ABSTRAK
Penyakit hepatitis merupakan salah satu jenis penyakit hati. Walaupun hepatitis memiliki
tipe yang bermacam-macam, tetapi gejala seseorang terkena penyakit hepatitis sangat mirip sehingga sangat sulit untuk menentukan bahwa orang tersebut terkena penyakit hepatitis tipe A, B atau C. Pada bidang teknik informatika, penelitian terkait hepatitis sudah pernah dilakukan sebelumnya oleh Estu Karunianingtyas. Pada penelitian tersebut hanya mendapatkan akurasi 51,11 % karena hanya menggunakan data gejala yang tidak pasti merujuk pada satu penyakit saja.
Pada penelitian ini menambahkan data laboratorium sehingga mempengaruhi hasil akurasi dimana data laboratorium dapat mendiagnosa dengan benar jenis penyakit hepatitis. Berdasarkan hal tersebut maka sistem cerdas dibuat untuk mengelompokkan pasien yang terinfeksi hepatitis A, B dan C sesuai dengan data gejala dan data laboratoriumnya. Tahap
pada penelitian ini menggunakan knowledge discovery in databases sehingga tujuan
penelitian dapat tercapai. Pengelompokkan ini menggunakan algoritma agglomerative
hierarchical clustering dengan pengukuran kemiripan single, average dan complete linkage. Ada empat pengujian yang dilakukan untuk menghitung akurasi, yaitu perhitungan data laboratorium yang mendapatkan hasil 100 %, data gabungan gejala dan laboratorium dengan hasil 82,72 %, data laboratorium dan data gejala yang sudah diproses dengan principal component analysisdengan hasil 80,90 % serta data laboratorium dan data gejala hasil dari
principal component analysisdengan 100 %. Hasil yang baik didapatkan oleh normalisasi
[0-1] dengan pengukuran kemiripan complete linkage. Data laboratorium yang digunakan untuk
Hepatitis is one of kind the liver diseases. There are many various types of hepatitis. However, the symptoms of hepatitis are very similar because of that it was very difficult to determine that the person was infected by hepatitis A, hepatitis B and hepatitis C. In informatics engineering’s field, the research about hepatitis diseases had been done by Estu Karunianingtyas. In that research, it just got accuracy about 51,11 % because it only used symptoms data that were not only indicated one disease.
This research added laboratory data to influence the result of accuracy in which laboratory data can diagnose the hepatitis diseases correctly. Based on the previous explanation, intelligent system was made in order to cluster the patients who were infected by hepatitis A, hepatitis B, and hepatitis C that were appropriate with the laboratory data and the symptoms data. The step of this research used knowledge discovery in databases so that the
purpose of this research can be achieved. The clustering’s algorithm that were
usedwereagglomerative hierarchical clustering with similarity measure of single, average and complete linkage.
i
IDENTIFIKASI PENYAKIT HEPATITIS DENGAN
PENDEKATAN AGGLOMERATIVE HIERARCHICAL
CLUSTERING
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun oleh : Christina Wienda Asrini
095314011
HALAMAN JUDUL
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
IDENTIFICATION OF HEPATITIS DISEASE BY USING
AGGLOMERATIVEHIERARCHICAL CLUSTERING
APPROACH
A Thesis
Presented as Partial Fulfillment of the Requirements
To Obtain the Sarjana Komputer Degree
In Informatics Engineering Study Program
By :
Christina Wienda Asrini 095314011
HALAMAN JUDUL (Inggris)
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
iii
iv
v
HALAMAN PERSEMBAHAN
Skripsi ini saya persembahkan untuk :
Tuhan Yesus Kristus,
Keluarga tercinta, Dosen serta sahabat yang terkasih
Terima Kasih atas segalanya
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa tugas akhir yang saya tulis tidak
memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam
kutipan dan daftar pustaka sebagaimana layaknya karya ilmiah.
Yogyakarta, 1 November 2013
Penulis
Christina Wienda Asrini
vii
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
HALAMAN PERSETUJUAN PUBLIKASI
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata Dharma :
Nama : Christina Wienda Asrini
NIM : 095314011
Demi pengembangan pengetahuan, saya memberikan kepada perpustakaan
Universitas Sanata Dhama karya ilmiah yang berjudul :
IDENTIFIKASI PENYAKIT HEPATITIS DENGAN PENDEKATAN AGGLOMERATIVE HIERARCHICAL CLUSTERING
Beserta perangkat yang diperlukan (bila ada) dengan demikian saya memberikan
kepada perpustakaan Universitas Sanata Dharma hak untuk menyimpan,
mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan
data, mendistribusikan secara terbatas dan mempublikasikan di internet atau
media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya
maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya
sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya. Yogyakarta, ….. November 2013
Yang menyatakan,
viii
IDENTIFIKASI PENYAKIT HEPATITIS DENGAN PENDEKATAN AGGLOMERATIVE HIERARCHICAL CLUSTERING
ABSTRAK
Penyakit hepatitis merupakan salah satu jenis penyakit hati. Walaupun
hepatitis memiliki tipe yang bermacam-macam, tetapi gejala seseorang terkena penyakit hepatitis sangat mirip sehingga sangat sulit untuk menentukan bahwa orang tersebut terkena penyakit hepatitis tipe A, B atau C. Pada bidang teknik informatika, penelitian terkait hepatitis sudah pernah dilakukan sebelumnya oleh Estu Karunianingtyas. Pada penelitian tersebut hanya mendapatkan akurasi 51,11 % karena hanya menggunakan data gejala yang tidak pasti merujuk pada satu penyakit saja.
Pada penelitian ini menambahkan data laboratorium sehingga mempengaruhi hasil akurasi dimana data laboratorium dapat mendiagnosa dengan benar jenis penyakit hepatitis. Berdasarkan hal tersebut maka sistem cerdas dibuat untuk mengelompokkan pasien yang terinfeksi hepatitis A, B dan C sesuai dengan data gejala dan data laboratoriumnya. Tahap pada penelitian ini menggunakan
knowledge discovery in databases sehingga tujuan penelitian dapat tercapai.
Pengelompokkan ini menggunakan algoritma agglomerative hierarchical
clustering dengan pengukuran kemiripan single, average dan complete linkage. Ada empat pengujian yang dilakukan untuk menghitung akurasi, yaitu perhitungan data laboratorium yang mendapatkan hasil 100 %, data gabungan gejala dan laboratorium dengan hasil 82,72 %, data laboratorium dan data gejala yang sudah diproses dengan principal component analysisdengan hasil 80,90 %
serta data laboratorium dan data gejala hasil dari principal component
analysisdengan 100 %. Hasil yang baik didapatkan oleh normalisasi [0-1] dengan
pengukuran kemiripan complete linkage. Data laboratorium yang digunakan untuk
ix
ABSTRACT
Hepatitis is one of kind the liver diseases. There are many various types of hepatitis. However, the symptoms of hepatitis are very similar because of that it was very difficult to determine that the person was infected by hepatitis A, hepatitis B and hepatitis C. In informatics engineering’s field, the research about hepatitis diseases had been done by Estu Karunianingtyas. In that research, it just got accuracy about 51,11 % because it only used symptoms data that were not only indicated one disease.
This research added laboratory data to influence the result of accuracy in which laboratory data can diagnose the hepatitis diseases correctly. Based on the previous explanation, intelligent system was made in order to cluster the patients who were infected by hepatitis A, hepatitis B, and hepatitis C that were appropriate with the laboratory data and the symptoms data. The step of this research used knowledge discovery in databases so that the purpose of this
research can be achieved. The clustering’s algorithm that were
usedwereagglomerative hierarchical clustering with similarity measure of single, average and complete linkage.
x
KATA PENGANTAR
Puji dan syukur saya panjatkan kepada Tuhan Yesus Kristus karena
limpahan kebaikan dan penyertaan-Nya sehingga saya dapat menyelesaikan tugas
akhir yang berjudul “Identifikasi Penyakit Hepatitis dengan Pendekatan
Aglomerative Hierarchical Clustering”. Pada proses penulisan tugas akhir ini,
saya mengucapkan terima kasih yang sebesar-besarnya kepada :
1. Romo Dr. Cyprianus Kuntoro Adi, SJ, MA, M.Sc selaku dosen
pembimbing, terima kasih atas segala bimbingan dan kesabarannya
sehingga saya dapat menyelesaikan tugas akhir ini.
