KLASIFIKASI DOKUMENT TEKS MENGGUNAKAN ALGORITMA NAIVE BAYES DENGAN BAHASA PEMOGRAMAN JAVA
Silfia Andini1
ABSTRACT
The development of technology nowadays has brought some effects to the sophisticated communication tools and technology itself. It is also influenced the improvement of information system that can caused an accumulation data such document text in online or offline. So, it is hard to find out the document based on needs. The necessity is helped by a classification of document text, that is a grouping process of a document to a category which can use for doing an analysis.
This research conducted by using text mining method and Algoritma Naive Bayes Classifier. Meanwhile the relationship among news is known by Probability result from the document and words in every documents. The classification process also could apply by using Java Programming.
Keywords : Text Document, Text Mining, Algoritma Naïve Bayes, Java Programming
INTISARI
Perkembangan teknologi saat ini telah membawa beberapa efek ke alat komunikasi canggih dan teknologi itu sendiri. Hal ini juga dipengaruhi peningkatan sistem informasi yang dapat menyebabkan data teks dokumen tersebut akumulasi dalam online atau offline. Jadi, sulit untuk mengetahui dokumen berdasarkan kebutuhan. Perlunya dibantu oleh klasifikasi dokumen teks, yaitu suatu proses pengelompokan dokumen ke kategori yang dapat digunakan untuk melakukan analisis.
Penelitian ini dilakukan dengan menggunakan metode text mining dan Algoritma Naif Bayes Classifier. Sementara itu hubungan antara berita dikenal dengan Probabilitas hasil dari dokumen dan kata-kata dalam setiap dokumen. Proses klasifikasi juga bisa berlaku dengan menggunakan Pemrograman Java.
Kata Kunci: Dokumen Teks, Teks Pertambangan, Algoritma Naïve Bayes, Pemrograman Java
1
PENDAHULUAN
Pada masa sekarang ini aliran informasi telah meningkat dalam jumlah yang besar setiap harinya, peningkatan aliran inrormasi ini akan menyebabkan terjadinya penumpukan data berupa dokumen teks, baik secara online maupun offline. Dokumen teks yang menumpuk menyebabkan sulitnya mencari dokumen yang sesuai dengan kebutuhan.
Ketersediaan data yang berlimpah yang dihasilkan dari penggunaan teknologi informasi dihampir semua bidang kehidupan menimbulkan kebutuhan untuk dapat memanfaatkan informasi dan pengetahuan yang terkandung di dalam limpahan data tersebut, yang kemudian melahirkan data mining. Data Mining merupakan proses untuk menemukan pengetahuan (knowledge discovery) yang ditambang dari sekumpulan data yang volumenya sangat besar.
Apabila jumlah data yang dicari sedikit, hal ini masih dapat dilakukan secara manual. Akan tetapi, dengan jumlah data yang banyak, proses pencarian secara manual akan menghabiskan waktu dan tenaga dalam jumlah yang banyak pula. Padahal waktu merupakan salah satu faktor yang menentukan efektivitas dan tingkat bermanfaatnya suatu data atau berita. Hal ini dikarenakan terdapat data yang bila telah melewati suatu waktu, data tersebut sudah tidak berguna atau tidak valid. Oleh karena itulah muncul kebutuhan untuk memperoleh data secara cepat dan tepat.
PENDEKATAN PEMECAHAN MASALAH
Data Mining
Menurut Maulani Kapiudin (2007) “Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan
menggunakan teknik atau metode tertentu. Pemilihan metode, teknik, atau algoritma yang tepat sangat bergantung pada tujuan dan proses penggalian data secara keseluruhan. Data mining atau Knowledge Discovery in Database (KDD) merupakan proses ekstraksi informasi-informasi penting atau knowledge dari basis data yang
besar. Data mining
menspesifikasikan pola-pola yang ditemukan pada kumpulan data tersebut sehingga data yang telah ada itu lebih bermanfaat dalam kehidupan nyata.
