Fakultas Ilmu Komputer
3182
Implementasi Metode
Backpropagation Neural Network
berbasis
Lexicon
Based Features
dan
Bag of Words
Untuk Identifikasi Ujaran Kebencian
Pada Twitter
Muhammad Mishbahul Munir1, Mochammad Ali Fauzi2, Rizal Setya Perdana3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Ujaran kebencian adalah bahasa yang mengekspresikan suatu kebencian terhadap suatu kelompok atau individu yang bermaksud untuk menghina atau mempermalukan dan medianya bisa terdapat dimana saja, salah satunya Twitter. Twitter merupakan media sosial yang memungkinkan pengguna untuk mengutarakan perasaan dan opini melalui tweet, termasuk tweet yang mengandung ujaran kebencian. Data dokumen atau tweet berasal dari penelitian yang terdahulu tentang ujaran kebencian. Metode yang digunakan dalam mengolah data dokumen tersebut adalah Backpropagation Neural Network dengan pembaruan fitur menggunakan Lexicon Based Features yang dikombinasikan dengan Bag of Words. Pada penelitian ini menggunakan data sebanyak 500 data yang dibagi menjadi data latih sebanyak 400 data dan data uji sebanyak 100 data. Dari hasil pengujian evaluasi, ketika menggunakan Lexicon Based Features nilai rata-rata f-measure sebesar 0%, lebih buruk dibandingkan dengan menggunakan Bag of Words yang nilai rata-rata f-measure sebesar 76,638%, sedangkan ketika Lexicon Based Features
dikombinasikan dengan Bag of Words mendapat nilai rata-rata terbaik diantara fitur sebelumnya dengan
f-measure sebesar 78,081%. Dan hasil perbandingan metode Backpropagation Neural Network berbasis
Lexicon Based Features dan Bag of Words tidak lebih baik dibandingkan dengan Random Forest Decision Tree menggunakan n-gram fitur pada penelitian sebelumnya.
Kata kunci: ujaran kebencian, twitter, bag of words, lexicon based features, backpropagation neural network
Abstract
Hate speech is a language that expresses a hatred of a group or individual who intends to insult or humiliate and the media can be found anywhere, one of them Twitter. Twitter is a social media that allows users to express feelings and opinions through tweets, including tweets that contain hate speech. Document or tweet data comes from previous research on hate speech. The method used in processing the document data is Backpropagation Neural Network with feature updates using Lexicon Based Features combined with Bag of Words. In this study using data as much as 500 data is divided into training data as much as 400 data and test data as much as 100 data. From the evaluation test results, when using Lexicon Based Features, the average value of f-measure is 0%, worse than using the Bag of Words with an average f-measure of 76.638%, while when Lexicon Based Features is combined with the Bag of Words got the best average score among the previous features with a f-measure of 78.081%. And the result Backpropagation Neural Network using Lexicon Based Features combined with Bag of Words is not better than Random Forest Decision Tree using n-gram from previous research.
Keywords: hate speech, twitter, bag of words, lexicon based features, backpropagation neural network
1. PENDAHULUAN
Ujaran kebencian adalah bahasa yang digunakan untuk mengekspresikan kebencian terhadap kelompok yang menjadi sasaran atau
dimaksudkan untuk menghina,
mempermalukan, atau untuk menghina anggota
Republik Indonesia (Bareskrim Polri) pada 2015 kejahatan siber berupa ujaran kebencian mencapai 143 kejadian, namun mengalami peningkatan menjadi 199 kejadian pada 2016 (Direktorat Tindak Pidana Siber Bareskrim, 2016). Kejadian yang ada pada data Bareskrim merupakan data yang masuk ke tingkat pidana saja, tentu masih banyak ujaran kebencian yang ada diberbagai macam media sosial.
Pertumbuhan media sosial dan layanan web microblogging seperti Twitter, memungkinkan untuk menganalisis tweet pengguna hampir real-time dapat dilakukan. Melalui tweet ini sumber data yang diperoleh bisa dianalisis, mengingat pengguna lebih cenderung mengekspresikan tingkat emosi terhadap setiap peristiwa ke sebuah postingan atau tweet (Burnap & Williams, 2014). Dengan analisis ini maka akan bisa diidentifikasi tweet mana saja yang mengandung ujaran kebencian dan dalam tweet
ini sering didasari oleh motif-motif tertentu. Berbagai motif yang didasari antara lain motif agama, politik, sosial, dan ekonomi serta SARA bisa menjadikan pemicu munculnya ujaran kebencian yang bisa menyebabkan potensi-potensi yang mengarah ke kerusuhan. Identifikasi ujaran kebencian merupakan sarana untuk mencegah tindakan kerusuhan yang bisa memecah belah persatuan bangsa khususnya Indonesia.
