BAB 2
LANDASAN TEORI
2.1. Sistem Pendukung Keputusan (SPK)
Definisi awal SPK menunjukkan SPK sebagai sebuah sistem yang dimaksudkan untuk mendukung para pengambil keputusan manajerial dalam situasi keputusan semiterstruktur. SPK dimaksudkan untuk menjadi alat bantu bagi para pengambil keputusan untuk memperluas kapabilitas mereka, namun tidak untuk menggantikan penilaian mereka.
Little (1970) mendefinisikan SPK sebagai “sekumpulan prosedur berbasis model untuk data pemrosesan dan penilaian guna membantu para manajer mengambil keputusan.” Dia menyatakan bahwa untuk sukses, sistem tersebut haruslah sederhana, cepat, mudah dikontrol, adaptif, lengkap dengan isu-isu penting dan mudah berkomunikasi.
McLeod (1998) mendefinisikan SPK merupakan suatu sistem informasi yang ditunjukkan untk membantu manajemen dalam memecahkan masalah yang dihadapinya.
Dari semua pengertian SPK yang dipaparkan di atas dapat disimpulkan bahwa SPK adalah sebuah sistem berbasis komputer yang dapat membantu seseorang dalam memecahkan masalah dari data yang ada serta mengambil keputusan dan melahirkan output yang bersifat altenatif.
2.1.1. Komponen Sistem Pendukung Keputusan
Adapun komponen-komponen dari Sistem Pendukung Keputusan adalah sebagai berikut :
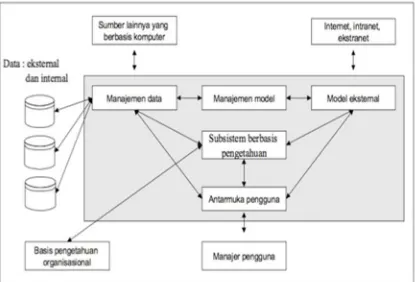
1. Manajemen Data
2. Manajemen Model
Manajemen model merupakan paket perangkat lunak yang memasukkan model-model finansial, statistik, ilmu manajemen atau model-model kuantitatif yang lain yang menyediakan kemampuan analisis sistem dan management software yang terkait. 3. Antarmuka Pengguna
Antarmuka pengguna merupakan media interaksi antara pengguna dan sistem sehingga pengguna dapat memberikan inputan kepada sistem agar didapatkan keputusan yang diproses oleh sistem.
4. Subsistem Berbasis Pengetahuan
Subsistem berbasis pengetahuan adalah subsistem yang dapat mendukung semua subsistem lain atau bertindak sebagai komponen yang berdiri sendiri.
Untuk lebih memahami komponen Sistem Pendukung Keputusan yang telah dijelaskan di atas dapat dilihat pada gambar 2.1.
2.2. Data Mining
Data mining merupakan disiplin ilmu yang mempelajari metode untuk mengekstrak pengetahuan atau menemukan pola dari suatu data (Han and Kamber, 2006). Data mining sering juga disebut Knowledge Discovery in Database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan (Santosa, 2007).
2.2.1. Tugas Utama Data Mining
Secara umum data mining memiliki empat tugas utama (Sahu, 2011): 1. Klasifikasi (Classification)
Klasifikasi bertujuan untuk mengklasifikasikan item data menjadi satu dari beberapa kelas standar. Sebagai contoh, suatu program email dapat mengklasifikasikan email yang sah dengan email spam. Beberapa algoritma klasifikasi antara lain pohon keputusan, nearest neighbor, naïve bayes, neural networks dan support vector machines.
2. Regresi (Regression)
Regresi merupakan pemodelan dan investigasi hubungan dua atau lebih variabel. Dalam analisis regresi ada satu atau lebih variabel independent / prediktor yang biasa diwakili dengan notasi x dan satu variabel respon yang biasa diwakili dengan notasi y (Santosa, 2007).
3. Pengelompokan (Clustering)
Clustering merupakan metode pengelompokan sejumlah data ke dalam klaster (group) sehingga dalam setiap klaster berisi data yang semirip mungkin.
4. Pembelajaran Aturan Asosiasi (Association Rule Learning)
2.2.2. Proses Data Mining
Proses dari data mining mempunyai prosedur umum dengan langkah-langkah sebagai berikut (Kantardzic, 2003):
1. Merumuskan permasalahan dan hipotesis
Pada langkah ini dispesifikasikan sekumpulan variabel yang tidak diketahui hubungannya dan jika memungkinkan dispesifikasikan bentuk umum dari keterkaitan variabel sebagai hipotesis awal.
