Penerapan Metode Non-Negative Matrix
Factorization dan Generic Relevance of Sentence
Pada Computer Based Test Essay
1st *Aslan Poetra Ramadhan Fakultas Ilmu Komputer Universitas Muslim Indonesia
Makassar, Indonesia [email protected]
2ndHerman Fakultas Ilmu Komputer Universitas Muslim Indonesia
Makassar, Indonesia [email protected]
3rd Herdianti Darwis Program Studi Teknik Informatika,
Fakultas Ilmu Komputer Universitas Muslim Indonesia
Makassar, Indonesia [email protected]
Abstrak—Computer Based Test (CBT) diera kemajuan teknologi informasi saat ini mulai menjadi pilihan baru terbarukan dalam hal uji kompetensi dalam berbagai instansi. Tidak hanya peruntukannya di dunia pendidikan. Computer Based Test (CBT) mulai ramai diimplementasikan diluar dunia pendidikan sebab efisiensi, efektifitas hingga kecepatan yang ditawarkan Computer Based Test (CBT) menjadi pertimbangan untuk diterapkan. Pada aspek lingkungan, dengan penggunaan CBT, peran Paper Based Test dalam uji kompetensi dapat menekan penggunaan kertas didalamnya. Hanya saja sistem eksaminasi CBT pada umumnya menggunakan sistem pilihan ganda pada proses uji kompetensi. Penelitian ini bertujuan untuk menerapkan Metode Non-Negative Matrix Factorization (NMF) pada sistem CBT dengan model uji kompetensi Essay dimana terdapat jawaban yang variatif dari model ujian ini. Penggunaan Metode Non-Negative Matrix Factorization (NMF) untuk mengolah string jawaban yang dikirimkan untuk dilakukan penilaian secara otomatis, dengan Metode NMF ini dilakukan Analisa hubungan antara sebuah frase/kalimat dengan sekumpulan string yang kemudian dilakukan pembobotan terhadap respon yang dikirimkan untuk diberi penilaian dengan bantuan Generic Relevance of Sentence (GRS).
Kata kunci—component, CBT, Essay, GRS, NMF
I. PENDAHULUAN
Seiring dengan berkembangnya peradaban manusia, berkembang pula ilmu pengetahuan manusia itu sendiri. Bersamaan dengan ini inovasi teknologi informasi tidak dapat dibendung perkembangannya. Kebutuhan di era teknologi modern menekankan pada kecepatan dan ketepatan terhadap pengolahan data. Pemanfaatan teknologi informasi dan komunikasi di dalam dunia pendidikan untuk menunjang aspek-aspek pendidikan saat ini memasuki babak baru. Pendidikan yang berkualitas demi meningkatkan kompetensi sumber daya manusia lebih maju dituntut dengan kualitas pendidikan yang harus maju pula salah satunya dengan meningkatkan kualitas pendidikan melalui eksaminasi berbasis komputer. Computer Based Test (CBT) merupakan solusi efektif untuk evaluasi eksaminasi yang massif. Meskipun berbagai pendekatan dan sistem eksaminasi digital telah
banyak dikembangkan sebelumnya namun kurangnya fleksibilitas, integritas, keamanan serta skalabilitas pada sistem-sistem yang ada sebelumnya.
Saat ini khususnya pendidikan yang ada telah memanfaatkan kemajuan teknologi dengan penerapan sistem eksaminasi dengan menggunakan komputer yang umum dikenal dengan ComputerBasedTest (CBT) hanya saja untuk saat ini sistem eksaminasi tersebut masih memiliki keterbatasan akan pengolahan data eksaminasi yang pada umumnya masih menerapkan eksaminasi dengan sistem pilihan ganda yang konvensional dengan mengubah sistem eksaminasi lama menggunakan kertas (PaperBasedTest – PBT) menjadi eksaminasi dengan menggunakan komputer sebagai pengganti kertas pada pendidikan di Indonesia belum mengakomodir sepenuhnya untuk sistem pendidikan digital demi peningkatan kualitas sumber daya manusia melalui pendidikan.
