11
REGRESI LINIER BERGANDA
Pengertian Regresi linier Berganda
Pada bab sebelumnya telah dibahas tentang regresi linier dengan 2 (dua) variabel (yaitu variabel Y dan X) atau biasa disebut dengan single linier regression. Pada bab ini jumlah variabel yang digunakan akan ditambah menjadi lebih banyak, yaitu satu variabel Y dan jumlah variabel X nya lebih dari 1 (satu) variabel. Artinya, variabel X bisa berjumlah 2, 3, atau lebih. Jumlah X yang lebih dari satu tersebut terkenal dengan istilah Regresi Linier Berganda atau multiple linier regression.
Bertambahnya jumlah variabel X hingga lebih dari satu sangat memungkinkan, karena dalam keilmuan sosial semua faktor-vaktor atau variabel-variabel saling berkaitan satu dengan lainnya. Sebagai misal, munculnya inflasi tentu tidak hanya dipengaruhi oleh bunga deposito (budep) saja seperti yang telah diterangkan di atas, tetapi sangat mungkin dipengaruhi oleh faktor lain seperti perubahan nilai tukar (kurs), jumlah uang beredar, kelangkaan barang, dan lain-lain.
70 70
1997 hingga 2003, gerakan lonjakan inflasi ternyata terjadi pula pada gerakan lonjakan nilai tukar rupiah (IDR) terhadap dollar Amerika Serikat (USD). Inflasi desakan biaya mempunyai sebab yang hampir serupa. Inflasi jenis ini terjadi akibat melonjaknya harga-harga faktor produksi. Kalau ditelusuri, melonjaknya harga-harga faktor produksi dapat disebabkan banyak hal seperti semakin langkanya jenis barang, tuntutan kenaikan gaji pekerja, semakin mahalnya ongkos transportasi, atau bisa juga disebabkan oleh adanya perubahan nilai tukar mata uang juga. Dari uraian singkat ini dapat disimpulkan bahwa pemicu terjadinya inflasi desakan biaya karena perubahan pada sisi supply, sedang inflasi tarikan permintaan disebabkan perubahan pada sisi demand.
Berbagai alasan yang dijelaskan di atas, maka untuk semakin memperjelas perihal terjadinya inflasi, dapat dicoba menambah satu variabel penduga (X2) yaitu
X1 Y X2
(Budep) (Inflasi) (Kurs)
13.06 8.28 9433.25
13.81 9.14 9633.78
13.97 10.62 10204.7
13.79 10.51 11074.75 14.03 10.82 11291.19
14.14 12.11 11294.3
14.39 13.04 10883.57
14.97 12.23 8956.59
15.67 13.01 9288.05
15.91 12.47 10097.91 16.02 12.91 10554.86 16.21 12.55 10269.42 16.19 14.42 10393.82 15.88 15.13 10237.42
15.76 14.08 9914.26
15.55 13.3 9485.82
15.16 12.93 9115.05
14.85 11.48 8688.65
14.22 10.05 8964.7
13.93 10.6 8928.41
13.58 10.48 8954.43
13.13 10.33 9151.73
324.22 260.49 216816.7
Perubahan model dari bentuk single ke dalam bentuk
multiple mengalami beberapa perubahan, meliputi: 1) jumlah variabel penjelasnya bertambah, sehingga spesifikasi model dan data terjadi penambahan. 2) rumus penghitungan nilai b mengalami perubahan, 3) jumlah
Model Regresi Linier Berganda
Penulisan model regresi linier berganda merupakan pengembangan dari model regresi linier tunggal. Perbedaannya hanya terdapat pada jumlah variabel X saja. Dalam regresi linier tunggal hanya satu X, tetapi dalam regresi linier berganda variabel X lebih dari satu. Model regresi linier umumnya dituliskan sebagai berikut:
Populasi: Y = A + B1X1 + B2X2 + B3X3 + ………+
BnXn + e
Atau Y = B0 + B1X1 + B2X2 + B3X3 + ………+
BnXn + e
Sampel : Y = a + b1X1 + b 2X2 + b 3X3 + ………+ b
nXn
+ e
Atau Y = b0 + b1X1 + b 2X2 + b 3X3 + ………+ b
nXn + e
Perlu diingat bahwa penulisan model sangat beragam. Hal ini dapat dimengerti karena penulisan model sendiri hanya bertujuan sebagai teknik anotasi untuk memudahkan interpretasi. Penulisan cara di atas adalah bentuk model yang sering dijumpai dalam beberapa literatur. Notasi model seperti itu tentu berbeda dengan notasi model Yale16. Apabila kita ingin menganalisis pengaruh Budep dan Kurs terhadap Inflasi dengan mengacu model Yale, maka notasi model menjadi seperti berikut:
Populasi: Y = B1.23 + B12.3X2i + B13.2X3i + e
16 G.U. Yale, On the Theory of Correlation for any Number of Variables,
Notasi model Yale ini mempunyai spesifikasi dalam menandai variabel terikat yang selalu dengan angka 1. Untuk variabel bebas notasinya dimulai dari angka 2, 3, 4, dan seterusnya.17 Notasi b1.23 berarti nilai perkiraan Y
kalau X2 dan X3 masing-masing sama dengan 0 (nol).
