BAB II
TINJAUAN PUSTAKA
2.1. Logika Fuzzy
Pada awalnya sistem logika fuzzy diperkenalkan oleh Profesor Lotfi A. Zadeh pada tahun 1965. Konsep fuzzy bermula dari himpunan klasik (crisp) yang bersifat tegas atau mutlak yang hanya memiliki dua nilai keanggotaan, jika benar bernilai satu dan jika salah bernilai nol. Pada himpunan fuzzy setiap nilai keanggotaan tidak dibatasi secara tegas. Proses transisi dari nilai sebagai anggota ke nilai bukan anggota terjadi secara bertahap dan sehalus mungkin. Karakteristik transisi tersebut dijabarkan dalam bentuk fungsi keanggotaan yang menjadikan himpunan fuzzy bersifat fleksibel dalam memodelkan ekspresi linguistik (Jang et al, 1997).
2.2 Fungsi Keanggotaan
Fungsi yang memberikan derajat terhadap sebuah elemen mengenai keberadaannya dalam sebuah gugus disebut fungsi keanggotaan. Jika X adalah koleksi obyek yang dinotasikan sebagai u, kemudian A adalah himpunan fuzzy dalam X maka dapat dituliskan sebagai berikut:
(
)
{
, u u ∈X}
= X A
A µ (2.1.)
µA(u) disebut sebagai fungsi keanggotaan (membership function) untuk himpunan
fuzzy A. Fungsi keanggotaan akan memetakan setiap elemen X dengan nilai derajat keanggotaan yang memiliki nilai antara 0 dan 1 (Jang et al, 1997).
Beberapa bentuk fungsi yang dapat digunakan untuk merepresentasikan fungsi keanggotaan fuzzy adalah bentuk kurva segitiga, trapesium dan Gauss (Jang et al, 1997). Fungsi keanggotaan untuk keempat bentuk tersebut adalah :
1. Segitiga menggunakan tiga parameter {a,b,c} dan dapat dituliskan sebagai berikut:
(
)
≤ ≤ − − ≤ ≤ − − ≥ ≤ = c x b b) x)/(c (c b x a b) a)/(a (x c x a x c b a x ; ; atau ; 0 , , , µ (2.2)Bentuk kurvanya adalah sebagai berikut:
Gambar 1 Fungsi Keanggotaan untuk Segitiga
2. Trapesium menggunakan empat parameter {a,b,c,d} dan dapat dituliskan sebagai berikut:
(
)
≤ ≤ ≤ ≤ − − ≤ ≤ − − ≥ ≤ = a x d d x c c) x)/(d (d b x a a) a)/(b (x d x a x d c b a x ; 1 ; ; atau ; 0 , , , , µ (2.3)Bentuk kurvanya adalah sebagai berikut:
Gambar 2 Fungsi Keanggotaan untuk Trapesium
3. Gauss menggunakan dua parameter {c,σ } dan dapat dituliskan sebagai berikut:
(
)
2 2 1,
,
− −=
s c xe
c
x
σ
µ
(2.4)a
b
c
1
0
µ:
[x]
a b c 1 0 µ:[x] dBentuk kurvanya adalah sebagai beikut:
Gambar 3 Fungsi Keanggotaan untuk Gauss
4. Kurva S menggunakan dua parameter {a,b} dan bentuk kurvanya adalah sebagai berikut:
Gambar 4 Fungsi Keanggotaan untuk kurva S
2.3 Operator Fuzzy
Menurut Jang et al (1997) operator dasar pada fuzzy adalah : 1. Gabungan
Operator gabungan dinotasik an dengan ∪(OR). Gabungan dari dua himpunan fuzzy A dan B adalah himpunan fuzzy C, dapat dituliskan C = A∪B dan dirumuskan sebagai berikut :
µc(u)= max(µA(u),µB(u))=µA(u)∪µB(u) (2.5) Pusat ( ) 0 0.5 1 σ Sigma (c) (x ) µ Pusat ( ) 0 0.5 1 σ Sigma (c) Pusat ( ) 0 0.5 1 σ Sigma (c) (x ) µ
2. Irisan
Operator irisan dinotasikan dengan ∩(AND). Irisan dari dua himpunan fuzzy A dan B adalah himpunan fuzzy C, dapat dituliskan C = A∩B dan dirumuskan sebagai berikut :
[ ] [ ]
u, u)[ ]
u[ ]
u ( min ) (u A B A B c µ µ µ µ µ = = ∩ (2.6) 3. KomplemenKomplemen dari himpunan fuzzy A dinotasikan dengan A (-A, NOT A) dan dirumuskan sebagai berikut :
(u) -1 A µ µA= (2.7)
2.4 Aturan Fuzzy dan Penalaran Fuzzy
Menurut Jang et al (1997) aturan fuzzy sering disebut juga implikasi fuzzy, atau pernyataan kondisi fuzzy, bentuknya adalah : if x adalah A then y adalah B.
