BAB 2
LANDASAN TEORI
Bab ini membahas tentang teori penunjang dan penelitian sebelumnya yang berhubungan dengan rekomendasi tag serta metode TF-IDF dan Collaborative tagging.
2.1 Rekomendasi Tag
Rekomendasi tag mengacu pada proses pemberian rekomendasi tag secara otomatis yang berguna dan informatif untuk sebuah objek yang muncul berdasarkan informasi historisnya. Objek yang akan ditandai dapat berupa foto, video atau dokumen. Secara umum, dokumen yang di-tag biasanya berhubungan dengan satu sama lain atau memiliki banyak koneksi tag. Pengguna juga dapat memberikan tag pada dokumennya dengan berbagai persepsi (Song et al, 2008).
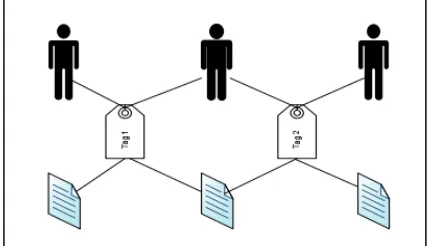
Gambar 2.1 Representasi Grafik Triplet (u, d, t) (Song et al, 2008)
baru hanya bisa dilakukan secara tidak langsung dari perspektif pengguna atau sudut pandang dokumen (Song et al, 2008).
Rekomendasi tag dapat dilakukan secara manual atau menggunakan autotag, yaitu pemberian tag secara otomatis dengan menggunakan suatu metode atau konsep pembelajaran tertentu seperti metode statistik dan text mining. Sistem rekomendasi tag secara otomatis memberikan kemudahan dalam memberikan rekomendasi tag terhadap informasi yang akan dipublikasikan terutama jika informasi tersebut memiliki ukuran yang besar atau cakupan yang luas. Selain itu, sistem rekomendasi tag secara otomatis juga akan menghemat penggunaan waktu dalam pemberian tag. Diharapkan rekomendasi yang diberikan dapat membantu pengguna dalam mengambil keputusan pemberian tag pada objek yang akan dipublikasikan sehingga nantinya dapat memudahkan dalam peroses filterasi objek tersebut ataupun objek lain yang memiliki kesamaan dengan objek tersebut.
Dari segi perilaku pengguna, sistem tag dapat diklasifikasikan menjadi 3, yaitu self-tagging, permission-based dan free-for-all. Pada self-tagging, pengguna hanya menandai konten yang mereka ciptakan untuk pengambilan pribadi di masa depan, contohnya seperti situs facebook (http://www.facebook.com/) dan YouTube (http://www.youtube.com/). Permission-based menetapkan berbagai tingkat izin untuk pemberian tag, contohnya seperti situs Flickr (http://www.flickr.com/). Kedua bentuk penandaan tersebut digolongkan sebagai ‘narrow folksonomies’ atau folksonomi sempit dan tidak mendukung atau tidak termasuk ke dalam collaborative tagging. Free-for-all memungkinkan pengguna untuk menandai setiap item dan merupakan sistem collaborative tagging, contohnya seperti situs Yahoo! MyWeb (http://myweb.yahoo.com/). Free-to-all tagging juga dikenal sebagai ‘broad folksonomy’ atau folksonomi luas (Ji et al, 2007).
2.2 Text Mining
pola-pola menarik tersebut tidak ditemukan diantara catatan database yang sudah diformalisasi melainkan dalam data tekstual yang tidak terstruktur di dalam koleksi dokumen-dokumen tersebut (Feldman et al, 2007).
Sama sepertihalnya data mining, text mining adalah salah satu bagian lain dari Knowledge Discovery. Text Mining sering juga disebut dengan Text Data Mining (TDM) atau Knowledge Discovery in Textual Database (KDT). Metode ini digunakan untuk menggali informasi dari data-data dalam bentuk teks seperti buku, makalah, paper, dan lain sebagainya. Secara umum text mining memiliki definisi ‘menambang’ data yang berupa teks dimana sumber data biasanya didapatkan dari dokumen, dan tujuannya adalah mencari kata-kata yang dapat mewakili isi dari dokumen sehingga dapat dilakukan analisa keterhubungan antar dokumen (Anggaradana, 2013).
