UNTUK KLASIFIKASI PENERIMA HIBAH PEMASANGAN SAMBUNGAN AIR MINUM PADA PDAM KABUPATEN
KENDAL
COMPARATIVE ANALYSIS OF ALGORITHM ID3 AND C4.5 FOR CLASSIFICATION RECIPIENTS GRANT INSTALLATION
DRINKING WATER IN PDAM KABUPATEN KENDAL
Diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana Teknik Informatika
Disusun oleh :
Nama : Dana Melina Agustina
NIM : A11.2012.07023
Program Studi : Teknik Informatika – S1
FAKULTAS ILMU KOMPUTER UNIVERSITAS DIAN NUSWANTORO
SEMARANG
2016
ii Program Studi : Teknik Informatika Fakultas : Ilmu Komputer
Judul Tugas Akhir : Analisis Perbandingan Algoritma ID3 dan C4.5 Untuk Klasifikasi Penerima Hibah Pemasangan Sambungan Air Minum Pada PDAM Kabupaten Kendal
Tugas Akhir ini telah diperiksa dan disetujui, Semarang, 20 Juni 2016
Menyetujui:
Pembimbing
Wijanarto, M.Kom
Mengetahui :
Dekan Fakultas Ilmu Komputer
Dr. Abdul Syukur, MM
iii
NIM : A11.2012.07023
Program Studi : Teknik Informatika Fakultas : Ilmu Komputer
Judul Tugas Akhir : Analisis Perbandingan Algoritma ID3 dan C4.5 Untuk Klasifikasi Penerima Hibah Pemasangan Sambungan Air Minum Pada PDAM Kabupaten Kendal
Tugas akhir ini telah diujikan dan dipertahankan dihadapan Dewan Penguji pada Sidang tugas akhir tanggal 20 Juni 2016. Menurut pandangan kami, tugas akhir ini
memadai dari segi kualitas maupun kuantitas untuk tujuan penganugrahan gelar Sarjana Komputer (S.Kom.)
Semarang, 20 Juni 2016 Dewan Penguji :
Umi Rosyidah, S.Kom, M.T Anggota I
Aisyatul Karima, S.Kom, MCS Anggota II
Heru Agus Santoso, Ph.D Ketua Penguji
iv Nama : Dana Melina Agustina
NIM : A11.2012.07023
Menyatakan bahwa karya tulis ilmiah saya yang berjudul :
Analisis Perbandingan Algoritma ID3 dan C4.5 Untuk Klasifikasi Penerima Hibah Pemasangan Sambungan Air Minum Pada PDAM Kabupaten Kendal Merupakan karya asli saya (kecuali cuplikan dan ringkasan yang masing-masing telah saya jelaskan sumbernya). Apabila di kemudian hari, karya saya disinyalir bukan merupakan karya asli saya, yang disertai dengan bukti-bukti yang cukup, maka saya bersedia untuk dibatalkan gelar saya beserta hak dan kewajiban yang melekat pada gelar tersebut. Demikian surat pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Semarang Pada tanggal : 20 Juni 2016
Yang menyatakan
(Dana Melina Agustina)
v
Sebagai mahasiswa Universitas Dian Nuswantoro, yang bertanda tangan di bawah ini, saya:
Nama : Dana Melina Agustina NIM : A11.2012.07023
demi mengembangkan Ilmu Pengetahuan, menyetujui untuk memberikan kepada Universitas Dian Nuswantoro Hak Bebas Royalti Non-Eksklusif (Non exclusive Royalty-Free Right) atas karya ilmiah saya yang berjudul:
Analisis Perbandingan Algoritma ID3 dan C4.5 Untuk Klasifikasi Penerima Hibah Pemasangan Sambungan Air Minum Pada PDAM Kabupaten Kendal.
Dengan Hak Bebas Royalti Non-Eksklusif ini Universitas Dian Nuswantoro berhak untuk menyimpan, mengcopy ulang (memperbanyak), menggunakan, mengelolanya dalam bentuk pangkalan data (database), mendistribusikannya dan menampilkan/mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya selama tetap mencantumkan nama saya sebagai penulis/pencipta.
Saya bersedia untuk menanggung secara pribadi, tanpa melibatkan pihak Universitas Dian Nuswantoro, segala bentuk tuntutan hukum yang timbul atas pelanggaran Hak Cipta dalam karya ilmiah saya ini.
Demikian surat pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Semarang Pada tanggal : 20 Juni 2016
Yang menyatakan
(Dana Melina Agustina)
vi
dan inayah-Nya kepada penulis sehingga laporan tugas akhir dengan judul
“ANALISIS PERBANDINGAN ALGORITMA ID3 DAN C4.5 UNTUK KLASIFIKASI PENERIMA HIBAH PEMASANGAN SAMBUNGAN AIR MINUM PADA PDAM KABUPATEN KENDAL” dapat penulis selesaikan sesuai dengan rencana karena dukungan dari berbagai pihak yang tidak ternilai besarnya. Oleh karena itu penulis menyampaikan terima kasih kepada :
1. Dr.Ir.Edi Noersasongko, M.Kom., selaku Rektor Universitas Dian Nuswantoro Semarang.
2. Dr.Abdul Syukur, selaku Dekan Fakultas Ilmu Komputer Unversitas Dian Nuswantoro.
3. Heru Agus Santoso, Ph.D selaku ka. Progdi Teknik Informatika.
4. Wijanarto, M.Kom selaku dosen pembimbing yang telah memberikan bimbingan kepada penulis dalam menyusun laporan tugas akhir ini.
5. Dosen-dosen pengampu di Fakultas Ilmu Komputer Teknik Informatika Universitas Dian Nuswantoro Semarang yang telah memberikan banyak ilmu.
6. Bapak, Ibu, Adek Putri, Adek Hashfi yang tidak pernah lelah memberikan doa serta dorongan kepada penulis untuk maju dan terus berusaha.
7. Direksi dan semua staf PDAM Kabupaten Kendal yang telah memberikan data-data untuk keperluan penyusunan tugas akhir.
8. Sahabat-sahabat dan teman-teman penulis yang selalu memberikan semangat dan dorongan untuk terus berusaha.
Semoga laporan tugas akhir ini dapat memperluas wawasan dan pengetahunan yang bermanfaat dan berguna sebagaimana fungsinya.
Semarang, 20 Juni 2016
Penulis
vii
pelayanan air minum yang diprioritaskan bagi masyarakat berpenghasilan rendah dalam rangka meningkatkan derajat kualitas kesehatan masyarakat.
Pengklasifikasian data masyarakat berperan untuk menentukan pemberian sambungan air minum secara objektif dan akurat. Dalam penelitian ini dilakukan perbandingan metode data mining yaitu algoritma ID3 dan C4.5 yang diterapkan pada data masyarakat berpenghasilan rendah pada PDAM Kabupaten Kendal dengan menggunakan RapidMiner. Hasil pengujian yang menunjukkan bahwa algoritma ID3 nilai akurasi sebesar 98,91%. Sedangkan pada algoritma C4.5 nilai accuracy sebesar 99,14%. Jadi algoritma C4.5 memiliki tingkat akurasi yang lebih besar dari pada algoritma ID3. Sehingga pada kasus penerima hibah pemasangan sambungan air minum diterapkan pada framework php dapat menentukan penerima hibah pemasangan sambungan air minum dengan menggunakan acuan pada algoritma C4.5 yang memiliki akurasi yang lebih baik.
Kata kunci : Klasifikasi, ID3, C4.5, hibah air minum.
