frequent sequences dan juga association rule.
Manfaat Penelitian
Hasil penelitian ini diharapkan mampu melihat keterkaitan antarbarang yang dibeli oleh pembeli pada data transaksi pembelian. Keterkaitan antara barang atau item tersebut dapat digunakan sebagai bahan pertimbangan dalam pengambilan keputusan yang berhubungan dengan penjualan barang atau item pada periode berikutnya. Selain itu, penelitian ini juga diharapkan dapat menjadi dasar penelitian selanjutnya yang terkait dengan penentuan pola sekuensial sehingga didapatkan algoritme yang memiliki kinerja yang lebih efektif dan efisien.
TINJAUAN PUSTAKA
Knowledge Discovery from Data (KDD)
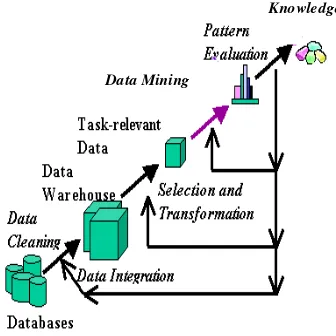
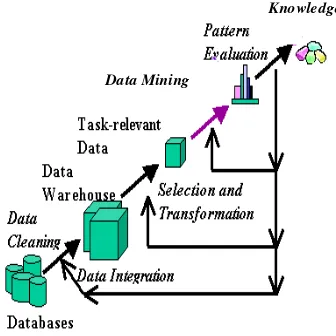
2 Gambar 1 Tahapan proses KDD (Han &
Kamber 2006).
Deskripsi mengenai tahapan-tahapan proses KDD pada gambar di atas adalah sebagai berikut :
1 Pembersihan data (Data cleaning)
Pembersihan data dilakukan untuk menghilangkan noise dan data yang tidak konsisten.
2 Integrasi data (Data integration)
Integrasi data dilakukan untuk menggabungkan data yang berasal dari berbagai sumber.
3 Seleksi data (Data selection)
Proses seleksi data merupakan proses pengambilan data yang relevan dengan proses analisis yang dilakukan.
4 Transformasi data (Data transformation) Data ditransformasikan atau digabungkan ke dalam bentuk yang sesuai untuk dilakukan proses mining dengan cara melakukan peringkasan atau operasi agregasi.
5 Data mining
Data mining merupakan proses yang penting dan merupakan tahapan ketika metode-metode cerdas diaplikasikan untuk mengekstrak pola-pola dari kumpulan data.
6 Evaluasi pola (Pattern evaluation)
Merupakan suatu proses untuk mengidentifikasi pola-pola tertentu pada data yang menarik dan merepresentasikan pengetahuan.
7 Representasi pengetahuan (Knowledge Representation)
Penggunaan visualisasi dan teknik representasi untuk menunjukkan penemuan pengetahuan hasil proses mining kepada pengguna.
Association Rule Mining
Aturan asosiasi (association rule) atau analisis afinitas (affinity analysis) berkenaan
dengan studi „apa bersama apa‟. Pada dasarnya
aturan ini digunakan untuk menggambarkan keterkaitan antara item pada sekumpulan data (Santoso 2007).
Secara umum, aturan asosiasi dapat dipandang sebagai proses yang terdiri atas dua tahap (Han & Kamber 2006), yaitu :
1 Menemukan kumpulan frequent item. Sebuah itemset dikatakan frequent item jika memiliki frekuensi kemunculan minimal sama dengan nilai minimum support.
2 Membangkitkan aturan asosiasi dari itemset yang dikatakan frequent item. Aturan ini harus memenuhi nilai minimum support. Support
Misalkan α merupakan sebuah sequence dan D sebuah sequence database. Support atau frequency yang dinotasikan sebagai σ(α, D) merupakan jumlah total dari sequence di dalam database D yang berisi α sebagai sebuah subsequence (Zaki 2001).
Confidence
Confidence untuk suatu aturan asosiasi XY, adalah ukuran keakuratan dari aturan tersebut yang dihitung dari persentase transaksi dalam database yang mengandung X dan juga mengandung Y. Definisi formal dari confidence adalah sebagai berikut:
� � =�( ∩ )
�( )
Pola Sekuensial
Pola sekuensial adalah daftar urutan dari sekumpulan item. Sebuah pola sekuensial dikatakan maksimum apabila tidak mengandung pola sekuensial lainnya (Zaki 2001). Sebuah pola sekuensial dengan k-item disebut k-sequence. Sebagai contoh, (A →BC) merupakan sebuah sequence dengan 3-sequence. Panjang sebuah pola sekuensial adalah jumlah item yang terdapat pada pola sekuensial tersebut yang dilambangkan dengan |s|.
Sebuah subsequence s’ dari s dilambangkan dengan s’ ⊆ s. Misalkan, sebuah pola sekuensial a = (a1,a2,...an) merupakan subsequence dari b = (b1,b2,...bm) dengan integer i1 < i2 < ...in, 1 ≤ ik ≤ m, sehingga a1 ⊆ b1, a2 ⊆ b2, ..., an ⊆ bm.
Sebagai contoh, (A→BC) merupakan
subsequence dari (A→DE→BC) atau Knowledge
3
(D→AB→BC) tetapi bukan subsequence dari
(ABC) atau (BC→A).
Misalkan α merupakan sebuah sequence dan D merupakan sebuah database. Apabila diberikan sebuah user-specified threshold σ yang disebut dengan minimum support, maka sebuah sequence dikatakan frequent jika σ (α, D) ≥ minimum support.
Misalkan D merupakan sebuah database dan Ƒ merupakan kumpulan dari semua frequent sequences dalam database D. Sebuah frequent sequence α ∈ Ƒ disebut maximal frequent sequence jika untuk masing-masing β∈ Ƒ , α ≠
β, dan α bukan merupakan ⊆β. Pendekatan Hyper-lattice
Hyper-lattice merupakan pendekatan dasar yang digunakan untuk menguraikan mining frequent sequences menjadi submasalah yang lebih kecil (Zaki 2001). Setiap kumpulan dari semua sequences disebut struktur hyper-lattice. Dalam struktur ini, sequences menjadi berlapis yang berarti bahwa setiap sequences dibentuk dengan menambah sebuah item baru ke sequences dari layer sebelumnya. Adapun dasar dari teori hyper-lattice sebagai berikut (Davey & Priestley 1990):
1. Join
Misalkan P himpunan terurut dari S ⊆ P. Sebuah elemen X ∈ P adalah sebuah upper bound dari S jika untuk semua s ∈ S, s ≤ X. Minimum upper bound dari S disebut join yang dinotasikan dengan S.
2. Meet
Misalkan P himpunan terurut dari S ⊆ P. Sebuah elemen X ∈ P adalah sebuah lower bound dari S jika untuk semua s ∈ S, s ≥ X. Maximum lower bound dari S disebut meet yang dinotasikan dengan S.
3. Lattice
Misalkan L merupakan himpunan terurut. L disebut sebuah join (meet) semilattice jika dan hanya jika x y (x y) ada untuk setiap x, y ∈ L. L disebut sebuah lattice jika terdapat sebuah join dan meet semilattice. Sebuah himpunan terurut M ⊂ L adalah sebuah sublattice dari L jika x, y ∈ M mengimplikasikan x y ∈ M x y ∈ M. Setiap lattice harus memiliki minimal satu minimum upper bound dan maximum lower bound, sementara semilattice hanya harus memiliki minimum upper bound atau maximum lower bound. Masing-masing himpunan terurut memiliki elemen terbesar yang disebut top
element yang dinotasikan dengan ┬ dan juga elemen terkecil yang disebut bottom element yang dinotasikan dengan ┴.
Atom
Sebuah lattice dimisalkan dengan L, dengan x, y, z ∈ L. x dikatakan dicakup oleh y jika x < y x ≤ z < y, menyiratkan bahwa z = y. ┴ dimisalkan sebagai bottom element dari lattice L, x ∈ L disebut sebuah atom apabila ┴ dicakup oleh x.
Equivalence Class
Equivalence Class merupakan sebuah kumpulan dari sequences yang membagi prefix yang sama dengan panjang k. Setiap equivalence class dibentuk dari relasi equvalence ⊖k yang merupakan sebuah
sub-hyper-lattice. Contoh Struktur hyper-lattice yang dibentuk berdasakan equivalence class dapat dilihat pada Lampiran 1.
