Universitas Sumatera Utara BAB 2
TINJAUAN PUSTAKA
2.1. Kompresi Data
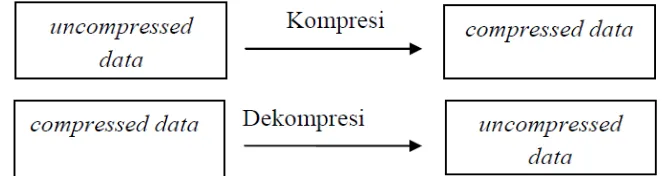
Kompresi data adalah sebuah proses yang dapat mengubah sebuah aliran data masukan (sumber atau data asli) ke dalam aliran data yang lain (keluaran atau data yang dimampatkan) yang memiliki ukuran yang lebih kecil (Salomon, 2007). Kompresi data bertujuan untuk mengurangi redundansi yang terdapat dalam data sehingga dapat disimpan atau ditransmisikan secara efisien (Sutardi, 2014).
Kompresi terdiri dari dua fase yaitu, Modeling dan Coding. Proses dasar dari kompresi data adalah menentukan serangkaian bagian dari data (stream of symbols) mengubahnya menjadi kode (stream of codes). Jika proses kompresi efektif maka hasil dari stream of codes akan lebih kecil dari segi ukuran dari pada stream of symbols (Sayood & Kaufmann, 2012). Modeling adalah kumpulan data dan aturan
yang menentukan pasangan antara symbol sebagai input dan code sebagai output dari proses kompresi. Sedangkan coding adalah proses untuk menerapkan modeling tersebut menjadi sebuah proses kompresi data (Sayood & Kaufmann, 2012). Dengan adanya kompresi data maka data yang telah dikompresi akan memperkecil kuota atau bandwith dalam pengiriman data melalui internet (Viliana, 2014). Proses kompresi
dan dekompresi data dapat ditunjukan melalui diagram blok seperti pada Gambar 2.1.
Universitas Sumatera Utara 2.1.1. Teknik Kompresi Data
Terdapat banyak metode untuk kompresi data. Metode-metode tersebut lahir dari ide yang berbeda-beda. Namun, prinsip dasar yang menjadi dasar tiap metode adalah sama, yaitu mengkompresi data dengan menghilangkan redundancy dari data asli. Salomon, 2004). Teknik kompresi data dikelompokkan menjadi dua bagian yaitu kompresi data lossless dan kompresi data Lossy (Erdiansyah, 2014):
1. Metode Lossless
Kompresi yang menggunakan metode Lossless ini berarti tidak ada data yang hilang selama proses kompresi berjalan. Lossless data kompresi adalah kelas dari algoritma data kompresi yang memungkinkan data yang asli dapat disusun kembali dari data kompresi. (Sayood & Kaufmann, 2012).
2. Metode Lossy
Kompresi yang menggunakan metode lossy ini berarti terjadi beberapa bagian komponen dari data yang hilang akibat dari proses kompresi. Lossy kompresi adalah suatu metode untuk mengkompresi data dan men-dekompresinya. Lossy kompresi ini paling sering digunakan untuk kompres data multimedia (Audio, gambar diam) (Sayood & Kaufmann, 2012).
2.1.2. Konsep Kompresi Data
Suatu metode pada kompresi data akan menghasilkan bit (satuan terkecil pembentuk data)
baru yang lebih pendek dibandingkan oleh bit data sebelum dikompresi. Bit data yang
lebih pendek tersebut biasanya tidak akan bisa dibaca oleh komputer sebelum dilakukan
proses kompresi. Pada proses kompresi, bit data tersebut dibaca setiap delapan bitnya,
sehingga membentuk satu karakter yang dapat dibaca oleh komputer. Begitu juga
sebaliknya, pada saat dekompresi bit data tersebut di dekompres kembali agar membentuk
bit data semula yang akan digunakan dalam proses dekompresi. Karena pada saat proses
dekompresi dibutuhkan bit data sebelum di kompres untuk dapat dibaca kembali dalam
proses dekompresi (Erdiansyah, 2014).
Universitas Sumatera Utara delapan). Karena di dalam komputer satu karakter direpresentasikan oleh bilangan ASCII (American Standard Code for Information Interchange) sebanyak delapan bit dalam bilangan biner. Jika ternyata jumlah bit data tersebut bukan merupakan kelipatan delapan. Maka dibentuk variabel baru sebagai penambahan bit data itu agar bit data tersebut habis dibagi delapan. Variabel ini disebut padding dan flag (Budiman, 2016):
1. Padding
Padding adalah penambahan bit 0 sebanyak kekurangan jumlah bit data pada hasil
proses kompresi sehingga jumlah keseluruhan bit data tersebut merupakan kelipatan delapan (habis dibagi delapan). Contoh misalkan dihasilkan bit data hasil kompresi yaitu 1100101101010001100001101. Terdapat 25 bit data dalam bilangan biner. Maka dilakukan penambahan bit 0 sebanyak 7 kali agar jumlah bit data tersebut habis dibagi delapan. Sehingga bit data itu menjadi 11001011010100011000011010000000 setelah diberikan padding (Budiman, 2016).
