Implementasi Algoritma K-Medoids Clustering Dalam
Pengelompokan Angka Kelahiran Di Kota Pematang Siantar
Fitri Sari Dewi Purba
1, Heru Satria Tambunan
2, Ilham Syahputra Saragih
3, Irfan
Sudahri Damanik4, Harly Okprana
51
Jurusan Sistem Informasi, STIKOM Tunas bangsa Pematangsiantar
1
[email protected]
Abstract
Birth rate is an element of natural population growth. Birth is a term used in the demographic field to describe the number of children actually born alive. The high birth rate in Indonesia is still a major problem in population, population and environmental problems or the main problem of population in Indonesia, namely the number and population growth that is highly developed, population distribution, population age composition, and quality of population. To solve the problem that there is a method used in this study is the K-Medoids Clustering method, using 2 Clusters namely low Clusters and Clusters This study aims to determine the population density and to determine the birth of children each year based on the village. In this study using data mining techniques with the k-Medoids clustering method, the source of this data was obtained from the Office of Population and Civil Registration Pematangsiantar. Input data is data on the number of birth rates in 2015-2019 which consists of 53 villages divided into 2 clusters, namely low clusters and high clusters from the calculation of K-Medoids obtained as many as 43 villages as low clusters, 10 villages as high clusters. The implementation process using the RapidMinner 5.3 application is used to help find accurate values.
Keywords: birth rate, K-Medoids Clustering.
1. Pendahuluan
Tingginya angka kelahiran di Indonesia merupakan salah satu masalah besar memerlukan perhatian khusus dalam penanganannya. Salah satu bentuk perhatian khusus pemerintah dalam menanggulangi angka kelahiran yang tinggi tersebut, adalah dengan melaksanakan pembangunan dan keluarga berencana secara kemphensif. Salah satu masalah kependudukan yang cukup besar di Indonesia adalah jumlah kepadatan penduduk yang sangat besar. Hal ini menimbulkan berbagai masalah lain, Untuk itu Pemerintah memberikan sosialisasi langsung kepada masyarakat atau ajakan-ajakan yang dapat merubah pola pikir masyarakat tentang perlunya meminimalisir jumlah pertumbuhan penduduk program keluarga berencana (KB) salah satunya untuk pembatas jumlah anak. Program KB adalah salah satu usaha untuk mencapai kesejahteraan keluarga atau merupakan bagian yang bertujuan untuk mewujudkan penduduk tumbuh seimbang. Program angka kelahiran ini merupakan salah satu upaya dalam pengurangan jumlah penduduk yang semakin banyak. Laju pertumbuhan penduduk ditentukan oleh tingkat kelahiran dan kematian. Kementerian pencatatan sipil mencatat jumlah angka kelahiran yang naik turunya setiap tahun. Oleh karena itu untuk dapat memutuskan mata rantai pada angka kelahiran dalam hal ini pemerintah memerlukan data yang akurat untuk melakukan pengelompokkan data pada angka kelahiran. Data diperoleh dari kantor capil secara langsung mengenai data persentasi angka kelahiran berdasarkan 53 Kelurahan di Pematangsiantar pada tahun 2015-2019.
Berdasarkan uraian di atas banyak cabang kecerdasan buatan dalam ilmu komputer yang dapat menyelesaikan permasalahan tersebut secara kompleks diantaranya sistem
tambah berupa informasi yang diperoleh dengan cara mengenali pola yang penting dari data yang terdapat pada basis data. Metode k-medoids merupakan salah satu metode pengelompokkan dalam data mining yang merupakan bagian dari partitional clustering. Metode ini menggunakan objek pada kumpulan objek untuk mewakili sebuah cluster. “Kelebihan dari metode ini mampu mengatasi kelemahan dari metode k-means yang sensitive terhadap outlier dan hasil proses clustering tidak bergantung pada urutan masuk dataset” [1].
