BAB II
TINJAUAN PUSTAKA
2.1 Batik Besurek
2.1.1 Sejarah Batik Besurek Bengkulu
Kain Batik Besurek merupakan salah satu bentuk batik hasil kerajinan tradisional daerah Bengkulu yang telah diwariskan dari generasi ke generasi. Kain Besurek merupakan salah satu hasil budaya daerah atau tradisional masyarakat Bengkulu yang sampai saat ini masih dipertahankan, bahkan terus ditumbuhkembangkan keberadaannya. Sehingga kain Besurek ini menjadi ciri khas tersendiri bagi Propinsi Bengkulu. Sebagai salah satu wujud fisik budaya daerah atau tradisional, tentu saja kain Besurek tersebut memebrikan andil di dalam pertumbuhkembangan peradaban masyarakat Bengkulu. Oleh sebab itu agar masyarakat Bengkulu tidak kehilangan jejak budaya dan sejarah dari keberadaan kain Besurek yang mempunyai kandungan tak ternilai harganya [8]. Kain Basurek merupakan batik tradisional daerah Bengkulu yang artinya kain yang mempunyai surat atau tulisan. Surat atau tulisan yang di maksud terdiri atas berbagai macam ragam hiasan (ornamen), baik yang berupa tulisan huruf Arab (kaligrafi) maupun bermacam ragam hiasan. Selain itu dapat juga berupa berbagai bentuk motif lainnya, seperti tumbuh-tumbuhan (flora) dan binatang (fauna), anyam-anyaman, serta ukir-ukiran [4]. Dulu kain besurek hanya digunakan dalam upacara ritual keagamaan di wilayah Bengkulu, namun karena adanya transisi dan perubahan zaman, kain besurek sekarang ini telah menyebar dan dimanfaatkan dalam berbagai acara dan kondisi. Motif dasar kain besurek merupakan motif peninggalan para nenek moyang yang sampai saat ini belum diketahui asalnya, ada yang mengatakan bahwa motif kain Basurek ini dulunya sangat sakral di karenakan huruf arabnya yang bisa terbaca dan menandakan hubungan manusia dengan Tuhan. Berdasarkan sejarah perkembangannya hingga saat ini, motif dasar tersebut sudah banyak mengalami perubahan.
2.1.2 Jenis-jenis Motif Dasar Batik Besurek
1. Motif Relung Paku
Motif ini menggambarkan keadaan tumbuh-tumbuhan dan keadaan binatang. Sering di gunakan untuk upacara adat cukuran bayi.
Gambar 2.1 Motif Relung Paku [4]
2. Motif Bunga Rafflesia
Bunga Rafflesia Arnoldi yang merupakan bunga raksasa khas Bengkulu. Motif bunga rafflesia bisa dibilang sebagai motif utama kain besurek setelah kaligrafi.
3. Motif Burung Kuau
Motif burung kuau menggambarkan keadaan binatang. Jenis motif ini pada waktu dahulu digunakan pada upacara pernikahan, yaitu pada acara ziarah kubur.
Gambar 2.3 Motif Burung Kuau [4]
4. Motif Rembulan
Motif rembulan menggambarkan bahwa segala sesuatu yang ada di dunia ini merupakan ciptaan Tuhan Yang Maha Esa. Motif ini dipakai pada rangkaian pernikahan, yaitu pada acara siraman (mandi).
2.2 Data Mining
Tan (2006) mendefinisikan data mining sebagai proses untuk mendapatkan informasi yang berguna dari gudang basis data yang besar [6]. Data mining juga dapat diartikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data besar yang membantu dalam pengambilan keputusan. Salah satu teknik yang dibuat dalam data
mining adalah bagaimana menelusuri data yang ada untuk membangun sebuah
model,kemudian menggunakan model tersebut agar dapat mengenali pola data yang lain yang tidak berada dalam basis data yang tersimpan. Dalam data mining, pengelompokan data juga bisa dilakukan. Tujuannya adalah agar kita dapat mengetahui pola universal data-data yang ada. Pekerjaan yang berkaitan dengan data
mining dapat dibagi menjadi empat kelompok, yaitu model prediksi (prediction modelling), analisis kelompok (cluster analysis), analisis asosiasi (association analysis), dan deteksi anomali (anomaly detection).
