Pengembangan Purwarupa Aplikasi
Mobile
untuk Pemeriksaan Bacaan dan Hafalan
Ayat Al-
Qur’an pada Sistem Operasi Android
Zain Fathoni
Program Studi Teknik Informatika Sekolah Teknik Elektro & Informatika
Institut Teknoogi Bandung Ganesha 10, Bandung, Indonesia
022-2508135, fax: 022-2500940
[email protected]
Dessi Puji Lestari
Program Studi Teknik Informatika Sekolah Teknik Elektro & InformatikaInstitut Teknoogi Bandung Ganesha 10, Bandung, Indonesia
022-2508135, fax: 022-2500940
[email protected]
Nur Ulfa Maulidevi
Program Studi Teknik Informatika Sekolah Teknik Elektro & InformatikaInstitut Teknoogi Bandung Ganesha 10, Bandung, Indonesia
022-2508135, fax: 022-2500940
[email protected]
ABSTRAK
Maraknya perkembangan komunitas pembaca dan penghafal
Al-Qur’an membuat pemeriksaan bacaan dan hafalan Al-Qur’an
melalui perangkat mobile semakin diperlukan. Sistem ini harus dapat mengenali ucapan bacaan Al-Qur’an pengguna dan memeriksa kebenarannya berdasarkan aturan tajwid yang berlaku. Aturan tajwid diterapkan pada teks transkripsi ayat
Al-Qur’an yang dijadikan referensi penilaian. Bagian penilai
dibangun dengan memanfaatkan library perbandingan string yang telah ada. Sistem ini juga melibatkan proses Automatic Speech Recognition (ASR). Prinsip modalitas Embedded Mobile Speech Recognition dipilih supaya hasil ASR dapat segera diperoleh, mengingat perkembangan kemampuan komputasi perangkat mobile saat ini telah cukup tinggi. Keterbatasan kapasitas penyimpanan perangkat mobile dapat diatasi dengan cara menyimpan data keseluruhan pada komputer server, sehingga data yang disimpan pada perangkat mobile cukup yang diperlukan saja. Kesimpulan dari hasil pembangunan dan pengujian purwarupa adalah mekanisme pemeriksaan bacaan dan hafalan Al-Qur’an mungkin untuk diterapkan pada perangkat mobile dengan prinsip modalitas tersebut, dengan catatan suara masukan ASR diperoleh dari file suara. Bagian penangkapan suara masih perlu diperbaiki agar dapat menghasilkan file yang dapat diproses ASR dengan baik. Selain itu, diperlukan penelitian yang lebih mendalam untuk membuat model ASR yang baik untuk ayat Al-Qur’an. Elemen penilai bacaan Al-Qur’an berhasil diimplementasikan, tetapi perlu pengembangan lanjutan untuk mengakomodasi aturan tajwid yang lebih komperehensif.
Kata Kunci
Al-Qur’an, ASR, bacaan, hafalan, penilaian, perangkat mobile.
1.
PENDAHULUAN
Salah satu kewajiban setiap muslim adalah membaca dan menghafalkan Al-Qur’an. Setiap muslim yang ingin belajar membaca dan menghafal Al-Qur’an tentu membutuhkan guru yang dapat memeriksa dan mengoreksi bacaan dan hafalan
Al-Qur’an, agar bacaannya sesuai dengan ilmu tajwid yang berlaku
tanpa ada kesalahan satu huruf pun. Salah satu alternatif pengganti guru membaca dan menghafal Al-Qur’an adalah perangkat lunak yang mampu menilai bacaan dan hafalan
Al-Qur’an secara otomatis.
Dalam beberapa tahun terakhir telah banyak dilakukan penelitian mengenai bagaimana membuat perangkat lunak yang
mampu untuk memeriksa bacaan atau hafalan Al-Qur’an dengan baik, tetapi hampir seluruh perangkat lunak semacam ini dijalankan di atas sistem operasi untuk komputer (PC atau laptop). Oleh karena itu, salah satu solusi yang mungkin dilakukan adalah mengembangkan perangkat lunak mobile
dengan pendekatan yang sama seperti perangkat lunak desktop
yang pernah dikembangkan sebelumnya, yakni menggunakan bantuan sistem Automatic Speech Recognition (ASR).
Masalah yang ingin diselesaikan dalam Tugas Akhir ini adalah bagaimana membuat purwarupa perangkat lunak mobile untuk pemeriksaan bacaan dan hafalan ayat Al-Qur’an pada sistem operasi Android dengan metode terotomatisasi dan menggunakan bantuan sistem pengenalan ucapan otomatis (Automatic Speech Recognition). Purwarupa ini dibatasi pada beberapa aspek, yaitu suara masukan yang bersih dari suara ribut, model ASR dibuat sendiri dengan data latih sederhana, data latih dan data uji yang sama, aspek estetika tidak menjadi fokus, algoritma penilaian diambil dari library yang telah ada, serta aturan tajwid yang ditangani baru aturan yang erat kaitannya dengan perubahan huruf dan harakat dalam membaca.
