Pemilihan Fitur Citra Hiperspektral Hymap Dan Model Prediksi Panen Padi Menggunakan Algoritma Genetika Dan Regresi Komponen Utama
(Feature selection of Hyperspectral remote sensing and prediction model with genetic algorithm and principal component regression)
Sidik Mulyono1, Erna Piantari2, Mohamad Ivan Fanany3, Tjan Basaruddin3 1
Badan Pengkajian dan Penerapan Teknologi
2
Mahasiswa S1 Departemen Ilmu Komputer Institut Pertanian Bogor
3
Fakultas Ilmu Komputer, Universitas Indonesia
Abstrak
Citra hiperspektral Hymap yang terdiri dari jumlah band yang sangat banyak, memerlukan metode analisa yang canggih untuk menganalisanya. Salah satu pendekatannya adalah mengurangi computational cost, dengan mengeliminasi band yang tidak memberikan nilai tambah terhadap analisa maupun model prediksi yang akan dilakukan, yaitu dengan menggunakan algoritma genetika yang dipadukan dengan regresi komponen utama. Nilai
fitnessyang digunakan untuk menentukan jumlah band yang paling optimal adalah nilaierrorterkecil berdasarkan kaidah norm dari model prediksi yang dibangun. Model prediksi yang terbangun ini dapat diaplikasikan ke dalam citra hiperspektral Hymapuntuk mengetahui sebaran produksifitas padi di suatu wilayah.
Kata kunci: Citra hiperspektral, algoritma genetika, regresi komponen utama, produktifitas padi
Abstract
Hymap Hyperspectral image consists of large number of bands which require sophisticated method to analyze. One approach to reduce computational cost and accelerate knowledge discovery, is to eliminate bands that do not add value to the analysis and prediction models that will be applied, by using genetic algorithms combined with principal component regression (GA-PCR). Fitness value that is used to determine the optimal number of band is defined as the smallest error based on norm principle which analysed from PCR. Prediction model developed in this study is then applied to the hyperspectral image to know the spatial distribution of paddy yield.
Index terms: Hymap hyperspectral image, genetic algorithms, principal component regression, paddy yield
1. Latar Belakang
Teknologi penginderaan jauh (inderaja) hiperspektral yang merupakan pengembangan teknologi inderaja terkini memiliki beberapa keunggulan yang sangat nyata dibanding teknologi inderaja multispektral sebelumnya. Dengan memiliki jumlah band yang berjumlah hingga ratusan kanal, membuat teknologi ini sangat memungkinkan untuk dikaji secara lebih rinci dalam memantau vegetasi pada umumnya, maupun yang lebih khusus seperti untuk memantau pertumbuhan dan perkembangan kondisi tanaman padi. Teknologi inderaja memiliki potensi untuk memberikan informasi tentang tanaman pertanian secara kuantitatif dan cepat, tanpa merusak tanaman itu sendiri di daerah cakupan yang sangat luas. Selain itu juga karena inderaja dapat memberikan informasi tentang status sebenarnya dari tanaman pertanian, maka integrasi antara data inderaja dan model simulasi pertumbuhan tanaman merupakan tren penting untuk estimasi hasil dan prediksi, (Huang Jing-feng et al., 2002).
Dalam makalah ini akan dibahas metode algoritma genetika yang dipadukan dengan regresi komponen utama (GA-PCR). Algoritma genetika akan membentuk konfigurasi band hiperspektral Hymap dari mulai pembentukan konfigurasi penuh seluruh band (berjumlah 116 band), dan melalui prosescross-overdan mutasi, akan dibentuk generasi baru yang jumlah bandnya semakin berkurang, tetapi keakurasiannya meningkat hingga mencapai titik konvergen. Setiap konfigurasi band yang terbentuk, akan dilakukan regresi menggunakan PCR terhadap 3 parameter agronomi, yaitu terhadap indeks luas daun (LAI), nilai kehijauan (yang direpresentasikan dalam bentuk nilai SPAD), serta produktifitas padi (yield). Penentuan kecocokan (fitness) dalam proses genetika ini dilakukan berdasarkan nilai terkecil dari error berdasarkan kaidahnorm yang dianalisis menggunakan PCR, lalu dikalibrasi dan diuji menggunakan 8 kali putaran sampling (8-fold train-test sampling). Proses genetika akan berhenti dengan sendirinya bila nilai fitness sudah mencapai nilai jenuh (convergence), dan konfigurasi band yang terbentuk menunjukan band optimal yang akan digunakan untuk membangun model prediksi tanaman padi.
