Fakultas Ilmu Komputer
Universitas Brawijaya
635
Clustering Data Kejadian Tsunami Yang Disebabkan Oleh Gempa Bumi
Dengan Menggunakan Algoritma K-Medoids
Daniel Alex Saroha Simamora1, M. Tanzil Furqon2, Bayu Priyambadha3 Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya E-mail : 1[email protected], 2[email protected], 3[email protected]
Abstrak
Tsunami adalah sebuah kejadian alam yang disebabkan oleh perubahan permukaan laut secara vertikal dengan tiba – tiba sehingga menyebabkan perpindahan volume air yang besar. Letusan gunung berapi bawah laut, gempa bumi yang berpusat dibawah laut, dan longsor bawah laut merupakan beberapa penyebab perubahan permukaan laut secara tiba – tiba. Tsunami telah sering terjadi dan menyebabkan banyak kerusakan dan korban jiwa. Tsunami yang sering terjadi secara tiba – tiba dan tidak dapat diprediksi menjadi penyebab utama banyaknya korban jiwa dan kerusakan yang terjadi dan juga kecilnya pengetahuan dan kesadaran tentang tsunami memperparah efek yang dapat ditimbulkan oleh
tsunami. K-Medoids merupakan salah satu metode clustering data yang telah banyak diaplikasikan terhadap dataset yang memiliki outlier. Subjek yang terdapat pada penelitian ini adalah aplikasi pengelompokan data dengan menggunakan K-Medoids untuk mengelompokan data kejadian tsunami
yang disebabkan oleh gempa bumi. Dataset yang digunakan pada penelitian ini bersumber dari database kejadian tsunami yang terdapat di situs resmi National Oceanic and Atmospheric Administration
(NOAA). Hasil dari penelitian ini adalah sebuah sistem yang mampu melakukan pengelompokan dataset
tsunami dengan menggunakan metode K-Medoids. Dari pengujian yang dilakukan didapatkan hasil bahwa jumlah cluster terbaik untuk mengelompokan dataset tsunami adalah 2 cluster.
Kata Kunci: tsunami, K-Medoids
Abstract
Tsunami is a natural events caused by sudden alteration in sea surface vertically, causing displacement of a large volume of water. Underwater volcano eruption, earthquake that is centered under the sea, and submarine landslide are some of the causes of sudden sea level change. Tsunami have occurred many times and causing many damages and fatalities. Tsunami often occurred so suddenly and cannot be predicted is the main reason for so many damages and fatalities, and the lack of knowledge and awareness are also worsen the effect of tsunami. K-Medoids is one of many clustering method which is applied to the dataset which have outlier. Subject in this research is a clustering application using K-Medoids to cluster the tsunami event which caused by earthquake dataset. Dataset used in this research come from the tsunami events database from the official site of National Oceanic and Atmospheric Administration (NOAA). The outcome from this research is a system that able to do clustering process on the tsunami events dataset using K-Medoids method. From the test, it is showed that the best number of clusters for tsunami events dataset is 2 clusters.
Keywords : tsunami, K-Medoids
1. PENDAHULUAN
Pada hari Minggu, 26 Desember 2004 terjadi gempa hebat berkekuatan Mw (moment magnitude) 9,1–9,3 dan berpusat di lepas pesisir barat Sumatera yang menyebabkan terjadinya serangkaian bencana tsunami yang menyerang sebagian besar daratan yang berbatasan dengan
Samudra Hindia. Dampak dari tsunami tersebut dirasakan oleh 14 negara termasuk negara kita dengan korban jiwa lebih dari 170.000 orang dan kerugian material diperkirakan mencapai US$ 4.000.000.000 – 4.500.000.000. Besarnya kerugian yang dialami Indonesia diantara lain disebabkan oleh dekatnya pusat gempa dengan pesisir pantai, kurangnya akses informasi dan pendidikan mengenai tanda - tanda tsunami.
Selama ini tsunami masih menjadi bahasan di lembaga – lembaga penelitian dan level perguruan tinggi dan belum merakyat.
