PENENTUAN PARAMATER PADA ALGORITMA
KLASIFIKASI
K-NEAREST NEIGHBOR BERBASIS ALGORITMA
GENETIKA
Karno
Pusat Inovasi, Lembaga Ilmu Pengetahuan Indonesia
Jln. Raya Jakarta-Bogor Km. 47 Cibinong 16912, Bogor, Indonesia email : [email protected]
ABSTRACT
In datamining K-Nearest Neighbor(KNN) is populer and simple. KNN is effective on large datasets and resistant to the noise. KNN has a problem in determining the parameters K-nearest. Determine of the parameter K is not optimal, causing distortion. Genetic algorithms are optimization algorithms for parameter determination. In this research is focused on the determination of the parameters K-nearest on KNN by genetic algorithm. Tthe conclusion , KNN based genetic algorithm has a higher accuracy than conventional KNN and resistant to noise on datasets. Experimental results have demonstrated that the proposed scheme could obtain promising clasification results. In the iris dataset, KNN-GA has an accuracy of 97,33% while KNN 66%, in the sonar dataset KNN-GA has an accuracy of 75,48% while KNN 59,55%, in the haberman’s survival dataset KNN-GA has an accuracy of 76,22% while KNN 73,55%, and in the ecoli dataset KNN-GA has an accuracy of 97,32% while KNN 86,29%,
Keywords
K-Nearest Neighbor, Genetic Algorithm, Parameter K
1. Pendahuluan
Datamining merupakan proses untuk mendapatkan informasi yang berguna dari basis data yang besar yang bias digunakan untuk membantu dalam proses pengambilan keputusan[1][2]. Salah satu algoritma datamining yang popular dan digunakan untuk melakukan klasifikasi adalah algoritma K-Nearest Neighbor[4]. Algoritma K-Nearest Neighbor(K-NN) merupakan algoritma klasifikasi berdasarkan kedekatan lokasi (jarak) suatu data dengan data yang lain.
Tujuan dari algoritma ini adalah mengklasifikasi objek baru berdasakan atribut dan data training. Proses pengklasifikasian tidak menggunakan model apapun untuk dicocokkan dan hanya berdasarkan jarak dengan data training. Pada prosesnya diberikan titik uji, akan ditemukan sejumlah K objek (titik training) yang paling dekat dengan titik uji. Klasifikasi menggunakan
voting terbanyak di antara klasifikasi dari K objek. Algoritma K-NN menggunakan klasifikasi ketetanggaan sebagai nilai prediksi dari sample uji yang baru. Algoritma K-NN memiliki kelebihan yaitu bahwa robust terhadap training data yang memiliki banyak noise dan efektif apabila memiliki data training yang besar[4].
Sedangkan salah satu kelemahan yang dihadapi pada algoritma K-Nearest Neighbor adalah pemilihan nilai K yang tepat sesuai dengan keadaan data training[6]. Cara voting yang menggunakan mayoritas dari nilai K-tetangga untuk nilai K yang terlalu besar dapat mengakibat kan dsitorsi data yang besar[2][3]. Misalkan dari percobaan perhitungan algoritma K-Nearest Neighbor diambil nilai K-tetangga 15. Pada hasil hasil perhitungan diperoleh kelas 0 dimiliki oleh 8 tetangga yang jauh sedangkan kelas 1 dimiliki oleh 7 tetangga yang dekat. Karena hasil klasifikasi berdasarkan voting mayoritas maka mengakibatkan data training tersebut akan terdistorsi sehingga ke 7 data akan ikut bergabung dengan kelas 0. Pada gambar 1 menggambarkan bahwa 7 data akan ikut bergabung dalam mayoritas 8 data. Sedangkan untuk penentuan K yang terlalu kecil bisa menyebabkan algoritma tersebut akan sensitif terhadap noise sehingga mengakibatkan akurasi dari algoritma K-Nearest Neighbor menurun.