2. Mengoleksi data
Langkah ini menitikberatkan pada cara bagaimana data dihasilkan dan dikoleksi. Secara umum ada dua kemungkinan yang berbeda. Yang pertama adalah ketika proses pembangkitan data dibawah kendali dari ahli. Pendekatan ini disebut juga dengan percobaan yang dirancang (designed experiment). Kemungkinan yang kedua adalah ketika ahli tidak memiliki pengaruh pada proses pembangkitan data, dikenal sebagai pendekatan observasional.
3. Pra pengolahan data
Pra pengolahan data melibatkan dua tugas utama yaitu: a. Deteksi dan pembuangan data asing (outlier)
Data asing merupakan data dengan nilai yang tidak dibutuhkan karena tidak konsisten pada sebagian pengamatan. Biasanya data asing dihasilkan dari kesalahan pengukuran, kesalahan pengkodean dan pencatatan dan beberapa nilai abnormal yang wajar. Ada dua strategi untuk menangani data asing, yang pertama mendeteksi dan berikutnya membuang data asing sebagai bagian dari fase pra pengolahan. Yang kedua adalah mengembangkan metode pemodelan yang kuat yang tidak merespon data asing.
b. Pemberian skala, pengkodean dan seleksi fitur
4. Mengestimasi model
Pemilihan dan implementasi dari tehnik data mining yang sesuai merupakan tugas utama dari fase ini. Proses ini tidak mudah, biasanya dalam pelatihan, implementasi berdasarkan pada beberapa model dan pemilihan model yang terbaik merupakan tugas tambahan.
5. Menginterpretasikan model dan menarik kesimpulan
Pada banyak kasus, model data mining akan membantu dalam pengambilan keputusan. Metode data mining modern diharapkan akan menghasilkan hasil akurasi yang tinggi dengan menggunakan model dimensi-tinggi.
Pengetahuan yang baik pada keseluruhan proses sangat penting untuk kesuksesan aplikasi. Tidak peduli seberapa kuat metode data mining yang digunakan, hasil dari model tidak akan valid jika pra pengolahan dan pengkoleksian data tidak benar atau jika rumusan masalah tidak berarti.
2.3. Klasifikasi
Salah satu tugas utama dari data mining adalah klasifikasi. Klasifikasi digunakan untuk menempatkan bagian yang tidak diketahui pada data ke dalam kelompok yang sudah diketahui. Klasifikasi menggunakan variabel target dengan nilai nominal. Dalam satu set pelatihan, variabel target sudah diketahui. Dengan pembelajaran dapat ditemukan hubungan antara fitur dengan variabel target. Ada dua langkah dalam proses klasifikasi (Han and Kamber, 2006) :
a. Pembelajaran (learning) : pelatihan data dianalisis oleh algoritma klasifikasi. b. Klasifikasi: data yang diujikan digunakan untuk mengkalkulasi akurasi dari aturan
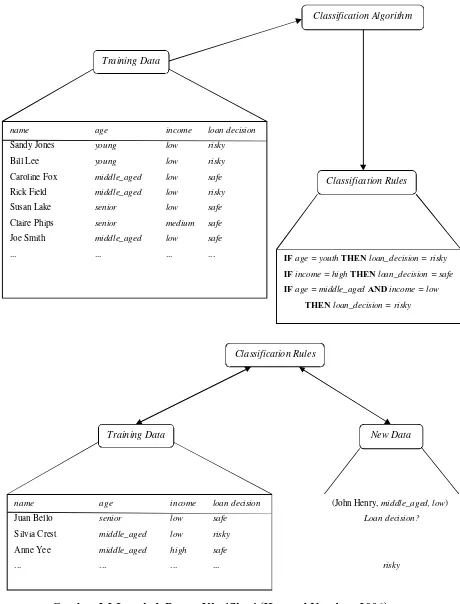
Berikut merupakan langkah proses klasifikasi, yang dapat dilihat pada gambar 2.2.
Gambar 2.2 Langkah Proses Klasifikasi (Han and Kamber, 2006)
Training Data New Data
Classification Rules
name age income loan decision
Juan Bello senior low safe
Silvia Crest middle_aged low risky
Anne Yee middle_aged high safe
... ... ... ...
