SIMULASI OPTIMASI QUERY MENGGUNAKAN HISTOGRAM UNTUK MEMINIMALISASI NILAI SUMBER DAYA PADA DATABASE TERDISTRIBUSI
Ignatius Hadi Prabowo1)
1) S1/Jurusan Sistem Informasi, Sekolah Tinggi Manajemen Informatika & Teknik Komputer
Surabaya, email : [email protected]
Abstract : Query optimization in a relational database become an "expensive" job when dealing with relationships in large numbers. Finding the best execute way with the fastest time is a liability since the wrong strategy could be implemented in a database so that increases the execution time of a query set. With the increasing complexity of a database, it becomes important for the methods of the query optimizer to adopt an algorithm that requires a low cost in terms of execution time.
There are several methods examined by experts to reduce the burden of DBMS. By taking advantage of a query optimization model that using a histogram and a model incorporating the concept of determination of the costs of operations performed by the DBMS is expected to reduce the burden on the DBMS performance. The combination model proposed would pass procedure simulation system with a verification and validation process. After pass some development process the optimization model will be tested using real data from 3 tables, MHS_MF_TA, KURLKL_MF_TA, FAK_MF_TA STIKOM Surabaya with a total of 19.344 records.
After testing and evaluation process of simulation models, the query optimization using a histogram could ease a DBMS performance on a selection attributes order that would be executed, so that based on a simulation results could be concluded that the proposed model can reduce the burden of query execution by the DBMS
Keyword: Query Optimization, histogram, simulation
Proses optimasi pada query dalam sebuah relasi database menjadi pekerjaan yang ”mahal” saat berurusan dengan relasi dalam jumlah besar. Jumlah kemungkinan cara untuk mengeksekusi sebuah set query meningkat secara eksponen bersamaan dengan jumlah relasi yang terdapat dalam set query tersebut. Mencari cara terbaik dengan waktu eksekusi tercepat adalah sebuah kewajiban semenjak strategi yang salah diterapkan dalam sebuah database sehingga meningkatkan waktu eksekusi sebuah set query. Dengan meningkatnya kompleksitas sebuah database, hal tersebut menjadi penting bagi metode-metode query optimizer untuk mengadopsi sebuah algoritma yang membutuhkan cost rendah dalam hal waktu eksekusi.
Usaha sebelumnya untuk menyelesaikan permasalahan tersebut berkisar pada strategi pencarian seperti deterministic, randomized dan heuristic. Banyak algoritma diajukan oleh banyak literatur, seperti Simulated Annealing (SA), Iterative Improvement (II), Two Phase Optimization (2PO) dan Genetic Algorithm. Contoh-contoh yang disebutkan adalah algoritma random yang umum yang telah diaplikasikan pada query optimization.
Dikatakan pada sebuah jurnal internasional yang membahas tentang distributed database adalah “a collection of multiple, logically interrelated databases distributed over a computer network” (Zafarani, Derakhshi, Asil, & Asil, 2010) Pada pernyataan tersebut menjelaskan bahwa
database terdistribusi merupakan kumpulan database yang tersebar pada sebuah jaringan komputer dan terintegrasi secara logika. Pada kenyataannya dalam database yang terdistribusi ini memerlukan sumber daya yang cukup tinggi untuk mendapatkan performa yang baik. Untuk mendukung pencapaian performa sistem database terdistribusi yang optimal diperlukan sebuah metode optimasi pula. Pada sebuah jurnal internasional menyatakan ”the cost function for query execution in grid environment involves three major parameters, namely, communication cost, I/O cost, and CPU cost” (Ray & Guha, 2010) bahwa fungsi biaya untuk eksekusi query dalam lingkungan grid/terdistribusi melibatkan tiga parameter utama, yang disebut, communication cost, I/O cost, dan CPU cost. Beberapa variabel tersebut yang diperhitungkan untuk mendapatkan nilai biaya sumber daya yang telah digunakan dan sebuah model yang dikembangkan untuk menghitung variabel-variabel pada jurnal tersebut.