A dan B adalah nilai linguistik. u adalah A disebut sebagai antecedent atau premis, sedangkan y adalah B disebut sebagai consequent atau kesimpulan.
Contoh aturan fuzzy adalah:
If tekanan tinggi, then volume kecil.
If jalanan licin, then berkendaraan sangat berbahaya. If tomat berwarna merah then tomat sudah masak.
Menurut Jang et al (1997) fuzzy reasoning adalah prosedur inferensi yang merupakan kesimpulan dari aturan if-then dan fakta. Aturan dasarnya adalah modus ponens.
Penalaran dibagi menjadi beberapa bentuk, yaitu : 1. Satu aturan dengan satu premis
Premis 1 : if x adalah A dan y adalah B, Kesimpulan : y adalah B
2. Satu aturan dengan banyak premis
Premis 1 : if x adalah A dan y adalah B then z adalah C, Kesimpulan : z adalah c
3. Banyak aturan dengan banyak premis
Premis 1 : if x adalah A1 dan y adalah B1 then z adalah C1,
Premis 2 : if x adalah A2 dan y adalah B2 then z adalah C2,
Kesimpulan : z adalah C
2. 5 Fuzzy Clustering
Clustering dapat diselesaikan secara fuzzy dan nonfuzzy. Pada fuzzy clustering hasil matriks transformasinya berupa nilai derajat keanggotaan antara 0 dan 1, sedangkan pada nonfuzzy nilainya 0 dan 1. Cluster dikatakan fuzzy jika tiap-tiap objek dihubungkan dengan menggunakan derajat keanggotaan. Fuzzy clustering telah diaplikasikan dalam berbagai bidang diantaranya text mining. Algoritme fuzzy clustering dapat digunakan untuk menentukan hubungan antara sumber-sumber informasi berdasarkan konteks tekstual dan juga untuk merepresentasikan pengetahuan melalui asosiasi topik yang tercakup dalam informasi tersebut.
2.6 Fuzzy Subtractive Clustering (FSC)
Menurut Kusumadewi dan Purnomo (2004) FSC merupakan algoritma yang tidak terawasi, dalam arti jumlah cluster yang akan dibentuk belum diketahui.
Pada prinsipnya FSC didasarkan atas ukuran densitas (potensi) titik-titik data dalam suatu ruang (variabel). Titik dengan jumlah tetangga terbanyak akan dipilih sebagai pusat cluster. Titik yang sudah terpilih sebagai pusat cluster ini akan dikurangi densitasnya. Kemudian algoritma akan memilih titik lain yang memiliki tetangga terbanyak untuk dijadikan sebagai pusat cluster yang lain. Hal ini dilakukan sampai semua titik diuji.
