ABSTRAK
Seiring perkembangan jaman yang semakin maju, peranan teknologi informasi dalam dunia bisnis masa kini mengalami perkembangan yang sangat pesat. Teknologi Data Mining atau penambangan data ini dapat membantu sebuah perusahaan untuk menemukan pengetahuan-pengetahuan baru, yang dapat membantu dalam pengaturan strategi bisnis. Informasi yang diperoleh dari dari proses penambangan data dapat membatu pelaku bisnis dalam meningkatkan proses bisnis dan membuat keputusan bisnis.
Data penjualan produk helm pada PT. XYZ akan dimanfaatkan menggunakan teknik analisis klaster. Analisis klaster merupakan sebuah analisis pengelompokan data yang mengelompokan data berdasarkan informasi yang ditentukan pada data. Tujuan dari pengelompokan data ini adalah agar obyek-obyek di dalam suatu kelompok memiliki kemiripan satu sama lain sedangakan obyek-obyek yang berbeda berada dalam kelompok yang memiliki perbedaan. Berkaitan dengan proses pengelompokan data pada penelitian ini, akan meggunakan metode hirarki divisive. Dalam metode divisive di setiap langkahnya terjadi penambahan kelompok ke dalam nilai dua nilai terkecil sampai akhirnya semua elemen bergabung. Metode ini merupakan proses pengklasteran yang didasarkan pada persamaan nilai rata-rata antar objek. Jika sebuah objek memiliki persamaan nilai rata-rata terbesar maka objek tersebut akan terpisah dan berubah menjadi splinter group. Dilakukan 7 kali percobaan pembentukan kelompok dan setiap percobaan dihitung pula nilai sum of square error (SSE)
Pada penelitian ini dibuat sebuah sistem yang mengimplementasikan teknik analisis klaster menggunakan algoritma hirarki divisive. Data yang digunakan adalah data penjualan. Hasil akhir dari proses pengolahan data penjualan adalah terbentuknya 8 kelompok dengan nilai SSE terkeci dari beberapa percobaan. Masing-masing kelompok akan dianalisa berdasarkan informasi yang terkait. Hasil dari analisis klaster tersebut dapat menjadi strategi bagi pemilik perusahaan dalam pengambilan keputusan hingga menyediakan serta memasarkan produk dengan efektif untuk meningkatkan aktivitas penjualan.
ABSTRACT
ABSTRACT
Along with advanced current development, the role of information technology in business world has been showing a great improvement. Data Mining Technology can help a company to discover new comprehensions that are very useful in setting business strategy. The information gathered from the data mining will be able to help business people in escalating the business process and making a business decision.
The product sales data at the XYZ Company will be used using cluster analysis technique. Cluster analysis is an analysis for gathering the data based on the information that has been chosen from the data. The aim from this data clustering is to make the objects that have similarities of each other will be placed in one group, while the different objects will be placed in one group that has dissimilarity. Regarding with the clustering data process in this research, the method that will be used is hierarchical divisive method. In the divisive method, there will be group adding in every step into the value, the two smallest values until finally all elements united. This method is a clustering process that is based on the average value equation between the objects. If an object has the biggest value equation, then the object will be separated and changed into splinter group. There will be seven group formation experiments conducted and every experiment will be counted the value of sum of square error (SSE).
This research creates a system that implements cluster analysis technique using hierarchical divisive algorithm. The data used is the sales data. The final result from processing the sales data is set-up of eight groups with the smallest SSE value of several experiments. Each group will be analyzed based on associated information. The outcome from the cluster analysis can be benefited as a strategy to the company owner in making a decision to provide and market the product effectively in order to increase sales activity.
IMPLEMENTASI DATA MINING MENGGUNAKAN METODE
CLUSTERING UNTUK PREDIKSI PENJUALAN DI PT. XYZ
HALAMAN JUDUL
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun oleh :
Isidorus Cahyo Adi Prasetyo ( 115314009 )
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
IMPLEMENTATION DATA MINING USING CLUSTERING METHOD
FOR SELLING PREDICTION OF XYZ COMPANY
HALAMAN JUDUL (Bahasa Inggris)
A Thesis
Presented as Partial Fulfillment of The Requirements To Obtain Sarjana Komputer Degree
In Informatics Engineering Study Program
Written by:
Isidorus Cahyo Adi Prasetyo ( 115314009 )
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
iii
HALAMAN PERSETUJUAN
iv SKRIPSI
v
vii
HALAMAN PERSEMBAHAN
HALAMAN PERSEMBAHAN
Karya Skripsi ini Saya persembahan kepada :
1. Tuhan Yesus Kristus, yang selalu mendampingiku dalam menyelesaikan karya skripsi ini.
2. Keluargaku, antara lain Bapak, Ibu, Kakek, Tante, dan Adikku yang selalu mendukungku baik berupa doa dan materi.
3. Kekasih dan segenap keluarganya yang selalu mendoakan dan memberikan semangat.
4. Para Dosen dan Teman-Teman Mahasiswa Teknik Informatika Universitas Sanata Dharma yang menjadi relasi dan penolong selama Saya menjalankan studi.
viii
HALAMAN MOTTO
HALAMAN MOTTO
Manusia tidak merancang untuk gagal, mereka gagal untuk merancang.
( William J. Siegel )
“IF YOU CAN’T FLY THEN RUN,
IF YOU CAN’T RUN THEN WALK
IF YOU CAN’T WALK THEN CRAWL,
BUT WHATEVER YOU DO YOU HEVE
YOU KEEP MOVING FORWARD”
(Martin Luther King.Jr.)
Stay Hungry, Stay Foolish
( Steve Jobs)
Because I actualy learned that in life you can Only trust, like, yourself, actualy.
Not in sense that you can’t trust people but,
Yeah, like I said: the one who will never let you down is yourself. Benedict Hang Yong Lim “HyHy”
Dota’s pro gamer – 2011
"One way to forget about pain is to do something you will be in,
completely. So. computer games."
ix ABSTRAK
Seiring perkembangan jaman yang semakin maju, peranan teknologi informasi dalam dunia bisnis masa kini mengalami perkembangan yang sangat pesat. Teknologi Data Mining atau penambangan data ini dapat membantu sebuah perusahaan untuk menemukan pengetahuan-pengetahuan baru, yang dapat membantu dalam pengaturan strategi bisnis. Informasi yang diperoleh dari dari proses penambangan data dapat membatu pelaku bisnis dalam meningkatkan proses bisnis dan membuat keputusan bisnis.
Data penjualan produk helm pada PT. XYZ akan dimanfaatkan menggunakan teknik analisis klaster. Analisis klaster merupakan sebuah analisis pengelompokan data yang mengelompokan data berdasarkan informasi yang ditentukan pada data. Tujuan dari pengelompokan data ini adalah agar obyek-obyek di dalam suatu kelompok memiliki kemiripan satu sama lain sedangakan obyek-obyek yang berbeda berada dalam kelompok yang memiliki perbedaan. Berkaitan dengan proses pengelompokan data pada penelitian ini, akan meggunakan metode hirarki divisive. Dalam metode divisive di setiap langkahnya terjadi penambahan kelompok ke dalam nilai dua nilai terkecil sampai akhirnya semua elemen bergabung. Metode ini merupakan proses pengklasteran yang didasarkan pada persamaan nilai rata-rata antar objek. Jika sebuah objek memiliki persamaan nilai rata-rata terbesar maka objek tersebut akan terpisah dan berubah menjadi splinter group. Dilakukan 7 kali percobaan pembentukan kelompok dan setiap percobaan dihitung pula nilai sum of square error (SSE)
Pada penelitian ini dibuat sebuah sistem yang mengimplementasikan teknik analisis klaster menggunakan algoritma hirarki divisive. Data yang digunakan adalah data penjualan. Hasil akhir dari proses pengolahan data penjualan adalah terbentuknya 8 kelompok dengan nilai SSE terkeci dari beberapa percobaan. Masing-masing kelompok akan dianalisa berdasarkan informasi yang terkait. Hasil dari analisis klaster tersebut dapat menjadi strategi bagi pemilik perusahaan dalam pengambilan keputusan hingga menyediakan serta memasarkan produk dengan efektif untuk meningkatkan aktivitas penjualan.
x ABSTRACT
ABSTRACT
Along with advanced current development, the role of information technology in business world has been showing a great improvement. Data Mining Technology can help a company to discover new comprehensions that are very useful in setting business strategy. The information gathered from the data mining will be able to help business people in escalating the business process and making a business decision.
