BAB 2
LANDASAN TEORI
2.1 Teori-teori Dasar / Umum
Landasan teori dasar / umum yang digunakan dalam penelitian ini mencakup teori speaker recognition dan program Matlab.
2.1.1 Speaker Recognition
Pada dasarnya, fungsi dari speaker recognition merupakan contoh klasik
dari masalah pattern recognition, yang pada umumnya berguna untuk
menemukan jenis pola tertentu dari data-data yang diperoleh dari sensor. Proses
training / pelatihan diperlukan untuk semua kasus pattern recognition. Misalnya
pada speaker authentication system, suara pengguna sistem perlu didaftarkan.
Selama proses tersebut, sistem “mempelajari” suara pengguna yang akan dikenali. Pengenalan pembicara (speaker recognition) dapat dilakukan dengan
bergantung teks (text dependent) ataupun tidak bergantung teks (text
independent). Istilah “teks” yang dimaksud disini adalah kata-kata yang
diucapkan oleh pembicara. (Heinz, Heirtlein. 2008. Definitions. The Speaker
Recognition Homepage, (Online), (http://speaker-recognition.org, accessed on
December 26, 2008))
Perlu diingat dan ditekankan bahwa pengertian dari speaker recognition
berbeda dengan pengertian speech recognition. Istilah speech recognition lebih
mengarah kepada proses mengetahui frasa apa yang diucapkan oleh pembicara, sedangkan istilah speaker recognition lebih mengarah kepada proses mengenali
pembicara.
2.1.2 MatLab (Matrix Laboratory)
Matlab merupakan salah satu perangkat lunak (program) yang banyak digunakan dalam perhitungan teknikal. Program Matlab mengintegrasikan komputasi, visualisasi dan pemrograman dalam suatu lingkungan program yang mudah digunakan, dimana masalah dan solusi diekspresikan ke dalam suatu notasi matematika yang mudah dipahami. Matlab adalah sebuah program berbasiskan operasi matematika, yang dalam hal ini berupa matriks. (The MathWorks, 2005)
Dalam pengoperasiannya, Matlab memiliki banyak toolbox guna
mempermudah pengguna menggunakan perangkat lunak ini, termasuk membantu pengguna dalam mengimplementasikan metode atau algoritma tertentu. Toolbox Matlab yang digunakan untuk membantu penelitian ini adalah :
o Wavelet Toolbox
Wavelet toolbox adalah salah satu toolbox yang terintegrasi dalam
Matlab. Wavelet toolbox menyediakan komponen untuk menganalisa dan
mensintesis sinyal dan gambar, serta komponen untuk pengolahan aplikasi statistik dengan menggunakan teori wavelet.
Wavelet toolbox merupakan toolbox untuk mengembangkan algoritma
kompresi sinyal. Analisa menggunakan teknik wavelet menghasilkan
informasi yang lebih presisi mengenai suatu sinyal dibandingkan dengan teknik algoritma analisa sinyal lainnya, misalnya fourier. Dengan
menggunakan wavelet toolbox ini, teknik transformasi wavelet dapat
dilakukan dengan mudah dan cepat. (Misiti et al, 2002)
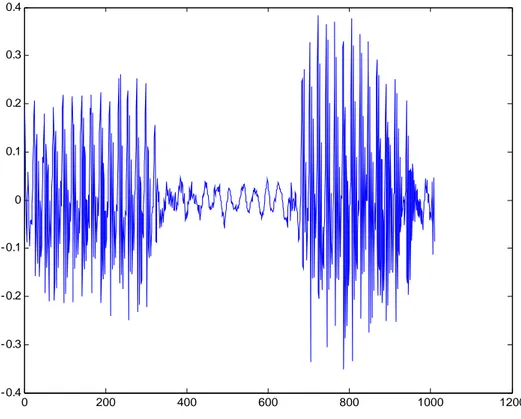
0 200 400 600 800 1000 1200 -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4
Gambar 2.1 Contoh Sinyal Yang Telah Diproses Oleh Wavelet Toolbox
Meskipun banyak keuntungan yang dapat diperoleh dari program Matlab, tapi tetap saja terdapat kelemahan / kekurangannya. Salah satu kekurangan dari pengimplementasian teknik-teknik pengolahan sinyal digital menggunakan Matlab adalah pengolahan sinyal yang tidak real time. Matlab perlu menyimpan
informasi terkumpul lengkap di dalam memori, barulah Matlab akan mulai melakukan operasi perhitungan sesuai deretan instruksi / perintah yang telah diberikan. Matlab tidak bisa bekerja secara langsung (real time) seperti halnya
prosesor–prosesor DSP yang ada sekarang ini. 2.2 Teori-teori Khusus
Landasan teori khusus yang digunakan dalam penelitian ini mencakup teori
fourier transform, wavelet transform, dynamic time warping, dan k-nearest
neighbor.
