Mengelompokkan Garis Kemiskinan Menurut
Provinsi Menggunakan Algoritma K-Medoids
Disty Wahyuli1, Handrizal2, Iin Parlina3, Agus Perdana Windarto4, Dedi Suhendro5, Anjar
Wanto6
STIKOM Tunas Bangsa Pematangsiantar Jln. Jendral Sudirman Blok A No. 1,2,3 Pematangsiantar
Abstract - Poverty is a situation where there is an inability to fulfill basic needs such as food,
clothing, shelter, education, and health. Poverty can be caused by scarcity of basic needs, or the difficulty of access to education and employment. Poverty is a global problem, some people understand this term subjectively and comparatively, while others see it from a moral and evaluative point of view, and others understand it from an established scientific perspective. The problem of poverty is a problem that arises in every country, especially in developing countries. The provincial poverty conditions in Indonesia have varying levels in cities and villages. In this study the data used was sourced from the central statistical body. The aim of the study was to determine the high and low number of cases of poverty based on the province using k-medoids. In Indonesia high poverty rates consist of 23 provinces and low poverty rates consist of 11 provinces. It is hoped that this research can provide input to the government in increasing employment, so as to improve the economy of the people in Indonesia.
Keywords: Data mining, K - Medoids, Proverty Level
Abstrak - Kemiskinan adalah keadaan dimana terjadi ketidakmampuan untuk memenuhi
kebutuhan dasar seperti makanan, pakaian, tempat berlindung, pendidikan, dan kesehatan. Kemiskinan dapat disebabkan oleh kelangkahan alat kebutuhan dasar, ataupun sulitnya akses terhadap pendidikan dan pekerjaan. Kemiskinan merupakan masalah global, sebagian orang memahami istilah ini secara subyektif dan komparatif, sementara yang lainya melihat dari segi moral dan evaluative, dan yang lainnya lagi memahaminya dari sudut ilmiah yang telah mapan. Masalah kemiskinan merupakan masalah yang muncul di setiap Negara, terutama di negara-negara berkembang. Kondisi kemiskinan provinsi di indonesia memiliki tingkat beragam di kota dan desa. Pada penelitian ini data yang digunakan bersumber dari badan pusat statistik. Tujuan penelitian adalah untuk mengetahui tinggi rendahnya jumlah kasus kemiskinan berdasarkan provinsi menggunakan k-medoids. Di Indonesia tingkat kemiskinan tinggi terdiri dari 23 provinsi dan tingkat kemiskinan rendah terdiri dari 11 provinsi. Diharapkan penelitian ini dapat memberikan masukan kepada pemerintah dalam meningkatkan lapangan pekerjaan, sehingga dapat memperbaiki perekonomian masyarakat di Indonesia.
Kata kunci: Data Mining, K-Medoids, Kemiskinan
1. PENDAHULUAN
Kemiskinan merupakan keadaan dimana ketidak mampuan masyarakat dalam memenuhi kebutuhan dasar seperti makanan, pakaian tempat berlindung, pendidikan, dan kesehatan. Disisi lain pengangguran atau kurangnya lahan produktif sebagai aset penghasilan pendapatan menjadi hal yang akut bagi
masyarakat miskin saat memperoleh kebutuhan paling dasar seperti makan, air dan tempat tinggal. Kondisi kemiskinan suatu negara atau daerah juga merupakan cerminan dari tingkat kesejahteraan penduduk yang tinggal pada negara/daerah tersebut [1]. Indonesia tergolong negara berkembang tetapi kemiskinan masih menjadi masalah yang harus di perhatikan. Semakin meningkat jumlah penduduk di perkotaan semakin menimbulkan berbagai permasalahan. Meningkatnya penduduk di perkotaan menyebabkan meningkatnya kriminalitas, kemacetan, pengangguran, sulit meyediakan perumahan yang layak dan fasilitas sosial lainya. Namun demikian, masalah ini dapat di atasi dengan cara ditingkatkanya sumber daya manusia yang memadai. Dengan sumber daya manusia yang baik maka seseorang akan memiliki peluang lebih besar untuk meningkatkan kesejahteraannya [2].
