PERBANDINGAN METODE SELEKSI FITUR
PADA
SPAM FILTER
MENGGUNAKAN KLASIFIKASI
MULTINOMIAL NAÏVE BAYES
JULIUS GIGIH DIMASTYO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Perbandingan Metode Seleksi Fitur pada Spam Filter Menggunakan Klasifikasi Multinomial Naïve Bayes
adalah
benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Desember 2014
Julius Gigih Dimastyo
ABSTRAK
JULIUS GIGIH DIMASTYO. Perbandingan Metode Seleksi Fitur pada Spam Filter Menggunakan Klasifikasi Multinomial Naïve Bayes. Dibimbing oleh JULIO ADISANTOSO.
Saat ini banyak email yang tidak diinginkan masuk pada inbox, yang dikenal dengan spam. Oleh karena itu dibuatlah piranti lunak spam filter untuk mengklasifikasikan email spam dan bukan spam (ham) secara otomatis. Naïve Bayes saat ini banyak digunakan dalam metode klasifikasi karena sederhana dan mudah untuk diimplementasikan. Dalam klasifikasi dokumen, multinomial Naïve Bayes kinerjanya lebih bagus dibandingkan multivariate Bernoulli untuk kasus
vocabulary yang besar. Untuk meningkatkan akurasi model klasifikasi dan mempercepat proses komputasi dengan jumlah fitur yang minimal maka perlu melakukan seleksi fitur. Ada tiga metode seleksi fitur yang digunakan yaitu
inverse document frequency (IDF), mutual information (MI)dan chi-square. Hasil akhir menunjukan bahwa metode seleksi fitur yang terbaik berdasarkan tingkat akurasi yang dihasilkan adalah MI dengan akurasi 93.77% dan jumlah vocabulary
sebanyak 9507 sebagai penciri.
Kata kunci : multinomial Naïve Bayes, seleksi fitur, spam filter
ABSTRACT
JULIUS GIGIH DIMASTYO. Comparison of Feature Selection Methods in Spam Filter Using Multinomial Naïve Bayes Classification. Supervised by JULIO ADISANTOSO.
Nowadays lots of unwanted email called spam may freely get into the inbox entry. Therefore spam filter software made to classify spam and non-spam email (ham) automatically. Naïve Bayes frequently used today as classification method for it simple and easy to be implemented. Naïve bayes has a good performance to classify multinomial document compared to multivariate Bernoulli when it comes to large vocabulary. Feature selection needed to improve classification model accuracy and make computation process more efficient. There are three feature selection methods used such as inverse document frequency (IDF), mutual information (MI), and chi-square. Based on accuracy level, the result of this study shows that MI is the best feature selection method with 93.77% accuracy and 9507 vocabulary as an identifier.
JULIUS GIGIH DIMASTYO
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
PERBANDINGAN METODE SELEKSI FITUR
PADA
SPAM FILTER
MENG
GUNAKAN KLASIFIKASI
MULTINOMIAL NAÏVE BAYES
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU ALAM INSTITUT PERTANIAN BOGOR
Penguji:
1 Ahmad Ridha, SKom MS
Judul Skripsi: Perbandingan Metode Seleksi Fitur pada Spam Filter Menggunakan Klasifikasi Multinomial Naïve Bayes
Nama : Julius Gigih Dimastyo
NIM : G64124021
Disetujui oleh
Ir Julio Adisantoso, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, Msi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Juni 2014 ini ialah Perbandingan Metode Seleksi Fitur pada Spam Filter Menggunakan Klasifikasi Multinomial Naïve Bayes
Terima kasih penulis ucapkan kepada Bapak Ir. Julio Adisantoso MKom selaku pembimbing. Ungkapan terima kasih juga disampaikan kepada kedua orang tua saya. Terimkasih juga disampaikan kepada teman satu bimbingan Mutia, Denis dan Lutfi serta teman-teman ekstensi Ilkom IPB angkatan 7 yang telah membantu dalam menyelesaikan penelitian ini.
Semoga karya ilmiah ini bermanfaat.
Bogor, Desember 2014
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Pengumpulan Data 3
Praproses Data 3
Fungsi Klasifikasi 8
Evaluasi Model Klasifikasi 9
Lingkungan Pengembangan 10
HASIL DAN PEMBAHASAN 10
Pengumpulan Data 10
Praproses Data 11
Seleksi Fitur 11
Pengujian Model Klasifikasi 13
Evaluasi Model Klasifikasi 14
SIMPULAN DAN SARAN 17
Simpulan 17
Saran 17
DAFTAR PUSTAKA 18
DAFTAR TABEL
1. Komponen header dan body 5
2. Tabel kontingensi antara kata dan kelas 6
3. Nilai kritis untuk taraf nyata dengan derajat bebas (Walpole
1968) 8
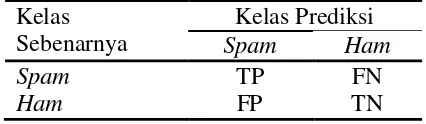
4. Confusion matrix kelas prediksi dan kelas sebenarnya 9
5. Jumlah vocabularyberdasarkan taraf nyata α 12
6. Batas nilai masing-masih seleksi fitur 12
