SISTEM TEMU-KEMBALI INFORMASI
DENGAN METODE VECTOR SPACE MODEL
PADA PENCARIAN FILE DOKUMEN BERBASIS TEKS
Firnas Nadirman 04/181070/EPA/00481
DEPARTEMEN PENDIDIKAN NASIONAL
UNIVERSITAS GADJAH MADA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
YOGYAKARTA
ii
SISTEM TEMU-KEMBALI INFORMASI
DENGAN METODE VECTOR SPACE MODEL
PADA PENCARIAN FILE DOKUMEN BERBASIS TEKS
Firnas Nadirman 04/181070/EPA/00481
Sebagai salah satu syarat untuk memperoleh derajat sarjana S1 pada
Program Studi Ilmu Komputer
DEPARTEMEN PENDIDIKAN NASIONAL
UNIVERSITAS GADJAH MADA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
YOGYAKARTA
iii
INFORMATION RETRIEVAL SYSTEM
WITH VECTOR SPACE MODEL METHOD
AT SEARCHING TEXT DOCUMENT FILE
Firnas Nadirman 04/181070/EPA/00481
Submitted to complete Sarjana S1 degree on the Computer Science Study Program
DEPARTEMEN PENDIDIKAN NASIONAL
UNIVERSITAS GADJAH MADA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
YOGYAKARTA
iv
SISTEM TEMU-KEMBALI INFORMASI
DENGAN METODE VECTOR SPACE MODEL
PADA PENCARIAN FILE DOKUMEN BERBASIS TEKS
Firnas Nadirman 04/181070/EPA/00481
Dinyatakan lulus ujian skripsi oleh tim penguji
pada tanggal : 13 Januari 2006
Tim Penguji
Dosen Pembimbing
Sigit Priyanta, S.Si., M.Kom
Ketua Tim Penguji
Drs. Janoe Hendarto, M.Kom
Penguji
Drs. Azhari, M.T.
Penguji
v
Puji syukur penulis panjatkan kepada Allah SWT atas segala karunia-Nya, sehingga skripsi dengan judul “SISTEM TEMU-KEMBALI INFORMASI
DENGAN METODE VECTOR SPACE MODEL PADA PENCARIAN FILE
DOKUMEN BERBASIS TEKS” dapat diselesaikan.
Penulis mengambil tema tentang sistem temu-kembali informasi di dalam skripsi ini karena keingintahuan penulis mengenai ilmu pencarian informasi dengan metode temu-kembali informasi. Di dalam skripsi ini juga penulis menjelaskan pengembangan sebuah sistem temu-kembali informasi yang digunakan di dalam sebuah sistem penyimpanan dokumen teks berbasis web.
Penulis pertama kali mengucapkan terima kasih yang sebesar-besarnya kepada bapak Sigit Priyanta selaku dosen pembimbing yang telah membantu penulis selama bimbingan skripsi ini. Beliau juga selalu memberikan motivasi kepada penulis untuk menyelesaikan skripsi ini tepat pada waktunya.
Selain beliau, penulis didalam menyelesaikan skripsi ini juga mendapat banyak sekali bantuan secara moral maupun materiil dari berbagai pihak, maka pada kesempatan ini penulis ingin mengucapkan terima kasih kepada:
1. Kedua orang tua serta adik dan kakak penulis yang tercinta, yang senantiasa memberikan dukungannya.
3. Bapak Ahmad Ridha atas waktunya untuk berdiskusi dengan penulis. 4. Yulia sebagai sahabat terbaik penulis yang selalu memberikan dorongan
dan dukungannya selama ini.
5. Widi, Farid, Dijas, Opus, Rahmad, Medha, Tina, Yaya, Okti, Abriel dan teman-teman seangkatan sejak diploma yang selalu memberikan dukungan dan sarannya kepada penulis
6. Harry, Rere, Isam, Dankos, Fajar, Lira, Anggun, Yudith, Arif dan Adib sebagai kakak kelas penulis sejak diploma yang menjadi sumber motivasi bagi penulis.
7. Semua teman kos, khususnya Mas Cahyo yang bersedia mencarikan buku untuk membantu penulis menyelesaikan skripsi ini.
8. Rio, Tiar, Roy, Siska, Mba Datu, Mba Leli dan seluruh teman-teman seangkatan penulis yang tidak bisa disebutkan semuanya.
9. Civitas Akademik Program Studi Swadaya Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Gadjah Mada yang telah membantu dan bekerja sama dengan penulis selama masa studi. Penulis menyadari bahwa di dalam pembuatan skripsi ini masih terdapat begitu banyak kekurangan, oleh karena itu penulis memohon saran dan kritik yang membangun bagi kesempurnaan skripsi ini. Semoga skripsi ini dapat bermanfaat bagi pembacanya.
vii
HALAMAN PENGESAHAN... iv
KATA PENGANTAR ... v
DAFTAR GAMBAR ... x
DAFTAR TABEL... xiii
INTISARI... xiv
ABSTRACT... xv
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 3
1.3. Batasan Masalah ... 3
1.4. Tujuan Penelitian ... 4
1.5. Manfaat Penelitian ... 4
1.6. Metode Penelitian ... 4
1.7. Sistematika Penulisan ... 5
1.8. Tinjauan Pustaka ... 6
BAB II LANDASAN TEORI ... 9
2.1 Temu-kembali Informasi (Information Retrieval) ... 9
2.2 Pengindeksan ... 12
2.3 Parsing... 14
2.4 Inverted index... 15
2.5 Pembobotan Istilah (Term Weighting) ... 16
2.6 Vector Space Model... 18
2.7 Recall dan Precision... 20
2.8 Model Pengembangan Perangkat Lunak Waterfall... 21
2.9 Data Flow Diagram (DFD) ... 24
2.10 Bagan Alir (Flow Chart)... 25
2.11 Basis Data (Database) ... 26
BAB III ANALISIS DAN PERANCANGAN... 29
3.1 Analisis... 29
3.2 Perancangan ... 30
3.2.1 DFD Level 1... 32
3.2.1.1 Proses 1 Mesin Indeks... 33
3.2.1.2 Proses 2 Proses Cari ... 34
3.2.2 DFD Level 2... 35
3.2.2.1 DFD Level 2 Proses 1 Mesin Indeks... 35
3.2.2.1.1 Proses 1.2 Parsing... 36
3.2.2.1.2 Proses 1.3 Penghilangan Stopwords... 37
3.2.2.1.3 Proses 1.4 Penghitungan Bobot ... 39
3.2.2.2 DFD Level 2 Proses 2 Proses Cari... 42
3.2.2.2.1 Proses 2.3 Cek Frasa ... 43
3.2.2.2.2 Proses 2.4 Fungsi Kesamaan... 45
3.2.3 Perancangan Basis Data ... 47
3.2.3.1 Model Data Konseptual ... 47
3.2.3.3 Model Data Fisik... 48
3.2.4 Perancangan Antarmuka ... 52
3.2.4.1 Antarmuka Pengindeksan ... 52
3.2.4.2 Antarmuka Pencarian ... 53
BAB IV IMPLEMENTASI DAN PEMBAHASAN... 54
4.1 Sistem Penyimpanan Data... 55
4.1.2 Halaman Manipulasi Bagian ... 57
4.1.3 Halaman Manipulasi Data... 60
4.1.4 Halaman Pengguna ... 66
4.2 Modul Pengindeksan... 68
4.2.1 Submodul Parsing dan Penghilangan Stopwords... 72
4.2.2 Submodul Perhitungan Variabel idf... 74
4.3 Modul Pencarian ... 77
4.3.1 Submodul Pencarian Frasa pada Query... 79
4.3.2 Submodul untuk Parsing dan Penghilangan Stopwords... 80
4.3.3 Submodul pencocokan dokumen yang memiliki frasa tepat ... 81
4.4 Evaluasi Sistem Temu-Kembali Informasi ... 84
4.4.1 Evaluasi Recall dan Precision... 85
BAB V KESIMPULAN DAN SARAN... 91
5.1 Kesimpulan ... 91
5.2 Saran... 92
x
Gambar 2.1 Kerangka dari sistem temu-kembali informasi sederhana (Ingwersen,
1992) ... 11
Gambar 2.2 Tahapan didalam pemrosesan teks (Baeza-Yates dan Ribeiro-Neto, 1999) ... 14
Gambar 2.3 Recall dan Precision pada contoh hasil temu-kemabali informasi (Baeza-Yates dan Ribeiro-Neto, 1999) ... 20
Gambar 2.4 Model Pengembangan Waterfall (Pressman, 2005)... 22
Gambar 3.1 Diagram Konteks... 31
Gambar 3.2 Data Flow Diagram Level 1 ... 32
Gambar 3.3 Data Flow Diagram Level 2 Proses 1 Mesin Indeks... 35
Gambar 3.4 Bagan Alir Proses 1.2 Parsing... 37
Gambar 3.5 Bagan Alir Proses 1.3 Penghilangan Stopwords... 38
Gambar 3.6 Bagan Alir Proses 1.4 Penghitungan Bobot ... 40
Gambar 3.7 DFD Level 2 Proses 2 Proses Cari ... 42
Gambar 3.8 Bagan Alir Proses 2.3 Cek Frasa... 44
Gambar 3.9 Bagan Alir Proses 2.4 Fungsi Kesamaan ... 46
Gambar 3.10 Model Data Konseptual Sistem Penyimpanan ... 47
Gambar 3.11 Model Data Logik Sistem Penyimpanan... 48
Gambar 3.12 Model Data Fisik Sistem Penyimpanan ... 49
Gambar 3.13 Perancangan Antarmuka Pengindeksan ... 52
Gambar 3.14 Perancangan Antarmuka Pencarian... 53
Gambar 4.2 Antarmuka Halaman Administrasi... 57
Gambar 4.3 Antarmuka Halaman Manipulasi Bagian ... 58
Gambar 4.4 Potongan Kode Program Manipulasi Bagian ... 60
Gambar 4.5 Antarmuka Halaman Manipulasi Data... 61
Gambar 4.6 Antarmuka Halaman Input Data ... 62
Gambar 4.7 Modul Pengubahan File dan Pengambilan Deskripsi File ... 64
Gambar 4.8 Potongan Kode Program Manipulasi Data... 66
Gambar 4.9 Antarmuka Halaman Pengguna... 66
Gambar 4.10 Antarmuka Halaman Dokumen... 67
Gambar 4.11 Antarmuka Halaman Pencarian Canggih ... 68
Gambar 4.12 Kode Program modul Pengindeksan bagian pertama ... 71
Gambar 4.13 Kode Program Submodul Parsing dan Penghilangan Stopwords... 72
Gambar 4.14 Kode Program Modul Pengindeksan Bagian Kedua... 73