2. Ibu Ridowati Gunawan, S.Kom, M.T dan Ibu Sri hartati Wijono, S.Si,
M.Kom, selaku dosen penguji yang telah memberikan banyak kritik dan
saran terhadap tugas akhir saya.
3. Seluruh staff dosen dan laboran teknik informatika universitas sanata
dharma yang telah banyak memberikan bantuan selama saya menempuh
studi.
4. Kedua orang tua saya, bapak Dwi Budiyanto dan ibu Endang Retno yang
senantiasa mendukung saya dengan doa, kasih sayang dan perhatiannya
sehingga saya mampu menyelesaikan studi saya.
5. Adik satu-satunya Enggar Jati, saya juga mengucapkan terimakasih karena
xi
6. Keluarga saya yang lain, Eyang kakung dan eyang putri dari Magelang
dan Temanggung, Angga Satria, Dolorosa Lintang, Tante Woro dan Om
Dwi yang juga telah memberikan dukungannya serta doa.
7. Sahabat yang luar biasa dari SMP, Lucia Septi dan Gofenni yang
senantiasa mendengarkan keluh kesah setiap saat serta memberi saya
dukungan moril.
8. Teman-teman dari Teknik Informatika 2009, Cosmas Dipta, Mirella Tri,
Fiona Endah, Fidelis Adi, Audris Evan, Astriana Krisma, Rafaela Rosi,
Dyah Ayu Paramita, Ade Ignatio, Nicodimus, Laurentius Puji, Petrus Kiki,
Setyo Resmi, Wiwinniarti,Yoseph Dian, Agustinus Wikrama dan semua
yang tidak sempat disebutkan, terimakasih atas segala dukungan, bantuan,
canda-tawa dan doa sehingga saya dapat tetap semangat.
9. Teman-teman dari PBSID dan PBI 2009, Yohanes Marwan dan Paulina
Ine, yang membantu saya mengoreksi dan memberikan dukungan.
Dengan rendah hati penulis menyadari bahwa tugas akhir ini masih jauh
dari sempurna. Oleh karena itu segala kritik dan saran untuk perbaikan tugas
akhir ini sangat diperlukan. Akhir kata, semoga tugas akhir ini dapat
bermanfaat bagi semua pihak. Sekian dan terima kasih.
Yogyakarta, 11 November 2013
xii
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN JUDUL (Inggris) ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
HALAMAN PERSEMBAHAN ... v
HALAMAN PERNYATAAN KEASLIAN KARYA ... vi
HALAMAN PERSETUJUAN PUBLIKASI... vii
ABSTRAK ... viii
2.1 Pengertian Knowledge Discovery in Databases (KDD) ... 6
2.2 Jenis-Jenis Metode Data mining ... 10
2.3 Metode Clustering ... 13
2.3.1 Pengertian Clustering ... 13
2.3.2 Agglomerative Hierarchical Clustering ... 19
2.4 Dimensionality Reduction ... 29
xiii
2.6 Pengujian Keakuratan Metode... 34
BAB III ... 37
METODOLOGI PENELITIAN... 37
3.1 Data ... 37
3.2 Metode Pengumpulan Data ... 38
3.3 Teknik Analisa Data ... 39
3.4 Design User Interface ... 46
3.5 Spesifikasi Software dan Hardware ... 49
BAB IV ... 50
IMPLEMENTASI DAN ANALISA HASIL ... 50
4.1 Hasil Penelitian dan Analisa... 50
4.2 Preprocessing Data ... 52
4.3 Hasil Uji Clustering dan Akurasi ... 56
4.4 Implementasi User Interface ... 83
4.4.1 Tampilan menu utama ... 83
4.4.2 Tampilan sub menu preprocessing ... 84
4.4.3 Tampilan sub menu clustering ... 86
xiv
DAFTAR GAMBAR
Gambar Keterangan Halaman
2.1 Proses KDD 7
2.2 Obyek dan atribut 9
2.3 Ilustrasi algoritma Apriori 11
2.4 Hasil clustering pada data
hipertensi
13
2.5 Dendrogram 16
2.6 Hasil ilustrasi clustering 19
2.7 Matriks jarak 21
2.8 Matriks jarak kedua single linkage 22
2.9 Matriks jarak ketiga single linkage 22
2.10 Matriks jarak terakhir single linkage
23
2.11 Dendrogram single linkage untuk jarak antara lima obyek
23
2.12 Matriks jarak kedua complete linkage
24
2.13 Matriks jarak ketiga complete linkage
25
2.14 Demdrogram complete linkage
untuk jarak antara lima obyek
25
2.15 Matriks jarak kedua average linkage
26
2.16 Matriks jarak ketiga average linkage
27
2.17 Matriks jarak terakhir average linkage
27
2.18 Demdrogram average linkage
untuk jarak antara lima obyek
28
2.19 Dendrogram yang sudah di
lakukan pemotongan (cut-off)
28
3.1 Diagram blok proses clustering 40
3.2 Dendrogram single linkage 41
3.3 Dendrogram average linkage 42
3.4 Dendrogram complete linkage 42
3.5 Halaman utama 47
3.6 Halaman preprocessing 48
3.7 Halaman clustering 49
4.1 Dendrogram complete linkage 60
4.2 Dendrogram complete linkage 61
xv
4.4 Dendrogram complete linkage 63
4.5 Dendrogram complete linkage 65
4.6 Grafik akurasi tanpa normalisasi 66
4.7 Dendrogram single linkage 68
4.8 Dendrogram average linkage 68
4.9 Dendrogram complete linkage 69
4.10 Dendrogram complete linkage 70
4.11 Dendrogram complete linkage 71
4.12 Dendrogram single linkage 73
4.13 Dendrogram average linkage 73
4.14 Dendrogram complete linkage 74
4.15 Hasil akurasi dengan normalisasi [0-1]
75
4.16 Dendrogram single linkage 76
4.17 Dendrogram complete linkage 78
4.18 Dendrogram complete linkage 79
4.19 Dendrogram complete linkage 80
4.20 Hasil akurasi dengan normalisasi
zscore
81
4.21 Halaman utama sistem 84
4.22 Halaman preprocessing sistem 85
4.23 Halaman clusterig sistem 87
4.24 Contoh Dendrogram 88
xvi
DAFTAR TABEL
Gambar Keterangan Halaman
2.1 Contoh data klasifikasi 11
2.2 Contoh data clustering 12
2.3 Contoh data 20
2.4 Contoh matrik similiarity 20
2.5 Cluster Evaluation 34
3.1 Data gejala hepatitis 40
3.2 Contoh matrik jarak dengan
Euclidean distance
43
3.3 Hasilcluster 45
3.4 Confusion matrix 46
4.1 Deskripsi data gejala hepatitis 51
4.2 Deskripsi data laboratorium
hepatitis
52
4.3 SGOT dan SGPT sebelum dan
sesudah normalisasi
54
4.4 Penanda hepatitis sebelum dan
sesudah normalisasi
55
4.5 Hasil tanpa normalisasi 59
4.6 Confusion matrix complete linkage 61 4.7 Confusion matrix complete linkage 62 4.8 Confusion matrix single linkage 63 4.9 Confusion matrix complete linkage 64 4.10 Confusion matrix complete linkage 65 4.11 Hasil akurasi dengan normalisasi
[0-1]
66
4.12 Confusion matrix single linkage, average lnkage, complete linkage
69
4.13 Confusion matrix complete linkage 70 4.14 Confusion matrix complete linkage 72 4.15 Confusion matrix complete linkage 74 4.16 Hasil akurasi dengan normalisasi
zscore
75
4.17 Confusion matrix single linkage 77 4.18 Confusion matrix complete linkage 78 4.19 Confusion matrix complete linkage 79 4.20 Confusion matrix complete linkage 80 4.21 Hasil pengelompokkan dengan
agglomerative hierarchical clustering
1
BAB I
PENDAHULUAN
Pada bab ini menjelaskan latar belakang yang menjadi landasan dalam penelitian
ini. Kemudian dari latar belakang yang ada dirumuskan permasalahan untuk
diselesaikan beserta batasan masalah yang diberikan pada penelitian ini. Pada bab
ini juga menjelaskan mengenai tujuan dari penelitian dan manfaat penelitian
1.1 Latar Belakang
Kesehatan merupakan hal yang sangat penting dan perlu dijaga oleh
masyarakat. Dewasa ini, masyarakat mudah terserang penyakit karena perubahan
cuaca yang ekstrim, kondisi lingkungan yang tidak bersih, dan pola hidup yang
tidak teratur. Selain itu, penyakityang ada kinimemiliki beragam tipe. Penyakit
tersebut mulai mengalami perubahan (mutasi) sehingga menghasilkan tipe
penyakit baru, seperti flu burung dengan tipe baru yang lebih ganas dari tipe
sebelumnya. Penyakit yang sudah lama pun ada yang memiliki beragam tipe
seperti hepatitis, jantung dan diabetes.