Hal yang membedakan data mining dengan text mining adalah proses analisis terhadap suatu datanya. Data Mining atau Knowledge Discovery in Database (KDD) adalah proses untuk menemukan pengetahuan dari sejumlah besar data yang disimpan baik di dalam databases, data warehouses atau tempat penyimpanan informasi lainnya. Sedangkan untuk text mining sering disebut dengan Keyword-Based Association Analysis. Keyword-BasedAssociation Analysis merupakan sebuah analisa yang mengumpulkan keywords atau terms (istilah) yang sering muncul secara bersamaan dan kemudian menemukan hubungan asosiasi dan korelasi diantara keywords atau terms itu (Kurniawan et al, 2009).
Secara garis besar dalam melakukan implementasi text mining terdiri dari dua tahap besar yaitu pre-processing dan processing (Anggaradana, 2013).
2.2.1 Pre-Processing
Tahap pre-processing adalah tahap dimana aplikasi melakukan seleksi data yang akan diproses pada setiap dokumen. Setiap kata akan dipecah-pecah menjadi struktur bagian kecil yang nantinya akan mempunyai makna sempit. Ada beberapa hal yang perlu dilakukan pada tahap pre-processing ini, yaitu Tokenizing, Filtering,dan Stemming.
a. Tokenizing
memecah kalimat tersebut menjadi kata-kata atau frase-frase. Untuk beberapa kasus, pada tahap ini tindakan yang dilakukan adalah to Lower Case, dengan mengubah semua karakter huruf menjadi huruf kecil. Kemudian, dilakukan tahap tokenizing yaitu merupakan proses penguraian abstrak yang semula berupa kalimat-kalimat berisi kata-kata dan tanda pemisah antar kata seperti titik (.), koma (,), spasi dan tanda pemisah lain menjadi kumpulan kata-kata saja baik itu berupa kata penting maupun kata tidak penting (Anggaradana, 2013).
b. Filtering atau Seleksi Fitur
Tahap filtering adalah tahap mengambil kata-kata penting dari hasil token. Dimana dalam tahap ini bisa digunakakan algoritma stoplist (membuang kata yang kurang penting) atau wordlist (menyimpan kata penting). Dalam tahap ini penulis menggunakan algoritma stoplist. Stoplist / stopword adalah kata-kata yang tidak deskriptif yang dapat dibuang. Contoh stopwords adalah “yang”, “dan”, “di”, “dari” dan seterusnya. Proses ini akan menghasilkan daftar istilah beserta informasi tambahan seperti frekuensi dan posisi yang akan digunakan dalam proses selanjutnya (Anggaradana, 2013).
c. Stemming
ditemukembalikan. Hal tersebut tidak akan diperoleh jika tiap bentuk suatu kata disimpan secara terpisah dalam indeks.
Beberapa algoritma yang telah dikembangkan untuk proses stemming diantaranya Algoritma Porter (Bahasa Indonesia dan Inggris) dan Algoritma Nazief & Adriani untuk teks berbahasa Indonesia (Nazief et al, 1996). Dalam hal ini, Penelitian yang dilakukan Agusta (2009) menunjukkan algoritma Nazief & Adriani memiliki tingkat akurasi yang lebih tinggi dalam proses stemming untuk bahasa Indonesia dibandingkan algoritma Porter.