Dalam bagian bahasa pemrograman yang telah dieksplor selama ini dapat melakukan penyusunan query dan melakukan optimasi query pada run-time. Dalam simulasi ini dilakukan sebuah pengembangan model yang melakukan optimasi query pada compile-time semaksimal mungkin menggunakan histogram. Menurut artikel dari sebuah halaman web (Wikipedia, 2011) tentang histogram, ”Pada bidang statistik,
histogram adalah tampilan grafis dari tabulasi frekuensi yang digambarkan dengan grafis batangan sebagai manifestasi data binning.” Histogram digunakan untuk mengestimasi urutan selektivitas dari distribusi data tertinggi hingga terendah yang ada dalam sebuah query. Selektivitas mengacu pada sebuah jurnal yang mengatakan, ”The selectivity of a predicate in a query is a decisive aspect for a query plan generation. The ordering of predicates can considerably affect the time needed to process a join query. To have the query plan ready at compile-time, we need to have the selectivities of all the query predicates. To calculate these selectivities, we use histograms.” (Li, Han, & Ding, 2010) Selektivitas predikat (where) dalam query adalah aspek yang menentukan untuk menghasilkan rencana query (query plan). Urutan predikat dapat mempengaruhi waktu yang dibutuhkan untuk proses query join. Untuk memiliki rencana query siap pada compile time, perlu dimiliki selektivitas dari semua query predikat. Untuk menghitung selektivitas ini, digunakan histogram. Dengan diterapkannya model optimasi query menggunakan histogram pada setiap database yang terdistribusi ini diharapkan dapat mengurangi nilai sumber daya yang akan diperhitungkan menggunakan model yang ada.
LANDASAN TEORI Simulasi
Simulasi adalah sebuah model matematika yang menjelaskan tingkah laku sebuah sistem dalam beberapa waktu dengan mengobservasi tingkah laku dari sebuah model matematika untuk beberapa waktu seseorang analis bisa mengambil kesimpulan tentang tingkah laku dari sistem dunia nyata yang disimulasikan. Karena simulasi membahas tentang sistem maka perlu adanya pengertian mengenai sistem. Sistem merupakan himpunan dari subsistem-subsistem yang bermanfaat untuk mencapai suatu tujuan yang telah ditetapkan. (Utama, 2010)
Model simulasi merupakan alat yang cukup fleksibel untuk memecahkan masalah yang sulit untuk dipecahkan dengan matematis biasa. Model simulasi sangat efektif digunakan untuk sistem yang relatif kompleks untuk pemecahan analitis dari model tersebut. (Suryani, 2006) Berikut merupakan beberapa kelebihan model simulasi, antara lain:
1. Tidak semua sistem dapat direpresentasikan dalam model matematis, simulasi merupakan alternatif yang tepat
2. Dapat bereksperimen tanpa adanya resiko pada sistem nyata
3. Simulasi dapat mengestimasi kinerja sistem pada kondisi tertentu dan memberikan alternatif desain terbaik
sesual dengan spesifikasi yang diberikan
Kontras dengan beberapa kelebihan yang disebutkan sebelumnya model simulasi juga memiliki beberapa kekurangan, antara lain: 1. Kualitas dan analisis model tergantung
pada si pembuat model
2. Hanya mengestimasi karakteristik sistem berdasarkan masukan tertentu
Validasi model merupakan proses pengujian terhadap model apakah model yang dibuat sudah sesuai dengan sistem nyatanya. Hal ini akan dilakukan secara manual melalui perhitungan matematika dengan formula (Suryani, 2006) sebagai berikut:
| | ... (1)
Dimana
adalah nilai rata-rata data
adalah nilai rata-rata hasil simulasi
Vensim
Vensim Simulation merupakan bahasa simulasi yang dapat digunakan sebagai tool untuk membantu menyelesaikan masalah-masalah bisnis maupun teknis. Software ini dikembangkan oleh Ventana Systems, Inc yang dikembangkan sebagai respon terhadap kebutuhan dalam mengembagkan model-model simulasi. (Suryani, 2006) Vensim merupakan salah satu dari beberapa perangkat lunak berbayar yang tersedia untuk memfasilitasi dalam pembangunan model
sistem dinamis. Vensim ini merupakan perangkat lunak shareware. Dengan demikian dapat membantu pelajar atau user dalam mempelajari software ini sebelum membelinya. Dengan Vensim pengguna dapat membangun Causal Loop Diagram, Stock Diagram, Flow Diagram.
Optimasi Query
Data yang tersimpan dalam database semakin lama akan semakin besar ukuran atau volumenya. Jika tidak didukung dengan kecepatan akses yang memadai maka akan semakin menurun unjuk kerjanya. Ukuran performa dalam hal ini kecepatan akses data dipengaruhi oleh banyak faktor. Pada subbab ini akan membahas tentang optimasi query serta faktor-faktor lain yang berpengaruh terhadap optimalisasi kecepatan akses data.
