i
PREDIKSI TINGKAT KEBERHASILAN MAHASISWA
TINGKAT I IPB DENGAN METODE k-NEAREST NEIGHBOR
NINON NURUL FAIZA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2009
PREDIKSI TINGKAT KEBERHASILAN MAHASISWA
TINGKAT I IPB DENGAN METODE k-NEAREST NEIGHBOR
NINON NURUL FAIZA
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2009
ABSTRACT
NINON NURUL FAIZA. Predicting Successful of First year Students at IPB using k-Nearest Neighbor. Under the direction of IMAS SUKAESIH SITANGGANG and ENDANG PURNAMA GIRI.
Analysis of academic data and personal data of first-year students in IPB is necessary to predict the successful of their study in the end of the first year. One of techniques in classification that can be used for completing that task is k-nearest neighbor that will build a classifier. This research aimed to develop classifier to predict the successful of first year students at IPB. The attributes used in this research are selected based on target class-influenced statistic hipotesis test. Chi-square test is implemented for nominal attributes whereas Spearman Rank Correlation Coeficient test is used for selecting the numerical attribute. The result of this research is a classifier with accuracy 52.97%.
Judul : Prediksi Tingkat Keberhasilan Mahasiswa Tingkat I IPB Dengan Metode k-Nearest
Neighbor
Nama : Ninon Nurul Faiza NIM : G64052959
Menyetujui:
Pembimbing I Pembimbing II
Imas Sukaesih Sitanggang, S.Si., M.Kom. Endang Purnama Giri, S.Kom., M.Kom. NIP 197501301998022001 NIP 198210102006041027
Mengetahui
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor
Dr. Drh. Hasim, DEA NIP 196103281986011002
PRAKATA
Alhamdulillahi Rabbil ‘alamin, puji dan syukur penulis panjatkan kepada Allah SWT atas
limpahan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan tugas akhir dengan judul Prediksi Tingkat Keberhasilan Mahasiswa Tingkat I IPB dengan metode k-Nearest Neighbor. Penelitian ini dilaksanakan mulai Februari 2009 sampai dengan Juni 2009, bertempat di Departemen Ilmu Komputer IPB.
Banyak pihak yang memberikan bantuan, dukungan, saran, kritik, serta koreksi dalam menyelesaikan tugas akhir ini. Ucapan terima kasih penulis sampaikan kepada:
1 Bapak, Mamah, Mbak Luthfa, Mbak Tia, Hanip, dan Jijah yang merupakan penyulut semangat bagi penulis. Terima kasih atas kasih sayang yang tulus dan lantunan doa yang tak pernah putus. 2 Ibu Imas S. Sitanggang, S.Si., M.Kom. selaku pembimbing I dan Bapak Endang Purnama Giri,
S.Kom., M.Kom. selaku pembimbing II atas kesediaannya meluangkan waktu untuk memberikan arahan selama pengerjaan tugas akhir.
3 Bapak Sony Hartono Wijaya, S.Kom., M.Kom selaku moderator dan dosen penguji.
4 Seluruh staf pengajar yang telah mendidik, membina, dan mengembangkan wawasan penulis selama menuntut ilmu di Departemen Ilmu Komputer.
5 Anindra Ageng Jihado dan Dimas CKP atas fasilitas yang diberikan saat seminar dan sidang. 6 Yuni Arti, sahabat terbaik yang senantiasa menjadi satu tim mulai dari perkuliahan, PKL, hingga
menyelesaikan tugas akhir.
7 Sri Danuriati, sahabat terbaik yang selama 2 tahun setia menemani penulis dari pagi hingga pagi lagi, senantiasa memberikan semangat dan dukungan kepada penulis, dan bersedia menjadi tim sukses konsumsi selama penulis seminar dan sidang.
8 Zissalwa Hafsari, sahabat terbaik penulis selama 4 tahun yang senantiasa memberikan semangat dan dukungan kepada penulis.
9 Sahabat terbaik lainnya (Vera Yunita, Karina Gusriani, Tsamrul Fuad) yang telah mengisi hari-hari penulis dengan kegembiraan dan kebersamaan.
10 Teman-teman seperjuangan ilkomerz 42, serta pihak lain yang turut membantu baik secara langsung maupun tidak langsung dalam penyelesaian tugas akhir ini.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juni 2009
RIWAYAT HIDUP
Penulis dilahirkan di Cirebon pada tanggal 14 Maret 1987 sebagai anak ketiga dari lima bersaudara dari pasangan Bapak Nashrudin dan Ibu Komariyah. Penulis menyelesaikan pendidikan menengah atas di SMU Negeri I Cirebon dan lulus pada tahun 2005.
Pada tahun yang sama penulis diterima sebagai mahasiswa Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB (USMI). Setelah menyelesaikan Tingkat Persiapan Bersama (TPB) pada Tingkat I, tahun 2006 penulis diterima sebagai mahasiswa Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor. Tahun 2008, penulis melaksanakan kegiatan praktik kerja lapangan di Badan Pengkajian dan Penerapan Teknologi (BPPT) selama dua bulan. Selain itu, penulis pernah menjadi asisten praktikum pada mata kuliah Sistem Pakar Mayor Ilmu Komputer IPB mulai bulan Februari 2009 sampai dengan bulan Juni 2009.
DAFTAR ISI
Halaman DAFTAR TABEL ...v DAFTAR GAMBAR ... v DAFTAR LAMPIRAN ... v PENDAHULUAN Latar Belakang ... 1 Tujuan ... 1 Ruang Lingkup ... 1 Manfaat ... 1 TINJAUAN PUSTAKA Klasifikasi dan Prediksi ... 1k-Nearest Neighbor ... 1
Normalisasi ... 2
k-Fold Cross Validation ... 2
Confusion Matrix ... 2
Koefisien Korelasi Peringkat Spearman ... 2
Uji Kebebasan Chi-Square ... 3
METODE PENELITIAN Pengadaan Data ... 4
Praproses Data ... 4
Penentuan Data Latih dan Data Uji ... 5
Aplikasi Teknik Klasifikasi ... 5
Jenis Percobaan dan Evaluasi Keluaran ... 5
Lingkungan Pengembangan ... 5
HASIL DAN PEMBAHASAN Data... ... 5
Penggabungan dan Pembersihan Data ... 5
Pemilihan Data ... 6
Transformasi Data ... 7
Aplikasi Teknik Klasifikasi ... 7
Penggunaan Classifier pada Data Baru ... 11
KESIMPULAN DAN SARAN Kesimpulan ... 11
Saran... ... 11
DAFTAR PUSTAKA ... 12
DAFTAR TABEL
Halaman
1 Confusion matrix dua kelas ... 4
2 Tabel kontingensi antara jenis kelamin dan kelas target ... 6
3 Nilai frekuensi harapan dan chi-square atribut jenis kelamin ... 6
4 Hasil uji hipotesis ... 6
5 Jumlah record data latih dan data uji percobaan 1 ... ...7
6 Akurasi klasifikasi percobaan 1 ... 8
7 Matrix confusion untuk percobaan 1 ... 8
8 Akurasi setiap proses uji pada 10-fold cross validation percobaan 2 ... 8
9 Matrix confusion proses uji ke-8 percobaan 2 ... 9
10 Jumlah record data latih dan data uji percobaan 3... ... 9
11 Akurasi klasifikasi percobaan 3.. ... ... 9
12 Matrix confusion untuk percobaan 3.. ... ... 9
13 Akurasi setiap proses uji pada 10-fold cross validation percobaan 4 ... 10
14 Matrix confusion proses uji ke-6 percobaan 4 ... 10
15 Akurasi empat classifier ... 10
16 Data tanpa label kelas ... 10
17 Hasil prediksi data baru tanpa label kelas ... 11
DAFTAR GAMBAR
Halaman 1 Tahapan penelitian ... 4 2 Histogram dengan k=65 ... 8 3 Histogram dengan k=70 ... 8DAFTAR LAMPIRAN
Halaman 1 Tabel kode jurusan mayor IPB tahun akademik 2007/2008 ... 142 Tabel penentuan asal daerah ... 15
3 Tabel kategorisasi atribut nominal dan kelas target ... 16
4 Tabel kontingensi ... 18
PENDAHULUAN Latar Belakang
Institut Pertanian Bogor (IPB) setiap tahunnya menerima mahasiswa baru dengan berbagai jalur masuk. Pada tingkat I, mahasiswa baru tersebut menjalani Tingkat Persiapan Bersama (TPB) yang merupakan tingkat awal bagi mahasiswa dalam memasuki dunia perkuliahan.
IPB menentukan kelulusan mahasiswa tingkat I berdasarkan hasil akademik mahasiswa pada akhir tingkat I. Mahasiswa yang berhasil lulus tingkat I dapat melanjutkan ke tingkat berikutnya. Analisis data akademik dan data diri mahasiswa IPB tingkat I perlu dilakukan untuk mengetahui tingkat keberhasilan mahasiswa IPB dalam menyelesaikan studi di tingkat I.
