155
PENERAPAN DATA MINING UNTUK PREDIKSI KELULUSAN UKP MENGGUNAKAN METODE NAÏVE BAYES
Iwan Mahendro1*
1Program Studi Nautika, UNIMAR AMNI SEMARANG Jl. Soekarno – Hatta 180 Semarang
*Email: [email protected]
Abstrak
Data – data yang dari hasil ujian kepelautan di UNIMAR AMNI Semarang belum pernah dilakukan pengolahan data yang maksimal. Artinya data yang sudah ada belum bisa untuk memprediksi untuk hasil kelulusan ujian kepelautan untuk tahun selanjutnya. Untuk itu tujuan dari penelitian ini adalah menggunakan sebuah metode data mining agar dapat memprediksi seberapa besar kelulusan yang akan diperoleh dari hasil ujian kepelautan. Upaya untuk menaikkan jumlah kelulusan yaitu dengan melakukan prediksi hasil lulusan sebelumnya.
Sehingga akan didapatkan manfaat yaitu dapat melakukan pengambilan keputusan yang tepat.
Data mining merupakan cabang ilmu yang bertujuan untuk mengatasi masalah penggalian sebuah informasi dari data yang berjumlah besar dan algoritma naïve bayes merupakan metode yang bertujuan untuk mengklasifikasi data yang ada kemudian dapat digunakan untuk memprediksi kelulusan UKP. Kesimpulan yang diperoleh yaitu dengan menerapkan data mining yang tepat maka akan dapat memprediksi kelulusan UKP di UNIMAR AMNI Semarang.
Kata kunci : Data, klasifikasi, kelulusan, Naïve Bayes, UKP
PENDAHULUAN
Indonesia mempunyai laut yang sangat luas, tentunya dengan luasnya laut di Indonesia mempunyai banyak keuntungan yang bisa didapat. Di dalam laut terdapat banyak ikan yang dapat diambil oleh nelayan Indonesia, selain itu dengan luasnya laut banyak kapal dari Indonesia sendiri maupun dari luar negeri yang berlayar. Banyaknya kapal yang berlayar maka dibutuhkan pelaut dalam jumlah yang banyak pula. Hal ini mendapat perhatian dari pemerintah Indonesia untuk dapat menghasilkan pelaut – pelaut yang handal agar berlayar di kapal Indonesia maupun kapal dari luar negeri, sehingga dapat mensejahterakan masyarakat Indonesia.
Pelaut yang handal tidak muncul secara tiba – tiba akan tetapi dihasilkan dari dunia pendidikan. Salah satu cara untuk menghasilkan pelaut yaitu melalui perguruan tinggi dibidang maritim. Di Indonesia terdapat banyak perguruan tinggi maritim baik negeri maupun swasta. Mereka setiap tahun meluluskan pelaut yang nantinya akan bekerja di kapal – kapal Indonesia maupun kapal – kapal dari luar negeri. Perguruan tinggi maritim untuk dapat membuat lulusannya dapat bekerja di kapal maka lulusannya harus sudah pernah dilakukan ujian kepelautan yang bertujuan agar dapat
diakui keterampilannya baik secara nasional mapun internasional.
Ujian kepelautan yang dilakukan biasanya ada taruna yang lulus dan ada yang gagal. Jika gagal dalam ujian tentunya harus dilakukan ujian ulang agar nantinya setelah lulus dari perguruan tinggi dapat langsung bekerja di kapal. Permasalahan yang sering terjadi diperguruan tinggi adalah mereka mempunyai data hasil ujian kepelautan di tiap tahunnya, akan tetapi belum diolah secara maksimal sehingga mereka belum bisa untuk memprediksi tingkat kelulusan untuk tahun berikutnya.
Data kelulusan yang sudah dimiliki oleh perguruna tinggi biasanya hanya disimpan dan dibuka hanya waktu diperlukan saja. Untuk itu peneliti tertarik untuk bisa mengolah data – data yang sudah tersimpan sehingga bisa untuk memprediksi kelulusan di tahun berikutnya.