Prefix
Misalkan s = (s1 → s2 → ∙ ∙ ∙ → sn) dan b = (b1 → b2 → ∙ ∙ ∙ → bm) merupakan dua buah sequences. Sequence b disebut prefix dari s jika dan hanya jika bi = si untuk (i ≤ m - 1) dan bm⊆
sm. Sebagai contoh, sequences (A→B) dan (A→BC→A) merupakan prefix dari sequence
(A→BC→ABC→C).
SPADE Algorithm
Algoritme SPADE merupakan algoritme untuk mencari pola sekensial yang menggunakan equivalence class untuk menguraikan masalah utama menjadi submasalah yang dapat diselesaikan secara terpisah menggunakan operasi join (Zaki 2001). Algoritme ini menggunakan representasi dari database vertikal di mana masing-masing baris berisi customer id (sid), waktu transaksi (eid), dan koleksi dari item transaksi seperti yang ditunjukkan pada Tabel 1.
Tabel 1 Sampel database vertikal
sid eid (date) items
1 10 C D
1 15 A B C
1 20 A B F
1 25 A C D F
2 15 A B F
2 20 E
3 10 A B F
4 10 D G H
4 20 B F
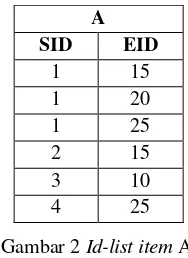
4 Pasangan (sid, eid) dari suatu item transaksi
x disebut dengan id-list yang dinotasikan dengan L(x) = {(sid, eid)}. Contoh id-list dari item A yang terdapat pada Tabel 1 dapat dilihat pada Gambar 2.
A
SID EID
1 15
1 20
1 25
2 15
3 10
4 25
Gambar 2 Id-list item A.
Fungsi utama dalam algoritme SPADE adalah memindai database D dan menemukan frequent 1-sequences yang mengacu pada atom dari sequence hyper-lattice. Sekumpulan atom-atom akan dibangkitkan dari frequent 1- sequences dengan assign sebuah id-list ke semua frequent 1- sequences. Kumpulan dari atom-atom ini merepresentasikan parent class untuk hyper-lattice yang diinduksi oleh [{}]⊖1.
Ringkasan algaoritme SPADE adalah sebagai berikut :
SPADE(min_sup, D , Ƒ):
Ƒ1 ← {Frequent 1-sequences}
ɛ ← {parent classes [{}]Ɵ1}
Enumerate-Frequent-Sequences
Ƒ ← Ƒ ⋃ Ƒ1
Fungsi Enumerate-Frequent-Sequences merupakan fungsi untuk membentuk semua frequent sequences. Tahapan Enumerate-Frequent-Sequences diawali dengan memproses masing-masing atom Ai dengan Aj yang lain.
Proses ini merupakan sebuah temporal join dari atom-atom di mana atom α yang baru diperoleh merepresentasikan sequence. Setelah proses join, akan dilakukan pengecekan frequency dari hasil id-list atom-atom untuk menentukan apakah sequence yang terbentuk frequent atau tidak. Jika sequence tersebut frequent, maka atom α ditambahkan ke dalam kumpulan atom-atom Ti yang merepresentasikan parent class untuk hyper-lattice berikutnya yang diinduksi oleh [Ai]⊖1. Setelah Ai selesai, fungsi secara rekursif
dipanggil dengan Ti sebagai parameter.
Sebagai ilustrasi, data yang terdapat pada Tabel 1 akan menghasilkan sekumpulan frequent atoms J = {A, B, D, F}. Semua frequent atoms yang dihasilkan akan mengalami proses temporal join untuk membentuk semua frequent 2-sequences hingga frequent
k-sequences yang bisa terbentuk. Proses temporal join dimulai dari atom A sebagai parent class pertama. Atom A akan dilakukan proses join dengan sisa frequent atoms J yang lain, yaitu B, D, dan F. Proses temporal join atom A dengan atom yang lain akan menghasilkan kumpulan atom yang merepresentasikan frequent sequences K = {AB, AF}. Algoritme kemudian pindah ke kumpulan atom K dan mengambil atom (AB) untuk dilakukan temporal join dengan sisa dari kumpulan atom K yang lain yakni (AF). Proses temporal join (AB) dengan sisa kumpulan atom K yang lain hanya akan menghasilkan sebuah atom yang merepresentasikan sequence yaitu L = {(ABF)}.
Algoritme kemudian berpindah secara rekursif ke kumpulan atom L dan setelah diketahui bahwa tidak ada lagi frequent sequence yang lain yang bisa dibangkitkan dari kumpulan L, maka algoritme akan tracks back ke kumpulan atom K sebelumnya dan mengambil atom selanjutnya yakni (AF). Atom (AF) ini akan di-join dengan sisa dari kumpulan atom K yang lain, dan berhubung tidak ada sisa dari kumpulan atom K yang lain, maka tidak ada frequent sequence lain yang bisa dibangkitkan sehingga algoritme tracks back ke kumpulan atom J sebelumnya dan mengambil atom selanjutnya yakni B. Atom B ini akan di-join dengan sisa dari kumpulan atom J yang lain yakni A, D dan F dan akan menghasilkan kumpulan atom yang merepresentasikan frequent sequence K2 = {(BF),(B→A)}.
Algoritme kemudian pindah ke kumpulan atom K2 dan mengambil atom (BF) untuk dilakukan temporal join dengan sisa kumpulan atom K2 yang lain yakni (B→A). Proses temporal join (BF) dengan sisa kumpulan atom K2 yang lain hanya akan menghasilkan sebuah atom yang merepresentasikan sequence yaitu L2
= {(BF→A)}. Algoritme kemudian berpindah
secara rekursif ke kumpulan atom L2 dan setelah diketahui bahwa tidak ada lagi frequent sequence yang lain yang bisa dibangkitkan dari kumpulan L2, maka algoritme akan tracks back
ke kumpulan atom K2 sebelumnya dan
mengambil atom selanjutnya yakni (B→A). Atom (B→A) ini akan dilakukan proses join dengan sisa dari kumpulan atom K yang lain, dan berhubung tidak ada sisa dari kumpulan atom K2 yang lain, maka tidak ada frequent
5 Enumerate-Frequent-Sequences adalah sebagai
berikut:
Enumerate-Frequent-Sequences
(Atomset, min_supp, Set Ƒ):
for all atoms Ai ϵ ɛ do
Ti ← {}
for all atoms Aj ϵ ɛ, j ≥ i
do
α = Ai Aj
L(α) = L(Ai) ∩ L(Aj)
if σ(α) ≥ min_supp then
Ti← Ti ⋃{α}
Ƒ = Ƒ ⋃ α
end if
end for
Enumerate-Frequent-Sequences (Ti,min_supp, Ƒ)
end for
Rule Generation
Rule Generation merupakan tahap pembentukan rule dari semua maximal frequent sequences yang terbentuk. Semua sequences yang merupakan subsequence dari sebuah maximal frequent sequences yang terbentuk akan dilakukan pembentukan rule dengan maximal frequence sequence itu sendiri. Dari semua kandidat rule yang ada akan dilakukan pengecekan apakah kandidat rule yang terbentuk tersebut memiliki confidence yang lebih besar atau sama dengan minimum confidence yang diberikan. Apabila kandidat rule tersebut memiliiki nilai confidence lebih besar atau sama dengan minimum confidence yang diberikan maka kandidat rule tersebut merupakan output rule yang diinginkan algoritme.