Gambar 1. K-NN dengan Nilai K yang besar Untuk mengatasi permasalahan penentuan k tersebut perlu adanya optimalisasi pada proses penentuan K-tetangga[8][9]. Algoritma genetika adalah algoritma optimasi yang melakukan pencarian dengan
sistem cerdas dan meniru mekanisme evolusi biologi[5]. Algoritma genetika adalah kelas khusus dari algoritma evolusioner dengan menggunakan teknik seperti warisan, mutasi, seleksi alam dan rekombinasi (crossover) Algoritma ini sering digunakan untuk mencari global optimum dari suatu permasalahan[8]. Penentuan solusi terbaik ini dapat di implementasikan pada proses penentuan tetangga pada algoritma K-Nearest Neighbor sehingga dapat memperbaiki permasalahan penentuan K yang paling optimal. Pada penelitian ini akan mencoba memperbaiki Algortima K-Nearest Neighbor yang memiliki kelemahan pada penetuan K-tetangga menggunakan algoritma Genetika. Sehingga diharapkan mendapatkan solusi global optimum pada penentuan K-tetangga. Selain itu proses klasifikasi ini diharapkan memiliki akurasi yang lebih tinggi dan robust terhadap noise.
2. Sistem Persamaan Linier
2.1 K-Nearest Neighbor
PenulisanAlgoritma K-Nearest Neighbor (K-NN) merupakan sebuah metode untuk melakukan klasifikasi terhadap obyek baru berdasarkan (K) tetangga terdekatnya [1][2]. K-NN termasuk algoritma supervised learning, dimana hasil dari query instance yang baru, diklasifikasikan berdasarkan mayoritas dari kategori pada K-NN. Kelas yang paling banyak muncul yang akan menjadi kelas hasil klasifikasi. Langkah-langkah algoritma K-Nearest Neighbor 1. Menentukan parameter K (jumlah tetangga paling
dekat),Parameter K pada testing ditentukan berdasarkan nilai K optimum pada saat training. 2. Menghitung kuadrat jarak euclidean (euclidean
distance) masing-masing obyek terhadap data sampel yang diberikan
……… (1) 3. Mengurutkan objek-objek tersebut ke dalam
kelompok yang mempunyai jarak euclidian terkecil 4. Mengumpulkan kategori Y (klasifikasi nearest
neighbor)
5. Dengan menggunakan kategori mayoritas,maka dapat hasil klasifikasi
2.2 Algoritma Genetika
Algoritma genetika adalah algoritma optimasi yang melakukan pencarian dengan sistem cerdas dan meniru mekanisme evolusi biologi[5]. Algoritma ini digunakan untuk penyelesaian masalah-masalah kombinatorial. Algoritma Genetika juga sering digunakan untuk mencari global optimum dari suatu
permasalahan[8]. Selain itu algoritma Genetika merupakan pelopor dalam pendekatan metaheuristik yang biasanya membangkitkan sejumlah populasi yang dalam masalah optimasi menjadi solusi awal. Sebagaimana halnya proses evolusi di alam, suatu algoritma genetika yang sederhana umumnya terdiri dari tiga operator yaitu: operator reproduksi, operator crossover (kawin silang) dan operator mutasi. Struktur umum dari suatu algoritma genetika dapat didefinisikan dengan langkah-langkah sebagai berikut[7][9]: 1. Membangkitkan populasi awal, Populasi awal atau
kromosom-kromosom ini dibangkitkan secara random sehingga didapatkan solusi awal. Evaluasi nilai setiap individu didalam populasi ini dengan menggunakan fitness. Tentukan ukuran populasi, probabilitas kawin silang dan probilitas mutasi. 2. Set iterasi t=1
3. Pilih individu terbaik untuk disalin sejumlah tertentu untuk mengganti indvidu lain (elitisme) 4. Lakukan seleksi kompetitif untuk memilih anggota
populasi sebagai induk untuk dilakukan kawin silang
5. Lakukan kawin silang untuk antar induk yang terpilih
6. Tentukan beberapa individu dalam populasi untuk mengalami proses mutasi
