Fakultas Ilmu Komputer
Universitas Brawijaya
10884
Prediksi Penerimaan Bea Cukai Menggunakan Metode Support Vector
Regression (Studi Kasus Di KPPBC Tipe Madya Pabean C Jember)
Dinda Adilfi Wirahmi1, Imam Cholissodin2, Indriati3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Instansi yang bergerak di bidang bea cukai memiliki tugas menghimpun penerimaan negara dalam sektor bea dan cukai. Penerimaan tersebut memegang peranan penting dalam mendukung pembangunan infrastruktur. Untuk mengontrol penerimaan, dibutuhkan prediksi sebagai syarat untuk melakukan perencanaan pembiayaan Anggaran Pendapatan dan Belanja Negara (APBN) yang baik. Prediksi digunakan sebagai tindakan untuk optimalisasi dan pengontrolan penerimaan. Namun, prediksi sulit dilakukan karena penerimaan tersebut juga mendapat pengaruh dari faktor eksternal yang sulit diprediksi. Untuk mengatasi masalah tersebut, diperlukan suatu pendekatan yang logis dan dapat dipertanggungjawabkan untuk memprediksi penerimaan. Metode prediksi yang digunakan adalah Support Vector Regression (SVR). Algoritme ini memiliki kinerja kuat dalam melakukan identifikasi terhadap pola dataset time series dan dapat memberikan hasil prediksi yang baik apabila penentuan parameter secara baik karena kinerjanya sangat bergantung pada parameter di dalamnya. Implementasi SVR pada penelitian ini menggunakan kernel RBF dengan nilai variasi parameter yaitu sigma = 0.13, lambda = 3.29 , cLR = 0.02, epsilon = 0.00001 dan C = 10, iterasi = 15000 serta menggunaan 4 fitur data menghasilkan MAPE terbaik <20% sehingga dapat dikategorikan bahwa SVR akurat dalam melakukan prediksi penerimaan bea cukai.
Kata kunci: bea cukai, penerimaan, support vector regression, prediksi
Abstract
Customs has the responsibility as a collector of state revenue. Revenue has an important role in supporting infrastructure development. To manage revenue, prediction is needed to make a good APBN planning. To control revenue, predictions are needed as a prerequisite for good planning of the National Budget (APBN). Prediction is used as an action to optimize and control reception. However, revenue prediction are difficult to do because of the revenue influenced by external factors that difficult to predict. Therefore, logical and accountable agreements are needed to to revenue prediction. Predictions are used to prevent actual are lower than predetermined targets thereby increasing revenue that can be controlled because it has an impact on economic growth in Indonesia. The prediction method used is Support Vector Regression (SVR). This algorithm has a strong performance to recognize time series dataset patterns and provides good prediction results if the parameters are well determined because their performance is very dependent on the parameters within them. SVR implementation in this study uses RBF kernel with parameter variation values, namely sigma = 0.13, lambda = 3.29, cLR = 0.02, epsilon = 0.00001 and C = 10, iteration = 15000 and using 4 data features produce the best MAPE <20% so that it can be categorized that SVR is accurate in predicting customs revenue.
Keywords: customs, revenue, support vector regression, prediction
1. PENDAHULUAN
Bea merupakan suatu pungutan oleh pemerintah yang ditujukan untuk barang ekspor maupun impor dan cukai adalah pungutan terhadap barang yang memiliki ciri – ciri yaitu konsumsinya perlu dikendalikan, peredarannya
dan pemakaian terhadap barang tersebut perlu untuk dilakukan pengawasan karena dapat menimbulkan efek negatif bagi masyarakat. Bea cukai sebagai instansi pemerintah yang di dalamnya juga terdapat KPPBC Tipe Madya Pabean C Jember merupakan salah satu kantor
pengawasan juga memiliki tugas pokok sebagai Revenue Collector yaitu menghimpun penerimaan negara untuk mengoptimalkan perkembangan ekonomi sehingga menunjang pembangunan nasional (Adomaviciute, 2013).
Menurut laporan kinerja DJBC pada tahun 2018 yang tercantum pada website resmi DJBC, pemerintah sedang gencar dalam membangun berbagai infrastruktur dalam beberapa tahun terakhir. Hal ini tentunya membutuhkan dukungan pembiayaan yang tidak sedikit. DJBC secara keseluruhan mendukung sekitar 25% dari total pendapatan negara yang meliputi bea masuk, bea keluar dan penerimaan cukai dan pajak pada tahun 2018. Oleh karena itu, penerimaan dari sektor bea cukai memegang peranan yang penting dalam mendukung kerja pembangunan infrastruktur negara. Penerimaan tersebut perlu dilakukan optimalisasi dan pengontrolan agar tetap stabil sehingga tidak berdampak pada kerja pembangunan.
Namun masalah yang terjadi di lapangan yaitu sulitnya melakukan prediksi nilai penerimaan bea dan cukai yang digunakan untuk pembiayaan APBN karena penerimaan tersebut banyak dipengaruhi oleh faktor eksternal yang seringkali sulit diprediksi menggunakan intuisi dan melihat pengalaman di masa lalu. Faktor eksternal yang mempengaruhi adalah seperti permintaan dan penawaran di pasar internasional, aktivitas perekonomian negara hingga perilaku masyarakat. Oleh karena itu diperlukan pendekatan yang logis dan dapat dipertanggungjawabkan untuk memprediksi penerimaan. Kebutuhan akan prediksi tersebut merupakan syarat untuk dapat melakukan perencanaan pembiayaan APBN yang baik. Prediksi digunakan sebagai tindakan untuk mencegah penerimaan aktual lebih rendah daripada target yang sudah ditentukan sehingga grafik penerimaan dari sektor bea cukai bisa dikontrol dan berdampak pada pertumbuhan ekonomi di Indonesia.