2.2.1 Fourier Transform (Transformasi Fourier)
Dengan bantuan transformasi fourier, dapat diketahui frekuensi-frekuensi
apa saja yang terkandung dalam sinyal tersebut (Spiegel, Murray R., 1974). Tetapi lama kelamaan, akhirnya disadarilah bahwa transformasi fourier masih
memiliki kelemahan pula. Transformasi fourier hanya baik digunakan untuk
menganalisa sinyal stasioner, tetapi sangat tidak efektif jika digunakan untuk menganalisa sinyal non-stasioner. Hal tersebut dikarenakan transformasi fourier
menganalisa sinyal dalam keseluruhan waktu (dari awal sampling hingga akhir
sampling), alhasil muncul asumsi bahwa informasi frekuensi sinyal yang
didapatkan terjadi dalam setiap waktu pada sinyal tersebut. Padahal belum tentu fekuensi-frekuensi tersebut terjadi dalam setiap waktu pada sinyal tersebut. Dengan kata lain, informasi waktu kapan terjadinya frekuensi-frekuensi tersebut tidak dapat diketahui dengan jelas dan tepat. (Stein et al, 2002)
Seiring berkembangnya teknik-teknik analisa sinyal, muncullah sebuah konsep baru yang dapat mengatasi kelemahan dari transformasi fourier tersebut,
teknik analisa sinyal tersebut bernama Wavelet Transform.
2.2.2 Wavelet Transform (Transformasi Wavelet)
Teori wavelet merupakan suatu konsep yang relatif baru dikembangkan.
Kata ”wavelet” sendiri diberikan oleh Jean Morlet dan Alex Grossmann pada
awal tahun 1980-an, dan berasal dari bahasa Perancis, ”ondelette” yang berarti
gelombang kecil. Kata ”onde” yang berarti gelombang kemudian diterjemahkan
ke bahasa inggris menjadi ”wave”, lalu digabungkan dengan kata aslinya
sehingga terbentuklah kata baru ”wavelet”. Dengan menggunakan wavelet
transform, informasi frekuensi berikut informasi waktu kapan terjadinya
frekuensi tersebut pada sinyal dapat diketahui dengan presisi. Fungsi dari mother
wavelet (fungsi window wavelet) adalah sebagai berikut :
( )
⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − Ψ = Ψ a b t a t b a 1 ,……(1)
,dimana a adalah bilangan positif yang menunjukkan parameter skala (scale)
dan b adalah bilangan real yang menyatakan pergeseran waktu (shift).
Berdasarkan jenis sinyal yang diprosesnya, transformasi wavelet dapat
dibagi menjadi dua bagian besar, yaitu Continuous Wavelet Transform (CWT)
2.2.2.1. Discrete Wavelet Transform (Transformasi Wavelet Diskrit)
Sesuai dengan namanya, discrete wavelet transform bekerja
mentransformasikan sinyal yang telah berbentuk diskrit. Discrete wavelet
transform dapat diaplikasikan dalam penelitian pengenalan speaker ini. Hal ini
sangat mendukung mengingat bahwa penelitian ini melibatkan data dan informasi input berupa sinyal suara yang nantinya akan diubah ke dalam bentuk diskrit.
Dibandingkan dengan continuous wavelet transform (CWT), discrete
wavelet transform (DWT) dianggap relatif lebih mudah dalam hal
pengimplementasiannya. Prinsip dasar dari discrete wavelet transform adalah
bagaimana cara mendapatkan representasi waktu dan skala dari sebuah sinyal menggunakan teknik pemfilteran digital dan operasi sub-sampling atau
down-sampling. (Mallat, Stephane, 1999)
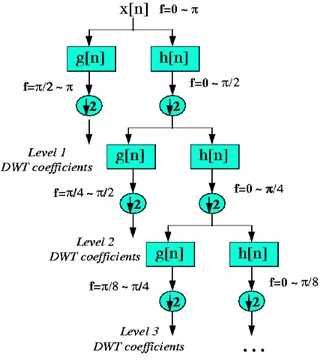
Sinyal pertama-tama dilewatkan pada rangkain high-pass filter dan
low-pass filter, kemudian setengah dari masing-masing keluaran diambil sebagai
sampel melalui operasi down-sampling. Proses ini disebut sebagai proses
dekomposisi satu tingkat. Keluaran dari low-pass filter digunakan sebagai
masukkan di proses dekomposisi tingkat berikutnya. Proses ini diulang sampai tingkat proses dekomposisi yang diinginkan. Gabungan dari keluaran-keluaran
high-pass filter dan satu keluaran low-pass filter yang terakhir disebut sebagai
koefisien wavelet, yang berisi informasi sinyal hasil transformasi yang telah
Gambar 2.2 Proses Dekomposisi Discrete Wavelet Transform
Pasangan high-pass filter dan low-pass filter yang digunakan harus
merupakan quadrature mirror filter (QMF), yaitu pasangan filter yang
memenuhi persamaan berikut :
]
1
[
.