Dengan teknologi yang berkembang pada saat ini tidak sulit untuk bisa mengumpulkan data – data statistik dari kejadian tsunami yang telah terjadi di masa lalu, mempelajari karakteristik dari setiap kejadian tersebut, dan melakukan pengelompokan data. Dengan bantuan teknologi maka pengelompokan data, atau yang disebut juga dengan Clustering, bisa dilakukan secara cepat, efektif dan efisien.
Clustering adalah suatu unsupervised learning, dimana sekelompok data langsung dikelompokan berdasarkan tingkat
kemiripannya tanpa dilakukan
supervisi. Prinsip dasar dari clusteringadalah memaksimalkan kesamaan antar anggota satu klaster dan meminimumkan kesamaan antar anggota cluster yang berbeda. Clusteringjuga dapat mengelompokan data yang berdasarkan tingkat kemiripannya dan juga berdasarkan tingkat akurasinya (Han&Kamber,2006).
Terdapat beberapa algoritma
pengelompokan data, diantaranya adalah K-Medoids, K-Means, dll. Algoritma K-Medoids merupakan metode yang diciptakan untuk mengatasi kelemahan algoritma K-Means yang sensitif terhadap outlier, karena nilai yang sangat besar dapat secara substansial mendistorsi distribusi data. Untuk mengatasi hal tersebut algoritma K-Medoidstidak mengambil nilai rata – rata dari objek dalam sebuah cluster sebagai titik acuan melainkan menggunakan objek yang sebenarnya untuk mewakili cluster, menggunakan satu objek perwakilan per cluster. Setiap objek yang tersisa berkumpul dengan objek perwakilan yang paling mirip dengan dirinya. Lalu metode partisi dilakukan berdasarkan prinsip meminimalkan jumlah ketidaksamaan antara tiap objek dengan titik referensinya (Han&Kamber,2006).
Pada skripsi ini dengan memanfaatkan metode untuk K-Medoids, dapat dikembangkan
untuk membangun aplikasi pada
pengelompokan data kejadian tsunami yang disebabkan oleh gempa bumi. Pentingnya melakukan pengelompokan data dari kejadian
tsunami karena data yang dihasilkan nantinya bisa berguna untuk mengetahui karakteristik
tsunami dan bisa digunakan untuk peringatan awal dan penanggulangan bencana tsunami
(National Academy of Science,2011).
Melihat pada penelitian sebelumnya yang dilakukan oleh Gandhi Gopi (Gandhi,2014)
menunjukan bahwa K-Medoids memiliki kinerja yang lebih baik daripada K-Means dalam melakukan pengelompokan pada dataset yang berukuran besar dan hasil dari penelitian yang dilakukan oleh T. Velmurugan dan T. Santhanam (Velmurugan,2010) menunjukan bahwa K-Medoids menunjukkan kinerja yang lebih bagus dari K-Means dalam melakukan pengelompokan terhadap dataset dengan jumlah objek yang besar
2. DATA PENELITIAN
Data yang digunakan dalam penelitian ini adalah dataset tsunami yang disebabkan oleh gempa bumi yang diambil dari website NOAA
(National Oceanic and Atmospheric Administration), dengan alamat website www.ngdc.noaa.gov. Parameter kejadian tsunami yang digunakan berjumlah 4 parameter yaitu kekuatan gempa, kedalaman pusat gempa (focal depth), latitude, longitude.
Data yang terdapat pada website NOAA memiliki beberapa kelompok parameter seperti
date, tsunami cause, tsunami source location, tsunami parameter, tsunami effect, tetapi hanya
tsunami cause yang digunakan dalam penelitian ini dikarenakan parameter yang ada didalamnya merupakan parameter penyebab tsunami. Data kejadian tsunami yang diperoleh untuk penelitian ini berjumlah total 197 data. Data yang digunakan merupakan data kejadian tsunami yang terjadi pada tahun 1990 – 2015 dikarenakan banyak data kejadian tsunami yang terjadi pada tahun – tahun sebelum tahun 1990 memiliki data yang kurang lengkap.