Pada implementasinya bisa digunakan dua pecahan sebagai faktor pembanding, yaitu accept ratio dan reject ratio. Accept ratio merupakan batas bawah dimana suatu titik data yang menjadi kandidat (calon) pusat cluster diperbolehkan untuk menjadi pusat cluster. Sedangkan reject ratio merupakan batas atas dimana
suatu titik data yang menjadi kandidat (calon) pusat cluster tidak diperbolehkan untuk menjadi pusat cluster. Ada tiga kondisi yang bisa terjadi dalam suatu iterasi:
• Apabila rasio > accept ratio, maka titik data tersebut diterima sebagai pusat baru. • Apabila reject ratio < rasio ≤ accept ratio maka titik data tersebut baru akan diterima sebagai pusat cluster baru hanya jika titik data tersebut terletak pada jarak yang cukup jauh dengan pusat cluster yang lainnya (hasil penjumlahan antara rasio dan jarak terdekat titik data tersebut dengan pusat cluster lainnya yang telah ada adalah 1).
• Apabila rasio ≤ reject ratio , maka sudah tidak ada lagi titik data yang akan dipertimbangkan untuk menjadi kandidat pusat cluster, iterasi dihentikan.
Rasio adalah hasil bagi antara potensi tertinggi titik data yang baru (Dk) dengan
potensi tertinggi titik data awal (Dh) (Rasio = Dk/ Dh) .
Algoritma Fuzzy Subtractive Clustering
1. Input data yang akan dicluster : Xij, dengan i = 1,2,….,n; dan j = 1,2,…,m
2. Tetapkan nilai :
a. rj (jari-jari setiap atribut data); j = 1,2,….,m
b. q (squash factor) c. accept ratio d. reject ratio
e. Xmin (nilai data yang minimum)
f. Xmax(nilai data yang maximum)
3. Normalisasi :
4. Tentukan potensi awal tiap titik data a. i = 1
b. Kerjakan hingga i = n o Tj = Xij; j = 1,2,…,m
o Hitung Potensi awal :
m 1,2,...., j n; 1,2,..., i , minj max min = = − − = X j X X X Xij ij j n 1,2,...., k m; 1,2,..., j , = = − = r X T j Distk j kj
o Jika m =1,maka :
o Jika m > 1, maka :
o i = i + 1
5. Cari titik dengan potensi tertinggi a. M = max
b. h=i, sedemikian sehingga Di = M
6. Tentukan pusat cluster dan kurangi potensinya terhadap titik-titik disekitarnya a. Center []
b. Vj = Xhj ; j = 1,2,…..,m
c. C = 0 (jumlah cluster) d. Kondisi = 1
e. Z = m
f. Kerjakan jika (kondisi # 0) dan (Z # 0):
Kondisi = 0 (jika sudah tidak ada calon pusat baru lagi);
Rasio = Z/M
Jika rasio > accept ratio, maka kondisi = 1; (ada calon pusat baru)
Jika tidak,
o Jika rasio > reject ratio , (calon baru akan diterima sebagai pusat jika keberadaannya akan memberikan keseimbangan terhadap data-data yang letaknya cukup jauh dengan pusat cluster yang telah ada), maka kerjakan : o Md = -1
o Kerjakan untuk i = 1 sampai i = C:
Jika (Md < 0) atau (Sd < Md),maka Md = Sd;
( )
∑
= − = n k k Dist e Di 1 1 4 2∑
= − ∑ = n = k kj Dist m j e Di 1 4 1 2[
Di Ιi=1,2,....,n]
m; 1,2,..., j , = − = r Center V Gij j ij∑
= = n j ij di G S 1 2 ) (o Jika (rasio + Smd) ≥ 1, maka kondisi = 1; data diterima sebagai pusat cluster o Jika (rasio + Smd) < 1, maka kondisi = 2; data tidak dipertimbangkan sebagai
pusat cluster
o Jika kondisi = 1 (calon pusat diterima sebagai pusat baru), kerjakan : o C = C + 1
o CenterC = V;
Kurangi potensi dari titik-titik didekat pusat cluster
o D = D – Dc
o Jika Di ≤ 0, maka Di = 0; i = 1,2,…,n
o Z = max
o Pilih h = i, sedemikian hingga Di = Z;
o Jika kondisi = 2 (calon pusat baru tidak diterima sebagai pusat baru), maka : o Dh = 0
o Z = max
o Pilih h = i, sedemikian hingga Di = Z;
o Kembalikan pusat cluster dari bentuk ternormalisasi ke bentuk semula
o Centerij = Centerij x (Xmaxj – Xminj) + Xminj
o Hitung nilai sigma cluster 8 / ) ( j=rj× Xmaxj− Xminj σ
Hasil dari algoritma FSC berupa matriks pusat cluster dan sigma yang akan digunakan untuk menentukan nilai derajat keanggotaan.