Selain itu hasil prediksi juga bisa untuk pengambilan keputusan perguruan tinggi tentang rencana apa yang dijalankan setelah mengetahui hasil prediksi. Tentunya perguruan tinggi brharap banyak taruna yang dapat lulus ujian tanpa harus mengulang apabila ujian kepelautan yang dilaksanakan dinyatakan gagal.
156
LANDASAN TEORIPeneliti dalam mengolah data akan menggunakan data mining. Data mining adalah suatu proses menemukan hubungan yang berarti, pola dan kecenderungan dengan memeriksa dalam sekumpulan besar data yang tersimpan dalam penyimpanan, dengan menggunakan teknik pengenalan pola seperti teknik statistik dan matematika (Larose,2005).
Pengertian data mining yang lain, data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terakit dari berbagai database besar. Turban, dkk.(2005).
Data mining mempunyai banyak metode yang bisa diterapkan untuk klasifikasi. Algoritma klasifikasi yang banayak digunakan peneliti yaitu Decision Trees, Neural Networks, k- Nearest Neighbours, Naïve Bayes, dan algoritma Genetik (Yukseltruk, Ozekes, &
Turel, 2014, p.119). penggunaan data mining untuk menganalisa penemuan baru yang tidak dapat diamati dengan pendekatan statistic tradisional (Sherrill, Eberle, & Talbert, 2011, p.56). oleh sebab itu dibutuhkan sistem yang dapat untuk memprediksi masa mendatang berdasarkan data – data yang sudah terkumpul sebelumnya.
Penelitian menggunakan data mining sudah pernah ada yang melakukan yaitu oleh Aries Saifudin, dalam penelitiannya menggunakan data mining untuk menseleksi calon mahasiswa pada penerimaan mahasiswa baru. Terbit di Jurnal Teknologi Volume 10 No.
1 Januari 2018. Di dalam jurnalnya menjelaskan bahwa penelitiannya menggunakan data mining dengan algoritma Support Vector Machine (SVM) untuk memprediksi ketepatan waktu lulus calon mahasiswa. Hasilnya dengan algoritma SVM diperoleh hasil dengan akurasi sebesar 65,00%.
Penelitian terdahulu lainnya dilakukan oleh Eni Hartika Harahap, Lailil Muflikhah, dan Bayu Rahayudi. Mereka meneliti tentang penentuan seleksi atlet pencak silat menggunakan data
mining dengan algoritma Support Vector Machine (SVM). Jurnal mereka terbit di Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer Volume 2 No.10 Oktober 2018.
Hasil yang didapat dari penelitian mereka adalah ketepatan akurasi untuk penerimaan seleksi atlet pencak silat sebesar 69,9%.
Peneliti melakukan penelitian dengan menggunakan data mining dengan metode Naïve Bayes bertujuan untuk mendapatkan hasil akurasi yang lebih baik dari penelitian sebelumnya. Manfaat dari penelitian ini adalah adanya alternatif pilihan dalam menggunakan data mining menggunakan metode SVM atau Naïve Bayes untuk penelitian – penelitian selanjutnya. Selain itu manfaat dari penelitian ini adalah hasil dari data mining bisa untuk pengambilan keputusan untuk masa mendatang karena adanya hasil prediksi dari data yang sebelumnya sudah ada kemudian diolah lagi.
Keuntungan menggunakan algoritma Naïve Bayes adalah metode Naïve Bayes membutuhkan data latih atau training data dalam jumlah yang kecil untuk menentukan parameter dalam proses pengklasifikasian.
Selain itu kelebihan yang lain adalah mudah dibuat dan hasilnya bagus. Metode Naïve Bayes juga mempunyai kekurangan yaitu asumsi independence antar atribut membuat akurasi berkurang.
METODE
Dataset penelitian diambil dari UNIMAR AMNI Semarang, data ini merupakan data sekunder karena diambil dari dokumen yang sudah ada sebelumnya. Metode penelitian ini adalah eksperimen, dimana ada tahapan – tahapan yang akan dilakukan dalam penelitian ini.