Salah satu algoritme yang bisa digunakan dalam memprediksi adalah Support Vector Regression (SVR) yang mana algoritme ini bekerja dengan menggunakan data – data pada masa lalu untuk melakukan prediksi data – data pada masa yang akan datang. Teknik machine learning SVR memiliki performansi atau kinerja kuat dalam melakukan identifikasi terhadap pola dataset time series dan dapat memberikan hasil prediksi yang baik apabila penentuan parameter
secara baik karena kinerja dari algoritme tersebut sangat bergantung pada parameter di dalamnya (Meesad & Rasel, 2013).
Penelitian sebelumnya terkait SVR merupakan penelitian oleh Kadir Kavaklioglu yang memprediksi penggunakan listrik di Turki dengan menggunakan metode SVR dan didapatkan hasil bahwa dengan menggunakan algoritme SVR dapat memberikan performa yang baik dengan error RMSE relatif kecil yaitu sebesar 0,76 (Kavaglioglu, 2010). Penelitian selanjutnya merupakan penelitian yang memprediksi konsumsi listrik rumah tangga \yang sulit diprediksi karena terdapat faktor ketidakpastian karena adanya keterlibatan perilaku manusia (Shen, et al., 2017). Penelitian tersebut menunjukkan bahwa SVR dengan kernel RBF memiliki MAPE terbaik sebesar 10,65% dibandingkan kernel lainnya yaitu linear kernel, polynomial dan radial kernel. Penelitian tersebut memberikan kesimpulan bahwa kinerja dari algoritme SVR dapat dikategorikan baik pada prediksi di masa depan untuk data time series.
Berdasarkan permasalahan dan referensi berupa penelitian yang telah ada sebelumnya, peneliti mengangkat judul Prediksi Penerimaan Bea Cukai Menggunakan Metode Support Vector Regression (Studi Kasus Di KPPBC Tipe Madya Pabean C Jember). Prediksi tersebut dapat mengontrol dan mengoptimalkan penerimaan sehingga dapat menaikkan grafik penerimaan bea cukai sebagai salah satu sumber penerimaan negara.
2. TINJAUAN PUSTAKA 2.1 Prediksi
Prediksi adalah proses estimasi untuk dapat memproyeksikan suatu nilai dengan menggunakan persamaan matematika dan statistika. Prediksi merupakan ilmu yang memperkirakan waktu yang akan datang dengan tambahan atau bantuan informasi yang didapatkan dari masa yang sudah lampau dan direpresentasikan menggunakan persamaan matematis (Dewi & Himawati, 2015). Prediksi tidak memberikan jawaban secara pasti suatu kejadian tetapi berusaha untuk mendapatkan jawaban optimal yang mendekati kejadian yang akan datang.
Prediksi dapat berfungsi sebagai dasar ketika mengambil sebuah keputusan akan
sesuatu. Keputusan yang diambil dapat menjadi suatu keputusan yang baik ketika adanya pertimbangan salah satunya hasil prediksi. Prediksi yang baik tentunya akan menghasilkan pengambilan keputusan yang baik pula.
2.2 Penerimaan Bea Cukai
Menurut laporan keuangan Kementrian Keuangan tahun 2018, Bea Cukai bertugas mengumpulkan penerimaan negara atau yang sering disebut sebagai Revenue Collector. Dalam beberapa tahun terakhir, pemerintah sedang gencar-gencarnya membangun berbagai infrastruktur di berbagai daerah. Ini tentunya membutuhkan dukungan pembiayaan yang tidak sedikit. Untuk itu DJBC yang secara keseluruhan mendukung sekitar 25% dari total pendapatan negara di tahun 2018 memegang peranan yang penting dalam mendukung kerja pembangunan infrastruktur ini.
DJBC mempunyai beberapa fungsi utama yaitu salah satunya adalah mengoptimalkan penerimaan negara dalam bentuk penerimaan pabean dan penerimaan cukai guna menunjang pembangunan nasional. Data penerimaan pabean terdiri dari bea masuk yaitu pungutan yang dilakukan negara terhadap barang impor dan bea keluar yang merupakan pungutan terhadap barang ekspor. Data penerimaan cukai terdiri dari jumlah pungutan dari semua jenis cukai seperti hasil tembakau seperti rokok dan sejenisnya, etil alkohol maupun minuman mengandung etil alkohol serta kemasan plastik. Data penerimaan merupakan penjumlahan dari penerimaan sektor pabean dan sektor cukai.
