PEN ERAPAN ASSOCIATION RULE MINING PADA DATA NOMOR UNIK PENDIDIK DAN TENAGA KEPENDIDIKAN UNTUK MENEMUKAN POLA
SERTIFIKASI GURU
Amiruddin*, Dr. I Ketut Eddy Purnama, ST, MT** Prof. Dr. Mauridhi Hery Purnomo, M.Eng*** [email protected], [email protected]
1 Jurusan Teknik Elektro FTI, ITS, Surabaya 2 Jurusan Teknik Elektro FTI, ITS, Surabaya 3 Jurusan Teknik Elektro FTI, ITS, Surabaya
Abstrak
Sebagai salah satu data penting Departemen Penddikan Nasional, database Nomor Unik
Pendidik dan Tenaga Kependidikan (NUPTK) yang terkumpul dan tersimpan terus
berkembang dan bertambah banyak. Jika data tersebut dibiarkan, maka akan menjadi
kuburan data yang tidak berarti dan tujuan pembangunan database NUPTK menjadi
tidak tercapai. Diperlukan struktur penyimpanan data yang berusaha untuk
memperbaiki efisiensi pengolahan dan penggalian data, terutama dalam membangun sebuah pola hubungan antar data dan mencari frequent itemset dalam database. Dalam penelitian ini digunakan association rule untuk menggali pola hubungan atribut-atribut dan frequent itemset dalam database NUPTK. Paradigma apriori digunakan untuk mencari large itemset dalam penetapan association rule. Integrasi association rule
dengan paradigma apriori telah berhasil menemukan sejumlah pola hubungan antar atribut dalam dalam database NUPTK. Rule dengan nilai lift = 1.9 dengan selisih
interpretasi0.002 dapat digunakan untuk penetapan pola sertifikasi guru.
1. Pendahuluan
NUPTK adalah Nomor Unik Pendidik dan Tenaga Kependidikan yang
merupakan Nomor Registrasi bagi Pendidik dan Tenaga Kependidikan pada jenjang Pendidikan Dasar dan Menengah baik Formal maupun Non Formal. Pembuatan
NUPTK bertujuan untuk mendukung pemerintah dalam hal mengidentifikasi jumlah
pendidik dan tenaga kependidikan secara riil sebagai upaya menunjang ketersediaan
data yang akurat dan mutakhir dalam mendukung perencanaan berbagai program,
analisa kebutuhan dan pemerataan tenaga pendidik serta pelaksanaan program dan kegiatan yang berkaitan dengan Peningkatan Mutu Pendidik dan Tenaga Kependidikan
di Indonesia. Setiap kebijakan yang berkaitan dengan program-program pemberdayaan, pemberian kesejahteraan dan peningkatan kompetensi, kualifikasi, peningkatan
profesionalisme, dan program sertifikasi yang diberikan oleh Pemerintah Pusat melalui
Ditjen Peningkatan Mutu Pendidik dan Tenaga Kependidikan Depdiknas kepada Pendidik dan Tenaga Kependidikan bersumber pada informasi yang diperoleh dari
NUPTK
Data NUPTK yang dimiliki saat ini semakin lama semakin bertambah banyak.
Jumlah data yang begitu besar justru dapat menjadi masalah jika tidak dapat
dimanfaatkan. Sehingga diperlukan usaha untuk memilah dan menggali data NUPTK yang dapat diolah menjadi informasi. Jika data NUPTK dibiarkan, maka data tersebut
hanya akan menjadi sampah yang tidak berarti dan tujuan pembangunan database NUPTK menjadi tidak tercapai. Oleh karena itu diperlukan sebuah pendekatan atau
metode pengolahan data yang mampu memilah dan memilih data yang besar, sehingga
dapat diperoleh informasi yang berguna bagi penggunanya.