Menurut dokumen tentang optimasi query yang diunduh dari internet menyatakan, “optimasi query adalah sebuah prosedur untuk meningkatkan strategi evaluasi dari suatu query untuk membuat evaluasi tersebut menjadi lebih efektif.” (Laila, 2011)Ada tiga aspek dasar yang mempengaruhi optimasi query, yaitu:
1. Search space 2. Cost model 3. Search strategy
Sedangkan untuk tujuan optimasi query tersebut, antara lain:
1. Untuk meminimumkan waktu proses
2. Untuk waktu respon, meminimumkan I/O dan meminimumkan penggunaan memory
3. Menemukan jalan akses yang termurah untuk meminimumkan total waktu pada saat proses sebuah query
Tahapan Optimasi Query
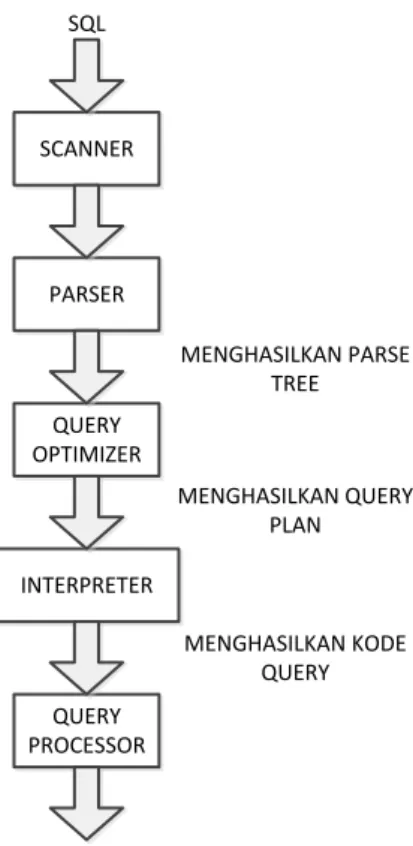
Proses optimasi query merupakan salah satu modul dalam proses mengeksekusi query dari tingkat user hingga menampilkan hasilnya. Berikut menunjukkan modul optimasi query dalam proses eksekusi suatu set query: SCANNER PARSER QUERY OPTIMIZER INTERPRETER QUERY PROCESSOR SQL HASIL QUERY MENGHASILKAN PARSE TREE MENGHASILKAN QUERY PLAN MENGHASILKAN KODE QUERY
Gambar 1 Tahapan Memproses Query (Laila, 2011)
Dikatakan dalam sebuah jurnal yang membahas tentang pemrosesan query dan optimasi bahwa scanner melakukan identifikasi (pengenalan) token-token seperti SQL keywords, atribut, dan nama relasi. Proses ini disebut dengan scanning. Query Parser mengecek kevalidan query dan kemudian menterjemahkannya ke dalam sebuah bentuk internal yaitu ekspresi relasi aljabar atau parse tree. Proses ini disebut dengan parsing. Query Optimizer memeriksa semua ekspresi-ekspresi aljabar yang sama untuk query yang diberikan dan memilih salah satu dari ekspresi tersebut yang terbaik yang memiliki perkiraan termurah. Tugas dari query optimizer adalah menghasilkan sebuah rencana eksekusi. Proses ini disebut dengan optimasi query. Code Generator atau Interpreter mentransformasikan rencana akses yang dihasilkan oleh optimizer ke dalam kode-kode. Setelah itu, kode-kode tersebut dikirimkan ke dalam query processor untuk dijalankan. Query Processor melakukan eksekusi query untuk mendapatkan hasil query yang diinginkan. (Laila, 2011)
Optimasi pada Perintah SQL
Desain aplikasi saja tidak cukup untuk meningkatkan unjuk kerja harus didukung dengan optimasi dari perintah SQL yang digunakan pada aplikasi tersebut. Dalam mendesain database, seringkali lokasi fisik data tidak menjadi perhatian penting
karena hanya desain logik saja yang diperhatikan. Padahal untuk menampilkan hasil query dibutuhkan pencarian yang melibatkan struktur fisik penyimpanan data. Inti dari optimasi query adalah meminimalkan “jalur” pencarian untuk menemukan data yang disimpan dalam lokasi fisik.
Index pada database digunakan untuk meningkatkan kecepatan akses data. Pada saat query dijalankan, index mencari data dan menentukan nilai ROWID yang membantu menemukan lokasi data secara fisik di disk. Akan tetapi penggunaan index yang tidak tepat, tidak akan meningkatkan unjuk kerja dalam hal ini kecepatan akses data.
