Volume 7. No
3 Novemb€r
2006
tssN
1411
.4453
SKNo
23a / DIKT /XBp/2004JURNAL TEKNOLOGI INFORMASI DAN BISNIS
Pusat
Pengembangan Sains
danTeknologi
Faklltas
Sains dan
Te(nologi
t nivorsiias Teknologi Yogyaka.ta
Seleksi
f?,ure
Xala
Berdasarli+n
!?.ia!si
l{cmrn.olan
Kala
Dalam
P6ningkatan
Unj!k
l<erj!
Docurr.rl
a]!sr!.rrg
Uihrk
ookumen
Berbahasa
Pera.c.nqan Pengonlrclan
1,46!rg!nai(an
lerqiolosi
Blurtoott'
i\rlclalui
Handphone
U.nritAIriL?:i
ii.,.,r).-,
iJurnal
PA(AR
dilerbillun
oleh Pusal Pengenbangan Sains dan Teknologr, FakulEsSains
dm
Tck.olosi,
Univesitas
'lcknolosi
Yosyakana.Jurnal
ini diharapke
sebagai mcdia bagi
staf
pensajar,alunni,
nalashw
danmdyeakar
luas yananemiliki
perhati&
lerhadapbidaos
dan perkcmbesm
teknologi
intomsi,
lransfomasi ilmu
pengeral andtu
bisnis. Redaksi6e.erima n6kah
berupa hasil penehian, srudi pustlka. penSamatd araupun pendapatars
suatumaelah
y,.g
limbuldalm
kaitamya denCan perkembmsan bidang-bida.gdials
Redaksibe
rl
nemp.daiki
aau FcmpdsiDslat
lanpa nengubahisi.
Ani*el
ymg dimual
tidakscl alu mencemi nkan Dddansan rcdals i.
I Rektor
Univedld
TeknologiYo8yakai!
:Dekd
F.luhosSais
dan TeknologiUnivesiras Teknoloei Yo8yakana
: Agus Sujafradi, S.Kom.
Prot
adhi
sus
to, M-sc,, Ph.D. Dr. Relantyo Wddoyo, M.Sc.k. Lul<ito
Edi NuEIoho. M,Sc., PILD.Dr.Ir.
sunano Goenadi. D A A.Dr. Tri Gumrsih.
sE.,M.M.
Sdmm,
S.Kom.,M.Kof,.Iwd Haiadi,
s.T.,M.Kom.AielHemawe, S.T.,
M.T. Yunns IndraPl]lma.
SE.Suhime.
S.Kon., M.Kom.Bmbdg
Muitono, SE.,M.M,
Erik Iman Hen Ujianlo,
s.T.,M.Koh.
Yuli Asriningtias, S.Kom.,M.Kod. DG. Supaman, M.Si, DEA, Ph.D.Adninhrm3i
danSirkulasi:
Alanlt
Rednlrd:Fakul6
Sainsde
Tcloolosi
Unive*ils
Teloolosi
YosFkaia
Jl,Linekr
Urda Jombor slehan Yocyakorta 55285 Telp. (0274)62lll0
Fd.(02?4)621306 E Mail:
oalana
v.ac.idHonepaEe:
httpr/@,utv.ac.id/pakar
.IIIRNAL TEKNOLOGI
W
INFORMASI OANBISNIS
Vollme
7
No.3 Nopember 2006tssN
1411-
4453JURNALTEKNOLOGIINFORMASI DAN BISNIS
Seleks,
/:azr,rr Kad
B&dasa*an Variansi Kemunculan Kara Dalad PeninekaranUijult
(erja
DocvnentClrckrinsUnlrk
Dokunen Berbahasa I n do nes iaanr
Han:ah
FS.esiahto
/ldhiSusantoPenggunam
lDl
Sebagai Pemodela.D&
Interpret6i Dah
Sistcm Nilai Di Balik Perancdgan
Podul
Induslri DalamKail&hya
Deng Peninslat Kuali6
HidupMeusia
Rnq.s
Bansun Dan Pemancar Penerima Ruminc Text SebagaiMcdia
Infomasi Broadcal
Fddil
Basfii
RahnaL EudvPr4ettd
Algoitn
Po
etste
erFd
Bahasa Indo"esiav&
Pre-Proce$ihgTen
ihingBetbsisMetode Mdket
Bas*etAnarsis
c."ot
\S
RudhilhhuGu aean
Fetrt
yrroko
Pongenalln Pola
GMran
Sidikjei
Dengm EksllaksiTitik
Ihoa4tbali-ELoj!!
