Fakultas Ilmu Komputer
8420
Algoritma Genetika Untuk Optimasi Fuzzy Time Series Dalam
Memprediksi Debit Air (Studi Kasus: PDAM Indramayu)
Mohamad Alfi Fauzan1, Budi Darma Setiawan2, Indriati3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Ketersediaan air di negara Indonesia mencapai 694 milyar m3 per tahun, dimana jumlah tersebut
merupakan potensi yang dapat dimanfaatkan namun hanya sekitar 23% yang termanfaatkan. Dengan jumlah kebutuhan air bersih masyarakat yang semakin meningkat namun distribusi debit air yang rendah, konsep peramalan atau prediksi sangat diperlukan sebagai salah satu input dalam pengambilan keputusan untuk peningkatan debit air yang akan didistribusikan. Untuk menyelesaikan permasalahan tersebut pada penelitian ini digunakan metode fuzzy time series yang dioptimasi dengan algoritme genetika dalam memprediksi distribusi debit air. Algoritme genetika digunakan untuk mengoptimasi sub interval di fuzzy time series. Berdasarkan hasil pengujian didapatkan tingkat akurasi hasil prediksi yang menggunakan metode Average Forecasting Error Rate (AFER) didapatkan hasil presentase tingkat error sebesar 15,33% yang termasuk ke dalam kualifikasi baik.
Kata Kunci: Debit air, prediksi, algoritme genetika, fuzzy time series.
Abstract
The availability of water in the country of Indonesia reaches 694 billion m3 per year, where the amount is a potential that can be utilized but only about 23% is utilized. With the increasing number of people needing clean water but low water debit distribution, the concept of forecasting or prediction is needed as one of the inputs in making decisions to increase the flow of water to be distributed. To solve these problems in this study fuzzy time series methods are optimized with genetic algorithms in predicting the distribution of water discharge. Genetic algorithm is used to optimize sub intervals in fuzzy time series. Based on the results of the test, the accuracy of the prediction results obtained using the Average Forecasting Error Rate (AFER) method obtained the percentage error rate of 15.33% which included in the good qualifications.
Keywords: Water debit, prediction, genetic algorithm, fuzzy time series
1. PENDAHULUAN
Air merupakan salah satu sumber daya alam yang memiliki peranan dalam keberlangsungan hidup dan kehidupan makhluk hidup terutama manusia (Arsyad, 1989). Ketersediaan air sangat berpengaruh terhadap kehidupan manusia, bahkan air dapat menjadi salah satu faktor penghambat pertumbuhan perekonomian suatu Negara (Schouten, 2006).
Seiring berkembangnya zaman, kebutuhan masyarakat akan air bersih dari tahun ke tahun semakin meningkat. Pada tahun 2000 dengan jumlah penduduk dunia sebesar 6,121 milyar kebutuhan air bersih mencapai 367 km3 per hari,
sehingga untuk memenuhi kebutuhan air bersih
penduduk dunia pada tahun 2025 diperlukan air bersih sebesar 492 km3 per hari dan pada tahun
2100 diperlukan air bersih sebesar 611 km3 per
hari (Suripin, 2002). Seperti hal nya di kecamatan Indramayu, kabupaten Indramayu yang menunujukan kebutuhan air bersih total penduduk kecamatan Indramayu pada tahun 2015 mencapai sebanyak 90 liter/orang/hari (Lukman dkk, 2015).
dalam 24 jam penuhBerdasarkan permasalahan tersebut dapat menggunakan program yang dapat melakukan prediksi terhadap produksi debit air yang akan didistribusikan. Prediksi produksi debit air ini dapat menggunakan proses peramalan kuantitatif berdasarkan data distribusi yang berada di PDAM Tirta Darma Ayu Indramayu.
Terdapat beberapa penelitian sebelumnya, Penelitian pertama yaitu yang dilakukan oleh Andhi, dkk (2018) dalam penelitiannya yang berjudul ”Algoritma Genetika Untuk Optimasi Fuzzy Time Series Dalam Memprediksi Kepadatan Lalu Lintas di Jalan Tol”, dimana hasil dari penelitian tersebut didapatkan hasil presentase tingkat error 16,66% yang termasuk ke dalam kualifikasi baik dan berhasil. Penelitian lain yang dilakukan oleh Afif, dkk (2018) dalam penelitiannya yang berjudul “Peramalan Produksi Gula Pasir Menggunakan Fuzzy Time Series Dengan Optimasi Algoritma Genetika (Studi Kasus PG Candi Baru Sidoarjo)”, dimana hasil dari penelitian tersebut didapatkan hasil presentase tingkat error 1,9% yang termasuk ke dalam kualifikasi baik.