Salah satu metode data mining yang dapat digunakan untuk membangun model klasifikasi (classifier) untuk menunjukkan tingkat keberhasilan mahasiswa tingkat I IPB adalah
k-Nearest Neighbor. Tujuan
Tujuan dari penelitian ini adalah:
1 Menerapkan metode k-Nearest Neighbor untuk membangun model klasifikasi dari data akademik (IPK) dan data penerimaan mahasiswa baru (PPMB) IPB.
2 Memprediksi tingkat keberhasilan mahasiswa tingkat I IPB pada tahun selanjutnya dengan model terbaik yang diperoleh.
Ruang Lingkup
Ruang lingkup penelitian ini difokuskan pada:
1 Penggunaan data mahasiswa IPB tahun ajaran 2007 yang berasal dari PPMB dan Direktorat TPB.
2 Pemilihan atribut yang diperkirakan merupakan faktor penentu keberhasilan mahasiswa tingkat I menggunakan uji hipotesis statistika.
3 Penerapan teknik data mining klasifikasi menggunakan metode k-Nearest Neighbor.
Manfaat
Model terbaik yang diperoleh diharapkan dapat digunakan untuk memprediksi tingkat keberhasilan mahasiswa-mahasiswa tingkat I IPB pada tahun selanjutnya, lebih lanjut IPB dapat memberikan treatment terhadap mahasiswa yang diprediksi drop out (memiliki tingkat keberhasilan rendah).
TINJAUAN PUSTAKA Klasifikasi dan Prediksi
Klasifikasi dan prediksi merupakan bentuk analisis data yang dapat digunakan untuk membangun model berdasarkan kelas data yang tersedia atau untuk memprediksi trend data selanjutnya (Han & Kamber 2006).
Klasifikasi terdiri atas dua proses yaitu tahap induktif yang merupakan tahap membangun model klasifikasi dari data latih dan tahap deduktif yang merupakan tahap menerapkan model untuk data uji. Klasifikasi mempunyai dua teknik pembelajaran yaitu
eager learners yang membuat model berdasarkan atribut input yang dipetakan terhadap kelas label setelah data latih tersedia dan lazy learners yang melakukan proses pemodelan dari data latih ketika ada data uji yang akan diklasifikasikan (Tan et al.2006).
k-Nearest Neighbor
Kelemahan dari teknik lazy learners adalah hanya mampu mengklasifikasikan data uji jika dan hanya jika atributnya sesuai dengan salah satu data latih. Jika atribut data uji tidak sesuai dengan data latih maka tidak akan diklasifikasikan. k-Nearest Neighbor
merupakan teknik yang lebih fleksibel karena mampu mengklasifikasikan data uji ke dalam kelas label dengan cara mencari data latih yang relatif sama dengan data uji (Tan et al.2006).
k-Nearest Neighbor merepresentasikan setiap data sebagai titik dalam k-ruang dimensi. Jika ada sebuah data uji maka akan dihitung kedekatan titik data tersebut dengan titik data lainnya pada data latih untuk diklasifikasikan berdasarkan kedekatannya yang didefinisikan dengan ukuran jarak (Han & Kamber 2006).
Analis data mendefinisikan ukuran kedekatan atau ukuran kesamaan menggunakan fungsi jarak. Fungsi jarak yang umumnya digunakan adalah jarak Euclidean (Larose 2005).
...(1) dengan
x=
y=
= selisih data uji dengan data latih m = jumlah atribut
Penentuan klasifikasi data uji berdasar pada kelas utama (majority voting) pada nearest
neighbor dengan menggunakan rumus berikut
ini:
…(2) dengan v adalah label kelas, yi adalah label kelas untuk satu nearest neighbor dan I adalah fungsi indikator yang mengembalikan nilai 1 jika pernyataan benar dan nilai 0 jika salah (Tan
et al. 2006). Normalisasi
Pada perhitungan jarak Euclidean, atribut berskala panjang dapat mempunyai pengaruh lebih besar daripada atribut berskala pendek. Untuk mencegah hal tersebut perlu dilakukan normalisasi terhadap nilai atribut (Larose 2005).
Salah satu metode normalisasi adalah
min-max normalization yang diterapkan untuk
atribut kontinu. Formula untuk normalisasi atribut X adalah:
…(3) dengan X* adalah nilai setelah dinormalisasi, X adalah nilai sebelum dinormalisasi, min(X) adalah nilai minimum dari atribut, dan max(X) adalah nilai maksimum dari suatu atribut. Untuk atribut kategori digunakan rumus berikut:
…(4)
k-Fold Cross Validation
k-fold cross validation dilakukan untuk
membagi data latih dan data uji. k-fold cross
validation mengulang k-kali untuk membagi
sebuah himpunan contoh secara acak menjadi k
subset yang saling bebas, setiap ulangan
disisakan satu subset untuk pengujian dan
subset lainnya untuk pelatihan (Fu 1994). Pada
metode tersebut, data awal dibagi menjadi k
subset atau “fold” yang saling bebas secara
acak, yaitu S1, S2, …, Sk, dengan ukuran setiap
subset kira-kira sama. Pada iterasi ke-i, subset
Si diperlukan sebagai data pengujian dan subset lainnya diperlukan sebagai data pelatihan. Prosedur ini diulang sebanyak k-kali sedemikian sehingga setiap subset digunakan untuk pengujian tepat satu kali. Total akurasi ditentukan dengan menjumlahkan akurasi untuk semua k proses tersebut.
Confusion Matrix
Evaluasi model klasifikasi berdasar pada proporsi antara data uji yang diprediksi secara tepat dengan total seluruh prediksi (Tan et
al.2006). Informasi mengenai klasifikasi sebenarnya (aktual) dengan klasifikasi hasil prediksi disajikan dalam bentuk tabel yang disebut confusion matrix seperti diperlihatkan pada Tabel 1.
Tabel 1 Confusion matrix dua kelas Kelas hasil prediksi
Kelas aktual Kelas1 Kelas2
Kelas1 a b
Kelas2 c d
Jumlah baris dan kolom pada tabel bergantung pada banyaknya kelas target. Akurasi merupakan proporsi jumlah prediksi yang tepat. Contoh perhitungan akurasi untuk tabel tersebut adalah:
…(5) Koefisien Korelasi Peringkat Spearman
Korelasi peringkat merupakan ukuran yang menunjukkan derajat keeratan hubungan diantara dua peubah. Salah satu ukuran asosiasi yang dikenal yaitu Koefisien Korelasi Peringkat
Spearman. Asumsi atau syarat yang harus
dipenuhi pada korelasi ini antara lain (Daniel 1990):
Data terdiri atas contoh acak n berpasangan pengamatan numerik atau bukan numerik. Tiap pasang pengamatan menunjukkan dua
ukuran yang diperoleh dari objek atau individu yang sama.
Langkah perhitungan koefisien korelasi peringkat Spearman (Daniel 1990):
Jika data terdiri atas pengamatan dari suatu populasi bivariabel, ditunjukkan n pasang pengamatan yang diperoleh yaitu (X1,Y1), (X2,Y2), …, (Xn,Yn).
Tiap X diperingkatkan terhadap seluruh pengamatan X lainnya dari nilai terkecil hingga terbesar. Peringkat nilai ke-i dari X ditunjukkan dengan R(Xi) dan R(Xi) = 1 jika Xi nilai pengamatan terkecil dari X.
Tiap Y diperingkatkan terhadap seluruh pengamatan Y lainnya dari nilai terkecil hingga terbesar. Peringkat nilai ke-i dari Y ditunjukkan dengan R(Yi) dan R(Yi) = 1 jika Yi nilai pengamatan terkecil dari Y. Jika ada nilai yang sama (ties) diantara X
Jika data bukan numerik, maka harus mampu diperingkatkan.
