195 PREDIKSI TINGKAT INFLASI DI INDONESIA BERBASIS JARINGAN SYARAF TIRUAN DAN
ALGORITMA GENETIKA
Rita Rismala1, Said Al Faraby2
1,2Prodi S1 Informatika, Fakultas Informatika, Universitas Telkom
1[email protected], 2[email protected]
Abstrak
Inflasi menjadi indikator yang sangat penting dalam menganalisis perekonomian negara. Oleh karena itu prediksi terhadap nilai inflasi menjadi penting agar dapat membantu pemerintah dalam mengambil kebijakan untuk menjaga stabilitas moneter dan perekonomian. Pada penelitian ini dilakukan prediksi tingkat inflasi di Indonesia dengan tidak hanya mempertimbangkan data historis inflasi, namun juga mempertimbangkan faktor-faktor lain yang mempengaruh tingkati inflasi di Indonesia. Prediksi dilakukan menggunakan Jaringan Syaraf Tiruan dengan menggunakan algoritma pembelajaran berbasis Algoritma Genetika. Hasil pengujian menunjukkan bahwa akurasi sistem dalam memprediksi nilai tingkat inflasi belum cukup baik. Namun dalam memprediksi kelas inflasi, sistem ini sudah cukup baik terutama dalam mengidentifikasi inflasi dengan kelas rendah.
Kata kunci : inflasi, prediksi, jaringan syaraf tiruan, algoritma genetika
Pendahuluan
Inflasi dapat menjadi indikator dalam menggambarkan kecenderungan umum tentang perkembangan harga. Indikator tersebut dapat dipakai sebagai informasi dasar untuk pengambilan keputusan baik tingkat ekonomi mikro atau makro, baik fiskal maupun moneter. Dalam lingkup yang lebih luas (makro) angka inflasi menggambarkan kondisi/ stabilitas moneter dan perekonomian [1]. Sehingga inflasi menjadi indikator yang sangat penting dalam menganalisis perekonomian negara [2]. Dikarenakan pentingnya hal tersebut, maka prediksi terhadap nilai inflasi menjadi penting agar dapat membantu pemerintah dalam mengambil kebijakan untuk menjaga stabilitas moneter dan perekonomian.
Pada penelitian sebelumnya telah dibangun sistem prediksi tingkat inflasi bulanan di Indonesia secara time series dengan menggunakan data historis inflasi dengan hasil yang cukup bagus [3]. Pada penelitian ini dilakukan pengembangan untuk melakukan prediksi dengan tidak hanya mempertimbangkan data historis inflasi, namun juga mempertimbangkan faktor-faktor ekonomi lain yang mempengaruh tingkati inflasi di Indonesia. Adapun faktor-faktor ekonomi yang mempengaruhi tingkat inflasi di Indonesia terdiri dari faktor domestik dan faktor eksternal. Faktor domestik terdiri dari jumlah uang yang beredar, tingkat suku bunga, dan produk domestik bruto; sedangkan faktor eksternal terdiri dari nilai tukar rupiah terhadap mata uang asing dan tingkat inflasi luar negeri [2][4]. Faktor lain yang turut menyebabkan inflasi adalah jumlah hutang luar negeri dan jumlah impor barang [5].
JST banyak digunakan untuk melakukan prediksi atau peramalan dan dapat digunakan untuk menyelesaikan permasalahan prediksi yang melibatkan banyak variabel yang saling berkorelasi (multivariate). Diantara algoritma pembelajaran yang umum digunakan adalah algoritma back-propagation. Namun kekurangan dari algoritma ini adalah koreksi bobot yang terbatas pada ruang pencarian metode steepest descent sehingga kurang mampu untuk mengeksplorasi ruang pencarian yang dapat menyebabkan terjadinya solusi yang lebih buruk atau konvergensi prematur [8]. Karena kekurangan tersebut, beberapa studi merekomendasikan GA untuk menggantikan algoritma pembelajaran umum dalam JST. Keuntungan dari penggunaan GA adalah tersedianya banyak solusi pada satu waktu sehingga dari sekumpulan solusi tersebut dapat dipilih satu solusi yang terbaik [8][9]. Sebuah studi menunjukkan bahwa ketersediaan banyak solusi memberikan performansi pembelajaran yang lebih superior dibandingkan dengan hanya tersedia satu solusi. [7]
Berdasarkan latar belakang di atas, maka pada penelitian ini dilakukan prediksi tingkat inflasi di Indonesia berdasarkan faktor-faktor ekonomi yang mempengaruhi tingkat inflasi serta melakukan analisis performansi terhadap sistem prediksi tersebut.