(John Henry, middle_aged, low)
Loan decision?
risky
Training Data
Classification Algorithm
Classification Rules
name age income loan decision
Sandy Jones young low risky
Bill Lee young low risky
Caroline Fox middle_aged low safe
Rick Field middle_aged low risky
Susan Lake senior low safe
Claire Phips senior medium safe
Joe Smith middle_aged low safe
... ... ... ... IF age = youth THEN loan_decision = risky
IF income = high THEN loan_decision = safe
IF age = middle_aged AND income = low
2.4. Metode Naive Bayes
Naive Bayes merupakan algoritma klasifikasi yang sederhana dimana setiap atribut bersifat independent dan memungkinkan berkontribusi terhadap keputusan akhir (Xhemali, 2009). Algoritma Naive Bayes merupakan salah satu algoritma yang terdapat pada teknik klasifikasi. Naive Bayes merupakan pengklasifikasian dengan metode probabilias dan statistik yang dikemukan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi peluang di masa depan berdasarkan pengalaman di masa sebelumnya sehingga dikenal sebagai Teorema Bayes. Teorema tersebut dikombinasikan dengan Naive dimana diasumsikan kondisi antar atribut saling bebas. Klasifikasi Naive Bayes diasumsikan bahwa ada atau tidak ciri tertentu dari sebuah kelas tidak ada hubungannya dengan ciri dari kelas lainnya.
Persamaan dari teorema Bayes adalah :
( | ) = ( | ). ( )( )
Keterangan :
X : Data dengan class yang belum diketahui
H : Hipotesis data X merupakan suatu class spesifik
P(H|X) : Probabilitas hipotesis H berdasar kondisi X (posterior probability)
P(H) : Probabilitas hipotesis H (prior probability)
P(X|H) : Probabilitas X berdasarkan kondisi pada hipotesis H
P(X) : Probabilitas X
Untuk menjelaskan teorema Naive Bayes, perlu diketahui bahwa proses klasifikasi memerlukan sejumlah petunjuk untuk menentukan kelas apa yang cocok bagi sampel yang dianalisis tersebut. Karena itu, teorema Bayes di atas disesuaikan sebagai berikut :
( | … ) = ( ). ( … | ) ( … )
karakteristik tertentu dalam kelas C (Posterior) adalah peluang munculnya kelas C (sebelum masuknya sampel tersebut, seringkali disebut Prior), dikali dengan peluang kemunculan karakteristik-karakteristik sampel pada kelas C (disebut juga likelihood), dibagi dengan peluang kemunculan karakteristik-karakteristik sampel secara global (disebut juga evidence). Karena itu, rumus di atas dapat pula ditulis secara sederhana sebagai berikut :
= ℎ
Nilai evidence selalu tetap untuk setiap kelas pada satu sampel. Nilai dari
posterior tersebut nantinya akan dibandingkan dengan nilai-nilai posterior kelas lainnya untuk menentukan ke kelas apa suatu sampel akan diklasifikasikan. Penjabaran lebih lanjut rumus Bayes tersebut dilakukan dengan menjabarkan
( | … ) menggunakan aturan perkalian sebagai berikut :
( | … ) = ( ). ( … | )
= ( ). ( | ) ( … | , )
= ( ). ( | ) ( | , ) ( … | , , )
= ( ). ( | ) ( | , ) ( | , , ) ( … | , , , ) = ( ). ( | ) ( | , ) ( | , , ) … ( | , , , … ! )
Dari persamaan di atas dapat disimpulkan bahwa asumsi independensi naif tersebut membuat syarat peluang menjadi sederhana, sehingga perhitungan menjadi mungkin untuk dilakukan. Selanjutnya penjabaran ( | … ) dapat disederhanakan menjadi :
( | … ) = ( ) ( | ) ( | ) ( | ) ... = ( ) ∏)*+ ( | )
Persamaan di atas merupakan model teorema Naive Bayes yang selanjutnya akan digunakan dalam proses klasifikasi. Untuk klasifikasi dengan data kontinyu digunakan rumus Densitas Gauss :
" # = # | , = -%& = 1
/2πσ 3 e
!(56!7#%)98#% 8
Keterangan :
P : Peluang # : Atribut ke i # : Nilai atribut ke i
Y : Kelas yang dicari
-% : Sub kelas Y yang dicari
µ : Mean, menyatakan rata-rata dari seluruh atribut
σ : Deviasi standar, menyatakan varian dari seluruh atribut
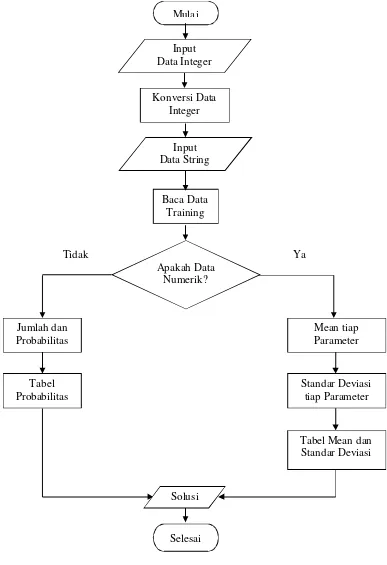
Adapun alur dari metode Naive Bayes adalah sebagai berikut : 1. Input data training