2.2.2 Processing
Tahap yang kedua adalah melakukan processing. Tahap ini merupakan tahap inti dimana setiap kata akan diolah dengan algoritma tertentu, yang dalam penelitian ini akan digunakan metode TF-IDF. Tahap ini sering disebut juga dengan Analizing. Dalam tahap processing, dokumen akan dianalisa oleh aplikasi. Secara umum terdapat dua jenis metode yaitu metode yang tidak melakukan perhitungan bobot kalimat dan yang melakukan perhitungan bobot kalimat. Metode yang tidak menghitung bobot kalimat hanya mengambil beberapa kalimat awal dan akhir. Metode-metode yang menghitung bobot kalimat menggunakan bobot term (kata maupun pasangan kata) dari setiap term yang terdapat dalam kalimat tersebut (Anggaradana, 2013).
Dalam penelitian ini digunakan metode yang menghitung bobot (term), dimana bobot term diperoleh dengan melakukan perhitungan terhadap Term Frequency dan Inverse Document Frequency dari term tersebut yaitu TF-IDF. Hasil perhitungan dari TF-IDF akan menghasilkan beberapa rekomendasi tag yang berasal dari dalam artikel tersebut. Selanjutnya digunakan teknik Collaborative tagging untuk mencari rekomendasi tag dari objek yang sudah dipublikasi sebelumnya.
2.3 Algoritma Nazief & Adriani
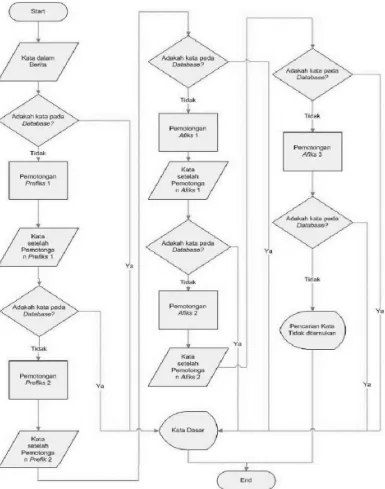
Gambar 2.2 Flow Chart Algoritma Nazief & Adriani (Nazief et al, 1996)
Proses stemming pada teks berbahasa Indonesia berbeda dengan stemming pada teks berbahasa Inggris. Pada teks berbahasa Inggris, proses yang diperlukan hanya proses menghilangkan sufiks. Sedangkan pada teks berbahasa Indonesia, selain sufiks, prefiks, dan konfiks juga dihilangkan (Nazief et al, 1996).
Tabel 2.1 Tabel kombinasi awalan akhiran yang tidak diijinkan (Adriani, et al. 2007) Awalan Akhiran yang tidak diijinkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
Adapun pemotongan kata dasar dibuat berdasarkan aturan peluruhan kata dasar seperti terlihat pada tabel 2.2.
Tabel 2.2 Tabel aturan peluruhan kata dasar (Adriani, et al. 2007)
Aturan Awalan Peluruhan
1 berV… Ber-V.. | be-rV…
2 belajar bel-ajar
3 berC1erC2 be-C1erC2.. dimana C1 !={‘r’ | ‘l’}
4 terV… ter-V.. | te-rV…
5 terCer… ter-Cer.. dimana C!==’r’
6 teC1erC2 te-C1erC2… dimana C1!=’r’
7 me{l|r|w|y}V… me-{l|r|w|y}V…
8 mem{b|f|v}… mem-{b|f|v}…
9 mempe… mem-pe…
10 mem{rV|V}… me-m{rV|V}…|me-p{rV|V}…
11 men{c|d|j|z}… men-{c|d|j|z}…
12 menV… me-nV…|me-tV…
13 meng{g|h|q|k }… meng-{g|h|q|k}…
14 mengV… meng-V…|meng-kV…
15 mengeC menge-C
16 menyV… me-ny.. | meny-sV…
17 mempV… mem-pV…
18 pe{w|y}V… pe-{w|y}V…
19 perV… per-V…|pe-rV…
20 pem{b|f|v}… pem-{b|f|v}…
21 pem{rV|V}… pe-m{rV|V}…|pe-p{rV|V}
22 pen{c|d|j|z}… pen-{c|d|j|z}…
Tabel 2.2 Tabel aturan peluruhan kata dasar (Adriani, et al. 2007)(Lanjutan)
Aturan Awalan Peluruhan
24 peng{g|h|q} peng-{g|h|q}
25 pengV peng-V | peng-kV
26 penyV pe-nya|peny-sV
27 pelV pe-lV…; kecuali untuk kata "pelajar" 28 PeCP pe-CP…dimana C!={r|w|y|l|m|n} dan P!='er' 29 perCerV per-CerV… dimana C!={r|w|y|l|m|n}
Untuk mengatasi keterbatasan pada algoritma di atas, maka ditambahkan aturan-aturan berikut:
1. Aturan untuk reduplikasi
a. Jika kedua kata yang dihubungan penghubung adalah kata yang sama maka root wordadalah bentuk tunggalnya, contoh “anak-anak” root word-nya adalah “anak”.