Hipotesis statistik adalah dugaan mengenai suatu populasi. Hipotesis yang dirumuskan dengan harapan akan ditolak disebut hipotesis nol (H0) sedangkan hipotesis alternatif dilambangkan dengan H1 (Walpole 1992). Hipotesis koefisien korelasi peringkat
Spearman (Daniel 1990):
H0: X dan Y saling bebas
H1: X dan Y berhubungan langsung atau kebalikan
Statistik uji yang digunakan adalah (Daniel 1990):
…(6) …(7) dengan:
di: jumlah kuadrat beda antara peringkat record X ke-i dengan peringkat record Y ke-i R(Xi): peringkat record ke-i pada atribut X R(Yi): peringkat record ke-i pada atribut Y n: banyaknya record
rs: koefisien korelasi, dimana -1 ≤ rs ≤ 1
Jika ada nilai pengamatan yang sama (ties), nilai menggunakan rumus:
…(8) dengan
…(9) …(10) …(11) …(12) dimana
tx=banyaknya pengamatan X yang sama untuk nilai tertentu (untuk suatu peringkat)
ty=banyaknya pengamatan Y yang sama untuk nilai tertentu (untuk suatu peringkat)
Jika n>100, maka gunakan tabel normal (z) dengan:
…
(13)Benar atau salahnya suatu hipotesis tidak akan pernah diketahui dengan pasti kecuali bila memeriksa seluruh populasi. Namun dalam kebanyakan situasi, hal itu tidak mungkin dilakukan. Oleh karena itu, dapat mengambil contoh acak dari populasi untuk memutuskan apakah hipotesis tersebut kemungkinan besar benar atau salah. Bukti dari contoh yang tidak konsisten dengan hipotesis yang dinyatakan tentu saja membawa pada penolakan hipotesis tersebut sedangkan bukti yang mendukung hipotesis membawa pada penerimaan hipotesis tersebut. Penerimaan suatu hipotesis statistik adalah karena tidak cukup bukti untuk menolaknya. Penolakan suatu hipotesis berarti menyimpulkan bahwa hipotesis itu salah (Walpole 1992). Kaidah keputusan hipotesis koefisien korelasi peringkat Spearman (Daniel 1990):
Jika rs > nilai Tabel koefisien korelasi peringkat Spearman untuk n dan α(2) atau rs < nilai tabel ini, maka tolak H0 dengan α adalah besarnya taraf nyata (tingkat error) dan dapat disimpulkan bahwa antara peubah satu dengan peubah lainnya tidak saling bebas (berpengaruh).
Uji Kebebasan Chi-Square
Hubungan diantara peubah kategorik dapat dilakukan melalui penggunaan uji kebebasan
chi-square. Data dalam pengujian hubungan
disajikan dalam bentuk tabel kontingensi. Bentuk umum tabel kontingensi, yaitu berukuran i baris × j kolom.
Hipotesis untuk menguji pengaruh antara peubah satu dengan peubah lainnya, yaitu (Freeman 1987):
H0: Pij = Pi.Pj (tidak ada hubungan) H1: Pij ≠ Pi.Pj (terdapat hubungan) dengan
Pi: peluang total atribut ke-i terhadap total data
Pj: peluang total kelas ke-j terhadap total data
Statistik uji yang digunakan adalah statistik 2 yang dirumuskan dengan (Freeman 1987) Eij = n (Pi) (Pj)
= n (ni/n) (nj/n) = [(ni) (nj)]/n
dengan
n: total data (banyaknya pengamatan) Oij: frekuensi pengamatan
Eij: frekuensi harapan ni: total data atribut ke-i nj: total data kelas ke-j Kaidah keputusan
Jika 2hitung > 2 (db, ) tabel
chi-square maka tolak H0 dan dapat disimpulkan bahwa antara peubah satu dengan lainnya tidak saling bebas (berpengaruh).
Derajat bebas (db) menunjukkan banyaknya parameter (informasi) minimum yang digunakan. Formula derajat bebas: db = (i 1) (j 1) dengan i=jumlah level atribut dan j=jumlah level kelas target.
METODE PENELITIAN
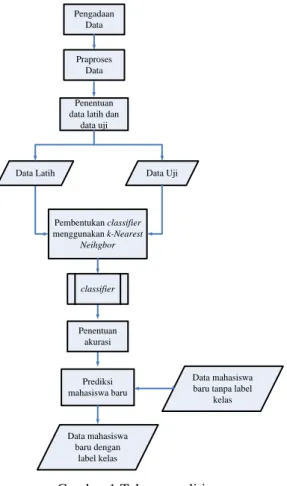
Penelitian ini dilakukan dalam beberapa tahap seperti diilustrasikan pada Gambar 1.
Pengadaan Data
Banyak studi yang telah lakukan untuk menjelaskan prestasi akademik atau memprediksi kesuksesan akademik dalam dunia pendidikan, salah satunya adalah studi yang dilakukan Parmentier pada tahun 1994.
Parmentier menunjukkan bahwa prestasi akademik mahasiswa dipengaruhi oleh tiga kumpulan faktor, yaitu berbagai hal yang berhubungan dengan latar belakang pribadi mahasiswa (identitas, pendidikan, keluarga, dan lain-lain), keterlibatan atau tingkah laku mahasiswa terhadap pendidikan (partisipasi pada kegiatan pilihan, bertemu dengan profesor untuk bertanya atau memperoleh feedback pada ujian berkala, dan lain-lain), dan persepsi dari mahasiswa (persepsi mahasiswa terhadap konteks akademik, profesornya, kuliah, dan lain-lain) (Superby et al. 2005).
Penelitian ini hanya menggunakan dua faktor Parmentier, yaitu faktor data pribadi mahasiswa dan faktor keterlibatan mahasiswa terhadap pendidikan. Data yang digunakan adalah data mahasiswa TPB IPB tahun ajaran 2007 yang berasal dari Panitia Penerimaan Mahasiswa Baru (PPMB) dan Direktorat Tingkat Persiapan Bersama (Direktorat TPB). Data tersebut terdiri dari dua kelompok data yaitu IPK dan Biodata. Biodata mahasiswa masuk ke dalam faktor data pribadi mahasiswa,
sedangkan IPK masuk ke dalam faktor keterlibatan mahasiswa terhadap pendidikan.
Penentuan akurasi Penentuan data latih dan
data uji Data Uji classifier Pembentukan classifier menggunakan k-Nearest Neihgbor Data Latih Pengadaan Data Praproses Data Data mahasiswa baru tanpa label
kelas Prediksi mahasiswa baru Data mahasiswa baru dengan label kelas
Gambar 1 Tahap penelitian.
Pengelompokan mahasiswa untuk menganalisis tingkat keberhasilan mahasiswa tingkat I dibagi menjadi tiga kategori, yaitu low
risk (memiliki kemungkinan/resiko rendah tidak
lulus), medium risk (dibolehkan lulus berdasarkan ukuran yang diambil perguruan tinggi), dan high risk (memiliki kemungkinan/resiko besar tidak lulus atau drop
out) (Superby et al. 2005). Praproses Data
Tahapan yang dilakukan dalam praproses diantaranya :
Penggabungan data, menggabungkan dua kelompok data yaitu Indeks Prestasi Mahasiswa (IPK) dan Biodata Mahasiswa. Pembersihan data, membuang data yang
missing value.
Pemilihan data, mengambil data yang relevan digunakan untuk proses analisis. Pada penelitian ini pemilihan data menggunakan uji hipotesis statistika yaitu Uji Kebebasan dan Uji Spearman.
Transformasi data, mengubah data ke bentuk yang dapat di-mine sesuai dengan perangkat lunak yang digunakan pada penelitian.
Penentuan Data Latih dan Data Uji
Dalam penelitian ini data terdapat dua metode uji yang digunakan yaitu pembagian data latih dan data uji dengan proporsi 70% data latih dan 30% data uji dan metode uji 10-fold
cross validation.
Aplikasi Teknik Klasifikasi
Tahapan ini merupakan tahap yang penting karena pada tahap ini teknik klasifikasi diaplikasikan terhadap data. Teknik klasifikasi yang digunakan adalah k-Nearest Neighbor. Langkah-langkah pada metode tersebut yaitu:
Hitung jarak Euclidean: Pada tahap ini setiap data uji akan dihitung jaraknya ke setiap data latih untuk mengetahui ukuran kedekatan atau ukuran kesamaan antara data uji dengan data latih.
Penentuan nilai k: Hal terpenting pada
k-Nearest Neighbor adalah menentukan nilai
yang tepat untuk k yang menunjukan jumlah tetangga terdekat.
Majority voting: Penentuan kelas target untuk data uji berdasarkan kelas yang utama pada tetangga terdekat.
Jenis Percobaan dan Evaluasi Keluaran
Dalam penelitian ini dilakukan beberapa bentuk percobaan yang dibedakan berdasarkan jenis dataset dan metode pembagian data latih dan data uji. Jenis-jenis percobaan tersebut adalah:
Percobaan menggunakan dataset yang proporsi record pada setiap kelas target tidak sama dengan metode uji 70% data latih dan 30% data uji.
Percobaan menggunakan dataset yang proporsi record pada setiap kelas target tidak sama dengan metode uji 10-fold cross
validation.
Percobaan menggunakan dataset yang proporsi record pada setiap kelas target sama dengan metode uji 70% data latih dan 30% data uji.
Percobaan menggunakan dataset yang proporsi record pada setiap kelas target sama dengan metode uji 10-fold cross
validation.