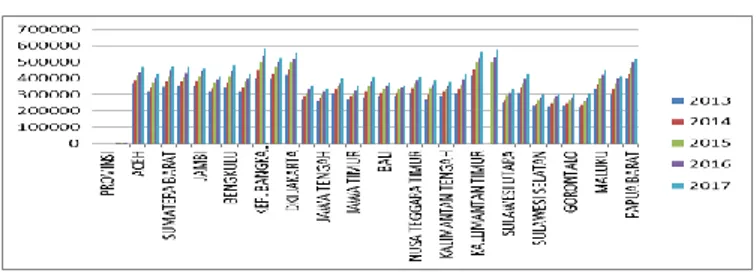
Pada penelitian ini, penulis akan membuat penelitian dalam mengelompokkan kemiskinan di indonesia dengan metode K-Medoids. Adapun data yang digunakan dalam penelitian ini bersumber dari Badan Pusat Statistik (BPS). Dimana data yang diperoleh adalah data presentase kemiskinan di indonesia dri tahun 2013 – 2017 yang menjelaskan bahwa kemiskinan di indonesia meningkat setiap tahunnya, seperti pada gambar 1.
Gambar 1. Persentase kemiskinaan di Indonesia
(Sumber : bps.go.id)
Beberapa penelitian terdahulu adalah [3] paralelisasi algoritma K-Medoids pada general purpose menggunakan open computing language tahun 2015, menjelaskan algoritma paralel K-Medoids terbukti dapat meningkatkan performa proses clustering hingga mencapai 364 kali lebih cepat dibanding algoritma sekuensial K-Medoids. Perancangan dan analisis clustering data menggunakan metode k-medoids untuk berita berbahasa inggris, dengan tujuan menentukan kalimat utama dalam sebuah dokumen berita menggunakan pembobotan term frequency – inverse document frequency [4]. Data mining adalah proses analitik yang dirancang untuk memeriksa sejumlah data yang besar dalam mencari suatu pengetahuan tersembunyi yang berharga dan konsisten. Tujuan dari data mining yaitu mencari trend atau pola yang diinginkan dalam database besar untuk membantu dalam pengambilan keputusan pada waktu yang akan datang [5]–[8]. Algoritma clustering salah satunya adalah K-Medoids yang merupakan salah satu metode pengelompokkan dalam data mining. Algoritma ini menggunakan objek pada kumpulan objek untuk mewakili sebuah cluster. Metode K-Medoids cukup efisien untuk dataset yang kecil. Kelebihan dari metode ini mampu mengatasi kelemahan dari metode K-Means yang sensitive terhadap outlier dan hasil proses clustering tidak bergantung pada urutan masuk dataset [9]. Berdasarkan masalah
di atas, penulis mengambil judul skripsi Mengelompokkan Garis Kemiskinan Menurut Provinsi Menggunakan Algoritma K-Medoids. Diharapkan penelitian ini dapat mengetahui kemiskinan menurut provinsi di Indonesia berdasarkan cluster tinggi dan rendah.