b. Kata lain misalnya “bolak-balik”, “berbalas-balasan” dan “seolah-olah”. Untuk mendapatkan root word-nya, kedua kata diartikan secara terpisah. Jika keduanya memiliki root word yang sama maka diubah menjadi bentuk tunggal, contoh: kata “berbalas-balasan”, “berbalas” dan “balasan” memiliki root word yang sama yaitu “balas”, maka root word “berbalas-balasan” adalah “balas”. Sebaliknnya, pada kata “bolak-balik”, “bolak” dan “balik” memiliki root word yang berbeda, maka root word-nya adalah “bolak-balik”.
2. Tambahan untuk awalan dan akhiran serta aturannya.
a. Tipe awalan “mem-”, kata yang diawali dengan awalan “memp-” memiliki tipe awalan “mem-”.
b. Tipe awalan “meng-”, kata yang diawali dengan awalan “mengk-” memiliki tipe awalan “meng-”.
2.4 Term Frequency-Invers Document Frequency (TF-IDF)
pada dokumen, tetapi diimbangi dengan frekuensi kata dalam korpus. Variasi dari skema pembobotan TF-IDF sering digunakan oleh mesin pencari sebagai alat utama dalam mencetak nilai (scoring) dan peringkat (ranking) sebuah relevansi dokumen yang diberikan user.
TF-IDF pada dasarnya merupakan hasil dari perhitungan antara TF (Term Frequency) dan IDF (Inverse Document Frequency). Banyak cara untuk menentukan nilai yang tepat dari kedua statistik yang ada. Dalam kasus term frequency tf (t, d), cara yang paling sederhana adalah dengan menggunakan raw frequency di dalam dokumen, yaitu berapa kali term t muncul di dokumen d. Jika menyatakan raw frequency t sebagai f (t,d), maka skema tf yang sederhana adalah tf (t, d) = f (t,d). Kemungkinan lain meliputi (Manning, et al. 2008):
- frekuensi Boolean : tf (t,d) = 1 jika t muncul di d dan 0 kebalikannya; - skala frekuensi logaritmik : tf (t,d) = log (f (t ,d) + 1);
- penambahan frekuensi, untuk mencegah bias terhadap dokumen lagi, misalnya raw frequency dibagi dengan raw frequency maksimum dari setiap term di dalam dokumen.
𝑡𝑓 (𝑡, 𝑑) = 0,5 +𝑚𝑎𝑥 {𝑓 (𝑤, 𝑑) ∶ 𝑤 ∈ 𝑑 (2.1)0,5 × 𝑓 (𝑡, 𝑑)
IDF (Inverse Document Frequency) merupakan ukuran apakah term itu umum atau langka di semua dokumen. Hal ini diperoleh dengan membagi jumlah dokumen di dalam korpus dengan jumlah dokumen yang berisi term, dan kemudian mengambil logaritma dari hasil bagi tersebut.
