BUKU AJAR
STATISTIKA NONPARAMETRIK
Oleh:
A N W A R
SYARIFUDDIN
PROGRAM STUDI AGRIBISNIS
JURUSAN SOSEK FAKULTAS PERTANIAN
UNIVERSITAS MATARAM
ANALISIS INSTRUKSIONAL
MATA KULIAH STATISTIKA NONPARAMETRIK
SKS = 3 (2-1), Semester VI
TUJUAN INSTRUKSIONAL UMUM:
Setelah menyelesaikan mata kuliah Statistika Nonparametrik mahasiswa akan dapat memilih Uji Statistik Nonparametrik
yang tepat untuk Penelitian Sosial Ekonomi Pertanian
Memilih Uji Statistik Nonparametrik untuk Penelitian Sosial Ekonomi Pertanian
Memilih Uji Statistik Memilih Uji Statistik Memilih Uji Statistik Memilih model Nonparametrik Nonparametrik Nonparametrik pengukuran
untuk Kasus untuk Kasus untuk Kasus korelasi dan Satu Sampel DuaSampel ”k”Sampel pengujiannya
Menerapkan prinsip dan prosedur Uji Hipotesis Statistik
Menjelaskan konsep & prosedur perhitungan dasar statistika
BAB I
STATISTIKA PARAMETRIK DAN NONPARAMETRIK
Secara garis besar ilmu statistika dibagi menjadi dua bagian, yaitu: statistika parametrik dan statistika nonparametrik. Perbedaan kedua statistika tersebut diuraikan pada ulasan berikut.
1. Statistika Parametrik
Statistika parametrik adalah ilmu statistika yang digunakan untuk data yang memiliki sebaran normal. Jika data tidak menyebar normal maka metode statistika nonparametrik dapat digunakan. Apa yang dapat dilakukan jika data tidak menyebar normal, namun statistika parametrik ingin tetap digunakan. Untuk kasus ini data sebaiknya ditransformasikan terlebih dahulu. Transformasi data perlu dilakukan agar data mengikuti sebaran normal. Transformasi dapat dilakukan dengan mengubah data ke dalam bentuk logaritma natural, menggunakan operasi matematik (membagi, menambah, atau mengali dengan bilangan tertentu), dan mengubah skala data dari nominal menjadi interval.
atau tidaknya distribusi ini baru dapat ditentukan apakah uji statistika parametrik atau nonparametrik yang digunakan.
Distribusi normal dikenal juga dengan istilah Gaussian Distribution. Distribusi normal mengandung dua parameter, yaitu rata-rata (mean = µ) dan ragam (varians = σ2). Parameter-parameter ini memberikan karakteristik yang unik pada suatu distribusi berdasarkan “lokasi”-nya (central tendency). Berbagai metode statistika mendasarkan perhi-tungannya pada kedua parameter tersebut.
Penggunaan metode statistika parametrik mengikuti prinsip-prinsip distribusi normal. Prinsip-prinsip dari distribusi normal adalah:
a. Distribusi dari suatu sampel yang dijadikan obyek pengukuran berasal dari populasi yang diasumsikan terdistribusi secara normal. b. Sampel diperoleh secara random, dengan jumlah sampel yang
dianggap dapat mewakili populasi (n > 30).
c. Distribusi normal merupakan bagian dari distribusi probabilitas yang kontinyu (continuous probability distribution). Implikasinya, skala pengukuran pun harus kontinyu. Skala pengukuran yang kontinyu adalah skala rasio dan interval. Kedua skala ini memenuhi syarat untuk menggunakan uji statistika parametrik.
2. Statistika Nonparametrik
Statistika nonparametrik disebut juga statistika bebas sebaran. Statistika nonparametrik tidak mensyaratkan bentuk sebaran parameter populasi. Statistika nonparametrik dapat digunakan pada data yang memiliki sebaran normal atau tidak.
Istilah nonparametrik pertama kali digunakan oleh Wolfowitz, pada tahun 1942. Metode statistika nonparametrik merupakan metode statistika yang dapat digunakan dengan mengabaikan asumsi-asumsi yang melandasi penggunaan metode statistika parametrik, terutama yang berkaitan dengan distribusi normal. Istilah lain yang sering digunakan untuk statistika nonparametric adalah statistika bebas distribusi (distribution-free statistics) dan uji bebas asumsi (assumption-free test). Statistika nonparametrik banyak digunakan pada penelitian-penelitian sosial. Data yang diperoleh dalam penelitian sosial pada umumnya berbentuk kategori atau berbentuk ranking.
Contoh metode statistika nonparametrik diantaranya adalah Chi-square test, Mann Withney test, Kruskal-Wallis, Friedman test, dan lain-lain.
Keunggulan Statistika Nonparametrik
Keunggulan statistika nonparametrik diantaranya:
1. Asumsi dalam uji-uji statistika nonparametrik relatif lebih longgar. Jika pengujian data menunjukkan bahwa salah satu atau beberapa asumsi yang mendasari uji statistika parametrik (misalnya mengenai sifat distribusi data) tidak terpenuhi, maka statistika nonparametrik lebih sesuai diterapkan dibandingkan statistika parametrik.
2. Perhitungan-perhitungannya dapat dilaksanakan dengan cepat dan mudah, sehingga hasil penelitian segera dapat disampaikan.
3. Untuk memahami konsep-konsep dan metode-metodenya tidak memerlukan dasar matematika serta statistika yang mendalam.
4. Uji-uji pada statistika nonparametrik dapat diterapkan jika kita menghadapi keterbatasan data yang tersedia, misalnya jika data telah diukur menggunakan skala pengukuran yang lemah (nominal atau ordinal).
Keterbatasan Statistika Nonparametrik
Disamping keunggulan, statistika nonparametrik juga memiliki keterbatasan. Beberapa keterbatasan statistika nonparametrik antara lain: a. Jika asumsi uji statistika parametrik terpenuhi, penggunaan uji nonparametrik meskipun lebih cepat dan sederhana akan menyebab-kan pemborosan informasi.
b. Jika jumlah sampel besar, tingkat efisiensi nonparametrik relatif lebih rendah dibandingkan dengan metode parametrik.
c. Statistika nonparametrik tidak dapat dipergunakan untuk membuat prediksi (peramalan).
3. Langkah-Langkah Pemilihan Metode Statistika
Kapan metode statistika nonparametrik digunakan? Metode pengujian ini digunakan bila salah satu syarat dalam statistika parametrik tidak terpenuhi. Syarat-syarat yang perlu diperhatikan untuk menentukan statistika apa yang akan digunakan dalam analisis, yaitu:
1. Apakah distribusi data diketahui?
Jika distribusi data tidak diketahui maka statistika yang sesuai adalah statistika nonparametrik. Jika distribusi data diketahui, maka kita harus melihat jenis distribusi data tersebut.
2. Apakah data berdistibusi normal?
3. Apakah sampel ditarik secara random?
Jika sampel tidak ditarik secara random, maka statistika yang sesuai adalah statistika nonparametrik. Jika sampel ditarik secara random, maka statistika yang sesuai adalah statistika parametrik.
4. Apakah varians kelompok sama?
Jika varians kelompok tidak sama, maka statistika yang sesuai adalah statistika nonparametrik. Jika varians kelompok sama, maka statistika yang sesuai adalah statistika parametrik.
5. Bagaimana jenis skala pengukuran data?
Jika skala pengukuran data nominal dan ordinal, maka statistika yang sesuai adalah statistika nonparametrik. Jika skala pengukuran data interval dan rasio, maka statistika yang sesuai adalah statistika parametrik.
Selain sebaran, salah satu indikator penggunaan metode statistik parametrik atau nonparametrik adalah jenis data. Distribusi normal merupakan bagian dari distribusi probabilitas yang kontinyu (continuous probability distribution), karena itu skala pengukurannya pun haruslah kontinyu. Jenis data yang memiliki skala pengukuran yang kontinyu adalah data rasio dan interval.
BAB II
DATA DAN SKALA PENGUKURAN
1. Jenis Data
Data adalah ukuran dari variabel. Data diperoleh dengan mengukur nilai satu atau lebih variabel dalam sampel (atau populasi). Data dapat diklasifikasikan menurut jenis, menurut dimensi waktu, dan menurut sumbernya.
Data Menurut Jenis
Menurut jenisnya, data terdiri dari data kuantitatif dan data kualitatif.
a. Data kuantitatif adalah data yang diukur dalam suatu skala
numerik (angka). Data kuantitatif dapat dibedakan menjadi:
- Data interval, yaitu data yang diukur dengan jarak di antara
dua titik pada skala yang sudah diketahui. Sebagai contoh: IPK mahasiswa (interval 0 hingga 4); usia produktif (interval 15 hingga 55 tahun); suhu udara dalam Celcius (interval 0 hingga 100 derajat).
- Data rasio, yaitu data yang diukur dengan suatu proporsi.
b. Data kualitatif, adalah data yang tidak dapat diukur dalam skala
numerik. Namun karena dalam statistik semua data harus dalam bentuk angka, maka data kualitatif umumnya dikuantifikasi agar dapat diproses. Kuantifikasi dapat dilakukan dengan mengklasi-fikasikan data dalam bentuk kategori. Data kualitatif dapat dibedakan menjadi:
- Data nominal, yaitu data yang dinyatakan dalam bentuk
kategori. Sebagai contoh, industri di Indonesia oleh Badan Pusat Statistik digolongkan menjadi:
* Industri rumah tangga, dengan jumlah tenaga kerjanya 1- 4 orang, yang diberi kategori 1.
* Industri kecil, dengan jumlah tenaga 5 -19 orang, yang diberi kategori 2.
* Industri menengah, dengan jumlah tenaga kerja 20-100 orang, yang diberi kategori 3.
* Industri besar, dengan jumlah tenaga kerja lebih dari 100 orang, yang diberi kategori 4.
Angka yang menyatakan kategori ini menunjukkan bahwa posisi data sama derajatnya. Dalam contoh di atas, angka 4 tidak berarti industri besar nilainya lebih tinggi dibanding industri kecil yang angkanya 1. Angka ini sekedar menunjukkan kode kategori yang berbeda.