The product sales data at the XYZ Company will be used using cluster analysis technique. Cluster analysis is an analysis for gathering the data based on the information that has been chosen from the data. The aim from this data clustering is to make the objects that have similarities of each other will be placed in one group, while the different objects will be placed in one group that has dissimilarity. Regarding with the clustering data process in this research, the method that will be used is hierarchical divisive method. In the divisive method, there will be group adding in every step into the value, the two smallest values until finally all elements united. This method is a clustering process that is based on the average value equation between the objects. If an object has the biggest value equation, then the object will be separated and changed into splinter group. There will be seven group formation experiments conducted and every experiment will be counted the value of sum of square error (SSE).
This research creates a system that implements cluster analysis technique using hierarchical divisive algorithm. The data used is the sales data. The final result from processing the sales data is set-up of eight groups with the smallest SSE value of several experiments. Each group will be analyzed based on associated information. The outcome from the cluster analysis can be benefited as a strategy to the company owner in making a decision to provide and market the product effectively in order to increase sales activity.
xi
KATA PENGANTAR
KATA PENGANTAR
Puji dan syukur kepada Tuhan Yang Maha Esa, karena pada akhirnya penulis dapat menyelesaikan penelitian tugas akhir ini yang berjudul
“IMPLEMENTASI DATA MINING MENGGUNAKAN METODE
CLUSTERING UNTUK PREDIKSI PENJUALAN DI PT. XYZ”.
Dalam seluruh proses penyusunan tugas akhir ini, penulis tak lepas dari doa, bantuan, dukungan, dan motivasi dari banyak pihak. Oleh karena itu, penulis ingin mengucapkan banyak terima kasih kepada:
1. Tuhan Yesus Kristus dan Bunda Maria yang selalu memberi anugerah, rahmat, dan kekuatan sehingga penulis dapat menyelesaikan penelitian dan penyusunan tugas akhir ini hingga selesai
2. Bapak Sudi Mungkasi, Ph.D. selaku Dekan Fakultas Sain dan Teknologi. 3. Ibu Rita selaku Ketua Program Studi Teknik Informatika.
4. Ibu Ridowati Gunawan, S. Kom., M.T. selaku Dosen Pembimbing Skripsi yang telah baik, sabar memberikan waktu, bimbingan, dan motivasi kepada peniulis.
5. Seluruh Dosen Teknik Informatika yang telah memberikan bekal ilmu dan pengalaman selama penulis menempuh studi dan seluruh staff Sekretariat Fakultas Sains dan Teknologi yang banyak membantu penulis dalam urusan administrasi akademik terutama menjelang ujian tugas akhir dan yudisium.
6. Kedua Orang Tua saya, F.X Suyatno dan Martha Sumini, terima kasih untuk setiap cinta, kasih, sayang, dukungan moral dan moril untuk penulis, dan doa demi kelancaran penyelesaian tugas akhir ini.
xiii DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN JUDUL (Bahasa Inggris) ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iii
PERNYATAAN KEASLIAN KARYA ... iv
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI... v
HALAMAN PERSEMBAHAN ... vii
HALAMAN MOTTO ... viii
ABSTRAK ... ix
ABSTRACT ... x
KATA PENGANTAR ... xi
DAFTAR ISI ... xiii
DAFTAR GAMBAR ... xvi
DAFTAR TABEL ... xvii
BAB I PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 3
1.3. Tujuan ... 3
1.4. Batasan Masalah ... 3
1.5. Sistematika Penulisan ... 4
BAB II LANDASAN TEORI ... 6
2.1. Data Mining ... 6
2.2. Tahapan Data Mining ... 7
xiv
2.4. Hierarchical Clustering ... 11
2.5. Definisi Metode Divisive ... 13
2.6. Algoritma Metode Divisive ... 13
2.7. Uji Akurasi Data ... 19
BAB III METODOLOGI PENELITIAN... 21
3.1. Sumber data ... 21
3.2. Teknik Analisis Data ... 21
BAB IV ANALISIS DAN PERANCANGAN SISTEM ... 29
4.1. Identifikasi Sistem ... 29
4.1.1. Diagram Use Case... 29
4.1.2. Narasi Use Case ... 29
4.2. Perancangan Umum Sistem ... 29
4.2.1. Masukan Sistem ... 29
4.2.2. Proses Sistem ... 30
4.2.3. Output Sistem ... 30
4.3. Perancangan Sistem ... 30
4.3.1. Diagram Aktivitas ... 30
4.3.2. Diagram kelas Analisis ... 31
4.3.3. Diagram Sequence ... 32
4.3.4. Diagram Kelas Desain... 33
4.3.5. Rincian Algoritma Setiap Method pada Tiap Kelas ... 33
4.4. Perancangan Stuktur Data ... 33
4.4.1. Matriks Dua Dimensi ... 34
4.5. Perancangan Antar Muka ... 35
4.5.1. Tampilan Halaman Utama ... 35
BAB V MPLEMENTASI DAN ANALISIS HASIL ... 40
5.1. Implementasi ... 40
5.1.1. Pengolahan Data... 40
xv
5.1.3. Impelentasi Kelas ... 53
5.1.4. Implementasi Struktur Data ... 54
5.2. Analisis Hasil ... 58
BAB VI PENGUJIAN SISTEM ... 67
6.1. Rencana Pengujian ... 67
6.1.1. Hasil Pengujian Black-box ... 68
6.1.2. Kesimpulan Hasil Pengujian Black-box ... 71
6.2. Kelebihan dan Kekurangan Sistem ... 71
6.2.1. Kelebihan Sistem ... 71
6.2.2. Kekurangan Sistem ... 71
BAB VII PENUTUP ... 73
7.1. Kesimpulan ... 73
7.2. Saran ... 74
DAFTAR PUSTAKA ... 75
LAMPIRAN 1 ... 76
LAMPIRAN 2 ... 77
LAMPIRAN 3 ... 82
LAMPIRAN 4 ... 86
LAMPIRAN 5 ... 89
LAMPIRAN 6 ... 95
LAMPIRAN 7 ... 125
xvi
DAFTAR GAMBAR
Gambar 2.1. Data Mining Sebagai Tahapan Dalam Proses KDD ... 8
Gambar 2.2. Gambar Ilustrasi Algoritma Divisive ... 18
Gambar 3.1. Block diagram proses program ... 21
Gambar 3.2. Jtree pembentukan Cluster ... 27
Gambar 4.1. Diagram kelas anaisis system ... 31
Gambar 4.2. Diagram kelas desain sistem ... 33
Gambar 4.3. Desain interface Halaman Utama tab Range Harga ... 35
Gambar 4.4. Desain interface Tab Range Harga... 36
Gambar 4.5. Desain interface Halaman Utama Tab Preprosesing ... 38
Gambar 4.6. Desain interface Halaman Utama Tab Custering ... 39
Gambar 5.1. Contoh Sampel data transaksi ... 43
Gambar 5.2. Grafik SSE pembentukan Cluster ... 46
Gambar 5.3. Implementasi Halaman Utama Sistem Tab Range harga ... 47
Gambar 5.4. Implementasi Halaman Tentang... 48
Gambar 5.5. Implementasi Halaman Manual Sistem ... 48
Gambar 5.6. Implementasi Input Range Harga ... 49
Gambar 5.7. Implementasi Input Data ... 50
Gambar 5.8. Implementasi Informasi Tabel Data Preprocessing ... 51
Gambar 5.9. Implementasi Hasil Divisive Clustering dan Akurasi ... 52
Gambar 5.10. Analisis – Grafik Hasil SSE ... 59
Gambar 5.11. Karakter cluster ... 63
Gambar 5.12. Data Baru... 65
xvii
DAFTAR TABEL
Tabel 3.1. Data contoh perhitungan jarak ... 22
Tabel 3.2. Hasil euclidean distance ... 23
Tabel 3.3. Matrik jarak tahap 2 ... 24
Tabel 3.4. Matrik jarak tahap 3 ... 25
Tabel 3.5. Matrik jarak tahap 4 ... 26
Tabel 3.6. Contoh pembentukan 3 cluster oleh sistem ... 28
Tabel 4.1 Tabel penjelasan diagram kelas analisis ... 31
Tabel 4.2. Contoh Matriks Dua Dimensi ... 34
Tabel 4.3. Contoh represntasi matriks dua dimensi ... 34
Tabel 5.1. Atribut dalam tabel detail penjualan ... 40
Tabel 5.2 Atribut hasil seleksi ... 42
Tabel 5.3. Hasil preprocessing data ... 44
Tabel 5.4. Implementasi Kelas ... 53
Tabel 5.5. Hasil Perhitungan Nilai SSE ... 59
Tabel 5.6. Hasil Clustering Divisive untuk 159 data ... 59
Tabel 5.7 Nilai rata-rata variabel quantity pada percobaan ke-7 ... 61
Tabel 5.8. Hasil Clustering Divisive untuk penambahan data baru ... 65
Tabel 6.1. Rencana pengujian Blackbox ... 67
Tabel 6.2. Tabel Pengujian input range harga... 68
Tabel 6.3. Tabel Pengujian input Data ... 69
1 BAB I
PENDAHULUAN
BAB I PENDAHULUAN
1.1.Latar Belakang
Seiring perkembangan jaman yang semakin maju, peranan teknologi informasi dalam dunia bisnis masa kini mengalami perkembangan yang sangat pesat dimana perkembangannya tidak dapat dihindari. Dampak dari perkembangan tersebut juga memiliki pengaruh lain terhadap dunia bisnis seperti peningkatan efektifitas dan efisiensi kerja, peningkatan marketing melalui digital marketing, atau peningkatan potensi bisnis untuk menjangkau berbagai macam permintaan konsumen. Hal tersebut memicu persaingan antar perusahaan yang lain oleh karena itu para pelakunya harus senantiasa memikirkan cara-cara untuk terus bertahan dan jika mungkin mengembangkan sekala bisnis mereka.
