Skripsi/TA Fakultas Teknik/ Teknik Informatika Universitas Pelita Bangsa
1
PENERAPAN METODE NAÏVE BAYES UNTUK PREDIKSI KUALITAS PRODUK
STUDI KASUS ( PT. SUPERNOVA FLEXIBLE PACKAGING )
Pipit Nur Ulfa
Teknik Informatika,Universitas Pelita Bangsa Email: [email protected]
Abstrak
Suatu produk yang dihasilkan suatu perusahaan harus mempunyai kualitas yang baik atau tanpa cacat. Produk cacat mempunyai pengaruh terhadap image pada perusahaan dan kepuasan konsumen, semakin banyak kualitas produk cacat / No Good yang dihasilkan perusahaan maka mempengaruhi efisiennya waktu dan biaya serta mempengaruhi proses bisnis yang ada. Merupakan sebuah hal penting dalam sebuah perusahaan harus mempertahankan kualitas produk yang dihasilkan, maka dari itu penelitian ini bermaksud mencari solusi untuk memprediksi kualitas produk di PT Supernova Flexible Packaging dengan menerapkan metode naive bayes dalam menentukan prediksi keputusan kualitas produk yang efisien. Pada penelitian ini menerapkan metode naive
bayes untuk menentukan nilai kepastian yang dihasilkan. Naive bayes adalah teknik prediksi berbasis
probabilistik sederhana yang berdasarkan pada penerapan Theorema Bayes dengan asumsi yang kuat. Hasil pengujian metode naive bayes pada RapidMiner yang didapatkan adalah menghasilkan akurasi 95,00% dan dengan tingkat eror 5.00%. sehingga dapat disimpulkan bahwa metode naïve bayes ini sangat baik untuk digunakan dalam memprediksi kualitas produk yang dihasilkan di PT Supernova Flexible Packaging.
Kata kunci: Image, No Good, Naive Bayes, Rapidminer.
APPLICATION OF NAÏVE BAYES METHOD FOR PREDICTING PRODUCTS
QUALITY
CASE STUDY ( PT. SUPERNOVA FLEXIBLE PACKAGING )
AbstractA product produced by a company must have good quality or without defects. Defective products have an influence on the image of the company and customer satisfaction, the more quality defective products / No Good produced by the company will affect the efficiency of time and costs and affect existing business processes. It is an important thing in a company to maintain the quality of the products produced, therefore this research intends to find solutions to predict product quality at PT Supernova Flexible Packaging by applying the naive bayes method in determining efficient product quality decision predictions. In this study applying the Naive Bayes method to determine the value of certainty produced. Naive Bayes is a simple probabilistic based prediction technique based on the application of Bayes Theorema with strong assumptions. The results of the naive bayes method test on RapidMiner obtained were to produce an accuracy of 95.00% and with an error rate of 5.00. so it can be concluded that the naïve bayes method is very good to be used in predicting the quality of products produced at PT Supernova Flexible Packaging.
.
Keywords: Image, No Good, Naive Bayes, Rapidminer.
1. PENDAHULUAN
Melalui era perdagangan bebas, persaingan bisnis antara perusahaan berlangsung ketat, termasuk pula pada perdagangan di bidang industri. Perusahaan perlu mengembangkan strategi yang tepat untuk menghadapi perubahan di dunia bisnis. Perusahaan tetap mempertahankan produk yang
berkualitas dan layak. Kualitas produk menjadi perhatian penting bagi perusahaan dalam menciptakan sebuah produk. Produk yang berkualitas menjadi kriteria utama konsumen dalam pemilihan produk yang ditawarkan oleh perusahaan. Kualitas produk dapat diartikan sebagai kesesuaian atau kepuasan konsumen atas suatu produk. Kepuasan tersebut mencakup kualitas produk
(quality of product), biaya (quality of cost), penyampaian (quality of delivery), keselamatan (quality of safety). Kualitas merupakan faktor dasar yang mempengaruhi pilihan konsumen untuk berbagai jenis produk dan jasa yang berkembang pesat dewasa ini. Kualitas telah menjadi bagian kekuatan yang penting yang membuahkan keberhasilan (Tjipto, F.,Diana.,1997).[1] Dengan demikian perusahaan dapat meningkatkan kepuasan pelanggan dimana perusahaan memaksimumkan produk berkualitas dan meminimumkan produk tidak berkualitas ( Not Good) serta menghindari lolosnya produk rusak ke tangan konsumen. Dalam penerapan pengendalian kualitas produk perlu diketahui juga mengenai faktor-faktor yang mempengaruhi kualitas suatu produk. Kualitas produk dipengaruhi oleh faktor tenaga kerja, bahan baku, metode kerja, mesin, dan lingkungan (Besterfield, 2009). Untuk itu perusahaan perlu melakukan pengendalian dan pengawasan secara intensif dan terus-menerus baik pada kualitas bahan baku, proses produksi, maupun produk akhirnya.
