Pengenalan Menu Eviews 4.1
Oleh
Dr. Nelmida, SE., M.Si
1Eviews merupakan salah satu software statistika yang powerful dalam menganalisis data khususnya data time series. Software ini bersifat user friendly karena berbasiskan window dengan berbagai fasilitas seperti data analysis¸ regression, dan forecasting. Dengan Eviews ini kita dapat mengaplikasikan dengan cepat dan mudah metode statistika sesuai dengan perilaku data, dan selanjutnya dengan metode terpilih ini akan digunakan untuk meramalkan nilai dugaan di masa depan. Beberapa contoh cakupan penggunaan Eviews antara lain: scientific data analysis and evaluation, financial analysis, macroeconomic forecasting, simulation, sales forecasting and cost analysis.
Untuk Menginstal Eviews ini diperlukan beberapa persyaratan kemampuan komputer yang digunakan:
1. Menggunakan processor Minimal A386,486, Pentium atau procesor intel lainnya yang dijalankan dengan Windows 3.1, Windows 95, atau Windows NT.
2. Minimal RAM 4 MB untuk Windows 3.1, untuk Windows 95 dan NT sangat disarankan 8 MB atau lebih.
3. Monitor VGA, Super VGA atau lainnya yang kompartibel. 4. Menggunakan mouse, trackball, atau pen pad.
5. Instalasi program akan membutuhkan sekitar lebih dari 10 MB.
Ketika pertama kali EViews dijalankan akan keluar tampilan sebagai berikut:
Tampilan awal EViews
Window Jika Clik
Minimize, membuat ukuran window kecil
Restore, ukuran window sedang, atau Maximize, ukuran window penuh/besar
Close, menutup window EViews Status line menunjukkan :
1. Tempat pesan suatu perintah 2. Default directory
1 Dosen Tetap Jurusan Manajemen Fakultas Ekonomi Bung Hatta Padang.
Email: [email protected].
Pembuatan Workfile
Sebelum menjalankan perintah metode statistika yang ada di Eviews, terlebih dahulu harus dibuka file Eviews workfile. Jika belum terdapat data yang dimaksud maka kita harus membuat workfile baru dengan mengimpor dari data Excel spreadsheet.
Dalam modul ini akan digunakan data dari tahun 1996 sampai tahun 2005 dalam file data1.xls
Tahapan berikut merupakan langkah membuat workfile data baru
Mengatur waktu dari data
File/New/Wokfile....
Pilihan waktu dari data , pilihan ini sesuai dengan waktu dari data di Excel spreadsheet
Annual : data tahunan
Semi-annual : data per semeter Quarterly : data triwulanan Monthly : data bulanan Weekly : data mingguan
Daily (5 day weeks) : data mingguan 5 hari Daily (7 day weeks) : data harian
Undated or irregular : bukan data time series atau tidak beraturan
Format Penulisan Waktu : tahun:bulan:hari atau tahun:bulan atau tahun
Pada Start date ketik 1996 dan End date ketik 2005 (sesuai dengan date data yang akan diimpor)
Mengimpor Data dari Excel
Procs/Impor/ReadText-Lotus-Exel...., baik pada toolbar window workfile:UNTITLED atau pada window Eviews. Atau dengan perintah
File/Impor/ReadText-Lotus-Exel...., dari menu window EViews
Tentukan lokasi file Excel berada misalnya di
d:Eviews/data/data1.xls terus pilih menu open
Ketik 4, pada Names for series or Number of series if names infiles
untuk menyatakan banyaknya series variabel yang diimpor.
OK
B2 menunjukkan lokasi sel di Excelspreadsheet yang pertama kali diimpor ke Eviews workfile. Input angka X Y menunjukkan banyaknya variabel yang diimpor, sedangkan tahun 1996 2005 adalah tahun series data sesuai dengan range yang ditentukan ketika membuat workfile baru.
Maka pada window workfile akan tampak sebagai berikut :
Save Workfile
Save, pada toolbar window workfile, atau File/save, pada menu windows EViews dan tulis nama file DATA (atau apa saja sesuai keinginan kita) pada suatu directori atau drive.
Cara Lain Entri Data atau Copy Data
Pada window workfile atau EViews Objects/New Object.... atau
click kiri/New Object... pada kolom kosong window workfile
Copy data dari Excel dengan cara : Block data1.xls (dengan judulnya) dan copy pada window Excel. Kemudian pindah ke
window Eviews, Klik kanan/paste pada window Series Data. Maka akan tampak sebagai berikut :
Klik Kanan
ORDINARY LEAST SQUARE
A. Regresi Sederhana (OLS Sederhana)
Model regresi sederhana adalah suatu model yang melihat hubungan antar dua variabel. Salah satu variabel menjadi variabel bebas (Independent variable) dan variabel yang lain menjadi variabel terikat (Dependent variable). Dalam regresi sederhana ini, akan kita ambil suatu contoh kasus mengenai hubungan antara pengeluaran konsumsi dan pendapatan di US pada tahun 1996 – 2005 (Gujarati, 2003: 6). Persamaan model ini adalah:
Y = 0 + 1X +
Dimana, Y adalah pengeluaran konsumsi, 0 adalah konsumsi autonom, X merupakan pendapatan dan adalah error term.
(lokasi file Excel berada di d:Eviews/data/data1.xls:data1)
Setelah muncul data yang akan diolah, kemudian blok variable X dan Y -Klik kanan: Open - as Group. Maka, akan muncul tampilan :
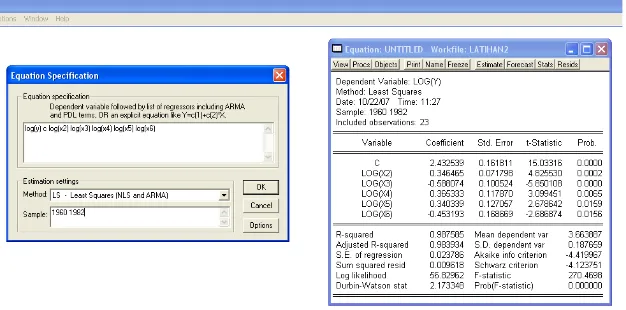
Kemudian Pilih Procs - Make Equation - Equation Specification
Setelah itu ketik data yang akan diolah : Y spasi c spasi X, pilih Method: LS – OK. Variabel yang kita tulis pertama adalah variabel dependen, selanjutnya adalah konstanta dan variabel independent.
Dependent Variable: Y Method: Least Squares Date: 08/24/07 Time: 01:18 Sample: 1996 2005
Included observations: 10 Variable Coefficien
t
Std. Error t-Statistic Prob.
C 24.45455 6.413817 3.812791 0.0051
X 0.509091 0.035743 14.24317 0.0000
R-squared 0.962062 Mean dependent
var 111.0000
Adjusted R-squared 0.957319 S.D. dependent var 31.4289 3 S.E. of regression 6.493003 Akaike info criterion 6.75618 4 Sum squared resid 337.2727 Schwarz criterion 6.81670 1
Log likelihood
-31.78092 F-statistic 202.8679 Durbin-Watson stat 2.680127 Prob(F-statistic) 0.00000 1
Intepretasi Hasil Regresi:
Dari hasil regresi diatas maka akan didapatkan persamaan sebagai berikut: Y = 24.45455 + 0.509091X
Sebagai contoh, apabila ditanyakan berapa tingkat konsumsi individu jika pendapatan tahun depan diperkirakan sebesar 5000 milyar dollar US?. Maka
Y = 24.45455 + 0.509091(5000) Y = 2569.91
B. Regresi Berganda
Model regresi berganda merupakan suatu model regresi yang terdiri dari lebih dari satu variabel independen. Bentuk umum regresi berganda dapat ditulis sebagai berikut:
Y1 = 0 + 1X1 + 2X2 + 3X3 + ….+ nXn + ei
Pada intinya, langkah – langkah estimasi regresi berganda didalam Eviews tidak jauh berbeda dengan regresi sederhana seperti yang telah dibahas sebelumnya. Berikut ini adalah tampilan data yang akan digunakan dalam regresi berganda.
(lokasi file Excel berada di d:Eviews/data/data1.xls:mul2)
Lakukan regresi berganda dengan cara :
Maka akan menghasilkan angka sebagai berikut :
Demand for Chickens, United States, 1960-1982
YEAR = Year
Y = Per Capita Consumption of Chickens, Pounds
X2 = Real Disposable Income Per Capita, $
X3 = Real Retail Price of Chicken Per Pound, Cents
Dari hasil regresi diatas maka akan didapatkan persamaan sebagai berikut: Y = 38.59690942 + 0.004889344622*X2 - 0.6518875293*X3 +
0.2432418207*X4 +
0.1043176111*X5 - 0.07111034011*X6
Dengan cara yang sama seperti pada regresi sederhana kita akan meregresi variabel dependen yaitu ekspor dan veriabel independen yang terdiri dari suku bunga, nilai tukar rupiah, serta inflasi.
(lokasi file Excel berada di d:Eviews/data/data1.xls:auto2)
Dari hasil regresi akan diperoleh estimasi sebagai berikut:
Cara mengintepretasikan hasil regresi sama dengan estimasi pada regresi sederhana.