Penyakit hepatitis merupakan salah satu penyakit yang sekarang ini mulai
banyak diderita terutama hepatitis B dan C (Abas, 2011). Penyakit hepatitis
mempunyai tipe-tipe yang berbeda, antara lain hepatitis A, hepatitis B, hepatitis C,
hepatitis D, hepatitis E, hepatitis F dan hepatitis G. Hepatitis A merupakan tipe
hepatitis yang paling ringan, sedangkan hepatitis B merupakan tipe hepatitis yang
dan C di Indonesia akan menjadi penyakit hati kronik, sedangkan 10 persen
penderita menjadi penyakit liver fibrosis dan kanker hati (Dimyati, 2011). Istilah
hepatitisberasal dari bahasa latin yang dipakai untuk semua jenis peradangan pada
hati (Wening Sari, 2008:10). Penyakit inimemiliki penyebab antara lain, virus,
komplikasi dari penyakit lain, alkohol, obat-obatan atau zat kimia sampai karena
penyakit autoimun (Wening Sari, 2008:16). Proses pemeriksaan yang dilakukan
dokter dengan cara melakukan pemeriksaan fisik dananamnesisserta pemeriksaan
laboratorium.
Pemilihan penyakit hepatitis dilakukan karena banyak orang yang tidak
sadar terkena penyakit hepatitis tipe tertentu karena gejalanya yang mirip. Hal ini
dapat dijadikan studi kasus pada data mining. Data mining adalah bagian dari
knowledge discovery in databasesyang merupakan keseluruhan proses konversi
data mentah menjadi pengetahuan yang bermanfaat yang terdiri dari serangkaian
tahap transformasi meliputi data preprocessing dan postprocessing. Pengertian
data mining itu merujuk pada “extracting” atau “mining” pengetahuan dari
sekumpulan besar data (Han&Kamber,2004). Data mining memiliki beberapa
metode, antara lain classification, association dan clustering.
Penelitian terkait hepatitis sudah pernah dilakukan sebelumnya, yaitu
“Sistem Diagnosa Penyakit Hepatitis dengan menggunakan Metode Naïve
Bayesian” oleh EstuKarunianingtyas. Penelitian tersebut menggunakan data
mining untuk menentukan pasien tertentu masuk pada kelas hepatitis A, B atau C
berdasarkan gejala. Akurasi pada penelitian sebelumnya tergolong rendah karena
per gejala. Penelitian ini akan memasukkan pemeriksaan laboratorium dalam
proses analisis. Metode clustering digunakan karena dengan menggunakan
pendekatan yang berbeda dan menambah feature yang lebih lengkap maka dapat
memberikan hasil pengelompokan yang berbeda dan lebih baik.Data gejala dan
data hasil laboratoriumhepatitis akan dikelompokkan sesuai dengan tipe
hepatitisnya dengan menemukan kemiripan antar data, maka akan terbentuk
kelompok yang berisi data pasien yang terkena hepatitis A, hepatitis B dan
hepatitis C.
Algoritmayang digunakandengan pendekatan hirarki yaituagglomerative
hierarchical clustering. Algoritma tersebut mengelompokkan data gejala yang
mirip ke dalam cluster yang sama, sedangkan yang jauh dikelompokkan pada
hirarki yang berbeda. Proses yang dikerjakan mulai dari Ncluster menjadi satu
kesatuan cluster, dimana N adalah jumlah data. Perbedaan penelitian ini dengan
penelitian sebelumnya adalah metode yang digunakan. Selain itu, penelitian ini
juga menambahkan data hasil laboratorium sehingga akurasi pengelompokkannya
dapat lebih tinggi.Penelitian ini penting untuk dilakukan karena dapat membantu
dalam mengelompokkan data gejala pasien menurut tipe penyakit
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah dikemukakan di atas, maka
permasalahan yang akan dibahas dalam penelitian ini, yaitu :
- Sejauh mana metode agglomerativehierarchicalclustering secara akurat
mampu mengelompokkan pasien yang terkena hepatitis A, B atau C?
1.3 Batasan Masalah
Pada pengerjaan penelitian ini diberikan batasan-batasan masalah untuk
permasalahan yang ada antara lain,
1. Metode data mining yang digunakan adalah dengan menggunakan
agglomerativehierarchical clustering.
2. Jenis pengukuran kemiripan yang digunakan adalah single linkage,
average linkage dan complete linkage menggunakan prinsip jarak
minimum yang diawali dengan mencari dua obyek terdekat dan keduanya
membentuk cluster
3. Penyakit hepatitis yang akan diteliti hanya yang bertipe A, B dan C
sampelnya akan diambil dari kumpulan pasien yang berobat pada dokter
1.4 Tujuan Penelitian
Berdasarkan rumusan permasalahan diatas, maka tujuan yang ingin dicapai
dalam penelitian ini, yaitu :
1. Menganalisa, merancang, mengimplementasikan sistem cerdas untuk
mengelompokan penyakit hepatitis.
2. Mengetahui hasil pengelompokan pasien yang terkena penyakit hepatitis
A, hepatitis B dan hepatitis C dengan metode agglomerative hierarchical
clustering.
3. Menguji kehandalan sistem dengan menghitung akurasi pengelompokan.
1.5 Manfaat Penelitian
Manfaat yang diberikan penelitian ini, yaitu :
1. Membantu menganalisa permasalahan yang ada dibidang kedokteran
dengan metode data mining.
2. Menjadi referensi bagi penelitian-penelitian berikut yang relevan dengan
6
BAB II
LANDASAN TEORI
Bab ini menjelaskan tentang dasar teori yang digunakan dalam penyusunan tugas
akhir ini untuk memperjelas materi-materi yang digunakan dalam penelitian.
Penjelasan dimulai dengan Knowledge Discovery in Databases, tentang penyakit
hepatitis, cara perhitunganagglomerative hierarchical clustering danmetode
akurasi yang akan dipakai.
2.1 Pengertian Knowledge Discovery in Databases (KDD)
Data mining adalah bagian dari Knowledge Discovery in Databases yang
merupakan kegiatan yang meliputi pengumpulan, pemakaian data historis untuk
menemukan keteraturan, pola atau hubungan dalam data yang berukuran besar
(Santoso, 2007). Data mining juga merupakan ilmu pengetahuan yang sekarang
sering digunakan untuk mencari informasi yang berada pada kumpulan data yang
berjumlah banyak. Pengertian data mining itu merujuk pada extracting atau
mining pengetahuan dari sekumpulan besar data (Han&Kamber,2004).
Knowledge discovery in databases memiliki proses yang harus dilakukan
dalam mencari pengetahuan yang diperlukan, yaitu data cleaning, data
integration, data selection, data transformation, data mining dan pattern
Gambar 2.1 : (Han& Kamber,2004)Proses KDD
1. Data cleaning
Langkah pertama adalah dengan melakukan pembersihan terhadap
data. Proses ini bertujuanuntuk menghilangkan noise dan data yang tidak
konsisten.
2. Data integration
Pada tahap ini, sumber data yang terpecah dan terpisah akan
digabungkan dari segala macam tempat penyimpanan menjadi satu tempat.