- Data ordinal, yaitu data yang dinyatakan dalam bentuk kategori,
dalam skala peringkat. Sebagai contoh, tingkat kosmopolitan petani suatu daerah diketegorikan:
Sangat rendah diberi kode 1. Rendah diberi kode 2.
Sedang diberi kode 3. Tinggi diberi kode 4.
Sangat tinggi diberi kode 5.
Dalam contoh di atas, angka 5 menunjukkan tingkat kosmopolitan yang tertinggi (besar nilainya lebih tinggi dibanding dengan tingkat 4, 3, 2, dan 1). Angka ini menunjukkan kode kategori dan nilai/derajat yang berbeda.
Data Menurut Dimensi Waktu
Menurut dimensi waktu, data dapat digolongkan menjadi:
a. Data runtut waktu (time-series), yaitu data yang secara kronologis
disusun menurut waktu. Data runtut waktu digunakan untuk melihat perubahan dalam rentang waktu tertentu. Variasi antar variabel terjadi karena adanya perbedaan waktu. Data runtut waktu dibedakan menjadi:
- Data harian, misalnya data Indeks Harga Saham setiap hari, data
harga sembilan bahan-bahan pokok.
- Data mingguan, misalnya data perkembangan harga beras
- Data bulanan, misalnya data tingkat inflasi, data suku bunga
Bank Indonesia.
- Data kuartalan, misalnya data Produk Domestik Bruto suatu
Negara.
- Data tahunan, misalnya data pendapatan nasional setiap tahun
(12 bulan).
b. Data silang tempat (cross-section), yaitu data yang dikumpulkan
pada suatu titik waktu. Data silang tempat digunakan untuk mengamati perilaku dalam periode yang sama. Variasi variabel terjadi karena adanya perbedaan antar pengamatan. Data ini biasanya lebih sesuai untuk mendukung penelitian atau kajian-kajian perilaku individu, perusahaan, atau wilayah. Misalnya:
- Data Sensus yang diterbitkan setiap 10 tahun sekali.
Sebagai contoh: sensus penduduk untuk setiap kabupaten pada tahun 2000; sensus ekonomi dari setiap perusahaan di setiap kabupaten pada tahun 2006.
- Data jumlah penduduk miskin pada setiap desa di Propinsi NTB
pada tahun tertentu.
- Data pendapatan petani jagung pada suatu daerah tertentu. c. Data pooling, adalah kombinasi antara data runtut waktu dan silang
Data Menurut Sumbernya
Berdasarkan sumbernya, data dapat digolongkan menjadi:
a. Data internal dan data eksternal. Data internal yaitu data yang
bersumber dari dalam organisasi. Data eksternal yaitu data yang bersumber dari luar organisasi.
b. Data primer dan data sekunder. Data primer adalah data yang
diperoleh melalui survei lapangan dengan menggunakan metode pengumpulan data tertentu. Data sekunder adalah data yang telah dikumpulkan oleh lembaga pengumpul data dan dipublikasikan kepada masyarakat pengguna data. Data sekunder akan lebih mempermudah dan mempercepat jalannya penelitian. Namun karena umumnya data sekunder dimaksudkan untuk konsumen peneliti dalam jumlah besar, seringkali data yang tersedia tidak sesuai benar dengan keinginan peneliti.
2. Skala Pengukuran Variabel
Dalam menentukan alat analisis statistika yang tepat dan cocok, seorang peneliti tidak hanya harus mengetahui model analisisnya tetapi juga harus memperhatikan skala pengukuran variabel dari data yang akan dianalisis. Misalnya saja seorang peneliti ingin mendeskripsikan seberapa besar penghasilan suatu kelompok masyarakat, maka statistika yang mungkin dapat digunakan adalah menggunakan rata-rata hitung (mean) dan simpangan baku (standar deviasi). Tetapi rata-rata (mean) ini kurang tepat kalau digunakan untuk menggambarkan tingkat pendidikan masyarakat tersebut. Salah satu statistik yang lebih cocok digunakan untuk menggam-barkan tingkat pendidikan masyarakat adalah modus, atau dapat juga menggunakan persentase. Meskipun model analisis yang dapat digunakan menggambarkan penghasilan dan tingkat pendidikan suatu masyarakat adalah analisis deskriptif, tetapi alat statistika yang digunakan berbeda. Kenapa hal ini berbeda ?
Perbedaan penggunaan alat analisis sangat terkait dengan skala pengukuran variabel yang akan dideskripsikan itu. Oleh karena itu, pemahaman tentang skala pengukuran variabel yang akan dianalisis harus diperhatikan. Ada empat macam skala pengukuran variabel, yaitu skala nominal, ordinal, interval, dan rasio.
a. Skala Nominal
bank pemerintah. Maka variabel jenis pekerjaan atau profesi itu mempunyai skala pengukuran nominal. Nilai dari skala nominal ini hanyalah menunjuk-kan sebagai perbedaan saja, tenaga pengajar
tentunya berbeda dengan seorang bankir.
Contoh lainnya adalah misalnya seorang peneliti ingin mengetahui jenis transportasi apa saja yang digunakan oleh karyawan PT BATAGOR. Untuk maksud itu peneliti menjaring pertanyaan "Alat angkutan apakah yang Anda gunakan untuk ke kantor?". Ada banyak kemungkinan jawaban dari karyawan itu, misalnya saja dengan bersepeda motor, dengan berkendaraan umum, dengan bersepeda, atau dengan mobil jemputan yang disediakan oleh perusahaan. Maka variabel alat transportasi itu berskala pengukuran nominal.
b. Skala Ordinal
Seorang ketua Lembaga Penelitian di Perguruan Tinggi bermaksud mengetahui usulan-usulan penelitian yang telah disetujui oleh Direktorat Jenderal Pendidikan Tinggi lima tahun terakhir berdasarkan jabatan fungsional peneliti utamanya. Tentunya informasi yang mungkin diperoleh adalah sekian peneliti utamanya lektor muda, sekian orang peneliti utamanya lektor, lektor madya, dan sebagainya. Nilai dari variabel jabatan fungsional itu menunjukkan adanya tingkatan atau order disamping adanya perbedaan. Varaibel yang demikian dinamakan sebagai skala
dapat diurutkan, jabatan lektor muda tentunya lebih rendah daripada lektor atau lektor madya.
Contoh lain untuk skala pengukuran ordinal adalah nilai mata kuliah mahasiswa. Ferry mendapat nilai C untuk mata kuliah Metodologi Penelitian, Sukino mendapat nilai B, Khaeruman mendapat nilai D. Nilai mata kuliah yang telah dikategorikan dengan A, B, C, D, dan E merupakan variabel yang berskala pengukuran ordinal. Nilai-nilai itu selain dapat membedakan kemampuan Ferry, Sukina, dan Khaeruman dalam mata kuliah Metodologi Penelitian tersebut tetapi juga menggambarkan
kedudukan,posisi, atauurutankemampuan tiap mahasiswa dalam mata
kuliah tersebut.
c. Skala Interval
berskala pengukuran interval mempunyai ciri membedakan, meng-urutkan, dan mengandung unsur jarak.
d. Skala Rasio
Variabel penghasilan merupakan contoh untuk skala pengukuran rasio. Misalnya penghasilan Rini setiap bulan sebagai dosen yang mempunyai jabatan Lektor Muda adalah 500 ribu rupiah, sedangkan Lusi yang baru setahun lalu menjabat Asisten Ahli berpenghasilan 300 ribu rupiah, ataupun Eko yang baru saja diangkat sebagai Asisten Ahli Madya hanya memperoleh 250 ribu rupiah per bulan. Penghasilan ketiga tenaga pengajar itu berbeda satu sama lainnya, dan juga Rini merupakan dosen yang berpenghasilan tertinggi diantara teman-temannya, dan Eko menduduki posisi yang terendah. Variabel penghasilan ini juga dapat memberikan informasi bahwa selisih penghasilan antara Rini dengan Lusi adalah 200 ribu rupiah, selisih penghasilan Lusi dengan Eko hanya sebesar 50 ribu rupiah. Dari contoh ini terlihat bahwa variabel penghasilan berskala pengukuran interval mempunyai ciri perbedaan, urutan, dan mengandung unsur adanya jarak atau selisih yang jelas dian-tara nilai variabelnya itu. Selain itu dapat juga dikatakan bahwa Rini berpenghasilan dua kali penghasilan Eko yang baru saja mengajar. Rasio dua kali ini sangat esak karena kedua nilai mempunyai nilai nol(titik nol) yang sama dan mutlak. Nol mutlak inilah yang membedakan skala pengukuran rasio
BAB III
REGRESI DENGAN VARIABEL DUMMY
Variabel di dalam analisis regresi bisa debedakan menjadi dua yaitu variabel kuantitatif dan variabel kualitatif. Model regresi pada bagian ini memfokuskan pada regresi dengan variabel independen kualitatif. Harga, volume produksi, volume penjualan, biaya promosi adalah beberapa contoh variabel yang datanya bersifat kuantitatif. Namun, bila kita membicarakan masalah jenis kelamin, tingkat pendidikan, status perkawinan, krisis ekonomi maupun kenaikan harga BBM berarti kita membicarakan variabel bersifat kualitatif.
Variabel-variabel kualitatif tersebut sangat mempengaruhi perilaku agen-agen ekonomi. Variabel kualitatif ini bisa terjadi pada dara cross section maupun data time series. Misalnya dalam data cross section kita bisa memasukkan jenis kelamin di dalam regresi dalam mempengaruhi volume penjualan handphone. Begitu pula data kualitatif seperti kenaikan harga BBM bisa kita masukkan di dalam regresi dalam mempengaruhi volume penjualan dalam datatime series.
Contoh kita ingin mengetahui jenis kelamin, lokasi, dan industri terhadap upah.