Pada permasalahan ujaran kebencian telah dilakukan penelitian untuk mengumpulkan data dalam Bahasa Indonesia (Alfina, et al., 2017). Penelitian tersebut mengumpulkan data dari Twitter dengan tweet yang berhubungan dengan Pemilihan Kepala Daerah (Pilkada) DKI Jakarta 2017. Metode yang digunakan adalah Naïve Bayes, Bayesian Logistic Regression, Random Forest Decision Tree, dan Support Vector Machine dengan fitur n-gram dan negative sentiment. Hasil dari penelitian bahwa metode
Random Forest Decision Tree
menggunakan
fitur
n-gram
mendapatkan
F-measure tertinggi dibanding metode lainnya dengan 93,5%.Dalam identifikasi ujaran kebencian ada beberapa metode yang telah digunakan. Metode pertama Logistic Regression with L2 Regularization dalam mendeteksi ujaran kebencian dan masalahnya terhadap offensive language menghasilkan akurasi precision 0,91,
recall 0,90, sedangkan 40% salah dalam hasil klasifikasi (Davidson, et al., 2017). Metode kedua Convolutional Neural Network (CNN) dalam mengklasifikasikan ujaran kebencian memiliki banyak model fitur tapi F-score-nya
hanya 78,3% (Gambäck & Sikdar, 2017). Metode selanjutnya Backpropagation Neural Network (BPNN) yang digunakan untuk filter spam email memiliki tingkat akurasi yang tinggi dimana precision 98,42%, dan recall-nya 93,5% (Tuteja & Bogiri, 2016).
Pada penelitian sebelumnya oleh (Siddiqua, et al., 2016) yang mengombinasikan Rule-based Classifier dengan Ensemble of Feature Sets dan teknik Machine Learning untuk analisis sentimen pada Microblog. Dalam penelitian tersebut, fiturnya adalah twitter specific features,
textual features, parts-of-speech (POS) features,
lexicon based features, and bag-of-words (BoW)
feature dengan fitur lexicon based features
memiliki pengaruh yang besar dengan precision
91,76%, recall 80,07%, F1 score sebesar 86,08%, dan accuracy 84,96%. Dalam penelitian lain (George & Joseph, 2014) tentang klasifikasi teks oleh Augmenting Bag of Words (BoW)
Representation dengan Co-occurrence Feature
menunjukan bahwa antara BoW dan
BoW+occurrence lebih unggul sedikit BoW+occurrence. Sedangkan pada penelitian (Sun, et al., 2015)tentang pelabelan konseptual pada Bag of Words, menggunakan Conceptual Labeling (CL) hasil penelitiannya diketahui bahwa solusi yang didapat efektif dalam merepresentasikan semantic bag of words.
Oleh karena itu, dalam penelitian ini akan menggunakan metode Backpropagation Neural Network (BPNN) dengan fitur yang dipilih adalah Lexicon Based Features dan Bag of Words untuk identifikasi ujaran kebencian, dilihat dari penelitian (Siddiqua, Ahsan, & Chy, 2016), (George & Joseph, 2014), dan (Sun, et al., 2015) kedua fitur ini mempunyai peran yang penting. Diharapkan penelitian ini dapat mencegah segala jenis ujaran kebencian dalam media sosial yang bisa mengurangi aksi kekerasan dan bentuk kejahatan lainnya.
2. METODE USULAN
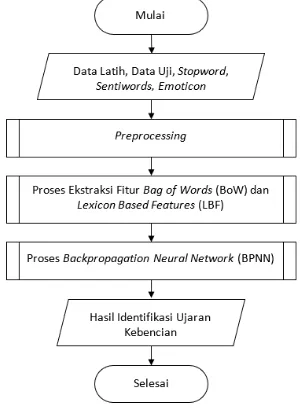
Pada penelitian ini tahapan proses yang dilakukan antara lain adalah preprocessing, estraksi fitur dengan bag of words dan lexicon based features, kemudian dilakukan proses klasifikasi atau identifikasi dengan
backpropagation neural network. Dalam
preprocessing sendiri memiliki tahapan, yaitu
cleaning, case folding, tokenizing, filtering,
bag of words dimana hasil dari preprocessing akan menjadi fitur masukan, kemudian akan dicocokan terhadap masing-masing dokumen atau tweet dalam data latih apakah kata tersebut ada atau tidak. Yang kedua adalah lexicon based features dimana fitur yang digunakan berjumlah empat (kata positif, negatif, netral, dan
emoticon) kemudian dicocokan dengan data latih sama seperti pada bag of words. Kemudian setelah data input didapatkan dari ekstraksi fitur maka kemudian akan dilakukan proses klasifikasi atau identifikasi dengan
backpropagation neural network dengan tahapan proses pelatihan terhadap data latih dan proses pengujian terhadap data uji. Tahapan alur proses sistem dapat ditunjukkan pada Gambar 1. Dalam penelitian ini data yang digunakan berasal dari penelitian sebelumnya tentang ujaran kebencian (Alfina, et al., 2017). Dengan rincian data latih 400 data dan data uji 100 data, dengan kelas ujaran kebencian dan bukan ujaran kebencian masing-masing kelas berjumlah setengah dari data latih dan uji.