3. Data selection
Pada data selection, data yang relevan diambil dari database untuk
dianalisis. Atribut yang tidak relevan tidak akan digunakan dalam proses
selanjutnya.
4. Data transformation
Pada tahap ini data diubah menjadi bentuk yang tepat untuk
smooting, aggregation, generalization dan attribute construction atau
feature construction. Contoh metode normalisasi, yaitu [0-1] dan zscore.
Definisi rumus normalisasi[0-1], sebagai berikut .
�= �− � �
� − � �
Keterangan :
- Xi = nilai yang akan dinormalisasi
- Xmin = nilai minimum dari variabel
- Xmax = nilai maksimum dari variabel
Definisi rumus zscore, sebagai berikut :
= � − � �
(2.2)
Keterangan :
- X = nilai yang akan di normalisasi
- µ = rata-rata
- σ = standar deviasi
5. Data mining
Pada proses data mining ini merupakan suatu proses utama saat
6. Pattern evaluation
Pada tahap ini, mengidentifikasi pola yang benar-benar menarik
yang mewakili pengetahuan berdasarkan atas beberapa pengukuran yang
penting.
7. Knowledge presentation
Langkah terakhir ini informasi yang sudah ditambang akan
divisualisasikan dan direpresentasikan kepada user.
Langkah 1 sampai dengan 4 merupakan langkah preprocessing. Setelah
melakukan serangkaian proses diatas seperti data cleaning, data integration, data
selection dan data transformation, maka hasilnya siap untuk dilakukan proses
mining. Pada data mining, data yang dipakai merupakan sekumpulan obyek data
dan atribut. Atribut merupakan karakteristik yang dimiliki oleh sebuah obyek.
Gambar 2.2 memperlihatkan obyek serta atribut pada sekumpulan dataset yang
akan diukur dengan menggunakan metode pada data mining.
2.2 Jenis-Jenis Metode Data mining
Pada model data mining dibuat dari metode pembelajaran dengan
supervised dan unsupervised. Fungsi pembelajaran supervised digunakan untuk
memprediksi suatu nilai dan mempunyai keluaran berupa label dari setiap data.
Pada supervised memiliki proses training dan testing terhadap data yang ada.
Setelah dilakukan proses tersebut, maka dapat diketahui parameter yang
digunakan untuk menentukan model. Model ini yang akan melakukan tugas
prediksi atau peramalan. Contoh dari algoritma dengan pembelajaran supervised,
yaitu naïve Bayesian. Fungsi pembelajaran unsupervised tidak memerlukan label
dan datanya tidak perlu dilakukan proses training dan testing. Label yang ada
pada unsupervised adalah label dari data yang akan dikelompokkan sehingga
dengan label tersebut dapat diketahui bahwa data tersebut masuk ke dalam
kelompok tertentu. Contoh algoritma unsupervised, yaitu k-means clustering dan
agglomerative hierarchical clustering.
Data mining memiliki beberapa metode yang sering dibahas, antara lain
classification, association danclustering. Setiap metode memiliki berbagai macam
algoritma sesuai dengan karakteristiknya masing-masing.
a. Classification mining adalah sebuah pengekstraksi pola pengelompokan
atau pengklasifikasian sebuah himpunan obyek atau data ke dalam kelas
tertentu berdasarkan atribut-atributnya. Contoh algoritma klasifikasi
adalah naïve bayesian, decision tree dan support vector machine. Berikut
Tabel 2.1 (Ali, 2006) contoh data klasifikasi
Pada contoh tersebut terdapat label pada setiap obyek data yang menjadi
kesimpulan bahwa orang tersebut terkena hipertensi atau tidak.
b. Association mining adalah sebuah cara untuk menemukan pola asosiasi
dalam data. Contoh pada association, mempunyai algoritma apriori,
FPTree. Berikut ini merupakan contoh kasus pada association.
Contohnya pada saat menganalisa keranjang belanja dengan menghitung
support dan confidence pada masing-masing item set, maka dapat
diketahui pola asosiasinya seperti barang-barang yang dibeli secara
bersamaan pada suatu transaksi pembelian. Pola tersebut berguna untuk
keperluan promosi, segmentasi pembeli, pembuatan catalog produk dan
melihat pola belanja pembeli.
c. Clustering mining adalah proses mencari cluster atau kelompok dari
sekumpulan obyek sehingga obyek-obyek di dalam sebuah cluster mirip
satu dengan lainnya, dan berbeda dengan obyek di luar cluster-nya. Ada 2
jenis clusteringyang biasa digunakan, yaitu hierarchical clustering dan
partition clustering. Contoh algoritma yang ada pada clustering adalah
K-Means dan agglomerative. Berikut ini contoh data pada clustering.
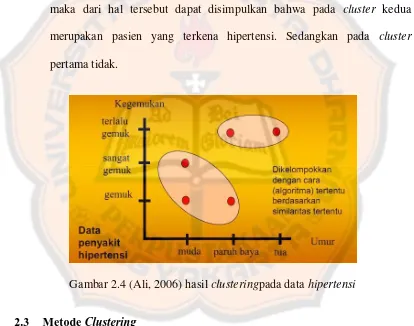
Pada gambar tersebut tidak terdapat label yang menyertakan orang tersebut
terkena hipertensi atau tidak. Pada clustering, ditentukan labelnya
berdasarkan tingkat kemiripan data. Seperti pada gambar dibawah ini
terdapat 2 buah cluster,cluster pertama berada pada tingkat gemuk dan
sangat gemuk serta terletak pada usia muda dan paruh baya. Sedangkan
cluster kedua pada tingkat terlalu gemuk dan usia paruh baya dan tua,
maka dari hal tersebut dapat disimpulkan bahwa pada cluster kedua
merupakan pasien yang terkena hipertensi. Sedangkan pada cluster
pertama tidak.
Gambar 2.4 (Ali, 2006) hasil clusteringpada data hipertensi
2.3 Metode Clustering
2.3.1 Pengertian Clustering
Metode data mining yang akan dipakai adalah clustering.Clustering
merupakan proses pengelompokan objek yang sama menjadi satu kelompok,
sedangkan obyek diantara kelompok tersebut berbeda satu sama lain. Pada proses
dalam cluster yang sama dan berbeda untuk objek dalam kelompok lain. Tujuan
dari cluster ini untuk menemukan kemiripan antara data, sesuai dengan
karakteristik yang ditemukan di dalam data dan pengelompokan data objek yang
sama ke dalam kelompok-kelompok tertentu (Han&Kamber.2004). Jadi, prinsip
dari clustering adalah memaksimalkan kesamaan antar anggota satu cluster dan
meminimumkan kesamaan antar cluster.
Pada clustering terdapat 2 jenis metode, yaituhierarchical clusteringdan
partition clustering. Hierarchical clusteringadalah teknik clustering yang
membentuk hirarki dimana data yang mirip akan ditempatkan pada hirarki yang
berdekatan dan yang tidak pada hirarki yang berjauhan. Metode ini terbagi
menjadi dua yaitu bottom-up (agglomerative) yang menggabungkan cluster kecil
menjadi cluster lebih besar dan top-down (divisive) yang memecah cluster besar
menjadi cluster yang lebih kecil. Sedangkan partition clustering adalah teknik
pengelompokan obyek ke dalam cluster tertentu dengan menentukan jumlah
cluster terlebih dahulu. Contohnya: algoritma K-Means dan Fuzzy K-Means.
Metode yang akan digunakan untuk penelitian ini menggunakan pendekatan
hirarki yaitu dengan menggunakan agglomerative hierarchical clustering.