C. Uji t dan Uji F
Uji t merupakan pengujian terhadap koefisien dari veriabel bebas secara parsial. Uji ini dilakukan untuk melihat tingkat signifikansi dari veriabel bebas secara individu dalam mempengaruhi variasi dari variabel terikat. Sedangkan Uji F merupakan uji model secara keseluruhan. Oleh sebab itu Uji F ini lebih relevan dilakukan pada regresi berganda. Uji F dilakukan untuk melihat apakah semua koefisien regresi berbeda dengan nol atau dengan kata lain model diterima.
Pada regresi sederhana maupun regresi berganda, pengujian koefisien 1, 2, dan n dapat dilakukan dengan Uji t. Pengujian ini dilakukan dengan cara
> t-tabel, maka Ho ditolak dan H1 diterima, dengan kata lain terdapat
hubungan antara variabel dependen dan variabel independen. Sebaliknya jika t-stat < t-tabel, maka Ho diterima dan H1 ditolak, yang artinya tidak terdapat
hubungan antara variabel dependen dan variabel independen.
Pada contoh kasus diatas, dengan tingkat kepercayaan 95% (α = 5%) maka daerah kritis untuk menolak Ho adalah t-stat < t 0.025;39. Kita bisa melihat
bahwa pada variabel inflasi memiliki nilai t-stat sebesar 5,479 sedangkan nilai t-tabel pada t0.025;39 adalah 2,021. Artinya nilai t-stat > t-tabel, sehingga
hipotesa H0 ditolak, dapat disimpulkan bahwa terdapat hubungan antara
ekspor dan inflasi.
Pengujian hipotesis dapat juga dilakukan dengan konsep P-Value. Cara ini relatif lebih mudah dilakukan karena tersedia pada menu Eviews. Konsep ini membandingkan α dengan nilai P-Value. Jika nilai P-Value kurang dari α, maka H0 ditolak. Pada contoh kasus diatas nilai P-Value dari variabel inflasi adalah 0,0000 artinya pada α = 1%, 5%, dan 10% hipotesa H0 ditolak. Artinya
pada berbagai tingkat keyakinan tersebut ekspor memiliki hubungan dengan inflasi.
Pada prinsipnya Uji F memiliki konsep yang tidak jauh berbeda dengan Uji t. Jika Uji t digunakan untuk melihat pengaruh variabel bebas terhadap variabel terikat secara individu, maka Uji F digunakan untuk melihat pengaruh variabel bebas terhadap varibel terikat secara bersama-sama. Formulasi dari Uji F adalah sebagai berikut:
Ho : 1 = 2 = 3 = 0, artinya antara variabel dependen dengan
variabel independen tidak ada hubungannya H1 : 12n 0, artinya antara variabel dependen dengan
Variabel independen ada hubungan.
Dengan menggunakan konsep P-Value, maka pada contoh diatas P-Value dari F = 0,000012. Artinya pada α = 1%, 5%, dan 10% hipotesa H0 ditolak dan H1
diterima. Dimana antara ekspor dengan inflasi, tingkat bunga, dan nilai tukar rupiah terdapat suatu hubungan. Dengan kata lain variabel independen dalam persamaan tersebut secara bersama-sama berpengaruh terhadap variasi dari variabel dependen.
D. Uji Asumsi Klasik
Dalam melakukan estimasi persamaan linier dengan menggunakan metode OLS, maka asumsi-asumsi dari OLS harus dipenuhi. Apabila asumsi tersebut tidak dipenuhi maka tidak akan menghasilkan nilai parameter yang BLUE (Best Linear Unbiased Estimator). Asumsi BLUE antara lain:
1. Model regresi adalah linier dalam parameter
2. Error term (u) memiliki distribusi normal. Implikasinya, nilai rata-rata kesalahan adalah nol.
3. Memiliki varian yang tetap (homoskedasticity).
4. Tidak ada hubungan antara variabel bebas dan error term. 5. Tidak ada korelasi serial antara error (no-autocorrelation).
6. Pada regresi linear berganda tidak terjadi hubungan antar variabel bebas (multicolinearity).
D.1. Uji Normalitas
Uji normalitas digunakan jika sampel yang digunakan kurang dari 30, karena jika sampel lebih dari 30 maka error term akan terdistribusi secara normal. Uji ini disebut Jarque – Bera Test.
Lakukan Prosedur berikut: Dari hasil estimasi - View – Residual test – Histogram Normality test
Dari hasil diatas maka langkah selanjutnya adalah melakukan uji normalitas error term:
1. H0 : error term terdistribusi normal
H1 : error term tidak terdistribusi normal
2. α = 5% maka daerah kritis penolakan H0 adalah P-Value < α 3. Karena P-Value = 0,678100 > 0,05 maka H0 diterima
4. Kesimpulan, dengan tingkat keyakinan 95%( α = 5% ) maka dapat dikatakan bahwa error term terdistribusi normal.
D.2. Uji Multikolinieritas
Multikolinearitas adalah adanya hubungan linier yang signifikan antara beberapa atau semua variabel independent dalam model regresi. Untuk melihat ada tidaknya multikolinieritas dapat dilihat dari koefisien korelasi dari masing-masing variabel bebas. Jika koefisien korelasi antara masing-masing variabel bebas lebih besar dari 0,8 berarti terjadi mulikolinieritas.
Lakukan prosedur berikut: Dari workfile – Blok semua variabel kecuali c dan resid – Klik kanan: Open – As Group
Setelah tampil semua variabel, Klik View – Correlation – Common Sampel.
Dari tampilan diatas terlihat bahwa antara variabel X2, X3, X4, X5, dan X6 terjadi
multikolinieritas, karena memiliki nilai Correlation matrix lebih dari 0,8. Cara mengatasi adanya multikol dapat dilakukan dengan cara: (1) menghilangkan variabel independent, (2) transformasi variabel, (3) penambahan data. Berikut ini dilakukan cara mengatasi multikol dengan transformasi data, yaitu penambahan log. Dari hasil tersebut, semua koefisien telah signifikan.
D.3. Heteroskedasitas
Heteroskedasitas merupakan keadaan dimana varians dari setiap gangguan tidak konstan. Uji heteroskedasitas dapat dilakukan dengan menggunakan White Heteroskedasticity yang tersedia dalam program Eviews. Hasil yang peril diperhatikan dari Uji ini adalah nilai F dan Obs*R-Squared. Jika nilai Obs*R-Squared lebih kecil dari X2 tabel maka tidak terjadi
heteroskedastisitas, dan sebaliknya
(lokasi file Excel berada misalnya di d:Eviews/data/data1.xls:het2)
Dependent Variable: PROFIT Method: Least Squares Date: 08/26/07 Time: 22:40 Sample: 1 18
Included observations: 18 Variable Coefficien
t
Std. Error t-Statistic Prob.
RD 0.369500 0.305947 1.207726 0.2459 SALES 0.068854 0.014112 4.879106 0.0002
C 791.5363 1214.194 0.651903 0.5243
R-squared 0.810248 Mean dependent var
8102.45 0 Adjusted R-squared 0.784947 S.D. dependent var 7281.31 5 S.E. of regression 3376.620 Akaike info criterion 19.2381 5 Sum squared resid 1.71E+08 Schwarz criterion 19.3865 5
Log likelihood
-170.1433
F-statistic 32.0252 1 Durbin-Watson stat 2.853771 Prob(F-statistic) 0.00000 4
Dengan melihat hasil tersebut, dapat diduga terjadi hetero pada hasil estimasi. Dimana residualnya membentuk suatu pola atau tidak konstan. Untuk membuktikan dugaan tersebut perlu dilakukan Uji White Hetero.
White Heteroskedasticity Test:
F-statistic 8.281590 Probability 0.001508 Obs*R-squared 12.92698 Probability 0.011638
Dengan melihat hasil Obs*R-Squared sebesar 12,92698 > 9,48773 (nilai kritis Chi square (X2) pada α = 5%), maka dapat disimpulkan bahwa pada estimasi
tersebut terjadi hetero. Cara lain yaitu dengan melihat nilai probabilitas dari nilai chi squares. Pada hasil diatas nilai probabilitasnya sebesar 0,011638 artinya terjadi hetero pada tingkat α = 1%. Semakin besar nilai probabilitasnya berarti semakin tidak terjadi hetero.
D.4. Autokorelasi
Autokorelasi menunjukkan adanya hubungan antar gangguan. Metode yang digunakan dalam mendeteksi ada tidaknya masalah autokorelasi adalah
Metode Bruesch-Godfrey yang lebih dkenal dengan LM-Test. Metode ini didasarkan pada nilai F dan Obs*R-Squared. Dimana jika nilai probabilitas dari
Obs*R-Squared melebihi tingkat kepercayaan maka Ho diterima, berarti tidak ada masalah autokorelasi.
(lokasi file Excel berada misalnya di d:Eviews/data/data1.xls:auto2)
Dapat dilihat dari hasil estimasi sepertinya tidak terjadi per masalahan yang melanggar asumsi klasik. Dimana terlihat bahwa nilai t-statistik signifikan., R2 bagus, dan Uji F juga signifikan. Namun dalam hasil tersebut terdapat DW stat yang relatif kecil. Nilai DW yang kecil tersebut merupakan salah satu indikator adanya masalah autokorelasi.