2. Bahan dan Metoda (Teknik Analisis)
2.1 Area studi dan sampling
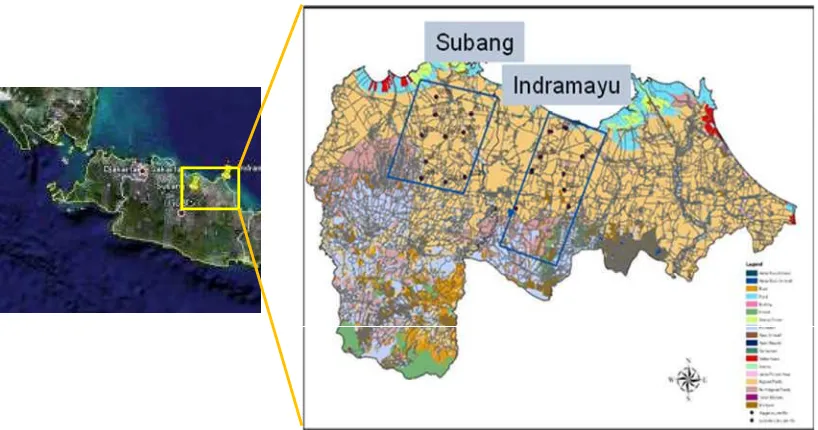
Studi dilakukan di 2 lokasi sentra produksi padi yaitu Kabupaten Subang (Koordinat : 107” 31’ - 107” 54’ Bujur timur dan 6” 1’ - 6” 49’ Lintang selatan) dan Kabupaten Indramayu (Koordinat : 107"51'-108"36' Bujur Timur dan 6"15' - 6"40' Lintang Selatan), propinsi Jawa Barat. Kedua kabupaten ini memiliki kontribusi lebih dari 2% dari seluruh produksi padi nasional dengan kemampuan panen rerata sekitar 5.5 sampai dengan 6.0 ton/ha.
Gambar 1. Lokasi studi pengamatan spectral (Field campaigndanAirborne campaign)
2.2 Pengambilan data
Pengamatan data hiperspektral dilakukan selama kegiatanairborne campaigntanggal 26 - 28 Juni 2008, menggunakan sensor Hymap yang dipasang di bawah lambung pesawat CESSNA 404 yang terbang dengan ketinggian 2.000 meter di atas permukaan laut, dan melintas di atas wilayah Subang dan Indramayu sebanyak 15 lintasan.
diukur posisinya menggunakan D-GPS. Data GPS ini akan digunakan untuk menentukan posisi petakan yang ada di dalam citra hiperspektral Hymap, dan menjadi acuan untuk mengekstrak data hiperspektral setiap petakan. Sedangkan untuk pengamatan ubinan (yield) dilakukan setelah pengukuran lapangan, yaitu menunggu waktu panen seluruh petakan yang menjadi objek pengamatan.
Data LAI, SPAD, dan yield disusun sedemikian rupa berdasarkan petakan, sehingga mudah untuk dipasangkan dengan nilai reflektan di setiap petakan pada citra HyMap, dan memiliki nilai statistik seperti yang ditunjukkan pada tabel 1.