2. Baca data training.
3. Hitung jumlah dan probabilitas, namun apabila data numerik maka :
a. Cari nilai mean dan standar deviasi dari masing-masing parameter yang merupakan data numerik.
Berikut merupakan skema Naive Bayes, yang dapat dilihat pada gambar 2.3.
Gambar 2.3 Skema Naive Bayes Selesai
Tidak Ya
Jumlah dan Probabilitas
Apakah Data Numerik? Baca Data Training
Tabel Probabilitas
Mean tiap Parameter
Standar Deviasi tiap Parameter
Tabel Mean dan Standar Deviasi Mulai
Input Data String
Solusi Konversi Data
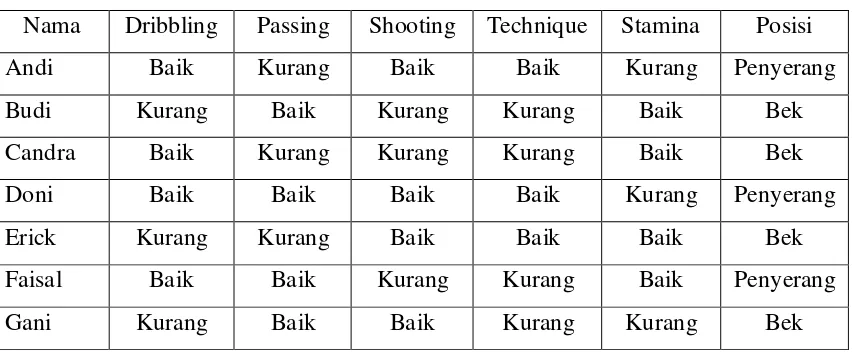
Konsep dari perhitungan Naive Bayes dapat dijelaskan dengan menggunakan contoh yang terdapat pada data sebagai berikut :
Tabel 2.1 Data Pemain dan Posisi
Nama Dribbling Passing Shooting Technique Stamina Posisi
Andi Baik Kurang Baik Baik Kurang Penyerang
Budi Kurang Baik Kurang Kurang Baik Bek
Candra Baik Kurang Kurang Kurang Baik Bek
Doni Baik Baik Baik Baik Kurang Penyerang
Erick Kurang Kurang Baik Baik Baik Bek
Faisal Baik Baik Kurang Kurang Baik Penyerang
Gani Kurang Baik Baik Kurang Kurang Bek
Naive Bayes akan menentukan kelas dari data pemain baru berikut :
Haris (Dribbling = Baik, Passing = Baik, Shooting = Kurang, Technique = Baik,
Stamina = Kurang)
P(Y = Bek) = : = 0.57 P(Y = Penyerang) = : = 0.43 P(Dribble = Baik | Y = Bek) = 1<4
P(Dribble = Baik | Y = Penyerang) = 3<3 P(Passing = Baik | Y = Bek) = 2<4 P(Passing = Baik | Y = Penyerang) = 2<3 P(Shooting = Kurang | Y = Bek) = 2<4 P(Shooting = Kurang | Y = Penyerang) = 1<3 P(Technique = Baik | Y = Bek) = 1<4
P(Bek) * P(Dribble | Bek) * P(Passing | Bek) * P(Shooting | Bek) * P(Technique | Bek) * P(Stamina | Bek)
= 4<7 * 1<4 * 2<4 * 2<4 * 1< 4* 1<4 = 0,0022
P(Penyerang) * P(Dribble | Penyerang) * P(Passing | Penyerang) * P(Shooting | Penyerang) * P(Technique | Penyerang) * P(Stamina | Penyerang)
= 3<7 * 3<3 * 2<3 * 1<3 * 2< 3* 2<3 = 0,0427
Dari hasil di atas, terlihat bahwa nilai probabilitas tertinggi ada pada kelas (P | Penyerang), sehingga dapat disimpulkan bahwa Haris masuk ke dalam klasifikasi “Penyerang”.