2.
STUDI LITERATUR
Pada bab ini dijelaskan hasil studi terhadap literatur dan penelitian sebelumnya yang terkait dengan topik ini.
2.1
Sistem Pemeriksaan Bacaan dan
Hafalan Al-
Qur’an
[Proses]
[Keluaran] Hasil Evaluasi (Nilai Ketepatan, Letak Kesalahan) [Masukan]
Pelafalan Bacaan atau Hafalan
Al-Quran
Penangkap
Suara ASR Penilai
Gambar 1. Sistem Pemeriksaan Bacaan dan Hafalan Al-Qur’an (Muhammad, 2012)
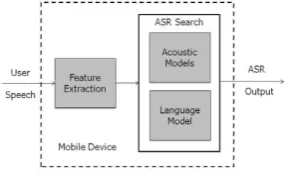
Pengenalan ucapan otomatis atau Automatic Speech Recognition (ASR) adalah proses algoritmik yang bertujuan untuk memroses masukan berupa suara ucapan manusia menjadi urutan kata yang sesuai dengan masukan tersebut. Dengan kata lain, ASR merupakan metode berbasis mesin yang mampu mengonversi ucapan menjadi teks. Arsitektur ASR modern dapat dilihat pada Gambar 2 (Marietha, 2010). Model probabilitas statistik digunakan dalam proses ini untuk mencari kemungkinan ucapan kata yang paling mendekati dan mirip dengan sinyal suara ucapan pengguna yang diterima sistem sebagai masukan.
Gambar 2. Arsitektur ASR Modern (Mansikkaniemi, 2010)
Salah satu kakas ASR yang telah terbukti kehandalannya dalam mengenali ucapan berbahasa Arab adalah Sphinx (Abushariah, 2010). Kakas Sphinx memiliki salah satu varian yang dikembangkan khusus untuk perangkat keras mobile, kakas ini diberi nama Pocketsphinx. Kakas Sphinx dan berbagai variannya dikembangkan oleh Carnegie Mellon University (CMU).
Hasil dari pengenalan ucapan otomatis ini direpresentasikan dalam bentuk teks/string. Oleh karena itu, penilaian dilakukan dengan cara membandingkan string hasil pengenalan ucapan pengguna dengan string hasil ucapan yang benar. Salah satu algoritma pencari perbedaan string yang cukup terkenal adalah algoritma O(ND) Difference yang ditemukan oleh Myers (1986).
2.2
Sistem Pengenalan Ucapan Otomatis
dalam Perangkat Mobile
Salah satu elemen penting yang cukup disorot dalam penerapan ASR pada perangkat mobile adalah di mana letak proses pengenalan ucapan dilakukan, hal ini berkaitan erat dengan terbatasnya sumber daya yang dimiliki oleh perangkat mobile. Huerta (2000) mengelompokkan sistem ASR dalam perangkat
mobile menjadi tiga buah prinsip modalitas, yaitu network speech recognition, terminal speech recognition, dan
distributed speech recognition. Dalam perkembangannya, ketiga prinsip ini dikembangkan oleh Kumar dkk. (2011) yang menyebutnya sebagai mode dan mengusulkan satu mode baru sebagai solusi untuk mengimplementasikan pengenalan ucapan otomatis dalam perangkat mobile, yakni mode shared speech recognition with user-based adaptation yang menitikberatkan pada adaptasi sistem terhadap kondisi fasilitas/infrastruktur yang dimiliki oleh pengguna.
Salah satu mode yang menarik adalah Embedded Mobile Speech Recognition. Mode ini serupa dengan prinsip terminal
speech recognition yang dimaksud oleh Huerta (2000). Dalam mode ini, pengenalan ucapan otomatis sepenuhnya dilakukan pada perangkat mobile, seperti yang ditunjukkan pada Gambar 3.
Gambar 3. Mode 1: Embedded Mobile Speech Recognition (Schmitt, 2008)
Keunggulan dari mode ini yaitu tidak dibutuhkannya komunikasi antara server dengan klien, hasil keluaran sistem ASR dengan mode ini tidak terpengaruh oleh kualitas transmisi data, tidak diperlukan tambahan biaya koneksi internet untuk mengirimkan/menerima data dari komputer server, serta performansi sistem ASR tidak terpengaruh oleh rendahnya kecepatan transmisi jaringan internet yang tersedia.
