Fakultas Ilmu Komputer
Universitas Brawijaya
6080
Analisis Sentimen Evaluasi Kinerja Dosen menggunakan Term
Frequency-Inverse Document Frequency dan Naïve Bayes Classifier
Sri Wulan Utami Vitandy1, Ahmad Afif Supianto2, Fitra Abdurrachman Bachtiar3
Program Studi Sistem Informasi, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Pengajaran yang baik dapat membantu mahasiswa dalam mencapai hasil yang maksimal. Untuk meningkatkan kualitas pembelajaran dan standarisasi akademik perlu dilakukan evaluasi sehingga dapat menghasilkan mahasiswa-mahasiswa yang berkualitas. Oleh karena itu, Jurusan Sistem informasi selalu melakukan evaluasi terhadap kinerja menggunakan kuisioner yang diisikan oleh mahasiswa disetiap akhir semester. Hasil kolom saran dapat dilakukan analisis sentimen untuk mengetahui saran tersebut bernilai positif, negatif atau netral. Salah satu metode yang bisa digunakan untuk menyelesaikan masalah opinion mining adalah Naive Bayes Classifier (NBC). NBC bisa digunakan untuk mengklasifikasikan opini kedalam kelas positif, negatif dan netral. Data komentar yang terkumpul sebanyak 3502 yang terbagi menjadi 3 semester. Data komentar ini kemudian dilakukan tahapan preprocessing, pembobotan TF-IDF dan klasifikasi menggunakan metode Naive Bayes Classifier. Hasil Pengujian terhadap 4 parameter menghasilkan akurasi sebesar 80,1%, Precision 80,3%, Recall 80,3% dan F1-Score 80%. Hasil dari Usability testing diperoleh nilai rata-rata SUS Score sebesar 75. Sehingga dapat disimpulkan bahwa Dashboard yang telah dibuat ini termasuk kedalam kategori Acceptance dan berada pada rating “Good”
Kata kunci: Penambangan teks, klasifikasi Naïve Bayes, pemprosesan, TF-IDF, PowerBI, Evaluasi Kinerja
Abstract
Effective and efficient in teaching can help students achieve maximum results. An evaluation is needed to improve the quality of learning and academic standardization, also it can improve the quality of the student. Therefore, the Information Systems Department always evaluates performance using questionnaires and filled by students at the end of each semester. The results of the suggestion column can be sentiment analysis to find out whether the suggestion is positive, negative or neutral. The classifier is a method that can classify data into several classes. Naive Bayes Classifier can be used to classify opinions into positive, negative and neutral classes. The comment data was collected 3502 comments which were divided into 3 semesters. Then, this comment data processed in preprocessing, weighting TF-IDF and classification using Naive Bayes Classifier. The test result on 4 parameters resulted in an accuracy of 80,1%, Precision 80,3%, Recall 80,3% and F1-Score 80%. The results of Usability testing obtained an average value of SUS Score of 75. So it can be concluded that the Dashboard is included in the Acceptance category and in the rating of "Good"
Keywords: Text Mining, Naïve Bayes Classifier, Preprocessing, TF-IDF, PowerBI, Job Evaluation
1. PENDAHULUAN
Seiring dengan perkembangan zaman, manusia dituntut untuk selalu mengembangkan ilmu yang dimilikinya. Didalam dunia pendidikan, seorang pengajar dituntut untuk mengembangkan ilmu pegetahuan dan cara mengajar yang baik dan efektif. Dalam Undang-undang Republik Indonesia Nomor 14 Tahun
2005 menyebutkan bahwa dosen adalah pendidik profesional dan ilmuwan dengan tugas utama mentransformasikan, mengembangkan, dan menyebarluaskan ilmu pengetahuan, teknologi, dan seni melalui pendidikan, penelitian, dan pengabdian kepada masyarakat.
Pengajaran yang baik dapat membantu mahasiswa dalam mencapai hasil yang maksimal. Untuk meningkatkan kualitas
pembelajaran dan standarisasi akademik perlu dilakukan evaluasi sehingga dapat menghasilkan mahasiswa-mahasiswa yang berkualitas (Sunardi, Fadlil and Suprianto, 2018). Pada setiap akhir semester, setiap universitas umumnya melakukan proses penilaian terhadap hasil kinerja dosen untuk mengetahui ketercapaian kesuksesan pembelajaran selama 1 semester.