2. METODOLOGI PENELITIAN 2.1 Analisa Data
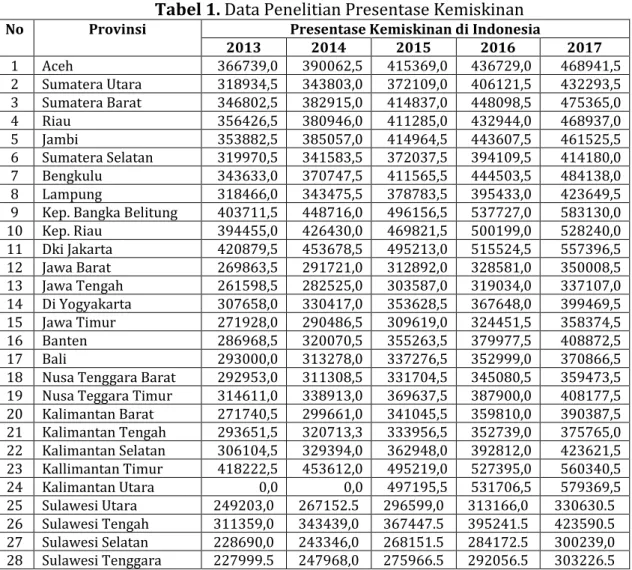
Dalam melakukan penelitian ini, analisis data yang digunakan adalah data adalah data skunder. Data yang diperoleh dari pihak lain, sudah dikumpulkan oleh pihak lain dan sudah diolah serta memiliki keterkaitan dengan permasalahan yang diteliti. Data yang terkumpul selanjutnya diolah menggunakan algoritma k-medoids. Kemudian diuji dengan tools RapidMiner menggunakan Performance yang berfungsi sebagai validasi dan reabilitas data untuk mencari keakuratan. Data diperoleh dari Badan Pusat Statistik Nasional dengan situs http://www.bps.go.id. Data yang digunakan data presentase kemiskinan dari tahun 2013 – 2017 yang terdiri dari 34 provinsi. Data akan diolah dengan melakukan Clustering kemiskinan tinggi, rendah berdasarkan provinsi di indonesia. Berikut adalah data penelitian yang digunakan, dapat dilihat pada tabel 1:
Tabel 1. Data Penelitian Presentase Kemiskinan
No Provinsi Presentase Kemiskinan di Indonesia
2013 2014 2015 2016 2017 1 Aceh 366739,0 390062,5 415369,0 436729,0 468941,5 2 Sumatera Utara 318934,5 343803,0 372109,0 406121,5 432293,5 3 Sumatera Barat 346802,5 382915,0 414837,0 448098,5 475365,0 4 Riau 356426,5 380946,0 411285,0 432944,0 468937,0 5 Jambi 353882,5 385057,0 414964,5 443607,5 461525,5 6 Sumatera Selatan 319970,5 341583,5 372037,5 394109,5 414180,0 7 Bengkulu 343633,0 370747,5 411565,5 444503,5 484138,0 8 Lampung 318466,0 343475,5 378783,5 395433,0 423649,5 9 Kep. Bangka Belitung 403711,5 448716,0 496156,5 537727,0 583130,0 10 Kep. Riau 394455,0 426430,0 469821,5 500199,0 528240,0 11 Dki Jakarta 420879,5 453678,5 495213,0 515524,5 557396,5 12 Jawa Barat 269863,5 291721,0 312892,0 328581,0 350008,5 13 Jawa Tengah 261598,5 282525,0 303587,0 319034,0 337107,0 14 Di Yogyakarta 307658,0 330417,0 353628,5 367648,0 399469,5 15 Jawa Timur 271928,0 290486,5 309619,0 324451,5 358374,5 16 Banten 286968,5 320070,5 355263,5 379977,5 408872,5 17 Bali 293000,0 313278,0 337276,5 352999,0 370866,5 18 Nusa Tenggara Barat 292953,0 311308,5 331704,5 345080,5 359473,5 19 Nusa Teggara Timur 314611,0 338913,0 369637,5 387900,0 408177,5 20 Kalimantan Barat 271740,5 299661,0 341045,5 359810,0 390387,5 21 Kalimantan Tengah 293651,5 320713,3 333956,5 352739,0 375765,0 22 Kalimantan Selatan 306104,5 329394,0 362948,0 392812,0 423621,5 23 Kallimantan Timur 418222,5 453612,0 495219,0 527395,0 560340,5 24 Kalimantan Utara 0,0 0,0 497195,5 531706,5 579369,5 25 Sulawesi Utara 249203,0 267152.5 296599,0 313166,0 330630.5 26 Sulawesi Tengah 311359,0 343439,0 367447.5 395241.5 423590.5 27 Sulawesi Selatan 228690,0 243346,0 268151.5 284172.5 300239,0 28 Sulawesi Tenggara 227999.5 247968,0 275966.5 292056.5 303226.5