Pemilihan metode agglomerative hierarchical clusteringkarena algoritmanya
yang sederhana, jarak untuk setiap gejala dapat diketahui, model
pengelompokannya dapat dilihat dengan dendrogram, dan tidak perlu menentukan
jumlah cluster yang diinginkan diawal. Metode tersebut bekerja dengan
mengelompokan data-data yang mirip ke dalam hirarki yang sama sedangkan
proses clustering dari Ncluster menjadi satu kesatuan cluster, dimana N adalah
jumlah data. Jenis pengukuran jarak yang akan digunakan adalah single linkage,
average linkagedan complete linkage. Penggunaan tiga pengukuran kemiripan
jarak karena dapat mengetahui mana hasil yang terbaik dengan melihat
dendrogram yang dihasilkan.
a. Single linkage merupakan jarak minimum antara elemen dari setiap
cluster. Jarak antara dua cluster didefinisikan sebagai
(2.3)
Keterangan :
- Sxy merupakan jarak antara dua data x dan y dari masing cluster A
dan B.
b. Average linkagemerupakan rata-rata jarak antara elemen dari setiap
cluster pada setiap data. Jarak antar cluster didefinisikan sebagai,
, = 1 { , }
� �
(2.4)
Keterangan :
- nA dan nB adalah banyaknya data dalam set A dan B.
c. Complete linkagemelihat jarak maksimum antar elemen dalam cluster.
Jarak antar cluster didefinisikan sebagai,
(2.5)
Keterangan :
- Sxy merupakan jarak antara dua data x dan y dari masing cluster A
dan B.
Ketiga jenis pengukuran jarak tersebutmenggunakan prinsip jarak minimum
yang diawali dengan mencari dua obyek terdekat dan keduanya membentuk
cluster yang pertama. Langkah selanjutnya dapat dipilih menjadi dua
kemungkinan, obyek ketiga akan bergabung dengan cluster yang telah terbentuk,
atau membentuk cluster baru. Proses ini akan berlanjut sampai akhirnya terbentuk
cluster tunggal. Hasil dari pengelompokan ini dapat ditampilkan dalam bentuk
dendrogram.
Gambar 2.5 : dendrogram
Pada dendrogram diatas terdapat jarak antar obyek. Garis vertikal
merupakan jarak, sedangkan garis horizontal merupakan obyek. Salah satu cara
untuk mempermudah pengembangan dendrogram untuk hierarchicalclustering ini
adalah dengan membuat similarity matrix yang memuat tingkat kemiripan antar
data yang dikelompokkan. Tingkat kemiripan bisa dihitung dengan berbagai
macam cara seperti :
a. Euclidean distance, pengukuran jarak yang biasa digunakan dan sering
disebut dengan formula phytagoras.
(2.6) Keterangan :
- n = jumlah atribut atau dimensi.
- pkdan qk= data.
b. Minskowski distance, merupakan generalisasi dari euclidean matrix.
(2.7)
Keterangan :
1. r = parameter
2. n = jumlah dimensi atau atribut,
c. Simple Matching Coefficients, biasa digunakan jika data hanya memiliki
atribut bertipe biner. Cara kerjanya adalah jumlah data yang cocok
dibagi dengan jumlah atribut.
SMC = (M11+ M00 ) / (M01 + M10 + M11+ M00 )
(2.8)
Keterangan :
1. M01 = jumlah atribut dimana p = 0 dan q = 1
2. M10 = jumlah atribut dimana p = 1 dan q = 0
3. M00 = jumlah atribut dimana p = 0 dan q = 0
4. M11 = jumlah atribut dimana p = 1 dan q = 1
d. Jaccard Coefficient, biasa digunakan jika data hanya memiliki atribut
bertipe biner. Cara kerjanya adalah jumlah biner 1 dan 1 yang cocok
dibagi dengan jumlah nilai atribut yang keduanya tidak 0.
J = (M11) / (M01 + M10 + M11)
(2.9)
Keterangan :
1. M01 = jumlah atribut dimana p = 0 dan q = 1
3. M00 = jumlah atribut dimana p = 0 dan q = 0
4. M11 = jumlah atribut dimana p = 1 dan q = 1
2.3.2 Agglomerative Hierarchical Clustering
Pada agglomerative hierarchical clustering, harus dihitung jarak
masing-masing obyek. Setelah jarak dari semua obyek dihitung, maka lakukan
langkah-langkah berikut ini :
1. Biarkan setiap data point menjadi sebuah cluster
2. Hitung matriks kemiripan
3. Kelompokkan data paling mirip untuk dimasukan ke dalam cluster yang
sama dengan melihat jarak dalam matriks kemiripan
4. Perbarui matriks kemiripan dengan jarak yang baru.
5. Ulangi sampai tersisa hanya satu cluster. (Tan,Steinbach,dkk 2004).
Rumus yang digunakan dalam menghitung jarak antar obyek
bermacam-macam dan salah satu yang digunakan adalah euclidean distance. Pada tabel
dibawah ini merupakan contoh data yang belum dihitung jarak kedekatannya. Dari
tabel inilah dapat dihitung dengan menggunakan rumus euclidean distance.
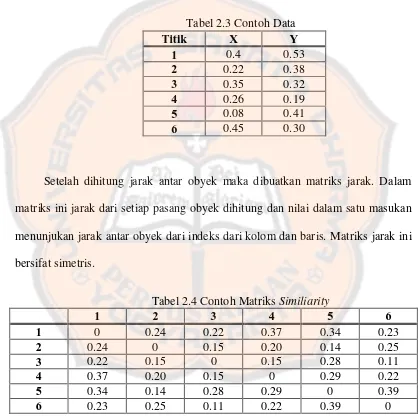
Tabel 2.3 Contoh Data
Setelah dihitung jarak antar obyek maka dibuatkan matriks jarak. Dalam
matriks ini jarak dari setiap pasang obyek dihitung dan nilai dalam satu masukan
menunjukan jarak antar obyek dari indeks dari kolom dan baris. Matriks jarak ini
bersifat simetris.
Tabel 2.4 Contoh Matriks Similiarity
1 2 3 4 5 6
Pada single linkage, akan mengelompokan data dengan cara melihat jarak
yang paling minimum.
Gambar 2.7 : matriks jarak
Pertama gabungkan dua item yang paling dekat, karena objek 5 dan 3
memiliki jarak yang minimum, maka kedua obyek tersebut digabung
min(dik ) = d53 = 2 untuk membentuk cluster (35). Kemudian untuk
menemukan cluster berikutnya, maka memerlukan jarak-jarak antara
cluster (35) dan objek-objek yang lain yang tersisa yaitu 1, 2 dan 4. Jarak
yang berdekatan, yaitu :
- d (35 )1 = min { d 31, d 51} = min {3, 11} = 3
- d (35 )2 = min { d 32, d 52} = min {7, 10} = 7
- d (35 )4 = min { d 34, d 54} = min { 9, 8} = 8
Kemudian menghapus baris dan kolom yang bersesuaian dengan objek 3,
Gambar 2.8 : matriks jarak keduasingle linkage
Dari matriks jarak yang baru tersebut, cari jarak terkecil antara
pasangan-pasangan cluster sekarang, yaitu d (35)1 = 3. Lalu menggabungkan cluster
(1) dengan cluster (35) untuk mendapatkan cluster berikutnya dengan
menghitung :
- d (135 )2 = min { d (35)2, d 12} = min {7, 9} = 7
- d (135 )4 = min { d (35)4, d 14} = min {8, 6} = 6
Kemudian hapus baris dan kolom dari cluster (35) dan (1), maka akan
mendapatkan matrik jarak untuk hasil cluster berikutnya, yaitu :
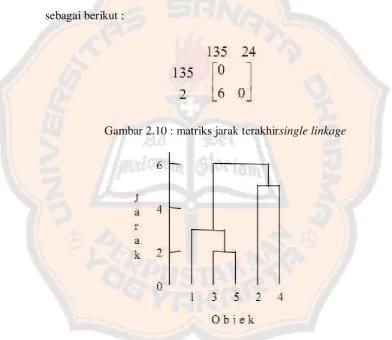
Gambar 2.9 : matriks jarak ketigasingle linkage
Jarak terdekat berikutnya yang paling kecil antara pasangan cluster adalah
Saat ini sudah mempunyai 2 cluster yang berlainan, (135) dan (24), maka
jarak terdekatnya, yaitu
- d (135 )24 = min { d (135 )2 , d (135 )4 } = min {7, 6} = 6
Proses perhitungan sudah selesai karena cluster sudah tersisa satu. Dari
hasil diatas menghasilkan matriks jarak yang terakhir dan dendrogramnya
sebagai berikut :
Gambar 2.10 : matriks jarak terakhirsingle linkage
Gambar 2.11: Dendrogram single linkage untuk jarak antara 5 obyek
b. Jarak maksimum antara elemen dalam cluster (complete linkage).