Sistem ASR dengan akurasi yang baik memerlukan konsumsi memori tinggi dan mengharuskan dilakukannya banyak operasi komputasi, sedangkan perangkat mobile memiliki sumber daya yang sangat terbatas sehingga diperlukan modifikasi yang tepat untuk setiap subsistem supaya sistem tetap dapat melakukan pemrosesan ASR sebagaimana mestinya. Hal ini dapat dicapai dengan menggunakan algoritma yang cepat dan skema penyimpanan memori yang tepat.
2.3
Penelitian Terkait
1) E-Hafiz: Salah satu contoh keberhasilan pembangunan perangkat lunak pada komputer untuk pemeriksaan hafalan
Al-Qur’an adalah aplikasi “E-Hafiz” yang dikembangkan oleh
Muhammad dkk. (2012). “E-Hafiz” adalah sistem intelijen yang dibangun untuk membantu muslim dalam memeriksa bacaan dan hafalan Al-Qur’an.
2) SMSsuara: Salah satu contoh keberhasilan integrasi sistem ASR pada perangkat mobileadalah aplikasi “SMSsuara” yang
dikebangkan oleh Marietha (2010). Integrasi sistem ASR ke dalam aplikasi ini dilakukan dengan menggunakan kakas PocketSphinx, SphinxTrain, dan CMU-CLMTK. Aplikasi
“SMSsuara” ini menggunakan prinsip modalitas ASR
Embedded Mobile Speech Recognition.
3) Aplikasi Bantu untuk Menghafalkan Al-Qur’an pada
Telepon Seluler: Pada tahun 2010 telah dilakukan pengembangan aplikasi bantu untuk menghafalkan Al-Qur’an pada telepon seluler oleh Firdausi (2010). Akan tetapi, aplikasi yang dikembangkan ini ternyata masih sekedar membantu menampilkan ayat Al-Qur’an saja, belum melibatkan sistem ASR di dalamnya. Dengan demikian, perlu pengembangan lebih lanjut supaya aplikasi bantu untuk menghafalkan
Al-Qur’an ini melibatkan sistem ASR di dalamnya.
4) Pemeriksaan Urutan Hafalan Al Quran Memanfaatkan Pengenalan Suara Otomatis: Tujuan penelitian tersebut serupa dengan tujuan penelitian ini, yaitu untuk membantu memeriksa hafalan Al-Qur’an dengan melibatkan sistem ASR. Jenis kesalahan yang diperiksa adalah kesalahan hafalan berupa penambahan (insertion), penghapusan (deletion), substitusi (substitution), atau kombinasinya. Namun demikian, perangkat lunak yang dihasilkan masih baru dapat dijalankan di perangkat
pengembangan lebih lanjut tetap perlu dilakukan supaya sistem ASR tersebut dapat diimplementasikan untuk keperluan serupa dan dijalankan pada perangkat mobile.
3.
ANALISIS PERMASALAHAN
3.1
Prinsip Modalitas
Berdasarkan hasil analisis, prinsip modalitas yang digunakan adalah Embedded Mobile Speech Recognition seperti yang terlihat pada Gambar 3 (Schmitt, 2008). Alasannya yaitu supaya proses pemeriksaan bacaan dan hafalan dapat dilakukan kapan saja, performansi sistem ASR tidak terpengaruh oleh rendahnya kecepatan transmisi jaringan internet, sumber daya yang dimiliki oleh perangkat mobile saat ini sudah cukup untuk menjalankan pengenalan ucapan otomatis sebagaimana yang telah diimplementasikan pada aplikasi SMSsuara (Marietha, 2010), serta kesalahan bacaan Al-Qur’an biasanya tidak terkait dengan konteks kalimat, tetapi lebih cenderung terkait dengan kesalahan huruf atau kata, sehingga mode Shared Speech Recognition with User-Based Adaptation yang diusulkan oleh Kumar dkk. (2011) tidak dipilih.
3.2
Penanganan Kapasitas Penyimpanan
pada Perangkat Mobile
Konsekuensi dari prinsip modalitas yang dipilih adalah diperlukannya pengkhususan data teks dan suara untuk ayat
Al-Qur’an yang disimpan secara terpisah untuk setiap ayat.
keseluruhan data tersebut cukup disimpan pada komputer
server yang memiliki kapasitas penyimpanan lebih luas, sehingga perangkat mobile dapat mengunduh data yang diperlukan dan menghapus data yang telah tidak diperlukan. Dengan demikian, diharapkan perangkat mobile dapat menghemat media penyimpanannya.
Batas kuantitas data yang dapat disimpan pada perangkat
mobile bervariasi mengikuti kapasitas penyimpanan pada perangkat mobile tersebut. Batas ini seharusnya dapat ditentukan sendiri oleh pengguna, tetapi pada purwarupa perangkat lunak yang dibangun, batas ini masih dibuat baku di dalam kode sumber program, yaitu maksimal empat buah data ayat Al-Qur’an untuk setiap jenis data.