viii
PENGESAHAN DEWAN PENGUJI ... iii
PERNYATAAN KEASLIAN SKRIPSI ... iv
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... v
UCAPAN TERIMA KASIH ... vi
ABSTRAK ... vii
DAFTAR ISI ... viii
DAFTAR GAMBAR ... x
DAFTAR TABEL ... xii
BAB I PENDAHULUAN ... 1
1. 1 Latar Belakang ... 1
1. 2 Rumusan Masalah ... 3
1. 3 Batasan Masalah ... 3
1. 4 Tujuan Penelitian ... 4
1. 5 Manfaat Penelitian ... 4
BAB II TINJAUAN STUDI DAN LANDASAN TEORI ... 5
2. 1 Tinjauan Studi ... 5
2. 2 Landasan Teori ... 8
2. 2. 1 Pengertian Hibah Air Minum ... 8
2. 2. 2 Data Mining ... 9
2. 2. 3 Decision Tree ... 11
2. 2. 4 Klasifikasi ... 14
2. 2. 5 Algoritma ID3 ... 15
2. 2. 6 Algoritma C4.5 ... 17
2. 2. 7 Confusion Matrix ... 18
2. 3 Tinjauan Objek Penelitian ... 20
2. 4 Kerangka Pemikiran ... 21
BAB III METODE PENELITIAN ... 23
3.1 Instrumen penelitian ... 23
3.1.1 Bahan... 23
3.1.2 Peralatan ... 23
3.2 Prosedur pengambilan atau pengumpulan data ... 24
3.3 Teknik analisis data (cara pengolahan data awal) ... 25
3.4 Model atau metode yang diusulkan ... 28
3.4.1 Tahapan Algoritma ID3 ... 29
3.4.2 Tahapan Rapid Miner pada Algoritma ID3 ... 30
3.4.3 Tahapan Algoritma C4.5 ... 31
3.4.4 Tahapan Rapid Miner pada Algoritma C4.5 ... 32
3.5 Evaluasi dan Validasi ... 33
BAB IV HASIL DAN ANALISIS ... 35
4. 1. Perhitungan Algoritma ... 35
4. 1. 1 Perhitungan Algoritma ID3 ... 35
4. 1. 2 Perhitungan Algoritma C4.5 ... 47
4. 2. Evaluasi dan Validasi ... 62
4. 3. Hasil Pengujian ... 65
4. 3. 1. Pohon Keputusan ... 65
4. 3. 2. Confusion Matrix ... 66
4. 4. Analisis Hasil ... 78
4. 5. Prototype ... 83
BAB V KESIMPULAN DAN SARAN ... 86
5. 1 Kesimpulan ... 86
5. 2 Saran ... 87
DAFTAR PUSTAKA ... 88
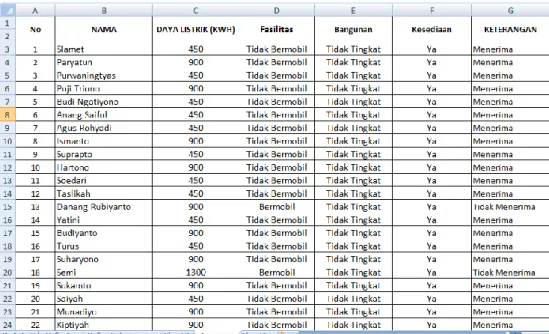
Lampiran 1 Data Masyarakat Berpenghasilan Rendah 2015... 90
x
Gambar 3. 1: Sebelum Penghapusan Atribut ... 25
Gambar 3. 2: Setelah Penghapusan Atribut ... 26
Gambar 3. 3: Penggabungan database ... 27
Gambar 3. 4: Dataset MBR ... 30
Gambar 3. 5: Dataset MBR ... 32
Gambar 4. 1: Node 1 Algoritma ID3 ... 42
Gambar 4. 2: Node 1.1 Algoritma ID3 ... 44
Gambar 4. 3: Node 1.1.1 Algoritma ID3 ... 45
Gambar 4. 4: Node 1.1.1.1 Algoritma ID3 ... 47
Gambar 4. 5: Node 1 Algoritma C4.5 ... 56
Gambar 4. 6: Node 1.1 Algoritma C4.5 ... 58
Gambar 4. 7: Node 1.1.1 Algoritma C4.5 ... 59
Gambar 4. 8: Node 1.1.1.1 Algoritma C4.5 ... 61
Gambar 4. 9: Import Data ... 63
Gambar 4. 10: Model Cross Validation pada Algoritma ID3 ... 63
Gambar 4. 11: Pengujian Cross Validation pada Algoritma ID3... 63
Gambar 4. 12: Model Cross Validation pada Algoritma C4.5 ... 64
Gambar 4. 13: Pengujian Cross Validation pada Algoritma C4.5 ... 64
Gambar 4. 14: Pohon Keputusan ID3 ... 65
Gambar 4. 15: Pohon Keputusan Algoritma C4.5 ... 66
Gambar 4. 16: Pengujian 50% dari Algoritma ID3... 67
Gambar 4. 17: Pengujian 50% dari Algoritma C4.5 ... 67
Gambar 4. 18: Pengujian 60% dari Algoritma ID3... 68
Gambar 4. 19: Pengujian 40% dari Algoritma ID3... 69
Gambar 4. 20: Pengujian 60% dari Algoritma C4.5 ... 69
Gambar 4. 21: Pengujian 40% dari Algoritma C4.5 ... 70
Gambar 4. 22: Pengujian 70% dari Algoritma ID3... 70
Gambar 4. 23: Pengujian 30% dari Algoritma ID3... 71
Gambar 4. 24: Pengujian 70% dari Algoritma C4.5 ... 72
Gambar 4. 25: Pengujian 30% dari Algoritma C4.5 ... 72
Gambar 4. 26: Pengujian 80% dari Algoritma ID3... 73
Gambar 4. 27: Pengujian 20% dari Algoritma ID3... 73
Gambar 4. 28: Pengujian 80% dari Algoritma C4.5 ... 74
Gambar 4. 29: Pengujian 20% dari Algoritma C4.5 ... 74
Gambar 4. 30: Pengujian 90% dari Algoritma ID3... 75
Gambar 4. 31: Pengujian 10% dari Algoritma ID3... 76
Gambar 4. 32: Pengujian 90% dari Algoritma C4.5 ... 76
Gambar 4. 33: Pengujian 10% dari Algoritma C4.5 ... 77
Gambar 4. 34: Grafik Precision ... 79
Gambar 4. 35: Grafik Recall ... 80
Gambar 4. 36: Grafik Accuracy ... 81
Gambar 4. 37: Pohon Keputusan Dari Algoritma Tertinggi ... 82
Gambar 4. 38 : Prototype ... 83
Gambar 4. 39: Pengisian Data ... 84
Gambar 4. 40: Hasil Keputusan ... 84
xii
Tabel 2. 3: Kerangka Pemikiran... 21
Tabel 3. 1: Atribut yang akan digunakan dalam pemodelan ... 28
Tabel 4. 1: Perhitungan ID3 Node 1 ... 41
Tabel 4. 2: Perhitungan ID3 Node 1.1 ... 43
Tabel 4. 3: Perhitungan ID3 Node 1.1.1 ... 44
Tabel 4. 4: Perhitungan ID3 Node 1.1.1.1 ... 46
Tabel 4. 5: Perhitungan C4.5 Node 1 ... 55
Tabel 4. 6: Perhitungan C4.5 Node 1.1 ... 57
Tabel 4. 7: Perhitungan C4.5 Node 1.1.1 ... 58
Tabel 4. 8: Perhitungan C4.5 Node 1.1.1.1 ... 60
Tabel 4. 9: Perbandingan hasil klasifikasi dari data training ... 77
Tabel 4. 10 : Perbandingan hasil klasifikasi dari data testing ... 78
1 1. 1 Latar Belakang
Program Hibah Air Minum adalah suatu upaya percepatan penambahan jumlah sambungan rumah (SR) baru berdasarkan kinerja yang terukur. Program Hibah Air Minum yang dimaksud disini adalah pemberian hibah dari pemerintah pusat kepada pemerintah daerah baik yang bersumber dari pendapatan murni APBN atau pinjaman dan /atau hibah luar negeri. Hibah air minum ini dimaksudkan juga sebagai insentif kepada pemprov atau pemkab/pemkot untuk dapat melaksanakan peran dan tanggung jawabnya dalam penyelenggaraan penyebaran pelayanan air minum di daerahnya [1].
PDAM merupakan instansi yang akan melaksanakan program hibah air minum yaitu dengan pemasangan sambungan air minum kepada Masyarakat Berpenghasilan Rendah (MBR) yang menjadi sasaran pada program tersebut. Program hibah air minum bertujuan untuk meningkatkan cakupan pelayanan air minum yang diprioritaskan bagi masyarakat berpenghasilan rendah dalam rangka meningkatkan derajat kualitas kesehatan masyarakat.
Berdasarkan proposal Program Hibah Air Minum APBN Februari 2015, pada PDAM ke pemerintah pusat, bahwa pemberian pemasangan sambungan air minum merupakan bantuan dari pemerintah pusat yang terdapat 1473 masyarakat yang akan direkomendasikan untuk mendapatkan pemasangan sambungan air minum. Adapun yang mendapatkan pemasangan sambungan air minum 1223 masyarakat, sedangkan yang gagal mendapatkan sebanyak 250 masyarakat. Dalam pemberian pemasangan sambungan air minum pada masyarakat dilihat
dari daya listrik yang digunakan, fasilitas, bangunan rumah, dan kesediaan menjadi pelanggan.
Pengklasifikasian data masyarakat berperan untuk menentukan pemberian sambungan air minum secara objektif dan akurat. Salah satu metode yang akan digunakan yaitu dengan data mining. Data mining adalah proses yang mempekerjakan satu atau lebih teknik pembelajaran komputer (machine learning) untuk menganalisis dan mengekstraksi pengetahuan (knowledge) [2]. Mengklasifikasi calon penerima sambungan air minum dapat dikategorikan sebagai tindakan pengambilan keputusan. Salah satu metode pengambilan keputusan yang sistematis adalah dengan menyusun sebuah pohon keputusan (decision tree). Pohon keputusan merupakan representasi sederhana dari teknik klasifikasi untuk sejumlah kelas berhingga, dimana simpul internal maupun simpul akar ditandai dengan nama atribut, dan simpul daun ditandai dengan kelas- kelas yang berbeda [2].
Menurut penelitian Yadav dan Pal [3] bahwa klasifikasi Decision Tree dilakukan untuk menemukan klasifikasi terbaik untuk prediksi kinerja siswa di tahun pertama ujian. Pada penelitian yang dilakukan Adhatrao [4] bahwa prediksi siswa disemester pertama menggunakan algoritma ID3 menunjukkan tingkat akurasi 75.145%, sedangkan dengan algoritma C4.5 menunjukkan tingkat akurasi 75.145%. Menurut penelitian Sharma dan Sahni [5] dalam klasifikasi data spam email, untuk menentukan apakah email tertentu termasuk spam atau tidak. Pada algoritma J48 memiliki akurasi tertinggi 92,7624%, sedangkan pada algoritma ID3 menunjukkan akurasi 89.111%.
Berdasarkan studi literatur diatas, penelitian ini akan mengimplementasikan metode data mining untuk membangun model klasifikasi masyarakat berpenghasilan rendah untuk penerima
pemasangan sambungan air minum pada program hibah air minum di PDAM Kabupaten Kendal. Metode yang digunakan adalah metode Decision Tree dengan menggunakan algoritma ID3 dan C4.5. Metode ini dipilih karena berdasarkan penelitian sebelumnya memiliki konsep yang mudah di interpretasikan hasilnya, serta akan membandingkan algoritma ID3 dan C4.5 mana yang memiliki tingkat akurasi yang lebih tinggi pada klasifikasi penerima hibah pemasangan air minum. Data yang akan digunakan dalam klasifikasi ini yaitu data masyarakat penerima hibah pemasangan sambungan air minum pada tahun 2015. Hasil dari Decision Tree mengklasifikasikan menerima atau tidak menerima hibah pemasangan sambungan air minum.
1. 2 Rumusan Masalah
Berdasarkan latar belakang diatas dapat diambil sebuah rumusan masalah yaitu :
1. Bagaimana perbandingan algoritma ID3 dan C4.5 berdasarkan data masyarakat berpenghasilan rendah dalam mendapatkan hibah pemasangan sambungan air minum.