7. Jika belum mencapai kovergensi set iterasi t=t+1 8. Kembali ke langkah 2
2.3 Metode yang diusulkan
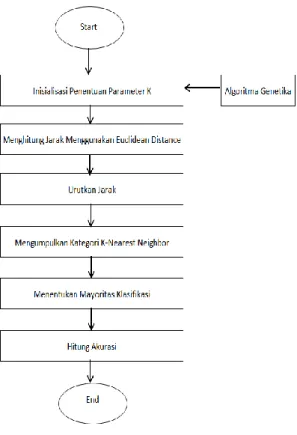
Pada gambar 2 ini menggambarkan bagaimana proses implementasi algoritma K-Nearest Neighbor dan Algoritma Genetika. Pada bagan ini algoritma genetika menentukan parameter tetangga pada K-NN. Sedangkan untuk menganalisa hasil klasifikasi menggunakan. Urutan langkah adalah dataset di inputkan kedalam sistem, kemudian algoritma genetika menentukan K-tetangga paling optimal sesuai dengan dataset, kemudian menghitung jarak menggunakan euclidean distance, mengurutkan jarak berdasarkan dari yang terkecil sampai terbesar, menentukan K-Nearest Neighbor pada data yang sudah dihitung jaraknya kemudian menentukan hasil klasifikasi berdasarkan perhitungan akurasi.
Berikut bagan yang menggambarkan metode yang diusulkan.
Gambar 2. Metode yang di Usulkan 2.4 Pengujian Model
Pada pengujian model ini berfungsi untuk mengetahui tingkat akurasi algortima yang kita gunakan dalam melakukan klasifikasi pada data yang diolah. Dengan melakukan evaluasi algoritma bisa digunakan untuk membandingkan antara algoritma K-Nearest Neighbor dan Algoritma K-K-Nearest Neighbor berbasis algoritma genetika. Jadi evaluasi dan validasi hasil akan dilakukan dengan menghitung kinerja metode yang diusulkan. Parameter kinerja yang diukur pada eksperimen ini adalah Akurasi.
Akurasi merupakan rasio jumlah data yang benar terdeteksi sebagai data positif (true positive) dan data negatif yang benar terdeteksi sebagai data negatif (true negative) terhadap jumlah keseluruhan data[10].
………… (2) Keterangan:
TP (true positive)= jumlah record positif yang diklasifikasikan sebagai positif .
TN (true negative)= jumlah record negatif yang diklasifikasikan sebagai negatif
FN (false negative) = jumlah record positif yang diklasifikasikan sebagai negatif
FP (false positive) = jumlah record negatif yang diklasifikasikan sebagai positif
3. H
a
sil Percobaan
Pada penelitian ini menggunakan empat dataset
yang bersumber pada
https://archive.ics.uci.edu/ml/datasets.html berikut ini adalah dataset tersebut :
1. Iris dataset
Terdiri dari 150 record data, 4 atribut, tipe data real, tidak ada missing atribut dan atributnya antara lain sepal length, sepal width , petal length, petal width, dan class: Iris Setosa, Iris Versicolour, Iris Virginica
2. Sonar dataset
Terdiri dari 208 record data, 60 jumlah atribut, tipe data real, dan tidak ada missing atribut
3. Haberman’s survival dataset
Terdiri dari 306 record data, 3 atribut, tipe data real dan atributnya adalah Age of patient at time of operation (numerical), Patient's year of operation (year - 1900, numerical), Number of positive axillary nodes detected (numerical), Survival status (class attribute)
4. Ecoli dataset
Terdiri dari 336 record data, jumlah atribut 8, tidak ada missing value pada atribut, dan tipe data real. Pada penelitian ini menggunakan k-fold cross validation untuk mendapatkan nilai akurasi algoritma. Pada penelitian ini nilai k yang digunakan adalah 10 sehingga disebut 10 fold cross validation dimana dilakukan pengujian sebanyak 10 kali. Dimana data dibagi menjadi 10 bagian secara bertingkat kemudian dilakukan pengujian silang antara data training dan data testing. Misalnya pada data bagian 1 sampai 9 digunakan untuk training dan bagian ke-10 digunakan sebagai data testing dan seterusnya secara bergantian. Hal ini dilakukan untuk untuk menilai/memvalidasi keakuratan sebuah model yang dibangun.