Oleh karena itu pada skripsi ini akan dilakukan penelitian dengan metode peramalan untuk prediksi produksi debit air menggunakan fuzzy time series dan dioptimasi dengan algoritme genetika guna mendapatkan tingkat akurasi yang tinggi dan tingkat kesalahan yang rendah. Diharapkan dalam penelitian yang dilakukan dapat membantu PDAM Tirta Darma Ayu Indramayu dalam memprediksi debit air yang akan di distribusi, sehingga pemilihan waktu untuk pengambilan air dari sumber air baku tidak berdampak pada semakin rendahnya distribusi air.
2. DASAR TEORI
2.1 Fuzzy Time Series
Menurut Chen (1996), fuzzy time series merupakan salah satu metode soft computing untuk memprediksi data dengan menggunakan dasar fuzzy. Prinsip kerja sistem fuzzy adalah dengan mencari pola-pola dari data yang telah tersedia untuk menghasilkan data baru yang diharapkan. Dalam memprediksi atau peramalan dengan metode fuzzy time series menggunakan nilai-nilai dalam himpunan fuzzy yang telah didapat dari bilangan real. Himpunan fuzzy dalam metode ini digunakan sebagai pengganti data sebelumnya menjadi data yang diharapkan. Menurut Robandi (2006), proses dari fuzzy time
series lebih mudah dari yang ada pada jaringan syaraf tiruan dan algoritme genetika sehingga dapat dikembangkan untuk penelitian sebelumya.
Berikut adalah langkah-langkah dalam melakukan peramalan dengan model fuzzy time series (Chen, 1996):
• Menentukan himpunan awal semesta (universe of discourse).
• Membagi sub himpunan semesta menjadi beberapa interval berdasarkan data distribusi debit air yang digunakan dengan mencari data maksimal dan data minimal. Dengan cara: U = [Dmin – D1 ; Dmax + D2],
dengan D1 dan D2 adalah nilai konstanta.
• Menentukan linguistic variable dan membership function dengan menggunakan interval.
• Melakukan proses fuzzyfikasi dari data historis.
• Menentukan nilai Fuzzy Logical Relationship dari hasil fuzzyfikasi kemudian melakukan Fuzzy Logical Relationship Group dimana jika mempunyai anggota relasi yang sama maka akan dikelompokan menjadi satu grup. • Melakukan proses inferensi dan
defuzzyfikasi.
2.2 Algoritme Genetika
Siklus algoritme genetika sendiri terdiri dari beberapa proses. Berikut ini adalah siklus dari algoritme genetika:
a. Inisialisasi
Pada tahap inisialisasi ini himpunan individu yang acak terdiri dari string chromosome akan ditempatkan pada penampungan dan menjadi populasi. Pada tahap ini juga akan menentukan ukuran dari populasi yang telah terbentuk.
b. Reproduksi
Pada tahap reproduksi terdiri dari dari dua jenis reproduksi yaitu Mutation dan Crossover. Dalam tahap reproduksi ini akan menghasilkan keturunan yang berasal dari induk yang sudah terpilih dari tahap inisialisasi dan ditempatkan di offspring.
c. Evaluasi
Pada tahap evaluasi, individu dan keturunan yang telah dibuat akan dicari nilai fitness nya untuk dilanjutkan ke tahap seleksi.
d. Seleksi
Tahap seleksi adalah tahap terakhir yang terdapat pada siklus algoritme genetika. Dalam tahap ini berfungsi untuk memilih individu dengan solusi terbaik berdasarkan nilai fitness tertinggi dan dijadikan sebagai individu untuk generasi selanjutnya.