2
ketersedian jumlah helm yang akan dipasarkan sesuai dengan permintaan agar kegiatan penjualan dapat berjalan secara optimal.
Dengan mengimplementasikan data mining menggunakan metode clustering merupakan cara yang efektif dalam melakukan peramalan, karena
metode ini akan mengelompokan barang penjualan kedalam beberapa klaster yang terpisah sesuai dengan jumlah transaksi yang lakukan. Dari masing-masing klaster yang terbentuk akan kelihatan barang mana saja yang memiliki tingkat pembelian yang tinggi ataupun rendah. Dari data tersebut akan didapatkan data yang valid tentang trend pembelian atau pola konsumsi konsumen.
Pembahasan dalam tugas akhir ini dititikberatkan hanya pada metode divisive. Metode divisive merupakan kebalikan dari metode agglomeratif dalam
analisis klaster. Metode divisive clustering termasuk dalam analisis klaster hierarchical. Pada setiap langkahnya, metode divisive terjadi penambahan
kelompok kedalam nilai dua nilai terkecil, sampai akhirnya semua elemen terkelompokkan. Alasan mengapa menggunakan metode divisive untuk pengelompokan penjualan karena tidak hanya menghasilkan jumlah cluster sebanyak inputan cluster tetapi metode ini juga dapat menghasilkan jumlah cluster dengan jumlah maksismal sama dengan jumlah sampel atau sesuai
3 1.2.Rumusan Masalah
Dari latar belakang diatas dapat dirumuskan masalah dari penelitian ini antara lain:
1. Bagaimanakah langkah-langkah penerapan metode divisive dalam pembentukan klaster pada data penjualan produk helm di PT. XYZ?
1.3.Tujuan
Tujuan dari penelitian ini adalah melakukan analisis terhadap data penjualan untuk mengetahui prediksi pendistribusian produk helm di perusahaan XYZ dengan bantuan data mining menggunakan algoritma divisive.
1.4.Batasan Masalah
Adapun batasan masalah dalam penelitian ini adalah sebagai berikut :
1. Data penjualan yang digunakan dalam proses data mining adalah tahun 2014. 2. Data yang digunakan sebagai atribut adalah data penjualan, yaitu berdasarkan
kelompok harga, harga jual, quantity, nama barang (merk, tipe, dan warna), wilayah dari produk tersebut.
3. Berdasarkan input data penjualan produk helm di perusahaan XYZ tahun 2014, output yang dihasilkan program ini adalah berupa klaster produk penjualan.
4 1.5.Sistematika Penulisan
BAB I PENDAHULUAN
Pada bab ini berisi gambaran umum penelitian meliputi: latar belakang masalah, batasan masalah, tujuan tugas akhir, rumusan masalah, dan sistematika penulisan.
BAB II LANDASAN TEORI
Pada bab ini berisi mengenai penjelasan dan uraian singkat mengenai teori-teori yang berkaitan dengan topik dari tugas akhir ini.
BAB III METODOLOGI PENELITIAN
Pada bab ini akan dijelaskan mengenai metode yang digunakan dalam penelitian ini.
BAB IV ANALISIS DAN PERANCANGAN
Pada bab ini berisi tentang analisis dan perancangan sistem yang akan dibuat meliputi gambaran umum sistem, data yang dibutuhkan untuk penelitian, percancangan struktur data, dan perancangan antar muka.
BAB V IMPLEMENTASI DAN ANALISIS HASIL
5 BAB VI PENGUJIAN SISTEM
Pada bab ini menjelaskan mengenai pengujian terhadap sistem yang telah dibuat dan evaluasi sistem tersebut.
BAB VII PENUTUP
Bab ini berisi tentang kesimpulan dari penelitian yang telah dilakukan dan saran dari sistem yang nantinya akan dikembangkan.
DAFTAR PUSTAKA
6 BAB II
LANDASAN TEORI
BAB II LANDASAN TEORI
Pada bab ini akan menjelaskan landasan teori yang digunakan dalam penelitian ini. Agar sebuah penelitian dapat berhasil maka diperlukan refrensi sebagai landasan teorinya. Landasan teori tersebut berisi tentang pengertian data mining, tahapan data mining atau tahapan dalam proses Knowledge Discovery In
Databases, hierarchical clustering sebagai algorima yang digunakan untuk
pengelompokan obyek data dari variabel yang telah dipilih dan bagian terakhir dalam bab ini akan dipaparkan tentang uji akurasi data.
2.1.Data Mining
Data mining adalah serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual. Data mining adalah proses yang menggunakan teknik statistik, perhitungan, kecerdasan buatan dan machine learning untuk mengekstrasi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai basis data besar (Hanif, 2007).
7
menemukan pola yang menarik dari data dalam jumlah besar, data dapat disimpan dalam database, data warehouse, atau penyimpanan informasi lainnya.
Berdasarkan beberapa pengertian tersebut dapat ditarik kesimpulan bahwa data mining adalah suatu teknik menggali informasi berharga yang terpendam atau tersembunyi pada suatu database yang sangat besar sehingga ditemukan suatu pola yang menarik yang sebelumnya tidak diketahui. Beberapa metode yang sering disebut-sebut dalam literatur data mining antara lain clustering, classification, association rules mining, neural network, genetic algorithm dan
lain-lain (Pramudiono, 2006). Data mining sering digunakan untuk membangun model prediksi/inferensi yang bertujuan untuk memprediksi tren masa depan atau perilaku berdasarkan analisis data terstruktur.
2.2.Tahapan Data Mining
Data tidak dapat langsung diolah dengan menggunakan sistem data mining. Data tersebut harus dipersiapkan terlebih dahulu agar hasil yang diperoleh
dapat lebih maksimal. Dan tahapan dalam proses Knowledge Discovery In Databases (KDD) dapat dilihat pada Gambar 2.1 terdiri dari tahapan-tahapan
8
Gam bar 1
Gambar 2.1. Data Mining Sebagai Tahapan Dalam Proses KDD (Sumber : J. Han & Kamber 2006)
1. Cleaning and Integration
Langkah pertama adalah dengan melakukan pembersihan terhadap data dan penggabungan data. Proses data cleaning bertujuan untuk menghilangkan noise dan data yang tidak konsisten dan proses data integration bertujuan untuk
9 2. Selection and Transformation
Pada tahap selection dan transformation, data dan atribut yang akan digunakan diambil dari database untuk dianalisis. Selanjutnya data tersebut diubah menjadi bentuk yang tepat untuk di-mining.
3. Data Mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan
4. Evaluation and Presentation
Pada tahap ini, dilakukan identifikasi pola-pola yang benar-benar menarik dari hasil data mining. Setelah didapatkan pola yang dihasilkan dari proses data mining perlu divisualisasikan atau ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan.
2.3.Clustering
Clustering atau klasterisasi adalah suatu alat bantu pada data mining yang
10
prinsip memaksimalkan kesamaan obyek pada klaster yang sama dan meminimalkan ketidaksamaan pada klaster yang berbeda. Kesamaan obyek bisanya diperoleh dari nilai-nilai atribut yang menjelaskan obyek data, sedangkan obyek-obyek data biasanya direpresentasikan sebagai sebuah titik dalam ruang multidimensi.
Dengan menggunakan klasterisasi, metode ini dapat mengidentifikasi daerah yang padat, menemukan pola-pola distribusi secara keseluruhan, dan menemukan keterkaitan yang menarik antar atribut-atribut data. Dalam data mining, usaha difokuskan pada metode-metode penemuan untuk klaster pada
basisdata berukuran besar secara efektif dan efesien. Kebutuhan klasterisasi dalam data mining meliputi skalabilitas, kemampuan untuk menangani tipe atribut yang berbeda, mampu menagani dimensionalitas yang tinggi, menangani data yang mempunyai noise, dan dapat diterjemahkan dengan mudah.
