SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
TITA TJAHYATI
10110400
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
BIODATA
Data Pribadi
Nama : Tita Tjahyati
Tempat/Tanggal Lahir : Bandung,15 Juli 1992
Jenis Kelamin : Perempuan
Alamat : Jl. Sindanglaya-Arcamanik No.27, Bandung
No. Telp : 085624281072
Email : [email protected]
Riwayat Pendidikan
1998–2004 Lulus SDN 06 Sindanglaya 2004–2007 Lulus SMPN 49 Bandung 2007–2010 Lulus SMAN 16 Bandung 2010–2014 Universitas Komputer Indonesia
v
KATA PENGANTAR ...iii
DAFTAR ISI... v
DAFTAR GAMBAR ...viii
DAFTAR TABEL... ix
DAFTAR SIMBOL... x
DAFTAR LAMPIRAN... xi BAB 1 PENDAHULUAN... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 2
1.3 Maksud dan Tujuan ... 3
1.4 Batasan Masalah ... 3
1.5 Metode Penelitian... 4
1.6 Sistematika Penulisan... 5
BAB 2 LANDASAN TEORI ... 7
2.1 Pengertian Deteksi... 7
2.2 Pengertian Disleksia ... 7
2.3 Kecerdasan Buatan ... 11
vi
2.3.2. MetodeNaïve Bayesian... 13
2.4 Metode Pengujian... 16
2.4.1. White Box ... 16
2.4.2. Black Box... 16
2.5 WAMP SERVER2.2 ... 17
2.6 PHP(Hypertext Prepocessor)... 17
2.7 MySQL ... 18
2.8 Adobe dreamweaver CS 5 ... 20
2.9 Adobe Photoshop CS 3... 21
BAB 3 ANALISIS METODE ... 23
3.1 Analisis Masalah ... 23
3.2 Alur Pendeteksi ... 24
3.3 Analisis Gejala Disleksia... 25
3.3.1 Analisis Data Masukkan ... 26
3.3.2 Analisis Data Keluaran ... 29
3.4 Tahapan Analisis Metode ... 30
3.4.1 Perhitungan Metode ... 31
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM ... 55
4.1 Implementasi Sistem ... 55
4.1.1 Implementasi Perangkat Keras... 55
4.1.2 Implementasi Perangkat Lunak... 56
4.1.3 Implementasi Antarmuka ... 56
vii
BAB 5 PENUTUP ... 75
5.1 Kesimpulan... 75
5.2 Saran ... 75
76
77 Factor Berbasis Web," no. 2085-9902, 2012.
[2] D. L. Fithri, "Sistem Pendeteksian Penyimpangan Tingkah Laku Anak Usia 0 sampa 3 tahun dengan Metode Bayesian," Simetris, vol. 4, no. 2252-4983, Nov. 2013.
[3] T. D. A. o. Indonesia. (2012, Nov.) Dyslexia Associztion of Indonesia. [Online]. http://dyslexiaindonesia.com
iii
KATA PENGANTAR
Puji dan syukur penulis panjatkan kehadirat Allah SWT atas berkat rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul :
“ANALISIS PERBANDINGAN METODE CERTAINTY FACTOR DAN
NAÏVE BAYESIAN DALAM MENDETEKSI KEMUNGKINAN ANAK
TERKENA DISLEKSIA”.
Tugas Akhir ini diajukan untuk memenuhi syarat mata kuliah Tugas Akhir program STRATA I Program Studi Teknik Informatika, Fakultas Teknik dan Ilmu Komputer, Universitas Komputer Indonesia (UNIKOM), Bandung. Dengan terselesaikannya Tugas Akhir ini, Penulis ungkapkan rasa syukur yang tiada terhingga kepada Allah SWT. dan Penulis mengucapkan terimakasih kepada :
1. Kedua Orang Tua yang saya hormati dan saya cintai yang telah memberikan kepada Penulis dukungan dan motivasi untuk menyelesaikan laporan Tugas Akhir ini.
2. Ibu Utami Dewi W,S.Kom.,M.Kom. selaku dosen pembimbing dan penguji 2 yang telah menyelesaikan waktunya dan memberikan banyak masukan kepada penulis.
3. Ibu Nelly Indriani Widiastuti,S.Si.,M.T. selaku reviewer dan Penguji 1 yang telah menyediakan waktunya dan memberikan banyak masukan kepada penulis.
4. Ibu Sufaatin S.T.,M.Kom. selaku Penguji 3 dan sebagai dosen wali yang telah menyediakan waktunya dan memberikan banyak masukan kepada penulis.
iv
Teknik dan Ilmu Komputer Universitas Komputer Indonesia.
8. Kakak saya, Tanti Nurhayati dan Wina Winiarti yang saya sayangi yang telah memberikan saya motivasi untuk menyelesaikan tugas akhir ini. 9. Rekan-rekan seperjuangan IF-09 angkatan 2010 yang selalu memberikan
semangat dan motivasi kepada penulis.
10. Rekan-rekan satu bimbingan Ibu Utami, rekan-rekan reviewer ibu Nelly. 11. Kepada Muhammad Akhdiat Munggaran terimakasih atas semua doa dan
dukungan selama ini yang selalu memberikan semangat dan motivasi kepada penulis sehingga bisa menyelesaikan skripsi ini.
12. Sahabat – sahabatku Dwikeu Novi Asrika, Dien Amalia, Eka Anisya,
Leni Mariani, Wulan fitriani, dan Mukti Alamsyah yang selalu memberikan semangat saat penulis butuh motivasi.
13. Pihak-pihak yang telah membantu yang tidak dapat disebutkan satu persatu.
Akhir kata, Penulis berharap semoga laporan ini dapat bermanfaat bagi para pembaca.
Bandung, 19 Agustus 2014
1
BAB 1
PENDAHULUAN
1.1 Latar Belakang Masalah
Deteksi merupakan suatu cara untuk mengetahui jenis masalah atau cara untuk menyelesaikan suatu permasalahan untuk membuat keputusan maupun pengambilan kesimpulan. Deteksi juga dapat digunakan pada penyakit atau gangguan terhadap anak-anak seperti disleksia, karena disleksia adalah gangguan terhadap anak yang terkadang gejalanya tidak diketahui karena anak tersebut terlihat normal, maka dari itu dibutuhkan suatu deteksi agar dapat mengetahui dengan benar mengenai disleksia. Anak terkena disleksia adalah anak yang mengalami salah satu gangguan dalam belajar yang mengkhawatirkan yang mengalami kesulitan dalam membaca, tetapi juga dalam hal mengeja, menulis dan sebagai suatu kondisi pemrosesan input atau informasi yang berbeda dari anak normal yang seringkali ditandai dengan kesulitan dalam membaca, yang dapat mempengaruhi daya ingat, kecepatan pemrosesan input, kemampuan pengaturan waktu, aspek koordinasi dan pengendalian gerak.
Dalam suatu deteksi, akurasi data adalah suatu komponen yang penting demi tercapainya solusi yang diharapkan. Dalam penelitian sebelumnya terdapat jurnal yang diteliti oleh Putu Ary Darma Yasa yang berjudul Sistem Pakar Penyakit Kulit pada Manusia Menggunakan Metode Certainty Factor
mendeteksi tingkah laku anak melalui gejala-gejala yang sudah ada tetapi dalam jurnal tersebut tidak dijelaskan mengenai tingkat akurasi metode Bayesian dalam mendeteksi kasus tersebut. Dalam kedua penelitian tersebut hanya metode Certainty Factor yang memiliki tingkat akurasi sedangkan metode
Bayesian tidak memiliki tingkat akurasi pada kasus tersebut. Maka dari itu akan dilakukan suatu analisis perbandingan mengenai akurasi dari kedua metode tersebut dengan kasus yang sama yaitu dalam mendeteksi kemungkinan anak terkena disleksia. Karena tidak diketahui apakah hasil akurasi yang dihasilkan oleh Certainty Factor akan lebih besar atau tidak begitu juga dengan Naïve
Bayesian apakah dapat menghasilkan akurasi yang lebih baik dari metode
Certainty Factor atau tidak jika dibandingkan dalam kasus yang sama. Karena suatu metode yang baik untuk suatu kasus belum tentu baik untuk kasus yang berbeda.
Berdasarkan permasalahan tersebut maka diterapkan metode Certainty Factor dan Naïve Bayesian dalam mendeteksi kemungkinan anak terrkena disleksia dan dibutuhkan suatu analisis perbandingan antara metode Certainty Factor dan Naïve Bayesian untuk mengetahui metode mana yang lebih baik dalam ketepatan akurasi data dengan jumlah masukkan yang sama melalui gejala-gejala disleksia.