3. TSUNAMI
Kata Tsunami berasal dari 2 kata dalam bahasa jepang yaitu tsu yang berarti pelabuhan dan nami yang berarti gelombang, secara bahasa tsunami dapat diartikan sebagai ombak besar di pelabuhan. Tsunami disebabkan oleh perubahan permukaan laut secara vertikal dengan tiba – tiba sehingga menyebabkan perpindahan volume air yang besar. Letusan gunung berapi bawah laut, gempa bumi yang berpusat dibawah laut, dan longsor bawah laut merupakan beberapa penyebab perubahan permukaan laut secara tiba – tiba.
Gelombang tsunami dapat merambat kesegala arah dengan kecepatan dan ketinggian tsunami didalam laut tetap tidak berubah. Di
lautan dalam, gelombang tsunami dapat melaju dengan kecepatan kecepatan 500-1000 km per jam tetapi ketinggiannya hanya sekitar 1 meter. Namun saat tiba dibibir pantai kecepatan gelombang tsunami turun hingga sekitar 30 km per jam dan ketinggiannya meningkat sampai puluhan meter dan gelombang tsunami dapat menjalar sampai puluhan kilometer dari tepi pantai.
4. K-MEDOIDS
Algoritma k-medoids adalah salah satu algoritma clustering yang terkait dengan algoritma k-means. K-medoids dan k-means bersifat partisional (memecah dataset kedalam beberapa kelompok) dan keduanya bertujuan untuk meminimalkan jarak antara titik yang ada di dalam kluster dengan titik yang menjadi titik tengah dari kluster.
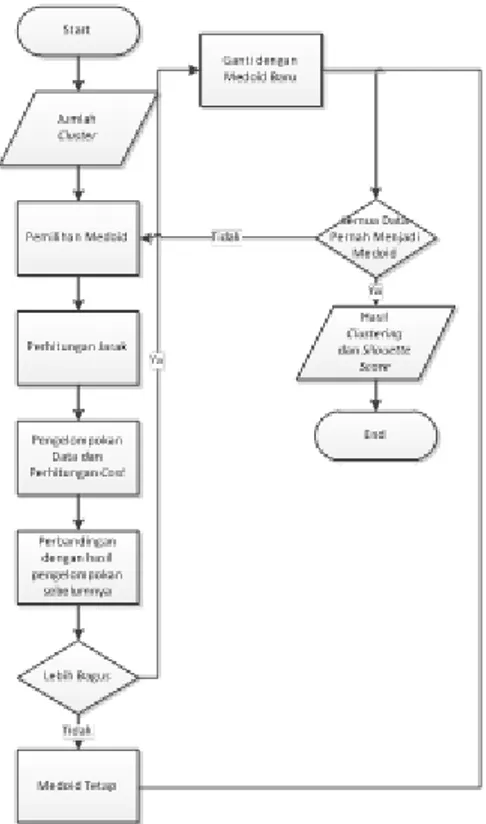
Berikut langkah-langkah dari metode
K-medoid menurut Han & Kamber:
1. Menentukan jumlah kluster yang diinginkan.
2. Memilih secara acak data untuk digunakan sebagai medoid awal sebanyak jumlah kluster yang ditentukan.
3. Melakukan perhitungan jarak data terhadap medoidawal.
4. Mengelompokan data dengan medoid yang berjarak paling dekat dengan data tersebut lalu menghitung jumlah cost. 5. Mengganti salah satu medoiddengan data
dari kelompoknya dan melakukan proses perhitungan jarak dan pengelompokan seperti pada proses nomor 3 dan 4. Jika jumlah cost yang dihasilkan lebih kecil dari cost sebelumnya maka medoid akan diganti dengan medoid yang baru dan jika tidak maka tidak terjadi perubahan dan diganti dengan data yang lainnya. Ulangi proses 3 – 5 sampai semua data telah menjadi medoid.
Gambar 1. Diagram AlirK-Medoids
5. SILHOUTTE COEFFICIENT
Silhoutte Coefficient adalah suatu metode evaluasi cluster untuk melihat kualitas penempatan suatu objek kedalam suatu cluster.