Selanjutnya akan dibentuk tabel confusion
matrix dari setiap classifier untuk mengevaluasi
klasifikasi yang dihasilkan metode k-Nearest
Neighbor.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini adalah sebagai berikut:
a Perangkat keras berupa komputer personal dengan spesifikasi:
Prosesor Intel(R) Pentium(R) D CPU 2.80 GHz (2 CPUs)
Memori DDR2 512 MB Harddisk 80 GB Keyboard dan mouse Monitor
b Perangkat Lunak
Sistem operasi Windows XP Professional
Microsoft Excel 2007 sebagai media merapihkan data
Microsoft Access 2007 sebagai media penggabungan data, pembersihan data, transformasi data
QtOctave 0.7.2 untuk menjalankan metode k-Nearest neighbor
HASIL DAN PEMBAHASAN Data
Data IPK dengan format spreadsheet Excel terdiri dari 2989 record dan 4 atribut (Nama, NRP, IPK, dan Status Studi). Sedangkan data Biodata dengan format spreadsheet Excel terdiri dari 3010 record dan 41 atribut (NRP, jalur masuk, jenis kelamin, tempat lahir, tanggal lahir, status kawin, warganegara, agama, nama ayah, tahun lahir ayah, pendidikan ayah, pekerjaan ayah, pendapatan orang tua, nama ibu, tahun lahir ibu, pendidikan ibu, pendidikan orang tua, pekerjaan ibu, alamat orang tua, kode pos, wilayah telp orang tua, nomor telp orang tua, nama wali, alamat wali, nama darurat, alamat darurat, nomor telp darurat, nomor SMA, nama SMA, nomor induk, status SMA, tahun ijazah, jumlah mata pelajaran UAN, nilai UAN, prestasi, minat/hobi, listrik, golongan darah, tinggi badan, berat badan, dan riwayat kesehatan).
Penggabungan dan Pembersihan Data
Data IPK dan Biodata digabung menggunakan Microsoft Access berdasarkan kesamaan NRP pada kedua data. Pada data hasil gabungan data IPK dan Biodata ditambahkan
atribut baru yaitu atribut jurusan dengan ketentuan berdasarkan tabel kode jurusan mayor IPB tahun akademik 2007/2008 (Lampiran 1), penambahan atribut asal daerah berdasarkan asal SMA. Penentuan asal daerah sesuai dengan ketentuan pada Lampiran 2. Selain itu ditambahkan juga kolom kelas target yang ditentukan berdasarkan IPK dengan ketentuan: resiko rendah (IPK≥2.76), resiko sedang (2≤IPK<2.76), dan resiko tinggi (IPK<2).
Selanjutnya dilakukan pemilihan atribut. Atribut yang tidak relevan dan atribut yang banyak mengandung missing value akan dihilangkan. Semua atribut terpilih yang bertipe nominal dan kelas target dikategorikan sesuai dengan ketentuan pada pada Lampiran 3.
Record yang mengandung nilai kosong dan atau
duplikat dihapus. Hasil akhir dari proses penggabungan data IPK dan Biodata terdiri dari 2785 record serta 9 atribut (jurusan, asal daerah, jalur masuk, jenis kelamin, pendapatan orang tua, pendidikan orang tua, nilai uan SMA, hobi, dan riwayat kesehatan) serta kolom kelas target.
Pemilihan Data
Dari 9 atribut yang ada akan dilakukan pemilihan atribut lagi menggunakan uji hipotesis statistika yaitu uji kebebasan
chi-square dan uji korelasi peringkat Spearman. Uji
kebebasan diterapkan untuk atribut yang bertipe nominal (jurusan, asal daerah, jalur masuk, jenis kelamin, pendapatan orang tua, pendidikan orang tua, hobi, dan riwayat kesehatan) sedangkan uji Spearman diterapkan untuk atribut yang bertipe numerik (nilai uan SMA).
Uji kebebasan dan uji Spearman dilakukan untuk melihat hubungan antara setiap atribut dengan kelas target, apakah berpengaruh atau tidak. Jika berdasarkan uji yang dilakukan suatu atribut dinyatakan tidak berpengaruh, maka atribut tersebut dihilangkan, dan sebaliknya. Dalam hal ini, kelas target menunjukkan tingkat keberhasilan mahasiswa.
Berikut merupakan salah satu contoh penerapan uji kebebasan pada atribut jenis kelamin. Penentuan hipotesis:
H0 : jenis kelamin tidak berhubungan dengan kelas target
H1 : jenis kelamin berhubungan dengan kelas target
Sebelum dilakukan uji kebebasan, dibuat tabel kontingensi terlebih dahulu antara setiap atribut dengan kelas target. Tabel kontingensi antara atribut jenis kelamin dan kelas target
dapat dilihat pada Tabel 2, sedangkan tabel kontingensi atribut lainnya dapat dilihat pada Lampiran 4.
Tabel 2 Tabel kontingensi antara jenis kelamin dan kelas target
Jenis kelamin
Kelas target Total
Resiko rendah Resiko sedang Resiko tinggi Perempuan 978 569 139 1686 Laki-laki 517 418 164 1099 Total 1495 987 303 2785
Selanjutnya, dihitung nilai frekuensi harapan (Eij) dan nilai chi-square ( 2) dari setiap tabel kontingensi. Hasil perhitungan Eij dan 2hitung untuk atribut jenis kelamin diperlihatkan pada Tabel 3.
Tabel 3 Nilai frekuensi harapan dan chi-square atribut jenis kelamin
Ei1 Ei2 Ei3 i12 i22 i32 905.052 597.516 183.432 5.879 1.360 10.762 589.947 389.484 119.568 9.020 2.087 16.511 2hitung 45.622 2 (db, α) = 2 (2, 0.05) 5.99
Jenis kelamin memiliki 2 level (perempuan dan laki-laki) dan kelas target memiliki 3 level (resiko rendah, resiko sedang, resiko tinggi) maka besarnya derajat bebas=(2-1) (3-1)=2. Nilai α yang digunakan yaitu sebesar 0.05. Berdasarkan Tabel 3, nilai 2hitung> 2(2, α). Oleh karena itu, dapat disimpulkan bahwa pada taraf nyata α = 0.05, peubah jenis kelamin berpengaruh terhadap atribut kelas target. Untuk nilai frekuensi harapan dan chi-square atribut lainnya dapat dilihat pada Lampiran 5.
Berdasarkan uji hipotesis yang telah dilakukan terhadap seluruh atribut, diperoleh hasil yang diperlihatkan pada Tabel 4.
Tabel 4 Hasil uji hipotesis
Atribut Keterangan terhadap
kelas target
Jurusan Berpengaruh
Asal daerah Berpengaruh
Jalur masuk Berpengaruh
Jenis kelamin Berpengaruh
Pendapatan Tidak Berpengaruh
Pendidikan orang tua Tidak Berpengaruh
Hobi Berpengaruh
Riwayat kesehatan Tidak Berpengaruh
Data akhir yang dihasilkan terdiri dari 2785
record dan 6 atribut yang berdasarkan uji
hipotesis berpengaruh, yaitu: jurusan, asal daerah, jalur masuk, jenis kelamin, hobi, dan nilai uan SMA serta satu kolom kelas target. Dari 6 atribut yang digunakan pada penelitian ini 5 diantaranya merupakan data nominal yaitu: jurusan, asal daerah, jalur masuk, jenis kelamin, dan hobi. Sedangkan atribut nilai uan SMA merupakan data numerik. Pada atribut nilai uan SMA terdapat 10 record yang tidak relevan sehingga data yang digunakan dalam proses
data mining terdiri dari 2775 record dan 6
atribut.
Transformasi Data
Karena adanya perbedaan range antar atribut maka perlu dilakukan normalisasi. Normalisasi yang dilakukan bergantung jenis datanya.
Untuk atribut nilai uan SMA yang bertipe numerik, normalisasi menggunakan min-max
normalization. Nilai maksimum atribut nilai uan
SMA sebesar 29,67 sedangkan nilai minimum sebesar 17.13. Contoh normalisasi untuk record pertama berdasarkan rumus normalisasi (persamaan 3) adalah:
Meskipun atribut nilai uan SMA bertipe numerik tetapi bisa dinormalisasi dengan rumus tersebut karena atribut numerik termasuk dalam atribut kontinu.
Pada penelitian ini perangkat lunak yang digunakan adalah QtOctave sehingga data yang digunakan disimpan dalam format yang dapat diolah dalam QtOctave yaitu format txt atau .m. Octave merupakan suatu perangkat lunak tiruan dari Matlab untuk komputasi numerik dan visualisasi data sedangkan QtOctave merupakan sebuah antar muka grafis yang dikembangkan untuk program Octave. Antar muka grafis ini dikembangkan untuk menambahkan beberapa fasilitas yang tidak terdapat pada program Octave yang langsung dijalankan dari shell
command sehingga program Octave lebih
mudah digunakan. Pada QtOctave, perintah-perintah yang diberikan tidak dimasukkan secara langsung pada baris perintah, melainkan pada kotak teks masukkan yang terdapat pada bagian bawah dari jendela QtOctave.
Aplikasi Teknik Klasifikasi
Dari total data sebanyak 2775 record, diambil 1% data dari setiap kelas target yang akan dihilangkan kelas targetnya sebagai data
tanpa label kelas yang akan diterapkan pada
classifier terbaik. Jadi dataset untuk pembagian
data latih dan data uji sebanyak 2747 record. Pada percobaan pertama, menggunakan seluruh dataset sebanyak 2747 record yang proporsi record pada setiap kelas target tidak sama dan metode uji yang digunakan 70% sebagai data latih sedangkan sisanya sebanyak 30% sebagai data uji. Jumlah record untuk data latih dan data uji dari setiap kelas diperlihatkan Tabel 5.