Pada complete linkage, semua item dalam satu cluster berada dalam jarak
paling jauh satu sama lain. Pada complete linkage ini menggunakan
Pada tahap pertama objek- objek 3 dan 5 digabung karena jaraknya paling
dekat. Perbedaan single linkagedengan complete linkageadalah pemilihan
jaraknya. Setelah dihitung maka akan menghasilkan matriks jarak baru.
Kolom dan baris 3 dan 5 akan dihapus untuk membentuk cluster 35.
- d (35 )1 = maks { d 31, d 51} = maks {3, 11} = 11
- d (35 )2 = maks { d 32, d 52} = maks {7, 10} = 10
- d (35 )4 = maks { d 34, d 54} = maks { 9, 8} = 9
Gambar 2.12 : matriks jarak keduacomplete linkage
Penggabungan berikutnya terjadi antara kelompok yang paling dekat 2 dan
4 untuk membentuk cluster (24) = 5. Pada tahap ini menghasilkan matrik
jarak yang baru dengan menghapus baris dan kolom yang bersesuaian.
- d (24)(35) = maks { d 2(35), d 4(35)} = maks {10, 9} = 10
Gambar 2.13: matriks jarak ketigacomplete linkage
Penggabungan berikutnya menghasilkan cluster (124). Pada tahap akhir
kelompok (35) dan (124) digabungkan menjadi cluster tunggal (12345)
pada perhitungan d (124)(35) = maks { d (1)(35) , d (24)(35) } = maks {11,
10} = 11. Dari hasil inilah maka dapat dibuat bentuk dendrogramnya
seperti pada gambar dibawah ini.
c. Rata-rata jarak antara elemen dari setiap cluster (average linkage).
Pada average linkage, jarak antara dua cluster dihitung sebagai jarak
rata-rata antara semua pasangan item-item yang ada pada tiap cluster. Pada
average linkageini juga masih menggunakan matriks jarak pertama. Pada
tahap pertama objek 3 dan 5 digabung karena mereka paling dekat
jaraknya. Pada tahap kedua, hitung jarak seperti dibawah ini.
- d (35 )1 = { d 31+ d 51}/ 2 = {3 +11}/ 2 = 7
- d (35 )2 = { d 32 + d 52}/2 = {7 + 10}/2 = 8,5
- d (35 )4 = { d 34 + d 54}/2 = { 9 + 8}/2 = 8,5
Gambar 2.15 : matriks jarak keduaaverage linkage
Kemudian cari jarak yang paling dekat berikutnya. Kelompok yang paling
mirip adalah 2 dan 4 untuk membentuk cluster (24) = 5. Pada tahap ketiga,
hitung gabungan cluster untuk menghasilkan matrik jarak yang baru.
- d (24)35 = {d (2,3) + d(2,5) + d(4,3) +d(4,5) }/4 = (7+10+9+8)/4 = 8,5
Gambar 2.16: Matriks jarak ketigaaverage linkage
Pada tahap ini, jarak yang paling dekat menghasilkan cluster (135).
Kemudian cluster (135) dan (24) digabungkan menjadi cluster tunggal
(13524). Perhitungan ini akan menghasilkan matriks jarak baru dan
dendrogram.
- d (135)(24) = { d (2,1)+ d (2,3) + d (2,5) + d (4,1)+ d (4,3) + d
(4,5) }/6 = 49/6 =8,17
Gambar 2.17: matriks jarak terakhir average linkage
Gambar 2.18 : Dendrogram average linkage untuk jarak 5 obyek.
Setelah proses perhitungan dengan single linkage, average linkage dan
complete linkage, maka dibuatkan dendrogram untuk mengetahui
pengelompokkan dari hasil perhitungan tersebut. Pada, agglomerative
hierarchical clustering, dapat menentukan jumlah cluster dengan cara memotong
dendrogram pada jarak tertentu. Contohnya pada gambar dibawah ini. Pada
gambar 2.21 dapat dilihat bahwa cluster terbagi menjadi 2. Cluster 1 berisi obyek
1, 3 dan 5, sedangkan cluster 2 berisi obyek 2 dan 4.
Gambar 2.19 : Dendrogram yang sudah dilakukan pemotongan (cut-off)
2.4 Dimensionality Reduction
Dimensionality reduction adalah proses pengurangan dimensi dari data yang
berdimensi besar menjadi data yang berdimensi kecil. Ada dua teknik dalam
dimensionality reduction ini, yaitu feature selection dan feature extraction.
Feature selection, memilih feature yang berpengaruh dari sekumpulan data asli.
Feature extraction, membentuk feature baru berdasarkan feature yang lama
dengan dimensi yang lebih sedikit dibandingkan dengan sebelumnya.
Teknik yang digunakan adalah featureextraction dengan principal
component analysis. Tujuan dari principal component analysis adalah
mengekstrak informasi yang paling penting dari dataset, mengompres ukuran dari
dataset dengan hanya menjaga informasi yang penting, menyederhanakan
deskripsi dari dataset dan menganalisa struktur dari observasi dan variable
(Herve,Lynne2010). Dalam pencapaian tujuan diatas, principal component
analysis menghitung variabel baru yang disebut dengan principal component yang
diperoleh sebagai kombinasilinear dari variabel yang asli.Principal component
analysis menganalisa semua variance di dalam variabel dan mengatur ulang ke
dalam sekumpulan komponen yang baru yang sama dengan jumlah variabel asli.
Cara kerja dari principal component analysis, antara lain :
1. Pada data matrix, kurangi rata-rata dari setiap dimensi data (scalling).
2. Hitung covariance matrix dari kumpulan data matrix.
3. Hitung eigenvector dan eigenvalue dari covariance matrix.
4. Pilih component dan bentuk vector feature dan ambil principal
5. Menurunkan data set yang baru. (Smith, 2002).
2.5 Penyakit Hepatitis
Penyakit hepatitisadalah penyakit yang disebabkan oleh beberapa jenis virus
yang menyebabkan peradangan serta merusak sel-sel organ hati manusia. Penyakit
hepatitis mempunyai tipe-tipe yang berbeda, antara lain hepatitis A, hepatitis B,
hepatitis C, hepatitis D, hepatitis E, hepatitis F dan hepatitis G. Hepatitis A
merupakan tipe hepatitis yang paling ringan, sedangkan hepatitis B merupakan
tipe hepatitis yang berbahaya. Sebanyak 50 persen atau 15 juta penderita hepatitis
B dan C di Indonesia akan menjadi penyakit hati kronik dan 10 persen menjadi
liver fibrosis dan kanker hati (dimyati, 2011). Istilah hepatitisberasal dari bahasa
latin yang dipakai untuk semua jenis peradangan pada hati (Wening Sari,
2008:10). Penyebabnya dapat berbagai macam, mulai dari virus, komplikasi dari
penyakit lain, alkohol, obat-obatan atau zat kimia sampai karena penyakit
autoimun (Wening Sari, 2008:16).
Hepatitis merupakan penyakit yang sangat menarik untuk dijadikan bahan
penelitian. Sebelumnya sudah ada penelitian yang membahas permasalahan
hepatitis ini. Perbedaan antara penelitian ini dengan penelitian sebelumnya adalah
metode yang digunakan. Metode yang digunakan adalah classification dengan
algoritma Naïve Bayesian. Hasil dari penelitian tersebut memiliki nilai akurasi
yang tergolong rendah. Akurasi per gejala menghasilkan 44,44 persen, sedangkan
kombinasi gejala menghasilkan akurasi 51,11 persen. Penulis beranggapan bahwa
hasil pemeriksaan laboratorium. Berdasarkan dari penelitian sebelumnya, maka
penelitian ini akan memakai data hasil pemeriksaan laboratorium sehingga hasil
akurasi yang didapatkan akan tinggi.
Penyakit yang akan dijadikan bahan penelitian adalah hepatitis karena
penyakit tersebut memiliki banyak tipe dan sulit untuk menggolongkan pasien
termasuk dalam tipe hepatitisyang ada karena memiliki gejala yang hampir sama.