Quality control mempunyai peran sebagai pengendali. Quality Control (QC) adalah semua usaha untuk menjamin agar hasil dari pelaksanaan sesuai dengan rencana yang telah ditetapkan dan memuaskan konsumen. Tujuan quality control agar tidak terjadi barang yang tidak sesuai dengan standar mutu yang diinginkan (second quality) terus-menerus dan bisa mengendalikan, menyeleksi, menilai kualitas, sehingga konsumen merasa puas dan perusahaan tidak rugi. Tujuan Pengusaha menjalankan QC untuk memperoleh keuntungan dengan cara yang fleksibel dan untuk menjamin agar pelanggan merasa puas, investasi bisa kembali, serta perusahaan mendapat keuntungan untuk jangka panjang.
PT. Supernova Flexible Packaging merupakan perusahaan yang bergerak di bidang produksi Plastik kemasan (inner layer , shopping
bag ). Dalam sistem produksinya, PT. Supernova
Flexible Packaging menerapkan sistem make to
order atau membuat produk sesuai permintaan
pelanggan dengan selalu memperhatikan kualitas produk yang dihasilkan. Karena dengan kebutuhan yang sangat besar tersebut maka PT. Supernova Flexible Packaging memiliki beberapa departemen diantaranya seperti departemen PPIC, Produksi ,
Quality control, Finish Good dan wherehouse.
Tugas quality control yaitu melihat hasil kualitas produk jadi, mempunyai tanggung jawab utama dari seorang Operator QC, mengetahui bagaimana cara mengontrol permasalahan di produksi, mengetahui bagaimana membuat penilaian yang baik dalam pekerjaan, mampu berkoordinasi dengan pihak yang terkait tentang suatu permasalahan kualitas dan bekerja dengan sikap yang ketat dalam mengambil keputusan yang baik.
Kualifikasi quality control secara keseluruhan dilihat dari berbagai aspek salah satu aspek yang paling penting harus dimiliki oleh
quality control yaitu menguasai Job Instruction (JI)
atau aturan kerja. Dalam aturannya (JI) operator QC harus mengikuti semua point check terhadap produk agar menghindari terjadinya kelolosan produk not
good kepada pelanggan sehingga kualitas produk
akan selalu terjamin dimata pelanggan, point check yang menjadi parameter agar produk dinyatakan “good” atau “ Not Good” diantaranya seperti ukuran, suhu, waktu aging, speed, dan tes kekebalan. Namun, pada kenyataannya terdapat permasalahan pada kualitas produk yang dihasilkan terlalu banyak NG yang ditemukan dan dalam proses pengecekan sampel produk memerlukan waktu kurang lebih 2 jam pada setiap tahapannya sehingga mempengaruhi efisien waktu yang dialami perusahaan. Banyaknya produk NG yang ditemukan sangat mempengaruhi jalannya proses bisnis bagi perusahaan menjadi terganggu. Adanya kesulitan untuk mengidentifikasi berbagai penyebab yang menimbulkan masalah produk NG dan akibatnya perusahaan menghadapi kendala dalam usaha mencari solusi dari masalah yang terjadi. Salah satu cara mengatasi masalah tersebut adalah dengan adanya metode yang dapat memberikan rekomendasi tentang kualitas produk sebagai bahan pertimbangan untuk memprediksi kualitas produk secara cepat dan efisien. Dari beberapa Teknik klasifikasi yang paling sering digunakan adalah metode Naïve Bayes. Menurut penelitian yang dilakukan Muhammad Bilal dan Human Israr, dkk (2016) telah melakukan perbandingan antara algoritma Naïve Bayes,
Decision Tree, dan K Nearest Neighbour untuk
klasifikasi sentiment yang menghasilkan kesimpulan bahwa algoritam Naïve Bayes adalah yang terbaik dari segi akurasi, presisi, recall dan F-measure. Dalam pengklasifikasi Naive Bayes sangat sederhana dan efisien.[2] Selain itu, Naïve Bayes adalah teknik machine learning yang popular untuk klasifikasi teks, serta memiliki performa yang baik pada banyak domain. [3][4]
Untuk itu dalam penelitian ini, penulis menggunakan metode naive bayes untuk mengidentifikasi kualitas produk melalui beberapa kriteria untuk mengetahui penyebab banyaknya produk NG. Naive bayes merupakan salah satu algoritma yang dapat digunakan untuk memprediksi keanggotaan dari suatu class didasarkan oleh teorema bayes yang mampu bekerja seperti decision