1.2 Rumusan Masalah
3
1.3 Maksud dan Tujuan
Maksud dari penelitian ini adalah menganalisis perbadningan metode
Certainty Factor dan Naïve Bayesian dalam mendeteksi kemungkinan anak terkena disleksia.
Adapun tujuan dari penelitian ini adalah untuk menentukan satu metode diantara metode Certainty Factor dan Naïve Bayesian yang memiliki akurasi data yang paling baik dalam mendeteksi kemungkinan anak terkena disleksia.
1.4 Batasan Masalah
Batasan masalah dalam penulisan skripsi ini sebagai berikut :
1. Data yang digunakan pada aplikasi ini adalah 20 gejala-gejala kemungkinan anak terkena disleksia.
2. Metode yang dibandingkan pada pendeteksi ini adalah Certainty Factor dan Naïve Bayesian.
3. Masing-masing variabel pada metode Naïve Bayesian gejala diberi nilai 1 untuk jawaban Ya dan 0 untuk jawaban Tidak.
4. Masing-masing variabel pada metode Certainty Factor gejala diberi nilai range antara 0 sampai 1 untuk jawban Ya dan 0 atau tidak di hitung untuk jawaban Tidak.
5. Komponen yang akan di ukur dalam membandingkan metode
Certainty factor dan Naïve Bayesian adalah akurasi data. Dengan rumus akurasi = ( jumlah data benar / jumlah data keseluruhan ) x 100%.
6. Keluaran dalam pendeteksian ini berisi kesimpulan kemungkinan anak terkena disleksia yang meliputi disleksia auditori, disleksia visual, disleksia kombinasi.
7. Pengujian sistem yang digunakan adalah pengujian Whitebox dan
8. Nilai MB (Meansure of Believe) dan MD ( Meansure of Disbelieve )
untuk metode Certainty Factor di dapat dari satu pakar.
1.5 Metode Penelitian
Metode penelitian yang digunakan dalam penulisan ini adalah sebagai berikut : 1. Tahap Pengumpulan Data
a. Studi Literatur
Pengumpulan data dengan cara mengumpulkan literature, jurnal, paper, dan e-book yang ada kaitannya dengan judul penelitian.
b. Observasi
Tekni pengumpulan data dengan mengadakan penelitian dan peninjauan langsung terhadap permasalahan yang diambil. Penelitian yang dilakukan dengan cara wawancara dengan Pakar yang bernama Adimia Rila Oktoga,S.Psi.,M.Psi. dengan alamat yang berada di Biro Psikologi Dwipayana di Jl. Taman Cibunut Dalam No. 7 untuk memperoleh gejala-gejala disleksia dan nilai MB (Meansure of Believe) dan MD
(Meansure of Disbelieve) untuk metode Certainty Factor mengenai kepastian terhadap setiap gejala. Dan mengambil data gejala disleksia di
www.dyslexiaindonesia.com untuk mencocokkan hasil wawancara. 2. Eksperimen
5
1.6 Sistematika Penulisan
Sistematika penulisan ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB 1 PENDAHULUAN
Bab ini berisi meliputi latar belakang permaslahan yaitu latar belakang berdasarkan latar belakang masalah tersebut, penulis menyusun identifikasi masalah yang diperjelas dengan pembatasan masalah yang akan di angkat dalam tugas akhir ini. Manfaat penelitian akan dapat dirasakan apabila tujuan penelitian telah tercapai. Metodologi penelitian merupakan tahapan dalam menuntun penulis dalam mencapai tujuan skripsi.
BAB 2 LANDASAN TEORI
Bab ini menguraikan tentang teori-teori pendekatan yang digunakan untuk menganalisis masalah dan teori yang di pakai dalam mengolah data penelitian yaitu teori mengenai deteksi, teori disleksia, teori metode Certainty Factor dan
Naïve Bayesian, dan teori mengenai software pembangun simulator. BAB 3 ANALISIS METODE
Bab ini merupakan tahapan untuk menganalisis perbandingan perhitungan metode Certainty Factor dan Naïve Bayesian pada pendeteksi kemungkinan anak terkena disleksia
BAB 4 IMPLEMENTASI DAN PENGUJIAN
Bab ini berisi tentang pengujian simulator menggunakan Blackbox dan
Whitebox, serta pengujian akurasi untuk kedua metode tersebut. Sehingga dapat terlihat hasil perbandingan dari kedua metode tersebut.
BAB 5 PENUTUP
7
BAB 2
LANDASAN TEORI
2.1 Pengertian Deteksi
Deteksi adalah suatu proses untuk memeriksa atau melakukan pemeriksaan terhadap sesuatu dengan menggunakan cara dan teknik tertentu. Deteksi dapat digunakan untuk berbagai masalah, misalnya dalam sistem pendeteksi suatu penyakit, dimana sistem mengidentifikasi masalah-masalah yang berhubungan dengan penyakit yang biasa disebut gejala.
Tujuan dari deteksi adalah memecahkan suatu masalah dengan berbagai cara tergantung metode yang diterapkan sehingga menghasilkan sebuah solusi.
2.2 Pengertian Disleksia
Disleksia berasal dari bahasa Greek, yakni dari kata “dys” yang berarti kesulitan, dan kata “lexis” yang berarti bahasa. Jadi disleksia secara harafiah berarti kesulitan dalam berbahasa. Anak disleksia tidak hanya mengalami kesulitan dalam membaca, tetapi juga dalam hal mengeja, menulis, dan beberapa aspek bahasa yang lain.
Kesulitan membaca pada anak disleksia ini tidak sebanding dengan tingkat intelegensi ataupun motivasi yang dimiliki untuk kemampuan membaca dengan tepat atau akurat, karena anak disleksia biasanya mempunyai level intelegensi yang normal bahkan diantaranya diatas normal. Disleksia merupakan kelainan dengan dasar kelainan neurobiologis, dan ditandai dengan kesulitan dalam mengenali kata dengan tepat/akurat, dalam pengejaan dan dalam kemampuan mengkode symbol.
ditandai dengan kesulitan dalam membaca, yang dapat mempengaruhi area kognisi seperti daya ingat, kecepatan pemrosesan input, kemampuan pengaturan waktu, aspek koordinasi dan pengendalian gerak. Dapat terjadi kesulitan visual dan fonologis, juga biasanya terdapat perbedaan kemampuan di berbagai aspek perkembangan.
Sebagian ahli membagi disleksia sebagai disleksia visual, disleksia auditori, dan disleksia kombinasi (visual-auditori). Sebagian ahli lain membagi disleksia berdasarkan apa yang dipersepsi oleh mereka yang mengalaminya yaitu persepsi pembalikan konsep ( suatu kata dipersepsi sebagai lawan katanya), persepsi disorientasi vertical atau horizontal (huruf atau kata berpindah tempat dari depan ke belakang atau sebaliknya, dari barisan atas ke barisan bawah dan sebaliknya), persepsi teks terlihat terbalik seperti di dalam cermin, dan persepsi dimana huruf atau kata-kata tertentu jadi seperti menghilang.
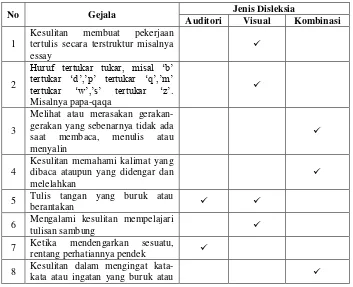
Adapun jenis-jenis dari disleksia yaitu disleksia auditori, disleksia visual, dan disleksia kombinasi dijelaskan pada tabel 2.1. :
Table 2.1 Jenis-Jenis Disleksia
Jenis Disleksia Gejala
Disleksia Auditori
Tulisan tangan yang buruk atau berantakan
Ketika mendengarkan sesuatu, rentang perhatiannya pendek Kesulitan membedakan huruf vocal dengan konsonan Kesulitan mengingat rutinitas aktivitas sehari-hari atau mencerna sesuatu secara berurutan
Ketidak akuratan dalam membaca seperti membaca lambat kata demi kata jika dibandingkan dengan anak seusianya, intonasi suara turun naik tidak teratur
Disleksia Visual
Kesulitan membuat pekerjaan tertulis secara terstruktur misalnya essay
Huruf tertukar tukar, misal ‘b’ tertukar ‘d’,’p’ tertukar ‘q’, ‘m’ tertukar ‘w’, ‘s’ tertukar ‘z’ misalnya papa-qaqa
Tulisan tangan yang buruk atau berantakan
Mengeluh pusing atau nyeri kepala atau sakit perut saat membaca
Membaca lambat lambat dan terputus putus dan tidak tepat Menghilangkan atau salah baca kata penghubung (“di”, “ke”, “pada”)
9
dibaca sebagai “tulis”)
Melihat atau merasakan gerakan-gerakan yang sebenarnya tidak ada saat membaca, menulis atau menyalin
Disleksia Kombinasi
Kesulitan memahami kalimat yang dibaca ataupun yang didengar dan melelahkan
Mengalami kesulitan mempelajari tulisan sambung
Kesulitan dalam mengingat kata-kata atau ingatan yang buruk atau lemah terhadap informasi yang tidak pernah dialami sebelumnya
Kesulitan mengingat nama-nama Kesulitan / lambat mengerjakan PR
Kesulitan memahami konsep waktu atau kesulitan dalam menyebutkan waktu, mengatur waktu ataupun melakukan sesuatu dengan tepat waktu
Kesulitan mengingat rutinitas aktivitas sehari-hari atau mencerna sesuatu secara berurutan
Kesulitan membedakan kanan kiri
Tertukar-tukar kata (misalnya : dia-ada, sama-masa, lahu-gula, batu-buta, tanam-taman, dapat-padat, mana-nama) Ketidakakuratan dalam membaca seperti membaca lambat kata demi kata jika dibandingkan dengan anak seusianya, intonasi suara turun naik tidak teratur
Secara lebih khusus, anak disleksia biasanya mengalami masalah sebagai berikut :
1. Masalah Fonologi
Yang dimaksud fonologi adalah hubungan sistematik antara huruf dan bunyi. Misalnya anak mengalami kesulitan membedakan “paku”
dengan “palu” atau anak keliru memahami kata-kata yang mempunyai
bunyi hampir sama, misalnya “lima puluh” dengan ‘lima belas”.