Secara garis besar, terdapat beberapa metode klasterisasi data. Pemilihan metode klasterisasi tergantung pada tipe data dan tujuan klasterisasi itu sendiri. Metode-metode berserta algoritmanya termasuk didalamnya meliputi:
1. Partitioning Method : Membuat berbagai partisi dan kemudian mengevaluasi partidi tersebut dengan beberapa kriteria. Yang termasik ke dalam metode ini meliputi algoritma K-Means, K-Medoid, PROCLUS, CLARA, CLARANS, dana PAM
11
atas dua macam, yaitu Agglomerative yang menggunakan stratedi bottom-up dan Divisive yang menggunakan strategi top-down. Metode ini
meliputi algoritma BIRCH, AGNES, DIANA, CURE, dan CHAMALEON.
3. Density-based Method : Metode ini berdasarkan konektivitas dan fungsi densitas. Metode ini meliputi algoritma DBSCAN, OPTICS, dan DENCLU.
4. Grid-base Method : Metode ini berdasarkan suatu struktur granularitas multi-level. Metode klasterisasi ini meliputi algoritma STING, WaveCluster, dan CLIQUE.
5. Model-base Method : Suatu model dihipotesiskan untuk masing-masing klaster dan ide untuk mencari best fit dari model tersebut untuk masing-masing yang lain. Metode klasterisasi ini meliputi pendekatan statistic, yaitu algoritma COBWEB dan jaringan syaraf tiruan, yaitu SOM.
2.4.Hierarchical Clustering
Metode hierarchical clustering mengelmpokan objek kedalam sebuah pohon klaster. Hierarchical clustering dapat diklasifikasikan sebagai agglomerative atau divisive, tergantung pada komposisi hirarki yang di tampilkan
dalam pendekatan bottom-up atau top down (split). (Han & Kamber, 2006). Pada umumya terdapat dua metode hierarchical clustering:
12
hingga sebua objek terhubung dalam satu buah cluster atau hingga mencapai jumlah cluster yang diinginkan.
2. Divisive, kebalikan dari metode agglomerative. Metode ini dimulai dari satu cluster dengan seluruh objek data di dalamnya, selanjutnya cluster tersebut dipecah kedalam cluster yang lebih kecil hingga setiap cluster memiliki dua atau satu buah objek atau hingga mencapai jumlah cluster yang diinginkan.
Sebelum pembentukan sebuah cluster perlu dihitung jarak kemiripan antara obyek data. Ada beberapa cara untuk mengetahui kemiripan data. Satu di antara cara yang ada adalah similarity matrix dengan perhitungan euclidean distance. Euclidean distance didefinisikan sebagai berikut:
√ | | | | | | | | (2.1)
Atau dapat disingkat dengan:
√∑ (2.2)
Keterangan:
13 2.5.Definisi Metode Divisive
Teknik divisive clustering termasuk kedalam analisis hierarchical clustering. Pada setiap langkahnya, metode divisive terjadi penambahan kelompok
kedalam dua nilai terkecil. Sampai akhirnya semua element terkelompokan.
Teknik divisive merupakan proses pengklasteran yang didasarkan pada persamaan nilai rata-rata antar objek. Jika sebuah objek memiliki persamaan nilai rata-rata terbesar maka objek tersebut akan terpisah dan berubah menjadi splinter group. Pada teknik divisive ini perhitungan juga di lihat dari perbedaan atau
selisih anatara persamaan nilai rata-rata dengan nilai elemen matrik yang telah menjadi splinter group. Jika selisih nilai antara persamaan nilai rata-rata dengan nilai elemen matrik splinter group bernilai negatif, maka perhitungan terhenti sehingga harus dibuat matrik baru untuk mendapatkan klaster yang lain. Perhitungan ini terus dilakukan sedemikian sehingga semua objek terpisah.
2.6.Algoritma Metode Divisive
Misalkan diberikan data X matriks berukuran n x p (n = jumlah sampel data, p = variabel setiap data). Xij= data sampel ke-j (j = 1, 2, …, n) dan variabel ke-i (i = 1, 2, …, p).
1. Bentuk suatu matriks jarak dengan menggunakan jarak euclidean. Rumusnya berikut :
14
Asumsikan setiap data dianggap sebagai klaster. Jika diberikan n data dan c klaster maka n = c, maka diperoleh matriks jaraknya, yaitu:
[
]
(2.4)
2. Hitung nilai rata-rata setiap obyek dengan obyek lainnya
3. Tentukan objek yang memiliki nilai rata-rata yang terbesar, objek yang memiliki nilai rata-rata yang terbesar akan dipisah dan berubah menjadi splinter group.
4. Hitung selisih nilai antara elemen matriks splinter group dengan nilai rata-rata setiap objek yang tersisa.
5. Tentukan objek yang memiliki nilai selisih terbesar antara elemen matriks splinter group dengan nilai rata-rata. Jika nilai selisih tersebut bernilai
positif, maka objek yang memiliki nilai selisih terbesar bergabung dengan splinter group.
15 CONTOH ALGORITMA DIVISIVE :
Untuk memperjelas metode tersebut dapat diperhatikan contoh berikut. Diketahui distance matriks D dengan 5 sample a, b, c, d, e seperti dibawah ini.
[
]
Data yang terdapat dalam matrik memiliki nilai yang berbeda antara objek a, b, c, d, dan e. Dari matrik diatas kemudian akan dihitung nilai rata-rata setiap obyek dengan obyek lainnya seperti dalam Tabel 2.1:
Tabel 2.1 Average dissimilarity to the other objects tahap 1
Objects Average dissimilarity to the other objects
a (2+6+10+9)/4=6.75
b (2+5+9+8)/4=6.00
c (6+5+4+5)/4=5.00
d (10+9+4+3)/4=6.50
e (9+8+5+3)/4=6.25
Dari tabel 2.1 objek a disebut splinter group. Sampai pada langkah ini menghasilkan dua grup yaitu grup {a} dan grup {b,c,d,e}, tetapi perhitungan tidak berhenti sampai disini. Untuk setiap objek dari group yang besar harus di hitung average dissimilarity dengan objek yang tersisa, dan membandingkan itu dengan
16
menghitung selisih dari nilai rata-rata obyek yang tersisa dengan nilai rata-rata dari splinter group:
Tabel 2.2 Difference tahap 1
Objects Average dissimilarity to the other objects
Average dissimilarity to
objects of splinter group Difference
b (5.0+9.0+8.0)/3 = 7.33 2.00 5.33
c (5.0+4.0+5.0)/3 = 4.67 6.00 -1.33
d (9.0+4.0+3.0)/3 = 5.33 10.00 -4.67
e (8.0+5.0+3.0)/3 = 5.33 9.00 -3.67
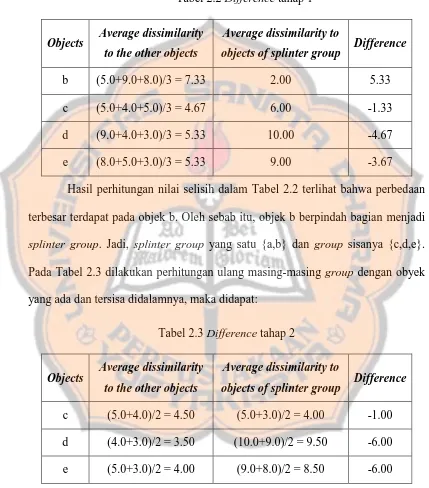
Hasil perhitungan nilai selisih dalam Tabel 2.2 terlihat bahwa perbedaan terbesar terdapat pada objek b. Oleh sebab itu, objek b berpindah bagian menjadi splinter group. Jadi, splinter group yang satu {a,b} dan group sisanya {c,d,e}.