Pengertian Text Mining
Text mining dapat diartikan sebagai penemuan informasi yang baru dan tidak diketahui sebelumnya oleh komputer, secara otomatis mengekstrak informasi dari sumber-sumber yang berbeda. Kunci dari proses ini adalah menggabungkan informasi yang berhasil diekstraksi dari berbagai sumber (Hearst,2003). Tahapan Text Mining
Walaupun inti dari suatu sistem klasifikasi adalah tahap penemuan pola (pattern discovery) namun secara lengkap proses text mining dibagi menjadi 3 tahap utama, yaitu :
1. Text Preprocessing
Tahapan awal dari text mining adalah text preprocessing yang bertujuan untuk mempersiapkan teks menjadi data yang akan mengalami pengolahan pada tahapan berikutnya. Pada tahap ini dilakukan proses tokenizing yaitu tahap pemotongan string input berdasarkan tiap kata yang menyusunnya.
Beberapa contoh tindakan yang dapat dilakukan pada tahap ini, mulai dari tindakan yang bersifat kompleks seperti partofspeech (pos) tagging, parse tree, hingga tindakan yang bersifat sederhana seperti
proses parsing sederhana terhadap teks, yaitu memecah suatu kalimat menjadi sekumpulan kata. Selain itu pada tahapan ini biasanya juga dilakukan case folding, yaitu pengubahan karakter huruf besar
menjadi huruf kecil. Keseluruhan proses ini disebut juga dengan proses Tokenizing.
Contoh dari tahap ini seperti pada Gambar 1 berikut:
[ Hasil Tokenizing ] [ Hasil Filtering ] Gambar 1. Contoh Tahap Tokenizing
2. Text Transformation (feature generation)
Pada tahap ini hasil yang diperoleh dari tahap text preprocessing akan melalui proses tranformasi atau disebut juga proses filtering. Proses transformasi / filtering ini dilakukan dengan mengurangi jumlah kata-kata yang ada, yaitu dengan penghilangan stopword . Stopword adalah
kata-kata yang bukan merupakan ciri (kata unik) dari suatu dokumen seperti kata sambung dan kata kepunyaan. Memperhitungkan stopword pada transformasi teks akan membuat keseluruhan sistem text mining bergantung kepada faktor bahasa.
Contoh dari tahap ini seperti pada Gambar 2 berikut:
[ Hasil Tokenizing ] [ Hasil Filtering ] Gambar 2. Contoh Tahap Filtering
Implementasi Metode
Naïve Bayes Pada
Klasifikasi Teks
Dokumen
implementasi
metode
naïve
bayes
pada
klasifikasi
teks
dokumen
implementasi
metode
naïve
bayes
pada
klasifikasi
teks
dokumen
implementasi naïve bayes klasifikasi dokumen3. Pattern Discovery
Tahap penemuan pola atau pattern discovery adalah tahap terpenting dari seluruh proses text mining. Tahap ini berusaha menemukan pola atau pengetahuan dari keseluruhan teks. Seperti yang disebutkan dalam bab sebelumnya bahwa dalam data/text mining terdapat dua teknik pembelajaran pada tahap pattern discovery ini, yaitu unsupervised dan supervised learning. Adapun perbedaan antara keduanya adalah pada supervised learning terdapat label atau nama kelas pada data latih (supervisi) dan data baru diklasifikasikan berdasarkan data latih.
Sedangkan pada unsupervised learning tidak terdapat label atau nama kelas pada data latih, data latih dikelompokkan berdasarkan ukuran kemiripan pada suatu kelas. Berdasarkan keluaran dari fungsi, supervised learning dibagi menjadi 2, regresi dan klasifikasi. Regresi terjadi jika output dari fungsi merupakan nilai yang kontinyu, sedangkan klasifikasi terjadi jika keluaran dari fungsi adalah nilai tertentu dari suatu atribut tujuan (tidak kontinyu). Tujuan dari supervised learning adalah untuk memprediksi nilai dari fungsi untuk sebuah data masukan yang sah setelah melihat sejumlah data latih. Algoritma Naive Bayes
Konsep Dasar Algoritma Naive Bayes
Bayesian filter atau Naïve Bayes Classifier merupakan metode terbaru yang digunakan untuk mengklasifikasikan sekumpulan dokumen. Algoritma ini memanfaatkan metode probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi probabilitas di masa depan berdasarkan pengalaman di masa sebelumnya.