Notasi b12.3 berarti besarnya pengaruh X2 terhadap Y jika
X3 tetap.
Notasi b13..2 berarti besarnya pengaruh X3 terhadap Y jika
X2 tetap.
Penulisan model dengan simbol Y untuk variabel dependen, dan X untuk variabel independen, saat ini mulai ada penyederhanaan lagi, yang intinya untuk semakin memudahkan interpretasi. Berdasar pada keinginan mempermudah dalam mengingat variabel yang akan dibahas, maka notasi model dapat pula ditulis sebagai berikut:
Inflasi = b0 + b1Budep + b2 Kurs + ε
... (Pers.f.2)
Penulisan dengan gaya seperti ini ternyata sekarang lebih disukai oleh penulis-penulis saat ini, karena memberikan kemudahan bagi para pembacanya untuk tidak mengingat-ingat arti dari simbol X yang dituliskan, tetapi cukup dengan melihat nama variabelnya. Dengan pertimbangan tersebut maka cara ini nanti juga akan banyak digunakan dalam pembahasan selanjutnya.
Penghitungan Nilai Parameter
Penggunaan metode OLS dalam regresi linier berganda dimaksudkan untuk mendapatkan aturan dalam
2
2
mengestimasi parameter yang tidak diketahui. Prinsip yang terkandung dalam OLS sendiri adalah untuk meminimalisasi perbedaan jumlah kuadrat kesalahan (sum of square) antara nilai observasi Y dengan Yˆ . Secara matematis, fungsi minimalisasi sum of square ditunjukkan dalam rumus:
n
∑
e 2 (b0, b1,b2) =∑
(Y − Yˆ ) 2n =1
n
=
∑
(Y − b0 − b1 X 1 − b2 X 2 ) n =1Untuk mendapatkan estimasi least square b0, b1,b2
minimum, dapat dilakukan melalui cara turunan parsial (partially differentiate) dari formula di atas, sebagai berikut:
∂
∑
e 2∂b0
∂
∑
2= 2nb0 + 2b1
∑
X 1 + 2b2∑
X 2 − 2∑
Ye
= 2b X 2b+ X 2 +
2b X X − 2 X Y
∂b1
∂
∑
e 20
∑
1 1∑
1 2∑
1 2∑
1∂b2 = 2b0
∑
X 2 + 2b1∑
X 1 X 2 +2b2∑
X 2 − 2∑
X 2YJadikan nilai-nilai turunan parsial di atas menjadi sama dengan 0 (nol), dengan cara membagi dengan angka 2, hingga menjadi:
nb0 +
∑
X 1b1 +∑
X 2 b2 =∑
Y∑
X 1b0 +∑
X 11 2
2 b
2
2
1 2
2
∑
X 2 b0 +∑
X 1 X 2 b1 +∑
X 22
=
∑
X 2YUntuk menyederhanakan rumus paling atas dilakukan pembagian dengan n, sehingga memperoleh rumus baru sebagai berikut:
b0 + b1 X 1 + b2 X 2 =
Y
b0 = Y − b1 X 1 − b2 X 2
Kalau kita notasikan:
y = Y −
Y
x1 = X 1 − X
1
x2 = X 2 − X
2
maka b1 dan b2 dapat dicari dengan rumus:
(
∑
x y )(∑
x 2 ) − (∑
x y )(∑
x x ) b1 = 1 2 1 21
∑
x2 ) − (∑
x1 x2 )b (
∑
x 2 y ) (∑
x1 ) − (∑
x1 y ) (∑
x1 x 2 )2 = (
∑
x 2 )(
∑
x 2 ) − (
∑
x1 x2 )
kemungkinan-kemungkinan yang menjelaskan model juga mengalami pertambahan. Dalam single linier
perubahan pada X1, meskipun X2 konstan, akan mampu
merubah nilai harapan dari Y. Begitu pula, perubahan pada X2, meskipun X1 konstan, akan mampu merubah
nilai harapan dari Y. Perubahan yang terjadi pada X1 atau
X2 tentu mengakibatkan perubahan nilai harapan Y atau
E(Y/X1,X2) yang berbeda. Oleh karena itu pencarian nilai
b mengalami perubahan.