𝑖𝑑𝑓 (𝑡, 𝐷) = log| { 𝑑 ∈ 𝐷 ∶ 𝑡 ∈ 𝑑 | (2.2)|𝑁|
dimana:
- |𝑁| : kardinalitas dari N, atau jumlah total dokumen di dalam korpus.
- | { 𝑑 ∈ 𝐷 ∶ 𝑡 ∈ 𝑑 | : jumlah dokumen dimana term t muncul (misalnya 𝑡𝑓 (𝑡, 𝑑) ≠ 0). Jika term tidak ada di dalam korpus, hal ini akan mengacu kepada division-by-zero. Oleh karena itu, biasanya untuk menyesuaikannya rumus menjadi:
Secara matematis fungsi dasar log tidak lah penting dan merupakan faktor pengali terhadap hasil keseluruhan. Maka TF-IDF dapat dirumuskan menjadi:
𝑡𝑓𝑖𝑑𝑓 (𝑡, 𝑑, 𝐷) = 𝑡𝑓 (𝑡, 𝑑) × 𝑖𝑑𝑓 (𝑡, 𝐷) (2.4)
2.5 Collaborative Tagging
Collaborative tagging menawarkan alternatif rekomendasi tag dan filterasi tag yang telah banyak digunakan. Collaborative tagging digambarkan seperti berbagai pengetahuan antara objek satu dengan berbagai objek lainnya. Collaborative tagging memungkinkan pengguna untuk berbagi tag pada objek mereka dengan objek pengguna lain. Teknik ini juga memungkinkan pengguna untuk menandai objek mereka secara bebas dan berbagi konten, sehingga para pengguna dapat mengkategorikan informasi dengan bebas, dan mereka dapat menelusuri kategori informasi yang dimiliki oleh pengguna lain. Tag klasifikasi, dan konsep menghubungkan set tag antara server web/blog, telah menyebabkan munculnya klasifikasi folksonomi pada objek-objek di internet. Mereka cenderung menggunakan tag yang ada untuk dengan mudah membentuk koneksi antar objek dengan tag yang berkaitan (Lee, et al, 2008).
Collaborative tangging memungkinkan rekomendasi tag untuk objek baru yang akan publikasikan dapat berasal dari objek itu sendiri dan atau dari objek yang mirip. Pada metode collaborative tagging, tag yang berasal dari objek tersebut (Obaru)
akan dicocokkan dengan tag pada objek lainnya yang telah diterbitkan (Olama).
Tingkat kemiripan tag pada Obaru dengan Olama harus ditetapkan terlebih dahulu. Jika
tingkat kemiripan yang ditentukan telah melewati ambang batasnya, maka tag-tag pada Olama (selain tag yang sama antar Obaru dan Olama) akan diikutsertakan menjadi
rekomendasi tag pada Obaru (tag recommendation = Obaru Olama). Semakin tinggi
derajat tingkat kemiripan yang ditentukan, maka semakin akurat rekomendasi tag yang akan didapatkan dan berlaku sebaliknya.
2.6 Penerapan TF-IDF dan Collaborative Tagging pada Rekomendasi Tag
Secara umum, tahap-tahap dalam membentuk sistem rekomendasi tag pada penelitian ini mengggunakan metode text-mining dimana tahap stemming-nya menggunakan algoritma Algoritma Nazief & Adriani, tahap processing-nya menggunakan metode TF-IDF. Untuk meningkatkan kemampuan sistem dalam memberikan rekomendasi, digunakan Collaborative tagging agar rekomendasi tag dapat berasal dari berita lain yang pernah diterbitkan sebelumnya.
Adapun langkah-langkah pada sistem rekomendasi tag yang akan dikembangkan adalah sebagai berikut:
1. Masukkan text berita yang akan dibuat rekomendasinya.
2. Lakukan tokenizing pada text yang telah dimasukkan sehingga setiap kalimat pada text menjadi satuan kata-kata atau frase-frase. Kemudian sistem akan merubah semua karakter huruf menjadi huruf kecil melalui proses toLowerCase.