Material dan Metodologi Data
Data yang digunakan sebagai input untuk sistem ini adalah jumlah uang yang beredar (M1), jumlah uang yang beredar (M2), tingkat suku bunga simpanan, tingkat suku bunga pinjaman, pertumbuhan produk domestik bruto, nilai tukar rupiah terhadap mata uang asing (diwakili oleh US Dollar), tingkat inflasi luar negeri (diwakili oleh Amerika Serikat), jumlah hutang luar negeri , jumlah impor barang, dan jumlah ekspor
barang, sedangkan outputnya adalah tingkat inflasi tahunan Indonesia. Banyaknya data yang digunakan adalah 25 data (1986 – 2010) yang diambil dari http://data.worldbank.org/.
Metodologi
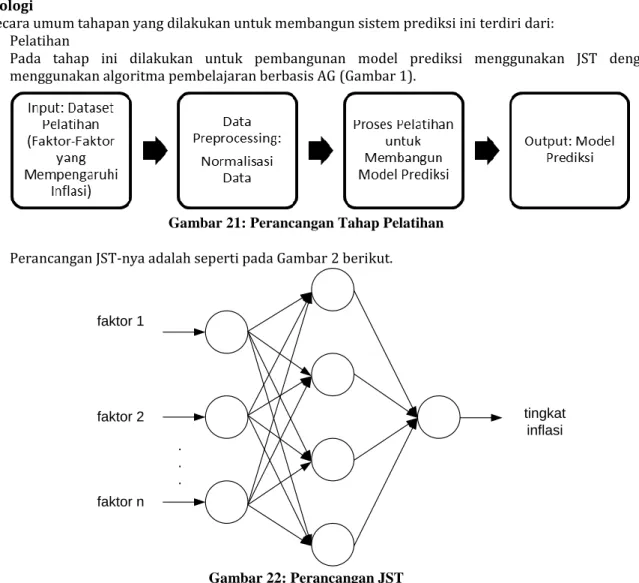
Secara umum tahapan yang dilakukan untuk membangun sistem prediksi ini terdiri dari: a. Pelatihan
Pada tahap ini dilakukan untuk pembangunan model prediksi menggunakan JST dengan menggunakan algoritma pembelajaran berbasis AG (Gambar 1).
Gambar 21: Perancangan Tahap Pelatihan
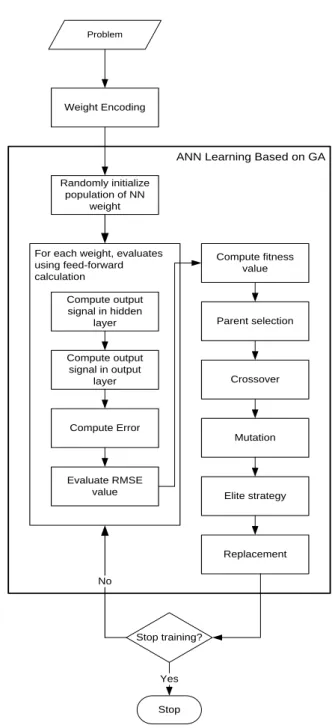
Perancangan JST-nya adalah seperti pada Gambar 2 berikut.
faktor 1 faktor 2 faktor n tingkat inflasi . . . Gambar 22: Perancangan JST
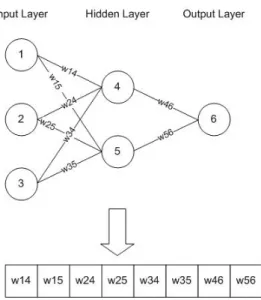
Sedangkan perancangan dari algoritma pembelajaran JST berbasis AG adalah seperti pada Gambar 3. Berikut adalah penjelasannya.