7. Perbandingan waktu komputasi klasifikasi antar seleksi fitur 13 8. Confusion matrix tanpa seleksi fitur 13 9. Perbandingan tingkat akurasi setiap seleksi fitur 14
DAFTAR GAMBAR
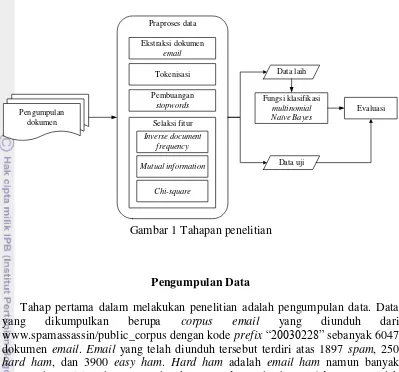
1. Tahapan penelitian 3
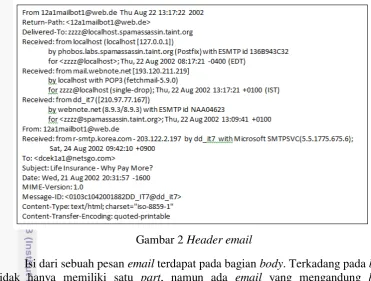
2. Header email 4
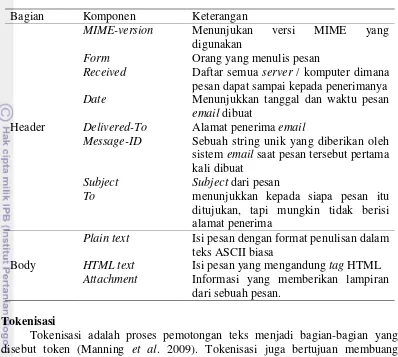
3. Body email 4
4. Tingkat akurasi berdasarkan jumlah vocabulary pada MI 14 5. Grafik tingkat akurasi dari ketiga seleksi fitur 15 6. Grafik tingkat akurasi ham dari ketiga seleksi fitur 16 7. Grafik tingkat akurasi spam dari ketiga seleksi fitur 16 8. Grafik perbandingan waktu komputasi klasifikasi setiap seleksi fitur 17
DAFTAR LAMPIRAN
1. Pseudocode perhitungan seleksi fitur chi square 19 2. Pseudocode perhitungan seleksi fitur MI 19 3. Pseudocode perhitungan seleksi fitur IDF 19
PENDAHULUAN
Latar Belakang
Saat ini banyak email yang tidak diinginkan masuk pada inbox, yang dikenal dengan spam. Perusahaan keamanan McAfee (2008) dalam laporannya menyatakan bahwa pada tahun 2008, terdapat sekitar 62 triliun spam yang dikirim ke seluruh dunia.
Menyaring spam secara manual sulit dilakukan untuk ukuran dokumen
email yang sangat besar. Oleh karena itu muncul piranti lunak spam filter untuk mengklasifikasikan email spam dan bukan spam (ham) secara otomatis. Metode
Naive Bayes classifier dapat digunakan sebagai fungsi klasifikasi, meskipun beberapa algoritme yang lain telah bekerja dalam pengembangan spam filter.
Naïve Bayes banyak digunakan dalam pengembangan spam filter, karena sederhana dan mudah untuk diimplementasikan (Metsis et al. 2006).
Secara umum Naïve Bayes classifier dapat dibagi menjadi dua, yaitu
multivariate Bernoulli dan multinomial Naïve Bayes (Manning et al. 2009).
Dalam penelitian ini Naïve Bayes classifier yang digunakan adalah multinomial Naïve Bayes. Multinomial Naïve Bayes mampu menurunkan kesalahan pada klasifikasi dokumen dengan nilai rata 27% bahkan mencapai 50% dari percobaan menggunakan multivariate Bernoulli (McCallum & Nigam 1998).
Penelitian Rachman (2011) mengukur kinerja spam filter menggunakan dua metode training TEFT dan TOE, serta metode Naïve Bayes Multinomial dan Graham sebagai classifier. Penelitian tersebut menghasilkan nilai maksimum pada evaluasi
spam recall sebesar 97.65% yang dihasilkan dari metode training TOE dan classifier Naïve Bayes Multinomial. Penelitian tersebut tidak membahas mengenai seleksi fitur dalam mengambil penciri. Tidak semua term dapat dijadikan sebagai penciri dalam klasifikasi, sehingga perlu dilakukan seleksi fitur. Menurut Manning et al. (2009) tujuan utama dari seleksi fitur adalah mempercepat proses komputasi dengan jumlah term yang minimal sebagai penciri dan meningkatkan akurasi model klasifikasi.
Metode seleksi fitur yang paling banyak digunakan dalam klasifikasi teks adalah inverse document frequency (IDF), Mutual information (MI), dan chi-square ( ) (Manning et al. 2009). IDF adalah metode yang sederhana dalam seleksi fitur namun menghasilkan fitur yang efektif untuk mengkategorikan dokumen teks (Yang dan Pedersen 1997). MI mengukur hubungan acak antar variabel, sehingga sesuai untuk menilai term dari sebagai penciri dalam klasifikasi (Battiti 1994). Chi-square ( ) dalam seleksi fitur digunakan untuk mengukur hubungan antara kata terhadap kelas. Manning et al. (2009) menyebutkan bahwa
2
Perumusan Masalah
Perumusan masalah pada penelitian ini adalah:
1 Bagaimana memodelkan klasifikasi multinomial Naïve Bayes di dalam spam filter?
2 Bagaimana pengaruh seleksi fitur IDF, MI dan chi-square dalam meningkatkan akurasi klasifikasi?
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Mengimplementasikan fungsi klasifikasi dengan metode multinomial Naïve Bayes.
2 Membandingkan akurasi spam filter dengan melihat pemilihan seleksi fitur IDF, MI dan
Manfaat Penelitian
Manfaat dari penelitian ini adalah mendapatkan metode seleksi fitur yang terbaik dalam meningkatkan akurasi spam filter dengan fungsi klasifikasi
multinomial Naïve Bayes.
Ruang Lingkup Penelitian
Korpus yang digunakan adalah dokumen email dengan standar
Multipurpose Internet Mail Extensions (MIME) dalam format raw. Korpus email
ini dibagi ke dalam 2 kelas yang berbeda yaitu kelas spam dan ham. Dalam praproses tidak dilakukan proses stemming karena dapat menurunkan kinerja klasifikasi (Manning et al. 2009).