No Provinsi Presentase Kemiskinan di Indonesia 2013 2014 2015 2016 2017 29 Gorontalo 231111,0 248395,0 268934.5 285732,0 305711.5 30 Sulawesi Barat 224701,0 240946.5 263042,0 276670.5 306777,0 31 Maluku 336540,0 366260.5 402638,0 418884,0 449598,0 32 Maluku Utara 300775,0 330396,0 369735.5 398078,0 412104.5 33 Papua Barat 398902.5 428199.5 465360.5 497994.5 519615,0 34 Papua Barat 375095,0 406681.5 442877,0 473139.5 503385.5 2.2 Kemiskinan
Kemiskinan merupakan persoalan yang kompleks dan kronis. faktor-faktor yang dapat mempengaruhi kemiskinan baik langsung maupun tidak langsung cukup banyak.mulai dari pertumbuhan ekonomi, produktifitas tenaga kerja, tingkat upah, jenis pekerjaan dan jumlah jam kerja, kesempatan kerja (termasuk jenis pekerjaan yang tersedia), inflasi, jumlah anggota rumah tangga, fasilitas kesehatan, konsumsi rumah tangga, sumber air bersih, transportasi, kepemilikan aset lahan pertanian, pendidikan dan jumlah tahun bersekolah seluruh anggota keluarga, akses permodalan, dan lokasi wilayah tempat tinggal penduduk dengan pusat pertumbuhan ekonomi yang kalau diamati, sebagian besar dari factor-faktor tersebut juga mempengaruhi satu sama lain [10].
2.3 Algoritma K-Medoids
Metode K-Medoids merupakan bagian algoritma clustering. Metode K-Medoids cukup efisien untuk dataset yang kecil. Langkah awal K- Medoids adalah mencari titik yang paling representatif (medoids) dalam sebuah dataset dengan menghitung jarak dalam kelompok dari semua kemungkinan kombinasi dari medoids sehingga jarak antar titik dalam suatu cluster kecil sedangkan jarak titik antar cluster besar [11]. Algoritma K-Medoids hadir untuk mengatasi kelemahan Algoritma K-Means yang sensitif terhadap outlier karena suatu objek dengan suatu nilai yang besar mungkin secara substansial menyimpang dari distribusi data [12]. Langkah-langkah K-Medoids adalah [4]:
1. Pilih poin k sebagai inisial centroid / nilai tengah (medoids) sebanyak k cluster. 2. Cari semua poin yang paling dekat dengan medoids, dengan cara menghitung
jarak vektor antar dokumen dengan menggunakan Euclidian Distance. Rumusnya adalah sebagai berikut :
2 1 ( , ) n | | i d x y
xiyj (1) Dimana:d(x,y) = jarak antara data ke-i dan data ke-j xi1 = nilai atribut ke satu dari data ke-i yj1 = nilai atribut ke satu dari data ke-j n = jumlah atribut yang digunakan
3. Secara acak, pilih poin yang bukan medoids. 4. Hitung total jarak antar medoid.
5. Jika TD baru < TD awal, tukar posisi medoids dengan medoids baru, jadilah medoids yang baru.
6. Ulangi langkah 2-5 sampai medoids tidak berubah. 3. HASIL DAN PEMBAHASAN
3.1 Analisa Algoritma K-Medoids
Langkah-langkah dalam menyelesaikan perhitungan manual data mining menggunakan k-medoids clustering menggunakan 2 cluster yaitu:
1. Inisialisasi pusat cluster sebanyak 2 cluster dari data sampel. Untuk pemilihan setiap medoid dipilih secara acak. Seperti pada tabel 2.