Kesulitan ini tidak disebabkan masalah pendengaran namun berkaitan dengan proses pengolahan input di dalam otak.
2. Masalah Mengingat Perkataan
Kebanyakan anak disleksia mempunyai level intelgensi normal atau diatas normal namun mereka mempunyai kesulitan mengingat perkataan. Mereka mungkin sulit menyebutkan nama teman-temannya
suatu cerita namun tidak dapat mengingat jawaban untuk pertanyaan yang sederhana.
3. Masalah Penyusunan yang Sistematis / Sekuensial
Anak disleksia mengalami kesulitan menyusun sesuatu secara berurutan misalnya susunan bulan dalam setahun, hari dalam seminggu atau susunan huruf dan angka. Mereka sering lupa susunan aktivitas yang sudah direncanakan sebelumnya, misalnya lupa apakah setelah pulang sekolah langsung pergi ke tempat latihan sepak bola. Padahal orang tua sudah mengingatkannya bahkan mungkin sudah pula ditulis dalam agenda kegiatannya. Mereka juga mengalami kesulitan yang berhubungan dengan perkiraan terhadap waktu. Misalnya mereka mengalami kesulitan memahami intruksi.
4. Masalah Ingatan Jangka Pendek
Anak disleksia mengalami kesulitan memahami intruksi yang panjang dalam satu waktu yang pendek. Misalnya ibu menyuruh anak untuk “ simpan tas di kamarmu dilantai atas, ganti pakaian, cuci kaki dan tangan lalu turun ke bawah lagi untuk makan siang bersama ibu, tapi
jangan lupa bawa serta buku PR matematikanya ya”, maka kemungkinan besar anak disleksia tidak melakukan seluruh intruksi tersebut dengan sempurna karena tidak mampu mengingat seluruh perkataan ibunya.
5. Masalah Pemahaman Sintaks
diterangkan-11
menerangkan (contoh : tas merah), namun dalam bahasa Inggris dikenal susunan menerangkan-diterangkan (contoh : red bag). [3]
2.3 Kecerdasan Buatan
Kecerdasan buatan atau Artificial Intelligence merupakan salah satu bagian ilmu computer yang membuat agar mesin (komputer) dapat melakukan pekerjaan seperti dan sebaik yang dilakukan manusia. Dengan adanya kecerdasan buatan, diharapkan tidak menutup kemungkinan hanya dengan data pengetahuan yang terbatas, sebuah computer dapat berpikir seperti manusia dalam menghadapi masalah.
2.3.1. Metode Certainty Factor
Certainty Factor merupakan suatu metode yang digunakan untuk menyatakan kepercayaan dalam sebuah kejadian ( fakta atau hipotesis) berdasarkan bukti atau penilaian pakar. Secara konsep Certainty Factor (CF) merupakan salah satu teknik yang digunakan untuk mengatasi ketidakpastian dalam pengambilan keputusan. Certainty Factor dapat terjadi dengan berbagai kondisi. Diantara kondisi yang terjadi adalah terdapat beberapa antensenden (dalam rule yang berbeda ) dengan satu konsekuen yang sama. Dalam kasus ini, kita harus mengagregasikan nilai CF keseluruhan dari setiap kondisi yang ada. Pada konsep
Certainty Factor ini juga sering dikenal dengan adanya believe dan
disbelieve. Believe merupakan keyakinan, sedangkan disbelieve
merupakan ketidakyakinan. [1]
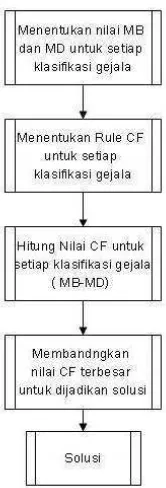
Gambar 2.1 Alur Metode Certainty Factor
Adapun Notasi atau rumusan dasar dari Certainty Factor , seperti tampak pada persamaan 2.1 sebagai berikut :
�[ℎ, ] = � [ℎ, ] − � [ℎ, ]
Persamaan 2.1
Keterangan :
CF[h,e] : Certainty Factor dalam hipotesis h yang dipengaruhi oleh fakta e.
MB[h,e] : Meansure of Believe, merupakan nilai kenaikan dari kepercayaan hipotesis h dpengaruhi oleh fakta e.
MD[h,e] : Meansure of Disbelieve, merupakan nilai kenaikan dari ketidakpercayaan hipotesis h dipengaruhi oleh fakta e.
h : hipotesis
13
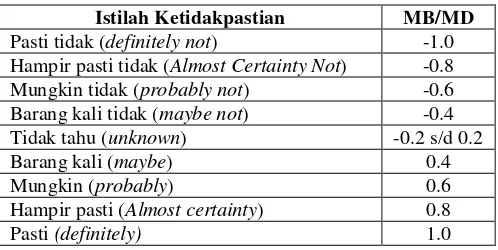
Adapun tipe-tipe nilai Certainty Factor untuk berbagai macam istilah ketidakpastian [4] dijelaskan pada tabel 2.2 :
Table 2.2Tipe - tipe Nilai Certainty Factor
Istilah Ketidakpastian MB/MD
Pasti tidak (definitely not) -1.0 Hampir pasti tidak (Almost Certainty Not) -0.8 Mungkin tidak (probably not) -0.6 Barang kali tidak (maybe not) -0.4 Tidak tahu (unknown) -0.2 s/d 0.2
Barang kali (maybe) 0.4
Mungkin (probably) 0.6
Hampir pasti (Almost certainty) 0.8
Pasti (definitely) 1.0
2.3.2. Metode Naïve Bayesian
Teorema bayes dikemukakan oleh Thomas Bayes pada tahun 1763. Teorema bayes digunakan untuk menghitung peluang atau probabilitas terjadinya suatu peristiwa berdasarkan pengaruh yang di dapat dari hasil observasi.
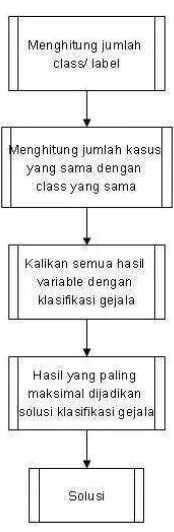
Metode Bayesian yang dipilih ialah metode Naïve Bayesian. Model statistic dalam metode Naïve Bayesian merupakan salah satu model yang sangat andal sebagai sistem pendukung keputusan. Konsep probabilitas merupakan salah satu bentuk model statistic. Pada metode ini semua atribut akan memberikan kontribusinya dalam pengambilan keputusan, dengan bobot atribut yang sama penting dan setiap atribut saling bebas satu sama lain.
Metode ini berfungsi untuk mencari nilai probabilitas tiap faktor sehingga nantinya hasilnya akan dijadikan perhitungan untuk menentukan apakah resikonya kecil, sedang atau besar.
Gambar 2.2 Alur Perhitungan Metode Naive Bayesian
Pada sistem ini hanya menggunakan jenis data yaitu data optional jika jawaban nya Yam aka bernilai 1 dan jika jawabannya Tidak maka bernilai 0. Untuk memperoleh hasil ekspektasi maksimal, probabilitas dapat dirubah dengan mempertimbangkan semua faktor yang mempengaruhi probabilitas tersebut, dalam hal ini metode ini sangat berperan untuk menentukan probabilitas yang telah dipengaruhi oleh faktor lain.
