DASAR TEORI
Pada bab ini diuraikan teori-teori yang mendasari pembuatan tugas akhir. Teori-teori ini meliputi pembahasan mengenai konsep mengenai OCR, image preprocessing, serta pattern recognition, dan teori mengenai jaringan saraf tiruan dan algoritma genetik. Konsep mengenai OCR yang akan dibahas di bab ini meliputi definisi OCR, langkah-langkah OCR, dan keuntungan dari penggunaan OCR. Teori mengenai jaringan saraf tiruan yang akan dibahas di bab ini meliputi definisi jaringan saraf tiruan serta proses-proses dalam jaringan saraf tiruan. Teori mengenai algoritma genetik yang akan dibahas di bab ini meliputi definisi algoritma genetik, kelebihan algoritma genetik, proses-proses dalam algoritma genetik, dan operator-operator dalam algoritma genetik.
2.1 Optical Character Recognition (OCR)
OCR adalah sebuah aplikasi untuk mengubah dokumen dalam bentuk gambar digital ke dalam bentuk dokumen dengan format teks (ASCII) yang dapat dengan mudah diubah isinya. Gambar digital tersebut biasa didapat dengan cara melakukan scanning dengan menggunakan perangkat keras berupa scanner. Gambar digital tersebut dapat berisi tulisan tangan maupun tulisan ketik.
Hal pertama yang dilakukan oleh aplikasi OCR moderen adalah membagi halaman ke dalam beberapa elemen dasar seperti teks, tabel, gambar, dan sebagainya. Teks akan dibagi lagi menjadi per baris. Baris teks akan dibagi menjadi kata dan akhirnya menjadi karakter. Kemudian karakter-karakter tersebut akan dibandingkan dengan berbagai pola karakter yang ada. Karakter tersebut akan melalui beberapa hipotesa dan kemungkinan yang pada akhirnya menunjuk kepada karakter tersebut. Pada akhirnya, karakter-karakter yang telah dikenali tersebut akan dirangkaikan kembali ke dalam bentuk teks seperti di awal menjadi sebuah dokumen teks digital hasil OCR. [ABBYY]
Beberapa keuntungan dari penggunaan OCR, yaitu:
1. Dokumen hasil OCR dapat dengan mudah diubah isinya. 2. Pencarian terhadap isi dokumen menjadi sangat mudah. 3. Biaya penyimpanan dokumen menjadi sangat rendah.
2.1.1 Handwriting Recognition
Handwriting recognition adalah kemampuan dari komputer untuk menerima dan mengenali masukan berupa tulisan tangan. Gambar masukan tulisan tangan dapat diterima secara offline, yaitu melalui proses scanning pada kertas, ataupun secara online, yaitu melalui gerakan pena pada komputer berbasis layar sentuh.
2.1.2 Digit Recognition
Digit recognition adalah sebuah aplikasi OCR yang terbatas pada pengenalan karakter angka saja. Angka yang dimaksud adalah 0, 1, 2, 3, 4, 5, 6, 7, 8, dan 9. Salah satu contoh penggunaan pengenalan angka adalah pada sistem pengenalan ZIP code surat di Amerika untuk memudahkan proses sorting surat.
2.2 Image Preprocessing and Enhancement
Image preprocessing adalah sekumpulan operasi citra pada level abstraksi terendah [SON99]. Image preprocessing bertujuan memperbaiki kualitas citra sehingga distorsi pada citra dapat dihilangkan atau ditekan sekecil mungkin. Noise serta informasi yang tidak dibutuhkan oleh proses selanjutnya akan dihilangkan dalam proses ini. Hal iniakan mempermudah pemrosesan citra selanjutnya.
Operasi-operasi pada image preprocessing meliputi image brightening, contrast stretching, image smoothing, gamma correction, histogram equalization, retinex, dan lain-lain. Operasi-operasi tersebut merupakan operasi yang biasanya digunakan untuk meningkatkan kualitas citra. Pada Tugas Akhir ini, citra akan melalui beberapa operasi terlebih dahulu, yakni binerisasi dan penipisan.
2.2.1 Binerisasi
Binerisasi adalah proses mengubah citra fullcolor atau grayscale menjadi citra biner. Citra biner hanya memiliki dua derajat nilai warna untuk setiap pixelnya, yaitu putih (0) dan hitam (1) sehingga sering disebut juga black-and-white atau monochrome image. 0 berarti pixel tersebut merupakan background, sedangkan 1 berarti pixel tersebut merupakan bagian dari objek.
Salah satu cara melakukan binerisasi yaitu dengan menggunakan nilai threshold. Nilai threshold akan menentukan apakah pixel merupakan bagian dari objek atau hanya merupakan background. Misalnya, sebuah gambar grayscale dalam RGB melalui proses binerisasi dengan nilai threshold 128 berarti semua pixel dengan nilai intensitas warna di atas 128 akan dinaikkan menjadi 255 dalam RGB atau 0 dalam biner merupakan background (putih), sedangkan pixel dengan nilai intensitas warna 128 ke bawah akan diturunkan menjadi 0 dalam RGB atau 1 dalam biner merupakan bagian dari objek (hitam).
2.2.2 Penipisan
Penipisan adalah pengurangan sebagian tepi objek melalui operasi beda himpunan [SON99]. Penipisan merupakan sebuah proses iterasi di mana tepi objek dikikis pada tiap iterasi hingga citra hanya memiliki ketebalan satu pixel, tanpa menghilangkan keterhubungan antar pixel pembentuk citra. Citra hasil penipisan disebut dengan rangka (skeleton). Contoh penipisan dapat dilihat pada Gambar II.1.