1. Model Prediksi (Prediction Modelling)
Model prediksi berkaitan dengan pembuatan sebuah model yang dapat melakukan pemetaan dari setiap himpunan variabel ke setiap targetnya, kemudian menggunakan model tersebut untuk memberikan nilai target pada himpunan baru yang didapat. Ada dua jenis model prediksi, yaitu klasifikasi dan regresi. Klasifikasi digunakan untuk variabel target diskret sedangkan regresi untuk variabel target kontinu.
2. Analisis Kelompok (cluster analysis)
Analisis kelompok melakukan pengelompokan data-data ke dalam sejumlah kelompok (cluster) berdasarkan kesamaan karakteristik masing-masing data pada kelompok-kelompok yang ada. Data-data yang masuk dalam batas kesamaan dengan kelompoknya akan bergabung dalam kelompok tersebut, dan akan terpisah dalam kelompok yang berbeda jika keluar dari batas kesamaan dengan kelompok tersebut.
3. Analisis Asosiasi (Association Analysis)
Analisis asosiasi digunakan untuk menemukan pola yang menggambarkan kekuatan hubungan fitur dalam data. Pola yang ditemukan biasanya merepresntasikan bentuk aturan implikasi atau subset fitur. Tujuannya adalah untuk menemukan pola yang menarik dengan cara yang efisien.
4. Deteksi Anomali (Anomaly Detection)
Pekerjaan deteksi anomali berkaitan dengan pengamatan sebuah data dari sejumlah data yang secara signifikan mempunyai karakteristik yang berbeda dengan dari sisa data yang lain [6].
2.3 K-Nearest Neighbor (K-NN)
K-Nearest Neighbor (K-NN) merupakan sebuah metode klasifikasi terhadap
sekumpulan data berdasarkan pembelajaran data yang sudah terklasifikasikan sebelumnya. K-Nearest Neighbor berdasarkan konsep ‘learning by analogy’. Data
learning dideskripsikan dengan atribut numerik n-dimensi. Jika sebuah data uji yang
labelnya tidak diketahui diinputkan,maka K-Nearest Neighbor akan mencari k buah data latih yang jaraknya paling dekat dengan data uji dihitung dengan cara mengukur jarak antara titik yang mempresentasikan data latih dengan rumus Euclidean
Distance.
Pada fase pelatihan untuk data latih, algoritma hanya melakukan penyimpanan vektor-vektor fitur dan klasifikasi data latih. Pada fase klasifikasi, fitur-fitur yang sama dihitung untuk data uji dimana data uji adalah data yang klasifikasinya belum diketahui atau pengujian kembali data latih untuk mengetahui ketepatan klasifikasi. Jarak dari vektor data uji terhadap seluruh vektor data latih dihitung dan sejumlah k buah yang paling dekat diambil. Titik dari data uji klasifikasinya diprediksikan berdasarkan klasifikasi data latih terbanyak dari titik-titik tersebut.
K-Nearest Neighbor merupakan teknik klasifikasi yang sederhana, tetapi mempunyai
hasil kerja yang cukup bagus. Meskipun begitu, K-NN juga mempunyai kelebihan dan kekurangan [6]. Beberapa karakteristik K-NN adalah sebagai berikut :
1. K-NN merupakan algoritma yang menggunakan seluruh data latih untuk melakukan proses klasifikasi. Hal ini mengaikibatkan proses prediksi yang sangat lama untuk data dalam jumlah yang sangat besar.
2. Algoritma K-NN tidak membedakan setiap fitur dengan suatu bobot.
3. Karena K-NN termasuk lazy learning yang menyimpan sebagian atau semua data, K-NN sangat cepat dalam proses pelatihan tetapi sangat lambat dalam proses prediksi.
4. Hal yang rumit adalah menentukan nilai K yang paling sesuai
5. Karena K-NN pada prinsipnya memilih tetangga terdekat, parameter jarak juga penting untuk dipertimbangkan sesuai dengan kasus datanya.
2.3.1 Algoritma K-NN
Algoritma K-NN menggunakan klasifikasi ketetanggaan sebagai nilai prediksi untuk query data yang baru atau data uji. Dekat atau jauhnya tetangga biasanya dihitung berdasarkan Euclidean Distance :
D(a,b) = √∑ ( )2 ...(1) Keterangan :
D(a,b) : jarak skalar dari a dan b
ak, bk : vektor a dan b yang berupa matrik berukuran d dimensi
Algoritma :
Langkah 1 : Tentukan parameter K
Langkah 2 : Hitung jarak antara data uji dengan data latih dengan rumus
Euclidean Distance.
