III-1
Bab ini menjelaskan mengenai analisis dan proses perancangan. Bagian analisis meliputi deskripsi umum sistem yang dibangun, spesifikasi kebutuhan perangkat lunak, data flow diagram, pemilihan struktur data yang digunakan dan pemilihan algoritma.
3.1 Analisis Perangkat Lunak
Deskripsi perangkat lunak yang dibangun, spesifikasi kebutuhan dan struktur data serta algoritma yang digunakan dijelaskan pada sub bab berikut.
3.1.1 Deskripsi Umum Sistem
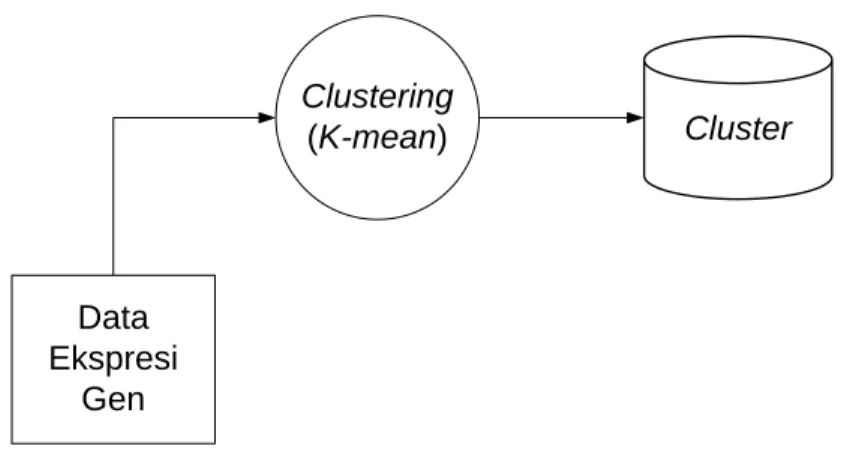
Clustering (K-mean) Data Ekspresi Gen Cluster
Gambar III-1 Gambaran Umum Perangkat Lunak
Gambaran umum sistem dapat dilihat pada gambar III-1. Aplikasi yang dibangun merupakan perangkat lunak sederhana yang menerima masukan berupa data ekspresi gen yang bersesuaian dan mengeluarkan keluaran berupa cluster.
Data ekspresi gen yang menjadi masukan merupakan file teks dengan nilai-nilai yang dipisahkan dengan karakter tab (tab delimited text file). Dengan menggunakan algoritma yang telah dipilih (dijelaskan kemudian), aplikasi menghasilkan keluaran berupa daftar cluster yang terbentuk, anggota-anggota dari cluster tersebut, serta kualitas dari cluster yang telah dihasilkan.
Berdasarkan data ekspresi gen yang banyak dipakai dan dipublikasikan, data tersebut tidak memiliki kelas (informasi tambahan) untuk analisis supervised. Selain itu, data ekspresi gen yang dipublikasikan juga tidak dapat diberikan atau diprediksi labelnya. Objek-objek pada data ekspresi gen pada umumnya berkelompok menjadi cluster secara alami sesuai dengan peran objek tersebut pada sel. Oleh karena itu, analisis yang paling ideal untuk dilakukan adalah analisis unsupervised, dalam hal ini adalah pengelompokan (clustering) dari data ekspresi gen yang diberikan. Dengan pemusatan kebutuhan perangkat lunak pada pengelompokan data ekspresi gen, maka perlu ditentukan algoritma yang sesuai dan metode perhitungan jarak.
Metode perhitungan jarak yang dipakai adalah metode Euclidean, karena metode ini merupakan metode yang umum digunakan untuk menghitung jarak, dan terjamin keabsahannya. Selain itu, metode Euclidean cepat dan sederhana [HOO04], hal ini sangat penting jika kompleksitas waktu akibat data yang begitu besar menjadi pertimbangan.