Salah satu algoritma penipisan yang cukup populer dan baik kinerjanya adalah algoritma penipisan Zhang-Suen. Kelebihan dari algoritma ini adalah topologi objek akan dipertahankan, waktu proses yang cepat, dan cukup mudah untuk diimplementasikan. Algoritma ini menggunakan metode paralel dalam arti nilai yang baru dapat dihasilkan dengan hanya menggunakan nilai-nilai pada iterasi sebelumnya.
Gambar II.2 Matriks penipisan Zhang-Suen
Algoritma penipisan Zhang-Suen dibagi menjadi dua sub iterasi. Algoritma ini mengacu pada matriks pixel seperti pada Gambar II.2. Pada sub iterasi pertama pixel P1 akan dihapus jika memenuhi kondisi berikut:
Di mana A(P1) adalah jumlah pola transisi 0-1 dalam urutan P2, P3, ..., P8, P9. B(P1) adalah jumlah tetangga P1 yang tidak bernilai 0, yaitu B(P1) = P2 + P3 + ... + P8 + P9.
Sedangkan pada sub iterasi kedua, kondisi (iii) dan (iv) di atas diubah menjadi:
Jika kondisi-kondisi tersebut terpenuhi pada sub iterasi pertama maupun kedua, pixel yang sedang diproses akan dihapus. Algoritma ini akan berhenti jika sudah tidak ada pixel yang dihapus pada sub iterasi pertama atau kedua.
2.3 Pattern Recognition
Pattern recognition adalah suatu ilmu yang berkaitan dengan pengklasifikasian atau pengenalan hasil pengukuran terhadap suatu objek. Pengklasifikasian adalah penempatan objek dengan pola tertentu ke dalam satu atau beberapa kelas pola yang sudah dispesifikasikan sebelumnya berdasarkan ciri-ciri tertentu. Kemampuan untuk mengklasifikasikan tersebut adalah pengenalan.
Berdasarkan bentuk alamiah objek, pengenalan pola dapat dibedakan menjadi pengenalan objek konkrit atau pengenalan sensorik dan pengenalan objek abstrak atau pengenalan konseptual. Pengenalan pola karakter digital termasuk pengenalan sensorik, sedangkan pengenalan solusi suatu masalah merupakan pengenalan konseptual. Yang akan dibahas di sini adalah pengenalan sensorik.
Dalam sistem pengenalan pola, ada tiga pendekatan yang sering dipakai yaitu pendekatan statistik, sintaktik, dan metode jaringan saraf tiruan. Setiap pendekatan memberikan bentuk aplikasi pengenalan pola yang berbeda. Pendekatan statistik dan sintaktik akan membentuk klasifikator pola, sedangkan pendekatan jaringan saraf tiruan akan membentuk asosiator pola.
2.4 Jaringan Saraf Tiruan (JST)
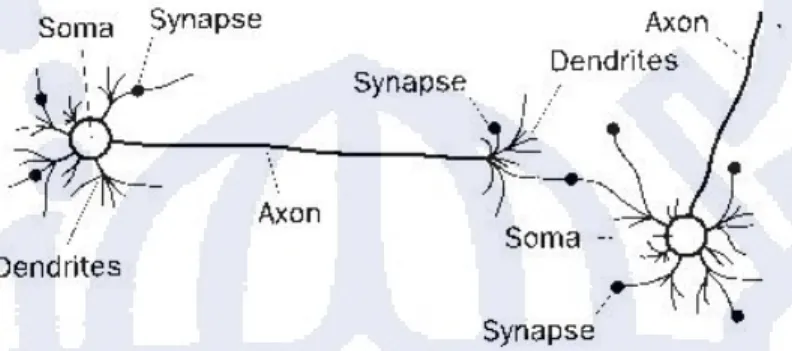
2.4.1 Jaringan Syaraf BiologisAktivitas berpikir dan bertingkah laku diyakini dikendalikan oleh otak dan seluruh sistem syaraf. Kemampuan untuk belajar dan bereaksi terhadap suatu perubahan di dalam lingkungan, tentunya memerlukan sesuatu yang dinamakan kecerdasan. Sebagai contoh adalah jalur optik pada sistem penglihatan manusia. Stimulus eksternal ditransformasikan melalui sel kerucut dan sel batang ke dalam sinyal yang memetakan fitur dari Gambar visual menjadi memori internal. Kecerdasan manusia kemudian digunakan untuk memahami bermacam-macam fitur visual yang diserap dan disimpan di dalam memori. Contoh jaringan syaraf biologis dapat dilihat pada Gambar II.3.
Gambar II.3 Biological Neuron Networks
2.4.2 Jaringan Saraf Tiruan
Jaringan saraf tiruan adalah sebuah model yang menyamai atau mengimitasi suatu jaringan syaraf biologis (Biological Neural Network). Node dalam JST didasari oleh representasi matematis yang disederhanakan dari neuron yang sebenarnya. Sekarang komputasi neural menggunakan konsep dari sistem syaraf biologis untuk mengimplementasikan simulasi software dari proses paralel yang besar, yang melibatkan elemen-elemen proses (disebut neurons atau neurodes) yang terhubung satu sama lain dalam arsitektur jaringan. Neurode adalah analogi dari neuron biologis, menerima input yang merepresentasikan impuls-impuls elektris, yang diterima oleh neuron biologis dari neuron-neuron lainnya. Output dari neurode dapat disamakan dengan sinyal yang dikirim oleh dari neuron biologis melalui axon. Axon pada neuron biologis bercabang menuju dendrite neuron lain, dan impuls-impuls ditransmisikan melalui synaps. Sebuah synaps dapat meningkatkan atau menurunkan kekuatannya, dengan demikian, mempengaruhi perambatan level sinyal. Hal tersebut mengakibatkan pembangkitan sinyal (excitation) atau penghalangan sinyal (inhibition) ke neuron berikutnya.