METODE
3
Tahap pertama dalam melakukan penelitian adalah pengumpulan data. Data yang dikumpulkan berupa corpus email yang diunduh dari www.spamassassin/public_corpus dengan kode prefix“20030228” sebanyak 6047 dokumen email. Email yang telah diunduh tersebut terdiri atas 1897 spam, 250
hard ham, dan 3900 easy ham. Hard ham adalah email ham namun banyak mengandung ciri pada spam sedangkan easy ham adalah email ham yang tidak mengandung ciri pesan spam.
Praproses Data
Sebelum dilakukan klasifikasi, data email diolah terlebih dahulu untuk menghasilkan penciri yang berupa term. Tahapan tersebut adalah ekstraksi dokumen, tokenisasi, membuang stopwords, dan seleksi fitur.
Ekstraksi Dokumen
Dokumen yang diperoleh melalui tahap pengumpulan data berupa email
dengan standar MIME dalam format raw. Email yang akan diproses didekomposisi terlebih dahulu struktur email-nya menjadi bagian yang lebih kecil. Secara umum struktur email dapat dibagi menjadi 2 bagian utama yaitu header
dan body.
Berdasarkan MIME bagian header email berisi komponen-komponen informasi seperti from, subject, date, MIME-version, received, message-id, delivered-to, to, Content-type, dan content-transfer-encoding. Untuk lebih jelasnya komponen header dapat dilihat pada Gambar 2. Header dari email
4
Gambar 2 Header email
Isi dari sebuah pesan email terdapat pada bagian body. Terkadang pada body
tidak hanya memiliki satu part, namun ada email yang mengandung body multipart. Bagian body yang memiliki informasi file attachment terdapat pada
body multipart. Email yang mengandung multipart akan digabungkan menjadi satu. Gambar 3 adalah contoh body pada email yang belum diproses.
Gambar 3 Body email
Bagian header dan body diekstrak menjadi dokumen email yang siap untuk dilakukan proses tokenisasi. Hasil dari ektraksi dokumen ini berupa informasi yang terdapat pada email seperti yang terlihat pada Tabel 1. Bagian header yang digunakan untuk proses tokensisasi adalah subject saja, sedangkan pada bagian
5 Tabel 1 Komponen header dan body
Bagian Komponen Keterangan
Header
MIME-version Menunjukan versi MIME yang digunakan
Form Orang yang menulis pesan
Received Daftar semua server / komputer dimana pesan dapat sampai kepada penerimanya
Date Menunjukkan tanggal dan waktu pesan
email dibuat
Delivered-To Alamat penerima email
Message-ID Sebuah string unik yang diberikan oleh sistem email saat pesan tersebut pertama kali dibuat
Subject Subject dari pesan
To menunjukkan kepada siapa pesan itu ditujukan, tapi mungkin tidak berisi alamat penerima
Body
Plain text Isi pesan dengan format penulisan dalam teks ASCII biasa
HTML text Isi pesan yang mengandung tag HTML
Attachment Informasi yang memberikan lampiran dari sebuah pesan.
Tokenisasi
Tokenisasi adalah proses pemotongan teks menjadi bagian-bagian yang disebut token (Manning et al. 2009). Tokenisasi juga bertujuan membuang karakter tertentu, seperti tanda baca. Token yang dihasilkan berupa kata tunggal yang nantinya akan menjadi sebuah term yang akan digunakan sebagai penciri untuk klasifikasi antara email spam dan ham. Hasil akhir dari proses tokenisasi adalah inverted index dalam bentuk matriks term-dokumen.
Membuang Stopwords
Stopwords adalah kata yang sangat umum dan sering muncul dengan frekuensi tinggi (Manning et al. 2009). Token didalam stopwords tidak dapat digunakan sebagai penciri dalam melakukan klasifikasi. Daftar stopwords yang digunakan adalah kata dalam bahasa Inggris yang diunduh dari http://jmlr.org/papers/volume5/lewis04a/a11-smart-stop-list/english.stop. yang memiliki 571 kata (Lampiran 4). Membuang stopwords juga bertujuan untuk memperkecil daftar token dari inverted index.
Seleksi Fitur
6
Menurut Garnes (2009) seleksi fitur secara umum dibagi menjadi 2 metode, yaitu unsupervised feature selection dan supervised feature selection. Unsupervised feature selection adalah sebuah metode seleksi fitur yang tidak menggunakan informasi kelas dalam data latih ketika memilih fitur untuk
classifier. Manning et al. (2009) unsupervised feature selection adalah seleksi fitur berbasis frekuensi. IDF adalah salah satu contoh seleksi fitur yang tidak menggunakan informasi kelas dalam pemilihan fiturnya.
Supervised feature selection adalah metode seleksi fitur yang menggunakan informasi kelas dalam data latih, sehingga untuk menggunakan seleksi fitur ini harus tersedia sebuah data latih yang sudah terklasifikasi. MI dan chi-square
adalah contoh dari supervised feature selection.