3.3
Penanganan Jenis Kesalahan pada
Hafalan Al-
Qur’an
Dalam penelitiannya, Muliati (2010) mendefinisikan bahwa perbandingan string pada proses pemeriksaan hafalan
Al-Qur’an dilakukan untuk mengetahui kesalahan hafalan berupa
penambahan (insertion), penghapusan (deletion), substitusi (substitution), atau kombinasinya. Setelah dianalisis lebih lanjut, salah satu bentuk kesalahan yang merupakan kombinasi dari ketiganya adalah kesalahan bacaan terhadap potongan ayat lain yang mirip. Misalnya, bagian akhir dari Surat Al-‘Ashr ayat 3 dapat tertukar dengan bagian akhir dari Surat At-Tiin ayat 6. Berbagai jenis kesalahan ini dapat diamati di Tabel 1 pada Bab V yang memuat data kasus uji untuk pengujian elemen penilai.
Proses perbandingan string ini dapat dilakukan dengan menggunakan library Google Diff-Match-Patch buatan Neil Fraser untuk menemukan perbedaan antara kedua string yang dibandingkan. Library ini mengimplementasikan algoritma
O(ND) Difference yang ditemukan oleh Myers (1986) mengenai metode perbandingan string. Hasil eksplorasi secara terpisah menunjukkan bahwa library ini mampu mengenali kesalahan hafalan yang telah didefinisikan oleh Muliati (2010), sehingga
library ini dapat langsung digunakan di dalam purwarupa perangkat lunak yang dibangun.
3.4
Analisis Model Akustik
Untuk dapat membuat model akustik dengan baik diperlukan definisi fonem dan kosakata yang jelas. Pada model ASR di purwarupa perangkat lunak ini, terdapat satu huruf Arab yang tidak muncul di dalam rentang ayat Al-Qur’an Surat ke-100 s.d. Surat ke-114, yaitu huruf zha (ظ). Apabila huruf zha ini dimasukkan, maka ayat Al-Qur’an secara keseluruhan memiliki 40 fonem. Dengan demikian, 39 fonem yang terdapat pada model ASR pada purwarupa perangkat lunak ini telah mencakup 97,5% (39/40) fonem pada ayat Al-Qur’an secara keseluruhan.
Untuk penentuan kosakata, perlu dilakukan pemenggalan terhadap setiap ayat Al-Qur’an. Pemenggalan dilakukan per suku kata, dengan aturan yang mirip dengan pemenggalan suku kata pada bahasa Indonesia. Aturan ini diperoleh dari hasil analisis terhadap aturan pemenggalan suku kata yang digunakan oleh Muliati (2010) dalam penelitiannya. Aturannya antara lain: (1) Setiap suku kata merupakan salah satu dari tiga permutasi jenis huruf berikut: <vokal>, <konsonan, vokal>, dan <konsonan, vokal, konsonan>; (2) Satu suku kata pasti memiliki satu huruf vokal atau satu diftong; (3) Huruf yang berharakat tasydid dipisah menjadi dua buah konsonan, satu melekat pada suku kata sebelumnya, satu lagi melekat pada suku kata setelahnya; (4) Rangkaian huruf konsonan yang cara pelafalannya berubah karena terpengaruh oleh hukum tajwid, dipisahkan ke dalam dua suku kata yang berbeda.
3.5
Spesifikasi Kakas dan Perangkat
Kakas yang digunakan untuk melakukan proses ASR adalah Pocketsphinx versi 0.8 yang merupakan sistem pengenalan ucapan yang dikembangkan oleh Carnegie Mellon University (CMU). Sistem Pocketsphinx ini dapat diimplementasikan ke dalam sistem operasi Android. Versi sistem operasi Android yang digunakan untuk uji coba pada masa pengembangan aplikasi ini adalah Android 2.3.4 (Gingerbread). Sistem operasi Android versi ini tergolong cukup rendah apabila dibandingkan dengan sistem operasi Android versi lain yang banyak digunakan, sehingga diharapkan purwarupa perangkat lunak yang dibangun ini dapat dijalankan pada kebanyakan perangkat
mobile lain dengan sistem operasi Android yang lebih tinggi versinya.
Perangkat keras mobile yang digunakan untuk uji coba memiliki spesifikasi prosesor ARMv6 compatible processor rev 5 (v61) Single-Core 600 MHz, RAM 279 MB, internal storage
180 MB, dan external storage 7688 MB.
4.
PEMBANGUNAN PERANGKAT
LUNAK
Purwarupa perangkat lunak mobile yang dibangun ini diberi nama Najmi yang dalam bahasa Arab berarti “bintangku”,
karena perangkat lunak mobile ini diharapkan dapat menjadi secercah cahaya harapan atas lahirnya perangkat lunak mobile
serupa yang disempurnakan menjadi lebih lengkap dan komperehensif.