Data Mining (Penggalian Data) didefinisikan sebagai sebuah proses untuk
menemukan hubungan, pola dan trend baru yang bermakna dengan menyaring data yang sangat besar, yang tersimpan dalam penyimpanan, menggunakan teknik
pengenalan pola seperti teknik statistik dan matematika [4]. Hubungan yang dicari
dalam data mining dapat berupa hubungan antara dua atau lebih dalam satu dimensi,
misalnya dalam dimensi produk, kita dapat melihat keterkaitan pembelian suatu produk
dengan produk yang lain. Selain itu hubungan juga dapat dilihat antara 2 atau lebih
dalam penelitian ini diusulkan sebuah algoritma untuk mencari kaidah aturan asosiasi
untuk menemukan pola-pola data NUPTK yang digunakan untuk menunjang
pengambilan keputusan sertifikasi guru.
Penggalian kaidah asosiasi mempunyai peranan penting dalam proses
pengambilan keputusan. Tahapan besar dari proses Data Mining adalah
mengidentifikasikan frequent itemset dan membentuk kaidah asosiasi dari itemset
tersebut. Kaidah asosiasi digunakan untuk menggambarkan hubungan antar item pada tabel data transaksional ataupun data relasional. Tapi semakin berkembangnya teknologi
komputer di dunia industri, semakin pesat pula perkembangan ukuran data yang
dihasilkan. Dan pada data yang besar (VLDB, Very Large Database) tersebut, proses
pencarian frequent itemset sangatlah sulit. Dari kondisi tersebut, maka dalam penelitian
ini diusulkan algoritma Apriori untuk mencari large itemset dari sebuah basis data. Ide dasar paradigma apriori ini adalah dengan mencari himpunan kandidat
dengan panjang (k+1) dari sekumpulan pola frequent dengan panjang k, lalu
mencocokkan jumlah kemunculan pola tersebut dengan informasi yang terdapat dalam database. Paradigma apriori yang dikembangkan oleh Agrawal dan Srikan (1994), yaitu anti-monotone Apriori Heuristic: Setiap pola dengan panjang pola k yang tidak sering muncul (tidak frequent) dalam sebuah kumpulan data, maka pola dengan panjang
(k+1) yang mengandung sub pola k tersebut tidak akan sering muncul pula (tidak
frequent) [7].
Tujuan yang hendak dicapai dalam penelitian ini adalah Untuk menetapkan
pola-pola informasi penting yang tersembunyi dalam database NUPTK melalui penggunaan aturan assosiatif (association rule) untuk analisa penetapan sertifikasi guru
berdasarkan tingkat kecenderungan munculnya persyaratan sertifikasi yang terpenuhi secara bersama dalam database.
2. Tinjauan Literatur dan Metode 2.1. Mining Association R ule
Mining association rules atau pencarian aturan-aturan hubungan antar item dari suatu basis data transaksi atau basis data relasional, telah menjadi perhatian utama
himpunan hubungan antar item dalam bentuk A1A...AAm => B1A...ABn dimana A, (
for i E {1,...,m}) dan B; ( for j C {1,...,n} ) adalah himpunan atribut nilai, dari sekumpulan data yang relevan dalam suatu basis data. Sebagai contoh, dari suatu
himpunan data transaksi, seseorang mungkin menemukan suatu hubungan berikut, yaitu
jika seorang pelanggan membeli selai, ia biasanya juga membeli roti dalam satu
transaksi yang sama. Oleh karena proses untuk menemukan hubungan antar item ini
mungkin memerlukan pembacaan data transaksi secara berulang- ulang dalam sejumlah besar data-data transaksi untuk menemukan pola-pola hubungan yang berbeda-beda,
maka waktu dan biaya komputasi tentunya juga akan sangat besar, sehingga untuk
menemukan hubungan tersebut diperlukan suatu algoritma yang efisien dan
metodemetode tertentu.