Gambar 1. Diagram Alir Sistem
2.1 Preprocessing
Preprocessing adalah tahapan untuk mempersiapkan teks sebelum diproses lebih lanjut, dimana tahapannya akan menyesuaikan dengan proses lanjut yang akan digunakan. Dalam preprocessing, teks yang ada memiliki struktur tersendiri, dan kemudian harus dipisahkan sesuai dengan tingkatannya. Tingkatan dalam teks atau dokumen ini meliputi bab, sub-bab, paragraf, kalimat dan terakhir akan menjadi kata atau token penyusun kalimat. Selain memisahkan strukturnya juga terdapat proses untuk menghapus karakter atau huruf
yang dinilai tidak bermaksa seperti digit angka, huruf kapital, atau karakter-karakter lainnya (Feldman & Sanger, 2007). Dalam
preprocessing sendiri mempunyai tahapan-tahapan berdasarkan (Triawati, 2009) beserta penjelasannya yang telah dimodifikasi adalah sebagai berikut:
1. Cleaning, bertujuan untuk membersihkan
tweet dari mention, hashtag, link dan karakter lainnya (kecuali emoticon). 2. Case Folding, tahapan yang bertujuan
untuk merubah semua huruf yang ada menjadi huruf kecil atau lowercase. 3. Tokenizing, tahap untuk melakukan
pemisahan kalimat atau dokumen mejadi kata-kata yang menyusun kalimat tersebut. 4. Filtering, tahapan untuk menghapus
kata-kata yang tidak memiliki makna yang berasal dari proses tokenizing.
5. Stemming, tahapan yang memiliki tujuan untuk mengembalikan sebuah kata menjadi kata dasar yang menyusun kata tersebut, pengubahan ini sesuai dengan algoritme yang digunakan.
6. Sorting Ascending, digunakan untuk mengurutkan hasil preprocessing sesuai dengan urutan kecil ke besar atau A-Z.
2.2 Lexicon Based Features (LBF)
Lexicon Based Features (LBF) adalah metode yang digunakan untuk proses analisis sentimen, dimana prosesnya menggunakan suatu leksikal atau sumber bahasa sebagai kamus. Prinsip kerja dari metode ini adalah dengan mencocokan kata yang berada di sentiment dictionaries (data yang berisi kata-kata bersentiment) dan menghitung frekuensi kemunculannya pada dokumen teks. Sentimen dalam penelitian ini yang digunakan adalah ujaran kebencian atau bukan ujaran kebencian.
2.3 Backpropagation Neural Network
(BPNN)
Backpropagation Neural Network (BPNN) atau Backpropagation adalah pelatihan terawasi dengan menggunakan banyak lapisan untuk mengubah bobot-bobot yang terhubung dengan neuron-neuron yang ada pada lapisan
tersembunyi. Metode Backpropagation
propagation) (Haryati, et al., 2016). Metode
Backpropagation ini merupakan metode yang memaksimalkan hasil akhir melalui perubahan bobot lewat kesalahan keluaran yang terjadi atau meminimalkan kesalahan yang terjadi. Tahapan dalam metode BPNN ditunjukkan pada Gambar 2.
Gambar 2. Diagram Alir BPNN
Keterangan:
1. Memasukan data latih dari hasil ekstraksi fitur BoW dan LBF, menentukan iterasi maksimum, dan nilai target MSE.
2. Menentukan nilai bobot dan bias dengan menggunakan bilangan acak.
3. Melakukan inisialisasi untuk nilai iterasi awal.
4. Masuk ke tahapan propagasi maju kemudian menghitung nilai MSE.
5. Setelah MSE didapat, maka akan dilakukan pengecekan apakah nilai MSE kurang dari sama dengan target MSE atau jumlah iterasi maksimum, jika tidak maka akan dilakukan proses propagasi mundur.
6. Masuk ke proses perhitungan perubahan bobot dan bias, kemudian melakukan perbaruan bobot.
7. Kemudian melakukan penambahan iterasi 1, dan kembali ke langkah 4 untuk kembali melakukan proses BPNN.
8. Jika iterasi atau target MSE sudah tercapai, maka akan menyimpan bobot yang digunakan untuk proses pengujian.
3. HASIL DAN PEMBAHASAN
3.1 Pengujian Pengaruh Max Epoch
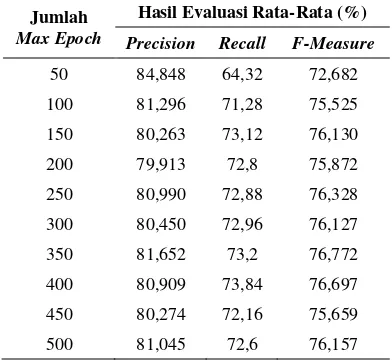
Pada proses pengujian pertama dilakukan untuk mengetahui pengaruh maximum epoch
terhadap hasil evaluasi sistem yang telah diimplementasikan. Dalam pengujian nilai max epoch yang dipilih adalah 50, 100, 150, 200, 250, 300, 350, 400, 450, dan 500. Dalam pengujian ini dari setiap pengujian fold akan dirata-rata untuk semua skenario pengujian. Untuk nilai hasil evaluasi pengujian pengaruh max epoch
telah tersaji pada Tabel 1.