i) Inverse document frequency (IDF)
Document frequency ( ) adalah banyaknya dokumen yang mengandung kata tertentu. Ukuran ketidakpentingan suatu termt dari dokumen yang digunakan sebagai penciri adalah kata yang sering muncul di seluruh dokumen. IDF adalah banyaknya dokumen dimana suatu term t muncul yang dikoreksi dengan banyaknya seluruh dokumen latih N. Nilai dari IDF disimbolkan dengan yang ditulis dengan formula (Manning et al. 2009)
(1)
ii) Mutual information (MI)
MI menunjukkan seberapa banyak informasi sebuah term memberikan konstribusi dalam membuat keputusan klasifikasi secara benar atau salah. Nilai dari MI menurut Manning et al. (2009) adalah
∑ ∑ (2)
sedangkan U adalah variabel acak dengan nilai-nilai = 1 (dokumen berisi kata
t) dan = 0 (dokumen tidak mengandung kata t), dan C adalah variabel acak dengan nilai-nilai = 1 (dokumen di kelas c ) dan = 0 (dokumen tidak di kelas
c). Perhitungan nilai MI pada setiap kata t yang muncul pada setipa kelas c
dapat dibantu dengan menggunakan tabel kontingensi (Tabel 2). Tabel 2 Tabel kontingensi antara kata dan kelas
Kata Kelas Jumlah
c ⌐c
t
⌐t
Jumlah
7
Chi-square ( biasanya digunakan dalam menguji independensi dari dua variabel yang berbeda. Hipotesis nol (H0) jika kedua variabel saling bebas satu sama lain. H0 diterima jika nilai penghitungan < nilai kritis pada derajat bebas dan taraf nyata tertentu.
Dalam seleksi fitur digunakan untuk mengukur independensi term t dan kelas c. H0 yang diuji adalah term dan kelas benar-benar independen, artinya fitur ini tidak berguna untuk mengelompokkan dokumen. Jika nilai dari term t > nilai kritis pada derajat bebas dan taraf nyata tertentu maka tolak H0, artinya term t
tersebut dapat digunakan sebagai penciri. Persamaan dari (Manning et al. frekuensi yang diamati dalam dokumen D dan E adalah frekuensi yang diharapkan. Dengan melihat tabel kontingensi pada Tabel 3, persamaan dapat disederhanakan menjadi (Manning et al. 2009)
(5) dengan N adalah jumlah seluruh dokumen latih yang memiliki nilai-nilai et dan ec
yang ditunjukan oleh dua subscript. Sebagai contoh, N10 adalah jumlah dokumen
yang mengandung t (et = 1) dan tidak dalam c (ec = 0). Untuk lebih jelasnya bisa
dilihat pada keterangan tabel kontingensi (Tabel 2) dalam persamaan MI.
8
Klasifikasi dokumen secara otomatis dilakukan menggunakan fungsi klasifikasi yang dapat memetakan dokumen ke dalam kategori tertentu
γ : X C
dengan X adalah kumpulan dokumen dan C adalah himpunan kelas atau kategori. Fungsi klasifikasi digunakan untuk mengelompokan email spam dan ham.
Manning et al. (2009) membagi fungsi klasifikasi menjadi dua metode yaitu berbasis vector dan berbasis peluang. Pada fungsi klasifikasi berbasis vektor, setiap dokumen training direpresentasikan sebagai vektor yang diberi label sesuai dengan kelasnya. Beberapa metode yang sering digunakan untuk klasifikasi berbasis vektor adalah kNN dan Rocchio classification. Metode kedua adalah berbasis peluang dimana penentuan label kelas akan ditentukan dari nilai peluang dokumen terhadap kelas. Metode berbasis peluang yang sering digunakan adalah
Naïve Bayes classifier. Nilai peluang dokumen d pada kelas c adalah (Manning et al. 2009)
| | (6)
Naïve Bayes classifier terbagi menjadi 2 model, yaitu multivariate Bernoulli
dan multinomial Naïve Bayes (Manning et al. 2009). Model pertama, multivariate Bernoulli menyatakan bahwa dokumen diwakili oleh atribut biner yang menunjukan ada dan tidak ada term dalam dokumen. Frekuensi kemunculan term
dalam dokumen tidak ikut diperhitungkan.
9 Terkadang term tidak muncul pada salah satu kelas saat proses klasifikasi sehingga nilai ̂ | yang dihasilkan adalah nol.Untuk mengatasi permasalahan tersebut, digunakan laplace smoothing, yaitu menambahkan frekuensi term
sebanyak 1 sehingga perhitungan dari ̂( | ) menjadi (Manning et al. 2009)
Pengujian dilakukan pada data uji terhadap fungsi klasifikasi yang sudah dilakukan training. Token yang dihasilkan dari proses seleksi fitur, masing-masing dihitung peluang berdasarkan kelasnya. Setelah mendapatkan nilai peluang masing-masing token maka dapat dihitung peluang dari dokumen email
uji.
Penghitungan nilai peluang dengan mengimplementasikan pada kode program dari persamaan (7) ternyata menghasilkan nilai peluang yang sangat kecil, pada bahasa pemrogaman PHP nilai peluang yang sangat kecil tersebut menjadi nilai 0. Oleh karena itu hal tersebut diatasi dengan melakukan perhitungan menggunakan logaritma untuk menghitung peluang dokumen. Persamaan diatas diubah menjadi
log | ( ) ∑ log | . (10)
Evaluasi dilakukan dengan cara membandingkan kelas aktual dari dari data uji dan kelas hasil prediksi dengan menggunakan confusion matrix. Confusion matrix berisi jumlah kasus-kasus yang diklasifikasikan dengan benar dan kasuskasus yang salah diklasifikasikan. Pada Kasus yang diklasifikasikan dengan benar muncul pada diagonal, karena kelompok prediksi dan kelompok aktual adalah sama. Elemen-elemen selain diagonal menunjukkan kasus yang salah diklasifikasikan. Format dari confusion matrix dapat dilihat pada Tabel 4.