Gambar 4.15 Kode Program Submodul perhitungan idf ... 75
Gambar 4.16 Antarmuka Halaman Pengindeksan ... 76
Gambar 4.17 Kode Program Modul Pencarian ... 77
Gambar 4.18 Kode Program Submodul Pencarian Frasa pada Query... 79
Gambar 4.19 Kode Program Submodul Parsing dan Penghilangan Stopwords... 81
Gambar 4.20 Kode Program submodul Pencocokan Dokumen yang memiliki frasa tepat. ... 82
Gambar 4.21 Tampilan Antarmuka Modul Pencarian ... 84
Gambar 4.22 Kurva Recall-Precision Sampel K01 ... 86
Gambar 4.23 Kurva Recall-Precision Sampel K02 ... 87
xiii
Tabel 2.1 Perbedaan sistem temu-kembali data dan sistem temu-kembali
informasi (Rijsbergen, 1979) ... 10
Tabel 3.1 Contoh Posisi Pencarian Dokumen... 43
Tabel 3.2 Struktur Data Tabel t_user ... 49
Tabel 3.3 Struktur Data Tabel t_data ... 50
Tabel 3.4 Struktur Data Tabel t_bagian ... 51
Tabel 3.5 Struktur Data Tabel t_index... 51
Tabel 3.6 Struktur Data Tabel t_term ... 51
Tabel 4.1 Daftar kata stopwords pada file stopwords.txt... 70
Tabel 4.2 Deskripsi Dokumen Sampel Pengujian ... 85
xiv
SISTEM TEMU-KEMBALI INFORMASI
DENGAN METODE VECTOR SPACE MODEL
PADA PENCARIAN FILE DOKUMEN BERBASIS TEKS
Oleh
Firnas Nadirman
04/181070/EPA/00481
Seiring berkembangnya teknologi, penyimpanan dokumen dalam bentuk file semakin banyak digunakan. Selain karena mengurangi jumlah ruang penyimpanan, media penyimpanannya dalam bentuk harddisk harganya pun relatif murah. Akan tetapi, file-file tersebut akan terus bertambah setiap harinya dan untuk mencari informasi dari isi file-file tersebut akan menjadi sulit. Untuk itu dikembangkanlah metode ilmu pencarian yang dikenal dengan temu-kembali informasi (information retrieval).
Metode-metode temu-kembali informasi sudah dikenal sejak lama, salah satu dari metode tersebut yang paling banyak digunakan karena kemudahan implementasinya adalah Vector Space Model (VSM). Pada metode ini dokumen hasil pencarian akan diurutkan berdasarkan bobot dari kata pencarian yang terdapat di dalam dokumen tersebut. Salah satu algoritma pembobotannya adalah algoritma tf·idf yang dipengaruhi oleh frekuensi kemunculan kata pada sebuah dokumen dan frekuensi dari dokumen yang memiliki kata tersebut.
xv
INFORMATION RETRIEVAL SYSTEM
WITH VECTOR SPACE MODEL METHOD
AT SEARCHING TEXT DOCUMENT FILE
by
Firnas Nadirman
04/181070/EPA/00481
Along expand the technology, depository of document in file format is more and more used. Besides, because lessening amount of depository space, [his/its] storage media in the form of harddisk of its price even also cheap relative. However, the file will be non-stoped to increase every day and to look for information from content of the file will become difficult. So Information Retrieval Method was developed for the searching technique.
Method of information retrieval have been found since along past year, one of the method which is at most used because easier of implementation is Vector Space Model (VSM). At this method, document of result of searching will sort pursuant to weight from term of keywords which the documents have. One of algorithm of its weight is algorithm called tf·idf influenced by frequency of term frequency and inversed document frequency.
1
1.1 Latar Belakang
Penggunaan sebuah komputer untuk menyimpan dokumen teks dalam bentuk file sampai saat ini sudah banyak dilakukan. Setelah munculnya internet pada akhir tahun 1980 yang terkenal dengan World Wide Web (Baeza-Yates & Ribeiro-Neto, 1999) yang bertujuan untuk memberikan berita atau informasi kepada masyarakat di seluruh dunia, berbagai macam informasi dalam bentuk file
semakin mudah didapatkan. Dilihat dari perkembangannya sekarang kurang lebih hampir 353 juta host (Internet Systems Consortium, 2005) di internet diakses oleh 957 juta orang di seluruh dunia (Internet World Stats, 2005) dengan menggunakan teknologi komputer sebagai media untuk penyimpanan dan pengaksesannya. Jumlah tersebut akan terus meningkat setiap tahunnya. Dari jumlah pemakaian komputer sampai saat ini membuat komputer merupakan salah satu alat yang dibutuhkan untuk mencari informasi.
pencarian data di dalam sebuah dokumen teks seperti metode pencarian find first. Namun hal itu bukan merupakan solusi yang tepat, karena pertumbuhan ukuran data yang tersimpan umumnya sangat tinggi dan jumlahnya setiap hari akan bertambah banyak. Sehingga mengakibatkan lambatnya pencarian informasi karena dilakukan satu per satu di setiap dokumen.
Dari permasalahan tersebut dikembangkanlah suatu ilmu yang diberi nama temu-kembali informasi (information retrieval). Temu-kembali informasi berkaitan dengan representasi penyimpanan, struktur dan akses dari dokumen-dokumen yang bertujuan untuk memudahkan pencarian sebuah informasi. Representasi dari dokumen itu nantinya harus mudah diakses oleh pengguna untuk mendapatkan informasi.
Akan tetapi, dilihat dari karakteristik pengguna mengenai kebutuhan informasi, untuk membuat sebuah sistem temu-kembali informasi yang cepat dan akurat tidaklah mudah. User pertama kali harus mengubah kebutuhan informasi kedalam sebuah bahasa query yang dapat di proses oleh sistem temu-kembali informasi. Salah satu caranya yaitu dengan memasukan satu atau beberapa istilah. Istilah tersebut nantinya di cocokkan dengan representasi data yang disebut indeks Indeks merupakan struktur data yang paling banyak digunakan oleh sistem temu-kembali informasi. Indeks adalah gugus kata atau konsep terpilih sebagai penunjuk ke informasi (atau dokumen) terkait. Indeks dalam berbagai bentuk, merupakan inti setiap sistem temu-kembali informasi modern karena menyediakan akses yang lebih cepat ke data dan juga mempercepat pemrosesan
Elemen dari bahasa indeks adalah istilah yang diperoleh dari teks dalam sebuah dokumen yang diuraikan (Rijsbergen, 1979). Nantinya indeks ini digunakan dalam mencari sebuah dokumen dengan menggunakan metode temu-kembali informasi.
Melihat dari penggunaan indeks, penulis mencoba menggunakan konsep temu-kembali informasi yang di terapkan di dalam sebuah sistem penyimpanan dokumen teks berbasis web. Dengan menerapkan konsep temu-kembali informasi, diharapkan sistem tersebut dapat melakukan pencarian dokumen berdasarkan informasinya secara cepat.
1.2 Rumusan Masalah
Permasalahan yang diambil dari penelitian ini yaitu untuk membuat suatu sistem yang dapat mencari informasi di dalam dokumen dengan menggunakan konsep temu-kembali informasi yang diterapkan di dalam sebuah sistem penyimpanan dokumen. Selain itu, permasalahan lainnya adalah untuk melakukan pencarian dokumen-dokumen yang disimpan oleh sistem berdasarkan informasinya.
1.3. Batasan Masalah
1.4. Tujuan Penelitian
Berdasarkan perumusan masalah tersebut di atas maka tujuan penelitian yang ingin dicapai adalah:
1. Mengembangkan dan mengimplementasikan pengindeksan otomatis untuk membangun sistem pencarian dokumen di dalam sebuah sistem penyimpanan dokumen teks dengan konsep temu-kembali informasi.
2. Untuk dapat melakukan pencarian dokumen secara cepat dan akurat dengan menerapkan konsep temu-kembali informasi.
3. Mengukur keakuratan dari hasil pencarian sistem berdasarkan relevansi dokumen, dari query yang diberikan.
1.5. Manfaat Penelitian
Dengan adanya penelitian dan tulisan ini diharapkan dapat memberikan konstribusi nyata pada pengembangan teknologi dan ilmu pengetahuan khususnya dapat bermanfaat langsung bagi IT. Dengan menerapkan konsep temu-kembali informasi pada sebuah sistem penyimpanan data diharapakan pencarian informasi dapat dilakukan lebih cepat dibandingkan dengan tidak menggunakan konsep temu-kembali informasi. Konsep dari temu-kembali informasi ini dapat diterapkan di dalam sistem penyimpanan data maupun di dalam digital library.