2.5. Android
Android merupakan sebuah sistem operasi yang berbasis Linux untuk telepon seluler
seperti smartphone dan komputer tablet. Android menyediakan platform terbuka bagi para pengembang untuk menciptakan aplikasi mereka sendiri untuk digunakan oleh berbagai macam peranti bergerak.
Sampai pada saat ini, sistem operasi Android sudah memasuki versi 4.2. Uniknya, penanaman versi Android selalu menggunakan nama makanan dan diawali dengan abjad yang berurutan seperti berikut (Arif, 2013) :
1. Android version 1.5 (Cupcake)
2. Android version 1.6 (Donut)
3. Android version 2.0/2.1 (Eclair)
4. Android version 2.2 (Frozen Yogurt/Froyo)
5. Android version 2.3 (Gingerbread)
6. Android version 3.0/3.1/3.2 (Honeycomb)
7. Android version 4.0 (Ice Cream Sandwich)
8. Android version 4.1/4.2 (Jelly Bean)
2.6. Sepak Bola
Awal mula munculnya sepak bola cukup membingungkan. Beberapa dokumen mengatakan sepak bola berasal dari masa Romawi, namun ada juga yang menyatakan bahwa sepak bola berasal dari daratan Cina. FIFA sendiri sebagai badan sepak bola dunia menyatakan bahwa sepak bola berawal dari permainan yang dilakukan oleh masyarakat Cina pada abad ke-2 hingga ke-3 sebelum Masehi. Olah raga ini dikenal dengan nama “Cuju“. Sepak bola modern yang kita kenal sekarang diakui oleh berbagai pihak berasal dari Inggris. Sepak bola modern ini mulai dimainkan pada pertengahan abad ke-19 di sekolah-sekolah di daerah Inggris Raya. Pada tahun 1857 berdiri klub sepak bola pertama di dunia, dengan nama Sheffield Football Club. Klub sepak bola ini merupakan gabungan dari beberapa sekolah yang memainkan permainan sepak bola. Pada saat yang sama, tepatnya tahun 1863, berdiri badan asosiasi sepak bola di Inggris, dengan nama Football Association (FA). Pada saat itu badan inilah yang mengeluarkan peraturan dasar permainan sepak bola, sehingga sepak bola menjadi lebih terorganisir.
Pada tahun 1886 terbentuk badan yang mengeluarkan peraturan sepak bola modern di dunia, dengan nama International Football Association Board (IFAB). IFAB terbentuk setelah adanya pertemuan antara FA dengan Scottish Football Association, Football Association of Wales, dan Irish Football Association di Manchester, Inggris. Hingga saat ini IFAB adalah badan yang mengeluarkan berbagai peraturan pada permainan sepak bola, mulai dari peraturan dasar hingga peraturan yang menyangkut teknik permainan serta perpindahan pemain.
2.6.1. Pengenalan Sepak Bola
Sepak bola adalah salah satu olahraga yang sangat populer di dunia. Dalam pertandingan, olahraga ini dimainkan oleh dua kelompok berlawanan yang masing-masing berjuang untuk memasukkan bola ke gawang kelompok lawan. Masing-masing kelompok beranggotakan sebelas pemain, dan karenanya kelompok tersebut juga dinamakan kesebelasan. Dua tim yang masing-masing terdiri dari 11 orang bertarung untuk memasukkan sebuah bola bundar ke gawang lawan ("mencetak gol"). Tim yang mencetak lebih banyak gol adalah sang pemenang (biasanya dalam jangka waktu 90 menit, tetapi ada cara lainnya untuk menentukan pemenang jika hasilnya seri). Akan diadakan tambahan waktu 2x15 menit dan apabila dalam tambahan waktu hasilnya masih seri, akan diadakan adu penalti yang setiap timnya akan diberikan lima kali kesempatan untuk menendang bola ke arah gawang dari titik penalti yang berada di dalam daerah kiper hingga hasilnya bisa ditentukan. Peraturan terpenting dalam mencapai tujuan ini adalah para pemain (kecuali penjaga gawang) tidak boleh menyentuh bola dengan tangan mereka selama masih dalam permainan.