Sebagai ilustrasi, data yang terdapat pada Tabel 1 akan menghasilkan 2 maximal frequent sequences yaitu (ABF) dan (D→BF→A). Semua subsequences dari masing-masing maximal frequent sequences tersebut akan dicari untuk selanjutnya dilakukan pembentukan rule. Sequence (ABF) memiliki enam subsequences, yaitu (A), (B), (F), (AB), (AF), dan (BF). Dari keseluruhan subsequences tersebut, akan terbentuk sebanyak enam kemungkinan rule yaitu, (A)⇒(ABF), (B)⇒(ABF), (F)⇒(ABF), (AB)⇒(ABF), (AF)⇒(ABF), dan (BF)⇒(ABF). Penghitungan confidence setiap kemungkinan rule dilakukan dengan membagi support dari maximal frequence sequences dengan support dari subsequences. Sebagai contoh, penghitungan confidence untuk rule (A)⇒(ABF) dilakukan dengan membagi
support (ABF) dengan support (A). Apabila nilai confidence dari kemungkinan rule lebih besar atau sama dengan minimum confidence yang diberikan maka rule tersebut merupakan rule yang sesuai dengan output algoritme Rule Generation. Algoritme Rule Generation adalah sebagai berikut :
RuleGen( Ƒ, min_conf):
for all maximal frequent sequence β ϵ Ƒ do
for all subsequence atoms α≺β
do
conf = fr (β) / fr (α) if (conf ≥ min_conf)then
output the rule α ⇒ β
Temporal join of id-lists
Temporal join adalah operasi dasar yang digunakan ketika proses enumerating-fequent-sequences (Zaki 2001). Misalkan [A→B] merupakan sebuah equivalence class dengan
atom {(A→BC), (A→BD), (A→B→A), (A→B→C)}. Misalkan P mewakili prefix
(A→B) sehingga [P] dapat ditulis ulang sebagai {(PC), (PD), (P→A), (P→C)}. Penulisan ulang
tersebut akan menghasilkan dua jenis atom, yaitu :
Event atoms {PC, PD}
Sequence atoms {(P→A), (P→C)} Operasi join dari atom di atas akan menghasilkan minimal tiga kemungkinan, antara lain sebagai berikut :
1. Event Atom dengan Event Atom
Jika operasi join antara PC dengan PD dilakukan, maka hanya akan menghasilkan event atom yang baru yaitu PCD.
2. Event Atom dengan Sequence Atom
Jika operasi join dilakukan antara (PC)
dengan (P→A), maka hanya akan
menghasilkan sequences atom yang baru
yaitu (PC→A).
3. Sequence Atom dengan Sequence Atom Jika operasi join dilakukan antara (P→A)
dengan (P→C), maka akan menghasilkan tiga kemungkinan keluaran: sebuah event atom (P→AC), dua sequences atoms
(P→A→C) dan (P→C→A). Kasus khusus
akan timbul apabila operasi join dilakukan
antara (P→A) dengan dirinya sendiri yang
akan menghasilkan sequences atom yang baru yaitu (P→A→A).
6 apakah sequences tersebut frequent atau tidak.
Perhitungan support ini didasarkan pada jumlah sid yang berbeda yang terdapat pada id-list dari sequences yang terbentuk dari hasil temporal join tersebut. Sebagai contoh, dari data hypothetical id-list atom sequence (P→A) dan
(P→C) yang terdapat pada Lampiran 2 dilakukan temporal join id-list untuk semua sequences yang mungkin terbentuk yakni
(P→AC), (P→A→C), dan (P→C→A).
Penghitungan support dari id-list sequence
(P→AC) dilakukan dengan memeriksa
pasangan (sid,eid) yang sama antara (P→A) dan (P→C). Pasangan (sid,eid) yang memenuhi syarat dari data tersebut hanya ((8,30), (8,50), (8,80)) sehingga diperoleh id-list sequence
(P→AC) adalah L(P→AC) = {(8,30), (8,50), (8,80)}. Penghitungan support dari id-list sequence (P→A→C) dilakukan dengan memisalkan (sid, eid1) pada L(P→A) dan kemudian memeriksa apakah terdapat pasangan (sid, eid2) pada L(P→C) dengan sid yang sama tetapi eid2 > eid1, dan apabila terdapat pasangan yang memenuhi kriteria tersebut, ini berarti bahwa item C mengikuti item A untuk sequence yang diidentifikasi berdasarkan sid. Sequence (P→C→A) dikonstruksi dengan cara yang sama dengan membalik peran P→A dan
P→C.
METODE PENELITIAN
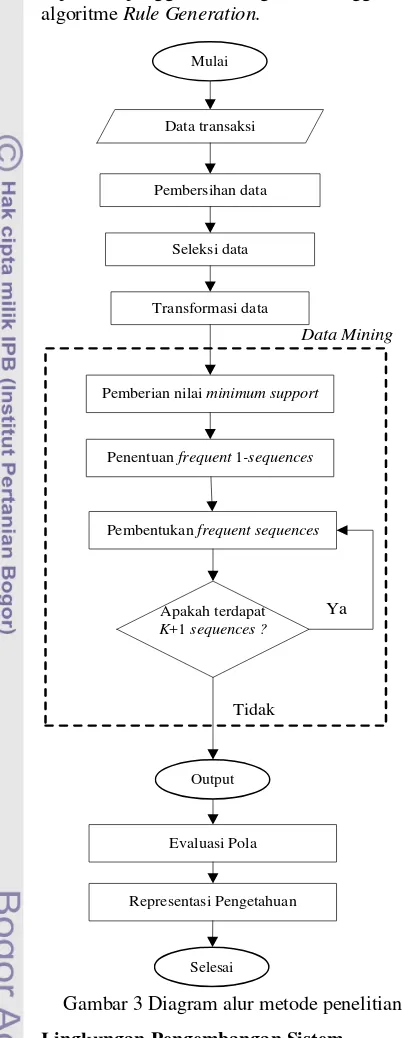
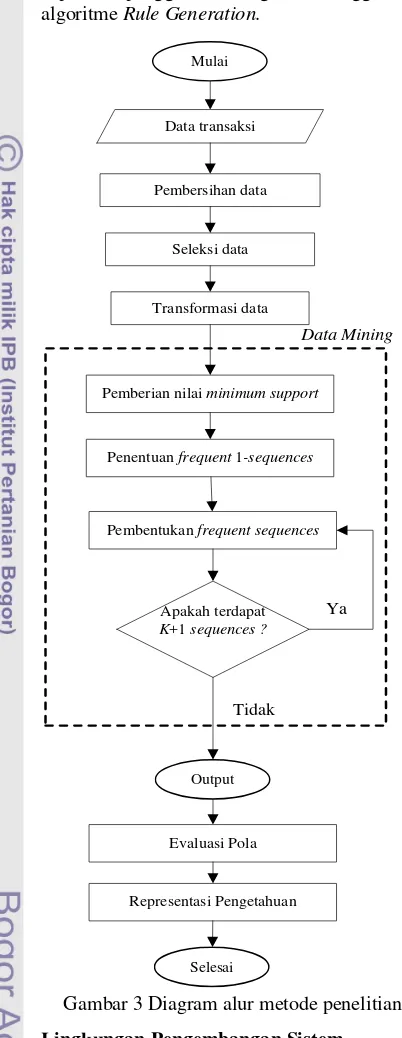
Proses Dasar Sistem
Proses dasar sistem mengacu pada proses dalam Knowledge Discovery from Data (KDD). Algoritme SPADE diterapkan pada tahap data mining. Diagram alur metode penelitian dapat dilihat pada Gambar 3. Tahapan KDD tersebut dapat diuraikan sebagai berikut :
1 Pembersihan data
Pembersihan data merupakan tahap yang dilakukan untuk menghilangkan noise dan data yang tidak konsisten. Pada tahap ini, transaksi yang terjadi pada waktu yang sama yang tercatat lebih dari satu kali akan dianggap sebagai satu transaksi. Selain itu, data yang tidak lengkap akan dibuang.
2 Seleksi data
Proses seleksi data merupakan proses pengambilan data yang relevan dengan proses analisis yang dilakukan. Pada tahap ini, akan dipilih atribut yang sesuai dengan kebutuhan algoritme, yaitu sid, eid, dan items.
3 Transformasi data
Data diubah ke dalam bentuk yang sesuai sebagai masukan bagi algoritme SPADE. Data diubah ke dalam bentuk numerik dan diurutkan secara menaik berdasarkan id customer (sid) dan waktu transaksi (eid).
4 Data mining
Tahap ini merupakan inti dari analisis data. Pada tahap ini diterapkan penggunaan algoritme SPADE yang diperkenalkan oleh Mohammed J. Zaki (2001).