1.6. Metode Penelitian
Metode studi pustaka ini dilakukan dengan mengambil referensi dari buku dan jurnal dari penelitian yang berhubungan dengan konsep temu-kembali informasi
2. Analisis dan Perancangan Sistem
Sebelum membuat sebuah sistem temu-kembali informasi harus dilakukan terlebih dahulu analisis kebutuhan dari sistem tersebut. Selanjutnya dilanjutkan dengan perancangan dengan menjabarkan langkah-langkah pembuatan sistem untuk nantinya implementasi dari sistem dapat berjalan dengan baik dan sesuai dengan yang di harapkan.
3. Implementasi Sistem
Setelah mempelajari langkah-langkah pembuatan sistem temu-kembali informasi, maka sistem diimplementasikan. Implementasi sistem dilakukan dengan menggunakan perangkat lunak Apache 2.053, bahasa pemrograman PHP 5.0.5 dan basis data MySQL 4.0.20a.
4. Evaluasi Sistem
Evaluasi sistem dilakukan dengan mengukur kemampuan pencarian sistem temu-kembali tersebut.
1.7. Sistematika Penulisan
Untuk mempermudah dalam pembuatan dan pembahasan penelitian ini, maka penulis menggunakan sistematika penulisan sebagai berikut:
Pada bab ini penulis akan membahas tentang latar belakang masalah, perumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metode penelitian, sistematika penulisan dan tinjauan pustaka. BAB II. LANDASAN TEORI
Bab kedua ini bersisi teori-teori dasar yang menguraikan tentang perkembangan sistem temu-kembali informasi.
BAB III. ANALISIS DAN PERANCANGAN
Bab ketiga ini menjelaskan analisis dan perancangan dari sistem temu-kembali informasi yang dikembangkan.
BAB IV. HASIL PENELITIAN DAN PEMBAHASAN
Pada bab ini penulis akan membahas implementasi dari sistem temu-kembali informasi yang di bangun dan evaluasi dari sistem tersebut. BAB V. KESIMPULAN DAN SARAN
Pada bab ini penulis mengemukakan tentang kesimpulan yang diambil mengenai pembuatan sistem temu-kembali informasi. Disamping itu penulis juga akan memberikan saran yang sekiranya dapat bermanfaat untuk penelitian selanjutnya.
1.8. Tinjauan Pustaka
Temu-kembali informasi berfokus pada proses yang terlibat di dalam representasi, media penyimpanan, mencari dan menemukan informasi yang relevan dari informasi yang diinginkan oleh user. Hal ini ditulis oleh Ingwersen (1992) di dalam buku yang berjudul Information Retrieval Interaction.
Menurut Rijsbergen (1979), temu-kembali informasi berbeda dengan temu-kembali data dilihat dari kemampuan kesamaan, pengambilan kesimpulan, model, klasifikasi, bahasa query, klasifikasi query, hasil yang diinginkan, dan respon kesalahannya.
Sistem temu-kembali informasi digunakan untuk mencari dokumen yang relevan. Di dalam sebuah jurnal penelitian, Mizzaro (1998) mengklasifikasikan jenis-jenis relevansi terhadap sebuah dokumen. Nantinya relevansi terhadap dokumen ini dapat digunakan untuk menganalisis dari sebuah sistem temu-kembali informasi.
Salah satu model temu-kembali informasi yang di gunakan adalah Vector Space Model (VSM). Model ini merupakan salah satu model tradisional yang dikembangkan oleh Salton (1969). Di dalam buku berjudul Modern Information Retrieval yang ditulis oleh Baeza-Yates dan Ribeiro-Neto (1999) dinyatakan bahwa model ini sangat populer sampai saat ini karena kemudahan dan kecepatannya.
sampai dengan yang agak relevan berdasarkan masukan kata kunci dari pengguna. Salton dan Buckley (1987) juga menyarankan penggunaan dari pembobotan indeks dalam melakukan pengurutan dokumen.
9
2.1 Temu-kembali Informasi (Information Retrieval)
Temu-kembali informasi adalah aktifitas utama yang dilakukan oleh sebuah penyedia informasi atau pusat pelayanan informasi, termasuk perpustakaan dan jenis dari layanan lainnya yang menyediakan informasi kepada masyarakat umum. Menurut sebuah ensiklopedia, temu-kembali informasi adalah seni dan ilmu dalam pencarian informasi di sekumpulan dokumen-dokumen, pencarian informasi di dokumen itu sendiri, pencarian metadata yang menjelaskan sekumpulan dokumen, atau pencarian di dalam basis data (WIKIPEDIA, 2005). Nantinya hasil akhir dari temu-kembali informasi adalah sebuah sistem yang dapat melakukan penemu-kembalian informasi atau disebut sistem temu-kembali informasi.
Menurut Lancaster (1968) di dalam Rijsbergen (1979): “sebuah sistem temu-kembali informasi tidak memberitahu (yakni tidak mengubah pengetahuan) pengguna mengenai masalah yang ditanyakannya. Sistem tersebut hanya memberitahukan keberadaan (atau ketidakberadaan) dan keterangan dokumen-dokumen yang berhubungan dengan permintaannya”.
pengguna akan kebutuhan informasi. Sedangkan sistem temu-kembali informasi memiliki tujuan untuk menemu-kembalikan semua dokumen yang relevan berdasarkan query yang dimasukan oleh pengguna dan menemu-kembalikan dokumen tidak relevan sedikit mungkin (Baeza-Yates dan Ribeiro-Neto, 1999).
Sifat pencarian sistem temu-kembali informasi berbeda dengan sistem temu-kembali data (misalnya dalam sistem manajemen basis data) dalam beberapa segi, antara lain spesifikasi query yang tidak lengkap, dan tingkat ketanggapan kesalahan yang tidak peka (Rijsbergen, 1979). Hal ini dapat dilihat pada Tabel 2.1.
Tabel 2.1 Perbedaan sistem temu-kembali data dan sistem temu-kembali
informasi (Rijsbergen, 1979)
Data Retrieval Information Retrieval
Matching Exact Match Partial (best) Match
Inference Deduksi Induksi
Model Deterministik Probabilistik
Klasifikasi Monothetic Polythetic
Bahasa Query Artificial Natural
Spesifikasi Query Lengkap Tidak Lengkap
Item yang diinginkan Matching Relevan
Respon Error Sensitif Tidak Sensitif
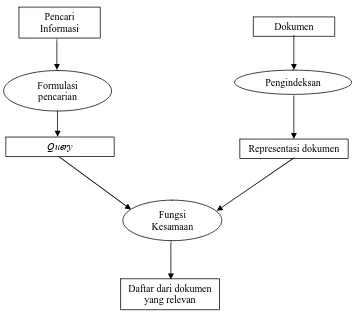
query yang dapat dimengerti oleh komputer. Bagian yang kedua adalah bagian dari dokumen. Pada bagian ini dokumen-dokumen direpresentasikan dalam bentuk indeks. Nanti query dari pengguna akan diproses melalui fungsi kesamaan untuk membandingkan query dengan indeks dari dokumen untuk mendapatkan dokumen yang relevan. Untuk lebih jelasnya mengenai kerangka sistem temu-kembali informasi dapat dilihat pada Gambar 2.1.
Gambar 2.1 Kerangka dari sistem temu-kembali informasi sederhana
(Ingwersen, 1992)
Perlu diingat bahwa pencarian sebuah informasi di dalam sistem temu-kembali informasi belum tentu mengembalikan seluruh dokumen yang relevan. Bisa hanya sebagian atau tidak sama sekali. Sistem temu-kembali informasi
Query Formulasi
pencarian
Pengindeksan Pencari
Informasi Dokumen
Representasi dokumen
Fungsi Kesamaan
mungkin tidak memberikan hasil apapun jika memang tidak ditemukan dokumen yang relevan.
2.2 Pengindeksan
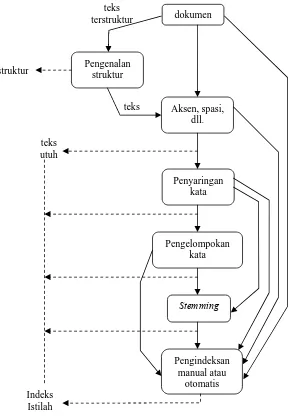
Mencari sebuah informasi yang relevan sangat tidak mungkin dapat dilakukan oleh sebuah komputer, meskipun dilakukan oleh sebuah komputer yang memiliki spesifikasi yang canggih. Agar komputer dapat mengetahui sebuah dokumen itu relevan terhadap sebuah informasi, komputer memerlukan sebuah model yang mendeskripsikan bahwa dokumen tersebut relevan atau tidak. Salah satu caranya adalah dengan menggunakan indeks istilah.
Indeks adalah bahasa yang digunakan di dalam sebuah buku konvensional untuk mencari informasi berdasarkan kata atau istilah yang mengacu ke dalam suatu halaman. Dengan menggunakan indeks si pencari informasi dapat dengan mudah menemukan informasi yang diinginkannya. Pada sistem temu-kembali informasi, indeks ini nantinya yang digunakan untuk merepresentasikan informasi di dalam sebuah dokumen.
Elemen dari indeks adalah istilah indeks (index term) yang didapatkan dari teks yang dipecah di dalam sebuah dokumen. Elemen lainnya adalah bobot istilah (term weighting) sebagai penentuan rangking dari kriteria relevan sebuah dokumen yang memiliki istilah yang sama.
a. Proses penentuan digit, tanda hubung, tanda baca dan penyeragaman dari huruf yang digunakan.
b. Penyaringan kata meliputi penghilangan kata yang memiliki arti niliai paling rendah (stopwords) untuk proses penemu-kembalian.
c. Penghilangan imbuhan kata, baik awalan maupun akhiran kata. Penghilangan imbuhan kata ini dikenal dengan stemming.
d. Pemilihan istilah untuk menentukan kata atau stem (atau kelompok kata) yang akan digunakan sebagai elemen indeks.
e. Pembentukan kategori istilah terstruktur seperti kelompok persamaan kata yang digunakan untuk perluasan dari query dasar yang diberikan oleh pengguna sistem temu-kembali informasi dengan istilah lain yang sesuai.