Analisis asosiasi atau association rule mining adalah teknik data mining untuk menemukan aturan assosiatif antara suatu kombinasi item. Contoh dari aturan assosiatif
dari analisa pembelian di suatu pasar swalayan adalah dapat diketahuinya berapa besar
kemungkinan seorang pelanggan membeli roti bersamaan dengan susu. Dengan pengetahuan tersebut pemilik pasar swalayan dapat mengatur penempatan barangnya
atau merancang kampanye pemasaran dengan memakai kupon diskon untuk kombinasi
barang tertentu. Karena analisis asosiasi menjadi terkenal karena aplikasinya untuk
menganalisa isi keranjang belanja di pasar swalayan, analisis asosiasi juga sering
disebut dengan
istilah market basket analysis [1]
Fungsi Association Rules seringkali disebut dengan "market basket analysis", yang digunakan untuk menemukan relasi atau korelasi diantara himpunan item. Market
Basket Analysis adalah Analisis dari kebiasaan membeli customer dengan mencari
asosiasi dan korelasi antara item- item berbeda yang diletakkan customer dalam keranjang belanjaannya. Fungsi ini paling banyak digunakan untuk menganalisa data
dalam rangka keperluan strategi pemasaran, desain katalog, dan proses pembuatan keputusan bisnis. Tipe association rule bisa dinyatakan sebagai misal : "70% dari
orangorang yang membeli mie, juice dan saus akan membeli juga roti tawar". Aturan
asosiasi mengcapture item atau kejadian dalam data berukuran besar yang berisi data
besar yang disebut dengan "basket data." Aturan asosiasi yang didefinisikan pada basket
data, digunakan untuk keperluan promosi, desain katalog, segmentasi customer dan target pemasaran. Secara tradisional, aturan asosiasi digunakan untuk menemukan trend
bisnis dengan menganalisa transaksi customer.
Berdasarkan definisi di [6] maka pencarian pola kaidah asosiasi mengunakan
dua buah parameter nilai yaitu dukungan (support) dan keterpercayaan (confidence)
yang memiliki nilai antara 0% - 100 %. Berikut sedikit penjelasan mengenai dukungan dan keterpercayaan.
Sebagai contoh terdapat relasi I berisi sejumlah kumpulan item yang kemudian
dikatakan sebagai itemset, dimana masing–masing itemset terdiri dari sekumpulan
atribute bertipe boolean I1, I2, …, In. Dan basis data transaksi D yang berisi transaksi T,
adalah himpunan dari I atau T Í I. Dimana transaksi T pada basis data transaksi D
memiliki sebuah atribut yang unik yang dinotasikan dengan TID. Dalam konteks ini, A
dan B merupakan itemset dari transaksi T, jika dan hanya jika A Í T dan B Í T.
Sehingga jumlah A dinotasikan σ (A) merupakan jumlah Support (support count) itemset A pada basis data transaksi D. Kaidah asosiasi A› B, jika dan hanya jika A I,
B I dan A B 0. Sehingga A› B memiliki Support s pada transaksi T, dimana S
merupakan persentase itemset A È B pada basis data transaksi D. Dan A› B memiliki
Confidence C pada transaksi T, dimana C merupakan persentase jumlah itemset A yang
terdapat pada relasi I, yang diikuti itemset B. Dukungan kaidah asosiasi A› B
dinyatakan dengan :
Support (A› B) = P(AÈB) (xx)
Sedangkan keterpercayaan kaidah asosiasi A› B dinyatakan dengan :
Confidence (A› B) = P(A|B) (xx)
dimana :A dan B adalah frequent itemset memiliki jumlah dukungan lebih besar
2.2. Algoritma Apriori
Persoalan association rule mining terdiri dari dua sub persoalan :
a. Menemukan semua kombinasi dari item, disebut dengan frequent itemsets,yang
memiliki support yang lebih besar daripada minimum support.
b. Gunakan frequent itemsets untuk men-generate aturan yang dikehendaki.Semisal,
ABCD dan AB adalah frequent, maka didapatkan aturan AB -> CD jika rasio dari
support(ABCD) terhadap support(AB) sedikitnya sama dengan minimum confidence. Aturan ini memiliki minimum support karena ABCD adalah frequent.