1) Weight Encoding
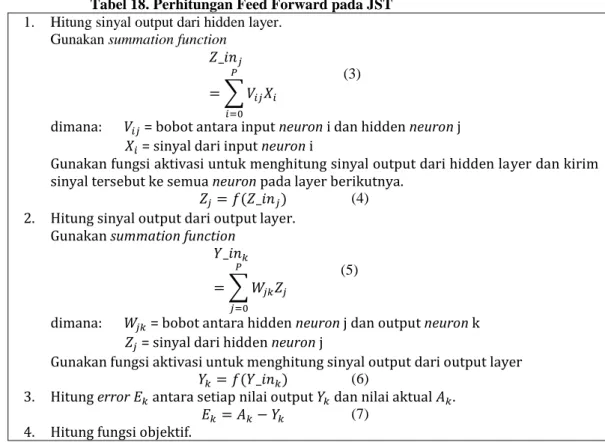
Setiap gen merepresentasikan bobot antar neuron dalam layer yang berbeda, seperti dapat dilihat pada Gambar 4. Kromosom dibangun dari sekumpulan gen dengan representasi real.
197
Stop Problem Randomly initialize population of NN weight Compute output signal in hidden layer Compute output signal in output layer Compute Error Evaluate RMSE value For each weight, evaluates using feed-forward calculation Parent selection Mutation Elite strategy Replacement Stop training? Crossover Compute fitness value NoANN Learning Based on GA
Yes Weight Encoding
Gambar 24. Weight Encoding
2) fungsi objektif
Karena tujuan dari pelatihan ini adalah untuk meminimalkan error, maka Root Mean Square Error (RMSE) digunakan sebagai fungsi objektif, persamaan (1).
√∑ (1)
dimana: =Nilai aktual = Nilai prediksi = Jumlah data 3) Fungsi fitnes
Konsep dari fitness adalah ‘the Larger the better’, sehingga nilai fitness dihitung dengan menggunakan persamaan (2).
(2)
4) ANN learning based on GA
a) Weight population initialization
Membangkitkan sejumlah kromosom bobot secara acak dalam range nilai [-1..1] sebagai populasi pertama.
b) Weight evaluation
Evaluasi dengan menggunakan perhitungan feed forward (Tabel 1). Dalam sistem ini, fungsi aktivasi sigmoid digunakan untuk menentukan sinyal output dari hidden layer dan output layer. Hitung error menggunakan RMSE.
199
Tabel 18. Perhitungan Feed Forward pada JST1. Hitung sinyal output dari hidden layer. Gunakan summation function
∑
(3)
dimana: = bobot antara input neuron i dan hidden neuron j
= sinyal dari input neuron i
Gunakan fungsi aktivasi untuk menghitung sinyal output dari hidden layer dan kirim sinyal tersebut ke semua neuron pada layer berikutnya.
(4) 2. Hitung sinyal output dari output layer.
Gunakan summation function ∑
(5)
dimana: = bobot antara hidden neuron j dan output neuron k
= sinyal dari hidden neuron j
Gunakan fungsi aktivasi untuk menghitung sinyal output dari output layer (6)
3. Hitung error antara setiap nilai output dan nilai aktual .
(7)
4. Hitung fungsi objektif. c) Compute fitness value
Hitung fungsi fitness menggunakan persamaan (2). d) Parent selection
Parent selection dilakukan menggunakan metode Roulette Wheel dengan Linear Fitness Ranking.
e) Crossover
Crossover dilakukan dengan menggunakan metode two-point crossover.