221
2142t5
244Perocangan P cngonlro lan M enesunakan Teknolosi
Melatui Handphone Unruk Aplikasi Komputer s e
ru
iU
nlur
is![-Lblitl:!!r!!@!!ji4w
lSeleksi Feature Kata Berdasarkan Variasi Kemunculan Kata dalam Peningkatan Unjuk Kerja Document
Clustering Untuk Dokumen Berbahasa Indonesia
Vol.7, No.3 Nopember 2006
Hal.:181 – 190
SELEKSI FEATURE KATA BERDASARKAN VARIANSI
KEMUNCULAN KATA DALAM PENINGKATAN UNJUK KERJA
DOCUMENT CLUSTERING UNTUK DOKUMEN BERBAHASA
INDONESIA
Oleh: Amir Hamzah, F.Soesianto, Adhi Susanto,Jazi Eko Istiyanto
ABSTRAK
Peranan Document Clustering dalam bidang text-mining dan information retrieval saat ini makin penting seiring dengan terus meningkatnya koleksi data digital online. Dalam teknik clustering berbasis feature kata dengan model ruang vektor selalu muncul problem tingginya dimensi ruang vektor akibat banyaknya kata terpakai. Hal ini menyebabkan kinerja clustering turun karena dalam dimensi tinggi jarak antar titik cenderung bernilai sama. Reduksi dimensi dengan seleksi feature kata menjadi cara penting untuk mengatasinya. Penelitian ini melakukan kajian tentang cara seleksi feature dengan analisis variansi kemunculan kata. Dua pendekatan clustering dicobakan, yaitu hierarchi dan partisi. Untuk pendekatan hierachi digunakan teknik aglomeratif dengan 5 model similaritas yaitu GroupAverage, CompleteLink, SingleLink, IntraCluster dan ClusterCenter. Untuk pendekatan partisi, yaitu K-Means, Bisecting K-Mean dan Buckshot clustering. Koleksi dokumen yang digunakan adalah 50, 100, 200, 300, 400, dan 500 dokumen berita kategori yang telah diketahui sebelumnya. Kriteria kinerja clustering diukur dengan validitas clustering menggunakan nilai F-measure, yaitu nilai yang diturunkan dari Recall dan Precision yang mengukur kemampuan algoritma melakukan klasifikasi secara benar. Hasil penelitian menunjukkan bahwa seleksi feature dengan analisis variansi kata dapat dijadikan cara handal untuk menurunkan dimensi ruang vektor sampai dengan 15% dari keseluruhan kata tersedia tanpa menurunkan nilai F-measure.
Kata Kunci: document clustering, seleksi feature, variansi kata, validitas clustering
1. PENDAHULUAN
M
eningkatnya informasi teks digital dari sumber infomasi online telah menyebabkan problem tersendiri dalam navigasi dan temu kembali informasi. Dalam web saat ini terindeks tidak kurang dari 16 milyar dokumen [13] dan 80% dari dokumen tersebut adalah dokumen teks. Hal ini mendorong kebutuhan riset untuk elaborasi koleksi teks (text-mining) dan riset untuk optimalisasi mesin pencari informasi (information retrieval system), atau sistem IR.Dalam model ruang vektor dimana koleksi dokumen diwakili oleh matrik kata-dokumen dan sebuah kata-dokumen diwakili oleh sebuah vektor dalam ruang dimensi t,
182
Pakar, Vol.7, No.3 Nopember 2006
dengan t jumlah kata dalam koleksi dokumen tersebut, umum dijumpai bahwa dimensi t sangat tinggi [4]. Dalam dimensi tinggi jarak antar titik akan cenderung bernilai sama [8]. Hal ini berakibat algoritma clustering yang bertumpu pada fungsi jarak menghasilkan solusi yang bias. Reduksi dimensi ruang vektor dapat ditempuh pada tahap clustering atau tahap pre-processing. Pada tahap clustering reduksi ditempuh dengan pendekatan misalnya projected clustering [1], analisis SVD atau PCA [7]. Reduksi tahap pre-processing ditempuh antara lain dengan seleksi kata [9]. Kata yang terlalu tinggi frekuensinya dibuang dengan cara stop-word removal, yaitu membuang kata seperti ‘dan’, ‘ini’,’itu’, ‘dengan’ dan lain-lain. Sedang kata frekuensi rendah dibuang dengan batas suatu treshold tertentu. Cara baku lain reduksi dimensi dalam tahap pre-processing adalah dengan stemming kata [10], yaitu mengembalikan kata ke dalam kata dasarnya.