1. Pengaruh jenis kelamin atas upah, modelnya, Upah = a + b1DJK
Dimana DJK adalahDummyjenis kelamin (laki-laki dan wanita) 2. Pengaruh lokasi terhadap upah, apakah desa lebih rendah
upahnya dari kota, modelnya, Upah = a + b1DLOK
dimana DLOK adalahdummylokasi
3. Pengaruh industri terhadap upah, modelnya Upah = a + b1DIND
dimana DIND adalahdummysetiap klasifikasi industri Untuk memudahkan lihat contoh data berikut:
Industri Kode Industri Upah
Pangan 31 500
Sandang 32 522
Sandang 32 530
Pangan 31 512
Peralatan logam 38 600
Peralatan logam 38 642
Pangan 31 540
Pangan 31 520
Sandang 32 580
Sandang 32 570
Cara Membuat Variabel
Dummy
pada kategori tersebut dan memberi nol bagi kategori lainnya data berubah menjadi sebagai berikut.
Industri Kode Industri Upah Dpangan Dsandang Dalat
Pangan 31 500 1 0 0
Sandang 32 520 0 1 0
Sandang 32 530 0 1 0
Pangan 31 520 1 0 0
Peralatan logam 38 600 0 0 1
Peralatan logam 38 640 0 0 1
Pangan 31 540 1 0 0
Pangan 31 520 1 0 0
Sandang 32 580 0 1 0
Sandang 32 570 0 1 0
Sekarang perhatikan upah rata-rata untuk masing-masing industri:
Pangan = 520
Jika kita memiliki 3 dummy variabel maka kita bisa memasukkan 2 variabeldummy, sedangkan yang satu akan berfungsi menjadi benchmark atau pematok. Besarnya benchmark tidak lain adalah intercept atau nilai konstanta (a).
Contoh:
Upah = a + b1Dsandang + b2Dalat
Jadi rata-rata upah industri pangan yang tidak dimasukkan ke dalam model menjadi intersep (benchmark) beda upah sandang terhadap pangan adalah nilai b1=30 dan beda upah rata-rata industri peralatan
terhadap industri pangan adalan 100.
Sebaliknya jika yang tidak dimasukkan dalam regresi adalah industri peralatan, maka hasil regresi akan berubah sebagai berikut:
Upah = 620 - 100 Dpangan - 70 Dsandang
Sekarang intersep (a) menjadi rerata industri alat, dan beda upah pangan terhadap industri alat adalah minus 100 dan beda upah industri alat adalah minus 70.
Kesimpulannya jika kita punya n variabel dummy, maka kita dapat memasukkan n-1 variabel dalam model regresi, dan yang menjadi intersep adalah nilai rata-rata variabel yang tidak dimasukkan. Perhatikan cara memaknai parameter hasil regresi yang menggunakan dummy di atas.
Sekarang kita akan memasukkan data pendidikan pada data yang kita miliki di atas, data lengkapnya menjadi sebagai berikut.
Industri Kode Industri Upah Dpangan Dsandang Dalat
Pangan 31 500 1 0 6
Sandang 32 520 0 1 9
Sandang 32 530 0 1 9
Pangan 31 520 1 0 9
Peralatan logam 38 600 0 0 12
Peralatan logam 38 640 0 0 11
Pangan 31 540 1 0 9
Pangan 31 520 1 0 6
Sandang 32 580 0 1 12
Hasil di atas dapat kita ringkas dan sajikan sebagai berikut:
Makna hasil regresisekarang adalah sebagai berikut:
Pada tingkat pendidikan yang sama, maka upah industri sandang adalah minus 18,6 di bawah industri pangan (industri yang tidak diikutkan dalam regresi). Upah industri peralatan pada tingkat pendidikan yang sama adalah 49,9 di atas industri pangan. Mengapa angkanya menjadi semakin kecil dari sebelumnya?
Hal ini disebabkan adanya perbedaan pendidikan di ketiga industri, perbedaan upah tidak semata disebabkan oleh perbedaan industri tetapi juga disebabkan oleh perbedaan pendidikan. Ini dapat juga dikatakan bahwa pendidikan menjadi variabel KONTROL yan bertugas memurnikan pengaruh perbedaan industri atas upah.
Contoh :
Menganalisis apakah masa kerja, tingkat pendidikan karyawan, dan jenis kelamin mempengaruhi gaji karyawan. Pendidikan dikategorikan menjadi dua yaitu Diploma dan Sarjana. Menggunakan data hipotetis sebanyak 20 karyawan suatu perusahaan.
Yi = βo + β1 Xi + β2 D1 + β3 D2
Upah = 448,4 - 18,62 Dsandang + 49,9 Dalat + 10,5 Pendidik
(12,)** (-1,04) (2,287)** (2,486)**
Dimana :
Yi = gaji karyawan
Xi = masa kerja karyawan (tahun)
D1 = 1 jika sarjana dan 0 jika tidak (diploma) D2 = 1 jika pria dan 0 bila wanita
Data 20 Karyawan di Perusahaan PT Maju Mundur Gaji (juta) Masa_kerja Pendidikan Kelamin
2,700 11 0 0
3,400 3 1 1
3,900 18 0 1
3,400 14 0 1
4,800 9 1 1
2,200 3 0 1
6,400 15 1 1
6,230 17 1 0
4,200 20 0 1
2,065 2 0 0
3,510 4 1 0
2,500 5 0 1
2,800 8 0 1
2,975 14 0 0
5,890 15 1 0
3,105 15 0 0
3,200 2 1 1
3,365 19 0 0
3,850 5 1 0
Data dianalisis dengan SPSS dan hasil outputnya seperti berikut.
Model Summary
,958a ,917 ,901 ,45176
Model
Predictors: (Constant), Kelamin, Pendidikan, Masa_ kerja
a.
Nilai koefisien determinasi sebesar 0,917 artinya hasil regresi menunjukkan bahwa variasi masa kerja, tingkat pendidikan karyawan dan jenis kelamin mampu menjelaskan variasi gaji karyawan sebesar 91,7% dan sisanya sebesar 9,3% dijelaskan oleh faktor lain di luar model.
ANOVAb
36,101 3 12,034 58,964 ,000a 3,265 16 ,204
Squares df Mean Square F Sig.
Predictors: (Constant), Kelamin, Pendidikan, Masa_kerja a.
Dependent Variable: Gaji b.
Coefficientsa
1,067 ,280 3,815 ,002
,156 ,016 ,703 9,448 ,000
2,183 ,207 ,774 10,560 ,000
,228 ,208 ,081 1,096 ,289
(Constant)
Uji signifikansi variabel independen terhadap variabel dependen menunjukkan bahwa nilai t-hitung variabel masa kerja sebesar 9,448; variabel dummy tingkat pendidikan sebesar 10,560; dan variabel dummy jenis kelamin sebesar 1,096. Sementara itu, nilai t-tabel uji dua sisi pada α=5% dengan df =16 sebesar 2,120 (cari dalam tabel t). Dengan demikian variabel masa kerja dan dummy tingkat pendidikan signifikan pada α=5% (nilai t-hitung > nilai t-tabel), sedangkan variabel dummy jenis kelamin tidak berpengaruh nyata. Bisa juga membandingkan nilai Sig. (probabilitas atau p-value) jika lebih kecil dari alpha maka Ho ditolak, artinya variabel tersebut berpengaruh nyata terhadap variabel dependen.
dummy jenis kelamin 0,228 artinya gaji karyawan pria lebih tinggi 0,228 juta dibandingkan dengan gaji karyawan wanita tetapi secara statistika perbedaan itu tidak berbeda nyata.
Karyawan Sarjana dan Pria :
E(Yi | D1=1; D2=1, Xi) = (βo + β2 + β3) + β1Xi Karyawan Tidak Sarjana dan Pria :
E(Yi | D1=0; D2=1, Xi) = (βo + β3) + β1Xi Karyawan Sarjana dan Wanita :
E(Yi | D1=1; D2=0, Xi) = (βo + β2) + β1Xi Karyawan Tidak Sarjana dan Wanita :
E(Yi | D1=0; D2=0, Xi) = βo + β1Xi
Persamaan regresi Yi = 1,067 + 0,156 Xi + 2,183 D1 + 0,228 D2 Gaji karyawan berpendidikan sarjana dan pria :
Y’ = (1,067 +2,183 + 0,228) + 0,156 Xi ===> Y’ = 3,478 + 0,156 Xi Gaji karyawan berpendidikan tidak sarjana dan pria :
Y’ = (1,067 + 0,228) + 0,156 Xi ===> Y’ = 1,295 + 0,156 Xi Gaji karyawan berpendidikan sarjana dan wanita :
Y’ = (1,067 + 2,183) + 0,156 Xi ===> Y’ = 3,250 + 0,156 Xi
Soal Latihan :
Sekarang buatlah analisis dengan data berikut.
INDUSTRI LABA KAPITAL
A 10 10
A 12 11
A 14 12
A 12 9
B 13 13
B 15 23
B 11 25
B 10 16
B 18 31
C 20 40
C 22 50
C 23 52
A 20 20
A 11 30
B 15 40
Buatlah model analisis yang menjawab pertanyaan penelitian berikut: 1. Apakah ketiga industri memiliki laba benar-benar yang berbeda?
Buatlahdummyvariabelnya.
2. Apakah laba itu disebabkan oleh beda industri atau modal, berapa sumbangan masing-masing?
3. Mana variabel yang signifikan? 4. Tunjukkan ketepatan modelnya. 5. Ujilah asumsi klasiknya.
6. Sajikan hasil regresi secara internasional
BAB IV
JENIS UJI STATISTIKA NONPARAMETRIK
1. Uji Chi Square (X
2)
Chi-Square disebut juga dengan Kai Kuadrat. Chi Square adalah salah satu jenis uji komparatif non parametrik yang dilakukan pada dua variabel, di mana skala data kedua variabel adalah nominal. (Apabila dari 2 variabel, ada 1 variabel dengan skala nominal maka dilakukan uji chi square dengan merujuk bahwa harus digunakan uji pada derajat yang terendah).