Tabel 5 Jumlah record data latih dan data uji percobaan 1
Data latih Data uji
Kelas 1 1033 record 443 record
Kelas 2 682 record 292 record
Kelas 3 208 record 89 record
Total 1923 record 824 record
Data tersebut kemudian diterapkan dalam metode k-Nearest Neighbor melalui tahap-tahap berikut ini:
1 Setiap record data uji dihitung jaraknya ke setiap record data latih untuk mengetahui ukuran kedekatan antara data uji dengan data latih. Untuk data bertipe nominal, selisih antara data uji dengan data latih dilihat dari kesamaan nilai kedua data. Jika nilai data uji sama dengan nilai data latih maka selisihnya 0, tetapi jika nilai data uji berbeda dengan nilai data latih maka selisihnya adalah 1. Untuk data bertipe numerik, selisih antara data uji dengan data latih adalah pengurangan nilai data uji dengan nilai data latih.
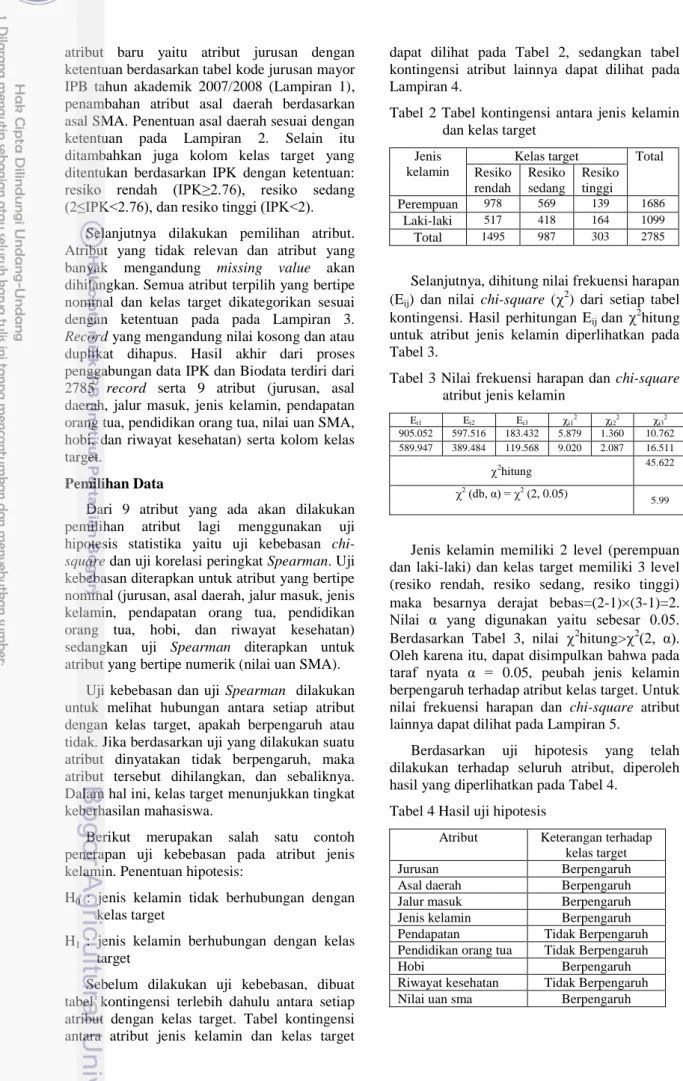
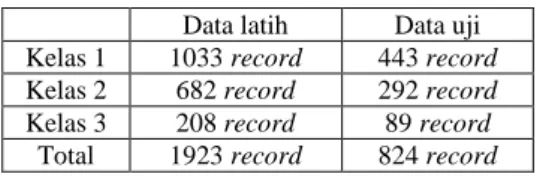
2 Penentuan nilai k tetangga terdekat pada percobaan 1 dilakukan dengan mencoba nilai k mulai dari 5 sampai 70 dengan selang 5 angka dalam metode k-Nearest Neighbor. Pada setiap percobaan dengan suatu nilai k dihitung akurasi classifier dan sebaran kelas target ditampilkan dalam histogram. Berdasarkan percobaan sampai nilai k=65, diperoleh bahwa sebaran kelas target mencakup ketiga kelas yaitu resiko rendah, sedang, dan tinggi. Jika nilai k dinaikkan menjadi 70, maka sebaran kelas target untuk kelas 3 (resiko tinggi) tidak tercakup seperti diperlihatkan Gambar 2 dan Gambar 3
Gambar 2 Histogram kelas target dengan k=65.
Gambar 3 Histogram kelas target dengan k=70.
Melihat kondisi tersebut, nilai k akan dipilih antara 5 sampai 65. Akurasi klasifikasi untuk nilai k=5 sampai k=70 diperlihatkan pada Tabel 6.
Tabel 6 Akurasi klasifikasi percobaan 1
k akurasi k akurasi 5 0.2609 40 0.4211 10 0.3095 45 0.4345 15 0.3325 50 0.4454 20 0.3701 55 0.4636 25 0.3908 60 0.4636 30 0.4078 65 0.4757 35 0.4333
Berdasarkan tabel tersebut (Tabel 6) akurasi yang diperoleh selisihnya tidak terlalu jauh berbeda. Hal inilah yang menyebabkan percobaan nilai k menggunakan selang 5 angka. Akurasi paling tinggi diperoleh untuk k=65 sehingga pada percobaan ini classifier terbaik diperoleh pada jumlah tetangga terdekat sebanyak 65.
3 Setiap record data uji dapat ditentukan kelas targetnya berdasarkan kelas utama pada 65 tetangga terdekat.
Untuk mengetahui record yang salah diklasifikasikan digunakan matrix confusion yang diperlihatkan Tabel 7.
Tabel 7 Matrix confusion untuk percobaan 1 Kelas hasil prediksi Kelas
aktual
Kelas 1 Kelas 2 Kelas 3
Kelas 1 351 92 0
Kelas 2 250 41 1
Kelas 3 57 32 0
Berdasarkan tabel tersebut (Tabel 7) kelas 1 yang tepat diklasifikasi sebagai kelas 1 sebanyak 351 record, kelas 1 yang salah diklasifikasi sebagai kelas 2 sebanyak 92
record, dan tidak ada kelas 1 yang salah
diklasifikasi sebagai kelas 3. Kelas 2 yang tepat diklasifikasi sebagai kelas 2 sebanyak 41
record, kelas 2 yang salah diklasifikasi sebagai
kelas 1 sebanyak 250 record, dan kelas 2 yang salah diklasifikasi sebagai kelas 3 sebanyak 1
record. Tidak ada kelas 3 yang tepat
diklasifikasi sebagai kelas 3, kelas 3 yang salah diklasifikasi sebagai kelas 1 sebanyak 57
record, dan kelas 3 yang salah diklasifikasi
sebagai kelas 2 sebanyak 32 record.
Berdasarkan persamaan 5, besarnya akurasi adalah:
akurasi = = 0.4757
Percobaan 2 menggunakan seluruh dataset sebanyak 2747 record yang proporsi record pada setiap kelas target tidak sama, menggunakan tetangga terdekat sebanyak 65 tetapi dengan metode uji 10-fold cross
validation. Data dibagi menjadi 10 subset yang
berbeda dengan jumlah yang hampir sama. Setiap kali sebuah subset digunakan sebagai data uji maka 9 subset lainnya menjadi data latih. Besarnya akurasi pada setiap proses uji diperlihatkan pada Tabel 8.
Tabel 8 Akurasi setiap proses uji pada 10-fold
cross validation percobaan 2
proses uji ke- akurasi
1 0.4436 2 0.5273 3 0.5273 4 0.4073 5 0.5309 6 0.5164 7 0.4873 8 0.5730
proses uji ke- akurasi
9 0.5292
10 0.4708
Berdasarkan Tabel 8 akurasi terbaik diperoleh pada proses uji ke-8 yaitu sebesar 0.5730. Matrix confusion untuk proses uji ke-8 pada percobaan 2 adalah:
Tabel 9 Matrix confusion proses uji ke-8 percobaan 2
Kelas hasil prediksi Kelas
aktual
Kelas 1 Kelas 2 Kelas 3
Kelas 1 130 17 0
Kelas 2 71 27 0
Kelas 3 17 12 0
Berdasarkan tabel tersebut (Tabel 9) kelas 1 yang tepat diklasifikasi sebagai kelas 1 sebanyak 130 record, kelas 1 yang salah diklasifikasi sebagai kelas 2 sebanyak 17
record, dan tidak ada kelas 1 yang salah
diklasifikasi sebagai kelas 3. Kelas 2 yang tepat diklasifikasi sebagai kelas 2 sebanyak 27
record, kelas 2 yang salah diklasifikasi sebagai
kelas 1 sebanyak 71 record, dan tidak ada kelas 2 yang salah diklasifikasi sebagai kelas 3. Kelas 3 tidak ada yang tepat diklasifikasikan sebagai kelas 3, kelas 3 yang salah diklasifikasi sebagai kelas 1 sebanyak 17 record, dan kelas 3 yang salah diklasifikasi sebagai kelas 2 sebanyak 12
record. Berdasarkan persamaan 5, besarnya
akurasi adalah: akurasi = = 0.5730
Akurasi rata-rata dari seluruh proses uji dengan 10 data uji yang berbeda pada percobaan kedua diperoleh sebesar 0.5013.