Algoritma Apriori yang bertujuan untuk menemukan frequent itemsets dijalankan
pada sekumpulan data. Pada iterasi ke -k, akan ditemukan semua itemsets yang
memiliki k items, disebut dengan k - itemsets. Tiap iterasi berisi dua tahap. Misal Oracle DataMining Fk merepresentasikan himpunan dari frequent k -itemsets, dan Ck adalah
himpunan candidate k-itemsets (yang potensial untuk menjadi frequent itemsets). Tahap
pertama adalah men-generate kandidat, dimana himpunan dari semua frequent (k- 1) itemsets, Fk-1, ditemukan dalam iterasi ke-(k-1), digunakan untuk men-generate
candidate itemsets Ck. Prosedur generate candidate memastikan bahwa Ck adalah
superset dari himpunan semua frequent k-itemsets. Struktur data hash-tree digunakan
untuk menyimpan Ck. Kemudian data di-scan dalam tahap penghitungan support. Untuk
setiap transaksi, candidates dalam Ck diisikan ke dalam transaksi, ditentukan dengan menggunakan struktur data hash-tree hashtree dan nilai penghitungan support
dinaikkan. Pada akhir dari tahap kedua, nilai Ck diuji untuk menentukan yang mana dari candidates yang merupakan frequent. Kondisi penghitung (terminate condition) dari
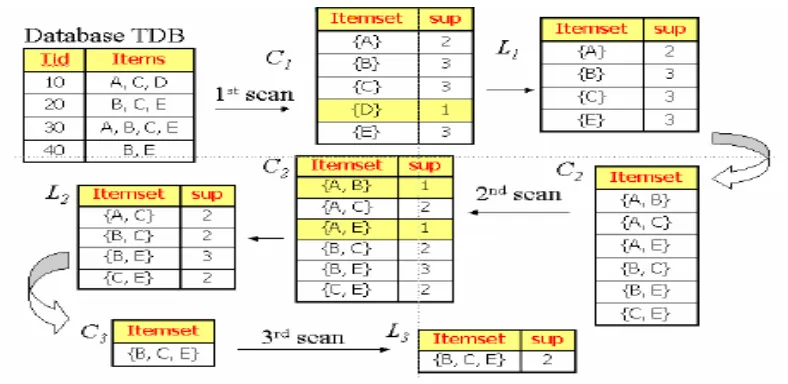
I lustrasi Algoritma Apriori
Gambar 1. Ilustrasi Algoritma Apriori
Dari ilustrasi di atas dapat dijelaskan bahwa:
a. Untuk menghasilkan Lk, maka diperlukan candidate k-itemset Ck yang dibentuk dari
proses join antar L k-1
b. Catatan konvensi: Apriori mengasumsikan bahwa item dalam transaksi atau itemset
telah terurut berdasarkan urutan lexicographic.
c. Proses join, L k-1 × L k-1, dilakukan jika (k-2 itemset dari L k-1 “sama”.
d. Misal ll dan ll adalah itemset dari L k-1, supaya proses join dapat dilakukan maka harus dipenuhi: (l 1[1] = l 2[1]) ^ l 1[2] = l 2 [2]) ^…^ (l 1 [k-2] = l 2 [k-2]) ^ l 1 [k-1] < l
2 [k-1])
e. Kondisi (l 1 [k-1] < l 2 [k-1]) menjamin tidak ada kembar pada proses join. Jadi itemset yang dihasilkan dari proses join antara I1 dan I2 adalah l 1[1] l 1[2] ... l 1 [k-1] I2
[k-2]
f. Notasi l 1 [j] menyatakan item yang ke-j dalam l.
3. Tahapan Mining Association R ule 3.1. Pembangunan Association Rules
Analisis asosiasi dikenal juga sebagai salah satu teknik data mining yang
analisis asosiasi yang disebut analisis pola frequensi tinggi (frequent pattern mining)
menarik perhatian banyak peneliti untuk menghasilkan algoritma yang efisien.