Tahapan perhitungan silhoutte coefficient
adalah sebagai berikut (Rousseeuw,1986). 1. Hitung rata – rata jarak objek ke-i
terhadap semua objek yang terdapat di kelompoknya. Rata – rata jarak tersebut kita sebut dengan a(i).
2. Hitung rata – rata jarak objek ke-i
terhadap semua objek pada cluster lain kita sebut dengan b(i), dan ambil nilai terkecilnya.
3. Nilai silhoutte coefficient didapatkan dengan menggunakan rumus :
𝑆(𝑖) = 𝑏(𝑖)−𝑎(𝑖)
max(𝑏(𝑖),𝑎(𝑖)) (1)
dan dapat di tulis dengan :
𝑆(𝑖) = { 1 −𝑎(𝑖) 𝑏(𝑖), 𝑖𝑓 𝑎(𝑖) < 𝑏(𝑖) 0, 𝑖𝑓 𝑎(𝑖) = 𝑏(𝑖) 𝑏(𝑖) 𝑎(𝑖)− 1, 𝑖𝑓 𝑎(𝑖) > 𝑏(𝑖) (2)
S(i) = Nilai Silhouette
a(i) = rata – rata jarak antara data i dengan semua objek pada cluster-nya.
b(i) = rata – rata jarak antara data i
Nilai dari silhoutte coefficient berada berkisar antara -1 sampai dengan 1. Jika nilai
silhoutte coefficient hampir 1 maka objek tersebut berada di cluster yang tepat, jika berada disekitar 0 maka objek tersebut bisa berada diantar 2 cluster, dan jika hasilnya negatif maka objek tersebut kemungkinan berada di cluster
yang salah.
6. IMPLEMENTASI SISTEM
Pada bagian ini akan dijelaskan tentang bagaimana alur kerja dari sistem clustering
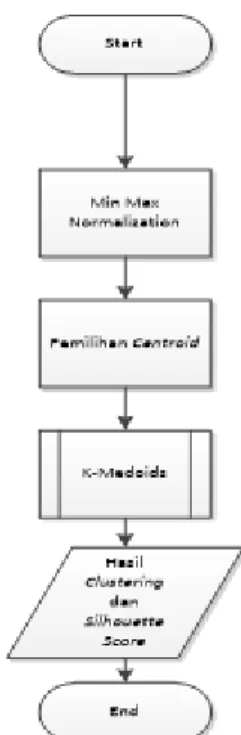
dengan metode K-Medoids ini nantinya. Diagram alir dari sistem dalam melakukan proses pengelompokan dengan menggunakan K-Medoids digambarkan pada gambar 2.
Pada gambar 2, terlihat sistem clustering ini memiliki 3 proses utama, yaitu :
1. Jumlah Cluster
Merupakan proses masukan dari
pengguna yang berupa berapa banyak jumlah cluster yang diinginkan. Proses ini penting karena merupakan proses awal yang diperlukan untuk menjalankan sistem. Proses ini juga akan menentukan berapa banyak jumlah data yang akan diambil secara acak untuk menjadi medoid
awal. 2. K-medoids
Pada proses ini dataset dikelompokan berdasarkan jumlah kluster yang diinputkan pada awal program dengan menggunkan metode K-medoid. sistem yang telah menentukan secara acak sejumlah medoid akan mengelompokan data yang tersisa berdasarkan jarak terdekat dengan medoid yang ada.
3. Hasil Clustering
Hasil dari clustering adalah data yang telah terkelompok sesuai dengan
cluster-nya masing – masing.
Gambar 2. Diagram AlirSistem
7. PENGUJIAN
Pengujian sistem yang dilakukan pada pengujian ini adalah pengujian jumlah cluster
dan pengujian clustering terhadap sampel data acak.
1. Pengujian jumlah cluster.
Pengujian ini bertujuan untuk mengetahui apakah sistem yang dibangun telah berjalan sesuai dengan perancangan dan berapa jumlah cluster yang menghasil kan nilai silhouette terbaik.