Tabel 2. Medoid Awal
No Provinsi 2013 2014 2015 2016 2017 1 Papua (C1) 375095,0 406681.5 442877,0 473139.5 503385.5 2 Gorontalo (C2) 231111,0 248395,0 268934.5 285732,0 305711.5
2. Menghitung nilai jarak (cost) dengan persamaan Euclidian Distance: untuk menghitung jarak antara titik centroid dengan titik tiap objek menggunakan Euclidian Distance. Rumus untuk menghitung jarak menggunakan persamaan (2). Maka perhitungan untuk jarak pada medoid ke – 1 adalah sebagai berikut: Perhitungan (C1) sebagai berikut:
60123.35326
147177.7909
0
Perhitungan (C2) sebagai berikut:
330683.8742
240784.687
387606.2215
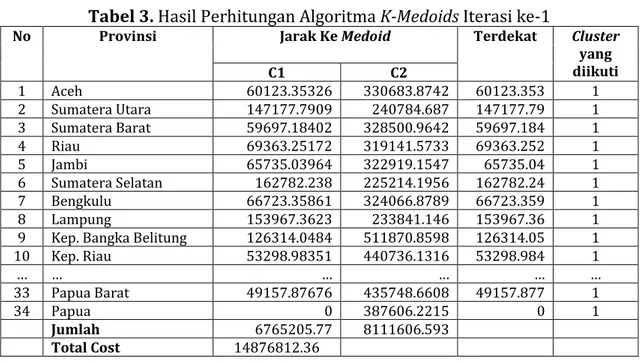
Tabel 3. Hasil Perhitungan Algoritma K-Medoids Iterasi ke-1
No Provinsi Jarak Ke Medoid Terdekat Cluster yang diikuti C1 C2 1 Aceh 60123.35326 330683.8742 60123.353 1 2 Sumatera Utara 147177.7909 240784.687 147177.79 1 3 Sumatera Barat 59697.18402 328500.9642 59697.184 1 4 Riau 69363.25172 319141.5733 69363.252 1 5 Jambi 65735.03964 322919.1547 65735.04 1 6 Sumatera Selatan 162782.238 225214.1956 162782.24 1 7 Bengkulu 66723.35861 324066.8789 66723.359 1 8 Lampung 153967.3623 233841.146 153967.36 1 9 Kep. Bangka Belitung 126314.0484 511870.8598 126314.05 1 10 Kep. Riau 53298.98351 440736.1316 53298.984 1 … … … … 33 Papua Barat 49157.87676 435748.6608 49157.877 1 34 Papua 0 387606.2215 0 1 Jumlah 6765205.77 8111606.593 Total Cost 14876812.36
Setelah didapatkan hasil jarak dari setiap objek (cost) pada iterasi pertama maka lanjut ke iterasi 2. Kandidat medoid baru (non medoid) pada iterasi ke-2 dapat dilihat pada tabel 4. berikut:
Tabel 4. Kandidat Medoid Baru
No Provinsi 2013 2014 2014 2016 2017 1 Aceh (C1) 366739 390062.5 415369 436729 468941.5 2 Sumatera Utara(C2) 318934.5 343803 372109 406121.5 432293.5
Dengan menggunakan langkah – langkah yang sama seperti sebelumnya untuk menentukan jarak dari setiap objek pada iterasi ke-2, yaitu:
Perhitungan (C1) sebagai berikut:
0
92609.57899
60123.35326
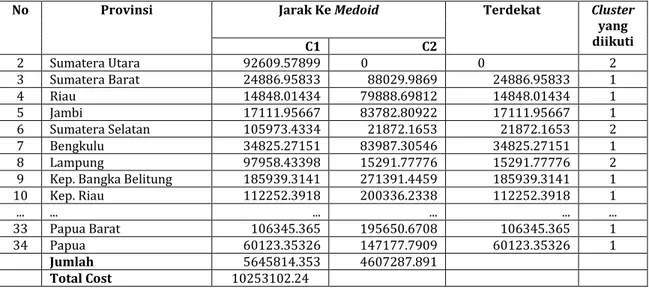
Sehingga diperoleh hasil dari keseluruhan pada tabel 5. sebagai berikut: Tabel 5. Hasil Perhitungan Algoritma K-Medoid Pada Iterasi ke-2
No Provinsi Jarak Ke Medoid Terdekat Cluster
yang diikuti
C1 C2
No Provinsi Jarak Ke Medoid Terdekat Cluster yang diikuti C1 C2 2 Sumatera Utara 92609.57899 0 0 2 3 Sumatera Barat 24886.95833 88029.9869 24886.95833 1 4 Riau 14848.01434 79888.69812 14848.01434 1 5 Jambi 17111.95667 83782.80922 17111.95667 1 6 Sumatera Selatan 105973.4334 21872.1653 21872.1653 2 7 Bengkulu 34825.27151 83987.30546 34825.27151 1 8 Lampung 97958.43398 15291.77776 15291.77776 2
9 Kep. Bangka Belitung 185939.3141 271391.4459 185939.3141 1
10 Kep. Riau 112252.3918 200336.2338 112252.3918 1 ... ... ... ... ... ... 33 Papua Barat 106345.365 195650.6708 106345.365 1 34 Papua 60123.35326 147177.7909 60123.35326 1 Jumlah 5645814.353 4607287.891 Total Cost 10253102.24
3. Hitung Total Simpangan (S)
Setelah didapatkan nilai jarak antara iterasi ke-1 dan iterasi ke-2, hitung total simpangan (S) dengan mengurangkan nilai total cost baru – nilai total cost lama. Dengan ketentuan jika S<0, maka tuakr nilai objek dengan menentukan medoid baru.