Fakultas Ilmu Komputer (FILKOM) merupakan sebuah fakultas yang berada dibawah naungan Universitas Brawijaya yang tentunya terdapat proses belajar mengajar. Di Fakultas Ilmu Komputer Universitas Brawijaya, pelaksanan evaluasi kinerja dosen dilakukan setelah ujian akhir semester (UAS) telah selesai. Untuk dapat melihat nilai akhir semester, mahasiswa diharuskan mengisi kuesioner yang terdapat di Sistem Akademik Mahasiswa (SIAM). Hasil kuisioner tersebut akan disimpan oleh Unit Jaminan Mutu (UJM) FILKOM UB sebagai bahan evaluasi kinerja dosen. Akan tetapi, hasil dari kolom saran tersebut hanya diberikan secara langsung kepada dosen-dosen yang ada. Sampai sekarang belum ada sistem yang dapat mengolah data kuesioner secara khusus untuk dapat melakukan monitoring dan evaluasi kinerja dosen.
Sebenarnya data hasil kolom saran dapat dilakukan analisis sentimen untuk mengetahui saran tersebut bernilai positif, negative atau netral. Analisis sentimen biasanya digunakan untuk mengekspresikan sentimen positif atau negatif (Liu, 2012). Untuk melakukan sebuah analisis sentimen perlu untuk memilih classifier yang akan digunakan. Salah satu metode dari text mining yang bisa digunakan untuk menyelesaikan masalah opinion mining adalah Naive Bayes Classifier (NBC). NBC bisa digunakan untuk mengklasifikasikan opini kedalam kelas positif, negatif dan netral.
Dalam salah satu penelitian yang disusun oleh Sunardi, Abdul Fadlil, dan Suprianto pada tahun 2018 dengan judul Analisis Sentimen menggunakan Naïve bayes Classifier pada Angket mahasiswa bertujuan melakukan analisis sentimen terhadap angket yang diisi oleh mahasiswa untuk mengetahui kepuasan siswa dalam proses pendidikam. Dalam penelitian ini pengklasifikasian dibagi menjadi 3 bagian yaitu kelas positif, negatif, dan netral. Metode yang digunakan yaitu pengklasifikasian Naive Bayes untuk mendapatkan model klasifikasi terhadap data uji. Klasifikasi metode ini memiliki tingkat presisi 75%, penarikan 75% dan akurasi 80%.
Berdasarkan permasalahan tersebut, peneliti tertarik untuk melakukan penelitian dengan judul “Analisis Sentimen Evaluasi Kinerja Dosen Menggunakan Term Frequency-Inverse Document Frequency dan Naïve Bayes Classifier”. Hasil yang didapatkan dari penelitian yaitu berupa dashboard yang berisi pengelompokan dosen. Diharapkan dashboard ini bisa digunakan oleh Fakultas Ilmu Komputer Universitas Brawijaya sebagai dasar untuk mengelompokan hasil evaluasi kinerja dari dosen-dosen di Fakultas Ilmu Komputer. 2. METODOLOGI PENELITIAN
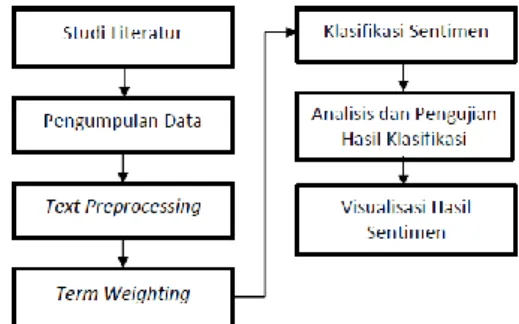
Metode penelitian yang akan digunakan digambarkan pada Gambar 1.
Gambar 1. Metodologi Penelitian
2.1. Studi Literatur
Salah satu penelitiang yang pernah menggunakan metode Naïve Bayes Classifier yaitu Implementasi Opinion Mining (Analisis Sentimen) untuk ekstraksi data opini publik pada perguruan tinggi oleh Rozi, Pramono dan Dahlan pada tahun 2012. Pada penelitian ini dikembangkan sistem opinion mining untuk menganalisis opini publik pada perguruan tinggi. Pada subproses document subjectivity dan target detection digunakan Part-of-Speech (POS) Tagging menggunakan Hidden Makov Model (HMM). Pada hasil proses POS Tagging kemudian diterapkan rule untuk mengetahui apakah suatu dokumen termasuk opini atau bukan, serta untuk mengetahui bagian kalimat mana yang merupakan objek yang menjadi target opini. Dokumen yang dikenali sebagai opini selanjutnya diklasifikasikan ke dalam opini negatif dan positif (subproses opinion orientation) menggunakan Naïve Bayes Classifier (NBC). Dari pengujian didapatkan nilai precission dan recall untuk subproses document subjectivity adalah 0,99 dan 0,88, untuk subproses target detection adalah 0,92 dan
0,93, serta untuk subproses opinion orientation adalah 0,95 dan 0,94.
