Fakultas Ilmu Komputer
Universitas Brawijaya 5349
Analisis Sentimen Opini Publik pada Media Sosial Twitter terhadap Vaksin Covid-19 menggunakan Algoritma Support Vector Machine dan Term
Frequency-Inverse Document Frequency
Edgar Maulana Thoriq1, Dian Eka Ratnawati2, Bayu Rahayudi3
Program Studi Teknologi Informasi , Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Media sosial adalah suatu wadah bagi masyarakat untuk menyampaikan aspirasi, ide, bahkan kritik mereka. Salah satu kebijakan yang dibuat baru-baru ini oleh pemerintah adalah pemberian vaksin COVID-19. Kebijakan tersebut ramai diperbincangkan di media sosial Twitter dan cukup menuai banyak pendapat yang beragam di masyarakat. Twitter merupakan media sosial yang memiliki basis pengguna cukup besar di Indonesia, dimana mayoritas dari penggunanya menyampaikan opini mereka terkait pemberian vaksin COVID-19. Twitter disini dapat menjadi sebuah sumber data yang dapat dipergunakan untuk melakukan analisis sentimen terhadap kebijakan pemerintah tersebut dengan mengklasifikasikan tweet (istilah konten didalam Twitter) kedalam kategori positif atau negatif. Proses klasifikasi dilakukan dengan menggunakan algoritma klasifikasi yaitu Support Vector Machine dan pembobotan kata dengan menggunakan metode Term Frequency – Inverse Document Frequency (TF- IDF). Penelitian ini menggunakan data sebanyak 450 tweet, kemudian pengujian dilakukan dengan menggunakan metode cross validation dengan jumlah fold = 10. Performa terbaik dari algoritma klasifikasi yang diperoleh adalah accuracy sebesar 86%, precision sebesar 88%, recall sebesar 82%, dan f-measure sebesar 85%. Nilai dari performa tersebut diperoleh dengan nilai C sebesar 1 dan nilai iterasi maksimum sebesar 300.
Kata kunci: Analisis Sentimen, Vaksin Covid-19, Klasifikasi, Support Vector Machine, TF-IDF Abstract
Social media is a place for people to express their aspirations, ideas, and even their critics. One of the policies made recently by the government is the provision of COVID-19 vaccine. This policy has been widely discussed on Twitter and attracted a lot of diverse opinions in the society. Twitter is a social media that has a fairly large user base in Indonesia, where many users share their opinions regarding the provision of COVID-19 vaccine. Twitter can be a source of data that can be used to conduct sentiment analysis on government policies by classifying tweets (a term for content in Twitter) into positive or negative categories. The classification process is utilizing a classification algorithm, namely Support Vector Machine and term weighting namely Term Frequency – Inverse Document Frequency (TF-IDF) method. This study uses 450 tweets, then testing is carried out using the cross validation method with number of fold = 10. Best performance of the classification algorithm is 86% accuracy, 88% precision, 82% recall, and 85% f-measure. Value of the performance is obtained with value C of 1 and the maximum iteration of 300.
Keywords: Sentimen Analysis, Covid-19 Vaccine, Classification, Support Vector Machine, TF-IDF
1. PENDAHULUAN
Media sosial adalah suatu wadah bagi masyarakat untuk menyampaikan aspirasi, ide, bahkan kritik mereka. Media sosial dapat diakses melalui perangkat telepon genggam atau komputer yang terhubung kedalam jaringan
internet.
Twitter merupakan platform media sosial untuk microblogging yang paling populer dibandingkan dengan microblog lainnya.
Indonesia merupakan negara dengan pengguna Twitter terbesar ke-7 di dunia. Hal ini berdasarkan jumlah pengguna aktif Twitter di
Indonesia yang berjumlah 13.8 juta per-tahun 2020 dan diprediksi akan menjadi 17.8 juta pada tahun 2025 (Twitter users in Indonesia 2025, 2021). Twitter menjadi salah satu tempat bagi masyarakat di Indonesia untuk menyampaikan aspirasi mereka terhadap suatu hal melalui tweet.