Pendekatan bayes pada saat klasifikasi adalah mencari probabilitas
tertinggi (VMAP) dengan masukan atribut (a1, a2, a3, …, an) seperti
tampak pada persamaan 2.2 berikut :
15
Teorema Bayes sendiri berawal dari rumus berikut :
� � | � = � � ∩ �� �
Persamaan 2.2
Dimana P (A | B) artinya peluang A jika diketahui keadaan B Rumus Formula Bayes
� �|� = � �|� � �� �
Persamaan 2.3
Dimana :
P(H|E) : Probabilitas hipotesis H jika terdapat evidence E
P(E|H) : Probabilitas munculnya evidence E jika diketahui hipotesa H
Jika setelah dilakukan pengujian terhadap hipotesis, muncul satu atau lebih evidence baru, maka :
� �|�, � = � �|� � �|�, �� �|�
Persamaan 2.4
Dimana :
e : evidence lama
E : evidence atau observasi baru
P(H|E,e) : Probabilitas adanya hipotesis H jika muncul evidence baru E dari evidence lama e
P(H|E) : Probabilitas hipotesis H jika terdapat evidence E P(e|E,H) : Probabilitas kaitan antara e dan e jika hipotesis h
benar
2.4 Metode Pengujian
2.4.1. White Box
Pengujian white box dilakukan untuk menguji prosedur-prosedur yang ada lintasan lojik yang dilalui oleh setiap bagian prosedur diuji dengan memberikan kondisi / loop spesifik. Pengujian white box
menjamin pengujian terhadap semua lintasan yang tidak bergantungan minimal satu kali, mencoba semua keputusan lojik dari sisi true dan
false, ekseskusi semua loop dalam batasan kondisi dan batasan operasionalnya data pengujian validasi data internal.
Konsep pengujian basis path ialah sebagai berikut :
a. Merupakan bagian dari pengujian white box dalam hal pengujian prosedur-prosedur.
b. Mempergunakan notasi aliran graph ( node, link untuk merepresentasikan sequence, if, while, until, dll ).
c. Konsep kompleksitas cyclomatic antara lain cara perhitungan daerah tertutup pada graph planar dimana dapat menghubungkan batas atas jumlah pengujian yang harus direncanakan dan di eksekusi untuk menjamin pengujian seluruh statement program.
d. Memunculkan kasus-kasus yang akan diuji dengan membuat daftar lintasan kasus pengujian berdasarkan kompleksitas dan
cyclomatic yang di dapat.
e. Membuat alat bantu untuk matrix graph yang membantu pengawasan pengujian.
2.4.2. Black Box
17
benar dan keluaran yang dihasilkan benar-benar tepat pengintegrasian dari eksternal data berjalan dengan baik.
Metode pengujian black box memfokuskan pada requirement fungsi dari perangkat lunak pengujian ini merupakan kompetensi dari pengujian white box. Pengujian white box dilakukan pada tahap akhir dari pengujian perangkat lunak.
Proses yang terdapat dalam proses pengujian black box antara lain sebagai berikut :
a. Pembagian kelas data untuk pengujian setiap kasus yang muncul pada pengujian white box.
b. Analisis batasan nilai yang berlaku untuk setiap data.
2.5 WAMP SERVER 2.2
WAMP ( Windows, Apache, MySQL, PHP) merupakan server yang dapat dijalankan computer tanpa memerlukan sambungan internet. Server di computer ini disebut dengan Local Server (Localhost) yang mana server ini nantinya akan kita install website hosting yang sudah memiliki system CMS (
Content Management System), proses intalasi WebHosting CMS di local server ini disebut juga proses pembuatan database di komputer /local Server (localhost).
2.6 PHP (Hypertext Prepocessor)
Pada awalnya PHP merupakan kependekan dari Personal Home Page
(Situs Personal). PHP pertama kali dibuat oleh Rasmus Lerdorf pada tahun 1995. Pada waktu itu PHP masih bernama Form Interpreted (FI), yang wujudnya berupa sekumpulan skrip yang digunakan untuk mengolah data formulir dari web.
terbuka, maka banyak pemrograman yang tertarik untuk ikut mengembangkan PHP.
Pada November 1997, dirilis PHP?FI 2.0 Pada rilis ini, interpreter PHP sudah diimplementasikan dalam program C. Dalam rilis ini disertakan juga modul-modul ekstensi yang meningkatkan kemampuan PHP/FI secara signifikan.
Pada tahun 1997, sebuah perusahaan bernama Zend menulis ulang interpreter PHP menjadi lebih bersih, lebih baik, dan lebih cepat. Kemudian pada Juni 1998, perusahaan tersebut merilis interpreter baru untuk PHP dan meresmikan rilis tersebut sebagai PHP 3.0 dan singkatan PHP diubah menjadi akronim berulang PHP : Hypertext Preprocessing.
Pada pertengahan tahun 1999, Zend merilis interpreter PHP baru dan rilis tersebut dikenal dengan PHP 4.0. PHP 4.0 adalah versi PHP yang paling banyak dipakai pada awal abad ke-21. Versi ini banyak dipakai disebabkan kemampuannya untuk membangun aplikasi web kompleks tetapi tetap memiliki kecepatan dan stabilitas yang tinggi.
Pada Juni 2004, Zend merilis PHP 5.0. Dalam versi ini dari interpreter PHP mengalami perubahan besar. Versi ini juga memasukkan model pemrograman berorieantasi objek ke dalam PHP untuk menjawab perkembangan bahasa pemrograman kea rah paradigm berorientasi objek.
2.7 MySQL
MySQL adalah sebuah perangkat lunak sistem manajemen basis data SQL
dalam bahasa Inggris yang berarti Database Management System atau DBMS yang multithread, multi-user, dengan sekitar 6 juta instalasi diseluruh dunia.
19
hampir atas semua kode sumbernya. Kedua orang Swedia dan satu orang Finlandia yang mendirikan MySQL AB adalah : David axmark, Allan Larsson,
dan Michael “Monty” Widenius.
MySQL adalah sebuah implementasi dari sistem manajemen basisdata relasional (RDBMS) yang didistribusikan secara gratis dibawah lisensi GPL (General Public License). Setiap pengguna dapat secara bebas menggunakan MySQL, namun dengan batasan perangkat lunak tersebut tidak boleh dijadikan produk turunan yang bersifat komersial. MySQL sebenarnya merupakan turunan salah satu konsep utama dalam basisdata yang telah ada sebelumnya. SQL (
Structured Query Language). SQL adalah sebuah konsep pengoperasian basisdata, terutama untuk pemilihan atau seleksi dan pemasukkan data, yang memungkinkan pengoperasian data dikerjakan dengan mudah secara otamatis.
Kehandalan suatu sistem basisdata (DBMS) dapat diketahui dari cara kerja pengoptimasi-nya dalam melakukan proses perintah-perintah SQL yang dibuat oleh pengguna maupun program-program aplikasi yang memanfaatkannya. Sebagai peladen basis data, MySQL mendukung operasi basis data transaksional maupun operasi basis data non-transaksional. Pada modus operasi non-transaksional, MySQL dapat dikatakan unggul dalam hal unjuk kerja dibandingkan perangkat lunak peladen basisdara competitor lainnya. Namun demikian pada modus non-transaksional tidak ada jaminan atas reliabilitas terhadap data yang tersimpan, karenanya modus non-transaksional hanya cocok untuk jenis aplikasi yang tidak membutuhkan reabilitas data seperti aplikasi blogging berbasis web (wordpress), CMS dan sejenisnya. Untuk kebutuhan sistem yang ditunjukkan untuk bisnis sangat disarankan untuk menggunakan modus basisdata transaksional, hanya saja sebagai konsekuensinya unjuk kerja MySQL pada modus transaksional tidak secepat unjuk kerja pada modus non-transaksional.
2.8 Adobe dreamweaver CS 5
Adobe Dreamweaver merupakan program penyunting halaman web keluaran Adobe System yang dulu dikenal sebagai Macromedia dreamweaver keluaran macromedia. Program ini banyak digunakan oleh pengembang web karena fitur-fiturnya yang menarik dan kemudahan penggunaannya. Versi terakhir macromedia Dreamweaver sebelum Macromedia dibeli oleh Adobe Systems yaitu versi 8. Versi terakhir Dreamweaver keluaran Adobe Systems adalah versi 12 yang ada dalam Adobe Creative Suite 6 (sering disingkat Adobe CS6).
Adobe Dreamweaver adalah aplikasi desain dan pengembangan web yang menyediakan editor WYSIWYG visual (bahasa sehari-hari yang disebut sebagai Design View) dank ode editor dengan fitur standar seperti syntax highlighting, code completion, dan code collapsing serta fitur lebih canggih seperti real-time syntax checking dan code introspection untuk menghasilkan petunjuk kode untuk membantu pengguna dalam menulis kode. Tata letak tampilan design memfasilitasi desain cepat dan pembuatan kode seperti memungkinkan pengguna dengan cepat membuat tata letak dan manipulasi elemen HTML.