2.2. Pengumpulan Data
Data komentar berjumlah 3502 komentar didapatkan dari Ketua Jurusan Sistem Informasi dan TIM UJM Jurusan Sistem Informasi. Data yang didapatkan terdiri dari 3 semester yaitu semester Genap tahun ajaran 2016/2017, semester Gansjil tahun ajaran 2017/2018, dan semester Genap tahun ajaran 2017/2018. 2.3. Text Preprocessing
Text preprocessing dilakukan untuk mengkondisikan data agar sesuai dengan kebutuhan. Text Preprocessing yang dilakukan terdiri dari 5 langkah, yaitu Case Folding, Cleansing, Stemming , Stopword Removal, dan Tokenization. Case Folding adalah kegiatan untuk mengubah huruf besar menjadi huruf kecil. Cleansing adalah kegiatan untuk menghapuskan tanda bacayang tidak memiliki nilai. Stemming ialah proses pencarian stem-base dari suatu kata. Stopword Removal merupakan proses penyeleksian kata-kata penting dari hasil fitur, yang nantinya digunakan untuk proses selanjutnya. Stopword list yang digunakan adalah stopword list berbahasa Indonesia. Tokenization adalah pemotongan string input tiap kata penyusunnya.
2.4. Term Frequency-Inverse Document Frequency
Algoritma Term Frequency – Inverse Document Frequency (TF-IDF) merupakan algoritma yang berasal dari bidang information retrieval, namun saat ini semakin banyak digunakan dalam perbandingan dokumen (Ryansyah and Andayani, 2017). Rumus untuk menghitung TF-IDF, yaitu :
𝑡𝑓 − 𝑖𝑑𝑓𝑡.𝑑 = 𝑡𝑓𝑡𝑑 X 𝑖𝑑𝑓𝑡 (1)
Dimana :
- 𝑡𝑓 − 𝑖𝑑𝑓𝑡𝑑 : bobot TF-IDF dari istilah t
dalam dokumen d
- 𝑡𝑓𝑡𝑑 : frekuensi munculnya istilah
t dalam dokumen d
- 𝑖𝑑𝑓𝑡 : nilai idf dalam istilah t
Term frequency (𝑡𝑓𝑡𝑑) merupakan metode
yang paling sederhana dalam membobotkan kata. Setiap kata diasumsikan memiliki kepentingan yang proporsional terhadap jumlah kemunculan kata pada dokumen. Sedangkan ,
IDF (𝑖𝑑𝑓𝑡) memperhatikan kemunculan term
pada kumpulan dokumen. Untuk mendapatkan nilai (𝑖𝑑𝑓𝑡) dapat menggunakan persamaan
𝑖𝑑𝑓𝑡= log
𝑁
𝑑𝑓𝑡 (2)
Dimana :
- 𝑖𝑑𝑓𝑡 : Nilai idf dari istilah t - 𝑁 : Banyaknya dokumen atau
koleksi yang ada
- 𝑖𝑑𝑓𝑡 : Banyaknya kemunculan istilah t dalam dokumen d
2.5. Naïve Bayes Classifier
Naïve bayes classifier adalah metode klasifikasi yang berdasarkan probabilitas dan Teorema Bayesian dengan asumsi bahwa setiap variabel X bersifat bebas atau berdiri sendiri dan tidak ada kaitannya dengan variabel lainnya. Perhitungan perbandingan antara term pada data testing dengan setiap kelas yang ada dapat dilakukan dengan persamaan (2) dibawah ini (Sunardi, Fadlil and Suprianto, 2018).