Tabel 1. Hasil Pengujian Pengaruh Max Epoch
Jumlah
Max Epoch
Hasil Evaluasi Rata-Rata (%)
Precision Recall F-Measure
50 84,848 64,32 72,682
100 81,296 71,28 75,525
150 80,263 73,12 76,130
200 79,913 72,8 75,872
250 80,990 72,88 76,328
300 80,450 72,96 76,127
350 81,652 73,2 76,772
400 80,909 73,84 76,697
450 80,274 72,16 75,659
500 81,045 72,6 76,157
Berikut ini adalah grafik hubungan antara pengaruh max epoch dengan hasil evaluasi sistem telah disajikan pada grafik pengaruh max epoch pada Gambar 3.
Gambar 3. Grafik Hasil Pengujian Pengaruh Max Epoch
precision mengalami kondisi nilai yang naik turun, pada max epoch 50 ke 100 mengalami penurunan nilai yang lumayan tinggi, sedangkan pada max epoch lainnya perubahan yang terlihat tidak begitu besar. Untuk nilai evaluasi precision
nilai tertinggi yang dicapai adalah pada max epoch 50 dengan nilai rata-rata 84,848%. Untuk nilai evaluasi recall dan f-measure grafiknya cenderung memiliki kesamaan, pada max epoch
50 ke 100 mengalami perubahan yang besar dan cenderung naik, sedangkan pada max epoch
lainnya tidak mengalami perubahan yang signifikan. Nilai evaluasi untuk recall tertinggi ada pada max epoch 400 dengan nilai rata-rata 73,84% dan untuk f-measure nilai rata-rata tertinggi pada max epoch 350 dengan nilai rata-rata f-measure 76,772%.
Hasil yang diperoleh pada grafik pengaruh
max epoch menunjukan bahwa perubahan nilai
max epoch tidak terlalu memberikan pengaruh besar pada nilai evaluasi yang dihasilkan. Nilai
max epoch diatas 100 cenderung tidak mengalami perubahan yang signifikan, dengan hasil rata-rata f-measure terbesar pada max epoch 350 yang memiliki nilai f-measure
76,772%.
3.2 Pengujian Pengaruh Learning Rate
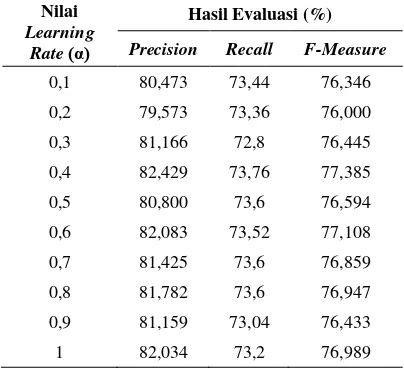
Pada pengujian ini akan dilihat nilai evaluasi sistem yang dihasilkan, apakah dipengaruhi oleh perubahan dari nilai learning rate. Nilai learning rate yang dalam pengujian ini adalah 0,1; 0,2; 0,3 sampai dengan 1. Karena pada pengujian menggunakan metode 5-Fold Cross Validation, maka nilai yag digunakan disini merupakan nilai rata-rata dari semua fold. Hasil dari pengujian ini telah tersaji pada Tabel 2.
Tabel 2. Hasil Pengujian Pengaruh Learning Rate
Nilai
Learning Rate(α)
Hasil Evaluasi (%)
Precision Recall F-Measure
0,1 80,473 73,44 76,346
0,2 79,573 73,36 76,000
0,3 81,166 72,8 76,445
0,4 82,429 73,76 77,385
0,5 80,800 73,6 76,594
0,6 82,083 73,52 77,108
0,7 81,425 73,6 76,859
0,8 81,782 73,6 76,947
0,9 81,159 73,04 76,433
1 82,034 73,2 76,989
Berikut ini merupakan grafik hubungan antara pengaruh learning rate dengan hasil evaluasi sistem telah disajikan pada Gambar 4.