3. Lakukan filtering pada kata-kata atau frase-frase yang telah ada dengan menggunakan metode stoplist (membuang kata-kata yang kurang penting seperti kata sambung, kata depan, dan lain sebagainya).
4. Lakukan stemming pada setiap kata (k) menggunakan Algoritma Nazief & Adriani untuk teks berbahasa Indonesia yang berfungsi menemukan kata dasar dari setiap kata masukan. Untuk k =1 hingga k=n dilakukan langkah berikut:
4.1Samakan kata atau frase dengan kata-kata di dalam kamus dimana jika ditemukan maka diasumsikan kata tersebut adalah kata dasar atau root word, jika tidak maka tahap selanjutnya dilakukan.
4.2Lakukan Infection suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”) dibuang. Jika berupa particles (“-lah”, “-kah”, “-tah”, atau “-pun”) maka langkah ini diulangi untuk menghapus Passive Pronouns (“-ku”, “-mu”, atau “-nya”), jika ada.
4.3Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan dikamus, maka diasumsikan kata tersebut adalah root word. Jika tidak maka dilanjutkan ke langkah 4.3.1.
4.3.2 Akhiran yang dihapus (“i”, “-an” atau “-kan”) dikambalikan, lanjut ke tahap 4.4.
4.4Hapus derivation prefix (“di-”, “ke-”, “se-”, “te-”, “be-” dan “me-”). Jika pada langkah 3 ada suffix yang dihapus maka dilanjutkan ke langkah 4.4.1, jika tidak pergi ke langkah 4.4.2.
4.4.1 Periksa tabel kombinasi awalan-akhiran yang tidak diijinkan seperti pada tabel 2.1. Jika ditemukan, maka diasumsikan kata tersebut adalah root word, jika tidak lanjut ke langkah 4.4.2.
4.4.2 Fori=1 to 3, tentukan tipe awalan kemudian hapus awalan dan lakukan perubahan kata dasar sesuai tabel 2.2. Jika root word belum ditemukan lakukan langkah 5, jika sudah maka diasumsikan kata tersebut adalah root word. Catatan: jika awalan kedua dan awalan pertama adalah sama maka kata tersebut adalah root word.
4.5Lakukan recoding.
4.6Jika semua langkah selesai tetapi masih tidak berhasil, maka kata awal diasumsikan sebagai root word. Jika root word merupakan kata reduplikasi seperti “anak-anak”, “bolak-balik”, atau “berbalas-balasan”, maka kata tersebut harus mengikti aturan reduplikasi.
4.7k+1, ulangi proses stemming untuk kata berikutnya.
5. Setelah hasil stemming kata telah didapatkan, tentukan bobot tiap-tiap kata dengan menggunakan metode TF-IDF sebagai berikut:
5.1 Hitung TF yaitu frekuensi kemunculan kata term (t) pada text berita (d). 5.2Hitung invers document frequency (idf) yaitu dengan persamaan berikut:
idf = Log10(N/(1+df) ) (2.5) dimana:
N = merupakan jumlah seluruh berita yang ada pada tabel berita.
df = jumlah kemunculan kata (term) terhadap daftar isi berita di database. 5.3Hitung bobot (W) masing-masing dokumen dengan persamaan 2.6.
Wt= tf * idf (2.6)
dengan :
t = kata(term) ke –t tf = term freqency
5.4Lakukan proses pengurutan (sorting) nilai kumulatif dari W untuk setiap kata dan mengambil 6 kata dengan bobot terbesar akan dijadikan sebagai hasil rekomendasi tag.
6. Hasil rekomendasi tag dari proses TF-IDF akan dicari kemiripannya dengan berita lainnya yang telah diterbitkan dan disimpan pada Tabel Berita di database dengan langkah berikut:
6.1Persentasi kemiripan berita dihitung dengan persamaan 2.7.