tree dan neural network (2016, Fadhil). Peneliti
biasanya menggunakan metode ini untuk menyelesaikan permasalahan perhitungan probabilitas terjadinya suatu peristiwa berdasarkan pengaruh yang didapat dari pengujian. Dari banyak hasil penelitian yang diberikan, terbukti dalam banyak implementasi, naive bayes memberi hasil akurasi yang baik, terutama dalam hal solusi yang dicapai. [5]
Berdasarkan latar belakang diatas, maka penulis mengajukan penelitian dengan judul “PENERAPAN METODE NAÏVE BAYES
UNTUK PREDIKSI KUALITAS PRODUK
”.
Dengan harapan dapat membantu memecahkan masalah pengendalian kualitas di perusahaan dan menjadi landasan bagi penerapan Pengendalian Mutu Terpadu di masa yang akan datang.
2. LANDASAN TEORI
a.
PengertianKualitas
Kualitas produk dapat diartikan sebagai kesesuaian atau kepuasan konsumen atas suatu produk. Kepuasan tersebut mencakup kualitas produk (quality of product), biaya (quality of
cost), penyampaian (quality of delivery),
keselamatan (quality of safety). Kualitas merupakan faktor dasar yang mempengaruhi pilihan konsumen untuk berbagai jenis produk dan jasa yang berkembang pesat dewasa ini. Kualitas telah menjadi bagian kekuatan yang penting yang membuahkan keberhasilan (Tjipto, F.,Diana.,1997).[1]
b. Pengertian Data Mining
Data mining adalah serangkaian proses untuk menggali nilai tambah berupa informasi yang selama ini tidak diketahui secara manual dari suatu basis data.[6]. Data Mining disebut juga
Knowledge Discovery in Database (KDD)
didefenisikan sebagai ekstraksi informasi potensial, implisit dan tidak dikenal dari sekumpulan data.
Tahapan-tahapan proses KDD
1.
Data SelectionData hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2.
Pre-processing/ CleaningProses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi).
3.
TransformationPencarian fitur-fitur yang berguna untuk mempresentasikan data bergantung kepada goal yang ingin dicapai.
4.
Data mining
Pemilihan tugas data mining; pemilihan goal dari proses KDD misalnya klasifikasi, regresi, clustering, dan lain-lain.
5.
Interpretation/ EvaluationTahap ini merupakan bagian dari proses KDD yang mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesa yang ada sebelumnya.
c.
PengertianPrediksi
Menurut Han dan Kamber, (2011, p24), Predictive merupakan proses untuk menemukan pola dari data dengan menggunakan beberapa variabel lain di masa depan.[7]
d. Pengertian Naïve Bayes
Berdasarkan Santoso (2007), teori keputusan
bayes adalah pendekatan statistika yang
fundamental dalam data mining. Pendekatan ini didasarkan pada kuantifikasi trade-off antara berbagai keputusan klasifikasi dengan menggunakan probabilitas.[6]
Teorema bayes diformulasikan sebagai berikut (Han, et, al, 2012):
( | ) ( ) ( )
( ) ………...( 2-1 ) e. Confusion matrix
Confusion matrix merupakan salah satu metode
yang dapat digunakan untuk mengukur kinerja suatu metode klasifikasi. Pada dasarnya confusion matrix mengandung informasi yang membandingkan hasil klasifikasi yang dilakukan oleh sistem dengan hasil klasifikasi yang seharusnya. Pada pengukuran kinerja menggunakan confusion matrix, terdapat 4 (empat) istilah sebagai representasi hasil proses klasifikasi. Keempat istilah tersebut adalah
True Positive (TP), True Negative (TN), False Positive (FP) dan False Negative (FN).[8]
f. Validation
Validation adalah teknik validasi yang membagi data menjadi dua bagian secara acak, sebagian sebagai data training dan sebagian lainnya sebagai data testing. Dengan menggunakan Validation akan dilakukan percobaan training berdasarkan split ratio yang telah ditentukan sebelumnya, untuk kemudian
sisa dari split ratio data training akan dianggap sebagai data testing.[8]
g.