Langkah 3 : Urutkan hasil jarak tersebut secara ascending dan tetapkan tetangga terdekat berdasarkan jarak minimum ke-K
Langkah 4: Dengan menggunakan klasifikasi K-Nearest Neighbor yang paling mayoritas, maka dapat diprediksikan klasifikasi dari data uji
Contoh Soal :
Terdiri dari 2 atribut dengan skala kuantitatif sebagai data latih yaitu X1 dan X2 serta Y yaitu kelas baik dan buruk seperti pada Tabel 2.1 [10]
Tabel 2.1 Klasifikasi Data Latih
X1 X2 Y
7 7 Buruk
7 4 Buruk
3 4 Baik
Terdapat data uji yaitu X1 = 3 dan X2 = 7, tentukan nilai Y! Langkah penyelesaian:
1. Tentukan parameter K = jumlah tetangga terdekat, misalkan ditetapkan K = 3 2. Hitung jarak antara data baru dengan semua data latih seperti pada Tabel 2.2
Tabel 2.2 Perhitungan kuadrat jarak data latih dengan data uji
X1 X2 Kuadrat jarak dengan data baru (3,7)
7 7 (7-3)2 + (7-7)2 = 16 7 4 (7-3)2 + (4-7)2 = 25 3 4 (3-3)2 + (4-7)2 = 9 1 4 (1-3)2 + (4-7)2 = 13
3. Urutkan hasil kuadrat jarak tersebut secara ascending dan tetapkan tetangga terdekat berdasarkan nilai K ( dimana K= 3) seperti pada tabel 2.3 dan tabel 2.4
Tabel 2.3 Penentuan 3 tetangga terdekat dari data uji
X1 X2 Euclidean Peringkat Jarak Tetangga terdekat
7 7 √ = 4 3 Ya
7 4 √ = 5 4 Tidak
3 4 √ = 3 1 Ya
1 4 √ = 3,6 2 Ya
Tabel 2.4 Klasifikasi kelas tetangga terdekat
X1 X2 Euclidean Distance Peringkat Jarak Tetangga terdekat Y 7 7 4 3 Ya Buruk 7 4 5 4 Tidak - 3 4 3 1 Ya Baik 1 4 3,6 2 Ya Baik
4. Berdasarkan hasil dari Tabel 2.4 dimana nilai K= 3 , mayoritas hasil Y yang diperoleh yaitu “Baik”. Jadi hasil klasifikasi data uji dengan nilai X1 = 3 dan X2 = 7 adalah Y = kelas Baik
2.4 Ekstraksi Ciri
Ekstraksi ciri adalah suatu proses dimana mengambil ciri-ciri yang terdapat pada objek dalam citra. Pada proses ini objek di dalam citra dihitung properti-properti objek yang berkaitan sebagai ciri. Dan pada penelitian ini untuk ekstraksi ciri citra akan digunakan dua tahapan yaitu threshold dan deteksi tepi Robert.
2.4.1 Thresholding
Dalam proses thresholding atau biasa disebut binerisasi yaitu melakukan pengubahan nilai dari derajat keabuan menjadi dua nilai yaitu 0 atau biasa dikenal dengan warna hitam dan juga 255 yang disebut dengan warna putih. Pemilihan nilai threshold yang ada juga mempengaruhi ketajaman dari suatu citra [8]. Proses threshold dari suatu citra adalah sebagai berikut:
g(x,y) = { ( )
( ) } Keterangan :
g(x,y) = citra biner dari citra f(x,y)
T = nilai threshold Citra awal = || | |
Misalkan dari nilai citra awal diatas threshold = 5, jika nilai
gradient(x,y) >= 5 maka citra(x,y) = 1 (putih/tepi). Jika nilai gradient(x,y) < 5
maka citra(x,y) = 0 (hitam/bukan tepi). Sehingga hasil citra threshold :
Citra Threshold = [ ]
Deteksi tepi adalah operasi yang dijalankan untuk mendeteksi garis tepi (edges) yang membatasi dua wilayah citra yang homogen yang memiliki tingkat kecerahan yang berbeda [5]. Sebuah operator deteksi tepi merupakan operasi bertetangga, yaitu sebuah operasi yang memodifikasi nilai keabuan sebuah titik berdasarkan nilai-nilai keabuan dari titik-titik yang ada di sekitarnya (tetangganya) yang masing-masing mempunyai bobot tersendiri. Bobot-bobot tersebut nilainya bergantung pada operasi yang dilakukan, sedangkan banyaknya titik tetangga yang terlibat biasanya adalah 2x2, 3x3, 3x4, 7x7, dan sebagainya.