Tabel 1. Nilai statistik dari hasil pengamatan LAI, SPAD, dan yield
Parameter yang
diamati Jumlah data
Nilai
Minimum Nilai rerata
Nilai Maksimum
Deviasi
standar Jangkauan
LAI (-) 109 0.146 2.450 5.432 1.359 5.286
SPAD (-) 110 28.3 37.87 44.3 3.52 16.0
Yield (ton/h) 73 2.27 6.452 9.87 1.835 7.60
2.3 Pemrosesan data
Pertama-tama dilakukan ekstraksi nilai spektral dari 126 band citra hiperspektral Hymap (yang sudah dilakukan koreksi radiometrik, koreksi atmosferik, serta koreksi geometrik) untuk setiap petakan, dengan menggunakan acuan data GPS setiap petakan. Dari hasil ekstrasi tersebut diperoleh data spektral hanya untuk 76 petakan saja. Jumlah ini sebetulnya sangat sedikit dibanding dengan rencana pengamatan di lapangan saatfield campaignberlangsung, sehingga diperlukan suatu teknik analisis yang handal untuk dapat membangun model prediksi yang akurat.
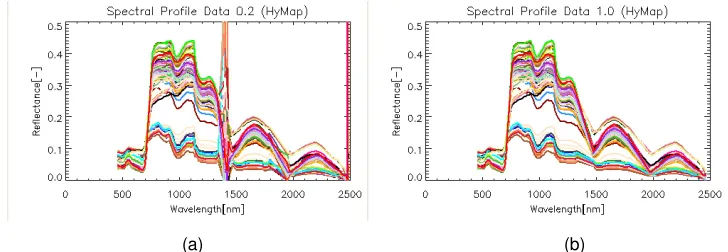
Data spektral yang sudah diekstrak tersebut kemudian diperiksa profil spektralnya yang mengalami derau akibat ketidakmampuan sensor mendeteksi cahaya pada panjang gelombang tertentu, karena telah diserap oleh uap air di udara (water absorption). Dari hasil pengamatan diketahui bahwa band yang mengalami derau ada sebanyak 10 band, dan band-band tersebut dieliminasi dari data set aslinya sehingga jumlah band yang tetap digunakan sebanyak 116 band.
Selanjutnya data spektral seluruh petakan yang sudah tereliminasi tersebut digabungkan ke dalam bentuk matriks, dimana jumlah kolom menunjukkan jumlah band hiperspektral dan jumlah baris menunjukkan jumlah petakan atau sampel spektral. Agar memudahkan dalam melakukan korelasi terhadap parameter agronomi dan Yield, maka setiap baris matriks tersebut diberi kode nama petakan. Dan untuk menghindari pengaruh ill condition dalam analisis, maka seluruh nilai spektral tersebut dinormalisasi dengan satuan 10.000.
(a) (b)
Gambar 2. Profil spektral hiperspektral Hymap (a) sebelum dan (b) sesudah eliminasi band
2.4 Kombinasi GA-PCR untuk menentukan jumlah band hiperspektral yang optimal
sehingga cocok diaplikasikan untuk pemilihan fitur dasar yang lebih handal dalam rangka meningkatkan kualitas analisis dan kualitas model prediksi.
Algoritma Genetika adalah algoritma yang dikembangkan dari proses pencarian solusi menggunakan pencarian acak, ini terlihat pada proses pembangkitan populasi awal yang menyatakan sekumpulan solusi yang dipilih secara acak. Selanjutnya pencarian dilakukan berdasarkan proses-proses teori genetika yang memperhatikan pemikiran bagaimana memperoleh individu yang lebih baik, sehingga dalam proses evolusi dapat diharapkan diperoleh individu yang terbaik (Achmad Basuki, 2003).