f) Mutation
Mutasi dilakukan dengan menggunakan creep mutation. g) Elite strategy
10% solusi terbaik dipertahankan untuk menjaga kualitas dari setiap generasi. h) Replacement
Populasi baru menggantikan populasi lama.
i) Stopping criteria
Pembelajaran JST dihentikan apabila
i. jumlah generasi sudah mencapai maksimum generasi, atau ii. fitness telah mencapai nilai maksimum, yaitu 10, atau iii. generalization lost (GL) dibawah -0.1
GL mengindikasikan penurunan relatif dari rata-rata nilai fitness. 𝑟
𝑟 𝑟 (8) dimana: = generasi
(9)
dimana: = maksimum nilai fitness latih pada generasi g = maksimum nilai fitness validasi pada generasi g = jumlah data latih
= jumlah data validasi b. Proses Pengujian
Proses ini dilakukan untuk menguji performansi dari model prediksi yang dihasilkan dari tahap pelatihan. Ukuran performansi yang digunakan adalah berupa akurasi yang diukur dalam MAPE.
𝑃 ( ∑ | |) (10) dimana = data aktual and = data prediksi.
3. Pembahasan 3.1. Skenario Data
Komposisi data yang digunakan untuk pelatihan: validasi: pengujian adalah 15: 5: 5. 3.2. Pelatihan
Untuk mendapatkan model prediksi yang paling optimal, dilakukan pelatihan dengan melibatkan beberapa skenario parameter.
a. Parameter JST
1) Jumlah hidden layer = 1
2) Jumlah neuron pada hidden layer = 1 – 16 b. Parameter AG
1) Ukuran populasi = 100
2) Maksimum generasi yang dievaluasi = 1000 3) Probabilitas crossover Pc = 0.6 dan 0.8 4) Probabilitas mutasi Pm = 0.01 dan 0.1
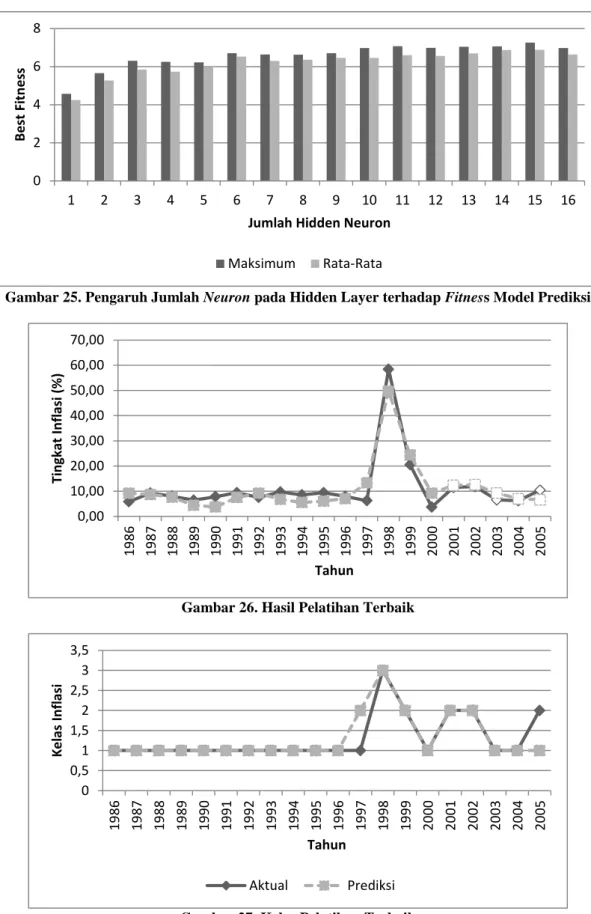
Dari hasil pengujian dengan menggunakan berbagai kombinasi parameter, didapatkan bahwa parameter yang paling berpengaruh terhadap model prediksi yang dihasilkan adalah jumlah layer pada hidden neuron seperti dapat dilihat pada Gambar 5. Untuk menentukan banyaknya neuron pada hidden layer memang merupakan hal yang sulit. Jumlah neuron yang semakin banyak tidak serta merta meningkatkan performansi sistem, namun jumlah neuron yang terlalu sedikit (1 – 2) juga kurang bagus karena dapat menghasilkan model dengan performansi yang buruk. Berdasarkan hasil tersebut jumlah neuron pada hidden layer dapat dibagi menjadi tiga kelompok, yaitu:
1. Kelompok 1: 1 – 2 neuron 2. Kelompok 2: 3 – 5 neuron 3. Kelompok 3: 6 – 16 neuron
Dari tiga kelompok ini, model yang paling baik dihasilkan saat digunakan jumlah layer pada kelompok 3. Hal ini terbukti dari rata-rata dan maksimum best fitness yang dihasilkan.