n ..., 1,2, i m; 1,2,..., j , j = = × − = q r X V Sij j ij − ∑ = = m j S e M D ij ci 1 2 ) ( * 4
[
Di Ιi=1,2,....,n]
[
Di Ιi=1,2,....,n]
2.7 Validitas cluster
Menurut Halkidi et al (2002) ada tiga pendekatan untuk menentukan validitas cluster, yaitu kriteria internal, eksternal dan relatif. Kriteria eksternal digunakan untuk mengevaluasi hasil dari sebuah algoritme clustering berdasarkan pada sebuah struktur yang ditentukan sebelumnya yang berlaku pada himpunan data. Pada kriteria internal hasil dari algoritma clustering dievaluasi dalam bentuk kuantitas yang melibatkan vektor-vektor dari himpunan data. Kriteria relatif membandingkan struktur clustering dengan skema-skema clustering lain yang dihasilkan oleh algoritme yang sama tapi dengan nilai parameter yang berbeda.
Beberapa indeks validitas cluster berdasarkan kriteria relatif yang digunakan untuk fuzzy clustering diantaranya adalah koefisien partisi, entropi partisi serta fungs i validitas kekompakkan dan pemisahan.
Fungsi validitas pemisahan dan kekompakkan (S) dihitung tidak hanya melibatkan derajat keanggotaan sebuah data tetapi juga data set itu sendiri. Fungsi tersebut dapat dihitung sebagai berikut: misalkan sebuah partisi fuzzy dari data set
{
x j n}
X = j =1,2,..., dengan vi i=1,2,...,nc adalah pusat-pusat setiap cluster, uij
adalah derajat keanggotaan titik data j terhadap cluster i. Deviasi fuzzy dari xj dari
cluster i, dij didefinisikan sebgai jarak antara xj dan pusat dari cluster diboboti oleh
derajat keanggotaan dari data j dalam cluster i.
=uij xj-vi
ij
d (2.8) Untuk sebuah cluster i, jumlah kuadrat dari deviasi fuzzy dari titik data dalam X dinamakan variasi dari cluster i, dinotasikan σi. Jumlah dari variasi semua cluster
dinamakan variasi total dari data set dan dinotasikan σ . Bentuk π =σi ni dinamakan
kekompakkan dari cluster i, karena ni adalah banyaknya titik dalam cluster anggota
cluster i. π adalah variasi rata-rata dalam cluster i, sedangkan π=σ n menyatakan kekompakkan partisi fuzzy dari data set. Pemisahan dari fuzzy didefinisikan sebagai jarak minimum antara pusat cluster, yaitu:
j i min2 =min v-v
Fungsi validitas kekompakkan dan pemisahan (S) didefinisikan sebagai: 2
min
D
S =π (2.10) dengan n adalah banyaknya titik dalam himpunan data. Semakin kecil nilai S, cluster semakin kompak dan terpisah dengan cluster lainnya (Xie XL, 1991).