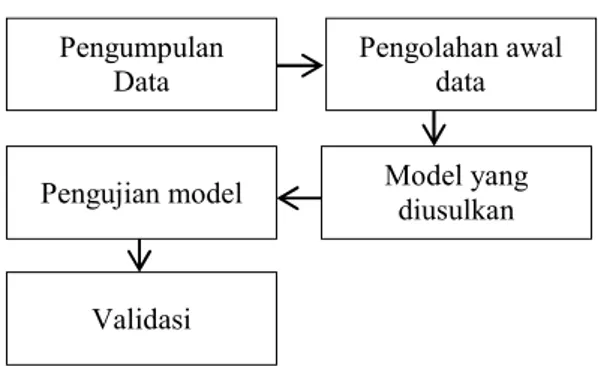
Gambar 1. Tahap Penelitian
Penjelasan pada gambar 1 adalah sebagai Pengumpulan
Data Pengolahan awal
data Model yang
diusulkan Pengujian model
Validasi
157
berikut. Tahap pertama adalah pengumpulan data berdasarkan sumbernya data primer dan data sekunder. Data primer adalah sumber data yang langsung memberikan data kepada pengumpul data. Sugiyono, (2015). Data ini diperoleh melalui wawancara. Data sekunder adalah sumber data yang tidak langsung memberikan data kepada pengumpul data, misalnya lewat orang lain atau lewat dokumen.Data yang diperoleh peneliti adalah data nilai hasil UKP.
Tahap kedua adalah pengolahan awal data, disini yang akan dilakukan adalah data yang sudah dikumpulkan akan diolah untuk mengurangi data yang tidak relevan tujuannya untuk mempermudah dalam pembentukan model. Tahap ketiga adalah modelyang diusulkan, tahap ini bertujuan untuk menggambarkan alur model dan cara kerja model yang diusulkan. Tahap keempat yaitu pengujian model, maksudnya adalah tahap ini akan menjabarkan bagaimana eksperimen yang akan dilakukan hingga terbentuk model. Tahap kelima yaitu validasi, pada tahap ini akan muncul hasil prediksi. Validasi akan dilakukan untuk memastikan bahwa hasilnya akan sama saat akan dilakukan secara independen.
Dataset
Data yang digunakan dala penelitian ini adalah data UKP yang diambil dari UNIMAR AMNI Semarang pada tahun 2019. Spesifikasi dataset ditunjukkan pada tabel 1.
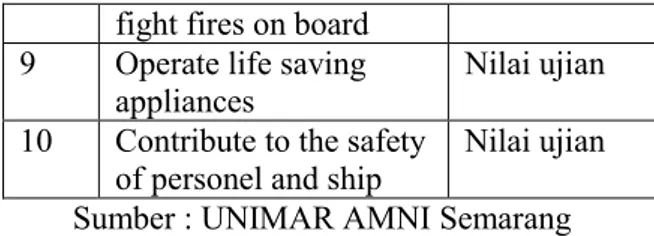
Tabel 1. Spesifikasi Dataset UKP No. Nama Atribut Keterangan 1 Paln and conduct a
passage and determine position
Nilai ujian
2 Maintain a safe
navigational wacth Nilai ujian 3 Manoevre the ship Nilai ujian 4 Respond to a distress
signal at sea Nilai ujian 5 Respon to emergencies Nilai ujian 6 Ensure complieance
with pollution prevention requirements
Nilai ujian
7 Maintain
seaworththiness of the ship
Nilai ujian 8 Prevent, control and Nilai ujian
fight fires on board 9 Operate life saving
appliances Nilai ujian
10 Contribute to the safety
of personel and ship Nilai ujian Sumber : UNIMAR AMNI Semarang Algoritma Naïve Bayes
Teori keputusan bayes adalah pendekatan statistik yang fundamental dalam pengenalan pola (pattern recognition), penggunaan algoritma ini dalam hal klasifikasi harus mempunyai masalah yang bisa dilihat statistiknya. Santosa, (2007). Naive Bayes merupakan pengklasifikasian dengan metode probabilitas dan statistik. Persamaan dari teorema Bayes adalah :
( | ) = ( | ). ( )( ) ... (1) Keterangan
: Data dengan class yang belum diketahui
: Hipotesis data merupakan suatu class spesifik
( | ) : Probabilitas hipotesis berdasar kondisi (posteriori probability) ( ) : Probabilitas hipotesis (prior
probability)
( | ) : Probabilitas berdasarkan kondisi pada hipotesis
( ) : Probabilitas Tabel 2. Data Training
No. Doku
men Uj 1 Uj 2 Uj 3 Uj 4 Uj 5
1 Dok 1 80 80 70 85 80
2 Dok 2 95 85 90 90 90
3 Dok 3 30 80 80 75 70
4 Dok 4 60 70 60 30 80
5 Dok 5 95 100 95 90 85 6 Dok 6 70 100 90 80 80 No. Uj 6 Uj 7 Uj 8 Uj 9 Uj 10 Status
1 80 80 80 85 90 Lulus
2 80 85 95 95 85 Lulus
3 80 80 80 80 80 Ulang
4 90 100 85 90 80 Ulang
5 80 80 80 80 80 Lulus
6 90 85 80 70 70 ?