Pada penelitian ini terbatas untuk hepatitis A, B dan C saja. Berikut ini
merupakan penjelasan mengenai hepatitistipe A, B dan C.
a. Hepatitis A
Hepatitis A adalah golongan penyakit Hepatitis yang ringan dan
jarang sekali menyebabkan kematian. Virus hepatitis A penyebarannya
melalui kotoran atau tinja penderita yang penularannya melalui makanan
dan minuman yang terkontaminasi dan bukan melalui aktivitas seksual atau
melalui darah. Penyakit Hepatitis A memiliki masa inkubasi dari 2 sampai 6
minggu sejak penularan terjadi. Kemudian penderita menunjukkan beberapa
tanda dan gejala terserang penyakit Hepatitis A. Pada gejala penyakit Hepatitis
A diantaranya yaitu pada minggu pertama, individu yang dijangkit akan
mengalami sakit seperti kuning, keletihan, demam, hilang selera makan,
muntah, pusing dan kencing yang berwarna hitam pekat. Demam yang terjadi
adalah demam yang terus menerus, tidak seperti demam yang lainnya yaitu
b. Hepatitis B
Hepatitis B merupakan salah satu penyakit menular yang tergolong
berbahaya didunia. Penyakit ini disebabkan oleh virus hepatitis B yang
menyerang hati dan menyebabkan peradangan hati akut, seperti hepatitis C,
kedua penyakit ini dapat menjadi kronis dan akhirnya menjadi kanker hati.
Proses penularan hepatitis B yaitu melalui pertukaran cairan tubuh atau kontak
dengan darah dari orang yang terinfeksi hepatitis B. Ada beberapa hal yang
menjadi pola penularan antara lain penularan dari ibu ke bayi saat
melahirkan, hubungan seksual, transfusi darah, jarum suntik, maupun
penggunaan alat kebersihan diri secara bersama-sama. Hepatitis B dapat
menyerang siapa saja, akan tetapi umumnya bagi mereka yang berusia
produktif akan lebih beresiko terkena penyakit ini. Pada gejala penyakit
Hepatitis B, secara khusus tanda dan gejala terserangnya hepatitis B yang
akut adalah demam, sakit perut dan kuning (terutama pada area mata yang
putih atau sklera). Namun, bagi penderita hepatitis B kronik akan cenderung
tidak tampak tanda-tanda tersebut, sehingga penularan kepada orang lain
menjadi lebih beresiko.
c. Hepatitis C
Penyakit hepatitis C adalah penyakit hati yang disebabkan oleh virus
hepatitis C. Proses penularannya melalui kontak darah seperti transfusi, jarum
suntik. Penderitahepatitis C kadang tidak menampakkan gejala yang jelas, akan
dan terdeteksi sebagai kanker hati. Sejumlah 85% dari kasus, infeksi hepatitis
C menjadi kronis dan secara perlahan merusak hati selama bertahun-tahun.
Penderita sering kali tidak menunjukkan gejala, walaupun infeksi telah terjadi
bertahun-tahun lamanya. Namun, beberapa gejala yang samar diantaranya
adalah lelah, hilang selera makan, sakit perut, urine menjadi gelap dan kulit
atau mata menjadi kuning yang disebut jaundice. Pada beberapa kasus dapat
ditemukan peningkatan enzyme hati pada pemeriksaan urine,
Pemeriksaan laboratorium diperlukan untuk memastikan diagnosis hepatitis
karena gejalahepatitis tidak khas. Berikut ini, tahap-tahap pemeriksaan untuk
hepatitis yang harus dilalui selain melihat dari sisi gejala yang tampak dari luar
(Marzuki Suryaatmadja, 2010).
1. Pemeriksaan untuk hepatitis akut:
Enzim SGOT, SGPT
Penanda hepatitis A (Anti HAV IgM)
Penanda hepatitis B (HbsAg, Anti HBc IgM)
Penanda hepatitis C (Anti HCV, HCV RNA)
2. Pemeriksaan untuk hepatitis kronis:
Enzim SGOT, SGPT.
Penanda hepatitis B (HbsAg, Hbe, Anti H Bc, Anti Hbe, HBV DNA).
2.6 Pengujian Keakuratan Metode
Pengujian keakuratan hasil pengelompokan hepatitis ini penting agar
hasilnya lebih valid. Oleh karena itu diperlukan suatu metode untuk mengetahui
keakuratan hasil yang telah diperoleh. Pada clustering biasanya menggunakan 3
pendekatan untuk memastikan bahwa proses clustering tepat. Tiga pendekatan itu
adalah external test, internal test dan relative test.
a. Pengujian dengan metode external test, pada pengujian ini digunakan
untuk mengukur sejauh mana label pada cluster cocok dengan label class
yang disediakan. Seperti pada tabel 2.5 terdapat tabel untuk mengevaluasi
cluster. Kolom mewakili jenis hepatitis, sedangkan baris mewakili
kelompok clustering. Contohnya menggunakan confusion matrix, entropy
dan purity. Rumus yang digunakan untuk menghitung akurasi dengan
confusion matrix, yaitu :
�= � ℎ � � cluster
� ℎ 100 %
(2.7)
Tabel 2.5 : Cluster evaluation
b. Pengujian dengan metode internal test, pada pengujian ini penyelesaian
cluster digunakan untuk melihat kualitas cluster tanpa informasi yang
berasal dari luar (external). Contoh pengukuran pada internal test, yaitu
cluster separation dan cluster cohesion.
a) Cluster cohesion adalah jumlah dari lebar semua link yang ada di
dalam cluster. Cohesion adalah pengukuran di dalam cluster
dengan sum of square (SSE).
(2.6)
b) Cluster separation, pengukuran antar cluster dengan sum of
square (SSE).
(2.7)
c. Pengujian dengan metode relative test, pada pengujian ini beberapa
penyelesaian cluster yang berbeda dari data dibandingkan dengan
menggunakan algoritma yang sama dengan parameter yang berbeda. Pada
relative test ini sering menggunakan external index atau internal index
untuk mengukurnya. Contohnya dengan SSE atau entropy.
Metode evaluasi untukclustering yang akan digunakan pada penelitian ini adalah
external test. External test bekerja dengan membandingkan hasil clustering yang
sudah didapat dengan class label yang sudah disediakan. Jadi dapat dilihat tingkat
kecocokan hasil clustering yang ada dengan label yang sudah tersedia. Hasil
pengelompokkan juga akan dihitung akurasinya sehingga dengan akurasi tersebut
37
BAB III
METODOLOGI PENELITIAN
Pada bab ini menjelaskan mengenai data yang digunakan pada penelitian dan
mengenai metode pengumpulan data. Selain itumembahas mengenai teknik
analisis dan evaluasi hasil.
3.1 Data
Pada penelitian yang dilakukan ini menggunakan data pasien yang berupa
data hasil laboratorium dan data dari hasil pemeriksaan dari dokter. Data
penelitian ini didapat dari rumah sakit di Yogyakarta. Data yang digunakan adalah
data gejala dan data laboratorium. Data hasil laboratorium sangat penting karena
hasil ini sangat berpengaruh langsung pada diagnosis akhir. Data gejala hasil
pemeriksaan dokter juga sama pentingnya untuk memberikan diagnosa awal pada
pasien tersebut dan dapat memperkuat hasil dari diagnosa akhir.
Data hasil pemeriksaan dokter yang dikumpulkan adalah hasil diagnosa
pada pasien dari tahun 2000 sampai dengan 2010. Data ini berupa data diri pasien,
gejala, diagnosa awal dan akhir. Data pasien yang digunakan terbatas pada pasien
yang terkena hepatitisA, B dan C.Sebelumnya, data gejala ini dipakai oleh
Karunia Estu pada skripsinya yang berjudul “Sistem diagnosa penyakit hepatitis
dengan menggunakan metode Naïve Bayesian”. Pada data hasil pemeriksaan
dokter yang digunakan terdapat 5 induk gejala, yaitu gejala otot, gejala perut,
gejala kulit, gejala mata dan gejala mirip flu. Jumlah data yang akan dipakai
Data hasil laboratorium merupakan hal yang sangat penting untuk
menetapkan pasien tersebut terkena hepatitis tipe tertentu. Pemeriksaan
laboratorium dibagi menjadi dua, yaitu kualitatif dan kuantitatif. Pada
pemeriksaan kualitatif hanya menetapkan bahwa pasien tersebut positif atau
negative terkena hepatitis, sedangkan pemeriksaan kuantitatif memiliki ukuran
atau kadar yang berasal dari penanda hepatitis. Pemeriksaan laboratorium untuk
hepatitis meliputi pemeriksaan fungsi hati, yaitu SGOT dan SGPT.Selain itu,
pemeriksaan yang paling penting untuk hasil diagnosa akhir adalah penanda
hepatitis, yaitu anti HAV untuk hepatitis A, HBsAg untuk hepatitis B dan anti
HCV untuk hepatitis C.