4.1
Analisis dan Perancangan Perangkat
Lunak
Pembangunan perangkat lunak diawali dengan analisis terhadap kebutuhan fungsional dari perangkat lunak Najmi. Kebutuhan fungsional ini diperoleh dari hasil analisis terhadap perangkat
lunak “E-Hafiz” yang telah ada (Muhammad dkk., 2012)
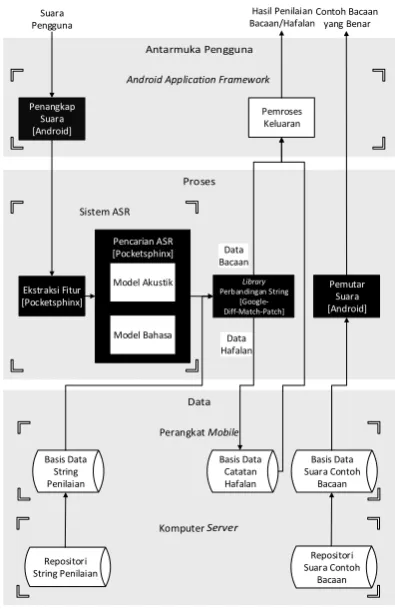
ada pada perangkat mobile. Arsitektur Najmi dapat dilihat pada Gambar 4 berikut.
Sistem ASR
Android Application Framework
Komputer Perangkat Mobile
Ekstraksi Fitur [Pocketsphinx]
Pencarian ASR [Pocketsphinx]
Model Akustik
Model Bahasa
Penangkap Suara [Android]
Basis Data Catatan Hafalan Data Hafalan
Pemroses Keluaran
Data Bacaan Suara
Pengguna
Hasil Penilaian Bacaan/Hafalan
Repositori String Penilaian
Basis Data String Penilaian
Basis Data Suara Contoh
Bacaan
Repositori Suara Contoh
Bacaan
Pemutar Suara [Android]
Contoh Bacaan yang Benar
Library
Perbandingan String [Google-Diff-Match-Patch]
Gambar 4. Arsitektur Perangkat Lunak Najmi
Gambar 5 merupakan hasil analisis use-case untuk perangkat lunak Najmi ini. Dari use-case ini dilakukan analisis skenario
use-case dan perancangan diagram kelas untuk perangkat lunak
Najmi.
System
Pengguna
Memeriksa Hafalan
Memeriksa Bacaan
Melihat Catatan Hafalan Mendengarkan Contoh Bacaan yang Benar
Menguji Penilaian
Gambar 5. Use-Case Perangkat Lunak Najmi
4.2
Perancangan Representasi Data
Setiap ayat direpresentasikan dalam satu file, dengan tipe file
.txt untuk teks ayat dan tipe file .wav untuk contoh suara bacaan ayat. Untuk mengetahui daftar file teks dan audio ayat yang dapat diunduh, pada perangkat mobile disediakan dua file yang masing-masing berisikan daftar nomor surat dan ayat beserta pranala tempat file terkait dapat diunduh.
Catatan hafalan ayat disimpan di dalam basis data lokal perangkat. Berhubung struktur data yang disimpan sangat sederhana, maka skema basis data yang dirancang pun sangat sederhana, hanya mengandung satu tabel dengan nama
tbl_ayat_hafalan yang memiliki 4 kolom, yaitu id_*,
surat_id, ayat_id, dan hafal.
Seluruh kasus uji direpresentasikan dalam satu file dengan tipe file .txt. Berikut contoh isi untuk file teks yang berisikan daftar kasus uji. Kolom pertama berisi ID kasus, kolom kedua berisi nomor surat, kolom ketiga berisi nomor ayat, kolom keempat berisi nama surat, kolom kelima berisi teks ayat yang benar, dan kolom terakhir berisi teks transkrip bacaan pengguna pada kasus tersebut. Setiap kolomnya dipisahkan dengan karakter tab.
4.3
Perancangan Antarmuka
Antarmuka Najmi dikembangkan dengan berbasiskan aplikasi
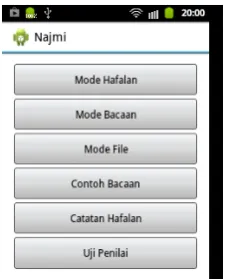
mobile dan memanfaatkan application framework yang telah disediakan oleh Android. Setiap layar tampilan ditangani oleh satu kelas Activity. Terdapat satu menu utama aplikasi yang berisikan lima tombol, dengan setiap tombolnya digunakan untuk mengakses setiap use case yang telah dirancang sebelumnya. Halaman utama antarmuka aplikasi ini dapat dilihat pada Gambar 6 berikut.