Guna mengetahui seberapa besar kontribusi X1
terhadap perubahan Y, tentu perlu untuk melakukan kontrol pengaruh dari X2. Begitu pula, untuk mengetahui kontribusi X2, maka perlu juga melakukan kontrol
terhadap X1. Dari sini dapat timbul pertanyaan,
bagaimana caranya mengontrolnya? Untuk menjawabnya, perlu ilustrasi secara konkrit agar mudah dipahami. Misalnya kita hendak mengontrol pengaruh linier X2 ketika melakukan pengukuran dampak dari perubahan X1 terhadap Y, maka dapat melakukan langkah-langkah sebagai berikut:
Tahap pertama: lakukan regresi Y terhadap X2.
Y = b0 + b2 X2 + e1
Dimana e1 merupakan residual, yang besarnya:
e1 = Y – b0 – b2X2
= Y- Yˆ
Tahap kedua: lakukan regresi X1 terhadap X2
X1 = b0 + b2 X2 + e2
1
2
2
2
X Y )
−
X Y )
−
∑
1e2 = X1 – b0 – b2X2
= X1- Xˆ
Tahap ketiga: lakukan regresi e1 terhadap e2
e1 = a0 + a1e2 +e3
Besarnya a1 pada tahap ketiga inilah yang
merupakan nilai pasti atau net effect dari perubahan satu unit X1 terhadap Y, atau menunjukkan kemiringan (slope)
garis Y atas variabel X1.
Logika dari teori tersebut yang mendasari rumus yang dapat digunakan untuk menentukan koefisien regresi parsial (partial regression coefficients) (baca: b1, b2).
Dengan memanfaatkan data yang telah tersedia, kita dapat pula menentukan nilai b1 variabel Budep maupun b2
variabel Kurs. Pencarian koefisien regresi tersebut dapat dilakukan dengan menggunakan rumus-rumus yang telah ditentukan di atas. Guna mempermudah dalam memasukkan angka-angka ke dalam rumus, maka data yang ada perlu diekstensifkan sesuai dengan kebutuhan rumus tersebut. Hasil ekstensifikasi dari beberapa rumus yang dicari sebagai berikut:
∑
x 2=
X 2 −
=
(∑=
X 1 )n
∑
x 2=
∑
X2
−
(
∑=
X 2 )∑
x y = (2
n
(
∑
X 1 )(∑
Y ) 1∑
1n
∑
x y = (2∑
2 (∑
X 2 )(∑
Y )X1 Y X2
∑
1∑
2∑
1∑
2∑
1 2324.22 260.49 216,816.70 22.40 14,318,503.69 32.48 7,274.46 2,227.72
) − 2 2 1 2 2 2
∑
x1 x2 =(
∑
X 1 X
(
∑
X 1 )(∑
X ) 2n
Dengan menggunakan rumus-rumus tersebut di atas, maka nilai total masing-masing komponen rumus yang dikembangkan adalah tertera sebagai berikut:
x 2 x 2
x y x y x x
Berdasarkan data-data yang tertera dalam tabel di atas, maka nilai b0, b1, dan b2
dapat ditentukan, melalui pencarian menggunakan rumus-rumus sebagai berikut:
Rumus untuk mencari nilai b1 (pada
model multiple regression) adalah:
b (
∑
x1 y )(
∑
x 2 ) − (∑
x 2 y )(∑
x1 x 2 )1=
(
∑
x 2
)(
∑
x 2 ) −(
∑
x1 x2 )
Rumus untuk mencari nilai b2 (pada
model multiple regression) adalah:
b2 =
(
∑
x 2 y )(∑
x1 ) − (∑
x1 y )(∑
x1 x 2 )1
∑
x2 ) − (∑
x1 x2 )Rumus untuk mencari nilai b0 (pada
model multiple regression) adalah:
Dengan menggunakan rumus pencarian b1 di atas, maka diketahui bahwa nilai b1
2
2
1 2
2
(
∑
x y )(∑
x 2 ) − (∑
x y )(∑
x x ) b1 = 1 2 1 21
∑
x2 ) − (∑
x1 x2 )= ( 32.49)( 2.227,72) ( 14.318.50 (22,41)(14.318.503,70) 3 ,70) − ( 7.27 4 ,64) − (2.227,72) 2
= 465.208.185, 21 − 16.205.861,02 320.877.667,92 − 4.962.736,40
= 449.002.324,19 315.914.931,52 b1 = 1,421
Dengan menggunakan rumus pencarian b2 di atas,
maka diketahui bahwa nilai b2 adalah:
b (
∑
x 2 y )(∑
x1 ) − (∑
x1 y )(∑
x1 x 2 )2 = (
∑
x2
)(
∑
x 2 ) − (∑
x1 x2 )
= ( 7.27( 2.227,72) 4 ,64) ( 22.4 (22.41)(14.318.503,70) 1 ) − ( 32.49) − (2.227.72) 2
= 163.024, 68 − 72.378,62 320.877.667,92 − 4.962.736,40
= 90.646,06 315.914.931,52
= 0,0002869 atau dapat ditulis dengan 2,869E-04
Dengan menggunakan rumus pencarian b0 di atas,
maka diketahui bahwa nilai b0 adalah:
80 80
= 11,84-1,421(14,73)-0,0002869(9.855,30) = 11,84-20,93,2,827
= -11,917
Nilai dari parameter b1 dan b2 merupakan nilai dari
suatu sampel. Nilai b1 dan b2 tergantung pada jumlah
sampel yang ditarik. Penambahan atau pengurangan akan mengakibatkan perubahan rentangan nilai b. Perubahan rentang nilai b1 dan b2 diukur dengan standar error.
