Informasi Dokumen
- Penulis:
- Enur Irdiansyah
- Pengajar:
- Andri Heryandi, S.T., M.T.
- Sekolah: Universitas Komputer Indonesia
- Mata Pelajaran: Teknik Informatika
- Topik: Penerapan Data Mining Pada Penjualan Produk Minuman Di PT. Pepsi Cola Indobeverages Menggunakan Metode Clustering
- Tipe: skripsi
- Tahun: 2010
- Kota: Bandung
Ringkasan Dokumen
I. PENDAHULUAN
Bagian ini menjelaskan latar belakang permasalahan yang dihadapi oleh PT. Pepsi Cola Indobeverages dalam menghadapi persaingan bisnis yang ketat di industri minuman. Ditekankan pentingnya analisis data penjualan untuk pengambilan keputusan yang tepat. Penelitian ini bertujuan untuk menerapkan data mining, khususnya metode clustering, untuk menganalisis pola penjualan dan karakteristik konsumen. Dengan memanfaatkan teknologi informasi yang ada, perusahaan dapat membuat keputusan yang lebih baik dalam strategi pemasarannya.
1.1. Latar Belakang Masalah
Dalam dunia bisnis yang dinamis, perusahaan perlu beradaptasi dan mengembangkan strategi untuk bertahan dan berkembang. PT. Pepsi Cola Indobeverages, sebagai pemain utama di industri minuman, harus mampu menganalisis data penjualannya untuk memahami tren dan perilaku konsumen. Dengan data yang melimpah, perusahaan dapat menggunakan teknik data mining untuk menemukan pola yang dapat membantu dalam pengambilan keputusan yang lebih baik.
1.2. Perumusan Masalah
Permasalahan utama yang diidentifikasi adalah bagaimana menerapkan data mining pada penjualan produk minuman di PT. Pepsi Cola Indobeverages menggunakan metode clustering. Penelitian ini bertujuan untuk menemukan cara yang efektif dalam menganalisis data penjualan untuk meningkatkan strategi pemasaran dan daya saing perusahaan.
1.3. Maksud dan Tujuan
Maksud dari penelitian ini adalah untuk membangun aplikasi data mining yang dapat membantu PT. Pepsi Cola Indobeverages dalam menganalisis data penjualan produk minuman. Tujuannya adalah untuk mempermudah analisis data, memberikan informasi berharga dari hasil analisis, dan membantu pengambilan keputusan yang lebih baik untuk strategi pemasaran.
1.4. Batasan Masalah
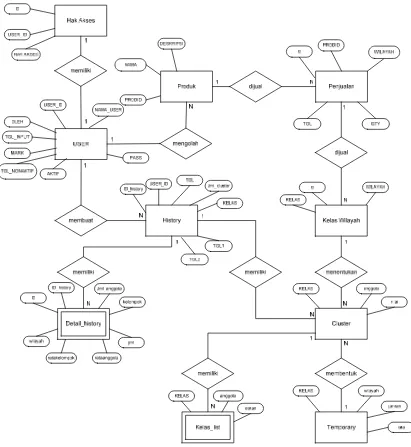
Batasan dalam penelitian ini mencakup fokus pada data penjualan produk minuman di PT. Pepsi Cola Indobeverages, penggunaan algoritma Agglomerative Hierarchical Clustering, dan penggunaan sistem operasi Microsoft Windows XP. Penelitian ini juga akan menggunakan diagram aliran data (DFD) dan diagram hubungan entitas (ERD) dalam analisis sistem.
1.5. Metodologi Penelitian
Metodologi yang digunakan dalam penelitian ini meliputi pengumpulan data melalui studi literatur, observasi, dan wawancara. Selanjutnya, pembuatan perangkat lunak akan mengikuti tahapan model waterfall, yang terdiri dari analisis, desain, pengkodean, pengujian, dan pemeliharaan.
1.6. Sistematika Penulisan
Sistematika penulisan dibagi menjadi lima bab: Pendahuluan, Tinjauan Pustaka, Analisis dan Perancangan Sistem, Implementasi dan Pengujian, serta Kesimpulan dan Saran. Setiap bab memiliki fokus dan tujuan yang jelas untuk memberikan gambaran menyeluruh mengenai penelitian ini.
II. TINJAUAN PUSTAKA
Bab ini membahas tentang perusahaan PT. Pepsi Cola Indobeverages serta teori-teori yang relevan dengan data mining dan metode clustering. Penjelasan mengenai sejarah perusahaan, visi dan misi, serta konsep dasar data mining dan teknik-teknik yang digunakan dalam penelitian ini sangat penting untuk memahami konteks dan aplikasi dari penelitian yang dilakukan.