Uji chi-square merupakan uji non parametrik yang paling banyak digunakan. Namun perlu diketahui syarat-syarat uji ini adalah: frekuensi responden atau sampel yang digunakan besar, sebab ada beberapa syarat di mana chi square dapat digunakan yaitu:
1. Tidak ada cell dengan nilai frekuensi kenyataan atau disebut juga Actual Count(F0) sebesar 0 (Nol).
2. Apabila bentuk tabel kontingensi 2 X 2, maka tidak boleh ada 1 cell saja yang memiliki frekuensi harapan atau disebut juga expected count("Fh") kurang dari 5.
Rumus chi-square sebenarnya tidak hanya ada satu. Apabila tabel kontingensi bentuk 2 x 2, maka rumus yang digunakan adalah "koreksi yates". Untuk rumus koreksi yates, sudah kami bahas dalam artikel sebelumnya yang berjudul "Koreksi Yates".
Apabila tabel kontingensi 2 x 2 seperti di atas, tetapi tidak memenuhi syarat seperti di atas, yaitu ada cell dengan frekuensi harapan kurang dari 5, maka rumus harus diganti dengan rumus "Fisher Exact Test".
Pada buku ajar ini, akan fokus pada rumus untuk tabel kontingensi lebih dari 2 x 2, yaitu rumus yang digunakan adalah "Pearson Chi-Square".
Formula uji Chi Square :
Dimana :
= Nilai kai-kuadrat
fo= frekuensi observasi/pengamatan fe= frekuensi ekspetasi/harapan
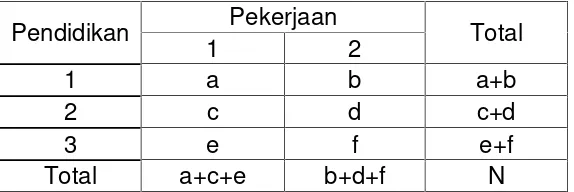
Untuk memahami apa itu "cell", lihat tabel di bawah ini: Pendidikan Pekerjaan Total
1 2
1 a b a+b
2 c d c+d
3 e f e+f
Total a+c+e b+d+f N
Sebagai contoh kita gunakan penelitian dengan judul "Perbedaan Pekerjaan Berdasarkan Pendidikan".
Teladan 1: Gunakan data berikut:
36 1 1 Karena variabel pendidikan memiliki 3 kategori dan variabel pekerjaan memiliki 2 kategori, maka tabel kontingensi yang dipakai adalah tabel 3 x 2. Maka akan kita lihat hasilnya sebagai berikut:
Dari tabel di atas, kita inventarisir per cell untuk mendapatkan nilai frekuensi kenyataan, sebagai berikut:
Cell Fo
a 11
b 9
c 8
d 16
e 7
f 9
Langkah berikutnya kita hitung nilai frekuensi harapan per cell, rumus menghitung frekuensi harapan adalah sebagai berikut:
Fh = (Jumlah Baris/Jumlah Semua) x Jumlah Kolom
1. Fh cell a = (20/60) x 26 = 8,667 2. Fh cell b = (20/60) x 34 = 11,333 3. Fh cell c = (24/60) x 26 = 10,400 4. Fh cell d = (24/60) x 34 = 13,600 5. Fh cell e = (16/60) x 26 = 6,933 6. Fh cell f = (16/60) x 34 = 9,067
Maka kita masukkan ke dalam tabel sebagai berikut:
Cell Fo Fh
a 11 8,667
b 9 11,333
c 8 10,400
d 16 13,600
e 7 6,933
f 9 9,067
1. Fh cell a = (11 - 8,667)2= 5,444
2. Fh cell b = (9 - 11,333)2= 5,444
3. Fh cell c = (8 - 10,400)2= 5,760
4. Fh cell d = (16 - 13,600)2= 5,760
5. Fh cell e = (7 - 6,933)2= 0,004
6. Fh cell f = (9 - 9,067)2= 0,004
Lihat hasilya pada tabel di bawah ini:
Cell Fo Fh Fo - Fh (Fo - Fh)2
a 11 8,667 2,333 5,444
b 9 11,333 -2,333 5,444
c 8 10,400 -2,400 5,760
d 16 13,600 2,400 5,760
e 7 6,933 0,067 0,004
f 9 9,067 -0,067 0,004
Kuadrat dari Frekuensi KenyataandikurangiFrekuensi Harapan per cell kemudian dibagi frekuensi harapannya:
1. Fh cell a = 5,444/8,667 = 0,628 2. Fh cell b = 5,444/11,333 = 0,480 3. Fh cell c = 5,760/10,400 = 0,554 4. Fh cell d = 5,760/13,600 = 0,424 5. Fh cell e = 0,004/6,933 = 0,001 6. Fh cell f = 0,004/9,067 = 0,000
Cell Fo Fh Fo - Fh (Fo - Fh)2 (Fo - Fh)2/Fh
a 11 8,667 2,333 5,444 0,628
b 9 11,333 -2,333 5,444 0,480
c 8 10,400 -2,400 5,760 0,554
d 16 13,600 2,400 5,760 0,424
e 7 6,933 0,067 0,004 0,001
f 9 9,067 -0,067 0,004 0,000
Chi-Square Hitung = 2,087
Untuk menjawab hipotesis, bandingkan chi-square hitung dengan chi-square tabel pada derajat kebebasan atau degree of freedom (DF) tertentu dan taraf signifikansi tertentu. Apabila square hitung >= chi-square tabel, maka perbedaan bersifat signifikan, artinya H0 ditolak atau H1 diterima.
DF pada teladan 2 di atas adalah 2. Didapat dari rumus ===> DF = (r - 1) x (k-1)
di mana: r = baris. k = kolom. Pada contoh di atas, baris ada 3 dan kolom ada 2, sehingga DF = (2 - 1) x (3 -1) = 2.
Apabila taraf signifikansi yang digunakan adalah 95% maka batas kritis 0,05 pada DF 2, nilai chi-square tabel sebesar = 5,991.
Karena 2,087 < 5,991 maka perbedaan tidak signifikan, artinya Ho diterima atau H1 ditolak.
Teladan 2 : untuk Data dari Sampel Tunggal
Prosedur ini banyak digunakan pada uji normalitas variabel. Rumus yang digunakan dalam uji tersebut adalah:
O = banyaknya kasus yang diamati dalam kategori i.
i
E = banyaknya kasus yang diharapkan
k
i 1
= penjumlahan semua kategorik.
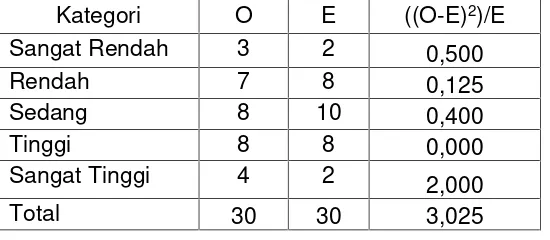
Misalkan hasil penelitian memperoleh frekuensi kategori hasil observasi (kolom O) dan frekuensi kategori harapan ditunjukkan (kolom E) pada Tabel, untuk menghitung ∑
i
Tabel Uji Statistik Nonparametrik Data dari Sampel Tunggal dengan Chi-Kuadrat
Kategori O E ((O-E)2)/E
Sangat Rendah 3 2 0,500
Rendah 7 8 0,125
Sedang 8 10 0,400
Tinggi 8 8 0,000
Sangat Tinggi 4 2 2,000
Total 30 30 3,025
Dengan cara tersebut, maka diperoleh χ2= 3,025. Derajad kebebasan (db) uji tersebut adalah jumlah kategori (k) dikurangi 1 = 4. Pada taraf signifikasi () = 5% harga χ2 tabel = 9,49. Karena χ2hitung <
2
Sola Latihan :
Jika data sudah tersusun dalam tabel distribusi frekuensi (tabel silang dua arah), misalnya suatu badan riset ingin mengetahui bagaimana sikap/penghargaan pegawai Pajak, Bank, TNI, dan Guru terhadap gaji/jaminan sosial yang diterimanya. Penelitian berdasarkan sampel random pada pegawai dari empat golongan tersebut. Hasil penelitian disajikan dalam tabel berikut.
Sikap Pegawai Total Baris
Pajak Bank TNI Guru
Memuaskan 80 75 55 50 260
Cukup 60 50 30 15 155
Kurang 40 70 25 30 165
Total Kolom 180 195 110 95 580
Apakah ada perbedaan yang signifikan atas sikap pegawai terhadap gaji/jaminan sosial dari empat golongan pegawai tersebut,
2. Uji Tanda (Sign Test)
Uji dilakukan pada 2 sampel terpisah (independen).
tanda (+)→ data pada sampel 1 > pasangannya pada sampel 2 tanda (–) → data pada sampel 1 < pasangannya pada sampel 2 tanda Nol (0)→ data pada sampel 1 = pasangannya pada sampel 2 Tanda Noltidak digunakandalam perhitungan.
Notasi yang digunakan:
n = banyaknya tanda (+) dan tanda (–) dalam sampel
p = proporsi SUKSES dalam sampel
q
= 1 –p
Statistik Uji zhitung=p
Ingat: kejadian SUKSES tergantung dari apa yang ditanyakan (ingin diuji) dalam soal.
Jika yang ingin diuji sampel 1 > sampel 2 maka SUKSES adalah banyak tanda (+)
Nilai p0 disesuaikan dengan nilai pengujian p yang diinginkan dalam soal,
atau jika ingin diuji proporsi sampel 1 = proporsi sampel 2 maka = p0= q0
= 0,5.
PenetapanH0danH1, dalam uji hipotesis terdapat 3 alternatifH0danH1:
1) H0: p = p0danH1: p < p0
Uji 1 arah dengan daerah penolakanH0: z < −zα
2) H0: p = p0danH1: p > p0
Uji 1 arah dengan daerah penolakanH0: z > zα
3) H0: p = p0danH1: p ≠ p0
Uji 2 arah dengan daerah penolakanH0: z < −zα/2dan z >zα/2
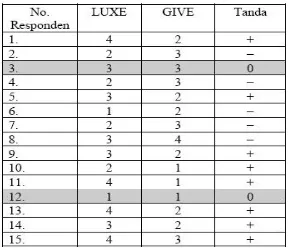
Teladan 3 :
Berikut adalah nilai preferensi konsumen terhadap 2 Merk Sabun Mandi (LUXE dan GIVE). Dengan taraf nyata 1%, ujilah apakah proporsi preferensi konsumen pada kedua merk bernilaisama?