Dreamweaver memiliki fitur browser yang terintegrasi untuk melihat halaman web yang dikembangkan di jendela pratinjau program sendiri agar konten memungkinkan untuk terbuka di web browser yang telah terinstalll. Aplikasi ini menyediakan transfer dan fitur sinkronisasi, kemampuan untuk mencari dan menggangti baris teks atau kode untuk mencari kata atau kalimat biasa di seluruh situs, dan templating feature yang memungkinkan untuk berbagi satu sumber kode atau memperbarui tata letak di seluruh situs tanpa server side includes atau scripting. Behavior panel juga memungkinkan penggunaan javascript dasar tanpa pengetahuan coding, dan integrasi dengan
21
Dreamweaver dapat menggunakan ekstensi dari pihak ketiga untuk memperpanjang fungsionalitas inti dari aplikasi, yang setiap pengembang web bisa menulis (sebagian besar dalam HTML dan javaScript). Dreamweaver didukung oleh komunitas besar pengembang ekstensi yang membuat ekstensi yang tersedia (baik komersial maupun yang gratis) untuk pengembangan web dari efek rollover sederhana sampai full-featured shopping chart.
2.9 Adobe Photoshop CS 3
Adobe photoshop, atau biasa disebut Photoshop, adalah perangkat lunak editor citra buatan adobe systems yang dikhususkan pengeditan foto/gambar dan pembuatan efek. Perangkat lunak ini banyak digunakan oleh fotografer digital dan perusahaan iklan sehingga dianggap sebagai pemimpin pasar (market leader) untuk perangkat lunak pengolah gambar/foto dan bersama Adobe acrobat, dianggap sebagai produk terbaik yang pernah diproduksi oleh Adobe Systems. Versi kedelapan aplikasi ini disebut dengan nama photoshop CS (Creative Suite), versi Sembilan disebut Adobe Photoshop CS2, versi sepuluh disebut Adobe Photoshop CS3, versi kesebelas adalah Adobe Photoshop CS4, versi keduabelas adalah Adobe Photoshop CS5, dan versi yang terakhir ketiga belas adalah Adobe Photoshop CS6.
Photoshop tersedia untuk Microsoft Windows, Mac OS X, dan Mac OS
versi 9 ke atas juga dapat digunakan oleh sistem operasi lain seperti Linux dengan bantuan perangkat lunak tertentu seperti Crossover.
Pada tahun 1987, Thomas Knoll, mahasiswa PhD di Universitas Michigan, mulai menulis sebuah program pada Macintosh Plus-nya untuk menampilkan gambar grayscale pada layar monokrom. Program ini, yang disebut Display,
program itu yang telah di ubah namanya menjadi ImagePro. Setelah itu, Thomas mengubah nama programnya menjadi Photoshop dan bekerja dalam jangka pendek dengan produsen scanner Barneyscan untuk mendistribusikan salinan dari program tersebut dengan slide scanner.
23
BAB 3
ANALISIS METODE
3.1 Analisis Masalah
Dalam suatu deteksi, akurasi data adalah suatu komponen yang penting demi tercapainya solusi yang diharapkan. Dalam penelitian sebelumnya terdapat jurnal yang diteliti oleh Putu Ary Darma Yasa yang berjudul Sistem Pakar Penyakit Kulit pada Manusia Menggunakan Metode Certainty Factor
Berbasis Web [1] dijelaskan bahwa metode Certainty Factor dalam mendeteksi penyakit kulit memiliki hasil akurasi sebesar 73,15%. Sedangkan pada penelitian yang dilakukan oleh Diana Laily Fithri yang berjudul Sistem Pendeteksian Penyimpangan Tingkah Laku Anak Usia 0 sampai 3 Tahun dengan Metode Bayesian [2] dijelaskan bahwa metode Bayesian mampu mendeteksi tingkah laku anak melalui gejala-gejala yang sudah ada tetapi dalam jurnal tersebut tidak dijelaskan mengenai tingkat akurasi metode Bayesian dalam mendeteksi kasus tersebut.
Berdasarkan permasalahan tersebut maka akan dilakukan suatu analisis untuk beberapa hal yang diperlukan dalam penelitian BAB 3 ini yaitu perbandingan antara metode Certainty Factor dan Naïve Bayesian untuk mengetahui metode mana yang lebih baik dalam ketepatan akurasi data dengan jumlah masukkan yang sama melalui gejala-gejala disleksia.
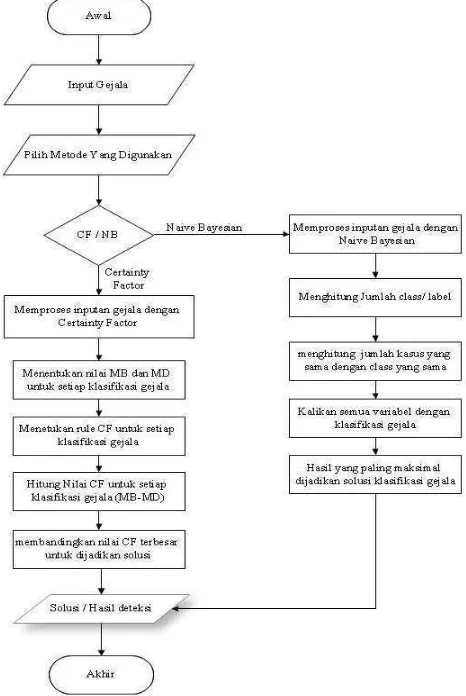
3.2 Alur Pendeteksi
Subbab ini akan menjelaskan alur dari keseluruhan deteksi kemungkinan anak terkena disleksia menggunakan Certainty Factor dan Naïve Bayesian
yang akan ditunjukkan dengan menggunakan flowchart pada Gambar 3.1 sebagai berikut :
25
Gambar 3.1 di atas menjelaskan alur dari keseluruhan sistem deteksi kemungkinan anak terkena disleksia. Proses-proses di dalam alur tersebut yaitu masukkan user berupa gejala-gejala disleksia, pemilihan metode yang akan digunakan yaitu metode Certainty Factor dan Naïve Bayesian, proses dengan menggunakan metode yang telah dipilih, dan hasil deteksi
Dari proses-proses tersebut maka akan diketahui hasil deteksi dari kedua metode tersebut mana yang lebih baik dalam segi akurasi data dalam menghasilkan solusi kemungkinan anak terkena disleksia.
3.3 Analisis Gejala Disleksia
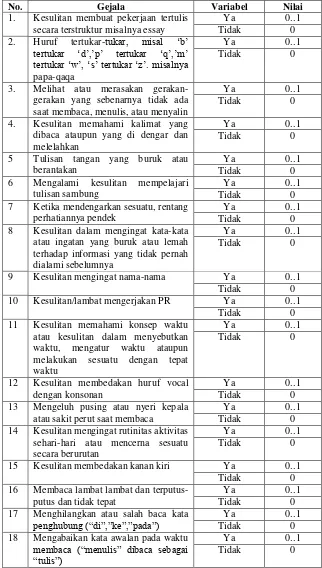
Gejala-gejala yang nanti nya akan diproses dan menjadi analisis masukan adalah gejala-gejala disleksia yang terbagi menjadi tiga jenis disleksia yaitu disleksia auditori, disleksia visual, dan disleksia kombinasi. Berikut adalah 20 gejala yang terdapat pada disleksia dapat dilihat di tabel 3.1.
Table 3.1 Gejala-Gejala Disleksia
No Gejala Jenis Disleksia
Auditori Visual Kombinasi
1
Kesulitan membuat pekerjaan tertulis secara terstruktur misalnya essay
Melihat atau merasakan gerakan-gerakan yang sebenarnya tidak ada saat membaca, menulis atau menyalin
4
Kesulitan memahami kalimat yang dibaca ataupun yang didengar dan melelahkan
5 Tulis tangan yang buruk atau
berantakan
6 Mengalami kesulitan mempelajari
tulisan sambung
7 Ketika mendengarkan sesuatu, rentang perhatiannya pendek
8 Kesulitan dalam mengingat
lemah terhadap informasi yang tidak pernah dialami sebelumnya
9 Kesulitan mengingat nama-nama
10 Kesulitan/lambat mengerjakan PR
11
Kesulitan memahami konsep waktu atau kesulitan dalam menyebutkan waktu, mengatur waktu ataupun melakukan sesuatu dengan tepat waktu
12 Kesulitan membedakan huruf vocal
dengan konsonan
13 Mengeluh pusing atau nyeri kepala
atau sakit perut saat membaca
14
Kesulitan mengingat rutinitas aktivitas sehari-hari atau mencerna sesuatu secara berurutan
15 Kesulitan membedakan kanan kiri
16 Membaca lambat-lambat dan
terputus-putus dan tidak tepat
17
Menghilangkan atau salah baca kata penghubung (“di”,
“ke”,”pada”)
18
Mengabaikan kata awalan pada waktu membaca(“menulis” dibaca
sebagai “tulis”)
19
Tertukar-tukar kata(misalnya : dia-ada, sama-masa, lagu-gula, batu-buta,tanam-taman, dapat-padat, mana-nama)
20
Ketidak akuratan dalam membaca seperti membaca lambat kata demi kata jika dibandingkan dengan anak sseusianya, intonasi suara turun naik tidak teratur
3.3.1 Analisis Data Masukkan
Data yang digunakan sebagai masukan ke dalam deteksi yaitu gejala. Berikut adalah 20 gejala yang berupa pertanyaan yang termasuk gejala-gejala disleksia untuk analisis data masukkan Certainty Factor
dan Naïve Bayesian.