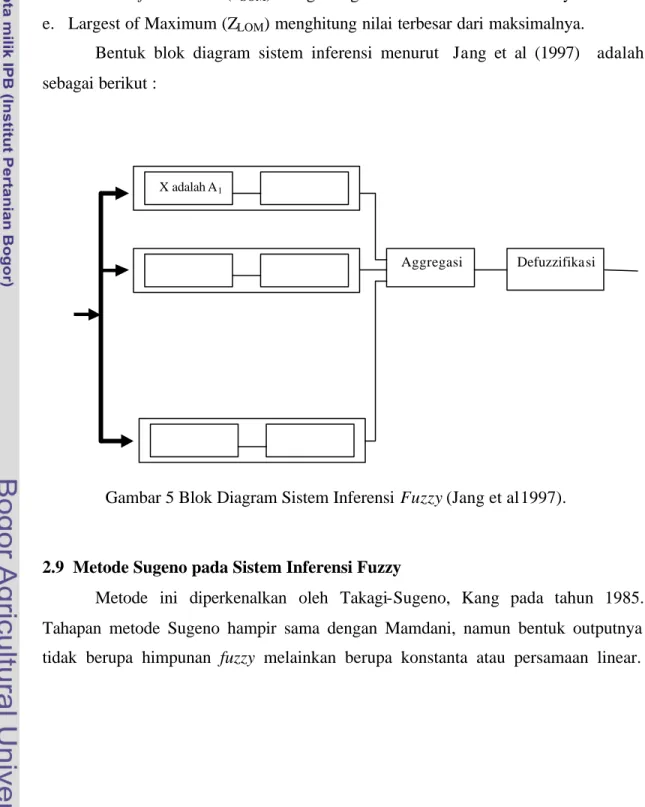
2.8 Sistem Inferensi Fuzzy (FIS)
FIS disebut juga suatu mekanisme pemetaan input ke output. Tahapan-tahapan yang diperlukan dalam mekanisme FIS secara umum adalah : input variabel, fuzzifikasi, rule (aturan), agregasi, defuzzifikasi dan output.
Fuzzifikasi adalah pembentukan himpunan fuzzy. Variabel input yang
berbentuk crisp diubah menjadi himpunan fuzzy. Setelah himpunan fuzzy terbentuk maka dilanjutkan dengan menentukan fungsi keanggotaannya.
Rule (aturan) merupakan aturan yang bisa dibuat berdasarkan pendapat pakar,
ilmu pengetahuan dan juga metode clustering. Jadi rule masing- masing masalah akan berbeda-beda banyaknya tergantung pada pendapat pakar, ilmu pengetahuan yang ada atau metode clustering yang dilakukan.
Agregasi merupakan kombinasi sebuah himpunan fuzzy dari output setiap
aturan. Metode yang umum digunakan adalah max dan sum. Max mengambil titik maksimum dari semua himpunan fuzzy, sedangkan sum mengambil penjumlahan dari semua himpunan fuzzy.
Defuzzifikasi adalah suatu pemetaan dari himpunan fuzzy ke titik crisp, yang
menghasilkan output dari sistem inferensi fuzzy. Metode untuk melakukan defuzzifikasi ada lima yaitu: centroid, bisektor, Mean of Maximum (MOM), Largest of Maximum (LOM), Smallest of Maximum (SOM). Definisi dari masing- masing metode defuzzifikasi ini adalah:
a. Centroid (ZCOA) didapat dengan menghitung rata-rata terbobot, rumusnya
adalah sebagai berikut :
( )
( )
z dz zdz z Z A A COA µ µ∫
∫
= z zb. Bisektor (ZBOA), didapat dengan cara menghitung luas yang sama, dipecah
menjadi dua, rumusnya adalah sebagai berikut: =
∫
( )
=∫
( )
β α µ µ zBOA ZBOA BOA Z Azdz Azdz c. Mean of Maximum (ZMOM) mencari rata-rata nilai maksimalnya, rumusnya adalah
sebagai berikut : dz zdz ZMOM ' z ' z
∫
∫
=d. Smallest of Maximum (ZSOM) menghitung nilai terkecil dari maksimalnya.
e. Largest of Maximum (ZLOM) menghitung nilai terbesar dari maksimalnya.