2.1. Tinjauan Tempat Penelitian
Tinjauan tempat penelitian mencakup sejarah perusahaan PT. Pepsi Cola Indobeverages, yang didirikan pada tahun 1965. Sejarah ini memberikan konteks tentang perkembangan perusahaan dan posisinya di pasar. Visi dan misi perusahaan juga dijelaskan, menekankan komitmen perusahaan untuk menjadi pemimpin dalam industri produk konsumen.
2.2. Landasan Teori
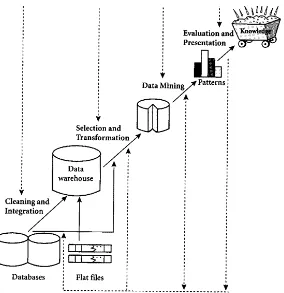
Bagian ini menjelaskan konsep dasar data mining, termasuk definisi, tahapan, dan arsitektur data mining. Data mining didefinisikan sebagai proses untuk mengekstrak informasi berharga dari data besar. Proses ini melibatkan beberapa tahapan, termasuk pembersihan data, integrasi data, pemilihan data, transformasi data, dan evaluasi pola. Konsep clustering juga diperkenalkan sebagai metode untuk mengelompokkan data berdasarkan kesamaan karakteristik.
2.2.1. Pengertian Data Mining
Data mining adalah teknik yang digunakan untuk menemukan pola tersembunyi dalam data besar. Proses ini menggabungkan analisis statistik dan kecerdasan buatan untuk mengekstraksi informasi yang bermanfaat. Data mining berfungsi untuk menggali nilai tambah dari database yang terus berkembang seiring dengan kemajuan teknologi informasi.
2.2.2. Tahapan Data Mining
Tahapan dalam data mining meliputi data cleaning, data integration, data selection, data transformation, data mining itu sendiri, pattern evaluation, dan knowledge presentation. Setiap tahapan memiliki peran penting dalam memastikan bahwa data yang dianalisis menghasilkan informasi yang akurat dan berguna.
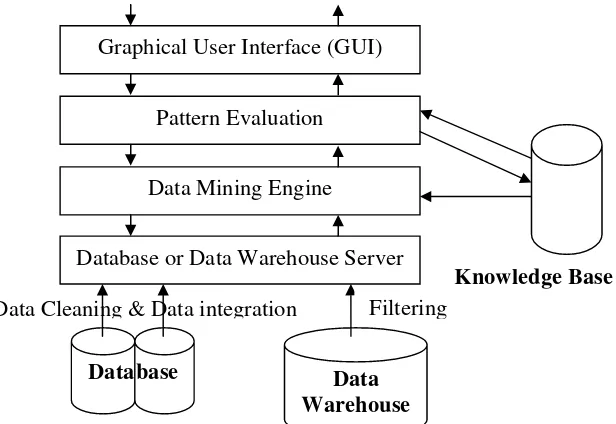
2.2.3. Arsitektur Data Mining
Arsitektur data mining terdiri dari beberapa komponen, termasuk database, server data warehouse, basis pengetahuan, mesin data mining, dan modul evaluasi pola. Struktur ini memungkinkan pengguna untuk berinteraksi dengan sistem dan mendapatkan informasi yang dibutuhkan dari data yang dianalisis.
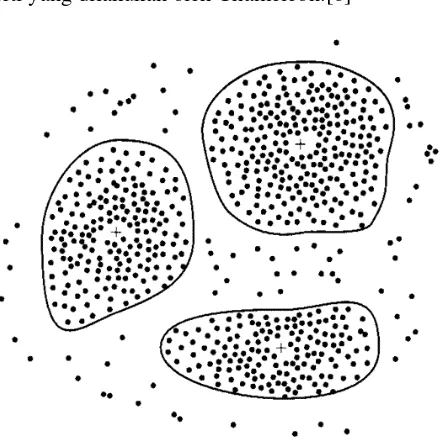
2.2.4. Pengelompokan (Clustering)
Pengelompokan adalah teknik yang digunakan untuk mengidentifikasi kelompok dalam data tanpa memerlukan label sebelumnya. Prinsip dasar dari clustering adalah memaksimalkan kesamaan antar anggota dalam satu kelompok dan meminimalkan kesamaan antar kelompok. Metode ini sering digunakan dalam analisis data untuk menemukan pola dan tren yang tidak terlihat.
III. ANALISIS DAN PERANCANGAN SISTEM
Di bab ini, analisis sistem dilakukan untuk mengidentifikasi masalah yang ada dan merancang solusi yang tepat menggunakan metode clustering. Proses perancangan sistem mencakup analisis kebutuhan fungsional dan non-fungsional, diagram konteks, dan spesifikasi proses. Hal ini penting untuk memastikan bahwa sistem yang dibangun dapat memenuhi kebutuhan pengguna dan memberikan hasil yang diharapkan.