2. Tinjuan Pustaka
2.1. Data MiningMenurut (Sudirman, Windarto & Wanto (2018) “Data mining merupakan proses dari beberapa teknik analisa untuk menemukan hubungan dan pola yang tersembunyi dengan mengolahnya sehingga menghasilkan informasi baru yang berguna dan konsisten”. Data mining digunakan untuk mencari pengetahuan yang terdapat dalam basis data yang besar sehingga sering disebut Knowledge Discovery Databases (KDD) yaitu tahapan yang dilakukan dalam menggali pengetahuan dari sekumpulan data
2.2. Algoritma K-Medoids
K-Medoids adalah algoritma clustering yang mirip dengan K-Means Perbedaan dari
kedua algoritma ini yaitu Metode k-medoids di usulkan pada tahun algoritma k-medoids menggunakan objek perwakilan (medoids) sebagai pusat cluster untuk sebai pusat cluster dan dikembangkan oleh Leonard Kaufman dan Peter J. Rousseeuw. Metode k-means dan
k-medoids yang partitional (melanggar dataset ke dalam kelompok) dan kedua upaya
untuk meminimalkan jarak antara titik berlabel berada dalam cluster dan titik yang ditunjuk sebagai pusat cluster. Berbeda dengan k-means, metode k-medoids memilih datapoint sebagai pusat (medoids atau eksemplar) dan bekerja dengan matriks sewenang-wenang dari jarak antara datapoints. Langkah-langkah metode k-medoids :
1. Inisialisasi pusat cluster sebanyak k (jumlah cluster)
2. Alokasikan setiap data (objek) ke cluster terdekat menggunakan persamaan ukuran jarak Euclidian Distance dengan persamaan:
... (2.1)
dimana i=1,…..,n; j=1,…..,n dan p adalah banyak variable, serta V adalah matrik varian kovarian.
3. Pilih secara acak objek pada masing-masing cluster sebagai kandidat medoid baru. 4. Hitung jarak setiap objek yang berada pada masing-masing cluster dengan kandidat
medoid baru.
5. Hitung total simpangan (S) dengan menghitung nilai total distance baru–total distance lama. Jika S < 0, maka tukar objek dengan data cluster untuk membentuk sekumpulan
k objek baru sebagai medoid.
6. Ulangi langkah 3 sampai 5 hingga tidak terjadi perubahan medoid, sehingga didapatkan cluster beserta anggota cluster masing-masing.
2.3. Pemodelan Metode
Setiap metode atau algoritma memiliki pemodelannya masing-masing yang sesuai pengerjaan, pada penelitianian ini penulis menggunakan metode k-medoids untuk mengelompokkan Angka Kelahiran Dikota Pematangsiantar Untuk pemodelan metode
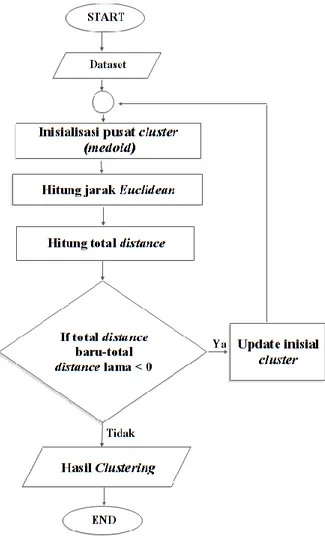
Gambar 1. Flowchart Metode K-Medoids
Gambar 3.4. ini menjelaskan bagaimana langkah-langkah metode K-Medoids yang dimula dari menentukan jumlah data yang akan dicluster atau dikelompokan dan Menetapkan nilai k jumlah cluster data sebanyak 2 cluster (k = 3), Menentukan nilai
centroid (pusat cluster) awal yang ditentukan secara random berdasarkan nilai variabel
data yang di cluster sebanyak k yang ditentukan sebelumnya da Pilih secara acak objek pada masing-masing cluster sebagai kandidat medoid baru kemudian hitung jarak setiap objek yang berada pada masing-masing cluster dengan kandidat medoid baru Lalu hitung total simpangan (S) dengan menghitung nilai total distance baru–total distance lama. Jika
S < 0, maka tukar objek dengan data cluster untuk membentuk sekumpulan k objek baru
sebagai medoid hingga selesai sampai hasil yang didaptkan tidak terjadi perubahan
medoid sehingga didapatkan cluster beserta anggota cluster masing-masing.