Tweet tersebut dapat menjadi sumber data yang berguna untuk memperoleh opini masyarakat terhadap suatu topik tertentu.
Opinion mining atau umumnya disebut analisis sentimen adalah satu dari sekian banyak bentuk dari implementasi text mining yang dapat digunakan untuk memahami, mengekstrak, serta memproses sebuah sentimen yang terdapat didalam sebuah kalimat opini (Pakpahan and Widyastuti, 2014). Pada sektor pemerintahan, analisis sentimen bisa dipergunakan sebagai alat untuk memperoleh gambaran dari opini publik terhadap suatu kebijakan yang dibuat oleh pemerintah tersebut.
Izzati et al. (2018) menyatakan bahwa media sosial dapat menjadi suatu jembatan komunikasi antara pemerintah dan masyarakat.
Pada saat inilah aspirasi dari masyarakat memiliki peranan penting dalam keberhasilan kebijakan yang dibuat oleh pemerintah, karena berhasilnya suatu kebijakan yang telah dibuat oleh pemerintah dapat diukur salah satunya melalui respon dari masyarakat itu sendiri.
Salah satu kebijakan yang dibuat baru-baru ini oleh pemerintah adalah pemberian vaksin COVID-19. Kebijakan tersebut ramai diperbincangkan di media sosial Twitter dan cukup menuai banyak pendapat yang beragam di masyarakat.
Metode yang akan digunakan peneliti dalam melakukan analisis sentimen adalah Support Vector Machine (SVM). SVM digunakan karena memiliki performa yang lebih baik dan tingkat kestabilan yang lebih tinggi dibandingkan dengan Naive Bayes Classifier (NBC). Hal ini dibuktikan oleh Saraswati (2013), yang dimana dari hasil penelitian tersebut didapatkan data bahwa SVM memiliki hasil akurasi yang lebih baik ketimbang Naive Bayes Classifier (NBC) pada data berbahasa Inggris dan Indonesia. Menurut penelitian dari Tuhuteru dan Iriani (2018), Support Vector Machine (SVM) juga terbukti memiliki performa yang lebih baik ketimbang Naive Bayes Classifier (NBC).
Pada penelitian ini, data yang diolah berbentuk teks sehingga diperlukan sebuah metode pembobotan kata. Metode dari term weighting yang digunakan dalam penelitian ini
Term Frequency – Inverse Document Frequency (TF-IDF).
2. METODOLOGI
Tahapan dari proses analisis sentimen dari opini publik terhadap vaksin COVID-19 dapat dilihat pada Gambar 1.
Gambar 1. Diagram Alir Tahapan Penelitian
Analisis sentimen opini publik terhadap vaksin COVID-19 dimulai secara runtut dari studi literatur, kemudian pengumpulan data, preprocessing data, pembobotan kata, pengklasifikasian dengan algoritma SVM (Support Vector Machine), pengujian, evaluasi performa, dan yang terakhir adalah pengambilan kesimpulan.
Studi literatur merupakan sebuah tahapan dimana peneliti mempelajari akan suatu literatur yang berkaitan dengan penelitian ini. Literatur tersebut bisa berupa jurnal, dokumentasi, studi eksperimen, penelitian sebelumnya, dll.
Selanjutnya pengumpulan data dilakukan pada tanggal 18–21 Maret menggunakan Tweepy dengan bantuan dari API Twitter.
Preprocessing data dapat dilakukan pada data yang telah dikumpulkan. Preprocessing data ini meliputi case folding, tokenization, filtrasi, data cleansing, dan stemming.
Preprocessing data diharapkan dapat mengurangi kompleksitas data dan membuat data menjadi lebih rapih dan terstruktur. Hasil dari proses preprocessing kemudian dilanjutkan dengan melakukan pembobotan kata dengan TF- IDF.