Tahapan-tahapan yang akan digunakan pada metode tersebut, yaitu:
a Pemberian nilai minimum support
Pemberian nilai minimum support terhadap data merupakan syarat awal berjalannya algoritme. Nilai minimum support digunakan untuk menyaring nilai support bagi masing-masing frequent sequences setelah dilakukan proses komputasi menggunakan algoritme SPADE. Nilai support yang lebih kecil dari nilai minimum support yang diberikan tidak akan diperhitungkan.
b Penentuan frequent 1-sequences
Penentuan frequent 1-sequences merupakan langkah pertama dalam tahapan algoritme SPADE. Pembentukan frequent 1-sequences ditentukan berdasarkan nilai minimum support σ yang diberikan terhadap data. Semua item yang memiliki support lebih besar atau sama dengan nilai minimum support merupakan frequent items yang disebut juga frequent 1-sequences. Perhitungan support dari item didasarkan pada jumlah sid yang berbeda yang terdapat pada pasangan (sid, eid) atau yang disebut juga sebagai id-list dari item tersebut.
c Pembentukan frequent sequences
Pembentukan frequent sequences merupakan tahap akhir dari algoritme SPADE. Pada tahap ini, semua frequent sequences mulai dari frequent 2-sequences hingga frequent k-sequences dibangkitkan dengan menggunakan fungsi Enumerate-Frequent-Sequences.
5 Evaluasi Pola
6 apakah sequences tersebut frequent atau tidak.
Perhitungan support ini didasarkan pada jumlah sid yang berbeda yang terdapat pada id-list dari sequences yang terbentuk dari hasil temporal join tersebut. Sebagai contoh, dari data hypothetical id-list atom sequence (P→A) dan
(P→C) yang terdapat pada Lampiran 2 dilakukan temporal join id-list untuk semua sequences yang mungkin terbentuk yakni
(P→AC), (P→A→C), dan (P→C→A).
Penghitungan support dari id-list sequence
(P→AC) dilakukan dengan memeriksa
pasangan (sid,eid) yang sama antara (P→A) dan (P→C). Pasangan (sid,eid) yang memenuhi syarat dari data tersebut hanya ((8,30), (8,50), (8,80)) sehingga diperoleh id-list sequence
(P→AC) adalah L(P→AC) = {(8,30), (8,50), (8,80)}. Penghitungan support dari id-list sequence (P→A→C) dilakukan dengan memisalkan (sid, eid1) pada L(P→A) dan kemudian memeriksa apakah terdapat pasangan (sid, eid2) pada L(P→C) dengan sid yang sama tetapi eid2 > eid1, dan apabila terdapat pasangan yang memenuhi kriteria tersebut, ini berarti bahwa item C mengikuti item A untuk sequence yang diidentifikasi berdasarkan sid. Sequence (P→C→A) dikonstruksi dengan cara yang sama dengan membalik peran P→A dan
P→C.
METODE PENELITIAN
Proses Dasar Sistem
Proses dasar sistem mengacu pada proses dalam Knowledge Discovery from Data (KDD). Algoritme SPADE diterapkan pada tahap data mining. Diagram alur metode penelitian dapat dilihat pada Gambar 3. Tahapan KDD tersebut dapat diuraikan sebagai berikut :
1 Pembersihan data
Pembersihan data merupakan tahap yang dilakukan untuk menghilangkan noise dan data yang tidak konsisten. Pada tahap ini, transaksi yang terjadi pada waktu yang sama yang tercatat lebih dari satu kali akan dianggap sebagai satu transaksi. Selain itu, data yang tidak lengkap akan dibuang.
2 Seleksi data
Proses seleksi data merupakan proses pengambilan data yang relevan dengan proses analisis yang dilakukan. Pada tahap ini, akan dipilih atribut yang sesuai dengan kebutuhan algoritme, yaitu sid, eid, dan items.
3 Transformasi data
Data diubah ke dalam bentuk yang sesuai sebagai masukan bagi algoritme SPADE. Data diubah ke dalam bentuk numerik dan diurutkan secara menaik berdasarkan id customer (sid) dan waktu transaksi (eid).
4 Data mining
Tahap ini merupakan inti dari analisis data. Pada tahap ini diterapkan penggunaan algoritme SPADE yang diperkenalkan oleh Mohammed J. Zaki (2001).
Tahapan-tahapan yang akan digunakan pada metode tersebut, yaitu:
a Pemberian nilai minimum support
Pemberian nilai minimum support terhadap data merupakan syarat awal berjalannya algoritme. Nilai minimum support digunakan untuk menyaring nilai support bagi masing-masing frequent sequences setelah dilakukan proses komputasi menggunakan algoritme SPADE. Nilai support yang lebih kecil dari nilai minimum support yang diberikan tidak akan diperhitungkan.
b Penentuan frequent 1-sequences
Penentuan frequent 1-sequences merupakan langkah pertama dalam tahapan algoritme SPADE. Pembentukan frequent 1-sequences ditentukan berdasarkan nilai minimum support σ yang diberikan terhadap data. Semua item yang memiliki support lebih besar atau sama dengan nilai minimum support merupakan frequent items yang disebut juga frequent 1-sequences. Perhitungan support dari item didasarkan pada jumlah sid yang berbeda yang terdapat pada pasangan (sid, eid) atau yang disebut juga sebagai id-list dari item tersebut.
c Pembentukan frequent sequences
Pembentukan frequent sequences merupakan tahap akhir dari algoritme SPADE. Pada tahap ini, semua frequent sequences mulai dari frequent 2-sequences hingga frequent k-sequences dibangkitkan dengan menggunakan fungsi Enumerate-Frequent-Sequences.
5 Evaluasi Pola
7 6 Representasi Pengetahuan
Tahap ini merupakan tahap akhir dari proses KDD. Sederetan aturan atau rule disajikan kepada pengguna dengan menggunakan algoritme Rule Generation.
Transformasi data Data transaksi
Representasi Pengetahuan Pembentukan frequent sequences
Penentuan frequent 1-sequences
Evaluasi Pola Pemberian nilai minimum support
Apakah terdapat
K+1 sequences ?
Output
Selesai Mulai
Ya
Tidak
Data Mining
Seleksi data Pembersihan data
Gambar 3 Diagram alur metode penelitian.
Lingkungan Pengembangan Sistem
Spesifikasi perangkat keras dan perangkat lunak yang digunakan dalam pengembangan sistem adalah sebagai berikut :
a. Perangkat keras dengan spesifikasi : Processor : Intel(R) Core(TM) 2 Duo Memory : 1 GB
Harddisk : 160 GB
Monitor 14” dengan resolusi 1024 x
768 pixel
Alat input : mouse dan keyboard b. Perangkat lunak yang digunakan :
Sistem Operasi : Microsoft Windows 7 Professional
Microsoft Excel 2007 sebagai lembar kerja (worksheet) dalam pengolahan data
Microsoft Visual Studio 2010 sebagai IDE pembangunan sistem.
C++ dan C# sebagai bahasa pemrograman
HASIL DAN PEMBAHASAN
Pada penelitian ini, data yang digunakan adalah data transaksi pembelian Sinar Mart Swalayan selama periode waktu 1 Maret hingga 31 Maret 2004. Data transaksi pembelian yang didapat memiliki tiga atribut yaitu, customer id (sid), waktu transaksi (eid), dan barang yang dibeli (items). Data didapat dalam format Microsoft Excel (transaksi_maret2004.xlsx). Deskripsi sampel data transaksi pembelian Sinar Mart Swalayan dapat dilihat pada Lampiran 3.
Sebelum dilakukan proses mining, data harus melewati tahap praproses (preprocessing) terlebih dahulu yang meliputi pembersihan data, seleksi data, dan transformasi data. Tahapan praproses dilakukan agar data benar-benar lengkap, valid, dan sesuai dengan masukan yang dibutuhkan algoritme.
Pembersihan Data
Pembersihan data dilakukan untuk menghilangkan noise. Sebagai contoh, apabila pembelian barang yang sama pada waktu yang sama tercatat dua kali, maka pembelian barang tersebut dianggap hanya satu kali dan apabila terdapat data yang tidak sesuai dengan data yang ada di Sinar Mart Swalayan maka data tersebut akan dibuang. Pembersihan data pada penelitian ini tidak dilakukan karena data yang didapatkan sudah tidak memiliki noise dan sesuai dengan kebutuhan algoritme.
Seleksi Data
7 6 Representasi Pengetahuan
Tahap ini merupakan tahap akhir dari proses KDD. Sederetan aturan atau rule disajikan kepada pengguna dengan menggunakan algoritme Rule Generation.
Transformasi data Data transaksi
Representasi Pengetahuan Pembentukan frequent sequences
Penentuan frequent 1-sequences
Evaluasi Pola Pemberian nilai minimum support
Apakah terdapat
K+1 sequences ?