Kemampuan untuk belajar berdasarkan adaptasi adalah faktor utama yang membedakan sistem syaraf tiruan dari aplikasi sistem pakar. Sistem pakar diprogram untuk membuat kesimpulan (inference) berdasarkan data yang menjelaskan lingkungan. Permasalahan sistem syaraf tiruan, dipihak lain, dapat menyesuaikan bobot node sebagai tanggapan input dan mungkin pada output yang diinginkan.
Kemajuan dalam komputasi neural sekarang, terinspirasi oleh pemahaman tentang jaringan syaraf biologis. Tapi, walaupun penelitian yang cukup banyak dalam neurobiology dan psikologi, pertanyaan penting tentang bagaimana otak dan pikiran bekerja, tetap tidak terjawab. Hal tersebut adalah salah satu alasan, mengapa model komputasi neural tidak begitu dekat atau sama dengan pemahaman tentang sistem biologis.
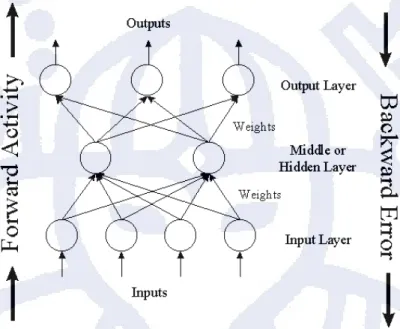
Penelitian dan pengembangan JST menghasilkan sistem yang menarik dan bermanfaat yang menggunakan beberapa fitur dari sistem biologis, meskipun sebenarnya kita masih jauh dari pembuatan mesin seperti otak (brain-like machine). Bidang penerapan komputasi neural terus berkembang, dengan lebih banyak penelitian dan pengembangan yang dibutuhkan untuk meniru otak manusia. Tetapi walaupun demikian, banyak teknik-teknik yang bermanfaat, yang terinspirasi dari sistem biologis, yang digunakan dalam aplikasi-aplikasi nyata. Tabel II.1 menunjukan perbandingan antara BNN dan JST. Sedangkan Gambar II.4 merupakan diagram dari JST.
Tabel II.1 Biological Neural Network vs Jaringan Saraf Tiruan
Fakta-fakta tentang Neuron
BNN JST
Soma Node
Dendrit Input
Axon Output
Synaps Weight
Kecepatan rendah Kecepatan tinggi
Gambar II.4 Typical Set Up Jaringan Saraf Tiruan
2.4.3 Dasar-dasar Komputasi Neural
2.4.3.1 Neurode
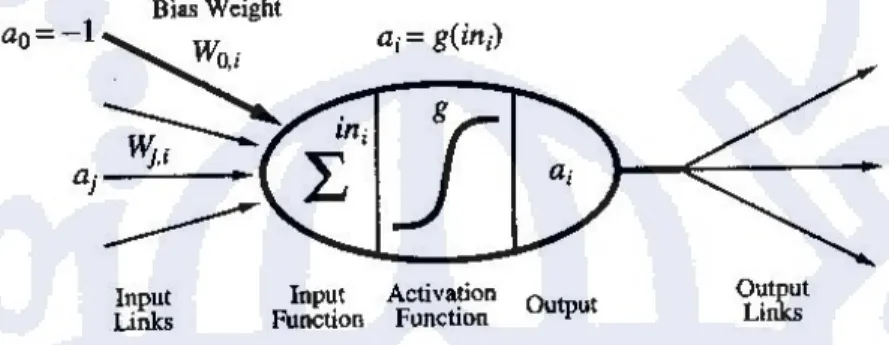
Sebuah JST terdiri dari unit-unit dasar yang disebut artificial neurons atau neurodes, yang merupakan elemen pemroses dalam sebuah jaringan. Setiap neurode menerima input data, memprosesnya, kemudian mengeluarkan sebuah output tunggal. Input bisa berasal dari data mentah maupun dari output neuron lainnya. Output bisa merupakan produk final, ataupun menjadi input bagi neuron lainnya.
2.4.3.2 Jaringan
Sebuah JST terdiri dari kumpulan neuron-neuron yang terhubung, yang sering dikelompokan dalam lapisan-lapisan (layers). Pada umumnya tidak ada asumsi yang spesifik mengenai arsitektur jaringannya. Bermacam-macam topologi jaringan syaraf merupakan pokok persoalan dari penelitian dan pengembangan JST. Dalam hal arsitektur berlapis, ada dua struktur dasar. Dua struktur dasar tersebut adalah:
Struktur dua lapisan: input dan output
Lapisan input (input layer) menerima data dari luar dan mengirimkan sinyal ke lapisan berikutnya. Lapisan terluar mengintepretasikan sinyal dari lapisan sebelumnya, untuk kemudian menghasilkan hasil yang ditransmisikan ke luar sebagai pemahaman jaringan terhadap input data yang diterimanya.
2.4.3.3 Input
Sebuah input dapat disamakan dengan sebuah atribut tunggal dari suatu pola atau data lainnya dari dunia luar. Jaringan dapat dirancang untuk menerima sekumpulan nilai input yang berupa nilai biner atau kontinu. Perlu dicatat, bahwa dalam komputasi neural, input hanya dapat berupa bilangan. Jadi apabila terdapat masalah yang bersifat kualitatif atau berupa grafik, maka informasi tersebut harus diproses terlebih dahulu untuk menghasilkan suatu nilai numerik yang ekivalen sebelum dapat diintepretasikan oleh JST.