Pada Tabel 2.3 dilakukan perhitungan ulang masing-masing group dengan obyek yang ada dan tersisa didalamnya, maka didapat:
Tabel 2.3 Difference tahap 2
Objects Average dissimilarity to the other objects
Average dissimilarity to
objects of splinter group Difference
17
Dalam langkah berikutnya akan dilakukan pembagian klaster. Pembagian klaster dilakukan pada klaster yang memiliki rata-rata terbesar. Rata-rata dari klaster {a,b} adalah 2, dan untuk klaster {c,d,e} adalah 5. Oleh sebab itu, akan terjadi pembagian klaster {c,d,e}, dengan matrik sebagai berikut :
[
]
Tabel 2.4 Average dissimilarity to the other objects tahap 2
Objects Average dissimilarity to the other objects
c (4.0+5.0)/2 = 4.50
d (4.0+3.0)/2 = 3.50
e (5.0+3.0)/2 = 4.00
Pada Tabel 2.4 adalah hasil perhitungan nilai rata-rata dengan objek yang tersisa. Ternyata objek c yang memiliki nilai positif terbesar, maka objek c masuk dalam splinter group. Jadi, terdapat dua grup yaitu {c} dan {d,e}, selanjutnya akan dihitung nilai selisih dari nilai rata obyek yang tersisa dengan nilai rata-rata dari splinter group seperti dalam Tabel 2.5:
Tabel 2.5 Difference tahap 3
Objects Average dissimilarity to the other objects
Average dissimilarity to
objects of splinter group Difference
d 3.0 4.00 -1.00
18
Dari Tabel 2.5 memperlihatkan proses pembentukan dihentikan karena semua difference bernilai negatif. Karena itu, pembagian pada langkah dua {c,d,e}
adalah {c} dan {d,e}. Jadi, klaster yang didapat {a,b}, {c}, dan {d,e}. klaster {c} disebut singleton karena hanya mengandung satu objek. Hasil dari hierarikal digambarkan seperti pada Gambar 2.2 :
a,b,c,d,e
a,b
c,d,e c
d,e a
b
Gam bar 2
19 2.7.Uji Akurasi Data
Setelah didapatkan hasil olahan dengan divisive perlu diuji akurasinya supaya diketahui validitas data tersebut. Ada beberapa teknik untuk uji akurasi data tersebut. Karena metode yang digunakan adalah metode clustering maka dapat digunakan dua jenis akurasi, yaitu Internal Evaluation dan External Evaluation (Prasetyo, 2014).
1. Internal Evaluation
Internal Evaluation merupakan pengujian data cluster demi validitasnya
tanpa informasi dari luar. Validasi ini contohnya adalah cohesion, separation, silhouette coefficient, dan sum of square error(SSE).
2. External Evaluation
Dengan menggunakan external evaluation akan diketahui kedekatan antara label cluster terbentuk dengan class yang disediakan. External evaluation ini dapat dilakukan dengan confusion matrix, entropy, dan purity.
Pada penelitian ini yang akan digunakan untuk uji akurasi adalah internal evaluation, secara khusus dengan menggunkan teknik sum of square error (SEE).
Pada setiap pembentukan cluster akan dihitung nilai SSE-nya. Semakin kecil nilai SSE menunjuakan bahwa cluster yang dibentuk semakin baik pula. Berukut formula SSE yang akan digunakan (Lior Rokach):
20 Keterangan
adalah jarak data x di indeks i
adalah rata-rata semua jarak data di cluster k
Berikut adalah algoritma SSE:
1. Tentukan matriks K yang akan dihitung menggunakan SSE adalah data set dari cluster k
Cluster k adalah anggota dari matriks K
2. Jika k=1
3. Hitung rata-rata cluster k ( ) … a
4. Lakukan langkah 5 dan 7 untuk setiap data x
5. Kurangkan a dengan data x di indek i ‖ ‖ … b 6. Hitung … c
7. c dijumlahkan untuk setiap cluster k … d 8. Jumlahkan total d di matriks K
21 BAB III
METODOLOGI PENELITIAN
BAB III METO DO LOG I PENELITIAN
Berdasarkan pada landasan teori yang telah disampaikan pada bab kedua. Pada bab ini akan dibahas mengenai metodologi yang digunakan dalam penelitian ini. Bab ketiga ini akan dipaparkan tentang sumber data yang diperoleh dan teknik analisis data.
3.1.Sumber data
Data yang digunakan adalah data penjualan tahun 2014 pada perusahaan XYZ. Data yang digunakan merupakan hasil eksport dari database perusahaan berjenis file csv. Total data transaksi penjualan bejumlah 933 record.
3.2.Teknik Analisis Data
Data yang telah diperoleh selanjutnya mulai dianalisis. Berkaitan dengan tahap-tahap teknik analisis dan jalannya program digambarkan dengan block diagram sebagai berikut
Data Preprocessing Perhitungan
Jarak Divisive Output Jtree
Akurasi
Gam bar 3 Gambar 3.1. Block diagram proses program
1. Data
22
detail. Data yag digunakan adalah data penjualan tahun 2014 selama kurun waktu satu tahun.
2. Preprocessing
Data yang sudah didapat selanjutnya diolah dengan tahap preprocessing. Pada tahap ini akan dilakukan data cleaning, data integration, data selection, dan data transformation.
3. Perhitungan Jarak
Setalah melalui tahap preprocessing, tahap selanjutnya adalah mengukur jarak setiap data. Perhitungan jarak menggunakan euclidean distance, seperti yang telah dipaparkan pada bab kedua dalam penelitina ini. Dengan menggunakan perhitungan euclidean distance akan didapatkan jarak antar obyek data dalam sebuah matriks. Matriks tersebut nantinya akan digunakan untuk tahap selanjutnya, yaitu clustering menggunakan metode divisive. Tabel 3.1 adalah contoh data yang akan digunakan untuk perhitungan euclidean distance:
Tabel 1 Tabel 3.1. Data contoh perhitungan jarak
Data x y
a 87.0 89.0
b 84.0 76.0
c 83.0 70.0
d 80.0 74.0
e 82.0 83.0
23
Dengan menggunakan rumus perhitungan euclidean distance, didapatkan matriks jarak seperti pada Tabel 3.2:
Tabel 2 Tabel 3.2. Hasil euclidean distance
a b c d e f
a 0.0 13.342 19.417 16.553 7.811 6.709 b 13.342 0.0 6.083 4.473 7.281 16.279
c 19.417 6.083 0.0 5.0 13.039 22.091
d 16.553 4.473 5.0 0.0 9.22 18.028
e 7.811 7.281 13.039 9.22 0.0 9.056
f 6.709 16.279 22.091 18.028 9.056 0.0 4. Divisive
Dalam tahap ini hasil dari matriks jarak akan digunakan untuk pembentukan cluster. Masing-masing obyek data akan dikelompokan berdsarkan jarak kemiripannya. Proses pengelompokan menggunakan perhitungan divisive. Langkah-langkah perhitungannya seperti yang dapat dilihat dalam bab kedua dalam penelitian ini. Berikut ini penerapan algoritma divisive:
Tahap 1
Langkah pertama: Dari matriks jarak pada Tabel 3.2 asumsikan setiap data dianggap sebagai klaster.
Langkah kedua : Hitung nilai rata-rata setiap objek dengan objek lainnya. Rata-rata objek a = 10.63866667
24 Rata-rata objek e = 7.7345 Rata-rata objek f = 12.02716667
Langkah ketiga: Tentukan objek yang memiliki nilai rata-rata yang terbesar, objek yang memiliki nilai rata-rata yang terbesar akan terpisah dan berubah menjadi splinter group. Diperoleh objek f memiliki rata-rata terbesar, maka objek f keluar dan menjadi splinter group.
Tahap 2
Diperoleh matrik jarak yang baru, seperti pada Tabel 3.3:
Tabel 3 Tabel 3.3. Matrik jarak tahap 1
a b c d e
a 0.0 13.342 19.417 16.553 7.811
b 13.342 0.0 6.083 4.473 7.281
c 19.417 6.083 0.0 5.0 13.039
d 16.553 4.473 5.0 0.0 9.22
e 7.811 7.281 13.039 9.22 0.0
Ulangi langkah kedua : Dari matriks jarak yang baru, kemudian pilih rata-rata antar antar objek dengan objek lainnya.
25
Kemudian selisihkan setiap nilai rata-rata tersebut dengan elemen matrik splinter group.
Rata-rata objek a = 11.4246 - 6.709 = 4.7156 Rata-rata objek b = 6.2358 - 16.279 = -10.0432 Rata-rata objek c = 8.7078 - 22.091 = -13.3832 Rata-rata objek d = 7.0492 - 18.028 = -10.9788 Rata-rata objek e = 7.4702 - 9.056 = -1.5858
Langkah ketiga : tentukan objek yang memiliki nilai selisih terbesar, objek yang memiliki nilai selisih terbesar akan terpisah dan bergabung dengan splinter group. Objek a memiliki nilai selisih terbesar, maka objek a
bergabung dengan objek f ke dalam splinter group.
Tahap 3
Diperoleh matrik jarak yang baru, , seperti pada Tabel 3.4:
4 Tabel 3.4. Matrik jarak tahap 3
b c d e
b 0.0 6.083 4.473 7.281
c 6.083 0.0 5.0 13.039
d 4.473 5.0 0.0 9.22
e 7.281 13.039 9.22 0.0
Ulangi langkah kedua : Dari matriks jarak yang baru, kemudian pilih rata-rata antar antar objek dengan objek lainnya.
26 Rata-rata objek d = 4.67325 Rata-rata objek e = 7.385
Kemudian selisihkan setiap nilai rata-rata tersebut dengan elemen matrik splinter group.