Hasil percobaan yang dilakukan menggunakan 4 dataset untuk melakukan uji coba dengan 10 kali uji dengan pembagian data secara bertingkat. Pada uji pertama hanya membandingkan antara algoritma K-Nearest Neighbor dengan algoritma K-K-Nearest Neighbor berbasis algoritma genetika. Pada pengujian ini menggunakan akurasi untuk mengevaluasi algoritma. Berikut hasil pengujian yang ditunjukan pada tabel 1.
Tabel 1. Perbandingan Akurasi algoritma K-NN dan algoritma Genetika Dataset K-NN K-NN+GA Iris 66% 97,33 % Sonar 59,55% 75,48% Haberman’s Survival 73,55% 76,22% Ecoli 86,29% 97,32%
Pada pengujian kedua ini membandingkan algoritma K-NN dengan algoritma K-NN berbasis
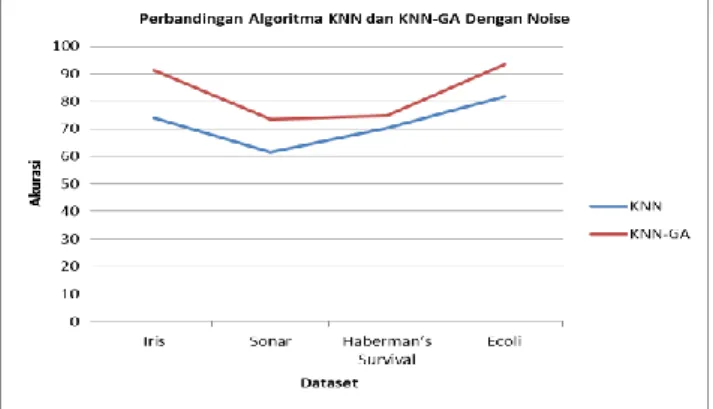
algoritma genetika. Pada pengujian ini dari dataset yang sudah ada ditambahkan noise berupa random. Pada pengujian ini masing-masing dataset diberikan noise kemudian diuji menggunakan akurasi. Tabel 2 merupakan hasil pengujian antara algorima K-NN dan algoritma K-NN berbasis algoritma genetika.
Tabel 2. Perbandingan Akurasi algoritma K-NN dan algoritma Genetika dengan Noise Ramdon
Dataset K-NN K-NN+GA
Iris 74,00% 91,33 %
Sonar 61,50% 73,50%
Haberman’s Survival 70,28% 74,86%
Ecoli 81,86% 93,46%
Grafik yang ditunjukan gambar 3 menunjukan bahwa algoritma KNN-GA memiliki akurasi yang lebih baik dibandingkan dengan algoritma KNN. Berikut grafik perbandingan nilai akurasi antara KNN dan Algoritma KNN-GA
Gambar 3. Grafik Perbandingan Algoritma KNN dan Algoritma KNN-GA
Pada Grafik yang ditunjukan gambar 4 merupakan perbandingan antara KNN dan algoritma KNN-GA tetapi pada dataset diberikan noise berupa random atribut. Pada pengujian ini membuktikan bahwa algoritma KNN-GA lebih robust terhadap noise dibandingkan dengan algoritma KNN. Jadi pada pengujian pada gambar 3 dan gambar 4 menunjukan penentuan parameter K-tetangga pada KNN berbasis algoritma genetika memiliki akurasi yang lebih baik dan lebih tahan (robust) terhadap noise pada dataset.