Perancangan Penelitian
Pada penelitian ini untuk memprediksi kelulusan hasil ujian UKP diusulkan
158
menggunakan data mining. Cross validation adalah metode statistik untuk mengevaluasi dan membandingkan algoritma pembelajaran dengan membagi data menjadi dua segmen, satu segmen digunakan untuk belajar atau data latih dan yang lain untuk memvalidasi model Refaeilzadeh, Tang & Liu, (2009). K-fold cross validation adalah teknik umum untuk memperkirakan kinerja pengklasifikasi. K-fold cross validation dilakukan dengan menggunakan kembali dataset yang sama, sehingga menghasilkan perpecahan dari kumpulan data menjadi non-overlapping dengan proporsi pelatihan (k-1)/k dan 1/k untuk pengujian. Korb & Nicholson, (2011)Dataset yang sudah ada akan dibagi menjadi dua yaitu data latih dan data uji menggunakan algoritma 10-fold cross validation. Data latih berfungsi untuk melatih algortima klasifikasi, kemudian data uji berfungsi untuk menguji algoritma yang telah dilatih. Pada proses pengujian akan digunakan confusion matrix untuk menghasilkan ukuran kinerja algoritma yang diusulkan. Setelah selesai diuji, maka akan muncul hasil akurasi.
Teknik Analisis
Sistem intelijen dan model matematiks untuk pengambilan keputusan dapat mencapai hasil yang akurat dan efektif jika data yang digunakan dapat diandalkan. Vercllis, (2009).
Pengukuran kinerja model dilakukan menggunakan confusion matrix. Confusion matrix diperoleh dari proses validasi menggunakan 10-fold cross validation, sehingga model yang terbentuk dapat langsung diuji dengan melakukan 10 kali pengujian.
HASIL DAN PEMBAHASAN Pengujian Model
Penelitian ini bertujuan untuk menguji keakuratan analisa kelulusan UKP dengan menggunakan algoritma Naïve Bayes.
Model diolah menggunaan Software RapidMiner 5.3. Dataset yang sudah disimpan dalam format CSV (Comma Separated Value) dibuka dengan menggunakan operator Read CSV. Dataset terdiri dari 11 atribut. Setelah dataset dibuka kemudian menampilkan operator Validation, pastikan sudah tersetting
dengan 10-fold cross validation.
Selanjutnya dataset keluarannya dihubungkan ke validation, dan validation dihubungkan keluar sistem.
Gambar 2. Susunan Validasi Langkah berikutnya yaitu yang dilakukan adalah melatih dan menguji model di dalam validation. Pada bagian Training diisi dengan operator Naïve Bayes dan pada bagian testing diisi dengan operator Apply Model dan Performance. Selanjutnya tarik garis untuk menghubungkan antara operator Naïve Bayes, operator Apply model dan Performance. Susunan operator seperti pada gambar 3.