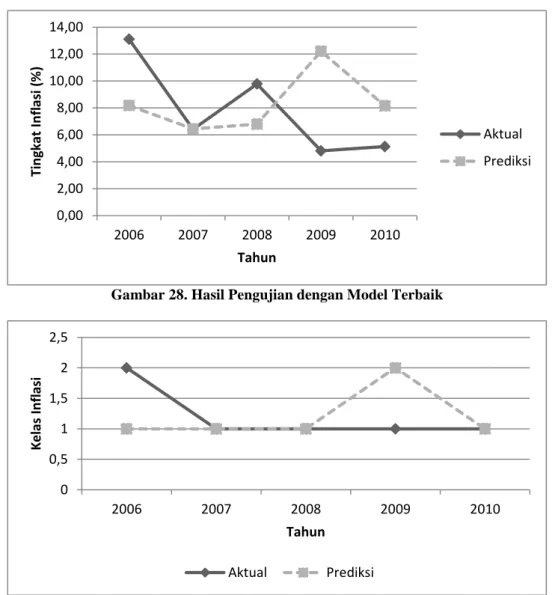
Dari hasil pelatihan, model prediksi terbaik didapatkan pada saat sistem dilatih dengan menggunakan kombinasi parameter jumlah neuron pada hidden layer = 15, Pc = 0.8, dan Pm = 0.01. Berdasarkan Gambar 9, terlihat bahwa pada saat proses pelatihan sistem mampu untuk mengadaptasi pola data latih dan validasi, bahkan untuk kasus data ekstrim pada tahun 1998 sistem mampu mendapatkan hasil prediksi yang mendekati data aktual. Apabila dipetakan dalam bentuk kelas (Gambar 10), terlihat bahwa sistem mampu menghasilkan akurasi yang bagus, yaitu 90%, serta sistem mampu untuk memprediksi inflasi berat pada tahun 1998 dengan tepat.
3.3. Pengujian
Model terbaik yang dihasilkan dari proses pelatihan kemudian diujikan dengan menggunakan dataset uji untuk mengetahui performansi dari sistem. MAPE yang dihasilkan dari proses pengujian adalah 56.24%. Penyebab tingginya nilai MAPE ini adalah melesetnya prediksi inflasi pada tahun 2006 dan 2009. Apabila dilihat dari sisi prediksi kelas inflasi, akurasi yang didapatkan adalah 60% dimana sistem dapat mengidentifikasi 75% kelas rendah (1) dengan tepat namun kurang tepat dalam mengidentifikasi kelas sedang (2). Hal ini bisa jadi disebabkan oleh ketersediaan data yang sangat sedikit dan ketidakseimbangan sebaran data inflasi dimana data inflasi dengan kelas rendah jumlahnya jauh lebih banyak daripada kelas yang lain. Sehingga sistem akan lebih cenderung menghasilkan model yang bagus untuk memprediksi inflasi dengan kelas rendah (tingkat inflasi di bawah 10%). Secara keseluruhan dari
201
Gambar 25. Pengaruh Jumlah Neuron pada Hidden Layer terhadap Fitness Model PrediksiGambar 26. Hasil Pelatihan Terbaik
Gambar 27. Kelas Pelatihan Terbaik 0 2 4 6 8 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 B e st Fi tn e ss
Jumlah Hidden Neuron Maksimum Rata-Rata 0,00 10,00 20,00 30,00 40,00 50,00 60,00 70,00 19 86 19 87 19 88 19 89 19 90 19 91 19 92 19 93 19 94 19 95 19 96 19 97 19 98 19 99 20 00 20 01 20 02 20 03 20 04 20 05 Ti n gkat In fl asi (% ) Tahun 0 0,5 1 1,5 2 2,5 3 3,5 19 86 19 87 19 88 19 89 19 90 19 91 19 92 19 93 19 94 19 95 19 96 19 97 19 98 19 99 20 00 20 01 20 02 20 03 20 04 20 05 K e las In fl asi Tahun Aktual Prediksi
Gambar 28. Hasil Pengujian dengan Model Terbaik