2.3 Normalisasi Data
Proses untuk melakukan normalisasi data merupakan proses transformasi data yang dilakukan dengan tujuan agar semua fitur berada pada rentang nilai yang sama yaitu pada range 0 - 1 sehingga tidak ada fitur dengan nilai yang lebih dominan. Proses normalisasi data yang dilakukan untuk penelitian ini menggunakan normalisasi min – max. Seluruh data yang digunakan sebaiknya dilakukan normalisasi sebelum proses training dan testing untuk memastikan agar nilai dari data yang akan dilakukan tidak ada yang lebih dominan sehingga dapat meningkatkan akurasi komputasi pada data (Mustaffa & Yusof, 2011). Perhitungan terhadap normalisasi data dengan Persamaan 1:
𝑥′= 𝑥− 𝑥𝑚𝑖𝑛
𝑥𝑚𝑎𝑥− 𝑥𝑚𝑖𝑛 (1) 𝑥′ = Hasil normalisasi
𝑥 = Data yang akan di normalisasi
𝑥𝑚𝑖𝑛 = Nilai minimum untuk seluruh data 𝑥𝑚𝑎𝑥 = Nilai maksimum untuk seluruh data
2.4 Support Vector Regression
Algoritme SVR melakukan penyelesaian terkait permasalahan regresi. Algoritme ini merupakan bagian Support Vector Machine (SVM) yang diusulkan oleh Vapnik dkk (Vapnik, et al., 1997). SVR dapat mengenali pola dataset time series serta parameter yang ditentukan secara baik dan optimal dapat menghasilkan prediksi yang baik sehingga parameter SVR berpengaruh besar pada hasil prediksi (Meesad & Rasel, 2013). Maka dari itu, diperlukan percobaan serta pengujian secara terus menerus pada parameternya. SVR di formulasikan seperti Persamaan 2.
𝑓(𝑥) = ∑ (α∗
𝑗−α𝑗)(𝐾(𝑥, 𝑥′) + λ2) 𝑙
𝑗=1 (2)
α∗
𝑗danα𝑗merupakanlangrange multipliers yang merupakan nilai maksimum serta nilai minimum dari suatu fungsi yang dibatasi pada suatu kondisi atau constraint condition (Spiegel & Wrede, 2002). Lagrange multipliers juga disebut sebagai support vector yang akan membantu grafik prediksi untuk mengikuti grafik pada data aktual.
Sebelum masuk ke tahapan SVR, penelitian ini melakukan normalisasi data terlebih dahulu menggunakan normalisasi min - max. SVR memerlukan fungsi kernel dalam prosesnya. Fungsi ini merupakan proses melakukan pemetaan fitur ke dimensi yang lebih tinggi terhadap data input non linier yang digunakan untuk membantu meningkatkan kinerja pembelajaran algoritme sehingga dapat mendekati grafik aktual data. Fungsi kernel Radial Basis Function (RBF) telah banyak digunakan dan terbukti baik digunakan untuk permasalahan regresi dengan kasus non – linier (Berk, et al., 2014). Fungsi kernel RBF dapat dihitung dengan Persamaan 3.
𝐾 (𝑥, 𝑥′) = exp(−||𝑥−𝑥′||2
2σ2 ) (3) 𝐾 (𝑥, 𝑥′) merupakan fungsi kernel yang mana terdapat 𝑥 yang merupakan nilai fitur data untuk menentukan prediksi. 𝑥′ adalah fitur data latih ke-i. Sedangkan σ merupakan sigma yang
merupakan nilai konstan dari suatu fungsi kernel RBF yang melakukan pengaturan terhadap persebaran data ke dalam fitur yang lebih tinggi (Furi, et al., 2015).
Algoritme penyelesaian menggunakan metode SVR (Vijayakumar & Wu, 1999): 1) Melakukan inisialisasi parameter SVR yaitu
complexity (C), cLR (constanta learning rate), lambda, sigma dan epsilon. Complexity
merupakan nilai besarnya toleransi terhadap kesalahan prediksi (Furi, et al., 2015). cLR merupakan suatu konstanta untuk mendapatkan nilai dari learning rate (gamma). Learning rate merupakan nilai skalar dari parameter training untuk menghitung laju pembelajaran (Vijayakumar & Wu, 1999).
Learning rate didapatkan dari pembagian coefficient learning rate yang merupakan
konstanta laju pembelajaran dan nilai maksimum dari matriks hessian. Variabel skalar (lambda) merupakan ukuran skalar atau faktor penambah yang digunakan untuk transformasi ruang pada kernel (Vijayakumar & Wu, 1999). Epsilon digunakan untuk menentukan batas kesalahan f(x) sebagai fungsi regresi (Furi, et al., 2015). Nilai epsilon digunakan sebagai constraint condition pada lagrange multipliers.
2) Menghitung Matriks Hessian ditunjukkan pada Persamaan 4.
𝑅𝑖𝑗= 𝐾(𝑥, 𝑥′) + λ2 𝑖, 𝑗 = 1, … , 𝑙 (4)
𝑅𝑖𝑗 merupakan matriks hessian yang merupakan hasil modifikasi kernel yang dilakukan penambahan nilai skalar yaitu lambda (Vijayakumar & Wu, 1999). Matriks hessian membantu dalam menentukan arah prediksi sehingga dapat mendekati aktual data (Bottou & Lin, 2006). 𝐾(𝑥, 𝑥′) merupakan kernel yang digunakan dalam algortime SVR.𝑙 adalah jumlah data. 3) Proses sequential learning
Inisialisasi awal pada Langrange Multipliers dengan nilai 0.
a) Perhitungan Error pada Persamaan 5.
𝐸𝑖= 𝑦𝑖− ∑ (𝛼∗
𝑗− 𝛼𝑗)𝑅𝑖𝑗 𝑙
𝑗=1 (5)
𝐸𝑖 merupakan nilai error data latih ke-i. 𝑦𝑖 adalah nilai aktual data latih ke-i.