RapidMinerRapid Miner merupakan perangakat lunak yang bersifat terbuka (open source).Rapid Miner adalah sebuah solusi untuk melakukan analisis terhadap data mining, text mining dan analisis prediksi. Rapid Miner menggunakan berbagai teknik deskriptif dan prediksi dalam memberikan wawasan kepada pengguna sehingga dapat membuat keputusan yang paling baik.[9]
h. Microsoft Excel
Microsoft excel adalah software spreadsheet
paling terkenal di dunia bisnis dan perkantoran.
Excel digunakan hampir semua bidang bisnis. Excel dapat dijumpai di mana-mana dan bisa
dikatakan sebagai aplikasi yang universal dan dipakai semua orang. Aplikasi excel memiliki fitur kalkulasi dan pembuatan grafik, serta mudah dipakai sehingga excel menjadi salah satu program komputer yang populer digunakan di PC hingga saat ini. Bahkan, saat ini excel merupakan program spreadsheet paling banyak digunakan, baik platform PC berbasis windows maupun platform macintosh berbasis Mac OS semenjak versi 5.0 yang keluar ditahun 1993. [9]
3. Metode Penelitian
3.1
Kerangka pikirGambar 3.1 Kerangka pikir
3.2 Metode Yang Digunakan
Gambar ini akan memberi gambaran atas tahapan penelitian .
1. Pengumpulan Data
Metode yang digunakan dalam pengumpulan data-data yang dibutuhkan pada penelitian.
2. Pengolahan Data Awal
a. Persiapan Data (Data Preparation)
b. Select Data
Data yang sudah ada selanjutnya dilakukan pemilihan terhadap parameter yang akan dianalisis. Parameter yang diambil adalah atribut dari data hasil laporan pengecekan quality control yang telah didapatkan sebelumya. Pemilihan parameter ini dilakukan dengan mempelajari lebih lanjut setiap atribut dengan mempertimbangkan tujuan penulisan,maka didapatkan atribut-atribut yang akan digunakan untuk menjadi masukan atau variable input.
Pengumpulan Data Pengolahan data awal Metode yang diusulkan Pengujian / Validasi hasil
c. Remove Duplicate
Pada proses ini bertujuan untuk menyeleksi data yang berulang. Sebab pada pengisian laporan seorang operator qc sering kali meng-input data dan isi yang sama. Hal ini menyebabkan banyaknya data terulang sehingga harus di proses saat pembentukan model dan mengakibatkan lamanya waktu pemrosesan data. Di bawah ini adalah proses remove duplicate yang dilakukan pada tabel laporan qc dengan menggunakan ms.excel.
d. Data Cleaning
Pada tahap ini akan dilakukan proses pembersihan data untuk memastikan data yang telah dipilih tersebut telah layak untuk dilakukan proses pemodelan. Tahapan ini antara lain memperbaiki data yang rusak, membersihkan dan menghapus data yang tidak diperlukan dengan tool Ms.Excel. Tahapan data cleaning akan dilakukan di bab selanjutnya.
e. Data Integration dan Transformation Untuk meningkatkan akurasi dan efisiensi algoritma. Data dalam penelitian ini dikategorikan atau diklasifikasi. Setelah mendapatkan data selanjutnya adalah menghilangkan atribut-atribut yang tidak dipakai karena kurang berpengaruh terhadap hasil prediksi.