Output
Selesai Mulai
Ya
Tidak
Data Mining
Seleksi data Pembersihan data
Gambar 3 Diagram alur metode penelitian.
Lingkungan Pengembangan Sistem
Spesifikasi perangkat keras dan perangkat lunak yang digunakan dalam pengembangan sistem adalah sebagai berikut :
a. Perangkat keras dengan spesifikasi : Processor : Intel(R) Core(TM) 2 Duo Memory : 1 GB
Harddisk : 160 GB
Monitor 14” dengan resolusi 1024 x
768 pixel
Alat input : mouse dan keyboard b. Perangkat lunak yang digunakan :
Sistem Operasi : Microsoft Windows 7 Professional
Microsoft Excel 2007 sebagai lembar kerja (worksheet) dalam pengolahan data
Microsoft Visual Studio 2010 sebagai IDE pembangunan sistem.
C++ dan C# sebagai bahasa pemrograman
HASIL DAN PEMBAHASAN
Pada penelitian ini, data yang digunakan adalah data transaksi pembelian Sinar Mart Swalayan selama periode waktu 1 Maret hingga 31 Maret 2004. Data transaksi pembelian yang didapat memiliki tiga atribut yaitu, customer id (sid), waktu transaksi (eid), dan barang yang dibeli (items). Data didapat dalam format Microsoft Excel (transaksi_maret2004.xlsx). Deskripsi sampel data transaksi pembelian Sinar Mart Swalayan dapat dilihat pada Lampiran 3.
Sebelum dilakukan proses mining, data harus melewati tahap praproses (preprocessing) terlebih dahulu yang meliputi pembersihan data, seleksi data, dan transformasi data. Tahapan praproses dilakukan agar data benar-benar lengkap, valid, dan sesuai dengan masukan yang dibutuhkan algoritme.
Pembersihan Data
Pembersihan data dilakukan untuk menghilangkan noise. Sebagai contoh, apabila pembelian barang yang sama pada waktu yang sama tercatat dua kali, maka pembelian barang tersebut dianggap hanya satu kali dan apabila terdapat data yang tidak sesuai dengan data yang ada di Sinar Mart Swalayan maka data tersebut akan dibuang. Pembersihan data pada penelitian ini tidak dilakukan karena data yang didapatkan sudah tidak memiliki noise dan sesuai dengan kebutuhan algoritme.
Seleksi Data
8 Transformasi Data
Pada tahap ini dilakukan beberapa proses transformasi data, yaitu :
1. Konversi waktu transaksi (eid) ke dalam bentuk numerik. Waktu transaksi (eid) yang semula berformat date diubah menjadi numerik dengan mengganti format date menjadi number yang terdapat pada Microsoft Excel.
2. Konversi items ke dalam bentuk numerik. Items yang dibeli oleh pembeli diubah ke dalam bentuk numerik dengan memberikan kode yang dimulai dari 1 hingga 35. Mie instan dikodekan dengan 1, minyak goreng dikodekan dengan 2, demikian halnya dengan jenis barang lain. Format items yang dikonversi ke dalam bentuk numerik dapat dilihat pada Lampiran 4. Data hasil konversi terdiri atas 11.866 baris, 308 pembeli yang berbeda dan 35 items yang berbeda. Sampel data transaksi pembelian setelah praproses dapat dilihat pada Lampiran 5.
3. Data yang memiliki format Microsoft Excel (transaksi_maret2004.xlsx) kemudian diubah ke dalam format text (transaksi_maret2004.txt) sebagai masukan bagi algoritme SPADE.
Data Mining
Tahapan data mining diterapkan dengan menggunakan algoritme SPADE (Zaki 2001). Secara garis besar, proses ini dibagi menjadi 2 bagian besar, yaitu melakukan proses komputasi untuk mendapatkan frequent 1-sequences dengan nilai support lebih besar atau sama dengan minimum support. Frequent 1-sequences yang dihasilkan akan bertindak sebagai parent class pada proses pembentukan frequent sequences. Kedua, melakukan proses pembentukan frequent sequences berukuran k yang didapatkan dari kombinasi frequent sequences berukuran k-1 dengan menerapkan fungsi Enumerate Frequent sequences.
Proses ini akan berhenti jika tidak memungkinkan lagi untuk melakukan proses pembentukan (k+1)-sequences. Percobaan dilakukan terhadap data transaksi pembelian Sinar Mart Swalayan yang telah melewati tahap praproses sebanyak 11.866 record.
a Pemberian minimum support
Sebagai syarat awal berjalannya algoritme, pengguna harus terlebih dahulu memberikan nilai minimum support. Nilai minimum support digunakan untuk menyaring nilai support bagi
masing-masing frequent sequences setelah dilakukan proses komputasi menggunakan algoritme SPADE. Nilai support yang lebih kecil dari nilai minimum support yang diberikan tidak akan diperhitungkan.
Percobaan dilakukan terhadap data transaksi pembelian Sinar Mart Swalayan periode Maret 2004. Pada awalnya, nilai minimum support yang diberikan pada percobaan ini dimulai dari 10% hingga batas maksimum minimum support yang masih bisa membangkitkan frequent sequences dengan penambahan minimum support sebesar 1%. Namun, proses pembentukan frequent sequences dengan menggunakan nilai minimum support yang dimulai dari 10% hingga minimum support yang lebih kecil dari 45% membutuhkan waktu eksekusi yang sangat lama sehingga pemberian nilai minimum support yang dimulai dari 45% hingga batas maksimum yang masih bisa membangkitkan frequent sequences merupakan pemberian minimum support yang paling ideal untuk penelitian ini. Pembentukan frequent sequences dengan pemberian nilai minimum support mulai dari 10% hingga nilai minimum support yang lebih kecil dari 45% membutuhkan waktu eksekusi yang lama. Hal ini disebabkan oleh keterbatasan spesifikasi perangkat keras yang digunakan dalam penelitian ini.
b Penentuan frequent 1-sequences
Penentuan frequent 1-sequences merupakan langkah pertama dalam tahapan algoritme SPADE setelah pemberian minimum support. Semua item yang memiliki support lebih besar atau sama dengan nilai minimum support yang diberikan merupakan frequent items yang disebut juga frequent 1-sequences.
Perhitungan support dari item didasarkan pada jumlah sid yang berbeda yang terdapat pada pasangan (sid, eid) atau yang disebut juga sebagai id-list dari item tersebut. Untuk tahap selanjutnya, semua item yang merupakan frequent 1-sequences akan menjadi parent class dalam pembentukan frequent k-sequences. Dalam proses pembentukan frequent k-sequences, semua frequent sequences yang terbentuk disebut juga sebagai frequent atoms.
masing-9 masing nilai minimum support tidak langsung
ditampilkan karena masih digunakan pada proses pembentukan frequent k-sequences untuk mendapatkan semua frequent sequences.
c Pembentukan frequent sequences
Pada tahap ini, metode sequential pattern mining diterapkan untuk membangkitkan semua kemungkinan frequent sequence dengan menggunakan fungsi Enumerate-Frequent-Sequences yang terdapat pada algoritme SPADE. Sebuah sequence berukuran k merupakan kombinasi dari sequences berukuran k-1
Percobaan dilakukan terhadap data transaksi pembelian Sinar Mart Swalayan periode Maret 2004. Percobaan dilakukan dengan memberikan nilai minimum support mulai dari 45% atau sekitar 138 transaksi yang dilakukan pembeli yang berbeda hingga batas maksimum yang masih bisa membentuk frequent sequences dengan penambahan nilai minimum support sebesar 1%. Dari data hasil percobaan diperoleh bahwa jumlah frequent sequences yang terbentuk bervariasi. Data percobaan dengan nilai minimum support 45% menghasilkan frequent sequences sebanyak 1.902 frequent sequences. Nilai minimum support tertinggi hingga masih terbentuk frequent sequences adalah 89% dengan jumlah frequent sequnces sebanyak satu. Hasil lengkap pembentukan frequent sequences yang terbentuk dari data transaksi pembelian Sinar Mart Swalayan periode Maret 2004 dapat dilihat pada Lampiran 6.
Pada beberapa minimum support yang digunakan pada saat percobaan, ternyata frequent sequence tidak terbentuk. Hal ini disebabkan karena tidak adanya frequent 1-sequences yang terbentuk. Tidak terbentuknya frequent 1-sequences disebabkan oleh tidak ada satu pun item atau barang yang memiliki support yang lebih besar atau sama dengan minimum support yang diberikan.