Percobaan 3 menggunakan dataset yang proporsi record pada setiap kelas target seimbang dengan pembagian data 70% data latih dan 30% data uji. Jumlah record untuk data latih dan data uji dari setiap kelas diperlihatkan Tabel 10.
Tabel 10 Jumlah record data latih dan data uji percobaan 3
Data latih Data uji
Kelas 1 208 record 89 record
Kelas 2 208 record 89 record
Kelas 3 208 record 89 record
Total 624 record 267 record
Pada percobaan 3 nilai k atau tetangga terdekat ditentukan lagi seperti halnya pada
percobaan 1 dengan cara mencoba menerapkan nilai k mulai dari 5 sampai 65 dengan selang 5 angka kedalam metode k-Nearest neighbor. Setiap menerapkan suatu nilai k dihitung akurasi klasifikasi tetapi tidak menampilkan histogram sebaran kelas target karena setiap kelas jumlahnya seragam. Akurasi klasifikasi untuk nilai k=5 sampai k=65 diperlihatkan pada Tabel 11.
Tabel 11 Akurasi klasifikasi percobaan 3
k akurasi k akurasi 5 0.4195 40 0.4382 10 0.4607 45 0.4457 15 0.4270 50 0.4644 20 0.4607 55 0.4232 25 0.4457 60 0.4419 30 0.4569 65 0.4494 35 0.4532
Berdasarkan tabel tersebut (Tabel 11) akurasi yang paling tinggi diperoleh untuk k=50 sehingga pada percobaan ini jumlah tetangga terdekat adalah 50.
Untuk mengetahui record yang salah diklasifikasikan digunakan matrix confusion yang diperlihatkan Tabel 12.
Tabel 12 Matrix confusion untuk percobaan 3 Kelas hasil prediksi Kelas
aktual
Kelas 1 Kelas 2 Kelas 3
Kelas 1 56 22 11
Kelas 2 25 42 22
Kelas 3 28 35 26
Berdasarkan tabel tersebut (Tabel 12) kelas 1 yang tepat diklasifikasi sebagai kelas 1 sebanyak 56 record, kelas 1 yang salah diklasifikasi sebagai kelas 2 sebanyak 22
record, dan kelas 1 yang salah diklasifikasi
sebagai kelas 3 sebanyak 11 record. Kelas 2 yang tepat diklasifikasi sebagai kelas 2 sebanyak 42 record, kelas 2 yang salah diklasifikasi sebagai kelas 1 sebanyak 25
record, dan kelas 2 yang salah diklasifikasi
sebagai kelas 3 sebanyak 22 record. Kelas 3 yang tepat diklasifikasi sebagai kelas 3 sebanyak 26 record, kelas 3 yang salah diklasifikasi sebagai kelas 1 sebanyak 28
record, dan kelas 3 yang salah diklasifikasi
sebagai kelas 2 sebanyak 35 record.
Berdasarkan persamaan 5, besarnya akurasi adalah:
Percobaan 4 dilakukan menggunakan
dataset yang proporsi record pada setiap kelas
target seimbang dengan metode 10-fold cross
validation. Data dibagi menjadi 10 subset yang
berbeda dengan jumlah yang hampir sama. Setiap kali sebuah subset digunakan sebagai data uji maka 9 subset lainnya menjadi data latih. Percobaan ini tetap menggunakan jumlah tetangga terdekat sebanyak 65 karena dataset percobaan 4 sama dengan dataset percobaan 3. Besarnya akurasi pada setiap proses uji diperlihatkan pada Tabel 13.
Tabel 13 Akurasi setiap proses uji pada 10-fold
cross validation percobaan 4
proses uji ke- akurasi
1 0.5843 2 0.4382 3 0.6067 4 0.5333 5 0.5393 6 0.6404 7 0.5169 8 0.4944 9 0.4494 10 0.4944
Berdasarkan Tabel 13 akurasi terbaik diperoleh pada proses uji ke-6 yaitu sebesar 0.6404. Matrix confusion untuk proses uji ke-6 pada percobaan 4 adalah
Tabel 14 Matrix confusion proses uji ke-6 percobaan 4
Kelas hadil prediksi Kelas
actual
Kelas 1 Kelas 2 Kelas 3
Kelas 1 24 5 1
Kelas 2 6 14 9
Kelas 3 2 9 19
Berdasarkan tabel tersebut (Tabel 14) kelas 1 yang tepat diklasifikasi sebagai kelas 1 sebanyak 24 record, kelas 1 yang salah diklasifikasi sebagai kelas 2 sebanyak 5 record, dan kelas 1 yang salah diklasifikasi sebagai kelas 3 sebanyak 1 record. Kelas 2 yang tepat diklasifikasi sebagai kelas 2 sebanyak 14
record, kelas 2 yang salah diklasifikasi sebagai
kelas 1 sebanyak 6 record, dan kelas 2 yang salah diklasifikasi sebagai kelas 3 sebanyak 9
record. Kelas 3 yang tepat diklasifikasi sebagai
kelas 3 sebanyak 19 record, kelas 3 yang salah diklasifikasi sebagai kelas 1 sebanyak 2 record, dan kelas 3 yang salah diklasifikasi sebagai kelas 2 sebanyak 9 record. Berdasarkan persamaan 5, besarnya akurasi adalah:
akurasi = = 0.6404
Akurasi rata-rata dari seluruh proses uji dengan 10 data uji yang berbeda pada percobaan 4 diperoleh sebesar 0.5297.
Setiap percobaan yang dilakukan menghasilkan sebuah classifier, sehingga dari empat percobaan diperoleh empat buah
classifier. Akurasi setiap classifier diperlihatkan
pada Tabel 15.
Tabel 15 Akurasi empat classifier
Percobaan Model yang
dihasilkan akurasi 1 classifier 1 0.4757 2 classifier 2 0.5013 3 classifier 3 0.4644 4 classifier 4 0.5297
Akurasi paling tinggi diperoleh pada
classifier 4 yang dihasilkan dari percobaan 4
yaitu menggunakan dataset 891 record yang proporsi record pada setiap kelas target seimbang dengan metode uji 10-fold cross
validation. Dengan demikian classifier 4
merupakan classifier terbaik yang dihasilkan dengan metode k–Nearest Neighbor.
Penggunaan Classifier pada Data Baru Classifier terbaik yang diperoleh digunakan
untuk memprediksi label kelas pada data yang baru. Pada Tabel 16 diberikan contoh data baru tanpa label kelas yang akan diterapkan pada
classifier.
Tabel 16 Data tanpa label kelas jur jalur jenis
kel
asal hobi NEM
19 1 1 5 1 0.8030 19 1 1 1 1 0.8565 19 1 0 5 1 0.7018 19 1 0 1 1 0.8349 19 1 0 1 1 0.7927 19 1 1 1 2 0.8724 19 1 0 4 1 0.7129 19 1 0 1 1 0.8134 19 1 0 1 4 0.8772 19 1 1 1 2 0.6651 19 1 0 1 1 0.7974 19 1 0 1 1 0.6116 19 1 1 1 1 0.8724 6 2 1 1 1 0.6276 19 1 1 1 1 0.8349 10 1 0 1 1 0.5742 2 1 1 5 1 0.3987 5 1 0 6 1 0.4625 10 1 1 1 1 0.3724 10 2 1 5 2 0.5159
jur jalur jenis
kel asal hobi NEM
10 1 0 1 1 0.5000 10 2 1 1 2 0.8246 2 1 1 1 1 0.6970 10 1 1 1 1 0.5638 2 1 1 1 4 0.6435 33 1 0 1 1 0.7767 33 1 0 5 1 0.6061 30 1 1 1 1 0.5478
Hasil prediksi data baru tanpa label kelas diperlihatkan pada Tabel 17
Tabel 17 Hasil prediksi data baru tanpa label kelas
record kelas prediksi
1 2 2 1 3 2 4 1 5 1 6 1 7 1 8 1 9 1 10 1 11 1 12 1 13 1 14 3 15 1 16 1 17 2 18 2 19 2 20 3 21 2 22 1 23 1 24 2 25 2 26 1 27 2 28 1
KESIMPULAN DAN SARAN Kesimpulan
Dari beberapa percobaan yang dilakukan terhadap data IPK dan Biodata dengan metode
k-Nearest Neighbor, diperoleh kesimpulan
sebagai berikut:
1 Metode k-Nearest Neighbor dapat digunakan untuk membuat classifier pada
data akademik dan biodata mahasiswa tingkat I IPB.