𝑷(𝒂𝒋|𝒗𝒋) = 𝒏𝒄+𝒎𝒑
𝒏+𝒎 (3)
Keterangan :
- 𝑛 : jumlah term pada data latih
- 𝑛𝑐 : jumlah term dimana v = vj dan a = aj - 𝑝 : probabilitas setiap kelas dalam data
latih
-
𝑚 : jumlah term pada data uji2.6. Confusion Matrix
Confusion matrix adalah alat yang berguna untuk menganalisis seberapa baik klasifikasi yang telah dibuat, dapat mengenali tuple dari kelas yang berbeda.
Tabel 1. Confusion Matrix
Prediksi Positif Negatif Aktual Positif TP FN
Negatif FP TN
Sumber: Han et al. (2012)
Han et al. (2012) menyebutkan ada 4 building blocks yang banyak digunakan sebagai bahan dalam banyak pengukuran evaluasi, yakni:
1. True Positives (TP): Data positif yang berhasil dilabeli dengan benar oleh classifier.
2. True Negatives (TN): Data negatif yang berhasil dilabeli dengan benar oleh classifier.
3. False Positives (FP): Data negatif yang ternyata salah dilabeli sebagai positif oleh classifier.
4. False Negatives (FN): Data positif yang ternyata salah dilabeli sebagai negatif oleh classifier.
Confussion matrix merepresentasikan tingkat akurasi dari proses klasifikasi yang telah dilakukan. Tingkat akurasi menunjukkan proporsi jumlah prediksi benar.
𝐴𝑐𝑢𝑟𝑎𝑛𝑐𝑦 = 𝑇𝑃+𝑇𝑁
𝑇𝑃+𝐹𝑃+𝑇𝑁+𝐹𝑁 (4)
Recall atau true positif rate (TP) adalah proporsi dari kasus positif yang telah diidentifikasi dengan benar, rumus mencari Recall:
𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒/𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃
𝑇𝑃+𝑇𝑁 (5)
True negative rate (TN) adalah proporsi dari kasus negatif yang telah diidentifikasi dengan benar, rumus TN:
𝑇𝑟𝑢𝑒 𝑁𝑒𝑔𝑎𝑡𝑖𝑣𝑒 = 𝑇𝑁
𝑇𝑁+𝐹𝑁 (6)
2.7. Dashboard
Dashboard adalah alat yang digunakan sebagai diagnostik yang dirancang untuk memberikan manajer sebuah gambaran singkat tentang kinerja perusahaan (Velcu-laitinen and Yigitbasioglu, 2012). Menurut Pauwels et al. (2009) (in Velcu-laitinen and Yigitbasioglu (2012)) terdapat 4 alasan dalam menggunakan
dashboard yaitu untuk pemantauan
(Monitoring), Konsistensi (Consistency), Perencanaan (Planning), dan komunikasi (Communication)
3. HASIL DAN PEMBAHASAN
Pada bagian ini kan dibahas mengenai proses bisnis, pengumpulan data, implementasi klasifikasi, analisis hasil klasifikasi hingga visualisasi dengan dashboard
3.1. Proses Bisnis
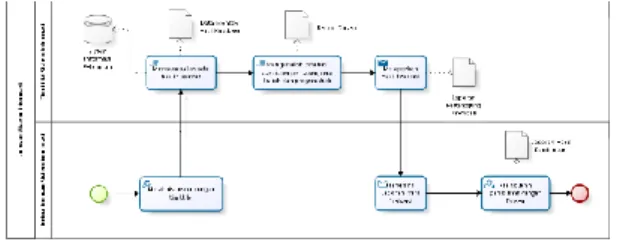
Proses bisnis AS-IS yang telah dibuat berdasarkan SOP yang dimiliki oleh TIM UJM dapat dilihat pada Gambar 2. Pertama-tama akan dilakukan rapat antara Ketua Jurusan Sistem
Informasi dan Tim UJM. Setelah itu, Tim UJM akan mengumpulkan data kuisioner selama 7 hari dan menghasilkan Data Mentah Hasil Kuisioner. Data mentah hasil kuisioner juga akan disimpan kedalam SIMPLE (Sistem Informasi Pelaporan) UB. Setelah pengumpulan data, akan dilakukan analisis terhadap kuisioner yang diisikan oleh mahasiswa selama 7 hari. Analisis dibagi menjadi 3 bagian yaitu analisis perdosen, analisis permata kuliah dan analisis preprogram studi. Hasil dari analisis ini akan menjadi Raport Dosen dan dilaporkan kepada Ketua Jurusan Sistem Informasi, serta menghasilkan Laporan Pertanggung Jawaban. Ketua Jurusan Sistem Informasi yang menerima Laporan Hasil Evaluasi dari TIM UJM akan memanggil dosen yang bersangkutan dan melakukan pembinaan dengan dosen yang terkait. Pembinaan ini dilakukan selama 7 hari dan menghasilkan Laporan Hasil Pembinaan.