f. Pembagian Data Set
Untuk Memperoleh dataset dengan jumlah atribut yang lebih sedikit tetapi bersifat informative. Maka dataset dibagi menjadi data training dan data testing. Data training di peroleh dari pembagian sumber data yang berjumlah 1100 record, dimana pembagian training data sebagai penentuan prediksi kualitas produk “OK” atau “NG”, data tersebut dilakukan cleaning data yaitu dengan menambahkan nilai pada atribut yang kosong dengan nilai rata-rata serta menghapus atribut apa saja yang tidak diperlukan karena tidak berpengaruh terhadap pengecekan kualitas produk. Sehingga nantinya dapat diperoleh prediksi pada data testing sebagai jawaban keputusan kualiatas produk “OK” atau “NG”.
3.3 Metode yang diusulkan
Pada tahapan ini dijelaskan penggunaan metode Naïve Bayes pada penelitian. Model yang diusulkan untuk klasifikasi menggunakan Naïve
bayes adalah menggunakan model split validation. Split validation membagi data menjadi
dua subset data yaitu data trainning dan data
testing. Data trainning merupakan data yang
digunakan untuk pelatihan, sedangkan data testing akan digunakan untuk pengujian. Adapun untuk melihat secara lebih jelas dari model split
validation dapat dilihat pada gambar.
Tabel 3. 1 Pembagian Data Pengujian
Training Testing 75% 25% 80% 20% 85% 15% 90% 10% 95% 5%
Dari lima kali percobaan yang dilakukan berdasarkan proporsi dari tabel 3.1 setiap hasil yang diperoleh akan ditentukan jumlahnya untuk diambil nilai rata- rata.
3.4 Pengujian dan validasi Hasil
Tahapan ini menjelaskan tentang pengujian, hasil pengujian akan di validasi dan kemudian di evaluasi. Tahapan evaluasi yang dilakukan dalam penelitian ini adalah untuk memberikan penilaian
Gambar 3. 2 Tahapan Penelitian
Training Model Development Preposed data Classifier Testing Model Assessment Prediction Accuration
dari hasil penggunaan algoritma naive bayes saja dan naive bayes yang disertai dengan confusion
matrix untuk mengklasifikasi data laporan
pengecekan quality control untuk memprediksi kualitas produk. Bagian yang akan dievaluasi adalah presentase data,jumlah data training, jumlah data testing , dan nilai akurasi yang dihasilkan.
Tabel 3. 2 Evaluasi Pengujian
Dari tabel 3.2 akan digunakan untuk validasi nilai akurasi dari algoritma naive bayes saja. Dari nilai akurasi yang dihasilkan akan ditentukan rata-rata akurasi dan keterkaitan antara setiap atribut. Algoritma Naïve Bayes akan mengevaluasi setiap atribut yang mengkontribusi prediksi pada atribut target. Kemudian akan dibandingkan dengan model yang dimiliki akurasi yang lebih tinggi untuk mengklasrifikasi data laporan pengecekan kualitas produk di PT. Supernova. Naïve Bayes tidak memperhitungkan relasi antar atribut-atribut kontributor prediksi. Bentuk tugas dasar yang dilakukan oleh algoritma Naïve Bayes adalah hanyalah klasifikasi (Jiawei Han, Micheline Kamber, Jian Pei, -3rd ed.2012. p. 351). [10]
4. Hasil dan Pembahasan
4.1 Hasil Pengujian
Hasil pada penelitian ini dilakukan dengan pengolahan data laporan pengecekan produk dengan menggunakan microsoft excel,
kemudian diuji dengan tool bantu aplikasi
Rapidminer dengan data traning dan data
testing yang telah dipersiapkan untuk menentukan prediksi kualitas produk. Pengujian pada penelitian ini dilakukan dengan menggunakan metode Naive Bayes. 4.2 Penerapan Metode Naïve Bayes dengan
Rapidminer
Rapidminer Studio 9.0 adalah salah satu tool untuk melakukan prediksi dan analisa data mining. Berikut adalah tahapan dalam melakukan data mining di rapidminer 9.0.
1. Proses Import Data
Pada tahapan ini data hasil pengecekan quality control yang sudah dicleaning, integration dan selection diimport kedalam tool rapidminer 9.0. yaitu terdiri dari data traning dan data testing.