3.3.1.1Analisis Data Masukkan Certainty Factor
27
Table 3.2 Variabel Input Gejala-gejala untuk Metode Certainty Factor
No. Gejala Variabel Nilai
1. Kesulitan membuat pekerjaan tertulis secara terstruktur misalnya essay
Ya 0..1
Tidak 0
2. Huruf tertukar-tukar, misal ‘b’ tertukar ‘d’,’p’ tertukar ‘q’,’m’ tertukar ‘w’, ‘s’ tertukar ‘z’. misalnya papa-qaqa
Ya 0..1
Tidak 0
3. Melihat atau merasakan gerakan-gerakan yang sebenarnya tidak ada saat membaca, menulis, atau menyalin
Ya 0..1
6 Mengalami kesulitan mempelajari tulisan sambung
Ya 0..1
Tidak 0
7 Ketika mendengarkan sesuatu, rentang perhatiannya pendek
Ya 0..1
Tidak 0
8 Kesulitan dalam mengingat kata-kata atau ingatan yang buruk atau lemah terhadap informasi yang tidak pernah dialami sebelumnya
Ya 0..1
Tidak 0
9 Kesulitan mengingat nama-nama Ya 0..1
Tidak 0
10 Kesulitan/lambat mengerjakan PR Ya 0..1
Tidak 0
11 Kesulitan memahami konsep waktu atau kesulitan dalam menyebutkan waktu, mengatur waktu ataupun melakukan sesuatu dengan tepat waktu
Ya 0..1
Tidak 0
12 Kesulitan membedakan huruf vocal dengan konsonan
Ya 0..1
Tidak 0
13 Mengeluh pusing atau nyeri kepala atau sakit perut saat membaca
Ya 0..1
Tidak 0
14 Kesulitan mengingat rutinitas aktivitas sehari-hari atau mencerna sesuatu secara berurutan
Ya 0..1
Tidak 0
15 Kesulitan membedakan kanan kiri Ya 0..1
Tidak 0
16 Membaca lambat lambat dan terputus-putus dan tidak tepat
Ya 0..1
Tidak 0
17 Menghilangkan atau salah baca kata
penghubung (“di”,”ke”,”pada”) Tidak Ya 0..1 0 18 Mengabaikan kata awalan pada waktu
membaca (“menulis” dibaca sebagai “tulis”)
Ya 0..1
19 Tetukar tukar kata (misalnya : dia-kata jika dibandingkan dengan anak seusianya, intonasi suara turun naik tidak teratur
Ya 0..1
Tidak 0
Berdasarkan tabel 3.1 gejala-gejala tersebut disusun yang akan menjadi data masukkan pada pendeteksi. Untuk setiap nilai range antara 0 sampai satu untuk jawaban “Ya” dan 0 atau tidak di hitung
untuk jawaban “Tidak”.
3.3.1.2Analisis Data Masukkan Naïve Bayesian
Berikut adalah variabel Input Gejala-gejala disleksia untuk dijadikan data masukkan pada sistem yang dijelaskan pada tabel 3.3
Table 3.3 Variabel Input Gejala-gejala untuk Metode Naive Bayesian
No. Gejala Variabel Nilai
1. Kesulitan membuat pekerjaan tertulis secara terstruktur misalnya essay
Ya 1
Tidak 0
2. Huruf tertukar-tukar, misal ‘b’ tertukar ‘d’,’p’ tertukar ‘q’,’m’ tertukar ‘w’, ‘s’ tertukar ‘z’. misalnya papa-qaqa
Ya 1
Tidak 0
3. Melihat atau merasakan gerakan-gerakan yang sebenarnya tidak ada saat membaca, menulis, atau menyalin
Ya 1
6 Mengalami kesulitan mempelajari tulisan sambung
Ya 1
Tidak 0
7 Ketika mendengarkan sesuatu, rentang perhatiannya pendek
Ya 1
Tidak 0
8 Kesulitan dalam mengingat kata-kata atau ingatan yang buruk atau lemah terhadap informasi yang tidak pernah dialami sebelumnya
Ya 1
Tidak 0
29
Tidak 0
10 Kesulitan/lambat mengerjakan PR Ya 1
Tidak 0
11 Kesulitan memahami konsep waktu atau kesulitan dalam menyebutkan waktu, mengatur waktu ataupun melakukan sesuatu dengan tepat waktu
Ya 1
Tidak 0
12 Kesulitan membedakan huruf vocal dengan konsonan
Ya 1
Tidak 0
13 Mengeluh pusing atau nyeri kepala atau sakit perut saat membaca
Ya 1
Tidak 0
14 Kesulitan mengingat rutinitas aktivitas sehari-hari atau mencerna sesuatu secara berurutan
Ya 1
Tidak 0
15 Kesulitan membedakan kanan kiri Ya 1
Tidak 0
16 Membaca lambat lambat dan terputus-putus dan tidak tepat
Ya 1
Tidak 0
17 Menghilangkan atau salah baca kata
penghubung (“di”,”ke”,”pada”) Tidak Ya 1 0 18 Mengabaikan kata awalan pada waktu
membaca (“menulis” dibaca sebagai “tulis”) kata jika dibandingkan dengan anak seusianya, intonasi suara turun naik tidak teratur
Ya 1
Tidak 0
Berdasarkan tabel 3.3 diatas metode Naïve Bayesian diasumsikan gejala-gejala dalam setiap variabel akan diberikan nilai 0 atau 1 dimana
nilai 0 untuk jawaban “Tidak” dan nilai 1 untuk jawban “Ya”.
3.3.2 Analisis Data Keluaran
3.3.2.1Analisis Data Keluaran Metode Certainty Factor
Berikut adalah keterangan hasil keluaran dari metode Certainty Factor yang dijelaskan pada tabel 3.4.
Table 3.4 Keterangan Hasil Keluaran Certainty Factor
Rumus Keterangan
Nilai CF auditori > CF visual > CF kombinasi
Disleksia Auditori
Nilai CF visual > CF auditori > CF kombinasi
Disleksia Visual
Nilai CF kombinasi > CF visual > CF auditori
Disleksia Kombinasi
Pada tabel 3.4 diatas menjelaskan bahwa hasil keluaran dari sistem pendeteksi disleksia menghasilkan klasifikasi disleksia atau jenis disleksia menggunakan metode Certainty Factor.
3.3.2.2Analisis Data Keluaran Metode Naïve Bayesian
Berikut adalah keterangan hasil keluaran dari metode Naïve Bayesian yang dijelaskan pada tabel 3.5.
Table 3.5 Keterangan Hasil Keluaran Naive Bayesian
Rumus Keterangan
P(Y=A) > P(Y=V) > P(Y=K) Disleksia Auditori P(Y=V) > P(Y=A) > P(Y=K) Disleksia Visual P(Y=K) > P(Y=A) > P(Y=V) Disleksia Kombinasi
Pada tabel 3.5 diatas menjelaskan bahwa hasil keluaran dari sistem pendeteksi disleksia menghasilkan klasifikasi disleksia atau jenis disleksia menggunakan metode Naïve Bayesian.
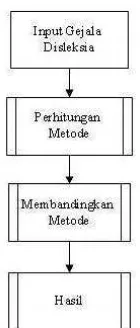
3.4 Tahapan Analisis Metode
31
Gambar 3.2 Tahapan Analisis Metode
Gambar 3.2 menjelaskan tahapan-tahapan analisis metode mulai dari menentukan inputan awal mengenai gejala-gejala disleksia dan dip roses menggunakan Certainty Factor dan Naïve Bayesian hasilnya akan dilakukan analisis perbandingan mengenai akurasi data dalam menghasilkan solusi kemungkinan anak terkena disleksia. Setelah menganalisis keempat tahapan tersebut kemudian di dapat sebuah hasil dari analisis yang telah di lakukan. Tahapan-tahapan di atas akan dijelaskan pada sub-bab selanjutnya.