Berdasarkan data hasil percobaan pada Lampiran 6, dapat dilihat bahwa semakin besar nilai minimum support yang diberikan maka akan semakin sedikit jumlah frequent sequences yang terbentuk.
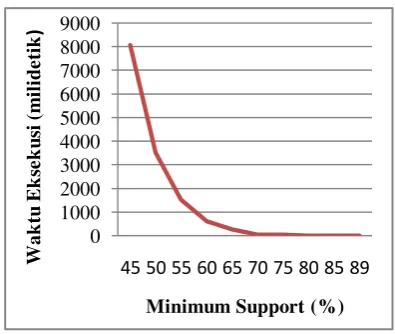
Waktu eksekusi yang diperlukan untuk membentuk frequent sequence sangat dipengaruhi minimum support yang digunakan. Perbandingan waktu eksekusi yang diperlukan untuk membentuk frequent sequences dari seluruh percobaan yang telah dilakukan dapat dilihat pada Gambar 4.
Gambar 4 Grafik waktu eksekusi.
Berdasarkan Gambar 4, semakin tinggi nilai minimum support yang diberikan maka semakin cepat waktu yang diperlukan untuk membentuk frequent sequences. Hal ini disebabkan semakin besar nilai minimum support maka akan semakin sedikit sequences yang membentuk frequent sequences sehingga waktu komputasinya akan semakin cepat.
Evaluasi Pola
Seluruh frequent sequences yang dihasilkan pada tahap data mining kemudian dievaluasi untuk mendapatkan pola sekuensial. Evaluasi dilakukan dengan mencari maximal frequent sequences dari seluruh frequent sequences yang ada. Suatu pola sekuensial dikatakan maksimal apabila pola sekuensial tersebut tidak termuat pada pola sekuensial lainnya.
Dari seluruh pola sekuensial yang terbentuk diambil pola sekuensial dengan jumlah k-sequences maksimal pada nilai minimum support tertinggi yang dilakukan selama tahap percobaan.
Suatu pola sekuensial dikatakan sering terjadi apabila pola sekuensial tersebut memiliki nilai support yang tinggi. Daftar pola sekuensial yang sering terjadi dari seluruh percobaan yang yang telah dilakukan pada data transaksi pembelian Sinar Mart Swalayan periode Maret 2004 dapat dilihat pada Tabel 2.
Dari evaluasi pola yang terdapat pada Tabel 2, diperoleh informasi sebagai berikut:
Nilai minimum support tertinggi yang masih bisa membentuk maximal frequent sequences adalah 89% dengan panjang sequences adalah 1-sequence.
Item yang paling sering dibeli oleh pembeli Sinar Mart Swalayan adalah snack (8) dengan support sebesar 89%.
0 1000 2000 3000 4000 5000 6000 7000 8000 9000
45 50 55 60 65 70 75 80 85 89
Wak tu Ek se k u si (m il id e ti k )
10 Tabel 2 Daftar pola sekuensial yang sering terjadi
Minimum Support
(%)
Panjang Sequence
maksimal Contoh Sequence
45-47 7-sequence <8><8><8><8><8><7><8> 48-54 6-sequence <8><8><8><8><8><8> 55-59 5-sequence <8><8><8><8><8> 60-62 4-sequence <8><8><7><8> 63-65 3-sequence <8><3><8> 66-73 2-sequence <3,8> 74-89 1-sequence <8>
Representasi Pengetahuan
Representasi pengetahuan dari pola sekuensial yang dihasilkan diperlukan agar pola yang ada mudah dimengerti dan diinterpretasikan. Berdasarkan hasil presentasi diharapkan dapat diperoleh pengetahuan yang berharga dari koleksi data yang telah dilakukan proses mining. Tahap representasi pengetahuan dilakukan dengan membentuk rule menggunakan algoritme Rule Generation.
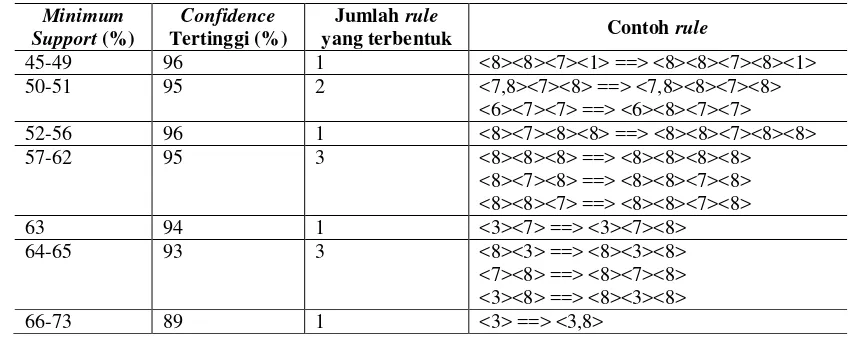
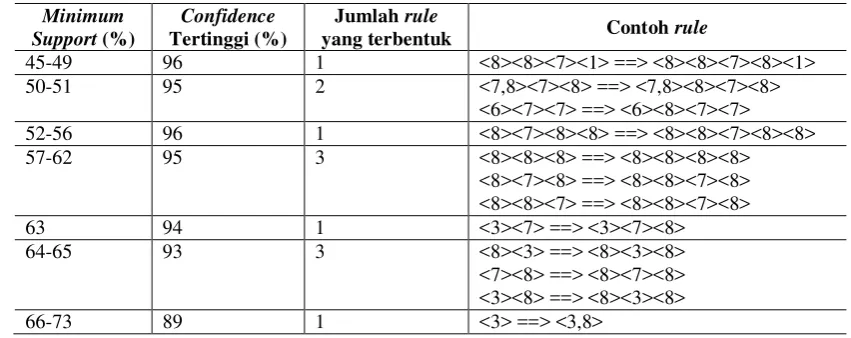
Percobaan dilakukan terhadap data transaksi pembelian Sinar Mart Swalayan periode Maret 2004. Percobaan dilakukan dengan mencari kemungkinan minimum confidence maksimal untuk setiap minimum support dimulai dari 45% hingga batas maksimal minimum confidence yang masih bisa membangkitkan rule. Dari data hasil percobaan diperoleh bahwa banyaknya rule yang terbentuk dari berbagai kombinasi nilai minimum support dengan nilai minimum confidence bervariasi. Hasil pembentukan rule dapat dilihat pada Tabel 3.
Data hasil percobaan yang terdapat pada Tabel 3 menunjukkan bahwa:
Nilai minimum confidence tertinggi yang masih bisa membentuk rule adalah 96% dengan nilai maksimal minimum support nya sebesar 56%.
Nilai minimum support tertinggi yang masih bisa membentuk rule adalah 73% dengan nilai maksimal minimum confidence sebesar 89% dan jumlah rule yang terbentuk sebanyak satu buah yaitu (susu) ==> (susu, snack). Rule (susu) ==> (susu, snack) yang memiliki confidence sebesar 89% mengandung arti bahwa apabila pembeli Sinar Mart Swalayan membeli susu maka peluang snack juga dibeli oleh pembeli tersebut adalah sebesar 89%.
Berdasarkan hasil penelitian, terdapat beberapa saran bagi pengelola Sinar Mart Swalayan, yaitu :
Menempatkan susu dan snack secara berdekatan pada rak yang sama sehingga pembeli dapat dengan mudah menjangkau kedua produk tersebut.
Memperbanyak variasi susu dan snack sehingga dapat menarik perhatian pembeli. Sebagai upaya untuk meningkatkan
11 Tabel 3 Hasil pembentukan rule
Minimum Support (%)
Confidence
Tertinggi (%)
Jumlah rule
yang terbentuk Contoh rule
45-49 96 1 <8><8><7><1> ==> <8><8><7><8><1> 50-51 95 2 <7,8><7><8> ==> <7,8><8><7><8>
<6><7><7> ==> <6><8><7><7> 52-56 96 1 <8><7><8><8> ==> <8><8><7><8><8> 57-62 95 3 <8><8><8> ==> <8><8><8><8>
<8><7><8> ==> <8><8><7><8> <8><8><7> ==> <8><8><7><8> 63 94 1 <3><7> ==> <3><7><8> 64-65 93 3 <8><3> ==> <8><3><8> <7><8> ==> <8><7><8> <3><8> ==> <8><3><8> 66-73 89 1 <3> ==> <3,8>
Untuk melakukan proses pembentukan frequent sequences dan juga pembentukan rule, telah dibangun sebuah aplikasi sederhana dengan menggunakan C++ dan C# sebagai bahasa pemrograman dan Visual Studio 2010 sebagai IDE pembangunan aplikasi. Salah antarmuka grafis dari aplikasi tersebut dapat dilihat pada Gambar 5.