2. Bagaimana menentukan penerima hibah pemasangan sambungan air minum berdasarkan analisis perbandingan algoritma ID3 dan C4.5 dengan memilih akurasi yang lebih tinggi.
1. 3 Batasan Masalah
Adapun batasan masalah dalam penelitian ini, yaitu :
1. Dataset merupakan data masyarakat berpenghasilan rendah tahun 2015 pada PDAM Kabupaten Kendal.
2. Penelitian ini dibatasi pada penerapan algoritma ID3 dan C4.5 untuk klasifikasi masyarakat berpenghasilan rendah untuk menentukan penerima hibah pemasangan sambungan air minum yang tepat sasaran.
3. Output yang dihasilkan berupa hasil keputusan.
1. 4 Tujuan Penelitian
Tujuan dari penelitian ini adalah :
1. Ingin mengetahui perbedaan tingkat akurasi algoritma ID3 dan C4.5 untuk kasus masyarakat berpenghasilan rendah dalam mendapatkan hibah pemasangan sambungan air minum pada PDAM.
2. Untuk menentukan penerima hibah pemasangan sambungan air minum berdasarkan algoritma yang mempunyai tingkat akurasi yang lebih tinggi.
1. 5 Manfaat Penelitian
Manfaat yang diharapkan dari penelitian ini adalah :
1. Dapat mengetahui tingkat akurasi algoritma ID3 dan C4.5 untuk kasus masyarakat berpenghasilan rendah dalam mendapatkan hibah pemasangan sambungan air minum.
2. Dapat menentukan penerima hibah pemasangan sambungan air minum secara objektif dan akurat berdasarkan algoritma yang mempunyai tingkat akurasi yang lebih tinggi.
5 2. 1 Tinjauan Studi
Penelitian yang berhubungan dengan penelitian ini adalah :
a. Penelitian yang dilakukan oleh Surjeet Kumar Yadav [3], yang menjelaskan metode klasifikasi yang diterapkan pada data pendidikan untuk memprediksi kinerja siswa. Prediksi ini untuk mengidentifikasi siswa yang lemah dan membantu untuk mendapat nilai yang lebih baik. Algoritma C4.5, ID3, dan CART yang akan digunakan untuk memprediksi kinerja siswa dalam ujian akhir.
Hasil dari pohon keputusan diprediksi nomor siswa yang cenderung untuk lulus, gagal atau dipromosikan ke tahun depan.
Dari akurasi pengklasifikasi bahwa algoritma ID3 tingkat akurasi 62.2222%, untuk algoritma C4.5 tingkat akurasinya 67.7778%, sedangkan tingkat akurasi algoritma CART yaitu 62.2222%.
Sehingga algoritma C4.5 mempunyai tingkat akurasi 67.7778%
dibandingakan dengan metode lain.
b. Penelitian yang dilakukan oleh Kalpesh Adhatrao [4], yang memprediksi kinerja siswa dengan menggunakan algoritma ID3 dan C4.5. Dengan menganalisis siswa yang terdaftar pada tahun pertama. Data yang digunakan termasuk nama lengkap, jenis kelamin, ID, nilai kelas X dan XII, nilai ujian masuk, kategori dan jenis permintaan. Hasil dari prediksinya menunjukkan bahwa algoritma ID3 dengan total 173 siswa yang menghasilkan prediksi benar terdapat 130 siswa, tingkat akurasinya 75.145% dengan waktu 47.6 milisekon. Sedangkan pada algoritma C4.5 dengan data pengujian yang sama yaitu 173 siswa yang benar prediknya 130 siswa dengan tingkat akurasi 75.145% pada waktu 39.1 milisekon.
c. Penelitian yang dilakukan oleh Aman Kumar Sharma [5], yang menjelaskan tentang metode klasifikasi untuk menentukan apakah email tertentu termasuk spam atau tidak, dengan bantuan alat data mining yang disebut dengan WEKA. Metode klasifikasi yang digunakan yaitu ID3, J48, SimpleCART, dan ADTree. Klasifikasi data mining membuat hubungan antara variabel output dan variabel input dengan memetakan titik data, maksudnya mengidentifikasi objek sebagai kelas tertentu misalnya apakah email tertentu adalah spam atau non-spam. Hasil akurasi pada algoritma J48 memiliki tingkat akurasi yang tertinggi (92,7624%) dimana memiliki 4.268 data dengan klasifikasi benar, 333 kasus telah diklasifikasikan salah. Klasifikasi kedua tertinggi akurasi untuk algoritma CART adalah 92,632% dimana 4.262 kasus telah diklasifikasikan benar.
Selain itu ADTree menunjukkan akurasi 90,915%. Algoritma ID3 hasil klasifikasi terendah yaitu 89,111%.
Rangkuman dari penelitian – penelitian yang sebelumnya sudah dilakukan yaitu sebagai berikut :
Tabel 2. 1: State Of The Art
No Publication Masalah Metode Hasil
1 S.K. Yadav and S.pal,
“Data Mining: A Prediction for Performance
Improvement of Engineering Students Using Clasification”, World od Computer
Science and
Information
Untuk memprediksi kinerja siswa dalam ujian akhir, dengan mengidentifika si siswa yang lemah dan membantu untuk
ID3, C4.5 dan CART
algoritma ID3 tingkat akurasi 62.2222%, untuk algoritma C4.5 tingkat akurasinya 67.7778%, sedangkan tingkat akurasi algoritma CART yaitu 62.2222%. Sehingga algoritma C4.5 mempunyai tingkat akurasi 67.7778%
dibandingakan dengan
Technology Journal (WCSIT), Vol. 2, 51- 56, ISSN : 2221-0741, 2012
peningkatan siswa.
metode lain.
2 K. Adhatrao, A.
Gaykar, A. Dhawan, R. Jha, and V.
Honrao, “Predicting Students Performance Using ID3 and C4.5 Clasification
Algorithms”,
International Journal of Data Mining &
Knowledge
Management Process (IJDKP), Vol.3, No.5, September 2013
Untuk memprediksi kinerja siswa terdaftar pada tahun pertama.
ID3 dan C4.5
Hasil dari prediksinya menunjukkan bahwa algoritma ID3 dengan total
173 siswa yang
menghasilkan prediksi benar terdapat 130 siswa, tingkat akurasinya 75.145% dengan waktu 47.6 milisekon.
Sedangkan pada algoritma C4.5 dengan data pengujian yang sama yaitu 173 siswa yang benar prediknya 130 siswa dengan tingkat akurasi 75.145% pada waktu 39.1 milisekon
3 A.K. Sharma and
S.Sahni, “A
Comparative Study of Classification
Algorithms for Spam Email Data Analysis”, International Journal on Computer Science and Engineering (IJCSE), Vol. 3, No.
3, ISSN : 0975-3397,
Klasifikasi untuk menentukan apakah email tertentu
termasuk spam atau tidak, dengan
bantuan alat data mining yang disebut
ID3, CART, ADTree, dan J48,
Hasil akurasi pada algoritma J48 memiliki tingkat akurasi yang tertinggi (92,7624%) dimana memiliki 4.268 data dengan klasifikasi benar,
333 kasus telah
diklasifikasikan salah.
Klasifikasi kedua tertinggi akurasi untuk algoritma CART adalah 92,632%
dimana 4.262 kasus telah
May 2011 dengan WEKA.
diklasifikasikan benar.
Selain itu ADTree menunjukkan akurasi 90,915%. Algoritma ID3 hasil klasifikasi terendah yaitu 89,111%.
2. 2 Landasan Teori
2. 2. 1 Pengertian Hibah Air Minum
Pengertian Hibah adalah pemberian yang dilakukan oleh seseorang kepada pihak lain yang dilakukan ketika masih hidup dan pelaksanaan pembagiannya biasanya dilakukan pada waktu penghibah masih hidup [6]. Menurut Permendagri No. 23 tahun 2006 tentang Pedoman Teknis dan Tata Cara Peraturan Tarif Air Minum pada Perusahaan Daerah Air Minum, Departemen dalam Negeri Republik Indonesia, Air Minum adalah air yang melalui proses pengolahan atau tanpa pengolahan yang memenuhi syarat kesehatan dan dapat langsung diminum [7].
Program Hibah Air Minum APBN tahun 2015 adalah suatu upaya percepatan penambahan jumlah sambungan rumah (SR) baru melalui penerapan output based atau berdasarkan kinerja yang terukur. Program Hibah Air Minum yang dimaksud disini adalah pemberian hibah dari pemerintah pusat kepada pemerintah daerah yang bersumber dari penerimaan dalam negeri APBN tahun 2015. Hibah Air Minum ini dimaksudkan juga sebagai insentif kepada pemprov atau pemkab/pemkot untuk dapat melaksanakan peran dan tanggung jawabnya dalam penyelenggaraan penyediaan pelayanan air minum sampai pada output terbangunnya sambungan rumah air minum kepada
masyarakat. Kedepannya pelaksanaan hibah air minum dikembangkan untuk mencapai output lainnya, seperti pengurangan Non Revenue Water (NRW), energi efisiensi dan sebagainya. Pelaksanaan program hibah air minum akan menggunakan mekanisme sesuai dengan PMK No.
188/PMK.07/2012 tentang Hibah dari pemerintah pusat kepada pemerintah daerah dan/atau Perturan Perundangan-undangan terkait hibah daerah dan tata cara penyaluran hibah kepada pemerintah daerah [8].