Gambar 2.2 Tahapan didalam pemrosesan teks
(Baeza-Yates dan Ribeiro-Neto, 1999)
2.3 Parsing
Parsing adalah proses pengenalan token (tokenizing) didalam rangkain teks (Grossman, 2002). Di dalam pembuatan sebuah indeks istilah, dokumen dipecah-pecah menjadi unit-unit yang lebih kecil misalnya berupa kata, frasa atau kalimat. Unit tersebut biasanya disebut sebagai token. Sedangkan algoritma untuk memecahkan kumpulan kalimat atau frasa menjadi token disebut tokenizer.
dokumen
Pengenalan struktur
Aksen, spasi, dll.
Penyaringan kata
Pengelompokan kata
Stemming
Pengindeksan manual atau
otomatis teks
teks terstruktur
struktur
teks utuh
Pemrosesan parsing sangat dipengaruhi oleh pengetahuan bahasa yang digunakan di dalam sebuah dokumen untuk menangani karakter-karakter khusus, serta untuk memberikan batasan-batasan token di dalam sebuah dokumen.
Parsing akan menghasilkan daftar istilah beserta informasi tambahan seperti frekuensi kemunculan istilah di dalam sebuah dokumen dan posisi-posisi ke berapa saja istilah itu muncul di sebuah dokumen untuk digunakan pada pemrosesan selanjutnya. Namun sebelumnya, terlebih dahulu dilakukan pembuangan kata-kata yang tidak perlu (stopwords) misalnya kata-kata seperti “yang”, “hingga”, “dan”, “dengan”, dll. Penghilangan kata-kata ini dilakukan agar pencarian informasi lebih terarah karena kata-kata tersebut tidak signifikan di dalam menentukan informasi suatu dokumen.
2.4 Inverted index
Inverted index adalah salah satu mekanisme untuk pengindeksan sebuah koleksi teks yang digunakan untuk mempercepat proses pencarian. Struktur dari
Misalkan istilah T1 terdapat dalam dokumen D1, D2, dan D3 sedangkan
istilah T2 terdapat dalam dokumen D1dan D2 maka inverted index yang dihasilkan
seperti berikut:
T1→ D1, D2, D3
T2→ D1, D2
Penggunaan inverted index di dalam sistem temu-kembali informasi memiliki kelemahan yaitu lambat di dalam pengindeksan, tetapi cepat di dalam proses pencarian informasi.
Menurut Grossman (2002), Inverted Index adalah struktur yang dioptimasi untuk proses penemukembalian sedangkan proses update hanya menjadi pertimbangan sekunder. Struktur tersebut membalik teks sehingga indeks memetakan istilah-istilah ke dokumen-dokumen (sebagaimana indeks sebuah buku yang memetakan istilah-istilah ke nomor halaman).
2.5 Pembobotan Istilah (Term Weighting)
Istilah di dalam suatu indeks harus bisa membedakan kepentingan dari sebuah dokumen pada sebuah informasi. Caranya yaitu dengan pemberian bobot kepada sebuah istilah terhadap suatu dokumen. Semakin tinggi bobot dari sebuah istilah maka semakin penting istilah tersebut dibandingkan dengan istilah lainnya di dalam sebuah dokumen. Bobot dari istilah ini dicantumkan pada inverted index
untuk digunakan dalam proses penemu-kembalian dokumen.
Hal ini menunjukkan penggunaan dari bobot istilah yang di cantumkan pada saat proses pengidentifikasian (Salton dan Buckley, 1987).
Sebagai contoh terhadap sebuah record R dinyatakan seperti:
R= {Ti1, 0.2; Ti2, 0.5 ; Ti3, 0,8}
Dari pernyataan tersebut dapat diambil kesimpulan bahwa istilah ketiga memiliki bobot 0.8, sedangkan istilah pertama memiliki bobot yang jauh lebih kecil yaitu sebesar 0.2.
Penggunaan dari bobot istilah selain untuk membedakan kepentingan suatu istilah di dalam sebuah dokumen juga dapat digunakan untuk menggunakan pengurutan saat penemukembalian dengan susunan menurun dari bobot yang besar ke kecil sesuai dengan bobot istilah-istilah yang sama antara query dan dokumen.
2.5.1 Pembobotan tf·idf
Pada model pengindeksan yang berdasarkan pada frekuensi istilah dapat diperkirakan bahwa istilah-istilah indeks terbaik adalah istilah-istilah yang sering muncul dalam dokumen individual tetapi jarang muncul dalam keseluruhan koleksi. Sebuah penanda kepentingan jenis ini yang umum adalah perkalian (tf·idf) dengan bobot wij sebuah istilah Ti dalam dokumen Di, didefinisikan sebagai
frekuensi istilah dikalikan dengan fungsi inverse document frequency.
Baeza-Yates dan Ribeiro-Neto (1999), menyebutkan bahwa pembobotan (tf·idf) terdiri dari dua faktor, yaitu:
tf adalah frekuensi kemunculan suatu istilah ki di dalam sebuah
dokumen dj dibandingkan dengan frekuensi istilah kl yang sering
muncul pada dokumen itu. Jika dimasukan dalam rumus matematika didapatkan:
2. idf (inverse document frequency)
idf adalah frekuensi kemunculan suatu istilah ki di dalam seluruh
dokumen. Penggunaan faktor idf didasarkan pada istilah yang muncul pada setiap dokumen tidak memberikan suatu ciri khusus untuk menentukan dokumen yang relevan dari yang tidak relevan. Jika jumlah seluruh dokumen di dalam sistem dinyatakan dengan nilai N
dan jumlah dokumen yang memiliki istilah ki tersebut dinyatakan
dengan ni, maka nilai idfi-nya dapat dinyatakan dengan:
i i
n N idf =log
Dari dua faktor tersebut maka pembobotan tf·idf dapat dinyatakan dengan:
i
kesamaan antara setiap dokumen yang disimpan di dalam sistem dengan query
yang diberikan oleh pengguna. Model ini pertama kali diperkenalkan oleh Salton (1989).
Pada VSM, setiap dokumen dan query dari pengguna direpresentasikan sebagai ruang vektor berdimensi n. Biasanya digunakan nilai bobot istilah (term weigthing) sebagai nilai dari vektor pada dokumen nilai 1 untuk setiap istilah yang muncul pada vektor query.
Pada model ini, bobot dari query dan dokumen dinyatakan dalam bentuk vektor, seperti:
Q = (wq1, wq2, wq3, . . . ,wqt) dan Di = (wi1, wi2, wi3, . . . , wit)
Dengan wqjdan wij sebagai bobot istilah Tj dalam query Q dan dokumen
Di. Selanjutnya koefisien kesamaan antara query dan dokumen dapat diperoleh
dengan formula inner product:
∑
= ⋅∑
2.7 Recall dan Precision
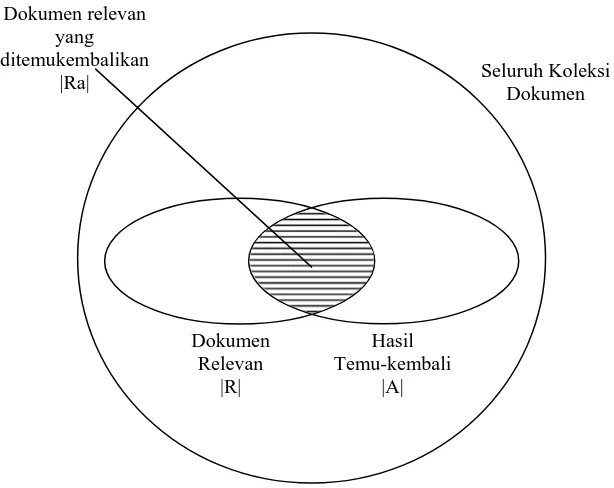
Evaluasi dari sistem temu-kembali informasi dipengaruhi oleh dua parameter utama yaitu recall dan precision. Recall adalah rasio antara dokumen relevan yang berhasil ditemukembalikan dari seluruh dokumen relevan yang ada di dalam sistem, sedangkan precision adalah rasio dokumen relevan yang berhasil ditemukembalikan dari seluruh dokumen yang berhasil ditemu-kembalikan (Grossman, 2002).
Gambar 2.3 Recall dan Precision pada contoh hasil temu-kemabali informasi
(Baeza-Yates dan Ribeiro-Neto, 1999)
A Ra ecision
R Ra call
= =
Pr Re
Dengan menggunakan nilai dari parameter recall dan precision akan dicari nilai dari average precision untuk menghitung keefektifan dan keakuratan dari algoritma sistem temu-kembali informasi. Average precision adalah suatu ukuran evaluasi sistem temu-kembali informasi yang diperoleh dengan cara menghitung rata-rata precision pada seluruh tingkat recall (Grossman, 2002).
Sedangkan untuk menentukan nilai dari recall dan precision harus didapatkan jumlah dokumen yang relevan terhadap suatu topik informasi. Satu-satunya cara untuk mendapatkannya yaitu dengan membaca dokumen itu satu per satu.
Menurut Rijsbergen (1979) relevansi merupakan sesuatu yang sifatnya subyektif. Setiap orang mempunyai perbedaan untuk mengartikan sesuatu dokumen tersebut relevan terhadap sebuah topik informasi.
Menurut Mizzaro (1998), evaluasi pada sebuah sistem temu-kembali informasi dengan menggunakan recall dan precision sudah cukup baik untuk menjadi ukuran dari sistem tersebut.
2.8 Model Pengembangan Perangkat Lunak Waterfall
dari pelanggan menuju tahap perencanaan, pemodelan, pembangunan dan pengiriman perangkat lunak tersebut, yang pada akhirnya akan kembali lagi dari awal untuk membentuk perangkat lunak yang sesuai dengan keinginan pelanggan.