Gambar 2. Proses Bisnis AS-IS
Berdasarkan analisis yang telah dilakukan, terdapat kegiatan yang dapat meningkatkan efektifitas dan efisiensi dari TIM UJM dalam melakukan evaluasi kinerja dosen. Kegiatan tambahan yang diusulkan yaitu melakukan klasifikasi sentimen pada kegiatan evaluasi kinerja dosen. Dimana data mentah hasil kuisioner akan dilakukan klasifikasi terhadap komentar-komentar dari mahasiswa agar dapat diperoleh nilai sentimen dari setiap komentar yang dapat mempermudah TIM UJM dalam melakukan analisis. Gambaran proses bisnis yang diusulkan dapat dilihat pada Gambar 3.
3.2. Preprocessing
Tahapan yang dilakukan dalam preprocessing, yaitu :
a. Case Folding
Case folding adalah tahapan mengubah semua huruf menjadi huruf kecil (lowercase).
Tabel 2. Case Folding
Sebelum Case Folding Sesudah Case Folding Semoga selalu menjadi
yang terbaik
semoga selalu menjadi yang terbaik Cukup baik dalam
pemberian materi, terima kasih.
cukup baik dalam pemberian materi, terima
kasih.
b. Cleansing
Cleansing adalah tahapan untuk menghilangkan elemen-elemen yang dianggap sebagai noise.
Tabel 3. Cleansing
Sebelum Cleansing Sesudah Cleansing semoga selalu menjadi yang
terbaik
semoga selalu menjadi yang terbaik cukup baik dalam
pemberian materi, terima kasih.
cukup baik dalam pemberian materi terima
kasih
c. Stemming
Stemming adalah tahapan mengubah kata menjadi bentuk dasar atau kata dasar.
Tabel 4. Stemming
Sebelum Stemming Sesudah Stemming
semoga selalu menjadi yang terbaik
moga selalu menjadi yang baik
cukup baik dalam pemberian materi terima kasih
cukup baik dalam beri materi terima kasih
d. Stopword
Stopword adalah tahapan menghilangkan kata-kata yang termasuk kedalam kategori stopword seperti di, pada, aku, yang, pak, dan lain sebagainya
.
Tabel 5. Stopword
Sebelum Stopword Sesudah Stopword
moga selalu menjadi yang baik
moga selalu menjadi yang baik
cukup baik dalam beri materi terima kasih
cukup baik beri materi terima kasih
e. Tokenization
Tokenization adalah tahapan untuk memecah kalimat menjadi kata.
Tabel 6. Tokenization
Sebelum Tokenisasi Sesudah Tokenisasi semoga selalu menjadi
yang terbaik
[‘moga’ ‘selalu’ ‘menjadi’ ‘yang’ ‘baik’] cukup baik dalam
pemberian materi terima kasih.
[’cukup’ ’baik’ ’dalam’ ’beri’ ’materi’ ’terima’
’kasih’]
3.3 TF-IDF
Perhitungan bobot kata dilakukan dengan menggunakan pembobotan Term Frequency-Inverse document Frequency (TF-IDF).
Tabel 7. Perhitungan TF, DF, dan IDF
Term TF DF IDF Log(N/D F) D1 D2 D3 D4 D5 Baik 1 1 0 1 1 4 0,0969 Cara 1 1 0 1 0 3 0,2218 Jelas 0 1 1 1 0 3 0,2218 Materi 0 1 1 0 0 2 0,3079
Dibawah ini merupakan contoh perhitungan manual TF-IDF pada kata ‘baik’ pada D1 :
𝑇𝑓−𝑖𝑑𝑓𝑡,𝑑 = TF * IDF = 1 * 0.69897 = 0,69897
Tabel 8. Hasil Perhitungan TF-IDF
Term TF-IDF D1 D2 D3 D4 D5 Baik 0,096 0,096 0 0,096 0,096 Cara 0,221 0,221 0 0,221 0 Jelas 0 0,221 0,221 0,221 0 Materi 0 0,3079 0,3079 0 0
Semester Genap 2016/2017
Data pada semester Genap 2016/2017 yang telah dilakukan klasifikasi menghasilkan 332 komentar. Pada Gambar 4 dapat dilihat jumlah komentar positif sebanyak 167 komentar, jumlah komentar netral netral sebanyak 86 komentar, dan jumlah komentar negatif sebanyak 79 komentar.