Permasalahan-permasalahan tersebut diatas mendasari untuk dikembangkannya sistem eksaminasi digital melalui Computer Based Test (CBT) yang mengakomodir sistem-sistem yang telah ada sebelumnya dan memenuhi kebutuhan khususnya pada proses eksaminasi dengan model essay. Eksaminasi dengan model essay sendiri merupakan eksaminasi yang menuntut peserta didik untuk menjawab dalam bentuk uraian, penjelasan, perbandingan, argumentasi dan bentuk lain yang sejenis dengan tuntutan pertanyaan dengan menggunakan frasa sendiri. Berbeda dengan sistem eksaminasi dengan pilihan ganda, di mana peserta didik diajukan beberapa pertanyaan di mana telah tersedia jawaban yang harus dipilih dengan tepat, eksaminasi dengan model essay mengandalkan tingkat pemahaman peserta didik dalam menjawab permasalahan dalam soal yang diajukan. Sehingga peserta didik diberikan kebebasan dalam beragumentasi dengan permasalahan yang diajukan dalam soal-soal tes yang diberikan, hanya saja pada saat pemrosesannya dengan pada sistem manual membutuhkan waktu untuk menilai setiap jawaban yang diberikan oleh peserta didik.
Sehingga dibutuhkan pengembangan pada sistem eksaminasi digital (Computer Based Test – CBT) yang tidak hanya terbatas pada model eksaminasi pilihan ganda, namun
▸ Baca selengkapnya: soal essay imperative sentence
(2)e-ISSN 2540-7902 dan p-ISSN 2541-366X
dapat mengakomodir model eksaminasi dalam bentuk essay. Dimana pada model ini, sistem mengandalkan pembobotan terhadap respon yang dikirimkan oleh peserta didik dalam bentuk string yang diolah menggunakan metode-metode khusus, dalam penelitian ini metode yang digunakan adalah metode Non-Negative Matrix Factorization (NMF) [1] dalam pengolahan respon terhadap jawaban yang telah tersedia pada basis data sistem dengan pembobotan string dengan bantuan metode Generic Relevance of Sentence (GRS) [2].
II. METODOLOGI
A. Non-Negative Matrix Factorization
Non-Negative Matrix Factorization adalah metode dekomposisi matriks term-by-sentence yang berukuran menjadi matriks dan yang hanya bernilai bilangan non-negatif dan bersifat lebih jarang [3]. Metode dekomposisi ini dapat dinyatakan dalam bentuk persamaan (1).
(1) Dimana matriks W merupakan representasi dari matriks term yang memiliki topik yang tersembunyi di dalamnya (hidden topic) dalam hal ini disebut sebagai Non-Negative Semantic Features Matrix (NSFM) serta ditunjukkan dalam setiap vektor barisnya. Kemudian matriks H merepresentasikan variable yang menyimpan bobot topik tersembunyi (hidden topic) dalam setiap kalimat, variable-variable ini merupakan Non-Negative Semantic Variable Matrix (NSVM) yang direpresentasikan pada Gambar 1.
Gambar. 1. Ilustrasi Matriks W (kiri) dan Matriks H (kanan)
Bentuk persamaan dapat dijabarkan sebagai bentuk kesamaan atau similaritas antara matriks A dengan hasil perkalian dari masing-masing matriks W dan matriks H yang pada awalnya kedua matriks tersebut bernilai acak, sehingga diperlukan suatu kriteria yang yang kemudian nilai masing-masing matriks W dan matriks H akan diperbarui agar hasilnya semakin mendekati atau similar dengan matriks A.
B. Multiplicative Matrix Update Rule Process
Multiplicative Matrix Update Rule Process merupakan sebuah proses yang bertujuan untuk memperbarui nilai dari matriks W dan matriks H sehingga kondisi dapat terpenuhi[4]. Oleh sebab itu proses pembaruan dilakukan dengan masing-masing persamaan untuk setiap matriks W dan matriks H dengan persamaan (2) [5].