Algoritma yang dipakai untuk pembentukan cluster adalah K-means, hal ini dikarenakan algoritma ini sangat sederhana, dan memiliki kompleksitas yang cukup rendah, yaitu berbanding lanjar dengan jumlah data (N). Sementara kompleksitas waktu dapat diperkirakan sebesar cN, dimana c adalah jumlah cluster yang diberikan. Dengan ini algoritma ini memiliki kompleksitas komputasi yang rendah dan sangat cepat dibandingkan dengan algoritma lain yang memiliki kompleksitas lebih besar [HOO04].
3.1.2 Spesifikasi Kebutuhan Perangkat Lunak
Berdasarkan tujuan dan rumusan masalah pada bab sebelumnya, maka spesifikasi perangkat lunak yang perlu dibangun yaitu:
• Perangkat lunak mampu melakukan clustering data baik menurut gen (baris) maupun sampel (kolom).
• Perangkat lunak menerima masukan berupa jumlah cluster (K) yang ingin dihasilkan.
• Perangkat lunak mampu menangani hingga ribuan data.
3.1.3 Analisis Masukan
Masukan utama perangkat lunak adalah:
1. File data ekspresi gen yang berformat tab delimited text file. Dijelaskan kemudian.
2. Jumlah cluster yang diinginkan.
3. Jenis clustering yang diinginkan, apakah mencari cluster pada gen (baris) atau sampel (kolom).
Tabel III-1 Format File Masukan
<nama_sampel_1> … <nama_sampel_n>
<gen_1> <nama_gen_1> <ekspresi_gen_1_dan_sampel_1> … <ekspresi_gen_1_dan_sampel_n>
… … … … …
<gen_n> <nama_gen_n> <ekspresi_gen_n_dan_sampel_1> … <ekspresi_gen_n_dan_sampel_n>
File data ekspresi gen harus memiliki format sebagai berikut: baris pertama diisi dengan nama sampel yang bersesuaian, sementara kolom pertama diisi dengan gen yang bersesuaian. Kolom kedua diisi dengan nama lengkap gen yang bersesuaian, data ini diperlukan untuk memudahkan membaca hasil, karena yang ditampilkan nama lengkap gen. Untuk sisanya, yaitu baris kedua dan seterusnya dan kolom ketiga da seterusnya diisi dengan tingkat ekspresi gen dari gen dan sampel yang bersesuaian. Masing-masing objek pada file dipisahkan dengan karakter tab. Jika digambarkan, file berisi data ekspresi gen dapat dilihat pada tabel III-1, sedangkan contoh nyata cuplikan data ekspresi gen masukan dapat dilihat pada gambar III-2.
3.1.4 Analisis Keluaran
Perangkat lunak menghasilkan keluaran berupa:
1. sejumlah cluster yang diinginkan dan anggota-anggota dari cluster tersebut. 2. kualitas dari cluster yang dihasilkan yang diukur dari:.
• perbandingan diameter cluster dengan jarak antar cluster
• jarak dari masing-masing anggota cluster terhadap titik tengah cluster • diameter dari cluster terkecil
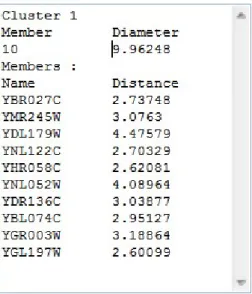
Dari cluster yang dihasilkan, dapat diambil kesimpulan antara lain, objek-objek (gen atau sampel) yang tergabung dalam satu cluster mungkin memiliki kedekatan yang berarti. Jika objek tersebut adalah gen, maka ada kemungkinan gen-gen yang berada pada satu cluster memiliki fungsi yang sama dalam regulasi sel, misalnya gen-gen yang saling berkaitan dalam membentuk ciri fisik. Jika objek merupaka sampel, maka sampel-sampel yang berada pada satu cluster mungkin memiliki sifat yang sama, misalnya seorang sampel pasien ternyata berada pada satu cluster dengan penderita jantung koroner, maka kemungkinan pasien tersebut juga berpenyakit jantung koroner. Contoh cuplikan keluaran aplikasi dapat dilihat pada gambar III-3. Pada gambar tersebut mamperlihatkan 1 cluster dengan 10 anggotanya.