Tabel 4 Confusion matrix kelas prediksi dan kelas sebenarnya Kelas
TP adalah email dari kelas spam yang benar diklasifikasikan sebagai spam, TN adalah email dari kelas ham yang benar diklasifikasikan sebagai ham, FP adalah email dari kelas ham yang salah diklasifikasikan sebagai spam, FN adalah
10
� � � � �
Untuk mengetahui akurasi setiap kelas maka dihitung akurasi ham dan akurasi
spam dengan formula
� �
� �
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini adalah sebagai berikut:
1 Perangkat keras berupa komputer personal dengan spesifikasi sebagai berikut : a) Processor Intel core i3
b) RAM 4 GB
c) Monitor LCD 14.0” HD d) Harddisk 500 GB HDD 2 Perangkat lunak :
a) Sistem Operasi Windows 7 b) Bahasa pemrograman PHP c) DBMS MySQL
d) Web server Apache 2.4.4
HASIL DAN PEMBAHASAN
Pengumpulan Data
Korpus yang digunakan pada penelitian ini adalah public email corpus yang
disediakan oleh Spamassasin dengan kode prefix “20030228” 1
. Korpus ini terdiri atas 6047 pesan email yang sudah diklasifikasikan sebelumnya secara manual. Pesan yang memiliki label easy-ham dan hard-ham tidak dibedakan secara khusus
dan digabungkan ke dalam satu kategori yaitu “ham”. Dari total korpus dibagi
masing-masing 70% sebagai data latih dan 30% data uji. Data latih spam
sebanyak 1328 dan data latih ham 2905 sedangkan data uji spam sebanyak 569 dan data uji ham 1245. Jadi total data latih 4233 atau 70% dari total korpus dan total data uji 1814 atau 30% dari total korpus.
11 Praproses Data
Ekstraksi Dokumen
Dokumen yang diperoleh melalui tahap pengumpulan dokumen berupa
email mentah. Email yang diunduh pada bagian file extension tidak memiliki nama yang sama sehingga harus dilakukan perubahan nama pada file extension
yang seragam menjadi “.mail”. Serta pada nama file dilakukan penamaan berurut
mulai dari “1.mail” untuk mempermudah looping pada program.
Ekstraksi dokumen dilakukan untuk memecah dokumen email menjadi bagian-bagian yang lebih kecil menggunakan library MIMEmailparse. Informasi
subject pada header dan plain text serta HTML text pada body hasil ekstraksi digabungkan menjadi satu untuk dilakukan tokenisasi. Isi dari subject dan plain text berupa teks biasa subject biasanya menggambarkan informasi yang terkandung pada bagian body. plain text paling banyak terdapat pada easy ham
sedangkan HTML text paling banyak terdapat pada spam dan hard ham. Pada dokumen easy-ham sebanyak 2708 mempunyai plain text sedangkan pada dokumen hard-ham dan spam masing-masing sebanyak 64 dan 771. HTML text pada dokumen easy-ham sebanyak 20 sedangkan pada dokumen hard-ham dan
spam masing-masing sebanyak 136 dan 671. Tokenisasi
Proses tokenisasi secara bertahap dilakukan sebagai berikut:
1 Tanda baca serta dihilangkan dan menggantinya dengan spasi. Tanda baca tersebut diantaranya ' - ) ( \ / = . , : ; ! ?
2 Proses pemotongan dokumen menjadi token -token berdasarkan white space
serta menghilangkan kata numerik
3 Penyeragaman token menjadi huruf kecil semua (lower case).
Pada bagian subject tokenisasi dilakukan seperti halnya pada plain text. Semua kata pada subject akan dipotong menjadi token. Proses tokenisasi ini juga dilakukan terhadap seluruh tag html yang terdapat pada dokumen email. Termasuk seluruh atribut yang terdapat pada tag htmlseperti “width”, “color” dan
lain sebagainya. Sebelum disimpan dalam basis data token-token yang dihasilkan harus terlebih dahulu dibuang kata-kata yang termasuk dalam stopwords. Token yang sudah bersih dari stopwords akan diproses melalui seleksi fitur untuk menghasilkan term yang nantinya akan digunakan sebagai penciri.
Seleksi Fitur
Seleksi fitur ini bertujuan agar akurasi yang dihasilkan dari proses klasifikasi email dapat meningkat, serta yang terpenting adalah untuk efisiensi dari token yang digunakan sebagai penciri. Hasil dari pembuangan stopwords
sebelum dilakukan proses seleksi fitur menghasilkan jumlah token unik atau
vocabulary sebanyak 50419. Setiap token yang ada akan diberikan bobot sesuai dengan nilai seleksi fitur yaitu dengan menggunakan IDF, MI atau chi-square.
12
Seleksi fitur yang pertama adalah chi-square. Pada metode diperlukan
taraf nyata α yang merupakan kesalahan yang dibuat pada waktu menguji H0 dan H1 saling bebas atau tidak, dengan kata lain untuk mengetahui hubungan antara
token dengan kelas. Jika menggunakan batas taraf nyata α = 0.01 maka token dengan bobot nilai lebih besar sama dengan 6.63 yang diambil sebagai penciri. Jumlah dari masing-masing vocabulary berdasarkan taraf nyata α dapat dilihat
pada Tabel 5. Pseudocode program dalam implementasi penghitungan nilai terdapat pada Lampiran 1.
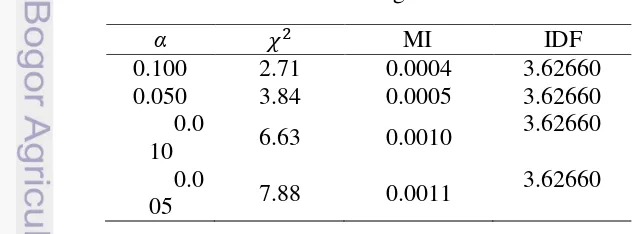
Tabel 5 Jumlah vocabulary berdasarkan taraf nyata α Taraf nyata
α Nilai kritis Jumlah vocabulary Persentase dari data awal
0.100 2.71 9361 18.6%
0.050 3.84 7733 15.3%
0.010 6.63 3851 7.6%
0.005 7.88 3390 6.7%
Seleksi fitur yang kedua adalah Mutual Information (MI). MI merupakan
supervised feature selection sama seperti yang merupakan metode seleksi fitur yang menggunakan informasi kelas dalam data pelatihan ketika memilih fitur untuk classifier. Sama seperti ada tiga nilai untuk melakukan batasan seleksi fitur. Nilai yang diambil dalam MI tidak ada taraf nyata tetapi menggunakan batasan sesuai yang kita inginkan. Dalam penelitian ini batasan yang diambil disamakan atau mendekati dengan jumlah vocabulary yang dihasilkan dari seleksi fitur agar bisa terlihat perbedaan dari masing-masing seleksi fitur untuk dibandingkan. Pseudocode program dalam implementasi penghitungan nilai MI terdapat pada Lampiran 2.