2. Pengujian clustering terhadap sampel data acak.
Pengujian ini bertujuan untuk mengetahui presentase data minimal yang dapat
digunakan untuk rekomendasi
pengambilan sampel data dari dataset dengan jumlah data yang besar.
8. ANALISIS
Berikut ini merupakan hasil dari pengujian jumlah cluster dan pengujian clustering terhadap sampel data acak. Tabel 1 dan gambar 3 merupakan hasil pengujian petama. Tabel 2 dan gambar 4 merupakan hasil pengujian kedua.
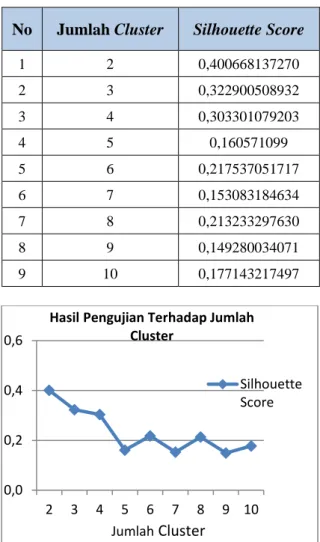
Tabel 1. Hasil Pengujian Pertama No Jumlah Cluster Silhouette Score
1 2 0,400668137270 2 3 0,322900508932 3 4 0,303301079203 4 5 0,160571099 5 6 0,217537051717 6 7 0,153083184634 7 8 0,213233297630 8 9 0,149280034071 9 10 0,177143217497
Gambar 3. Hasil Pengujian Pertama Dari hasil pengujian perubahan jumlah
cluster yang ditampilkan pada tabel 1 terlihat bahwa sistem telah berhasil menjalankan metode K-Medoids seperti yang telah dirancang sebelumnya. Sistem mampu menerima masukan dari user dan menampilkan hasilnya. Analisa hasil clustering dengan pengujian jumlah cluster
sebanyak 2 sampai dengan 10 cluster
menunjukan bahwa kualitas clustering dengan jumlah cluster sama dengan 2 memiliki kualitas yang paling bagus dengan nilai silhouettescore
sebesar 0,400668137270. Selain itu, semakin banyak jumlah cluster yang dimasukan maka semakin rendah nilai silhouette score yang dihasilkan. Hal ini disebabkan karena ketika jumlah cluster yang digunakan semakin sedikit maka rata – rata jarak antara data di dalam suatu
cluster semakin kecil dan rata – rata jarak antar
cluster semakin besar sehingga menghasilkan nilai silhouette score yang lebih baik dan hal yang sebaliknya akan terjadi ketika jumlah
cluster semakin besar.
Tabel 2. Hasil Pengujian Kedua Data
Acak
Nilai silhouette score 50% 60% 70% 80% 90% 1 0,351 0,410 0,463 0,415 0,451 2 0,401 0,442 0,446 0,461 0,466 3 0,342 0,406 0,417 0,441 0,443 4 0,373 0,432 0,439 0,457 0,452 5 0,442 0,422 0,445 0,441 0,457 Rata 0,382 0,423 0,442 0,443 0,454
Gambar 4. Hasil Pengujian Kedua
Gambar 4 menggambarkan hasil pengujian terhadap 25 dataset yang diambil secara acak dari dataset tsunami dapat dilihat bahwa kelompok dataset dengan jumlah data sebesar 90% dari total dataset kejadian tsunami
menghasilakan rata – rata nilai silhouette score
paling baik dengan nilai silhouette score sebesar 0,45363334, dan dapat dilihat juga bahwa semakin kecil presentase pengambilan data acak maka nilai silhouette score yang dihasilkan akan semakin kecil. Hal ini dapat terjadi karena semakin kecil presentase data acak yang diambil maka kesamaan karakteristik antar data didalam dataset akan berkurang yang akan menyebabkan rata – rata jarak antar data dalam suatu cluster
akan semakin besar dan rata – rata jarak antar
cluster akan semakin kecil.
