BAB 2
LANDASAN TEORI
2.1 Kompr esi
2.1.1 Sejarah kompresi
Kompresi data merupakan cabang ilmu komputer yang bersumber dari Teori Informasi. Teori Informasi sendiri adalah salah satu cabang Matematika yang berkembang sekitar akhir dekade 1940-an. Tokoh utama dari teori informasi adalah Claude Shannon dari Bell Laboratory. Teori Informasi memfokuskan pada berbagai metode tentang informasi termasuk penyimpanan dan pemrosesan pesan. Teori informasi mempelajari pula tentang redundancy (informasi tak berguna) pada pesan. Semakin banyak redundancy semakin besar pula ukuran pesan, upaya mengurangi redundancy inilah yang akhirnya melahirkan subyek ilmu tentang kompresi data.
Teori Informasi menggunakan terminologi entropi sebagai pengukur berapa banyak informasi yang dapat diambil dari sebuah pesan. Kata “entropi” berasal dari ilmu termodinamika. Semakin tinggi entropi dari sebuah pesan semakin banyak informasi yang terdapat di dalamnya (Widhiartha, 2008).
2.1.2 Definisi kompresi
beberapa literatur, istilah kompresi sering disebut juga source coding, data compression, bandwidth compression, dan signal compression” (Putra, 2009).
Beberapa defenisi kompresi yaitu, kompresi adalah proses pengolahan sekumpulan data menjadi suatu bentuk untuk menghemat kebutuhan tempat penyimpanan data waktu untuk transmisi data (Utami, 2013). Sedangkan menurut Sukiman dan Chandra (2013) kompresi data atau juga dikenal sebagai pemadatan data adalah teknik yang dipakai untuk mengurangi data atau memperkecil data menjadi bentuk data lain dimana data tersebut diubah menjadi simbol yang lebih sederhana. Kompresi data dilakukan untuk mereduksi ukuran data atau file.
Dari beberapa defenisi diatas dapat disimpulkan bahwa kompresi dapat digunakan untuk meminimalisasi ukuran dari data yang akan disimpan sehingga menghemat ukuran penyimpanan. Data yang telah dikompresi akan mengalami penyusutan ukuran tanpa mempengaruhi informasi yang ada didalamnya.
Data dan informasi adalah dua hal yang berbeda. Pada data terkandung suatu informasi. Namun tidak semua bagian data terkait dengan informasi tersebut atau pada suatu data terdapat bagian-bagian data yang berulang untuk mewakili informasi yang sama. Bagian data yang tidak terkait atau bagian data yangg berulang tersebut disebut dengan data yang berlebihan (redundancy data) (Putra, 2009).
2.1.3 Tujuan kompresi
2.1.4 Metode Kompresi
Berdasarkan teknik pengkodean / pengubahan simbol yang digunakan, metode kompresi dapat dibagi kedalam tiga kategori, yaitu:
1. Metode Symbolwise : menghitung peluang kemunculan dari tiap simbol dalam file input, lalu mengkodekan satu simbol dalam satu waktu, dimana simbol yang lebih sering muncul diberi kode lebih pendek dibandingkan simbol yang lebih jarang muncul. Contoh algoritma Huffman.
2. Metode Dictionary : Menggantikan karakter/fragmen dalam file input dengan indeks lokasi dari karakter/fragmen tersebut dalam sebuah kamus (dictionary), contoh algoritma LZW.
3. Metode Predictive : Menggunakan model finite-context atau finite state untuk memprediksi distribusi probabilitas dari simbol-simbol selanjutnya, contoh : algoritma DMC (Utami, 2013).
2.2 Dekompresi
2.2.1. Pengertian dekompresi
Menurut Sukiman dan Chandra (2013), Proses dekompresi secara harfiah merupakan proses yang dilakukan bila data hasil kompresi ingin dikembalikan ke ukuran dan bentuknya semula.