Pembobotan kata bertujuan untuk memberikan nilai akan suatu kata. Nilai tersebut diperuntukkan sebagai acuan dalam proses klasifikasi. Berikut tahapan dari pembobotan kata:
1.Term Frequency
Term Frequency merupakan jumlah frekuensi kemunculan tiap kata didalam suatu dokumen. Persamaan dari term frequency didefinisikan dalam Persamaan 1 (Christian, Agus and Suhartono, 2016):
𝑡𝑓𝑎,𝑏 = 𝑘𝑒𝑚𝑢𝑛𝑐𝑢𝑙𝑎𝑛 𝑘𝑎𝑡𝑎 𝑎 𝑑𝑎𝑙𝑎𝑚 𝑏 𝑡𝑜𝑡𝑎𝑙 𝑘𝑎𝑡𝑎 𝑑𝑎𝑙𝑎𝑚 𝑑𝑜𝑘𝑢𝑚𝑒𝑛 𝑏 (1) 2.Inverse Document Frequency
Inverse document frequency merupakan bentuk kebalikan bobot dari document frequency. Semakin jarang kata tersebut muncul di dalam dokumen, maka kata tersebut mempunyai bobot inverse document frequency yang tinggi (Rofiqoh, Perdana and Fauzi, 2017).
Persamaan dari IDF didefinisikan dalam Persamaan 2 (Christian, Agus and Suhartono, 2016):
𝑖𝑑𝑓𝑎= 𝑙𝑜𝑔𝑗𝑢𝑚𝑙𝑎ℎ 𝑠𝑒𝑙𝑢𝑟𝑢ℎ 𝑑𝑜𝑘𝑢𝑚𝑒𝑛 𝑗𝑢𝑚𝑙𝑎ℎ 𝑚𝑢𝑛𝑐𝑢𝑙 𝑘𝑎𝑡𝑎 𝑎 (2)
3.Term Frequency – Inverse Document Frequency
Term Frequency – Inverse Document Frequency adalah hasil perkalian dari perhitungan term frequency dengan inverse document frequency. Persamaan dari TF-IDF didefinisikan dalam Persamaan 3:
𝑡𝑓𝑖𝑑𝑓𝑎,𝑏= 𝑡𝑓𝑎,𝑏 × 𝑖𝑑𝑓𝑎 (3)
Hasil dari preprocessing data dan pembobotan kata kemudian digunakan untuk melakukan klasifikasi data. Klasifikasi data dilakukan dengan menggunakan algoritma SVM. SVM merupakan sebuah teknik yang dapat dibilang baru untuk mengaplikasikan prediksi, dalam kasus klasifikasi maupun regresi. SVM termasuk dalam supervised learning class, karena dalam penggunaanya diperlukan tahap pelatihan dan tahap pengujian (Santosa, 2015). Persamaan SVM didefinisikan dalam Persamaan 4:
𝑦 = 𝑤𝑥 + 𝑏 (4)
Keterangan:
𝑦 : Label data
𝑤 : Garis hyperplane dan support vector 𝑏 : nilai bias
Penelitian ini menggunakan kernel linear yang didefinisikan dalam Persamaan 5:
∑1𝑖=1,𝑗=1𝑥𝑖𝑥𝑗𝑇, (𝑖, 𝑗 = 1,2, … , 𝑛) (5)
Keterangan:
𝑥𝑖 : Data input
𝑥𝑗𝑇 : Nilai transpose dari 𝑥𝑖
Gambar 2. Ilustrasi Support Vector Machine Hasil dari klasifikasi kemudian dilakukan evaluasi untuk mengukur performa dari model klasifikasi tersebut. Evaluasi pada model klasifikasi dilakukan dengan menggunakan sebuah metode yang bernama confusion matrix.