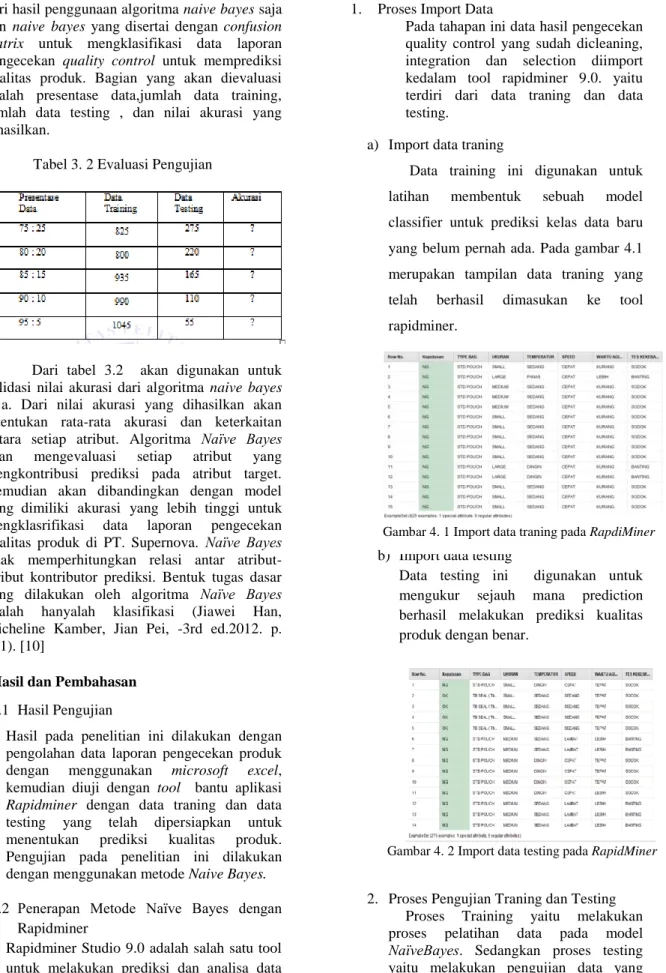
a) Import data traning
Data training ini digunakan untuk latihan membentuk sebuah model classifier untuk prediksi kelas data baru yang belum pernah ada. Pada gambar 4.1 merupakan tampilan data traning yang telah berhasil dimasukan ke tool rapidminer.
b) Import data testing
Data testing ini digunakan untuk mengukur sejauh mana prediction berhasil melakukan prediksi kualitas produk dengan benar.
2. Proses Pengujian Traning dan Testing Proses Training yaitu melakukan proses pelatihan data pada model
NaïveBayes. Sedangkan proses testing
yaitu melakukan pengujian data yang akan menghasilkan grafik dan pola.
Gambar 4. 1 Import data traning pada RapdiMiner
3. Hasil Apply Model
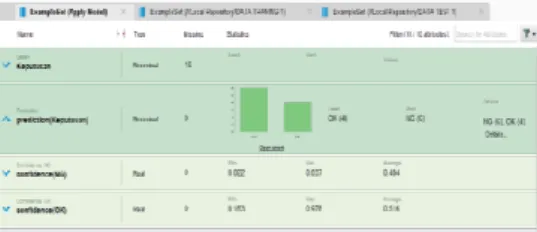
Pada tahap ini Operator apply model menerapkan suatu model terlatih pada sebuah ExampleSet yaitu sebuah model pertama kali dilatih disebuah ExampleSet, informasi yang berkaitan dengan ExampleSet dipelajari oleh model. Maka model tersebut dapat diterapkan pada ExampleSet yang lain sehingga menghasilkan prediksi dari label keputusan dalam kualitas produk. Hasil dari apply model adalah sebagai berikut :
Dari 275 record data testing yang dibaca, menghasilkan prediksi keputusan “OK” 70 dan keputusan “ NG” 205.
4.3 Pengujian Prediksi Pada Data Testing Dalam pengujian ini menggunakan data testing berjumlah 10 record yang belum diketahui hasil dari keputusan kualitas produk tersebut.
1. Data Testing
Data testing ini digunakan untuk pengujian metode naïve bayes pada RapidMiner dalam menentukan hasil prediksi keputusan kualitas produk. Hal ini berguna untuk mengukur kinerja pada peneitian yang dilakukan.