2.2.2. Tujuan dekompresi
Tujuan dari dekompresi data yaitu mengembalikan data yang telah dikompresi ke bentuk semula, karena data yang telah dikompresi tidak dapat dibaca begitu saja tanpa dikembalikan kebentuk semula.
2.3 Rasio Kompr esi
2.3.1. Pengertian rasio kompresi
Menurut Sayood (2006), rasio kompresi adalah perbandingan antara jumlah bit yang diperlukan untuk merepresentasikan data sebelum dikompresi dengan jumlah bit yang diperlukan untuk merepresentasikan data setelah dikompresi.
“Compression rate atau laju kompresi adalah laju dari data yang dikompresi. Secara tipikal, satuannya adalah bits/sample, bits/character, bits/pixel, atau bits/ second” (Sukiman & Chandra, 2013).
2.3.2. Rumus rasio kompresi
Rasio kompresi secara matematis dapat ditulis sebagai berikut :
Rasio Kompresi =
2.4 Data Berlebihan (Data Redundancy)
Menurut Kadir (2008), istilah duplikasi data seringkali juga disebut redudansi data. Duplikasi data yang berlebihan memberikan konsekuensi yang tidak bagus. Sedangkan menurut Putra (2009) data berlebihan adalah data yang tidak terkait ataupun data yang berulang.
Uncompress bit
Data berlebihan adalah suatu faktor penting yang harus diperhatikan dalam kompresi data. Karena semakin banyak data berlebihan yang terdapat pada data yang dikompresi maka semakin lambat proses kompresi yang terjadi.
Data berlebihan dapat dinyatakan secara matematis. Jika n1 adalah jumlah bit sebelum dikompresi dan n2 menyatakan jumlah bit setelah dikompresi, maka data berlebihan relatif (relative data redundancy) RD dapat dinyatakan sebagai berikut.
= 1 - x 100% ... (1) Dimana CR merupakan rasio kompresi (compression ratio) yang dinyatakan sebagai berikut :
CR = ... (2)
Dari persamaan diatas dapat diambil beberapa kesimpulan sebagai berikut :
1. Bila n1 = n2 maka CR = 1 dan RD = 0, berarti bahwa data n1 tidak mengandung data berlebihan.
2. Bila n2 << n1 maka CR mendekati tidak berhingga, sehingga RD mendekati 1, berarti terjadi kandungan data berlebihan yang sangat tinggi.
3. Bila n2 >> n1 maka CR mendekati nol, sehingga RD mendekati minus tak berhingga, berarti n2 mengandung informasi jauh lebih banyak dibandingkan n1 (Putra, 2009).
2.5 Teknik Kompr esi
2.5.1. Kompresi lossy (lossy compression)
Kompresi data yang bersifat lossy mengijinkan terjadinya kehilangan sebagian data tertentu dari pesan tersebut, sehingga dapat menghasilkan rasio kompresi yang tinggi (Putra, 2009). Sedangkan menurut Wiryadinata (2007) Lossy compression memiliki perubahan antara stream data masukan dan stream data keluaran, pada proses secara lossy ini banyak digunakan pada kompresi jenis citra dan audio.
Alasan mengapa kompresi lossy banyak digunakan pada kompresi jenis citra dan audio, karena hasil kompresi dengan data aslinya terlihat hampir sama meskipun dengan menggunakan kompresi lossy ada data yang hilang dari file aslinya. Ilustrasi kompresi lossy ditunjukkan pada gambar 2.1.
Gambar 2.1. Ilustrasi Kompr esi Lossy
2.5.2. Kompresi lossless (lossless compression)
Lossless compression tidak terjadi perubahan antara stream data masukan dan stream data keluaran, proses kompresi secara lossless ini merupakan salah satu klasifikasi yang sering ditemukan pada kompresi jenis text, executable file, dan beberapa data citra (.gif, .png, .bmp, .pcx dan lain-lain) (Wiryadinata, 2007).
