11 BAB II
KAJIAN PUSTAKA
2.1 State Of The Art Review
Beberapa penelitian yang berkaitan dengan pengembangan model untuk
nearly real time data warehouse (NRTDWH) telah banyak dilakukan, diantaranya
penelitian yang dilakukan oleh Wisswani dkk, (2012) yang melakukan pemodelan
change data capture untuk nearly real time data warehouse dengan meletakkan trigger pada sisi On Line Transactional Processing (OLTP). NRTDWH dalam
penelitian ini diimplementasikan dalam dua tahapan. Tahap pertama dilakukan dengan memodelkan teknik pengambilan data agar data yang dikelola oleh mesin
extract, transfer, load (ETL) menjadi lebih ringkas. Tahap ini meletakkan staging area pada on line transactional processing (OLTP). Selain itu pada OLTP juga
diterapkan metode change data capture (CDC) yang akan diimplementasikan dengan active database berupa trigger. Tahap kedua adalah proses sinkronisasi pemindahan data dari staging area ke NRTDWH.
Penelitian lain tentang NRTDWH juga dilakukan oleh Bokade dkk, (2013) yang membahas tentang framework dari change data capture berdasarkan pada
transaction log file dari suatu basis data dan proses ekstraksi data pada real time data warehouse. Pada penelitian ini dijelaskan bahwa ada beberapa teknik dan
teknologi yang dapat diterapkan untuk menangani proses CDC, diantaranya yaitu : (1) Transaction Log File; (2) Trigger Method; (3) RDBMS Replication. Pada penelitian ini dinyatakan bahwa hampir semua DBMS memiliki
transaction log file yang mencatat semua perubahan yang terjadi dalam basis data
yang dilakukan oleh setiap transaksi. Untuk menangkap perubahan yang terjadi pada basis data, kita harus memeriksa dan menganalisa isi dari transaction log file dari basis data. Ketika proses CDC diimplementasikan menggunakan teknik
transaction log file maka proses analisa transaction log file tidak akan
mempengaruhi operational transactional database.
Dari penelusuran yang penulis lakukan di beberapa sumber pustaka, termasuk di beberapa database hasil penelitian seperti www.doaj.com, www.proquest.com, scholar.google.com, ieeexplore.ieee.org, Penelitian yang membahas tentang integrasi NRTDWH dengan SOA masih sangat jarang dilakukan (jumlah jurnal yang ditemukan kurang dari 6).
Cristian, (2010) melakukan penelitian tentang pembuatan model data
warehouse dengan menggunakan metode service oriented architecture untuk
menunjang sistem informasi eksekutif pada Universitas Budi Luhur. Model ini dikembangkan dengan menggunakan metode SOA dengan tujuan untuk menghasilkan data yang bisa diakses oleh end application yang berbeda-beda dan independen terhadap DBMS. Pengembangan data warehouse dalam penelitian ini menggunakan pendekatan business dimensional life cycle. Salah satu pendekatan yang diusulkan oleh Ralph Kimball, yaitu mengintegrasikan pengembangan dari tiga sudut pandang berbeda, yaitu teknologi, data dan aplikasi dari pendekatan bisnis. Untuk model skema yang digunakan ialah star schema, dimana satu tabel fakta dikelilingi oleh beberapa tabel dimensi. Penggunaan skema ini dilandasi atas kemudahan query dan akses terhadap tabel dimensi yang lebih mudah. Model
distribusi data warehouse yang dikembangkan berbasis web service dengan
framework WSF/PHP. Web service dikembangkan dalam bentuk file PHP dengan
format yang disesuaikan dengan framework. Untuk keperluan prototipe ini, dikembangkan contoh 6 service.
Penelitian tentang SOA telah banyak dilakukan, diantaranya penelitian Mankad dan Sajja, (2010) yang membahas bagaimana arsitektur Procedural
Developments, Structured Design, Client Server Technology, Transaction Processing, Component Oriented N tier, World Wide Web, Object Oriented Architecture telah berhasil membuktikan bahwa mereka sudah mampu memberikan
keuntungan dalam perancangan suatu perangkat lunak tertentu. Akan tetapi disaat yang bersamaan mereka kurang efisien untuk memenuhi kebutuhan yang cepat dalam penyediaan beberapa aplikasi seperti aplikasi terintegrasi. Dalam penelitian ini dijelaskan bahwa arsitektur SOA mampu memberikan solusi terhadap kekurangan dari arsitektur seperti di atas karena:
1. SOA dapat dikembangkan dari sistem yang sudah ada. Service dapat dibuat menggunakan teknologi yang sudah ada dengan pendekatan berbasis komponen. Hal ini membuat SOA mampu memberikan alternatif solusi lain secara fleksibel. 2. SOA dapat ditanamkan pada arsitektur berbasis objek dengan menambahkan
lapisan abstraksi.
3. SOA bukan hanya suatu arsitektur dari services jika dilihat dari perspektif teknologi tapi juga suatu kebijakan, praktek dan kerangka kerja dimana SOA dapat memastikan bahwa suatu service yang tepat sudah disediakan dan dikonsumsi.
4. SOA dapat menawarkan services baru kepada pelanggan tanpa harus khawatir dengan infrastruktur IT yang ada dibelakangnya.
5. SOA dapat memberikan efektivitas biaya dengan mengintegrasikan sistem historis terpisah dengan penurunan waktu siklus dan biaya.
6. SOA dapat mengurangi risiko dengan meningkatkan visibilitas operasi bisnis. Tabel 2.1 berisi daftar penelitian yang sudah dilakukan yang terkait dengan topik yang penulis ambil pada pembuatan thesis ini.
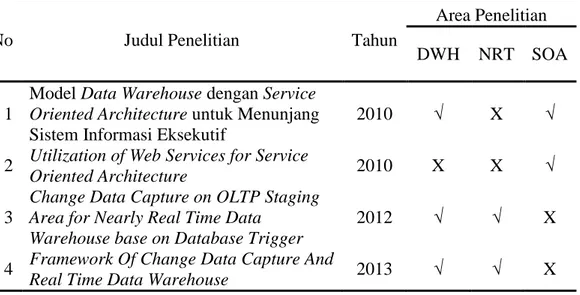
Tabel 2.1 Daftar Penelitian yang dijadikan acuan
No Judul Penelitian Tahun
Area Penelitian DWH NRT SOA
1
Model Data Warehouse dengan Service
Oriented Architecture untuk Menunjang
Sistem Informasi Eksekutif
2010 √ X √
2 Utilization of Web Services for Service
Oriented Architecture 2010 X X √
3
Change Data Capture on OLTP Staging Area for Nearly Real Time Data
Warehouse base on Database Trigger
2012 √ √ X
4 Framework Of Change Data Capture And
Real Time Data Warehouse 2013 √ √ X
2.2 Konsep Data Warehouse
Rainardi (2008:p.1) menjelaskan data warehouse merupakan suatu sistem yang mengambil dan menkonsolidasikan data secara periodik dari sistem asal menjadi suatu penyimpanan data dimensional atau ternormalisasi. Data warehouse biasanya akan tetap menyimpan informasi yang berasal dari beberapa tahun belakangan yang akan dipakai untuk business intelligence atau untuk keperluan-keperluan analisis. Data warehouse biasanya diperbarui dalam suatu periode waktu tertentu, tidak setiap suatu transaksi terjadi pada sistem asal.
Menurut Vincent Rainardi, ada dua definisi utama dari data warehouse yang dikonsepsikan oleh dua orang yang disebut sebagai bapak dari data
warehouse, yaitu Bill Inmon dan Ralph Kimball (Rainardi, 2008:p.16). Menurut
Bill Inmon, data warehouse merupakan sekumpulan data yang berorientasi subjek, terintegrasi, non-volatile dan time-variant untuk mendukung pengambilan keputusan oleh pihak manajemen (Inmon, 2005:p.29). Menurut Ralp Kimball, data
warehouse adalah suatu sistem yang mengambil, membersihkan, menyesuaikan,
dan mengirimkan sumber data ke dalam penyimpanan data dimensional dan kemudian mendukung serta mengimplementasikan query dan analisis untuk tujuan pengambilan keputusan (Kimball, 2004:p.23).
Definisi lain yang cukup menarik tentang data warehouse dikemukakan oleh Hammergren dan Simon (2009), yang menyebutkan data warehouse sebagai data yang dikoordinasikan, dibangun, dan secara periodik disalin dari berbagai sumber ke dalam sebuah lingkungan yang dioptimalkan untuk analisis dan pengolahan informasi (Hammergren, 2009:p.9).