Dalam penelitian ini algoritma genetika diaplikasikan ke dalam data hiperspektral untuk mencari jumlah band yang optimal yang dapat digunakan untuk membangun model prediksi. Yang dimaksud dengan jumlah band optimal adalah jumlah band yang relatif lebih sedikit dari data set aslinya, tetapi dapat meningkatkan keakuratan model yang akan dibangun serta dapat mengurangi beban komputasi (computational cost). Populasi awal yang dibentuk adalah sebanyak 20 individu dengan 116 gen biner, yaitu sesuai dengan jumlah band hiperspektral yang telah dieliminasi. Untuk generasi pertama, seluruh individu dibuat memiliki nilai biner 1, sebagai acuan solusi untuk seluruh band yang tersedia. Kemudian untuk generasi berikutnya akan dikombinasikan dengan pembangkitan acak, seleksi, perkawinan silang (cross-over) dan mutasi gen.
Seleksi dilakukan berdasarkan nilaifitnesssetiap individu, dimana setiap individu memiliki nilaifitness sesuai dengan gen yang terbentuk secara acak, yang merupakan penentu dari solusi yang paling optimal. Nilaifitness ini diperoleh dari proses korelasi antara gen (yang merupakan representasi dari jumlah band) yang terbentuk secara acak dalam proses seleksi dan dikorelasikan dengan suatu variable terikat. Untuk mendapatkan korelasi tersebut sebagai acuan fitness, adalah dengan mengaplikasikan regresi komponen utama (principal component regression) ke dalam algoritma genetika.
Analisa komponen utama merupakan salah satu solusi untuk menghindari masalah multi kolinearitas. Pada dasarnya analisa ini adalah bertujuan untuk menyederhanakan variabel yang diamati dengan cara menyusutkan (mereduksi) dimensinya. Hal ini dilakukan dengan cara menghilangkan korelasi diantara variabel bebas melalui transformasi variabel-variabel bebas asal ke variabel baru yang tidak berkorelasi sama sekali atau yang biasa disebut dengan komponen utama (principal component). Setelah beberapa komponen utama yang bebas multikolinearitas diperoleh, maka komponen-komponen tersebut menjadi variabel bebas baru yang akan diregresikan atau dianalisa pengaruhnya terhadap variabel tak bebas dengan menggunakan analisis regresi. Salah satu cara untuk mendapatkan komponen utama adalah dengan metode Singular Value Decomposition(SVD), yaitu dengan memfaktorkan matrik yang terbentuk dari gen pada proses algoritma genetika, ke dalam 2 matrik orthogonal dan 1 matrik diagonal. Setelah komponen utama terbentuk, kemudian diregresikan menggunakan metode kuadrat terkecil (least square method). Dan model prediksi yang terbentuk dari hasil regresi komponen utama (Bent Jørgensen et al, 2007)ditunjukan pada persamaan (1).
(1)
Dari hasil analisa regresi ini kemudian dihitung besar simpangan (error) terhadap nilai aslinya, dengan menggunakan kaidahnorm-p(T. Basaruddin, 2007), ditunjukan oleh persamaan (2).
Dimana merupakan anggota dari [1,2,∞], adalah jumlah sampel, dan masing-masing adalah nilai variabel terikat hasil pengukuran dan hasil prediksi. Norm-2 lebih dikenal sebagai euclidean norm atau setara dengan nilai root mean square error (RMSE), sedangkan norm-1 merupakan akumulasi jumlaherrorkeseluruhan, dannorm-∞ merupakan nilaierrormaksimum yang ada diantara seluruh sampel yang ada. Bila jumlah generasi yang dibangkitkan melalui algoritma genetika ini dinotasikan sebagai , maka nilai fitness dari setiap tahapan seleksi dihitung menggunakan persamaan (3).
(3)
Sedangkan koefisien determinasi (R2) yang menunjukan nilai kedekatan suatu model prediksi terhadap variable terikat dihitung setelah proses fitness sudah mencapai kondisi konvergen pada suatu titik, yang dihitung menggunakan persamaan statistik berikut ini.