2.4.3.4 Output
Output dari sebuah jaringan adalah solusi dari masalah. Tujuan dari sebuah jaringan adalah untuk menghitung nilai output. Dalam tipe JST supervised, output awal dari jaringan biasanya tidak tepat, dan jaringan harus disesuaikan sampai didapatkan output yang benar.
2.4.3.5 Hidden Layer
Dalam arsitektur banyak lapisan (multi-layered), hidden layers tidak berinteraksi secara langsung dengan dunia luar, tetapi menambah tingkat kompleksitas agar JST dapat beroperasi dalam masalah yang lebih kompleks. Hidden layer menambah sebuah representasi internal dari suatu masalah, yang dapat menjadikan jaringan memiliki kemampuan untuk berurusan secara robust dengan masalah yang bersifat kompleks dan non linear.
2.4.3.6 Bobot (weight)
Weight atau bobot dalam JST mengungkapkan kekuatan relatif (atau nilai matematis) dari berbagai koneksi yang mentransfer data dari layer ke layer. Dengan kata lain, bobot mengungkapkan kepentingan relatif dari setiap input ke dalam elemen proses (neuron). Bobot sangat penting untuk JST, karena dengan bobot ini jaringa disesuaikan secara berulang untuk menghaasilkan output yang diinginkan, dengan bobot demikian juga membuat jaringan untuk belajar. Tujuan dari melatih JST adalah untuk menemukan himpunan bobot yang akan dapat mengintepretasikan data input dari suatu masalah dengan tepat.
2.4.3.7 Fungsi Penjumlahan (Summation Function)
Summation function menghitung rata-rata bobot dari semua elemen input. Sebuah summation function sederhana akan mengalikan setiap nilai input dengan bobotnya dan menjumlahkannya untuk weighted sum.
Dengan demikian neurodes dalam dalam sebuah JST memiliki kebutuhan pemrosesan yang sangat sederhana. Intinya, mereka harus memantau sinyal yang datang dari neurodes lain, menghitung weighted sum, dan kemudian menentukan sinyal yang cocok untuk dikirimkan ke neurodes yang lainnya.
2.4.3.8 Fungsi Transfer / Aktivasi
Fungsi transfer yang dipakai dalam metode belajar backpropagation harus memiliki sifat kontinu dan dapat diturunkan. Terdapat banyak fungsi transfer yang digunakan, pemakaiannya tergantung dari aplikasi yang dirancang, yang penting fungsi transfer tersebut turunannya mudah dihitung untuk dapat mengimplementasikan algoritma backpropagation ini. Fungsi transfer yang biasa dipakai oleh metode belajar backpropagation adalah fungsi sigmoid biner. Sistem kerja fungsi aktivasi ditujukan melalui Gambar II.5.
Gambar II.5 Fungsi Aktivasi
Fungsi aktivasi / transfer sigmoid bipolar (-1 … 1): g(x) = 1 – e-x
1 + e
2.4.4 Arsitektur Jaringan Saraf Tiruan -x
Model jaringan syaraf yang telah dipelajari dan diimplementasikan banyak sekali ragamnya. Tiga arsitektur representatif adalah sebagai berikut:
a. Associative Memory Systems
Sistem ini mengkorelasi data input dengan informasi yang disimpan di dalam memori. Informasi ini dapat dipanggil kembali dari input yang tidak lengkap atau input yang terganggu. Associative memory systems ini dapat mendeteksi kesamaan (similarity) antara input baru dan pola yang telah disimpan. Sebagian besar arsitektur jaringan syaraf dapat digunakan sebagai associative memory, dan contoh utamanya adalah jaringan Hopfield (Medsker dkk, 1994).
b. Multiple Layer Structure
Associative memory systems dapat memiliki satu atau lebih lapisan tengah (hidden layers). Algoritma belajar yang paling lazim dipakai untuk arsitektur ini adalah backpropagation, dimana pendekatannya adalah dengan mengkoreksi jaringan ketika disesuaikan dengan data yang diberikan padanya. Tipe lain dari supervised learning adalah competitive filter associative memory. Tipe ini dapat belajar dengan cara
mengubah bobotnya dalam pengenalan kategori data input, tanpa disediakan contoh oleh external trainer. Contoh utama dari tipe ini adalah jaringan Kohonen.
c. Double Layer Structure
Struktur ini dicontohkan oleh pendekatan Adaptive Resonance Theory, tidak memerlukan pengetahuan tentang banyaknya kelas dalam training data, tapi menggunakan feed forward dan feedback untuk menyesuaikan parameter. Pada tipe ini data dianalisis utuk membangun banyaknya kategori yang dapat berubah-ubah, yang merepresentasikan input data yang diberikan.
2.4.5 Paradigma Belajar
Pertimbangan yang penting dalam JST adalah penggunaan algritma yang sesuai untuk belajar. JST telah didesain untuk tipe belajar yang berbeda. Tipe-tipe belajar tersebut adalah:
a. Heteroassociation
Memetakan satu set data ke data yang lainnya. Tipe ini akan menghasilkan output yang pada umumnya berbeda dengan pola inputnya. Tipe ini digunakan, sebagai contoh, dalam aplikasi prediksi stock market.
b. Autoassociation
Menyimpan pola untuk toleransi error. Tipe ini menghasilkan pola output yang mirip atau tepat sama dengan pola inputnya. Contoh penggunaan tipe ini adalah dalam sistem pengenalan karakter secara optik.
c. Regularly detection
Mencari fitur yang berguna dalam data (feature extraction). Tipe ini digunakan dalam sistem identifikasi sinyal sonar.
d. Reinforce learning
Beraksi terhadap feedback. Tipe ini digunakan pada pengendali dalam pesawat luar angkasa.