2.3 Karakteristik Data Warehouse
Berikut ini adalah karakteristik utama dari data warehouse menurut Turban (2005:p.306-307):
a. Berorientasi-subjek
Data diorganisasikan oleh subjek detail (misal berdasarkan pelanggan, jenis kebijakan, dan klaim dalam perusahaan asuransi), yang berisi hanya informasi yang relevan untuk mendukung keputusan. Orientasi subjek memungkinkan para pengguna untuk menentukan tidak hanya bagaimana bisnis mereka sedang
berjalan, tetapi juga mengapa ia berjalan. Data warehouse berbeda dengan
database operasional dalam hal kebanyakan database operasional mempunyai
sebuah orientasi produk dan disetel untuk menangani transaksi yang memperbarui database; orientasi subjek menyediakan sebuah pandangan yang menyeluruh mengenai organisasi.
b. Terintegrasi
Data pada sumber berbeda dapat dienkode dengan cara yang berbeda. Sebagai contoh, data jenis kelamin dapat dienkode sebagai 0 dan 1 di satu tempat dan ‘m’ dan ‘f’ di tempat lain. Di dalam warehouse, enkode tersebut dibuat (dibersihkan) ke dalam satu format sehinga mereka distandarisasi dan konsisten. Banyak organisasi menggunakan terminologi yang sama untuk data dari jenis yang berbeda. Sebagai contoh, “penjualan bersih” bisa berarti komisi bersih untuk departemen pemasaran, tetapi retur penjualan kotor bagi departemen akuntansi. Data yang terintegrasi mengatasi inkonsistensi dan menyediakan istilah yang seragam di organisasi keseluruhan. Juga, format, waktu dan data bervariasi di seluruh bumi.
c. Time-variant (time series)
Data tidak menyediakan status saat ini. Mereka disimpan untuk lima atau sepuluh tahun atau lebih dan digunakan untuk tren, peramalan, dan perbandingan. Ada kualitas sementara pada sebuah data warehouse. Waktu
adalah dimensi penting yang harus didukung oleh semua data warehouse. Data
untuk analisis dari berbagai sumber berisi berbagai poin waktu (misal harian, mingguan, bulanan).
d. Non-volatile
Sekali dimasukkan ke dalam warehouse, data adalah read-only, mereka tidak bisa diubah atau dibarui. Data usang dibuang, dan perubahan direkam sebagai data baru. Ini memungkinkan data warehouse untuk disesuaikan hampir secara eksklusif untuk akses data. Sebagai contoh, sejumlah besar ruang kosong (untuk pertumbuhan data) umumnya tidak diperlukan dan reorganisasi database dapat dijadwalkan bersama dengan operasi pengisian sebuah data warehouse.
e. Ringkas
Jika diperlukan, data operasional dikumpulkan ke dalam ringkasan-ringkasan. f. Tidak ternormalisasi
Data di dalam sebuah data warehouse biasanya tidak dinormalisasi dan sangat redundan.
g. Sumber
Semua data ada, baik internal maupun eksternal. h. Metadata
Metadata digambarkan sebagai data tentang data.
2.4 Arsitektur Data Warehouse
Sistem data warehouse memiliki dua arsitektur utama yaitu : arsitektur aliran data dan arsitektur sistem (Rainardi, 2008:p.29).
2.4.1 Arsitektur aliran data
Arsitektur aliran data berisi mengenai bagaimana penyimpanan data diatur di dalam data warehouse dan bagaimana data mengalir dari sistem asal ke pengguna melalui penyimpanan-penyimpanan data ini (Rainardi, 2008:p.29).
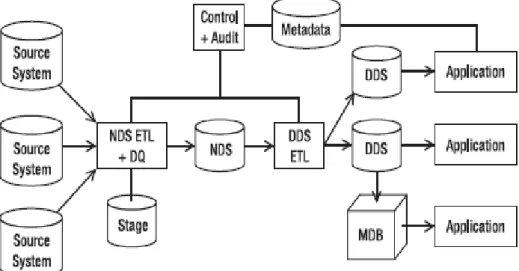
Penyimpanan data (data stores) merupakan komponen penting dari arsitektur aliran data. Penyimpanan data merupakan satu atau beberapa basis data atau file-file yang berisi data dari data warehouse, yang disusun dalam suatu format tertentu dan terlibat dalam proses-proses data warehouse. Berdasarkan hak akses dari pengguna maka penyimpanan data dapat diklasifikasikan menjadi tiga (Rainardi, 2008:p.30), yaitu:
a. User facing data store
Penyimpanan data yang tersedia untuk end user dan di-query oleh aplikasi end
user.
b. Internal data store
Penyimpanan data yang digunakan secara internal oleh komponen data
warehouse untuk tujuan integrasi, pembersihan, pencatatan dan persiapan data
dan tidak dibuka untuk diakses oleh end user dan aplikasi end user. c. Hybrid data store
Penyimpanan data yang digunakan baik untuk mekanisme internal data
warehouse dan untuk diakses oleh end user dan aplikasi end user.
Berdasarkan format data, penyimpanan data dapat diklasifikasikan menjadi empat (Rainardi, 2008:p.30), yaitu:
a. Stage
Stage merupakan penyimpanan data internal yang digunakan untuk merubah dan
mempersiapkan data yang diperoleh dari sistem asal, sebelum data dikirim ke penyimpanan data yang lain dalam data warehouse.
b. Normalized data store (NDS)
NDS merupakan penyimpanan data master internal dalam bentuk satu atau beberapa basis data relasional ternormalisasi untuk tujuan integrasi data yang berasal dari beberapa sumber data yang ditangkap dalam proses stage, sebelum data dikirim ke user-facing data store.
c. Operational data store (ODS)
ODS merupakan penyimpanan data hybrid dalam bentuk satu atau beberapa basis data relasional ternormalisasi yang mengandung data transaksi serta data master versi terkini untuk tujuan mendukung aplikasi operasional.
d. Dimensional data store (DDS)
DDS merupakan user facing data store dalam bentuk satu atau beberapa basis data relasional, dimana data disusun dalam format dimensional untuk tujuan mendukung permintaan analisis data.
Untuk lebih jelasnya arsitektur aliran data dapat dilihat pada gambar 2.1:
Gambar 2.1 Arsitektur Aliran Data (Sumber : Rainardi, 2008:p.35)
2.4.2 Arsitektur sistem
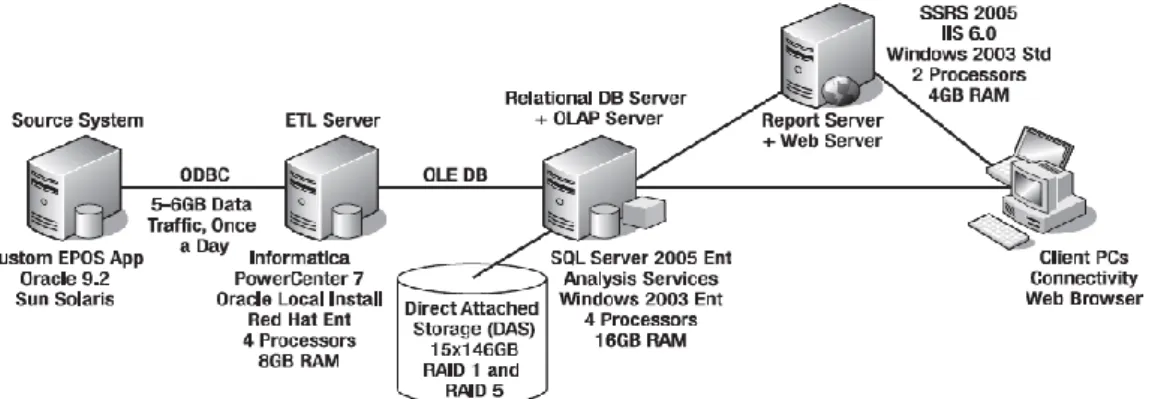
Arsitektur sistem berisi mengenai konfigurasi fisik dari server-server, jaringan, perangkat lunak, perangkat penyimpanan, dan klien-klien (Rainardi, 2008:p.29).
Perancangan arsitektur sistem membutuhkan pengetahuan tentang perangkat keras (khususnya server), jaringan (yang berhubungan dengan keamanan dan kinerja) serta media penyimpanan (SAN, RAID, Tape Backup).
Untuk lebih jelasnya arsitektur sistem dapat dilihat pada gambar 2.2:
Gambar 2.2 Arsitektur Sistem (Sumber : Rainardi, 2008:p.42) 2.5 Metodologi Pengembangan Data Warehouse
Pembuatan data warehouse pada penelitian ini menggunakan pendekatan
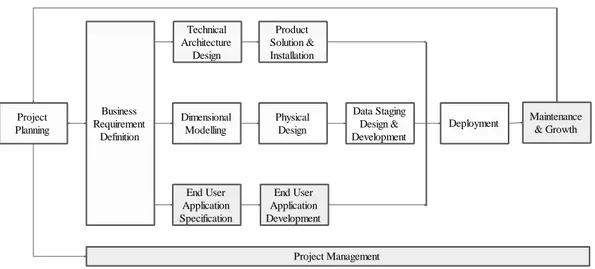
business dimensional lifecycle dari Ralph Kimball. Adapun diagram dari
Gambar 2.3 Diagram Business Dimensional Life Cycle (Sumber : Kimball, 1998:p.2.3)
Pendekatan business life cycle yang diusulkan oleh Ralp Kimball ini adalah pendekatan yang mengintegrasikan 3 konsepsi yang berbeda dari sudut pandang bisnis, yaitu teknologi, data, dan aplikasi (Kimball, 1998:p.2.2).
Berikut ini akan dijelaskan masing-masing komponen yang terdapat pada diagram business dimensional lifecycle:
a. Project Planning
Perencanaan proyek membahas definisi dan cakupan dari proyek data
warehouse, termasuk penilaian kesiapan dan justifikasi bisnis. Perencanaan
proyek berfokus pada sumber daya, ditambah dengan tugas proyek yang akan diberikan, durasi waktu, dan urutan pengerjaan.
b. Data Track : Dimensional Modelling
Definisi dari kebutuhan bisnis menentukan data yang diperlukan untuk kebutuhan analisis pengguna bisnis. Merancang model data untuk mendukung analisis membutuhkan pendekatan yang berbeda dari yang digunakan untuk
Project Planning Technical Architecture Design Product Solution & Installation Dimensional Modelling Physical Design Data Staging Design & Development End User Application Specification End User Application Development Deployment Maintenance & Growth Project Management Business Requirement Definition
desain sistem operasional. Tahapan ini mengidentifikasi tabel fakta, dimensi-dimensi yang terkait dan atribut-atribut. Desain database logis dilengkapi dengan struktur tabel yang sesuai dan hubungan primary / foreign key. Rencana agregasi awal juga dikembangkan pada tahapan ini.
c. Data Track : Physical Design
Desain database fisik yang berfokus pada bagaimana cara mendefinisikan struktur fisik yang diperlukan untuk mendukung desain database logis. Elemen utama dari proses ini meliputi mendefinisikan penamaan standar dan menyiapkan lingkungan database. Pengindeksan awal dan strategi partisi juga ditentukan pada tahapan ini.