Seleksi fitur yang terakhir adalah IDF. Proses pemilihan token dengan menggunakan seleksi fitur IDF juga dilakukan percobaan empat kali, dengan pengambilan jumlah vocabulary mendekati hasil seleksi fitur . Pseudocode
program dalam implementasi penghitungan nilai IDF terdapat pada Lampiran 3. Dalam seleksi fitur IDF pemotongan jumlah vocabulary atau proses seleksi fitur tidak ada batasan khusus, sama halnya dengan MI. Nilai IDF dan MI yang digunakan dalam seleksi fitur dapat dilihat pada Tabel 6.
Tabel 6 Batas nilai masing-masih seleksi fitur
α MI IDF
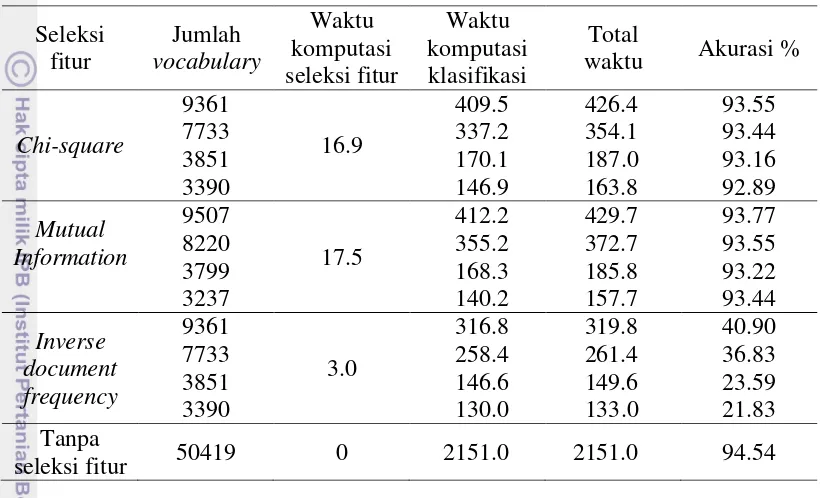
13 komputasi yang paling lama. Hasil perbandingan waktu komputasi dapat dilihat pada Tabel 7. Cara pencatatan waktu komputasi tersebut untuk masing-masing seleksi fitur dilakukan tiga kali percobaan kemudian ketiga waktu komputasi dicatat dan diambil rataannya.
Tabel 7 Perbandingan waktu komputasi klasifikasi antar seleksi fitur Seleksi
Sebelum melakukan pengujian klasifikasi menggunakan token hasil reduksi dari seleksi fitur, penelitian ini mencoba melakukan klasifikasi dokumen email
tanpa melakukan seleksi fitur dengan jumlah vocabulary 50419. Proses pengujian klasifikasi dilakukan menggunakan 1814 data uji yang terdiri dari 1245 dokumen
ham dan 569 dokumen spam. Hasil akurasi total dari percobaan ini adalah 94.54% dengan akurasi ham sebesar 98.23% dan akurasi spam sebesar 86.47%. Nilai detail dari klasifikasi tersebut dapat dilihat pada tabel confusion matrix pada Tabel 8.
Tabel 8 Confusion matrix tanpa seleksi fitur
Spam Ham Total
Spam 492 77 569
Ham 22 1223 1245
Total 514 1300 1814
Pengujian selanjutnya dengan dokumen yang sama namun menggunakan token yang sebelumnya sudah dilakukan proses seleksi fitur. Untuk setiap seleksi fitur dilakukan empat kali percobaan dengan membandingkan jumlah vocabulary
14
Tabel 9 Perbandingan tingkat akurasi setiap seleksi fitur akurasi % akurasi spam % akurasi ham % Selain mencatat hasil akurasi dari setiap seleksi fitur berdasarkan jumlah
vocabulary juga dilakukan pencatatan waktu komputasinya. Cara pencatatan untuk setiap seleksi fitur dan setiap batas nilai dilakukan tiga kali percobaan dan diambil waktu rataannya. Hasil pencatatan waktu komputasi klasifikasi dapat dilihat pada Tabel 7.
Evaluasi Model Klasifikasi
Dengan menggunakan seleksi fitur yang diterapkan pada multinomial Naïve Bayes untuk klasifikasi memang memiliki sedikit penurunan. Setelah dilakukan klasifikasi berdasarkan masing-masing seleksifitur terlihat bahwa ada sedikit penurunan dari akurasinya. Penurunan akurasi ini disebabkan karena jumlah
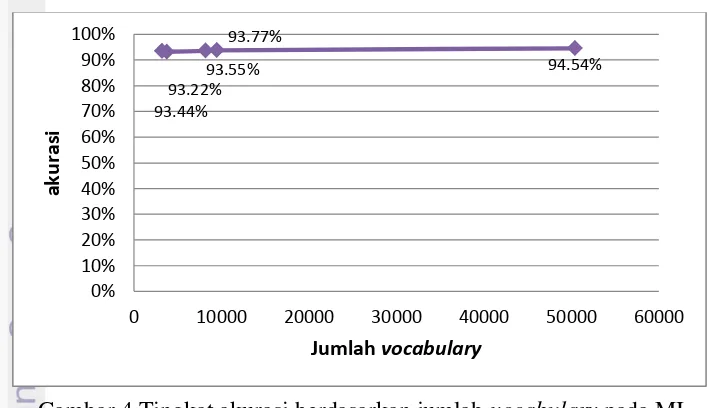
vocabulary yang digunakan sebagai penciri mengalamai penurunan. Hampir pada semua seleksi fitur semakin sedikit jumlah vocabulary maka akurasi ikut menurun juga. Grafik pada Gambar 4 menunjukan penurunan akurasi berdasarkan jumlah
vocabulary pada seleksi fitur IDF.