Umumnya setelah kedua langkah di atas, jumlah kata masih cukup tinggi. Dengan asumsi bahwa tiap kata memiliki kekuatan pembeda dokumen yang tidak sama maka seleksi kata dapat dipilih berdasarkan sebaran frekuensi kemunculan kata. Kata yang selalu muncul atau jarang muncul merupakan pembeda yang buruk. Kedua jenis kata ini memiliki varians frekuensi kemunculan yang kecil. Dengan demikian varians merupakan salah satu petunjuk yang dapat digunakan untuk kriteria seleksi kata, yakni kata dengan varian frekeunsi kemunculan yang besar diharapkan akan menjadi pembeda yang baik. Penelitian ini mengelaborasi asumsi itu untuk memilih kata berdasarkan analisis varians frekuensi kemunculan kata.
2. LANDASAN TEORI
2.1. Model ruang vektor koleksi dokumen
Model ruang vektor untuk koleksi dokumen memandang dokumen sebagai sebuah vektor dalam ruang kata (feature). Dari koleksi n buah dokumen diindeks t buah term. Dokumen dilihat sebagai vektor berdimensi t dalam ruang term tersebut. Koleksi dokumen dapat dituliskan sebagai matrik kata-dokumen X, ditulis sebagai :
X = {xij } i= 1,2,..t ; j =1,2,.. n (1)
xij adalah bobot term i dalam dokumen ke j
Menurut Luhn [9], kekuatan pembeda terkait dengan frekuensi term (term-frequency, tf). Term yang memiliki kekuatan diskriminasi adalah term dengan frekuensi sedang (lihat Gambar 1). Kata dengan frekuansi tinggi dibuang karena biasanya membawa sedikit informasi, sedangkan frekuensi rendah dibuang karena jarang muncul dalam query.
Seleksi Feature Kata Berdasarkan Variasi Kemunculan Kata dalam Peningkatan Unjuk Kerja Document
Clustering Untuk Dokumen Berbahasa Indonesia
Gambar 1. Hubungan frekuensi kata dan kata ter-ranking frekuensi (Luhn, 1958)
Untuk menghindari bias yang muncul dari faktor banyaknya dokumen yang memuat term tersebut, atau faktor panjang dokumen dimana term tersebut muncul [10], normalisasi frekuensi term terhadap panjang dokumen diperlukan. Pembobotan akhir term umum dirangkumkan sebagai berikut [3] :
wij=Lij.Gi.Nj (2)
di mana wij adalah bobot total term i dalam dokumen ke j, Lij adalah bobot lokal term i
dalam dokumen ke j, Gi bobot global term i yang mengukur bobot term i dalam koleksi
dokumen, dan Nj adalah faktor normalisasi untuk terhadap panjang dokumen.
Kombinasi terbaik yang sering digunakan adalah fij untuk bobot lokal Lij (disebut TF),
dan i n N
log sebagai bobot global Gi (disebut IDF) dan pembobotan normal sehingga
panjang vektor adalah satu, yaitu : Nj=
m i 0 GiLij 2 1 (3)Sehingga bentuk akhir disebut sebagai pembobotan TF-IDF ternormalisasi, yaitu :
wij= 2 log ). 1 ) (ln( log ). 1 ) (ln( i ij i ij n N f n N f (4)
di mana wij adalah bobot term i dalam dokumen ke j, fij adalah frekuensi kata ke-i dalam
dokumen ke-j, N cacah dokumen total, ni cacah dokumen mengandung term i.