d. Data Track : Data Staging Design and Development
Tahapan ini berfokus pada perencanaan dan pembuatan database data staging. Proses pada data staging ini meliputi extraction, transformation, dan load. e. Technology Track : Technical Architecture Design
Lingkungan data warehouse membutuhkan integrasi dari beberapa jenis teknologi. Pada tahapan ini akan ditentukan jenis teknologi yang akan dipakai pada data warehouse seperti spesifikasi perangkat keras server, jaringan, perangkat lunak sistem operasi, perangkat lunak basis data, dll. Ada tiga hal penting yang harus dipertimbangkan dalam tahapan ini, yaitu : analisa kebutuhan arsitektur, arsitektur yang sedang berjalan dan arah pengembangan arsitektur di masa depan.
f. Technology Track : Product Selection and Installation
Pada tahapan ini akan dilakukan proses evaluasi dan pemilihan dari komponen-komponen hardware dan software yang telah dipilih pada tahapan technical
architecture design. Setelah dipilih maka komponen ini kemudian akan
dipakai/dipasang.
g. Application Track : End User Application Specification
Sebaiknya mendefinisikan satu set aplikasi pengguna akhir yang standar karena tidak semua bisnis pengguna memerlukan akses ad hoc ke gudang data. Spesifikasi aplikasi menggambarkan template laporan, parameter yang harus dimasukkan oleh pengguna, dan perhitungan yang diperlukan. Spesifikasi ini memastikan bahwa tim pengembangan dan pengguna bisnis memiliki pemahaman umum yang sama akan aplikasi yang akan dikembangkan.
h. Application Track : End User Application Development
Pada tahapan ini akan dikembangkan end user application yang telah disesuaikan dengan spesifikasi yang telah ditentukan pada tahapan end user
application specification.
i. Deployment
Deployment merupakan proses konvergensi dari teknologi, data, dan aplikasi
pengguna akhir yang diakses dari komputer desktop pengguna bisnis. j. Maintenance and Growth
Pada tahapan ini akan dilakukan proses pemeliharaan pada teknologi, data, dan aplikasi pengguna akhir yang terdapat dalam lingkungan data warehouse. Seiring perkembangan waktu pasti akan terjadi pertumbuhan data yang pesat
dimana mengakibatkan terjadinya penyesuaian pada teknologi, data, dan aplikasi pengguna akhir terhadap kebutuhan yang baru.
k. Project Management
Manajemen proyek memastikan bahwa kegiatan-kegiatan yang terdapat dalam
business dimensional lifecycle tetap berada pada jalur yang benar (spesifikasi
yang telah ditentukan sebelumnya) dan berjalan sinkron antar kegiatan satu dengan kegiatan yang lain.
2.6 Sistem ETL dalam Data Warehouse
ETL merupakan singkatan dari extract, transform, load. Sistem ETL merupakan sekumpulan proses-proses yang mengambil data dari sistem sumber, melakukan perubahan pada data dan mengirimkan data ke suatu sistem target (Rainardi, 2008:p.4).
Menurut Kimball, sistem ETL merupakan pondasi dari data warehouse. Sebuah sistem ETL yang dirancang dengan baik akan mengekstrak data dari sistem sumber, memberlakukan standar kualitas data dan konsistensi data, melakukan penyesuaian data sehingga beberapa sumber berbeda dapat digunakan secara bersama-sama, dan pada akhirnya akan mengirimkan data dalam format siap pakai sehingga pengembang aplikasi dapat membangun aplikasi dan pengguna akhir dapat membuat keputusan (Kimball, 2004:p.xxi).
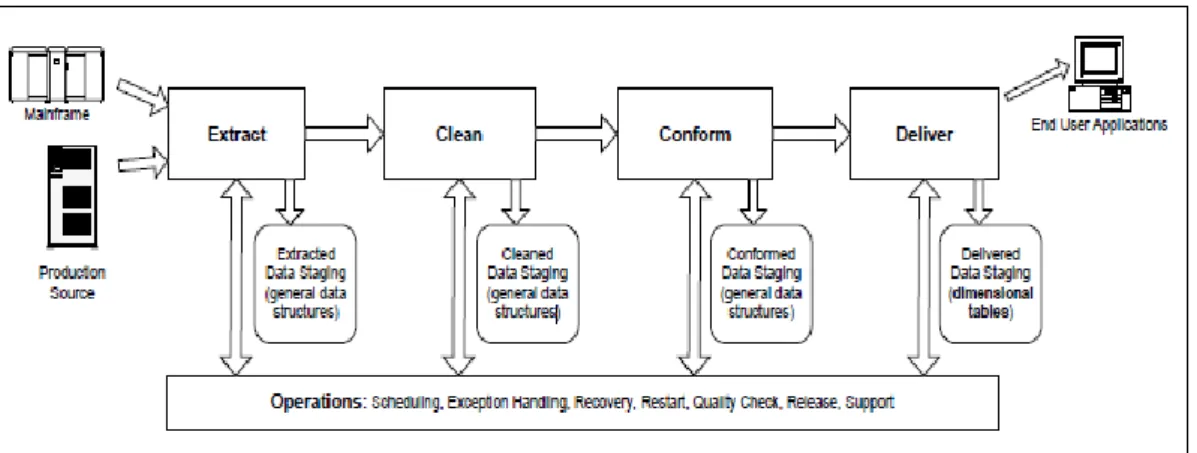
Berikut ini pada gambar 2.4 akan ditunjukkan arsitektur sistem ETL dalam
Gambar 2.4 Arsitektur Sistem ETL pada Bagian Staging Area (Sumber : Kimball, 2004:p.18)
2.6.1 Extraction
Data mentah yang berasal dari sistem sumber biasanya ditulis langsung ke
disk dengan beberapa restrukturisasi minimal sebelum transformasi konten yang
signifikan terjadi. Data dari sistem sumber terstruktur (seperti IMS database, atau
XML data set) sering ditulis ke flat file atau tabel relasional dalam langkah ini. Hal
ini memungkinkan proses ekstraksi data menjadi sesederhana dan secepat mungkin serta memungkinkan fleksibilitas yang lebih besar untuk mengulangi proses ekstraksi data jika ada gangguan. Data awal yang diambil kemudian dapat dibaca beberapa kali seperlunya untuk mendukung langkah-langkah berikutnya. Dalam beberapa kasus, data awal yang diambil akan dibuang setelah langkah pembersihan selesai, sedangkan pada kasus lain data akan disimpan sebagai arsip cadangan jangka panjang. Data awal yang diambil juga dapat disimpan untuk setidaknya satu siklus capture sehingga perbedaan antara proses ekstraksi data yang berturut-turut dapat dihitung (Kimball, 2004:p.18).
2.6.2 Cleaning
Proses cleaning ini merupakan salah satu bagian dari proses data
transformation. Dalam kebanyakan kasus, tingkat kualitas data yang dapat diterima
dari sistem sumber bisa berbeda dengan kualitas yang dibutuhkan oleh data
warehouse. Kualitas pengolahan data dapat melibatkan banyak langkah diskrit,
termasuk memeriksa nilai-nilai yang valid (apakah ada kode pos? dan apakah kode pos berada dalam rentang nilai yang valid?), memastikan konsistensi pada nilai (apakah kode pos dan kota konsisten?), menghapus duplikat (apakah pelanggan yang sama muncul dua kali dengan atribut sedikit berbeda?), dan memeriksa apakah aturan bisnis yang kompleks dan prosedur telah ditegakkan (apakah pelanggan platinum memiliki keterkaitan dengan status kredit diperpanjang?). Transformasi
data-cleaning bahkan mungkin melibatkan intervensi manusia. Hasil langkah
pembersihan data sering disimpan secara semi permanen karena transformasi yang diperlukan sulit dan tidak dapat diubah. Ini adalah pertanyaan yang menarik dalam lingkungan apapun, apakah data yang sudah dibersihkan dapat dikirim kembali ke sistem sumber untuk meningkatkan kualitas data mereka dan mengurangi kebutuhan untuk memproses masalah data yang sama berulang-ulang. Bahkan jika data yang sudah dibersihkan tidak dapat dikirimkan ke sistem sumber, permasalahan ini tetap harus dilaporkan supaya dapat dilakukan perbaikan dalam sistem sumber (Kimball, 2004:p.18-19).
2.6.3 Conforming
Proses conforming merupakan salah satu bagian dari proses data
digabungkan ke dalam data warehouse. Sumber data terpisah tidak dapat dilihat bersama-sama kecuali beberapa atau semua label tekstual dalam sumber-sumber ini telah dibuat identik dan kecuali langkah-langkah numerik yang serupa telah dirasionalisasi secara matematis sehingga perbedaan dan rasio antara langkah-langkah ini menjadi masuk akal. Data konformasi merupakan langkah-langkah signifikan yang lebih sederhana dari data cleaning. Data konformasi memerlukan kesepakatan perusahaan besar untuk penggunaan domain dan langkah-langkah standar (Kimball, 2004:p.19).