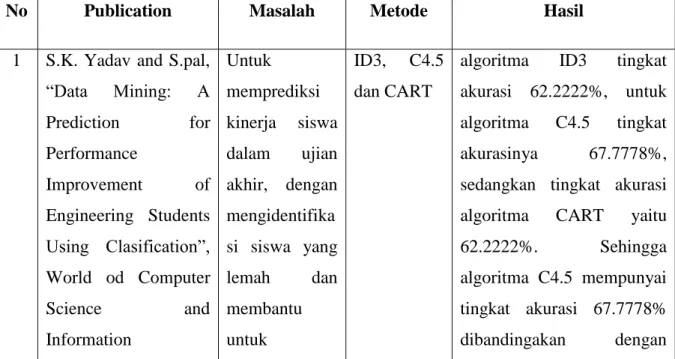
2. 2. 2 Data Mining
Data mining adalah analisis pengamatan data set untuk menemukan hubungan tak terduga dan untuk meringkas data dengan cara baru yang baik dimengerti dan berguna untuk pemilik data [9].
Data mining merupakan proses yang mempekerjakan satu atau lebih teknik pembelajaran komputer (machine learning) untuk menganalisis dan mengekstraksi pengetahuan (knowledge) secara otomatis. Definisi lain diantaranya adalah pembelajaran berbasis induksi (induction-based learning) adalah proses pembentukan definisi-definisi konsep umum yang dilakukan dengan cara mengobservasi contoh-contoh spesifik dari konsep- konsep yang akan dipelajari. Knowledge Discovery in Database (KDD) adalah penerapan metode saintifik pada data mining.
Dalam konteks ini data mining merupakan satu langkah dari proses KDD [2].
Gambar 2. 1: Data mining sebagai langkah dalam proses Knowledge Discovery
Suatu proses Knowledge Discovery digambarkan pada Gambar 1 dan terdiri dari urutan berulang dari langkah-langkah berikut [10]:
1. Pembersihan data (Data cleaning)
Pembersihan data merupakan proses untuk menghilangkan data yang invalid dan data yang tidak konsisten.
2. Integrasi data (Data integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru. Dimana beberapa sumber data dapat dikombinasikan.
3. Seleksi data (Data selection)
Data yang relevan dengan tugas analisis yang diambil dari database.
4. Transformasi data (Data transformation)
Data diubah atau digabung ke dalam bentuk yang sesuai untuk diproses dalam data mining dengan melakukan ringkasan.
5. Data mining
Proses penting dimana metode cerdas yang diterapkan untuk mengekstrak pola data.
6. Evaluasi pola (Pattern evaluation)
Untuk mengidentifikaasi pola-pola yang benar menarik kedalam knowledge based yang ditemukan.
7. Presentasi pengetahuan (Knowledge presentation)
Visualisasi dan representasi pengetahuan teknik yang digunakan untuk menyajikan pengetahuan ditambang untuk pengguna.
Beberapa teknik dan sifat data mining adalah sebagai berikut [2]:
Classification [Predictive]
Clustering [Descriptive]
AssociationRule Discovery [Descriptive]
SequentialPattern Discovery [Descriptive]
DeviationDetction [Predictive]
2. 2. 3 Decision Tree
Decision tree (pohon keputusan) adalah flowchart seperti struktur pohon, dimana setiap simpul internal menunjukkan tes pada atribut, setiap cabang merupakan hasil dari tes, dan masing- masing daun simpul (leaf node) menunjukkan label kelas [10].
Model Decision tree adalah metode yang paling sering digunakan dalam data mining. Tujuannya adalah untuk menciptakan sebuah model yang memprediksi hasilnya dari variabel target berdasarkan beberapa masukan variabel yang diberikan oleh pengguna sebagai kumpulan data training [11].
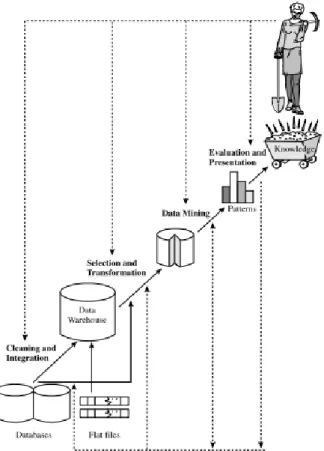
Salah satu algoritma yang digunakan untuk membangun pohon keputusan yang berbasis algoritma induksi pohon keputusan seperti ID3, C4.5 dan CART [2].
Gambar 2. 2: Model Pohon Keputusan
Seperti dilihat pada gambar, sebuah pohon keputusan untuk konsep membeli komputer, yaitu memprediksi apakah seorang pelanggan di AllElectronics kemungkinan untuk membeli komputer. Setiap node internal (non leaf) merupakan atribut tes.
Setiap simpul daun merepresentasikan kelas (membeli komputer
= yes atau tidak membeli komputer = no) [10].
Node internal dilambangkan dengan persegi panjang, dan node daun dilambangkan dengan oval. Beberapa algortima pohon keputusan hanya menghasilkan pohon biner (dimana masing- masing cabang simpul internal untuk dua node lain).
Pembangunan pohon keputusan untuk klasifikasi tidak memerlukan pengetahunan domain atau parameter pengetahuan dan sesuai untuk penemuan pengetahuan eksplorasi. Pohon keputusan dapat menangani data dimensi tinggi. Representasi pohon keputusan dalam bentuk pohon dan mudah untuk dipelajari
oleh manusia. Pengklasifikasi pohon keputusan memiliki akurasi yang baik [10].
Kelebihan dari pohon keputusan yaitu sebagai berikut [12] :
Daerah pengambilan keputusan lebih simpel dan spesifik.
Eliminasi perhitungan-perhitungan tidak diperlukan, karena ketika menggunakan metode pohon keputusan maka sampel diuji hanya berdasarkan kriteria atau kelas tertentu.
Fleksibel untuk memilih fitur dari internal node yang berbeda. Sehingga dapat meningkatkan kualitas keputusan yang dihasilkan jika dibandingkan ketika menggunakan metode perhitungan satu tahap yang lebih konvesional.
Dengan menggunakan pohon keputusan, penguji tidak perlu melakukan estimasi pada distribusi dimensi tinggi ataupun parameter tertentu dari distribusi kelas tersebut. Karena metode ini menggunakan kriteria yang jumlahnya lebih sedikit pada setiap node internal tanpa banyak mengurangi kualitas keputusan yang dihasilkan.
Sedangkan untuk kekurangan pohon keputusan yaitu [12] :
Kesulitan dalam mendesain pohon keputusan yang optimal.
Hasil kualitas keputusan yang didapat sangat tergantung pada bagaimana pohon tersebut didesain. Sehingga jika pohon keputusan yang dibuat kurang optimal, maka akan berpengaruh pada kualitas dari keputusan yang didapat.
Terjadi overlap terutama ketika kelas-kelas dan kriteria yang digunakan jumlahnya sangat banyak sehingga dapat menyebabkan meningkatnya waktu pengambilan keputusan dan jumlah memori yang diperlukan.
Pengakumulasian jumlah eror dari setiap tingkat dalam sebuah pohon keputusan yang besar.
2. 2. 4 Klasifikasi
Klasifikasi adalah menentukan sebuah record data baru ke salah satu dari beberapa kategori (atau kelas) yang telah didefinisikan sebelumnya. Disebut juga dengan supervised learning [2].
Proses klasifikasi didasarkan pada empat komponen mendasar [13] :
1. Kelas (Class)
Variabel dependen dari model yang merupakan variabel kategori mewakili label, menempatkan pada objek setelah klasifikasinya. Contoh kelas seperti adanya kelas penyakit jantung, loyalitas pelanggan, kelas bintang (galaksi), kelas gempa bumi (badai), dll.
2. Prediktor (Predictor)
Variabel independen dari model diwakili oleh karakteristik (atribut) dari data yang akan diklasifikasikan dan berdasarkan klasifikasi yang dibuat. Contoh prediktor tersebut adalah merokok, konsumsi alkohol, tekanan darah, frekuensi pembelian, status perkawinan, karakteristik (satelit) gambar, catatan geologi tertentu, dan kecepatan arah angin, musim, lokasi terjadinya fenomena, dll.
3. Pelatihan dataset (Training dataset)
Himpunan data yang berisi nilai-nilai untuk dua komponen sebelumnya, dan digunakan untuk pelatihan model untuk mengenali kelas yang tepat, berdasarkan prediksi yang tersedia. Contoh set tersebut adalah kelompok pasien yang diuji pada serangan jantung, kelompok pelanggan dari supermarket (diselidiki oleh
jajak pendapat internal), database yang berisi gambar untuk pemantauan dan pelacakan teleskopik objek astronomi, database pada badai, database penelitian gempa.
4. Dataset pegujian (Testing Dataset)
Berisi data baru yang akan diklasifikasikan oleh (classifier) model yang telah dibangun diatas, dan akurasi klasifikasi (model performance) dapat dievaluasi.
Model (metode) klasifikasi yang paling populer yaitu sebagai berikut [13]:
Decision/classification trees;
Bayesian classifiers/Naive Bayes Classifiers;
Neural networks;
Statistical analysis;
Genetic algorithms;
Rough sets;
K-nearest neighbor classifier;
Rule-based methods;
Memory based reasoning;
Support vector machines;
2. 2. 5 Algoritma ID3
Iterative Dichotomiser 3 (ID3) adalah sebuah algoritma diciptakan oleh Ross Quinlan digunakan untuk menghasilkan pohon keputusan dari dataset. ID3 biasanya digunakan dalam machine learning, teknik pohon keputusan untuk model proses klasifikasi [4]. Algoritma ID3 melakukan pencarian secara serakah/ menyeluruh, atribut terbaik diambil dan tidak pernah mempertimbangkan kembali pilihan sebelumnya [5].
ID3 menggunakan ukuran information gain untuk memilih membelah atribut. Hanya menerima atribut ketegorikal dalam membangun model pohon. Tidak memberikan hasil yang akurat ketika ada data yang tidak valid. Untuk menghilangkan yang tidak valid teknik pra-pengolahan harus digunakan. Untuk membangun pohon keputusan, information gain dihitung untuk masing-masing atribut dan pilih atribut dengan information gain tertinggi untuk menunjuk sebagai simpul akar. Label atribut sebagai simpul akar dan nilai yang mungkin dari atribut yang direpresentasikan sebagai busur. Semua contoh hasil yang mungkin adalah diuji untuk memeriksa apakah jatuh dibawah kelas yang sama atau tidak. Jika semua kasus yang jatuh dibawah kelas yang sama, simpul diwakili dengan nama kelas satu, jika tidak memilih membelah atribut untuk mengklasifikasikan kasus. Atribut kontinyu dapat ditangani dengan menggunakan algoritma ID3 dengan cara mendiskritkan atau langsung, dengan mempertimbangkan nilai-nilai untuk menemukan titik perpecahan terbaik dengan mengambil permulaan nilai atribut [3].