Gambar III-3 Contoh keluaran aplikasi
Dari keluaran perangkat lunak berupa cluster, jika kualitas cluster mencukupi maka data keluaran tersebut dapat dijadikan acuan untuk penelitian lain seperti, mencari
kemungkinan penyebab tumor lain sejenis atau melihat kemungkinan variasi tumor dengan mencari sampel anggota cluster yang berada di cluster yang sama dengan sampel penderita tumor.
3.2 Analisis Algoritma dan Struktur Data
Pada bagian ini dijelaskan algoritma dan struktur data yang dipakai pada perangkat lunak, serta alasan mengapa bentuk tersebut yang dipilih.
3.2.1 K-means
Algoritma K-means dapat dilihat pada algoritma II-1 [HOO04]. Algoritma ini dipilih karena memiliki kompleksitas yang rendah. Kompleksitas waktunya dapat didekati dengan cN dimana c adalah jumlah cluster yang diinginkan dan N adalah jumlah data ekspresi gen yang diberikan. Dibandingkan dengan algoritma lain, yaitu hierarchical dan self-organizing map, algoritma ini jauh lebih sederhana, sehingga kompleksitas komputasinya pun cukup rendah [HOO04]. Hal lain yang menonjol dari algoritma ini dibandingkan algoritma lain adalah kecepatannya. Namun, algoritma ini juga memiliki kelemahan yaitu:
1. jumlah cluster harus ditentukan terlebih dahulu
2. penentuan cluster awal secara acak dapat menyebabkan hasil yang berbeda 3. sebuah cluster kadang tercipta tanpa memiliki kedekatan, hal ini disebabkan
algoritma akan selalu menghasilkan k buah cluster
Meskipun memiliki kelemahan seperti disebut di atas, algoritma ini tetap menjadi pilihan yang paling sesuai untuk pengelompokan data ekspresi gen, dalam hal ini analisis unsupervised. Hal ini dikarenakan kesederhanaan algoritma yang menyebabkan rendahnya kompleksitas waktu dan komputasi. Hal ini efektif untuk data yang cukup besar.
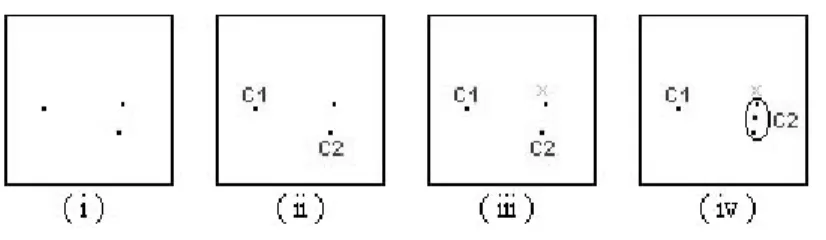
Contoh sederhana penggunaan algoritma K-means dapat dilihat pada gambar III-4. Terdapat 3 titik yang akan dijadikan 2 cluster (i). Secara acak dipilih 2 titik sebagai titik tengah cluster yang disebut C1 dan C2 (ii). Kemudian titik ketiga dihitung
jaraknya terhadap titik tengah kedua cluster. Diambil jarak yang terdekat yaitu terhadap C2 (iii). Titik tengah cluster kemudian dihitung ulang (iv). Hal tersebut dilakukan sampai tidak ada titik yang berpindah cluster.