Kpn = (%kemiripan * hslTfidf)/100 (2.7) Dimana:
Kpn = Jumlahkemiripan tag, %kemiripan = Persentase kemiripan tag,
hslTfidf = Jumlah rekomendasi tag hasil TF-IDF (hasil Langkah 5.4). 6.2Untuk setiap berita yang telah di-upload pada kategori yang sama dan
memiliki jumlah kemiripan tag Kpn maka tag pada berita lainnya akan ditambahkan ke dalam rekomendasi tag otomatis.
2.7 Teknik Rekomendasi Tag Terdahulu
Penelitian mengenai rekomendasi tag telah banyak dilakukan dengan berbagai algoritma guna mendapatkan hasil rekomendasi yang lebih relevan dan efektif.
Muflikah, Fadilah, dan Rido (2013) menggunakan Algoritma Latent Semantic Indexing untuk sistem rekomendasi tag pada dokumen blog. Adapun langkah-langkah rekomendasi tag dengan menggunakan Algoritma Latent Semantic Indexing yang mereka lakukan adalah sebagai berikut:
1. Parsing Dokumen Blog berformat .html ke .txt.
2. Proses Training Data meliputi pengelompokan tag dan pembentukan Graf term frequency (TF) dan first occurrence (FO).
4. Tahap ekstraksi TI merupakan proses untuk mendapatkan sekumpulan kata kunci TI sebanyak jumlah input TI dari user. TI yang diambil adalah sebanyak m kata dengan bobot score terbesar. Semakin tinggi nilai TF dan semakin rendah nilai FO maka semakin besar kemungkinan kata tersebut merupakan kata kunci.
5. Teknik dekomposisi matriks dengan Singular Value Decomposition (SVD). SVD berkaitan erat dengan singular value atau nilai singular dari sebuah matriks yang merupakan salah satu karakteristik matriks.
6. Ekstraksi tag (Tag-Out) menggunakan algoritma Latent Semantic Indexing (LSI) dengan langkah kerja sebagai berikut:
Matriks berukuran 𝑚𝑥𝑠 dibentuk pada saat proses dokumen uji, setelah tahap ekstraksi TI. Sebanyak m jumlah TI dicari pasangan co-occurrence-nya di dalam graf. Maka didapatkan sebanyak s jumlah TO yang paling sedikit memiliki nilai co-occurrence 1 dengan paling sedikit 1 buah TI.
Selanjutnya dibentuk matriks 𝐴𝑚𝑥𝑠 yang berisikan bobot untuk m TI dan s TO yang memiliki co-occurrence pada bipartite graph (bigraf). Bigraf dibentuk saat training data.
Kemudian dilakukan reduksi matriks menjadi Uk, Vk, dan Sk. Baris-baris pada
matriks Vk adalah kumpulan dari vektor eigen, maka tiap baris matriks Vk
merupakan koordinat vektor masing-masing dokumen.
Tahap terakhir adalah mengukur tingkat kesamaan (similarity) antara vektor query dan masing-masing vektor dokumen menggunakan rumus perhitungan cosine similarity.
Setelah didapatkan hasil kedekatan masing-masing vektor kemudian dilakukan pengurutan secara descending hasil similarity antara query dan semua dokumen. Semakin besar nilai similarity artinya semakin dekat hubungan antara TO dengan m TI yang telah dipilih pada proses ekstraksi keyword. 7. Metode Evaluasi dengan ukuran evaluasi terhadap sistem rekomendasi tag adalah
sebagai berikut:
Top-k accuracy. Prosentase dari dokumen yang rekomendasi tag-nya benar paling sedikit 1 dari sejumlah k tag teratas yang direkomedasikan (top-kth tag).
Tag-recall. Prosentase hasil tag rekomendasi yang benar dari seluruh tag yang telah diberikan oleh user. Tag rekomendasi yang benar adalah tag yang sama antara tag yang dihasilkan oleh program dan tag yang dibuat oleh user.
Tag-precision. Prosentase hasil tag rekomendasi yang benar dari seluruh tag yang dihasilkan oleh algoritma program.