Entropi mengukur jumlah dari informasi yang ada pada atribut dengan rumus [14]:
𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑆 = − 𝑃𝑖log 2 𝑃𝑖
𝑐
𝑖
Entropy (S) = (- P+ log2 P+) + (- P- log2 P-)
Berdasarakan rumus di atas, P+ adalah probabilitas sampel S yang mempunyai class positif. P+ dihitung dengan membagi jumlah sampel positif (S+) dengan jumlah sampel keseluruhan (S) sehingga P+ = 𝑆+
𝑆 . P- adalah probabilitas sampel S yang
mempunyai class negatif. P- dihitung dengan jumlah sampel keseluruhan (S) sehingga P- = 𝑆_
𝑆 .
Pada algoritma ID3 pengurangan entropy disebut dengan information gain. Pembagian sampel S terhadap atribut A dapat dihitung information gain dengan rumus [14] :
Gain(S,A) = Entropy (S) – |𝑆𝑣|
𝑣𝐸 𝑛𝑖𝑙𝑎𝑖 (𝐴) |𝑆| 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆𝑣) Keterangan :
A : Atribut
V : Suatu nilai yang mungkin untuk atribut A Nilai (A) : Himpunan yang mungkin untuk atribut A
|Sv| : Jumlah sampel untuk nilai v
|S| : Jumlah seluruh sampel data
Entropy(Sv) : Entropy untuk sampel yang memiliki nilai v
2. 2. 6 Algoritma C4.5
Algoritma C4.5 adalah penerus ID3 dikembangkan oleh Quinlan Ross [3]. C4.5 adalah algoritma terkenal yang digunakan untuk menghasilkan pohon keputusan. Pohon-pohon keputusan yang dihasilkan oleh algoritma C4.5 dapat digunakan untuk klasifikasi, juga disebut sebagai classifier statistik. Algoritma C4.5 secara rekursif mengunjungi tiap simpul keputusan, memilih percabangan optimal, sampai tidak ada cabang lagi yang mungkin dihasilkan [9].
Algoritma C4.5 memiliki prinsip dasar kerja yang sama dengan algoritma ID3, C4.5 menggunakan Rasio Gain sebagai pemilihan atribut [15]:
Gain Ratio(S,A) = 𝐺𝑎𝑖𝑛 𝑅𝑎𝑡𝑖𝑜 (𝑆,𝐴) 𝑆𝑝𝑙𝑖𝑡 𝐼𝑛𝑓𝑜𝑟𝑚𝑎𝑡𝑖𝑜𝑛 (𝑆,𝐴)
Atribut dengan Gain Ratio tertinggi dipilih sebagai atribut.
Dengan Gain adalah information gain, split information menyatakan entropy gain informasi potensial dengan rumus :
Split Information(S,A) = - |𝑆𝑡|
|𝑆|
0𝑖=1 𝑙𝑜𝑔2|𝑆𝑡|
𝑆
Perhitunngan Gain dilakukan dengan rumus berikut : Gain(S,A) = Entropy(S) – 𝑛𝑖=1 𝑆𝑖 𝑆 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆𝑖) Keterangan :
S : Himpunan kasus A : Atribut
N : Jumlah partisi atribut A
|Si| : Jumlah kasus pada partisi ke-i
|S| : Jumlah kasus dalam S
Untuk nilai entropy dapat dihitung menggunakan rumus : Entropy(S) = - 𝑛𝑖=1𝑝𝑖 + 𝑙𝑜𝑔2 𝑝𝑖
Keterangan :
S : Himpunan kasus A : Atribut
N : Jumlah partisi S
Pi : Prororsi dari Si terhadap S 2. 2. 7 Confusion Matrix
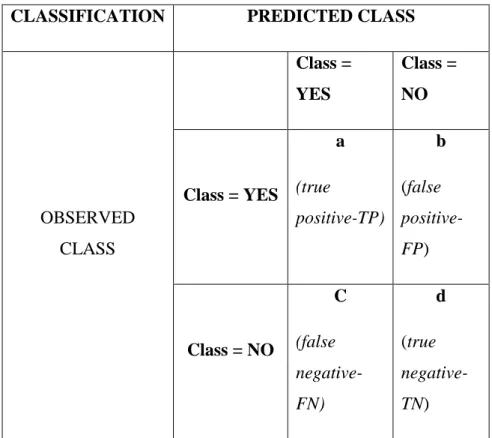
Confusion Matrix merupakan evaluasi kinerja dari model klasifikasi berdasarkan objek dengan memperkirakan yang benar atau salah. Confusion Matrix memberikan keputusan yang diperoleh dalam data training dan testing [13].
Tabel 2. 2: Confusion Matrix 2 Kelas
CLASSIFICATION PREDICTED CLASS
OBSERVED CLASS
Class = YES
Class = NO
Class = YES
a (true
positive-TP)
b (false positive- FP)
Class = NO
C (false negative- FN)
d (true negative- TN)
Keterangan :
True Positive (TP) : proporsi positif yang terdapat dalam data set yang diklasifikasikan positif.
False Negative (FN) : proporsi negatif yang terdapat dalam data set yang diklasifikasikan negatif.
False Positive (FP) : proporsi negatif yang terdapat dalam data set yang diklasifikasikan positif.
True Negatif (TN) : proporsi positif yang terdapat dalam data set yang diklasifikasikan negatif.
Akurasi adalah proporsi jumlah prediksi yang benar. Rumus untuk menghitung tingkat akurasi pada matrik adalah :
Accuracy = 𝑎 +𝑑
𝑎+𝑏+𝑐+𝑑 = 𝑇𝑃+𝑇𝑁
𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁
Berikut ini adalah persamaan model confusion matrix :
o Sensitivity mengukur proporsi true positive (TP) yaitu perbandingan TP terhadap tupelo positif yang diidentifikasi secara benar, yang dihitung dengan menggunakan persamaan :
Sensitivity = 𝑇𝑃
𝑇𝑃+𝐹𝑁
o Specificity mengukur proporsi true negative (TN) yaitu perbandingan proporsi TN terhadap tupelo negatif yang diidentifikasi secara benar, yang dihitung dengan menggunakan persamaan :
Specificity = 𝑇𝑁
𝑇𝑁+𝐹𝑃
o PPV (positive predictive value ) adalah proporsi kasus dengan hasil tes positif yang didiagnosis dengan benar, yang dihitung dengan menggunakan persamaan :
PPV = 𝑇𝑃
𝑇𝑃+𝐹𝑃
o NPV (negative predictive value) adalah proporsi kasus dengan hasil tes negatif yang didiagnosis dengan benar, yang dihitung dengan menggunakan persamaan :
NPV = 𝑇𝑁
𝑇𝑁+𝐹𝑁
2. 3 Tinjauan Objek Penelitian
Pada jaman pemerintahan hindia belanda kota kendal telah mendapat pelayanan air berih berawal dari pembuatan sumur-sumur artetis untuk umum (tanpa pompa air keluar sendri, rakyat mengambi gratis).
Tahun 1975 dikelola oleh Kanwil PU Provinsi Jawa Tengah yang dalam pelaksanaannya oleh Proyek Pengadaan Sarana Air Bersih (P2SAB).
Tahun 1978 untuk perkembangan selanjutnya pengelolaan pelayanan dan perawatan jaringan diserrahkan oleh Badan Pengelolaan Air Minum
(BPAM) dengan dasar Surat Keputusan Direktorat Jendral Cipta Karya DPU No.054/KOTS/CK/VII/1978.
Pada tahun 1986 dalam kurun waktu pengelolaan selanjutnya berdasarkan Peraturan Daerah Kabupaten Kendal No.3 tahun 1986 tanggal 27 Pebruari 1986 status pengelolaannya diubah menjadi Perusahaan Daerah Air Minum. Tahun 2003 keberadaan PDAM Kebupaten Dati II Kendal diperbaharui dengan PERDA Kabupaten Kendal No.14 Tahun 2003 tanggal 18 Desember 2003 Tentang Perusahaan Daerah Air Minum.
Tahun 2008 peraturan daerah kabupatenn Kendal No 8 tahun 2008 Tentang Perusahaan Daerah Air Minum “Tirto Panguripan” kabupaten Kendal. Tanggal 17 Juni 2008.
2. 4 Kerangka Pemikiran
Tabel 2. 3: Kerangka Pemikiran
Masalah
1. Bagaimana perbandingan algoritma ID3 dan C4.5 berdasarkan data masyarakat berpenghasilan rendah dalam mendapatkan hibah pemasangan sambungan air minum.
2. Bagaimana menentukan penerima hibah pemasangan sambungan air minum berdasarkan analisis perbandingan algoritma ID3 dan C4.5 dengan memilih akurasi yang lebih tinggi.
Tujuan
1. Ingin mengetahui perbedaan tingkat akurasi algoritma ID3 dan C4.5 untuk kasus masyarakat berpenghasilan rendah dalam mendapatkan hibah pemasangan sambungan air minum pada PDAM.
2. Untuk menentukan penerima hibah pemasangan sambungan air minum berdasarkan algoritma yang mempunyai tingkat akurasi yang lebih tinggi.
Metode
Metode yang digunakan untuk pengelompokan data ini adalah metode klasifikasi decision tree
Eksperimen
Data Tools
Data masyarakat berpeghasilan rendah di PDAM Kabupaten Kendal pada tahun 2015
RapidMiner
Pengujian Confusion matrix
Hasil
Akurasi algoritma ID3 dan C4.5 serta mengetahui penerima hibah pemasangan sambungan air minum secara objektif dan tepat berdasarkan algortima yang memiliki tingkat akurasi yang tinggi.