Confusion matrix itu sendiri merupakan sebuah metode yang digunakan untuk mengukur efektivitas sebuah algoritma klasifikasi dengan cara menganalisa seberapa akurat algoritma klasifikasi dapat mengenali tuple dari kelas yang berbeda (Han, Pei and Kamber, 2011).
▪ True positive (TP) adalah label positif yang telah dilabeli secara benar oleh algoritma klasifikasi.
▪ True negative (TN) adalah label negatif yang telah dilabeli secara benar oleh algoritma klasifikasi.
▪ False positive (FP) adalah label negatif yang salah diberi label sebagai positif oleh algoritma klasifikasi.
▪ False negative (FN) adalah label positif yang salah diberi label sebagai negatif oleh algoritma klasifikasi.
True positive dan true negative menjelaskan dimana algoritma klasifikasi telah memberi label data secara benar, dan false positive serta false negative menjelaskan dimana algoritma klasifikasi salah dalam memberi label data.
Contoh dari confusion matrix akan dijelaskan pada Tabel 1:
Tabel 1. Confusion Matrix Predicted Class Positive Negative Actual
Class
Positive TP FN
Negative FP TN
Dari confusion matrix diatas, dapat diperoleh nilai untuk akurasi, precision, recall, dan f-measure dari model klasifikasi.
3. IMPLEMENTASI
Implementasi penelitian ini dimulai dari pengumpulan data tweet, preprocessing data, pembobotan kata, klasifikasi dengan menggunakan algoritma SVM, dan evaluasi performa.
3.1. Pengumpulan Data
Pengumpulan data dilakukan dengan menggunakan Tweepy. Tweepy disini menggunakan API Key dan secret key dari Twitter sebagai autentikasi, yang bisa didapatkan dengan cara mendaftar sebagai developer untuk Twitter.
Gambar 3. Halaman pembuatan keys dan token Setelah didapatkan API key dan secret key, maka kemudian Tweepy dapat digunakan dengan terlebih dahulu memasukkan key kedalam query autentikasi Tweepy. Setelah autentikasi berhasil, maka Tweepy dapat digunakan untuk mengumpulkan data tweets berbahasa Indonesia. Pengumpulan data dilaksanakan pada tanggal 18-21 Maret. Data yang dikumpulkan sebanyak 450 data, yang kemudian data tersebut dapat dibagi menjadi 2 kategori, yaitu 225 data positif dengan 225 data negatif.
Gambar 4. Halaman query pengumpulan data Proses pengumpulan tweets dilaksanakan
dengan menggunakan beberapa parameter query tertentu yang dijelaskan pada Tabel 2:
Tabel 2. Parameter Tweepy
Parameter Deskripsi
searchQuery Kata kunci pada data yang dicari
maxTweets Jumlah data maksimal dari pencarian Filter_retweet Tidak memasukkan hasil
retweet
sinceId Pencarian kata kunci spesifik pada suatu pengguna
3.2. Preprocessing Data
Preprocessing data dilakukan dengan urutan case folding, tokenization, filtrasi, data cleansing, dan stemming. Proses ini dilaksanakan dengan bantuan library NLTK dan pySastrawi. Contoh hasil dari preprocessing data dapat dilihat pada Tabel 3
Tabel 3. Hasil Preprocessing Data
Sebelum Sesudah
Vaksinasi Yuk Gaes Yuk kita dukung
bersama pengembangan vaksin
Merah Putih dan vaksin Nusantara https://t.co/TkdbJswN2
4
[‘vaksinasi’, ‘dukung’,
‘pengembangan’,
‘vaksin’, ‘merah’,
‘putih’, ‘vaksin’,
‘nusantara’]
3.3. Pembobotan Kata
Pembobotan kata dilakukan dengan menggunakan TF-IDF. Setelah data selesai dilakukan preprocessing, pembobotan kata diperlukan untuk memberikan nilai kepada kata secara unigram sehingga dapat dilakukan proses klasifikasi pada data. Proses ini dilaksanakan dengan bantuan library Scikit-Learn.