Sedangkan 𝛼∗
𝑖 dan 𝛼𝑖 merupakan lagrange multipliers iterasi sekarang. b) Menghitung δα∗𝑖 dan δα𝑖 atau perubahan
pada lagrange multipliers pada Persamaan 6 dan 7. δ𝛼∗ 𝑖 = min {max [𝛾 (−𝐸𝑖− ε), − 𝛼𝑖] , 𝐶 − 𝛼𝑖} (6) δ𝛼𝑖 = min {max [𝛾 (−𝐸𝑖− ε), − 𝛼𝑖] , 𝐶 − 𝛼𝑖} (7) c) Perhitungan lagrange multipliers pada
Persamaan 8 dan 9.
𝛼∗
𝑖 = 𝛼∗𝑖 + δ𝛼∗𝑖 (8)
𝛼𝑖 = 𝛼𝑖 + δ𝛼𝑖 (9) 4) Ulangi proses poin 3 hingga mencapai maksimum iterasi yang ditentukan atau mencapai konvergensi yang akan berhenti pada kondisi Persamaan 10.
𝑚𝑎𝑥(|δα∗
𝑖|) < ε dan 𝑚𝑎𝑥(|δα𝑖|) < ε (10) Fungsi regresi SVR seperti tertera pada
Persamaan 1.
2.5 MAPE
Penggunaan Mean Absolute Percentage Error (MAPE) bertujuan untuk mengevaluasi teknik prediksi yang digunakan untuk mengukur kualitas hasil prediksi. MAPE melakukan perhitungan selisih data aktual dengan data hasil prediksi dalam bentuk persentase yang kemudian dicari nilai rata – ratanya. MAPE dapat dihitung dengan Persamaan 11.
MAPE = ∑ |𝐴𝑖−𝐹𝑖| 𝐴𝑖 𝑙 𝑖=1 𝑙 𝑥 100% (11) 𝐴𝑡 merupakan nilai aktual data ke-i. 𝐹𝑡 merupakan Nilai hasil ramalan data ke-i. Sedangkan 𝑙 merupakan jumlah data.
3. PERANCANGAN DAN IMPLEMENTASI
Data yang digunakan sebagai penunjang utama dalam penelitian ini untuk melakukan prediksi merupakan suatu data sekunder dari yang diperoleh dari pihak Kanwil Jatim II Malang. Pihak tersebut berperan dalam mengurus pelayanan kepabeanan dan cukai pada kantor wilayah yang mana kantor tersebut menaungi beberapa kantor pelayanan dan pengawasan lainnya salah satunya kantor Bea dan Cukai Kota Jember. Adapun data yang digunakan adalah data per bulan penerimaan dari
Januari 2013 – September 2019.
Untuk memprediksi penerimaan tersebut, SVR melakukan proses yaitu pelatihan (training) dan pengujian (testing). Proses tersebut dilakukan pembagian data terlebih dahulu dengan rasio sebesar 80% dan 20% yang mana pembagian tersebut masing – masing terdiri dari data untuk training dan data untuk testing dari total dataset yang digunakan (Kavaglioglu, 2010).
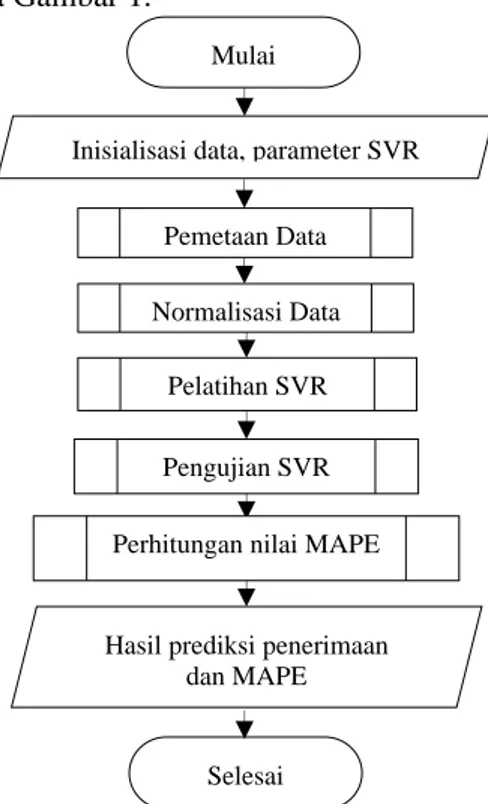
Implementasi pada penelitian ini menggunakan bahasa pemrograman Java dan dilengkapi dengan antarmuka. Pengolahan data yang dilakukan menggunakan database MySQL sebagai tempat manajemen data yang mana terdapat informasi dari bulan penerimaan, tahun penerimaan dan value atau penerimaan berupa besaran nilai dalam rupiah. Penggunaan database untuk manajemen data bertujuan untuk lebih mempermudah penggunaan dan penyimpanan data secara real time. Metode pelatihan dalam penelitian ini adalah sequential learning dengan fungsi kernel RBF. Berikut merupakan diagram alir dari algoritme SVR pada Gambar 1.
Gambar 1. Diagram Alir Algoritme SVR Tahapan dari algoritme tersebut yaitu menerima input data penerimaan per bulan dan inisialisasi parameter support vector regression. Melakukan proses pemetaan data untuk mendapatkan fitur. Digunakan 4 data bulan
sebelum dari bulan penerimaan yang akan diprediksi untuk pemetaan data. Selanjutnya adalah melakukan proses normalisasi data dengan normalisasi min-max, proses pelatihan sampai iterasi maksimum, proses pengujian, denormalisasi data dan yang terakhir adalah melakukan perhitungan nilai MAPE sehingga output yang dihasilkan berupa hasil prediksi dan nilai MAPE.