Rata-rata objek b = 4.45925 - 14.8105 = -10.35125 Rata-rata objek c = 6.0305 - 20.754 = -14.7235 Rata-rata objek d = 4.67325 - 17.2905 =-12.61725 Rata-rata objek e = 7.385 - 8.4335 = -1.0485
Karena semua nilai selisih bernilai negatif, maka algoritma kembali ke awal. Rata-rata objek terbesar pada matriks tersebut dimiliki oleh objek e, maka objek e keluar dan membentuk klaster baru.
Tahap 4
Diperoleh matrik jarak yang baru, , seperti pada Tabel 3.5:
5 Tabel 3.5. Matrik jarak tahap 4
b c d
b 0.0 6.083 4.473
c 6.083 0.0 5.0
d 4.473 5.0 0.0
Ulangi langkah kedua : Dari matriks jarak yang baru, kemudian pilih rata-rata antar antar objek dengan objek lainnya.
27 Rata-rata objek d = 3.157666667
Kemudian selisihkan setiap nilai rata-rata tersebut dengan elemen matrik splinter group.
Rata-rata objek b = 3.518666667 - 7.281 = -3.762333333 Rata-rata objek c = 3.694333333 - 13.039 = -9.344666667 Rata-rata objek d = 3.157666667 - 9.22 = -6.062333333
Karena semua nilai selisih bernilai negatif, maka algoritma berhenti sampai disini. Maka objek b, c,dan d keluar dan membentuk klaster baru.
Dengan mengimplementasikan algoritma divisive menggunakan java, data sampel yang digunakan pada Tabel 3.1 menghasilhan skruktur tree cluster seperti pada Gambar 3.2:
Gam bar 4
28 5. Cluster
Proses Divisive menghasilkan jumlah cluster maksimum sesuai dengan proses iterasi pada algoritma divisive. Hasil pembentukan cluster ditampilkan pula kedalam struktur tree. Dari hasil Jtree tersubut juga dapat ditentukan cluster yang diinginkan seperti pada Tabel 3.6.
Tabel 6 Tabel 3.6. Contoh pembentukan 3 cluster oleh sistem
Cluster 1 Cluster 2 Cluster 3
a e c
f b
d 6. Perhitungan Akurasi
Pada penelitian ini akan dilakukan uji akurasi pada setiap pembentukan cluster dan mengevaluasi pola yang ditemukan dari hasil pengelompokan.
29 BAB IV
ANALISIS DAN PERANCANGAN SISTEM
BAB IV ANALISI S DAN P ERANCANG AN SI STEM
Pada bab ini akan dijelaskan mengenai perancangan sistem yang akan diimplementasikan. Meliputi identifikasi sistem, perancangnan umum sistem, perancangan system, perancangan struktur data dan perancangan antar muka.
4.1. Identifikasi Sistem
4.1.1. Diagram Use Case
Diagram use case adalah sebuah gambaran fungsi/pekerjaan yang dapat dilakukan oleh sistem tersebut. diagram use case yang digunakan dapat dilihat pada bagian lampiran 1 untuk melihat definisi use case tersebut.
4.1.2. Narasi Use Case
Pada bagian ini setiap use case akan dirinci dalam sebuah narasi yang merupakan diskripsi tekstual dari kejadian bisnis dan bagaimana pengguna berinteraksi dengan sistem untuk menyelesaikan tugas tersebut. untuk mengetahui secara keseluruhan narasi use case dapat dilihat pada lampiran 2.
4.2. Perancangan Umum Sistem
4.2.1. Masukan Sistem
30
perlu diperhatikan. Pilihan untuk menyertakan nama kolom harus dipilih, pemisah kolom mengunakan tanda koma, dan tidak boleh ada nilai null.
4.2.2. Proses Sistem
Proses dari sistem yang menghasilkan cluster yang berfungsi untuk mempediksi ini terdiri dari beberapa langkah:
a. Memasukan nilai range harga kelompok, kelompok 1 sampai dengan 5. b. Penginputan file data penjualan yang akan digunakan untuk proses data
mining.
c. Proses clustering untuk memprediksi dijalankan.
d. Uji akurasi dari cluster yang telah berhasil dibentuk dan menganalisa hasil cluster.
4.2.3. Output Sistem
Sistem yang akan dirancang ini akan menampilkan hasil proses clustering diantaranya, jumlah cluster yang terbentuk, anggota setiap cluster, dan struktur tree pembentukan cluster.
4.3. Perancangan Sistem
4.3.1. Diagram Aktivitas
Diagram aktivitas berfungsi untuk menunjukan seluruh tahapan alur kerja dari sistem yang dirancang.
31 3. Diagram Aktivitas clustering
4. Diagram Aktivitas Simpan Hasil Clustering
Penjelasan dari masing-masing diagram aktivitas akan di jelaskan pada bagian lampiran 3
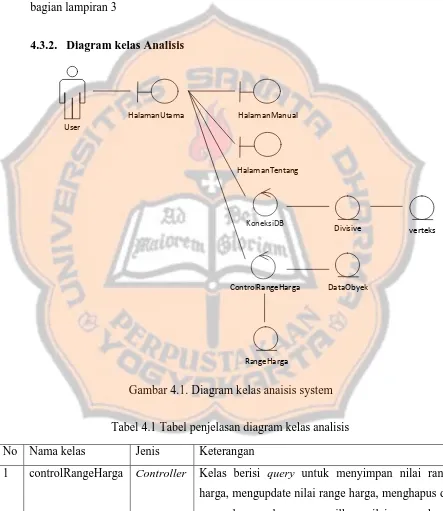
4.3.2. Diagram kelas Analisis
HalamanManual
HalamanTentang
ControlRangeHarga KoneksiDB User
HalamanUtama
RangeHarga
verteks
DataObyek Divisive
Gam bar 5 Gambar 4.1. Diagram kelas anaisis system
Tabel 7 Tabel 4.1 Tabel penjelasan diagram kelas analisis
No Nama kelas Jenis Keterangan
32
2 KoneksiDB Controller Kelas ini digunakan untuk menghubungkan sistem dengan database yang di gunakan oleh sistem. 3 DataObyek Model Kelas ini digunakan untuk menyimpan hasil input
data penjualan
4 Divisive Model Kelas ini di gunakan untuk membentuk sebuah matriks utama. Didalam kelas ini juga terdapat method-method untuk perhitungan divisive.
5 RangeHarga Model Kelas ini digunakan untuk menyimpan nilai range harga kelompok.
6 Verteks Model Kelas ini di gunakan untuk membentuk sebuah vertex dalam matriks.
7 HalamanBantuan View Kelas ini digunakan untuk menampilkan halaman manual yang berisis tentang petunjuk penggunaan sistem
8 HalamanTentang View Kelas ini digunakan untuk menampilkan informasi yang berkaitan dengan pembuatan sistem
9 HalamanUtama View Kelas ini digunakan untuk menampilkan fungsi-fungsi utama dari sistem. Mulai dari tahap input range harga, tahap preprocessing, dan tahap
clustering divisive
4.3.3. Diagram Sequence
Berikut merupakan diagram sequence yang digunakan pada sistem ini untuk lebih jelasnya terlampir pada bagian lampiran 4:
1. Diagram Sequence Input Nilai Range Harga 2. Diagram Sequence Input Data File
3. Diagram Sequence Proses Cluster
33 4.3.4. Diagram Kelas Desain
Diagram kelas desain digunakan untuk merujuk daftar setiap kelas yang nantinya akan digunakan dalam pembuatan sistem Penjelasan masing-masing kelas berserta dengan atribut dan method yang digunakan dijelasakan pada lampiran 5.
Gam bar 6 Gambar 4.2. Diagram kelas desain sistem
4.3.5. Rincian Algoritma Setiap Method pada Tiap Kelas
Rincian algoritma setiap method pada tiap kelas ini akan dijelakan pada lampiran 6.
4.4. Perancangan Stuktur Data
34
tersebut dapat digunakan secara efisien. Perancangan struktur data yang digunakan adalah matriks dua dimensi.
4.4.1. Matriks Dua Dimensi
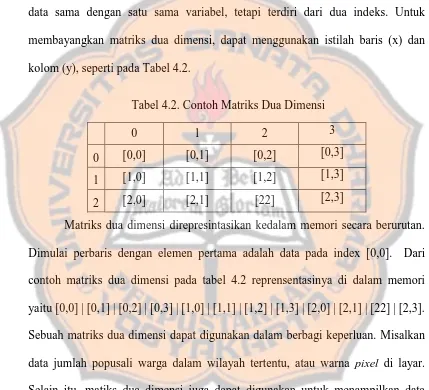
Matrik dua dimensi merupakan kumpulan elemen-elemen yang bertipe data sama dengan satu sama variabel, tetapi terdiri dari dua indeks. Untuk membayangkan matriks dua dimensi, dapat menggunakan istilah baris (x) dan kolom (y), seperti pada Tabel 4.2.