Gambar 4. Grafik Hasil Pengujian Pengaruh Max Epoch
Dari grafik pada Gambar 4. bisa dilihat bahwa hasil evaluasi sistem pada pengujian ini tidak berbeda jauh antara nilai evaluasi ketika nilai learning rate berubah-ubah dari 0,1 sampai 1. Hasil nilai dari evaluasi precision, recall dan
f-measure memiliki grafik perubahan yang cenderung sama, pada semua nilai antara
precision, recall dan f-measure mengalami kondisi grafik naik turun. Dapat dilihat bahwa grafik menunjukan perubahan antara nilai
learning rate satu sama lain tidak signifikan. Untuk nilai precision tertinggi terdapat pada nilai learning rate 0,4 dengan nilai rata-rata 82,429%, recall mendapatkan hasil evaluasi maksimal pada kondisi learning rate 0,4 dengan nilai rata-rata evaluasi yang didapat adalah
73,76%, sedangkan nilai f-measure
mendapatkan nilai rata-rata evaluasi tertinggi 77,385% ketika nilai learning rate 0,4. Ketika nilai learning rate semakin kecil learning rate
maka akan lama mencapai proses konvergensi tetapi lebih akurat, sedangkan saat nilai learning rate semakin besar maka proses konvergensi lebih cepat dan kurang akurat.
Pada hasil yang diperoleh pada pengujian pengaruh learning rate menunjukan bahwa perubahan nilai learning rate tidak terlalu memberikan pengaruh yang signifikan pada nilai evaluasi yang dihasilkan. Nilai learning rate dari 0,1 sampai 1 memberikan perubahan yang tidak signifikan pada hasil evaluasi, dengan rata-rata f-measure terbesar pada learning rate 0,4 dengan nilai evaluasi 77,385%.
3.3 Pengujian Pengaruh Lexicon Based Features (LBF)
features terhadap nilai evaluasi sistem yang dihasilkan. Pada pengujian ini fitur yang digunakan hanya dengan lexicon based features. Nilai max epoch dan learning rate merupakan nilai yang diambil pada pengujian sebelumnya. Pengujian dilakukan dengan melakukan proses
running sistem dengan data uji sebanyak lima kali untuk setiap fold. Dari lima kali proses pengujian akan dilakukan rata-rata untuk evaluasi precision, recall, dan f-measure untuk memaksimalkan nilai bobot yang bervariasi karena inisialisasinya yang random. Hasil dari pengujian pengaruh lexicon based features telah tersaji pada Tabel 3.
Tabel 3. Hasil Pengujian PengaruhLBF
Fold
Precision Recall
F-Measure sistem mendapatkan persentase 0% mulai dari
precision, recall, dan f-measure. Hasil evaluasi yang bernilai 0% dikarenakan pada lexicon based features hanya menggunakan empat fitur saja, sedangkan data yang digunakan pada data latih adalah 400. Hal ini menunjukan bahwa data uji akan cenderung menghasilkan identifikasi kedalam kelas bukan ujaran kebencian.
Hasil yang diperoleh pada pengujian pengaruh lexicon based features menunjukkan bahwa walaupun ketika nilai max epoch dan
learning rate sudah optimal, tetapi pada hasil evaluasi bisa dikatakan sangat buruk. Hasil ini bisa terjadi karena ketika menggunakan lexicon based features fitur yang dipakai hanya berjumlah empat, sehingga kurang bervariasi dan tidak bisa digunakan untuk melakukan pengujian terhadap data uji.
Faktor lain yang menyebabkan lexicon based features disini sangat buruk hasilnya adalah lexicon yang digunakan pada penelitian ini merupakan lexicon secara umum. Sedangkan, pada penelitian ini data tweet ujaran kebencian yang digunakan sangat spefisik yakni mengenai pilkada DKI 2017. Sehingga kata-kata yang biasanya bukan merupakan ujaran kebencian
dalam penelitian ini dianggap sebagai ujaran kebencian. Jadi, kesimpulannya bahwa ketika hanya menggunakan lexicon based features
maka proses identifikasi menjadi gagal atau tidak berjalan.
3.4 Pengujian Pengaruh Bag of Words
(BoW)
Pada pengujian ini fitur bag of words akan dilihat pengaruhnya terhadap nilai evaluasi sistem yang dihasilkan. Disini pengujian yang dilakukan, hanya menggunakan fitur bag of words. Nilai max epoch dan learning rate
merupakan nilai yang diambil pada pengujian sebelumnya. Pengujian dilakukan dengan melakukan proses running sistem dengan data uji sebanyak lima kali untuk setiap fold. Dari lima kali proses pengujian akan dilakukan rata-rata untuk evaluasi precision, recall, dan f-measure untuk memaksimalkan nilai dari variabel bobot. Hasil pengujian pengaruh bag of words dapat dilihat pada Tabel 4.