Gambar 4 Tingkat akurasi berdasarkan jumlah vocabulary pada MI
Dalam proses pengujian klasifikasi tanpa menggunakan seleksi fitur membutuhkan waktu komputasi selama 2151 detik (35.8 menit) dengan akurasi 94.54%. Jika dibandingkan dengan hasil seleksi fitur MI dengan akurasi
0 10000 20000 30000 40000 50000 60000
15 klasifikasi tertinggi 93.77% membutuhkan waktu komputasi hanya 429.7 detik (7.2 menit) dengan jumlah vocabulary 9507. Dilihat dari penurunan akurasi yang tidak begitu signifikan dibandingkan dengan waktu eksekusi dan jumlah
vocabulary yang sedikit, maka seleksi fitur dapat digunakan sebagai efisiensi token sebagai penciri dalam klasifikasi.
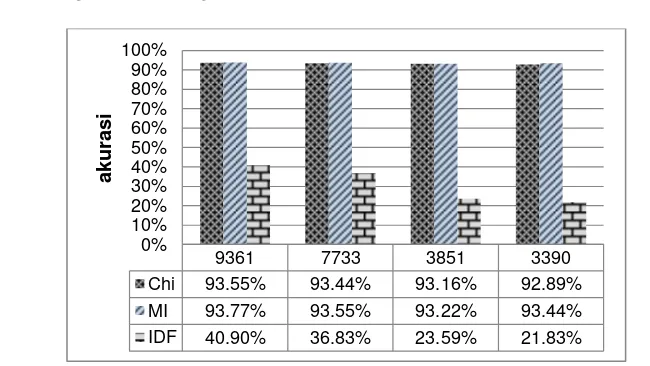
Seperti yang sudah dijelaskan sebelumnya secara umum semakin sedikit jumlah vocabulary yang digunakan sebagai penciri maka akurasi semakin mengecil. Dari ketiga seleksi fitur tersebut akurasi klasifikasi tebaik terdapat pada jumlah vocabulary terbesar atau pada nilai taraf nyata α 0.100 pada seleksi fitur (Gambar 5). Akurasi terbaik dihasilkan dari seleksi fitur MI dengan nilai akurasi 93.77%. Tetapi tidak semua akurasi menurun jika menggunakan jumlah
vocabulary yang sedikit. Seleksi fitur MI denga jumlah vocabulary terkecil (3237) memiliki tingkat akurasi lebih bagus dari pada jumlah vocabulary 3799. Akurasi tersebut mengalami peningkatan dari 93.22% menjadi 93.44%.
Gambar 5 Grafik tingkat akurasi dari ketiga seleksi fitur
Hampir sama dengan akurasi yang ditunjukan pada Gambar 5, akurasi ham
16
Gambar 6 Grafik tingkat akurasi ham dari ketiga seleksi fitur
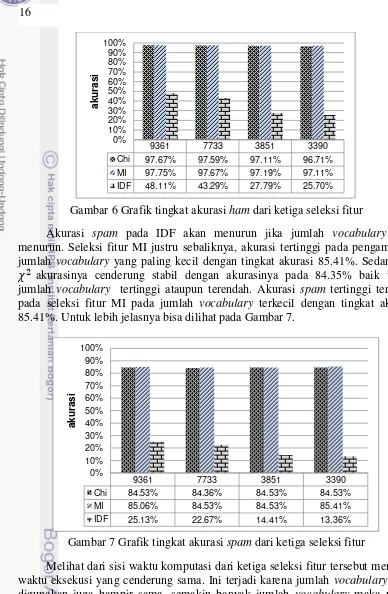
Akurasi spam pada IDF akan menurun jika jumlah vocabulary juga menurun. Seleksi fitur MI justru sebaliknya, akurasi tertinggi pada pengambilan jumlah vocabulary yang paling kecil dengan tingkat akurasi 85.41%. Sedangkan akurasinya cenderung stabil dengan akurasinya pada 84.35% baik untuk jumlah vocabulary tertinggi ataupun terendah. Akurasi spam tertinggi terdapat pada seleksi fitur MI pada jumlah vocabulary terkecil dengan tingkat akurasi 85.41%. Untuk lebih jelasnya bisa dilihat pada Gambar 7.
Gambar 7 Grafik tingkat akurasi spam dari ketiga seleksi fitur
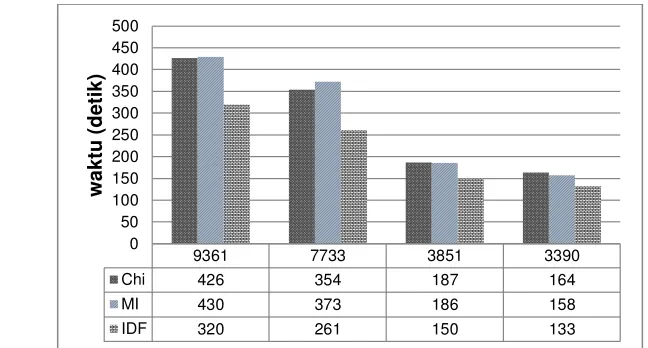
Melihat dari sisi waktu komputasi dari ketiga seleksi fitur tersebut memiliki waktu eksekusi yang cenderung sama. Ini terjadi karena jumlah vocabulary yang digunakan juga hampir sama. semakin banyak jumlah vocabulary maka waktu komputasi untuk melakukan klasifikasi juga semakin lama. Grafik dari lama waktu eksekusi dari masing-masing seleksi fitur dapat dilihat pada Gambar 8.