2. Flag
Flag adalah penambahan bilangan biner sepanjang delapan bit setelah padding dimana
flag ini adalah sejumlah bilangan yang memberikan sebuah tanda bahwa terdapat n
buah padding di dalam bit data hasil dari kompresi. Penambahan flag ini dimaksudkan untuk mempermudah dalam membaca bit data hasil kompresi pada saat proses dekompresi. Contoh misalkan bit data yang telah diberikan padding adalah 11001011010100011000011010000000. Karena terdapat 7 bit penambahan padding maka flag nya adalah bilangan biner dari 7 dengan panjang 8 bit yaitu 00000111. Sehingga bitdatanya menjadi 1100101101010001100001101000000000000111 setelah diberikan flag (Budiman, 2016).
2.1.3. Parameter Analisis Kinerja Algoritma Kompresi
Universitas Sumatera Utara 1. Ratio of compression (Rc)
Ratio of compression (Rc) adalah perbandingan antara ukuran data sebelum
dikompresi dengan ukuran data setelah dikompresi (Salomon & Motta, 2010).
=
Misalkan didapat sebuah nilai Ratio of compression sebesar 2.75. Itu berarti besar data sebelum kompresi adalah 2.75 kali lipat dari besar data setelah dikompresi.
2. Compression ratio (Cr)
Compression ratio (Cr) adalah persentasi besar data yang telah dikompresi yang
didapat dari hasil perbandingan antara ukuran data setelah dikompresi dengan ukuran data sebelum dikompresi (Salomon & Motta, 2010).
= 100 %
Misalkan didapat sebuah nilai Compression ratio sebesar 35%. Itu berarti setelah dikompresi ukuran data adalah 35% dari data sebelum dikompresi.
3. Space Saving (Ss)
Space Saving (Ss) adalah Presentase selisih ukuran data setelah di kompres dengan
ukuran data sebelum dikompres (Salomon & Motta, 2010).
= −
Misalkan didapat sebuah nilai Space Saving sebesar 140 bit. Itu berarti 140 ÷ 4 = 17,5 byte untuk persentase selisih antara ukuran data semula dengan data yang telah di kompres.
4. Time Process (t)
Time Process (t) adalah waktu yang berjalan selama proses kompresi dan dekompresi.
Universitas Sumatera Utara 2.2. Dekompresi Data
Dekompresi adalah mengembalikan informasi ke bentuk semula. Teknik dekompresi memiliki proses dekoding dan encoding yang menjadikan data menjadi lebih besar dibandingkan data yang sebelumnya, secara keseluruhan dipengaruhi faktor kecepatan, berbanding dengan kualitas data hasil dekompresi.
2.3. Algoritma
Algoritma merupakan suatu metode khusus yang tepat dan terdiri dari serangkain langkah yang terstruktur dan dituliskan secara sistematis yang akan dikerjakan untuk menyelesaikan suatu masalah dengan bantuan komputer (Napitupulu & Sihombing, 2010). Algoritma merupakan suatu prosedur untuk melakukan satu tugas spesifik berupa gagasan dibalik suatu program (Hariyanto, 2008).
Dalam algoritma kompresi data, tidak ada algoritma yang cocok untuk semua jenis data. Hal ini disebabkan karena data yang akan dimampatkan harus dianalisis terlebih dahulu, dan berharap menemukan pola tertentu yang dapat digunakan untuk memperoleh data dalam ukuran yang lebih kecil. Karena itu muncul banyak algoritma-algoritma kompresi data (Hariyanto, 2008).
Sebuah algoritma kompresi dapat dievaluasi dalam sejumlah cara yang berbeda. Yang di ukur adalah kompleksitas relatif dari algoritma kompresi, memori yang diperlukan untuk melaksanakan algoritma, seberapa cepat algoritma melakukan pada mesin yang diberikan, jumlah kompresi, dan bagaimana erat rekonstruksi menyerupai aslinya (Sayood & Kaufmann, 2012).