Gambar 2.4 Model Pengembangan Waterfall (Pressman, 2005)
Dari Gambar 2.4, model pengembangan waterfall pada awalnya dimulai dari tahap komunikasi. Pada tahap ini pihak pelanggan melakukan komunikasi dengan pihak pengembang perangkat lunak mengenai masalah yang didapatkan sehingga dibutuhkan suatu solusi untuk membuat perangkat lunak didalam memecahkan masalah tersebut. Pada tahap ini kebutuhan perangkat lunak didefinisikan dan inisiasi proyek pembuatan perangkat lunak dilakukan bersama-sama oleh pihak pelanggan dan pihak pengembang.
Tahap perencanaan pada model ini meliputi kegiatan perencanaan pembuatan perangkat lunak. Pada kegiatan ini, estimasi waktu pembuatan perangkat lunak, penjadwalan serta kegiatan yang akan dilakukan untuk menunjang pembuatan perangkat lunak dibahas bersama-sama oleh pihak pengembang dan pelanggan.
Komunikasi
Perencanaan
Pemodelan
Pembangunan
Dari tahap perencanaan nantinya akan dilanjutkan ke tahap pemodelan. Pada tahap ini kegiatan utamanya yaitu analisis kebutuhan perangkat lunak yang merupakan proses pengumpulan kebutuhan yang diintensifkan dan difokuskan, khususnya pada perangkat lunak. Tujuannya yaitu untuk memahami sifat program yang akan dibangun. Perekayasa perangkat lunak harus memahami domain informasi, tingkah laku, cara kerja dan antar muka yang diperlukan. Kebutuhan baik untuk sistem maupun perangkat lunak didokumentasikan dan dilihat lagi dengan pelanggan.
Selain analisis kebutuhan perangkat lunak, pada tahap ini juga meliputi kegiatan desain perangkat lunak. Pada kegiatan desain perangkat lunak dilakukan proses multi langkah yang berfokus pada empat atribut sebuah perangkat lunak yang berbeda; struktur data, arsitektur perangkat lunak, representasi interface, dan detail (algoritma) prosedural. Proses desain menerjemahkan syarat/kebutuhan ke dalam sebuah representasi perangkat lunak yang dapat diperkirakan demi kualitas sebelum dimulai pemunculan kode. Sebagaimana persyaratan, desain didokumentasikan dan menjadi bagian dari konfigurasi perangkat lunak.
Kegiatan implementasi pada akhirnya akan menghasilkan perangkat lunak yang siap diuji. Proses pengujian berfokus pada logika internal perangkat lunak, memastikan bahwa semua pernyataan sudah diuji, dan pada eksternal fungsional yaitu mengarahkan pengujian untuk menemukan kesalahan-kesalahan dan memastikan bahwa input yang dibatasi akan memberikan hasil yang sesuai dengan hasil yang dibutuhkan.
Tahap yang terakhir dari pengembangan perangkat lunak pada model waterfall adalah tahap pengiriman. Pada tahap ini seluruh perangkat lunak sudah selesai dan diserahkan kepada pelanggan. Akan tetapi, pada tahap ini perangkat lunak akan mengalami perubahan setelah dikirmkan kepada pelanggan. Perubahan akan terjadi karena kesalahan-kesalahan ditentukan, karena perangkat lunak harus disesuaikan untuk mengakomodasi perubahan-perubahan di dalam lingkungan eksternalnya, atau karena pelanggan membutuhkan perkembangan fungsional. Pada tahap ini kegiatan utama bagi para pengembang perangkat lunak adalah pemeliharaan. Pemeliharaan perangkat lunak mengaplikasikan lagi setiap fase program sebelumnya dan tidak membuat baru lagi.
2.9 Data Flow Diagram (DFD)
Elemen-elemen dasar dari DFD adalah :
Pada DFD aliran data digambarkan dalam bentuk hirarki, yaitu model DFD yang pertama (biasanya disebut DFD level 0 atau diagram konteks) merepresentasikan sistem secara keseluruhan. Bagian DFD lainnya menjelaskan dari konteks diagram tersebut, dan menyediakan secara detail proses yang digunakan pada setiap bagian level.
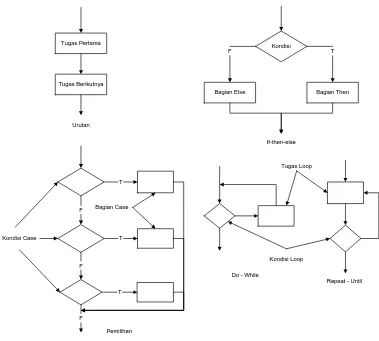
2.10 Bagan Alir (Flow Chart)
Bagan alir merupakan Representasi grafis yang paling luas dipakai untuk desain prosedural. Konstruksi dari bagan alir sangat sederhana. Sebuah kotak digunakan untuk mengindikasikan suatu langkah pemrosesan. Diamon merepresentasikan suatu kondisi logis dan anak panah memperlihatkan aliran kontrol (Presman, 2002). Gambar 2.5 mengilurtrasikan tiga kondisi prosedural dengan menggunakan bagan alir.
Transfer informasi (fungsi) yang ada di dalam
bound sistem untuk dimodelkan.
Prosedur atau konsumer informasi yang ada di luar bound sistem untuk dimodelkan.
Objek data; anak panah menunjukkan arah aliran data.
Tugas Pertama
Tugas Berikutnya
Urutan
Bagian Then Kondisi
T
Bagian Else F
If-then-else
F
F
T
T
T
F Kondisi Case
Bagian Case
Kondisi Loop Tugas Loop
Do - While
Repeat - Until
Pemilihan
Gambar 2.5 Konstruksi Bagan Alir
2.11 Basis Data (Database)
Basis Data terdiri dari dua kata, yaitu Basis dan Data. Basis dapat diartikan sebagai markas atau gudang yaitu tempat bersarang/berkumpul. Sedangkan Data adalah representasi fakta dunia nyata yang mewakili suatu objek seperti manusia, barang, hewan, peristiwa, konsep, keadaan dan sebagainya, yang direkam dalam bentuk angka, huruf, simbol, teks, gambar, bunyi atau kombinasinya (Fathansyah, 2001).
1. Basis data merupakan himpunan kelompok data (arsip) yang saling berhubungan yang diorganisasi sedemikian rupa agar kelak dapat dimanfaatkan kembali dengan cepat dan mudah.
2. Kumpulan data yang saling berhubungan yang disimpan secara bersama sedemikian rupa dan tanpa pengulangan (redudansi) yang tidak perlu, untuk memenuhi berbagai kebutuhan.
3. Kumpulan file/tabel/arsip yang saling berhubungan yang disimpan dalam media penyimpanan elektronis.
Menurut Connoly (1998), basis data adalah koleksi dari relasi data logikal (dan deskripsi dari data ini), yang dirancang untuk mencari informasi yang dibutuhkan oleh organisasi. Sedangkan menurut C.J Date (2004), basis data adalah sebuah koleksi dari data yang tahan lama yang digunakan oleh sistem aplikasi dari perusahaan tertentu
29
Pengembangan perangkat lunak dengan menggunakan model pengembangan waterfall meliputi beberapa tahapan. Di dalam penelitian ini, pengembangan sistem temu-kembali informasi ini hanya akan dibahas tahap pemodelan dan pembangunan perangkat lunak yang meliputi analisis, perancangan, pembuatan serta pengujian perangkat lunak. Pada bab ini akan dibahas mengenai analisis dan perancangan pengembangan sistem temu-kembali informasi, sedangkan mengenai implementasi dan pengujian sistem akan dibahas di bab selanjutnya.
3.1 Analisis
Sistem temu-kembali yang akan dibangun merupakan bagian dari sistem pencarian penyimpanan data. Akan tetapi, pada pembahasan analisis dan perancangan serta implementasi dan pengujian pada bab selanjutnya akan lebih diutamakan kepada sistem temu-kembali informasi saja.
Untuk lebih jelasnya mengenai sistem penyimpanan data secara garis besar akan dijelaskan sebagai berikut :
• Sistem penyimpanan data akan menyimpan file dokumen berbasis teks yang dimasukan oleh administrator pada media penyimpanan.
disebut “bagian”. Informasi mengenai bagian akan disimpan ke dalam basis data.
• Informasi mengenai file dokumen (nama dokumen, bagian, letak file, ukuran file, tipe file, dll) akan disimpan ke dalam basis data. Nantinya basis data ini yang akan digunakan dan diakses oleh sistem untuk menampilkan dan memberikan dokumen (informasi dokumen) kepada pengguna.
Pada sistem penyimpanan nantinya akan disimpan file dokumen dengan format word, pdf, dan excel. Pengguna yang ingin mencari file dokumen dengan informasi tertentu harus mengambil file dokumen tersebut dan membacanya satu per satu untuk mendapatkan dokumen yang cocok dengan informasi yang ingin dicari. Dengan banyaknya dokumen yang disimpan di dalam sistem penyimpanan, maka cara pencarian tersebut akan tidak efektif. Untuk itu dibutuhkan sistem pencarian yang dapat mencari informasi dari isi file dokumen yang disimpan di dalam sistem penyimpanan data.
Sistem pencarian harus dapat membaca dan menganalisis isi informasi yang dimiliki oleh file dokumen yang disimpan. Sistem pencarian juga harus dapat mengurutkan hasil pencarian dokumen berdasarkan keakuratan pencarian informasi dari file dokumen untuk memudahkan pengguna dalam mencari informasi. Sistem pencarian juga harus menyesuaikan dengan struktur data dari sistem penyimpanan yang sudah dibuat.