)
1
(
]
[
n
g
L
n
h
=
−
n+
−
……(2)dengan h[n] adalah high-pass filter, g[n]adalah low-pass filter dan L adalah
panjang masing-masing filter.
Berkat operasi down-sampling yang menghilangkan informasi sinyal
yang berlebihan, transformasi wavelet telah menjadi salah satu metode
kompresi data yang paling handal. Biro investigasi federal (FBI) Amerika Serikat menggunakan metode ini dalam proses kompresi data sidik jari mereka.
2.2.3 Dynamic Time Warping (DTW)
Dynamic time warping merupakan sebuah metode untuk mengukur jarak
antara 2 koefisien data yang mungkin berbeda dalam hal waktu atau kecepatan. Jarak tersebut merepresentasikan seberapa besar kemiripan antara 2 koefisien data tersebut. Sebagai contoh, dalam proses perekaman pertama, pengguna berbicara dengan kecepatan yang cepat sedangkan dalam proses perekaman kedua, pengguna berbicara lebih lambat dibandingkan dengan proses perekaman pertama. Pada kedua proses perekaman tersebut, pengguna mengucapkan kata yang sama tapi dengan kecepatan yang berbeda sehingga menghasilkan data yang panjangnya berbeda pula. Dengan menggunakan metode dynamic time
warping, jarak (kemiripan) antara kedua rekaman tersebut dapat diketahui. Hal
inilah yang menjadi kelebihan utama dari metode dynamic time warping. (Berndt
dan Clifford, 1996)
Secara umum, dynamic time warping merupakan sebuah metode yang
memungkinkan komputer untuk mendapatkan jarak (kemiripan) yang optimal antara 2 koefisien data yang diberikan. Koefisien-koefisien data tersebut di “warp” secara non-linear dalam dimensi waktu untuk mengetahui jarak
(kemiripan) antara 2 koefisien tersebut.
Di st a n c e 0 1 3 5 7 9 10 12 -0.2 0 0.2 0.4 30 20 10 0 30 20 10 0 30 20 10 0 30 20 10 0 30 20 10 0 30 20 10 0 30 20 10 0 Sa m p le s Amp 50 100 150 200 250 -0.2 0 0.2 0.4 Samples Am p
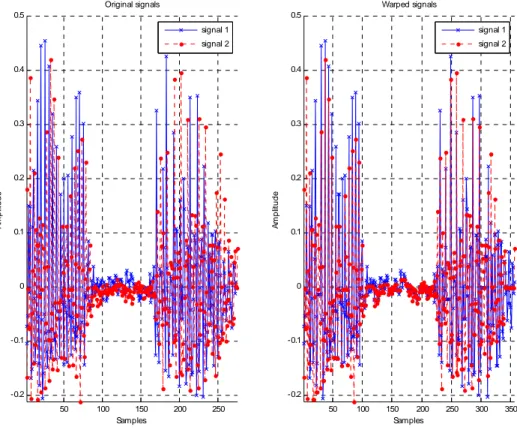
50 100 150 200 250 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.5 Samples A m p lit u d e Original signals signal 1 signal 2 50 100 150 200 250 300 350 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.5 Samples A m p lit u d e Warped signals signal 1 signal 2
Gambar 2.5 Sinyal Sebelum (kiri) dan Sesudah (kanan) di-DTW
2.2.3.1 DTW Grid
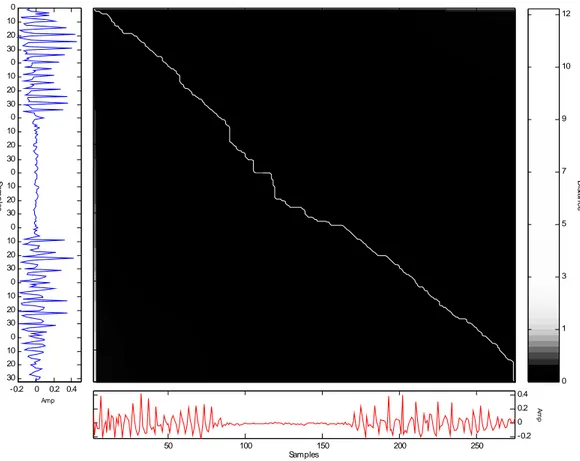
Koefisien-koefisien data yang ingin diukur jarak atau kemiripannya dapat diatur pada sisi-sisi sebuah grid, seperti pada gambar 2.6 berikut :
Gambar 2.6 di atas menggambarkan koefisien data suara yang ingin dikenali (sisi bawah grid) dan koefisien data suara referensi yang tersimpan di dalam database
(sisi kiri grid). Awal dari kedua koefisien data tersebut dimulai dari bagian kiri
bawah grid. Total jarak (kemiripan) terdekat diwakili oleh jalur grid berwarna
biru. Setelah jalur tersebut ditemukan, maka akan didapatkan jarak (kemiripan) terdekat antara koefisien data input dengan koefisien data referensi database.