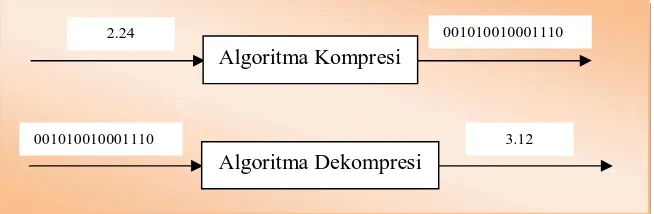
Ada banyak algoritma yang digunakan pada kompresi lossless ini beberapa diantaranya adalah algoritma Huffman, Shannon-Fano, RLE, LZ77, LZW, LZSS, Elias Gamma Code dan lain sebagainya. Ilustrasi kompresi lossless dapat dilihat pada gambar 2.2.
Algoritma Kompresi
2.24 001010010001110
Algoritma Dekompresi
Algoritma Kompresi
ABBAAB 000110001101010
Algoritma Dekompresi
ABBAAB 000110001101010
Gambar 2.2 Ilustrasi Kompr esi Lossless
2.6 Algoritma Elias Gamma Code
Algoritma Elias Gamma Code adalah sistem pemampatan yang dikembangkan oleh Peter Elias yang digunakan untuk membuat kode dalam bentuk bilangan bulat positif (Bagherzandi & Oktay, 2014). Contoh bilangan bulat yang dimaksud adalah 2M ≤ n < 2 M+1. Algoritma kompresi ini telah lama ditemukan, cara kerja kompresi data yang digunakan dalam kompresi ini dibuat berdasarkan urutan dari posisi karakter yang akan dikompresi.
Pada kode Elias Gamma, suatu integer positif x direpresentasikan oleh 1 + dalam bentuk unary (sehingga 0 bit diikuti oleh 1-bit), diikuti oleh representasi bit dari x tanpa mengandung most significant bit. Sehingga 9 direpresentasikan sebagai 0001001, karena 1 + = 4, atau 0001 dalam unary, dan 9 adalah 001 dalam bentuk biner dengan most significant bit yang dihilangkan. Dengan cara ini, 1 direpresentasikan oleh 1, yang mewakili 1 bit.
Jika kode dari sebuah karakter bernilai n maka diandaikan n = 2M + L, dimana M adalah pangkat tertinggi yang menghasilkan angka terdekat dengan nilai n yang dicari disimbolkan dengan β (n) dan L adalah sisa dari (n - 2M) disimbolkan dengan α (n). Algoritma Elias Gamma Code dapat digunakan untuk pemampatan (kompresi) juga dapat digunakan untuk penirmampatan (dekompresi).
2.6.1. Langkah-langkah kompresi algoritma elias gamma code
1. Tentukan nilai M untuk pangkat yang paling mendekati nilai n yang dituliskan sebagai β (n). Nilai ini disebut sebagai unary code, dimana jumlah nilai M ditulis menjadi angka 0 dan diakhiri dengan angka 1.
2. Dapatkan nilai L dengan mengurangi nilai n dengan nilai 2M, nilai yang didapat diubah menjadi bilangan biner.
Contoh : n = 13
Nilai M yang tertinggi yang mendekati 13 adalah 3 karena 2M = 23 = 8, ubah menjadi bilangan unary menjadi 0001.
Sehingga dihasilkan L = 13 – 8 = 5, ubah nilai L menjadi nilai biner menjadi 101. Sehingga kode elias gamma dari 13 adalah 0001101. Agar lebih jelas berikut hasil pengkodean elias gamma code dapat dilihat pada gambar 2.3.
Gambar 2.3. Daftar Elias Gamma Code (Salomon, 2007)
2.6.2. Langkah-langkah dekompresi algoritma elias gamma code
2. Selanjutnya baca nilai setelah N dan jadikan sebagai bilangan bulat L. Hitung n = 2N + L.
Contoh : 0001101
Jumlah angka 0 didepan sebelum angka 1 adalah 3, sehingga N = 3. Angka 101 adalah L dan diubah menjadi bilangan biner L = 5 Sehingga Nilai n = 23 + 5 = 13.