2.6.4 Delivering
Proses delivering ini lebih dikenal dengan nama proses loading. Proses
delivering adalah suatu proses untuk mengirim data hasil proses transformasi data
(data yang sudah dibersihkan dan data yang sudah disesuaikan formatnya) ke dalam
data warehouse. Data warehouse ini berupa penyimpanan data dimensional (Data Dimensional Store). Isi dari data dimensional store (DDS) inilah yang akan diakses
oleh aplikasi end user baik untuk kepentingan business intelligence (BI), analytics
(On Line Analytical Processing), data mining, dashboard, scorecards, reports
(Rainardi, 2008). 2.7 Metode ETL
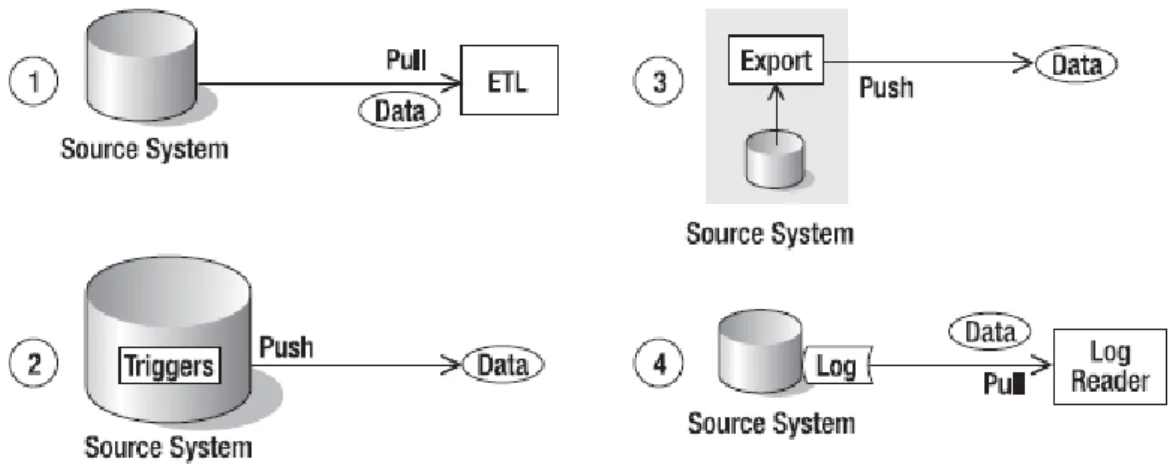
Dalam hal siapa yang memindahkan data keluar dari sistem sumber, kita dapat mengkategorikan metode ETL menjadi empat pendekatan (Rainardi, 2008:p.176):
a. Proses ETL menarik data keluar dari sistem sumber dengan melakukan query secara reguler ke basis data sistem sumber. Ini merupakan pendekatan yang paling umum digunakan. Proses ETL melakukan koneksi ke basis data sistem sumber, melakukan query data, dan membawa data keluar.
b. Proses trigger di basis data sistem sumber mendorong data yang berubah keluar dari sistem sumber. Trigger basis data adalah kumpulan dari perintah SQL yang dieksekusi setiap ada operasi insert, update, atau delete pada suatu tabel. Dengan menggunakan trigger, kita dapat menyimpan baris data yang berubah ke dalam tabel yang lain.
c. Proses terjadwal yang terdapat pada sistem sumber yang mengirim data keluar secara reguler. Hal ini mirip dengan pendekatan yang pertama, akan tetapi program yang melakukan query ke basis data bukanlah suatu program ETL eksternal, melainkan suatu program eksporter internal yang berjalan pada server sistem sumber.
d. Log reader membaca file log basis data untuk mengidentifikasi perubahan data. File log basis data mengandung suatu catatan dari suatu transaksi yang terjadi pada basis data tersebut. Log reader adalah suatu program yang memahami format dari data yang terdapat pada file log. Log reader membaca file-file log, mengirim data ke luar sistem sumber, dan menyimpan data di tempat lain.
Gambar 2.5 Empat Metode ETL (Sumber : Rainardi, 2008:p.176) 2.8 Pendekatan dalam Pembuatan Data Warehouse
Menurut Ponniah, ada dua pendekatan dalam pembuatan data warehouse yaitu pendekatan top-down dan pendekatan bottom-up (Ponniah, 2010:p.29). 2.8.1 Pendekatan Top-Down
Bill Inmon adalah salah satu pendukung terdepan dari pendekatan top-down. Dia telah mendefinisikan data warehouse sebagai repositori terpusat untuk seluruh perusahaan. Dalam pendekatan ini, data di gudang data disimpan pada tingkat terendah dari granularity yang didasarkan pada model data dinormalisasi. Dalam visi Inmon, gudang data pada pusat "Corporate Information Factory" (CIF) menyediakan kerangka logis untuk memberikan kecerdasan bisnis (BI) untuk perusahaan. Operasi bisnis menyediakan data untuk mendorong CIF. Data
warehouse terpusat akan menyediakan kebutuhan untuk dependent data mart yang
mungkin dirancang berdasarkan model data dimensi. Keuntungan dari pendekatan ini adalah:
a. Bukan penggabungan dari data mart-data mart yang berbeda. b. Tempat penyimpanan data hanya satu, terpusat.
c. Aturan dan kontrol dilakukan secara terpusat.
d. Dapat melihat hasil cepat jika diimplementasikan secara iteratif. Kerugian dari pendekatan ini adalah:
a. Membutuhkan waktu pengembangan yang lebih lama walaupun dengan menggunakan metode iteratif.
b. Memiliki resiko kegagalan yang sangat tinggi.
c. Membutuhkan keterampilan lintas fungsional yang sangat tinggi. d. Pengeluaran akan besar jika tidak terdapat pembuktian dari konsep. 2.8.2 Pendekatan Bottom-Up
Ralp Kimball, merupakan salah satu pendukung terdepan untuk pendekatan
Bottom-Up. Dalam pendekatan ini data mart dibuat pertama kali untuk memberikan
analisis dan kemampuan pelaporan untuk subjek bisnis yang spesifik berdasarkan pada model data dimensi. Data mart berisi data pada tingkat terendah dari
granularity dan juga sebagai ringkasan, tergantung pada kebutuhan untuk analisis. Data mart ini kemudian akan digabungkan menjadi suatu data warehouse.
Keuntungan dari pendekatan ini:
a. Cepat dan mudah untuk diimplementasikan.
b. Dapat memberikan keuntungan atas investasi dengan suatu konsep yang dapat dibuktikan.
c. Resiko kegagalan kecil.
d. Dapat melakukan penjadwalan supaya data mart yang penting dibuat terlebih dahulu.
Kerugian dari pendekatan ini:
a. Setiap data mart memiliki pandangan yang berbeda akan data. b. Dapat terjadi data redundan pada setiap data mart.
c. Data tidak konsisten. d. Interface tidak dapat diatur. 2.9 Dimensional Data Modelling
Menurut Rainardi (2008), Sebuah gudang data adalah sistem yang mengambil data dari sistem sumber dan meletakkannya ke dalam penyimpanan data dimensi (data dimensional store). Sebuah data dimensional store (DDS) adalah satu atau beberapa database yang berisi kumpulan data mart dimensional. Data
mart dimensional adalah sekelompok tabel fakta yang terkait satu sama lainnya dan
dikelilingi oleh beberapa tabel dimensi yang berhubungan dengan tabel fakta, yang berisi pengukuran dari kegiatan bisnis yang dikategorikan oleh tabel dimensi (Rainardi, 2008:p.7).
Sebuah penyimpanan data dimensional merupakan penyimpanan data dalam bentuk yang tidak dinormalisasi dimana semua tabel dimensinya telah disesuaikan. Tabel dimensi yang sesuai berarti semua tabel dimensi memiliki dimensi yang sama atau satu tabel dimensi adalah subset dari tabel dimensi yang lain. Dimensi A dikatakan himpunan bagian dari dimensi B ketika semua kolom dimensi A ada di dimensi B dan semua baris dimensi A ada di dimensi B (Rainardi, 2008:p.7).
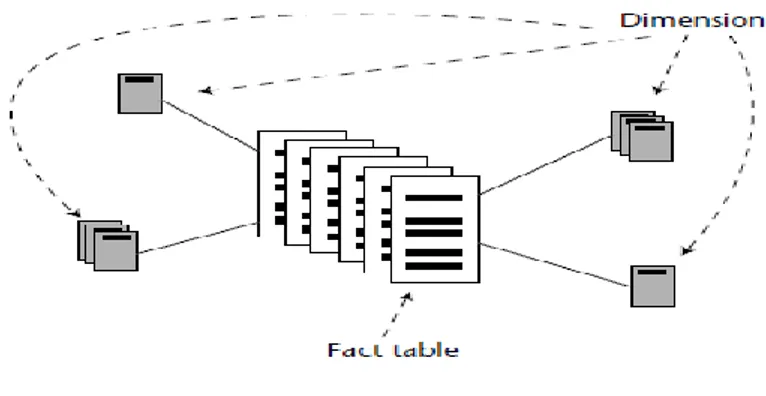
Sebuah penyimpanan data dimensional dapat diimplementasikan secara fisik dalam beberapa bentuk skema yang berbeda: skema bintang (star schema), skema kepingan salju (snow flake schema), dan skema galaksi (galaxy schema). a. Skema Bintang
Dalam skema bintang, dimensi tidak memiliki sub tabel (sub dimensi). Skema bintang dapat dilihat pada gambar 2.6.
Gambar 2.6 Skema Bintang (Sumber : Inmon, 2005:p.360) b. Skema Kepingan Salju
Dalam skema kepingan salju, dimensi dapat memiliki sub dimensi. Tujuan adanya sub dimensi ini adalah untuk meminimalkan terjadinya pengulangan data yang sama (data redundansi). Skema kepingan salju dapat dilihat pada gambar 2.7.
Gambar 2.7 Skema Kepingan Salju (Sumber : Inmon, 2005:p.361)
c. Skema Galaksi
Galaksi skema juga dikenal dengan nama skema konstelasi fakta (fact
constellation schema). Dalam skema galaksi kita memiliki dua atau lebih tabel
fakta yang saling terkait satu sama lainnya yang dikelilingi oleh beberapa tabel dimensi.
Kelebihan dari skema bintang adalah skema bintang lebih sederhana dan lebih konsisten dari skema kepingan salju dan skema galaksi, karena hanya memiliki satu level pada semua dimensi, sehingga memudahkan proses ETL untuk memuat data ke DDS. Kekurangan skema bintang adalah membutuhkan ruang penyimpanan data yang besar karena banyak terjadi pengulangan data (data redundansi) (Rainardi, 2008:p.7).
Kelebihan dari skema kepingan salju adalah bahwa beberapa aplikasi analisis data bekerja lebih baik dengan skema kepingan salju dibandingkan dengan skema bintang atau skema galaksi. Kelebihan yang lain dari skema kepingan salju adalah mengurangi terjadinya data redundansi, sehingga lebih sedikit ruang penyimpanan data yang diperlukan. Kekurangan dari skema kepingan salju adalah skemanya lebih komplek karena adanya sub dimensi. Hal ini menyebabkan waktu respon dari suatu query juga akan menurun karena adanya operasi JOIN untuk menggabungkan tabel dimensi dengan tabel sub dimensi (Rainardi, 2008:p.7).