Sebuah pertandingan diperintah oleh seorang wasit yang mempunyai "wewenang penuh untuk menjalankan pertandingan sesuai peraturan permainan dalam suatu pertandingan yang telah diutuskan kepadanya", dan keputusan-keputusan pertandingan yang dikeluarkannya dianggap sudah final. Sang wasit dibantu oleh dua orang asisten wasit dan seorang ofisial keempat yang dapat menggantikan seorang ofisial lainnya jika diperlukan.
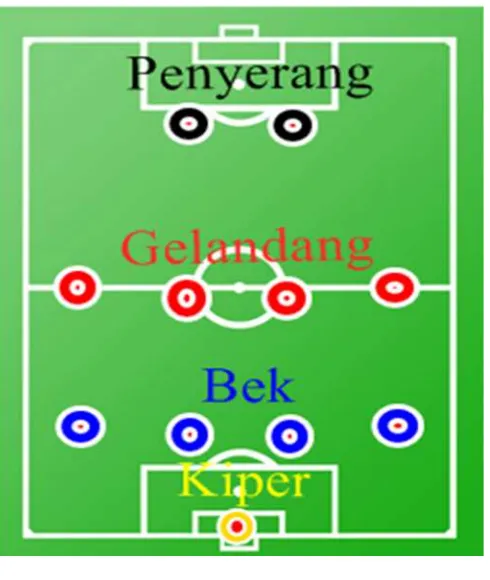
2.6.2. Posisi dan Peran Pemain
Satu tim sepak bola terdiri dari 11 orang pemain yang memiliki posisi dan tugas yang berbeda-beda. Secara umum ada 4 posisi pemain dalam sepak bola, diantaranya: 1. Penjaga Gawang / Kiper
Bertugas menjaga daerah gawang dan mencegah bola masuk ke gawang. 2. Pemain Bertahan / Bek
Bertugas menjaga daerah pertahanan sendiri agar lawan tidak bisa membobol gawang yang dijaga oleh penjaga gawang.
3. Pemain Tengah / Gelandang
bola dari bek untuk diarahkan ke penyerang, sedangkan waktu diserang seorang gelandang adalah orang pertama yang harus merebut bola dari kaki lawan, sebelum bek.
4. Pemain Depan / Penyerang
Bertugas untuk mencetak gol. Untuk posisi ini, seorang pemain harus mempunyai naluri dan penempatan posisi yang bagus. Penyerang juga harus bisa memaksimalkan peluang sekecil apapun untuk menjadi sebuah gol. Karena dalam permainan yang sebenarnya, seorang penyerang akan mendapat kawalan dari pemain bertahan lawan.
Berikut merupakan gambaran dari posisi pemain sepak bola, yang dapat dilihat pada gambar 2.4.
Gambar 2.4 Posisi Pemain Sepak Bola
2.7. Penelitian yang Relevan
Berikut ini beberapa penelitian tentang sistem pendukung keputusan yang terkait dengan metode Naive Bayes :
Bayes didukung oleh ilmu probabilistik dan ilmu statistika khususnya penggunaan data petunjuk untuk mendukung keputusan pengklasifikasian. Pada algoritma
Naive Bayes, semua atribut akan memberikan kontribusinya dalam pengambilan keputusan, dengan bobot atribut yang sama penting dan setiap atribut saling bebas satu sama lain.
b. Sri Kusumadewi (2009) dalam jurnal yang berjudul Klasifikasi Status Gizi Menggunakan Naive Bayes Classification. Menyatakan bahwa algoritma Naive Bayes Classification dapat digunakan sebagai salah satu metode untuk klasifikasi status gizi berdasarkan hasil pengukuran antropometri dan model sistem yang dibangun memiliki kinerja yang baik karena hasil pengujian menunjukkan total kinerja sebesar 0,932 atau 93,2%.
c. Hera Wasiati dan Dwi Wijayanti (2014) dalam jurnal yang berjudul Sistem Pendukung Keputusan Penentuan Kelayakan Calon Tenaga Kerja Indonesia
Menggunakan Metode Naive Bayes. Menyatakan bahwa dari pengujian yang