Ada dua pendekatan dasar belajar dalam JST, yaitu supervised learning dan unsupervised learning.
2.4.5.1 Supervised Learning
Dalam pendekatan supervised learning, kita menggunakan sekumpulan input dimana output yang sesuai telah diketahui. Perbedaan antar output aktual dan output yang diinginkan digunakan untuk mengkalkulasi koreksi pada bobot jaringan syaraf (disebut learning with a teacher).
2.4.5.2 Unsupervised Learning
Dalam unsupervised learning, JST mengorganisasikan dirinya untuk menghasilkan kategori dimana kumpulan input akan termasuk ke dalamnya. Tidak ada pengetahuan tentang apakah klasifikasi yang dibuat benar atau tidak, dan darimana jaringan berasal bisa berarti atau tidak untuk orang yang menggunakan jaringan. Tetapi, banyaknya kategori dapat dikontrol dengan cara mengubah-ubah parameter tertentu dalam model. Dalam kasus unsupervised learning ini, harus ada pemeriksaan manusia dalam kategori final untuk memberikan arti dan menentukan kegunaan dari output yang dihasilkan. Contoh dari tipe belajar ini adalah ART dan Kohonen self-organizing feature maps.
2.4.6 Perbedaan Kemampuan Jaringan Syaraf
Tabel II.2 Kemampuan Jaringan Syaraf
Paradigma Metode Training Waktu Training Waktu Eksekusi
Backpropagation Supervised Lambat Cepat
ART2 Unsupervised Cepat Cepat
Kohonen Unsupervised Medium Cepat
Hopfield Supervised Cepat Medium
Boltzmann Supervised Lambat Lambat
Pertimbangan yang penting pada tahap ini adalah banyaknya neuron dan layer yang digunakan. Aplikasi yang akan dibangun harus dianalisis terlebih dahulu mengenai banyaknya nodes yang digunakan untuk merepresentasikan input dan untuk menghasilkan output. Jumlah nodes ini harus sesuai dengan teknologi yang tersedia. Untuk teknik yang ada sekarang, jaringan dikatakan besar jika mencapai kira-kira 1000 nodes.
Tipe output yang dihasilkan JST bermacam-macam yaitu:
a. Klasifikasi. Aplikasi ini umumnya memerlukan output diskrit yang menentukan ke kategori mana input termasuk.
b. Pengenalan pola. Penggunaan JST terbanyak adalah untuk fungsi pengenalan pola ini. Jenis aplikasi JST ini memerlukan beberapa node. Dalam aplikasinya nodeoutput dapat aktif secara keseluruhan atau beberapa node saja. Contoh terbanyak penggunaan pola adalah pada aplikasi pengidentifikasian tanda tangan nasabah di bank.
c. Bilangan riil. Outputnya berupa bilangan riil. Area aplikasinya termasuk perencanaan financial dan robotics.
d. Optimasi. Output berupa matriks yang merepresentasikan sesuatu, misalnya sumber daya yang harus dialokasikan.
2.4.7 Backpropagation
Metode backpropagation sering juga disebut dengan generalized delta rule. Backpropagation adalah metode turunan gradien (gradient descent method) untuk meminimalkan total squared error dari output yang dikeluarkan oleh jaringan.
Karakteristik dari jaringan backpropagation (jaringan multilayer dan feedforward yang dilatih oleh backpropagation) ini adalah dapat digunakan untuk menyelesaikan masalah dalam bermacam-macam area. Aplikasi yang menggunakan jaringan backpropagation dapat ditemukan dalam banyak bidang yang menggunakan jaringan syaraf untuk maslah yang melibatkan pemetaan suatu input tertentu terhadap output yang tertentu pula (supervised learning). Tujuan dari jaringan syaraf tersebut adalah keseimbangan antara kemampuan untuk merespon secara tepat pola input yang digunakan untuk training (memorization) dan kemampuan untuk memberikan respon yang baik terhadap nput yang mirip, tapi tidak identik, yang digunakan dalam training (generalization).
Proses training jaringan dengan backpropagation melibatkan 3 tahap, yaitu tahap feedforward dari pola input training, penghitungan dan propagasi balik error, dan penyesuaian bobot.
Berikut merupakan algoritma dari back propagation:
function BACK-PROP-LEARNING(examples, network) returns a neural network inputs: examples, a set of examples, each with input vector x and ouput vector y
network, a multilayer network with L layers, weights Wj,i, activation fuction g repeat
for each e in examples do
for each node i in the input layer do aj← xj[e] for l = 2 to M do
ini← ∑j Wj,i aj ai← g(ini)
for each node i in the output layer do
∆i← g’(ini) x (yi[e] - ai) for l = M – 1 to 1 do
for each node j in layer l do
∆j ← g’(inj) ∑i Wj,i∆i
for each node i in layer l + 1 do Wj,i← Wj,i+ α x aj x ∆
2.5 Algoritma Genetik
i until some stopping criterion is satisfied
return NEURAL-NET-HYPOTHESIS(network)
Algoritma genetik menurut Mitchell [MIT97] adalah metode pencarian solusi untuk masalah optimasi berdasarkan analogi terhadap teori seleksi alam Darwin dan teori mutasi dalam reproduksi biologi. Ide untuk menggunakan prinsip dari proses evolusi alam sebagai metoda pencarian nilai optimum telah muncul dua dekade yang lalu. Pendekatan untuk meniru operasi genetik dan pemprosesan informasi, seperti reproduksi dan seleksi dari populasi dipakai untuk mendapatkan algoritma yang efisien [GEN97]
Prinsip yang mendasari algoritma genetik pertama kali dipublikasikan oleh John Holland dari Universitas Michigan pada tahun 1962. Kerangka matematika yang dikembangkan pada akhir tahun 1960 dalam adaptation in natural and artificial system dipublikasikan pada tahun 1975. Dalam buku tersebut, Holland menuliskan bahwa algoritma genetik memiliki kemampuan untuk melakukan optimasi parameter.