3.4.1 Perhitungan Metode
Perhitungan metode menjelaskan cara-cara dari metode Certainty Factor dan Naïve Bayesian dalam mendeteksi kemungkinan anak terkena disleksia auditori, visual atau kombinasi.
3.4.1.1Perhitungan Metode Certainty Factor
Berdasarkan gejala-gejala yang di masukkan ke dalam sistem, sistem tersebut akan melakukan proses perhitungan dengan metode
bagan alir perhitungan metode Certainty Factor yang dijelaskan pada Gambar 3.3 berikut ini :
Gambar 3.3 Alur Perhitungan Metode Certainty Factor
Berikut adalah perhitungan Metode Certainty Factor. Dimulai dari inisialisasi gejala untuk metode Certainty Factor yang akan dijelaskan pada tabel 3.6 berikut ini :
Table 3.6 Inisialisasi Gejala untuk Metode Certainty Factor
Inisialisasi
Gejala Keterangan Gejala
A : Kesulitan membuat pekerjaan tertulis secara terstruktur B : Huruf tertukar-tukar misal ‘b’ tertukar ‘d’, ‘p’ tertukar ‘q’, ‘m’
tertukar ‘w’, ‘s’ tertukar ‘z’. misalnya papa-qaqa
C : Melihat atau merasakan gerakan-gerakan yang sebenarnya tidak ada saat membaca, menulis atau menyalin
D : Kesulitan memahami kalimat yang dibaca ataupun yang di dengar dan melelahkan
E : Tulisan tangan yang buruk atau berantakan F : Mengalami kesulitan mempelajari tulisan sambung
33
atau lemah terhadap informasi yang tidak pernah dialami sebelumnya
I : Kesulitan mengingat nama-nama J : Kesulitan/ lambat mengerjakan PR
K : Kesulitan memahami konsep waktu atau kesulitan dalam menyebutkan waktu, mengatur waktu ataupun melakukan sesuatu dengan tepat waktu.
L : Kesulitan membedakan huruf vocal dengan konsonan
M : Mengeluh pusing atau nyeri kepala atau sakit perut saat membaca
N : Kesulitan mengingat rutinitas aktivitas sehari-hari atau mencerna sesuatu secara berurutan
O : Kesulitan membedakan kanan kiri
P : Membaca lambat-lambat dan terputus-putus dan tidak tepat Q : Menghilangkan atau salah baca kata penghubung
(“di”.”ke”,”pada”)
R : Mengabaikan kata awalan pada waktu membaca (“menulis” dibaca “tulis”)
S : Tertukar-tukar kata (misalnya : dia-ada, sama-masa, lagu-gula, batu-bata, tanam-taman, dapat-padat, mana-nama)
T : Ketidak akuratan dalam membaca seperti membaca lambat kata demi kata jika dibandingkan dengan anak seusianya, intonasi suara turun naik tidak teratur
Setelah inisialisasi gejala diatas selanjutnya menentukan nilai MB dan MD untuk setiap klasifikasi disleksia. Nilai MB dan MD untuk setiap klasifikasi disleksia di dapat dari seorang pakar bernama Adimia Rila Oktoga, Spsi.,M.Psi. yang sudah dilakukan wawancara yang ada di lampiran mengenai nilai kepastian atau nilai ketidakpastian terhadap masing-masing gejala yang dapat dijelaskan pada tabel 3.7 berikut ini :
Table 3.7 Nilai MB dan MD untuk Setiap Klasifikasi Gejala Disleksia
No Gejala Disleksia Auditori Disleksia Visual
10 J 0.6 0.4 0.8 0.2 0.6 0.4
11 K 0.6 0.4 0.4 0.6 0.4 0.6
12 L 0.4 0.6 0.4 0.6 0.6 0.4
13 M 0.8 0.2 1 0 0.8 0.2
14 N 0.4 0.6 0.4 0.6 0.4 0.6
15 O 0.6 0.4 0.6 0.4 0.6 0.4
16 P 0.8 0.2 0.8 0.2 0.6 0.4
17 Q 0.6 0.4 0.6 0.4 0.6 0.4
18 R 0.6 0.4 0.6 0.4 0.6 0.4
19 S 0.6 0.4 0.6 0.4 0.6 0.4
20 T 0.8 0.2 0.8 0.2 0.6 0.4
Keterangan :
MB : Nilai Kepastian terhadap setiap gejala MD : Nilai ketidakpastian terhdap setiap gejala
Setelah di dapat nilai MB dan MD untuk setiap gejala maka dapat ditentukan Rule untuk setiap perhitungan Certainty Factor. Rule dipakai dengan menggunakan operator AND dimana jika tidak ada salah satu gejala diantara beberapa gejala yang ada pada satu klasifikasi maka hasilnya akan termasuk ke dalam klasifikasi gejala disleksia yang telah di sesuaikan menurut klasifikasi disleksia. Berikut cara perhitungan metode Certainty Factor dengan Rule jika 20 gejala disleksia yang di pilih maka hasilnya disleksia kombinasi. Jika tidak maka perhitungan tidak sesuai dengan klasifikasi disleksia. Hal ini disebakan oleh nilai MB dan nilai MD yang kurang tepat.
Berikut adalah proses perhitungan CF berdasarkan persamaan 2.1 rumus Certainty Factor untuk setiap klasifikasi disleksia yang dijelaskan pada beberapa tabel berikut ini :
1. Disleksia Auditori
Table 3.8 Proses Perhitungan Nilai CF Disleksia Auditori
Gejala Perhitungan MB
A 0.6+(0.6*(1-0.6)) 0.84
35
A AND B AND C 0.968+(0.2*(1-0.968)) 0.9744 A AND B AND C
AND D
0.9744+(0.8*(1-0.9744)) 0.99488
A AND B AND C AND D AND E
0.99488+(0.4*(1-0.99488)) 0.996928
A AND B AND C
37
AND Q AND R AND S AND T
Gejala Perhitungan MD
A 0.4+(0.4*(1-0.4)) 0.64
A AND B 0.64+(0.2*(1-0.64)) 0.712 A AND B AND C 0.712+(0.2*(1-0.712)) 0.7696 A AND B AND C
AND D
0.7696+(0.2*(1-0.7696)) 0.81568
A AND B AND C AND D AND E
0.81568+(0.6*(1-0.81568)) 0.926272
39
Nilai CF menurut persamaan 2.1 di dapat dari hasil perhitungan selisih MB dan MD sebagai berikut :
CF = MB – MD
= 0.999999999 – 0.999941566 = 0.000058433
2. Disleksia Visual
Table 3.9 Proses Perhitungan Nilai CF Disleksia Visual
Gejala Perhitungan MB
A 0.8+(0.8*(1-0.8)) 0.96
A AND B 0.96+(0.8*(1-0.96)) 0.992 A AND B AND C 0.992+(0.4*(1-0.992)) 0.9952 A AND B AND C
AND D
0.9952+(0.8*(1-0.9952)) 0.99904
A AND B AND C AND D AND E
0.99904+(0.6*(1-0.99904)) 0.999616
41
Gejala Perhitungan MD
A 0.2+(0.2*(1-0.2)) 0.36
A AND B 0.36+(0.2*(1-0.36)) 0.488 A AND B AND C 0.488+(0.6*(1-0.488)) 0.7952 A AND B AND C
AND D
0.7952+(0.3*(1-0.7952)) 0.83616
A AND B AND C AND D AND E
0.83616+(0.4*(1-0.83616)) 0.901696
43
Nilai CF menurut persamaan 2.1 di dapat dari hasil perhitungan selisih MB dan MD sebagai berikut :
CF = MB – MD
Table 3.10 Proses Perhitungan Nilai CF Disleksia Kombinasi
Gejala Perhitungan MB
A 0.4+(0.4*(1-0.4)) 0.64
A AND B 0.64+(0.8*(1-0.64)) 0.928 A AND B AND C 0.928+(0.6*(1-0.928)) 0.9712 A AND B AND C
AND D
0.9712+(0.6*(1-0.9712)) 0.98848
A AND B AND C AND D AND E
0.98848+(0.6*(1-0.98848)) 0.993088
AND H AND I
Gejala Perhitungan MD
A 0.6+(0.6*(1-0.6)) 0.84
A AND B 0.84+(0.2*(1-0.84)) 0.872 A AND B AND C 0.872+(0.4*(1-0.872)) 0.9232 A AND B AND C
AND D
0.9232+(0.4*(1-0.9232)) 0.95392
A AND B AND C AND D AND E
0.95392+(0.6*(1-0.95392)) 0.981568
AND O AND P AND Q AND R
AND S A AND B AND C
AND D AND E AND F AND G AND H AND I AND I AND J AND K AND L AND M AND N AND O AND P AND Q AND R AND S AND T
0.9999942937+(0.4*(1-0.9999942937))
0.9999965762
Nilai CF menurut persamaan 2.1 di dapat dari hasil perhitungan selisih MB dan MD sebagai berikut :
CF = MB – MD
= 0.9999999875 – 0.9999965762 = 0.0000034113
Semua nilai CF dengan Rule jika 20 gejala yang di pilih maka hasilnya termasuk ke dalam disleksia kombinasi, namun menggunakan metode CF dengan nilai MB dan MD maka di ambil nilai CF yang terbesar yaitu disleksia visual sebesar 0.0000160309.