(4)
Dimana,
Karena jumlah sampel yang sangat terbatas, maka untuk meningkatkan akurasi dalam proses kalibrasi regresi (model prediksi), sampel yang tersedia dibagi ke dalam 8 bagian secara acak, yaitu 1 bagian merupakan data pengujian (test set), sedangkan sisanya merupakan data pelatihan (train set). Proses kalibrasi dilakukan secara iterasi sebanyak 8 kali pelatihan dan pengujian. Dari hasil pengujian diperoleh 8 alternatif hasil dan model yang terbaik dipilih berdasarkan nilai norm yang paling minimum, hal ini mirip seperti metode penentuan nilaifitnesspada persamaan (3).
Gambar 3. Siklus GA-PCR untuk pemilihan band optimal dan pembangunan model prediksi
Populasi awal
Reproduksi: Cross-Over dan
mutasi Seleksi individu Elitism
Popu lasi baru
PC
Evaluasi fitness
Yes
No
3. Hasil dan Pembahasan
Kode program untuk algoritma genetika ini diadopsi dariIDL genetic algorithmsAllard De Wit yang bebas diunduh dan digunakan tanpa harus menggunakan lisensi hak cipta. Dengan sedikit modifikasi kode program IDL yang dipadukan dengan kode program PCR, program ini dijalankan dengan membangkitkan 100 generasi, menggunakan data hiperspektral HyMap dan parameter agronomi sertayieldsebagai data input.
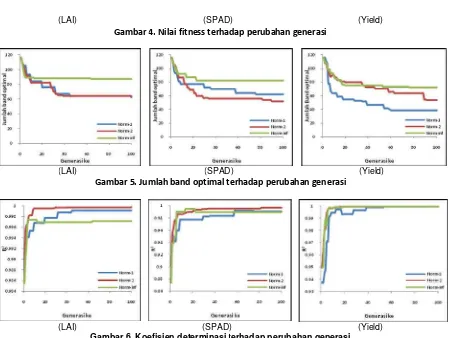
Gambar 4, 5, dan 6 masing-masing menunjukkan perubahan nilaifitness, jumlah band optimal, serta nilai koefisien determinasi R2 selama proses generasi berlangsung yang dikorelasikan terhadap variabel terikat LAI, SPAD, dan Yield. Secara umum dapat diketahui bahwafitness yang menggunakan norm-∞ lebih cepat mencapai kondisi konvergen, karena penggunaan computational cost untuk norm-∞ adalah yang paling sederhana dibanding dengan normlainnya. Tetapi dilihat dari sisi capaian jumlah band dan koefisien determinasi yang dihasilkannorm-∞ tidak seoptimalnormlainnya, sehingga dalam hal ininorm
-∞ tidak digunakan untuk penentuan band optimal, dan cenderung menggunakan norm-1 atau norm-2. Untuk prediksi LAI dan SPAD, fitness yang paling tepat digunakan adalah error dengan kaidahnorm-2 yang capaian jumlah band paling sedikit (52 band dan 62 band) dan capaian R2paling tinggi (0.9998 dan 0.9972). Sedangkan untuk model prediksi Yield, fitness yang paling tepat digunakan adalah norm-1 dengan capaian jumlah band adalah 39 dan R2 mencapai 0.9996. Dengan memilih jumlah band paling sedikit, diharapkan dapat mengurangi beban komputasi pada saat model ini diaplikasikan ke dalam citra yang sesungguhnya dan tanpa mengurangi tingkat keakurasiannya.