Kelebihan dari skema galaksi adalah kemampuan untuk memodelkan peristiwa bisnis (business event) secara lebih akurat dengan menggunakan beberapa tabel fakta. Kekurangan dari skema galaksi adalah arsitekturnya lebih komplek karena terdapatnya dua atau lebih tabel fakta. Hal ini menyebabkan skema ini lebih
susah untuk dipahami dan waktu respon juga jauh lebih lambat dibandingkan skema kepingan salju karena operasi JOIN menjadi lebih komplek karena melibatkan beberapa tabel fakta yang terhubung dengan beberapa tabel dimensi (Rainardi, 2008:p.7).
2.10 Komponen Dimensional Data Modelling
Dalam dimensional modelling, basis data dibangun berdasarkan pengukuran numerik dari perusahaan. Tabel fakta mengandung pengukuran dan tabel dimensi mengandung konteks pengukuran yang terdapat disekitarnya (Kimball, 2004:p.209).
Dalam dimensional data modelling terdapat dua komponen utama yaitu tabel fakta dan tabel dimensi.
2.10.1 Tabel fakta
Hubungan antara tabel fakta dan pengukuran adalah sangat sederhana. Jika pengukuran ada, maka dapat dimodelkan menjadi suatu baris pada tabel fakta. Jika suatu baris dari tabel fakta ada maka itu adalah pengukuran (Kimball, 2004:p.209). Sebuah tabel fakta adalah struktur yang berisi banyak kejadian data. Disekitar tabel fakta adalah tabel dimensi, yang menggambarkan salah satu aspek penting dari tabel fakta. Jumlah kemunculan data pada tabel dimensi lebih sedikit dibandingkan dengan jumlah kemunculan data pada tabel fakta (Inmonn, 2005: p.360).
Tabel fakta adalah suatu tabel yang menjadi pusat dari beberapa tabel dimensi dalam skema bintang (Inmonn, 2005:p.497).
Ciri-ciri tabel fakta adalah (Wiswani, 2012:p.22):
a. Primary key pada tabel fakta terdiri atas gabungan lebih dari satu primary key yang dimiliki tabel-tabel dimensi yang terkait (concatenated key).
b. Memiliki tingkatan data yang telah teridentifikasi. c. Mudah untuk melakukan rekap data.
d. Memiliki jumlah record yang banyak. e. Memiliki kolom atau atribut yang sedikit. f. Tidak memiliki baris yang berisi nilai null. 2.10.2 Tabel dimensi
Tabel dimensi merupakan tempat dimana sekumpulan data yang berhubungan dengan tabel fakta ditempatkan dalam suatu tabel multi dimensi (Inmonn, 2005:p.495).
Tabel dimensi adalah tabel yang berisi berbagai atribut yang menjelaskan kunci dimensi yang terdapat pada tabel fakta (Rainardi, 2008:p.76).
Ciri-ciri tabel dimensi adalah (Wiswani, 2012:p.22): a. Memiliki key unik pada tabel dimensi (primary key). b. Memiliki jumlah kolom atau atribut yang banyak. c. Atributnya textual dan tidak saling berhubungan. d. Tabelnya tidak dilakukan normalisasi.
e. Mempunyai kemampuan untuk drill-down dan roll-up.
2.11 Agregasi Tabel Fakta
Agregasi adalah proses perhitungan ringkasan data dari keseluruhan data (record) yang ada. Hal ini sering digunakan untuk mengurangi ukuran tabel fakta dengan menggabungkan data ke dalam ringkasan data jika tabel fakta dibuat. Namun, ketika data diringkas dalam tabel fakta, informasi rinci tidak lagi langsung tersedia bagi analis. Jika informasi rinci diperlukan, baris detail yang diringkas harus diidentifikasi dan dicari, mungkin dalam sistem sumber yang memberikan data. Data tabel fakta harus dipertahankan pada kemungkinan granularity terbaik. Menggabungkan data dalam tabel fakta hanya boleh dilakukan setelah mempertimbangkan konsekuensinya (Technet, 2014).
Mencampur data agregat dan rinci dalam tabel fakta dapat menyebabkan masalah dan komplikasi bila menggunakan data warehouse. Sebagai contoh, order penjualan sering berisi beberapa item baris dan mungkin berisi diskon biaya, pajak, atau pengiriman yang diterapkan pada total order bukan item baris individu, namun jumlah dan identifikasi barang dicatat pada tingkat item baris. Permintaan
summarization menjadi lebih kompleks dalam situasi ini, dan alat-alat seperti Analysis Services sering membutuhkan pembuatan suatu filter khusus untuk
menangani permasalahan ini (Technet, 2014).
Ada dua pendekatan yang dapat digunakan dalam situasi ini. Satu pendekatan adalah untuk mengalokasikan nilai-nilai tingkat untuk baris item berdasarkan nilai, kuantitas, atau berat pengiriman. Pendekatan lain adalah untuk membuat dua tabel fakta, satu berisi data pada tingkat item baris, yang lain berisi informasi order-level. Kunci identifikasi urutan harus dilakukan dalam tabel rinci
fakta sehingga dua tabel dapat dihubungkan. Urutan tabel kemudian dapat digunakan sebagai tabel dimensi ke tabel detail, dengan nilai order-level yang dianggap sebagai atribut dari tingkat urutan hirarki dimensi (Technet, 2014). 2.12 Manajemen Kunci
Sebuah surrogate key adalah identifier dari baris data master dalam data
warehouse. Dalam DDS, surrogate key digunakan sebagai primary key dari tabel
dimensi. Surrogate key adalah bilangan bulat berurutan, mulai dari 0. Jadi,
surrogate key adalah 0, 1, 2, 3, ..., dan seterusnya. Dengan menggunakan surrogate key, kita dapat mengidentifikasi data unik yang terdapat pada tabel dimensi. Surrogate key juga ada pada tabel fakta untuk mengidentifikasi atribut dimensi
untuk suatu transaksi bisnis tertentu. Surrogate key digunakan untuk menghubungkan tabel fakta dan tabel dimensi. Misalnya, dengan menggunakan
surrogate key, kita dapat mengetahui data detail dari seorang pelanggan yang
terlibat pada suatu transaksi tertentu (Rainardi, 2008:p.37).
Natural key adalah suatu identifier unik dari baris data pada suatu tabel
master yang terdapat dalam sistem sumber (OLTP). Ketika terjadi pengambilan data dari OLTP untuk dikirim ke data staging, maka kita perlu menerjemahkan
natural key dari sistem sumber menjadi surrogate key untuk data warehouse. Hal
ini dapat dilakukan dengan memeriksa surrogate key yang terdapat pada data
staging, untuk setiap nilai natural key dari sistem sumber. Jika natural key ada di data staging, itu berarti data sudah ada di data staging dan perlu diperbarui. Jika
natural key tidak ada di data staging, itu berarti data tidak ada di data staging dan
perlu dibuat (Rainardi, 2008:p.37).
Surrogate key tidak akan memiliki arti apa-apa sebelum dilakukan mapping dengan natural key yang terdapat pada sistem sumber (Kimball,
2004:p.214).
2.13 Metode Ekstraksi Data
Setelah kita berhasil melakukan koneksi ke sumber data (sistem sumber) maka selanjutnya kita bisa melakukan proses ekstraksi data. Ketika melakukan ekstraksi data dari suatu basis data relasional yang terdiri dari banyak tabel, kita dapat menggunakan salah satu dari empat metode di bawah ini (Rainardi, 2008:p.180-186) :
a. Whole Table Every Time
Metode whole table every time akan digunakan jika ukuran tabelnya kecil, seperti suatu tabel yang terdiri dari 3 kolom bertipe integer atau varchar (10), dan hanya berisi beberapa baris data.
Alasan yang lebih umum mengapa memakai metode ini adalah karena tidak ada
timestamp atau kolom identitas yang dapat digunakan untuk mengetahui baris
mana yang telah diperbarui sejak proses ekstraksi data yang terakhir.
b. Incremental Extract
Tabel transaksi dalam suatu organasisasi besar adalah suatu tabel besar yang berisi ratusan ribu baris bahkan ratusan juta baris (atau lebih banyak lagi). Hal ini menyebabkan proses ekstraksi data dapat memakan waktu berhari-hari untuk mengekstrak data dari seluruh tabel. Proses ini merupakan proses yang sangat
intensif memakai sumber daya harddisk (storage device) sehingga dapat menurunkan kinerja transaksional pada aplikasi front-end karena terjadi
bottleneck pada basis data. Hal Ini bukanlah pilihan yang layak sebagai metode
ekstraksi data (karena waktu yang dibutuhkan untuk mengekstraksi data), jadi perlu suatu metode lain untuk mengekstrak data dari sistem sumber. Untuk mengatasi permasalah seperti kasus ini maka digunakan metode incremental
extraction.
Incremental extraction adalah teknik untuk men-download hanya baris yang
mengalami perubahan data pada sistem sumber, bukan men-download seluruh baris yang terdapat pada suatu tabel. Kita dapat menggunakan beberapa hal untuk mengekstraksi data dengan metode incremental extraction, yaitu : kolom
timestamp, kolom identitas, tanggal transaksi, pemicu (triggers), atau kombinasi
dari beberapa metode ini.
c. Fixed Range
Jika tidak mungkin untuk mengekstrak seluruh tabel karena tabel terlalu besar dan tidak mungkin untuk melakukan metode incremental extraction, misalnya, karena tidak ada kolom timestamp atau kolom timestamp tidak dapat diandalkan, karena tidak ada kolom identitas incremental extraction yang dapat diandalkan, dan karena tidak mungkin untuk memasang pemicu (triggers) dalam sistem sumber maka ada satu pendekatan yang lain yang bisa kita lakukan. Kita dapat menggunakan metode "fixed range".