Tabel 8 Tabel 4.2. Contoh Matriks Dua Dimensi
0 1 2 3
0 [0,0] [0,1] [0,2] [0,3]
1 [1,0] [1,1] [1,2] [1,3]
2 [2,0] [2,1] [22] [2,3]
Matriks dua dimensi direpresintasikan kedalam memori secara berurutan. Dimulai perbaris dengan elemen pertama adalah data pada index [0,0]. Dari contoh matriks dua dimensi pada tabel 4.2 reprensentasinya di dalam memori yaitu [0,0] | [0,1] | [0,2] | [0,3] | [1,0] | [1,1] | [1,2] | [1,3] | [2,0] | [2,1] | [22] | [2,3]. Sebuah matriks dua dimensi dapat digunakan dalam berbagi keperluan. Misalkan data jumlah popusali warga dalam wilayah tertentu, atau warna pixel di layar. Selain itu, matiks dua dimensi juga dapat digunakan untuk menampilkan data multidimensi, contoh data jumlah mahasiswa lulus di suatu universitas, seprti pada Tabel 4.3.
Tabel 9 Tabel 4.3. Contoh represntasi matriks dua dimensi
35
TI 40 20 50 80
TM 60 55 70 4
TE 30 45 80 100
4.5. Perancangan Antar Muka
4.5.1. Tampilan Halaman Utama
Pada Gambar 4.3 ini merupakan interface pertama saat masuk sistem.
Dalam halaman ini, hanya terdapat 2 tombol menu yang bertuliskan „Keluar‟ dan
“Bantuan‟. Tombol “Bantuan‟memiliki 2 menu items yaitu menu item „Tentang‟,
dan „Manual‟. Menu „Keluar‟ untuk keluar dari sistem ini. Menu item Menu item
„Tentang‟ digunakan untuk masuk ke dalam bagian informasi sistem dan menu
item „Manual‟digunakan untuk masuk ke dalam bagian bantuan penggunaan
sistem.
SISTEM PREDIKSI PENJUALAN HELM
MENG GUNAKAN ALG ORITMA HIERARCHICAL DIVISIVE
LOGO
Range Harga Preprosesing Clustering
Kelompok harga
Kelompok – 1 Kelompok – 2 Kelompok – 3 Kelompok – 4 Kelompok - 5
Batas bawah Batas Atas
Simpan Reset
Delete isi
Keluar Bantuan
36
Halaman Utama merupakan halaman yang akan menampilkan keseluruhan proses utama pada sistem. Pada halaman ini user dapat melakukan proses imput batas harga kelompok, proses penginputan data untuk kemudian dilakukan proses clustering-nya.
1. Input range harga
Pada Gambar 4.4 ini adalah tab „Range Harga‟ tangberfungsi untuk menentukan batasan nilai kelompok harga. Pada tab ini pengguna harus mengisikan batas-batas nilai kelompok harga. Nantinya batas kelompok harga ini digunakan untuk menandai setiap obyek data. Untuk inputan batasan kelompok mempunyai aturan bahwa harga batas atas tidak boleh kurang dari batas bawah kelompok sebelumnya begitu pula sebaliknya. Sebagai contoh pada kelompok 1 batas bawah 0 dan batas atasnya 20000. Maka batas atas dan bawah kelompok 2 harus lebih atau sama dengan batas atas kelompok 1. Misal batas bawah 20000 dan batas atas 30000.
Kelompok harga
Kelompok – 1
Kelompok – 2
Kelompok – 3
Kelompok – 4
Kelompok - 5
Batas bawah Batas Atas
Simpan Reset
Delete isi
Range Harga Preprosesing Clustering
37 2. Input data dan Informasi Tabel Data
Pada tab kedua ’Preprosesing’ ini berfungsi untuk menginputkan data dan melakukan proses pembentukan cluster. Bagian input program yang diberi title input data terdapat tombol pilih file untuk menginputkan data file. File yang digunakan harus bertipe file *.csv. Setelah file dipilih sistem akan menampilkasn isi data secara utuh pada tabel data. Selain itu terdapat tombol Submit Data untuk melakukan proses trasformasi data dengan cara menyeleksi atribut yang diperlukan dalam proses clustering. Setelah tombol Submit Data di pilih hasil dari proses transformasi akan di tampilkan pada tabel trasformasi data yang di beri title trasnformasi data. Untuk memulai proses preprocessing, pengguna harus memilih tombol Preprocessing. Setelah itu hasil data dari proses preprocessing akan
38 Range Harga Preprosesing Clustering
Input data
Pilih File
Tabel data
Submit Data
Jumlah Data
Tabel data preprocessing
Proses Jumlah Data preprocessing
Data Preprocessing
Batal
Tabel Transformasi data
Trasformasi data
Preprocessing
Gam bar 9 Gambar 4.5. Desain interface Halaman Utama Tab Preprosesing
3. Hasli Proses Clustring dan Akurasi
Setelah tombol proses dipilih sistem akan menampilkan hasli pembentukan cluster dan hasil akurasi pada tab ketiga „Clustering‟ ke tabel -tabel yang ada. Pada tab ini terdapat tabel-tabel, antara lain tabel jumlah cluster dan tabel label anggota cluster. Untuk menyimpan hasil
39
Range Harga Preprosesing Clustering
simpan Waktu Pembantukan Cluster
Tabel jumlah clsuter
Tree
Tabel Label anggota clsuter
SISTEM PREDIKSI PENJUALAN HELM
MENGGUNAKAN ALGORITMA HIERARCHICAL DIVISIVE
LOGO Menu
Total SSE
40 BAB V
IMPLEMENTASI DAN ANALISIS HASIL
BAB V MPLEMENTA SI DAN ANALI SI S HA SI L
Pada bab ini akan dijelaskan mengenai implementasi sistem sesuai rancangan sistem yang telah dijelaskan pada bab sebelumya. Implementasi sistem ini menggunakan bahasa pemrograman Java dengan aplikasi pemrograman NetBeans 7.2 pada komputer dengan spesifikasi processor intel i5 2.3 GHz, memori 4GB, dan harddisk 1T.
5.1. Implementasi
5.1.1. Pengolahan Data
Data yang diperoleh merupakan hasil eksport dari database perusahaan berjenis file csv. Total data transaksi penjualan bejumlah 933 record dengan 21 atribut. Data tersebut akan diproses melalui tahap preprocessing, clustering, dan akhirnya perhitungan akurasi secara internal (Internal evaluation) dalam clustering yang coba dibentuk. Pada Tabel 5.1 adalah atribut dari tabel data
penualan.
Tabel 10 Tabel 5.1. Atribut dalam tabel detail penjualan
No Nama Atribut Keterangan
1 noFaktur Nomor nota transaksi penjualan
2 kodeBarang Kode dari masing-masing nama barang 3 namaBarang Nama dari produk helm
41
5 Size Ukuran dari suatu produk helm
6 hargaJual Harga dari produk helm
7 Quantity Jumlah dari pembelian barang dalam suatu transaksi 8 disscount Potongan harga dari suatu produk helm
9 discountReal Potongan harga dari suatu produk helm 10 discount2 Potongan harga dari suatu produk helm
11 Total Total harga pembelian suatu produk helm setelah discount
12 Urut Nomer urut dari setiap nota transaksi
13 Hpp -
14 Hppdpp -
15 hargaSatuan Harga satuan suatu produk helm 16 sisaPesanan -
17 statusReturOrder Berisi status dari pengembalian pembelian 18 statusNoKedit Berisi statis dari nota kredit
19 noUrut Nomer urut setiap transaksi
20 kodeArea Berisi kode are pemasaran wilayah 21 kelompokHarga Berisi label range klompok harga
5.1.1.1Preprocessing
1. Data Cleaning
42
Pada record penjualan detai tercatat beberapa transaksi dengan nama barang
„Helm Penjualan Lama‟, record data-data yang mengandung nama barang
tersebut akan dihapus karena tidak diperlukan dalam penelitian ini. Setelah dilakukan pembersihan didapatkan 834 jumlah data yang diap untuk digunakan dalam penelitian ini.
2. Data Integration
Setelah data penjualan melewati tahap data cleaning selanjutnya data di diurutkan mulai dari harga jual terendah sampai harga jual tertinggi. Kemudian di simpan dalam sebuah file tipe *.csv. kode barang menjadi identitas setiap sempel obyek data.
3. Data Selection
Pada tahap ini dilakukan penyeleksian terhadap data-data yang akan digunakan selama proses penelitian ini. Pada data penjualan detail terdapat 21 atribut yaitu noFaktur, kodeBarang, namaBarang, satuan, size, hargaJual, quantity, discount, discountReal, discount2, total, urut, Hpp, hppdpp, hargasatuan, sisapesan, statusReturOrder, statusNotaKredit, nourut, kodeCanvaser, KelompokHarga. Bebrapa atribut data yang diseleksi adalah noFaktur, satuan, size, discount, discountReal, discount2, urut, Hpp, hppdpp, hargasatuan, sisapesan, statusReturOrder, statusNotaKredit, nourut. Setelah dilakukan seleksi data, hanya ada 7 atribut yang digunakan dalam proses data mining seperti pada Tabel 5.2.