2.7 Algoritma Shannon-Fano
Algoritma Shannon-Fano coding ditemukan oleh Claude Shannon (bapak teori informasi) dan Robert Fano pada tahun 1949. Pada saat itu metode ini merupakan metode yang paling baik tetapi hampir tidak pernah digunakan dan dikembangkan lagi setelah kemunculan algoritma Huffman. Pada dasarnya metode ini menggantikan setiap simbol dengan sebuah alternatif kode biner yang panjangnya ditentukan berdasarkan probabilitas dari simbol tersebut (Wiryadinata, 2007).
Menurut Putra (2009) berdasarkan probabilitas tersebut kemudian dibentuk daftar kode untuk setiap simbol dengan ketentuan sebagai berikut:
1. Setiap simbol berbeda memiliki kode berbeda.
2. Simbol dengan probabilitas kehadiran yang lebih rendah memiliki kode jumlah bit yang lebih panjang dan simbol dengan probabilitas yang lebih tinggi memiliki jumlah bit yang lebih pendek.
3. Meskipun memiliki panjang kode yang berbeda, simbol tetap dikodekan secara unik.
2.7.1 Langkah-langkah kompresi algoritma shannon-fano
1. Buatlah daftar peluang atau frekuensi kehadiran setiap simbol dari data (pesan) yang akan dikodekan.
3. Bagilah daftar tersebut menjadi dua bagian dengan pembagian didasari pada jumlah total frekuensi suatu bagian (disebuat bagian atas) sedekat mungkin dengan jumlah total frekuensi dengan bagian yang lain (disebut bagian bawah). 4. Daftar bagian atas dinyatakan dengan digit 0 dan bagian bawah dinyatakan
dengan digit 1. Hal tersebut berarti kode untuk simbol-simbol pada bagian atas akan dimulai dengan 0 dan kode untuk simbol-simbol pada bagian bawah akan dimulai dengan 1.
5. Lakukanlah proses secara rekursif langkah 3 dan 4 pada bagian atas dan bawah. Bagilah menjadi kelompok-kelompok dan tambahkan bit-bit pada kode sampai setiap simbol mempunyai kode yang bersesuaian pada pohon tersebut (Putra, 2009).
Berikut disajikan suatu contoh pengkodean Shannon-Fano. Pesan yang akan dikodekan adalah :
KUKU KAKI KAKEK KAKU
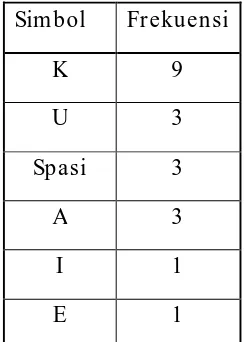
Berikut adalah daftar frekuensi kemunculan simbol pada pesan, karena kemunculan pesan telah terurut secara menurun maka tidak perlu diurutkan lagi.
Tabel 2.1 Fr ekuensi kemunculan simbol
Sim bol Fr ekuensi
K 9
U 3
Spasi 3
A 3
I 1
E 1
Tabel 2.2 Pembagian Pertama
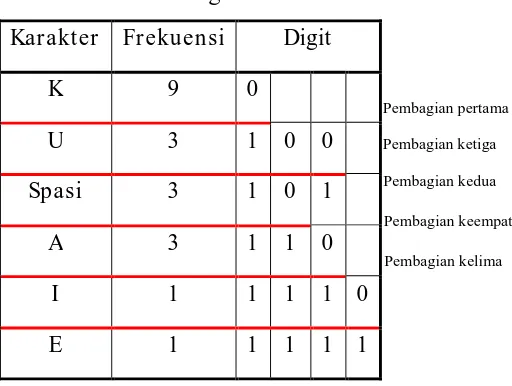
Proses diatas dilakukan secara rekursif terhadap bagian bawah saja karena bagian atas tidak dapat dibagi lagi. Sehingga pembagiannya dapat dilihat pada tabel 2.3.