Gambar 4. Grafik hasil klasifikasi sentimen
Berdasarkan jumlah komentar pada Gambar 4, komentar-komentar tersebut dapat disaring berdasarkan kemunculan katanya dan dapat dibagi menurut komentar positif dan komentar negatif.
Gambar 5. Kata yang paling sering muncul pada komentar negatif
Pada Gambar 5 dapat dilihat kata yang paling sering muncul pada komentar negatif yaitu ‘materi’ sebanyak 24 kali, ‘jelas’ sebanyak 20 kali, dan ‘ajar’ sebanyak 18 kali. Kata ‘materi’ pada komentar negatif memberikan informasi mengenai pemberian materi yang kurang jelas, materi terlalu banyak, pembelajaran hanya berupa materi tanpa dijelaskan secara praktek dan lain sebagainya.
Kata-kata yang paling sering muncul pada komentar positif. Pada Gambar 6 dapat dilihat kata ‘baik’ muncul sebanyak 122 kali, kata ‘ajar’ sebanyal 64 kali, dan kata ‘cukup’ sebanyak 21 kali. Kata ‘baik’ pada komentar positif memberikan informasi seperti cara mengajar
baik, penyampaian materi sudah baik sehingga mahasiswa dapat memahami materi yang diberikan, baik dalam membuat suasana kelas menjadi lebih interaktif sehingga mahasiswa tidak merasa bosan dan mengantuk selama pembelajaran, dan lain sebagainya.
Gambar 6. Kata yang paling sering muncul pada komentar positif
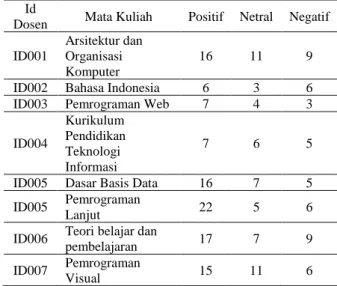
Pada Tabel 9 menunjukkan perbandingan jumlah komentar positif, netral dan negatif per dosennya. Pada Tabel 9 dapat dilihat id dosen ID005 memiliki jumlah komentar positif paling banyak yaitu 22 komentar dan id dosen ID002 memiliki jumlah komentar positif paling sedikit yaitu 6 komentar. Kemudian, untuk komentar netral id dosen ID001 dan ID007 memiliki komentar paling banyak yaitu 11 komentar dan id dosen ID002 memiliki jumlah komentar netral yang paling sedikit yaitu 3 komentar. Selain itu, id dosen ID008 memiliki jumlah komentar negatif paling banyak yaitu 14 komentar dan id dosen ID012 memiliki komentar paling sedikit yaitu 1 komentar. Jumlah komentar yang sedikit ini dapat dipengaruhi oleh jumlah mahasiswa di dalam kelasnya, selain itu juga dipengaruhi oleh tahapan preprocessing yang telah dibahas sebelumnya.