3.2 Perancangan
informasi, modul-modul dan fungsi yang dapat diterjemahkan ke dalam arsitektural, antarmuka dan level desain komponen. Pada akhirnya, model analisis dan spesifikasi kebutuhan dapat menyediakan nilai/kualitas dari perangkat lunak yang akan dibangun kepada pihak pengembang dan pelanggan. Salah satu representasi dari modul-modul dan fungsi dari perangkat lunak menggunakan
toolsData Flow Diagram.
Sistem temu-kembali informasi yang akan dibangun menggunakan model ruang vektor (Vector Space Model). Proses utama yang digunakan oleh sistem temu-kembali informasi adalah indexing yang lebih lanjut akan dijelaskan pada tahap perancangan.
Sistem ini nantinya akan dibagi menjadi dua bagian besar, yaitu proses
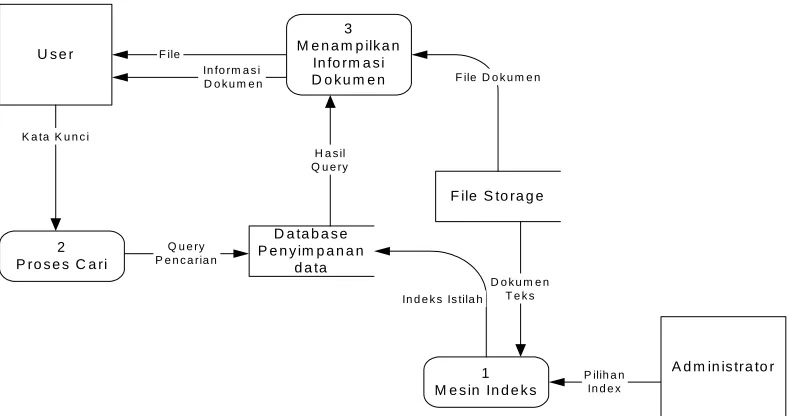
indexing yang berhubungan dengan dokumen-dokumen dan proses query yang berhubungan dengan pengguna. Pengaturan indexing dokumen berbasis teks menjadi kumpulan indeks istilah akan dilakukan oleh administrator. Sedangkan proses query pengguna akan direpresentasikan melalui pengiriman kata kunci berupa teks untuk diproses menjadi query yang dapat digunakan oleh sistem ini untuk mencari informasi di dalam dokumen yang disimpan. Gambaran mengenai sistem temu-kembali informasi pada sistem penyimpanan data dapat dilihat pada Gambar 3.1.
Gambar 3.1 Diagram Konteks
User Kata Kunci kembali InformasiSistem Temu- PilihanIndex Administrator
Dari diagaram konteks maka dapat diturunkan menjadi Data Flow Diagram (DFD) level 1. DFD adalah sebuah teknik grafis yang menggambarkan aliran data yang bergerak dari input ke output. Selain itu DFD juga menyajikan fungsi-fungsi sistem yang mengolah data input dan menghasilkan data output. Diagram alur data dapat digunakan untuk menyajikan suatu sistem perangkat lunak pada setiap tingkat abstraksi.
Dari bentuk diagram konteks sistem temu-kembali informasi, maka bentuk DFD level 1 dari sistem temu-kembali informasi dapat dilihat pada Gambar 3.2. Pada Gambar 3.2 DFD level 1 dapat dilihat 2 proses utama dalam sistem temu-kembali informasi, yaitu proses Indexing yang diberi nama dengan mesin indeks
dan proses Query yang diberi nama dengan proses cari.
Gambar 3.2 Data Flow Diagram Level 1
3.2.1 DFD Level 1
Pada Gambar 3.2, DFD level 1 memiliki 3 proses yaitu : 1. Mesin Indeks
2. Proses Cari
3. Menampilkan Informasi Data
Proses 1 dan 2 merupakan proses utama yang digunakan untuk sistem temu-kembali informasi, sedangkan proses 3 merupakan bagian dari sistem penyimpanan data. Proses 1 merupakan proses indexing, sedangkan proses 2 merupakan proses querying.
3.2.1.1 Proses 1 Mesin Indeks
Pada proses ini dokumen-dokumen yang sudah disimpan pada sistem akan diproses untuk dijadikan indeks istilah yang akan digunakan dalam proses cari. Salah satu input dari proses ini merupakan pilihan indeks, yaitu pilihan yang diberikan oleh administrator untuk melaksanakan indeks. Pilihan itu terdiri dari tiga macam, yaitu :
1. Seluruh dokumen, yaitu pilihan bagi administrator untuk mengindeks seluruh dokumen yang disimpan di dalam sistem.
2. Bagian, yaitu pilihan bagi administrator untuk mengindeks seluruh dokumen berdasarkan pada suatu bagian di dalam sistem.
3. Dokumen, yaitu pilihan bagi administrator untuk mengindeks satu atau lebih dokumen tertentu yang terdapat di dalam sistem.
pengolahan teks menjadi indeks istilah akan melalui beberapa tahapan subproses, yaitu pengambilan dokumen teks, parsing, penghilangan stopwords dan penghitungan nilai bobot pada tiap istilah di dalam indeks. Subproses ini akan dimodelkan pada DFD level 2. Secara umum proses 1 Mesin Indeksini bertujuan untuk membentuk informasi indeks dari koleksi dokumen sebagai input dengan melalui beberapa tahapan.
3.2.1.2 Proses 2 Proses Cari
Input pada Proses 1 Proses Cari dari entitas eksternal User adalah kata kunci. Kata kunci ini akan diproses menjadi query untuk mendapatkan dokumen sesuai dengan informasi yang ingin dicari oleh pengguna. Proses pada kata kunci untuk diubah menjadi sebuah query pada sistem temu-kembali informasi juga memiliki beberapa tahapan yang hampir sama dengan pemrosesan teks pada pengindeksan dokumen yaitu parsing, penghilangan stopwords, cek frasa serta fungsi kesamaan untuk mengurutkan dokumen dari bobotnya yang paling besar ke yang paling kecil. Tahap pencarian dokumen menggunakan fungsi kesamaan ruang vektor, yang sudah dibahas pada bab sebelumnya untuk mendapatkan kesamaan dokumen dengan query yang diberikan oleh pengguna.
Setelah dilakukan query pada basis data maka hasil query akan diberikan ke Proses 3 Menampilkan Informasi Dokumen yang akan memberikan output
3.2.2 DFD Level 2
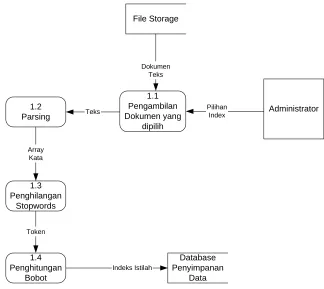
3.2.2.1 DFD Level 2 Proses 1 Mesin Indeks
Pada Gambar 3.3 DFD Level 2 Proses 1 Mesin Indeks di bagi menjadi 4 sub proses. Akan tetapi proses utama pada mesin indeks ini hanya terdiri dari 3 proses utama yaitu :
1. Parsing
2. Penghilangan Stopwords
3. Penghitungan bobot
Ketiga proses tersebut yang akan digunakan oleh sistem temu-kembali informasi untuk mengubah teks menjadi indeks istilah untuk digunakan dalam proses pencarian dokumen.
Pilihan
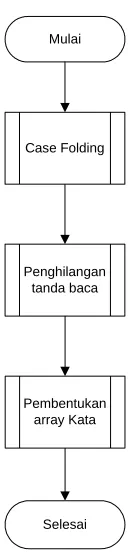
3.2.2.1.1 Proses 1.2 Parsing
Parsing merupakan proses pengenalan kata di dalam rangkaian teks. Input pada proses ini merupakan teks mentah yang masih dalam bentuk paragraf. Nanti teks ini akan diproses dengan menggunakan algoritma tokenizer untuk dipecah menjadi unit-unit yang lebih kecil misalnya berupa kata (token).
Tokenizer menerima masukan berupa rangkaian karakter dan memilahnya menjadi token dengan aturan sebagai berikut:
• Suatu kata dimulai oleh huruf atau angka
• Kata dipisahkan oleh karakter whitespace (spasi, tabulasi, baris baru, dll)
• Karakter-karakter khusus yang mengikuti huruf atau angka dianggap bagian dari kata (misalnya tanda persen dalam 125%) namun dianggap sebagai pemisah kata jika tidak.
Gambar 3.4 Bagan Alir Proses 1.2 Parsing
3.2.2.1.2 Proses 1.3 Penghilangan Stopwords
Proses penghilangan stopwords ini berfungsi sebagai penyaring kata-kata umum yang hampir selalu ada pada dokumen dan tidak signifikan untuk dijadikan indeks suatu dokumen. Kata-kata umum ini telah didefinisikan sebelumnya sehingga pada proses ini hanya membandingkan kata yang merupakan hasil proses parsing dengan stopwords.
Input pada proses 1.2 Penghilangan Stopwords (Gambar 3.5) adalah array kata hasil dari proses parsing. Algoritmanya adalah sebagai berikut :
1. Baca array kata yang didapat dari proses parsing. 2. Ambil daftar stopwords
3. Bandingkan array kata dengan daftar stopwords
Jika kata termasuk ke dalam daftar stopwords, maka buang kata dari array. Mulai
Selesai Case Folding
Penghilangan tanda baca
4. Ulangi ke langkah no.3 sampai array kata paling terakhir.
i = jumlah array Tidak
Gambar 3.5 Bagan Alir Proses 1.3 Penghilangan Stopwords
berisi array yang digunakan untuk informasi masing-masing token di dalam sebuah dokumen, sedangkan array di dimensi kedua digunakan untuk mencari kata yang memiliki nilai frekuensi maksimal didalam sebuah dokumen. Array token ini nantinya akan digunakan sebagai masukan pada pemrosesan selanjutnya.