Tabel 11 Tabel 5.2 Atribut hasil seleksi
43
1 kodeBarang Kode dari masing-masing nama barang 2 namaBarang Nama dari produk helm
3 hargaJual Harga dari produk helm
4 quantity Jumlah dari pembelian barang dalam suatu transaksi 5 Total Total harga pembelian suatu produk helm setelah discount 6 kodeArea Berisi kode are pemasaran wilayah
7 kelompokHarga Berisi label range klompok harga 4. Data Transformation
Pada tahap ini Transformasi yang dilakukan adalah memberi label kelompok harga pada setiap record sesuai dengan yang di tentukan oleh pengguna dan menggabungkan nama barang yang sama dan menjumlahkan total quantity-nya pada setiap kelompok hargaquantity-nya masing-masing. Praktikquantity-nya, sebagai pada Gambar 5.1 dari data berjumlah 24 transakasi:
44
Setelah data dalam Gambar 5.1 melalui tahap preprocessing data oleh sistem akan menghasilkan 19 data seperti dalam Tabel 5.3:
Tabel 12 Tabel 5.3. Hasil preprocessing data
Nama Barang Kelompok
Harga
Total quantity
GM EVO HELLO KITTY #4 WH 1 2.0
GM EVO HELLO KITTY #5 - SR PINK 1 4.0 GM EVO LOLA BUNNY & BUGS BUNNY #1 WH/RED 1 3.0 GM EVO ANGRY BIRD #3 - SR WH/RED 1 2.0
GM EVO MICKEY MOUSE # 10 - WH 1 1.0
GM EVO ROSSI - SR BK 1 1.0
GM NEW IMPREZZA GENT - 2V RED/BK 2 2.0 GM NEW IMPREZZA GEN - 2V BL MET BK 2 1.0 GM NEW IMPREZZA GENT - 2V WH/BK 2 1.0 NHK PREDATOR 2 VISOR SOLID - 2V WH 3 1.0 NHK PREDATOR 2 VISOR SOLID - 2V PP 3 1.0 NHK PREDATOR 2 VISOR SOLID - 2V R. RED 3 2.0 GM AIRBORNE SOLID - 2V GUN MET 3 1.0
GM AIRBORNE SOLID - 2V WH 3 1.0
GM SUPERCROSS NEUTRON - NV WH/RED 4 1.0
GM SUPERCROSS NEUTRON - WH/PP 4 1.0
NHK TERMINATOR SOLID 2V - RED F 4 2.0 GM SUPERCROSS NEUTRON - NV WH/GREEN 4 1.0 GM SUPERCROSS NEUTRON - NV WH/GOLD 4 1.0
5.1.1.2Cluster dan Akurasi
45
dilakukan uji akurasi dari setiap proses pembentukan kelompok dengan internal evaluation.
Dalam penelitian ini, pengelompokan menggunakan metode hierarchical clustering divisive. Setelah data melalui tahap preprocessing selanjutnya data akan
di proses menggunakan hierarchical clustering divisive. Dari data penjualan sejumlah 933 record kemudian setelah melalui tahap preprocessing menjadi 159 record dengan tiga atribut yang diproses dengan menggunakan hierarchical
clustering divisive sehingga terbentuk kelompok-kelompok. Pada setiap proses
pembentukan kelompok terebut diuji menggunakan sum of squares error (SSE).
System yang dibentuk melakukan proses hierarchical clustering divisive, dengan menggunakan perhitungan euclidean distance sebahai metode untuk menghitungjarak kedekatan atau kemiripan antar obyek. Hasil pengelompokan ditampilkan dalam tabel-tabel informasi cluster dan Jtree sebagai visualisasi pembentukan kelompok.
46
Gam bar 12 Gambar 5.2. Grafik SSE pembentukan Cluster
Dari hasil tujuh perbobaan pembentukan cluster menunjukkan bahwa SSE terendah didapat pada percobaan ketujuh dengan nilai SSE 38092.636 yang menghasilkan 8 buah cluster.
5.1.2. Implementasi Antarmuka
Pembuatan user interface sistem ini menggunakan NetBeans 7.3 dengan bahasa pemrograman Java. Desain user interface yang dipaparkan pada baba sebelumnya diimplementasikan dan digunakan sebagai sarana untuk menentukan batas harga kelompok sampai untuk mengetahui akurasi dari pengelompokan data dengan Hierarchical Divisive. Sistem ini dapat langsung menampilkan hasil keseluruhan proses dengan melau 2 tahap, yang pertama menentukan batas kelompok harga, preprocessing data lalu di proses clustering. User interface ini tersimpan dalam file HalamanUtama.Java (lanjut lampiran 8 coding) berikut tampilan keseluruhan sistem.
0 50,000 100,000 150,000 200,000 250,000 300,000 350,000
47 5.1.3.1 Implementasi Halaman Utama
Gam bar 13 Gambar 5.3. Implementasi Halaman Utama Sistem Tab Range harga
48
Gam bar 14 Gambar 5.4. Implementasi Halaman Tentang
Submenu Manual apabila diklik, maka akan menampilkan Halaman Manual tentang cara penggunaan sistem. Tampak seperti Gambar 5.5.
Gam bar 15 Gambar 5.5. Implementasi Halaman Manual Sistem
Selain menu tersebut pada setiap halaman Tentang dan Manual terdapat 1
tombol „Kembali‟ untuk kembali ke halaman utama sistem. Pada praktiknya,
49
tampilan tersebut adalah input range harga, input data, informasi tabel data, dan yang terakhir proses divisive clustering dan akurasi. Proses range harga dan preprocessing dilakukan dalam file HalamanUtama.java. Untuk proses clustering,
dan SSE dilakukan dalam file bernama Divisive.java (lampiran 8)
1. Input Range Harga
Setelah sistem dijalankan, sistem akan menampilkan Halaman Utama Tab Range harga sebagai tahap awal untuk memproses data. Pada tahap ini pengguna
harus menginputkan nilai range harga untuk setiap kelompok. Sebelumnya sistem akan menampilkan nilai yang sudah tersimpan dalam database, jika nilai dalam database sudah ada pengguna bisa mengupdatenya dengan mengisi nilai baru dan
mengklik tombol simpanm, dan jika nilai dalam database kosong pengguna harus memasukan nilai range harga baru. Tombol Delete isi untuk menghapus nilai range yang sudah ada sedangkan tombol Reset digunakan untuk mengset nilai 0.
Fungsi dari nilai batas range harga kelompok nantinya berguna untuk memberi label pada setiap data obyek.
50 2. Input Data dan Informasi Tabel Data
Setelah selesai mengisi nilai range harga, masuk ke tahap berikutnya yaitu tahap input data Preprocessing. Tombol Pilih File berfungsi untuk menginputkan data yang akan di proses. File yang dapat di proses oleh sistem hanyalah yang bertipe file *.csv. setelah diinputkan sistem akan menampilkan data secara utuh pada tabel data, setelah tombol Submit Data dipilih sistem akan melakukan proses transformasi data dengan menseleksi atribut data inputan kemudian menampilkannya dalam tabel transformasi data. Tampilan dibawah ini adalah tampilan dimana data berhasil dimasukan kedalam sistem dan berhasil melalui proses transformasi.
51
Pada bagian input disediakan tombol Submit Data, Preprocessing dan Batal. Tombol Submit Data berfungsi untuk melakukan proses trasformasi. Tombol Batal berfungsi untuk membatalkan proses input data. Setelah pengguna mengklik tombol Preprocessing hasil data dari tahapan trasformasi akan masuk ke tabel data preprocessing, seperti tampak pada Gambar dibawah ini.
Gam bar 18 Gambar 5.8. Implementasi Informasi Tabel Data Preprocessing
52 3. Hasil Proses Divisive Clustering dan Akurasi
User interface dari implementasi proses pengelompokan dan perhitungan
akurasi dapat dilihat pada Gambar 5.9.
Gam bar 19 Gambar 5.9. Implementasi Hasil Divisive Clustering dan Akurasi
Penjelasan tentang Gambar 5.9:
a. Pada title Jumlah Cluster berisi Jumlah anggota tiap cluster.
b. Pada title Label Cluster adalah isi label anggota yang dimiliki cluster itu sendiri.
c. Pada bagian paling kanan adalah visualisasi kelompok dalam jtree. d. Bagian bawah terdapat informasi lama waktu pembentukan cluster dan