Untuk membuktikan adanya masalah autokorelasi dalam model dapat kita lakukan dengan melakukan uji LM.
Breusch-Godfrey Serial Correlation LM Test: F-statistic 13.24422
Probability 0.000060 Obs*R-squared 17.36554
Probability 0.000169
Dari hasil test diatas dapat disimpulkan bahwa dalam hasil estimasi tersebut terjadi masalah autokorelasi. Hal ini dapat dilihat dari nilai probabilitas kurang dari tingkat keyakinan (α = 1%) maka Ho ditolak yang berarti dalam model terdapat autokorelasi.
AUTOREGRESSIVE INTEGRATED MOVING AVERAGE
(ARIMA)
1. Pengantar
ARIMA merupakan suatu teknik yang mengabaikan independent variable dalam melakukan peramalan. Model ini hanya menggunakan nilai-nilai sekarang dan masa lalu dari dependent variable untuk melakukan peramalan jangka pendek. Metode ini disebut juga dengan metode Box-Jenkins.
2. Petunjuk Operasional dalam Eviews a. Uji Stasioneritas Data
Uji stasioneritas data digunakan untuk melihat apakah data mengandung akar unit atau tidak. Data time series dikatakan stasioner jika data tersebut tidak mengandung akar-akar unit (unit root) dengan kata mean, variance, dan covariant konstan sepanjang waktu. Pengujian akar-akar unit root dilakukan dengan metode Augmented Dickey Fuller(ADF), yaitu dengan membandingkan nilai ADFstatistik dengan Mackinnon critical value 1%, 5%, dan
critical value 1%, 5%, dan 10% serta nilai probabilitasnya signifikan dibawah 10%. Jika ADFstatistik lebih kecil dari Mackinnon critical value 1%, 5%, dan 10%
serta nilai probabilitasnya diatas 10% (tidak signifikan) maka data dikatakan tidak stasioner.
Lakukan prosedur berikut :
Klik Workfile – Klik variabel yang akan di uji – View - Unit root test (lokasi file Excel berada di d:Eviews/data/data2 ARIMA.xls)
Lakukan pengujian pada tingkat Level dengan asumsi trend dan intercept -OK
Augmented Dickey-Fuller Test Equation Dependent Variable: D(GDP)
Method: Least Squares Date: 10/22/07 Time: 20:59 Sample(adjusted): 1970:3 1991:4
Included observations: 86 after adjusting endpoints Variable Coefficien
t Std. Error t-Statistic Prob.
GDP(-1)
-0.078661
0.035508 -2.215287 0.0295
D(GDP(-1)) 0.355794 0.102691 3.464708 0.0008
C 234.9729 98.58764 2.383391 0.0195
@TREND(1970:1) 1.892199 0.879168 2.152260 0.0343 R-squared 0.152615 Mean dependent
var
Adjusted R-squared 0.121613 S.D. dependent var 35.9379 4 S.E. of regression 33.68187 Akaike info criterion 9.91719 1 Sum squared resid 93026.38 Schwarz criterion 10.0313 5
Log likelihood
-422.4392 F-statistic 4.922762 Durbin-Watson stat 2.085875 Prob(F-statistic) 0.00340 6
Dari hasil pengujian dapat dilihat nilai ADFstatistik sebesar 2,215287 lebih kecil
dari dengan probabilitas diatas 10%, yaitu 0,4749. Berarti data masih mengandung akar unit, dengan kata lain data tidak stasioner pada tingkat level. Lakukan kembali pengujian unit root pada tingkat first difference.
Klik View – Unit root test – Pilih first difference - Intercept – OK
Null Hypothesis: D(GDP) has a unit root Exogenous: Constant, Linear Trend
Lag Length: 0 (Automatic based on SIC, MAXLAG=4)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -6.588446 0.0000 Test critical values: 1% level -4.068290
5% level -3.462912
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(GDP,2)
Method: Least Squares Date: 10/22/07 Time: 21:00 Sample(adjusted): 1970:3 1991:4
Included observations: 86 after adjusting endpoints Variable Coefficien
t Std. Error t-Statistic Prob.
D(GDP(-1))
-0.682459 0.103584 -6.588446 0.0000
C 17.25493 7.965990 2.166074 0.0332
@TREND(1970:1)
-0.028246
0.149731 -0.188649 0.8508
R-squared 0.343833 Mean dependent
var 0.206977
Adjusted R-squared 0.328022 S.D. dependent var 42.0444 1 S.E. of regression 34.46559 Akaike info criterion 9.95206 1 Sum squared resid 98593.78 Schwarz criterion 10.0376 8
Log likelihood
-424.9386 F-statistic 21.74613 Durbin-Watson stat 2.035932 Prob(F-statistic) 0.00000 0
Dari pengujian yang kedua didapat bahwa nilai ADFstatistik lebih besar dari
critical value dan probabilitasnya signifikan pada tingkat keyakinan 1%. Hal ini berarti data telah stasioner pada first difference. Secara tidak langsung ordo integrasi telah ditemukan, yaitu d = 1. Berikutnya adalah penentuan ordo suku AR dan MA.
b. Penentuan Ordo AR – MA
Lakukan pengujian correlogram, dengan hasil derajat integrasi yang diperoleh dari uji unit root dan biarkan Eviews menentukan panjang lag maksimumnya. Lakukan prosedur berikut ini:
Dari grafik diatas terlihat bahwa terjadi pelanggaran garis batang AC pada lag 1, 8, dan 12, maka kita memiliki kandidat MA (1). Dari grafik batang PAC, terlihat kalau pelanggaran garis batas juga terjadi pada lag 1, maka diperoleh juga kandidat AR (1). 3 kandidat model yang akan digunakan adalah bentuk ARIMA (1,1,1); ARIMA (1,1,0) atau ARI (1) dan ARIMA (0,1,1) atau IMA (1). Selanjutnya adalah penentuan model terbaik.
c. Penentuan Model Terbaik.
Untuk model ARIMA (1,1,1) : Klik Quick – Estimate equation – Ketik: d(gdp) c AR(1) MA(1) – OK
Jangan lupa untuk memberi nama persamaan tersebut, Klik Name – Arima – OK
Cara melihat stasioner atau tidaknya model bisa di lihat dari nilai AC dan PAC dibandingkan dengan + 1.96 ( ), atau sama dengan
+1.96( ) =
+ 1.96 (0.1066)= -0.208 sd + 0.208
Jadi kalau AC dan PAC ada diantara
Variable Coefficien t
Std. Error t-Statistic Prob.
C 23.50643 5.942537 3.955622 0.0002
AR(1) 0.499690 0.275101 1.816384 0.0729
MA(1)
-0.201502 0.312614 -0.644572 0.5210 R-squared 0.105750 Mean dependent
var 23.34535
Adjusted R-squared 0.084202 S.D. dependent var 35.9379 4 S.E. of regression 34.39166 Akaike info criterion 9.94776 6 Sum squared resid 98171.24 Schwarz criterion 10.0333 8
Log likelihood
-424.7539 F-statistic 4.907606 Durbin-Watson stat 1.994227 Prob(F-statistic) 0.00967 3 Inverted AR Roots .50
Inverted MA Roots .20
Hasil regresi pada model ARIMA (1,1,1) menunjukkan bahwa probabilitas MA(1) tidak signifikan, yaitu sebesar 0,5210, maka model ini dinyatakan gugur.
Selanjutnya kita akan melihat model yang kedua yaitu model ARI(1)
Variable Coefficien t
Std. Error t-Statistic Prob.
C 23.44152 5.412216 4.331223 0.0000
AR(1) 0.317238 0.102975 3.080716 0.0028 R-squared 0.101516 Mean dependent
var 23.34535
Adjusted R-squared 0.090820 S.D. dependent var 35.9379 4 S.E. of regression 34.26717 Akaike info criterion 9.92923 4 Sum squared resid 98636.06 Schwarz criterion 9.98631 1
Log likelihood
-424.9570 F-statistic 9.490809 Durbin-Watson stat 2.034425 Prob(F-statistic) 0.00279 1 Inverted AR Roots .32
Variable Coefficien t
Std. Error t-Statistic Prob.
C 22.79699 4.666313 4.885441 0.0000
MA(1) 0.258497 0.104584 2.471667 0.0154 R-squared 0.080866 Mean dependent
var 22.93333
Adjusted R-squared 0.070053 S.D. dependent var 35.9344 8 S.E. of regression 34.65297 Akaike info criterion 9.95136 4 Sum squared resid 102070.4 Schwarz criterion 10.0080 5
Log likelihood
-430.8843 F-statistic 7.478367 Durbin-Watson stat 1.911508 Prob(F-statistic) 0.00759 8 Inverted MA Roots -.26
Model ARI(1) dan IMA(1), memiliki nilai probabilitas yang signifikan, hal ini didukung pula oleh nilai │IRM│< 1. Maka pemilihan modeol terbaik akan dilanjutkan dengan pengujian autokorelasi.