Tujuan dari deteksi tepi antara lain :
1. Meningkatkan penampakan garis batas suatu daerah atau objek dalam sebuah citra.
2. Mencirikan batas objek dan berguna untuk proses segmentasi dan identifikasi objek.
2.4.2.1 Deteksi Tepi Robert
Operator Roberts, yang pertama kali dipublikasikan pada tahun 1965, terdiri atas dua filter berukuran 2x2. Ukuran filter yang kecil membuat komputasi sangat cepat. Namun, kelebihan ini sekaligus menimbulkan kelemahan, yakni sangat terpengaruh oleh derau. Selain itu, operator Roberts memberikan tanggapan yang lemah terhadap tepi, kecuali kalau tepi sangat tajam (Fisher, dkk., 2003).
(b) Gx
(a) Posisi pada citra f
z1 z2 z3 z4 x x+1 y y+1 1 0 0 -1 0 -1 1 0 (c) Gy Gambar 2.5 Operator Roberts [6]
Bentuk operator Roberts ditunjukkan pada Gambar 2.5. Maka, nilai operator Roberts pada (y, x) didefinisikan sebagai
Dalam hal ini, Z1 = f(y, x), Z2 = f(y, x+1), Z3 = f(y+1, x), dan Z4 = f(y+1, x+1).
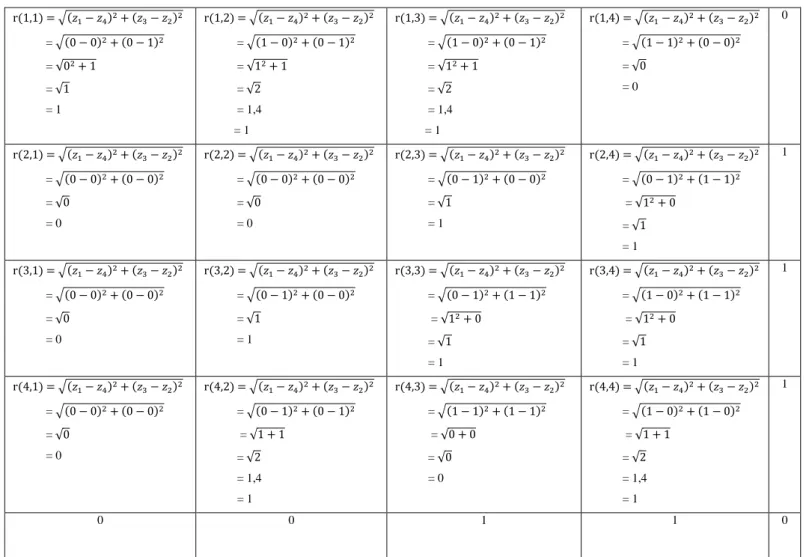
Berikut ini perhitungan deteksi tepi Robert terhadap citra threshold seperti yang ditunjukkan pada Tabel 2.5
Citra Threshold = [ ]
Tabel 2.5 Perhitungan Deteksi Tepi Robert
r(1,1) = √( ) ( ) = √( ) ( ) = √ = √ = 1 r(1,2) = √( ) ( ) = √( ) ( ) = √ = √ = 1,4 = 1 r(1,3) = √( ) ( ) = √( ) ( ) = √ = √ = 1,4 = 1 r(1,4) = √( ) ( ) = √( ) ( ) = √ = 0 0 r(2,1) = √( ) ( ) = √( ) ( ) = √ = 0 r(2,2) = √( ) ( ) = √( ) ( ) = √ = 0 r(2,3) = √( ) ( ) = √( ) ( ) = √ = 1 r(2,4) = √( ) ( ) = √( ) ( ) = √ = √ = 1 1 r(3,1) = √( ) ( ) = √( ) ( ) = √ = 0 r(3,2) = √( ) ( ) = √( ) ( ) = √ = 1 r(3,3) = √( ) ( ) = √( ) ( ) = √ = √ = 1 r(3,4) = √( ) ( ) = √( ) ( ) = √ = √ = 1 1 r(4,1) = √( ) ( ) = √( ) ( ) = √ = 0 r(4,2) = √( ) ( ) = √( ) ( ) = √ = √ = 1,4 = 1 r(4,3) = √( ) ( ) = √( ) ( ) = √ = √ = 0 r(4,4) = √( ) ( ) = √( ) ( ) = √ = √ = 1,4 = 1 1 0 0 1 1 0
Deteksi Tepi Operator Robert = ||
| |
1.4 Pengenalan Pola (Pattern Recognition)
Pengenalan pola merupakan suatu proses yang dilakukan untuk mengelompokkan atau mengklasifikasikan data numerik dan simbol. Banyak teknik statistik dan sintaksis yang telah dikembangkan untuk keperluan klasifikasi pola dan teknik-teknik ini dapat memainkan peran yang penting dalam sistem visual untuk pengenalan objek yang biasanya memerlukan banyak teknik. Bantuk-bentuk objek tertentu dalam dunia nyata yang sangat kompleks dapat dibandingkan dengan pola-pola dasar di dalam citra sehingga penggolongan objek yang bersangkutan dapat dilakukan lebih mudah [1].