2. Pengujian pada Rapidminer
Berikut ini adalah desain proses pengujian pada aplikasi RapidMiner.
Data traning dan data testing yang telah diimport dengan label pada atribut keputusan akan diseleksi oleh select atribut dihubungkan pada blok naïve bayes dan blok apply model yang akan menghasilkan prediksi dari data testing tersebut. Sehingga hasil akan muncul seperti pada tampilan Gambar 4.6 berikut:
Gambar 4. 3 Proses permodelan Naive Bayes
Gambar 4. 4 Hasil Proses apply model pada data kategori keputusan kualitas produk
Gambar 4. 5 Statistic ExampleSet Apply Model
Tabel 4 1 Data Testing Untuk Pengujian
Gambar 4. 6 Proses Pengujian
Dari Gambar 4.8 dapat dijelaskan bahwa dari pengujian 10 record data testing menghasilkan prediksi keputusan “ OK “ sama dengan 4 dan keputusan “ NG “ sama dengan 6.
4.4 Pembahasan Analisa Hasil Pengujian Analisa dilakukan secara deskriptif dalam rangka memperoleh gambaran mengenai prediksi kualitas produk yang dilakukan oleh perusahaan dengan berbagai tahapan - tahapan yang biasanya dilakukan dalam pengecekan kualitas produk oleh quality control. Berdasarkan hasil penelitian yang telah diperoleh, disertai dengan data-data yang ada, maka selanjutnya penulis akan melakukan analisis terhadap hasil penelitian yang telah dipaparkan sebelumnya, untuk mengetahui dari analisis data tersebut dapat diketahui dengan menghitung presentase dari data analisis. 1. Performance Vektor
Penerapan metode naive bayes pada RapidMiner yang digunakan untuk prediksi data pengecekan produk dengan label katagori keputusan kualitas produk pada penelitian ini diperoleh nilai Accuracy, Precision, dan Recall.
2. Accuracy / Akurasi
Dengan mengetahui jumlah data yang diklasifikasikan secara benar maka dapat diketahui akurasi hasil prediksi yaitu 93.45% dari hasil data testing. Prediksi NG yang true NG adalah 133 ( prediksi benar ) dan true OK adalah 11 ( Prediksi salah ). Sedangkan untuk prediksi OK adalah true NG samadengan 0 nol ( prediksi salah ) dan true OK samadengan 76 ( prediksi benar ).
3. Precision
Dari hasil tampilan Gambar 4.11 menjelaskan bahwa precision adalah jumlah data yang true positive “TP” ( jumlah data positif yang dikenali secara benar sebagai positif OK ) dibagi dengan jumlah data False Positif “FP” ( false OK ) ditambah data true positif “TP” dikenali sebagai positif OK dan dikali 100%. Maka dari pengujian ini hasil nilai precisionnya yaitu 100% untuk class Ok dan 92.36 % untuk class NG.
4. Recall
Gambar 4. 8 Statistics ExampleSet ApplyModel
Gambar 4. 9 Hasil Performance Vector
Gambar 4. 10 Hasil Accuracy
Gambar 4. 11 Hasil Precision
Recall adalah jumlah data yang true positive dibagi dengan jumlah data yang sebenarnya positive (true positive – true negative) dikali 100%. Sehingga untuk nilai Recall yaitu 87,36 % untuk positif class Ok dan 100% untuk positif class NG.
Setelah dilakukan pengujian dengan nilai perbandingan data traning dan data testing sebanyak 5 kali pengujian seperti yang ditunjukan pada Tabel 4.2 tersebut, maka didapatkan nilai rata – rata akurasi sebesar 91,752 % rata – rata akurasi ini menunjukan bahwa tingkat kinerja suatu metode pada aplikasi rapidminer dapat diukur sehingga dengan hasil ini maka penggunaan metode naïve bayes untuk prediksi kualitas produk pada data laporan pengecekan produk quality control PT. Supernova cukup bagus dan dapat dipakai sebagai acuan untuk penelitian selanjutnya.