2 Classifier terbaik dihasilkan dari percobaan 4 yaitu menggunakan dataset 891 record yang proporsi record pada setiap kelas target seimbang dengan metode uji 10-fold
cross validation.
3 Akurasi yang diperoleh pada classifier terbaik hanya sebesar 52.97%.
4 Classifier terbaik yang dihasilkan dapat digunakan untuk memprediksi keberhasilan mahasiswa baru IPB.
5 Atribut yang mempengaruhi tingkat keberhasilan mahasiswa tingkat I IPB berdasarkan uji hipotesis adalah jurusan, jalur masuk, jenis kelamin, asal daerah, hobi, dan nilai uan (NEM).
Saran
Pada penelitian ini masih terdapat beberapa kekurangan yang dapat diperbaiki pada penelitian selanjutnya. Beberapa saran yang dapat dilakukan antara lain:
1. Penggunaan metode lain untuk memperoleh classifier yang lebih baik, karena akurasi classifier dari k-Nearest
Neighbor hanya sebesar 52.97% .
2. Dibangun aplikasi sederhana yang dapat memprediksi keberhasilan mahasiswa baru dengan menerapkan model terbaik.
DAFTAR PUSTAKA
Daniel, Wayne W. 1990. Applied Non
Parametric Statistics Second Edition.
Boston : PWS-Kend Publ.co.
Freeman, Daniel H. 1987. Applied Categorical
Data Analysis. New York: Marcel Dekker,
Inc.
Fu L. 1994. Neural Network In Computer
Intelligence. Singapura: McGraw Hill.
Han J, Kamber M. 2006. Data Mining Concepts
and Techniques. Morgan Kaufmann Publishers.
Larose, Daniel T. 2005. Discovering Knowledge
in Data: An Introduction to Data Mining.
John Wiley&Sons, Inc.
Superby, J. F, et al. 2005. Determination of
factors influencing the achievement of the first-year university students using data mining methods. Belgia: Production and
Operations Management Department, Catholic University of Mons.
Tan, Pang-Ning,et al. 2006. Introduction to
Data Mining. Boston: Pearson Education,
Inc.
Walpole, Ronald E. 2005. Pengantar Statistika. Ed ke-3. Jakarta: PT Gramedia Pustaka Utama.
Lampiran 1 Tabel kode jurusan mayor IPB tahun akademik 2007/2008
Kode NRP Jurusan
A1 Manajemen Sumberdaya Lahan
A2 Agronomi dan Hortikultura
A3 Proteksi Tanaman
A4 Arsitektur Lanskap
B Kedokteran Hewan
C1 Teknologi dan Manajemen Perikanan Budidaya
C2 Manajemen Sumberdaya Perairan
C3 Teknologi Hasil Perairan
C4 Teknologi dan Manajemen Perikanan Tangkap
C5 Ilmu dan Teknologi Kelautan
D Peternakan
E1 Manajemen Hutan
E2 Teknologi Hasil Hutan
E3 Konservasi Sumberdaya Hutan dan Ekowisata
E4 Silvikultur
F1 Teknik Pertanian
F2 Teknologi Pangan
F3 Teknologi Industeri Pertanian
G1 Statistika G2 Meteorologi Terapan G3 Biologi G4 Kimia G5 Matematika G6 Ilmu Komputer G7 Fisika G8 Biokimia
H1 Ekonomi dan Studi Pembangunan
H2 Manajemen
H3 Agribisnis
H4 Ekonomi Sumberdaya dan Lingkungan
I1 Ilmu Gizi
I2 Ilmu Keluarga dan Konsumen
Lampiran 2 Tabel penentuan asal daerah
Pulau Propinsi
JAWA DKI Jakarta, Banten, Jawa Barat, Jawa Tengah, Jawa Timur, DIY
KALIMANTAN Kalbar, Kalteng, Kaltim, Kalsel
MALUKU Maluku, Maluku utara
NUSA TENGGARA Bali, NTB, NTT
SUMATERA NAD, Sumut, Sumbar, Riau, Jambi, Sumsel, Bengkulu, Lampung, Kep.
Riau, Kep. Bangka belitung
SULAWESI Sulut, Sulsel, Sulteng, Gorontalo
Lampiran 3 Tabel kategorisasi atribut nominal dan kelas target
Kelas Target kategori
Resiko rendah 1
Resiko sedang 2
Resiko tinggi 3
Jurusan kategori
Manajemen Sumberdaya Lahan 1
Agronomi dan Hortikultura 2
Proteksi Tanaman 3
Arsitektur Lanskap 4
Kedokteran Hewan 5
Teknologi dan Manajemen Perikanan Budidaya 6
Manajemen Sumberdaya Perairan 7
Teknologi Hasil Perairan 8
Teknologi dan Manajemen Perikanan Tangkap 9
Ilmu dan Teknologi Kelautan 10
Peternakan 11
Manajemen Hutan 12
Teknologi Hasil Hutan 13
Konservasi Sumberdaya Hutan dan Ekowisata 14
Silvikultur 15
Teknik Pertanian 16
Teknologi Pangan 17
Teknologi Industeri Pertanian 18
Statistika 19 Meteorologi Terapan 20 Biologi 21 Kimia 22 Matematika 23 Ilmu Komputer 24 Fisika 25 Biokimia 26
Ekonomi dan Studi Pembangunan 27
Manajemen 28
Agribisnis 29
Ekonomi Sumberdaya dan Lingkungan 30
Ilmu Gizi 31
Ilmu Keluarga dan Konsumen 32
Komunikasi dan Pengembangan Masyarakat 33
Jenis kelamin kategori
Perempuan 0
Laki-laki 1
Jalur masuk kategori
USMI 1
SPMB 2
PIN 3
Lampiran 3 Lanjutan
Pendapatan orang tua kategori
(< 500) 1 (500<=P<1000) 2 (1000<=P<2500) 3 (2500<=P<5000) 4 (5000<=P<7500) 5 (>=7500) 6
Pendidikan orang tua Kategori
Tidak sekolah 0 Tidak tamat SD 1 SD 2 SLTP 3 SLTA 4 Diploma 5 Sarjana muda 6 Sarjana 7 S2/Master 8 S3/Doktor 9
Riwayat kesehatan kategori
Sehat 0 Hepatitis 1 Diabetes 3 Paru-paru 4 Tipus 5 Lain-lain 7 Minat/Hobi kategori Bidang khusus 1 OR 2 Keagamaan 3 Kesenian 4 Bela diri 5
Asal daerah kategori
JAWA 1 KALIMANTAN 2 MALUKU 3 NUSA TENGGARA 4 SUMATERA 5 SULAWESI 6 PAPUA 7 LUAR INDONESIA 8
Lampiran 4 Tabel kontingensi a Atribut riwayat pendidikan
b Atribut jalur masuk
c Atribut riwayat kesehatan
Riwayat Kesehatan Kelas Target Total Resiko rendah Resiko sedang Resiko tinggi 0 Sehat 1362 913 285 2560 1 Hepatitis 6 1 0 7 2 Jantung 0 1 1 2 3 Diabetes 1 0 0 1 4 Paru-paru 11 3 2 16 5 Tipus 81 49 11 141 6 Hipertensi 1 0 0 1 7 dll 33 20 4 57 Total 1495 987 303 2785
Riwayat pendidikan Kelas Target
Total Resiko rendah Resiko sedang Resiko tinggi 0 9 4 0 13 1 Tidak tamat SD 38 20 6 64 2 SD 102 63 17 182 3 SLTP 89 65 18 172 4 SLTA 550 358 102 1010 5 Diploma 95 62 20 177 6 Sarjana muda 88 56 20 164 7 Sarjana 392 260 89 741 8 S2/Master 100 73 25 198 9 S3/Doktor 32 26 6 64 Total 1495 987 303 2785 Jalur Masuk Kelas Target Total Resiko rendah Resiko sedang Resiko tinggi 1 USMI 1153 652 159 1964 2 SPMB 267 282 114 663 3 PIN 1 1 1 3 6 BUD 74 52 29 155 Total 1495 987 303 2785
Lampiran 4 Lanjutan d Atribut asal daerah
Asal Daerah Kelas Target Total
Resiko rendah Resiko sedang Resiko tinggi 1 JAWA 1172 725 208 2105 2 KALIMANTAN 19 7 3 29 3 MALUKU 2 1 1 4 4 NUSA TENGGARA 14 15 3 32 5 SUMATERA 264 213 77 554 6 SULAWESI 14 18 11 43 7 PAPUA 10 5 0 15 8 LUAR INDONESIA 0 3 0 3 Total 1495 987 303 2785 e Atribut pendapatan
Pendapatan Kelas Target Total
Resiko rendah Resiko sedang Resiko tinggi 1 (< 500) 4 6 1 11 2 (500<=P<1000) 119 68 12 199 3 (1000<=P<2500) 242 143 51 436 4 (2500<=P<5000) 514 385 110 1009 5 (5000<=P<7500) 487 311 101 899 6 (>=7500) 129 74 28 231 Total 1495 987 303 2785 f Atribut hobi