3.4. Klasifikasi
Klasifikasi dapat diimplementasikan setelah data selesai dilakukan preprocessing dan pembobotan kata. Data terlebih dahulu dibagi menjadi 10 kelompok data dengan metode K- Fold. Metode K-Fold digunakan untuk melihat efektivitas dari model klasifikasi pada data yang terbatas. Proses klasifikasi kemudian dilakukan menggunakan metode SVM dengan bantuan library Scikit-Learn.
4. PENGUJIAN DAN ANALISIS 4.1. Pengujian Nilai C
Pengujian nilai C dilaksanakan dalam
rangka melihat pengaruh nilai C terhadap SVM.
Nilai C dimulai dari 1, 5, 10, 15, 20. Nilai iterasi maksimum yang digunakan pada pengujian ini sebesar -1. Rata-rata akurasi dari pengujian akan dijelaskan pada Tabel 4:
Tabel 4. Hasil Pengujian Pengaruh Nilai C
Fold Ke-
Nilai C
1 10 20 30 40
1 84% 82% 82% 82% 82%
2 87% 87% 87% 87% 87%
3 84% 78% 78% 78% 78%
4 89% 87% 87% 87% 87%
5 89% 87% 87% 87% 87%
6 82% 82% 82% 82% 82%
7 82% 82% 82% 82% 82%
8 84% 82% 82% 82% 82%
9 87% 89% 89% 89% 89%
10 87% 87% 87% 87% 87%
Rata-
rata 86% 84% 84% 84% 84%
Dari hasil pengujian diatas dapat dilihat bahwa nilai akurasi dipengaruhi akan besarnya nilai C. Semakin tinggi nilai C, maka semakin turun, kemudian stabil setelah nilai C = 10. Hal ini diakibatkan nilai C mempengaruhi posisi dari garis hyperplane pada proses klasifikasi dengan menggunakan kernel linear.
Dari Tabel 4 dapat dilihat nilai C = 1 merupakan nilai C yang memiliki rata-rata accuracy tertinggi, yaitu 86%. Nilai accuracy tertinggi yang diperoleh pada saat pengujian adalah 89%. Dengan ini dapat disimpulkan bahwa nilai C terbaik merupakan C = 1 dengan mempertimbangkan bahwa rata-rata accuracy tertinggi diperoleh pada nilai C tersebut.
4.2. Pengujian Nilai Iterasi Maksimum Pengujian nilai iterasi maksimum dilakukan untuk melihat pengaruh nilai iterasi maksimum terhadap SVM. Nilai iterasi maksimum dimulai dari 100, 200, 300, 400, 500. Nilai C yang digunakan pada pengujian ini sebesar 1. Rata- rata akurasi dari pengujian akan dijelaskan pada Tabel 5:
Tabel 5. Hasil Pengujian Pengaruh Nilai Iterasi Maksimum
Fold Ke-
Nilai Iterasi Maksimum 100 200 300 400 500 1 84% 84% 84% 84% 84%
2 91% 87% 87% 87% 87%
3 78% 84% 84% 84% 84%
4 87% 89% 89% 89% 89%
5 87% 89% 89% 89% 89%
6 76% 80% 82% 82% 82%
7 84% 82% 82% 82% 82%
8 84% 84% 84% 84% 84%
9 87% 87% 87% 87% 87%
10 87% 87% 87% 87% 87%
Rata-
rata 84% 85% 86% 86% 86%
Dari hasil pengujian diatas dapat dilihat bahwa nilai akurasi dipengaruhi akan besarnya nilai iterasi maksimum. Semakin tinggi nilai iterasi maksimum, maka semakin tinggi akurasi yang diperoleh. Hal ini diakibatkan semakin besar nilai iterasi, semakin banyak data yang dipelajari algoritma klasifikasi dalam mengelompokkan data.