Tabel 9. Rekap jumlah komentar mahasiswa
Id
Dosen Mata Kuliah Positif Netral Negatif ID001
Arsitektur dan Organisasi Komputer
16 11 9
ID002 Bahasa Indonesia 6 3 6
ID003 Pemrograman Web 7 4 3
ID004 Kurikulum Pendidikan Teknologi Informasi 7 6 5
ID005 Dasar Basis Data 16 7 5
ID005 Pemrograman
Lanjut 22 5 6
ID006 Teori belajar dan
pembelajaran 17 7 9
ID007 Pemrograman
ID008 Statistika 18 4 14 ID009 Penelitian
Tindakan Kelas 14 7 3
ID010 Interaksi Manusia
Komputer 11 10 4
ID011 Sistem Operasi 11 7 8
ID012 Bahasa Indonesia 7 4 1
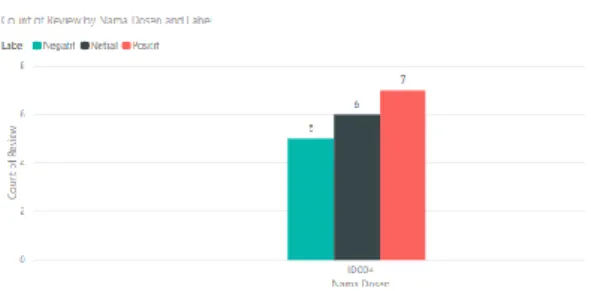
Berdasarkan Tabel 9, dapat dibuat menjadi sebuah dashboard yang menampilkan perbandingan nilai positif, negatif, dan netral berdasarkan dosen dan mata kuliah. Berdasarkan data tersebut terdapat poin-poin yang dapat dievaluasi, salah satunya yaitu masukan terhadap pengajaran suatu mata kuliah. Pada Gambar 7 merupakan salah satu contoh grafik yang menampilkan hasil klasifikasi sentimen dari id dosen ID004, dimana komentar positif terdapat 7 komentar, komentar netral sebanyak 6 komentar, dan komentar negatif sebanyak 5 komentar. Id Dosen ID004 mengampu mata kuliah Kurikulum Pendidikan Teknologi Informasi dan memiliki beberapa komentar yang berulang dan mendapatkan nilai sentimen negatif. Pada mata kuliah ini mahasiswa menyampaikan bahwa perlu adanya sebuah contoh penerapan khususnya dibidang IT, selain itu diperlukan juga sebuah tugas yang dapat meperluas pengetahuan mahasiswa dalam memahami mata kuliah Kurikulum Pendidikan Teknologi Informasi.
Gambar 7. Grafik hasil klasifikasi pada id dosen ID004
3.5 Pengujian hasil klasifikasi sentimen Pengujian klasifikasi sentimen ini membandingkan 4 buah parameter yaitu Accuracy, Precision, Recall, dan F1-Score.
Tabel 10. Hasil Pengujian
Semester Accura cy Precision Recall F1-Score Genap 2016/2017 0,825 0,83 0,83 0,82 Ganjil 2017/2018 0,79 0,79 0,79 0,79 Genap 2017/2018 0,789 0,79 0,79 0,79 Rata-rata 0,801 0,803 0,803 0,8 3.6 Visualisasi Dashboard
Visualisasi dashboard dilakukan pada masing-masing hasil klasifikasi sentimen setiap semesternya. Pada Gambar 8 merupakan desain dashboard yang diusulkan dimana terdapat list komentar, filter atau menyaring berdasarkan dosen dan mata kuliah, serta diagram batang yang menampilkan hasil klasifikasi sentimen terhadap komentar berdasarkan dosen dan mata kuliah.
Gambar 8. Visualisasi desain dashboard
3.7 Analisis Hasil System Usability Scale Pada Tabel 11 menunjukan hasil rata-rata yang diperoleh dari perhitungan kuisioner SUS kedua responden. Responden 1 memiliki nilai SUS sebersar 75 dan responden 2 memuliki nilai SUS sebesar 75. Setelah rata-ratakan didapatkan nilai SUS score sebesar 75.
Tabel 11. Perhitungan SUS Score
Responden SUS Score
Responden 1 75
Responden 2 75
Rata-rata 75
Berdasarkan hasil Usability testing yang dilakukan diperoleh nilai rata-rata SUS Score sebesar 75. Sehingga dapat disimpulkan bahwa Dashboard yang telah dibuat ini termasuk kedalam kategori Acceptance dan berada pada rating “Good” yang berarti Dashboard yang menampilkan hasil evaluasi kinerja dosen dapat
diterima dengan baik oleh pihak Responden selaku Tim UJM FILKOM UB Jurusan Sistem Informasi.
4. PENUTUP
4.1. Kesimpulan
Kesimpulan yang dapat diambil berdasarkan hasil penelitian yaitu pada Semester Genap tahun ajaran 2016/2017 terdapat komentar positif sebanyak 167 komentar, komentar netral netral sebanyak 86 komentar, dan komentar negatif sebanyak 79 komentar. Untuk Semester Ganjil 2017/2018 terdapat komentar positif sebanyak 324 komentar, komentar netral netral sebanyak 137 komentar, dan komentar negatif sebanyak 130 komentar. Dan untuk Semester Genap 2017/2018 terdapat komentar positif sebanyak 346 komentar, komentar netral netral sebanyak 141 komentar, dan komentar negatif sebanyak 87 komentar.