3. Hasil Dan Pembahasan
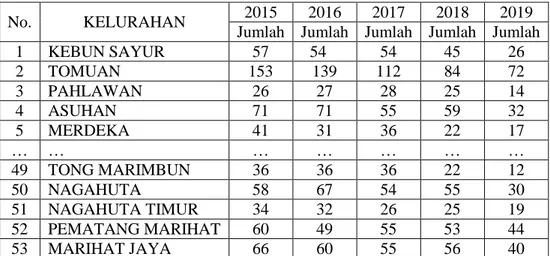
Pada bagian ini penulis akan menjelaskan bagaimana proses pengelolahan data, yang akan dilakukan, dan uraian penyajian hasil penelitian. Berikut ini contoh data yang akan diolah dengan menggunakan perhitungan K-Medoids sebagai berikut:
No. KELURAHAN 2015 2016 2017 2018 2019 Jumlah Jumlah Jumlah Jumlah Jumlah
1 KEBUN SAYUR 57 54 54 45 26 2 TOMUAN 153 139 112 84 72 3 PAHLAWAN 26 27 28 25 14 4 ASUHAN 71 71 55 59 32 5 MERDEKA 41 31 36 22 17 … … … … 49 TONG MARIMBUN 36 36 36 22 12 50 NAGAHUTA 58 67 54 55 30 51 NAGAHUTA TIMUR 34 32 26 25 19 52 PEMATANG MARIHAT 60 49 55 53 44 53 MARIHAT JAYA 66 60 55 56 40
3.1. Pengelolahan Data
Berikut adalah langkah-langkah dalam penyelesaikan yang akan dilakukan penulis dalam mengelompokan Angka Kelahiran perhitungan menggunakan Algoritma
k-medoids clustering dan akan diuji dengan aplikasi RapidMinner dan menggunakan .
1. Inisialisasi pusat cluster sebanyak 2 cluster dari data sampel.
Untuk pemilhan setiap medoid dipilih secara acak (random). Diasumsikan Tambunan Nabolon, Dan Bahsorma sebagai medoid awal.
Tabel 2. Medoid Awal
KELURAHAN 2015 2016 2017 2018 2019 TAMBUN NABOLON (C1) 125 98 98 92 40 BAH SORMA (C2) 51 55 63 47 19
2. Menghitung nilai jarak terdekat (cost) dengan persamaan Euclidian Distance. untuk menghitung jarak antara titik centroid dengan titik tiap objek menggunakan Euclidian
Distance. Rumus untuk menghitung jarak menggunakan persamaan. maka perhitungan
untuk menghitung jarak setiap objek dengan medoid awal adalah sebagai berikut : Perhitungan Jarak (C1) Sebagai berikut:
D(Kebun Sayur)
= 104,4078541
D(Dwikora)
= 165,2331686 Perhitungan Jarak (C2) Sebagai berikut:
D(Kebun Sayur)
= 13,07669683
D(Dwikora)
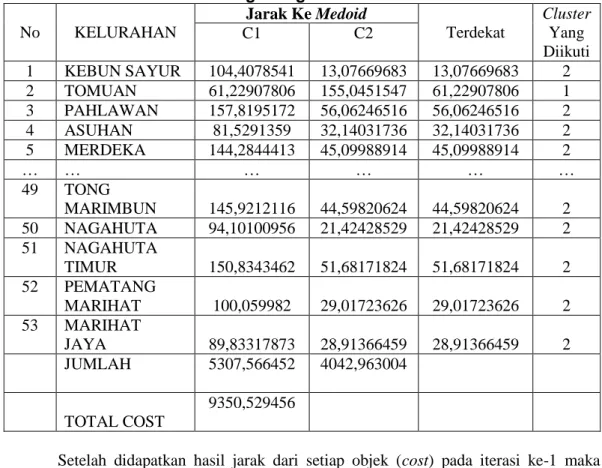
= 64,76109943 Hasil dari keseluruhan dapat diihat pada tabel 4.3 sebagai berikut :
Tabel 3. Hasil Perhitungan Algoritma K-Medoids Iterasi ke-1 No KELURAHAN Jarak Ke Medoid Terdekat Cluster Yang Diikuti C1 C2 1 KEBUN SAYUR 104,4078541 13,07669683 13,07669683 2 2 TOMUAN 61,22907806 155,0451547 61,22907806 1 3 PAHLAWAN 157,8195172 56,06246516 56,06246516 2 4 ASUHAN 81,5291359 32,14031736 32,14031736 2 5 MERDEKA 144,2844413 45,09988914 45,09988914 2 … … … … 49 TONG MARIMBUN 145,9212116 44,59820624 44,59820624 2 50 NAGAHUTA 94,10100956 21,42428529 21,42428529 2 51 NAGAHUTA TIMUR 150,8343462 51,68171824 51,68171824 2 52 PEMATANG MARIHAT 100,059982 29,01723626 29,01723626 2 53 MARIHAT JAYA 89,83317873 28,91366459 28,91366459 2 JUMLAH 5307,566452 4042,963004 TOTAL COST 9350,529456