Misal digunakan index yang melibatkan tiga buah kolom yang mengurutkan kolom menurut kota, propinsi dan kode pos dari tabel karyawan, sebagai berikut:
CREATE INDEX idx_kota_prop_kodepos ON karyawan(kota, propinsi, kode_pos) TABLESPACE INDX;
Kemudian user melakukan query sebagai berikut:
SELECT * FROM karyawan WHERE propinsi=’Jawa Barat’;
Pada saat melakukan query ini, index tidak akan digunakan karena kolom pertama (kota) tidak digunakan dalam klausa WHERE. Jika user sering melakukan query ini, maka kolom index harus diurutkan menurut propinsi. Selain itu, proses
pencarian data akan lebih cepat jika data terletak pada blok tabel yang berdekatan daripada harus mencari di beberapa datafile yang terletak pada blok yang berbeda.
Misal pada perintah SQL berikut ini :
SELECT * FROM karyawan
WHERE id BETWEEN 1010 AND 2010;
Query ini akan melakukan “scan” terhadap sedikit blok data jika tabel karyawan diatas diurutkan berdasarkan kolom id. Untuk mengurutkan berdasarkan kolom yang berbeda-beda maka tabel disimpan dalam flat file, kemudian tabel diekspor dan diurutkan sesuai kebutuhan.
Alternatif yang lain, bisa digunakan perintah untuk membuat tabel lain yang memiliki urutan yang berbeda dari tabel asal, seperti perintah SQL berikut :
CREATE TABLE karyawan_urut AS SELECT * FROM karyawan ORDER BY id;
Pada SQL diatas, tabel karyawan_urut berisi data yang sama dengan tabel karyawan hanya datanya terurut berdasarkan kolom id.
Optimasi Query menggunakan Histogram
Dalam sebuah jurnal tentang optimasi dengan memanfaatkan histogram menggunakan dari distribusi data yang ada dibangun sebuah histogram yang berisikan frekuensi munculnya data tertentu dan dikelompokkan (buckets). Jika data tersebut bersifat numerik maka pengelompokan dapat
dengan mudah ditentukan melalui sebuah batasan. Jika data tersebut bersifat kategori maka dapat dikelompokkan berdasarkan urutan hurufnya. Selanjutnya, dilakukan eksekusi query beberapa sampel. Eksekusi sampel ini mengkonsumsi sejumlah kecil dari sumber daya yang tersedia. Dari hasil query tersebut, akan diperkirakan frekuensi untuk histogram. Namun, data yang mendasar dapat cenderung mengalami perubahan. Jadi perlu memiliki perkiraan untuk pola perubahan data. Untuk ini, mencatat perubahan data, perkiraan delta perubahan dan pola perubahan yang dapat disimpulkan sebagai eksekusi dilanjutkan sehingga histogram yang beradaptasi untuk penambahan data. (Nerella, Surapaneni, Madria, & Weigert, 2010)
Terdapat pendekatan khusus dalam menentukan estimasi biaya untuk masing-masing predikat dan join yang terdapat dalam suatu query. Jika sebuah tabel T terdapat 100.000 baris dan predikat a menghasilkan 10 baris (T.a=10) dan dalam sebuah histogram menunjukkan T.a=10 adalah 10% (Nerella, Surapaneni, Madria, & Weigert, 2010), maka
... (1)
Beban predikat a dalam query adalah 10.000
Pemeliharaan Histogram
Dijelaskan dalam sebuah jurnal internasional tentang optimasi query menggunakan histogram bahwa data yang
mendasar bisa berubah. Untuk data yang dapat berubah seperti itu, dibutuhkan sebuah teknik untuk merestrukturisasi histogram sesuai perkembangan data. Dengan demikian, jika database diperbarui, maka dihitung kesalahan estimasi dari histogram dengan menggunakan persamaan berikut. (Nerella, Surapaneni, Madria, & Weigert, 2010) √ ∑ ( ) ... (2) ... (3) Dimana:
1. μ_a adalah estimasi kesalahan/error pada setiap atribut
2. β adalah jumlah pengelompokan/wadah 3. N adalah jumlah baris dalam R
4. S adalah jumlah baris yang diseleksi 5. f_i adalah frekuensi dari
pengelompokan/wadah i pada histogram 6. q_f= S⁄N adalah frekuensi query
7. B_i adalah frekuensi yang diamati
8. T_i adalah perkiraan kesalahan untuk setiap tabel
9. W_i adalah bobot setiap atribut tergantung pada tingkat perubahan
Jika kesalahan (Ti) adalah> 0,5 maka update histogram. Jika tidak, maka menggunakan histogram lama yang sama untuk memberikan estimasi selektivitas.