Dari Tabel 5 dapat disimpulkan bahwa nilai iterasi maksimum dimulai dari 300 merupakan nilai iterasi maksimum terbaik dengan mempertimbangkan nilai rata-rata accuracy tertinggi diperoleh pada nilai iterasi maksimum tersebut.
4.3. Evaluasi Performa
Evaluasi performa akan dilakukan pada SVM yang memiliki parameter terbaik pada pengujian sebelumnya, yaitu dengan menggunakan parameter nilai C sebesar 1 dan iterasi maksimum sebesar 300. Nilai evaluasi yang ditampilkan adalah akurasi, precision, recall, dan f-measure.
Confusion matrix yang diperoleh dari hasil prediksi SVM akan dijelaskan pada Tabel 6:
Tabel 6. Confusion Matrix
Actual Class Predicted Class Positive Negative
Positive 185 40
Negative 25 200
Dari confusion matrix pada Tabel 6, dapat dilihat bahwa terdapat 225 data dengan sentimen positif, dan 225 data dengan sentimen negatif.
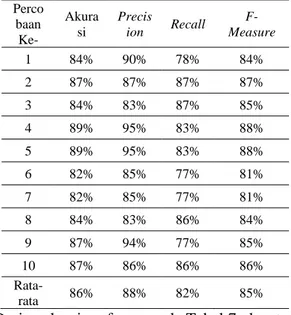
Data bernilai positif yang terprediksi dengan benar berjumlah 185 data, data bernilai positif yang terprediksi salah berjumlah 40 data, data bernilai negatif yang terprediksi benar berjumlah 200 data, dan data bernilai negatif yang terprediksi salah berjumlah 25 data. Evaluasi performa pada Support Vector Machine akan dijelaskan pada Tabel 7:
Tabel 7. Evaluasi Performa Perco
baan Ke-
Akura si
Precis
ion Recall F- Measure
1 84% 90% 78% 84%
2 87% 87% 87% 87%
3 84% 83% 87% 85%
4 89% 95% 83% 88%
5 89% 95% 83% 88%
6 82% 85% 77% 81%
7 82% 85% 77% 81%
8 84% 83% 86% 84%
9 87% 94% 77% 85%
10 87% 86% 86% 86%
Rata-
rata 86% 88% 82% 85%
Dari evaluasi performa pada Tabel 7, dapat dilihat bahwa rata-rata akurasi yang didapatkan sebesar 86%, yang berarti model klasifikasi tersebut berhasil melakukan prediksi akan 385 data secara tepat dari total 450 data yang diproses. Nilai precision yang didapatkan sebesar 88%, yang berarti model klasifikasi tersebut berhasil melakukan prediksi akan 185 data bernilai positif secara tepat dari total 210 data yang diprediksi memiliki nilai positif. Nilai recall yang didapatkan sebesar 82%, yang berarti model klasifikasi tersebut berhasil melakukan prediksi akan 185 data bernilai positif secara tepat dari total 225 data yang memiliki nilai positif. Nilai f-measure yang didapatkan sebesar 85%. Nilai tersebut merupakan rata-rata harmonis dari nilai precision dan recall.
4.4. Analisa Word Cloud
Analisa word cloud dilakukan dengan melakukan perbandingan hasil dari word cloud antara dua kategori yaitu positif dan negatif. Hal ini dilakukan agar mendapat gambaran dari kata apa saja yang paling menjelaskan tentang vaksin COVID-19 berdasarkan masing masing sentimen. Berikut merupakan bentuk word cloud dari sentimen positif:
Gambar 5. Word Cloud Sentimen Positif
Berikut merupakan bentuk dari word cloud sentimen negatif:
Gambar 6. Word Cloud Sentimen Negatif
Pada tweet yang memiliki sentimen baik mau itu positif ataupun negatif, keduanya mengandung kata-kata seperti vaksin, covid, dan indonesia. Kata tersebut adalah kata yang paling sering muncul pada tweet mengenai vaksin COVID-19. Dari word cloud diatas dapat disimpulkan bahwa setiap opini dari masayarakat mengandung kata yang saling bertolak belakang. Misal kata-kata dengan konotasi positif seperti sehat, pulih, ayo, yuk, dukung, aman muncul pada tweet yang berkategori positif. Sedangkan pada tweet dengan kategori negatif, kata dengan konotasi negatif seperti tolak, mati, lumpuh, sakit, takut, paksa lebih sering muncul. Hal ini menggambarkan akan polaritas yang terjadi pada pengguna Twitter mengenai opini mereka akan vaksin COVID-19.