Correlogram AR Correlogram MA
Ternyata kedua model berhasil menyelesi
kan permasalahan autokorelasi
masing-masing, terlihat dari nilai Q-stat yang tidak signifikan di setiap lag. Maka
langkah terakhir pemilihan model akan bergantung pada nilai SC yang lebih kecil.
ARI (1) memiliki nilai SC sebesar 9.986, sementara IMA (1) sebesar 10.00805,
maka model ARI(1)- lah yang terbaik.
Model Adjusted
R-square AIC SC
IMA (1) 0.070053 9.951364 10.00805
ARI (1) 0.09082 9.929234 9.986311
ARIMA (1,1,1) 0.084202 9.947766 10.03338
d. Peramalan
Terlihat bahwa nilai bias proportion sebesar 0.053880 (dibawah 0.2), sementara covariance proportion 0.856076 (hampir mendekati 1), maka model ini dapat meramal nilai GDP kedepan.
Bila mengasumsi model sudah benar, maka langkah selanjutnya adalah memperpanjang range data. Pada menu utama :
Ubah juga sample data : Procs – sample – ketik tahun yang akan diforcast
Kembali ke estimasi : Procs - Make model – Solve – OK
Langkah berikutnya anda buka ar1
Jangan lupa diganti tahun estimasi yang diinginkan Contoh :
Langkah berikutnya anda klik menu solve
Sehingga akan terbentuk variabel forecast gdpf dengan tambahan nilai konsumsi 1992:1
1991:2 4865.329
1991:3 4888.771
1991:4 4912.212
ARCH/GARCH
1. Pengantar
Data time series, terutama seperti data indeks saham, tingkat bunga, nilai tukar, dan inflasi, sering kali bervolatilitas. Implikasi data yang bervolatilitas adalah variance dari error tidak constant. Dengan kata lain mengalami heteroskedatisitas. Implikasi dari adanya heteroskedatisitas terhadap estimasi OLS tetap tidak bias, tetapi standart error dan interval keyakinan menjadi terlalu sempit sehingga dapat memberikan sense of precision yang salah.
ARCH Test:
F-statistic 6235215.
Probability 0.000000 Obs*R-squared 635.9353
Probability 0.000000
Tampak hasil pengujian dengan menggunakan ARCH LM Test menunjukkan hasil yang signifikan, oleh karena itu secara statistik kita menolak H nul (Ho) yang berarti varian residual tidak konstan atau dengan kata lain model yang digunakan mengandung unsur ARCH.
Model Estimasi ARCH
Untuk mengestimasi model ARCH dapat dilakukan dengan cara :
quick/estimate equation
Sehingga akan menghasilan model estimasi sebagai berikut :
Dependent Variable: CPI
Method: ML - ARCH (Marquardt) Date: 10/25/07 Time: 12:29 Sample(adjusted): 2 637
Included observations: 636 after adjusting endpoints Convergence achieved after 14 iterations
Variance backcast: ON
Coefficien
t Std. Error z-Statistic Prob.
C 66.22193 24.37509 2.716787 0.0066
AR(1) 0.981749 0.004680 209.7636 0.0000 Variance Equation
C 534.3886 52.58769 10.16186 0.0000
ARCH(1)
-67.88467
11.90989 -5.699856 0.0000
R-squared 0.999511 Mean dependent
var 70.64623
Adjusted R-squared 0.999508 S.D. dependent var 48.2501 9 S.E. of regression 1.069711 Akaike info criterion 7.95114 7 Sum squared resid 723.1859 Schwarz criterion 7.97916 7
Log likelihood
-2524.465 F-statistic 430432.6 Durbin-Watson stat 0.029878 Prob(F-statistic) 0.00000 0 Inverted AR Roots .98
Tampak ARCH menunjukkan hasil yang signifikan berarti kesalahan prediksi (residual) CPI dipengaruhi oleh residual kuadrat periode sebelumnya ARCH(1). Namun dengan memasukkan unsur persamaan ARCH ini, apakah kemudian model terbebas dari unsur ARCH? Lakukan pengujian dengan klik
View/Residual Test/ARCH LM Test
ARCH Test:
F-statistic 0.091028 Probability 0.76297 4 Obs*R-squared 0.091302 Probability 0.76252 8
Test Equation:
Dependent Variable: STD_RESID^2 Method: Least Squares
Date: 10/25/07 Time: 12:37 Sample(adjusted): 3 637
Included observations: 635 after adjusting endpoints Variable Coefficien
t
Std. Error t-Statistic Prob.
C 0.008176 0.004775 1.712304 0.0873
STD_RESID^2(-1) 0.011991 0.039745 0.301708 0.7630 R-squared 0.000144 Mean dependent
var 0.008275
Adjusted R-squared
-0.001436 S.D. dependent var 0.119956 S.E. of regression 0.120042 Akaike info criterion -1.39879 9 Sum squared resid 9.121638 Schwarz criterion -1.38477 2 Log likelihood 446.1188 F-statistic 0.09102 8 Durbin-Watson stat 2.000168 Prob(F-statistic) 0.76297 4
Kemudian pilih metode estimasinya dengan menggunakan GARCH, lalu klik metode tersebut sehingga aka muncul tampilan sebagai berikut :
Sehingga akan menghasilan model estimasi sebagai berikut :
Dependent Variable: CPIMethod: ML - ARCH (Marquardt) Date: 10/25/07 Time: 12:48 Sample(adjusted): 2 637
Included observations: 636 after adjusting endpoints Failure to improve Likelihood after 26 iterations Variance backcast: ON
Coefficien t
Std. Error z-Statistic Prob.
C 98.39845 11.72393 8.392958 0.0000
AR(1) 1.172699 0.024129 48.60187 0.0000 Variance Equation
C 1102.365 160.9089 6.850866 0.0000
ARCH(1)
-R-squared 0.960115 Mean dependent var
Log likelihood
-2541.909 F-statistic 3797.387 Durbin-Watson stat 0.000473 Prob(F-statistic) 0.00000 0 Inverted AR Roots 1.17
Estimated AR process is nonstationary
Tampak GARCH menunjukkan hasil yang signifikan berarti varian kesalahan prediksi (residual) CPI dipengaruhi oleh varian residual periode sebelumnya GARCH(1). Nilai ARCH juga menunjukkan hasil yang signifikan berarti varian kesalahan prediksi (residual) CPI dipengaruhi oleh varian residual kuadrat periode sebelumnya GARCH(1)
Namun dengan memasukkan unsur persamaan GARCH ini, apakah kemudian model terbebas dari unsur ARCH? Lakukan pengujian dengan klik View/Residual Test/ARCH LM Test
ARCH Test:
F-statistic 405.6918 Probability 0.00000 0 Obs*R-squared 248.0180 Probability 0.00000 0
Test Equation:
Dependent Variable: STD_RESID^2 Method: Least Squares
Date: 10/25/07 Time: 12:53 Sample(adjusted): 3 637
Included observations: 635 after adjusting endpoints Variable Coefficien
t Std. Error t-Statistic Prob.
C 0.160692 0.018725 8.581812 0.0000
STD_RESID^2(-1) 0.618926 0.030728 20.14179 0.0000 R-squared 0.390580 Mean dependent
var 0.425404
Log likelihood
-207.6488 F-statistic 405.6918 Durbin-Watson stat 3.192647 Prob(F-statistic) 0.00000 0
Tampak hasil perhitungan menunjukkan nilai prob sebesar 0.000 (lebih kecil dari 0.05), dengan demikian pada lag (1) secara statistik signifikan sehingga kita menolak hipotesis nul (Ho) yang berarti varian residual tidak konstan atau dengan kata lain model yang digunakan sudah masih mengandung unsur stasioner. Keberadaan hubungan kointegrasi memberikan peluang bagi data-data yang secara individual tidak stasioner untuk menghasilkan sebuah kombinasi linier diantara mereka sehingga tercipta kondisi yang stasioner. Secara sederhana, dua variabel disebut terkointegrasi jika hubungan kedua variabel tersebut dalam jangka panjang akan mendekati atau mencapai kondisi equilibriumnya. Error Correction Model (ECM) merupakan model yang digunakan untuk mengoreksi persamaan regresi antara variabel-variabel yang secara individual tidak stasioner agar kembali ke nilai equilibriumnya di jangka panjang, dengan syarat utama berupa keberadaan hubungan kointegrasi diantara variabel-variabel penyusunnya. Ada banyak cara untuk melakukan uji kointegrasi, namun dalam modul ini hanya memaparkan Engle-Granger Cointegration Test.
2. Petunjuk Operasional Dalam Eviews. a. Uji Stasioneritas Data
Pada kasus ini, uji stasioneritas juga dilakukan pada setiap variabel. Dengan cara yang sama seperti pada modul sebelumnya, maka didapat bahwa hasil sebagai berikut:
(lokasi file Excel berada di d:Eviews/data/data4 ECM.xls)
Null Hypothesis: D(PDI) has a unit root
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -9.592898 0.0000 Test critical values: 1% level -4.068290
5% level -3.462912
10% level -3.157836
Null Hypothesis: D(PCE) has a unit root
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -7.567202 0.0000 Test critical values: 1% level -4.068290
10% level -3.157836 Date: 08/24/07 Time: 17:18 Sample: 1970:1 1991:4 Included observations: 88
Variable Coefficien t
Std. Error t-Statistic Prob.