PENGEMBANGAN MODEL
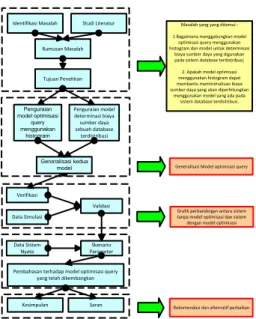
Gambar 2 Tahapan Penelitian
Berdasarkan gambar diagram di atas dalam tahap pengembangan model akan dimulai dengan penguraian dari kedua model.
Model Histogram
Dijelaskan dalam sebuah jurnal internasional tentang optimasi query menggunakan histogram bahwa data yang mendasar bisa berubah. Untuk data yang dapat berubah seperti itu, dibutuhkan sebuah teknik untuk merestrukturisasi histogram sesuai perkembangan data. (Nerella, Surapaneni, Madria, & Weigert, 2010) Dengan demikian, jika database diperbarui, maka dihitung kesalahan estimasi dari histogram dengan menggunakan persamaan yang disebutkan sebelumnya.
Identifikasi Masalah Studi Literatur Rumusan Masalah
Tujuan Penelitian
Masalah yang yang ditemui : 1.Bagaimana menggabungkan model
optimisasi query menggunakan histogram dan model untuk determinasi
biaya sumber daya yang digunakan pada sistem database terdistribusi; 2. Apakah model optimisasi menggunakan histogram dapat membantu meminimalisasi biaya sumber daya yang akan diperhitungkan
menggunakan model yang ada pada sistem database terdistribusi. Tahap Identifikasi Masalah Tahap Pengembangan Model Penguraian model optimisasi query menggunakan histogram Penguraian model determinasi biaya sumber daya sebuah database terdistribusi
Generalisasi Model optimisasi query
Verifikasi Tahap
Pengujian
PROSES OUTPUT
Grafik perbandingan antara sistem tanpa model optimisasi dan sistem dengan model optimisasi
Pembahasan terhadap model optimisasi query yang telah dikembangkan Pembahasan
Kesimpulan Saran Rekomendasi dan alternatif perbaikan Generalisasi kedua model Validasi Skenario Parameter Data Simulasi Data Sistem Nyata
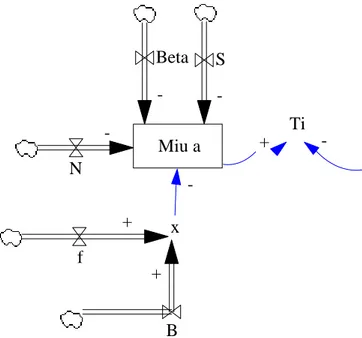
Gambar 3 Optimasi menggunakan histogram Gambar 3 menunjukkan hubungan masing-masing variabel terhadap Miu a. Variabel S, Beta, N, dan x berpengaruh negatif terhadap Miu a, yang artinya semakin besar nilai variabel akan mengurangi Miu a. Sedangkan variabel f dan B berpengaruh positif terhadap x. Miu a sendiri akan berpengaruh positif terhadap Ti, semakin besar nilai Miu a maka akan menambah nilai Ti. Sedangkan Wn berpengaruh negatif terhadap Ti.
Gambar 4 Model variabel formulasi database terdistribusi
Dalam lingkungan sistem terdistribusi terdapat dua tipe query yang berbeda, yaitu query terpusat dan terdistribusi. Pada query
terpusat sumber daya yang dibutuhkan untuk memproses query adalah memory dan CPU. Maka dari itu, pekerjaan pemrosesan query tersebut dapat dibebankan pada salah satu titik dalam suatu sistem terdistribusi yang memiliki sumber daya yang cukup besar terutama dalam memori dan CPU. Tidak ada beban transmisi yang terlibat dalam hal ini. Dalam kasus query terdistribusi, query teruraikan dalam beberapa subquery dan data yang diperlukan dalam subquery tersebut dapat berada dalam beberapa titik dalam database terdistribusi pula. Dalam hal ini biaya transmisi juga dipertimbangkan. Dengan demikian fungsi biaya dalam mengeksekusi query pada sistem terdistribusi melibatkan tiga parameter utama, antara lain biaya komunikasi, biaya I/O dan biaya CPU.