Gambar 3. Susunan Operator Semua operator jika sudah terhubung semua maka selanjutnya dilakukan eksekusi. Maka hasilnya akan muncul berupa prediksi dari model Naïve Bayes.
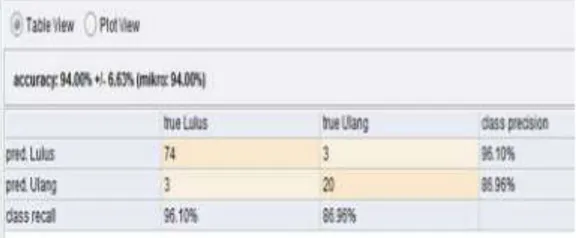
Hasil dari Accuracy sebesar 94,00%. Hasil
Precision sebesar 96,10% dan Recall
86,98%. Hasil prediksi dapat dilihat dari
gambar 4 berikut ini.
159 Gambar 4. Accuracy dari Naïve Bayes
Evaluasi dan Validasi ModelPenelitian ini untuk evaluasi dan validasi menggunakan confusion matrix. Percobaan yang dilakukan mendapatkan hasil sebagai berikut.
Tabel 3. Hasil Eksperimen Naïve Bayes
Dataset Jml
record Jml atribut
Accuracy (%)
Precisi (%) on
Recall (%) Nilai
UKP 100 11 94 96,10 86,96
Hasil dari eksperimen atau percobaan bahwa algoritma mempunyai akurasi yang lebih baik dari penelitian sebelumnya menggunakan metode SVM. Jadi algoritma Naïve Bayes dapat digunakan sebagai alternatif untuk mengolah data.
KESIMPULAN
Kesimpulan
Penerapan data mining dengan metode Naïve Bayes dapat digunakan untuk mengolah data kelulusan UKP. Dari percobaan yang sudah dilakukan terlihat bahwa akurasi dari Naïve Bayes sangat baik yaitu mencapai 94,00%. Nilai ini melebihi dari penelitian sebelumnya yang sudah dilakukan dengan metode SVM.
Saran
Untuk masa mendatang dalam mengolah data menggunakan data mining bisa mencoba untuk dilakukan dengan metode yang lain sebagai pembanding dari metode
Naïve Bayes. Karena selain metode SVM dan Naïve Bayes masih ada lagi metode lain yang terdapat dalam data mining.
DAFTAR PUSTAKA
Korb, K. B., & Nicholson, A. E. 2011. Bayesian Artifical Intelligence (2nd ed.). Florida : CRC Press.
Larose, Daniel T, 2005, Discovering Knowledge in Data: An Introduction to Data Mining : John Willey & Sons. Inc.
Refaeilzadeh, P., Tang, L., & Liu, H.2009.
Cross-Validation. In L. Liu, & M.T.
Ozsu Encyclopedia of Database Systems (pp. 532-538). Arizona : Springer US.
Saifudin, Aries. 2018. Metode Data Mining untuk Seleksi Calon Mahasiswa pada Penerimaan Mahasiswa baru di Universitas Pamulang. Jurnal Teknologi, 10(1) 25 – 36.
Santosa, Budi. 2007. Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta : Graha Ilmu
Sherril, B., Eberle, W.., & Talbert, D. 2011.
Analysis of Student Data for retention Using Data Mining Techniques 7th Annual National sysmposium on Student Retention (pp. 65-66). Charleston : C- IDEA
Sugiyono 2015. Metode Penelitian Kombinasi (Mix Methods). Bandung: Alfabeta Turban, E., dkk, 2005. Decision Support
Systems and Intelligent Systems, Andi Offset
Vercellis, C. 2009. Business Intelligence Data Mining and Optimization for Decision making. West Sussex : John Wiley &
Sons.
Yukseltruk, E., Ozekes, S., & Turel, Y.K. 2014.
Predicting Dropout Student : An Apllication of Data Mining Methods in an online Education Program. European Journal of Open, Distance and e-learning, 17(1), 118 – 133. Doi : 10.2478/eurodl-2014-0008