Gambar 6. Arsitektur Perangkat Lunak Najmi
4.4
Implementasi Sistem Pemeriksaan
Hafalan dan Bacaan Ayat Al-
Qur’an
Model akustik dan model bahasa yang digunakan pada aplikasi
Najmi ini dibuat sendiri dengan corpus yang diperoleh dari sebagian kecil Al-Qur’an, yaitu dari Surat ke-100 (Al-‘Aadiyat) hingga Surat ke-114 (An-Naas). Banyaknya ayat yang terdapat pada rentang tersebut adalah 91 ayat, dengan 895 suku kata di dalamnya.
Data suara bacaan ayat Al-Qur’an adalah rekaman bacaan Muhammad Siddiq al-Minshawi yang diperoleh dari pranala http://quranicaudio.com/quran/6. Metode transkripsi yang digunakan mengikuti metode yang telah dirumuskan oleh Muliati (2010) dalam penelitiannya. Dalam penelitian tersebut, ayat Al-Qur’an dipenggal per suku kata, sehingga kosakata yang diperoleh pada model bahasanya pada dasarnya merupakan suku kata. Model bahasa yang dihasilkan memiliki kosakata sebanyak 341 buah suku kata, sedangkan model akustik yang dihasilkan memiliki 39 fonem dengan sentence error sebesar 23.1% dan word error rate sebesar 7.0%.
Perangkat lunak Najmi dikembangkan pada perangkat keras dengan spesifikasi prosesor AMD E-450 APU with Radeon™ HD Graphics 1,65 GHz dan RAM 2,60 GB, serta lingkungan implementasi berupa sistem operasi Windows 8.1 32 bit, Java Runtime Environment version 7, dan kakas pengembangan Android Developer Tools (Eclipse) Build: v22.6.2-1085508.
5.
PENGUJIAN
5.1
Deskripsi Pengujian
Pengujian sistem dilakukan dengan menggunakan metode
kemampuan perangkat lunak dalam menjalankan fungsionalitas yang telah didefinisikan dan kemampuan elemen penilaian dalam memeriksa transkrip bacaan pengguna terhadap ayat
Al-Qur’an yang sesungguhnya.
5.2
Lingkungan dan Data Pengujian
Pengujian perangkat lunak dilakukan di lingkungan perangkat lunak dan perangkat keras yang sama dengan lingkungan implementasi seperti yang telah dijelaskan sebelumnya. Untuk pengujian pertama, data suara yang digunakan untuk pengujian diambil dari data suara yang juga digunakan sebagai data latih. Untuk pengujian kedua, data kasus uji yang digunakan adalah seperti yang tercantum pada Tabel 1. Data kasus uji tersebut telah mencakup semua jenis kesalahan yang mungkin muncul seperti yang telah didefinisikan oleh Muliati (2010), yaitu penambahan (insertion), penghapusan (deletion), substitusi (substitution), atau kombinasinya.
Tabel 1. Data kasus uji untuk pengujian penilai
ID Kasus
Ayat
Al-Qur’an Teks Ayat Transkrip Bacaan
Jenis
Sesuai dengan aspek-aspek yang ingin diuji, pengujian fungsionalitas perangkat lunak Najmi ini juga dibagi menjadi dua skenario utama, yaitu skenario pengujian fungsionalitas untuk menguji kemampuan perangkat lunak dalam menjalankan kelima use case yang telah didefinisikan di awal dan skenario pengujian elemen penilai untuk menguji kemampuan elemen
penilaian dalam memeriksa transkrip bacaan pengguna terhadap ayat Al-Qur’an yang sesungguhnya.
5.4
Hasil Pengujian
Tabel 2 menampilkan hasil pengujian pertama, ternyata tidak semua fungsionalitas telah sesuai dengan kriteria lolos pengujian. Tabel 3 menampilkan hasil pengujian kedua, ternyata seluruh kasus uji memenuhi kriteria lolos pengujian. Pada tabel tersebut, suatu kasus dinyatakan lolos pengujian apabila hasil penilaian dan penentuan letak kesalahan yang ditampilkan oleh aplikasi sesuai dengan data kasus uji pada Tabel 1.