Pada dasarnya dengan menggunakan metode fixed range, kita akan mengekstrak sejumlah data yang berada pada suatu jangka waktu tertentu. Misalnya, kita
mengekstrak data enam bulan terakhir, berdasarkan tanggal transaksi. Kita bisa mendapatkan durasi periode waktu transaksi dari sumber aplikasi jika ada pembatasan pada aplikasi front-end. Sebagai contoh, ketika proses closing (tutup buku) akhir bulan dilakukan, maka baris data tidak akan dapat diubah lagi. Dalam kasus ini, kita dapat men-download data pada lima minggu terakhir pada saat setiap kali proses ETL berjalan atau kita dapat men-download data di mana tanggal transaksi terjadi setelah tanggal akhir bulan (closing date). Jika tidak ada kolom tanggal transaksi dalam tabel dan kita tidak dapat mengekstrak seluruh tabel karena merupakan suatu tabel besar, maka kita dapat menggunakan
system-assigned row ID untuk mengekstrak data dengan metode fixed range, seperti
mengekstrak 100.000 baris data yang terakhir.
Yang dimaksud dengan system-assigned row ID adalah kolom tersembunyi dalam setiap tabel yang berisi nilai-nilai sekuensial yang diberikan oleh sistem. Tidak semua sistem database memiliki system-assigned row ID; misalnya,
Oracle dan Informix memiliki system-assigned row ID, tapi SQL Server dan DB/2 tidak. (Dalam DB/2, system-assigned row ID adalah tipe data, bukan
kolom tersembunyi.) Bila menggunakan system-assigned row ID, kita tidak memiliki batasan pada aplikasi front-end, jadi kita perlu memonitor sistem sumber dan mencari tahu berapa banyak baris yang kita perlu ambil setiap kali proses ekstraksi data dilakukan. Men-download kolom primary key setiap hari, dan membandingkan data primary key antar setiap proses download, setiap hari, untuk mendeteksi perubahan pada data. Proses identifikasi baris baru dan baris yang dihapus sangat mudah dilakukan dengan membandingkan primary key.
d. Related Tables
Jika baris dalam tabel sumber diperbarui, maka kita perlu untuk mengambil baris yang bersesuaian dalam tabel lain yang terkait dengan baris pada tabel yang diperbarui. Sebagai contoh, jika order ID 34552 di tabel header order diperbarui dan diekstraksi ke gudang data, baris untuk order ID 34552 pada tabel detail order juga harus diekstrak ke gudang data, dan sebaliknya. Sebagai contoh, jika sebuah baris dalam tabel detail order diperbarui dan baris tersebut diekstraksi ke dalam gudang data, maka baris yang bersesuaian di tabel header order juga perlu diekstrak ke dalam gudang data. Hal ini juga berlaku pada waktu menyisipkan dan menghapus baris data. Jika baris baru (order baru) dimasukkan ke dalam tabel header order dalam sistem sumber, maka baris tabel detail order yang bersesuaian dengan baris baru pada tabel header order juga perlu dimasukkan ke dalam data warehouse tabel detail order.
Jika suatu baris ditandai sebagai “canceled” (soft delete) dalam tabel header order pada sistem sumber, maka baris yang bersesuaian pada tabel detail order juga harus dibatalkan (canceled). Kita juga dapat melakukan hal ini dalam aplikasi data warehouse, tapi idealnya hal itu dilakukan dalam database data
warehouse. Jika suatu baris secara fisik dihapus dalam tabel header order, maka
baris yang bersesuaian pada tabel detail order dalam data warehouse juga perlu ditandai sebagai dihapus. Untuk melakukan hal ini, maka kita harus mengidentifikasi perubahan baris dalam tabel pertama, dan kemudian menggunakan hubungan relasi antara kunci primer (primary key) dan kunci asing (foreign key), kita juga mengidentifikasi baris dalam tabel kedua, dan
sebaliknya. Sebagai contoh, dalam kasus yang melibatkan tabel header order dan tabel detail order, terlebih dahulu kita menemukan adanya baris yang berubah pada tabel header order, maka kemudian kita akan mengidentifikasi baris yang bersesuaian dalam tabel detail order, dan pada akhirnya kita akan mengekstrak kedua set baris dari kedua tabel tersebut ke dalam data warehouse.
2.14 Slowly Changing Dimension
Slowly Changing Dimension (SCD) adalah suatu teknik yang digunakan
untuk menyimpan nilai historis dari atribut-atribut yang terdapat pada suatu tabel dimensi (Rainardi, 2008:p.80).
Ada tiga tipe dari SCD yaitu : a. SCD tipe 1
SCD tipe 1 adalah suatu teknik SCD yang menimpa nilai lama dari suatu atribut dengan nilai yang baru, sehingga nilai lama tidak dipertahankan.
b. SCD tipe 2
SCD tipe 2 adalah suatu teknik SCD yang mempertahankan nilai lama dari suatu atribut dengan membuat baris data baru setiap terjadi perubahan pada nilai atribut tersebut.
c. SCD tipe 3
SCD tipe 3 adalah suatu teknik SCD yang mempertahankan nilai lama dari suatu atribut dengan meletakkan nilai lama ini pada kolom yang lain pada baris data yang sama.
Umumnya, SCD tipe 2 lebih fleksibel untuk menyimpan nilai historis dari atribut-atribut dimensional. Hal ini dikarenakan dengan SCD tipe 2, kita dapat
menyimpan banyak versi nilai historis dari atribut-atribut dimensional tanpa mengubah struktur tabel (Rainardi, 2008:p.81).
SCD tipe 3 menggunakan kolom untuk menyimpan nilai-nilai lama, sehingga SCD tipe 3 menjadi tidak fleksibel. SCD tipe 3 ideal digunakan untuk situasi di mana kita tidak memiliki banyak versi nilai (lima atau lebih sedikit) dan kita tahu hanya akan ada sejumlah versi dari nilai atribut tersebut. SCD tipe 3 ini juga cocok digunakan ketika perubahan nilai atribut ini mempengaruhi cukup banyak baris data. Dengan kata lain, banyak baris dimensi mengubah nilai atribut ini pada saat yang sama (simultan) (Rainardi, 2008:p.81).
2.15 Real Time Data Warehouse
Data warehouse tradisional adalah pasif, memberikan tren historis,
sedangkan real-time data warehouse adalah dinamis, memberikan pandangan yang paling up-to-date tentang suatu bisnis secara real time. Sebuah real time data
warehouse akan akan diperbarui secara terus menerus, dengan waktu tunggu
hampir mendekati nol (Ponniah, 2010:p.50).
Real-time ETL bukanlah layanan data warehouse yang benar-benar real time. Dengan kata lain, real time ETL merupakan suatu perangkat lunak yang
memindahkan data secara asynchronous (secara terus menerus) ke dalam suatu data
warehouse dengan terdapat waktu jeda setelah proses eksekusi transaksi bisnis pada
sistem sumber (Kimball, 2004:p.424).
Sebuah gudang data, beberapa tahun yang lalu, biasanya diperbarui setiap hari atau setiap minggu. Dalam dua sampai tiga tahun terakhir, telah terjadi lebih banyak dan lebih banyak lagi permintaan untuk meningkatkan frekuensi update
data pada gudang data. Para pengguna ingin melihat data dalam gudang data diperbarui setiap dua menit atau bahkan secara real time. Sebuah real time data
warehouse adalah gudang data yang diperbarui (dengan ETL) saat transaksi terjadi
dalam sistem sumber (Rainardi, 2008:p.27).
Sebagai contoh, kita dapat menempatkan pemicu (triggers) pada tabel transaksi penjualan dalam sistem sumber sehingga setiap kali ada transaksi penjualan yang dimasukkan ke dalam database, maka triggers akan aktif dan kemudian akan mengirim data baru ke gudang data sebagai sebuah pesan. Data
warehouse memiliki active listener yang dapat menangkap pesan saat pesan sampai
ke data warehouse, membersihkan pesan itu, menerapkan data quality service (DQS) pada pesan itu, mengubah format pesan supaya sesuai dengan format data
warehouse, dan kemudian memasukkan pesan ke dalam tabel fakta. Ada perbedaan
waktu dua detik di sini, antara saat pelanggan membeli produk di situs web dan saat data ini tersedia dalam tabel fakta (Rainardi, 2008:p.27).
Pendekatan lain untuk mengimplementasikan real-time data warehouse adalah memodifikasi sumber aplikasi operasional (OLTP) untuk melakukan penulisan ke area data staging dari data warehouse, segera setelah menulis data ke dalam database internal. Dalam staging database, kita dapat menempatkan pemicu yang akan dipanggil setiap kali ada data baru yang akan dimasukkan, dan pemicu ini secara otomatis akan memperbarui data warehouse (Rainardi, 2008:p.27).
Pendekatan near real-time data warehouse dapat diimplementasikan dengan menggunakan mini-batch dengan frekuensi dua sampai lima menit. Pendekatan ini lebih memilih untuk menarik data dari area data staging dengan
frekuensi dua sampai lima menit dibandingkan menggunakan pemicu. Mini batch ini juga melakukan proses ETL yang standar yaitu pekerjaan-mengubah data dan memuatnya ke dalam basis data dimensional dari data warehouse. Mini-batch juga dapat menarik data secara langsung dari sistem sumber, menghilangkan kebutuhan memodifikasi sistem sumber untuk memperbarui area data staging (Rainardi, 2008:p.27).