Implementasi antarmuka sistem terdiri dari beberapa textfield untuk melakukan input parameter SVR, jumlah bulan sekuensial dan jumlah iterasi yang digunakan untuk melakukan komputasi algoritme SVR. Pada antarmuka juga tersedia tab untuk melihat data yang digunakan sebagai dataset, data latih dan data serta hasil prediksinya. Tersedia informasi error rate yang dihasilkan. Implementasi antarmuka tersebut ditunjukkan pada Gambar 2.
Gambar 2. Implementasi Antarmuka
4. PENGUJIAN DAN ANALISIS
Pengujian yang dilakukan pengujian jumlah iterasi, variasi parameter SVR, variasi jumlah data latih dan uji serta pengujian pada pemetaan data.
4.1 Pengujian Jumlah Iterasi
Pengujian dari jumlah iterasi ini dilakukan untuk menguji banyak pembelajaran atau iterasi dalam SVR. Dalam pengujian banyaknya jumlah iterasi, terdapat parameter SVR yang digunakan yaitu dengan rincian nilai sigma = 0.13, lambda = 3.29 , nilai cLR = 0.02, nilai epsilon = 0.00001 dan nilai C = 10. Grafik hasil pengujian jumlah iterasi ditunjukkan oleh Gambar 3.
Pelatihan SVR Mulai
Inisialisasi data, parameter SVR
Normalisasi Data Pemetaan Data
Pengujian SVR Perhitungan nilai MAPE
Hasil prediksi penerimaan dan MAPE
Gambar 3. Hasil Pengujian Jumlah Iterasi Hasil dari pengujian pada jumlah iterasi divisualisasikan ke dalam bentuk grafik. Hal ini dilakukan untuk melihat pola dalam pengaruh banyaknya iterasi terhadap nilai MAPE. Berdasarkan grafik tersebut, terjadi kecenderungan penurunan nilai MAPE ketika jumlah iterasi yang dilakukan semakin banyak.
Hal ini membuktikan bahwa banyaknya iterasi yang dilakukan akan dapat menghasilkan nilai MAPE yang semakin kecil karena melalui iterasi tersebut akan mampu untuk meningkatkan kemampuan sistem untuk mengenal pola data sehingga hal tersebut membuat nilai MAPE akan semakin bagus pula. Pada penelitian ini, jumlah iterasi maksimum ditetapkan yaitu 15000 dengan MAPE yang dihasilkan sebesar 19.07131.
4.2 Pengujian Nilai Parameter Sigma
Pengujian ini dilakukan dengan melakukan perubahan pada parameter sigma sesuai dengan nilai – nilai parameter sigma yang telah ditentukan. Dalam pengujian nilai parameter sigma, terdapat parameter SVR lainnya yang digunakan yaitu dengan rincian nilai lambda = 3.29, nilai epsilon = 0.00001, nilai cLR = 0.02, nilai C = 10 dan iterasi = 15000. Grafik hasil pengujian nilai sigma ditunjukkan oleh Gambar 4.
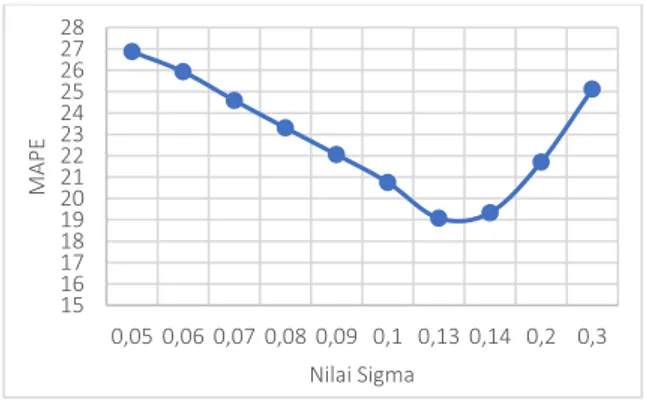
Gambar 4. Hasil Pengujian Nilai Sigma Pengujian pada penelitian ini menghasilkan kesimpulan yaitu parameter sigma yang
ditentukan dengan nilai yang kecil akan berdampak pada persebaran data yang kurang baik sehingga akan meningkatkan nilai MAPE. Parameter sigma dengan nilai yang semakin/relatif besar akan berdampak pada nilai MAPE yang cenderung menurun. Hal ini dikarenakan persebaran yang dilakukan pada data akan semakin merata. Pernyataan tersebut dibuktikan dengan cenderung menurunnya nilai MAPE yang ditunjukkan pada range parameter sigma 0.05 – 0,13 yang tertera pada grafik di atas.
Akan tetapi, jika nilai sigma diinisialisasi terlalu besar, maka error rate yang diperoleh juga akan menjadi naik yang ditunjukkan pada rentang 0,14 – 0,3. Hal ini disebabkan karena sigma memiliki pengaruh yang besar terhadap hasil prediksi. Parameter ini merupakan suatu nilai konstanta atau ketetapan dari suatu fungsi kernel yaitu kernel RBF yang melakukan pengaturan pada persebaran data ke dalam dimensi fitur yang lebih tinggi.
Parameter sigma merupakan parameter SVR yang bekerja untuk memperoleh hasil dari kernel RBF yang digunakan. Oleh karena itu, parameter ini sangat mempengaruhi pada proses pemetaan data yang terbentuk melalui kernel RBF. Nilai MAPE terbaik pada pengujian didapat ketika sigma bernilai 0.13 dengan MAPE sebesar 19.07131.