Kesamaan antara dokumen Di dengan dokumen Dj umumnya diukur dengan
fungsi similaritas tertentu. Menurut [12] untuk tujuan clustering dokumen fungsi yang baik adalah fungsi similaritas Cosine, berikut :
184
Pakar, Vol.7, No.3 Nopember 2006
Cosine-sim(Di,Dj)=
t i t i j i t i j iD
D
D
D
1 1 2 2 1)
(
)
(
(5)Jika vektor Di dan Dj masing-masing ternormalisasi maka fungsi menjadi : Cosine-sim(Di,Dj) =
t i j iD
D
1 (6)2.2. Seleksi Feature dengan Analisis Varians Term
Meskipun proses stemming dapat menurunkan dimensi ruang vektor sampai 25%, feature yang terpilih setelah upaya reduksi dimensi melalui preprocessing dan stemming masih berukuran cukup besar dan masih terlalu mahal proses komputasinya. Dhillon et.al. [4][5] menyarankan untuk melakukan analisis terhadap feature/term dengan melakukan evaluasi term quality. Hal ini dilakukan dengan menghitung term variance quality qi(t), seperti persamaan (7) berikut :
qi(t)=
ni j ni j j j f ni f 1 2 1 2 1 (7)di mana ni adalah total jumlah dokumen dan fj adalah frekuensi term t dalam dokumen
j. Jika i = 0 maka term t bernilai nol dalam dokumen tertentu ikut dipertimbangkan dalam menghitung variance, jika i = 1 maka dokumen yang dilibatkan dalam perhitungan variance hanya dokumen yang memiliki term t minimal 1. [5] menunjukkan bahwa penggunaan 15% term dengan variance terbesar menghasilkan cluster yang cukup baik.
2.3. Clustering Dokumen
Clustering didefinisikan sebagai upaya pengelompokan data ke dalam kluster sehingga data-data didalam kluster yang sama memiliki lebih kesamaan dibandingkan dengan data-data pada kluster yang berbeda [6]. Dikenal dua pendekatan, yaitu herarchical dan partisional dengan masing-masing memiliki banyak variasi.
Metode Hierarchi Agglomerative untuk Clustering dokumen
Metode klustering secara aglomerative berawal dari n= cacah dokumen sebagai cluster. Dengan menggunakan fungsi similaritas antar kluster kemudian proses penggabungan kluster terdekat dilakukan. Ukuran similaritas antar kluster antara lain, misalnya: Single Link, Complete Link, UPGMA [6], atau CST dan IST [11].
Seleksi Feature Kata Berdasarkan Variasi Kemunculan Kata dalam Peningkatan Unjuk Kerja Document
Clustering Untuk Dokumen Berbahasa Indonesia K-Means Clustering
Algoritma K-means clustering merupakan algortima iteratif dengan meminimalkan jumlah kuadrat error antara vektor objek dengan pusat kluster terdekatnya [9], yaitu :
k j x j j m x 1 2 (8)di mana mj adalah pusat kluster (mean vector) dalam kluster ke j. Proses dimulai
dengan mula-mula memilih secara random k buah dokumen sebagai pusat kluster awal.
Bisecting K-Means Clustering
Metode Bisecting K-means [11] mencoba menggabungkan pendekatan partitional dengan divisive hierarchi, yaitu mula-mula seluruh dokumen dibagi dua dengan cara K-means (bisecting-step). Selanjutnya cara itu dikenakan pada tiap-tiap kluster sampai diperoleh K buah kluster.
Buckshot Clustering
Algoritma Buckshot menggunakan pendekatan hierarchie agglomerative untuk mendapatkan k buah vektor sebagai pusat kluster awal. Langkah Buckshot mula-mula mengambil sampel acak sebesar
kn
dokumen, dikluster dengan prosedur hierarchie agglomerative untuk mendapatkan k buah kluster. Selanjutnya dari partisi awal Buckshot proses refinement dilakukan sebagaimana dalam K-means clustering.2.4 Validitas Clustering (Cluster validity)
Validitas yang digunakan diturunkan dari Confusion Matrix yaitu matriks yang disusun berdasarkan berapa banyak objek yang diklasifikasikan dengan benar oleh proses clustering. Parameter kualitas clustering yang dapat diturunkan dari confusion matrix yang umum digunakan untuk document clsutering adalah F-measure (persamaan (9)). F-measure = R P PR 2 (9)
3. EKSPERIMEN
Bahan eksperimen berupa test-collection dokumen teks yang diambil dari [2] disusun jadi 6 koleksi yang masing-masing telah dikluster secara manual (Tabel 1 ).