Tabel 4. Hasil Pengujian PengaruhBoW
Fold
Precision Recall
F-Measure
Pada Tabel 4. dapat dilihat bahwa dari hasil pengujian nilai evaluasi yang didapatkan sangat beragam. Nilai rata-rata evaluasi yang didapat pada precision adalah 81,417%, recall 73,12%, dan nilai evaluasi f-measure 76,638%. Dari semua fold didapatkan nilai evaluasi precision
tertinggi adalah 88,603%, sedangkan untuk
recall 86,4%, dan nilai f-measure adalah 86,907%. Dari hasil pengujian ini menunjukan fitur bag of words sangat sesuai untuk metode
Backpropagation Neural Network (BPNN), karena pelatihan yang dihasilkan berhasil mengidentifikasi ujaran kebencian dan bukan ujaran kebencian.
dikarenakan dalam bag of words jumlah fitur yang digunakan sangat dinamis tergantung pada jumlah data latih, semakin besar data latih maka jumlah fitur bag of words akan semakin banyak. Ketika jumlah fitur bag of words ini semakin besar, dalam data latih metode BPNN akan sangat bervariasi.
Pengaruh lain yang menyebabkan bag of words sangat relevan digunakan untuk metode BPNN adalah fitur yang digunakan untuk membuat pola pembelajaran BPNN akan menyesuaikan dari data latihnya. Hal ini bisa terjadi karena fitur yang digunakan ketika metode BPNN dikombinasikan dengan bag of words merupakan fitur hasil ekstraksi data latih yang digunakan.
Jadi, kesimpulan yang didapat adalah ketika metode Backpropagation Neural Network
(BPNN) menggunakan fitur bag of words, maka proses identifikasi akan berhasil dengan nilai rata-rata evaluasi f-measure sebesar 76,638%.
3.5 Pengujian Perbandingan Evaluasi Metode BPNN menggunakan Lexicon Based Features dan Bag of Words
Pengujian kelima disini dimaksudkan untuk mencari fitur terbaik yang digunakan untuk metode Backpropagation Neural Network
(BPNN) dalam identifikasi ujaran kebencian. Disini pengujian yang dilakukan menggunakan kombinasi fitur yaitu BPNN dengan LBF, BPNN dengan BoW, dan BPNN dengan LBF + BoW. Pengujian dilakukan dengan melakukan proses
running sistem dengan data uji sebanyak lima kali. Dari lima kali proses pengujian akan dilakukan rata-rata untuk evaluasi f-measure
untuk memaksimalkan nilai bobot. Hasil dari pengujian perbandingan metode BPPN dengan LBF dan BoWtelah disajikan pada Tabel 5.
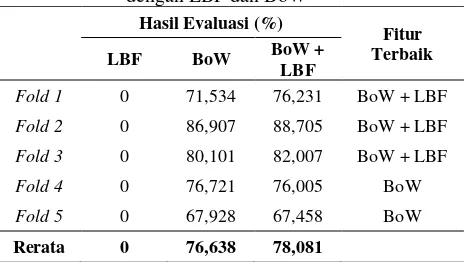
Tabel 5. Hasil Perbandingan Evaluasi BPNN dengan LBF dan BoW
Hasil Evaluasi (%)
Fitur Terbaik
LBF BoW BoW +
LBF
Fold 1 0 71,534 76,231 BoW + LBF
Fold 2 0 86,907 88,705 BoW + LBF
Fold 3 0 80,101 82,007 BoW + LBF
Fold 4 0 76,721 76,005 BoW
Fold 5 0 67,928 67,458 BoW
Rerata 0 76,638 78,081
Dan untuk grafik perbandingan antara kedua fitur LBF dan BoW dengan hasil evaluasi sistem
telah disajikan pada Gambar 5.
Gambar 5. Grafik Hasil Perbandingan Evaluasi BPNN dengan LBF dan BoW
Dari grafik pada Gambar 5. bisa dilihat bahwa hasil evaluasi sistem pada pengujian ini antara fitur BoW dengan BoW + LBF tidak terdapat perbedaan yang signifikan. Disini untuk hasil f-measure fold 1, fold 2, dan fold 3 fitur BoW + LBF yang memiliki hasil lebih tinggi, sedangkan untuk fold 4 dan fold 5 fitur BoW memiliki hasil yang tinggi walaupun perbedaannya tidak signifikan. Untuk nilai f-measure yang tertinggi ada pada fitur BoW + LBF pada fold 2 dengan nilai evaluasinya 88,705%.
Pada hasil yang diperoleh pada pengujian pengaruh perbandingan evaluasi metode BPNN menggunakan LBF dan BoW menunjukan bahwa ketika fitur LBF digunakan tanpa dikombinasikan dengan fitur BoW maka nilai f-measure yang didapat 0%, fitur BoW tanpa
menggunakan LBF mendapat f-measure
tertinggi 86,907%, sedangkan fitur LBF + BoW menghasilkan nilai untuk f-measure tertinggi dari ketiga fitur yakni 88,705%.
Dari hasil tersebut juga didapat bahwa ketika LBF dan BoW dikombinasikan dan dilakukan pengujian dengan 5-Fold Cross Validation didapatkan hasil tiga fold dengan nilai f-measure tertinggi diantara fitur lainnya. Hasil rata-rata f-measure yang didapat yaitu 0% untuk LBF, 76,638% untuk BoW, dan 78,081% ketika fitur BoW dikombinasikan dengan LBF.