Selain itu, setelah melakukan klasifikasi dengan menggunakan metode TF-IDF dan Naïve Nayes Classifier, dilakukan pengujian terhadap hasil klasifikasi pada setiap semester yang hasilnya kemudian di rata-rata dan memperoleh hasil Accuracy sebesar 80,1%, Precision sebesar 80,3%, Recall sebesar 80,3%, dan F1-Score sebesar 80%.
Dashboard yang telah dibuat memuat tabel yang menampilkan seluruh komentar dari mahasiswa, filtering berdasarkan id dosen dan matakuliah, dan 2 diagram batang yang menampilkan hasil sentimen komentar mahasiswa berdasarkan id dosen dan mata kuliah.
4.2. Saran
Berikut adalah saran perbaikan yang dapat dilakukan pada penelitian selanjutnya yaitu hasil analisis ini dapat diterapkan menjadi sebuah Sistem Informasi yang dapat digunakan secara real time. Selain itu, penggunaan metode Lexicon Based – Barasa untuk melakukan pelabelan terhadap komentar-komentar sehingga pelabelan yang dilakukan tidak dilakukan secara manual. Hal ini bertujuan untuk menghindari adanya sifat subyektif yang di berikan pada pelabelan 1 komentar. Serta, menggunaan metode untuk memperbaiki kata-kata yang tidak baku pada tahap preprocessing dan penggunaan metode translasi bahasa asing yang ada.
5. DAFTAR PUSTAKA
Bangor, A., Staff, T., Kortum, P., Miller, J. and Staff, T., 2009. Determining What Individual SUS Scores Mean : Adding an Adjective Rating Scale. 4(3), pp.114–123. Burlton, Roger T. 2001. Business Process Management: Profiting From Process. Amerika Serikat : Sams Publishing. FILKOM, 2016. Kurikulum Berbasis Standar
Nasional Pendidikan Tinggi( SN-DIKTI ) Program Studi Pendidikan Teknologi Informasi Jenjang S1 Universitas Brawijaya.
Han, J., Kamber, M. and Pei, J., 2012. Data Mining: Concepts and Techniques. San Francisco, CA, itd: Morgan Kaufmann. Holle, K.F.H., 2015. Preference Based Term
Weighting For Arabic Fiqh Document Ranking.
JetBrains, 2019. PyCharm. [online] Available at: <https://www.jetbrains.com/pycharm/> [Accessed 19 Jan. 2019].
Liu, B., 2012. Sentiment Analysis and Opinion Mining Morgan & Claypool Publishers. Language Arts & Disciplines. p.167 Microsoft, 2018. Microsoft Power BI Guide
Learning. [online] Microsoft. Available at: <https://docs.microsoft.com/en-us/power-bi/guided-learning/index> [Accessed 1 Sep. 2018].
Miftakul, 2016. Opini Mahasiswa Tentang Emoticon LGBT. pp.16–33.
Object Management Group, 2011. Business Process Model and Notation. s.l.:Object Management Group.
Pang, B. and Lee, L., 2016. Opinion mining and sentiment analysis. World Journal of Gastroenterology, 22(45), pp.9898–9908. Rozi, I.F., Pramono, S.H. and Dahlan, E.A., 2012. Implementasi Opinion Mining ( Analisis Sentimen ) untuk Ekstraksi Data Opini Publik pada Perguruan Tinggi.
Electrical Power, Electronics,
Communications, Controls, and
Informatics Seminar (EECCIS), 6(1), pp.37–43.
Ryansyah, A. and Andayani, S., 2017. Implementasi Algoritma TF-IDF Pada Pengukuran Kesamaan Dokumen. (1),
pp.1–10.
Sharfina, Z. and Santoso, H.B., 2016. An Indonesian Adaptation of the System Usability Scale ( SUS ). 2016 International Conference on Advanced Computer Science and Information Systems (ICACSIS), pp.145–148.
Sunardi, Fadlil, A. and Suprianto, 2018. Analisis sentimen menggunakan metode naïve bayes classifier pada angket mahasiswa. (2), pp.1–9.
Undang-undang Republik Indonesia Nomor 14 Tahun 2005 tentang Guru dan Dosen. Produk Hukum, p.54.
Velcu-laitinen, O. and Yigitbasioglu, O.M., 2012. The Use of Dashboards in Performance Management : Evidence from Sales Managers. 12(November 2011), pp.39–58.