Setelah didapatkan hasil jarak dari setiap objek (cost) pada iterasi ke-1 maka lanjut ke iterasi ke-2. Kandidat medoid baru (non-medoid) pada iterasi ke-2 dapat dilihat pada tabel 3.3 berikut:
Tabel 4. Medoid Baru (Non-Medoid 1) Iterasi ke-2
KELURAHAN 2015 2016 2017 2018 2019
SETIA NEGARA (C1) 162 147 156 112 98
BANTAN (C2) 215 208 171 156 100
Hitung kembali jarak dari setiap objek pada iterasi ke-2 dengan menggunakan
medoid baru pada tabel 3.3.
Perhitungan Jarak (C1) Sebagai berikut:
D(Kebun Sayur) = 199,3765282 D(Dwikora) = 261,7479704
Perhitungan Jarak (C2) Sebagai berikut:
D(Kebun Sayur)
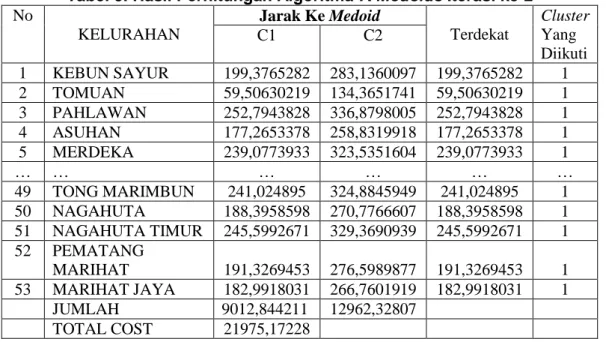
Maka didapatkan hasil keseluruhannya dari iterasi ke-2 dapat dilihat pada tabel 3.4 sebagai berikut:
Tabel 5. Hasil Perhitungan Algoritma K-Medoids Iterasi ke-2 No KELURAHAN Jarak Ke Medoid Terdekat Cluster Yang Diikuti C1 C2 1 KEBUN SAYUR 199,3765282 283,1360097 199,3765282 1 2 TOMUAN 59,50630219 134,3651741 59,50630219 1 3 PAHLAWAN 252,7943828 336,8798005 252,7943828 1 4 ASUHAN 177,2653378 258,8319918 177,2653378 1 5 MERDEKA 239,0773933 323,5351604 239,0773933 1 … … … … 49 TONG MARIMBUN 241,024895 324,8845949 241,024895 1 50 NAGAHUTA 188,3958598 270,7766607 188,3958598 1 51 NAGAHUTA TIMUR 245,5992671 329,3690939 245,5992671 1 52 PEMATANG MARIHAT 191,3269453 276,5989877 191,3269453 1 53 MARIHAT JAYA 182,9918031 266,7601919 182,9918031 1 JUMLAH 9012,844211 12962,32807 TOTAL COST 21975,17228
1. Hitung Total Simpangan (S)
Setelah didapatkan nilai jarak antara iterasi ke-1 dan iterasi ke-2, hitung total simpangan (S) dengan mencari selisih dari nilai total cost baru- nilai total cost lama. Dengan ketentuan jika S<0, maka tukar nilai objek dengan menentukan medoid baru. S =Total cost baru – Total cost lama
=21975,17228 - 9350,529456 = -12624,64282
2. Karna hasil pada simpangan pertama masih di bawah nilai 0 maka ulangi langkah sebelumnya hingga nilai S > 0, sehingga didapatkan cluster beserta anggota cluster masing-masing.