Sebuah keuntungan dari Naive Bayes classifier adalah bahwa ia
memerlukan sejumlah kecil data pelatihan untuk mengestimasi parameter (sarana dan varians dari variabel) yang diperlukan untuk klasifikasi. Karena variabel bebas diasumsikan, hanya varians dari variabel-variabel untuk setiap kebutuhan kelas yang akan ditentukan dan tidak seluruh matriks kovarians.
Dasar dari teorema naïve Bayes yang digunakan dalam pemrograman adalah rumus Bayes berikut ini:
P (A| B) =
Peluang kejadian A sebagai B ditentukan dari peluang B saat A, peluang A, dan peluang B.
Metode Naive Bayes Untuk Klasifikasi Teks
Pada Naïve Bayes Classifier, setiap dokumen berita direpresentasikan dalam pasangan atribut (a1, a2, …., an ), dimana a1
adalah kata pertama, a2 kata kedua dan seterusnya. Sedangkan V adalah himpunan kategori berita (olahraga, sains, edukasi dan sebagainya). Pada saat klasifikasi, pendekatan Bayes akan menghasilkan label kategori yang paling tinggi probabilitasnya (VMAP)
dengan masukan atribut (a1,a2, …. ,an).
VMAP = argmax P (Vj |a1, a2, ... , an) 1
Vj € V
Teorema Bayes menyatakan: P (B| A) =
2 P(a1,a2 … an) nilainya konstan untuk semua Vj sehingga persamaan ini dapat ditulis sebagai berikut :
VMAP = argmax P (Vj |a1, a2, ... , an | Vj ) P(Vj) 3
Vj € V
Tingkat kesulitan menghitung P(a1, a2 …. an | Vj) menjadi tinggi karena jumlah term P(a1, a2 …. an | Vj) bisa
jadi akan sangat besar. Ini disebabkan jumlah term tersebut sama dengan jumlah semua kombinasi posisi kata dikali dengan jumlah kategori. Naïve Bayes Classifier menyederhanakan hal ini dengan mengasumsikan bahwa di dalam setiap kategori, setiap kata independen satu sama lain. Dengan kata lain:
VMAP = argmax P (Vj) ∏i P(ai | Vj) 4
Vj € V
P(Vj) dan probabilitas kata Wk untuk
setiap kategori P(Wk | Vj ) dihitung pada saat pelatihan.
P ( Vj ) =
5
P (Wk | Vj ) =
6
di mana | docsj | adalah jumlah kata pada kategori j dan |Contoh| adalah jumlah dokumen yang digunakan dalam pelatihan. Sedangkan nk
adalah jumlah kemunculan kata Wk
pada kategori Vj , n adalah jumlah
semua kata pada kategori Vj dan
|kosakata| adalah jumlah kata yang unik (distinc) pada semua data latihan.
Ringkasan algoritma untuk Naïve Bayes Clasifier adalah sebagai berikut:
A. Proses pelatihan. Input adalah dokumen-dokumen contoh yang telah diketahui kategorinya. 1. Kosakata himpunan semua kata yang unik dari dokumen-dokumen contoh 2. Untuk setiap kategori Vj
lakukan: a. Docsj Himpunan dokumen-dokumen yang berada pada kategori Vj b. Hitung P(Vj) dengan persamaan 5
c. Untuk setiap kata Wk
pada kosakata lakukan: Hitung P(Wk | Vj)
dengan persamaan 6
B. Proses klasifikasi. Input adalah dokumen yang belum diketahui kategorinya:
Hasilkan Vmap sesuai
dengan persamaan 2.4 dengan menggunakan P(Vj) dan P(Wk | Vj) yang
telah diperoleh dari pelatihan.