3.2 Metode Pengumpulan Data
Data- data yang digunakan dalam penelitian ini menggunakan data yang
didapat dari hasil laboratorium dan hasil wawancara dengan dokter. Pada
pembuatan sistem data mining untuk pengelompokan data penyakit hepatitis
dengan menggunakan metode data mining, menggunakan beberapa teknik
pengumpulan data dan variabel, yaitu :
1. Studi kepustakaan.
Proses ini digunakan untuk mendapatkan informasi tentang penyakit
hepatitis dan metode-metode data mining yang akan digunakan untuk
memecahkan masalah. Buku-buku yang akan digunakan terkait dengan
data mining dan aplikasinya.
2. Mengadakan wawancara dengan dokter terkait dengan penjelasan
Wawancara yang akan dilakukan ini secara lisan dan mempunyai tujuan
untuk mengetahui mengenai penyakit hepatitis itu beserta dengan gejala.
Tujuannya agar lebih mudah memahami mengenai penyakit hepatitis itu
sendiri yang nantinya dapat berguna dalam menentukan atribut untuk
menganalisa data-data pasien.
3. Mengajukan permohonan untuk meminta data sample pasien yang
berobat untuk mengetahui penyakit hepatitis yang diderita.
Proses pengajuan untuk meminta data pasien perlu dilakukan karena
data-data pasien yang ada tidak dapat secara langsung disebarluaskan
karena bersifat pribadi, maka diperlukan adanya surat izin untuk meminta
data pasien hepatitis.
3.3 Teknik Analisa Data
Sumber data yang digunakan diperoleh dari survey lapangan di rumah sakit.
Data yang akan diambil berupa hasil pemeriksaan laboratorium yang ditunjukan
oleh setiap pasien kepada dokter yang berobat di rumah sakit yang bersangkutan.
Sumber data ini akan terbatas pada data-data pasien yang hasil diagnosa akhirnya
terkena hepatitisA, B maupun C. Data-data yang sudah didapat akan dianalisa
untuk diketahui jenis pengelompokan berdasarkan tipe penyakitnya. Tahap-tahap
jalannya program, sebagai berikut.
Gambar 3.1 Diagram blok proses clustering
Data Preprocessing Clustering Output
Single Average Complete
Dendrogram
Akurasi Perhitun
a. Preprocessing
Data yang sudah dikumpulkan masuk pada tahap preprocessing yang ada
padaknowledge discovery in databases, yaitu data cleaning, data integration,
data selectiondan data transformation. Data gejala pasien hepatitis masih
terpisah berdasarkan hasil identifikasi penyakit antara satu sama lain sehingga
perlu digabungkan untuk mempermudah proses pengelompokkan seperti pada
tabel dibawah ini.
Tabel 3.1 Data gejala hepatitis
Feature
berkurang Normal kuning demam,batuk A
2
Normal
muntah,mual,nafsu
makan berkurang Normal normal
demam,pusing
makan berkurang Gatal kuning
demam,pusing,
lesu,batuk B
4
Pegal
mual, nyeri perut
sebelah kanan Normal normal lesu,batuk B
Dari data diatas gejalanya dikelompokkan menurut gejala masing-masing
seperti gejala otot, gejala perut, gejala kulit, gejala mata dan gejala mirip flu.
Setelah itu menjabarkan masing-masing gejala seperti pegal, nyeri sendi dan
normal untuk gejala otot. Gejala mual, muntah, diare, nyeri perut sebelah
kanan, kencing berwarna gelap, nafsu makan berkurang dan perut acites untuk
gejala perut. Gejala normal, kuning, lembab, gatal, kemerahan, kering untuk
gejala kulit. Gejala normal dan kuning untuk gejala mata Sedangkan gejala
demam, pusing, lesu, mialgia, lelah, menggigil, dan batuk untuk gejala mirip
flu. Dari gejala-gejala tersebut dilakukan proses binerisasi yang sudah
dilakukan pada penelitian Karunia Estu.
Kemudian, selain data gejala ditambahkan pula data laboratorium dengan
atribut SGOT, SGPT, anti HAV, HbsAg dan Anti HCV. Gejala laboratorium
memiliki range yang berbeda-beda sehingga perlu untuk di normalisasi agar
rentang nilai antar data tidak jauh. Jenis normalisasi yang diberikan adalah
zscore atau normalisasi [0-1]. Selain itu, pengurangan dimensi dengan
principal component analysis dapat dilakukan agar mengurangi dimensi data
tetapi tidak menghilangkan informasi penting yang terkandung pada data.
b. Pengukuran jarak
Data yang sudah di preprocessing akan dilakukan pengukuran jarak antar
data dengan menggunakan salah satu dari pilihan pengukuran jarak. Seperti
yang sudah dijelaskan pada bab sebelumnya. Ada pengukuran dengan
danjaccard coefficients. Hasil dari pengukuran jarak ini berupa matriks jarak
antar obyek data.
c. Clustering
Hasil dari matriks jarakakan masuk pada tahap clustering. Metode yang
dipakai untuk menyelesaikan pengelompokan data-data pasien yang terkena
hepatitis dengan memakai agglomerativehierarchical clustering. Data pasien
yang akan terkumpul pada masing-masing cluster menggunakan metode
pengukuran kemiripan single linkage (jarak minimum), average linkage (jarak
rata-rata) dan complete linkage (jarak maksimum)dengan memilih jarak
minimum atau yang paling mirip untuk tiap data.Berikut ini adalah tabel untuk
jarak keseluruhan antara ke enam data sample yang sudah dihitung dengan
menggunakan rumus jarak euclidean distance.
Tabel 3.2: Contoh matriks jarak dengan Euclidean distance
1. Pengukuran jarak dengan single linkage merupakan pengukuran jarak
minimum antara elemen dari setiap cluster. Dari matriks jarak yang ada,
Kemudian pasangkan obyek data lainnya dengan jarak yang minimum
agar mendapatkan hasil jarak baru pada matriks jarak dan masuk ke
dalam cluster.Hasil jarak baru yang sudah didapat, akan membentuk
matriks jarak baru sehingga dapat dibentuk dendrogram, sebagai berikut.
Gambar 3.2 : Dendrogram singlelinkage
2. Pengukuranaverage linkage yang merupakan pengukuran rata-rata jarak
antara elemen dari setiap cluster. Dari matriks jarak yang ada, jarak yang
paling minimum adalah 2 dari obyek 1 ke 2. Kemudian pasangkan
dengan seluruh data agar didapat hasil jarak baru pada matrik jarak dan
keseluruhan data sudah masuk ke dalam cluster.Pada average
linkageumlah jarak antar data dibagi dengan jumlah anggota di
dalamcluster. Hasil jarak baru yang sudah didapat, akan membentuk
Gambar 3.3 : Dendrogram untuk average linkage
3. Pengukuran complete linkagemerupakan pengukuranyang melihat jarak
maksimum antar elemen dalam cluster. Dari matriks jarak yang ada,
jarak yang paling minimum adalah 2 dari obyek 1 ke 2. Pemilihan jarak
diawal tiap iterasi tetap nilai yang paling minimum, sedangkan untuk
perhitungan kemiripan menggunakan nilai yang paling maksimum.
Pasangkan dengan seluruh data agar didapat hasil jarak baru pada matriks
jarak dan keseluruhan data sudah masuk ke dalam cluster.Hasil jarak
baru yang sudah didapat, akan membentuk matriks jarak baru sehingga