23 3.1 Instrumen penelitian
Berdasarkan permasalahan yang telah diuraikan pada bab sebelumnya, maka bahan dan peralatan yang diperlukan untuk penelitian ini meliputi : 3.1.1 Bahan
Dalam penelitian ini bahan yang dibutuhkan adalah data masyarakat berpenghasilan rendah di PDAM Kabupaten Kendal tahun 2015.
3.1.2 Peralatan
Peralatan dalam penelitian ini meliputi kebutuhan perangkat lunak dan kebutuhan perangkat keras .
Kebutuhan perangkat lunak :
1. Microsoft Windows 7 Ultimate sebagai notebook.
2. Microsoft Exel 2007 sebagai media penulisan dataset.
3. RapidMiner versi 5.3, framework yang akan digunakan untuk melihat hasil akurasi.
4. PHP, framework yang akan digunakan untuk prototipe.
Kebutuhan perangkat keras : 1. Processor Intel Core 2 Duo 2. Memori RAM 2GB
3. Hardisk 320GB
3.2 Prosedur pengambilan atau pengumpulan data
Pada penelitian ini prosedur pengambilan data sesuai dengan prosedur penelitian dengan menyerahkan surat ijin penelitian yang ditujukan pada PDAM Kabupaten Kendal. Adapun kriteria dari penerima hibah pemasangan sambungan air minum adalah :
1. Masyarakat berpenghasilan rendah yang memiliki daya listrik terpasang dirumah tangga tersebut ≤ 1300 VA dan minimal 50%
diantara target sasaran tersebut memiliki daya listrik ≤ 900 VA dan/atau tidak memiliki sambungan listrik.
2. Bersedia dan memenuhi persyaratan sebagai pelanggan PDAM.
3. Masyarakat penerima hibah bersedia membayar biaya pemasangan sambungan sesuai dengan yang telah ditetapkan PDAM, yang besarnya lebih murah dari pada biaya sambungan reguler.
4. Masyarakat miskin, yang tidak memiliki fasilitas mobil, dan keadaan rumah tidak bertingkat.
Sehingga data yang diperoleh berupa data softcopy yang tersedia pada PDAM Kabupaten Kendal berupa data masyarakat berpenghasilan rendah tahun 2015 untuk penerima hibah pemasangan air minum sebanyak 1473 data. Dengan data tersebut terdapat atribut nama, alamat, desa, RT, RW, Kecamatan, daya listrik yang digunakan, KTP dan gambar. Atribut tambahan yang didapat dari hasil survai, yaitu berupa fasilitas yang dimiliki, kondisi bangunan, dan kesediaan.
Selain itu penyusunan tugas akhir menggunakan studi pustaka yang diperoleh dari beberapa sumber yaitu :
1. Buku yang menjelaskan data mining mengenai algoritma ID3 dan C4.5.
2. E-book yang menjelaskan data mining beserta algoritma yang digunakan.
3. Jurnal menjelaskan kasus pada metode klasifikasi.
3.3 Teknik analisis data (cara pengolahan data awal)
Teknik yang dilakukan sebagai tahap awal yaitu persiapan data, data yang diperoleh diambil sebanyak 300 data yang akan dijadikan data sampel. Teknik pengolahan data awal sebagai berikut :
1. Pembersihan data
Melakukan pembersihan data dengan tujuan untuk menghilangkan data yang tidak valid dan data yang tidak konsisten. Jika terdapat data atribut yang tidak diperlukan maka atributnya dihilangkan selama proses klasifikasi, sehingga tidak mengganggu proses selanjutnya.
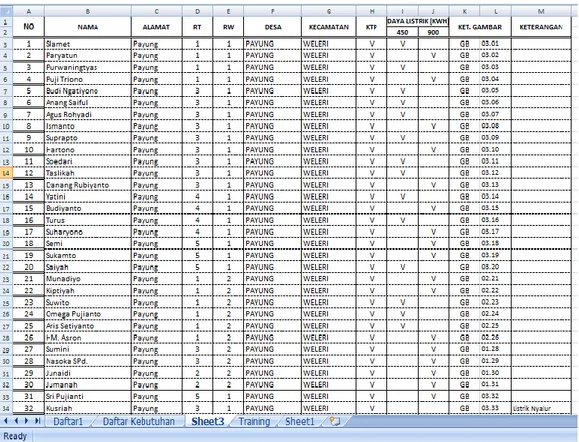
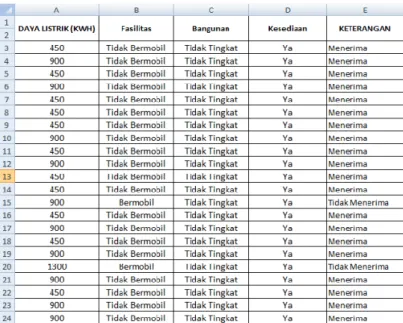
Gambar 3. 1: Sebelum Penghapusan Atribut
Gambar diatas terdapat beberapa atribut yang tidak berpengaruh dan tidak diperlukan seperti atribut nama, alamat, Rt, Rw, Desa, Kecamatan dan KTP. Yang selanjutnya akan dilakukan pengelompokan pada atribut daya listrik dan keterangan dari daya listrik yang lainnya.
Gambar 3. 2: Setelah Penghapusan Atribut
Setelah dilakukan penghapusan atribut, sehingga atribut yang mempengaruhi dalam proses klasifikasi yaitu daya listrik yang digunakan.
2. Integrasi data
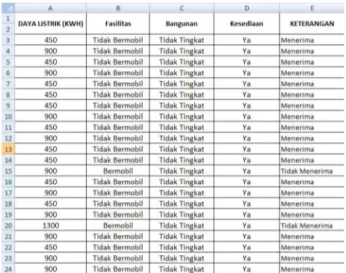
Melakukan integrasi data dengan menggabungan data dari berbagai database ke dalam satu database baru. Dimana beberapa sumber data dapat dikombinasikan. Dalam data mining terdapat data yang tidak didapat secara langsung, seperti data yang di peroleh dari hasil survai dilakukan analisis. Sehingga data dapat di gabungkan menjadi satu dataset.
Gambar 3. 3: Penggabungan database
Gambar diatas menerangkan bahwa atribut fasilitas, bangunan, dan kesediaan, merupakan hasil dari hasil survai yang dilakukan.
Setelah dilakukan preprosesing terhadap data set dan terdapat data sebanyak 1473 data penerima hibah pemasangan sambungan air minum.
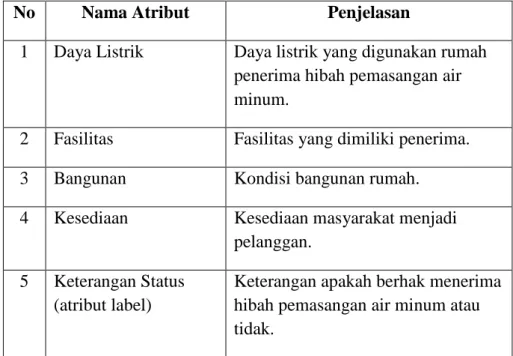
Atribut yang akan digunakan dalam klasifikasi ini ada 4 yaitu daya listrik, fasilitas, bangunan, kesediaan, serta 1 atribut yang menjadi target yaitu atribut keterangan status.
Tabel 3. 1: Atribut yang akan digunakan dalam pemodelan
No Nama Atribut Penjelasan
1 Daya Listrik Daya listrik yang digunakan rumah penerima hibah pemasangan air minum.
2 Fasilitas Fasilitas yang dimiliki penerima.
3 Bangunan Kondisi bangunan rumah.
4 Kesediaan Kesediaan masyarakat menjadi pelanggan.
5 Keterangan Status (atribut label)
Keterangan apakah berhak menerima hibah pemasangan air minum atau tidak.
Tabel diatas menjelaskan atribut yang digunakan untuk pemodelan data yang mana terdapat atribut daya listrik, fasilitas, bangunan, kesediaan, dan keterangan status. Daya listrik yang digunakan pada rumah penerima hibah pemasangan air minum terdapat 5 kategori dalam daya listrik yang digunakan meliputi 450 KWH, 900 KWH, 1300 KWH, pulsa listrik, dan listrik nyalur. Pada atribut fasilitas disini yang dijadikan atribut terdapat 2 kategori fasilitas yaitu fasilitas dengan mempunyai mobil dan tidak mempunyai mobil. Untuk atribut bangunan merupakan kondisi bangunan rumah dari penerima hibah, disini terdapat 2 kategori yaitu kondisi bangunan bertingkat atau tidak. Pada atribut kesediaan merupakan kesediaan dari masyarakat yang akan menerima hibah tersebut bersedia menjadi pelanggan PDAM atau tidak. Yang terakhir atribut yang dijadikan target adalah keterangan status apakah masyarakat yang berpenghasilan rendah berhak menerima hibah pemasangan air minum atau tidak.
3.4 Model atau metode yang diusulkan
Metode yang akan digunakan pada penelitian ini dengan 2 metode yaitu ID3 dan C4.5. Kemudian akan dilakukan pengukuran tingkat akurasi
dari kedua metode tersebut, menggunakan confusion Matrix yang terdapat pada framework RapidMiner Ver.5.3
3.4.1 Tahapan Algoritma ID3
Tahapan dari proses algoritma ID3 yaitu sebagai berikut : 1. Menyiapkan data training
2. Hitung nilai Entropy dengan rumus : 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑆 = − 𝑃𝑖log 2 𝑃𝑖
𝑐
𝑖
Entropy (S) = (- P+ log2 P+) – (P- log2 P-)
3. Setelah mendapatkan nilai Entropy akan mencari Information Gain dari setiap atribut untuk mendapatkan nilai Information Gain yang paling tinggi.