Banyaknya tanda (+) = 8 Banyaknya tanda (–) = 5 Total n = 8 + 5 = 13
Jika kita asumsikan LUXE lebih disukai dibanding GIVE maka SUKSES dalam sampel adalah
p
= proporsi banyaknya tanda (+) dalam sampel.13
8
n
positif
banyak
p
= 0,62q
= 1 –p
= 1 – 0,62 = 0,38Karena ingin diuji proporsi yang suka LUXE = GIVE, maka p0= q0 = 0,50.
Langkah pengujiannya adalah:
1. H0: p = 0,50 H1: p ≠ 0,50
2. Statistik Uji : z 3. Arah uji: 2 arah
6. Nilai statistik Uji:
z hitung = 0,87 ada di daerah penerimaan H0, sehingga H0 di-terima.
Proporsi konsumen yang menyukai LUXE masih sama dengan yang menyukai GIVE.
Teladan 4 :
Dengan menggunakan data pada Teladan 3 di atas dan taraf nyata 1%, ujilah apakah proporsi preferensi konsumen pada sabun LUXE dibanding sabun GIVE sudah lebih dari 0,30?
Diketahui: p0= 0,30
q0= 1 – 0,30 = 0,70
1) H0: p = 0,30 H1: p > 0,30
2) Statistik Uji: z 3) Arah uji: 1 arah
6) Nilai statistik uji:
z hitung = 2,52 ada di daerah penolakan H0, sehingga H0 ditolak dan
H1 diterima. Proporsi konsumen yang menyukai LUXE sudah lebih dari 0,30.
Soal Latihan
:
diadakan pengamatan terhadap 26 rumah yang dipilih secara acak. Misalnya ada empat tingkat kebersihan rumah masing-masing diberi nilai 1, 2, 3, dan 4 berdasarkan pedoman penilaian tertentu. Data hasil pengamatan sebelum dan sesudah diadakan penyuluhan sebagai berikut.
Resp Sebelum Sesudah
1 2 3
2 3 2
3 1 3
4 2 3
5 1 2
6 2 3
7 3 4
8 2 3
9 4 4
10 1 3
11 2 3
12 2 1
13 2 4
14 1 3
15 2 3
16 3 2
17 3 2
18 2 3
19 1 2
20 1 3
21 2 3
22 1 1
23 3 2
24 2 3
25 1 4
26 2 2
3. Uji Pangkat Bertanda Wilcoxon
Uji ini dipergunakan untuk membandingkan dua sampel yang anggota-anggotanya berpasangan dan berasal dari dua populasi yang tidak diketahui distribusinya. Untuk menguji perbedaan median dua populasi berdasarkan median dua sampel berpasangan. Uji ini selain mempertimbangkan arah perbedaan, juga mempertimbangkan besar relatif perbedaannya. Dengan demikian bisa dikatakan bahwa Uji Pangkat Bertanda Wilcoxon memiliki kualitas yang lebih baik dibandingkan dengan Uji Tanda. Data paling tidak berskala ordinal.
Notasi yang digunakan:
n1= ukuran sampel ke-1 n2= ukuran sampel ke-2
n1<n2ukuran sampel ke-1 selalu lebih kecil dari sampel ke-2
W = jumlah peringkat pada sampel berukuran terkecil. Nilai Ekspektasi (W) = E(W) =
2
1
2 11
n
n
n
Standar Error = SE =
12
)
1
(
1 22
1
n
n
n
n
Statistik uji = z =
SE
W
E
W
(
)
Dengan taraf nyata 5% ujilah apakah (peringkat) pendapatan di de-partemen Qlebih kecildibandingkan dari departemen Z?
Jawab:
1. H0: μ 1= μ 2 H1: μ 1< μ 2
2. Statistik Uji : z 3. Arah uji: 1 arah
4. Taraf nyata pengujian = α = 5% = 0,05
5. Daerah PenolakanH0: lihat diagram pada halaman berikutnya!
6. Statistik uji: n1= 4 n2= 8 W = 19
z hitung = –1,19 ada di daerah penerimaan H0, sehingga H0 diterima.
4. Uji Jumlah Pangkat Wilcoxon
Uji ini dipergunakan untuk membandingkan dua sampel yang anggota-anggotanya tidak berpasangan dan berasal dari dua populasi yang tidak diketahui distribusinya. Hipotesis nol yang akan diuji menyatakan bahwa mean dari dua populasi sama.
Ho : µ1 = µ2 lawan H1 : µ1 ≠ µ2
Kedua populasi yang diselidiki tidak diketahui distribusinya dan tidak perlu sama macam distribusinya, dengan demikian uji parametrik tidak tepat untuk digunakan.
Bila besar sampel pertama dan kedua dinyatakan dengan n1 dan n2, maka langkah-langkah pengujiannya sebagai berikut :
1. Gabungkan kedua sampel dan beri pangkat (jenjang) pada tiap-tiap anggotanya mulai dari nilai pengamatan terkecil ke nilai pengamatan terbesar. Apabila ada dua atau lebih nilai pengamatan yang sama maka pangkat yang diberikan pada tiap-tiap anggota sampel adalah pangkat rata-rata.
2. Hitung pangkat masing-masing bagi sampel pertama dan kedua, dan notasikan dengan R1 dan R2.
3. Ambillah jumlah pangkat yang lebih kecil antara R1 dan R2, notasikan dengan R.
4. Bandingkan nilai R yang diperoleh dari hasil pengamatan dengan Rα dari tabel.
Teladan 6
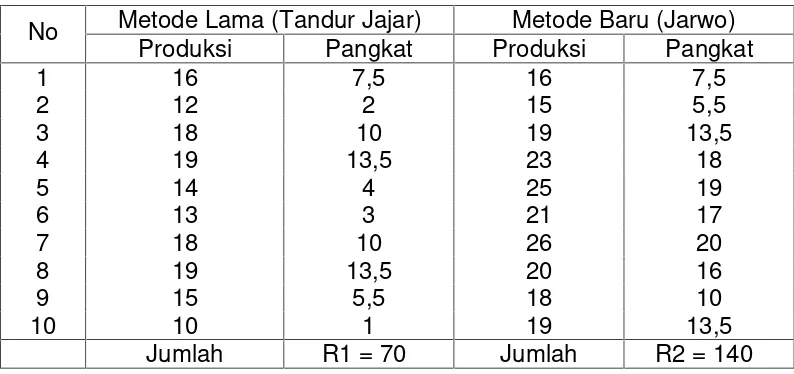
Suatu metode penanaman padi model baru (Jajar Legowo=Jarwo) hendak dicobakan. Untuk mengetahui apakah cara baru (Jarwo) tersebut memberikan hasil panenan (produksi) yang berbeda dengan cara lama (Tandur Jajar). Kemudian dilakukan penelitian, cara lama dicobakan pada 10 orang petani dan cara baru dicobakan pada 10 orang petani lainnya, masing-masing dipilih secara random dari berbagai tempat yang kira-kira memiliki luas lahan dan kesuburan yang sama. Hasil penelitian dan pangkatnya disajikan pada tabel berikut.
Tabel Hasil Panenan (Produksi) dan Pangkat Cara Lama dan Cara Baru No Metode Lama (Tandur Jajar) Metode Baru (Jarwo)
Produksi Pangkat Produksi Pangkat
1 16 7,5 16 7,5
2 12 2 15 5,5
3 18 10 19 13,5
4 19 13,5 23 18
5 14 4 25 19
6 13 3 21 17
7 18 10 26 20
8 19 13,5 20 16
9 15 5,5 18 10
10 10 1 19 13,5
Jumlah R1 = 70 Jumlah R2 = 140 Jumlah pangkat yang lebih kecil adalah R1 = 70 ===> R. Untuk n1 = 10 dan n2 = 10, dari tabel R diperoleh R 5% = 78 dan R 1% = 71, nilai R hitung < R tabel maka Ho ditolak, artinya produksi padi cara baru berbeda nyata dengan produksi padi cara lama.
nilai pengamatan terbesar (pangkat I) dan dari nilai pengamatan terbesar ke nilai pengamatan terkecil (pangkat II).
Apabila n1 atau n2 atau kedua-duanya lebih besar dari 20, pengujian hipotesis dilakukan dengan menggunkan distribusi Z, dengan rumus sebagai berikut :
n* (n1 + n2 + 1) – 2 R* Z-hit =
---(n1 n2 ---(n1 + n2 + 1) / 3)1/2
R* = jumlah pangkat yang lebih kecil n* = jumlah sampel dari R*
Jika Z-hit ≤ Z tabel maka Ho diterima (H1 ditolak) Jika Z-hit > Z tabel maka Ho ditolak (H1 diterima)
Soal Latihan :
Seorang peneliti ingin mengetahui apakah kenaikan upah akan meningkatkan output per jam dari pekerja. Output per jam dalam unit sebelum kenaikan upah (X) dan output per jam dalam unit setelah kenaikan upah (Y). Sampel dengan 10 pekerja memberikan hasil sebagai berikut :
Pekerja 1 2 3 4 5 6 7 8 9 10
X 91 83 70 64 85 86 91 66 72 61
Y 88 87 67 69 83 81 94 67 76 65
5. Uji Mann-Whitney
Uji ini merupakan alternatif uji beda dua rata-rata parametrik dengan menggunakan referensi distribusi t (sampel-sampel berukuran kecil).
Langkah pertama pengujian ini adalah pengurutan nilai mulai dari yang terkecil hingga terbesar. Pengurutan dilakukan tanpa pemisahan kedua sampel. Selanjutnya lakukan penetapan Rank (Peringkat) dengan aturan berikut:
Peringkat ke -1 diberikan pada nilai terkecil di urutan pertama dan peringkat tertinggi diberikan pada nilai terbesar.