4.5 Evaluasi
Hasil analisa antara data yang di tes dengan data training dan data testing pada Rapidminer. Untuk menghitung akurasinya sebagai berikut :
Jumlah data yang diuji 220 Jumlah data yang diprediksi benar 209 Jumlah data yang diprediksi salah 11
Maka, Akurasi = ×100% = 209/220 ×100% = 95,00% Error = = 11/220 ×100% = 5,00%
Dari perhitungan tersebut dapat disimpulkan bahwa klasifikasi dengan menggunakan metode naive bayes untuk prediksi kualitas produk menghasilkan tingkat akurasi sebesar 95,00% dan tingkat error 5,00%.
5. KESIMPULAN
Berdasarkan hasil penelitian yang telah dilakukan mengenai prediksi kualitas produk pada PT. Supernova dengan metode naive bayes maka dapat diambil kesimpulan bahwa metode Naive
Bayes memanfaatkan data training untuk menghasilkan probabilitas setiap kriteria untuk class yang berbeda, sehingga nilai-nilai probabilitas dari kriteria tersebut dapat dioptimalkan untuk menentukan prediksi kualitas produk Good “ OK “ dan kualitas produk Not Good “NG “ dengan cepat dan efisien berdasarkan klasifikasi yang dilakukan oleh metode naive bayes itu sendiri. Dan dari hasil pengujian yang telah dilakukan maka hasil penelitian dengan metode naive bayes pada
RapidMiner maka didapatkan sebuah hasil bahwa
nilai akurasinya adalah 95%, precision yaitu 100% ( positive class pred.OK ) dan recall yaitu 87.36 % serta tingkat eror 5% dari laporan periode Januari 2019 . Nilai akurasi menggambarkan seberapa akurasi sistem dapat mengklasifikasi data secara benar sehingga hasil ini adalah termasuk akurasi yang sangat baik. Dengan begitu metode ini bisa diterapkan dalam memprediksi kualitas produk di PT Supernova Flexible Packaging.
6. DAFTAR PUSTAKA
[1] Dudung, “Quality of Product Development,”
Influ. Psychol. Factors Prod. Dev., pp. 1–31,
2016.
[2] L. Xu, C. Jiang, J. Wang, J. Yuan, and Y. Ren, “Information Security in Big Data: Privacy and Data Mining,” IEEE Access, vol. 2, pp. 1–28, Jan. 2014.
[3] D. Ayu Muthia, “Integrasi Algoritma Genetika Dan Information Gain Untuk Seleksi Fitur Pada Analisis Sentimen Review Film Menggunakan Algoritma Naïve Bayes Bayes,” J. Tek. Komput. AMIK
BSI, vol. 4, no. 1, pp. 186–193, 2013.
[4] Q. Ye, Z. Zhang, and R. Law, “Sentiment classification of online reviews to travel destinations by supervised machine learning approaches,” Expert Syst. Appl., vol. 36, no. 3 PART 2, pp. 6527–6535, 2009.
[5] R. Rupitaida, “Penerapan Metode Naive Bayes dalam Pengidentifikasian Kualitas Daging,” pp. 3–4, 2017.
[6] Retno Tri vulandari, Data Mining Teori dan
Aplikasi RapidMiner. Yogyakarta: GAVA
MEDIA, 2017.
[7] R. Wijayatun and Y. Sulistyo, “Prediksi Rating Film Menggunakan Metode Naive Bayes,” J. Tek. Elektro, vol. 8, no. 2, pp. 60– 63, 2016.
[8] A. Prianto, “KLASIFIKASI REKRUITMEN KARYAWAN BARU DI PT OMRON MENGGUNAKAN ALGORITMA NAÏVE BAYES,” STT PELITA BANGSA, 2018. [9] D. C. Aprilla Donny Aji Baskoro Lia
Ambarwati I Wayan Simri Wicaksana Editor and R. Sanjaya, “Identitas Belajar Data Mining dengan RapidMiner,” in Belajar
Data Mining dengan RapidMiner, R.
Sanjaya, Ed. Jakarta: amazonaws, 2014, pp. 1–139.
[10] A. Jamaluddin, “Sistem Pendukung Keputusan Seleksi Karyawan Pt . Japfa Comfeed Indonesia Tbk Cabang Kediri Menggunkan Metode Naive Bayes Berbasis Web,” vol. 02, no. 04, pp. 1–13, 2018.