186
Pakar, Vol.7, No.3 Nopember 2006
Tabel 1. Koleksi Dokumen Untuk Pengujian algoritma clustering
Colec Name doc clus
Clust Size uniq Word avg
word/doc T50 50 5 Sama 2.860 382 T100 100 10 Sama 4.385 368 T200 200 10 Sama 6.652 372 T300 300 10 Beda 8.472 373 T400 400 11 Beda 10.153 388 T500 500 13 Beda 11.637 385
Format tiap dokumen dalam koleksi dokumen diatur seperti gambar 2.
Gambar 2. Format koleksi dokumen untuk Tes
Prosedur eksperimen
Tahapan eksperimen dimulai dengan pre-processing dokumen dengan ekstrak kata, penyusunan matrik kata-dokumen, proses stemming pada kata dan penyusunan ulang matrik kata-dokumen dan pembobotan ternormalisasi. Selanjutnya metode-metode clustering diujikan pada koleksi, yaitu : adalah hierarchi aglomerative (strategi similaritas: Single Link, Complete Link, Group Average, centroid similarity, intra cluster similarity), metode partitional (K-means, bisecting k-means, Buckshot).
Dengan berbagai variasi jumlah term yang dipilih berdasar besarnya varians term, clustering pada koleksi dilakukan. Digunakan nilai F-measure sebagai kriteria unjuk kerja clustering. Analisis statistik dilakukan dengan TWO-WAY ANOVA. Pengolahan data dilakukan dengan paket SPSS for Windows.
4. HASIL DAN PEMBAHASAN
Analisis varians dilakukan untuk memilih term pada koleksi yang diuji coba. Untuk 100% term dengan frekuensi diatas 3 , 20% term dan 5% term dengan varians tertinggi sebagai feature dalam clustering menghasilkan nilai F-measure terbaik seperti pada Tabel 2. Terlihat dari tabel bahwa pengurangan term pada seluruh koleksi yang
<DOC>
<DOCNO>news035-html</DOCNO>
mayjen syafrie samsuddin akan jadi kapuspen tni jakarta media mantan pangdam jaya mayjen syafrie samsuddin akan menjadi kapuspen tni menggantikan marsekal muda graito husodo menurut informasi yang diperoleh antara jakarta kamis syafrie samsuddin menjadi kapuspen tni dan serah terima jabatan akan dilakukan pada akhir februari 2002 namun kebenaran informasi tersebut hingga kini belum dapat dikonfirmasikan ke kapuspen tni </DOC>
Seleksi Feature Kata Berdasarkan Variasi Kemunculan Kata dalam Peningkatan Unjuk Kerja Document
Clustering Untuk Dokumen Berbahasa Indonesia
diuji tidak menyebabkan nilai F-measure turun secara siginifikan, bahkan dibeberapa koleksi mengalami kenaikan (koleksi T100 dan T200).
Tabel 2. Seleksi Term dan Efeknya pada Nilai F-measure
doc 100% Term f>3 F-best 100% Term 20% Term F-best 20% Term 5% Term F-best 5% Term 100
1048
0.9599 210 0.9694 52 0.9794 200 1856 0.9455 371 0.9752 93 0.9899 300 2522 0.9278 504 0.9564 126 0.9078 400 3179 0.8734 636 0.8910 159 0.8384 500 3814 0.8634 763 0.8309 191 0.8392Untuk hasil clustering 8 metode clustering pada koleksi 400 dokumen dengan jumlah term 100% dan berturut-turut 20%,15%,10% dan 5% dengan varian term tertinggi memberikan hasil clustering dengan F-measure seperti Tabel 3. Uji statistik menunjukkan bahwa prosentase term tidak menghasilkan F-measure yang berbeda secara signifikan (F-value =0.152 ; sig =0.961).