S = Total cost baru – Total cost lama = 10253102.24– 14876812.36 = -4623710.1
4. Ulangi langkah sebelumnya hingga S>0, sehingga didapatkan cluster beserta anggota cluster.
Tabel 6. Kandidat Medoid Baru
No Provinsi 2013 2014 2015 2016 2017 1 Papua (C1) 375095 406681.5 442877 473139.5 503385.5 2 Maluku Utara(C2) 300775 330396 369735.5 398078 412104.5
Dengan menggunakan langkah-langkah yang sama seperti sebelumnya untuk menentukan jarak dari setiap objek pada iterasi ke-3, yaitu:
Perhitungan (C1) sebagai berikut:
60123.35326
147177.7909 0
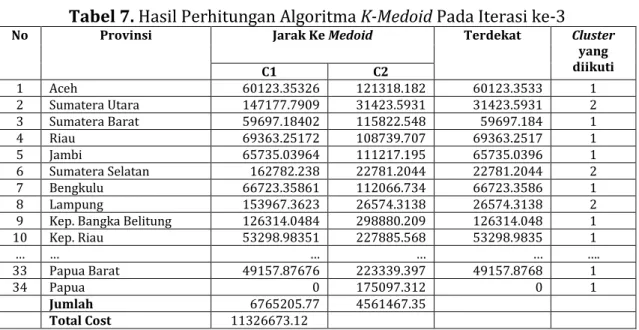
Tabel 7. Hasil Perhitungan Algoritma K-Medoid Pada Iterasi ke-3
No Provinsi Jarak Ke Medoid Terdekat Cluster
yang diikuti C1 C2 1 Aceh 60123.35326 121318.182 60123.3533 1 2 Sumatera Utara 147177.7909 31423.5931 31423.5931 2 3 Sumatera Barat 59697.18402 115822.548 59697.184 1 4 Riau 69363.25172 108739.707 69363.2517 1 5 Jambi 65735.03964 111217.195 65735.0396 1 6 Sumatera Selatan 162782.238 22781.2044 22781.2044 2 7 Bengkulu 66723.35861 112066.734 66723.3586 1 8 Lampung 153967.3623 26574.3138 26574.3138 2
9 Kep. Bangka Belitung 126314.0484 298880.209 126314.048 1
10 Kep. Riau 53298.98351 227885.568 53298.9835 1 … … … …. 33 Papua Barat 49157.87676 223339.397 49157.8768 1 34 Papua 0 175097.312 0 1 Jumlah 6765205.77 4561467.35 Total Cost 11326673.12
Setelah didapatkan hasil jarak dari setiap objek (cost) pada iterasi pertama maka lanjut ke iterasi 2. Kandidat medoid baru (non medoid) pada iterasi ke-2 dapat dilihat pada tabel 4.6 berikut:
5. Hitung Total Simpangan (S)
Setelah didapatkan nilai jarak antara iterasi ke-2 dan iterasi ke-3, hitung total simpangan (S) dengan mengurangkan nilai total cost baru – nilai total cost lama. Dengan ketentuan jika S<0, maka tuakar nilai objek dengan menentukan medoid baru.