Jadi, bisa disimpulkan bahwa LBF dapat digunakan untuk meningkatkan akurasi evaluasi apabila dikombinasikan dengan BoW, tetapi sangat jelek ketika LBF hanya digunakan sebagai fitur tunggal untuk metode BPNN. Dan selisih yang didapat ketika BoW dikombinasikan dengan LBF mengalami peningkatan sekitar 1,443%.
Bag of Words dengan RFDT menggunakan fitur n-gram
Analisis disini dimaksudkan untuk mengetahui perbandingan hasil dari Metode
Backpropagation Neural Network (BPNN) berbasis Bag of Words (BoW) dan Lexicon Based Features (LBF) dengan Random Forest Decision Tree (RFDT) menggunakan fitur n-gram. Dari penelitian sebelumnya diambil hasil terbaik dan penelitian ini diambil hasil terbaik dari metode yang digunakan, dan perancangan analisis disajikan pada Tabel 6.
Tabel 6. Hasil Perbandingan Metode BPNN berbasis Lexicon Based Features dan Bag of Words
dengan RFDT menggunakan fitur n-gram
Fitur
Hasil Evaluasi F-Measure (%)
BPNN RFDT
Terbaik 88,705 93,5
Dari Tabel 6. diperoleh hasil bahwa metode terbaik yang digunakan untuk identifikasi ujaran kebencian adalah dengan metode Random Forest Decision Tree (RFDT) menggunakan n-gram fitur dengan hasil f-measure 93,5% yang merupakan hasil dari penelitian sebelumnya (Alfina, et al., 2017). Sedangkan dalam penelitian ini ketika menggunakan metode
Backpropagation Neural Network (BPNN) berbasis Lexicon Based Features dan Bag of Words mendapatkan hasil f-measure 88,705%.
Hasil dari analisis disini bahwa metode BPNN berbasis Lexicon Based Features dan Bag of Words yang digunakan tidak lebih baik dari penelitian sebelumnya. Hal ini bisa terjadi karena pada penelitian ini fitur yang menjadi kombinasi Lexicon Based Features masih belum maksimal untuk digunakan identifikasi ujaran kebencian. Pada pengujian pengaruh Lexicon Based Features hasil yang didapatkan bahwa fitur ini gagal untuk melakukan identifikasi karena sistem cenderung mengidentifikasikan ke kelas bukan ujaran kebencian.
Faktor lain yang menyebabkan kurang bagusnya hasil dari metode pada penelitian ini
adalah pada penelitian sebelumnya
menggunakan RFDT dengan n-gram fitur. Metode RFDT merupakan metode dengan
random forest yakni merupakan gabungan dari beberapa pohon keputusan. Pohon keputusan yang digabung menjadi random forest
memberikan dugaan yang lebih tinggi akurasinya dibandingkan hanya dengan pohon tunggal.
Jadi, kesimpulan yang didapat bahwa metode Backpropagation Neural Network
berbasis Lexicon Based Features dan Bag of Words tidak lebih baik dibandingkan dengan metode Random Forest Decision Tree
menggunakan n-gram fitur. Karena fitur yang digunakan dalam ekstraksi fitur yakni Lexicon Based Features belum maksimal dan random forest masih lebih baik untuk meningkatkan hasil identifikasi.
4. KESIMPULAN
Berdasarkan pada hasil pengujian yang telah dilakukan sebelumnya, maka dapat disimpulkan
mengenai implementasi metode
Backpropagation Neural Network berbasis
Lexicon Based Features dan Bag Of Words
untuk identifikasi ujaran kebencian pada Twitter adalah sebagai berikut:
1. Metode Backpropagation Neural Network
berbasis Lexicon Based Features dan Bag of Words dapat diimplementasikan pada identifikasi ujaran kebencian dengan hasil identifikasi berupa ujaran kebencian dan bukan ujaran kebencian. Data latih datih dan uji diproses melalui tahapan
Preprocessing, kemudian hasil
Preprocessing dilakukan ekstraksi fitur dengan Bag of Words dan Lexicon Based Features, dan fitur tersebut digunakan untuk proses pembelajaran pada metode
Backpropagation Neural Network
kemudian dilakukan pengujian dengan data uji untuk mendapatkan identifikasi berupa ujaran kebencian dan bukan ujaran kebencian.