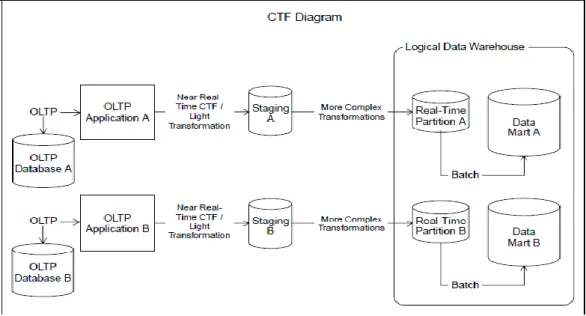
2.16 Capture Transform Flow
Capture, Transform, dan Flow (CTF) adalah tools untuk proses integrasi
data yang relatif baru muncul, yang dirancang untuk menyederhanakan proses pemindahan data secara real time antar teknologi basis data yang berbeda-beda. Lapisan aplikasi dari aplikasi transaksional dihilangkan. Pertukaran langsung antar
database-to-database akan dilakukan. Semua transaksi, baik perubahan pada tabel
fakta dan tabel dimensi dapat dipindahkan secara langsung dari sistem operasional ke tabel data staging dari data warehouse dengan waktu tunggu yang sangat kecil, hanya beberapa detik (Kimball, 2004:p.444).
CTF merupakan suatu pendekatan yang sangat baik untuk perusahaan yang membutuhkan near real time reporting dengan kebutuhan integrasi data yang tidak begitu besar serta (Kimball, 2004:p.445). Skema proses CTF dapat dilihat pada gambar 2.8.
Gambar 2.8 Proses Capture, Transform, dan Flow (Sumber : Kimball, 2004:p.445)
2.17 Change Data Capture
Change data capture (CDC) mencatat aktifitas insert, update, delete yang
dilakukan pada sebuah tabel. Hal ini membuat detail dari perubahan data yang terjadi akan tersedia dalam format relasional yang mudah untuk dipahami. Informasi kolom dan metadata yang diperlukan untuk menerapkan perubahan ini ke lingkungan target ditangkap untuk baris yang diubah dan disimpan dalam tabel perubahan yang mencerminkan struktur kolom pada tabel sumber yang akan dilacak. Fungsi table-valued disediakan untuk memungkinkan akses sistematis ke data yang dirubah oleh konsumen (Technet, 2014).
Sebuah contoh yang baik dari konsumen data yang ditargetkan oleh teknologi ini adalah aplikasi extraction, transformation, dan loading (ETL). Sebuah aplikasi ETL secara bertahap mengirim perubahan data dari tabel sumber ke data
warehouse atau data mart. Meskipun representasi dari tabel sumber dalam data warehouse harus mencerminkan perubahan dalam tabel sumber, sebuah teknologi
end-to-end yang memperbarui data pada replika dari sumber tidaklah tepat.
Sebaliknya, kita perlu aliran perubahan data yang handal yang terstruktur sehingga konsumen dapat menerapkannya pada representasi sasaran yang berbeda dari data (Technet, 2014).
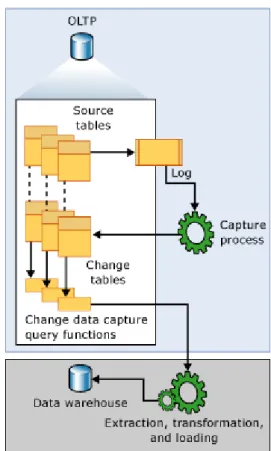
Gambar 2.9 akan menunjukkan aliran data pada teknologi change data
capture.
Gambar 2.9 Aliran Data pada Change Data Capture (Sumber : Technet, 2014)
Sumber perubahan data untuk change data capture adalah transaction log. Setelah proses insert, update, dan delete dilakukan pada tabel sumber yang akan dilacak, entri yang menggambarkan terjadinya perubahan data ini akan ditambahkan ke dalam log. Log ini akan menjadi input untuk proses capture.
Kemudian proses change data capture akan membaca log ini dan menyimpan informasi perubahan data pada log ini ke tabel perubahan. Isi dari tabel perubahan ini kemudian akan di-query oleh proses ETL sampai akhirnya perubahan data ini akan dikirim ke dalam data warehouse. Jadi hanya perubahan data terbaru saja yang akan disimpan ke dalam data warehouse (Technet, 2014).
2.18 MS SQL SERVER 2008 R2
SQL Server 2008 R2 adalah kumpulan dari komponen yang dapat kita
terapkan secara terpisah atau sebagai sebuah kelompok untuk membentuk sebuah
platform data yang scalable. Dalam arti luas, platform data ini terdiri dari dua jenis
komponen yaitu : komponen yang akan membantu dalam mengelola data dan komponen-komponen yang akan membantu dalam mewujudkan suatu business
intelligence (BI) (Mistry, 2010:p. xvii).
Salah satu fitur baru pada SQL Server 2008 R2 adalah Parallel Data
Warehouse. Parallel Data Warehouse ditujukan untuk sebuah enterprise data warehouse. Parallel Data Warehouse terdiri dari perangkat lunak dan perangkat
keras yang dirancang untuk memenuhi kebutuhan gudang data yang sangat besar. Solusi ini memiliki kemampuan untuk menampung data warehouse sampai ratusan
terabyte dengan penggunaan teknologi baru yang disebut sebagai massively parallel processing (MPP). Parallel data warehouse dapat dihubungkan melalui
perangkat keras murah yang dikonfigurasi dalam arsitektur hub and spoke. Peningkatan kinerja dapat dicapai dengan pendekatan desain parallel data
warehouse karena teknik ini melakukan partisi tabel besar ke beberapa node fisik,
instance. Desain ini secara langsung menghilangkan masalah yang terkait dengan kecepatan dan memberikan skalabilitas karena control node mendistribusikan data secara merata ke semua compute node. Control node juga bertanggung jawab untuk mengumpulkan data dari semua compute note ketika jawaban untuk sebuah query harus diberikan ke aplikasi (Mistry, 2010:p. 8-9).
Keuntungan Penggunaan MS SQL Server 2008 R2 adalah sebagai berikut (Mistry, 2010:p. 10-11):
a. Maximum scalability
Windows Server 2008 R2 mendukung hingga 256 processor dan 2 terabyte memori dalam sebuah sistem operasi.
b. Hyper-V improvements
Hyper-V dapat menggunakan hingga 64 processor dalam host processor pool, yang memungkinkan untuk mengkonsolidasikan lebih banyak SQL Server VMs pada satu host Hyper-V.
c. Windows Server 2008 R2 Server Manager
Server Manager telah dioptimalkan pada Windows Server 2008 R2. d. Best Practices Analyzer (BPA)
Membantu mengurangi kesalahan-kesalahan yang terjadi, yang pada akhirnya dapat membantu memperbaiki dan mencegah penurunan kinerja, skalabilitas, dan downtime.
e. Windows PowerShell 2.0
Database Administration (DBA) dapat meningkatkan produktivitas mereka
mengotomatisasi, dan mengkonsolidasikan tugas-tugas yang berulang dan melakukan proses manajemen server di lingkungan SQL Server terdistribusi. 2.18.1 Tipe data pada MS SQL SERVER 2008
Pada SQL Server 2008 terdapat beberapa tipe data, diantaranya adalah: a. Tipe data untuk Bilangan
Jenis-jenis dari tipe data bilangan ini dapat dilihat pada tabel 2.2. Tabel 2.2 Tipe Data Numerik
Nama Tipe Data
Kelas Ukuran / Bytes
Keterangan
Bit Integer 1 Bit tipe data pertama dalam tabel menggunakan 1 byte.
Bigint Integer 8 Tipe data ini memungkinkan untuk menggunakan angka dari –263 sampai dengan 263–1.
Int Integer 4 Tipe data ini meliputi angka dari –2,147,483,648 sampai dengan
2,147,483,647.
SmallInt Integer 2 Tipe data ini meliputi angka –32,768 sampai dengan 32,767.
TinyInt Integer 1 Tipe data ini meliputi angka 0 sampai dengan 255.
Decimal or Numeric
Decimal / Numeric
Varies Memiliki presisi yang tetap dengan skala dari –1038–1 sampai dengan 1038–1. Money Money 8 Satuan moneter dari -263 sampai 263
ditambah presisi sampai empat tempat desimal.
SmallMoney Money 4 Satuan moneter dari -214,748.3648 sampai dengan +214,748.3647.
Float Approximate Numeric
Varies Menerima argumen (misalnya, Float (20)) yang menentukan ukuran dan presisi. Perhatikan bahwa argumen dalam bit, bukan byte. Berkisar dari-1.79E + 308 sampai dengan dari-1.79E + 308. (Sumber : Viera, 2009:p.12-15)
b. Tipe Data Special Numeric dan Karakter
Jenis-jenis dari tipe data special numeric dan karakter ini dapat dilihat pada tabel 2.3.
Tabel 2.3 Tipe Data Special Numeric dan Karakter Nama Tipe Data Kelas Ukuran / Bytes Keterangan Cursor Special Numeric 1 Pointer ke kursor. Timestamp / rowversion Special Numeric (binary)
8 Nilai khusus yang unik yang diberikan oleh basis data.
UniqueIdentifier Special Numeric (binary)
16 Globally Unique Identifier (GUID).
Char Character Varies Fixed-length data karakter. Data adalah non-Unicode. Panjang maksimal adalah 8.000 karakter.
VarChar Character Varies Variabel-length data karakter. Data adalah non-Unicode. Panjang maksimal adalah 8.000 karakter. Dapat menggunakan kata kunci MAX.
Text Character Varies Dukungan warisan dari SQL Server 2005 - gunakan varchar (max) sebagai gantinya!
Nchar Unicode Varies Fixed-length data karakter. Data adalah Unicode. Panjang maksimal adalah 4.000 karakter.
NVarChar Unicode Varies Variabel-length data karakter. Data adalah Unicode. Panjang maksimal adalah 4.000 karakter. Dapat menggunakan kata kunci MAX.
Ntext Unicode Varies Ntext ini adalah warisan dari MS SQL Server 2005, gunakan nvarchar (max). Variable-length Unicode Data karakter. Binary Binary Varies Fixed-length data biner dengan Panjang
maksimal 8.000 bytes.
VarBinary Binary Varies Variabel-length data biner dengan panjang maksimal 8.000 byte.