3.1. Analisis Sistem
Analisis sistem dimulai dengan mengidentifikasi masalah yang ada dalam pengolahan data penjualan di PT. Pepsi Cola Indobeverages. Analisis non-fungsional juga dilakukan untuk menentukan kebutuhan perangkat keras dan perangkat lunak yang diperlukan untuk mendukung sistem. Hal ini penting agar sistem yang dibangun dapat berjalan dengan baik dan efisien.
3.2. Analisis Kebutuhan Fungsional
Analisis kebutuhan fungsional mencakup pembuatan diagram konteks dan data flow diagram (DFD) untuk menggambarkan aliran data dalam sistem. DFD digunakan untuk menggambarkan proses pengolahan data penjualan dan bagaimana data tersebut akan dianalisis menggunakan metode clustering. Ini membantu dalam memahami bagaimana sistem akan berfungsi dan berinteraksi dengan pengguna.
3.3. Perancangan Antar Muka
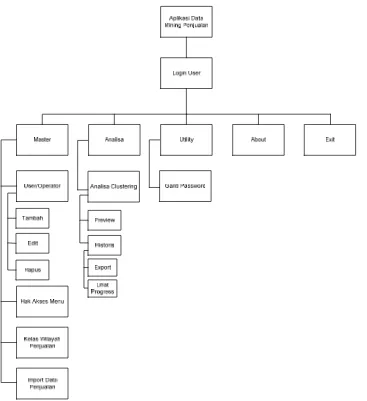
Perancangan antar muka sistem dilakukan untuk menciptakan tampilan yang user-friendly bagi pengguna. Berbagai tampilan program dirancang, termasuk tampilan awal aplikasi, tampilan login, dan tampilan menu utama. Desain yang baik akan mempermudah pengguna dalam berinteraksi dengan sistem dan meningkatkan pengalaman pengguna secara keseluruhan.
IV. IMPLEMENTASI DAN PENGUJIAN
Bab ini menjelaskan proses implementasi sistem yang telah dirancang dan pengujian untuk memastikan bahwa sistem berfungsi dengan baik. Implementasi perangkat keras dan perangkat lunak, serta pengujian terhadap berbagai fitur sistem dilakukan untuk memastikan bahwa aplikasi dapat memenuhi kebutuhan pengguna dan menghasilkan informasi yang akurat.
4.1. Implementasi Sistem
Implementasi sistem mencakup pemasangan perangkat keras dan perangkat lunak yang diperlukan untuk menjalankan aplikasi. Selain itu, implementasi juga melibatkan pengaturan basis data dan antarmuka pengguna. Proses ini penting untuk memastikan bahwa semua komponen sistem dapat berfungsi secara harmonis.
4.2. Pengujian
Pengujian dilakukan untuk memastikan bahwa sistem berfungsi sesuai dengan yang diharapkan. Rencana pengujian mencakup pengujian login, pengolahan data pengguna, dan analisis clustering. Hasil pengujian dievaluasi untuk menentukan apakah sistem siap digunakan dan memenuhi kebutuhan pengguna.
V. KESIMPULAN DAN SARAN
Bab ini menyajikan kesimpulan dari penelitian yang dilakukan serta saran untuk pengembangan lebih lanjut. Penelitian ini menunjukkan bahwa penerapan data mining dengan metode clustering dapat membantu PT. Pepsi Cola Indobeverages dalam menganalisis data penjualan dan meningkatkan strategi pemasaran. Saran diberikan untuk penelitian selanjutnya agar dapat memperluas cakupan analisis dan meningkatkan akurasi hasil.
5.1. Kesimpulan
Kesimpulan dari penelitian ini adalah bahwa penerapan metode clustering dalam data mining dapat memberikan wawasan yang berharga bagi PT. Pepsi Cola Indobeverages. Dengan menganalisis data penjualan, perusahaan dapat memahami pola konsumsi dan membuat keputusan yang lebih baik dalam strategi pemasaran.
5.2. Saran
Saran untuk penelitian selanjutnya adalah untuk mengeksplorasi teknik data mining lainnya yang dapat digunakan bersamaan dengan clustering. Selain itu, pengembangan aplikasi yang lebih interaktif dan mudah digunakan juga disarankan untuk meningkatkan pengalaman pengguna dan efektivitas analisis.
Referensi Dokumen
- Data Mining dan Web Mining ( Andi )
- SQL (Structured Query Language) dengan delphi ( Andri Heryandi, S.T. )
- Pengantar Data Mining: Menambang Permata Pengetahuan di Gunung Data ( Iko Pramudiono )
- Konsep Dan Tuntunan Basis Data ( Kadir, Abdul )
- PENERAPAN DATA MINING DENGAN METODE INTERPOLASI UNTUK MEMPREDIKSI MINAT KONSUMEN ASURANSI (Studi Kasus Asuransi Metlife) ( Sandy Kurniawan, Taufiq Hidayat )
- Sistem Informasi Management ( Susanti, Azhar )
- Data Mining ( Yusta Noverison )