Semakin besar standar error mencerminkan nilai b sebagai penduga populasi semakin kurang representatif. Sebaliknya, semakin kecil standar error maka keakuratan daya penduga nilai b terhadap populasi semakin tinggi. Perbandingan antara nilai b dan standar error ini memunculkan nilai t, yang dapat dirumuskan sebagai berikut:
t = S b
b
dimana:
b = nilai parameter
Sb = standar error dari b. Jika b sama dengan 0 (b=0) atau
Sb bernilai sangat besar, maka nilai t akan sama dengan
atau mendekati 0 (nol).
Untuk dapat melakukan uji t, perlu menghitung besarnya
standar error masing-masing parameter ( baik b0, b1, b2),
seperti diformulakan Gujarati (1995:198-199) sebagai berikut:
S = + 1 ⎢
∑
2 2∑
1 1 2∑
1 2 ⎥∑
⎡ 1 X
2
b
x 2 + X
2 x
2 − 2 X
X
x x ⎤ E 2
81 81
1 2
1 2
2
2
∑
x2
∑
ESb1 =
(
∑
x 2 )(
∑
2
x 2 ) − (
∑
x1 x2 )2
n − 3
∑
x1
∑
E Sb 2 =(
∑
x 2 )(
∑
2
x 2 ) − (
∑
x1 x2 )
2
n − 3
Rumus-rumus di atas, dapat kita masuki dengan angka-angka yang tertera pada tabel, hanya saja belum semuanya dapat terisi. Kita masih memerlukan lagi angka untuk mengisi rumus
∑
e 2 . Untuk dapat mengisi rumustersebut, perlu terlebih dulu mencari nilai e. Nilai e adalah
standar error yang terdapat dalam persamaan regresi. Perhatikan persamaan regresi:
Y = b0 + b1X1 + b2 X2 + e
atau
Inflasi = b0 + b1Budep + b2 Kurs + e
Secara matematis, dari persamaan regresi di atas nilai e dapat diperoleh, dengan cara mengubah posisi tanda persamaan hingga menjadi:
e = Y- (b0 + b1X1 + b2 X2)
Dengan memasukkan nilai b0, b1, b2, yang telah
didapatkan, dan X1i, X2i, yang ada pada data, maka nilai
X1 Y X2 B0 B1 B2 e e^2 13.06 8.28 9433.25 -11.933 1.421 0.000287 -1.05 1.11 13.81 9.14 9633.78 -11.933 1.421 0.000287 -1.31 1.73 13.97 10.62 10204.70 -11.933 1.421 0.000287 -0.23 0.05 13.79 10.51 11074.75 -11.933 1.421 0.000287 -0.33 0.11 14.03 10.82 11291.19 -11.933 1.421 0.000287 -0.42 0.18 14.14 12.11 11294.30 -11.933 1.421 0.000287 0.71 0.50 14.39 13.04 10883.57 -11.933 1.421 0.000287 1.40 1.97 14.97 12.23 8956.59 -11.933 1.421 0.000287 0.32 0.10 15.67 13.01 9288.05 -11.933 1.421 0.000287 0.01 0.00 15.91 12.47 10097.91 -11.933 1.421 0.000287 -1.10 1.21 16.02 12.91 10554.86 -11.933 1.421 0.000287 -0.95 0.90 16.21 12.55 10269.42 -11.933 1.421 0.000287 -1.50 2.24 16.19 14.42 10393.82 -11.933 1.421 0.000287 0.37 0.13 15.88 15.13 10237.42 -11.933 1.421 0.000287 1.56 2.43 15.76 14.08 9914.26 -11.933 1.421 0.000287 0.77 0.60 15.55 13.3 9485.82 -11.933 1.421 0.000287 0.41 0.17 15.16 12.93 9115.05 -11.933 1.421 0.000287 0.71 0.50 14.85 11.48 8688.65 -11.933 1.421 0.000287 -0.18 0.03 14.22 10.05 8964.70 -11.933 1.421 0.000287 -0.80 0.63 13.93 10.6 8928.41 -11.933 1.421 0.000287 0.18 0.03 13.58 10.48 8954.43 -11.933 1.421 0.000287 0.55 0.30 13.13 10.33 9151.73 -11.933 1.421 0.000287 0.98 0.96 324.22 260.49216816.70 -11.933 1.421 0.000287 0.09 15.90
Dari tabel di atas dapat diketahui bahwa nilai total nilai e adalah sebesar 0.09, sedangkan total nilai e2 adalah sebesar 15,90. Berdasarkan angka yang didapatkan tersebut, maka standar error b0, b1, b2, dapat dicari
⎦
⎢
⎢
=
Mencari Sb0.