17
Gambar 8 Grafik perbandingan waktu komputasi klasifikasi setiap seleksi fitur Melihat dari percobaan yang sudah dilakukan dalam melakukan klasifikasi seleksi fitur MI secara umum memiliki tingkat akurasi yang terbaik. Bahkan dalam klasifikasi dokumen spam dengan jumlah vocabulary yang sedikit mampu menghasilkan akurasi klasifikasi terbaik. Meskipun waktu komputasi relativ paling lama dibandingkan metode seleksi fitur yang lain. Untuk klasifikasi dokumen spam jika ingin menggunakan jumlah vocabulary yang sedikit dan waktu komputasi yang seminimal mungkin maka seleksi fitur MI dapat digunakan.
SIMPULAN DAN SARAN
Simpulan
Metode seleksi fitur yang terbaik berdasarkan tingkat akurasi yang dihasilkan adalah mutual information dengan akurasi 93.77% dengan waktu komputasi 429.7 detik dan jumlah vocabulary sebanyak 9507. MI juga lebih bagus dalam melakukan klasifikasi dokumen spam dibandingkan dengan seleksi fitur yang lainnya jika menggunakan jumlah vocabulary yang sedikit (sebanyak 3390).
Meskipun dalam seleksi fitur mengalami sedikit penurunan akurasi namun efisiensi dari term yang dihasilkan sebagai penciri sangat terlihat. Tanpa menggunakan seleksi fitur membutuhkan waktu komputasi selama 35.8 menit dengan akurasi 94.54% dengan jumlah vocabulary 50419. Dibandingkan dengan hasil seleksi fitur MI mampu menghasilkan akurasi 93.77%.
Saran
Menggunakan seleksi fitur banyak terjadi pembuangan token dan mungkin merupakan penciri. Akibatnya ada beberapa penciri yang ikut terbuang, sedangkan multinomial Naïve Bayes merupakan metode klasifikasi dengan basis peluang sehingga pada saat data uji diuji ada token yang sebagai penciri tidak dihitung peluangnya. Untuk mengatasi hilangnya token yang digunakan sebagai
18
penciri dapat menggunakan background smoothing, dengan memodelkan seluruh dokumen latih sebagai collection background model.
DAFTAR PUSTAKA
Battiti R. 1994. Using Mutual Information for Selecting Features in Supervised Neural Net Learning. IEEE Computational Intelligence Society. 5(4):537 – 550. doi: 10.1109/72.298224
Garnes Ø L. 2009. Feature Selection for Text Categorisation. Norwegia (NO): NTNU
Manning C D, Raghavan P, Schütze H. 2009. Introduction to Information Retrieval. Cambridge (GB): Cambridge University Press.
McAfee. 2008. The Carbon Footprint of Email Spam Report. Santa Clara (US): McAfee, Inc.
McCallum A, Nigam K. 1998. A Comparison of Event Models for Naive Bayes Text Classification. Didalam : AAAI-98 workshop on learning for text categorization. hlm 41-48
Metsis V, Androutsopoulos I, Paliouras G. 2006. Spam Filtering with Naive Bayes – Which Naive Bayes?. Didalam : CEAS 2006 - Third Conference on Email and AntiSpam. California (US): CEAS
Rachman W. 2011. Pengukuran kinerja spam filter menggunakan metode Naive Bayes classifier graham. [Skripsi]. Bogor (ID): Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Walpole E R. 1968. Introduction to Statistics. New York (US): Macmillan
19 Lampiran 1 Pseudocode perhitungan seleksi fitur chi square
Lampiran 2 Pseudocode perhitungan seleksi fitur MI
Lampiran 3 Pseudocode perhitungan seleksi fitur IDF $totalham = 2905;
$totalspam = 1328;
$N = $totalham+$totalspam;
$query = mysql_query("SELECT temp_a.token,A,B,C,D FROM temp_b, temp_a WHERE temp_a.token = temp_b.token");
while($row3 = mysql_fetch_array($query)) {
$pow = (($row3['A']*$row3['D'])-($row3['C']*$row3['B'])) *(($row3['A']*$row3['D'])-($row3['C']*$row3['B']));
$chi = ($N*$pow)/(($row3['A']+$row3['C'])*($row3['B']+$row3['D']) *($row3['A']+$row3['B'])*($row3['C']+$row3['D']));
}
$totalham = 2905; $totalspam = 1328; $N = $totalham+$totalspam;
$query = mysql_query("SELECT temp_a.token,A,B,C,D FROM temp_b, temp_a WHERE temp_a.token = temp_b.token");
while($row3 = mysql_fetch_array($query)) { if ($row3['A'] == 0)
(log((($N*$row3['B'])/(($row3['A']+$row3['B'])*($row3['B']+$row3['D'])))));
$c1 = ($row3['C']/$N) *
(log((($N*$row3['C'])/(($row3['C']+$row3['D'])*($row3['A']+$row3['C'])))));
$d1 = ($row3['D']/$N) *
(log((($N*$row3['D'])/(($row3['C']+$row3['D'])*($row3['B']+$row3['D']))))); $hasil = $a1+$b1+$c1+$d1;
}
$totalham = 2905; $totalspam = 1328;
$N = $totalham+$totalspam;
$query = mysql_query("SELECT token, sum(df) as N from df group by token");
while ($row = mysql_fetch_array($query)){ $term = $row['token'];
$dft = $row['N'];
20
Lampiran 4 Daftar kata stopwords
22