(2)
Persamaan diatas digunakan untuk melakukan proses pembaruan rule pada matriks H. kemudian untuk proses pembaruan rule pada matriks W, digunakan persamaan (3).
(3) Sehingga dengan pengolahan matriks W dan matriks H menggunakan persamaan-persamaan diatas, dapat diperoleh tingkat similaritas atau kesamaan antara matriks A dengan hasil perkalian matriks W dan matriks H.
C. Generic Relevance of Sentences
Pemberian nilai pada Computer Based Test Essay dilakukan dengan metode Generic Relevance of Sentences (GRS) pada setiap kalimat respon yang dikirimkan oleh peserta didik. Perhitungan nilai Generic Relevance of Sentences (GRS)[6] ini melibatkan elemen-elemen pada matriks H sebagai matriks yang merepresentasikan variable yang berisi hidden topic dalam setiap kalimat. Proses pada metode Generic Relevance of Sentences (GRS) ini berfokus pada proses ekstraksi kalimat/frase dari respon yang dikirimkan oleh peserta didik dengan pengambilan n kalimat dengan skor kalimat/frase tertinggi. Perolehan skor ini didapatkan dari persamaan (4) Generic Relevance of Sentence (GRS) berikut [7].
(4) Pada persamaan diatas menunjukkan skor untuk setiap vektor kolok ke-j pada matriks H. Sedangkan nlai weight atau nilai bobot pada persamaan tersebut merupakan bobot dari elemen (i,j) pada matriks H diperoleh dengan persamaan (5).
(5) Dimana, dari persamaan diatas
Hij = elemen matriks H pada posisi (i,j) dengan j adalah indeks kolom yang merepresentasikan kalimat dimana 1< j <n r = jumlah baris pada matriks H
i = indeks baris, dimana 1< i <r n = jumlah kalimat
q = indeks kolom kalimat dimana 1< q <n
Hpq = elemen-elemen matriks H pada posisi (p,q) yang merupakan keseluruhan elemen pada matriks H.
D. Term Frequency-Inverse Document Frequency
Term Frequency merupakan frekuensi dari kemunculan sebuah term [8], dalam hal ini frekuensi respon yang dikirimkan. Semakin besar jumlah kemunculan satu term dalam respon yang dikirimkan, maka semakin besar pula bobotnya. Sedangkan Inverse Document Frequency merupakan sebuah proses perhitungan dari bagiamana term terdistribusi secara luas pada koleksi respon yang bersangkutan. Penggunaan Term Frequency-Inverse Document Frequency (TF-IDF)[9] bertujuan untuk membentuk sebuah matriks
term-by-sentences yang digunakan pada proses dekomposisi matriks. Dimana digunakan persamaan (6).
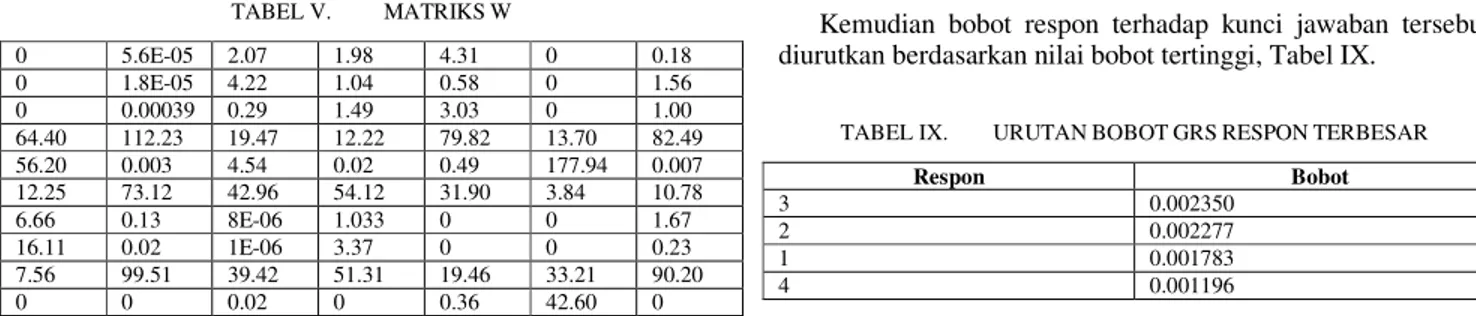
(6) Pada proses ini dibutuhkan pembobotan setiap term yang telah diambil dalam bentuk dasarnya, pada penelitian ini bentuk dasar yang dimaksud adalah kunci jawaban yang telah dibuat yang membentuk pola jawaban yang untuk dilakukan pengolahan pada metode-metode yang digunakan pada penelitian ini dan kemudian dilakukan pembobotan dari respon yang dikirimkan terhadap pola kunci jawaban yang telah disediakan sebelumnya. Sehingga dapat digambarkan dengan skema pada Gambar 2.