S = + 1 ⎢
∑
2 2∑
1 1 2∑
1 2 ⎥∑
⎡ 1 X 2 x 2 + X
2 x
2 − 2 X
X
x x ⎤ e 2
b 0 2 2 2
⎢⎣ n
∑
x1∑
x2 − (∑
x1 x2 ) ⎥⎦ n − 3⎡ 1 (14,74 ) 2 (14 .318 .503,69 ) + (9.855 ,3) 2 (22,40 ) − 2(14,74 )(9.855 ,3)( 2.227 ,72 ) ⎤ 15,90
⎢ + ⎣ 22
(22,40 )(14 .318 .503,69 ) − (2.227 ,72 ) 2 ⎥ 22 − 3
=
⎡ 1
+ 3.110.946.932,32 + 2.175.643.413, 22 − 647.228.946,04 ⎤ 15,90 ⎣ 22 320.734.482.66 − 4.962.736,40 ⎦ 19
= ⎡ 1 + 4.639.361.399,50 ⎤ 15,90 ⎣ 22 315.771.746,26 ⎦ 19
= (0.045 + 14,69) (0,84) = 3,84 (0,84) = 3,226
Mencari Sb1.
S =
∑
x 2 2∑
b1
( x 2 )( x 2 ) − (
x x ) 2
e 2 n − 3
∑
1∑
2∑
1 2⎡ 14.318. 503,69 ⎤ 15,9
⎢ 2 ⎥
⎣ (22,40)(14.318.503,69) − (2.227,72) ⎦ 19
1 2 2
=
= 0,045 (0.84) = 0,213 x 0,84 = 0,179
Mencari Sb2:
∑
x1
∑
e Sb 2 =(
∑
x 2 )(
∑
2
x 2 ) − (
∑
x1 x2 ) 2
n − 3
⎡ 22, 40 ⎤ 15,9
⎢ 2 ⎥
⎣ (22,40)(14.318.503,69) − (2.227,72) ⎦ 19
= 22, 40 (0,84) 315.771.746,26
= 0,000000070 (0.84) = 0,000266 x 0,84 = 0,000223
Setelah diketahui semua nilai standar error (Sb0, Sb1, Sb2)
melalui penggunaan rumus-rumus di atas, maka nilai t untuk masing-masing parameter dapat diperoleh, karena nilai t merupakan hasil bagi antara b dengan Sb. Pencarian nilai t mempunyai kesamaan dengan model regresi linier sederhana, hanya saja pencarian Sb
Pencarian masing-masing nilai t sebagai berikut:
nya yang berbeda. dapat dirumuskan
t = b0
b 0
Sb 0
Mencari nilai statistik tb1:
t = b1
b1
Sb 1
Mencari nilai statistik tb2:
t = b2 ;
b 2
Sb 2
Dengan menggunakan rumus-rumus di atas, maka nilai tb0
adalah:
tb 0 = − 11,917 = -3,694 3,226
dan nilai tb1 adalah:
tb1 = 1, 421 =7,938 0,179
sedangkan nilai tb2 adalah:
tb 2 = 0,0002869 = 1,284 0,0002234
t hitung lebih kecil darit tabel, maka variabel penjelas tersebut tidak signifikan.
Karena nilai tb1 adalah sebesar 7,938, yang berarti
lebih besar dibanding nilai tabel pada α=5% dengan df 19 yang besarnya 2,093, maka dapat dipastikan bahwa variabel budep secara individual signifikan mempengaruhi inflasi. Sedangkan nilai tb2 yang besarnya
1,284 adalah lebih kecil dibandingkan dengan nilai t tabel pada α =5% dengan df 19 yang besarnya 2,093, maka dapat dipastikan bahwa variabel Kurs secara individual tidak signifikan mempengaruhi inflasi.