Daya tarik algoritma genetik terletak pada kesederhanaan dan pada kemampuan untuk mencari solusi yang baik dengan cepat untuk masalah yang kompleks [GEN97]. Algoritma genetik sangat cocok dan efisien dipakai apabila:
1. Ruang pencarian luas, kompleks, dan sulit dipahami.
2. Domain pengetahuan jarang atau pengetahuan ahli susah diterapkan untuk mempersempit ruang pencarian.
3. Tidak adanya analisis matematis.
Algoritma genetik disebut pula algoritma evolusioner karena cara kerjanya mirip dengan prinsip-prinsip evolusi makhluk hidup. Langkah pertama dalam algoritma genetik adalah menciptakan solusi awal yang mungkin untuk sebuah masalah. Solusi ini kemudian diuji kelayakannya (atau seberapa baik solusi yang ditawarkan). Semua solusi yang mungkin diseleksi untuk mendapatkan himpunan solusi yang baik. Proses evolusi dilakukan pada solusi-solusi yang terpilih untuk menghasilkan generasi-generasi baru (yang diharapkan lebih baik dari generasi sebelumnya). Keuntungan teknik ini adalah mampu mencari sebuah solusi yang baik dari sekian banyak solusi yang mungkin dengan kemungkinan keberhasilan yang lebih besar daripada memakai metode lain yang membatasi pencarian pada domain yang sempit di mana hasil yang diperoleh kurang memuaskan.
Algoritma genetik berbeda dengan metode-metode optimasi dan prosedur pencarian konvensional dalam beberapa hal yang sangat fundamental. Goldberg [GOL89] menyimpulkan perbedaan-perbedaan tersebut sebagai berikut:
1. Algoritma genetik bekerja dengan sekumpulan kode solusi, bukan solusi itu sendiri.
2. Algoritma genetik mencari dari populasi solusi, bukan solusi tunggal.
3. Algoritma genetik menggunakan fungsi fitness, bukan turunan atau pengetahuan bantu lain.
4. Algoritma genetik menggunakan aturan transisi probabilistik.
2.5.1 Proses-proses dalam Algoritma Genetik
Proses pertama yang dilakukan oleh algoritma genetik adalah membangkitkan populasi awal secara acak. Kemudian dari populasi awal tersebut dihasilkan populasi-populasi baru melalui operator-operator genetik seperti produksi, mutasi, dan persilangan. Proses pembangkitan populasi tersebut akan dilakukan secara berulang-ulang sampai tercapai tercapainya batas nilai iterasi atau tujuan akhir.
Berikut merupakan algoritma dari GA:
function GENETIC-ALGORITHM(population, FITNESS-FN) returns an individual inputs: population, a set of individuals
FITNESS-FN, a function that measures the fitness of an individual repeat
new_population ← empty set
loop for i from 1 to SIZE(population) do
x ← RANDOM-SELECTION(population, FITNESS-FN)
y ← RANDOM-SELECTION(population, FITNESS-FN) child ← REPRODUCE(x,y)
if (small random probability) then child ← MUTATE(child) add child to new_population
population ← new_population
until some individual is fit enough, or enough time has elapsed return the best individual in population, according to FITNESS-FN
function REPRODUCE(x,y) returns an individual input: x, y, parent individuals
n ← LENGHT(x)
c ← random number from 1 to n
return APPEND(SUBSTRING(x, 1, c), SUBSTRING(y, c + 1, n))
2.5.2 Komponen dan Operator-operator Algoritma Genetik
Algoritma genetik menurut Mitchell [MIT97] mempunyai beberapa komponen penting seperti populasi dan fungsi fitness. Selain komponen tersebut, algoritma mempunyai beberapa operator seperti operator reproduksi, persilangan, mutasi, dan operator khusus lainnya. Berikut ini adalah penjelasan dari setiap komponen dan setiap operator tersebut
2.5.2.1 Populasi
Populasi menurut Mitchell [MIT97] adalah kumpulan dari hipotesa dalam bentuk kromosom. Kromosom-kromosom ini dibangkitkan secara acak dan terdiri atas fungsi dan terminal yang sesuai dengan persoalan yang dihadapi. Jumlah individu yang
dibangkitkan sesuai dengan jumlah maksimal individu dalam suatu populasi. Proses pembangkitan populasi ini sendiri merupakan proses pertama yang akan dilakukan oleh algoritma genetik.
2.5.2.2 Kromosom
Kromosom merupakan unsur dari pembentuk populasi. Kromosom ini merupakan kumpulan dari gen dengan aturan-aturan tertentu. Pada populasi, kromosom akan dikenakan mutasi dan persilangan sebanyak parameter yang diberikan pada sistem. Tiap kromosom dapat dinilai kelayakan hidupnya dalam populasi dengan menggunakan sebuah parameter bernama fungsi fitness.
2.5.2.3 Fungsi Fitness (Fitness Function)
Fungsi fitness menurut Mitchell [MIT97] adalah kriteria dalam membuat peringkat dari setiap hipotesis dan secara probabilistik menentukan kelayakan hipotesis tersebut untuk disertakan ke generasi berikutnya dari populasi. Fungsi fitness yang akan dipakai dapat dilihat di rumus (II - 1).