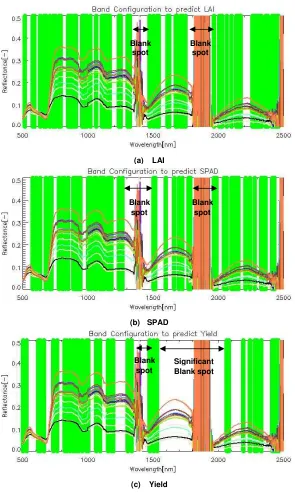
Pada tabel 3a – 3c ditunjukkan k onfigurasi band optimal dalam bentuk biner, dimana nilai 1 menunjukkan band yang aktif, dan nilai 0 menunjukkan band yang tidak diperlukan. Dari bentuk biner kemudian konfigurasi band optimal ini ditampilkan dalam bentuk pita hijau di atas profil hiperspektral,yang masing-masing digunakan untuk memprediksi LAI, SPAD, dan Yield, seperti yang ditunjukan pada gambar 7. Dari gambar tersebut diketahui bahwa konfigurasi band optimal untuk LAI dan SPAD memiliki konfigurasi yang unik, yaitu terdapat daerah blank spot (band kosong) yang hampir sama minimal di 2 lokasi, masing-masing adalah 1280 ~ 1488 nm, dan 1736 ~ 1784 nm. Sedangkan untuk Yield terlihat terdapat blank spot yang lebih luas lagi di sekitar 1543 ~ 2045 nm. Hal ini menunjukan bahwa untuk keperluan prediksi, daerah-daerahblank spottersebut tidak diperlukan sama sekali sehingga dapat dieliminasi dan dapat meningkatkan kecepatan komputasi serta meningkatkan akurasi. Dari gambar ini juga dapat diketahui bahwa pemilihan fitur hiperspektral menggunakan GA-PCR secara relatif dapat juga menghilangkan pengaruh derau (water absorption) di sekitar 1280 ~ 1488 nm dan 1736 ~ 1784 nm, tetapi tidak mampu mengeliminasi derau yang terjadi di atas 2000 nm, karena kemampuan algoritma genetika yang tidak sensitive terhadap derau kecil.
(LAI) (SPAD) (Yield)
Gambar 4. Nilai fitness terhadap perubahan generasi
(LAI) (SPAD) (Yield)
Gambar 5. Jumlah band optimal terhadap perubahan generasi
(LAI) (SPAD) (Yield)
Gambar 6. Koefisien determinasi terhadap perubahan generasi
Tabel 2. Kumulasi hasil pemilihan fitur (band) menggunakan GA-PCR
Parameter agronomi n bandNorm-1 R2 Norm-2 Norm-∞
n band R2 n band R2
LAI 64 0.9999 62 0.9998 87 0.9997
SPAD 62 0.9910 52 0.9972 82 0.9896
Yield 39 0.9996 54 0.9999 72 0.9998
Tabel 3a. Konfigurasi biner band optimal (459 ~ 1094 nm)
LAI 0 1 1 0 1 0 0 0 1 1 0 0 1 0 1 1 0 1 0 1 1 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 1 1 0 1 0 0 1 0 0 SPAD 0 1 0 0 0 0 0 0 1 0 1 0 1 0 0 1 0 1 1 0 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 0 0 0 1 1 0 1 1 0 1 Yield 1 1 0 1 0 1 0 0 0 0 0 1 1 0 1 0 0 0 0 1 0 1 0 0 0 1 1 0 1 0 1 0 1 1 0 1 0 1 1 0 0 0 1 0 1
Tabel 3b. Konfigurasi biner band optimal (1109 ~ 2006 nm)
LAI 1 1 1 1 1 0 0 0 0 1 1 0 0 0 1 1 0 1 0 1 0 1 1 0 0 0 0 1 1 0 0 0 1 1 0 1 1 0 1 0 0 0 1 0 1 SPAD 1 1 0 1 1 1 0 0 0 1 0 1 0 0 0 0 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 1 0 0 1 0 1 0 0 0 1 1 1 1 0 Yield 0 0 0 1 0 1 1 0 0 0 0 0 0 0 1 0 1 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Tabel 3c. Konfigurasi biner band optimal (2026~ 2460 nm)
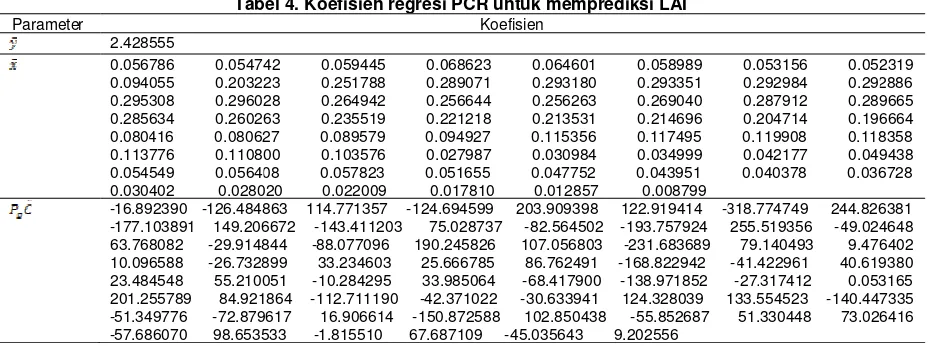
Tabel 4. Koefisien regresi PCR untuk memprediksi LAI
Parameter Koefisien