Pengujian kedua nilai t dapat dijelaskan dalam bentuk gambar sebagai berikut:
Daerah diterima
7,938 Daerah d i t o lak
t α /2; (n-k-1) (+) 2,093
Gb.3.2. Daerah Uji t Variabel Budep
Daerah diterima
Daerah ditolak 1,284
t α /2; (n-k-1) (+) 2,093
Bantuan dengan SPSS
Tahapan-tahan yang dilalui untuk melakukan regresi linier
berganda dengan penghitungan-penghitungan nilai a, b, Sb di atas,
dapat dilakukan dengan bantuan SPSS dengan tahapan sebagai berikut:
• Pastikan data SPSS sudah siap
• Lakukan regresi, caranya: pilih Analyze, Reression, Linear
48.261 2 24.130 28.836
15.899 19 .837
64.160 21
Regression Residual Total Model 1
df Mean Square F Sig.
• Hasil regresi akan tampak dalam output regression yang menunjukkan tabel: model summary (memuat R2), ANOVA (memuat nilai F), Coefficient (memuat nilai t).
Model Summary
Model R R Square
Adjusted R Square
Std. Error of the Estimate
1 .867a .752 .726 .9148
a. Predictors: (Constant), X2, X1
ANOVAb
Sum of Squares
.000a
Coefficientsa
Model
Unstandardized Coefficients
Standardi zed Coefficien
ts
t Sig.
B Std. Error Beta 1 (Constant)
X1 X2
-11.933 1.421 2.869E-04
3.511 .195 .000
.840 .136
-3.399 7.298 1.177
.003 .000 .254 a. Dependent Variable: Y
Catatan:
• Nilai a, b1, b2, antara hitungan manual dengan hitungan SPSS terdapat sedikit perbedaan angka di belakang koma. Ini disebabkan oleh pembulatan angka saat penghitungan.
90 90
2
Koefisien Determinasi (R2)
Disamping menguji signifikansi dari masing-masing variabel, kita dapat pula menguji determinasi seluruh variabel penjelas yang ada dalam model regresi. Pengujian ini biasanya disimbolkan dengan koefisien regresi yang biasa disimbolkan dengan R2. Uraian tentang koefisien determinasi sedikit banyak telah disinggung pada single linier regression. Pada sub bahasan ini hanya menambah penjelasan-penjelasan agar menjadi lebih lengkap saja.
Koefisien determinasi pada dasarnya digunakan untuk mengkur goodness of fit dari persamaan regresi, melalui hasil pengukuran dalam bentuk prosentase yang menjelaskan determinasi variabel penjelas (X) terhadap variabel yang dijelaskan (Y). Koefisien determinasi dapat dicari melalui hasil bagi dari total sum of square (TSS) atau total variasi Y terhadap explained sum of square
(ESS) atau variasi yang dijelaskan Y. Dengan demikian kita dapat mendefinisikan lagi R2 dengan arti rasio antara variasi yang dijelaskan Y dengan total variasi Y. Rumus tersebut adalah sebagai berikut:
R 2 = ESS
TSS
Total variasi Y (TSS) dapat diukur menggunakan derajat deviasi dari masing-masing observasi nilai Y dari rata-ratanya. Hasil pengukuran ini kemudian dijumlahkan hingga mencakup seluruh observasi. Jelasnya:
n
TSS =
∑
(Yt − Yt
2
1
Nilai explained sum of square (ESS) atau variasi yang dijelaskan Y didapat dengan menggunakan rumus sebagai berikut:
n ESS =
∑
(Yˆ − Y )
2
t −1
Jadi, rumus di atas dapat pula dituliskan menjadi sebagai berikut:
2
∑
(Yˆ − Y )dimana:
R =
∑
(Y − Y ) 2Yˆ (baca: Y cap) adalah nilai perkiraan Y atau
estimasi garis regresi.
Y (baca: Y bar) adalah nilai Y rata-rata.
Y cap diperoleh dengan cara menghitung hasil regresi dengan memasukkan nilai parameter dan data variabel. Penghitungan nilai Y cap menjadi penting untuk dilakukan agar mempermudah kita dalam menggunakan rumus R2 yang telah ditentukan di atas. Sebagai contoh menghitung Y cap, berikut ini dihitung nilai Y cap pada observasi 1.