S = Total cost baru – Total cost lama = 11326673.12 – 10253102.24 = 1073570.878
3.2 Hasil
Untuk mendapatkan hasil berupa pengelompokkan maka pada tahap selanjutnya dapat dilakukan dengan cara pengujian menggunakan tools RapidMiner. Hasil akhir yang akan ditampilkan adalah berupa pengelompokkan dimana hasil dari pengujian data akan tampak cluster dengan masing – masing anggota, Untuk melihat provinsi – provinsi yang termasuk dalam cluster 1 dan 2 terdapat pada gambar 2 berikut:
3.3 Pembahasan
Berdasarkan penjelasan diatas mengenai penggunaan serta hasil yang telah ditampilkan, keterkaitan dari hasil yang diperoleh antara perhitungan algoritma dengan hasil pengujian pada tools rapidminer 5.3. Dalam melakukan validasi data perhitungan algoritma harus menghasilkan hasil akhir berupa pengelompokkan dengan 2 cluster, serta data yang digunakan merupakan data yang valid dan sama dengan yang dipakai pada tools rapidminer 5.3. Berikut ditampilkanhasil yang didapatkan dari perhitungan algotirma dan pengujian pada rapidminer 5.3.
Tabel 8. Hasil perhitungan algotirma dan pengujian pada rapidminer 5.3
No Provinsi Perhitungan Algoritma K-Medoids Pengujian Dengan Rapidminer 5.3
1 Aceh cluster_1 cluster_1
2 Sumatera Utara cluster_2 cluster_2
3 Sumatera Barat cluster_1 cluster_1
4 Riau cluster_1 cluster_1
5 Jambi cluster_1 cluster_1
6 Sumatera Selatan cluster_2 cluster_2
7 Bengkulu cluster_1 cluster_1
8 Lampung cluster_2 cluster_2
9 Kep. Bangka Belitung cluster_1 cluster_1
10 Kep. Riau cluster_1 cluster_1
11 Dki Jakarta cluster_2 cluster_2
12 Jawa Barat cluster_1 cluster_1
13 Jawa Tengah cluster_2 cluster_2
14 Di Yogyakarta cluster_2 cluster_2
15 Jawa Timur cluster_2 cluster_2
16 Banten cluster_2 cluster_2
17 Bali cluster_2 cluster_2
18 Nusa Tenggara Barat cluster_2 cluster_2
19 Nusa Tenggara Timur cluster_2 cluster_2
20 Kalimantan Barat cluster_2 cluster_2
21 Kalimantan Tengah cluster_2 cluster_2
22 Kalimantan Selatan cluster_2 cluster_2
23 Kalimantan Timur cluster_1 cluster_1
24 Kalimantan Utara cluster_2 cluster_2
25 Sulawesi Utara cluster_2 cluster_2
26 Sulawesi Tengah cluster_2 cluster_2
27 Sulawesi Selatan cluster_2 cluster_2
28 Sulawesi Tenggara cluster_2 cluster_2
29 Gorontalo cluster_2 cluster_2
30 Sulawesi Barat cluster_2 cluster_2
31 Maluku cluster_2 cluster_2
32 Maluku Utara cluster_2 cluster_2
33 Papua Barat cluster_1 cluster_1
34 Papua cluster_1 cluster_1
Hasil cluster_1 11
cluster_2 23
4. KESIMPULAN
Berdasarkan pembahasan diatas dapat disimpulkan bahwa :
a. Penerapan Data Mining menggunakan algoritma K-MEDOIDS untuk mengelompokkan garis kemiskinan menurut provinsi dengan data uji sebanyak
34 provinsi dengan menggunakan dua cluster. cluster 1 (nilai terendah) sebanyak 11, cluster 2 (nilai tinggi) sebanyak 23 .
b. Pengujian data pada Rapiminer 5.3 dengan menggunakan K-MEDOIDS dapat menampilkan dua kelas dari hasil klasifikasi dengan persentase keakuratan sebesar 100 %.