2.428555
0.056786 0.054742 0.059445 0.068623 0.064601 0.058989 0.053156 0.052319 0.094055 0.203223 0.251788 0.289071 0.293180 0.293351 0.292984 0.292886 0.295308 0.296028 0.264942 0.256644 0.256263 0.269040 0.287912 0.289665 0.285634 0.260263 0.235519 0.221218 0.213531 0.214696 0.204714 0.196664 0.080416 0.080627 0.089579 0.094927 0.115356 0.117495 0.119908 0.118358 0.113776 0.110800 0.103576 0.027987 0.030984 0.034999 0.042177 0.049438 0.054549 0.056408 0.057823 0.051655 0.047752 0.043951 0.040378 0.036728 0.030402 0.028020 0.022009 0.017810 0.012857 0.008799
-16.892390 -126.484863 114.771357 -124.694599 203.909398 122.919414 -318.774749 244.826381 -177.103891 149.206672 -143.411203 75.028737 -82.564502 -193.757924 255.519356 -49.024648 63.768082 -29.914844 -88.077096 190.245826 107.056803 -231.683689 79.140493 9.476402 10.096588 -26.732899 33.234603 25.666785 86.762491 -168.822942 -41.422961 40.619380 23.484548 55.210051 -10.284295 33.985064 -68.417900 -138.971852 -27.317412 0.053165 201.255789 84.921864 -112.711190 -42.371022 -30.633941 124.328039 133.554523 -140.447335 -51.349776 -72.879617 16.906614 -150.872588 102.850438 -55.852687 51.330448 73.026416 -57.686070 98.653533 -1.815510 67.687109 -45.035643 9.202556
Tabel 5. Koefisien regresi PCR untuk memprediksi SPAD
Parameter Koefisien
37.749996
0.057146 0.068904 0.062817 0.059323 0.052578 0.094434 0.141725 0.288234 0.295002 0.295906 0.292415 0.293466 0.294572 0.295277 0.290965 0.278318 0.261020 0.268419 0.282926 0.287181 0.288218 0.289158 0.285270 0.234933 0.220884 0.215247 0.213293 0.214558 0.080275 0.084179 0.112169 0.120527 0.115918 0.110548 0.097990 0.097269 0.027786 0.027942 0.037574 0.041866 0.049111 0.051992 0.054269 0.056087 0.059079 0.055144 0.047536 0.036534 0.033248 0.030149 0.021773 0.017727
388.418228 -495.939145 -1016.715647 183.452978 1013.702405 -712.678291 671.011847 522.548986 -1304.549693 969.119853 -622.764520 1113.728824 -608.559438 487.286865 -928.612533 243.789893 290.376472 974.521030 -1366.957283 285.471966 1336.329101 -682.564494 -280.166293 -381.628049 -928.385622 -617.609881 2667.819969 -1207.056213 671.844826 -45.714218 110.373108 -852.870351 -983.021433 964.197080 1228.341638 -83.127371 -399.706674 -305.846498 -495.813787 1325.498711 1769.742110 -2310.988441 -692.192917 -985.784091 730.977199 -2334.821629 1067.920814 1060.261927 1492.997230 -310.268263 146.439134 -681.072187
Tabel 6. Koefisien regresi PCR untuk memprediksi Yield
Parameter Koefisien
7.318333
0.063726 0.061328 0.059564 0.071924 0.067070 0.065782 0.060419 0.198180 0.262338 0.279387 0.278320 0.277606 0.279869 0.280813 0.276979 0.254628 0.248250 0.252849 0.277403 0.278643 0.231379 0.213105 0.210209 0.204173 0.188494 0.085639 0.086684 0.095746 0.047704 0.051244 0.064653 0.060363 0.052516 0.048524 0.040644 0.025539 0.020453 0.015548 0.010038