HASIL DAN PEMBAHASAN Proses Klasifikasi
Judul : Waktu Berubah Buat LeBron dan Cleveland
(Olahraga)
MIAMI, Kompascom - Jika pada Februari tahun lalu, LeBron James membawa Cleveland Cavaliers meraih kemenangan ke 40, tahun ini ia melakukan hal sebaliknya. James yang kini bermain untuk Miami Heat membawa klubnya mengalahkan Cleveland Cavaliers 117-90 Ironisnya, ini merupakan kekalahan Cavs ke 40 pada musim ini.
Ini deret kekalahan ke 21 secara berturut-turut buat Cavs. Jumlah ini sama dengan jumlah kekalahan untuk musim 2009-2010 Saat itu James terpilih sebagai pemain terbaik NBA.
LeBron sendiri menolak berkomentar terlalu banyak tentang bekas klubnya, "Saya tidak ingin mengatakan apa pun tentang para
pemain," kata LeBron . "Saya hanya inginkan yang terbaik buat para pendukung klub . Bagaimana pun kami pernah bersama-sama selama beberapa tahun," kata LeBron. Dokumen (yang sudah di preprocessing) :
Judul : Waktu Berubah Buat LeBron dan Cleveland
miami kompas com jika februari lebron james cleveland cavaliers meraih kemenangan sebaliknya james bermain miami heat klubnya mengalahkan cleveland cavaliers ironisnya kekalahan cavs musim ini ini deret kekalahan berturut turut buat cavs jumlah kekalahan musim james terpilih pemain terbaik nba lebron menolak berkomentar bekas klubnya pemain lebron inginkan terbaik buat pendukung klub lebron dalam pertandingan lebron menyumbangkan poin
Kategori = Olahraga
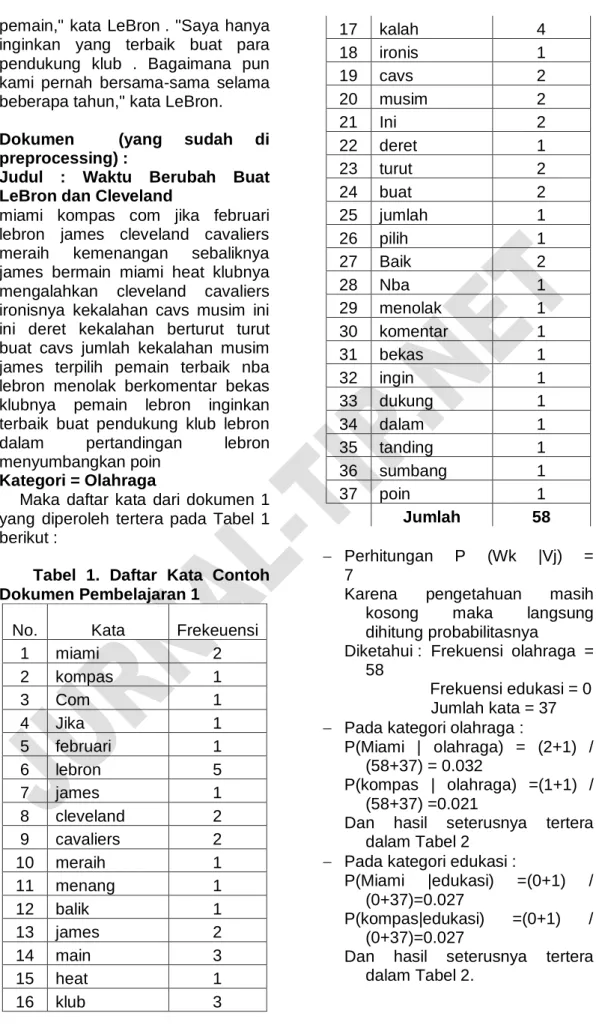
Maka daftar kata dari dokumen 1 yang diperoleh tertera pada Tabel 1 berikut :
Tabel 1. Daftar Kata Contoh Dokumen Pembelajaran 1
No. Kata Frekeuensi
1 miami 2 2 kompas 1 3 Com 1 4 Jika 1 5 februari 1 6 lebron 5 7 james 1 8 cleveland 2 9 cavaliers 2 10 meraih 1 11 menang 1 12 balik 1 13 james 2 14 main 3 15 heat 1 16 klub 3 17 kalah 4 18 ironis 1 19 cavs 2 20 musim 2 21 Ini 2 22 deret 1 23 turut 2 24 buat 2 25 jumlah 1 26 pilih 1 27 Baik 2 28 Nba 1 29 menolak 1 30 komentar 1 31 bekas 1 32 ingin 1 33 dukung 1 34 dalam 1 35 tanding 1 36 sumbang 1 37 poin 1 Jumlah 58 Perhitungan P (Wk |Vj) = 7