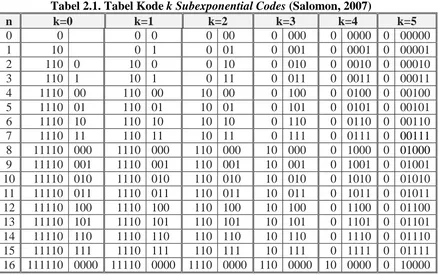
2.4. Algoritma Subexponential Codes
Subexponential Codes merupakan algoritma yang menghasilkan bit tertentu yang
Universitas Sumatera Utara memiliki kode yang memulai atau mengakhiri dengan cara yang khusus, seperti pada Algoritma Subexponential Codes ini yang menyajikan kode awalan yang berakhir dengan 1 (Salomon, 2007).
Beberapa cara untuk membangun kode tersebut dan membuktikan berikut ini batas pada panjang rata-rata mereka. Rata-rata panjang E dari kode layak optimal untuk sumber diskrit dengan entropi H memenuhi H + pN ≤ E ≤ H + 1.5 di mana pN adalah probabilitas terkecil simbol dari sumber (Salomon, 2007).
Tabel 2.1. Tabel Kode k Subexponential Codes (Salomon, 2007)
n k=0 k=1 k=2 k=3 k=4 k=5
Inverted Elias Delta adalah kebalikan dari Elias Delta Code. Elias Delta Code adalah
sebuah algoritma kompresi yang dibuat oleh Peter Elias menggunakan kode yang telah di buat sebelumnya, yaitu Elias Gamma Code (Salomon, 2007).
Pada Elias Gamma Code, ada tambahan kode dalam unary (!). Dalam kode berikutnya # (delta), ditambahkan pada panjang kode dalam biner ($). Maka Elias Delta Code, yang juga untuk bilangan bulat positif, sedikit lebih kompleks (Salomon,
Universitas Sumatera Utara
Gambar 2.2. Gambar Proses Kompresi dari Algoritma Inverted Elias DeltaCode (Antoni, et al, 2014)
Tabel 2.2. Tabel Kode Elias Delta Code (Salomon, 2007)
1 = 1 11 = 0100011
Create Characters Map Codeand
Universitas Sumatera Utara 9 = 0100001 19 = 01010011
10 = 0100010 20 = 01010100
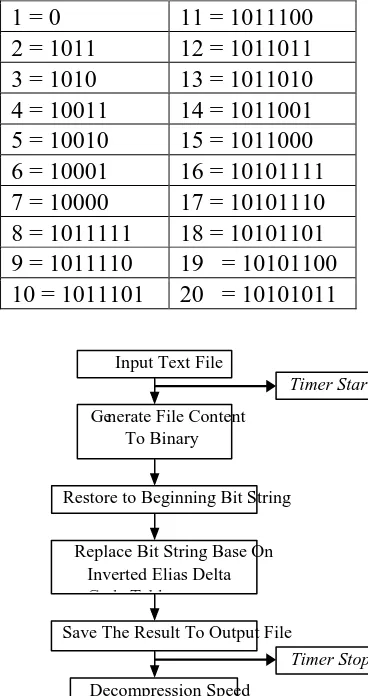
Sehingga didapat kodeInverted Elias Delta yaitu kebalikan dari Elias Delta Code.
Tabel 2.3. Tabel Kode Inverted Elias Delta (Salomon, 2007)
1 = 0 11 = 1011100
Gambar 2.3. Gambar Proses Dekompresi Algoritma Elias Delta (Antoni, et al, 2014)
2.6. File Teks
File merupakan kumpulan informasi yang biasanya disimpan dalam sebuah disk
Universitas Sumatera Utara Standard Code for Information Interchange) merupakan suatu standar internasional
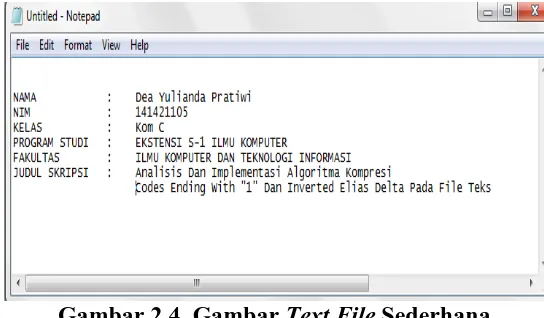
dalam kode huruf dan simbol dan kode ASCII lebih bersifat universal. ASCII digunakan oleh komputer dan alat komunikasi lain untuk menunjukkan tek (Suprapto, et al, 2008). Dalam hal ini penulis menggunakan input-an format teks berupa teks sederhana (Plain Text) berekstensi (*.txt). Saat ini perangkat lunak yang paling banyak digunakan untuk memanipulasi format data ini adalah Notepad (Suprapto, et al, 2008).