Metodologi dasar analisis asosiasi terbagi menjadi dua tahap :
Analisa pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai
support dalam database. Nilai support sebuah item diperoleh dengan rumus 1 berikut[3]:
…...[rumus 1]
sedangkan nilai support dari 2 item diperoleh dari rumus 2 berikut [3]:
...[rumus 2]
Pembentukan aturan assosiatif
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan assosiatif
yang memenuhi syarat minimum untuk confidence dengan menghitung confidence aturan assosiatif A › B Nilai confidence dari aturan A› B diperoleh dari rumus 3
berikut:
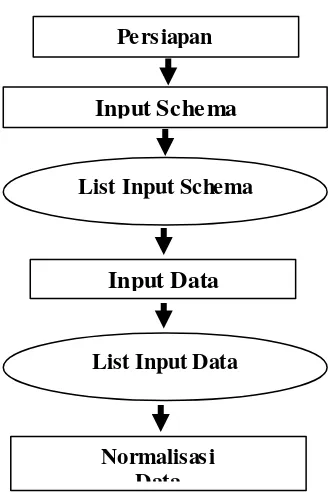
Gambar 2. Preprocessing Mining Data NUPTK
3.1.1 Persiapan Data
Adapun tahapan-tahapan yang harus dilalui dalam proses data mining antara lain: a. Seleksi Data
Atribut-atribut data NUPTK yang digunakan dalam penelitian ini adalah Nomor
Identitas (ID), NUPTK, Kualifikasi Pendidikan, Mapel Sertifikasi, Jenjang Sekolah
Tempat Bertugas, Usia, Jumlah Jam Mengajar, Portofolio/PLPG, mata pelajaran
yang diampu, matapelajaran yang disertifikasi, jumlah jam per minggu, dan
pengembangan profesi. Data sekolah terkait dengan nama sekolah, alamat sekolah,
jenjang sekolah, status sekolah, dan status akreditasi sekolah.
b. Pembersihan Data
Proses pembersihan data dilakukan untuk membuang record yang keliru, menstandarkan attribut-attribut, merasionalisasi struktur data, dan mengendalikan data yang hilang.
c. Reduksi Data
Reduksi data dilakukan dengan menghilangkan atribut-atribut yang tidak diperlukan seperti atribut tahun lulus, alamat sekolah, jumlah kelas, alamat rumah, nama ibu, nama istri, nomor rekening, hingga data yang dikutkan dalam proses datamining adalah data
Persiapan
Input Sche ma
Input Data
Normalisasi Data
List Input Schema
yang berisi atribut-atribut penting yang sesuai dengan tuntutan informasi yang ingin digali seperti atribut yang dijelaskan pada poin a di atas.
d. Bentuk Standar
Bentuk standar adalah adalah bentuk data yang akan diakses oleh algoritma data mining. Data dalam penelitian ini dibuat dalam bentuk binary valued data. Pengubahan data dalam bentuk binary valued data dilakukan dengan menggunakan software LUCS-KDD-DN yang dikembangkan oleh The University of Liverpool
3.1.2. Input Sche ma
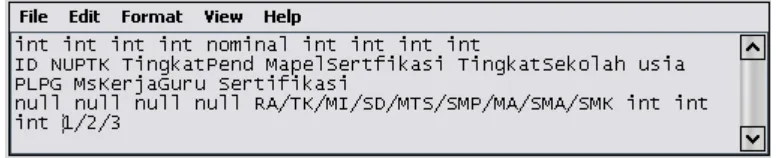
Proses input schema diawali dengan menetapkan atribut-atribut yang akan dicari pola
asosiasinya. Schema dibuat dalam tiga baris teks yang masing- masing berisi urutan dari N literal yang dipisahkan dengan spasi, dimana N adalah jumlah atribut dalam
kumpulan data yang akan dikonversi.
Baris pe rtama: digunakan untuk mendiskripsikan “type” dari setiap field dengan pilihan : Unused, nominal, integer dan double
Baris kedua: digunakan untuk mendiskripsikan untuk pemberian nama fields hal ini akan berfungsi untuk mencocokkan nomor kolom yang terkandung
dalam Association Rules dan CAR untuk keluaran schema
Baris ke tiga: digunakan untuk mendiskripsikan legal value dari setiap dataitem. Misalnya untuk tipe Unuseds, integer dan double digunakan literal
Null sedangkan nilai nominal digunakan karakter dengan tanda “/” (backslash)
Maka input schema data NUPTK adalah sebagai berikut:
Ga mbar 3. Input Schema Data NUPTK
3.1.3.ListInput Schema
Dari hasil input schema sebagaimana dijelaskan pada poin 3.2.2 diperoleh
(1) int: ID
3.2.4. Normalisasi Data
Proses normalisasi meliputi normalisasi Input schema dan normalisasi Input data. Normalisasi dilakukan sebagai ujicoba pada relasi dalam data NUPTK untuk
menentukan apakah relasi tersebut sudah baik. Apabila terdapat atribut yang tidak tepat
dapat dilakukan proses modifikasi, insert, update ataupun delete tanpa mempengaruhi
integritas data dalam relasinya.