START Respon Peserta Dekomposisi Matriks Respon Dataset Pembobotan Data Term Faktorisasi Matriks Respon dengan Dataset Hasil SELESAI Gambar. 2. Skema Metode NFM dan GRS
E. Metode Pengujian
Metode pengujian dilakukan dengan sekupulan data test yang merupakan kumpulan jawaban yang diperoleh dari respon peserta eksaminasi kemudian diproeses dengan data training yang selanjutnya dikenal sebagai hidden topic yang merupakan kunci jawaban dari eksaminasi.
III. HASIL DAN PEMBAHASAN
Berdasarkan metode-metode yang dijabarkan diatas, dilakukan pengujian terhadap terhadap beberapa respon dengan kunci jawaban pada proses eksaminasi dengan model essay. Berikut ini adalah sebuah respon pertanyaan eksaminasi model essay beserta kunci jawaban yang telah dibuat sebelumnya yang kemudian akan diperoleh tingkat similaritasnya.
TABEL I. DATA EKSAMINASI PADA DATA SET Pertanyaan
Pada paradigma Object Oriented Programming, terdapat beberapa konsep agar sebuah pemrograman dikatakan berorientasi objek, sebut dan jelaskan secara singkat konsep tersebut !
Jawaban
Pada paradigma Object Oriented Programming, terdapat 3 konsep utama yaitu enkapsulasi yang merupakan pembungkusan data, inheritance yang merupakan pewarisan atau penurunan dan polimorfisme yang merupakan kosep banyaknya bentuk dari sebuah data
TABEL II. DATA RESPON PESERTA
Responden Jawaban
1
Abstrac Class, Enkapsulasi (pembungkusan : private, public, protected), inheritance (pewarisan), polymorphisme (banyak bentuk)
2
Enkapsulasi pengkapsulan dan hak akses dari fungsi dan variable, inheritance penurunan sifat dari satu class ke class lain, polimorfisme pembuatan fungsi dengan nama yang sama dengan parentnya.
3
Terdapat 3 konsep, Enkapsulasi : penggunaan akses modifier sebagai hak akses suatu atribut dan fungsi, Inheritance : Konsep pewarisan atribut dan method dari induk class ke anak class, Polymorphisme : Konsep dimana digunakan konsep overloading dan overriding pada fungsi
4 Enkapsulasi, polimorfisme, inheritance
Pada Tabel I diatas merupakan data training pada data set, kemudian pada Tabel II diatas merupakan respon dari peserta yang kemudian akan diolah untuk memperoleh tingkat hubungan antar kalimat yang kemudian akan menghasilkan tingkat similaritas dengan kunci jawaban.
A. Penerapan Metode
Metode Non-Negative Matrix Factorization (NMF) melakukan analisa hubungan antar kaliat dengan beberapa langkah sebagai berikut :
• Data testing yang merupakan respon yang dikirimkan oleh peserta diolah dengan melakukan proses case folding dimana respon peserta diubah kedalam bentuk lower case
• Respon peserta kemudian dilakukan proses tokenizing untuk memotong string respon yang menyusunnya dan penghapusan tanda baca.