Gambar 7 Antarmuka grafis aplikasi utama.
KESIMPULAN DAN SARAN
Kesimpulan
Dari hasil percobaan dengan penerapan algoritme SPADE yang dilakukan terhadap data transaksi pembelian di Sinar Mart Swalayan diperoleh kesimpulan bahwa nilai minimum support tertinggi hingga masih terbentuk
frequent sequence terjadi pada nilai minimum support 89% dengan frequent sequence yang terbentuk sebanyak satu buah yang sekaligus merupakan maximal frequent sequences. Maximal frequent sequences yang terbentuk ketika minimum support yang diberikan sebesar 89% adalah sequence yang panjang sequence nya 1 (frequent 1-sequences) yaitu (<8>) atau (<snack>). Frequent sequences yang hanya memiliki satu item menandakan bahwa item tersebut merupakan item yang paling sering dibeli oleh pembeli.
Dari hasil percobaan juga diperoleh bahwa nilai minimum confidence tertinggi hingga masih bisa membentuk rule adalah 96% dengan nilai maksimal minimum support sebesar 56%. Nilai minimum support tertinggi yang masih bisa membentuk rule adalah 73% dengan nilai maksimal minimum confidence sebesar 89% dengan jumlah rule yang terbentuk sebanyak satu buah yaitu (susu) ==> (susu, snack). Hal ini menunjukkan bahwa susu dan snack merupakan barang yang paling sering dibeli oleh pembeli Sinar Mart Swalayan.
11 Tabel 3 Hasil pembentukan rule
Minimum Support (%)
Confidence
Tertinggi (%)
Jumlah rule
yang terbentuk Contoh rule
45-49 96 1 <8><8><7><1> ==> <8><8><7><8><1> 50-51 95 2 <7,8><7><8> ==> <7,8><8><7><8>
<6><7><7> ==> <6><8><7><7> 52-56 96 1 <8><7><8><8> ==> <8><8><7><8><8> 57-62 95 3 <8><8><8> ==> <8><8><8><8>
<8><7><8> ==> <8><8><7><8> <8><8><7> ==> <8><8><7><8> 63 94 1 <3><7> ==> <3><7><8> 64-65 93 3 <8><3> ==> <8><3><8> <7><8> ==> <8><7><8> <3><8> ==> <8><3><8> 66-73 89 1 <3> ==> <3,8>
Untuk melakukan proses pembentukan frequent sequences dan juga pembentukan rule, telah dibangun sebuah aplikasi sederhana dengan menggunakan C++ dan C# sebagai bahasa pemrograman dan Visual Studio 2010 sebagai IDE pembangunan aplikasi. Salah antarmuka grafis dari aplikasi tersebut dapat dilihat pada Gambar 5.
Gambar 7 Antarmuka grafis aplikasi utama.
KESIMPULAN DAN SARAN
Kesimpulan
Dari hasil percobaan dengan penerapan algoritme SPADE yang dilakukan terhadap data transaksi pembelian di Sinar Mart Swalayan diperoleh kesimpulan bahwa nilai minimum support tertinggi hingga masih terbentuk
frequent sequence terjadi pada nilai minimum support 89% dengan frequent sequence yang terbentuk sebanyak satu buah yang sekaligus merupakan maximal frequent sequences. Maximal frequent sequences yang terbentuk ketika minimum support yang diberikan sebesar 89% adalah sequence yang panjang sequence nya 1 (frequent 1-sequences) yaitu (<8>) atau (<snack>). Frequent sequences yang hanya memiliki satu item menandakan bahwa item tersebut merupakan item yang paling sering dibeli oleh pembeli.
Dari hasil percobaan juga diperoleh bahwa nilai minimum confidence tertinggi hingga masih bisa membentuk rule adalah 96% dengan nilai maksimal minimum support sebesar 56%. Nilai minimum support tertinggi yang masih bisa membentuk rule adalah 73% dengan nilai maksimal minimum confidence sebesar 89% dengan jumlah rule yang terbentuk sebanyak satu buah yaitu (susu) ==> (susu, snack). Hal ini menunjukkan bahwa susu dan snack merupakan barang yang paling sering dibeli oleh pembeli Sinar Mart Swalayan.
12 suatu barang, keinginan mereka untuk
menikmati snack dan susu juga terpuaskan tanpa harus membeli.
Saran
Penerapan algoritme SPADE pada data transaksi pembelian Sinar Mart Swalayan yang hanya terdiri atas pembelian selama kurun waktu satu bulan masih belum bisa mewakili pola pembelian yang sesungguhnya yang terjadi di Sinar Mart Swalayan. Terdapat beberapa faktor lain yang mempengaruhi pola pembelian suatu barang, di antaranya musim, dan juga hari besar keagamaan sehingga pengambilan data dalam kurun waktu satu bulan belum relevan untuk menunjukkan pola pembelian yang sesungguhnya. Oleh karena itu, diharapkan pada penelitian selanjutnya dilakukan analisis terhadap data yang lebih besar dan mewakili setiap bulan selama satu tahun sehingga diperoleh gambaran nyata dari pola pembelian yang sesungguhnya.
Gambaran nyata yang terlihat dari pola sekuensial yang terbentuk dapat dijadikan sebagai acuan untuk mengambil kebijakan terkait dengan data tersebut. Disamping itu, analisis terhadap data transaksi pembelian juga dapat dilakukan dengan menerapkan algoritme lain seperti PrefixSpan serta membandingkan hasil percobaan yang diperoleh dengan penerapan algoritme SPADE yang dilakukan pada penelitian ini sehingga dapat dilihat perbedaan antara algoritme SPADE dengan algoritme lain. Perbedaan antara algoritme tersebut dapat dilihat dari waktu eksekusi yang dibutuhkan untuk membentuk pola sekuensial.
Algoritme SPADE juga dapat diterapkan pada data log akses server suatu situs web untuk melihat pola kunjungan dari situs web tersebut. Atribut dari data log akses server web yang dapat dijadikan sebagai masukan bagi algoritme SPADE, yaitu alamat IP sebagai sid, date / waktu pengaksesan sebagai eid, dan URL yang dikunjungi sebagai items.
DAFTAR PUSTAKA
Davey, B. A. & Priestley, H. A. 1990. Introduction to lattices and order. Cambridge: Cambridge University Press.
Han J & Kamber M. 2006. Data Mining: Concept and Techniques. Edisi ke-2. San Diego, USA: Morgan-Kauffman.
Santoso B. 2007. Data Mining: Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta: Graha Ilmu.
PENENTUAN POLA SEKUENSIAL DATA TRANSAKSI PEMBELIAN
MENGGUNAKAN ALGORITME
SPADE
RIFERSON SIJABAT
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENENTUAN POLA SEKUENSIAL DATA TRANSAKSI PEMBELIAN
MENGGUNAKAN ALGORITME
SPADE
RIFERSON SIJABAT
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENENTUAN POLA SEKUENSIAL DATA TRANSAKSI PEMBELIAN
MENGGUNAKAN ALGORITME
SPADE
RIFERSON SIJABAT
Skripsi
Sebagai salah satu syarat untuk memperoleh
gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
RIFERSON SIJABAT. Sequential Pattern Discovery on Sales Transaction Data using SPADE Algorithm. Supervised by MEUTHIA RACHMANIAH and ANNISA.
The rapid development of information technology that is happening these days requires people to adapt into these developments. This human efforts can be seen from the many activities carried out by computerization that produces large amounts of data. From these available abundant data, the discovery of useful knowledge from large database becomes popular and attractive. This discovery of useful knowledge can be done using the concept of sequential pattern mining. One of the algorithms that applies the concept of sequential pattern mining is Sequential Pattern Discovery using Equivalence classes (SPADE) that is able to determine the sequential pattern of a data transaction. By adopting the functions contained in the SPADE algorithm, the purchasing tendency of items by customer at a specific time period can be seen. This research use the purchase transactions data of Sinar Mart Swalayan in period of 1 March to 31 March 2004. In this research, the minimum support was tested starting from 45% to 89% and minimum confidence from 20% to 96%. Minimum support and minimum confidence which is given is determined based on the condition of the data. Experimental results showed that the maximum value of minimum support that still could generate frequent sequences was 89%.