Hobi Kelas Target Total
Resiko rendah Resiko sedang Resiko tinggi 1 Bidang khusus 1272 755 217 2244 2 OR 150 182 66 398 3 Keagamaan 41 25 10 76 4 Kesenian 24 17 7 48 5 Bela diri 8 8 3 19 Total 1495 987 303 2785
Lampiran 4 Lanjutan g Atribut jurusan
Jurusan Kelas Target Total
Resiko rendah Resiko sedang Resiko tinggi MSL 34 21 16 71 AGH 90 58 18 166 Proteksi 24 30 14 68 Lanskap 31 27 3 61 FKH 73 44 22 139 BDP 33 31 11 75 MSP 16 35 9 60 THP 37 29 8 74 PSP 15 20 13 48 ITK 30 23 7 60 Fapet 72 82 29 183 Menehe 49 40 13 102 THH 30 22 12 64 KSH 39 43 12 94 Silvi 14 18 13 45 TEP 55 39 5 99 TPG 100 9 1 110 TIN 78 24 4 106 STAT 49 10 0 59 GFM 26 17 7 50 BIO 49 36 4 89 KIM 53 15 2 70 MAT 44 19 5 68 KOM 61 20 6 87 FIS 20 23 5 48 BIOKIM 37 20 5 62 IE 40 40 8 88 MENE 43 45 9 97 AGB 74 24 9 107 ESL 41 35 9 85 GIZI 77 28 3 108 IKK 22 17 4 43 KPM 39 43 17 99 Total 1495 987 303 2785
Lampiran 5 Nilai frekuensi harapan dan chi-square a Atribut riwayat pendidikan
b Atribut jalur masuk
c Atribut riwayat kesehatan
Ei1 Ei2 Ei3 i12 i22 i32 1374.219 907.2603 278.5206 0.108647 0.036311397 0.15073218 3.75763 2.48079 0.76158 1.3381366 0.883887355 0.761579892 1.073609 0.708797 0.217594 1.0736086 0.11963806 2.813303826 0.536804 0.354399 0.108797 0.3996806 0.354398564 0.108797127 8.588869 5.670377 1.740754 0.6768706 1.257573068 0.038608825 75.68941 49.9702 15.34039 0.3726069 0.018836891 1.228066719 2 hitung 13.57622516 2 (db,α)= 2 (14,0.05) 23.685 Ei1 Ei2 Ei3 i1 2 i2 2 i3 2 6.978456 4.607181 1.414363 0.5856081 0.080020546 1.414362657 34.35548 22.68151 6.963016 0.3866212 0.31701973 0.133189425 97.69838 64.50054 19.80108 0.1893982 0.034908485 0.39624276 92.33034 60.95655 18.71311 0.1201249 0.268215034 0.027174541 542.1724 357.9425 109.8851 0.1130122 9.22096E-06 0.56581632 95.01436 62.72855 19.25709 2.171E-06 0.008461522 0.028660244 88.03591 58.12136 17.84273 1.465E-05 0.077427417 0.260824373 397.772 262.6093 80.61867 0.0837563 0.02592685 0.8713449 106.2873 70.17092 21.54183 0.3719124 0.114060339 0.555149237 34.35548 22.68151 6.963016 0.1614958 0.48552277 0.133189425 2 hitung 5.729480473 2 (db,α)= 2 (18,0.05) 28.869 Ei1 Ei2 Ei3 i12 i22 i32 1054.284 696.0388 213.6776 9.2431626 2.786359222 13.99134008 355.9013 234.9662 72.1325 22.206815 9.414857969 24.30094675 1.610413 1.063196 0.326391 0.2313717 0.003756313 1.390197763 29.13 16.75 4.13 1.74 0.00 11.46 2 hitung 93.47797937 2 (db,α)= 2 (6,0.05) 12.59
Lampiran 5 Lanjutan d Atribut asal daerah
Ei1 Ei2 Ei3 i12 i22 i32 1129.973 746.009 229.018 1.5631017 0.591651192 1.928907125 15.56732 10.27756 3.155117 0.7569225 1.045227705 0.007626085 2.147217 1.417594 0.435189 0.0100935 0.123014721 0.733043295 17.17774 11.34075 3.481508 0.5878549 1.180704647 0.066594713 297.3896 196.3368 60.27361 3.7488351 1.414213151 4.641702647 23.08259 15.23914 4.678276 3.5738352 0.500182985 8.542502439 8.052065 5.315978 1.631957 0.4712397 0.018781563 1.631956912 1.610413 746.009 0.326391 1.6104129 740.0210409 0.326391382 2 hitung 775.0958369 2 (db,α)= 2(14, 0.05) 23.69 e Atribut pendapatan Ei1 Ei2 Ei3 i12 i22 i32 5.904847 3.898384 1.196768 0.6144856 1.132979393 0.032351961 106.8241 70.52531 21.65063 1.3878295 0.090424436 4.301705534 234.0467 154.5178 47.43555 0.270268 0.858536269 0.267843879 541.6355 357.5882 109.7763 1.4100321 2.101326552 0.000455845 482.5871 318.6043 97.80862 0.0403532 0.181496328 0.104131128 124.0018 81.86607 25.13214 0.2014652 0.755808 0.327255957 2 hitung 14.07874879 2 (db,α)= 2 (10,0.05) 18.31 f Atribut hobi Ei1 Ei2 Ei3 i12 i22 i32 1204.589 795.2704 244.1408 3.7724577 2.039184801 3.017196095 213.6481 141.0506 43.30126 18.961471 11.88829186 11.8987989 40.79713 26.93429 8.268582 0.0010088 0.138911438 0.362554243 25.76661 17.01113 5.222262 0.1211219 7.28349E-06 0.605169159 10.19928 6.733573 2.067145 0.4742335 0.238185306 0.420975542 2 hitung 53.9395675 2 (db,α)= 2 (8,0.05) 15.51
Lampiran 5 Lanjutan g Atribut jurusan Ei1 Ei2 Ei3 i12 i22 i32 38.11311 25.1623 7.724596 0.4438799 0.688519182 8.865487604 89.10952 58.83016 18.06032 0.0088987 0.011714539 0.000201485 36.50269 24.0991 7.398205 4.2823507 1.444891714 5.891118665 32.74506 21.61831 6.636625 0.0929986 1.339723519 1.992735797 74.6158 49.2614 15.1228 0.03499 0.561947763 3.127454421 40.26032 26.57989 8.159785 1.3092864 0.735042567 0.988607442 32.20826 21.26391 6.527828 8.1565305 8.873251886 0.93624349 39.72352 26.22549 8.050987 0.1867296 0.293526795 0.000322907 25.76661 17.01113 5.222262 4.4988393 0.525146595 11.58371701 32.20826 21.26391 6.527828 0.1514023 0.14174226 0.034153281 98.23519 64.85494 19.90987 7.0065027 4.532471891 4.150221312 54.75404 36.14865 11.09731 0.6046854 0.410329803 0.326226953 34.35548 22.68151 6.963016 0.5521731 0.020477177 3.643709227 50.45961 33.31346 10.22693 2.6025282 2.816547618 0.307401859 24.15619 15.94794 4.895871 4.2700549 0.264044791 13.41475596 53.14363 35.08546 10.77092 0.0648454 0.436751906 3.091981059 59.04847 38.98384 11.96768 28.400861 23.06162593 10.05124238 56.90126 37.56625 11.5325 7.823324 4.899160528 4.919879533 31.67145 20.90952 6.419031 9.4810455 5.692026895 6.419030521 26.84022 17.71993 5.439856 0.0263024 0.029249362 0.447447133 47.77558 31.54147 9.682944 0.03138 0.630232802 3.335334303 37.5763 24.8079 7.615799 6.3308644 3.877591168 4.141022874 36.50269 24.0991 7.398205 1.5398758 1.078913407 0.777402882 46.70197 30.83268 9.46535 4.3774064 3.805924995 1.268695942 25.76661 17.01113 5.222262 1.2905756 2.108416605 0.009459588 33.28187 21.97271 6.745422 0.4153767 0.177110076 0.451639299 47.23878 31.18707 9.574147 1.1092565 2.490380231 0.258815684 52.07002 34.37666 10.55332 1.5798962 3.282905786 0.228630132 57.43806 37.92065 11.64129 4.7755411 5.110260841 0.599282831 45.62837 30.12388 9.247756 0.4694837 0.78929302 0.006637605 57.97487 38.27504 11.75009 6.2433219 2.758365083 6.516041362 23.08259 15.23914 4.678276 0.0507738 0.203465189 0.098339418 53.14363 35.08546 10.77092 3.7641799 1.785354446 3.602432104 2 hitung 298.338239 2 (db,α)= 2 (64,0.05) 79.08