4. Rumus dari Information Gain yaitu : Gain(S,A) = Entropy (S) – |𝑆𝑣|
𝑣𝐸 𝑛𝑖𝑙𝑎𝑖 (𝐴) |𝑆| 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆𝑣) 5. Nilai Information Gain yang tertinggi akan terbentuk
menjadi simpul yang pertama dan akan menempati paling atas.
6. Proses perhitungan Information Gain diulangi sampai semua data yang termasuk dalam kelas yang sama.
7. Sehingga akan terbentuk pohon keputusan.
8. Maka akan terbentuk Rule-Rule.
3.4.2 Tahapan Rapid Miner pada Algoritma ID3
1. Buat data dalam format excel seperti pada gambar berikut.
Gambar 3. 4: Dataset MBR
Gambar diatas merupakan data set MBR yang digunakan untuk pemodelan data dalam RapidMiner, didalam gambar terdapat 4 atribut yaitu daya listrik yang digunakan, fasilitas, bangunan dan kesediaan serta 1 atribut target yaitu keterangan yang menyatakan menerima atau tidak menerima hibah pemasangan sambungan air minum.
2. Setelah data yang tersedia dibuat dalam bentuk tabel format xls, selanjutnya melakukan Importing Data kedalam Repositori.
3. Kemudian melakukan Drag dan Drop pada tabel MBR kedalam Main Process, tabel tersebut dinamakan operator Retrieve.
4. Selanjutnya akan membutuhkan operator Decision Tree, operator tersebut terdapat pada view operator, lalu kita
memilih Modelling dan pilih Classification and Regression, kemudian pilih tree Induction dan pilih pada ID3.
5. Setelah menemukan operator Decision Tree, maka drag operator lalu letakkan ke dalam main process.
6. Selanjutnya hubungkan operator Retrieve dengan operator Decision Tree dengan menarik garis dari tabel MBR ke operator Decision Tree dan menarik garis lagi dari operator Decison Tree ke result yang ada disisi kanan.
7. Kemudian mengatur parameter Decision Tree sesuai dengan kebutuhan.
8. Setelah itu, klik ikon Run pada toollbar untuk menampilkan hasilnya.
9. Hasil yang keluar berupa pohon keputusan.
3.4.3 Tahapan Algoritma C4.5
Tahapan dari proses algoritma C4.5 adalah : 1. Mempersiapkan data training.
2. Hitung nilai entropy dengan rumus :
Entropy(S) = - 𝑛𝑖=1𝑝𝑖 + 𝑙𝑜𝑔2 𝑝𝑖
3. Setelah mendapatkan nilai dari Entropy maka akan digunakan untuk mencari nilai Gain.
4. Rumus yang digunakan untuk menghitung Gain sebagai berikut :
Gain(S,A) = Entropy(S) – 𝑆𝑖
𝑆
𝑛𝑖=1 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆𝑖) 5. Kemudian mencari nilai Split Info dengan rumus :
Split Information(S,A) = - |𝑆𝑡|
|𝑆|
0𝑖=1 𝑙𝑜𝑔2|𝑆𝑡|
𝑆
6. Setelah mendapatkan nilai Gain dan Split Info, lalu mencari nilai Gain Ratio dengan rumus sebagai berikut :
Gain Ratio(S,A) = 𝐺𝑎𝑖𝑛 𝑅𝑎𝑡𝑖 𝑜(𝑆,𝐴) 𝑆𝑝𝑙𝑖𝑡 𝐼𝑛𝑓𝑜𝑟𝑚𝑎𝑡𝑖𝑜𝑛 (𝑆,𝐴)
7. Nilai Gain Ratio tertinggi akan digunakan sebagai atribut akar. Dengan itu akan terbentuk pohon keputusan sebagai node 1.
8. Ulangi proses ke-2 sampai semua cabang memiliki kelas yang sama.
9. Maka akan terbentuk pohon keputusan.
10. Dari pohon keputusan yang terbentuk maka dapat ditentukan Rule-Rule.
3.4.4 Tahapan Rapid Miner pada Algoritma C4.5
1. Buat data dalam format excel seperti pada gambar berikut.
Gambar 3. 5: Dataset MBR
Gambar diatas merupakan data set MBR yang digunakan untuk pemodelan data dalam RapidMiner, didalam gambar terdapat 4 atribut yaitu daya listrik yang digunakan, fasilitas, bangunan dan kesediaan serta 1 atribut target yaitu keterangan yang menyatakan menerima atau tidak menerima hibah pemasangan sambungan air minum.
2. Setelah data yang tersedia dibuat dalam bentuk tabel format xls, selanjutnya melakukan Importing Data kedalam Repositori.
3. Kemudian melakukan Drag dan Drop pada yang sudah di tabel MBR kedalam Main Process, tabel tersebut dinamakan operator Retrieve.
4. Selanjutnya akan membutuhkan operator Decision Tree, operator tersebut terdapat pada view operator, lalu kita memilih Modelling dan pilih Classification and Regression, kemudian pilih tree Induction dan pilih pada Decision Tree.
5. Setelah menemukan operator Decision Tree, maka drag operator lalu letakkan ke dalam main process.
6. Selanjutnya hubungkan operator Retrieve dengan operator Decision Tree dengan menarik garis dari tabel MBR ke operator Decision Tree dan menarik garis lagi dari operator Decison Tree ke result yang ada disisi kanan.
7. Kemudian mengatur parameter Decision Tree sesuai dengan kebutuhan.
8. Setelah itu, klik ikon Run pada tollbar untuk menampilkan hasilnya.
9. Hasil yang keluar berupa pohon keputusan.
3.5 Evaluasi dan Validasi
Pengujian pada algoritma ID3 dan C4.5 dilakukan dengan confusion matrix untuk mengetahui tingkat Sensitivity (recall), PPV (positive predictive value ) atau precision, dan akurasi dari metode klasifikasi yang dibuat :
Untuk menghitung recall dengan rumus : Recall = 𝑇𝑃
𝑇𝑃+𝐹𝑁
Recall bertujuan untuk mengukur proporsi true positive (TP) terhadap tupelo positif yang diidentifikasi secara benar.
Untuk perhitungan precision menggunakan rumus : Precision = 𝑇𝑃
𝑇𝑃+𝐹𝑃
Precision bertujuan untuk mengukur proporsi jumlah kasus yang diprediksi positif yang juga positif benar pada data yang sebenarnya.
Akurasi dihitung dengan rumus : Accuracy = 𝑎 +𝑑
𝑎+𝑏+𝑐+𝑑 = 𝑇𝑃+𝑇𝑁
𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁
Akurasi bertujuan untuk menjumlah prediksi penerima hibah pemasangan air minum yang benar.
Sehingga dengan mengetahui Recall, Precision, dan Akurasi dapat mengetahui suatu algoritma dikatakan cepat, presisi dan akurat sebagai nilai perbandingan antara algoritma C4.5 dengan ID3.
Untuk menentukan menerima atau tidak menerima hibah sambungan air minum untuk masyarakat berpenghasilan rendah dengan melihat hasil perbandingan antara algoritma C4.5 dan ID3. Antara kedua algoritma tersebut yang memiliki tingkat akurasi yang lebih tinggi yaitu akan digunakan sebagai klasifikasi penerima hibah sambungan air minum secara objektif dan akurat dengan melihat rule-rule yang terbentuk dari algoritma yang memiliki akurasi yang lebih tinggi. Sehingga data yang diolah saat ini dan yang memiliki tingkat akurasi tinggi akan digunakan dalam pengambilan keputusan selanjutnya.
35
Didalam bab ini penulis akan membahas mengenai data yang akan digunakan dalam penelitian, data tersebut akan dihitung menggunakan algoritma ID3 dan C4.5 yang kemudian akan diuji menggunakan Cross Validation. Pada penelitian ini, data yang digunakan adalah data Masyarakat Berpenghasilan Rendah tahun 2015 pada PDAM Kabupaten Kendal dengan jumlah data 1473(lampiran 1).
4. 1. Perhitungan Algoritma
4. 1. 1 Perhitungan Algoritma ID3
Dibawah ini merupakan contoh perhitungan manual dari penerapan algoritma ID3 untuk klasifikasi penerima hibah air minum dengan menggunakan 240 data training. Pada Algoritma ID3 harus menentukan pohon keputusan yang kemudaian akan menjadi rule untuk mengklasifikasi penerima hibah air minum.