3.2.2.1.3 Proses 1.4 Penghitungan Bobot
Setelah proses penghilangan stopwords proses pengindeksan dokumen dilanjutkan dengan proses berikutnya yaitu proses penghitungan bobot. Proses 1.4 Penghitungan Bobot menggunakan array token hasil dari Proses 1.3 Penghilangan
Stopwords sebagai masukannya. Token pada dimensi pertama dari hasil dari Proses 1.3 ini juga yang menjadi indeks istilah yang akan digunakan dalam proses pencarian.
Mulai
Algoritma penghitungan variabel tf setiap kata didalam sebuah dokumen adalah sebagai berikut :
1. Ambil sebuah dokumen 2. Baca array token
3. Cek tabel t_term, jika kata belum ada di dalam basis data, maka tambahkan informasi kata ke dalam basis data.
4. Hitung nilai tf
5. Tambahkan id_data, id_term, tf dan posisi ke tabel t_index. 6. Ulangi dari nomor 2 sampai array token terakhir
7. Ulangi dari nomor 1 sampai dokumen terakhir
Algoritma penghitungan variabel idf setiap kata adalah sebagai berikut : 1. Ambil kata dari tabel t_term pada basis data
2. Hitung nilai idf
3. Update tabel t_term berdasarkan kata yang diambil
4. Ulangi dari nomor 1 sampai kata terakhir di dalam basis data.
3.2.2.2 DFD Level 2 Proses 2 Proses Cari
Gambar 3.7 DFD Level 2 Proses 2 Proses Cari
Pada DFD Level 2 (Gambar 3.7), Proses 2 Proses Cari di pecah menjadi 4 buah subproses. Proses Cari ini merupakan proses pengubahan kata kunci menjadi
query pencarian yang akan diproses untuk mencari dokumen berdasarkan kata kunci yang dimasukan oleh pengguna. Dua subproses awal pada proses cari sama dengan subproses pada pengindeksan dokumen yaitu parsing, penghilangan
stopwordsI,cek frasa dan fungsi kesamaan.
3.2.2.2.1 Proses 2.3 Cek Frasa
Input dari Proses 2.3 Cek Frasa yaitu token query hasil dari Proses 2.2 Penghilangan Stopwords. Proses ini merupakan proses pencarian frasa tepat dalam dokumen. Pencarian frasa ini menggunakan posisi token yang terdapat di dalam tabel t_index. Penentuan frasa tepat yang diberikan oleh pengguna dibatasi oleh tanda kutip dua (“) di dalam kata kunci yang dimasukan oleh pengguna.
Contoh :
• Seorang pengguna ingin mencari frasa tepat “kota yogya”, maka sistem pertama kali akan mencari seluruh dokumen yang memiliki kata kota dan yogya.
• Lalu setelah sistem menemukan dokumen memiliki kata tersebut, maka sistem akan mencari dokumen yang memiliki posisi kata “kota” dan “yogya“ tepat bersebelahan dimulai dari kata “kota” dan diikuti kata “yogya”.
Tabel 3.1 Contoh Posisi Pencarian Dokumen
Dokumen Posisi kata “kota” Posisi “yogya”
Dokumen 1 8,44,80,178 15,56,81,56
Dokumen 2 4,35,77,203,567 22,98,123
Gambar 3.8 Bagan Alir Proses 2.3 Cek Frasa
Algoritma Proses 2.3 Cek Frasa (Gambar 3.8) adalah sebagai berikut : 1. set status match=false.
2. Ambil data id_data, id_term dan posisi term sesuai dengan array token yang diberikan dari tabel t_index.
3. Ambil posisi dari array token
4. Jika posisi array token pertama ditambah 1 tidak sama dengan seluruh posisi array token berikutnya, maka lanjutkan nomor 3 sampai posisi sama.
5. Jika posisi array token pertama ditambah 1 sama dengan salah satu posisi array token berikutnya lanjutkan dari nomor 2 sampai array token terakhir. 6. Jika posisi array token pertama sampai terakhir telah berurut ubah status
match menjadi true.
7. Jika status match = true maka masukan id_data ke dalam array vektor dokumen.
3.2.2.2.2 Proses 2.4 Fungsi Kesamaan
Setelah vektor dokumen sudah dibuat maka vektor tersebut akan dimasukan ke dalam rumus fungsi kesamaan untuk dicari nilai bobot dari masing-masing dokumen berdasarkan query pengguna agar dapat diurutkan. Fungsi kesamaan disini menggunakan model ruang vektor, dengan rumus :
Mulai Vektor
Ambil nilai tf dan idf dari t_term dan t_index berdasarkan id_data dokumen ke i
dan token ke j
Gambar 3.9 Bagan Alir Proses 2.4 Fungsi Kesamaan
Algoritma dari Proses 2.4 Fungsi Kesamaan (Gambar 3.9) adalah sebagai berikut :
3. Ambil nilai tf dan idf dari tabel tbl_index dan t_term berdasarkan dokumen dan token. Hitung nilai wij=tf·idf.
4. Set atas = atas + (wij*wqj), set bawah = bawah+(wij*wij), set qvektor =
qvektor + (wqj*wqj)
5. Ulangi dari nomor 2 sampai array token terakhir
6. Hitung nilai :
qvektor bawah
atas
× dan simpan nilainya ke dalam array sim.
7. Ulangi dari nomor 1 sampai vektor dokumen terakhir. 8. Urutkan nilai di dalam array sim.
3.2.3 Perancangan Basis Data
3.2.3.1 Model Data Konseptual
Tahap perancangan konseptual meliputi dua kegiatan yang tidak dapat dipisahkan, yaitu perancangan skema konseptual tentang organisasi data yang harus disimpan dalam basis data, dan rancangan transaksi yang dilakukan untuk memperoleh informasi dari sistem basis data. Perancangan basis data secara konseptual dapat dilihat pada Gambar 3.10.
Gambar 3.10 Model Data Konseptual Sistem Penyimpanan
3.2.3.2 Model Data logik
Gambar 3.11 Model Data Logik Sistem Penyimpanan
Perancangan basis data secara logik bertujuan untuk menyusun rancangan konseptual dan skema eksternal yang sesuai dengan sistem manajemen basis data yang dipilih. Perancangan basis data secara logik dapat dilihat pada Gambar 3.11.
3.2.3.3 Model Data Fisik
t_user
Gambar 3.12 Model Data Fisik Sistem Penyimpanan
Pada basis data yang digunakan dalam Sistem Penyimpanan, terdapat lima tabel yaitu tabel t_user, t_data, t_bagian, t_index, dan t_term. Basis data untuk sistem menggunakan MySQL Versi 4.0.20a. Tabel 3.2 sampai dengan Tabel 3.6 menjelaskan deskripsi tabel yang digunakan dalam Sistem Penyimpanan.
Tabel 3.2 Struktur Data Tabel t_user
Nama Kolom Tipe Keterangan
id_user Auto Number
(Primary Key)
uname Varchar (25) Username untuk administrator password Varchar (255) Password untuk login
Tabel t_user (Tabel 3.2) digunakan untuk proses login pada bagian administrator, isi dari tabel ini merupakan nama user dan password serta hak akses yang dimiliki oleh administrator.
Tabel 3.3 Struktur Data Tabel t_data
Nama Kolom Tipe Keterangan
id_data AutoNumber (Primary Key)
id_bagian Integer (10) tanggal Date
nama_data Varchar (100) Nama dari dokumen
letak Varchar (150) Path file dokumen di dalam Harddisk nama_file Varchar (80) Nama file dokumen sebenarnya yang
dimasukan oleh administrator type_file Varchar (30) Ekstension dari file dokumen ukuran_file Integer (16) Ukuran dari file dokumen penulis Varchar (80) Penulis dari dokumen deskripsi Varchar (160) Deskripsi dari file dokumen
temp_file Varchar (150) Path file temporary di dalam harddisk
Sistem penyimpanan akan menyimpan informasi dari dokumen yang dimasukan oleh administrator pada tabel t_data (Tabel 3.3). Informasinya berupa nama dari data, letak path dari file dokumen pada harddisk, nama file asli dari dokumen tersebut, tipe ekstensi dari file (.doc, .pdf atau .xls), ukuran file, penulis, deskripsi dari file dan letak file temporary dari file dokumen.
Tabel 3.4 Struktur Data Tabel t_bagian
Nama Kolom Tipe Keterangan
id_bagian AutoNumber (Primary Key)
bagian Varchar (255) Nama bagian
folder Varchar (255) Nama Folder bagian di dalam sistem
Dokumen pada sistem penyimpanan akan direlasikan kepada kata-kata indeks pada tabel t_index (Tabel 3.5). Pada tabel ini juga akan disimpan informasi dari variabel tf setiap kata yang dimiliki oleh dokumen dan seluruh posisi dari kata pada dokumen.
Tabel 3.5 Struktur Data Tabel t_index
Nama Kolom Tipe Keterangan
id_data Integer (10) (Primary Key)
id_term Integer (10) (Primary Key)
tf Double Nilai variabel tf dari suatu term pada sebuah dokumen
position Text Posisi term di dalam sebuah dokumen
Tabel 3.6 Struktur Data Tabel t_term
Nama Kolom Tipe Keterangan
id_term Auto Number
(Primary Key)
term Varchar (50) Term suatu indeks istilah
Tabel t_term (Tabel 3.6) menyimpan informasi setiap kata hasil pemrosesan dokumen yang berupa kata term tersebut dan nilai variabel idf dari kata.