• Penyusunan matriks A dan q sesuai dengan masing-masing kata yang ditemukan dalam semua kailmat dengan melakukan pemisahan masing-masing kata berdasarkan karakter dan spasi, lalu pengurutan data menurut alfabet kemudian dilakukan penghitungan pada masing-masing kata yang ditemukan.
Kemudian dilakukan proses dekomposisi matriks dengan menggunakan metode Non-Negative Matrix Factorization.
• Dilakukan perhitungan bobot Hi dan penghitungan Generic Relevance of Sentences setelah itu dilakukan pengurutan skor GRS tertinggi, Tabel III.
e-ISSN 2540-7902 dan p-ISSN 2541-366X Matriks A Responden 1 Responden 2 Responden 3 Responden 4 paradigma 0 0 0 0 konsep 0 0 0 0 object 0 0 0 0 oriented 0 0 0 0 program 0 0 0 0 enkapsulasi 1 1 1 1 fungsi 0 1 1 0 data 0 0 0 0 bungkus 1 0 0 0 inheritance 1 1 1 1 waris 1 0 1 0 turun 0 1 0 0 polimorfisme 1 1 1 1 banyak 1 0 0 0 bentuk 1 0 0 0 overload 0 0 1 0 override 0 0 1 0
Kemudian dilakukan pengurutan data berdasarkan abjad guna kemudahan pembacaan data, Tabel IV.
TABEL IV. MATRIKSAPADAPROSESPENGURUTAN
Matriks A Responden 1 Responden 2 Responden 3 Responden 4 banyak 1 0 0 0 bentuk 1 0 0 0 bungkus 1 0 0 0 data 0 0 0 0 enkapsulasi 1 1 1 1 fungsi 0 1 1 0 inheritance 1 1 1 1 konsep 0 0 0 0 object 0 0 0 0 oriented 0 0 0 0 overload 0 0 1 0 override 0 0 1 0 paradigma 0 0 0 0 polimorfisme 1 1 1 1 program 0 0 0 0 turun 0 1 0 0 waris 1 0 1 0
Kemudian dilakukan proses dekomposisi pada matriks a dengan penerapan metode Non-Negative Matrix factorization sehingga diperoleh matriks W dan matriks H, Tabel V dan VI.
TABEL V. MATRIKSW 0 5.6E-05 2.07 1.98 4.31 0 0.18 0 1.8E-05 4.22 1.04 0.58 0 1.56 0 0.00039 0.29 1.49 3.03 0 1.00 64.40 112.23 19.47 12.22 79.82 13.70 82.49 56.20 0.003 4.54 0.02 0.49 177.94 0.007 12.25 73.12 42.96 54.12 31.90 3.84 10.78 6.66 0.13 8E-06 1.033 0 0 1.67 16.11 0.02 1E-06 3.37 0 0 0.23 7.56 99.51 39.42 51.31 19.46 33.21 90.20 0 0 0.02 0 0.36 42.60 0 5.36 0.002 3.91 94.40 0.19 0 21.87 TABEL VI. MATRIKSH
1.3E-5 0.0006 0.003 1.6E-05 0.001 0.0007 0.002 0.004 0.001 0.001 0.0004 5.8E-05 0.002 3E-06 0.002 2E-05 0.002 0.001 0.0001 0.0006 0 0.008 0.0005 0 0.002 2.4E-06 0.002 0.0007 0.008 1E-06 1E-05 7E-06 7.9E-05 0.007 6.4E-05 5.7E-05 5.6E-05 0.002 0.001 0.004 5E-06 5.1E-05 0.009 0
Matriks W dan matriks H diatas merupakan matriks yang telah melalui proses Multiplicative Update Rule Process sehingga diperoleh matriks diatas. Untuk memperoleh bobot setiap term maka dilakukan penghitungan bobot pada matriks H dimasing-masing elemen pada baris matriks, Tabel VII.