Bentuk blok diagram sistem inferensi menurut Jang et al (1997) adalah sebagai berikut :
Gambar 5 Blok Diagram Sistem Inferensi Fuzzy (Jang et al 1997).
2.9 Metode Sugeno pada Sistem Inferensi Fuzzy
Metode ini diperkenalkan oleh Takagi-Sugeno, Kang pada tahun 1985. Tahapan metode Sugeno hampir sama dengan Mamdani, namun bentuk outputnya tidak berupa himpunan fuzzy melainkan berupa konstanta atau persamaan linear.
X adalahA1
Defuzifikasi hanya menggunakan nilai rata-rata (Kusumadewi dan Purnomo, 2004). Model fuzzy Sugeno ada yang disebut sebagai orde nol, dan orde satu. Dikatakan orde-nol jika z konstan, sedangkan orde satu jika z bilangan pangkat satu.
Menurut Jang et al (1997) secara umum bentuk model fuzzy Sugeno orde satu adalah : If x1 adalah A dan y adalah B then z = f(x,y)
dengan : A dan B adalah anteseden, z = f(x,y) adalah fungsi crisp sebagai konsekuen.
Gambar 6 Model Sistem Inferensi Fuzzy Sugeno
2.10 Membentuk Sistem Inferensi Fuzzy berdasarkan Fuzzy Subtractive
Clustering
Menurut Kusumadewi dan Purnomo (2004) langkah-langkah yang diperlukan untuk membentuk sistem inferensi fuzzy dari hasil fuzzy subtactive clustering adalah : 1. Memisahkan data input dan output.
2. Membuat aturan. µ µ µ X B2 µ Y X Y W1 W2 Nilai rata-rata 2 1 2 2 1 1 W W Z W Z W Z + + =
[R1] IF (X1 adalah A11) o (X2 adalah A12) o … o (Xn adalah A1m) THEN
(z=k11x11 + ….. + k1mxm + k10);
[R2] IF (X1 adalah A21) o (X2 adalah A22) o … o (Xn adalah A2m) THEN
(z=k21x11 + ….. + k2mxm + k20);
[Rr] IF (X1 adalah Am1) o (X2 adalah Am2) o … o (Xn adalah Arm) THEN
(z=kr1x11 + ….. + krmxm + kr0);
Keterangan :
Aij adalah himpunan fuzzy aturan ke- i variabel ke-j sebagai anteseden.
kij adalah koefisien persamaan output fuzzy aturan ke- i variabel ke-j (i=1,2…,r;
j=1,2,…m), dan ki0 adalah konstanta persamaan output fuzzy aturan ke- i.
Tanda o menunjukkan operator yang digunakan dalam anteseden. 3. Menyusun matriks konstanta, k = r x (m+1)
= 0 2 1 20 2 22 21 10 1 12 11 .... .... .... r rm r r m m k k k k k k k k k k k k K Μ Μ Μ Μ
disusun menjadisatu vektor k:
K= [k11 k12…k1m k10 k21 k22…k2m k20…k21 kr2 Μ krm kr0]T
4. Mencari derajat keanggotaan setiap data i dalam kluster, dengan cara mengalikan dengan setiap atribut j dari data i.
dkij = xij*µki dengan j=1,2,…,m(m=jumlah variabel input).
5. Melakukan normalisasi data dan dapat dirumuskan sebagai berikut :
6. Membentuk matriks U yang berukuran n x (r x(m+1)), yaitu :
= + + + + + + + + + 1)) (m * n(r .... 2) n(m 1) n(m nm .... n2 n1 1)) (m * 2(r .... 2) 2(m 1) 2(m 2m 22 21 1)) (m * 1(r .... 2) 1(m 1) 1(m 1m 12 11 u u u u u u u u u u ... u u u u u u ... u u Μ Μ Μ Μ Μ Μ Μ Μ U
∑
= = r k ki k k d ij ij d 1 µ7. Membentuk vektor z sebagai output sebagai berikut : Z = [z1,z2,….,zn]T. Sehingga