3.4.1.2Perhitungan Metode Naïve Bayesian
Dalam metode Naïve Bayesian ini akan digunaka Teorema Bayes
49
Gambar 3.4 Alur Perhitungan Metode Naive Bayesian
Pada tugas akhir ini, metode Naïve Bayesian akan diterapkan pada studi kasus mendeteksi kemungkinan anak terkena disleksia. Diketahui 60 dat pasien penderita disleksia dengan berbagai jenis, diantaranya disleksia auditori, disleksia visual, disleksia kombinasi sebagai data train set yang telah terlampir. Terdapat 20 gejala berbeda dari setiap jenis disleksia tersebut. Nilai dari setiap gejala tersebut adalah 1 untuk
jawaban “Ya” dan 0 untuk jawaban “Tidak” pada saat pendeteksian.
Gejala-gejala tersebut di inisialisasikan pada tabel 3.11 sebagai berikut :
Table 3.11 Inisialisasi Gejala Metode Naive Bayesian
Inisialisasi
Gejala Keterangan Gejala
A : Kesulitan membuat pekerjaan tertulis secara terstruktur B : Huruf tertukar-tukar misal ‘b’ tertukar ‘d’, ‘p’ tertukar ‘q’, ‘m’
tertukar ‘w’, ‘s’ tertukar ‘z’. misalnya papa-qaqa
C : Melihat atau merasakan gerakan-gerakan yang sebenarnya tidak ada saat membaca, menulis atau menyalin
dengar dan melelahkan
E : Tulisan tangan yang buruk atau berantakan F : Mengalami kesulitan mempelajari tulisan sambung
G : Ketika mendengarkan sesuatu, rentang perhatiannya pendek H : Kesulitan dalam mengingat kata-kata atau ingatan yang buruk
atau lemah terhadap informasi yang tidak pernah dialami sebelumnya
I : Kesulitan mengingat nama-nama J : Kesulitan/ lambat mengerjakan PR
K : Kesulitan memahami konsep waktu atau kesulitan dalam menyebutkan waktu, mengatur waktu ataupun melakukan sesuatu dengan tepat waktu.
L : Kesulitan membedakan huruf vocal dengan konsonan
M : Mengeluh pusing atau nyeri kepala atau sakit perut saat membaca
N : Kesulitan mengingat rutinitas aktivitas sehari-hari atau mencerna sesuatu secara berurutan
O : Kesulitan membedakan kanan kiri
P : Membaca lambat-lambat dan terputus-putus dan tidak tepat Q : Menghilangkan atau salah baca kata penghubung
(“di”.”ke”,”pada”)
R : Mengabaikan kata awalan pada waktu membaca (“menulis” dibaca “tulis”)
S : Tertukar-tukar kata (misalnya : dia-ada, sama-masa, lagu-gula, batu-bata, tanam-taman, dapat-padat, mana-nama)
T : Ketidak akuratan dalam membaca seperti membaca lambat kata demi kata jika dibandingkan dengan anak seusianya, intonasi suara turun naik tidak teratur
Adapun cara perhitungan atau alur perhitungan metode Naïve Bayesian adalah sebagai berikut :
1. Menghitung jumlah label atau class
Untuk menentukannya terlebih dahulu harus mengklasifikasikan jenis disleksia tersebut yang berada pada data train set. Setelah diklasifikasikan maka terdapat tiga jenis disleksia yaitu disleksia auditori, disleksia visual, disleksia kombinasi yang masing-masing terdapat 20 data. Setelah diklasifikasikan maka dibagi dengan jumlah data train set. Dalam studi kasus ini jumlah data train sebanyak 60 data.
51
P(Y = Auditori) = 20/60 b. Class “Disleksia Visual”
P(Y = Visual) = 20/60 c. Class “Disleksia Kombinasi”
P(Y = Kombinasi) = 20/60
2. Menghitung jumlah kasus yang sama dengan class yang sama
Untuk perhitungan tahap ini kita bagi dan hitung pergejalanya. Sehingga perhitungannya adalah jumlah gejala “Ya” dibagi classnya
dan jumlah gejala “tidak” dibagi classnya.
Berikut adalah jumlah kasus yang sama dengan class yang sama : P(A=Ya|Y=Auditori)=15/20
P(D= Tidak |Y=Auditori)=13/20
53
P(R=Tidak|Y=Auditori)=8/20
P(R=Tidak|Y=Visual)=12/20
P(R=Tidak|Y=Kombinasi)=11/2
0
P(S=Ya|Y=Auditori)=8/20
P(S=Ya|Y=Visual)=11/20
P(S=Ya|Y=Kombinasi)=12/20
P(S=Tidak|Y=Auditori)=12/20
P(S=Tidak|Y=Visual)=9/20
P(S=Tidak|Y=Kombinasi)=8/20
P(T=Ya|Y=Auditori)=11/20
P(T=Ya|Y=Visual)=9/20
P(T=Ya|Y=Kombinasi)=11/20
P(T=Tidak|Y=Auditori)=9/20
P(T=Tidak|Y=Visual)=11/20
P(T=Tidak|Y=Kombinasi)=9/20
3. Kalikan semua hasil variabel sesuai dengan kolom hasil
Misalkan dalam contoh kasus user memasukan data gejala seperti pada tabel 3.2 berikut ini :
Table 3.12 Data Uji Pasien Baru Metode Naive Bayesian
Gejala Nilai Gejala Nilai
A 0 K 0
B 0 L 1
C 1 M 0
D 0 N 0
E 1 O 1
F 1 P 0
G 1 Q 0
H 1 R 1
I 1 S 0
J 1 T 0
Maka perhitungannya adalah : a. Class Disleksia Auditori
P(Y|Auditori) = 5/20 * 7/20 * 15/20 * 13/20 * 6/20 * 5/20 * 6/20 * 4/20 * 10/20 * 6/20 * 10/20 * 7/20 * 11/20 * 11/20 * 7/20 * 14/20 * 11/20 * 12/20 * 12/20 * 9/20
P(Y|Visual) = 5/20 * 7/20 * 11/20 * 10/20 * 4/20 * 5/20 * 5/20 * 6/20 * 7/20 * 6/20 * 10/20 * 7/20 * 12/20 * 12/20 * 7/20 * 12/20 * 13/20 * 8/20 * 9/20 * 11/20
= 0.0000000088
c. Class Disleksia Kombinasi
P(Y|Kombinasi) = 5/20 * 7/20 * 15/20 * 13/20 * 6/20 * 5/20 * 6/20 * 4/20 * 10/20 * 6/20 * 10/20 * 7/20 * 11/20 * 11/20 * 7/20 * 14/20 * 11/20 * 12/20 * 12/20 * 9/20
= 0.0000000023
4. Bandingkan setiap nilai probabilitas dari setiap class atau label 5. Ambil hasil paling maksimal
Nilai yang paling maksimal adalah nilai P(Y|Auditori) dengan nilai = 0.0000000333
75
BAB 5 PENUTUP
Pada bab ini akan dikemukan kesimpulan yang dapat diperoleh dari pembahasan bab-bab sebelumnya serta saran untuk perbaikan dan pengembangan sistem yang lebih lanjut.
5.1 Kesimpulan
Berdasarkan hasil yang didapat dalam penelitian dan penyusunan skripsi ini serta disesuaikan dengan tujuannya, maka diperoleh kesimpulan, tingkat akurasi rat-rata 58% untuk metode Certainty Factor dan rata-rata akurasi data untuk metode Naïve Bayesian adalah 93%. Hasil tersebut sudah menunjukkan metode mana yang lebih baik dalam mendeteksi kemungkinan anak terkena disleksia, yakni metode Naïve Bayesian karena selisih nya jauh lebih baik dibandingkan metode Certainty Factor ini disebabkan oleh parameter pada metode Certainty Factor yaitu nilai MB (Meansure of Believe) dan nilai MD
(Meansure of Disbelieve) yang berikan langsung dari seorang pakar. Dan kedua metode tersebut dapat diterapkan dalam sistem pendeteksi disleksia sesuai cara dan perhitungan kedua metode tersebut.
5.2 Saran