PDI 0.967250 0.008069 119.8712 0.0000
C
-171.4412 22.91725 -7.480880 0.0000 R-squared 0.994051 Mean dependent
var
2537.04 2 Adjusted R-squared 0.993981 S.D. dependent var 463.113 4 S.E. of regression 35.92827 Akaike info criterion 10.0233 9 Sum squared resid 111012.3 Schwarz criterion 10.0796 9
Log likelihood
-439.0292 F-statistic 14369.10 Durbin-Watson stat 0.531629 Prob(F-statistic) 0.00000 0
Hasil estimasi ini dapat ditulis ulang menjadi : PCEt = -171.4412 + 0.967250 PDIt + ut
Null Hypothesis: RESID01 has a unit root Exogenous: None
Lag Length: 0 (Automatic based on SIC, MAXLAG=11)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -3.779071 0.0002 Test critical values: 1% level -2.591813
5% level -1.944574
10% level -1.614315
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(RESID01) Method: Least Squares
Date: 10/25/07 Time: 13:20 Sample(adjusted): 1970:2 1991:4
Included observations: 87 after adjusting endpoints Variable Coefficien
t
Std. Error t-Statistic Prob.
RESID01(-1)
-0.275312 0.072852 -3.779071 0.0003 R-squared 0.142205 Mean dependent
var
5 S.E. of regression 24.25937 Akaike info criterion 9.22691 1 Sum squared resid 50612.48 Schwarz criterion 9.25525 5
Log likelihood
-400.3706
Durbin-Watson stat 2.27751 2
Hasil unit root test dapat ditulis dalam bentuk persamaan sebagai berikut: ∆ût = -0275132ut-1
Hasil uji unit root dari residual (u) kita bandingkan dengan nilai �=0+1T-1+2T-2
Jika nilai t-statistik > dari nilai �, maka residual tersebut (u) terkointegrasi. Berdasarkan perhitungan nilai r = -2.899, sehingga karena nilai t-statistik lebih besar dari nilai � (-3.779071) maka residualnya teritegrasi
Bentuk persamaan regresi ECM adalah sebagai berikut: ∆PCEt = α0 + α1∆PDI + α2ut-1 + t
Hasil regresi Eviews akan menghasilkan output pada tabel dibawah ini:
Dependent Variable: D(PCE)Method: Least Squares
Variable Coefficien t
Std. Error t-Statistic Prob.
C 11.69183 2.195675 5.324936 0.0000
D(PDI) 0.290602 0.069660 4.171715 0.0001
RESID01(-1)
-0.086706 0.054180 -1.600311 0.1133 R-squared 0.171727 Mean dependent
var
16.9034 5 Adjusted R-squared 0.152006 S.D. dependent var 18.2902 1 S.E. of regression 16.84283 Akaike info criterion 8.51960 1 Sum squared resid 23829.19 Schwarz criterion 8.60463 2
Log likelihood
-367.6026 F-statistic 8.707918 Durbin-Watson stat 1.923381 Prob(F-statistic) 0.00036 6
Hasil regresi ECM dapat dituliskan menjadi:
∆PĈEt = 11.69183 + 0.2906 ∆PDIt – 0.0867 ût-1
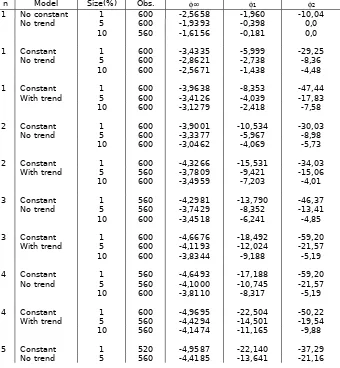
Tabel Respon Surface For Critical Value Cointegration Test
n Model Size(%) Obs. ∞ 1 2
1 No constant 1 600 -2,5658 -1,960 -10,04
No trend 5 600 -1,9393 -0,398 0,0
10 560 -1,6156 -0,181 0,0
1 Constant 1 600 -3,4335 -5,999 -29,25
No trend 5 600 -2,8621 -2,738 -8,36
10 600 -2,5671 -1,438 -4,48
1 Constant 1 600 -3,9638 -8,353 -47,44
With trend 5 600 -3,4126 -4,039 -17,83
10 600 -3,1279 -2,418 -7,58
2 Constant 1 600 -3,9001 -10,534 -30,03
No trend 5 600 -3,3377 -5,967 -8,98
10 600 -3,0462 -4,069 -5,73
2 Constant 1 600 -4,3266 -15,531 -34,03
With trend 5 560 -3,7809 -9,421 -15,06
10 600 -3,4959 -7,203 -4,01
3 Constant 1 560 -4,2981 -13,790 -46,37
No trend 5 560 -3,7429 -8,352 -13,41
10 600 -3,4518 -6,241 -4,85
3 Constant 1 600 -4,6676 -18,492 -59,20
With trend 5 600 -4,1193 -12,024 -21,57
10 600 -3,8344 -9,188 -5,19
4 Constant 1 560 -4,6493 -17,188 -59,20
No trend 5 560 -4,1000 -10,745 -21,57
10 600 -3,8110 -8,317 -5,19
4 Constant 1 600 -4,9695 -22,504 -50,22
With trend 5 560 -4,4294 -14,501 -19,54
10 560 -4,1474 -11,165 -9,88
5 Constant 1 520 -4,9587 -22,140 -37,29
10 600 -4,1327 -10,638 -5,48
5 Constant 1 600 -5,2497 -26,606 -49,56
With trend 5 600 -4,7154 -17,432 -16,50
10 600 -4,4245 -13,654 -5,77
6 Constant 1 480 -5,2400 -26,278 -41,65
No trend 5 480 -4,7048 -17,120 -11,17
10 480 -4,4242 -13,347 0,0
6 Constant 1 480 -5,5127 -30,735 -52,50
With trend 5 480 -4,9161 -20,883 -9,05
10 480 -4,6999 -16,445 0,0
VECTOR AUTOREGRESSIONS (VAR)
1. Pengantar
Metode Vector Autoregression (VAR) pertama kali dikembangkan oleh Christoper Sims (1980). Kerangka analisis yang praktis dalam model ini akan memberikan informasi yang sistematis dan mampu menaksir dengan baik informasi dalam persamaan yang dibentuk dari data time series. Selain itu perangkat estimasi dalam model VAR mudah digunakan dan diintepretasikan. Perangkat estimasi yang akan digunakan dalam model VAR ini adalah fungsi
impulse respon dan variance decompotition.
Ada beberapa keuntungan dari VAR (Gujarati, 1995:387) yaitu :
1. VAR mampu melihat lebih banyak variabel dalam menganalisis fenomena ekonomi jangka pendek dan jangka panjang.
2. VAR mampu mengkaji konsistensi model empirik dengan teori ekonometrika.
3. VAR mampu mencari pemecahan terhadap persoalan variabel runtun waktu yang tidak stasioner ( non stasionary ) dan regresi lancung ( mengkhawatirkan tentang penentuan variabel endogen dan variabel eksogen. Semua variabel dianggap sebagai variabel endogen.
2. Kemudahan dalam estimasi, metode Ordinary Least Square (OLS) dapat diaplikasikan pada tiap persamaan secara terpisah. 3. Forecast atau peramalan yang dihasilkan pada beberapa kasus ditemukan lebih baik daripada yang dihasilkan oleh model persamaan simultan yang kompleks.
5. Variance Decompotition, memberikan informasi mengenai kontribusi (persentase) varians setiap variabel terhadap perubahan suatu variabel tertentu.
Di sisi lain, terdapat beberapa kritik terhadap model VAR menyangkut permasalahan berikut (Gujarati, 2003:853) :
1. Model VAR merupakan model yang atheoritic atau tidak berdasarkan teori, hal ini tidak seperti pada persamaan simultan. Pada persamaan simultan, pemilihan variabel yang akan dimasukkan dalam persamaan memegang peranan penting dalam mengidentifikasi model.
2. Pada model VAR penekanannya terletak pada forecasting atau peramalan sehingga model ini kurang cocok digunakan dalam menganalisis kebijakan.
3. Permasalahan yang besar dalam model VAR adalah pada pemilihan lag length atau panjang lag yang tepat. Karena semakin panjang lag, maka akan menambah jumlah parameter yang akan bermasalah pada
degrees of freedom.