Gambar 2.6 Pengenalan Pola [3]
Adapun penjelasan seperti Gambar 2.6 adalah:
1. Prapengolahan
Proses awal yang dilakukan untuk memperbaiki kualitas citra (image
enhacement) dengan menggunakan teknik-teknik yang ada [3]. Pada pola batik
berguna memisahkan gambar batik dengan latar belakangnya dan tahap ini akan memproses data dengan mengubah citra batik menjadi grayscale [13].
2. Ekstrasi Ciri
Proses mengambil ciri-ciri yang terdapat pada objek di dalam citra. Pada proses ini objek di dalam citra dihitung properti-properti objek yang berkaitan sebagai ciri. Untuk tahap ini citra batik dilakukan dengan mengubah citra
3. Klasifikasi
Proses pengelompokan objek ke dalam kelas yang sesuai pada saat pelatihan. Pada penelitian ini untuk pengujian akan menggunakan klasifikasi dengan metode K-Nearest Neighbor menggunakan Euclidean Distance untuk menghitung jarak terdekat dalam metode klasifikasi.
4. Pemilihan Ciri
Proses memilih ciri pada suatu objek agar diperoleh ciri yang optimum, yaitu ciri yang dapat membedakan suatu objek dengan objek lainnya sesuai berdasarkan hasil ekstraksi ciri.
5. Pembelajaran
Proses belajar membuat aturan klasifikasi sehingga jumlah kelas yang tumpang tindih dibuat sekecil mungkin
1.5 Format File Citra
1.5.1 JPEG (Joint Photographic Expert Group)
JPG atau JPEG ( Joint Photographic Experts Group) adalah format file yang paling umum digunakan dalam digital fotografi. Format ini mendukung kedalaman warna 24 bit (3 saluran warna masing-masing 8 bit). Hampir setiap kamera digital mampu membaca gambar menggunakan format ini dan secara luas dapat dibaca oleh program penampil gambar lainnya. Format citra JPG menghasilkan ukuran file kecil menggunakan kompresi lossy. Setiap kali menyimpan gambar dalam format ini, kualitas degradasi menurun karena kompresi lossy tersebut. Kompresi Lossy (Lossy Compression) adalah metode memperkecil ukuran file citra dengan membuang beberapa data, hal ini menyebabkan adanya sedikit penurunan kualitas citra. JPEG merupakan teknik dan standar universal untuk kompresi dan dekompresi citra tidak bergerak yang digunakan pada kamera digital dan sistem pencitraan dengan menggunakan komputer [10].
![Gambar 2.2 Motif Bunga Rafflesia [2]](https://thumb-ap.123doks.com/thumbv2/123dok/4368523.3189083/2.892.306.726.754.998/gambar-motif-bunga-rafflesia.webp)
![Gambar 2.3 Motif Burung Kuau [4]](https://thumb-ap.123doks.com/thumbv2/123dok/4368523.3189083/3.892.302.732.696.916/gambar-motif-burung-kuau.webp)

![Gambar 2.6 Pengenalan Pola [3]](https://thumb-ap.123doks.com/thumbv2/123dok/4368523.3189083/11.892.168.700.407.592/gambar-pengenalan-pola.webp)