TABEL VII. BOBOTTERMMATRIKSH
Baris i Pada Matriks H Bobot i
1 0.049514 2 0.119125 3 0.039843 4 0.073758 5 0.056826 6 0.119799 7 0.077204 8 0.119084 9 0.098252 10 0.112491 11 0.134104
Kemudian dari pembobotan setiap baris term pada matriks H diatas dilakukan pemrosesan dengan penerapan metode Generic Relevance of Sentences respon dengan kunci jawaban yang disediakan sehingga, diperoleh bobot pada setiap respon terhadap kunci jawaban pada Tabel VIII.
TABEL VIII. BOBOT GRSRESPON TERHADAP KUNCI JAWABAN
Respon Bobot
1 0.001783 2 0.002277 3 0.002350 4 0.001196
Kemudian bobot respon terhadap kunci jawaban tersebut diurutkan berdasarkan nilai bobot tertinggi, Tabel IX.
TABEL IX. URUTANBOBOTGRSRESPONTERBESAR
Respon Bobot
3 0.002350 2 0.002277 1 0.001783 4 0.001196
IV. KESIMPULAN
Berdasarkan hasil dari penelitian ini, dapat disimpulkan bahwa metode Non-Negative Matrix Factorization dan Generic Relevance of Sentence dapat digunakan untuk pada eksaminasi berbasis komputer dengan model essay atau Computer Based Test Essay, metode ini melakukan pembobotan terhadap sebuah respon yang memiliki hubungan terhadap kunci jawaban yang tersedia pada dataset. Dimana, berdasarkan hasil penelitian ini, pada respon 3 memiliki bobot tertinggi yang memiliki tingkat relevansi respon terhadap kunci jawaban lebih tinggi dibanding dengan respon lainnya sehingga dapat dilakukan penilaian pada sistem eksaminasi dengan model essay menggunakan metode ini.
DAFTAR PUSTAKA
[1] N. K. Batcha, “Mining Frequent Patterns using Non-negative Matrix Factorization,” no. 1, pp. 1–4, 1999.
[2] A. Ridok, “PERINGKASAN DOKUMEN BAHASA INDONESIA BERBASIS NON-NEGATIVE MATRIX FACTORIZATION ( NMF ),” vol. 1, no. 1, pp. 39–44, 2014.
[3] P. O. Hoyer, “Non-negative matrix factorization with sparseness constraints,” vol. 5, pp. 1457–1469, 2004.
[4] “ORTHOGONALITY-REGULARIZED MASKED NMF FOR LEARNING ON WEAKLY LABELED AUDIO DATA Iwona Sobieraj , Lucas Rencker , Mark D . Plumbley University of Surrey Centre for Vision Speech and Signal Processing Guildford , Surrey GU2 7XH , United Kingdom,” pp. 2436–2440, 2018.
[5] D. Metode and F. Matriks, “Implementasi peringkasan otomatis pada dokumen terstruktur dengan metode faktorisasi matriks nonnegatif,” no. November, 2017.
[6] Y. Gong and X. Liu, “Generic text summarization using relevance measure and latent semantic analysis,” Proc. 24th Annu. Int. ACM SIGIR Conf. Res. Dev. Inf. Retr. - SIGIR ’01, pp. 19–25, 2001. [7] H. Maharani and M. Sanjaya, “Peringkasan Dokumen dengan Metode
Non-Negative Matrix Factorization,” vol. 8, no. 2, 1858.
[8] G. Al-Talib and H. Hassan, “A Study on Analysis of SMS Classification Using TF-IDF Weighting,” Int. J. Comput. Networks Commun. Secur., vol. 1, no. 5, pp. 189–194, 2013.
[9] A. Mishra and S. Vishwakarma, “Analysis of TF-IDF Model and its Variant for Document Retrieval,” pp. 772–776, 2015.