3.2.4 Perancangan Antarmuka
3.2.4.1 Antarmuka Pengindeksan
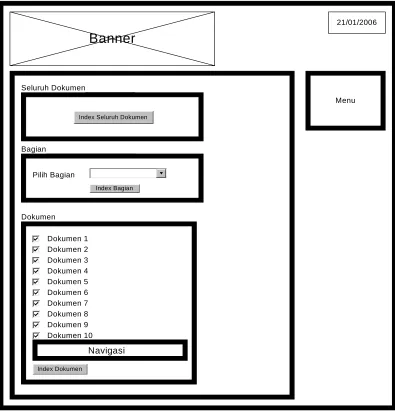
Gambar 3.13 Perancangan Antarmuka Pengindeksan
Banner
21/01/2006
Menu
Index Seluruh Dokumen
Seluruh Dokumen
Index Bagian
Bagian
Pilih Bagian
Dokumen
Dokumen 1 Dokumen 2 Dokumen 3 Dokumen 4 Dokumen 5 Dokumen 6 Dokumen 7 Dokumen 8 Dokumen 9 Dokumen 10
Navigasi
Antarmuka pengindeksan (Gambar 3.13) dirancang untuk digunakan oleh administrator untuk memilih pilihan indeks. Pilihan terdiri dari tiga macam yaitu seluruh dokumen, bagian dan indeks. Sistem akan mengindeks dokumen sesuai dengan pilihan yang diberikan oleh administrator.
3.2.4.2 Antarmuka Pencarian
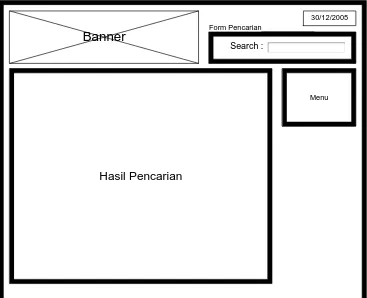
Antarmuka pencarian digunakan oleh pengguna sistem untuk mencari dokumen yang berisi informasi yang diinginkan. Form pencarian dapat ditemukan pada setiap halaman dari sistem pencarian data. Gambar dari antarmuka pencarian dapat dilihat pada Gambar 3.14.
Banner
30/12/2005
Menu
Hasil Pencarian
Search :
Form Pencarian
54
Setelah selesai melakukan tahap pemodelan, pengembangan perangkat lunak mulai memasuki tahap pembangunan yaitu kegiatan implementasi dan pengujian perangkat lunak. Pada kegiatan implementasi ini menerjemahkan hasil analisis dan perancangan perangkat lunak ke dalam bahasa mesin yang dikenal oleh komputer. Sedangkan untuk tahap pengujian kinerja sistem diperhitungkan untuk menyesuaikan dengan hasil yang diinginkan.
Pada tahap implementasi dibuat dua buah modul dan lima buah submodul untuk mendukung penelitian mengenai temu-kembali informasi. Modul dan submodul tersebut adalah :
• Modul pengindeksan
o Submodul untuk parsing dan penghilangan stopwords pada pengindeksan
o Submodul perhitungan nilai variable idf
• Modul pencarian
o Submodul untuk pencarian frasa dari query
o Submodul untuk parsing dan penghilangan stopwords pada query
o Submodul pencocokan dokumen yang memiliki frasa tepat
a. Perangkat lunak yang digunakan:
• Sistem operasi : Microsoft Windows XP.
• Bahasa Pemrograman : PHP Versi 5.0.5
• Basis data : MySQL Versi 4.0.20a
b. Perangkat keras yang digunakan :
• Processor AMD Athlon (tm) XP 1800+ 1,533 Ghz
• Monitor 15”
• Harddisk 80 GB
• RAM 1 GB
• Keyboard + Mouse
4.1 Sistem Penyimpanan Data
Gambar 4.1 Antarmuka Login Sistem Penyimpanan
Namun sebelum menambahkan bagian dan dokumen, administrator harus melakukan login ke dalam sistem dengan memasukan nama user dan password. Sistem selanjutnya akan melakukan verifikasi nama user dan password yang dimasukan oleh administrator tadi dengan cara mencari nama user dan password
tersebut pada tabel t_user di dalam basis data. Antarmuka dari halaman login sistem penyimpanan dapat dilihat pada Gambar 4.1.
Gambar 4.2 Antarmuka Halaman Administrasi
4.1.2 Halaman Manipulasi Bagian
Gambar 4.3 Antarmuka Halaman Manipulasi Bagian
Pada halaman manipulasi bagian yang dapat dilihat pada Gambar 4.3, administrator akan memasukan nama bagian ke dalam form tambah bagian.untuk menambah bagian. Nanti nama bagian ini akan dimasukan ke dalam basis data. Namun, sebelumnya akan dilakukan pemeriksaan ke dalam basis data. Jika nama bagian yang akan ditambahkan sudah ada di dalam basis data, maka sistem akan menolak nama tersebut, sebaliknya jika nama tersebut belum ada maka sistem akan memasuki proses penambahan bagian baru.
Untuk pengubahan nama bagian, juga akan mengubah nama folder dari bagian tersebut. Dan untuk penghapusan bagian, akan menghapus seluruh dokumen yang ada di dalam bagian serta menghilangkan folder pada mendia penyimpanan harddisk. Potongan kode program dari penambahan, pengubahan dan penghapusan bagian dapat dilihat pada Gambar 4.4.
if ($action== "add"){
$bagian =$_POST['bagian']; if ($bagian==""){
$msg = "Error : Nama Bagian harus diisi !! <br>"; } else{
$sql = "select * from t_bagian where nama_bagian='$bagian'"; if (@mysql_num_rows(mysql_query($sql))){
$msg = "Error : Nama Bagian Sudah ada!! <br>"; }else {
$bag = preg_replace("/\W+/i","",$bagian); if (!$bag|| strlen($bag) <=1){
$msg = "Nama Bagian salah!!<br>"; } else{
$folder = preg_replace("/\W+/i","",$bagian); $folder = strtolower($folder);
header('Location: admin_bagian.php?msg='.urlencode(":: Bagian Berhasil di tambahkan!!"));
}else{
} elseif($action =="edit"){
$bagian_baru = $_GET['bagian_baru']; if ($bagian_baru==""){
$msg = "Error : Nama Bagian Baru harus diisi !! <br>"; } else{
$sql = "select * from t_bagian where nama_bagian='$bagian_baru'"; if (@mysql_num_rows(mysql_query($sql))){
$msg = "Error : Nama Bagian Sudah ada!! <br>"; }else {
$bag = preg_replace("/\W+/i","",$bagian_baru); if (!$bag|| strlen($bag) <=1){
$msg = "Nama Bagian Baru salah!!<br>"; } else{
$folder = preg_replace("/\W+/i","",$bagian_baru); $folder = strtolower($folder);
$folder = ereg_replace(" ", "_",$folder); $dir= "data/";
$sql = "Update t_bagian set nama_bagian='$bagian_baru', folder='$folder' where id_bagian='$id_bagian'"; if (mysql_query($sql)){
rename($dir.$folder_lama,$dir.$folder);
Gambar 4.4 Potongan Kode Program Manipulasi Bagian
4.1.3 Halaman Manipulasi Data
Setelah administrartor menambah sebuah bagian pada sistem, maka selanjutnya administrator dapat mulai menambahkan data yang berupa dokumen teks ke dalam sistem. Halaman manipulasi data (Gambar 4.5) pertama kali akan memberikan daftar dari dokumen yang disimpan di dalam sistem sesuai dengan nama bagian yang dipilih oleh administrator. Untuk menambah data baru pada bagian tersebut, maka administrator dapat menekan tombol “add” yang berada
}else{
} elseif($action == "empty"){
$sql = "select letak,temp_file from t_data where id_bagian='$id_bagian'"; $rs = mysql_query($sql);
while ($row = mysql_fetch_array($rs)){ unlink($row[0]);
@unlink($row[1]); }
$sql = "DELETE from t_data where id_bagian='$id_bagian'"; if (mysql_query($sql)){
header('Location: admin_bagian.php?msg='.urlencode(":: Bagian Berhasil di Kosongkan!!"));
}else{
$msg = "Query Error!! <br>"; $id_bagian="";
}
} elseif($action == "delete"){ $dir = "data/";
$sql = "select letak,temp_file from t_data where id_bagian='$id_bagian'"; $rs = mysql_query($sql);
while ($row = mysql_fetch_array($rs)){ unlink($row[0]);
@unlink($row[1]); }
$sql = "select folder from t_bagian where id_bagian='$id_bagian'"; $folder = mysql_fetch_row(mysql_query($sql));
$sql = "DELETE from t_data where id_bagian='$id_bagian'"; mysql_query($sql);
$sql = "Delete from t_bagian where id_bagian='$id_bagian'"; if (mysql_query($sql)){
rmdir($dir.$folder[0]);
header('Location: admin_bagian.php?msg='.urlencode(":: Bagian Berhasil di Hapus!!"));
}else{
$msg = "Query Error!! <br>"; $id_bagian="";
pada kanan atas dari daftar dokumen. Selanjutnya, halaman input data (Gambar 4.6) akan ditampilkan kepada administrator. Pada halaman ini, sebelum administrator memasukan dokumen, maka administrator minimal harus memasukan informasi mengenai nama data, bagian serta file dari data yang akan dimasukan ke dalam sistem. Jika semua persyaratan untuk memasukan dokumen sudah terpenuhi maka sistem akan melakukan proses penambahan data ke dalam tabel t_data pada basis data..
Gambar 4.6 Antarmuka Halaman Input Data
Sebelum sistem melakukan penambahan data dokumen ke dalam basis data, file dari dokumen akan di-upload ke dalam sistem dan diletakan sesuai dengan folder bagian yang sudah dipilih, selanjutnya sistem akan mengubah nama file dokumen menjadi format tahun_bulan_tanggal_jam_menit_detik_[nama file yang sudah di hilangkan spasi dan diubah huruf kapitalnya]. Hal ini bertujuan agar file yang memiliki nama yang sama tetapi isinya berbeda dapat dimasukan oleh administrator ke dalam sistem. Namun nama asli dari file dokumen tersebut akan disimpan di dalam basis data untuk digunakan pada saat pengguna dari sistem ingin men-download file tersebut.