Hasil regresi adalah:
Y = -11,917 + 1,421 (X1) + 0,0002869(X2)
Jika observasi nomor 1 (satu) kita hitung, dimana X1=
13,06 dan X2 = 9.433,25, maka nilai Yˆ = -11,917 + 1,421
2
∑=
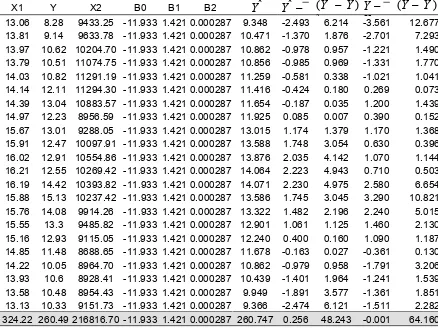
Hasil hitungan Y cap individual maupun total, beserta ekstensinya diperlukan untuk menyesuaikan dengan rumus mencari R2. Hasil perhitungan dan pengembangan data selengkapnya tertera dalam tabel sebagai berikut:
X1 Y X2 B0 B1 B2 Yˆ Yˆ −
Y
(Yˆ − Y )
2 Y Y−
(Y − Y ) 2
13.06 8.28 9433.25 -11.933 1.421 0.000287 9.348 -2.493 6.214 -3.561 12.677
13.81 9.14 9633.78 -11.933 1.421 0.000287 10.471 -1.370 1.876 -2.701 7.293
13.97 10.62 10204.70 -11.933 1.421 0.000287 10.862 -0.978 0.957 -1.221 1.490
13.79 10.51 11074.75 -11.933 1.421 0.000287 10.856 -0.985 0.969 -1.331 1.770
14.03 10.82 11291.19 -11.933 1.421 0.000287 11.259 -0.581 0.338 -1.021 1.041
14.14 12.11 11294.30 -11.933 1.421 0.000287 11.416 -0.424 0.180 0.269 0.073
14.39 13.04 10883.57 -11.933 1.421 0.000287 11.654 -0.187 0.035 1.200 1.439
14.97 12.23 8956.59 -11.933 1.421 0.000287 11.925 0.085 0.007 0.390 0.152
15.67 13.01 9288.05 -11.933 1.421 0.000287 13.015 1.174 1.379 1.170 1.368
15.91 12.47 10097.91 -11.933 1.421 0.000287 13.588 1.748 3.054 0.630 0.396
16.02 12.91 10554.86 -11.933 1.421 0.000287 13.876 2.035 4.142 1.070 1.144
16.21 12.55 10269.42 -11.933 1.421 0.000287 14.064 2.223 4.943 0.710 0.503
16.19 14.42 10393.82 -11.933 1.421 0.000287 14.071 2.230 4.975 2.580 6.654
15.88 15.13 10237.42 -11.933 1.421 0.000287 13.586 1.745 3.045 3.290 10.821
15.76 14.08 9914.26 -11.933 1.421 0.000287 13.322 1.482 2.196 2.240 5.015
15.55 13.3 9485.82 -11.933 1.421 0.000287 12.901 1.061 1.125 1.460 2.130
15.16 12.93 9115.05 -11.933 1.421 0.000287 12.240 0.400 0.160 1.090 1.187
14.85 11.48 8688.65 -11.933 1.421 0.000287 11.678 -0.163 0.027 -0.361 0.130
14.22 10.05 8964.70 -11.933 1.421 0.000287 10.862 -0.979 0.958 -1.791 3.206
13.93 10.6 8928.41 -11.933 1.421 0.000287 10.439 -1.401 1.964 -1.241 1.539
13.58 10.48 8954.43 -11.933 1.421 0.000287 9.949 -1.891 3.577 -1.361 1.851
13.13 10.33 9151.73 -11.933 1.421 0.000287 9.366 -2.474 6.121 -1.511 2.282
324.22 260.49 216816.70 -11.933 1.421 0.000287 260.747 0.256 48.243 -0.001 64.160
Dengan menggunakan angka-angka yang terdapat dalam tabel di atas, maka nilai R2 dapat ditentukan. Adapun rumus untuk mencari nilai R2 adalah sebagai berikut:
(Yˆ − Y ) 2
R =
dengan demikian nilai R2 dari model yang ada adalah sebesar:
R2 = 4 8 , 243 64,160
R2 = 0,751
Nilai R2 sebesar 0,751 tersebut menunjukkan arti bahwa determinasi variabel Budep (X1) dan Kurs (X2) dalam
mempengaruhi inflasi (Y) adalah sebesar 75,1%. Nilai sebesar ini mengindikasikan bahwa model yang digunakan dalam menjelaskan variabel Y cukup baik, karena mencapai 75,1%. Sisanya sebesar 24,1% dijelaskan oleh variabel lain yang tidak dijelaskan dalam model.