Jika tidak ada nilai yang sama maka urutan = peringkat.
Jika ada nilai yang sama, maka ranking dihitung dengan rumus:
Peringkat (R) =
sama
bernilai
yang
data
banyaknya
sama
bernilai
yang
data
urutan
Ranking untuk nilai 70 =
Ranking untuk nilai 75 =
2
R1= Jumlah peringkat dalam sampel ke-1
R2= Jumlah peringkat dalam sampel ke-2
n1= ukuran sampel ke-1
n2= ukuran sampel ke-2
Ukuran kedua sampel tidak harus sama Rata-rata R1 =
Standar Error (Galat Baku) =
12
Statistik uji: z =
1
Dalam perhitungan hanya R1 yang digunakan, karena ia menjadi subyek
dalamH0danH1.
Teladan 8 :
Jawab:
1. H0: μ 1= μ 2 H1: μ 1> μ 2
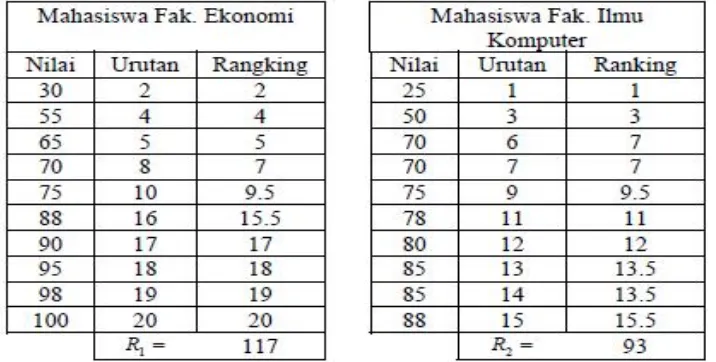
2. Statistik Uji: z 3. Arah uji: 1 arah
4. Taraf nyata pengujian = α = 5% = 0,05 5. Daerah PenolakanH0:
6. Nilai statistik uji:
7. Kesimpulan:
z hitung = 0,91 ada di daerah penerimaan H0, sehingga H0 diterima.
Dengan demikian (peringkat) nilai UAS Statistika di Fakultas Pertanian sama dengan Fakultas Ekonomi.
Soal Latihan :
Seorang Manajer ingin mengetahui apakah iringan musik lembut berpengaruh terhadap produktivitas kerja. Output per jam dalam unit pekerja tanpa iringan musik (X) dan output per jam dalam unit pekerja dengan iringan musik (Y). Sampel dengan 10 pekerja memberikan hasil sebagai berikut :
Pekerja 1 2 3 4 5 6 7 8 9 10
X 13 12 12 10 10 10 14 11 9 8
Y 15 13 12 12 14 16 13 8 10 7
6. Uji Run (Run Test)
Uji Run(s) digunakan untuk menguji keacakan dalam suatu sampel. Run adalah satu atau lebih lambang-lambang yang identik yang didahului atau diikuti oleh suatu lambang yang berbeda atau tidak ada lambang sama sekali.
→ terdapat 9 runs
Statistik uji yang digunakan: z Notasi yang digunakan:
n1= banyaknya lambang 1 dalam sampel n1> 10
n2= banyaknya lambang 2 dalam sampel n2> 10
n = n1+ n2
Statistik uji: z =
r
H0: susunan acak (random)
H1: susunan tidak acak (not random)
Teladan 9 :
Berikut ini adalah urutan duduk mahsiswa dan mahasiswi dalam suatu kelas:
LL P L PP L P L P L P LL P LLLLLLL PP L P LL PP LLLLLL L = Laki-laki, P = Perempuan
Dengan taraf nyata 5%, ujilah apakah urutan ini sudah random? Diketahui:
n1= banyak L = 24 ; n2= banyak P = 12 ; nr= banyak runs = 19 Jawab:
1. H0: susunan acak H1: susunan tidak acak
2. Statistik Uji : z
3. Arah pengujian: 2 Arah
6. Statistik uji:
z hitung = 0,76 ada di daerah penerimaan H0, maka H0 diterima. Jadi,
dengan demikian susunan tersebut terbukti acak.
Soal Latihan :
Seorang mahasiswa Fakultas Pertanian melakukan penelitian untuk mengetahui Apakah Pria dan Wanita yang Berbelanja ke Kios Saprotan (Sarana Produksi Pertanian) Berdatangan Secara Acak atau Tidak. Pada hari penelitian mahasiswa tersebut melakukan pencatatan terhadap jenis kelamin orang yang berbelanja dari mulai kios dibuka hingga ditutup kembali, dan diperoleh data, ada 30 orang yang berbelanja, terdiri dari 20 orang Pria (n1) dan 10 orang Wanita (n2) dengan susunan seperti berikut.
7. Uji Kruskal-Wallis
Analisis varian ranking satu arah Kruskal-Wallis atau biasa disebut Uji Kruskal-Wallis pertama kali diperkenalkan oleh William H. Kruskal dan W. Allen Wallis pada tahun 1952. Uji ini merupakan salah satu uji statistik nonparametrik dalam kasus k sampel independen. Uji Kruskal-Wallis digunakan untuk menguji apakah k sampel independen berasal dari populasi yang berbeda, dengan kata lain uji ini dapat digunakan untuk menguji hipotesis nol bahwa k sampel independen berasal dari populasi yang sama atau identik dalam hal harga rata-ratanya. Oleh karena itu, uji Kruskal-Wallis juga merupakan perluasan dari uji Mann-Whitney.
Menurut D.C. Montgomery (2005), apabila asumsi kenormalan yang dibutuhkan oleh metode statistika parametrik tidak dapat dipenuhi, maka peneliti dapat menggunakan metode alternatif sebagai pengganti analisis varian satu arah (One way ANOVA) yaitu Kruskal-Wallis Test. Sedangkan menurut Wayne W. Daniel dalam bukunya Applied Nonparametric Statistic, beberapa syarat yang harus dipenuhi dalam menggunakan Kruskal-Wallis Test adalah:
1. Pengamatan harus bebas satu sama lain (tidak berpasangan). 2. Tipe data setidak-tidaknya adalah ordinal.
Dasar Pemikiran dan Metode
Data untuk pengujian Kruskal-Wallis pada umumnya dituangkan dalam tabel r baris dan k kolom. Banyaknya sampel yang terpilih dituliskan dalam tabel secara baris, sedangkan kelompok atau kategori yang tersedia dituliskan secara kolom.
Dalam penghitungan uji Kruskal-Wallis ini, masing-masing nilai observasi diberi ranking secara keseluruhan dalam satu rangkaian. Pemberian ranking diurutkan dari nilai yang terkecil hingga nilai yang terbesar. Nilai yang terkecil diberi ranking 1 dan nilai yang terbesar diberi ranking N (dimana N adalah jumlah seluruh observasi). Apabila terdapat angka yang sama, maka ranking dari nilai-nilai tersebut adalah rata-rata ranking dari nilai-nilai observasi tersebut.
Jika seluruh nilai observasi telah diberi ranking, langkah selanjutnya adalah menghitung jumlah ranking dari masing-masing kolom (Rj).
Sampel Kelompok / Kategori
Selanjutnya, uji Kruskal-Wallis dapat didefinisikan dengan rumus:
dimana:
Metode dan Prosedur
1. Penentuan Hipotesis Nol dan Hipotesis Alternatif H0: k sampel berasal dari populasi yang sama
H1: k sampel berasal dari populasi yang berbeda
2. Menentukan Tes Statistik / Statistik Uji
Karena tujuannya adalah menguji apakah k sampel independen berasal dari populasi yang sama maka uji statistik yang kita gunakan adalah uji Kruskal-Wallis dengan statistik ujinya H yang berdistribusi Chi-Square dengan derajat bebas (k-1).
3. Menentukan Tingkat Signifikansi
Tingkat signifikansi adalah bilangan yang mencerminkan
besarnya peluang menolak hipotesis nol ketika hipotesis nol bernilai benar.
H: nilai Kruskal-Wallis dari hasil penghitungan Rj: jumlah rank dari kelompok/kategori ke-j
nj: banyaknya kasus dalam sampel pada kelompok/kategori ke-j
4. Distribusi Sampling
H mendekati distribusi Chi-Square dengan derajat bebas (k-1). Nilai H dapat dihitung dengan rumus di atas. Adapun ketentuan penggunaan tabel adalah sebagai berikut:
a. Jika k=3 dan nj 5 (j=1;2;3), Tabel O dapat digunakan untuk
menentukan nilai yang berkaitan dengan harga di bawah H0.
b. Dalam kasus lain, dapat digunakan Tabel C dengan derajat bebas (k-1).
5. Daerah Penolakan
Daerah penolakan terdiri dari semua harga H yang sedemikian besar sehingga kemungkinan yang berkaitan dengan terjadinya harga-harga itu di bawah H0sama dengan atau kurang dari .
6. Keputusan
H0akan ditolak jika nilai H (k-1)atau nilai p-value sebaliknya
H0akan gagal ditolak jika nilai H < (k-1)atau nilai p-value >.
Ringkasan Prosedur
1. Berilah ranking pada masing-masing nilai observasi dengan urutan dari ranking 1 hingga N.
2. Tentukan harga R (jumlah ranking) untuk masing-masing kelompok atau kategori.
a. Jika k=3 dan nj 5 (j=1;2;3), Tabel O dapat digunakan untuk
menentukan nilai yang berkaitan dengan harga di bawah H0.
b. Dalam kasus lain, dapat digunakan Tabel C dengan derajat bebas (k-1).