Tabel 3. Nilai F hasil clustering untuk koleksi 400 dokumen
Metode
Prosentase Term terpakai
5% 10% 15% 20% 100% HCA-UPGMA (1) 0.802 0.805 0.806 0.742 0.854 HCA-CST (2) 0.797 0.512 0.564 0.580 0.304 HCA-IST (3) 0.790 0.771 0.811 0.728 0.585 HCA-SL (4) 0.189 0.184 0.243 0.257 0.185 HCA-CL (5) 0.844 0.727 0.907 0.822 0.784 K-MEANS (6) 0.709 0.781 0.752 0.669 0.728 Bisect K-M (7) 0.854 0.863 0.856 0.837 0.876 Buckshot (8) 0.631 0.787 0.758 0.729 0.755
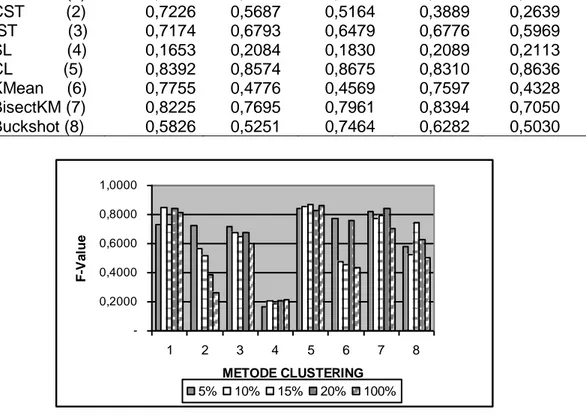
Untuk koleksi 500 dokumen hasil clustering juga menunjukkan nilai F-measure yang tidak mengalami penurunan meskipun term yang digunakan diambil 10% atau bahkan 5%. Bahkan untuk metode CST(2) term yang 100% jauh lebih buruk hasilnya dibandingkan dengan 5%,10% atau 15% dari total term. Tabel 4 dan gambar 3 menunjukkan kinerja clustering untuk koleksi 500 dokumen. Uji statistik meunjukkan bahwa perbedaan prosentase term tidak menyebabkan perbedaan F-measure secara signifikan (F-value =0.32; sig = 0.861).
188
Pakar, Vol.7, No.3 Nopember 2006
Tabel 4. Nilai F hasil clustering untuk 500 dokumen untuk 8 metode
Metode Prosentase Term 5% 10% 15% 20% 100% UPGMA (1) 0,7310 0,8473 0,7339 0,8399 0,8107 CST (2) 0,7226 0,5687 0,5164 0,3889 0,2639 IST (3) 0,7174 0,6793 0,6479 0,6776 0,5969 SL (4) 0,1653 0,2084 0,1830 0,2089 0,2113 CL (5) 0,8392 0,8574 0,8675 0,8310 0,8636 KMean (6) 0,7755 0,4776 0,4569 0,7597 0,4328 BisectKM (7) 0,8225 0,7695 0,7961 0,8394 0,7050 Buckshot (8) 0,5826 0,5251 0,7464 0,6282 0,5030
Gambar 3. Nilai F-measure pada berbagai prosentase Term (500dok)
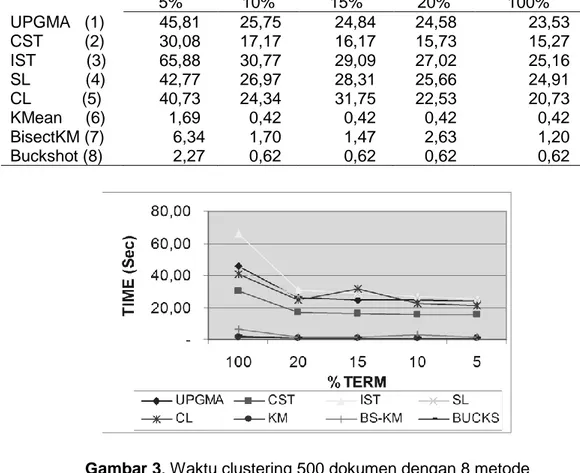
Adapun pengamatan terhadap waktu clustering dengan adanya penurunan jumlah term maka terjadi penurunan waktu clustering. Pada koleksi 400 dokumen penurunan waktu clustering tidak terlihat berbeda signifikan secara statistik. Pada koleksi 500 dokumen perbedaan penurunan waktu terjadi secara signifikan terutama untuk algoritma hierarchi (Lihat Tabel 6 dan gambar 3). Statistik uji menunjukkan F-value = 8.48 ; sig =0.000. (Tabel 5)
Tabel 5. Hasil Anova Uji beda Waktu clustering Untuk Algo Hierarchi
-0,2000 0,4000 0,6000 0,8000 1,0000 1 2 3 4 5 6 7 8 METODE CLUSTERING F -V a lu e 5% 10% 15% 20% 100%
Seleksi Feature Kata Berdasarkan Variasi Kemunculan Kata dalam Peningkatan Unjuk Kerja Document
Clustering Untuk Dokumen Berbahasa Indonesia
Tabel 6. Waktu clustering (sec) untuk koleksi 500 dokumen
Metode Prosentase Term
5% 10% 15% 20% 100% UPGMA (1) 45,81 25,75 24,84 24,58 23,53 CST (2) 30,08 17,17 16,17 15,73 15,27 IST (3) 65,88 30,77 29,09 27,02 25,16 SL (4) 42,77 26,97 28,31 25,66 24,91 CL (5) 40,73 24,34 31,75 22,53 20,73 KMean (6) 1,69 0,42 0,42 0,42 0,42 BisectKM (7) 6,34 1,70 1,47 2,63 1,20 Buckshot (8) 2,27 0,62 0,62 0,62 0,62