Uji F
Seperti telah dikemukakan di atas, bahwa dalam regresi linier berganda variabel penjelasnya selalu berjumlah lebih dari satu. Untuk itu, maka pengujian tingkat signifikansi variabel tidak hanya dilakukan secara individual saja, seperti dilakukan dengan uji t, tetapi dapat pula dilakukan pengujian signifikansi semua variabel penjelas secara serentak atau bersama-sama. Pengujian secara serentak tersebut dilakukan dengan teknik analisis of variance (ANOVA) melalui pengujian nilai F hitung yang dibandingkan dengan nilai F tabel. Oleh karena itu disebut pula dengan uji F.
variansi means (variance between means) yang dibandingkan dengan variansi di dalam kelompok variabel (variance between group). Hasil pembandingan keduanya itu (rasio antara variance between means
terhadap variance between group) menghasilkan nilai F hitung, yang kemudian dibandingkan dengan nilai F tabel. Jika nilai F hitung lebih besar dibanding nilai F tabel, maka secara serentak seluruh variabel penjelas yang ada dalam model signifikan mempengaruhi variabel terikat Y. Sebaliknya, jika nilai F hitung lebih kecil dibandingkan dengan nilai F tabel, maka tidak secara serentak seluruh variabel penjelas yang ada dalam model signifikan mempengaruhi variabel terikat Y.
Atau secara ringkas dapat dituliskan sebagai berikut:
F ≤ Fα ;( k −1);( n −k ) Æ berarti tidak signifikan Æ atau
H0
diterima
F > Fα ;( k −1);( n−k ) Æ berarti signifikan Æ atau H0
ditolak
H0 diterima atau ditolak, adalah merupakan suatu
keputusan jawaban terhadap hipotesis yang terkait dengan uji F, yang biasanya dituliskan dalam kalimat sebagai berikut:
H0 : b1 = b2 = 0 Variabel penjelas secara serentak tidak
signifikan mempengaruhi variabel yang dijelaskan.
H0 : b1 ≠ b2 ≠ 0 Variabel penjelas secara
Nilai F hitung dapat dicari dengan menggunakan rumus sebagai berikut:
R 2 /(k − 1)
F =
(1 − R 2 ) /(n − k )
Sedangkan nilai F tabel telah ditentukan dalam tabel. Yang penting untuk diketahui adalah bagaimana cara membaca tabelnya. Seperti yang telah dituliskan pada pembandingan antara nilai F hitung dan nilai F tabel di atas, diketahui bahwa F tabel dituliskan Fα;k-1; (n-k).
Arti dari tulisan tersebut adalah:
• Simbol α menjelaskan tingkat signifikansi (level of significance) (apakah pada α =0,05 atau α =0,01 ataukah α =0,10, dan seterusnya).
• Simbol (k-1) menunjukkan degrees of freedom for numerator.
• Simbol (n-k) menunjukkan degrees of freedom for denominator.
Guna melengkapi hasil analisis data yang dicontohkan di atas, kita dapat menghitung nilai F berdasarkan rumus. Nilai F dari model tersebut ternyata besarnya adalah:
R 2 /(k − 1)
F =
(1 − R 2 ) /(n − k )
= ( 0 , 75 1 ) / ( 3 − 1 ) (1 − 0,751) /(22 −
3) = 0.3755
Dari hasil penghitungan di atas diketahui bahwa nilai F hitung adalah sebesar 28,66. Nilai ini lebih besar dibanding dengan nilai F tabel pada α = 0,05 dengan (k-1)
= 2, dan (n-k) = (22-3) = 19 yang besarnya 3,52. Dengan demikian dapat disimpulkan bahwa variabel Budep dan Kurs secara serentak signifikan mempengaruhi inflasi. Dengan demikian, maka null hyphothesis ditolak.
Daerah penolakan atau penerimaan hipotesis dapat dilihat pada gambar berikut ini:
Daerah diterima
Daerah ditolak
F(α; k-1; n-k)
F0,05;2;19; 3,52
F
Gb.3.2. Daerah Uji F
-000-Tugas:
1. Buatlah rangkuman dari pembahasan di atas!
2. Cobalah untuk menyimpulkan maksud dari uraian bab ini!
3. Lakukanlah perintah-perintah di bawah ini:
a. Coba jelaskan apa yang dimaksud dengan regresi linier berganda!
b. Coba tuliskan model regresi linier berganda! c. Coba uraikan arti dari notasi atas model yang
telah anda tuliskan!
e. Jelaskan informasi apa yang dapat diungkap pada koefisien regresi!
f. Coba sebutkan perbedaan-perbedaan antara model regresi linier sederhana dengan model regresi linier berganda!
g. Jelaskan mengapa rumus untuk mencari nilai b pada model regresi linier erganda berbeda dengan model regresi linier sederhana!
h. Coba jelaskan apakah pencarian nilai t juga mengalami perubahan! kenapa?
i. Coba uraikan bagaimana menentukan nilai t yang signifikan!
j. Jelaskan apa kegunaan nilai F!
k. Bagaimana menentukan nilai F yang signifikan?
l. Jelaskan apakah rumus dalam mencari koefisien determinasi pada model regresi linier berganda berbeda dengan regresi linier sederhana! kenapa?