Gambar 5 Model optimasi yang diajukan Model yang diajukan seperti yang ada pada gambar 5 terbagi atas dua model. Model yang pertama adalah model optimasi query
COST IN DATAGRIDS +
I/O Cost + Communication
Cost + CPU Cost Y COST IN DATAGRIDS +
I/O Cost + Communication Cost + CPU Cost Miu a -S -N -Beta Wn Ti + -x + B + f -Y Miu a - S - N - Beta Wn Ti + - x + B + f -
menggunakan histogram dari distribusi data dalam suatu database. Pemodelan menggunakan Vensim tersebut menggambarkan variable-variabel yang digunakan untuk menghitung tingkat kesalahan dalam suatu histogram. Jika tingkat kesalahan dalam suatu histogram kurang dari 0,5 maka histogram tersebut akan valid dan diasumsikan sudah berhasil untuk mengoptimasi suatu set query.
IMPLEMENTASI DAN EVALUASI
Dalam bagian ini akan dibahas tentang implementasi simulasi optimasi query. Tahap-tahap implementasi akan terbagi atas 3 proses utama, antara lain verifikasi, validasi dan pengujian model. Hal ini dapat dilihat pada gambar berikut.
Verifikasi Validasi Pengujian Model Model Data Simulasi Data Sistem Nyata
Hasil Uji
Gambar 6 Rencana implementasi danevaluasi
Verifikasi
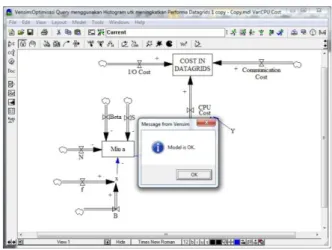
Verifikasi model merupakan proses pengecekan terhadap model apakah sudah bebas dari eror (Suryani, 2006). Tahapan ini akan dibantu dengan alat ukur yang sudah ada dalam perangkat lunak, Vensim. Hal ini akan Nampak seperti pada gambar berikut:
Gambar 7 Verifikasi model
Validasi Model
Untuk menguji tingkat validitas model yang diajukan diperlukan adanya skenario. Skenario yang ditentukan adalah dengan mengeksekusi query sebagai berikut:
select * from mhs_mf_ta m, kurlkl_mf_ta k, fak_mf_ta f where
m.nim=00410100005 and k.fakul_id=f.id and m.jur_id=f.id;
Berikut merupakan biaya total menurut model.
Gambar 8 Biaya total menurut model Maka total biaya menurut model adalah 10.92% dan hasil tersebut akan dibandingkan dengan total biaya sistem nyata bila tidak menggunakan histogram.
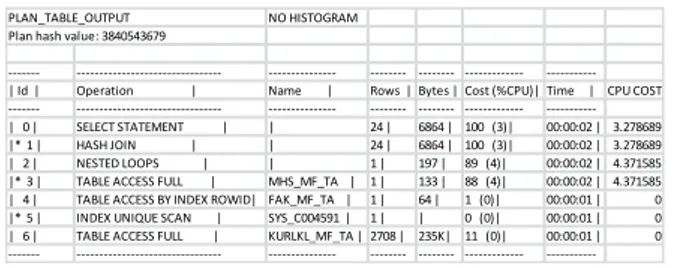
Tabel 1 CPU cost masing-masing operasi
Dari tabel di atas nampak CPU Cost untuk masing-masing operasi. Dengan diketahui biaya dari masing-masing operasi maka dapat diketahui total biaya eksekusi, yaitu 15.30%.
Suatu model simulasi akan dinyatakan valid apabila tingkat kesalahan kurang dari sama dengan 5% (E≤3%). (Suryani, 2006) Maka dengan formula perhitungan tingkat kesalahan yang telah diberikan sebelumnya dapat dihitung tingkat kesalahan dari hasil biaya menurut sistem nyata dengan model simulasi. Diketahui total biaya eksekusi suatu perintah sql menurut sistem nyata adalah 15.30%, sedangkan total biaya eksekusi perintah sql menurut model simulasi adalah 10.92%. Dari kedua data yang diketahui tersebut maka dicari tingkat kesalahannya untuk membuktikan kevalidan model. Maka,
| |
Dengan diketahui tingkat kesalahan adalah 0.29% maka model dapat dinyatakan bahwa tergolong valid karena 0.29% < 5%.