5. KESIMPULAN
Berdasarkan hasil dari penelitian yang telah dilakukan, diperoleh kesimpulan sebagai berikut:
1. Penerapan dari algoritma SVM dalam melakukan analisis sentimen pada media sosial Twitter terhadap vaksin COVID- 19 dilakukan dengan melalui beberapa tahapan, yaitu data scraping, tweet labeling, preprocessing, pembobotan kata, menggunakan algoritma TF-IDF, pelatihan dan pengujian dengan menggunakan algoritma SVM, serta evaluasi performa.
2. Algoritma SVM mendapat hasil terbaik ketika parameter nilai C bernilai 1 dan iterasi maksimum bernilai 300. Selain itu juga didapatkan bahwa seiring bertambahnya nilai C, maka nilai akurasi yang didapatkan semakin kecil. Hal ini berbanding terbalik dengan nilai iterasi maksimum, yang dimana semakin bertambahnya nilai iterasi maksimum, maka didapatkan hasil akurasi yang semakin besar. Rata-rata dari akurasi terbaik yang didapatkan dari model
klasifikasi ini adalah sebesar 86%.
Selain itu juga didapatkan rata-rata precision sebesar 88%, rata-rata recall sebesar 82%, dan rata-rata f-measure sebesar 85%
3. Pada analisa word cloud, diperoleh kesamaan dan perbedaan dari kedua kategori sentimen. Persamaan dari kedua kategori sentimen adalah kata-kata vaksin, sinovac, dan Indonesia sangat sering muncul pada kedua kategori sentimen. Sedangkan perbedaan dari kedua kategori sentimen adalah terdapat kata-kata yang saling bertolak belakang.
Kata-kata dengan konotasi positif seperti ayo, dukung, yuk, pulih, aman muncul pada tweet dengan kategori positif.
Sedangkan kata-kata dengan konotasi negatif seperti gagal, benci, salah, tolak muncul pada tweet dengan kategori negatif. Hal ini menggambarkan polaritas dari opini para pengguna Twitter terhadap vaksin COVID-19.
6. DAFTAR PUSTAKA
Anon 2021. Twitter users in Indonesia 2025.
[online] Statista. Available at:
<https://www.statista.com/forecasts/1145 550/twitter-users-in-indonesia>
[Accessed 27 Jan. 2021]
Christian, H., Agus, M.P. and Suhartono, D., 2016. Single Document Automatic Text Summarization using Term Frequency- Inverse Document Frequency (TF-IDF).
ComTech: Computer, Mathematics and Engineering Applications, 7(4), p.285.
https://doi.org/10.21512/comtech.v7i4.37 46.
Han, J., Pei, J. and Kamber, M., 2011. Data Mining: Concepts and Techniques.
Elsevier
Pakpahan, D. and Widyastuti, H., 2014. Aplikasi Opinion Mining dengan Algoritma Naïve Bayes untuk Menilai Berita Online.
JURNAL INTEGRASI, 6(1), pp.1–10.
Rofiqoh, U., Perdana, R.S. and Fauzi, M.A., 2017. Analisis Sentimen Tingkat Kepuasan Pengguna Penyedia Layanan Telekomunikasi Seluler Indonesia Pada Twitter Dengan Metode Support Vector Machine dan Lexicon Based Features. p.8.
Santosa, B., 2015. Tutorial Support Vector
Machines. p.19.