Pada penelitian ini proses perhitungan berakhir pada iterasi ke 4. Karna nilai Simpangan (S) sudah diatas 0.
S = Total cost baru – Total cost lama = 19004,6935 - 12556,28437 = 6448,409137
Dengan nilai S>0 proses cluster dihentikan, sehingga diperoleh anggota tiap cluster dapat dilihat pada tabel 3.5.
Tabel 6. Hasil Pengklasteran Data Dengan K-Medoids Clustering
No KELURAHAN Jarak Ke Medoid Terdekat Cluster Yang Diikuti C1 C2 1 KEBUN SAYUR 283,1360097 72,67736924 72,67736924 2 2 TOMUAN 134,3651741 224,7398496 134,3651741 1 3 PAHLAWAN 336,8798005 19,54482029 19,54482029 2 4 ASUHAN 258,8319918 96,63332758 96,63332758 2 5 MERDEKA 323,5351604 34,71310992 34,71310992 2 6 PARDOMUAN 253,2548124 107,6475731 107,6475731 2
No KELURAHAN Jarak Ke Medoid Terdekat Cluster Yang Diikuti C1 C2 7 SIOPAT SUHU 104,0672859 252,8082277 104,0672859 1 8 DWIKORA 344,5097967 12,28820573 12,28820573 2 9 PROKLAMASI 353,8756844 11,40175425 11,40175425 2 10 BANTAN 0 355,3223888 0 1 11 TIMBANG GALUNG 291,585322 65,17668295 65,17668295 2 12 SIMARITO 183,191157 177,2653378 177,2653378 2 13 SIPINGGOLPING GOL 259,1717577 97,97958971 97,97958971 2 14 BANJAR 210,3520858 146,4513571 146,4513571 2 15 TELADAN 335,5368832 22,69361144 22,69361144 2 16 MELAYU 181,3477323 176,4964589 176,4964589 2 17 MARTOBA 107,5499884 255,9277242 107,5499884 1 18 BARU 207,6511498 151,4958745 151,4958745 2 19 SUKADAME 251,9404692 104,1153207 104,1153207 2 20 KAHEAN 167,002994 190,8978785 167,002994 1 21 SIGULANGGULA NG 212,2969618 148,3172276 148,3172276 2 22 BANE 198,1236987 157,5150786 157,5150786 2 23 TOBA 343,1559412 18,65475811 18,65475811 2 24 KARO 301,0597947 54,5802162 54,5802162 2 25 SIMALUNGUN 324,1172627 35,55277767 35,55277767 2 26 MARTIMBANG 308,0422049 54,64430437 54,64430437 2 27 KRISTEN 333,1576204 25,88435821 25,88435821 2 28 AEK NAULI 306,6317009 50,10987927 50,10987927 2 29 SUKARAJA 296,6175989 60,86049622 60,86049622 2 30 BP NAULI 291,2576179 67,31270311 67,31270311 2 31 PARDAMEAN 260,0499952 95,6765384 95,6765384 2 32 SUKAMAJU 274,9545417 81,44937078 81,44937078 2 33 PARHORASAN NAULI 299,8966489 57,18391382 57,18391382 2 34 SUKA MAKMUR 355,3223888 0 0 2 35 MEKAR NAULI 321 34,94281042 34,94281042 2 36 SUMBER JAYA 137,5172716 224,8132558 137,5172716 1 37 TAMBUN NABOLON 182,2772613 175,6729917 175,6729917 2 38 NAGA PITA 40,45985665 332,5462374 40,45985665 1 39 PONDOK SAYUR 160,3870319 197,2460393 160,3870319 1 40 TANJUNG TONGAH 264,3879725 92,51486367 92,51486367 2 41 NAGA PITU 226,2167103 131,7649422 131,7649422 2 42 TANJUNG PINGGIR 196,4408308 163,0429391 163,0429391 2 43 GURILLA 314,8841057 44 44 2 44 BAH KAPUL 57,51521538 306,2776518 57,51521538 1 45 SETIA NEGARA 93,24698387 271,8032377 93,24698387 1 46 BUKIT SOFA 219,4789284 138,0108691 138,0108691 2 47 BAH SORMA 283,5683339 74,66592262 74,66592262 2 48 SIMARIMBUN 304,0888028 53,68426213 53,68426213 2 49 TONG