4. Jika kemungkinan yang berkaitan dengan harga observasi H adalah sama atau kurang dari, maka tolak H0dan terima H1.
Teladan 8 :
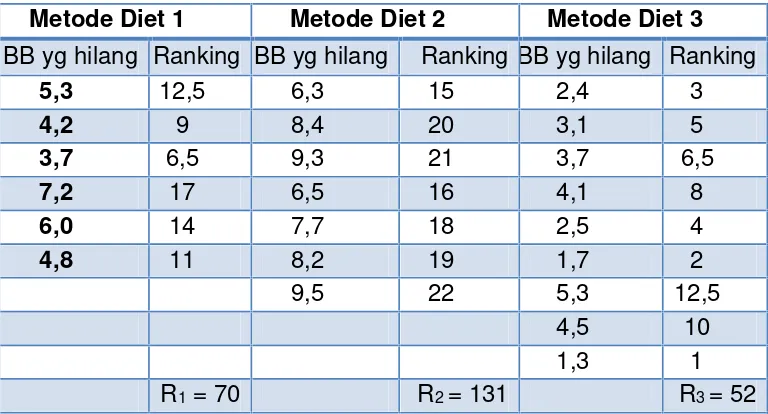
Untuk membandingkan tingkat keefektifan dari 3 macam metode diet, maka sebanyak 22 orang mahasiswi yang dipilih dari suatu universitas dibagi ke dalam 3 kelompok yang mana masing-masing kelompok mengikuti program diet selama empat minggu sesuai dengan metode yang telah dibuat. Setelah program diet berakhir, maka diperoleh banyaknya berat badan yang hilang (dalam kg) dari mahasiswi-mahasiswi tersebut sebagai berikut:
Metode Diet 1 Metode Diet 2 Metode Diet 3 Sampel Berat Badan
(BB) yg hilang Sampel
Berat Badan
(BB) yg hilang Sampel
Berat Badan (BB) yg hilang
1 5,3 1 6,3 1 2,4
2 4,2 2 8,4 2 3,1
3 3,7 3 9,3 3 3,7
4 7,2 4 6,5 4 4,1
5 6,0 5 7,7 5 2,5
6 4,8 6 8,2 6 1,7
7 9,5 7 5,3
8 4,5
Untuk menguji Ho yang menyatakan bahwa tingkat keefektifan dari ketiga
metode diet di atas adalah sama, terhadap hipotesis alternatif yang menyatakan bahwa tingkat keefektifan ketiga metode di atas adalah tidak sama (α = 5%).
Jawaban :
o Hipotesis
H0: tingkat keefektifan dari ketiga metode diet adalah sama
H1: tingkat keefektifan dari ketiga metode diet adalah tidak sama
o Tes Statistik : Kruskal-Wallis Test o Tingkat Signifikansi : α=5%, o Distribusi sampling :
H mendekati distribusi Chi-Square dengan derajat bebas (k-1), sehingga wilayah kritis dapat ditentukan dengan menggunakan Tabel Chi Square.
o Penghitungan
n1=6 ; n2=7 ; n3=9 ; N= n1+ n2 + n3= 22
Metode Diet 1 Metode Diet 2 Metode Diet 3
BB yg hilang Ranking BB yg hilang Ranking BB yg hilang Ranking
5,3 12,5 6,3 15 2,4 3
4,2 9 8,4 20 3,1 5
3,7 6,5 9,3 21 3,7 6,5
7,2 17 6,5 16 4,1 8
6,0 14 7,7 18 2,5 4
4,8 11 8,2 19 1,7 2
9,5 22 5,3 12,5
4,5 10
1,3 1
)
o Kesimpulan : Dengan tingkat kepercayaan 95 %, belum cukup bukti
untuk menyatakan bahwa tingkat keefektifan dari ketiga metode diet tersebut adalah sama.
Teladan 9 :
Sebuah perusahaan ingin mengetahui apakah terdapat perbedaan keterlambatan masuk kerja antara pekerja yang rumahnya jauh atau dekat dari lokasi perusahaan. Misalkan jarak rumah dikategorikan dekat (kurang dari 10 km), sedang (10 – 15 km) dan jauh (lebih dari 15 km). Keterlambatan masuk kerja dihitung dalam menit keterlambatan selama sebulan terakhir.
Dekat Sedang Jauh
59 77 89
110 99 102
132 128 121
143 144
165
Jawaban :
o Hipotesis
H0 : Tidak ada perbedaan lama keterlambatan antara tiga kategori
pekerja berdasarkan jarak rumahnya.
H1 : Ada perbedaan lama keterlambatan antara tiga kategori
pekerja berdasarkan jarak rumahnya
o Tes Statistik : Kruskal-Wallis Test. Karena data berada pada skala
pengukuran rasio (lama keterlambatan), maka kruskal-wallis dapat digunakan.
o Tingkat Signifikansi : α = 0,05
o Penghitungan, n1= 5 ; n2= 4 ; n3= 3 ; N= n1+ n2 + n3= 12
Dekat Rank Sedang Rank Jauh Rank
59 1 77 2 89 3
110 6 99 4 102 5
132 9 128 8 121 7
143 10 144 11
165 12
= 1,004
o Daerah penolakan : p-value o Keputusan :
Karena k=3 dan nj5 (j=1;2;3), maka kita dapat menggunkan Tabel
Kruskal Wallis untuk menentukan nilai yang berkaitan dengan harga di bawah H0.
Untuk nilai , , dan , p-value untuk H = 1,004 adalah lebih besar dari 0,103 (p-value > 0,103). Karena p-value > 0,05, maka gagal tolak H0
o Kesimpulan : Dengan tingkat kepercayaan 95 %, belum cukup bukti
untuk menyatakan bahwa ada perbedaan lama keterlambatan antara tiga kategori pekerja berdasarkan jarak rumahnya.
Soal Latihan :
Suatu percobaan untuk membandingkan umur rata-rata lima merk bola lampu telah dilakukan serta memberikan data sebagai berikut (data dalam satuan jam). Ujilah apakah ada perbedaan umur merk bola lampu.
Merk A Merk B Merk C Merk D Merk E
308 202 283 279 331
313 206 299 238 251
331 204 411 256 246
251 280 167 276 204
246 255 294 281
8. Uji Friedman (Friedman Test)
Pengujian dengan uji Friedman sama sepertidalam uji analisis dua arah dalam statistik parametrik. Uji ini diperkenalkan oleh Milton Friedman tahun 1937 dan termasuk dalam uji nonparametrik yang tidak membutuhkan asumsi distribusi normal dan varians populasi tidak diketahui. Skala data yang digunakan dapat berupa ordinal. Uji Friedman merupakan alternatif yang dilakukan apabila pengujian dalam ANOVA tidak terpenuhi asumsi-asumsi seperti tersebut di atas. Setiap sampel mendapatkan perlakukan yang berbeda (repeated measurement). Pegambilan data pada setiap sampel dilakkan sebelum (pre test) dan sesudah (post test). Pemberian ranking menurut baris (per observasi).
Uji yang digunakan untuk membandingkan skor (nilai pengamatan) dari k sampel atau kondisi yang berpasangan (banyaknya pengamatan setiap sampel atau kondisi sama).
Untuk menguji hipotesis dua sampel berpasangan dimana perlakuan yang diterapkan terhadap obyek lebih dari 2 kali. Formulanya sebagai berikut :
Teladan 10 :
Dilakukan sebuah penelitian pada 15 responden tentang perbedaan 3 shift kerja terhadap kinerja perawat sebuah RS Swasta di Mataram, berikut merupakan datanya.
Nomor Observasi
Kinerja Perawat
Shift 1 Shift 2 Shift 3
Nilai Rank Nilai Rank Nilai Rank
1 76 3 70 1 75 2
2 71 2 65 1 77 3
3 56 1 57 2 74 3
4 67 3 60 2 59 1
5 70 2 56 1 76 3
6 77 3 71 1 73 2
7 45 1 47 2 78 3
8 60 1 67 3 62 2
9 63 2 60 1 75 3
10 60 2 59 1 74 3
11 61 3 57 1 60 2
12 56 1 60 2 75 3
13 59 2 54 1 70 3
14 74 3 72 2 71 1
15 66 3 63 1 65 2
Rank (peringkat) ditentukan berdasarkan banyaknya k dari observasi 1 dalam semua perlakuan/kondisi. Misal: observasi 1 mendapat nilai kinerja pada shift 1, 2 dan 3 masing-masing 76, 70 dan 75. Makarank (peringkat)-nya ditentukan berdasarkan nilai terkecil, yaitu 70, 75, dan 76 masing-masing peringkat 1, 2, dan 3.
Jumlah-jumlah tersebut kemudian dimasukan ke dalam rumus, yaitu : 12
= --- [(322+222+362)] - 3(15)(3+1) = 6,93
Dengan df = k-1 =3-1=2, pada α =0,05 dan CI 95 % , maka nilai chi square pada tabel adalah = 5,59.
Ternyata nilai chi square hitung > nilaichi square pada tabel = 6,93 > 5,59 ====> Ho ditolak, artinya, ada perbedaan kinerja perawat pada masing-masing shift kerja.
Soal Latihan :
Manajemen restoranfastfood sangat ingin tahu pendapat langganannya mengenai pelayanan, kebersihan dan kualitas makanan dari restorannya. Pihak management ingin membandingkan hasil rating pelanggan untuk tigashift yang berbeda, yaitu:
Shift1: 16.00 – midnight;Shift2: midnight – 08.00; Shift3: 08.00 – 16.00 Pelanggan diberi kesempatan untuk mengisi kartu saran. Pada penelitian ini 10 kartu saran (customer card) dipilih secara random, untuk setiap shift. Ratingdigolongkan dalam empat kategori yaitu 4 = sempurna, 3 = baik, 2 = biasa, 1 = buruk. Diperoleh data seperti dibawah ini:
16.00 - Midnight Midnight - 08.00 08.00 - 16.00
4 3 3
4 4 1
3 2 3
4 2 2
3 3 1
3 4 3
3 3 4
3 3 2
2 2 4
3 3 1
9. Uji Korelasi Rank Spearman
Dua uji Mann-Whitney dan Wilcoxon ditujukan untuk 2 sampel yang saling bebas (independen), sedangkan Uji Rank Spearman ditujukan untuk penetapan peringkat data berpasangan.
Konsep dan interpretasi nilai Korelasi Rank Spearman (rS) sama
dengan konsep Koefisien Korelasi Product Moment pada Regresi (Linier Sederhana).