Karena pengetahuan masih kosong maka langsung dihitung probabilitasnya
Diketahui : Frekuensi olahraga = 58
Frekuensi edukasi = 0 Jumlah kata = 37 Pada kategori olahraga :
P(Miami | olahraga) = (2+1) / (58+37) = 0.032
P(kompas | olahraga) =(1+1) / (58+37) =0.021
Dan hasil seterusnya tertera dalam Tabel 2
Pada kategori edukasi :
P(Miami |edukasi) =(0+1) / (0+37)=0.027
P(kompas|edukasi) =(0+1) / (0+37)=0.027
Dan hasil seterusnya tertera dalam Tabel 2.
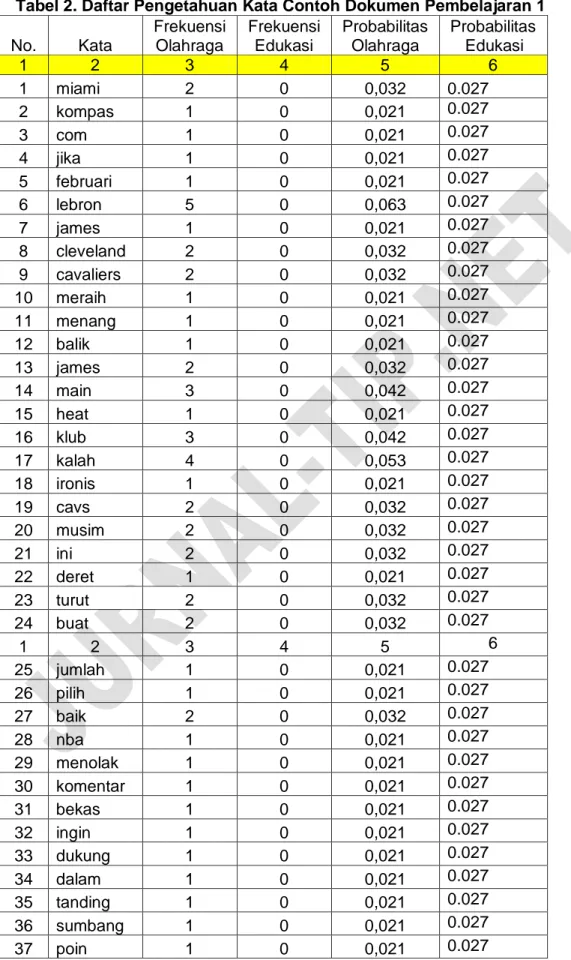
Pengetahuan kata pada dokumen 1 yang terbentuk terlihat pada
Tabel 2 berikut :
Tabel 2. Daftar Pengetahuan Kata Contoh Dokumen Pembelajaran 1
No. Kata Frekuensi Olahraga Frekuensi Edukasi Probabilitas Olahraga Probabilitas Edukasi 1 2 3 4 5 6 1 miami 2 0 0,032 0.027 2 kompas 1 0 0,021 0.027 3 com 1 0 0,021 0.027 4 jika 1 0 0,021 0.027 5 februari 1 0 0,021 0.027 6 lebron 5 0 0,063 0.027 7 james 1 0 0,021 0.027 8 cleveland 2 0 0,032 0.027 9 cavaliers 2 0 0,032 0.027 10 meraih 1 0 0,021 0.027 11 menang 1 0 0,021 0.027 12 balik 1 0 0,021 0.027 13 james 2 0 0,032 0.027 14 main 3 0 0,042 0.027 15 heat 1 0 0,021 0.027 16 klub 3 0 0,042 0.027 17 kalah 4 0 0,053 0.027 18 ironis 1 0 0,021 0.027 19 cavs 2 0 0,032 0.027 20 musim 2 0 0,032 0.027 21 ini 2 0 0,032 0.027 22 deret 1 0 0,021 0.027 23 turut 2 0 0,032 0.027 24 buat 2 0 0,032 0.027 1 2 3 4 5 6 25 jumlah 1 0 0,021 0.027 26 pilih 1 0 0,021 0.027 27 baik 2 0 0,032 0.027 28 nba 1 0 0,021 0.027 29 menolak 1 0 0,021 0.027 30 komentar 1 0 0,021 0.027 31 bekas 1 0 0,021 0.027 32 ingin 1 0 0,021 0.027 33 dukung 1 0 0,021 0.027 34 dalam 1 0 0,021 0.027 35 tanding 1 0 0,021 0.027 36 sumbang 1 0 0,021 0.027 37 poin 1 0 0,021 0.027
Perhitungan P (Vj) = 8 Diketahui: Jumlah dokumen
olahraga = 1 Jumlah dokumen edukasi = 0 P(olahraga) = 1/1 = 1 P(edukasi) = 0/1 = 0 KESIMPULAN