4. Variabel yang tergabung pada model VAR harus stasioner. Apabila tidak stasioner, perlu dilakukan transformasi bentuk data, misalnya melalui
first difference. menggunakan model VECM (Harris,1995: 76) yaitu :
1. Data yang digunakan harus stasioner 2. Identifikasi bentuk model
3. Penentuan lag length optimal
2. Prosedur dalam Eviews a. Uji Stasioneritas Data
Salah satu prosedur yang harus dilakukan dalam estimasi model ekonomi dengan data time series adalah dengan menguji stasioneritas pada data atau disebut juga stationary stochastic process. Data time series
dikatakan stasioner jika data tersebut tidak mengandung akar-akar unit (unit root) dengan kata mean, variance, dan covariant konstan sepanjang waktu. Pengujian akar-akar unit root dilakukan dengan metode Augmented Dickey Fuller ( ADF), yaitu dengan membandingkan nilai ADFstatistik dengan Mackinnon
critical value 1%, 5%, dan 10%. Lakukan prosedur berikut :
Workfile – Klik variabel yang akan di uji – View - Unit root test
Kemudian akan muncul tampilan seperti dibawah ini :
Kita akan menguji data pada tingkat level I(0). Jika nilai ADFstatistik lebih besar
dari Mackinnon critical value, maka data tidak mengandung unit root sehingga data dikatakan stasioner. Demikian pula sebaliknya, jika nilai ADFstatistik lebih
kecil dari t-statistik pada Mackinnon critical value berarti terdapat unit root
sehingga data dikatakan tidak stasioner.
Null Hypothesis: M1 has a unit root Exogenous: Constant, Linear Trend
Lag Length: 0 (Automatic based on SIC, MAXLAG=9)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -0.931216 0.9419 Test critical values: 1% level -4.211868
5% level -3.529758
10% level -3.196411
*MacKinnon (1996) one-sided p-values.
Dari hasil pengujian ternyata variabel M1 pada tingkat level tidak stasioner. Hal ini dapat dilihat pada nilai ADF test statistic yang lebih kecil dari
level, maka untuk memperoleh data yang stasioner dapat dilakukan dengan cara differencing data, yaitu dengan mengurangi data tersebut dengan data periode sebelumnya, sehingga akan diperoleh data dalam bentuk first difference.
Setelah data dirubah kedalam bentuk first difference maka diperoleh hasil sebagai berikut:
Null Hypothesis: D(M1) has a unit root Exogenous: Constant, Linear Trend
Lag Length: 0 (Automatic based on SIC, MAXLAG=9)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -5.065505 0.0011 Test critical values: 1% level -4.219126
5% level -3.533083
10% level -3.198312
*MacKinnon (1996) one-sided p-values.
Null Hypothesis: D(R) has a unit root Exogenous: Constant, Linear Trend
Lag Length: 1 (Automatic based on SIC, MAXLAG=9)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -4.478920 0.0053 Test critical values: 1% level -4.226815
5% level -3.536601
10% level -3.200320
*MacKinnon (1996) one-sided p-values.
Baik pada variabel M1 dan R data telah stasioner pada tingkat first difference. Dapat dilihat bahwa nilai ADF test statistic kedua variabel lebih besar dari nilai test critical values-nya dan nilai probabilitas keduanya signifikan pada α = 1%. Sehingga kedua variabel tersebut telah stasioner.
b. Penetuan Lag Optimal
Penentuan jumlah lag dalam model VAR ditentukan pada kriteria informasi yang direkomendasikan oleh Final Prediction Error (FPE), Aike Information Criterion (AIC), Schwarz Criterion (SC), dan Hannan-Quinn (HQ). Tanda bintang menunjukkan lag optimal yang direkomendasikan oleh kriteria diatas.
Lakukan prosedur berikut:
Dari VAR Estimation - Pilih View – Lag Structure - Lag Length Criteria
VAR Lag Order Selection Criteria
Endogenous variables: M1 R Exogenous variables: C Date: 08/23/07 Time: 07:32 Sample: 1979:1 1988:4 Included observations: 37
Lag LogL LR FPE AIC SC HQ
Dari hasil diatas terlihat bahwa semua tanda bintang berada pada lag 2. Hal ini menunjukkan bahwa lag optimal terletak pada lag 2.
c. Uji Kausalitas Granger
Uji Kausalitas Granger digunakan untuk melihat arah hubungan suatu variabel dengan variabel yang lain. Bagaimana pengaruh x terhadap y dengan melihat apakah nilai sekarang dari y bisa dijelaskan dengan nilai historis y serta melihat apakah penambahan lag x bisa meningkatkan kemampuan menjelaskan model. Adapun persamaan Granger-Causality adalah:
persamaan Granger Causality diatas (Gujarati,2003:696-697) :1. Unidirectional causality dari Y ke X, artinya kausalitas satu arah dari Y ke X terjadi jika koefisien lag Y pada persamaan Yt adalah secara
statistik signifikan berbeda dengan nol, koefisien lag X pada persamaan Xt sama dengan nol,
2. Unindirectional causality dari X ke Y, artinya kausalitas satu arah dari X ke Y terjadi jika koefisien lag X pada persamaan Xt adalah secara
statistik signifikan berbeda dengan nol dan koefisien lag Y pada persamaan Yt secara statistik signifikan sama dengan nol.
3. Feedback/bilaterall causality, artinya kausalitas timbal balik yang terjadi jika koefisien lag Y dan lag X adalah secara statistik signifikan berbeda dengan nol pada kedua persamaan Yt dan Xt di atas.
4. Independence, artinya tidak saling ketergantungan yang terjadi jika koefisien lag Y dan lag X adalah secara statistik sama dengan nol pada masing-masing persamaan Yt dan Xt diatas.
Sedangkan hipotesis statistik untuk pengujian kausalitas dengan menggunakan pendekatan Granger adalah :
Ho :
0
artinya suatu variabel tidak mempengaruhi variabel lainH1 :
0
artinya suatu variabel mempengaruhi variabel lainnya.Lakukan prosedur berikut:
Pairwise Granger Causality Tests Lags: 2
Null Hypothesis: Obs F-Statistic Probability R does not Granger Cause M1 38 12.9266 7.1E-05 M1 does not Granger Cause R 3.22343 0.05263
Dari hasil pengujiann Granger disebutkan bahwa Ho menyatakan R tidak mempengaruhi M1 dan M1 tidak mempengaruhi R. Dengan melihat nilai probabilitas sebesar 7.1E-05 maka Ho ditolak, berarti R mempengaruhi M1. Selanjutnya untuk pernyataan yang kedua, dengan probabilitas 0.05263 dan pada α = 1% maka Ho ditolak. Sehingga M1 mempengaruhi R. Dari pengujian Granger diatas dapat disimpulkan bahwa kedua variabel mempunyai hubungan 2 arah atau saling mempengaruhi.
d. Estimasi VAR
Pada kasus ini persamaan VAR dapat ditulis sebagai berikut:
Vector Autoregression Estimates
Standard errors in ( ) & t-statistics in [ ]
D(M1) D(R)
D(M1(-1)) 0.169618 0.001629 (0.17182) (0.00056) R-squared 0.414380 0.250815 Adj. R-squared 0.341178 0.157166 Sum sq. resids 7187605. 76.62843 S.E. equation 473.9332 1.547462 F-statistic 5.660741 2.678264 Log likelihood -277.7743 -65.96965 Akaike AIC 15.28510 3.836198 Schwarz SC 15.50279 4.053889 Mean
dependent
405.9368 -0.026126
S.D. dependent 583.8926 1.685579 Determinant Residual
Covariance 536064.1
Log Likelihood (d.f.
adjusted) -349.0536
Akaike Information Criteria 19.40830 Schwarz Criteria 19.84369
Untuk melihat apakah variabel M1 mempengaruhi R dan sebaliknya dapat dilihat dengan cara membandingkan nilai t-statistic hasil estimasi dengan nilai t-tabel. Jika nilai t-statistic lebih besar dari nilai t-tabelnya, maka dapat dikatakan bahwa variabel M1 mempengaruhi R.
e. Fungsi Impulse Respon
Untuk mengetahui pengaruh shock dalam perekonomian maka digunakan metode impulse respon function. Selama koefisien pada persamaan struktural VAR di atas sulit untuk diintepretasikan maka banyak praktisi menyarankan menggunakan impulse respon function. Fungsi impulse respon
menggambarkan tingkat laju dari shock variabel yang satu terhadap variabel yang lainnya pada suatu rentang periode tertentu. Sehingga dapat dilihat lamanya pengaruh dari shock suatu variabel terhadap variabel lain sampai pengaruhnya hilang atau kembali ke titik keseimbangan. Fungsi ini akan melacak respon dari variabel tergantung apabila terdapat shock dalam u1 dan
Lakukan Prosedur berikut ini:
Dari Hasil Estimasi VAR – View – Impulse Respon Impulse Respon – Multiple graph - Analytic
Dari hasil diatas, dapat diintepretasikan sebagai berikut:
Pada kuadran kanan atas, menunjukkan perubahan variabel M1 dalam merespon adanya shock/perubahan variabel R. Pada awal periode, adanya shock pada R direspon negatif oleh M1 hingga periode ke-2, yaitu mencapai titik tertinggi. Setelah periode ke-2 mulai bergerak naik hingga periode ke -5, kemudian bergerak menghimpit titik keseimbangan.
f. Variance Decompositions
Variance decompotition akan memberikan informasi mengenai proporsi dari pergerakan pengaruh shock pada sebuah variabel terhadap shock
variabel yang lain pada periode saat ini dan periode yang akan datang.