Tabel 2.3 Pembagian rekur sif
Kar akter Fr ekuensi Digit
K 9 0
U 3 1 0 0
Spasi 3 1 0 1
A 3 1 1 0
I 1 1 1 1 0
E 1 1 1 1 1
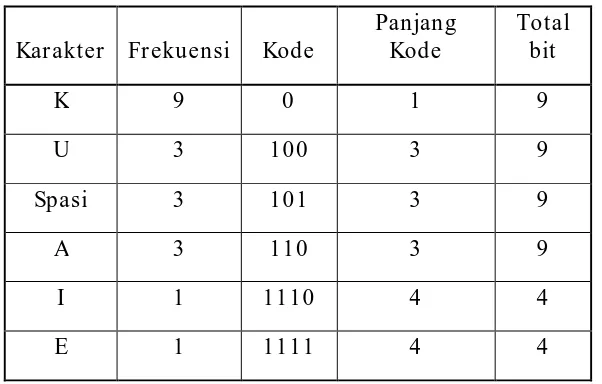
Setelah langkah-langkah diatas dilakukan maka didapatkan kode dan panjang Shannon-Fano seperti pada tabel 2.4.
Kar akter Fr ekuensi Digit
K 9 0
U 3 1
Spasi 3 1
A 3 1
I 1 1
E 1 1
Pembagian pertama
Pembagian pertama
Pembagian kedua Pembagian ketiga
Pembagian keempat
Tabel 2.4 Kode dan Panjang Kode Shannon-Fano
1. Baca bit pertama dari kode Shannon-Fano yang telah dihasilkan.
2. Jika bit terdapat pada tabel, maka bit diterjemahkan menjadi karakter sesuai dengan bit yang ada pada kode.
3. Jika bit yang dicari tidak ditemukan pada tabel kode, gabungkan bit tersebut dengan bit selanjutnya dalam rangkaian kode, cocokkan dengan tabel hasil pengkodean.
4. Ulangi langkah 3 hingga ada rangkaian bit yang sesuai dengan kode yang ada ditabel sehingga dapat diterjemahkan menjadi karakter yang ada.
5. Baca bit selanjutnya dan ulangi langkah 2, 3, dan 4 hingga rangkaian kode habis diterjemahkan.
2.8 Penelitian yang Relevan
Berikut ini beberapa penelitian yang terkait dengan algoritma Elias Gamma Code dan Shannon-Fano :
Suatu nilai yang menggunakan n bit diusahakan dua kali kemungkinan kemunculannya, dibandingkan nilai lain yang menggunakan n + 1 bit.
2. Luca (2014) dalam skripsi yang berjudul Implementasi Metode Kuantisati Pada Kompresi dan Dekompresi Citra Bitmap dan JPEG. Menyatakan kompresi citra merupakan suatu proses pengolahan citra yang bisa mengurangi ukuran dari sebuah citra agar lebih mempermudah dalam proses penyimpanan dan pengiriman. Metode yang digunakan adalah metode kuantisasi untuk melakukan kompresi citra. Metode kuantisasi adalah jenis lossy compression, karena pada proses kompresi ada bagian citra yang hilang. Pada pengujian format .jpeg menghasilkan rasio kompresi citra rata-rata 58.9% dan rata-rata rasio dekompresi citra adalah 39.4%.
3. Solihin (2013) dalam skripsi yang berjudul Perancangan Sistem Pengamanan dan Kompresi Data Teks dengan Fibonacci Encoding dan Algoritma Shannon-Fano serta Algoritma Deflate. Penelitian yang dibuat bertujuan untuk merancang sebuah aplikasi komputer yang dapat mengamankan sekaligus mengkompresi ukuran teks. Pengamanan teks dilakukan dengan menggunakan Fibonacci Encoding, kemudian hasil pengkodean dikompresi menggunakan algoritma Shannon-Fano, setelah itu dikompresikan lagi dengan algoritma Deflate. Hasil kompresi algoritma deflate adalah hasil akhir proses pengkodean dan kompresi data.