Pengujian Model
Dalam pengujian akan ditetapkan sebagai berikut:
1. Spesifikasi CPU yang digunakan adalah 1.83Ghz
2. Menggunakan sistem operasi Windows 7 Ultimate
3. Menggunakan sistem manajemen database Oracle 10g
4. Terdapat 3 tabel yang tersimpan dalam database lengkap dengan ribuan data 5. Vensim sebagai tools untuk menjalankan
model dengan inputan yang ditentukan 6. Terdapat 3 query yang berbeda, antara
lain
select * from mhs_mf_ta m, fak_mf_ta f where f.id=m.jur_id;
select * from mhs_mf_ta m, fak_mf_ta
f where m.nim=00410100005 and
m.jur_id=f.id;
select * from mhs_mf_ta m, fak_mf_ta
f, kurlkl_mf_ta k where
m.jur_id=f.id and f.id=k.fakul_id;
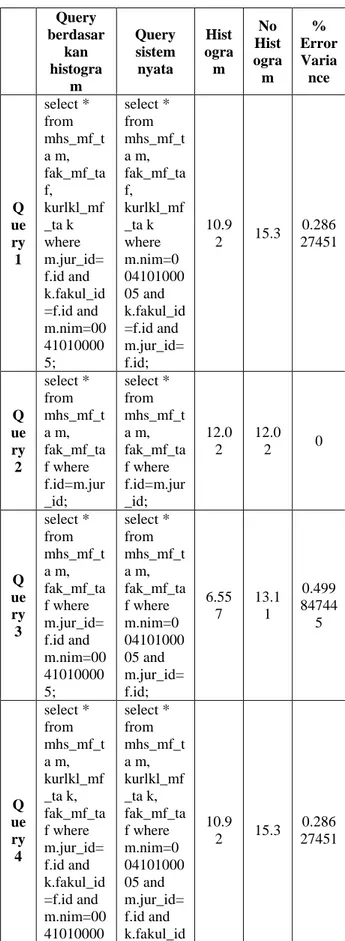
Berikut ini merupakan tabel perbandingan dari keseluruhan query sebagai ringkasan.
PLAN_TABLE_OUTPUT NO HISTOGRAM Plan hash value: 3840543679
--- --- --- --- --- --- ---| Id ---| Operation | Name | Rows | Bytes | Cost (%CPU)| Time | CPU COST --- --- --- --- --- --- ---| 0 ---| SELECT STATEMENT | | 24 | 6864 | 100 (3)| 00:00:02 | 3.278689 |* 1 | HASH JOIN | | 24 | 6864 | 100 (3)| 00:00:02 | 3.278689 | 2 | NESTED LOOPS | | 1 | 197 | 89 (4)| 00:00:02 | 4.371585 |* 3 | TABLE ACCESS FULL | MHS_MF_TA | 1 | 133 | 88 (4)| 00:00:02 | 4.371585 | 4 | TABLE ACCESS BY INDEX ROWID| FAK_MF_TA | 1 | 64 | 1 (0)| 00:00:01 | 0 |* 5 | INDEX UNIQUE SCAN | SYS_C004591 | 1 | | 0 (0)| 00:00:01 | 0 | 6 | TABLE ACCESS FULL | KURLKL_MF_TA | 2708 | 235K| 11 (0)| 00:00:01 | 0 --- --- --- --- --- ---
---Tabel 2 Perbandingan hasil masing-masing query Query berdasar kan histogra m Query sistem nyata Hist ogra m No Hist ogra m % Error Varia nce Q ue ry 1 select * from mhs_mf_t a m, fak_mf_ta f, kurlkl_mf _ta k where m.jur_id= f.id and k.fakul_id =f.id and m.nim=00 41010000 5; select * from mhs_mf_t a m, fak_mf_ta f, kurlkl_mf _ta k where m.nim=0 04101000 05 and k.fakul_id =f.id and m.jur_id= f.id; 10.9 2 15.3 0.286 27451 Q ue ry 2 select * from mhs_mf_t a m, fak_mf_ta f where f.id=m.jur _id; select * from mhs_mf_t a m, fak_mf_ta f where f.id=m.jur _id; 12.0 2 12.0 2 0 Q ue ry 3 select * from mhs_mf_t a m, fak_mf_ta f where m.jur_id= f.id and m.nim=00 41010000 5; select * from mhs_mf_t a m, fak_mf_ta f where m.nim=0 04101000 05 and m.jur_id= f.id; 6.55 7 13.1 1 0.499 84744 5 Q ue ry 4 select * from mhs_mf_t a m, kurlkl_mf _ta k, fak_mf_ta f where m.jur_id= f.id and k.fakul_id =f.id and m.nim=00 41010000 5 select * from mhs_mf_t a m, kurlkl_mf _ta k, fak_mf_ta f where m.nim=0 04101000 05 and m.jur_id= f.id and k.fakul_id =f.id; 10.9 2 15.3 0.286 27451
Ditampilkan pada tabel 2 informasi-informasi tentang beberapa query yang dibangun menurut histogram, query sistem nyata yang dimaksud adalah query jika tanpa dasar histogram untuk penyusunannya, biaya yang dibutuhkan untuk mengeksekusi masing-masing query tersebut berdasarkan histogram maupun tidak berdasarkan histogram, dan masing-masing tingkat error dari besar perbandingan biaya kedua teknik. Tampak dari informasi yang diberikan tabel 2 bahwa mayoritas biaya yang dibutuhkan untuk mengeksekusi query yang dibangun menggunakan histogram lebih kecil dibandingkan query yang dibangun tidak berdasarkan histogram.