4.3 Pengujian Nilai Parameter C
Pengujian pada paremeter C dilakukan dengan melakukan perubahan pada nilai parameter C berdasarkan variasi nilai parameter C yang telah ditentukan. Dalam pengujian dari nilai parameter C, terdapat parameter – parameter SVR lainnya yang digunakan yaitu dengan rincian nilai sigma = 0.13, nilai lambda = 3.29, nilai epsilon = 0.00001, nilai cLR = 0.02 dan iterasi = 15000. Grafik hasil pengujian nilai C ditunjukkan oleh Gambar 5.
10 15 20 25 500 1000 5000 10000 15000 M AP E Jumlah Iterasi 15 16 17 18 19 20 21 22 23 24 25 26 27 28 0,05 0,06 0,07 0,08 0,09 0,1 0,13 0,14 0,2 0,3 M AP E Nilai Sigma 0 5 10 15 20 25 30 0,1 0,5 1 5 10 50 100 M AP E Nilai C
Gambar 5. Hasil Pengujian Nilai C Nilai C yang cenderung konstan pada batas nilai yang ditentukan. Namun pada dasarnya, semakin besar nilai C akan menunjukkan bahwa algoritme yang digunakan semakin tidak melakukan toleransi pada kesalahan yang dilakukan sistem ketika proses learning. C atau complexity merupakan nilai besarnya toleransi terhadap kesalahan prediksi. Hasil dari pengujian pada nilai pada parameter C atau complexity divisualisasikan ke dalam bentuk grafik.
Berdasarkan grafik tersebut, dalam pengujian nilai parameter C ini menghasilkan nilai error rate yang cenderung semakin menurun jika nilai parameter C di set semakin tinggi. Nilai C pada rentang 5 – 100 menunjukkan pola grafik yang konstan. Pada pengujian ini diperoleh nilai C terbaik yaitu 5 – 100 dengan MAPE sebesar 19.07131.
4.4 Pengujian Nilai Parameter Lambda
Pengujian pada parameter lambda ini dilakukan dengan melakukan perubahan pada nilai parameter lambda berdasarkan nilai variasi pada parameter lambda yang telah ditentukan. Dalam pengujian dari nilai parameter lambda, terdapat parameter – parameter SVR lainnya yang digunakan yaitu dengan rincian nilai sigma = 0.13, nilai epsilon = 0.00001, nilai cLR = 0.02, nilai C = 10 dan iterasi = 15000. Grafik hasil pengujian parameter lambda ditunjukkan oleh Gambar 6.
Gambar 6. Hasil Pengujian Nilai lambda Hasil dari pengujian pada variasi nilai parameter lambda divisualisasikan ke dalam grafik. Hasil pengujian parameter nilai lambda pada grafik tersebut menunjukkan nilai MAPE yang dipengaruhi oleh perubahan nilai lambda.
Pada penelitian ini didapatkan bahwa nilai lambda yang kecil membuat persebaran data yang tidak sesuai sehingga meningkatkan nilai MAPE. Parameter lambda yang memiliki nilai cenderung tinggi akan berdampak pada nilai MAPE yang cenderung menurun.
Pada rentang 2.8 – 3.29, nilai MAPE memiliki penurunan namun tidak terlalu signifikan karena masih cenderung konstan. Akan tetapi, hal tersebut dapat mempengaruhi hasil prediksi berupa ketelitian prediksi sehingga didapatkan hasil prediksi yang lebih optimal. MAPE terbaik pada pengujian didapat ketika lambda bernilai 3.29 dengan MAPE sebesar 19.07131.
4.5 Pengujian Nilai Parameter cLR
Pengujian pada nilai parameter ini dilakukan dengan melakukan perubahan pada nilai parameter cLR berdasarkan nilai variasi nilai parameter cLR yang telah ditentukan. Dalam pengujian nilai parameter cLR, terdapat parameter – parameter SVR lainnya yang digunakan yaitu dengan rincian nilai sigma = 0.13, lambda = 3.29, nilai epsilon = 0.00001, nilai C = 10 dan iterasi = 15000. Grafik hasil pengujian parameter cLR ditunjukkan oleh Gambar 7.
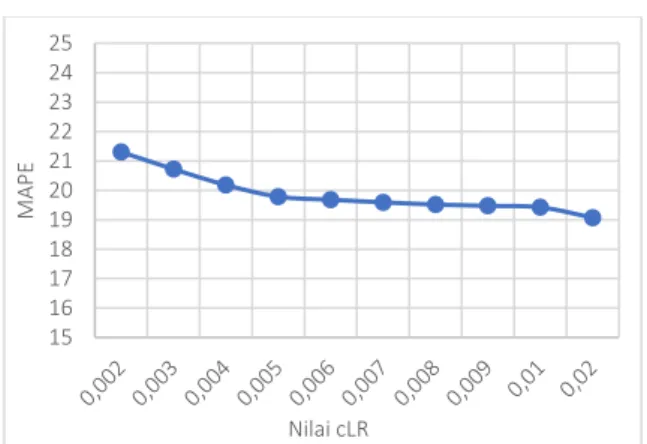
Gambar 7. Hasil Pengujian Nilai cLR Hasil dari pengujian pada variasi nilai parameter cLR divisualisasikan ke dalam bentuk grafik. Nilai cLR digunakan sebagai konstanta untuk memperoleh nilai gamma sebagai salah satu parameter yang berfungsi dalam mengatur laju pembelajaran dari algoritme yang digunakan.