Gambar 2.4. Gambar Text File Sederhana
2.7. Unified Modeling Language (UML)
Unified Modeling Language (UML) merupakan kesatuan dari bahasa pemodelan yang
dikembangkan oleh Booch, Object Modeling Technique (OMT) dan Object Oriented Software Engineering (OOSE) yang menjadikan proses analisis dan desain ke dalam
empat tahapan iteratif, yaitu identifikasi kelas-kelas dan objek-objek, identifikasi semantik dari hubungan objek dan kelas tersebut, perincian interface dan implementasi (Munawar, 2005). Dalam penelitian ini, hanya akan menggunakan 4 jenis UML di antaranya adalah Use Case Diagram, Activity Diagram, Sequence Diagram dan Class Diagram.
1. Use Case Diagram
Use case diagram adalah serangkainan scenario yang digabungkan
Universitas Sumatera Utara Activity diagram adalah teknik untuk mendeskripsikan logika procedural, aliran
kerja dalam banyak kasus (Munawar, 2005). 2. Sequence Diagram
Sequence diagram digunakan untuk menggambarkan perilaku pada sebuah
scenario, pada diagram ini menunjukkan sejumlah contoh objek dan pesan yang
diletakkan diantara objek-objek di dalam use case diagram (Munawar, 2005). 3. Class Diagram
Class diagram adalah sebuah spesifikasi yang menunjukkan adanya hubungan
antar class dalam sistem yang sedang dibangun (Hermawan, 2003).
2.8. Bahasa Pemograman C#
C# merupakan sebuah program yang lengkap untuk membangun desktop dan Mobile.
Pemograman C# atau sering disebut dengan C Sharp adalah sebuah bahasa pemograman yang berorientasi objek yang dikembangkan oleh Microsoft (Seputra, 2013). C# menyediakan beberapa tool untuk otomatisasi proses development, yaitu visual tool untuk melakukan beberapa operasi pemograman, desain umum, dan
tampilan antar muka (Mackenzie & Sharkey, 2004). C# bias digunakan untuk membuat berbagai macam aplikasi, seperti pengolahan data, grafik, spreadsheet, atau bahkan membuat compiler untuk sebuah bahasa pemograman (Nugroho, et al, 2013). Penulis menggunakan Microsoft Visual Studio 2010.
Universitas Sumatera Utara 2.9. Penelitian Yang Relevan
Berikut ini beberapa penelitian yang terkait dengan algoritma Subexponential Codes dan Inverted Elias Delta, adalah sebagai berikut:
1. Umri Erdiansyah (2014) dalam Skripsi yang berjudul Perbandingan Algoritma Elias Delta Code dengan Levenstein untuk Kompresi File Teks. Dalam skripsi ini, dapat disimpulkan bahwa hasil pengujian kompresi file teks dengan karakter yang berbeda (heterogen) berdasarkan (RC), (CR), (RD) dan waktu kompresi menunjukkan bahwa metode Elias Delta Code lebih baik dibandingkan dengan metode Levenstein dengan rasio kompresi rata-rata sebesar 134.40%. Dan dengan karakter yang sama dan karakter yang berbeda dengan metode Levenstein dan Elias Delta Code menunjukkan bahwa Elias Delta memerlukan
waktu yang lebih sedikit untuk mengembalikan file teks hasil kompresi ke file teks semula, dengan rata-rata 7.286 sekon untuk homogen dan 63.275 sekon untuk heterogen (Erdiansyah, 2014).
2. Antoni, Erna Budhiarti Nababan, dan Muhammad Zarlis (2014) dalam jurnal yang berjudul Results Analysis of Text Data Compression On Elias Gamma Code, Elias Delta Code and Levenstein Code. Dalam jurnal ini, maka dapat
disimpulkan bahwa rasio kompresi yang dihasilkan oleh algoritma Elias Gamma memberikan rasio kompresi yang paling baik dalam penelitian ini, yang kedua adalah algoritma Elias Delta dan yang terakhir adalah algoritma Levenstein. Oleh karena itu, nilai penghematan ruang yang dihasilkan dari rasio kompresi dengan mengurangi 100% dengan rasio kompresi dalam hal itu dihasilkan oleh algoritma Elias Gamma, kemuadia algoritma Elias Delta dan yang terakhir algoritma Levenstein. Besarnya rasio kompresi tergantung pada jumlah set karakter dan jumlah terjadinya masing-masing karakter. Untuk kecepatan kompresi, algoritma Elias Gamma membutuhkan waktu minimum dibandingkan dengan Elias Delta dan Levenstein (Antoni, et al, 2014).
3. Li, Lei. & Chakrabarty, K. (2004) dalam jurnal yang berjudul On Using Exponential-Golomb Codes and Subexponential Codes for System-on-a-Chip