Klasifikasi merupakan salah satu teknik dalam data mining yang merupakan kegiatan penunjang dalam bidang sistem informasi. Dengan adanya proses klasifikasi ini, diharapkan dapat membantu mempermudah user dalam memilih dan mengkategorikan dokumen, sehingga meminimalkan waktu dan sumber daya manusia dalam pengklasifikasian dan pencarian dokumen teks itu sendiri.
Metoda Naïve Bayes classifier merupakan metoda klasifikasi yang berdasarkan kepada teorema bayes, sebuah teorema yang terkenal di dalam bidang ilmu probabilitas. Selain itu, metoda ini turut didukung oleh ilmu statistika khususnya dalam penggunaan data petunjuk untuk
mendukung keputusan
pengklasifikasian. Metoda ini sangat luas dipakai dalam berbagai bidang, khususnya dalam proses klasifikasi dokumen. Seperti halnya metoda-metoda lain, metoda-metoda Naïve Bayes classifier ini tidaklah 100% sempurna. Ada banyak kelebihan dan kekurangan dari metoda ini, yang dapat menjadi dasar bahan kajian lebih lanjut untuk mendapatkan atau mengembangkan metoda klasifikasi lain, yang dapat bekerja dengan lebih efektif dan efisien, serta mengurangi jumlah titik kelemahan yang dapat disalah gunakan oleh orang lain.
Berdasarkan hasil eksprimen, Naïve Bayes Classifier terbukti dapat digunakan secara efektif untuk mengklasifikasikan dokumen secara otomatis. Algoritma NBC yang sederhana dan kecepatannya yang
tinggi dalam proses pelatihan dan klasifikasi membuat algoritma ini menarik untuk digunakan sebagai salah satu metode klasifikasi.
DAFTAR PUSTAKA
[1] Even.Yahir dan Zohar. 2002. Introduction to Text Mining. Automated Learning Group National Center For Supercomputing Aplications. University of Illionis. http://algdocs.ncsa.uiuc.edu/ PR200211162.ppt. Diakses tanggal 1 Maret 2011.
[2] Harlian, Milka. 2006. Machine Learning Text Kategorization. Austin : University of Texas. [3] Santoso, Budi. 2007. Data
Mining Teknik Pemanfaatan data Untuk Keperluan Bisnis. Yogyakarta : Graha Ilmu
[4] Y. Wibisono. 2005. Klasifikasi Berita Berbahasa Indonesia Menggunakan Naïve Bayes Classifier. Internal Publication, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Pendidikan Indonesia, Bandung, Jawa Barat.