1 5 7 9 17 20 23 25 27 1 5 7 9 13 20 23 25 27 2 5 7 9 13 21 23 26 27 3 5 6 8 13 21 22 26 29
…
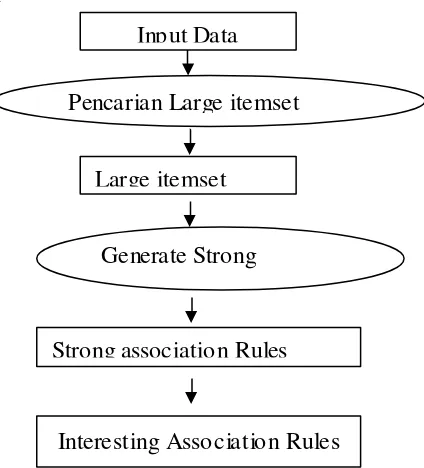
3.2. Pemodelan Sistem
Gambar 4. Proses Mining Data NUPTK
4. Hasil Association Rule Mining
Banyaknya rules yang dihasilkan memberikan banyak kemungkinan untuk melihat
pola-pola yang muncul dalam database NUPTK. Sehingga memberikan berbagai
kemungkinan yang dapat dijadikan sebagai dasar untuk membuat keputusan. Tidak
semua rules yang ditemukan dalam penelitian ini diinterpretasi. Yang diinterpretasi
adalah rule-rule yang memiliki nilai Lift yang tinggi (alasan obyektif) dan rule yang memiliki relevansi dengan kebutuhan (alasan subyektif).
Lift merupakan sebuah angka ratio yang menunjukkan berapa banyak kemungkinan menemukan sebuah atribut (misal ID) muncul bersama dengan atribut
lainnya (misal Kualifikasi, Nomor Unik, dan Mapel sertifikasi) dibandingkan dengan
seluruh kejadian adanya atribut yang terpenuhi. Input Data
Pencarian Large itemset
Large itemset
Generate Strong Association Rule
Strong association Rules
Lift menunjukkan adanya tingkat kekuatan rule atas kejadian acak dari
antecedent dan consequence berdasarkan pada supportnya masing- masing. Hal ini akan mermberikan informasi tentang perbaikan dan peningkatan probabilitas dari consequent
berdasarkan antecedent. Lift didefinisikan sebagai berikut:
Lift = Confidence / Expected Confidence Dimana
Expecte d Confi de nce = (Juml ah Tr ansaksi me miliki item c onse quent) / (Total jumlah tr ansaksi)
Atau dengan cara:
Ketika Lift sama dengan 1 maka A dan B adalah independen karena
Pr(C|A)=Pr(C). Ketika probabilitas C terjadi dipengaruhi oleh terjadinya A maka Lift lebih besar dari 1. Ketetapan lift ratio adalah apabila hasil perhitungan berada di bawah
1 maka item- item tersebut tidak menunjukkan adanya saling keterkaitan antara antecedent dengan consequent.
Berikut adalah interpretasi sebagian rule-rule yang berhasil ditemukan setelah
dilakukan proses Association Rules Mining sebagaimana pada tabel 4.3. di atas:
Rule 1: {NUPTK=1 TingkatPend=1 MapelSertfikasi=1} -> {PLPG=1 Sertifikasi=1}
Jika Pendidik (guru) dan Tenaga Kependidikan (non guru) memiliki NUPTK
(Nomor Unik Pendidik dan Tenaga Kependidikan), Tingkat Pendidikan
(Kualifikasinya S1) dan Mata Pelajaran yang disertifikasinya tidak miss-match maka Pendidik atau Tenaga Kependidikan tersebut juga dapat diprediksi
memiliki sertifikat PLPG dan status Sertifikasinya diterima.