No KELURAHAN Jarak Ke Medoid Terdekat Cluster Yang Diikuti C1 C2 51 NAGAHUTA TIMUR 329,3690939 27,27636339 27,27636339 2 52 PEMATANG MARIHAT 276,5989877 82,21313764 82,21313764 2 53 MARIHAT JAYA 266,7601919 89,61584681 89,61584681 2
4. Kesimpulan Dan Saran
4.1. Kesimpulan
Hasil akhir dari penelitian seluruh kelurahan dapat disimpulkan bahwa telah didapat nilai dengan 2 cluster yaitu cluster rendah dan cluster tinggi dalam pengelompokan Angka Kelahiran yaitu:
1. Penerapan data mining dengan metode k-medoids clustering dapat diterapkan. Sumber data yang digunakan pada penelitian ini adalah data yang diambil langsung dari Kantor Dinas Kependudukan Dan Pencatatan Sipil Pematangsiantar dengan subjek data Angka Kelahiran berdasarkan Kelurahan (2015-2019). Jumlah record yang digunakan sebanyak 53 Kelurahan dengan menghasilkan 2 cluster yakni cluster terendah sebanyak 43 Kelurahan cluster dan cluster tinggi sebanyak 10 Kelurahan
4.2. Saran
Saran penulis terhadap penelitian ini adalah sebagai berikut:
1. Untuk mendapatkan hasil yang lebih akurat perlu dilakukan penelitian selanjutnya dengan data yang terbaru agar dapat diketahui Jumlah Angka kelahiran dimasa yang akan datang.
2. Untuk peneliti selanjutnya, penelitian ini dapat dikembangkan dengan menggunakan metode datamining lainnya agar mendapatkan hasil perbandingan dengan metode yang lain.
Daftar pustaka
[1] E. Setyowati, A. Rusgiyono, and M. A. Mukid, “Analisis Pengelompokan Daerah Menggunakan Metode Non- Hierarchical Partitioning K-Medoids dari Hasil Komoditas Pertanian Tanaman Pangan,” J. GAUSSIAN, vol. 4, no. 4, 2015.
[2] Sudirman, A. P. Windarto, and A. Wanto, “Data mining tools | rapidminer : K-means method on clustering of rice crops by province as efforts to stabilize food crops in Indonesia,” in 2nd Nommensen International Conference on Technology and Engineering, 2018
[3] Barakbah, A. R., Karlita, T., & Ahsan, A. S. (2013). Logika dan Algoritma.
[4] Defiyanti, S., Jajuli, M., & W, N. rohmawati. (2017). Optimalisasi K - Medoid Dalam Pengklasteran Mahasiswa Pelamar Beasiswa dengan Cubic Clustering Criterion. TEKNOSI, 3(1).
[5] Hendini, A. (2016). Pemodelan UML Sistem Informasi Monitoring Penjualan dan Stok Barang (Studi Kasus: Distro Zhezha Pontianak). JURNAL KHATULISTIWA INFORMATIKA, 4(2).
[6] Idris, M., & Bayes, N. (2019). IMPLEMENTASI DATA MINING DENGAN ALGORITMA NAÏVE BAYES UNTUK MEMPREDIKSI ANGKA KELAHIRAN, 18, 160–167.