Gambar III-4 Contoh algoritma K-means
Setelah membahas algoritma, perlu ditentukan metode penghitungan jarak yang sesuai. Metode penghitungan yang biasa dipakai adalah metode penghitungan jarak Euclidean, dengan kompleksitas yang sederhana, metode ini terjamin keabsahannya untuk data ekspresi gen. Jarak Euclidean dihitung dengan akar kuadrat dari jumlah seluruh kuadrat selisih dari dua buah titik pada ruang dimensi n. Dengan bentuk yang sederhana metode ini digunakan dalam perangkat lunak yang dibangun. Meskipun secara teori, tidak ada metode penghitungan jarak yang benar – benar valid [BRA00].
3.2.2 Struktur Data
Karena data yang dikelola sangat besar, sebagai contoh, data ekspresi gen dari [EIS05] yang mencapai kira – kira 6000 gen dan 80 sampel, maka diperlukan sebuah struktur data yang dapat mengelola data tersebut meskipun dengan resource yang minimal. Untuk menghemat pemakaian memori komputer, terutama RAM, maka data ekspresi gen tidak disimpan pada RAM, data tetap berada pada arsipnya tanpa diubah sedikitpun. Data yang perlu disimpan di RAM beserta jenis tipenya antara lain:
1. data cluster, mencakup: • ID cluster, berupa integer
• Titik tengah cluster, berupa tipe bentukan titik, terdiri dari dua buah angka real
• Diameter cluster (dihitung kemudian), berupa angka real • List anggota cluster, berupa pointer ke anggota pertama
• jarak antar cluster, berupa real
• jarak masing-masing anggota cluster terhadap titik tengah cluster, berupa real
Untuk menghemat memori, maka list anggota cluster diimplementasikan dengan pointer berupa list of objek biasa.
3.3 Perancangan Antarmuka Perangkat Lunak
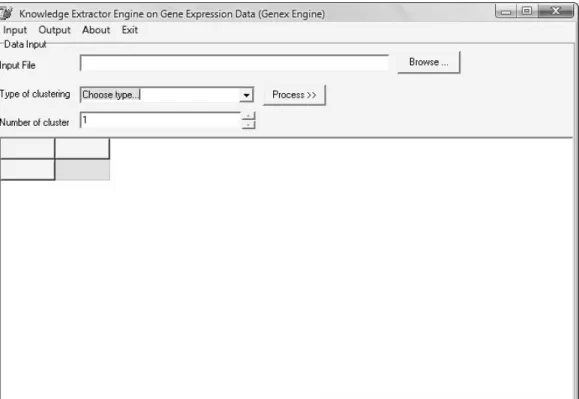
Gambar III-5 Rancangan antarmuka input
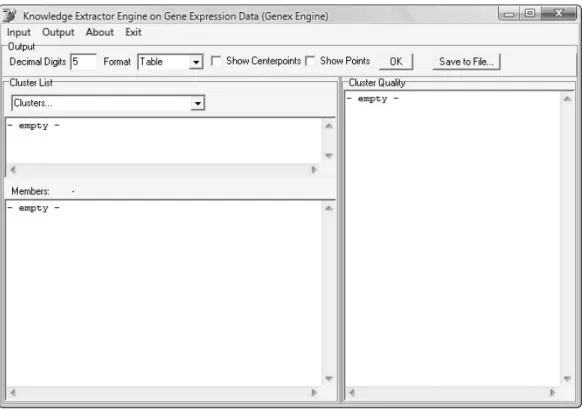
Perangkat lunak dibuat dengan tampilan yang sederhana. Implementasi perangkat lunak lebih menitikberatkan pada penanganan data ekspresi gen yang sangat besar. Rancangan antarmuka perangkat lunak dapat dilihat pada gambar III-5 dan gambar III-6. Terdapat dua tampilan utama perangkat lunak yaitu untuk data masukan dan keluaran. Pada antarmuka masukan dapat dipilih file data yang diinginkan dan pilihan lainnya untuk algoritma K-means, yaitu tipe clustering dan jumlah cluster yang diinginkan.
Gambar III-6 Rancangan antarmuka output
Pada antarmuka keluaran ditampilkan cluster – cluster yang dihasilkan dan kualitas dari cluster tersebut.