Pada pengujian ini, digunakan nilai cLR dengan rentang 0.002 – 0.02. Berdasarkan pengujian di atas dapat dilihat bahwa ketika nilai cLR yang diinisialisasi cenderung tinggi, maka 15 16 17 18 19 20 21 22 23 24 25 2,8 2,9 3,0 3,1 3,2 3,25 3,29 3,3 3,4 3,5 M AP E Nilai Lambda 15 16 17 18 19 20 21 22 23 24 25 M AP E Nilai cLR
nilai dari MAPE yang dihasilkan akan semakin mengalami penurunan. Penurunan yang ditunjukkan pada grafik di atas terlihat signifikan. Akan tetapi, tidak menutup kemungkinan nilai MAPE akan naik ketika nilai cLR yang didefinisikan terlalu besar. Nilai parameter cLR yang memiliki MAPE yang terkecil dalam pengujian ini adalah 0.02 dengan MAPE sebesar 19.07131.
4.6 Pengujian Nilai Parameter Epsilon
Pengujian ini dilakukan dengan melakukan perubahan pada nilai parameter epsilon berdasarkan nilai variasi nilai parameter epsilon yang telah ditentukan. Dalam pengujian nilai parameter – parameter epsilon, terdapat parameter SVR lainnya yang digunakan yaitu dengan rincian nilai sigma = 0.13, nilai lambda = 3.29, nilai cLR = 0.02, nilai C = 10 dan jumlah iterasi = 15000. Grafik hasil pengujian parameter epsilon ditunjukkan oleh Gambar 8.
Gambar 8. Hasil Pengujian Nilai epsilon Hasil dari pengujian pada variasi nilai parameter epsilon divisualisasikan ke dalam grafik untuk mengetahui pola dalam pengaruh nilai parameter epsilon terhadap nilai MAPE. Paramter epsilon merupakan nilai parameter yang menunjukkan tingkat ketelitian dalam SVR. Grafik tersebut menunjukkan bahwa semakin kecil nilai epsilon maka nilai MAPE yang dihasilkan juga semakin kecil. Nilai epsilon dengan rentang 0.00000000001 – 0.00001 menunjukkan bahwa nilai MAPE yang semakin turun namun penurunannya tidak signifikan.
Akan tetapi jika nilai epsilon didefinisikan terlalu besar misalnya seperti pada rentang 0.0001 – 0.01, nilai MAPE akan mengalami kenaikan yang cukup signifikan. Pada nilai cLR sebesar 0.00001 memiliki tingkat ketelitian lebih optimal. Hal ini menunjukkan bahwa nilai
epsilon terbaik adalah pada nilai 0.00001 dengan MAPE sebesar 19.07131.
4.7 Pengujian Variasi Jumlah Data Latih dan Data Uji
Pengujian ini dilakukan dengan melakukan perubahan pada jumlah data latih serta data uji berdasarkan jumlah data latih serta data uji yang telah ditentukan. Dalam pengujian pada variasi jumlah data latih dan data uji, terdapat parameter – parameter SVR yang digunakan yaitu dengan rincian nilai sigma = 0.13, nilai lambda = 3.29, nilai epsilon = 0.00001, nilai cLR = 0.02, nilai C = 10 dan iterasi = 15000. Jumlah dari data latih yang digunakan berurut dari 10% - 80% dari total dataset penerimaan yang digunakan. Sebaliknya, jumlah dari data uji yang digunakan berurut dari 80% - 10% total dataset penerimaan yang digunakan. Grafik hasil pengujian variasi jumlah data latih dan data uji ditunjukkan oleh Gambar 9.
Gambar 9. Hasil Pengujian Variasi Jumlah Data Latih dan Data Uji
Pada pengujian di atas dapat dilihat bahwa data latih yang jumlahnya lebih banyak digunakan maka akan memiliki kecenderungan penurunan nilai MAPE. Data latih tersebut digunakan dalam proses learning dalam SVR sehingga sistem akan smakin banyak melakukan proses pembelajaran. Proses tersebut dilakukan untuk melatih sistem agar dapat menemukan hasil prediksi optimal sesuai dengan iterasi yang dilakukan.
Namun pada jumlah data latih yang semakin banyak pula tidak menutup kemungkinan akan terjadi kenaikan pada nilai MAPE. Hal ini disebabkan oleh algoritme SVR yang performanya bergantung kepada parameter – parameter lain yang digunakan. Pengujian variasi jumlah data latih terbaik yang dihasilkan 15 16 17 18 19 20 21 22 23 24 25 M AP E Nilai Epsilon 0 5 10 15 20 25 30 35 40 45 8 16 24 32 41 49 57 65 73 65 57 49 40 32 24 16 M AP E
yaitu sebanyak 65 data latih dengan MAPE sebesar 19.07131.
4.8 Pengujian Pemetaan Data
Dalam pengujian pada pemetaan data atau jumlah fitur yang digunakan, terdapat parameter SVR yang digunakan yaitu dengan rincian sigma = 0.13, lambda = 3.29, epsilon = 0.00001, cLR = 0.02, C = 10 dan iterasi = 15000. Grafik hasil pengujian pemetaan data untuk mendapatkan fitur ditunjukkan oleh Gambar 10.
Gambar 10. Hasil Pengujian Pemetaan Data Pada pengujian di atas menunjukkan bahwa pemetaan data secara sekuensial 4 bulan sebelumnya (4 fitur) lebih memberikan nilai MAPE yang kecil dibandingkan dengan jumlah fitur lainnya. Pada grafik tersebut ditunjukkan bahwa pemetaan data dengan 2 fitur dan 3 fitur memiliki hasil MAPE cukup besar. Hal ini menunjukkan bahwa SVR dapat melakukan kinerja yang baik untuk kumpulan data yang kompleks dalam melakukan prediksi.