Judul Skripsi
Nama
NIM
:
:
:
Penentuan Pola Sekuensial Data Transaksi Pembelian
Menggunakan Algoritme
SPADE
Riferson Sijabat
G64060063
Menyetujui :
Pembimbing I,
Pembimbing II,
Ir. Meuthia Rachmaniah, M.Sc.
Annisa, S.Kom., M.Kom.
NIP 19590711 198403 2 001 NIP 19790731 200501 2 002
Mengetahui :
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc.
NIP 19601126 198601 2 001
PRAKATA
Puji syukur penulis panjatkan kepada Tuhan Yesus Kristus atas segala rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan tugas akhir dengan judul Penentuan Pola Sekuensial Data Transaksi Pembelian Menggunakan Algoritme SPADE. Tugas akhir ini merupakan salah satu syarat untuk memperoleh gelar Sarjana Komputer di FMIPA IPB.
Penghargaan serta rasa terima kasih penulis sampaikan kepada Ibu Ir. Meuthia Rachmaniah, M.Sc. dan Ibu Annisa, S.Kom., M.Kom. selaku pembimbing yang telah bersedia meluangkan waktu serta memberikan saran dan bimbingannya selama penelitian dan penulisan tugas akhir ini. Penghargaan dan rasa terima kasih juga penulis sampaikan kepada Bapak Rindang Karyadin, ST., M.Kom. yang telah berkenan sebagai moderator dan penguji dalam pelaksanaan seminar dan sidang.
Penulis menyampaikan terima kasih dan penghargaan yang sangat mendalam kepada seluruh keluarga, Ayahanda L. Sijabat, Ibunda R. Purba (Almh), dan kakak-kakakku tercinta yang senantiasa memberikan dukungan moral, doa, kasih sayang, dan perhatian. Penulis menyampaikan terima kasih kepada sahabatku (Corry, Eka, Eko, Mada, dan Sandro), Kak Irfan, Kak Edo, Ilkom 43 (Hendrex, Wildan, dan Luqman) atas dukungan, motivasi dan masukan yang telah diberikan. Semua teman-teman Ilkom 43 lainnya, terima kasih untuk persahabatan dan kebersamaan selama kuliah di Ilkom IPB. Penulis juga menyampaikan terima kasih kepada teman-teman di Pondok Syalom (Dhimas, Doli, Zega, Rudy, dan Sylvester) dan juga Komisi Literatur 43 PMK IPB atas doa, bantuan dan motivasinya.
Penulis mengucapkan terima kasih kepada seluruh staf pengajar yang telah memberikan wawasan serta ilmu yang berharga selama penulis menuntut ilmu di Departemen Ilmu Komputer. Seluruh staf administrasi dan perpustakaan Departemen Ilmu Komputer FMIPA IPB yang selalu memberi kemudahan dalam mengurus segala macam hal berkaitan dengan perkuliahan, serta pihak-pihak lain yang tidak dapat disebutkan satu-persatu.
Penulis menyadari bahwa tugas akhir ini masih jauh dari sempurna. Namun, penulis berharap semoga tugas akhir ini dapat memberikan manfaat bagi pembacanya.
Bogor, Mei 2011
RIWAYAT HIDUP
Penulis dilahirkan pada tanggal 3 September 1986 di Gambiri, Sumatera Utara. Penulis merupakan anak kesembilan dari sembilan bersaudara pasangan L. Sijabat dan R. Purba (almh).
Pada tahun 2005, penulis lulus dari Sekolah Menengah Atas (SMA) Negeri 4 Pematang Siantar dan pada tahun 2006 diterima di Institut Pertanian Bogor (IPB) melalui jalur Seleksi Penerimaan Mahasiswa Baru (SPMB) di Tingkat Persiapan Bersama (TPB). Pada tahun 2007, penulis diterima di Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam (FMIPA) IPB.
Selama mengikuti perkuliahan, penulis pernah menjadi pengurus Himpunan Mahasiswa Ilmu Komputer (HIMALKOM) IPB tahun kepengurusan 2007/2008. Pada tahun 2009, penulis melakukan kegiatan praktik lapang selama dua bulan di PT. Waindo Specterra Jakarta dengan bidang kajian Sistem Informasi Tender. Pada tahun 2010, penulis terpilih mewakili Indonesia pada “17th
DAFTAR ISI
Halaman
DAFTAR TABEL... v
DAFTAR GAMBAR... v
DAFTAR LAMPIRAN... v
PENDAHULUAN
Latar Belakang ... 1 Tujuan .. ... 1 Ruang Lingkup ... 1 Manfaat Penelitian... ..1
TINJAUAN PUSTAKA
Knowledge Discovery in Database (KDD) ... 1 Association Rule Mining ... 2 Pola Sekuensial... 2 Pendekatan Hyper-lattice ... 3 Equivalence Class... 3 SPADE Algorithm ... 3 Rule Generation ... 5 Temporal join of id-lists ... 5
METODE PENELITIAN
Proses Dasar Sistem ... 6 Lingkungan Pengembangan Sistem ... 7
HASIL DAN PEMBAHASAN
Pembersihan Data ... 7 Seleksi Data ... 7 Transformasi Data ... 8 Data Mining ... 8 a Pemberian minimum support ... 8 b Penentuan frequent 1-sequences ... 8 c Pembentukan frequent sequences ... 9 Evaluasi Pola ... 9 Representasi Pengetahuan ... 10
KESIMPULAN DAN SARAN
Kesimpulan ... 11 Saran ... 12
DAFTAR PUSTAKA ... 12
LAMPIRAN ... 13
DAFTAR TABEL
Halaman
1 Sampel database vertikal ... 3 2 Daftar pola sekuensial yang sering terjadi ... 10 3 Hasil pembentukan rule ... 11
DAFTAR GAMBAR
Halaman
1 Tahapan proses KDD... 2 2 Id-list item A ... 4 3 Diagram alur metode penelitian ... 7 4 Grafik waktu eksekusi ... 9 5 Antarmuka grafis aplikasi utama ... 11
DAFTAR LAMPIRAN
Halaman
1 Struktur hyper-lattice berdasarkan equivalence class ... 14 2 Temporal id-list join ... 15 3 Deskripsi sampel data transaksi pembelian Sinar Mart Swalayan ... 16 4 Format konversi items ke dalam bentuk numerik ... 17 5 Sampel data transaksi pembelian setelah praproses ... 18 6 Hasil pembentukan frequent sequences ... 19
1 PENDAHULUAN
Latar Belakang
Perkembangan teknologi informasi yang sangat pesat yang terjadi dewasa ini menuntut manusia untuk mampu beradaptasi dengan perkembangan tersebut. Upaya adaptasi yang dilakukan manusia dapat dilihat dari banyaknya kegiatan yang dilakukan secara komputerisasi sehingga menghasilkan data dalam jumlah yang besar. Dengan ketersediaan data yang semakin melimpah tersebut, penemuan pengetahuan yang berguna dari suatu database yang besar semakin populer dan menarik perhatian.
Penemuan pengetahuan yang berguna tersebut dapat dilakukan menggunakan teknik data mining. Data mining merupakan proses ekstraksi informasi atau pola dalam database yang berukuran besar (Han & Kamber 2006). Salah satu teknik data mining adalah sequential pattern mining yang berguna untuk menemukan pola sekuensial yang terdapat pada database yang pertama kali diperkenalkan oleh Agrawal dan Srikant pada tahun 1995.
Pada database, salah satu data yang sering dijumpai adalah data transaksi. Data transaksi merupakan data konsumen atau pelanggan pada sebuah lembaga komersil maupun non-komersil yang berisi id konsumen, waktu transaksi, dan item transaksi. Dari data transaksi seperti halnya transaksi supermarket, dapat ditemukan pola sekuensial untuk mengetahui keterkaitan antarbarang atau item.
Salah satu algoritme yang dapat digunakan untuk mengetahui pola sekuensial dari suatu data transaksi yaitu Sequential PAttern Discovery using Equivalence classes (SPADE). Algoritme SPADE merupakan algoritme berbasis candidate generation and test dan merupakan penyempurnaan dari algoritme penentuan pola