DAFTAR PUSTAKA
[1] N. Zuhdiyaty and D. Kaluge, “Analisis Faktor-faktor yang Mempengaruhi Kemiskinan di Indonesia Selama Lima Tahun Terakhir (Studi Kasus Pada 33 Provinsi),” Jurnal Jibeka, vol. 11, no. 2, pp. 27–31, 2017.
[2] N. Zuhdiyaty, “ANALISIS FAKTOR - FAKTOR YANG MEMPENGARUHI KEMISKINAN DI INDONESIA SELAMA LIMA TAHUN TERAKHIR (Studi Kasus Pada 33 Provinsi),” JIBEKA, vol. 11, no. 2, pp. 1–5, 2015.
[3] M. T. Furqon, A. Ridok, and W. F. Mahmudy, “Paralelisasi Algoritma K-MedoidS Pada General Purpose menggunakan Open Computing Language,” Konferensi Nasional Sistem Informasi 2015, pp. 1–7, 2015.
[4] H. Zayuka, S. M. Nasution, and Y. Purwanto, “Perancangan Dan Analisis Clustering Data Menggunakan Metode K-Medoids Untuk Berita Berbahasa Inggris,” e-Proceeding of Engineering : Vol.4, No.2 Agustus 2017, vol. 4, no. 2, pp. 1–9, 2017.
[5] I. Parlina, A. P. Windarto, A. Wanto, and M. R. Lubis, “Memanfaatkan Algoritma K-Means dalam Menentukan Pegawai yang Layak Mengikuti Asessment Center untuk Clustering Program SDP,” CESS (Journal of Computer Engineering System and Science), vol. 3, no. 1, pp. 87–93, 2018.
[6] M. G. Sadewo, A. P. Windarto, and A. Wanto, “Penerapan Algoritma Clustering dalam Mengelompokkan Banyaknya Desa/Kelurahan Menurut Upaya Antisipasi/ Mitigasi Bencana Alam Menurut Provinsi dengan K-Means,” KOMIK (Konferensi Nasional Teknologi Informasi dan Komputer), vol. 2, no. 1, pp. 311–319, 2018.
[7] R. W. Sari, A. Wanto, and A. P. Windarto, “Implementasi Rapidminer dengan Metode K-Means (Study Kasus : Imunisasi Campak pada Balita Berdasarkan Provinsi),” KOMIK (Konferensi Nasional Teknologi Informasi dan Komputer), vol. 2, no. 1, pp. 224–230, 2018. [8] S. Sudirman, A. P. Windarto, and A. Wanto, “Data Mining Tools | RapidMiner : K-Means
Method on Clustering of Rice Crops by Province as Efforts to Stabilize Food Crops In Indonesia,” IOP Conference Series: Materials Science and Engineering, vol. 420, no. 12089, pp. 1–8, 2018.
[9] D. F. Pramesti, M. T. Furqon, and C. Dewi, “Implementasi Metode K-Medoids Clustering Untuk Pengelompokan Data Potensi Kebakaran Hutan / Lahan Berdasarkan Persebaran Titik Panas ( Hotspot ),” vol. 1, no. 9, pp. 723–732, 2017.
[10] M. Kurniawan.DP, “ANALISIS FAKTOR-FAKTOR PENYEBAB KEMISKINAN ( StudiKasus di kecamatan Sungai Lilin ),” vol. 8, no. 1, pp. 16–20, 2017.
[11] M. Harival Zayuka, Surya Mircharandi Nasution, ST., MT, Yudha Purwanto, ST., “PERANCANGAN DAN ANALISIS CLUSTERING DATA MENGGUNAKAN METODE K-MEDOIDS UNTUK BERITA BERBAHASA INGGRIS DESIGN AND ANALYSIS OF DATA CLUSTERING USING K-MEDOIDS METHOD FOR ENGLISH NEWS,” vol. 4, no. 2, pp. 2–9, 2017.
[12] W. A. Triyanto, “ALGORITMA K-MEDOIDS UNTUK PENENTUAN STRATEGI PEMASARAN,” vol. 6, no. 1, pp. 183–188, 2015.