Tabel 2. Hasil pengujian fungsionalitas
Use-Case Skenario Hasil
UC-001
File teks dan audio kalimat sudah tersimpan dalam perangkat, hafalan benar
Tidak Lolos Pengujian
File teks dan audio kalimat sudah tersimpan dalam perangkat, hafalan salah
Lolos Pengujian
File teks belum tersimpan dalam perangkat, hafalan benar
Tidak Lolos Pengujian
File audio belum tersimpan dalam perangkat, hafalan salah
Lolos Pengujian
UC-002
File teks dan audio kalimat sudah tersimpan dalam perangkat, bacaan benar
Tidak Lolos Pengujian
File teks dan audio kalimat sudah tersimpan dalam perangkat, bacaan salah
Lolos Pengujian
File teks belum tersimpan dalam perangkat, bacaan benar
Tidak Lolos Pengujian
File audio belum tersimpan dalam perangkat, bacaan salah
Lolos Pengujian
UC-003
File audio kalimat sudah tersimpan dalam perangkat
Lolos Pengujian
File audio kalimat belum tersimpan dalam perangkat
Lolos Pengujian
File audio ayat belum tersimpan dalam perangkat, file audio yang tersimpan telah mencapai batas kapasitas
Lolos Pengujian
UC-004 Melihat catatan hafalan
Lolos Pengujian
UC-005 Menguji penilaian
Lolos Pengujian
Tabel 3. Hasil pengujian elemen penilai
ID
TC-001 Tidak ada
Lolos Pengujian
TC-002
Huruf di akhir ayat tidak
di-waqaf
Lolos Pengujian
TC-003
Salah membaca potongan ayat lain yang mirip (Surat At-Tiin
95:6)
Lolos Pengujian
TC-004 Suku kata “bi him” hilang
Lolos Pengujian
TC-005
Suku kata “wa” berubah menjadi “fa”
Lolos Pengujian
5.5
Analisis Hasil Pengujian
Pada pengujian pertama, terdapat beberapa skenario pengujian yang tidak lolos kriteria pengujian, yaitu skenario pengujian yang kriteria lolos ujinya adalah menunjukkan hasil penilaian bacaan yang benar. Skenario pengujian tersebut terkait dengan fungsionalitas melakukan pengenalan ucapan otomatis dengan menggunakan model akustik dan model bahasa yang tersedia. Kesalahan yang terjadi adalah berupa kesalahan hasil pengenalan ucapan pengguna oleh sistem ASR, karena hampir tidak satu kata pun dapat dikenali dengan baik.
Untuk mencari penyebab pasti kesalahan tersebut, selanjutnya dilakukan penyelidikan terhadap proses penangkapan suara dan ASR pada perangkat lunak Najmi. Penyelidikan dilakukan dengan cara memberikan masukan berupa file suara data latih ke dalam sistem ASR pada perangkat mobile untuk diproses dan ditampilkan hasilnya. Dari penyelidikan tersebut, ditemukan bahwa proses ASR pada perangkat mobile dapat dijalankan dengan baik, seperti yang dapat dilihat pada Gambar 7 berikut. Dengan demikian, dapat disimpulkan bahwa kesalahan pada pengujian pertama ini disebabkan oleh buruknya proses penangkapan suara sebagai masukan untuk proses ASR. Hal ini terjadi akibat proses penangkapan suara dilakukan secara
realtime dan paralel dengan proses ASR.
Gambar 7. Hasil Penilaian dengan Masukan ASR Berupa File Audio
Pada tahapan penyelidikan kesalahan ini, telah diupayakan pula perbaikan proses penangkapan suara dengan cara membuat penangkap suara merekam dan menyimpan suara terlebih dahulu ke dalam suatu file audio untuk selanjutnya file audio tersebut diproses oleh sistem ASR pada perangkat mobile. Upaya yang telah berhasil dilakukan adalah membuat proses penangkapan suara dan menyimpannya ke dalam file .wav,
tetapi file yang dihasilkan ternyata masih belum dapat dikenali dengan baik sebagai format .wav.
Dengan demikian, dapat disimpulkan bahwa penyebab penangkapan suara masih belum berhasil dilakukan adalah belum masuknya suara yang diterima oleh perangkat mobile ke dalam variabel buffer yang telah disediakan. Gagalnya penangkapan suara ini kemungkinan besar akibat dari kesalahan pemrograman dalam pemanfaatan mikrofon pada perangkat
mobile. Kompleksitas pemrograman pada perangkat mobile
relatif lebih tinggi daripada perangkat komputer biasa. Hal ini terkait erat dengan terbatasnya sumber daya serta tingginya kompleksitas arsitektur pada perangkat mobile. Diharapkan perbaikan penangkap suara ini dapat dilanjutkan pada penelitian berikutnya.
Supaya purwarupa aplikasi ini tetap dapat digunakan untuk memeriksa bacaan dan hafalan Al-Qur’an, diberikan mode tambahan pada menu aplikasi, yaitu mode file, di mana pengguna dapat memeriksa bacaan Al-Qur’an yang telah tersimpan di dalam file .wav yang diperoleh dari perekaman dengan menggunakan perangkat lain. Penambahan menu ini terlihat pada Gambar 9.