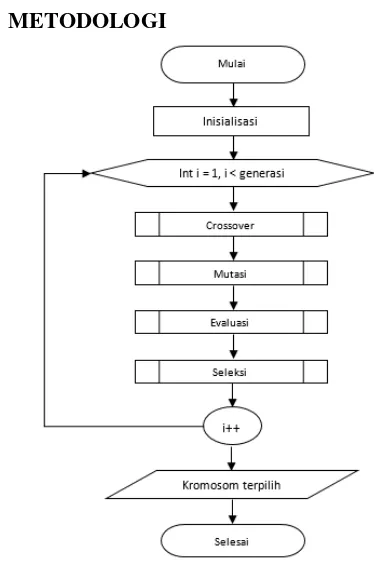
3. METODOLOGI
Gambar 1. Tahapan Alur Sistem
Pada penelitian ini, algoritma fuzzy time series digunakan dalam pembuatan sistem
prediksi distribusi debit air di PDAM Indramayu. Dalam pembuatan sistemnya, dioptimasikan dengan algoritme genetika. Langkah-langkah selama proses pembuatan sistem dari algoritma dapat dilihat pada Gambar 1.
4. PENGUJIAN DAN ANALISIS
4.1 Pengujian Ukuran Populasi
Pengujian ini dilakukan dengan percobaan 15 kali dengan nilai populasi kelipatan 10 yang mana jumlah akhir dari nilai populasi yaitu 150. Untuk generasi yaitu 1000, Cr yaitu 0.5, Mr yaitu 0,5.
Gambar 1. Pengujian Ukuran Populasi
Pada Gambar 1 dapat disimpulkan bahwa nilai 70, 110, dan 150 menghasilkan nilai fitness tertinggi dengan nilai fitness sebesar 0.000045, kemudian nilai fitness yang diambil untuk pengujian selanjutnya dengan nilai 110, karena nilai selanjutnya dinyatakan konvergen, karena perubahan pada nilai fitness tersebut tidak mengalami perubahan yang signifikan.
4.2 Pengujian Crossover Rate (Cr)
Pengujian ini dilakukan dengan percobaan 10 kali dengan nilai crossover rate kelipatan 0.1 yang mana jumlah akhir dari nilai crossover rate yaitu 1. Untuk nilai populasi yaitu 110, generasi yaitu 1000, dan Mr yaitu 0,5.
Gambar 2. Pengujian Crossover Rate (Cr)
fitness yang paling besar terjadi pada nilai 0.9 yang menghasilkan nilai fitness sebesar 0.000053, sedangkan pada nilai 0.1 yang menghasilkan nilai fitness sebesar 0.000029 dapat dikatakan rata-rata fitness yang paling kecil.
4.3 Pengujian Mutation Rate (Mr)
Pengujian ini dilakukan dengan percobaan 10 kali dengan nilai mutation rate kelipatan 0.1 yang mana jumlah akhir dari nilai mutation rate yaitu 1. Untuk nilai populasi yaitu 110, generasi yaitu 1000, dan Cr yaitu 0,9.
Gambar 3. Pengujian Mutation Rate (Mr)
Pada Gambar 3 didapatkan nilai rata-rata fitness yang paling besar terjadi pada pengujian mutation rate dengan nilai 0.5 yang menghasilkan nilai fitness sebesar 0.000055, sedangkan pada nilai 0.9 yang menghasilkan nilai fitness sebesar 0.000049 dapat dikatakan rata-rata fitness yang paling kecil.
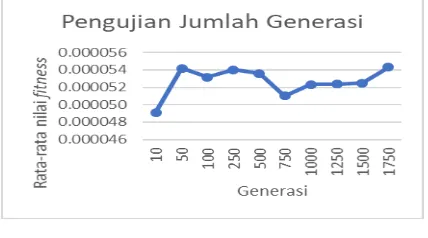
4.4 Pengujian Jumlah Generasi
Pengujian ini dilakukan dengan percobaan 10 kali. Untuk populasi yaitu 110, Cr yaitu 0.9, Mr yaitu 0,5.
Gambar 4. Pengujian Jumlah Generasi
Pada Gambar 4 dapat disimpulkan bahwa rata-rata nilai fitness yang paling besar terjadi
pada pengujian jumlah generasi dengan nilai 1750 yang menghasilkan nilai fitness sebesar 0.000054, sedangkan pada jumlah generasi dengan nilai 10 yang menghasilkan nilai fitness sebesar 0.000049 dapat dikatakan rata-rata fitness yang paling kecil.