9. KESIMPULAN
Berdasarkan pada hasil perancangan, implementasi dan pengujian sistem yang telah dilakukan maka kesimpulan yang didapat sebagai berikut :
1. Metode K-Medoids dapat diaplikasikan untuk pengelompokkan dataset kejadian
tsunami. Pengimplementasian metode
K-0,0 0,2 0,4 0,6
2 3 4 5 6 7 8 9 10
Hasil Pengujian Terhadap Jumlah Cluster Silhouette Score JumlahCluster 0,1 0,2 0,3 0,4 0,5 0,6 50% 60% 70% 80% 90%
Hasil Pengujian Clustering Terhadap Sampel Data Acak
Silhouette Score
Medoids pada penelitian ini dimulai dengan pengambilan dataset dari situs NOAA yaitu http://www.ngdc.noaa. gov. Dataset yang telah diambil akan dimasukkan kedalam proses clustering
dengan dengan menggunakan metode K-Medoids. Metode silhouette juga digunakan didalam sistem untuk mengetahui kualitas dari hasil clustering
yang telah dihasilkan. Metode silhouette
menghitung tingkat kesamaan
karakteristik data di dalam suatu cluster
dan data antar cluster. Setelah proses K-Medoids dan perhitungan kualitas selesai maka sistem akan menampilkan hasil
clustering beserta nilai silhouette score. 2. Pada penelitian ini terdapat 2 pengujian
yang dilakukan berdasarkan perancangan pengujian pada bab perancangan.
a. Pengujian Terhadap Jumlah Cluster
Dari hasil pengujian jumlah cluster
yang telah dilakukan didapatkan bahwa jumlah cluster terbaik yang didapatkan adalah 2 cluster dengan nilai silhouette score sebesar 0,400668137270. Nilai tersebut dapat dapat diartikan bahwa kesamaan karakteristik data yang terdapat dalam kluster tidak terlalu bagus sehingga jarak antar data dalam suatu kluster berjauhan. Hal ini dapat terjadi karena perbedaan data yang sangat besar antara data satu dengan data lainnya dan juga bisa disebabkan karena belum ditemukan kombinasi medoid awal yang terbaik.
b. Pengujian Clustering Terhadap Sampel Data Acak
Hasil pengujian clustering terhadap sampel data acak menunjukkan bahwa 90% data merupakan presentase minimal untuk pengambilan sampel data.
10. SARAN
Saran yang diberikan untuk pengembangan sistem dalam penelitian selanjutnya adalah:
1. Dapat dilakukan penelitian lebih lanjut tentang metode K-Medoids dalam pemilihan medoid agar medoid yang terpilih merupakan medoid terbaik sehingga mendapatkan hasil clustering
yang terbaik.
2. Dapat dilakukan penelitian lebih lanjut tentang clustering dataset tsunami dengan menggunakan metode clustering lainnya sebagai perbandingan.
3. Penelitian ini dapat dikembangkan dengan menambahkan beberapa fitur lain untuk mengetahui pengaruh fitur terhadap hasil
clustering.
DAFTAR PUSTAKA
Bauckhage, C. (2015) NumPy / SciPy Recipes for Data Science: K-Medoids Clustering. University of Bonn.
Gandhi, G. & Srivastava, R. (2014) Analysis And Implementation Of Modified
K-Medoids Algorithm To Increase
Scalability And Efficiency For Large Dataset. International Journal of Research in Engineering and Technology.
3(6), 150 – 153.
Han, J. & Kamber, M. (2006) Data Mining : Concepts and Technique, 2nd edn. San Francisco, Elsevier Inc.
Hinga, B. D. R. (2015) An Encyclopedia of the Pacific Rim’s Earthquakes, Tsunamis, and Volcanoes. Santa Barbara, ABC-CLIO.
Richter, C. F. (1935) Bulletin of the Seismological Society of America. Pasadena, Carnegie Institution of Washington.
Rousseeuw, P. J. (1986) Silhouettes : A Graphical Aid to the Interpretation and Validation of Cluster Analysis. Fribourg, University of Fribourg.
Velmurugan, T. & Santhanam, T. (2010) Computational Complexity between K-Means and K-Medoids Clustering Algorithms for Normal and Uniform Distributions of Data Points. Journal of Computer Science. 6(3), 363 – 368.