Gambar 8. Tambahan Mode File untuk Memeriksa Bacaan Al-Qur’an dari File Audio
Pada pengujian skenario kedua, hasil pengujian yang ditampilkan pada Tabel 3 menunjukkan bahwa seluruh kasus uji berhasil dijalankan dengan memenuhi kriteria lolos untuk masing-masing kasus uji tersebut. Dengan demikian, purwarupa perangkat lunak ini terbukti mampu menilai transkrip bacaan pengguna sesuai dengan aturan tajwid yang berlaku dalam
Al-Qur’an serta menampilkan hasil penilaian tersebut dengan
tampilan yang dapat dipahami dengan baik oleh pengguna.
Perangkat lunak Najmi ini mampu menjalankan proses ASR dan melakukan penilaian transkrip bacaan Al-Qur’an, sehingga dapat disimpulkan bahwa perangkat lunak ini juga akan dapat berjalan dengan baik apabila proses penangkapan suara diperbaiki serta proses ASR disempurnakan dengan model bahasa dan model akustik untuk ayat Al-Qur’an yang benar -benar dibuat dengan fokus penelitian lebih dalam dan menggunakan data latih yang lebih lengkap.
6.
KESIMPULAN
Kesimpulan yang diperoleh dari pelaksanaan Tugas Akhir ini adalah:
disediakan mode tambahan untuk memeriksa bacaan
Al-Qur’an yang telah disimpan ke dalam file .wav.
2) Mekanisme pemeriksaan bacaan dan hafalan Al-Qur’an mungkin untuk diterapkan pada perangkat keras mobile
dengan prinsip modalitas Embedded Mobile Speech Recognition, dengan catatan bahwa mekanisme penangkapan suara masih perlu diperbaiki. Selain itu, penelitian yang jauh lebih mendalam juga perlu dilakukan untuk dapat membuat model akustik dan model bahasa yang baik untuk pengenalan ucapan otomatis terhadap ayat Al-Qur’an.
3) Algoritma penilaian bacaan Al-Qur’an dapat diambil dari library perbandingan string yang telah ada. Akan tetapi, untuk mengakomodasi aturan tajwid yang lebih komperehensif lagi diperlukan pengembangan lebih lanjut.
7.
REFERENSI
Abushariah, M. A. M., dkk. Natural Speaker-Independent Arabic Speech Recognition System Based on Hidden Markov Models Using Sphinx Tools. International Conference on Computer and Communication Engineering, Kuala Lumpur. 2010.
Firdausi, Husein Azmi El, Pengembangan Aplikasi Bantu untuk Menghafalkan Al-Qur’an pada Telepon Seluler. Tugas Akhir Sarjana, Institut Teknologi Bandung. Bandung, Indonesia: Program Studi Teknik Informatika. 2010.
Harrag, A., & Mohamadi, T. QSDAS: New Quranic Speech Database for Arabic Speaker Recognition. The Arabian Journal for Science and Engineering, Vol. 35, No. 2C. 2010.
Huerta, Juan M. Speech Recognition in Mobile Environments. Carnegie Mellon University, Pittsburgh. 2000.
Khan, Ali F. A., dkk. Automatic Arabic Pronunciation Scoring for Computer Aided Language Learning. University of Malaya, Kuala Lumpur. 2013.
Kumar, Anuj, dkk. Rethinking Speech Recognition on Mobile Devices. Carnegie Mellon University, Pittsburgh. 2010.
Mansikkaniemi, Andre. Acoustic Model and Language Model Adaptation for a Mobile Dictation Service. Aalto University. 2010.
Marietha, Sonya. Aplikasi SMSsuara dengan Automatic Speech Recognition dan Text To Speech pada Telepon Selular. Tugas Akhir Sarjana, Institut Teknologi Bandung, Bandung, Indonesia: Program Studi Sistem dan Teknologi Informasi. 2010.
Meier, Reto. Professional Android 4 Application Development. Hoboken, NJ: John Wiley & Sons. 2012.
Muhammad, Aslam, dkk. E-Hafiz: Intelligent System to Help Muslims in Recitation and Memorization of Quran. Life Science Journal, Vol. 9, No. 1. 2012.
Muliati, Mira. Pemeriksaan Urutan Hafalan Al Quran Memanfaatkan Pengenalan Suara Otomatis. Tugas Akhir Sarjana, Institut Teknologi Bandung. Bandung, Indonesia: Program Studi Teknik Informatika. 2010.
Myers, Eugene W. An O(ND) Difference Algorithm and Its Variations. Algorithmica, Vol. 1, Halaman 251 – 256. 1986.
Razak, Zaidi, dkk. Quranic Verse Recitation Feature Extraction Using Mel-Frequency Cepstral Coefficient (MFCC). 4th International Colloquium on Signal Processing and its Applications, Kuala Lumpur. 2008.
Schmitt, Alexander., dkk. Speech Recognition for Mobile Devices. Springer Science. 2008.