Lakukan Prosedur berikut:
Dari hasil estimasi VAR – View – Variance Decompotition Variance Decompotition – Table – None (standart Errors)
Variance Decomposition of D(M1):
Period S.E. D(M1) D(R)
1 473.9332 100.0000 0.000000
2 600.7910 63.20104 36.79896
3 617.5066 60.58988 39.41012
4 618.7257 60.37357 39.62643
5 619.1933 60.35171 39.64829
6 619.2605 60.35639 39.64361
7 619.2820 60.35240 39.64760
8 619.2870 60.35144 39.64856
9 619.2886 60.35114 39.64886
10 619.2889 60.35113 39.64887
Variance Decomposition of D(R):
Period S.E. D(M1) D(R)
1 1.547462 0.335039 99.66496
2 1.753751 20.38336 79.61664
3 1.787127 19.67987 80.32013
4 1.789185 19.63479 80.36521
5 1.790513 19.61104 80.38896
6 1.790990 19.61349 80.38651
7 1.791009 19.61517 80.38483
8 1.791011 19.61527 80.38473
9 1.791013 19.61530 80.38470
10 1.791014 19.61528 80.38472
Pada tabel pertama, menjelaskan tentang variance decompotition dari variabel M1, variabel apa saja dan seberapa besar variabel tersebut mempengaruhi variabel M1. Pada periode pertama, variabel M1 dipengaruhi oleh variabel itu sendiri (100%). Namun pada periode kedua variabel R memberikan kontribusinya sebesar 36,79%, nilai ini terus meningkat hingga periode ke-10 sebesar 39,64%.
Pada tabel kedua, menjelaskan tentang variance decompotition dari variabel R. Pada awal periode, variabel M1 memberikan pengaruhnya sebesar 0,33%. Pada periode ke -2, pengaruhnya mulai meningkat hingga 20,38%. Kemudian menurun sebesar 1% hingga periode ke-10, yaitu sebesar 19,61%
g. Forecast
Metode VAR juga dapat digunakan untuk meramal data di periode yang akan datang. Lakukan prosedur berikut: Klik Procs – Change Workfile Range (Ubah End date: 1989:4)
Ubah juga pada sampel, Klik Procs – Sample – Ubah End date: 1989:4
Kembali ke estimasi VAR, Klik Procs – Make Model – Solve – OK
Maka di kertas kerja akan muncul data baru yang didalamnya terdapat data periode yang diramalkan.
1. Pengantar
VECM merupakan bentuk VAR yang terestriksi. Restriksi tambahan ini harus diberikan karena keberadaan bentuk data yang tidak stasioner namun terkointegrasi. VECM kemudian memanfaatkan informasi restriksi kointegrasi tersebut kedalam spesifikasinya. Karena itulah VECM sering disebut sebagai desain VAR bagi series nonstasioner yang memiliki hubungan kointegrasi.
Spesifikasi VECM merestriksi hubungan jangka panjang variabel-variabel endogen agar konvergen ke dalam hubungan kointegrasinya, namun tetap membiarkan keberadaan dinamisasi jangka pendek. Istilah kointegrasi dikenal juga sebagai istilah error, karena deviasi terhadap ekuilibrium jangka panjang dikoreksi secara bertahap melalui series parsial penyesuaian jangka pendek.
2. Prosedur dalam Eviews a. Uji Stasioneritas Data
Uji stasioneritas data dalam kasus ini digunakan untuk melihat tingkat kestasioneritasan suatu data. Jika dalam suatu data terdapat derajat integrasi yang berbeda maka diindikasikan adanya kointegrasi. Dengan prosedur yang sama seperti modul sebelumya, didapat hasil uji kointegrasi sebagai berikut: y = m + r
I(1) = I(0) I(1)
b. Penentuan Lag Optimal
Prosedur penentuan lag optiomal ini sama dengan ketika kita menentukan lag optimal pada metode VAR. Namun, terdapat perbedaan jumlah lag pada VECM. Ketika lag optimal pada VAR adalah p, maka lag pada VECM adalah p-1.
(lokasi file Excel berada di d:Eviews/data/data6 VECM.xls)
Prosedurnya: Tandai semua variabel – Klik kanan: as VAR.
Lag LogL LR FPE AIC SC HQ 0 45.06723 NA 8.51E-05 -0.858515 -0.779383 -0.826508 1 257.3937 407.3201 1.34E-06 -5.008034 -4.691508* -4.880006 2 272.7921 28.59704 1.18E-06 -5.138614 -4.584692 -4.914564 3 281.1133 14.94429 1.20E-06 -5.124762 -4.333446 -4.804691 4 319.0398 65.79086 6.65E-07 -5.715099 -4.686387 -5.299006
* 5 328.3972 15.65928 6.63E-07* -5.722392* -4.456286 -5.210278 6 329.5543 1.865521 7.82E-07 -5.562333 -4.058831 -4.954197 7 335.7140 9.553857 8.36E-07 -5.504368 -3.763472 -4.800211 8 348.0830 18.42718* 7.89E-07 -5.573122 -3.594830 -4.772944
Berdasarkan hasil penentuan lag optimal, Lag optimal pada VAR adalah 5 (tanda bintang yang paling banyak). Maka lag optimal pada VECM adalah 4
c. Uji Kointegrasi
Kemudian muncul hasil estimasi VEC, Pilih View - Cointegration test – pilih no.6 (summary) - OK
Perhatikan letak tanda bintang, tanda bintang menunjukkan lag yang digunakan. Dari hasil regresi tersebut terdapat dua kriteria, yaitu SC dan AIC. Keputusan penentuan kriteria antara SC dan AIC tidak dipermasalahkan. Selain penentuan lag, dari hasil tersebut juga diperlukan dalam menentukan spesifikasi deterministik. Penentuannya adalah dengan melihat letak tanda bintang berada pada kolom apa Dari hasil tersebut, berdasarkan kriteria yang kita pilih, misalnya AIC, maka spesifikasi deterministiknya adalah Linear intercept and trend
Setelah tren data diketahui, langkah selanjutnya adalah menentukan apakah data tersebut terkointegrasi atau tidak. Penentuan ini dapat dilihat dengan membandingkan nilai Eigen dan nilai trace-nya. Jika nilai Max-Eigen dan nilai trace-nya lebih besar dari nilai kritis 1% dan 5% maka data terkointegrasi.
Unrestricted Cointegration Rank Test Hypothesiz
ed
Trace 5 Percent 1 Percent
No. of
CE(s) Eigenvalue Statistic CriticalValue CriticalValue
At most 1 0.186624 24.67886 25.32 30.45 At most 2 0.037078 3.816108 12.25 16.26 *(**) denotes rejection of the hypothesis at the 5%(1%) level
Trace test indicates 1 cointegrating equation(s) at both 5% and 1% levels
Hypothesiz
ed Max-Eigen 5 Percent 1 Percent
No. of *(**) denotes rejection of the hypothesis at the 5%(1%) level
Max-eigenvalue test indicates 2 cointegrating equation(s) at the 5% level Max-eigenvalue test indicates no cointegration at the 1% level
Berdasarkan hasil uji kointegrasi, terlihat bahwa nilai Trace statistic lebih besar dari nilai kritis 5% dan 1%. Selain itu, nilai Max-Eigen juga lebih besar nilai kritis 5%, maka dapat disimpulkan bahwa data tersebut terkointegrasi. Hal ini menujukkan behwa terdapat hubungan jangka panjang antara variabel y, m, dan r. Terkointegrasinya suatu data menunjukkan sinyal yang tepat untuk menggunakan metode VECM. Selanjutnya kita dapat menentukan estimasi VECM.