Gambar 29. Klasifikasi Hasil Pengujian dengan Model Terbaik
18. Kesimpulan
Dari penelitian ini dapat disimpulkan beberapa hal:
a. Parameter yang paling berpengaruh terhadap model prediksi yang dihasilkan adalah jumlah neuron pada hidden layer. Dalam kasus ini, jumlah neuron yang menghasilkan model paling baik adalah jumlah neuron dari kelas 3 yaitu 6 – 16 neuron.
b. Dari sisi akurasi prediksi nilai tingkat inflasi, sistem ini belum cukup baik dimana MAPE yang dihasilkan masih sangat tinggi yaitu 39.45%. Namun dari segi akurasi dalam memprediksi kelas inflasi, sistem ini sudah cukup baik dimana akurasi keseluruhan yang dihasilkan adalah 84%. Saran untuk pengembangan lebih lanjut:
a. Menggunakan data dengan jumlah yang lebih banyak dan dalam unit yang berbeda misal bulanan atau tiga bulanan.
b. Mempertimbangkan faktor-faktor lain selain faktor ekonomi. Daftar Pustaka:
[1] Badan Pusat Statistik. 2011. Data Strategis BPS. Jakarta: Badan Pusat Statistik.
[2] Endri. 2008. Analisis Faktor-Faktor yang Mempengaruhi Inflasi di Indonesia. Jurnal Ekonomi Pemban gunan Vol. 13 No. 1, April 2008 Hal: 1-13.
[3] Rismala, Rita; Suyanto; Retno Novi Dayawati. 2011. Prediksi Data Time Series Tingkat Inflasi di 0,00 2,00 4,00 6,00 8,00 10,00 12,00 14,00 2006 2007 2008 2009 2010 Ti n gkat In fl asi (% ) Tahun Aktual Prediksi 0 0,5 1 1,5 2 2,5 2006 2007 2008 2009 2010 K e las In fl asi Tahun Aktual Prediksi
203
[4] Sasana, Hadi. 2004. Analisis Faktor-Faktor yang Mempengaruhi Inflasi diIndonesia dan Filipina(Pendekatan Error Correction Model), Jurnal Bisnis dan Ekonomi. September 2004.
[5] Atmadja, Adwin S. 1999. Inflasi di Indonesia: Sumber-Sumber Penyebab dan Pengendaliannya. Jurnal Akuntansi dan Keuangan Vol. 1, No. 1, Mei 1999 : 54-67.
[6] Singh, Yashpal; Alok Singh Chauhan. 2005. Neural Networks in Data mining. Journal of Theoretical and Applied Information Technology: 2005 – 2009.
[7] Bullinaria, John A. Evolving Neural Networks: Is it Really Worth the Effort?
[8] Chang , Pei-Chann., Wang, Yen-Wen., Tsai , Chi-Yang. 2005. Evolving neural network for printed circuit board sales forecasting. Expert Systems with Applications 29, 83–92.
[9] Floreano, Dario., Durr, Peter., Mattiussi, Claudio. 2008. Neuroevolution: from architectures to learning. Evol. Intel. (2008) 1:47–62.