Dengan rule ini dapat dijadikan sebagai dasar untuk menetapkan Pendidik dan
Tenaga Kependidikan yang lulus sertifikasi adalah mereka yang memenuhi atribut-atribut NUPTK, Kualifikasi Pendidikan S1, dan Mata Pelajaran yang
disertifikasi linear dengan Mata pelajaran yang diampu Pr(A|C)
Rule 50: {PLPG=1} -> {NUPTK=1 TingkatPend=1} 1.64
Rule ini dijadikan sebagai dasar untuk menetapkan Pendidik dan Tenaga Kependidikan yang lulus PLPG adalah mereka yang memenuhi atribut NUPTK
dan Kualifikasi Pendidikan S1
Rule 150: {NUPTK=1 TingkatPend=1 PLPG=1} -> {MapelSertfikasi=1} 1.4 Rule ini dijadikan sebagai dasar untuk menetapkan bahwa ketika Pendidik dan
Tenaga Kependidikan memenuhi persyaratan NUPTK, Tingkat Pendidikan dan PLPG maka persyaratan lain yang harus dipenuhi adalah Mata Pelajaran yang
diajukan untuk disertifikasi tidak miss-match.
Rule 181 : {NUPTK=1} -> {32.0<=usia<50.0} 1.04, Rule 182 :
{32.0<=usia<50.0} -> {NUPTK=1} 1.04 Rule 183 {NUPTK=1} -> {MsKerjaGuru<11 } 1.03, dan R ule 184: {MsKerjaGuru<11} -> {NUPTK=1} 1.03
Rule 181,182,183 dan 184 dijadikan sebagai dasar untuk menetapkan bahwa
Pendidik dan Tenaga Kependidikan yang memiliki masa kerja dari 11 tahun dan
berusia 32 – 50 tahun berhak untuk memiliki NUPTK. Pendidik dan Tenaga
Kependidikan yang memiliki masa kerja di atas 11 tahun dan belum memiliki
NUPTK hendaknya diberi kemudahan untuk melakukan pengurusan NUPTK
5. Kesimpulan
Dari hasil analisa dan interpretasi Association rule data mining NUPTK, maka dapat disimpulkan bahwa:
1. Association rule mining menggunakan metode apriori berhasil
diimplementasikan menemukan 184 rule penting yang tersembunyi dalam database NUPTK
2. Pola data yang ditemukan pada data NUPTK yang memuat atribut sertfikasi dengan kategori lulus memiliki kecenderungan asosiasi yang kuat dengan
atribut-atribut PLPG, NUPTK, Kualifikasi Pendidikan S1 dan Mata Pelajaran
3. Kecendurangan pola yang terbentuk dari association rule mining data NUPTK
dapat ditetapkan bahwa guru-guru yang Lulus sertfikasi adalah guru yang memenuhi atribut PLPG, NUPTK, Kualifikasi Pendidikan S1 dan Mata
Daftar Pustaka
[1] Berry, Michael J.A dan Linoff , Gordon S., 2004, Data Mining TechniquesFor Marketing, Sales, Customer RelationshipManagementSecond Editon, Wiley Publishing, Inc.
[2] Dunham, Margaret H. 2003. Data Mining Introductory and Advanced Topics, New Jersey: Prent ice Hall
[3] Larose , Daniel T, 2005, Discovering Knowledge in Data: An Introduction to Data Mining, John Willey & Sons. Inc
[4] Ponniah, P., 2001, Datawarehouse Fundamentals : A comprehensive Guide for IT Professional, John Willey & Sons. Inc
[5] Pramudiono, I., 2006, Apa itu data mining?, http://datamining.japati.net/cgibin/
indodm.cgi?bacaarsip&1155527614&artikel, tanggal terakhir akses 16 Januari 2007
[6] R. Agrawal and R. Srikant. Fast Algorithm for Mining Association Rules. In Proceedings of the International Conference on Very Large Data Bases, 1994.
[7] R. Agrawal and et al. Mining Association Rules Between Sets of Items in Large Databases. In Proceedings of the ACM SIGMOD, 1993.
[8] R. Agrawal, H. Mannila , R. Srikant, H. Toivonen, and A. Inkeri Verkamo,