Akan tetapi jika fitur bulan yang digunakan lebih dari 4 fitur, MAPE yang diperoleh akan megalami kenaikan walaupun tidak terlalu besar seperti hasil MAPE ketika fitur yang digunakan adalah 2 dan 3 fitur. Algoritme SVR melakukan pembelajaran dari 4 fitur yang merupakan 4 bulan sebelumnya yang dipetakan secara sekuensial sehingga dihasilkan nilai MAPE terbaik sebesar 19.07131.
4.9 Hasil dan Pembahasan
Pengujian yang dilakukan terhadap 81 data yang telah dilakukan komputasi menggunakan algoritme SVR menunjukkan bahwa nilai MAPE terbaik adalah sebesar 19.07131 atau 19.07% yang dikategorikan baik/akurat untuk hasil prediksi. Analisis yang dibahas pada penelitian ini adalah terkait bagaimana peran SVR terhadap hasil prediksi yang diperoleh dan bagaimana
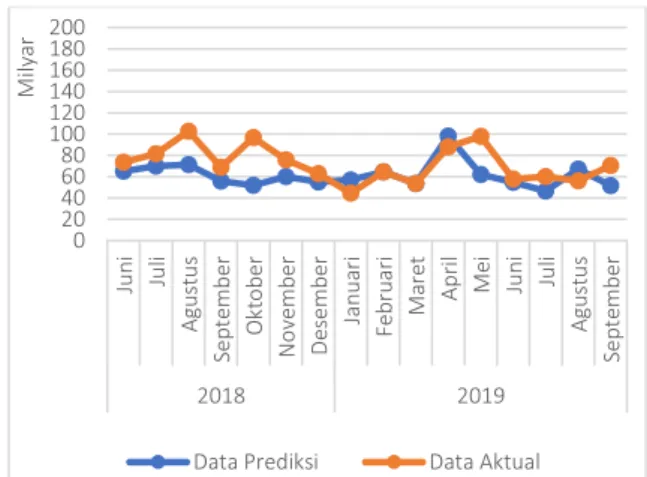
pola prediksi terhadap pola aktual dan alasan mengapa pola tersebut diperoleh. Grafik hasil perbandingan data aktual dan data prediksi yang telah dilakukan komputasi menggunakan algoritme SVR dapat dilihat pada Gambar 11.
Gambar 11. Hasil Perbandingan Data Aktual dan Data Prediksi
Grafik perbandingan prediksi dan aktual pada Gambar 11 menunjukkan bahwa kinerja SVR pada prediksi penerimaan bea cukai dengan menggunakan 4 fitur. Dari perbandingan tersebut didapatkan nilai MAPE sebesar 19.07131 atau 19.07% yang dikategorikan baik untuk hasil prediksi. Akan tetapi, SVR belum cukup mampu untuk mengikuti pola data aktual. Hal ini dikarenakan algoritme SVR sangat bergantung pada nilai parameter di dalamnya.
Selain itu, penerimaan bea cukai memiliki pola yang relatif fluktuatif sehingga lebih sulit untuk diprediksi. Fluktuasi pada penerimaan ini dipengaruhi oleh beberapa faktor yang sulit untuk dikendalikan. Faktor yang dimaksud yaitu permintaan dan penawaran di pasar internasional, aktivitas perekonomian negara hingga perilaku masyarakat. Permintaan dan penawaran di pasar internasional mempengaruhi penerimaan sektor pabean karena berkenaan dengan ekspor maupun impor.
Faktor aktivitas perekonomian negara menjadi salah satu alasan penerimaan menjadi sulit diprediksi karena melibatkan perubahan nilai tukar (kurs) dan inflasi. Hal tersebut menyebabkan naik turunnya nilai penerimaan. Faktor selanjutnya yaitu perilaku masyarakat dalam hal ini permintaan terhadap barang kena cukai misalnya rokok. Semakin banyak permintaan rokok di pasar maka akan perusahaan produksi rokok akan melakukan peningkatan produksi. Sebagai pihak yang 0 5 10 15 20 25 30 2 3 4 5 6 7 M AP E Jumlah Fitur 0 20 40 60 80 100 120 140 160 180 200 Ju n i Ju li Ag u st u s Se p te m b er O kt o b er No ve m b er D ese m b er Ja n u ar i Fe b ru ar i M ar et Ap ri l M ei Ju n i Ju li Ag u st u s Se p te m b er 2018 2019 M ily ar
melakukan penekanan pada produksi, Bea cukai akan melakukan kebijakan kenaikan tarif pada pita cukai untuk proses legalitas produk rokok tersebut. Kenaikan tarif ini dilakukan untuk menekan peredaran barang kena cukai di masyarakat. Hal tersebut menyebabkan nilai penerimaan dalam sektor cukai akan mengalami kenaikan dengan asumsi ketika produksi rokok meningkat karena permintaan dari konsumen juga meningkat.
Namun ketika produksi rokok menjadi menurun dan tarif rokok mengalami kenaikan, maka hal tersebut akan mempengaruhi penerimaan dalam sektor cukai yaitu memungkinkan penerimaan akan mengalami kenaikan, penurunan atau kondisi tetap. Kondisi tersebut merupakan keadaan yang tidak bisa dikendalikan oleh pihak Bea Cukai melainkan mendapat pengaruh dari pihak produsen dan konsumen cukai.
5. DAFTAR PUSTAKA