Fit(ij) =-∑(Ot – Tt)2
2.5.2.4 Operator Reproduksi/Seleksi
(II - 1)
Fungsi fitness ini dipakai untuk menghilangkan efek seasonal. Penjelasan tentang besaran O dan T adalah sebagai berikut ini:
O : adalah nilai keluaran yang dihasilkan kromosom T : adalah nilai target.
Semakin besar nilai fitness, semakin baik fungsi tersebut.
Operator reproduksi menurut Mitchell [MIT97] bersifat aseksual yaitu hanya beroperasi pada satu individu dan menghasilkan hanya satu anak pada setiap kesempatan operator tersebut diterapkan. Operasi reproduksi terdiri dari dua langkah. Pertama, satu individu
dalam populasi dipilih menurut metode seleksi berdasarkan nilai fitness tertentu. Kedua, individu yang dipilih pada langkah pertama disalin dari populasi yang lama ke populasi yang baru. Ada banyak metode seleksi berdasarkan nilai fitness. Yang paling populer adalah seleksi nilai kesesuaian fitness (fitness-proportionate selection). Jika fit(ij) adalah nilai fitness individu ij
(II - 2)
dalam populasi P dengan p individu, maka probabilitas individu tersebut akan disalin ke populasi hasil operasi reproduksi dapat dilihat dalam rumus
. Pr(ij ∑= p j j j i fit i fit 1 ( ) ) ( ) = (II - 2)
Dua metode seleksi yang lain adalah seleksi turnamen dan seleksi peringkat. Pada seleksi peringkat, seleksi dilakukan berdasarkan peringkat dari nilai fitness individu-individu dalam populasi. Sedangkan pada seleksi turnamen satu grup yang terdiri dari beberapa individu (biasanya dua individu) dipilih secara acak dari populasi dan individu yang memiliki nilai fitness terbaiklah yang akan dipilih.
Selain fitness-proportionate selection, seleksi turnamen dan seleksi peringkat, terdapat metode seleksi lain yang bernama roulette wheel selection. Langkah-langkah seleksi dengan roulette wheel selection adalah sebagai berikut:
1. Hitung nilai fitness untuk tiap kromosom v 2. Hitung total fitness untuk populasi:
k F =
∑
= populasi ukuran k x f _ 1 ) ( (II - 3)3. Hitung probabilitas seleksi (selection probability) untuk tiap kromosom:
Pk F
x f( )
= , k = 1,2,... ukuran populasi (II - 4)
4. Hitung probabilitas kumulatif (cumulative probability) untuk tiap kromosom:
Qk
∑
= k j j p 1Proses seleksi dimulai dengan melakukan iterasi sebanyak ukuran populasi. Pada setiap iterasi dipilih sebuah kromosom dengan cara sebagai berikut:
Langkah 1. Bangkitkan bilangan acak r dengan rentang [0,1]
Langkah 2. Jika r ≤q1 maka pilih kromosom pertama v1; jika tidak, pilih kromosom ke-k dimana 2 ≤ k≤ ukuran populasi sedemikian hingga qk-1 ‹ r≤ qk
2.5.2.5 Operator Persilangan
.
Persilangan menurut Mitchell [MIT97] menciptakan variasi dalam populasi dengan menghasilkan keturunan baru dengan komponen-komponen yang diambil dari setiap induk. Induk pertama dipilih dari populasi dengan metode seleksi dan induk kedua dapat juga dipilih dengan metode seleksi yang sama. Operasi dimulai dengan memilih titik persilangan pada setiap individu induk secara acak. Keturunan diperoleh melalui kombinasi komponen-komponen yang berasal dari kedua induk berdasarkan titik-titik persilangan yang dipilih.
Inti dari operator ini adalah pemilihan kedua induk dan titik persilangan yang acak. Dalam operator ini tidak ada jaminan bahwa turunan yang dihasilkan oleh persilangan lebih baik dari orang tuanya [GEN97]
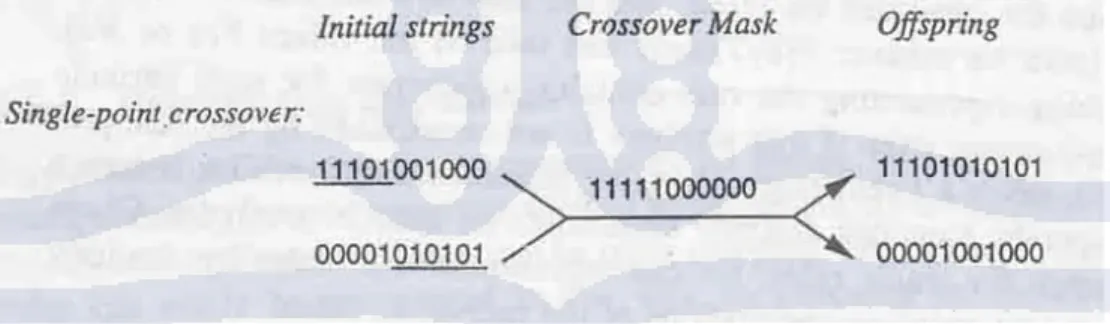
Terdapat tiga metode dalam operator persilangan. Metode pertama adalah single-point crossover. Metode kedua dalam operator persilangan adalah two-point crossover. Metode ketiga dalam operator persilangan adalah Uniform crossover. Gambar II.6 merupakan contoh dari single-point crossover.
2.5.2.6 Operator Mutasi
Mutasi menurut Mitchell [MIT97] adalah operator yang melakukan perubahan struktur secara acak dalam populasi. Dalam algoritma genetik, operasi mutasi berperan dalam membangkitkan keragaman dalam populasi sehingga memiliki kecenderungan mengarah ke solusi dengan lebih cepat.