Image Binary Varies Dukungan warisan dari SQL Server 2005 - gunakan VarBinary(max) sebagai gantinya!
c. Tipe Data Tanggal dan Waktu
Jenis-jenis dari tipe data tanggal dan waktu ini dapat dilihat pada tabel 2.4. Tabel 2.4 Tipe Data Tanggal dan Waktu
Nama Tipe Data Kelas Ukuran / Bytes Keterangan DateTime Date / Time
8 Data tanggal dan waktu dari 1 Januari 1753, sampai dengan 31 Desember 9999, dengan akurasi tiga-seperseratus detik. DateTime2 Date /
Time
Varies (6-8)
Tipe Data DateTime yang diperbarui. Mendukung rentang tanggal yang lebih besar dan presisi fraksi waktu besar (hingga 100 nanodetik).
SmallDateTime Date / Time
4 Data tanggal dan waktu dari tanggal 1 Januari 1900, sampai dengan 6 Juni 2079, dengan akurasi satu menit.
DateTimeOffsett Date / Time
Varies (8-10)
Serupa dengan tipe data DateTime tipe, tetapi juga mengharapkan offset -14:00 sampai dengan +14:00 dari waktu UTC. Waktu disimpan secara internal sebagai waktu UTC, dan setiap perbandingan, pengurutan, dan pengindeksan akan didasarkan pada zona waktu bersatu.
Date Date /
Time
3 Menyimpan hanya tanggal data dari tanggal 1 Januari 0001, sampai dengan 31 Desember 9999 seperti yang didefinisikan oleh kalender Gregorian. Menggunakan format tanggal standar ANSI (YYYY-MM-DD), tapi akan secara implisit mengkonversi dari beberapa format lain.
Time Date /
Time
Varies (3-5)
Menyimpan hanya data waktu yang secara presisi dipilih oleh user sebagai granular 100 nanodetik (yang merupakan default).
d. Tipe Data Lain
Jenis-jenis tipe data ini dapat dilihat pada tabel 2.5. Tabel 2.5 Tipe Data Lain Nama Tipe
Data
Kelas Ukuran / Bytes
Keterangan
Table Other Special Tipe data ini biasanya digunakan pada waktu bekerja dengan result sets. Tipe data biasanya dipakai pada User-defined Function atau sebagai parameter untuk Stored Procedures. Tipe data ini tidak dapat digunakan sebagai tipe data dalam tabel definition (Anda tidak bisa membuat tabel bersarang (tabel dalam tabel)).
HierarchyID Other Special Tipe data khusus yang menangani informasi posisi hirarki. Menyediakan fungsi khusus untuk kebutuhan hirarki. Perbandingan kedalaman, orangtua / anak, hubungan, dan pengindeksan diperbolehkan. Ukuran yang tepat bervariasi dengan jumlah dan rata-rata kedalaman node dalam hirarki.
sql_variant Other Special Tipe data ini terkait dengan tipe data Variant yang terdapat pada VB dan C + +. Pada dasarnya, tipe data ini adalah wadah yang memungkinkan kita untuk memegang sebagian besar tipe data SQL Server lainnya di dalamnya. Kita dapat menggunakan tipe data ini ketika satu kolom atau fungsi harus mampu menangani beberapa tipe data. Tidak seperti pada VB, dengan menggunakan tipe data ini kita dapat memaksa untuk melakukan casting data pada tipe data ini secara eksplisit untuk mengubahnya menjadi tipe data yang lebih spesifik.
XML Character Varies Mendefinisikan field karakter untuk XML data. Menyediakan validasi data untuk XML Schema seperti penggunaan
fungsi-XML berorientasi khusus.
Table Other Special Tipe data ini biasanya digunakan pada waktu bekerja dengan result sets. Tipe data biasanya dipakai pada User-defined Function atau sebagai parameter untuk Stored Procedures. Tipe data ini tidak dapat digunakan sebagai tipe data dalam tabel definition (Anda tidak bisa membuat tabel bersarang (tabel dalam tabel)).
2.18.2 Basic query pada MS SQL SERVER 2008
Ada 4 operasi dasar yang dapat dilakukan pada suatu basis data, yaitu:
select, insert, update, dan delete. Pada SQL Server 2008, sintak untuk penggunaan
dari empat operasi basis data ini dapat dilihat pada tabel 2.6: Tabel 2.6 Sintaks Query pada SQL Server 2008 Nama
Query
Fungsi Sintak
SELECT Membaca data SELECT <column list>
[FROM <source table(s)> [[AS] <table alias>] [[{FULL|INNER|{LEFT|RIGHT}
OUTER|CROSS}] JOIN <next table> [ON <join condition>] [<additional JOIN clause> ...]]]
[WHERE <restrictive condition>]
[GROUP BY <column name or expression using
a column in the SELECT list>]
[HAVING <restrictive condition based on the
GROUP BY results>]
[ORDER BY <column list>]
[[FOR XML {RAW|AUTO|EXPLICIT|PATH [(<element>)]}[, XMLDATA][, ELEMENTS][, BINARY
base 64]]
[OPTION (<query hint>, [, ...n])]
[{ UNION [ALL] | EXCEPT | INTERSECT }] [;]
INSERT Menyisipkan data INSERT [INTO] <table> [(<column list>)] VALUES (<data values>)
[, (<data values>) [, . . . n]] UPDATE Memperbarui data UPDATE <table name>
SET <column> = <value> [,<column> = <value>]
[FROM <source table(s)>]
[WHERE <restrictive condition>]
DELETE Menghapus data DELETE [TOP (<expression>) [PERCENT] [FROM ] <table name>
[FROM ] <table list/JOIN conditions> [WHERE <search condition>]
2.19 Service Oriented Architecture
SOA adalah sebuah metode membangun aplikasi yang menggunakan sejumlah kecil, komponen independen yang berkomunikasi satu sama lain dengan saling menawarkan dan menggunakan layanan antar komponen-komponen independen ini. Komponen-komponen ini dapat didistribusikan; pada kenyataannya, mereka dapat berada di sisi yang berbeda dari dunia (Rainardi, 2008:p.26).
Hampir setiap aplikasi besar bisa mendapatkan keuntungan dari pendekatan SOA. Kita tidak perlu untuk membangun satu aplikasi besar lagi. Sebaliknya, kita membangun banyak potongan-potongan kecil aplikasi yang terhubung dan berkomunikasi satu sama lain. Salah satu sifat dari industri TI adalah aplikasi akan perlu diganti setiap beberapa tahun (setiap 4-8 tahun). Bisa jadi karena teknologi yang digunakan sudah usang atau karena fungsionalitas dari aplikasi tersebut sudah tidak mampu mengakomodasi kebutuhan perusahaan. Kepailitan, merger, dan pengambilalihan perusahaan juga merupakan alasan lain untuk melakukan penggantian aplikasi ini (Rainardi, 2008:p.26).
Jika kita membuat satu aplikasi raksasa, itu akan menjadi mahal untuk menggantinya. Jika kita membuatnya dari sejumlah kecil, komponen independen, lebih mudah untuk menggantinya. SOA memberi kita lebih banyak fleksibilitas untuk mengganti komponen. Dengan kata lain, kita dapat melakukannya secara bertahap sepotong demi sepotong tanpa mempengaruhi fungsi tersebut. Hal ini karena komponen yang independen; yaitu, mereka tidak peduli bagaimana komponen lainnya bekerja secara internal selama eksternal mereka mendapatkan
tanggapan yang mereka butuhkan. Hal ini memungkinkan kita untuk membangun kembali salah satu komponen dengan teknologi yang lebih baru tanpa mempengaruhi yang lain (Rainardi, 2008:p.26).
Bagaimana SOA ini berhubungan dengan data warehouse? Sebuah sistem
data warehouse terdiri dari banyak komponen: sistem sumber, sistem ETL,
mekanisme kualitas data, sistem metadata, audit dan sistem kontrol, sebuah portal BI, aplikasi pelaporan, aplikasi OLAP/analitik, aplikasi data mining, dan sistem
database itu sendiri (Rainardi, 2008:p.26).
Kita dapat membangun data warehouse sebagai satu aplikasi raksasa dengan semua komponen digabungkan; Hal ini akan menyebabkan kita tidak akan dapat mengganti salah satu komponen tanpa mempengaruhi komponen lainnya. Atau kita dapat membangun data warehouse dengan pendekatan SOA. Kita membangunnya sebagai jumlah yang lebih kecil, komponen independen yang terhubung dan berkomunikasi satu sama lain dengan saling menawarkan dan menggunakan layanan antar komponen-komponen independen ini (Rainardi, 2008:p.26).
Semakin banyak aplikasi data warehousing di semua lini yang dibangun menggunakan SOA, seperti misalnya : ETL, pelaporan, analisis, aplikasi BI, data
mining, metadata, kualitas data, dan pembersihan data. Di masa depan, dengan
menggunakan pendekatan SOA, akan lebih mudah untuk memperbarui salah satu komponen tanpa mempengaruhi komponen yang lain dan untuk menghubungkan berbagai komponen yang dibuat dengan menggunakan teknologi yang berbeda-beda (Rainardi, 2008:p.26).
SOA adalah pendekatan yang berbeda untuk memisahkan antara perhatian dan pembangunan solusi bisnis dengan memanfaatkan komponen-komponen kecil yang digabungkan dan digunakan kembali. Dengan mengadopsi SOA, organisasi dapat mengaktifkan aplikasi bisnis mereka dengan cepat dan efisien menanggapi bisnis, proses, dan perubahan integrasi yang biasanya terjadi dalam lingkungan perusahaan (Kankanamge, 2012:p. 8).
2.19.1 Arsitektur SOA
Gambar 2.10 Arsitektur SOA (Sumber : Barry, 2013:p.18)
Pada gambar 2.10 dapat dilihat bahwa arsitektur SOA yang paling sederhana adalah dimana ada sebuah service provider dan sebuah service consumer.
Service consumer akan mengirimkan service request ke service provider dan
kemudian service provider akan mengirimkan service response ke service
consumer.
2.19.2 Building block SOA
Ketika mempelajari solusi standar berorientasi pada layanan, kita dapat mengindentifikasi tiga building block besar seperti berikut ini (Kankanamge, 2012:p. 9-11):