2. Hasil pengujian nilai-nilai parameter
Backpropagation Neural Network yaitu nilai learning rate yang diuji tidak memberikan pengaruh yang signifikan, karena hasil yang didapat cenderung tidak mengalami perubahan terhadap hasil evaluasi precision, recall dan f-measure. Juga untuk nilai max epoch yang diujikan sesuai dengan skenario tidak memberikan hasil perubahan yang signifikan, ini dibuktikan dengan hasil evaluasi yang tidak mengalami peningkatan yang besar, tetapi menunjukan hasil yang cenderung stabil. Parameter terbaik yang didapatkan dari hasil pengujian, yaitu max epoch 350 dan
3. Pada evaluasi sistem didapatkan sebagai hasil berikut: ketika hanya menggunakan
Lexicon Based Features nilai rata-rata f-measure sebesar 0%, lebih buruk dibandingkan dengan menggunakan Bag of Words yang nilai rata-rata f-measure
sebesar 76,638%, dan ketika Lexicon Based Features dan Bag of Words dikombinasikan menghasilkan nilai f-measure tertinggi dari fitur sebelumnya dengan nilai rata-rata f-measure 78,081%. Dengan hasil berikut dapat disimpulkan bahwa kombinasi dua fitur yakni Lexicon Based Features dan Bag of Words dapat meningkatkan performa pada sistem.
4. Hasil perbandingan metode
Backpropagation Neural Network berbasis
Lexicon Based Features dan Bag of Words
masih tidak lebih baik dibandingkan dengan
Random Forest Decision Tree
menggunakan n-gram fitur. Karena fitur yang digunakan dalam ekstraksi fitur yakni
Lexicon Based Features belum maksimal dan random forest masih lebih baik untuk meningkatkan hasil identifikasi.
5. DAFTAR PUSTAKA
Alfina, I., Mulia, R., Fanany, M. I. & Ekanata, Y., 2017. Hate Speech Detection in the Indonesian Language: A Dataset and Preliminary Study. 9th International Conference on Advanced Computer Science and Information Systems 2017 (ICACSIS).
Burnap, P. & Williams, M. L., 2014. Hate Speech, Machine Classification and Statistical Modelling of Information Flows on Twitter: Interpretation and Communication for Policy Decision Making.
Davidson, T., Warmsley, D., Macy, M. & Weber, I., 2017. Automated Hate Speech Detection and the Problem of Offensive Language. Proceedings of the Eleventh International AAAI Conference on Web and Social Media (ICWSM 2017).
Dewa, P. E., 2014. Menguak Jejaring Sosial.
Serpong: s.n.
Direktorat Tindak Pidana Siber Bareskrim, 2016.
Fausett, L., 1994. Fundamentals of Neural Networks: Architecture, Algorithms, and Aplications. New Jersey: Prentice Hall.
Fawcett, T., 2006. Anintroduction to ROC Analysis. Pattern Recognition Letters,
Volume 27, pp. 861-874.
Feldman, R. & Sanger, J., 2007. The Text Mining Handbook Advanced Approaches in Analyzing Unstructured Data. USA: Cambridge University Press.
Gambäck, B. & Sikdar, U. K., 2017. Using Convolutional Neural Networks to Classify Hate-Speech. Proceedings of the First Workshop on Abusive Language Online, pp. 85-90.
George, S. K. & Joseph, S., 2014. Text Classification by Augmenting Bag of Words (BOW) Representation with Co-occurrence Feature. IOSR Journal of Computer Engineering (IOSR-JCE), pp. 34-38.
Gorunescu, F., 2011. Data Mining Concept Model and Techniques. Berlin: Springer.
Haryati, D. F., Abdillah, G. & Hadiana, A. I., 2016. Klasifikasi Jenis Batubara menggunakan Jaringan Syaraf Tiruan dengan Algoritma Backpropagation.
Seminar Nasional Teknologi Informasi dan Komunikasi 2016 (SENTIKA 2016).
Hastuti, K., 2012. Analisis Komparasi Algoritma Klasifikasi Data Mining. Seminar Nasional Teknologi Informasi & Komunikasi Terapan 2012, pp. 241-249.
Hermawan, A., 2006. Jaringan Syaraf Tiruan (Teori dan Aplikasi). Yogyakarta: Andi.
Lan, M., Tan, C. L. & Su, J., 2007. Supervised and Traditional Term Weighting
Methods for Automatic Text
Categorization. Journal of IEEE PAMI,
10(10), pp. 1-36.
Mangantibe, V., 2016. Ujaran Kebencian dalam
Surat Edaran Kapolri Nomor:
SE/6/X/2015 Tentang Penanganan Ucapan Kebencian (Hate Speech).
Conference on Computer and Information Technology.
Sun, X., Xiao, Y., Wang, H. & Wang, W., 2015. On Conceptual Labeling of a Bag of Words. Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence.
Tala, F. Z., 2003. A Study of Stemming Effect on Information Retrieval in Bahasa Indonesia. Netherland: Universiteti van Amsterdam.
Triawati, C., 2009. Metode Pembobotan Statistical Concept Based untuk Klastering dan Kategorisasi Dokumen Berbahasa Indonesia. Bandung: Institut Teknologi Bandung.
Turban, E., Sharda, R., Delen, D. & King, D., 2010. Bussiness Intelligence A Managerial Approach. United States: Prentice Hall.
Tuteja, S. K. & Bogiri, N., 2016. Email Spam Filtering using BPNN Classification.
International Conference on Automatic Control and Dynamic Optimization Techniques (ICACDOT).