F-Measure merupakan gabungan antara precision dan recall.
Pada tahun 2013, Purbasari, Cai, Lao, dan Al-Rawali melakukan penelitian mengenai rekomendasi tag pada situs berbagi gambar di Flikr®. Langkah-langkah yang dilakukan oleh dalam penelitian mereka adalah sebagai berikut:
1. Pengambilan tag dari Flickr®. Proses ini menggunakan API dari Flickr® dengan menggunakan implementasi Java sebagai bahasa pemrogramannya.
2. Lakukan crawling pada semua gambar di Flickr yang memiliki tag tersebut. Untuk setiap gambar yang ditemukan, diambil seluruh tag-nya dan dilakukan crawling kembali untuk mengambil tag dari gambar lain yang mengandung tag tersebut. Sejumlah gambar yang tidak memiliki tag tidak disimpan dalam database.
3. Lakukan iterasi selama stopping condition masih belum terpenuhi. Untuk menentukan stopping condition. Jika iterasi sudah melebihi maksimal iterasi maka pelatihan dihentikan. Bila nilai MAPE kurang dari atau sama dengan error tolerance maka pelatihan dihentikan.
4. Kegiatan pra-proses pada tag, yang meliputi pengecekan dengan kamus untuk menyaring kata yang berbahasa Inggris saja, Pembuangan tag yang memiliki frekuensi dengan frekuensi tertinggi maupun terendah,
5. Pembuatan matriks untuk memetakan tag dengan gambar. 6. Proses clustering untuk memudahkan proses mining tag.
7. Pencarian association rule pada setiap cluster untuk menghasilkan kombinasi tag yang sering muncul bersamaan. Algoritma Apriori mencari pasangan tag yang paling sering muncul bersamaan dengan menetapkan batasan confidence dan minimum support.
9. Pengambilan kembali gambar yang memiliki tag yang sama atau yang irekomendasikan. Selain menghasilkan output berupa tag hasil rekomendasi, sistem juga akan menampilkan sejumlah gambar dari Flickr yang memiliki tag yang direkomendasikan tersebut. Ini juga dilakukan melalui Flickr API dengan menggunakan metode SEARCH pada interface PhotoInterface.
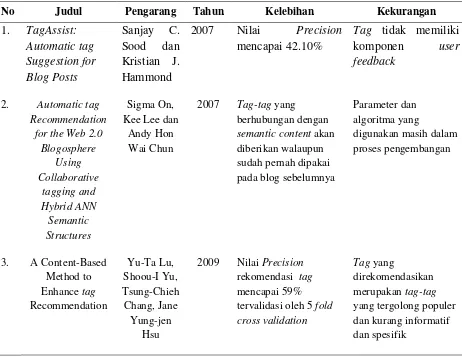
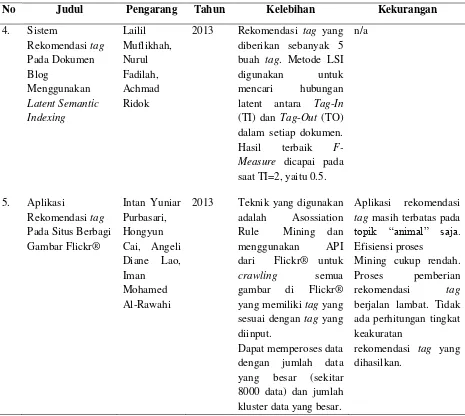
Adapun ringkasan beberapa penelitian terdahulu yang telah dilakukan untuk memberikan rekomendasi tag pada beberapa masalah yang berbeda dapat dilihat pada tabel 2.3.
Tabel 2.3 Penelitian Sebelumnya
No Judul Pengarang Tahun Kelebihan Kekurangan
Tabel 2.3 Penelitian Sebelumnya (Lanjutan)
No Judul Pengarang Tahun Kelebihan Kekurangan