Pada dasarnya, prosedur perhitungan dari algoritma DTW adalah menemukan semua jalur yang memungkinkan di dalam grid. Karena itu dalam
sejumlah koefisien data yang diberikan akan menghasilkan jumlah kemungkinan jalur yang sangat banyak. Metode DTW akan menghasilkan proses perbandingan antara 2 koefisien data yang lebih efisien.
2.2.4 k-Nearest Neighbor
Metode k-nearest neighbor (k-NN) adalah sebuah metode untuk melakukan
klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut. Data pembelajaran diproyeksikan ke ruang berdimensi banyak, dimana masing-masing dimensi merepresentasikan fitur dari data. Ruang ini dibagi menjadi bagian-bagian berdasarkan klasifikasi data pembelajaran. Sebuah titik pada ruang ini ditandai kelas c jika kelas c
merupakan klasifikasi yang paling banyak ditemui pada k buah tetangga terdekat
titik tersebut. Dekat atau jauhnya tetangga biasanya dihitung berdasarkan jarak
Untuk P=(p1,p2,...,pn) danQ=(q1,q2,...,qn), maka 2 2 2 2 2 1 1 ) ( ) ... ( ) (p q p q pn qn Jarak= − + − + + −
……(3)
∑
= − = n i i i q p Jarak 1 2 ) (……(4)
Pada fase pembelajaran, metode ini hanya melakukan penyimpanan vektor-vektor fitur dan klasifikasi dari data pembelajaran. Pada fase klasifikasi, fitur-fitur yang sama dihitung untuk data pengujian (yang klasifikasinya tidak diketahui). Jarak dari vektor yang baru ini terhadap seluruh vektor data pembelajaran dihitung, dan sejumlah k buah yang paling dekat diambil. Titik
yang baru klasifikasinya diprediksikan termasuk pada klasifikasi terbanyak dari titik-titik tersebut.
Nilai k yang terbaik untuk algoritma ini tergantung pada data, secara
umumnya, nilai k yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi
membuat batasan antara setiap klasifikasi menjadi lebih kabur. Nilai k yang
bagus dapat dipilih dengan optimasi parameter, misalnya dengan menggunakan
cross-validation. Kasus khusus dimana klasifikasi diprediksikan berdasarkan
data pembelajaran yang paling dekat (dengan kata lain, k = 1) disebut metode
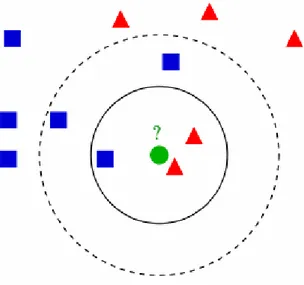
Gambar 2.7 Contoh Klasifikasi Dengan Metode k-Nearest Neighbor
Gambar 2.7 di atas merupakan gambaran sekilas mengenai klasifikasi pada metode k-Nearest Neighbor (k-NN). Lingkaran kecil yang berwarna hijau di
tengah itu merupakan sampel, sedangkan simbol yang berbentuk kotak menunjuk pada klasifikasi kelas pertama (first class) atau speaker 1 dan simbol
yang berbentuk segitiga merupakan klasifikasi kelas kedua (second class) atau
speaker 2. Jika nilai resolusi dari algoritma k-NN yang digunakan adalah 3,
maka hasil algoritma k-NN akan menghasilkan klasifikasi kelas kedua (second
class) atau speaker 2 karena terdapat 2 buah segitiga dan hanya 1 buah kotak di
dalam lingkaran resolusi pada gambar 2.7. Sedangkan jika resolusi dari metode ini diganti menjadi 5, maka metode ini akan menghasilkan klasifikasi kelas pertama (first class) atau speaker 1 karena terdapat 3 buah kotak dan hanya 2
buah segitiga di dalam lingkaran resolusi luar pada gambar 2.7. (Belur V, 1991)
Ketepatan metode k-NN ini sangat dipengaruhi oleh ada atau tidaknya
relevansinya terhadap klasifikasi. Riset terhadap metode ini sebagian besar membahas bagaimana memilih dan memberi bobot terhadap fitur, agar performa klasifikasi menjadi lebih baik.
Metode k-NN ini memiliki konsistensi yang kuat. Ketika jumlah data
mendekati tak hingga, metode ini menjamin error rate yang tidak lebih dari dua
kali Bayes error rate (error rate minimum untuk distribusi data tertentu). (Belur