(a) LAI
(b) SPAD
(c) Yield
Gambar 7. Konfigurasi band optimal
Significant Blank spot Blank spot Blank
spot
Blank spot Blank
spot
4. Kesimpulan
Pada penelitian ini telah dilakukan pemilihan fitur (band) hiperspektral Hymap dengan metode kombinasi GA-PCR. Nilai fitness yang digunakan adalah mengacu pada nilai error terkecil dari 3 kaidah norm. Karena nilai fitness diorientasikan untuk mencari nilai error yang terkecil, maka model prediksi yang dihasilkan GA-PCR ini memiliki tingkat keakurasian yang cukup tinggi. Ini terbukti dari koefisien determinasi yang dihasilkan hampir mendekati nilai 1.
Selain itu, GA-PCR juga menghasilkan konfigurasi band optimal yang jauh lebih sedikit dari jumlah band aslinya, sehingga akan dapat meningkatkan kecepatan komputasi pada saat melakukan prediksi terhadap citra hiperspektral Hymap.
Secara relatif, GA-PCR juga dapat menghilangkan band-band yang berpengaruh derau yang diakibatkan oleh resapan spectrum cahaya oleh uap air di udara, sehingga diharapkan dapat membantu tahapan pra proses pengolahan citra hiperspektral.
Model prediksi yang dibangun dalam penelitian ini dikalibrasi dengan data hiperspektral tanaman padi, sehingga hanya efektif digunakan untuk objek tanaman padi saja. Agar model prediksi ini dapat digunakan secara optimal, maka harus diintegrasikan dengan metode klasifikasi citra yang khusus untuk objek tanaman padi.
Teknologi hiperspektral telah membuka wawasan dan paradigma berpikir baru bagi para peneliti di bidang inderaja, serta memberikan peluang yang sangat luas untuk mengaplikasikan teknologi ini untuk berbagai keperluan yang lebih mendukung kebutuhan hidup dan kesejahterraan manusia.
5. Referensi.
Achmad Basuki, “ALGORITMA GENETIKA, Suatu Alternatif Penyelesaian Permasalahan Searching, Optimasi dan Machine Learning”, Politeknik Elektronika Negeri Surabaya, PENS –ITS, Surabaya 2003
Allard de Wit, “IDL Genetic Algorithms”, available at http://ajwwag.home.xs4all.nl/, 21 March 2011
Bent Jørgensen and Yuri Goegebeur, “Multivariate Data Analysis and Chemometrics: Modul 6: Principal Components Regression”, http://statmaster.sdu.dk/courses/ST02, 2007
Gustavo Camps-Valls, and Lorenzo Bruzzone, “Kernel Based Method for Hyperspectral Image Classification”, IEEE Transactions on Geoscience and Remote Sensing, Vol. 43, no. 6, June 2005
Haleh Vafaie and Kenneth De Jong, “Genetic Algorithms as a Tool for Feature Selection in Machine Learning”, Center for Artificial Intelligence, George Mason University
Huang Jingfeng, Tang Shuchuan, Ousama Abou-Ismail, Wang Renchao, “Rice yield estimation using remote sensing and simulation model”, JOURNAL OF ZHEJIANG UNIVERSITY SCIENCE, 2002, 3 (4): 461-466