Gambar 3. Waktu clustering 500 dokumen dengan 8 metode
5. KESIMPULAN DAN SARAN
Pemilihan term menggunakan analisis varian frekuensi kemunculan term memberikan hasil seleksi feature yang sangat baik. Dengan menggunakan 5% sampai 15% term dengan varian tertinggi hasil clustering menunjukkan kinerja yang tetap baik dibandingkan dengan penggunaan 100% term tersedia. Keuntungan lain adalah dengan hanya 15% term digunakan maka waktu clustering menurun secara signifikan. Hal ini terjadi terutama untuk algoritma clustering secara hierarchi.
Untuk konsistensi hasil penelitian ini masih perlu diterapkan pada penelitian lanjutan terutama untuk koleksi dokumen jenis lain dan jumlah dokumen yang labih besar.
190
Pakar, Vol.7, No.3 Nopember 2006
DAFTAR PUSTAKA
[1] Aggarwal,C. C. and P.S. Yu, 2000, Finding Generalized Projected Cluster in High Dimensional Spaces, Proc.ACM SIGMOD Conf., 2000
[2] Asian, J., H. E. Williams, and S. M. M. Tahaghoghi, 2004, Tesbed for Indonesian Text Retrieval, 9th Australian Document Computing Symposiom, Melbourne December, 13 2004
[3] Chisholm, E. and T. G. Kolda, 1999, New Term Weighting Formula for the Vector Space Method in Information Retrieval, Research Report, Computer Science and Mathematics Division, Oak Ridge National Library, Oak Ridge, TN 3781-6367, March 1999.
[4] Dhillon, S. I., J. Fan, and Y. Guan, 2001, Efficient Clustering of Very Large Document Collection, www.citeseer.ist.psu.edu/dhillon01.html
[5] Dhillon, I., J. Kogan, and C. Nicholas, 2002, Feature Selection and Document
Clustering, www.csee.umbc.edu/cadip/2002Symposim/koghan.pdf
[6] Jain, A.K. and R. C. Dubes, 1988, Algorithms for Clustering Data, Prentice-Hall [7] Gao, J. and J. Zhang, 2003, Clustered SVD Strategies in Latent Semantic Indexing,
Technical Report No. 382–03, Department of Computer Science, University of Kentucky, Lexington, KY,2003
[8] Hinneburg, A. and D.K. Keim, 1999, Optimal Grid-Clustering: Towards Breaking the Curse of Dimensionality in High-Dimensional Clustering”, Proceeding of 25th VLDB Conference, Edinburg, Scotland, 1999
[9] Luhn, H.P. (1958), The Automatic Creation of Literature Abstracts. IBM Journal of Research and Development, 2:159-165
[10] Rijsbergen, C. J.,1979, Information Retrieval, Information Retrieval Group, University of Glasgow , UK
[11] Steinbach, M., G. Karypis, and V. Kumar , 2000, A Comparison of Document
Clustering Techniques, KDD Workshop on Text Mining,
www.citeseer.ist.psu.edu/steincah00comparison.html
[12] Strehl, A., J. Ghosh, and R. Mooney, 2000, Impact of Similarity Measures on Web-Page Clustering, Proceeding of the Workshop of Artificial Intelligent for Web Search, 17th National Conference on Artificial Intelligence, July 2000.