d. Estimasi VECM
Dalam estimasi VECM ini akan menunjukkan hubungan antara variabel satu dengan variabel lain baik dalam jangka panjang maupun jangka pendek. Pada tabel bagian atas menunjukkan hubungan antar variabel dalam jangka panjang, sedangkan bagian bawah menunjukkan hubungan jangka pendek. Prosedur: Dari hasil kointegrasi sebelumnya, pilih estimate – pastikan lag pada lag optimal – check lagi spesifikasinya sesuai dengan hasil uji kointegrasi Johansen – pada endogenous variabel, pastikan variabel dependent ada didepan – OK
(Lag Optimal 4, spesifikasi deterministiknya adalah Linear intercept and trend)
Vector Error Correction Estimates Date: 10/26/07 Time: 23:25 Sample(adjusted): 6 106
[-7.78090]
C -13.45238
Error Correction: D(Y) D(M) D(R)
CointEq1 0.007934 -4.783336 0.006771 (0.01536) (0.92859) (0.01736) [ 0.51661] [-5.15120] [ 0.38998]
D(Y(-1)) -0.308585 19.62085 0.334980 (0.09643) (5.83017) (0.10901) [-3.20015] [ 3.36540] [ 3.07303]
D(Y(-2)) -0.272241 14.05796 0.124763 (0.10212) (6.17436) (0.11544) [-2.66585] [ 2.27683] [ 1.08075]
D(Y(-3)) -0.238260 12.22537 0.170040 (0.09873) (5.96948) (0.11161) [-2.41319] [ 2.04798] [ 1.52351]
D(Y(-4)) 0.554164 14.92603 0.269248 (0.09161) (5.53857) (0.10355) [ 6.04945] [ 2.69492] [ 2.60006]
D(M(-1)) 0.000507 0.199383 -0.000312 (0.00354) (0.21420) (0.00400) [ 0.14322] [ 0.93084] [-0.07795]
D(M(-2)) -0.001527 0.126259 -0.000339 (0.00299) (0.18082) (0.00338) [-0.51060] [ 0.69827] [-0.10032]
D(M(-3)) -0.000698 0.100044 0.000161 (0.00241) (0.14542) (0.00272) [-0.29027] [ 0.68797] [ 0.05934]
D(M(-4)) 0.000885 0.052163 0.000283 (0.00170) (0.10253) (0.00192) [ 0.52177] [ 0.50876] [ 0.14776]
D(R(-1)) -0.098170 -4.973172 -0.304232 (0.09380) (5.67144) (0.10604) [-1.04656] [-0.87688] [-2.86907]
D(R(-2)) -0.114581 -5.638503 -0.127013 (0.09638) (5.82742) (0.10896) [-1.18881] [-0.96758] [-1.16574]
D(R(-3)) -0.069431 -6.977150 -0.076394 (0.09694) (5.86081) (0.10958) [-0.71626] [-1.19048] [-0.69716]
D(R(-4)) -0.194061 -1.270933 -0.087437 (0.09286) (5.61428) (0.10497) [-2.08987] [-0.22638] [-0.83297]
(0.00325) (0.19668) (0.00368) [ 2.74250] [-2.18740] [-1.76076]
R-squared 0.683735 0.566555 0.200525
Adj. R-squared 0.636477 0.501788 0.081063
Sum sq. resids 0.038467 140.6189 0.049157
S.E. equation 0.021027 1.271342 0.023770
F-statistic 14.46814 8.747515 1.678571
Log likelihood 254.2770 -160.0249 241.8940
Akaike AIC -4.757961 3.446038 -4.512752
Schwarz SC -4.395469 3.808530 -4.150260
Mean dependent 0.007178 0.026289 5.69E-05
S.D. dependent 0.034876 1.801172 0.024796
Determinant Residual Covariance
3.99E-07
Log Likelihood 336.7935
Log Likelihood (d.f. adjusted) 314.1878
Akaike Information Criteria -5.310650
Schwarz Criteria -4.119605
e. Fungsi Impulse Respon
Impulse respon pada kasus ini mempunyai fungsi yang sama dengan impulse respon pada VAR. Fungsi impulse respon menggambarkan tingkat laju dari shock variabel yang satu terhadap variabel yang lainnya pada suatu rentang periode tertentu. Sehingga dapat dilihat lamanya pengaruh dari
shock suatu variabel terhadap variabel lain sampai pengaruhnya hilang atau kembali ke titik keseimbangan. Fungsi ini akan melacak respon dari variabel tergantung apabila terdapat shock dalam u1 dan u2.
Lakukan Prosedur berikut ini:
Dari Hasil Estimasi VECM – View – Impulse Respon Impulse Respon – Multiple graph - Analytic
bagaimana respon dari variabel Y ketida ada shock/perubahan pada variabel M. Pada awal periode perubahan pada variabel M direspon positif oleh Y hingga periode ke-3, kemudian kembali ke titik keseimbangan hingga period eke-4. Setelah periode ke-4, kembali direspon positif hingga periode ke-7, dan seterusnya. Cara analisis yang sama juga berlaku untuk kuadran-kuadran yang lain.
f. Variance Decompotition
Variance decompotition akan memberikan informasi mengenai proporsi dari pergerakan pengaruh shock pada sebuah variabel terhadap shock
variabel yang lain pada periode saat ini dan periode yang akan datang. Fungsi variance decompotition pada VAR dan VECM adalah sama
Lakukan Prosedur berikut:
Dari hasil estimasi VECM – View – Variance Decompotition Variance Decompotition – Table – None (standart Errors)
8
Variance Decomposition of R:
Period S.E. Y M R
Panel Data
1. Pengantar
Data panel atau pooled data adalah kombinasi dari data time series dan data cross section. Dengan menggabungkan data time series dan cross section (pooling), maka jumlah observasi bertambah secara signifikan tanpa melakukan treatment apapun terhadap data.
Ada tiga metode yang bisa digunakan untuk bekerja dengan data panel. Menurut Verbeek (2000:313-19) metode yang pertama adalah pendekatan
pooled least square (PLS) secara sederhana menggabungkan (pooled) seluruh data time series dan cross section dan kemudian mengestimasi model dengan menggunakan metode ordinary least square (OLS). Kedua, pendekatan fixed effect (FE) memperhitungkan kemungkinan bahwa peneliti menghadapi masalah omitted variables dimana omitted variables mungkin membawa perubahan pada intercept time series atau cross section. Model dengan FE menambahkan dummy variables untuk mengizinkan adanya perubahan
intercept ini. Ketiga, pendekatan efek acak (random effect) memperbaiki efisiensi proses least square dengan memperhitungkan error dari cross section dan time series.
a. Pooled least square
Yit = β1 + β2 + β3X3it +....+ βnXnit + uit ...
(3.1)
b. Fixed effect
Yit = α1 + α2D2 + ...+ αnDn + β2X2it + ...+ βnXnit + uit ...
c. Random effect
Yit = β1 + β2X2it + ...+ βnXnit + εit + uit ...
(3.3)
Pemilihan Model Estimasi dalam Data Panel
Untuk menentukan metode antara pooled least square dan fixed effect
dengan menggunakan uji F sedangkan uji Hausman digunakan untuk memilih antara random effect atau fixed effect. Dalam fixed effect, bentuk umum regresi data panel adalah (Aulia, 2004:28):
Yit = β1 + β2X2it + β3X3it + ... + βnXnit + uit ...
(3.4)
Selain itu, dalam teknik estimasi model regresi data panel, terdapat uji F dan CHOW test dan uji Hausman. Uji F dapat digunakan untuk memilih teknik dengan model pooled least square (PLS) atau model fixed effect dengan rumus sebagai berikut (Gujarati, 2003:643):
)
m = jumlah restricted variabel
n = jumlah sample
k = jumlah variabel penjelas
Hipotesis nol dari pada restricted F test adalah : H0 = Model Pooled Least Square (restricted)
H1 = Model Fixed Effect (unrestricted)
Dari rumus diatas, jika kita mendapatkan hasil nilai F hitung > F tabel pada tingkat keyakinan ( α ) tertentu maka kita menolak hipotesis H0 yang
menyatakan kita harus memilih teknik PLS, sehingga kita menerima hipotesis H1yang menyatakan kita harus menggunakan model Fixed Effect untuk teknik
estimasi dalam penelitian ini.
Sedangkan uji Hausman digunakan untuk memilih antara metode
fixed effect atau metode random effect. Uji Hausman didapatkan melalui
command eviews yang terdapat pada direktori panel (Widarjono, 2005:272). Rumus untuk mendapatkan nilai Chi Square uji Hausman adalah:
Matrix b_dif = b_fixed – b_random Matrix var_dif = cov_fixed – cov_random
Matrix qform = @transpose(b_dif)*@inverse(var_dif)*b_dif
Hipotesis nol dari pada uji Hausman adalah : H0 = random effect
H1 = fixed effect
Apabila Chi Sqare hitung > Chi Square tabel dan p-value signifikan maka H0
units dan 20 time period. Untuk keseluruhan terdapat 80 observasi. X2 dan X3 diperkirakan berhubungan positif terhadap Y.
Pooling atau combining semua 80 observasi, kita dapat menulis fungsi investasi sebagai berikut:
2. Prosedur dalam Eviews
Untuk menganalisa fungsi investasi dari empat perusahaan tadi maka kita lakukan olah data dengan menggunakan perangkat Eviews. langkah-langkahnya adalah:
Buka program Eviews. Klik File New Workfile
Selanjutnya akan muncul Workfile baru.
Selanjutnya pada direktori New Object pilih Pool dan Klik OK.
Setelah itu masih tetap pada Pool, Klik Procs Import Pool data.
(lokasi file Excel berada di d:Eviews/data/data7 PANEL.xls)
Kemudian kita cari file data panel yang telah disimpan sebelumnya.
Maka tampilan pada Eviews akan tampak sebagai berikut:
Dalam Excel Spreadsheet import: Pada Series order: pilih In Columns.
Pada Excel5 + sheet name : kita tulis sesuai sheet lokasi data kita.
Setelah semua lengkap Klik OK, maka pada lembar Workfile akan muncul tampilan berikut:
Pada lembar Pool, Klik Procs Estimate.
Kemudian muncul tampilan berikut:
Pada dependent variable : KetikY?
Pada common coefficient : Ketik X2? dan X3?.
Pada Intercept : Pilih none, common, fixed effect, atau random effect. Misal kita Klik Common OK. Maka estimasi pooled least square tampak sebagai berikut:
Maka persamaanya menjadi :
^
Y
it = -63.30 + 0.11X2it + 0.3Xit + uitSelanjutnya kita coba dengan model fixed efect. Pada PoolKlik Objects