4.1.1. 1. Perhitungan Node 1 o Total
Jumlah kasus (S) = 240
Jumlah Tidak Menerima (S1) = 47 Jumlah Menerima (S2) =193
Entropy(Total) = − 𝑆1 𝑆 ∗ log 2 𝑆1 𝑆 + − 𝑆2 𝑆 log 2 𝑆2 𝑆
= − 47 240∗ log 2 47 240 + − 193 240log 2 193 240
= − 0,196 ∗ −2,351 + − 0,804 ∗ −0,315 = 0,461 + 0,253
=0,714
1. Perhitungan Daya Listrik o Daya listrik 450
Jumlah kasus (S) = 85 Jumlah Tidak Menerima (S1) = 7 Jumlah Menerima (S2) =78
Entropy(450) = − 𝑆1 𝑆 ∗ log 2 𝑆1 𝑆 + − 𝑆2 𝑆 log 2 𝑆2 𝑆
= − 7 85∗ log 2 7 85 + − 78 85log 2 78 85
= − 0,082 ∗ −3,608 + − 0,918 ∗ −0,123 = 0,296 + 0,113
=0,409
o Daya listrik 900
Jumlah kasus (S) = 86 Jumlah Tidak Menerima (S1) = 9 Jumlah Menerima (S2) =77
Entropy(900) = − 𝑆1 𝑆 ∗ log 2 𝑆1 𝑆 + − 𝑆2 𝑆 log 2 𝑆2 𝑆
= − 9 86∗ log 2 9 86 + − 77 86log 2 77 86
= − 0,105 ∗ −3,252 + − 0,895 ∗ −0,160 = 0,341 + 0,143
=0,484
o Daya listrik 1300
Jumlah kasus (S) = 33 Jumlah Tidak Menerima (S1) = 17 Jumlah Menerima (S2) =16
Entropy(1300) = − 𝑆1 𝑆 ∗ log 2 𝑆1 𝑆 + − 𝑆2 𝑆 log 2 𝑆2 𝑆
= − 17 33∗ log 2 17 33 + − 16 33log 2 16 33
= − 0,515 ∗ −0,957 + − 0,485 ∗ −1,044
= 0,493 + 0,506
=0,999
o Daya listrik pulsa
Jumlah kasus (S) = 20 Jumlah Tidak Menerima (S1) = 6 Jumlah Menerima (S2) =14
Entropy(pulsa) = − 𝑆1 𝑆 ∗ log 2 𝑆1 𝑆 + − 𝑆2 𝑆 log 2 𝑆2 𝑆
= − 6 20∗ log 2 6 20 + − 14 20log 2 14 20
= − 0,3 ∗ − 1,737 + − 0,7 ∗ −0,515 = 0,521 + 0,361
=0,882
o Daya listrik nyalur
Jumlah kasus (S) = 16 Jumlah Tidak Menerima (S1) = 8 Jumlah Menerima (S2) =8
Entropy(nyalur) = − 𝑆1 𝑆 ∗ log 2 𝑆1 𝑆 + − 𝑆2 𝑆 log 2 𝑆2 𝑆
= − 8 16∗ log 2 8 16 + − 8 16log 2 8 16
= − 0,5 ∗ −1 + − 0,5 ∗ −1
= 0,5 + 0,5
= 1
𝐺𝑎𝑖𝑛 𝑇𝑜𝑡𝑎𝑙, 𝑑𝑎𝑦𝑎 𝑙𝑖𝑠𝑡𝑟𝑖𝑘
= 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑇𝑜𝑡𝑎𝑙 − |𝑑𝑎𝑦𝑎 𝑙𝑖𝑠𝑡𝑟𝑖𝑘𝑖|
|𝑇𝑜𝑡𝑎𝑙|
𝑛
𝑖−1
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑑𝑎𝑦𝑎 𝑙𝑖𝑠𝑡𝑟𝑖𝑘𝑖
= 0,714
− 85
240∗ 0,409 + 86
240∗ 0,484 + 33
240∗ 0,999 + 20
240∗ 0,882 + 16
240∗ 1
= 0,714 − 0,145 + 0,173 + 0,137 + 0,074 + 0,067
= 0,714 − 0,596
= 0,118
2. Perhitungan Fasilitas
o Fasilitas Tidak Bermobil
Jumlah kasus (S) = 216 Jumlah Tidak Menerima (S1) = 23 Jumlah Menerima (S2) =193
𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑡𝑖𝑑𝑎𝑘 𝑏𝑒𝑟𝑚𝑜𝑏𝑖𝑙 = − 𝑆1 𝑆 ∗ log 2 𝑆1 𝑆 + − 𝑆2 𝑆 log 2 𝑆2 𝑆
= − 23 216∗ log 2 23 216 + − 193 216log 2 193 216
= − 0,106 ∗ −3,238 + − 0,894 ∗ −0,162
= 0,343 + 0,145
=0,488
o Fasilitas Bermobil
Jumlah kasus (S) = 24 Jumlah Tidak Menerima (S1) = 24 Jumlah Menerima (S2) =0 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑏𝑒𝑟𝑚𝑜𝑏𝑖𝑙 =
− 𝑆1 𝑆 ∗ log 2 𝑆1 𝑆 + − 𝑆2 𝑆 log 2 𝑆2 𝑆
= − 24 24∗ log 2 24 24 + 0
= 0 + 0
= 0
𝐺𝑎𝑖𝑛 𝑇𝑜𝑡𝑎𝑙, 𝑓𝑎𝑠𝑖𝑙𝑖𝑡𝑎𝑠
= 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑇𝑜𝑡𝑎𝑙 − |𝑓𝑎𝑠𝑖𝑙𝑖𝑡𝑎𝑠𝑖|
|𝑇𝑜𝑡𝑎𝑙|
𝑛
𝑖−1
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑓𝑎𝑠𝑖𝑙𝑖𝑡𝑎𝑠𝑖
= 0,714 − 216 240∗ 0,488 + 0
= 0,714 − 0,439
= 0,275
3. Perhitungan Bangunan
o Bangunan Tidak Tingkat
Jumlah kasus (S) = 229 Jumlah Tidak Menerima (S1) = 37 Jumlah Menerima (S2) =192
𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑡𝑖𝑑𝑎𝑘 𝑡𝑖𝑛𝑔𝑘𝑎𝑡 = − 𝑆1 𝑆 ∗ log 2 𝑆1 𝑆 + − 𝑆2 𝑆 log 2 𝑆2 𝑆
= − 37 229∗ log 2 37 229 + − 192 229log 2 192 229
= − 0,162 ∗ −2,626 + − 0,838 ∗ −0,255 = 0,425 + 0,214
=0,639
o Bangunan Tingkat
Jumlah kasus (S) = 11 Jumlah Tidak Menerima (S1) = 10 Jumlah Menerima (S2) =1
𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑡𝑖𝑛𝑔𝑘𝑎𝑡 =
− 𝑆1 𝑆 ∗ log 2 𝑆1 𝑆 + − 𝑆2 𝑆 log 2 𝑆2 𝑆
= − 10 11∗ log 2 10 11 + − 1 11log 2 1 11
= − 0,909 ∗ −0,138 + − 0,091 ∗ −3,458 = 0,125 + 0,315
=0,440
𝐺𝑎𝑖𝑛 𝑇𝑜𝑡𝑎𝑙, 𝑏𝑎𝑛𝑔𝑢𝑛𝑎𝑛
= 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑇𝑜𝑡𝑎𝑙 − |𝑏𝑎𝑛𝑔𝑢𝑛𝑎𝑛𝑖|
|𝑇𝑜𝑡𝑎𝑙|
𝑛
𝑖−1
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑏𝑎𝑛𝑔𝑢𝑛𝑎𝑛𝑖
= 0,714 − 229 240∗ 0,639 + 11 240∗ 0,639
= 0,714 − 0,609 + 0,020
= 0,714 − 0,629
= 0,085
4. Perhitungan Kesediaan o Kesediaan ya
Jumlah kasus (S) = 225 Jumlah Tidak Menerima (S1) = 32 Jumlah Menerima (S2) =193
𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑦𝑎 = − 𝑆1 𝑆 ∗ log 2 𝑆1 𝑆 + − 𝑆2 𝑆 log 2 𝑆2 𝑆
= − 32 225∗ log 2 32 225 + − 193 225 log 2 193 225
= − 0,142 ∗ −2,816 + − 0,858 ∗ −0,221 = 0,399 + 0,189
=0,588
o Kesediaan tidak
Jumlah kasus (S) = 15 Jumlah Tidak Menerima (S1) = 15 Jumlah Menerima (S2) =0 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑡𝑖𝑑𝑎𝑘 =
− 𝑆1 𝑆 ∗ log 2 𝑆1 𝑆 + − 𝑆2 𝑆 log 2 𝑆2 𝑆
= − 15 15∗ log 2 15 15 + 0
= 0 + 0
= 0
𝐺𝑎𝑖𝑛 𝑇𝑜𝑡𝑎𝑙, 𝑘𝑒𝑠𝑒𝑑𝑖𝑎𝑎𝑛
= 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑇𝑜𝑡𝑎𝑙 − |𝑘𝑒𝑠𝑒𝑑𝑖𝑎𝑎𝑛𝑖|
|𝑇𝑜𝑡𝑎𝑙|
𝑛
𝑖−1
∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 𝑘𝑒𝑠𝑒𝑑𝑖𝑎𝑎𝑛𝑖
= 0,714 − 225 240∗ 0,588 + 0
=0,714 − 0,551
=0,164
Berdasarkan komputasi dengan algoritma ID3 maka dapat disajikan tabel perhitungan node 1 sebagai berikut :
Tabel 4. 1: Perhitungan ID3 Node 1
Atribut Jumlah
Kasus
Tidak Menerima
(S1)
Menerima (S2)
Entropy Inf Gain Total
Kasus
240 47 193 0,714
Daya Listrik
0,118
450 85 7 78 0,409
900 86 9 77 0,484
1300 33 17 16 0,999
Pulsa 20 6 14 0,882
Nyalur 16 8 8 1
Fasilitas 0,275 Tidak
Bermobil
216 23 193 0,488
Bermobil 24 24 0 0
Bangunan 0,085
Tidak Tingkat
229 37 192 0,639
Tingkat 11 10 1 0,440
Kesediaan 0,164
Ya 225 32 193 0,588
Tidak 15 15 0 0
Tabel diatas merupakan hasil perhitungan pada Node 1, diketahui bahwa nilai Information Gain terbesar yaitu pada atribut Fasilitas yaitu 0,275. Sehingga atribut Fasilitas menjadi node akar. Pada atribut Fasilitas terdapat 2 nilai atribut yaitu tidak bermobil dan bermobil. Nilai atribut yang pertama yaitu tidak bermobil belum mengklasifikasikan kasus menjadi satu keputusan sehingga perlu dilakukan perhitungan lagi, sedangkan nilai atribut bermobil sudah mengklasifikasikan menjadi 1 yaitu dengan hasil Menerima, sehingga tidak perlu dilakukan perhitungan lebih lanjut.
Berdasarkan tabel perhitungan Node 1 dapat dibentuk pohon keputusan sebagai berikut :
Node 1 Fasilitas
Tidak Menerima Bermobil
Node 1.1 Tidak Bermobil
Gambar 4. 1: Node 1 Algoritma ID3
Gambar diatas merupakan pohon keputusan yang menjadi node akar yaitu atribut fasilitas yang memiliki 2 cabang yaitu sesuai dengan nilai pada fasilitas, pada nilai