Gambar 4. Grafik Perbandingan Algoritma KNN dan Algoritma KNN-GA Dengan Noise
4. Kesimpulan
Pada penelitian ini diperoleh kesimpulan yaitu : 1. Algoritma K-Nearest Neighbor berbasis
algoritma genetika memiliki akurasi yang lebih tinggi dibandingkan algoritma K-Nearest Neighbor konvensional yang ditunjukan pada hasil pengujian akurasi dimana pada dataset iris KNN-GA 97,33% dan KNN 66%, pada sonar dataset KNN-GA 75.48% dan KNN 59,55%, pada haberman’s survival dataset KNN-GA 76,22% dan KNN 73,55% dan pada ecoli dataset KNN-GA 97,32% dan KNN 86,29% 2. Selain itu algoritma K-Nearest Neighbor
berbasis algoritma genetika memiliki ketahanan (robust) yang lebih baik terhadap noise pada dataset dibandingkan KNN Konvesional. Hal ini ditunjukan pada pengujian akurasi yaitu pada dataset iris KNN-GA 91,33% dan KNN 74,00%, pada sonar dataset KNN-GA 73.50% dan KNN 61,50%, pada haberman’s survival dataset KNN-GA 74,86% dan KNN 70,28% dan pada ecoli dataset KNN-GA 93,46% dan KNN 81,86%
REFERENSI
[1] F. Gorunescu, Data Mining Concepts, Models and
Techniques, vol. 12. Berlin, Heidelberg: Springer Berlin
Heidelberg, 2011
[2] D. T. Larose, Data Mining Methods and Models. Hoboken, NJ, USA: John Wiley & Sons, Inc., 2005 [3] Y. Jamshidi and V. G. Kaburlasos, “Engineering
Applications of Arti fi cial Intelligence gsaINknn : A GSA optimized , lattice computing knn classifier,” vol. 35, pp. 277–285, 2014.
[4] E. Prasetyo, Data Mining Konsep dan Aplikasi
Menggunakan Matlab. Yogyakarta: Penerbit Andi.
2012
[5] B. Santosa and P. Willy, Metode Metaheuristik Konsep
dan Implementasi. Surabaya: Guna Widya. 2011.
[6] Y. Jamshidi and V. G. Kaburlasos, “Engineering Applications of Arti fi cial Intelligence gsaINknn : A GSA optimized , lattice computing knn classifier,” vol. 35, pp. 277–285, 2014.
[7] M. a. Balafar, A. R. Ramli, M. Iqbal Saripan, R. Mahmud, S. Mashohor, and H. Balafar, “MRI segmentation of Medical images using FCM with initialized class centers via genetic algorithm,” 2008
International Symposium on Information Technology,
pp. 1–4, 2008.
[8] D. Goldberg, Genetic Algorithms in Search, Optimization and Machine Learning, Addison-Wesley ,MA ,1989.
[9] M. Mitchel, An Introduction to Genetic Algorithms, MIT Press, Fifth printing, 1999
[10] J. Fleiss, B. Levin, and M. Paik, “The measurement of interrater agreement,” in Statistical Methods for Rates and Proportions, Third Edition, 1981, pp. 598–626.
Karno, tertarik pada bidang data mining, image processing dan machine learning. Memperoleh gelar S.Kom pada STMIK Sinar Nusantara Surakarta, aktif sebagai mahasiswa Pasca Sarjana jurusan Teknik Informatika di Universitas Dian Nuswantoro. Saat ini bekerja di Pusat Inovasi, Lembaga Ilmu Pengetahuan Indonesia
![Gambar 1. K-NN dengan Nilai K yang besar Untuk mengatasi permasalahan penentuan k tersebut perlu adanya optimalisasi pada proses penentuan K-tetangga[8][9]](https://thumb-ap.123doks.com/thumbv2/123dok/4835209.3460832/1.892.489.769.864.1062/gambar-nilai-mengatasi-permasalahan-penentuan-optimalisasi-penentuan-tetangga.webp)