4.5 Pengujian Tingkat Akurasi
Pengujian tingkat akurasi ini akan dijelaskan beberapa langkah untuk mendapatkan nilai presentase error guna mengetahui seberapa akurat hasil yang didapatkan. Pengujian ini menggunakan Average Forecasting Error Rate (AFER).
Tabel 2. Tabel pengujian tingkat akurasi Bulan
(2017)
Distribusi debit air
(a)
Hasil Prediksi
(b)
Error a-b
Januari 596.525 649.634 53.109 Februari 554.454 659.025 104.571
Maret 570.332 616.954 46.622 April 637.164 632.832 4.332
Mei 597.852 669.664 71.812 Juni 661.061 669.727 8.666
Jumlah 3.617.388 289.112
AFER = ∑|𝐴𝑖−𝐹𝑖|/𝐴𝑖
𝑛 x 100% = 3617388−289112/3617388
6 x 100%
= 15,33%
Pada perhitungan AFER, Ai merupakan nilai data aktual dan Fi merupakan jumlah dari semua nilai selisih dari data aktual dan hasil prediksi. Adapun n merupakan banyaknya data yang digunakan dalam pengujian. Nilai AFER adalah nilai yang menyatakan presentase selisih antara data prediksi dengan data asli. Nilai AFER dapat dikatakan baik jika nilai errornya semakin kecil (Rahmadiani, 2012). Dengan menggunakan error AFER ini bisa dikatakan mendekati kebenaran jika nilai error yang didapatkan mendekati 0% meskipun jarang sekali ada kasus yang menghasilkan nilai benar-benar tepat 0% (Stevenson, 2009).
5. PENUTUP
5.1 Kesimpulan
0.9, Mr = 0.5, dan nilai jumlah generasi = 1750. Pengujian tingkat akurasi yang dilakukan pada penelitian ini menggunakan metode Average Forecasting Error Rate (AFER). Nilai sebesar 15,33% dengan data latih sebanyak 6 bulan. Dapat dikatakan nilai persentase tingkat error pada pengujian tersebut masih dikatakan belum terlalu optimal karena kurangnya pada data latih yang digunakan.
5.2 Saran
Menggunakan metode fuzzy time series yang lainnya untuk dibandingkan nilai akurasinya.
Menggunakan lebih banyak data sehingga tingkat akurasi dalam pengujian lebih optimal.
6. DAFTAR PUSTAKA
Afif, Dian, dan Bayu, R. 2018. Peramalan Produksi Gula Pasir Mneggunakan Fuzzy Time Series Dengan Optimasi Algoritma Genetika (Studi Kasus PG Candi Baru Sidoarjo). Jurnal PTIIK Vol. 2, No. 8, Agustus 2018, Hlm. 2542-2548
Arsyad, S. 1989. Konservasi Tanah dan Air. IPB Press, Bogor.
Chen, S.M., 1996, “Forecasting enrollments based on fuzzy time series - Fuzzy Sets and Systems” International Journal of Applied Science and Engineering Vol. 81 (1996) 311-319.
Kusumadewi, Sri. 2003. Artificial Intelligence (Teknik dan Aplikasinya). Graha Ilmu. Yogyakarta. Pramonoaji, dkk. 2013. Prediksi Produksi Air PDAM dengan Jaringan Syaraf Tiruan. Fakultas Ilmu Komputer, Universitas Dian Nuswantoro, Semarang.
Lukman., dkk. 2015. Proyeksi Kebutuhan Air Bersih Pneuduk Kecamatan Indramayu Kabupaten Indramayu Sampai Tahun 2035. Antologi Geografi, Vol. 3, No. 3. Desember, 2015.
Robandi, Iman. 2006. Desain Tenaga Modern Optimisasi, Logika Fuzzy, dan Algoritma Genetika. Yogyakarta.
Schouten, M. 2006. Integrated Water Resources Management. Unpublish Lectures Note. Delft: UNESCO-IHE Institute for Water Education
Suripin. 2002. Pelestarian Sumber Daya Tanah dan Air. Andi. Yogyakarta
Wicaksana, Andhi., dkk. 2018. Algoritma Genetika Untuk Optimasi Fuzzy Time