Notasi yang digunakan:
n = banyak pasangan data
di= selisih peringkat pasangan data ke-i
rS= Korelasi Spearman
rS= 1 −
Terdapat 3 alternatif H0dan H1, yaitu:
a) H0: R = 0 (korelasi 0, tidak ada hubungan /tidak ada kecocokan)
H1: R < 0 (korelasi negatif)
Uji 1 arah dengan daerah penolakanH0: z < −zα
b) H0: R = 0 (korelasi 0, tidak ada hubungan/tidak ada kecocokan)
H1: R > 0 (korelasi positif)
c) H0: R = 0 (korelasi 0, tidak ada hubungan /tidak ada kecocokan)
H1: R ≠ 0 (ada korelasi/kecocokan, korelasi tidak sama dengan 0)
Uji 2 arah dengan daerah penolakanH0: z < −zα/2dan z >zα/2
Peringkat diberikan tergantung pada kategori penilaian. Jika ada item yang dinilai berperingkat sama, maka penetapan peringkat seperti halnya dalam Mann-Whitney dapat dilakukan (ambil rata-rata peringkatnya!)
Teladan 11 :
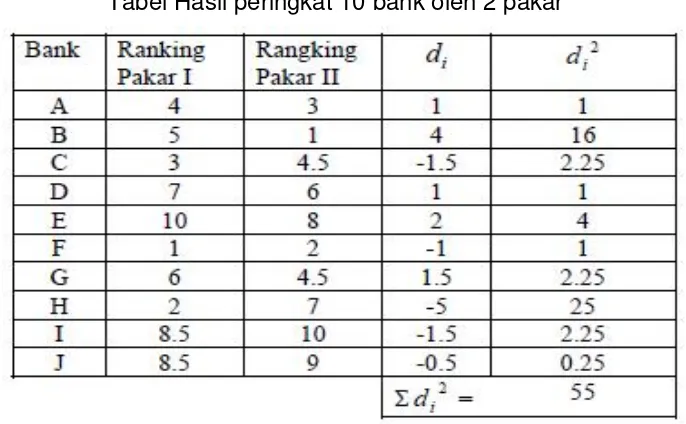
Dua orang pakar (ahli) diminta memberikan peringkat kinerja pada 10 Bank di Indonesia. Peringkat diberikan mulai dari bank terbaik (peringkat 1) sedang yang terburuk diberi peringkat 10. Hasilnya disajikan dalam tabel berikut ini.
Tabel Hasil peringkat 10 bank oleh 2 pakar
Jawab:
1. H0: R = 0 H1: R ≠ 0
2. Statistik Uji: z
3. Arah pengjian: 2 Arah
4. Taraf nyata pengujian = α = 5% → α/2 = 2,5% = 0,025 5. Daerah PenolakanH0:
6. Statistik uji:
Soal Latihan :
Seorang manajer perusahaan ingin mengetahui apakah terdapat hubungan antara Motivasi Kerja dengan Prestasi Kerja karyawan di perusahaan yang ia pimpin. Untuk itu diambilah 12 pekerja untuk dijadikan sampel penelitian. Data yang diperoleh dapat dilihat pada tabel di bawah ini.
Pekerja Motivasi Kerja Prestasi Kerja
1 75 71
2 83 88
3 75 77
4 68 70
5 63 73
6 62 67
7 80 80
8 72 83
9 75 88
10 77 79
11 69 75
12 81 85
10. Uji Konkordansi Kendall
Adalah pengujian sampel berpasangan ganda (multiple-paired samples). Orang yang memberi peringkat lebih dari 2. Statistik Uji yang digunakan : χ2(chi kuadrat) dengan derajat bebas (db) = n−1
Notasi yang digunakan:
n = banyak pasangan data, n ≥ 8 R = jumlah peringkat
k = banyaknya orang yang memberi peringkat (k >2)
Statistik uji = χ2=
1
1
3
12
2 2
n
kn
n
k
n
R
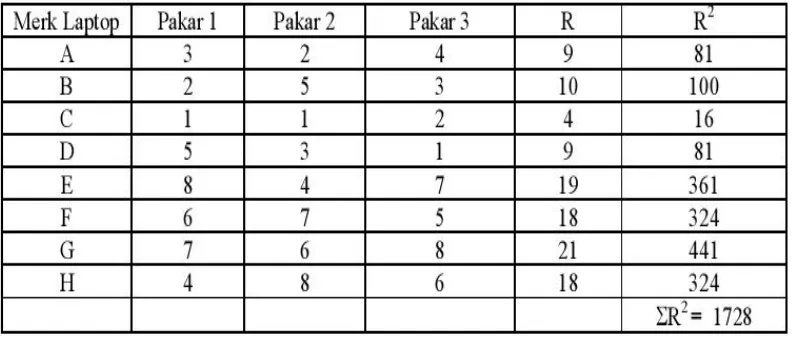
Teladan 12 :
Tiga konsultan Teknologi Informasi (TI) diminta memberi peringkat pada 8 merk laptop. Dengan taraf nyata 5% ujilah apakah terdapat kecocokan peringkat ?
Jawab:
1. H0: RKendall= 0 (tidak ada korelasi/tidak ada kecocokan)
H1: RKendall≠ 0 (ada korelasi/ada kecocokan)
2. Statistik uji: χ2
11. Uji Korelasi Rank Kendall (
τ
)
Merupakan ukuran kadar asosiasi/relasi/hubungan antara dua variabel yang didasarkan atas ranking dan data berskala ordinal.
Prosedur Perhitungan dan Pengujian:
1. Berikan ranking pada variabel X dan Y, jika ada ranking kembar buat rata-ratanya.
2. Urutkan ranking X dari terkecil hingga terbesar (1, 2, ….., n)
3. Tentukan harga S berdasarkan ranking Y yang telah disusun mengikuti X. Amati ranking Y mulai dari yang paling kecil menurut X, hingga yang terbesar menurut X. Kemudian beri nilai +1 untuk setiap harga yang lebih tinggi berdasarkan susunan ranking X dan – 1 untuk setiap harga yang lebih rendah.
4. Hitung koefisien korelasi kendall, digunakan rumus. S
τ
=
---½N(N − 1)
Teladan 13 :
kerja serta dicatat ketidakhadirannya (absen) selama sebulan kerja. Data yang diperoleh dapat dilihat pada tabel dibawah ini.
Pekerja NilaiTest Prestasi Kerja Motivasi Kerja Absen
1 78 79 84 3
Hasil olahan dengan menggunakan program SPSS
Correlations
Correlation is significant at the 0.01 level (2-tailed). **.
Soal Latihan :
Manajer Personalia PT. Duta Makmur ingin mengetahui apakah terdapat hubungan yang signifikan dan erat antara Nilai Test masuk seorang karyawan dengan Motivasi kerja, Prestasi kerja dan jumlah Absensi selama sebulan kerja. Untuk itu diambil 11 orang pekerja untuk dijadikan sampel penelitian, yang kemudian dinilai motivasi dan prestasi kerja serta dicatat ketidakhadirannya (absen) selama sebulan kerja. Data yang diperoleh dapat dilihat pada tabel dibawah ini.
Pekerja NilaiTest Prestasi Kerja Motivasi Kerja Absen
1 73 77 81 3
2 77 75 88 2
3 75 69 84 2
4 79 81 82 3
5 82 83 70 1
6 85 88 59 1
7 86 90 59 1
8 72 74 64 4
9 80 84 68 2
10 69 71 91 4
12. Uji Asosiatif (Uji Koefisien Kontingensi)
Analisis koefisien kontingensi digunakan untuk menganalisis data penelitian yang mempunyai karakteristik:
a. Hipotesis yang diajukan hipotesis asosiatif/menganalisis hubungan dua variabel yang berskala nominal
b. Data berskala nominal Rumus X2:
Lalu cari C (koefisien kontingensi) dan C max nya untuk melihat derajat keeratan hubungan yang terjadi :
m
m
C
maks
1
−
=
Makin dekat Nilai C dengan Cmaks makin besar derajat hubungan antar
variabel. Kemudian lakukan uji signifikansi berdasarkan nilai X2dengan df
(db) = (baris-1) (kolom-1).
Teladan 14 :
Ingin diketahui hubungan antara daerah tempat tinggal (urban dan rural) terhadap kemungkinan beberapa penyakit degeneratif (PJK, ginjal, ca paru, ca colon). Sampel yang diambil sebanyak 200 orang. Berikut datanya dalam bentuk tabel 2x2 (tabel kontingensi).
Daerah Penyakit Total
PJK Ginjal Ca Paru Ca colon
Fo fe fo fe fo fe fo fe fo fe
Urban 27 24 35 30 33 36 25 30 120 120
Rural 13 16 15 20 27 24 25 20 80 80
Total 40 40 50 50 60 60 50 50 200 200
a. Mencari frekuensi yang diharapkan fe (freq.expected) =
Misal : fe sel pertama (sel urban yang PJK) = 120x40/200 = 24 b. Menghitung nilai X2
= 0,375 + 0,833 + 0,250 + 0,833 + 0,563 + 1,250 + 0,375 + 1,250 = 5,729
c. Masukan ke rumus untuk mencari koefisien kontingensi (C)
= √ ((5,279) / (200 + 5,279)) = 0,16
Masukan ke rumus 3 untuk mencari nilai C max
m m C
maks
1 −
= = √ (2-1) /2 = √ 0,5 = 0,70
Dari point c dan d diperoleh nilai C sebesar 0,16 dan C max = 0,70. Karena nilai C dan C max cukup jauh, artinya derajat keeratan hubungan antara variabel independen (daerah tempat tinggal) dengan variabel dependen (penyakit degeneratif) tidak kuat.
d. Menentukan X2 tabel : df (dk) = (baris-1) (kolom-1) = (2-1) (4-1) =3
Dengan melihat tabelchi square pada df =3 dan α = 0,05 diperoleh nilai X2tabel = 7,815.
e. Bandingkan X2 hitung dengan X2 tabel
X2 hitung < X2 tabel = 5,279 < 7,815 H0 gagal ditolak (tidak ada