KESIMPULAN
Setelah dilakukan uji coba dan evaluasi terhadap model simulasi optimasi query menggunakan histogram, maka dapat ditarik kesimpulan sebagai berikut:
1. Untuk menggabungkan model optimasi query menggunakan histogram dan model untuk determinasi biaya sumber daya adalah dengan mempelajari variabel penghubung kedua model setelah dilakukan studi literatur dari jurnal-jurnal pendukung. Setelah itu menterjemahkan variabel-variabel yang terdapat dalam jurnal menjadi sebuah model menggunakan Vensim Simulation.
2. Pada tabel 2 sebelumnya menampilkan tiga dari empat query yang diuji menunjukkan hasil eksekusi menggunakan
konsep histogram lebih kecil dibandingkan eksekusi query tanpa menggunakan histogram. Maka, model yang diajukan dapat membantu meminimalisasi biaya sumber daya.
SARAN
Adapun beberapa saran yang dapat diberikan kepada peneliti berikutnya apabila ingin mengembangkan model yang telah dibuat ini agar menjadi lebih baik adalah sebagai berikut:
1. Model dapat dikembangkan lagi dengan mengimplementasikan algoritma tambahan, yaitu split and merge.
2. Prinsip model dapat dikembangkan lagi menjadi suatu software yang secara otomatis menjalankan proses optimasi.
DAFTAR RUJUKAN
Anh, N. K. (2009). Query Processing and Optimization. The Connexions Project, 3.
Bellinger, G. (2004). Translating Systems Thinking Diagrams to Stocks & Flow Diagrams. Retrieved February 11, 2012, from The Way of Systems:
http://www.systems-thinking.org/stsf/stsf.htm
Chhanda Ray, N. G. (2010). Determination of Cost Model for Constraintbased. ACEEE, 237.
Li, D., Han, L., & Ding, Y. (2010). SQL Query Optimization Methods of Relational Database System. 2010 Second International Conference on Computer Engineering and Applications, 558.
Nerella, V. K., Surapaneni, S., Madria, S. K., & Weigert, T. (2010). Exploring Query Optimization in Programming Codes by Reducing Run-Time Execution. IEEE 34th Annual Computer Software and Applications Conference, 407-411.
Pegasus Communications, Inc. (2011). Causal Loop Diagrams. Retrieved February 11, 2012, from www.pegasuscom.com:
http://www.pegasuscom.com/cld.html
Rebba, R., & Mahadevan, S. (2006). Validation of models with multivariate output. Elsevier.
Silberschatz, A., Korth, H. F., & Sudarshan, S. (2005, September 1). Database System Concept - 5th edition. Retrieved Januari 30, 2011, from Department of Computer Science and Engineering Indian Institute of
Technology Bombay:
http://www.cse.iitb.ac.in/~sudarsha/d b-book/slide-dir/ch14.pdf
Stockinger, H. (2003). Distributed Database Management Systems and the Data Grid. IEEE, 1.
Suryani, E. (2006). Pemodelan dan Simulasi. Yogyakarta: Graha Ilmu.
Utama, I. G. (2010). Pemodelan dan Simulasi. Surabaya: STIKOM.
Wah, T. Y., & A. B, Z. (2000). Query Processing Techniques in Data Warehousing Using Cost Model. The Electronic Journal on Information Systems in Developing Countries, 1-9.
Wiktionary. (2010, Oktober 23). compile time. Retrieved Januari 30, 2011,
from Wiktionary:
http://en.wiktionary.org/wiki/compile _time
Zafarani, E., Derakhshi, M. R., Asil, H., & Asil, A. (2010). Presenting a New Method for Optimizing Join Queries Processing in Heterogeneous Distributed Databases. Third International Conference on Knowledge Discovery and Data Mining, 379-382.