Operasi mutasi menjadi penting karena proses reproduksi dan persilangan hanya akan memunculkan banyak string baru tetapi gen-gen hanya dapat melakukan reproduksi atau mati. Hal ini akan mengakibatkan jika pada posisi tertentu seluruh gen mempunyai harga yang sama, maka tidak ada jalan yang membuat persilangan dan reproduksi dapat memperoleh kembali gen-gen yang hilang. Mutasi diperlukan sebagai sumber gen-gen baru[RAS02]. Operator mutasi bekerja pada satu individu induk. Hasil dari operasi ini adalah satu individu keturunan.
Mutasi rate didefinisikan sebagai jumlah gen total dalam populasi. Mutasi rate mengendalikan rate kemunculan gen-gen baru dalam populasi. Jika nilainya terlalu rendah, maka akan rendah kemungkinan munculnya mutasi. Tetapi jika nilainya terlalu tinggi, akan terjadi banyak gangguan acak. Kromosom-kromosom keturunan akan mulai kehilangan unsur dari kromosom induknya. Algoritmanya sendiri akan kehilangan kemampuan untuk belajar dari pengalaman pencarian. Dalam kode biner, operator mutasi secara sederhana membalik state bit dari 0 ke satu ataupun sebaliknya. Gambar II.7 merupakan contoh dari one point mutation.
2.6 Database MNIST
Database MNIST adalah kumpulan data angka tulisan tangan yang dibuat oleh Yann LeCun dan Corrina Cortes. Database ini gratis dan bisa didapatkan di http://yann.lecun.com/exdb/mnist/. Database MNIST berisi 60000 gambar angka sebagai training set dan 10000 gambar angka sebagai test set. Database ini merupakan subset dari database yang lebih besar yaitu database NIST. Gambar angka pada database MNIST merupakan gambar angka grayscale yang telah dinormalisasi ukurannya dan telah diketengahkan dalam ukuran 28x28 pixel dengan menggunakan titik pusat massa angka.
Database MNIST dibangun dari database NIST SD-3 dan SD-1 yang berisi gambar biner angka tulisan tangan. Pada database NIST awalnya SD-3 digunakan sebagai training set, sedangkan SD-1 sebagai test set. SD-3 merupakan tulisan tangan dari para pegawai sensus di pemerintahan sedangkan SD-1 merupakan tulisan tangan dari siswa SMU, sehingga SD-3 lebih rapi dan lebih mudah dikenali daripada SD-1. Cara ini kurang baik sehingga perlu dibuat sebuah database baru dengan mencampur SD-3 dan SD-1, yang menghasilkan database MNIST.
Gambar angka pada training set database MNIST terdiri atas 30000 angka tulisan tangan dari SD-3 dan 30000 angka tulisan tangan dari SD-1. Sedangkan, test set database MNIST terdiri atas 5000 angka tulisan tangan dari SD-3 dan 5000 angka tulisan tangan dari SD-1. 60000 angka pada training set database MNIST merupakan tulisan tangan dari kurang lebih 250 orang. Penulis dari angka pada training set tidak beririsan dengan penulis dari angka test set. Gambar II.8 merupakan contoh dari tulisan tangan pada database MNIST.
Gambar II.8 Label
Database MNIST terdiri dari empat buah file:
Berikut ini adalah format untuk file label:
Nilai label adalah 0 sampai 9. Gambar II.9 merupakan contoh isi file label jika dibuka dengan menggunakan aplikasi hex editor.
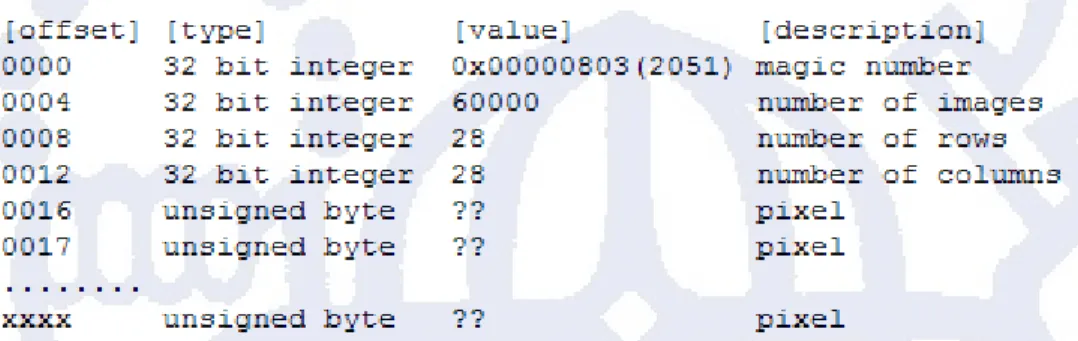
Berikut ini adalah format untuk file gambar:
Gambar II.10 merupakan contoh isi file image jika dibuka dengan menggunakan aplikasi hex editor.
Gambar II.10 Image
2.7 Normalisasi Data
Normalisasi data merupakan suatu proses pemetaan data yang akan menghasilkan data pada nilai jangkauan tertentu sehingga dapat diproses lebih lanjut. Salah satu contoh normalisasi data adalah normalisasi data sigmoid. Sigmoid berarti data hasil normalisasi berada pada jangkauan -1 sampai 1.
2.8 Root Mean Square Error (RMSE)
RMSE adalah salah satu metode perhitungan nilai kesalahan yang sering digunakan. Metode ini biasanya digunakan untuk mengukur perbedaan suatu nilai yang diprediksi oleh suatu model pemecahan masalah. RMSE sangat baik untuk digunakan untuk mengukur tingkat akurasi suatu model.